CSC2515 Winter 2015 Introduc3on to Machine Learning. Lecture 5: Clustering, mixture models, and EM
|
|
|
- Berenice Hill
- 5 years ago
- Views:
Transcription
1 CSC2515 Winter 2015 Introdu3on to Mahine Learning Leture 5: Clustering, mixture models, and EM All leture slides will be available as.pdf on the ourse website: CSC2515_Winter15.html
2 Overview Clustering with K- means, and a proof of onvergene Clustering with K- medians Clustering with a mixture of Gaussians The EM algorithm, and a proof of onvergene Variational inferene
3 Unsupervised Learning Supervised learning algorithms have a lear goal: produe desired outputs for given inputs Goal of unsupervised learning algorithms (no expliit feedbak whether outputs of system are orret) less lear: Redue dimensionality Find lusters Model data density Find hidden auses Key utility Compress data Detet outliers Failitate other learning
4 Major types Primary problems, approahes in unsupervised learning fall into three types: 1. Dimensionality redution: represent eah input ase using a small number of variables (e.g., prinipal omponents analysis, fator analysis, independent omponents analysis) 2. Clustering: represent eah input ase using a prototype example (e.g., k- means, mixture models) 3. Density estimation: estimating the probability distribution over the data spae
5 Clustering Grouping N examples into K lusters one of anonial problems in unsupervised learning Motivations: predition; lossy ompression; outlier detetion We assume that the data was generated from a number of different lasses. The aim is to luster data from the same lass together. How many lasses? Why not put eah datapoint into a separate lass? What is the objetive funtion that is optimized by sensible lusterings?
6 The K- means algorithm Assume the data lives in a Eulidean spae. Assume we want K lasses. Assignments Initialization: randomly loated luster enters The algorithm alternates between two steps: Assignment step: Assign eah datapoint to the losest luster. Refitted means Re]itting step: Move eah luster enter to the enter of gravity of the data assigned to it.
7 K- means algorithm Initialization: Set K means {m k } to random values Assignment: Eah datapoint n assigned to nearest mean responsibilities: ˆk (n) = argmin k {d(m k, x (n) )} r k (n) =1 ˆk (n) = k Update: Model parameters, means, are adjusted to math sample means of datapoints they are responsible for: m k = n (n) r n k r k (n) x (n) Repeat assignment and update steps until assignments do not hange
8 Ques3ons about K- means Why does update set m k to mean of assigned points? Where does distane d ome from? What if we used a different distane measure? How an we hoose best distane? How to hoose K? How an we hoose between alternative lusterings? Will it onverge? Hard ases unequal spreads, non- irular spreads, inbetween points
9 Why K- means onverges Whenever an assignment is hanged, the sum squared distanes of datapoints from their assigned luster enters is redued. Whenever a luster enter is moved the sum squared distanes of the datapoints from their urrently assigned luster enters is redued. Test for onvergene: If the assignments do not hange in the assignment step, we have onverged (to at least a loal minimum).
10 K- means: Details Objetive: minimize sum squared distane of datapoints to their assigned luster enters E({m},{r}) = (n) r k n k m k x (n) 2 s.t. r (n) k =1, n; r (n) k {0,1}, k, n k Optimization method is a form of oordinate desent ( blok oordinate desent ) Fix enters, optimize assignments (hoose luster whose mean is losest) Fix assignments, optimize means (average of assigned datapoints)
11 Loal minima There is nothing to prevent k- means getting stuk at loal minima. A bad loal optimum We ould try many random starting points We ould try non- loal split- and- merge moves: Simultaneously merge two nearby lusters and split a big luster into two.


12 Applia3on of K- Means Clustering
13 K- medioids K- Means: Choose number of lusters K; algorithm s primary aim is to strategially position these K means Alternative: allow eah datapoint to potentially at as a luster representative; algorithm assigns eah point to one of these representatives (exemplars)
14 K- medioids algorithm Initialization: Set random set K of datapoints as medioids Assignment: Eah datapoint assigned to nearest medioid ˆk () = argmin k {d(x k, x () )} r k () =1 ˆk () = k Update: For eah medioid k, for eah datapoint, swap k and and ompute total ost J Selet on]iguration with lowest ost k J({x},{r}) = r k d(x (), x k ) Repeat assignment and update steps until assignments do not hange
15 K- medioids vs. K- means Both partition data into K partitions Both an utilize various distane funtions, but K- medioids an pre- ompute pairwise distanes K- medioids hooses datapoints as enters (medioids/exemplars), while K- means allows the means to be arbitrary loations à disrete vs. ontinuous optimization K- medioids more robust to noise and outliers
16 SoP k- means Instead of making hard assignments of datapoints to lusters, we an make soft assignments. One luster may have a responsibility of.7 for a datapoint and another may have a responsibility of.3. Allows a luster to use more information about the data in the re]itting step. What happens to our onvergene guarantee? How do we deide on the soft assignments?
