Lecture 10 Support Vector Machines II
|
|
|
- Ashlynn Cunningham
- 6 years ago
- Views:
Transcription


1 Lecture 10 Support Vector Machnes II 22 February 2016 Taylor B. Arnold Yale Statstcs STAT 365/665 1/28
2 Notes: Problem 3 s posted and due ths upcomng Frday There was an early bug n the fake-test data; fxed as of /28
3 Today: Optmzaton theory behnd support vector machnes More examples 3/28
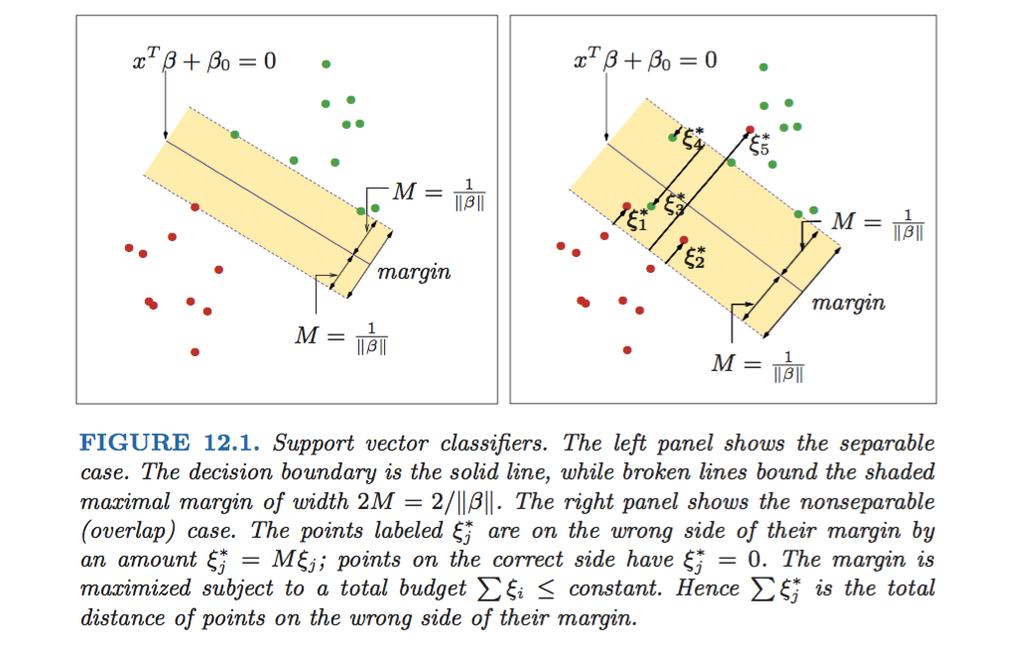
4 Recall that we settled on the followng defnton for a the support vector machne: max β 2 =1 M s.t. y (x t β + β 0 ) > M ξ, = 1,..., n ξ > 0, ξ Constant. Ths defnes a margn around the lnear decson plane of wdth and tres to mnmze the number of errors (ξ) for ponts that are on the wrong sde of the margn. 4/28
5 We then re-parameterzed ths by settng the margn to 1 but allowng the sze of β to grow: mn 1 2 β 2 2 s.t. y (x t β + β 0 ) > 1 ξ, = 1,..., n ξ > 0, ξ Constant. Ths defnes a margn around the lnear decson plane of wdth 1 β, and tred to mnmze the number of errors ξ of ponts that are on the wrong sde of the margn. 5/28
6 6/28
7 Notce that we can rewrte mn 1 2 β 2 2 s.t. y (x t β + β 0 ) > 1 ξ, = 1,..., n ξ > 0, ξ Constant Wth a constant C > 0, whch depends only on the constant n the orgnal formulaton, as: mn 1 2 β C ξ s.t. y (x t β + β 0 ) > 1 ξ, ξ > 0, = 1,..., n. By notcng that the second form wll fnd a β that mnmzes β 2 2 such that ξ ξ. 7/28
8 TheLagrangan Gven a constraned optmzaton problem: mnf(x) s.t. g j (x) = 0, j = 1,..., K We can defne the prmal Lagrangan functon as: K L P = f(x) λ j g j (x) j=1 What does ths functon look lke? 8/28
9 TheLagranganDual The Lagrangan dual functon s then gven as the nfmum of L P as functon of the λ j over values of x: L D (λ) = nf L P(x, λ) x K = nf x f(x) λ j g j (x). And the dualproblem s to fnd the maxmum of the dual functon over all choces of λ: j=1 λ = arg max L D (λ). λ The optmal value of the prmal problem, x, can be reconstructed by workng backwards: x = arg mn L P (x, λ ). x 9/28

10 For a better understandng of the dual problem we can vsualze the Lagrangan soluton as a saddle pont /28
11 It turns out that ths s a very good framework for workng wth support vector machnes. We can defne the Lagrangan functon as: L P = 1 2 β C ξ α [ y (x t β + β 0 ) (1 ξ ) ] µ ξ Where α and µ are the Lagrangan multplers. 11/28
12 Asde: Techncally, the theory of Lagrangan multplers only apply when the constrants on the soluton are equalty constrants rather than nequalty constrants. The larger theory needed for the general case uses the Karush-Kuhn-Tucker (KKT) condtons. These add addtonal constrants on top of those presented here. Followng the Elements of Statstcal Learnng, we wll not worry wth those detals here as they are more an annoyance than an nterestng conceptual dfference. 12/28
13 To construct the dual functon, we need to take partal dervatves wth respect to the prmal varables: β, β 0, and ξ. If we plug these nto the prmal problem, we get the dual functon. 13/28
14 For β j : { L P = 1 β j β j = β j 2 β C ξ [ α y (x t β + β 0 ) (1 ξ ) ] { 1 2 β 2 2 } α y (x t β) µ ξ } = β j α y x,j 14/28
15 For β j : { L P = 1 β j β j = β j 2 β C ξ [ α y (x t β + β 0 ) (1 ξ ) ] { 1 2 β 2 2 } α y (x t β) µ ξ } = β j α y x,j Settng ths equal to zero, and wrtng the equaton smultaneously for all β j, we get: β = α y x 14/28
16 Ths necessary condton for the soluton of the support vector machne s of ndependent nterest. It says that β can be wrtten as a lnear combnaton of the data ponts x. Any such that α s non-zero s called a support vector. 15/28
17 For β 0, the dervatve s gven as: { L P = 1 β 0 β 0 2 β C ξ { = } α y β 0 β 0 α [ y (x t β + β 0 ) (1 ξ ) ] µ ξ } = α y Whch when set to zero gves: 0 = α y Ths explans why the term β 0 s often called the bas of the support vector machne. 16/28
18 Fnally, the dervatve wth respect to ξ s gven as: { L P = 1 ξ ξ 2 β C ξ [ α y (x t β + β 0 ) (1 ξ ) ] { = C ξ + α (1 ξ ) } µ ξ µ ξ } = C α µ 17/28
19 Fnally, the dervatve wth respect to ξ s gven as: { L P = 1 ξ ξ 2 β C ξ [ α y (x t β + β 0 ) (1 ξ ) ] { = C ξ + α (1 ξ ) } µ ξ µ ξ } = C α µ Settng ths equal to zero we see that: α = C µ. 17/28
20 We now want to plug ths nto the Lagrangan prmal functon. We frst use the fact that α = C µ to unte the tralng terms wth respect to α : L D = 1 2 β C ξ [ α y (x t β + β 0 ) (1 ξ ) ] µ ξ = 1 2 β (C µ )ξ α y x t β α y β 0 + α (1 ξ ) = 1 2 β α ξ α y x t β α y β 0 + α (1 ξ ) = 1 2 β α α y x t β α y β 0 18/28
21 We now want to plug ths nto the Lagrangan prmal functon. We frst use the fact that α = C µ to unte the tralng terms wth respect to α : L D = 1 2 β C ξ [ α y (x t β + β 0 ) (1 ξ ) ] µ ξ = 1 2 β (C µ )ξ α y x t β α y β 0 + α (1 ξ ) = 1 2 β α ξ α y x t β α y β 0 + α (1 ξ ) = 1 2 β α α y x t β α y β 0 And the last term drops out: L D = 1 2 β α α y x t β β 0 α y = 1 2 β α α y x t β 18/28
22 Now, notce that snce β = α y x, we have that: β 2 2 = j β 2 j = (α y x ) t (α y x ) = α α y y x t x Also see that we can rewrte the last term n our dual functon as: α y x t β = α α y y x t x = β /28
23 Fnally, the dual functon can be wrtten as: L D = 1 2 β α α y x t β = = α 1 2 β 2 2 α 1 2 α α y y x t x. Whch we want to maxmze under the constrants (the frst s from the KKT condtons, the second from the partal dervatve of the bas): 0 α C, α y = 0. 20/28
24 To what extent can we make some sense of ths equaton? Frst notce the dualty of the problem f we flp the ±1 labelng of the classes y : L D = α 1 2 α α y y x t x The functon only depends on the sgn of y y. Also note that t only depends on the data that serve as support vectors: L D = α 1 2 α α y y x t x. 21/28
25 Perhaps most mportantly though, notce that only the outer product XX t effects the fnal results: L D = α 1 2 α α y y x t x. As x t x s the (, ) th element of XX t. Ths s a measurement of how smlar x and x are to one another (f scaled to both have length one, t s the cosne of the angle between them). 22/28
