Some Interesting Problems in Pattern Recognition and Image Processing
|
|
|
- Todd Tyler
- 5 years ago
- Views:
Transcription
1 Some Interesting Problems in Pattern Recognition and Image Processing JEN-MEI CHANG Department of Mathematics and Statistics California State University, Long Beach University of Southern California Women in Math
2 Outline 1 Face Recognition - PCA 2 Bankruptcy Prediction - LDA 3 Cocktail Party Problem - BSS 4 Speech Recognition - DFT 5 Handwritten Digit Classification - Tangent 6 Image Compression - SVD and DWT 7 Smoothing and Sharpening - Convolution and Filtering

3 Background: Data Matrix An r-by-c gray scale digital image corresponds to an r-by-c matrix where each entry enumerates one of the 256 possible gray levels of the corresponding pixel.
4 Background: Data Vector Realize the data matrix by its columns and concatenate columns into a single column vector. IMAGE MATRIX VECTOR


5 Classification/Recognition Problem 1.5 Preprocessing Geometric normalization, Feature extraction, etc 1. Data collection Database creation a.k.a. Gallery 3. Classification Assign label to probe and assess accuracy 2. Present novel data a.k.a. Probe
6 Face Recognition Problem True Positive = Who is it? False Positive Gallery Probe =

 d (2) (, ).")
 x (N) x")

 X (2) X (N) X Image")
7 Architectures Historically single-to-single Currently subspace-to-subspace (1) d ( P, x ) d (2) (, )... (3) d( P, x ) P G (1) x,,, (2) x (N) x single-to-many many-to-many G Image Set 1 P, p * Grassmann Manifold (1) X (2) X (N) X Image Set 2 q * Project Eigenfaces
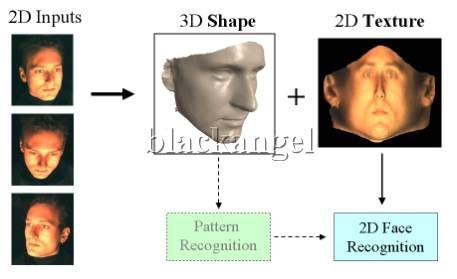



8 Commercial Applications


9 A Possible Mathematical Approach Eigenfaces Image space Feature space (Adapted from Vladimir Bondarenko at University of Konstanz, ST; 08/Lab2/5 FaceRecognition/html/myFaceRecognition.html


10 A Possible Mathematical Approach Classification in feature space Database in feature space (Adapted from Vladimir Bondarenko at University of Konstanz, ST; 08/Lab2/5 FaceRecognition/html/myFaceRecognition.html
![X = USV T Left singular vector Singular value Right singular vector V = [v 1,..., v r, v r+1,..., v n ] is orthogonal with v i s eigenvectors of X T X.](/docs-images/89/99789703/images/11-0.jpg "S = diag(s 1,..., s r, 0,..., 0) is diagonal with s i s square root of eigenvalues of X T X. U = S 1 XV is orthogonal with u i s eigenvectors of XX T.")
11 X = USV T Left singular vector Singular value Right singular vector V = [v 1,..., v r, v r+1,..., v n ] is orthogonal with v i s eigenvectors of X T X. S = diag(s 1,..., s r, 0,..., 0) is diagonal with s i s square root of eigenvalues of X T X. U = S 1 XV is orthogonal with u i s eigenvectors of XX T.
12 Bankruptcy prediction is the art of predicting bankruptcy and various measures of financial distress of public firms. It is a vast area of finance and accounting research. The importance of the area is due in part to the relevance for creditors and investors in evaluating the likelihood that a firm may go bankrupt 1. Form a feature vector for each firm where each entry in the feature vector is a numerical value for a certain characteristic, e.g., number of customers and annual profit. This is a two-class (bankrupt or non-bankrupt) classification problem. 1 adapted from Wikipedia
13 A Possible Mathematical Approach Bad projection Good projection Question: What are the characteristics of a good projection?
14 A Possible Mathematical Approach Bad projection Good projection Question: What are the characteristics of a good projection?
15 Two-Class LDA m 1 = 1 w T x, m 2 = 1 w T y n 1 n 2 x D 1 y D 2 Look for a projection w that maximizes (inter-class) distance in the projected space, and minimizes the (intra-class) distances in the projected space.
16 Two-Class LDA Namely, we desire a w such that w = arg max w (m 1 m 2 ) 2 S 1 + S 2, where S 1 = (w T x m 1 ) 2 and S 2 = (w T y m 2 ) 2. x D 1 y D 2 Alternatively, (with scatter matrices) w = arg max w 2 with S W = (x m i )(x m i ) T, i=1 x D i S B = (m 2 m 1 )(m 2 m 1 ) T. w T S B w w T S W w, (1)
17 Two-Class LDA Namely, we desire a w such that w = arg max w (m 1 m 2 ) 2 S 1 + S 2, where S 1 = (w T x m 1 ) 2 and S 2 = (w T y m 2 ) 2. x D 1 y D 2 Alternatively, (with scatter matrices) w = arg max w 2 with S W = (x m i )(x m i ) T, i=1 x D i S B = (m 2 m 1 )(m 2 m 1 ) T. w T S B w w T S W w, (1)
18 LDA The criterion in Equation (1) is commonly known as the generalized Rayleigh quotient, whose solution can be found via the generalized eigenvalue problem S B w = λs W w. Once we have the good projection w, we can predict whether a given bank will go bankruptcy by projecting it onto the real line using w. Multi-class LDA follows similarly.