17 SoP K- means algorithm Initialization: Set K means {m k } to random values Assignment: Eah datapoint n given soft degree of assignment to eah luster mean k, based on responsibilities r k (n) = k' exp[ βd(m k, x (n) )] exp[ βd(m k', x (n) )] Update: Model parameters, means, are adjusted to math sample means of datapoints they are responsible for: m k = n (n) r n k r k (n) x (n) Repeat assignment and update steps until assignments do not hange
18 Ques3ons about sop K- means How to set β? What about problems with elongated lusters? Clusters with unequal weight and width
19 Latent variable models Adopt a different view of lustering, in terms of a model with latent variables: variables that are always unobserved We may want to intentionally introdue latent variables to model omplex dependenies between variables without looking at dependenies between them diretly - - this an atually simplify the model Form of divide- and- onquer: use simple parts to build omplex models (e.g., multimodal densities, or pieewise- linear regression)
20 Mixture models Most ommon example is a mixture model: most basi form of latent variable model, with single disrete latent variable We have de]ined the hidden ause to be disrete: a multinomial random variable And the observation is Gaussian The model allows for other distributions Example: Bernoulli observations Another example: Continuous hidden (latent) variable see next leture Hidden ause Visible effet But these are only the simplest models: an add many hidden & visible nodes, layers
21 Learning is harder with latent variables In fully observed settings, probability model is a produt, so the log likelihood is a sum, terms deouple: With latent variables, probability ontains a sum so the log- likelihood has all parameters oupled together + = = ), ( log ) ( log ), ( log ) ; ( y x p p p D θ θ θ θ x y x y x l ), ( ) ( log ), ( log ) ; ( x z p p p D θ θ θ θ z x z z x z z = = l
22 Diret learning in mixtures of Gaussians We an treat likelihood as an objetive funtion and try to optimize it as a funtion of θ by taking gradients (as we did before, for example in neural networks) If you work thru the gradients, you ll ]ind that In a mixture of Gaussians for example: To use optimization methods (e.g., onjugate gradient), have to ensure that parameters respet onstraints reparametrize in terms of unonstrained values = = k ) ( log ) ( ) ( k k k k k k k k k p r r θ θ α θ θ α θ θ x l l = k 2 ) / ( ) ( k k k k k r σ α θ µ x µ l
23 EM: An alterna3ve learning approah Use the posterior weightings to softly label the data Then solve for parameters given these urrent weightings, and realulate posteriors (weights) given new parameters Expetation- Maximization is a form of bound optimization, as opposed to gradient desent With respet to latent variables, guessing their values makes the learning fully- observed l( θ; D) = l( θ; D) = log p( x, z θ) = log p( z θz ) + log log z p( z p( x z, θ ) Note: EM is not a ost funtion, suh as ross- entropy; and EM is not a model, suh as a mixture- of- Gaussians With latent variables, probability ontains a sum so the log- likelihood has all parameters oupled together θ ) p( x z z, θ ) x x
24 Graphial model view of mixture models Eah node is a random variable Blue node: observed variable (data, aka visibles) Red node: hidden variable [luster assignment] The model de]ines a probability distribution over all the nodes The model generates data by piking state for hidden node based on prior The distribution over leaf node (data) is de]ined by its parent(s). Hidden ause Visible effet
25 The mixture of Gaussians genera3ve model First pik one of the k Gaussians with a probability that is alled its mixing proportion. Then generate a random point from the hosen Gaussian. The probability of generating the exat data we observed is zero, but we an still try to maximize the probability density. Adjust the means of the Gaussians Adjust the varianes of the Gaussians on eah dimension. Adjust the mixing proportions of the Gaussians.
26 FiTng a mixture of Gaussians Optimization uses the Expetation Maximization algorithm, whih alternates between two steps: E- step: Compute the posterior probability that eah Gaussian generates eah datapoint M- step: Assuming that the data really was generated this way, hange the parameters of eah Gaussian to maximize the probability that it would generate the data it is urrently responsible for.
27 The E- step: Compu3ng responsibili3es In order to adjust the parameters, we must ]irst solve the inferene problem: Whih Gaussian generated eah datapoint? We annot be sure, so it s a distribution over all possibilities. Use Bayes theorem to get posterior probabilities Posterior for Gaussian i p(i x () ) = p(i)p(x() i) p(x () ) j p(x () ) = p( j)p(x () j) p(i) = π i p(x () i) = Prior for Gaussian i d=d d=1 Mixing proportion 1 2πσ i,d x d e Bayes theorem () µ i,d 2 2 2σ i,d Produt over all data dimensions
28 The M- step: Compu3ng new mixing propor3ons Eah Gaussian gets a ertain amount of posterior probability for eah datapoint. The optimal mixing proportion to use (given these posterior probabilities) is just the fration of the data that the Gaussian gets responsibility for. π i new = Posterior for Gaussian i =N =1 p(i x () ) N Data for training ase Number of training ases
29 More M- step: Compu3ng the new means We just take the enter- of gravity of the data that the Gaussian is responsible for. Just like in K- means, exept the data is weighted by the posterior probability of the Gaussian. Guaranteed to lie in the onvex hull of the data Could be big initial jump µ i new = p(i x () ) x () p(i x () )
30 More M- step: Compu3ng the new varianes We ]it the variane of eah Gaussian, i, on eah dimension, d, to the posterior- weighted data Its more ompliated if we use a full- ovariane Gaussian that is not aligned with the axes. 2 σ i,d = p(i x () ) x () d µ new i,d 2 p(i x () )

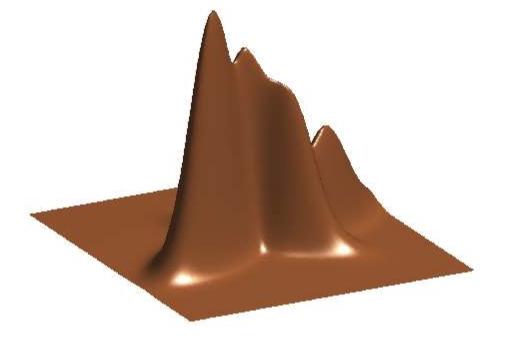
31 Visualizing a Mixture of Gaussians
32 Mixture of Gaussians vs. K- means EM for mixtures of Gaussians is just like a soft version of K- means, with ]ixed priors and ovariane Instead of hard assignments in the E- step, we do soft assignments based on the softmax of the squared distane from eah point to eah luster. Eah enter moved by weighted means of the data, with weights given by soft assignments In K- means, weights are 0 or 1
33 How do we know that the updates improve things? Updating eah Gaussian de]initely improves the probability of generating the data if we generate it from the same Gaussians after the parameter updates. But we know that the posterior will hange after updating the parameters. A good way to show that this is OK is to show that there is a single funtion that is improved by both the E- step and the M- step. The funtion we need is alled Free Energy.
34 Deriving varia3onal free energy We an derive variational free energy as the objetive funtion that is minimized by both steps of the Expetation and Maximization algorithm (EM).
35 Why EM onverges Free energy F is a ost funtion that is redued by both the E- step and the M- step. Cost = F = expeted energy entropy The expeted energy term measures how dif]iult it is to generate eah datapoint from the Gaussians it is assigned to. It would be happiest assigning eah datapoint to the Gaussian that generates it most easily (as in K- means). The entropy term enourages soft assignments. It would be happiest spreading the assignment probabilities for eah datapoint equally between all the Gaussians.
36 The expeted energy of a datapoint The expeted energy of datapoint is the average negative log probability of generating the datapoint The average is taken using the probabilities of assigning the datapoint to eah Gaussian. Can use any probabilities we like use some distribution q (more on this soon) q(i x () ) logπ i log p(x () µ i,σ i 2 ) probability of assigning to Gaussian i i parameters of Gaussian i ( ) datapoint Gaussian Loation of datapoint
37 The entropy term This term wants the assignment probabilities to be as uniform as possible (max. entropy) It ]ights the expeted energy term. entropy = q(i x () ) logq(i x () ) i log probabilities are always negative
38 The E- step hooses assignment probabili3es that minimize F (with parameters of Gaussians fixed) How do we ]ind assignment probabilities for a datapoint that minimize the ost and sum to 1? The optimal solution to the trade- off between expeted energy and entropy is to make the probabilities be proportional to the exponentiated negative energies: energy of assigning to i = logπ i log p(x () µ i,σ i 2 ) optimal value of q(i x () ) exp( energy(,i)) π i p(x () i) So using the posterior probabilities as assignment probabilities minimizes the ost funtion!