26 Perhaps most mportantly though, notce that only the outer product XX t effects the fnal results: L D = α 1 2 α α y y x t x. As x t x s the (, ) th element of XX t. Ths s a measurement of how smlar x and x are to one another (f scaled to both have length one, t s the cosne of the angle between them). So, we can see that: 1. There s a penalty for ncludng two smlar x s wth the same class label 2. There s a beneft for ncludng two smlar x s wth dfferent class labels Both of whch actually make sense for a classfcaton algorthm. 22/28
27 Takng a step back now, how does logstc regresson and support vector machnes compare? 1. Both separate the plane nto two half-spaces whch attempt to splt the classes as well as possble 2. However, logstc regresson s (prmarly) concerned wth the correlaton matrx X t X between the varables and support vector machnes only care about the smlarty matrx XX t between observatons 23/28
28 TheKernelTrck In the case of logstc and lnear regresson I have shown how bass expanson can be used to add non-lnear effects nto a lnear model. One observaton that makes support vector machnes attractve s that t s possble to mmc bass expanson wthout ever havng to actually project nto a hgher dmensonal space. 24/28
29 TheKernelTrck, cont. Assume that we have a mappng h of samples x nto a hgher dmensonal space. We can re-wrte the dual functon usng nner product notaton: L D = α 1 2 α α y y < h(x ), h(x ) >. It quckly becomes apparent that we only need a fast way of calculatng nner products n the space of h, whch may not requre actually determnng and calculatng h tself. 25/28
30 TheKernelTrck, cont. The projected nner product < h(x ), h(x ) > s usually wrtten drectly as K(x, x ) for a functon K called the kernel. Popular choces nclude: 1. Lnear: K(x, x ) =< x, x > 2. Polynomal: K(x, x ) = (1+ < x, x >) d 3. Radal: K(x, x ) = exp( γ x x 2 ) 4. Sgmod: K(x, x ) = tanh(κ 1 < x, x > +κ 2 ) Notce that these all requre approxmately the same effort to calculate as the lnear kernel. 26/28
31 Fnshngtheoptmzaton Now, we can re-wrte the optmzaton problem as: max s.t. 1 t α α t Kα 0 α C For a sutable matrx K, called the kernel matrx. Ths s a quadratc program wth box constrants, and can be solved farly effcently by general purpose solvers. 27/28
32 Morenformaton I try to provde addtonal references for all of my lectures on the class webste. For today s materal (and Wednesday s) I would lke to make a partcular pont to menton two references: Elements of Statstcal Learnng, Sectons Convex Optmzaton, S. Boyd, Chapter 5 (5.5 n partcular) These contan many more detals than I have tme to cover, and assume a deeper background n statstcs / convex calculus. 28/28
Support Vector Machines. Vibhav Gogate The University of Texas at dallas
 Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Lecture 3: Dual problems and Kernels
 Lecture 3: Dual problems and Kernels C4B Machne Learnng Hlary 211 A. Zsserman Prmal and dual forms Lnear separablty revsted Feature mappng Kernels for SVMs Kernel trck requrements radal bass functons SVM
Lecture 3: Dual problems and Kernels C4B Machne Learnng Hlary 211 A. Zsserman Prmal and dual forms Lnear separablty revsted Feature mappng Kernels for SVMs Kernel trck requrements radal bass functons SVM
Support Vector Machines
 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Lagrange Multipliers Kernel Trick
 Lagrange Multplers Kernel Trck Ncholas Ruozz Unversty of Texas at Dallas Based roughly on the sldes of Davd Sontag General Optmzaton A mathematcal detour, we ll come back to SVMs soon! subject to: f x
Lagrange Multplers Kernel Trck Ncholas Ruozz Unversty of Texas at Dallas Based roughly on the sldes of Davd Sontag General Optmzaton A mathematcal detour, we ll come back to SVMs soon! subject to: f x
Which Separator? Spring 1
 Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Lecture 10 Support Vector Machines. Oct
 Lecture 10 Support Vector Machnes Oct - 20-2008 Lnear Separators Whch of the lnear separators s optmal? Concept of Margn Recall that n Perceptron, we learned that the convergence rate of the Perceptron
Lecture 10 Support Vector Machnes Oct - 20-2008 Lnear Separators Whch of the lnear separators s optmal? Concept of Margn Recall that n Perceptron, we learned that the convergence rate of the Perceptron
Kernel Methods and SVMs Extension
 Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Support Vector Machines CS434
 Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? + + + + + + + + + Intuton of Margn Consder ponts
Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? + + + + + + + + + Intuton of Margn Consder ponts
princeton univ. F 17 cos 521: Advanced Algorithm Design Lecture 7: LP Duality Lecturer: Matt Weinberg
 prnceton unv. F 17 cos 521: Advanced Algorthm Desgn Lecture 7: LP Dualty Lecturer: Matt Wenberg Scrbe: LP Dualty s an extremely useful tool for analyzng structural propertes of lnear programs. Whle there
prnceton unv. F 17 cos 521: Advanced Algorthm Desgn Lecture 7: LP Dualty Lecturer: Matt Wenberg Scrbe: LP Dualty s an extremely useful tool for analyzng structural propertes of lnear programs. Whle there
10-701/ Machine Learning, Fall 2005 Homework 3
 10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
Natural Language Processing and Information Retrieval
 Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Support Vector Machines
 /14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
/14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
U.C. Berkeley CS294: Beyond Worst-Case Analysis Luca Trevisan September 5, 2017