19 Cocktail Party Problem (adapted from André Mouraux)

20 Cocktail Party Problem (adapted from André Mouraux)

21 Cocktail Party Problem (adapted from André Mouraux)

22 A Similar Problem: EEG (adapted from André Mouraux)

23 Commercial Applications (
24 A Possible Mathematical Approach Decompose observed data into its noise and signal components: x (µ) = s (µ) + n (µ), or, in terms of data matrices, X = S + N. (S = signal, N = noise ) The optimal first basis vector, φ, is taken as a superposition of the data, i.e., φ = ψ 1 x (1) + + ψ P x (P) = Xψ. May decompose φ into signal and noise components φ = φ n + φ s, where φ s = Sψ and φ n = Nψ.
25 MNF/BBS The basis vector φ is said to have maximum noise fraction (MNF) if the ratio D(φ) = φt n φ n φ T φ is a maximum. A steepest descent method yields the symmetric definite generalized eigenproblem N T Nψ = µ 2 X T Xψ. This problem may be solved without actually forming the product matrices N T N and X T X, using the generalized SVD (gsvd). Note that the same orthonormal basis vector φ optimizes the signal-to-noise ratio. And this technique is called Blind Source Separation (BSS).

26 Audio (adapted from AT&T Lab Inc. -

27 Audio-Visual (adapted from Project MUSSLAP -



28 Commercial Applications
29 A Possible Mathematical Approach Continuous F(ω) = Discrete f (ω) = c k e ikω k Z f (t)e iωt dt window Frequency Amplitude Time Time
30 Discrete Fourier Transform (DFT) Fourier analysis is applied to speech waveform in order to discover what frequencies are present at any given moment in the speech signal with time on the horizontal axis and frequency on the vertical. The speech recognizer has a database of several thousand such graphs (called a codebook) that identify different types of sounds the human voice can make. The sound is identified by matching it to its closest entry in the codebook.
31 Handwritten Digits
32 Handwritten Digit Classification How do we tell whether a new digit is a 4 or a 9?
33 Commercial Applications Santa thought to himself, only if these mails can go to the right place according to their zip code.
34 A Possible Mathematical Approach Imagine a high-d surface (red curve) where all 4 s live on and a high-d surface (blue curve) where all 9 s live on.
35 Manifold Learning Create a Tangent Space of the 4 s at F and create a Tangent Space of the 9 s at N.
36 Which Distance?
37 Classification So, is it a 4 or a 9?