39 M- step hooses parameters that minimize F (with the assignment probabili3es held fixed) This is easy. We just ]it eah Gaussian to the data weighted by the assignment probabilities that the Gaussian has for the data. The entropy term is unaffeted (sine it only depends on the assignment probabilities) When you ]it a Gaussian to data you are maximizing the log probability of the data given the Gaussian. This is the same as minimizing the energies of the datapoints that the Gaussian is responsible for. If a Gaussian is assigned a probability of 0.7 for a datapoint the ]itting treats it as 0.7 of an observation. Sine both the E- step and the M- step derease the same ost funtion, EM onverges.
40 Summary: EM is oordinate desent in Free Energy F(x () ) = q(i x () ) logπ i log p(x () i) i ( ) q(i x () )( logq(i x () )) Think of eah different setting of the hidden and visible variables as a on]iguration. The energy of the on]iguration has two terms: The log prob of generating the hidden values The log prob of generating the visible values from the hidden ones The E- step minimizes F by ]inding the best distribution over hidden on]igurations for eah data point. The M- step holds the distribution ]ixed and minimizes F by hanging the parameters that determine the energy of a on]iguration. i
41 Reap: EM algorithm A way of maximizing likelihood for latent variable models EM is general algorithm: ]inds ML parameters when the original hard problem an be broken up into two easier piees: Infer distribution over hidden variables (given urrent parameters) Using this omplete data, ]ind the maximum likelihood parameter estimates Allows onstraints to be enfored easily (versus Lagrange multipliers in gradient desent) Works ]ine if distribution over hidden variables easy to ompute
42 The advantage of using F to understand EM There is learly no need to use the optimal distribution over hidden on]igurations. We an use any distribution that is onvenient so long as: we always update the distribution in a way that improves F We hange the parameters to improve F given the urrent distribution. This is very liberating. It allows us to justify all sorts of weird algorithms
43 A trade- off between how well the model fits the data and the auray of inferene parameters data approximating posterior distribution true posterior distribution F(q,θ) = d log p(d θ) KL(q(d) p(d)) new objetive funtion How well the model fits the data The inauray of inferene This makes it feasible to ]it very ompliated models, but the approximations that are tratable may be poor.
44
Probabilistic Graphical Models
 Probabilisti Graphial Models David Sontag New York University Leture 12, April 19, 2012 Aknowledgement: Partially based on slides by Eri Xing at CMU and Andrew MCallum at UMass Amherst David Sontag (NYU)
Probabilisti Graphial Models David Sontag New York University Leture 12, April 19, 2012 Aknowledgement: Partially based on slides by Eri Xing at CMU and Andrew MCallum at UMass Amherst David Sontag (NYU)
Maximum Entropy and Exponential Families
 Maximum Entropy and Exponential Families April 9, 209 Abstrat The goal of this note is to derive the exponential form of probability distribution from more basi onsiderations, in partiular Entropy. It
Maximum Entropy and Exponential Families April 9, 209 Abstrat The goal of this note is to derive the exponential form of probability distribution from more basi onsiderations, in partiular Entropy. It
10.5 Unsupervised Bayesian Learning
 The Bayes Classifier Maximum-likelihood methods: Li Yu Hongda Mao Joan Wang parameter vetor is a fixed but unknown value Bayes methods: parameter vetor is a random variable with known prior distribution
The Bayes Classifier Maximum-likelihood methods: Li Yu Hongda Mao Joan Wang parameter vetor is a fixed but unknown value Bayes methods: parameter vetor is a random variable with known prior distribution
max min z i i=1 x j k s.t. j=1 x j j:i T j
 AM 221: Advaned Optimization Spring 2016 Prof. Yaron Singer Leture 22 April 18th 1 Overview In this leture, we will study the pipage rounding tehnique whih is a deterministi rounding proedure that an be
AM 221: Advaned Optimization Spring 2016 Prof. Yaron Singer Leture 22 April 18th 1 Overview In this leture, we will study the pipage rounding tehnique whih is a deterministi rounding proedure that an be
Model-based mixture discriminant analysis an experimental study
 Model-based mixture disriminant analysis an experimental study Zohar Halbe and Mayer Aladjem Department of Eletrial and Computer Engineering, Ben-Gurion University of the Negev P.O.Box 653, Beer-Sheva,
Model-based mixture disriminant analysis an experimental study Zohar Halbe and Mayer Aladjem Department of Eletrial and Computer Engineering, Ben-Gurion University of the Negev P.O.Box 653, Beer-Sheva,
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
But if z is conditioned on, we need to model it:
 Partially Unobserved Variables Lecture 8: Unsupervised Learning & EM Algorithm Sam Roweis October 28, 2003 Certain variables q in our models may be unobserved, either at training time or at test time or
Partially Unobserved Variables Lecture 8: Unsupervised Learning & EM Algorithm Sam Roweis October 28, 2003 Certain variables q in our models may be unobserved, either at training time or at test time or
Variables which are always unobserved are called latent variables or sometimes hidden variables. e.g. given y,x fit the model p(y x) = z p(y x,z)p(z)
 = z p(y x,z)p(z)") CSC2515 Machine Learning Sam Roweis Lecture 8: Unsupervised Learning & EM Algorithm October 31, 2006 Partially Unobserved Variables 2 Certain variables q in our models may be unobserved, either at training
CSC2515 Machine Learning Sam Roweis Lecture 8: Unsupervised Learning & EM Algorithm October 31, 2006 Partially Unobserved Variables 2 Certain variables q in our models may be unobserved, either at training
CMSC 451: Lecture 9 Greedy Approximation: Set Cover Thursday, Sep 28, 2017
 CMSC 451: Leture 9 Greedy Approximation: Set Cover Thursday, Sep 28, 2017 Reading: Chapt 11 of KT and Set 54 of DPV Set Cover: An important lass of optimization problems involves overing a ertain domain,
CMSC 451: Leture 9 Greedy Approximation: Set Cover Thursday, Sep 28, 2017 Reading: Chapt 11 of KT and Set 54 of DPV Set Cover: An important lass of optimization problems involves overing a ertain domain,
2 The Bayesian Perspective of Distributions Viewed as Information
 A PRIMER ON BAYESIAN INFERENCE For the next few assignments, we are going to fous on the Bayesian way of thinking and learn how a Bayesian approahes the problem of statistial modeling and inferene. The
A PRIMER ON BAYESIAN INFERENCE For the next few assignments, we are going to fous on the Bayesian way of thinking and learn how a Bayesian approahes the problem of statistial modeling and inferene. The
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Lecture 3 - Lorentz Transformations
 Leture - Lorentz Transformations A Puzzle... Example A ruler is positioned perpendiular to a wall. A stik of length L flies by at speed v. It travels in front of the ruler, so that it obsures part of the
Leture - Lorentz Transformations A Puzzle... Example A ruler is positioned perpendiular to a wall. A stik of length L flies by at speed v. It travels in front of the ruler, so that it obsures part of the
CSC321: 2011 Introduction to Neural Networks and Machine Learning. Lecture 11: Bayesian learning continued. Geoffrey Hinton
 CSC31: 011 Introdution to Neural Networks and Mahine Learning Leture 11: Bayesian learning ontinued Geoffrey Hinton Bayes Theorem, Prior robability of weight vetor Posterior robability of weight vetor
CSC31: 011 Introdution to Neural Networks and Mahine Learning Leture 11: Bayesian learning ontinued Geoffrey Hinton Bayes Theorem, Prior robability of weight vetor Posterior robability of weight vetor
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Lecture 7: Sampling/Projections for Least-squares Approximation, Cont. 7 Sampling/Projections for Least-squares Approximation, Cont.