 U.C. Berkeley CS94: Beyond Worst-Case Analyss Handout 4s Luca Trevsan September 5, 07 Summary of Lecture 4 In whch we ntroduce semdefnte programmng and apply t to Max Cut. Semdefnte Programmng Recall that
U.C. Berkeley CS94: Beyond Worst-Case Analyss Handout 4s Luca Trevsan September 5, 07 Summary of Lecture 4 In whch we ntroduce semdefnte programmng and apply t to Max Cut. Semdefnte Programmng Recall that
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
Maximal Margin Classifier
 CS81B/Stat41B: Advanced Topcs n Learnng & Decson Makng Mamal Margn Classfer Lecturer: Mchael Jordan Scrbes: Jana van Greunen Corrected verson - /1/004 1 References/Recommended Readng 1.1 Webstes www.kernel-machnes.org
CS81B/Stat41B: Advanced Topcs n Learnng & Decson Makng Mamal Margn Classfer Lecturer: Mchael Jordan Scrbes: Jana van Greunen Corrected verson - /1/004 1 References/Recommended Readng 1.1 Webstes www.kernel-machnes.org
COS 521: Advanced Algorithms Game Theory and Linear Programming
 COS 521: Advanced Algorthms Game Theory and Lnear Programmng Moses Charkar February 27, 2013 In these notes, we ntroduce some basc concepts n game theory and lnear programmng (LP). We show a connecton
COS 521: Advanced Algorthms Game Theory and Lnear Programmng Moses Charkar February 27, 2013 In these notes, we ntroduce some basc concepts n game theory and lnear programmng (LP). We show a connecton
Solutions to exam in SF1811 Optimization, Jan 14, 2015
 Solutons to exam n SF8 Optmzaton, Jan 4, 25 3 3 O------O -4 \ / \ / The network: \/ where all lnks go from left to rght. /\ / \ / \ 6 O------O -5 2 4.(a) Let x = ( x 3, x 4, x 23, x 24 ) T, where the varable
Solutons to exam n SF8 Optmzaton, Jan 4, 25 3 3 O------O -4 \ / \ / The network: \/ where all lnks go from left to rght. /\ / \ / \ 6 O------O -5 2 4.(a) Let x = ( x 3, x 4, x 23, x 24 ) T, where the varable
For now, let us focus on a specific model of neurons. These are simplified from reality but can achieve remarkable results.
 Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
APPENDIX A Some Linear Algebra
 APPENDIX A Some Lnear Algebra The collecton of m, n matrces A.1 Matrces a 1,1,..., a 1,n A = a m,1,..., a m,n wth real elements a,j s denoted by R m,n. If n = 1 then A s called a column vector. Smlarly,
APPENDIX A Some Lnear Algebra The collecton of m, n matrces A.1 Matrces a 1,1,..., a 1,n A = a m,1,..., a m,n wth real elements a,j s denoted by R m,n. If n = 1 then A s called a column vector. Smlarly,
Solutions HW #2. minimize. Ax = b. Give the dual problem, and make the implicit equality constraints explicit. Solution.
 Solutons HW #2 Dual of general LP. Fnd the dual functon of the LP mnmze subject to c T x Gx h Ax = b. Gve the dual problem, and make the mplct equalty constrants explct. Soluton. 1. The Lagrangan s L(x,
Solutons HW #2 Dual of general LP. Fnd the dual functon of the LP mnmze subject to c T x Gx h Ax = b. Gve the dual problem, and make the mplct equalty constrants explct. Soluton. 1. The Lagrangan s L(x,
Linear Feature Engineering 11
 Lnear Feature Engneerng 11 2 Least-Squares 2.1 Smple least-squares Consder the followng dataset. We have a bunch of nputs x and correspondng outputs y. The partcular values n ths dataset are x y 0.23 0.19
Lnear Feature Engneerng 11 2 Least-Squares 2.1 Smple least-squares Consder the followng dataset. We have a bunch of nputs x and correspondng outputs y. The partcular values n ths dataset are x y 0.23 0.19
ADVANCED MACHINE LEARNING ADVANCED MACHINE LEARNING
 1 ADVANCED ACHINE LEARNING ADVANCED ACHINE LEARNING Non-lnear regresson technques 2 ADVANCED ACHINE LEARNING Regresson: Prncple N ap N-dm. nput x to a contnuous output y. Learn a functon of the type: N
1 ADVANCED ACHINE LEARNING ADVANCED ACHINE LEARNING Non-lnear regresson technques 2 ADVANCED ACHINE LEARNING Regresson: Prncple N ap N-dm. nput x to a contnuous output y. Learn a functon of the type: N
Additional Codes using Finite Difference Method. 1 HJB Equation for Consumption-Saving Problem Without Uncertainty
 Addtonal Codes usng Fnte Dfference Method Benamn Moll 1 HJB Equaton for Consumpton-Savng Problem Wthout Uncertanty Before consderng the case wth stochastc ncome n http://www.prnceton.edu/~moll/ HACTproect/HACT_Numercal_Appendx.pdf,
Addtonal Codes usng Fnte Dfference Method Benamn Moll 1 HJB Equaton for Consumpton-Savng Problem Wthout Uncertanty Before consderng the case wth stochastc ncome n http://www.prnceton.edu/~moll/ HACTproect/HACT_Numercal_Appendx.pdf,
Feature Selection: Part 1
 CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
APPROXIMATE PRICES OF BASKET AND ASIAN OPTIONS DUPONT OLIVIER. Premia 14
 APPROXIMAE PRICES OF BASKE AND ASIAN OPIONS DUPON OLIVIER Prema 14 Contents Introducton 1 1. Framewor 1 1.1. Baset optons 1.. Asan optons. Computng the prce 3. Lower bound 3.1. Closed formula for the prce
APPROXIMAE PRICES OF BASKE AND ASIAN OPIONS DUPON OLIVIER Prema 14 Contents Introducton 1 1. Framewor 1 1.1. Baset optons 1.. Asan optons. Computng the prce 3. Lower bound 3.1. Closed formula for the prce
Lectures - Week 4 Matrix norms, Conditioning, Vector Spaces, Linear Independence, Spanning sets and Basis, Null space and Range of a Matrix
 Lectures - Week 4 Matrx norms, Condtonng, Vector Spaces, Lnear Independence, Spannng sets and Bass, Null space and Range of a Matrx Matrx Norms Now we turn to assocatng a number to each matrx. We could
Lectures - Week 4 Matrx norms, Condtonng, Vector Spaces, Lnear Independence, Spannng sets and Bass, Null space and Range of a Matrx Matrx Norms Now we turn to assocatng a number to each matrx. We could
Assortment Optimization under MNL
 Assortment Optmzaton under MNL Haotan Song Aprl 30, 2017 1 Introducton The assortment optmzaton problem ams to fnd the revenue-maxmzng assortment of products to offer when the prces of products are fxed.