38 High-Resolution Image The objective of image compression is to reduce redundancy of the image data in order to be able to store or transmit data in an efficient form.
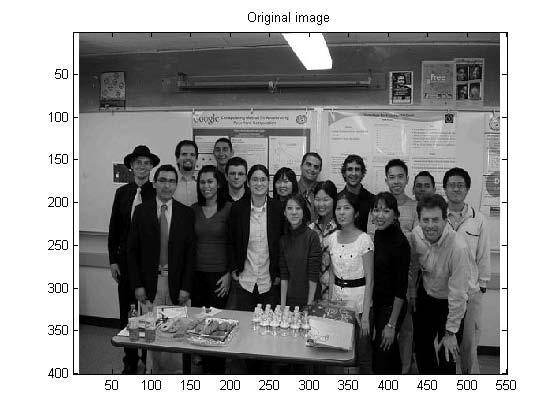
39 Low-Resolution Image
40 Compression with SVD If we know the correct rank of A, e.g., by inspecting the singular values, then we can remove the noise and compress the data by approximating A by a matrix of the correct rank. One way to do this is to truncate the singular value expansion: Theorem (Approximation Theorem) If A k = k i=1 σ i u i v T i (1 k r) then A k = min rank(b)=k A B 2 and A k = min rank(b)=k A B F.
 full rank (rank 480) (b) rank 10, rel. err. = 0.0551 (c) rank 50, rel. err. = 0.0305 (d) rank 170, rel. err. = 0.0126")
41 Compression with SVD The error term of rank k approximation is given by the (k + 1) th singular value σ k+1. (a) full rank (rank 480) (b) rank 10, rel. err. = (c) rank 50, rel. err. = (d) rank 170, rel. err. =

42 Compression with DWT X(b, a) = 1 a Original Image x(t)ψ ( t b a ) dt Approximation coef. at level dwt Synthesized Image Image Selection idwt Decomposition at level 1
43 Convolution as Filters f (x, y) s(x, y) = a b s(m, n)f (x m, y n) m= a n= b s f zero-padded s rotated f cropped result Convolution