 Stat60/CS94: Randomized Algorithms for Matries and Data Leture 7-09/5/013 Leture 7: Sampling/Projetions for Least-squares Approximation, Cont. Leturer: Mihael Mahoney Sribe: Mihael Mahoney Warning: these
Stat60/CS94: Randomized Algorithms for Matries and Data Leture 7-09/5/013 Leture 7: Sampling/Projetions for Least-squares Approximation, Cont. Leturer: Mihael Mahoney Sribe: Mihael Mahoney Warning: these
CSC321: 2011 Introduction to Neural Networks and Machine Learning. Lecture 10: The Bayesian way to fit models. Geoffrey Hinton
 CSC31: 011 Introdution to Neural Networks and Mahine Learning Leture 10: The Bayesian way to fit models Geoffrey Hinton The Bayesian framework The Bayesian framework assumes that we always have a rior
CSC31: 011 Introdution to Neural Networks and Mahine Learning Leture 10: The Bayesian way to fit models Geoffrey Hinton The Bayesian framework The Bayesian framework assumes that we always have a rior
The Hanging Chain. John McCuan. January 19, 2006
 The Hanging Chain John MCuan January 19, 2006 1 Introdution We onsider a hain of length L attahed to two points (a, u a and (b, u b in the plane. It is assumed that the hain hangs in the plane under a
The Hanging Chain John MCuan January 19, 2006 1 Introdution We onsider a hain of length L attahed to two points (a, u a and (b, u b in the plane. It is assumed that the hain hangs in the plane under a
Advanced Computational Fluid Dynamics AA215A Lecture 4
 Advaned Computational Fluid Dynamis AA5A Leture 4 Antony Jameson Winter Quarter,, Stanford, CA Abstrat Leture 4 overs analysis of the equations of gas dynamis Contents Analysis of the equations of gas
Advaned Computational Fluid Dynamis AA5A Leture 4 Antony Jameson Winter Quarter,, Stanford, CA Abstrat Leture 4 overs analysis of the equations of gas dynamis Contents Analysis of the equations of gas
Some facts you should know that would be convenient when evaluating a limit:
 Some fats you should know that would be onvenient when evaluating a it: When evaluating a it of fration of two funtions, f(x) x a g(x) If f and g are both ontinuous inside an open interval that ontains
Some fats you should know that would be onvenient when evaluating a it: When evaluating a it of fration of two funtions, f(x) x a g(x) If f and g are both ontinuous inside an open interval that ontains
Millennium Relativity Acceleration Composition. The Relativistic Relationship between Acceleration and Uniform Motion
 Millennium Relativity Aeleration Composition he Relativisti Relationship between Aeleration and niform Motion Copyright 003 Joseph A. Rybzyk Abstrat he relativisti priniples developed throughout the six
Millennium Relativity Aeleration Composition he Relativisti Relationship between Aeleration and niform Motion Copyright 003 Joseph A. Rybzyk Abstrat he relativisti priniples developed throughout the six
Methods of evaluating tests
 Methods of evaluating tests Let X,, 1 Xn be i.i.d. Bernoulli( p ). Then 5 j= 1 j ( 5, ) T = X Binomial p. We test 1 H : p vs. 1 1 H : p>. We saw that a LRT is 1 if t k* φ ( x ) =. otherwise (t is the observed
Methods of evaluating tests Let X,, 1 Xn be i.i.d. Bernoulli( p ). Then 5 j= 1 j ( 5, ) T = X Binomial p. We test 1 H : p vs. 1 1 H : p>. We saw that a LRT is 1 if t k* φ ( x ) =. otherwise (t is the observed
Complexity of Regularization RBF Networks
 Complexity of Regularization RBF Networks Mark A Kon Department of Mathematis and Statistis Boston University Boston, MA 02215 mkon@buedu Leszek Plaskota Institute of Applied Mathematis University of Warsaw
Complexity of Regularization RBF Networks Mark A Kon Department of Mathematis and Statistis Boston University Boston, MA 02215 mkon@buedu Leszek Plaskota Institute of Applied Mathematis University of Warsaw
Danielle Maddix AA238 Final Project December 9, 2016
 Struture and Parameter Learning in Bayesian Networks with Appliations to Prediting Breast Caner Tumor Malignany in a Lower Dimension Feature Spae Danielle Maddix AA238 Final Projet Deember 9, 2016 Abstrat
Struture and Parameter Learning in Bayesian Networks with Appliations to Prediting Breast Caner Tumor Malignany in a Lower Dimension Feature Spae Danielle Maddix AA238 Final Projet Deember 9, 2016 Abstrat
18.05 Problem Set 6, Spring 2014 Solutions
 8.5 Problem Set 6, Spring 4 Solutions Problem. pts.) a) Throughout this problem we will let x be the data of 4 heads out of 5 tosses. We have 4/5 =.56. Computing the likelihoods: 5 5 px H )=.5) 5 px H
8.5 Problem Set 6, Spring 4 Solutions Problem. pts.) a) Throughout this problem we will let x be the data of 4 heads out of 5 tosses. We have 4/5 =.56. Computing the likelihoods: 5 5 px H )=.5) 5 px H
Probabilistic Graphical Models
 Probabilisti Graphial Models 0-708 Undireted Graphial Models Eri Xing Leture, Ot 7, 2005 Reading: MJ-Chap. 2,4, and KF-hap5 Review: independene properties of DAGs Defn: let I l (G) be the set of loal independene
Probabilisti Graphial Models 0-708 Undireted Graphial Models Eri Xing Leture, Ot 7, 2005 Reading: MJ-Chap. 2,4, and KF-hap5 Review: independene properties of DAGs Defn: let I l (G) be the set of loal independene
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Expectation Maximization Algorithm
 Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Hankel Optimal Model Order Reduction 1
 Massahusetts Institute of Tehnology Department of Eletrial Engineering and Computer Siene 6.245: MULTIVARIABLE CONTROL SYSTEMS by A. Megretski Hankel Optimal Model Order Redution 1 This leture overs both
Massahusetts Institute of Tehnology Department of Eletrial Engineering and Computer Siene 6.245: MULTIVARIABLE CONTROL SYSTEMS by A. Megretski Hankel Optimal Model Order Redution 1 This leture overs both
General Equilibrium. What happens to cause a reaction to come to equilibrium?