Assortment Optmzaton under MNL Haotan Song Aprl 30, 2017 1 Introducton The assortment optmzaton problem ams to fnd the revenue-maxmzng assortment of products to offer when the prces of products are fxed.
Lecture Notes on Linear Regression
 Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Support Vector Machines CS434
 Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? Intuton of Margn Consder ponts A, B, and C We
Support Vector Machnes CS434 Lnear Separators Many lnear separators exst that perfectly classfy all tranng examples Whch of the lnear separators s the best? Intuton of Margn Consder ponts A, B, and C We
PHYS 705: Classical Mechanics. Calculus of Variations II
 1 PHYS 705: Classcal Mechancs Calculus of Varatons II 2 Calculus of Varatons: Generalzaton (no constrant yet) Suppose now that F depends on several dependent varables : We need to fnd such that has a statonary
1 PHYS 705: Classcal Mechancs Calculus of Varatons II 2 Calculus of Varatons: Generalzaton (no constrant yet) Suppose now that F depends on several dependent varables : We need to fnd such that has a statonary
Lecture 21: Numerical methods for pricing American type derivatives
 Lecture 21: Numercal methods for prcng Amercan type dervatves Xaoguang Wang STAT 598W Aprl 10th, 2014 (STAT 598W) Lecture 21 1 / 26 Outlne 1 Fnte Dfference Method Explct Method Penalty Method (STAT 598W)
Lecture 21: Numercal methods for prcng Amercan type dervatves Xaoguang Wang STAT 598W Aprl 10th, 2014 (STAT 598W) Lecture 21 1 / 26 Outlne 1 Fnte Dfference Method Explct Method Penalty Method (STAT 598W)
CSci 6974 and ECSE 6966 Math. Tech. for Vision, Graphics and Robotics Lecture 21, April 17, 2006 Estimating A Plane Homography
 CSc 6974 and ECSE 6966 Math. Tech. for Vson, Graphcs and Robotcs Lecture 21, Aprl 17, 2006 Estmatng A Plane Homography Overvew We contnue wth a dscusson of the major ssues, usng estmaton of plane projectve
CSc 6974 and ECSE 6966 Math. Tech. for Vson, Graphcs and Robotcs Lecture 21, Aprl 17, 2006 Estmatng A Plane Homography Overvew We contnue wth a dscusson of the major ssues, usng estmaton of plane projectve
Support Vector Machines. Jie Tang Knowledge Engineering Group Department of Computer Science and Technology Tsinghua University 2012
 Support Vector Machnes Je Tang Knowledge Engneerng Group Department of Computer Scence and Technology Tsnghua Unversty 2012 1 Outlne What s a Support Vector Machne? Solvng SVMs Kernel Trcks 2 What s a
Support Vector Machnes Je Tang Knowledge Engneerng Group Department of Computer Scence and Technology Tsnghua Unversty 2012 1 Outlne What s a Support Vector Machne? Solvng SVMs Kernel Trcks 2 What s a
Chapter 6 Support vector machine. Séparateurs à vaste marge
 Chapter 6 Support vector machne Séparateurs à vaste marge Méthode de classfcaton bnare par apprentssage Introdute par Vladmr Vapnk en 1995 Repose sur l exstence d un classfcateur lnéare Apprentssage supervsé
Chapter 6 Support vector machne Séparateurs à vaste marge Méthode de classfcaton bnare par apprentssage Introdute par Vladmr Vapnk en 1995 Repose sur l exstence d un classfcateur lnéare Apprentssage supervsé
n α j x j = 0 j=1 has a nontrivial solution. Here A is the n k matrix whose jth column is the vector for all t j=0
 MODULE 2 Topcs: Lnear ndependence, bass and dmenson We have seen that f n a set of vectors one vector s a lnear combnaton of the remanng vectors n the set then the span of the set s unchanged f that vector
MODULE 2 Topcs: Lnear ndependence, bass and dmenson We have seen that f n a set of vectors one vector s a lnear combnaton of the remanng vectors n the set then the span of the set s unchanged f that vector
Convex Optimization. Optimality conditions. (EE227BT: UC Berkeley) Lecture 9 (Optimality; Conic duality) 9/25/14. Laurent El Ghaoui.
 Lecture 9 (Optimality; Conic duality) 9/25/14. Laurent El Ghaoui.") Convex Optmzaton (EE227BT: UC Berkeley) Lecture 9 (Optmalty; Conc dualty) 9/25/14 Laurent El Ghaou Organsatonal Mdterm: 10/7/14 (1.5 hours, n class, double-sded cheat sheet allowed) Project: Intal proposal
Convex Optmzaton (EE227BT: UC Berkeley) Lecture 9 (Optmalty; Conc dualty) 9/25/14 Laurent El Ghaou Organsatonal Mdterm: 10/7/14 (1.5 hours, n class, double-sded cheat sheet allowed) Project: Intal proposal
Kristin P. Bennett. Rensselaer Polytechnic Institute
 Support Vector Machnes and Other Kernel Methods Krstn P. Bennett Mathematcal Scences Department Rensselaer Polytechnc Insttute Support Vector Machnes (SVM) A methodology for nference based on Statstcal
Support Vector Machnes and Other Kernel Methods Krstn P. Bennett Mathematcal Scences Department Rensselaer Polytechnc Insttute Support Vector Machnes (SVM) A methodology for nference based on Statstcal
Linear Classification, SVMs and Nearest Neighbors
 1 CSE 473 Lecture 25 (Chapter 18) Lnear Classfcaton, SVMs and Nearest Neghbors CSE AI faculty + Chrs Bshop, Dan Klen, Stuart Russell, Andrew Moore Motvaton: Face Detecton How do we buld a classfer to dstngush
1 CSE 473 Lecture 25 (Chapter 18) Lnear Classfcaton, SVMs and Nearest Neghbors CSE AI faculty + Chrs Bshop, Dan Klen, Stuart Russell, Andrew Moore Motvaton: Face Detecton How do we buld a classfer to dstngush
Differentiating Gaussian Processes
 Dfferentatng Gaussan Processes Andrew McHutchon Aprl 17, 013 1 Frst Order Dervatve of the Posteror Mean The posteror mean of a GP s gven by, f = x, X KX, X 1 y x, X α 1 Only the x, X term depends on the
Dfferentatng Gaussan Processes Andrew McHutchon Aprl 17, 013 1 Frst Order Dervatve of the Posteror Mean The posteror mean of a GP s gven by, f = x, X KX, X 1 y x, X α 1 Only the x, X term depends on the
Supplement: Proofs and Technical Details for The Solution Path of the Generalized Lasso
 Supplement: Proofs and Techncal Detals for The Soluton Path of the Generalzed Lasso Ryan J. Tbshran Jonathan Taylor In ths document we gve supplementary detals to the paper The Soluton Path of the Generalzed
Supplement: Proofs and Techncal Detals for The Soluton Path of the Generalzed Lasso Ryan J. Tbshran Jonathan Taylor In ths document we gve supplementary detals to the paper The Soluton Path of the Generalzed
Generalized Linear Methods
 Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
p 1 c 2 + p 2 c 2 + p 3 c p m c 2
 Where to put a faclty? Gven locatons p 1,..., p m n R n of m houses, want to choose a locaton c n R n for the fre staton. Want c to be as close as possble to all the house. We know how to measure dstance
Where to put a faclty? Gven locatons p 1,..., p m n R n of m houses, want to choose a locaton c n R n for the fre staton. Want c to be as close as possble to all the house. We know how to measure dstance