 3 3 (c) 5 5 (d) 9 9")
44 Smoothing with Low-pass Filters Filtering with k k low-pass filters k (a) original (b) 3 3 (c) 5 5 (d) 9 9 (e) (f) 35 35
 Noise reduction with a 3 3 averaging filter.")
45 Smoothing with Median Filter (a) (b) (c) Figure: (a) X-ray image of circuit board corrupted by salt-and-pepper noise. (b) Noise reduction with a 3 3 averaging filter. (c) Noise reduction of a 3 3 median filter.
46 Sharpening with High-pass Filters The simplest isotropic filter (direction independent) derivative operator is the discrete Laplacian of two variables: 2 f (x, y) = f (x + 1, y) + f (x 1, y) + f (x, y + 1) + f (x, y 1) 4f (x, y). This equation can be implemented using the filter mask (x, y 1) (x 1, y) (x, y) (x + 1, y) (x, y + 1) Blurred image Filter mask 1 Laplacian enhanced image
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation)
") Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
PCA and LDA. Man-Wai MAK
 PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Lecture 24: Principal Component Analysis. Aykut Erdem May 2016 Hacettepe University
 Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Machine Learning: Basis and Wavelet 김화평 (CSE ) Medical Image computing lab 서진근교수연구실 Haar DWT in 2 levels
 Medical Image computing lab 서진근교수연구실 Haar DWT in 2 levels") Machine Learning: Basis and Wavelet 32 157 146 204 + + + + + - + - 김화평 (CSE ) Medical Image computing lab 서진근교수연구실 7 22 38 191 17 83 188 211 71 167 194 207 135 46 40-17 18 42 20 44 31 7 13-32 + + - - +
Machine Learning: Basis and Wavelet 32 157 146 204 + + + + + - + - 김화평 (CSE ) Medical Image computing lab 서진근교수연구실 7 22 38 191 17 83 188 211 71 167 194 207 135 46 40-17 18 42 20 44 31 7 13-32 + + - - +
PCA and LDA. Man-Wai MAK
 PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
Dimensionality Reduction
 Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Image Analysis & Retrieval. Lec 14. Eigenface and Fisherface
 Image Analysis & Retrieval Lec 14 Eigenface and Fisherface Zhu Li Dept of CSEE, UMKC Office: FH560E, Email: lizhu@umkc.edu, Ph: x 2346. http://l.web.umkc.edu/lizhu Z. Li, Image Analysis & Retrv, Spring
Image Analysis & Retrieval Lec 14 Eigenface and Fisherface Zhu Li Dept of CSEE, UMKC Office: FH560E, Email: lizhu@umkc.edu, Ph: x 2346. http://l.web.umkc.edu/lizhu Z. Li, Image Analysis & Retrv, Spring
Face Detection and Recognition
 Face Detection and Recognition Face Recognition Problem Reading: Chapter 18.10 and, optionally, Face Recognition using Eigenfaces by M. Turk and A. Pentland Queryimage face query database Face Verification
Face Detection and Recognition Face Recognition Problem Reading: Chapter 18.10 and, optionally, Face Recognition using Eigenfaces by M. Turk and A. Pentland Queryimage face query database Face Verification
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Machine Learning - MT & 14. PCA and MDS
 Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Signal Modeling Techniques in Speech Recognition. Hassan A. Kingravi
 Signal Modeling Techniques in Speech Recognition Hassan A. Kingravi Outline Introduction Spectral Shaping Spectral Analysis Parameter Transforms Statistical Modeling Discussion Conclusions 1: Introduction
Signal Modeling Techniques in Speech Recognition Hassan A. Kingravi Outline Introduction Spectral Shaping Spectral Analysis Parameter Transforms Statistical Modeling Discussion Conclusions 1: Introduction
Lecture 8. Principal Component Analysis. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. December 13, 2016
 Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Example: Face Detection
 Announcements HW1 returned New attendance policy Face Recognition: Dimensionality Reduction On time: 1 point Five minutes or more late: 0.5 points Absent: 0 points Biometrics CSE 190 Lecture 14 CSE190,
Announcements HW1 returned New attendance policy Face Recognition: Dimensionality Reduction On time: 1 point Five minutes or more late: 0.5 points Absent: 0 points Biometrics CSE 190 Lecture 14 CSE190,
Machine Learning (Spring 2012) Principal Component Analysis
 Principal Component Analysis") 1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
ECE 661: Homework 10 Fall 2014
 ECE 661: Homework 10 Fall 2014 This homework consists of the following two parts: (1) Face recognition with PCA and LDA for dimensionality reduction and the nearest-neighborhood rule for classification;
ECE 661: Homework 10 Fall 2014 This homework consists of the following two parts: (1) Face recognition with PCA and LDA for dimensionality reduction and the nearest-neighborhood rule for classification;
HST.582J/6.555J/16.456J
 Blind Source Separation: PCA & ICA HST.582J/6.555J/16.456J Gari D. Clifford gari [at] mit. edu http://www.mit.edu/~gari G. D. Clifford 2005-2009 What is BSS? Assume an observation (signal) is a linear
Blind Source Separation: PCA & ICA HST.582J/6.555J/16.456J Gari D. Clifford gari [at] mit. edu http://www.mit.edu/~gari G. D. Clifford 2005-2009 What is BSS? Assume an observation (signal) is a linear
Principal Component Analysis and Linear Discriminant Analysis
 Principal Component Analysis and Linear Discriminant Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/29
Principal Component Analysis and Linear Discriminant Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/29