 General Equilibrium Chemial Equilibrium Most hemial reations that are enountered are reversible. In other words, they go fairly easily in either the forward or reverse diretions. The thing to remember
General Equilibrium Chemial Equilibrium Most hemial reations that are enountered are reversible. In other words, they go fairly easily in either the forward or reverse diretions. The thing to remember
CSE446: Clustering and EM Spring 2017
 CSE446: Clustering and EM Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, and Luke Zettlemoyer Clustering systems: Unsupervised learning Clustering Detect patterns in unlabeled
CSE446: Clustering and EM Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, and Luke Zettlemoyer Clustering systems: Unsupervised learning Clustering Detect patterns in unlabeled
Modeling Probabilistic Measurement Correlations for Problem Determination in Large-Scale Distributed Systems
 009 9th IEEE International Conferene on Distributed Computing Systems Modeling Probabilisti Measurement Correlations for Problem Determination in Large-Sale Distributed Systems Jing Gao Guofei Jiang Haifeng
009 9th IEEE International Conferene on Distributed Computing Systems Modeling Probabilisti Measurement Correlations for Problem Determination in Large-Sale Distributed Systems Jing Gao Guofei Jiang Haifeng
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering, K-Means, EM Tutorial
 Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
DIGITAL DISTANCE RELAYING SCHEME FOR PARALLEL TRANSMISSION LINES DURING INTER-CIRCUIT FAULTS
 CHAPTER 4 DIGITAL DISTANCE RELAYING SCHEME FOR PARALLEL TRANSMISSION LINES DURING INTER-CIRCUIT FAULTS 4.1 INTRODUCTION Around the world, environmental and ost onsiousness are foring utilities to install
CHAPTER 4 DIGITAL DISTANCE RELAYING SCHEME FOR PARALLEL TRANSMISSION LINES DURING INTER-CIRCUIT FAULTS 4.1 INTRODUCTION Around the world, environmental and ost onsiousness are foring utilities to install
Based on slides by Richard Zemel
 CSC 412/2506 Winter 2018 Probabilistic Learning and Reasoning Lecture 3: Directed Graphical Models and Latent Variables Based on slides by Richard Zemel Learning outcomes What aspects of a model can we
CSC 412/2506 Winter 2018 Probabilistic Learning and Reasoning Lecture 3: Directed Graphical Models and Latent Variables Based on slides by Richard Zemel Learning outcomes What aspects of a model can we
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
A Queueing Model for Call Blending in Call Centers
 A Queueing Model for Call Blending in Call Centers Sandjai Bhulai and Ger Koole Vrije Universiteit Amsterdam Faulty of Sienes De Boelelaan 1081a 1081 HV Amsterdam The Netherlands E-mail: {sbhulai, koole}@s.vu.nl
A Queueing Model for Call Blending in Call Centers Sandjai Bhulai and Ger Koole Vrije Universiteit Amsterdam Faulty of Sienes De Boelelaan 1081a 1081 HV Amsterdam The Netherlands E-mail: {sbhulai, koole}@s.vu.nl
Data Preprocessing. Cluster Similarity
 1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Mixtures of Gaussians continued
 Mixtures of Gaussians continued Machine Learning CSE446 Carlos Guestrin University of Washington May 17, 2013 1 One) bad case for k-means n Clusters may overlap n Some clusters may be wider than others
Mixtures of Gaussians continued Machine Learning CSE446 Carlos Guestrin University of Washington May 17, 2013 1 One) bad case for k-means n Clusters may overlap n Some clusters may be wider than others
Statistical learning. Chapter 20, Sections 1 4 1
 Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Modes are solutions, of Maxwell s equation applied to a specific device.