Inner Product. Euclidean Space. Orthonormal Basis. Orthogonal
 Inner Product Defnton 1 () A Eucldean space s a fnte-dmensonal vector space over the reals R, wth an nner product,. Defnton 2 (Inner Product) An nner product, on a real vector space X s a symmetrc, blnear,
Inner Product Defnton 1 () A Eucldean space s a fnte-dmensonal vector space over the reals R, wth an nner product,. Defnton 2 (Inner Product) An nner product, on a real vector space X s a symmetrc, blnear,
Using T.O.M to Estimate Parameter of distributions that have not Single Exponential Family
 IOSR Journal of Mathematcs IOSR-JM) ISSN: 2278-5728. Volume 3, Issue 3 Sep-Oct. 202), PP 44-48 www.osrjournals.org Usng T.O.M to Estmate Parameter of dstrbutons that have not Sngle Exponental Famly Jubran
IOSR Journal of Mathematcs IOSR-JM) ISSN: 2278-5728. Volume 3, Issue 3 Sep-Oct. 202), PP 44-48 www.osrjournals.org Usng T.O.M to Estmate Parameter of dstrbutons that have not Sngle Exponental Famly Jubran
Math 217 Fall 2013 Homework 2 Solutions
 Math 17 Fall 013 Homework Solutons Due Thursday Sept. 6, 013 5pm Ths homework conssts of 6 problems of 5 ponts each. The total s 30. You need to fully justfy your answer prove that your functon ndeed has
Math 17 Fall 013 Homework Solutons Due Thursday Sept. 6, 013 5pm Ths homework conssts of 6 problems of 5 ponts each. The total s 30. You need to fully justfy your answer prove that your functon ndeed has
Bezier curves. Michael S. Floater. August 25, These notes provide an introduction to Bezier curves. i=0
 Bezer curves Mchael S. Floater August 25, 211 These notes provde an ntroducton to Bezer curves. 1 Bernsten polynomals Recall that a real polynomal of a real varable x R, wth degree n, s a functon of the
Bezer curves Mchael S. Floater August 25, 211 These notes provde an ntroducton to Bezer curves. 1 Bernsten polynomals Recall that a real polynomal of a real varable x R, wth degree n, s a functon of the
Lecture 20: Lift and Project, SDP Duality. Today we will study the Lift and Project method. Then we will prove the SDP duality theorem.
 prnceton u. sp 02 cos 598B: algorthms and complexty Lecture 20: Lft and Project, SDP Dualty Lecturer: Sanjeev Arora Scrbe:Yury Makarychev Today we wll study the Lft and Project method. Then we wll prove
prnceton u. sp 02 cos 598B: algorthms and complexty Lecture 20: Lft and Project, SDP Dualty Lecturer: Sanjeev Arora Scrbe:Yury Makarychev Today we wll study the Lft and Project method. Then we wll prove
Report on Image warping
 Report on Image warpng Xuan Ne, Dec. 20, 2004 Ths document summarzed the algorthms of our mage warpng soluton for further study, and there s a detaled descrpton about the mplementaton of these algorthms.
Report on Image warpng Xuan Ne, Dec. 20, 2004 Ths document summarzed the algorthms of our mage warpng soluton for further study, and there s a detaled descrpton about the mplementaton of these algorthms.
Lecture 12: Discrete Laplacian
 Lecture 12: Dscrete Laplacan Scrbe: Tanye Lu Our goal s to come up wth a dscrete verson of Laplacan operator for trangulated surfaces, so that we can use t n practce to solve related problems We are mostly
Lecture 12: Dscrete Laplacan Scrbe: Tanye Lu Our goal s to come up wth a dscrete verson of Laplacan operator for trangulated surfaces, so that we can use t n practce to solve related problems We are mostly
1 Convex Optimization
 Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
Convex Optmzaton We wll consder convex optmzaton problems. Namely, mnmzaton problems where the objectve s convex (we assume no constrants for now). Such problems often arse n machne learnng. For example,
MMA and GCMMA two methods for nonlinear optimization
 MMA and GCMMA two methods for nonlnear optmzaton Krster Svanberg Optmzaton and Systems Theory, KTH, Stockholm, Sweden. krlle@math.kth.se Ths note descrbes the algorthms used n the author s 2007 mplementatons
MMA and GCMMA two methods for nonlnear optmzaton Krster Svanberg Optmzaton and Systems Theory, KTH, Stockholm, Sweden. krlle@math.kth.se Ths note descrbes the algorthms used n the author s 2007 mplementatons
Hidden Markov Models
 Hdden Markov Models Namrata Vaswan, Iowa State Unversty Aprl 24, 204 Hdden Markov Model Defntons and Examples Defntons:. A hdden Markov model (HMM) refers to a set of hdden states X 0, X,..., X t,...,
Hdden Markov Models Namrata Vaswan, Iowa State Unversty Aprl 24, 204 Hdden Markov Model Defntons and Examples Defntons:. A hdden Markov model (HMM) refers to a set of hdden states X 0, X,..., X t,...,
Linear Approximation with Regularization and Moving Least Squares
 Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
IV. Performance Optimization
 IV. Performance Optmzaton A. Steepest descent algorthm defnton how to set up bounds on learnng rate mnmzaton n a lne (varyng learnng rate) momentum learnng examples B. Newton s method defnton Gauss-Newton
IV. Performance Optmzaton A. Steepest descent algorthm defnton how to set up bounds on learnng rate mnmzaton n a lne (varyng learnng rate) momentum learnng examples B. Newton s method defnton Gauss-Newton
SELECTED SOLUTIONS, SECTION (Weak duality) Prove that the primal and dual values p and d defined by equations (4.3.2) and (4.3.3) satisfy p d.
 Prove that the primal and dual values p and d defined by equations (4.3.2) and (4.3.3) satisfy p d.") SELECTED SOLUTIONS, SECTION 4.3 1. Weak dualty Prove that the prmal and dual values p and d defned by equatons 4.3. and 4.3.3 satsfy p d. We consder an optmzaton problem of the form The Lagrangan for ths
SELECTED SOLUTIONS, SECTION 4.3 1. Weak dualty Prove that the prmal and dual values p and d defned by equatons 4.3. and 4.3.3 satsfy p d. We consder an optmzaton problem of the form The Lagrangan for ths
EEE 241: Linear Systems
 EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
Support Vector Machines
 CS 2750: Machne Learnng Support Vector Machnes Prof. Adrana Kovashka Unversty of Pttsburgh February 17, 2016 Announcement Homework 2 deadlne s now 2/29 We ll have covered everythng you need today or at
CS 2750: Machne Learnng Support Vector Machnes Prof. Adrana Kovashka Unversty of Pttsburgh February 17, 2016 Announcement Homework 2 deadlne s now 2/29 We ll have covered everythng you need today or at
The Geometry of Logit and Probit
 The Geometry of Logt and Probt Ths short note s meant as a supplement to Chapters and 3 of Spatal Models of Parlamentary Votng and the notaton and reference to fgures n the text below s to those two chapters.