Least Squares Optimization
 Least Squares Optimization The following is a brief review of least squares optimization and constrained optimization techniques. I assume the reader is familiar with basic linear algebra, including the
Least Squares Optimization The following is a brief review of least squares optimization and constrained optimization techniques. I assume the reader is familiar with basic linear algebra, including the
Linear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
PCA Review. CS 510 February 25 th, 2013
 PCA Review CS 510 February 25 th, 2013 Recall the goal: image matching Probe image, registered to gallery Registered Gallery of Images 3/7/13 CS 510, Image Computa5on, Ross Beveridge & Bruce Draper 2 Getting
PCA Review CS 510 February 25 th, 2013 Recall the goal: image matching Probe image, registered to gallery Registered Gallery of Images 3/7/13 CS 510, Image Computa5on, Ross Beveridge & Bruce Draper 2 Getting
Extraction of Individual Tracks from Polyphonic Music
 Extraction of Individual Tracks from Polyphonic Music Nick Starr May 29, 2009 Abstract In this paper, I attempt the isolation of individual musical tracks from polyphonic tracks based on certain criteria,
Extraction of Individual Tracks from Polyphonic Music Nick Starr May 29, 2009 Abstract In this paper, I attempt the isolation of individual musical tracks from polyphonic tracks based on certain criteria,
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Invariant Scattering Convolution Networks
 Invariant Scattering Convolution Networks Joan Bruna and Stephane Mallat Submitted to PAMI, Feb. 2012 Presented by Bo Chen Other important related papers: [1] S. Mallat, A Theory for Multiresolution Signal
Invariant Scattering Convolution Networks Joan Bruna and Stephane Mallat Submitted to PAMI, Feb. 2012 Presented by Bo Chen Other important related papers: [1] S. Mallat, A Theory for Multiresolution Signal
Least Squares Optimization
 Least Squares Optimization The following is a brief review of least squares optimization and constrained optimization techniques. Broadly, these techniques can be used in data analysis and visualization
Least Squares Optimization The following is a brief review of least squares optimization and constrained optimization techniques. Broadly, these techniques can be used in data analysis and visualization
20 Unsupervised Learning and Principal Components Analysis (PCA)
") 116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
Independent Component Analysis (ICA)
") Independent Component Analysis (ICA) Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Independent Component Analysis (ICA) Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Singular Value Decomposition
 Singular Value Decomposition Motivatation The diagonalization theorem play a part in many interesting applications. Unfortunately not all matrices can be factored as A = PDP However a factorization A =
Singular Value Decomposition Motivatation The diagonalization theorem play a part in many interesting applications. Unfortunately not all matrices can be factored as A = PDP However a factorization A =
Independent Component Analysis. Contents
 Contents Preface xvii 1 Introduction 1 1.1 Linear representation of multivariate data 1 1.1.1 The general statistical setting 1 1.1.2 Dimension reduction methods 2 1.1.3 Independence as a guiding principle
Contents Preface xvii 1 Introduction 1 1.1 Linear representation of multivariate data 1 1.1.1 The general statistical setting 1 1.1.2 Dimension reduction methods 2 1.1.3 Independence as a guiding principle
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Announcements (repeat) Principal Components Analysis
 Principal Components Analysis") 4/7/7 Announcements repeat Principal Components Analysis CS 5 Lecture #9 April 4 th, 7 PA4 is due Monday, April 7 th Test # will be Wednesday, April 9 th Test #3 is Monday, May 8 th at 8AM Just hour long
4/7/7 Announcements repeat Principal Components Analysis CS 5 Lecture #9 April 4 th, 7 PA4 is due Monday, April 7 th Test # will be Wednesday, April 9 th Test #3 is Monday, May 8 th at 8AM Just hour long
MATH36001 Generalized Inverses and the SVD 2015
 MATH36001 Generalized Inverses and the SVD 201 1 Generalized Inverses of Matrices A matrix has an inverse only if it is square and nonsingular. However there are theoretical and practical applications
MATH36001 Generalized Inverses and the SVD 201 1 Generalized Inverses of Matrices A matrix has an inverse only if it is square and nonsingular. However there are theoretical and practical applications
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
(a) If A is a 3 by 4 matrix, what does this tell us about its nullspace? Solution: dim N(A) 1, since rank(a) 3. Ax =
 If A is a 3 by 4 matrix, what does this tell us about its nullspace? Solution: dim N(A) 1, since rank(a) 3. Ax =") . (5 points) (a) If A is a 3 by 4 matrix, what does this tell us about its nullspace? dim N(A), since rank(a) 3. (b) If we also know that Ax = has no solution, what do we know about the rank of A? C(A)
. (5 points) (a) If A is a 3 by 4 matrix, what does this tell us about its nullspace? dim N(A), since rank(a) 3. (b) If we also know that Ax = has no solution, what do we know about the rank of A? C(A)