 Mirowave Integrated Ciruits Prof. Jayanta Mukherjee Department of Eletrial Engineering Indian Institute of Tehnology, Bombay Mod 01, Le 06 Mirowave omponents Welome to another module of this NPTEL mok
Mirowave Integrated Ciruits Prof. Jayanta Mukherjee Department of Eletrial Engineering Indian Institute of Tehnology, Bombay Mod 01, Le 06 Mirowave omponents Welome to another module of this NPTEL mok
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
Chapter 8 Hypothesis Testing
 Leture 5 for BST 63: Statistial Theory II Kui Zhang, Spring Chapter 8 Hypothesis Testing Setion 8 Introdution Definition 8 A hypothesis is a statement about a population parameter Definition 8 The two
Leture 5 for BST 63: Statistial Theory II Kui Zhang, Spring Chapter 8 Hypothesis Testing Setion 8 Introdution Definition 8 A hypothesis is a statement about a population parameter Definition 8 The two
Likelihood-confidence intervals for quantiles in Extreme Value Distributions
 Likelihood-onfidene intervals for quantiles in Extreme Value Distributions A. Bolívar, E. Díaz-Franés, J. Ortega, and E. Vilhis. Centro de Investigaión en Matemátias; A.P. 42, Guanajuato, Gto. 36; Méxio
Likelihood-onfidene intervals for quantiles in Extreme Value Distributions A. Bolívar, E. Díaz-Franés, J. Ortega, and E. Vilhis. Centro de Investigaión en Matemátias; A.P. 42, Guanajuato, Gto. 36; Méxio
Sensitivity Analysis in Markov Networks
 Sensitivity Analysis in Markov Networks Hei Chan and Adnan Darwihe Computer Siene Department University of California, Los Angeles Los Angeles, CA 90095 {hei,darwihe}@s.ula.edu Abstrat This paper explores
Sensitivity Analysis in Markov Networks Hei Chan and Adnan Darwihe Computer Siene Department University of California, Los Angeles Los Angeles, CA 90095 {hei,darwihe}@s.ula.edu Abstrat This paper explores
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Expectation Maximization Mark Schmidt University of British Columbia Winter 2018 Last Time: Learning with MAR Values We discussed learning with missing at random values in data:
CPSC 540: Machine Learning Expectation Maximization Mark Schmidt University of British Columbia Winter 2018 Last Time: Learning with MAR Values We discussed learning with missing at random values in data:
Supplementary Materials
 Supplementary Materials Neural population partitioning and a onurrent brain-mahine interfae for sequential motor funtion Maryam M. Shanehi, Rollin C. Hu, Marissa Powers, Gregory W. Wornell, Emery N. Brown
Supplementary Materials Neural population partitioning and a onurrent brain-mahine interfae for sequential motor funtion Maryam M. Shanehi, Rollin C. Hu, Marissa Powers, Gregory W. Wornell, Emery N. Brown
Local quality functions for graph clustering
 Loal quality funtions for graph lustering Twan van Laarhoven Institute for Computing and Information Sienes Radoud University Nijmegen, The Netherlands Lorentz workshop on Clustering, Games and Axioms
Loal quality funtions for graph lustering Twan van Laarhoven Institute for Computing and Information Sienes Radoud University Nijmegen, The Netherlands Lorentz workshop on Clustering, Games and Axioms
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Final Review. A Puzzle... Special Relativity. Direction of the Force. Moving at the Speed of Light
 Final Review A Puzzle... Diretion of the Fore A point harge q is loated a fixed height h above an infinite horizontal onduting plane. Another point harge q is loated a height z (with z > h) above the plane.
Final Review A Puzzle... Diretion of the Fore A point harge q is loated a fixed height h above an infinite horizontal onduting plane. Another point harge q is loated a height z (with z > h) above the plane.
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
SOA/CAS MAY 2003 COURSE 1 EXAM SOLUTIONS
 SOA/CAS MAY 2003 COURSE 1 EXAM SOLUTIONS Prepared by S. Broverman e-mail 2brove@rogers.om website http://members.rogers.om/2brove 1. We identify the following events:. - wathed gymnastis, ) - wathed baseball,
SOA/CAS MAY 2003 COURSE 1 EXAM SOLUTIONS Prepared by S. Broverman e-mail 2brove@rogers.om website http://members.rogers.om/2brove 1. We identify the following events:. - wathed gymnastis, ) - wathed baseball,
Relative Maxima and Minima sections 4.3
 Relative Maxima and Minima setions 4.3 Definition. By a ritial point of a funtion f we mean a point x 0 in the domain at whih either the derivative is zero or it does not exists. So, geometrially, one
Relative Maxima and Minima setions 4.3 Definition. By a ritial point of a funtion f we mean a point x 0 in the domain at whih either the derivative is zero or it does not exists. So, geometrially, one
Quantum Mechanics: Wheeler: Physics 6210
 Quantum Mehanis: Wheeler: Physis 60 Problems some modified from Sakurai, hapter. W. S..: The Pauli matries, σ i, are a triple of matries, σ, σ i = σ, σ, σ 3 given by σ = σ = σ 3 = i i Let stand for the
Quantum Mehanis: Wheeler: Physis 60 Problems some modified from Sakurai, hapter. W. S..: The Pauli matries, σ i, are a triple of matries, σ, σ i = σ, σ, σ 3 given by σ = σ = σ 3 = i i Let stand for the
Speed-feedback Direct-drive Control of a Low-speed Transverse Flux-type Motor with Large Number of Poles for Ship Propulsion
 Speed-feedbak Diret-drive Control of a Low-speed Transverse Flux-type Motor with Large Number of Poles for Ship Propulsion Y. Yamamoto, T. Nakamura 2, Y. Takada, T. Koseki, Y. Aoyama 3, and Y. Iwaji 3
Speed-feedbak Diret-drive Control of a Low-speed Transverse Flux-type Motor with Large Number of Poles for Ship Propulsion Y. Yamamoto, T. Nakamura 2, Y. Takada, T. Koseki, Y. Aoyama 3, and Y. Iwaji 3
( ) ( ) Volumetric Properties of Pure Fluids, part 4. The generic cubic equation of state:
 ( ) Volumetric Properties of Pure Fluids, part 4. The generic cubic equation of state:") CE304, Spring 2004 Leture 6 Volumetri roperties of ure Fluids, part 4 The generi ubi equation of state: There are many possible equations of state (and many have been proposed) that have the same general
CE304, Spring 2004 Leture 6 Volumetri roperties of ure Fluids, part 4 The generi ubi equation of state: There are many possible equations of state (and many have been proposed) that have the same general
Transformation to approximate independence for locally stationary Gaussian processes
 ransformation to approximate independene for loally stationary Gaussian proesses Joseph Guinness, Mihael L. Stein We provide new approximations for the likelihood of a time series under the loally stationary
ransformation to approximate independene for loally stationary Gaussian proesses Joseph Guinness, Mihael L. Stein We provide new approximations for the likelihood of a time series under the loally stationary
MOLECULAR ORBITAL THEORY- PART I
 5.6 Physial Chemistry Leture #24-25 MOLECULAR ORBITAL THEORY- PART I At this point, we have nearly ompleted our rash-ourse introdution to quantum mehanis and we re finally ready to deal with moleules.
5.6 Physial Chemistry Leture #24-25 MOLECULAR ORBITAL THEORY- PART I At this point, we have nearly ompleted our rash-ourse introdution to quantum mehanis and we re finally ready to deal with moleules.
A simple expression for radial distribution functions of pure fluids and mixtures
 A simple expression for radial distribution funtions of pure fluids and mixtures Enrio Matteoli a) Istituto di Chimia Quantistia ed Energetia Moleolare, CNR, Via Risorgimento, 35, 56126 Pisa, Italy G.
A simple expression for radial distribution funtions of pure fluids and mixtures Enrio Matteoli a) Istituto di Chimia Quantistia ed Energetia Moleolare, CNR, Via Risorgimento, 35, 56126 Pisa, Italy G.