The Geometry of Logt and Probt Ths short note s meant as a supplement to Chapters and 3 of Spatal Models of Parlamentary Votng and the notaton and reference to fgures n the text below s to those two chapters.
Lecture 20: November 7
 0-725/36-725: Convex Optmzaton Fall 205 Lecturer: Ryan Tbshran Lecture 20: November 7 Scrbes: Varsha Chnnaobreddy, Joon Sk Km, Lngyao Zhang Note: LaTeX template courtesy of UC Berkeley EECS dept. Dsclamer:
0-725/36-725: Convex Optmzaton Fall 205 Lecturer: Ryan Tbshran Lecture 20: November 7 Scrbes: Varsha Chnnaobreddy, Joon Sk Km, Lngyao Zhang Note: LaTeX template courtesy of UC Berkeley EECS dept. Dsclamer:
Week 5: Neural Networks
 Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
Kernel Methods and SVMs
 Statstcal Machne Learnng Notes 7 Instructor: Justn Domke Kernel Methods and SVMs Contents 1 Introducton 2 2 Kernel Rdge Regresson 2 3 The Kernel Trck 5 4 Support Vector Machnes 7 5 Examples 1 6 Kernel
Statstcal Machne Learnng Notes 7 Instructor: Justn Domke Kernel Methods and SVMs Contents 1 Introducton 2 2 Kernel Rdge Regresson 2 3 The Kernel Trck 5 4 Support Vector Machnes 7 5 Examples 1 6 Kernel
Dr. Shalabh Department of Mathematics and Statistics Indian Institute of Technology Kanpur
 Analyss of Varance and Desgn of Exerments-I MODULE III LECTURE - 2 EXPERIMENTAL DESIGN MODELS Dr. Shalabh Deartment of Mathematcs and Statstcs Indan Insttute of Technology Kanur 2 We consder the models
Analyss of Varance and Desgn of Exerments-I MODULE III LECTURE - 2 EXPERIMENTAL DESIGN MODELS Dr. Shalabh Deartment of Mathematcs and Statstcs Indan Insttute of Technology Kanur 2 We consder the models
2E Pattern Recognition Solutions to Introduction to Pattern Recognition, Chapter 2: Bayesian pattern classification
 E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
E395 - Pattern Recognton Solutons to Introducton to Pattern Recognton, Chapter : Bayesan pattern classfcaton Preface Ths document s a soluton manual for selected exercses from Introducton to Pattern Recognton
Canonical transformations
 Canoncal transformatons November 23, 2014 Recall that we have defned a symplectc transformaton to be any lnear transformaton M A B leavng the symplectc form nvarant, Ω AB M A CM B DΩ CD Coordnate transformatons,
Canoncal transformatons November 23, 2014 Recall that we have defned a symplectc transformaton to be any lnear transformaton M A B leavng the symplectc form nvarant, Ω AB M A CM B DΩ CD Coordnate transformatons,
6.854J / J Advanced Algorithms Fall 2008
 MIT OpenCourseWare http://ocw.mt.edu 6.854J / 18.415J Advanced Algorthms Fall 2008 For nformaton about ctng these materals or our Terms of Use, vst: http://ocw.mt.edu/terms. 18.415/6.854 Advanced Algorthms
MIT OpenCourseWare http://ocw.mt.edu 6.854J / 18.415J Advanced Algorthms Fall 2008 For nformaton about ctng these materals or our Terms of Use, vst: http://ocw.mt.edu/terms. 18.415/6.854 Advanced Algorthms
Bézier curves. Michael S. Floater. September 10, These notes provide an introduction to Bézier curves. i=0
 Bézer curves Mchael S. Floater September 1, 215 These notes provde an ntroducton to Bézer curves. 1 Bernsten polynomals Recall that a real polynomal of a real varable x R, wth degree n, s a functon of
Bézer curves Mchael S. Floater September 1, 215 These notes provde an ntroducton to Bézer curves. 1 Bernsten polynomals Recall that a real polynomal of a real varable x R, wth degree n, s a functon of
Econ107 Applied Econometrics Topic 3: Classical Model (Studenmund, Chapter 4)
") I. Classcal Assumptons Econ7 Appled Econometrcs Topc 3: Classcal Model (Studenmund, Chapter 4) We have defned OLS and studed some algebrac propertes of OLS. In ths topc we wll study statstcal propertes
I. Classcal Assumptons Econ7 Appled Econometrcs Topc 3: Classcal Model (Studenmund, Chapter 4) We have defned OLS and studed some algebrac propertes of OLS. In ths topc we wll study statstcal propertes
1 Matrix representations of canonical matrices
 1 Matrx representatons of canoncal matrces 2-d rotaton around the orgn: ( ) cos θ sn θ R 0 = sn θ cos θ 3-d rotaton around the x-axs: R x = 1 0 0 0 cos θ sn θ 0 sn θ cos θ 3-d rotaton around the y-axs:
1 Matrx representatons of canoncal matrces 2-d rotaton around the orgn: ( ) cos θ sn θ R 0 = sn θ cos θ 3-d rotaton around the x-axs: R x = 1 0 0 0 cos θ sn θ 0 sn θ cos θ 3-d rotaton around the y-axs:
C4B Machine Learning Answers II. = σ(z) (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )
 (1 σ(z)) 1 1 e z. e z = σ(1 σ) (1 + e z )") C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
C4B Machne Learnng Answers II.(a) Show that for the logstc sgmod functon dσ(z) dz = σ(z) ( σ(z)) A. Zsserman, Hlary Term 20 Start from the defnton of σ(z) Note that Then σ(z) = σ = dσ(z) dz = + e z e z
Economics 101. Lecture 4 - Equilibrium and Efficiency
 Economcs 0 Lecture 4 - Equlbrum and Effcency Intro As dscussed n the prevous lecture, we wll now move from an envronment where we looed at consumers mang decsons n solaton to analyzng economes full of
Economcs 0 Lecture 4 - Equlbrum and Effcency Intro As dscussed n the prevous lecture, we wll now move from an envronment where we looed at consumers mang decsons n solaton to analyzng economes full of
Learning Theory: Lecture Notes
 Learnng Theory: Lecture Notes Lecturer: Kamalka Chaudhur Scrbe: Qush Wang October 27, 2012 1 The Agnostc PAC Model Recall that one of the constrants of the PAC model s that the data dstrbuton has to be
Learnng Theory: Lecture Notes Lecturer: Kamalka Chaudhur Scrbe: Qush Wang October 27, 2012 1 The Agnostc PAC Model Recall that one of the constrants of the PAC model s that the data dstrbuton has to be
NUMERICAL DIFFERENTIATION
 NUMERICAL DIFFERENTIATION 1 Introducton Dfferentaton s a method to compute the rate at whch a dependent output y changes wth respect to the change n the ndependent nput x. Ths rate of change s called the
NUMERICAL DIFFERENTIATION 1 Introducton Dfferentaton s a method to compute the rate at whch a dependent output y changes wth respect to the change n the ndependent nput x. Ths rate of change s called the
The Expectation-Maximization Algorithm
 The Expectaton-Maxmaton Algorthm Charles Elan elan@cs.ucsd.edu November 16, 2007 Ths chapter explans the EM algorthm at multple levels of generalty. Secton 1 gves the standard hgh-level verson of the algorthm.
The Expectaton-Maxmaton Algorthm Charles Elan elan@cs.ucsd.edu November 16, 2007 Ths chapter explans the EM algorthm at multple levels of generalty. Secton 1 gves the standard hgh-level verson of the algorthm.
Homework Notes Week 7
 Homework Notes Week 7 Math 4 Sprng 4 #4 (a Complete the proof n example 5 that s an nner product (the Frobenus nner product on M n n (F In the example propertes (a and (d have already been verfed so we
Homework Notes Week 7 Math 4 Sprng 4 #4 (a Complete the proof n example 5 that s an nner product (the Frobenus nner product on M n n (F In the example propertes (a and (d have already been verfed so we
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 89 Fall 206 Introducton to Machne Learnng Fnal Do not open the exam before you are nstructed to do so The exam s closed book, closed notes except your one-page cheat sheet Usage of electronc devces
CS 89 Fall 206 Introducton to Machne Learnng Fnal Do not open the exam before you are nstructed to do so The exam s closed book, closed notes except your one-page cheat sheet Usage of electronc devces
4 Analysis of Variance (ANOVA) 5 ANOVA. 5.1 Introduction. 5.2 Fixed Effects ANOVA
 5 ANOVA. 5.1 Introduction. 5.2 Fixed Effects ANOVA") 4 Analyss of Varance (ANOVA) 5 ANOVA 51 Introducton ANOVA ANOVA s a way to estmate and test the means of multple populatons We wll start wth one-way ANOVA If the populatons ncluded n the study are selected
4 Analyss of Varance (ANOVA) 5 ANOVA 51 Introducton ANOVA ANOVA s a way to estmate and test the means of multple populatons We wll start wth one-way ANOVA If the populatons ncluded n the study are selected
THE ARIMOTO-BLAHUT ALGORITHM FOR COMPUTATION OF CHANNEL CAPACITY. William A. Pearlman. References: S. Arimoto - IEEE Trans. Inform. Thy., Jan.
 THE ARIMOTO-BLAHUT ALGORITHM FOR COMPUTATION OF CHANNEL CAPACITY Wllam A. Pearlman 2002 References: S. Armoto - IEEE Trans. Inform. Thy., Jan. 1972 R. Blahut - IEEE Trans. Inform. Thy., July 1972 Recall
THE ARIMOTO-BLAHUT ALGORITHM FOR COMPUTATION OF CHANNEL CAPACITY Wllam A. Pearlman 2002 References: S. Armoto - IEEE Trans. Inform. Thy., Jan. 1972 R. Blahut - IEEE Trans. Inform. Thy., July 1972 Recall
Homework Assignment 3 Due in class, Thursday October 15
 Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
INF 5860 Machine learning for image classification. Lecture 3 : Image classification and regression part II Anne Solberg January 31, 2018
 INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
INF 5860 Machne learnng for mage classfcaton Lecture 3 : Image classfcaton and regresson part II Anne Solberg January 3, 08 Today s topcs Multclass logstc regresson and softma Regularzaton Image classfcaton
Module 9. Lecture 6. Duality in Assignment Problems
 Module 9 1 Lecture 6 Dualty n Assgnment Problems In ths lecture we attempt to answer few other mportant questons posed n earler lecture for (AP) and see how some of them can be explaned through the concept
Module 9 1 Lecture 6 Dualty n Assgnment Problems In ths lecture we attempt to answer few other mportant questons posed n earler lecture for (AP) and see how some of them can be explaned through the concept
ECE559VV Project Report
 ECE559VV Project Report (Supplementary Notes Loc Xuan Bu I. MAX SUM-RATE SCHEDULING: THE UPLINK CASE We have seen (n the presentaton that, for downlnk (broadcast channels, the strategy maxmzng the sum-rate
ECE559VV Project Report (Supplementary Notes Loc Xuan Bu I. MAX SUM-RATE SCHEDULING: THE UPLINK CASE We have seen (n the presentaton that, for downlnk (broadcast channels, the strategy maxmzng the sum-rate
Nonlinear Classifiers II
 Nonlnear Classfers II Nonlnear Classfers: Introducton Classfers Supervsed Classfers Lnear Classfers Perceptron Least Squares Methods Lnear Support Vector Machne Nonlnear Classfers Part I: Mult Layer Neural
Nonlnear Classfers II Nonlnear Classfers: Introducton Classfers Supervsed Classfers Lnear Classfers Perceptron Least Squares Methods Lnear Support Vector Machne Nonlnear Classfers Part I: Mult Layer Neural
Winter 2008 CS567 Stochastic Linear/Integer Programming Guest Lecturer: Xu, Huan
 Wnter 2008 CS567 Stochastc Lnear/Integer Programmng Guest Lecturer: Xu, Huan Class 2: More Modelng Examples 1 Capacty Expanson Capacty expanson models optmal choces of the tmng and levels of nvestments
Wnter 2008 CS567 Stochastc Lnear/Integer Programmng Guest Lecturer: Xu, Huan Class 2: More Modelng Examples 1 Capacty Expanson Capacty expanson models optmal choces of the tmng and levels of nvestments
MAE140 - Linear Circuits - Fall 13 Midterm, October 31
 Instructons ME140 - Lnear Crcuts - Fall 13 Mdterm, October 31 () Ths exam s open book. You may use whatever wrtten materals you choose, ncludng your class notes and textbook. You may use a hand calculator
Instructons ME140 - Lnear Crcuts - Fall 13 Mdterm, October 31 () Ths exam s open book. You may use whatever wrtten materals you choose, ncludng your class notes and textbook. You may use a hand calculator
CS 229, Public Course Problem Set #3 Solutions: Learning Theory and Unsupervised Learning
 CS9 Problem Set #3 Solutons CS 9, Publc Course Problem Set #3 Solutons: Learnng Theory and Unsupervsed Learnng. Unform convergence and Model Selecton In ths problem, we wll prove a bound on the error of
CS9 Problem Set #3 Solutons CS 9, Publc Course Problem Set #3 Solutons: Learnng Theory and Unsupervsed Learnng. Unform convergence and Model Selecton In ths problem, we wll prove a bound on the error of
Introduction to Vapor/Liquid Equilibrium, part 2. Raoult s Law:
 CE304, Sprng 2004 Lecture 4 Introducton to Vapor/Lqud Equlbrum, part 2 Raoult s Law: The smplest model that allows us do VLE calculatons s obtaned when we assume that the vapor phase s an deal gas, and
CE304, Sprng 2004 Lecture 4 Introducton to Vapor/Lqud Equlbrum, part 2 Raoult s Law: The smplest model that allows us do VLE calculatons s obtaned when we assume that the vapor phase s an deal gas, and
Radar Trackers. Study Guide. All chapters, problems, examples and page numbers refer to Applied Optimal Estimation, A. Gelb, Ed.