Convergence of reinforcement learning with general function approximators
 Convergene of reinforement learning with general funtion approximators assilis A. Papavassiliou and Stuart Russell Computer Siene Division, U. of California, Berkeley, CA 94720-1776 fvassilis,russellg@s.berkeley.edu
Convergene of reinforement learning with general funtion approximators assilis A. Papavassiliou and Stuart Russell Computer Siene Division, U. of California, Berkeley, CA 94720-1776 fvassilis,russellg@s.berkeley.edu
K-means. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. November 19 th, Carlos Guestrin 1
 EM Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 19 th, 2007 2005-2007 Carlos Guestrin 1 K-means 1. Ask user how many clusters they d like. e.g. k=5 2. Randomly guess
EM Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 19 th, 2007 2005-2007 Carlos Guestrin 1 K-means 1. Ask user how many clusters they d like. e.g. k=5 2. Randomly guess
An Adaptive Optimization Approach to Active Cancellation of Repeated Transient Vibration Disturbances
 An aptive Optimization Approah to Ative Canellation of Repeated Transient Vibration Disturbanes David L. Bowen RH Lyon Corp / Aenteh, 33 Moulton St., Cambridge, MA 138, U.S.A., owen@lyonorp.om J. Gregory
An aptive Optimization Approah to Ative Canellation of Repeated Transient Vibration Disturbanes David L. Bowen RH Lyon Corp / Aenteh, 33 Moulton St., Cambridge, MA 138, U.S.A., owen@lyonorp.om J. Gregory
Name Solutions to Test 1 September 23, 2016
 Name Solutions to Test 1 September 3, 016 This test onsists of three parts. Please note that in parts II and III, you an skip one question of those offered. Possibly useful formulas: F qequb x xvt E Evpx
Name Solutions to Test 1 September 3, 016 This test onsists of three parts. Please note that in parts II and III, you an skip one question of those offered. Possibly useful formulas: F qequb x xvt E Evpx
Optimization of replica exchange molecular dynamics by fast mimicking
 THE JOURNAL OF CHEMICAL PHYSICS 127, 204104 2007 Optimization of replia exhange moleular dynamis by fast mimiking Jozef Hritz and Chris Oostenbrink a Leiden Amsterdam Center for Drug Researh (LACDR), Division
THE JOURNAL OF CHEMICAL PHYSICS 127, 204104 2007 Optimization of replia exhange moleular dynamis by fast mimiking Jozef Hritz and Chris Oostenbrink a Leiden Amsterdam Center for Drug Researh (LACDR), Division
EE 321 Project Spring 2018
 EE 21 Projet Spring 2018 This ourse projet is intended to be an individual effort projet. The student is required to omplete the work individually, without help from anyone else. (The student may, however,
EE 21 Projet Spring 2018 This ourse projet is intended to be an individual effort projet. The student is required to omplete the work individually, without help from anyone else. (The student may, however,
Mixture of Gaussians Models
 Mixture of Gaussians Models Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
Mixture of Gaussians Models Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Properties of Quarks
 PHY04 Partile Physis 9 Dr C N Booth Properties of Quarks In the earlier part of this ourse, we have disussed three families of leptons but prinipally onentrated on one doublet of quarks, the u and d. We
PHY04 Partile Physis 9 Dr C N Booth Properties of Quarks In the earlier part of this ourse, we have disussed three families of leptons but prinipally onentrated on one doublet of quarks, the u and d. We
4.3 Singular Value Decomposition and Analysis
 4.3 Singular Value Deomposition and Analysis A. Purpose Any M N matrix, A, has a Singular Value Deomposition (SVD) of the form A = USV t where U is an M M orthogonal matrix, V is an N N orthogonal matrix,
4.3 Singular Value Deomposition and Analysis A. Purpose Any M N matrix, A, has a Singular Value Deomposition (SVD) of the form A = USV t where U is an M M orthogonal matrix, V is an N N orthogonal matrix,
Lecture 2: Simple Classifiers
 CSC 412/2506 Winter 2018 Probabilistic Learning and Reasoning Lecture 2: Simple Classifiers Slides based on Rich Zemel s All lecture slides will be available on the course website: www.cs.toronto.edu/~jessebett/csc412
CSC 412/2506 Winter 2018 Probabilistic Learning and Reasoning Lecture 2: Simple Classifiers Slides based on Rich Zemel s All lecture slides will be available on the course website: www.cs.toronto.edu/~jessebett/csc412
ELECTROMAGNETIC WAVES
 ELECTROMAGNETIC WAVES Now we will study eletromagneti waves in vauum or inside a medium, a dieletri. (A metalli system an also be represented as a dieletri but is more ompliated due to damping or attenuation
ELECTROMAGNETIC WAVES Now we will study eletromagneti waves in vauum or inside a medium, a dieletri. (A metalli system an also be represented as a dieletri but is more ompliated due to damping or attenuation
Probabilistic & Unsupervised Learning
 Probabilistic & Unsupervised Learning Week 2: Latent Variable Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College
Probabilistic & Unsupervised Learning Week 2: Latent Variable Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
The Expectation Maximization or EM algorithm
 The Expectation Maximization or EM algorithm Carl Edward Rasmussen November 15th, 2017 Carl Edward Rasmussen The EM algorithm November 15th, 2017 1 / 11 Contents notation, objective the lower bound functional,
The Expectation Maximization or EM algorithm Carl Edward Rasmussen November 15th, 2017 Carl Edward Rasmussen The EM algorithm November 15th, 2017 1 / 11 Contents notation, objective the lower bound functional,
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
LECTURE NOTES FOR , FALL 2004
 LECTURE NOTES FOR 18.155, FALL 2004 83 12. Cone support and wavefront set In disussing the singular support of a tempered distibution above, notie that singsupp(u) = only implies that u C (R n ), not as
LECTURE NOTES FOR 18.155, FALL 2004 83 12. Cone support and wavefront set In disussing the singular support of a tempered distibution above, notie that singsupp(u) = only implies that u C (R n ), not as
Determination of the reaction order
 5/7/07 A quote of the wee (or amel of the wee): Apply yourself. Get all the eduation you an, but then... do something. Don't just stand there, mae it happen. Lee Iaoa Physial Chemistry GTM/5 reation order
5/7/07 A quote of the wee (or amel of the wee): Apply yourself. Get all the eduation you an, but then... do something. Don't just stand there, mae it happen. Lee Iaoa Physial Chemistry GTM/5 reation order
4. (12) Write out an equation for Poynting s theorem in differential form. Explain in words what each term means physically.