 Radar rackers Study Gude All chapters, problems, examples and page numbers refer to Appled Optmal Estmaton, A. Gelb, Ed. Chapter Example.0- Problem Statement wo sensors Each has a sngle nose measurement
Radar rackers Study Gude All chapters, problems, examples and page numbers refer to Appled Optmal Estmaton, A. Gelb, Ed. Chapter Example.0- Problem Statement wo sensors Each has a sngle nose measurement
UVA CS / Introduc8on to Machine Learning and Data Mining. Lecture 10: Classifica8on with Support Vector Machine (cont.
 UVA CS 4501-001 / 6501 007 Introduc8on to Machne Learnng and Data Mnng Lecture 10: Classfca8on wth Support Vector Machne (cont. ) Yanjun Q / Jane Unversty of Vrgna Department of Computer Scence 9/6/14
UVA CS 4501-001 / 6501 007 Introduc8on to Machne Learnng and Data Mnng Lecture 10: Classfca8on wth Support Vector Machne (cont. ) Yanjun Q / Jane Unversty of Vrgna Department of Computer Scence 9/6/14
MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.265/15.070J Fall 2013 Lecture 12 10/21/2013. Martingale Concentration Inequalities and Applications
 MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.65/15.070J Fall 013 Lecture 1 10/1/013 Martngale Concentraton Inequaltes and Applcatons Content. 1. Exponental concentraton for martngales wth bounded ncrements.
MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.65/15.070J Fall 013 Lecture 1 10/1/013 Martngale Concentraton Inequaltes and Applcatons Content. 1. Exponental concentraton for martngales wth bounded ncrements.
College of Computer & Information Science Fall 2009 Northeastern University 20 October 2009
 College of Computer & Informaton Scence Fall 2009 Northeastern Unversty 20 October 2009 CS7880: Algorthmc Power Tools Scrbe: Jan Wen and Laura Poplawsk Lecture Outlne: Prmal-dual schema Network Desgn:
College of Computer & Informaton Scence Fall 2009 Northeastern Unversty 20 October 2009 CS7880: Algorthmc Power Tools Scrbe: Jan Wen and Laura Poplawsk Lecture Outlne: Prmal-dual schema Network Desgn:
Maximum Likelihood Estimation
 Maxmum Lkelhood Estmaton INFO-2301: Quanttatve Reasonng 2 Mchael Paul and Jordan Boyd-Graber MARCH 7, 2017 INFO-2301: Quanttatve Reasonng 2 Paul and Boyd-Graber Maxmum Lkelhood Estmaton 1 of 9 Why MLE?
Maxmum Lkelhood Estmaton INFO-2301: Quanttatve Reasonng 2 Mchael Paul and Jordan Boyd-Graber MARCH 7, 2017 INFO-2301: Quanttatve Reasonng 2 Paul and Boyd-Graber Maxmum Lkelhood Estmaton 1 of 9 Why MLE?
C/CS/Phy191 Problem Set 3 Solutions Out: Oct 1, 2008., where ( 00. ), so the overall state of the system is ) ( ( ( ( 00 ± 11 ), Φ ± = 1
, so the overall state of the system is ) ( ( ( ( 00 ± 11 ), Φ ± = 1") C/CS/Phy9 Problem Set 3 Solutons Out: Oct, 8 Suppose you have two qubts n some arbtrary entangled state ψ You apply the teleportaton protocol to each of the qubts separately What s the resultng state obtaned
C/CS/Phy9 Problem Set 3 Solutons Out: Oct, 8 Suppose you have two qubts n some arbtrary entangled state ψ You apply the teleportaton protocol to each of the qubts separately What s the resultng state obtaned
DISCRIMINANTS AND RAMIFIED PRIMES. 1. Introduction A prime number p is said to be ramified in a number field K if the prime ideal factorization
 DISCRIMINANTS AND RAMIFIED PRIMES KEITH CONRAD 1. Introducton A prme number p s sad to be ramfed n a number feld K f the prme deal factorzaton (1.1) (p) = po K = p e 1 1 peg g has some e greater than 1.
DISCRIMINANTS AND RAMIFIED PRIMES KEITH CONRAD 1. Introducton A prme number p s sad to be ramfed n a number feld K f the prme deal factorzaton (1.1) (p) = po K = p e 1 1 peg g has some e greater than 1.
Supporting Information
 Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
STAT 3008 Applied Regression Analysis
 STAT 3008 Appled Regresson Analyss Tutoral : Smple Lnear Regresson LAI Chun He Department of Statstcs, The Chnese Unversty of Hong Kong 1 Model Assumpton To quantfy the relatonshp between two factors,
STAT 3008 Appled Regresson Analyss Tutoral : Smple Lnear Regresson LAI Chun He Department of Statstcs, The Chnese Unversty of Hong Kong 1 Model Assumpton To quantfy the relatonshp between two factors,
Predictive Analytics : QM901.1x Prof U Dinesh Kumar, IIMB. All Rights Reserved, Indian Institute of Management Bangalore
 Sesson Outlne Introducton to classfcaton problems and dscrete choce models. Introducton to Logstcs Regresson. Logstc functon and Logt functon. Maxmum Lkelhood Estmator (MLE) for estmaton of LR parameters.
Sesson Outlne Introducton to classfcaton problems and dscrete choce models. Introducton to Logstcs Regresson. Logstc functon and Logt functon. Maxmum Lkelhood Estmator (MLE) for estmaton of LR parameters.
Difference Equations
 Dfference Equatons c Jan Vrbk 1 Bascs Suppose a sequence of numbers, say a 0,a 1,a,a 3,... s defned by a certan general relatonshp between, say, three consecutve values of the sequence, e.g. a + +3a +1
Dfference Equatons c Jan Vrbk 1 Bascs Suppose a sequence of numbers, say a 0,a 1,a,a 3,... s defned by a certan general relatonshp between, say, three consecutve values of the sequence, e.g. a + +3a +1
Chapter Newton s Method
 Chapter 9. Newton s Method After readng ths chapter, you should be able to:. Understand how Newton s method s dfferent from the Golden Secton Search method. Understand how Newton s method works 3. Solve
Chapter 9. Newton s Method After readng ths chapter, you should be able to:. Understand how Newton s method s dfferent from the Golden Secton Search method. Understand how Newton s method works 3. Solve
14 Lagrange Multipliers
 Lagrange Multplers 14 Lagrange Multplers The Method of Lagrange Multplers s a powerful technque for constraned optmzaton. Whle t has applcatons far beyond machne learnng t was orgnally developed to solve
Lagrange Multplers 14 Lagrange Multplers The Method of Lagrange Multplers s a powerful technque for constraned optmzaton. Whle t has applcatons far beyond machne learnng t was orgnally developed to solve