 Write out an equation for Poynting s theorem in differential form. Explain in words what each term means physically.") Eletrodynamis I Exam 3 - Part A - Closed Book KSU 205/2/8 Name Eletrodynami Sore = 24 / 24 points Instrutions: Use SI units. Where appropriate, define all variables or symbols you use, in words. Try to
Eletrodynamis I Exam 3 - Part A - Closed Book KSU 205/2/8 Name Eletrodynami Sore = 24 / 24 points Instrutions: Use SI units. Where appropriate, define all variables or symbols you use, in words. Try to
Average Rate Speed Scaling
 Average Rate Speed Saling Nikhil Bansal David P. Bunde Ho-Leung Chan Kirk Pruhs May 2, 2008 Abstrat Speed saling is a power management tehnique that involves dynamially hanging the speed of a proessor.
Average Rate Speed Saling Nikhil Bansal David P. Bunde Ho-Leung Chan Kirk Pruhs May 2, 2008 Abstrat Speed saling is a power management tehnique that involves dynamially hanging the speed of a proessor.
A Spatiotemporal Approach to Passive Sound Source Localization
 A Spatiotemporal Approah Passive Sound Soure Loalization Pasi Pertilä, Mikko Parviainen, Teemu Korhonen and Ari Visa Institute of Signal Proessing Tampere University of Tehnology, P.O.Box 553, FIN-330,
A Spatiotemporal Approah Passive Sound Soure Loalization Pasi Pertilä, Mikko Parviainen, Teemu Korhonen and Ari Visa Institute of Signal Proessing Tampere University of Tehnology, P.O.Box 553, FIN-330,
Measuring & Inducing Neural Activity Using Extracellular Fields I: Inverse systems approach
 Measuring & Induing Neural Ativity Using Extraellular Fields I: Inverse systems approah Keith Dillon Department of Eletrial and Computer Engineering University of California San Diego 9500 Gilman Dr. La
Measuring & Induing Neural Ativity Using Extraellular Fields I: Inverse systems approah Keith Dillon Department of Eletrial and Computer Engineering University of California San Diego 9500 Gilman Dr. La
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Math 151 Introduction to Eigenvectors
 Math 151 Introdution to Eigenvetors The motivating example we used to desrie matrixes was landsape hange and vegetation suession. We hose the simple example of Bare Soil (B), eing replaed y Grasses (G)
Math 151 Introdution to Eigenvetors The motivating example we used to desrie matrixes was landsape hange and vegetation suession. We hose the simple example of Bare Soil (B), eing replaed y Grasses (G)
FINITE WORD LENGTH EFFECTS IN DSP
 FINITE WORD LENGTH EFFECTS IN DSP PREPARED BY GUIDED BY Snehal Gor Dr. Srianth T. ABSTRACT We now that omputers store numbers not with infinite preision but rather in some approximation that an be paed
FINITE WORD LENGTH EFFECTS IN DSP PREPARED BY GUIDED BY Snehal Gor Dr. Srianth T. ABSTRACT We now that omputers store numbers not with infinite preision but rather in some approximation that an be paed
RIEMANN S FIRST PROOF OF THE ANALYTIC CONTINUATION OF ζ(s) AND L(s, χ)
 AND L(s, χ)") RIEMANN S FIRST PROOF OF THE ANALYTIC CONTINUATION OF ζ(s AND L(s, χ FELIX RUBIN SEMINAR ON MODULAR FORMS, WINTER TERM 6 Abstrat. In this hapter, we will see a proof of the analyti ontinuation of the Riemann
RIEMANN S FIRST PROOF OF THE ANALYTIC CONTINUATION OF ζ(s AND L(s, χ FELIX RUBIN SEMINAR ON MODULAR FORMS, WINTER TERM 6 Abstrat. In this hapter, we will see a proof of the analyti ontinuation of the Riemann
ELG 5372 Error Control Coding. Claude D Amours Lecture 2: Introduction to Coding 2
 ELG 5372 Error Control Coding Claude D Amours Leture 2: Introdution to Coding 2 Deoding Tehniques Hard Deision Reeiver detets data before deoding Soft Deision Reeiver quantizes reeived data and deoder
ELG 5372 Error Control Coding Claude D Amours Leture 2: Introdution to Coding 2 Deoding Tehniques Hard Deision Reeiver detets data before deoding Soft Deision Reeiver quantizes reeived data and deoder
Computer Science 786S - Statistical Methods in Natural Language Processing and Data Analysis Page 1
 Computer Siene 786S - Statistial Methods in Natural Language Proessing and Data Analysis Page 1 Hypothesis Testing A statistial hypothesis is a statement about the nature of the distribution of a random
Computer Siene 786S - Statistial Methods in Natural Language Proessing and Data Analysis Page 1 Hypothesis Testing A statistial hypothesis is a statement about the nature of the distribution of a random
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
The Concept of Mass as Interfering Photons, and the Originating Mechanism of Gravitation D.T. Froedge
 The Conept of Mass as Interfering Photons, and the Originating Mehanism of Gravitation D.T. Froedge V04 Formerly Auburn University Phys-dtfroedge@glasgow-ky.om Abstrat For most purposes in physis the onept
The Conept of Mass as Interfering Photons, and the Originating Mehanism of Gravitation D.T. Froedge V04 Formerly Auburn University Phys-dtfroedge@glasgow-ky.om Abstrat For most purposes in physis the onept
Singular Event Detection
 Singular Event Detetion Rafael S. Garía Eletrial Engineering University of Puerto Rio at Mayagüez Rafael.Garia@ee.uprm.edu Faulty Mentor: S. Shankar Sastry Researh Supervisor: Jonathan Sprinkle Graduate
Singular Event Detetion Rafael S. Garía Eletrial Engineering University of Puerto Rio at Mayagüez Rafael.Garia@ee.uprm.edu Faulty Mentor: S. Shankar Sastry Researh Supervisor: Jonathan Sprinkle Graduate
Remark 4.1 Unlike Lyapunov theorems, LaSalle s theorem does not require the function V ( x ) to be positive definite.
 to be positive definite.") Leture Remark 4.1 Unlike Lyapunov theorems, LaSalle s theorem does not require the funtion V ( x ) to be positive definite. ost often, our interest will be to show that x( t) as t. For that we will need
Leture Remark 4.1 Unlike Lyapunov theorems, LaSalle s theorem does not require the funtion V ( x ) to be positive definite. ost often, our interest will be to show that x( t) as t. For that we will need
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Where as discussed previously we interpret solutions to this partial differential equation in the weak sense: b
 Consider the pure initial value problem for a homogeneous system of onservation laws with no soure terms in one spae dimension: Where as disussed previously we interpret solutions to this partial differential
Consider the pure initial value problem for a homogeneous system of onservation laws with no soure terms in one spae dimension: Where as disussed previously we interpret solutions to this partial differential