Introduction to SVD and Applications
 Introduction to SVD and Applications Eric Kostelich and Dave Kuhl MSRI Climate Change Summer School July 18, 2008 Introduction The goal of this exercise is to familiarize you with the basics of the singular
Introduction to SVD and Applications Eric Kostelich and Dave Kuhl MSRI Climate Change Summer School July 18, 2008 Introduction The goal of this exercise is to familiarize you with the basics of the singular
Salt Dome Detection and Tracking Using Texture Analysis and Tensor-based Subspace Learning
 Salt Dome Detection and Tracking Using Texture Analysis and Tensor-based Subspace Learning Zhen Wang*, Dr. Tamir Hegazy*, Dr. Zhiling Long, and Prof. Ghassan AlRegib 02/18/2015 1 /42 Outline Introduction
Salt Dome Detection and Tracking Using Texture Analysis and Tensor-based Subspace Learning Zhen Wang*, Dr. Tamir Hegazy*, Dr. Zhiling Long, and Prof. Ghassan AlRegib 02/18/2015 1 /42 Outline Introduction
Principal components analysis COMS 4771
 Principal components analysis COMS 4771 1. Representation learning Useful representations of data Representation learning: Given: raw feature vectors x 1, x 2,..., x n R d. Goal: learn a useful feature
Principal components analysis COMS 4771 1. Representation learning Useful representations of data Representation learning: Given: raw feature vectors x 1, x 2,..., x n R d. Goal: learn a useful feature
Principal Component Analysis and Singular Value Decomposition. Volker Tresp, Clemens Otte Summer 2014
 Principal Component Analysis and Singular Value Decomposition Volker Tresp, Clemens Otte Summer 2014 1 Motivation So far we always argued for a high-dimensional feature space Still, in some cases it makes
Principal Component Analysis and Singular Value Decomposition Volker Tresp, Clemens Otte Summer 2014 1 Motivation So far we always argued for a high-dimensional feature space Still, in some cases it makes
Numerical Methods I Singular Value Decomposition
 Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
PCA and admixture models
 PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
Least Squares Optimization
 Least Squares Optimization The following is a brief review of least squares optimization and constrained optimization techniques, which are widely used to analyze and visualize data. Least squares (LS)
Least Squares Optimization The following is a brief review of least squares optimization and constrained optimization techniques, which are widely used to analyze and visualize data. Least squares (LS)
Face Recognition. Face Recognition. Subspace-Based Face Recognition Algorithms. Application of Face Recognition
 ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
Singular Value Decompsition
 Singular Value Decompsition Massoud Malek One of the most useful results from linear algebra, is a matrix decomposition known as the singular value decomposition It has many useful applications in almost
Singular Value Decompsition Massoud Malek One of the most useful results from linear algebra, is a matrix decomposition known as the singular value decomposition It has many useful applications in almost
Fisher s Linear Discriminant Analysis
 Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Principal Component Analysis CS498
 Principal Component Analysis CS498 Today s lecture Adaptive Feature Extraction Principal Component Analysis How, why, when, which A dual goal Find a good representation The features part Reduce redundancy
Principal Component Analysis CS498 Today s lecture Adaptive Feature Extraction Principal Component Analysis How, why, when, which A dual goal Find a good representation The features part Reduce redundancy
The Essentials of Linear State-Space Systems
 :or-' The Essentials of Linear State-Space Systems J. Dwight Aplevich GIFT OF THE ASIA FOUNDATION NOT FOR RE-SALE John Wiley & Sons, Inc New York Chichester Weinheim OAI HOC OUOC GIA HA N^l TRUNGTAMTHANCTINTHUVIIN
:or-' The Essentials of Linear State-Space Systems J. Dwight Aplevich GIFT OF THE ASIA FOUNDATION NOT FOR RE-SALE John Wiley & Sons, Inc New York Chichester Weinheim OAI HOC OUOC GIA HA N^l TRUNGTAMTHANCTINTHUVIIN
Main matrix factorizations
 Main matrix factorizations A P L U P permutation matrix, L lower triangular, U upper triangular Key use: Solve square linear system Ax b. A Q R Q unitary, R upper triangular Key use: Solve square or overdetrmined
Main matrix factorizations A P L U P permutation matrix, L lower triangular, U upper triangular Key use: Solve square linear system Ax b. A Q R Q unitary, R upper triangular Key use: Solve square or overdetrmined
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
Image Analysis & Retrieval Lec 14 - Eigenface & Fisherface
 CS/EE 5590 / ENG 401 Special Topics, Spring 2018 Image Analysis & Retrieval Lec 14 - Eigenface & Fisherface Zhu Li Dept of CSEE, UMKC http://l.web.umkc.edu/lizhu Office Hour: Tue/Thr 2:30-4pm@FH560E, Contact:
CS/EE 5590 / ENG 401 Special Topics, Spring 2018 Image Analysis & Retrieval Lec 14 - Eigenface & Fisherface Zhu Li Dept of CSEE, UMKC http://l.web.umkc.edu/lizhu Office Hour: Tue/Thr 2:30-4pm@FH560E, Contact:
Principal Component Analysis (PCA) CSC411/2515 Tutorial
 CSC411/2515 Tutorial") Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
System 1 (last lecture) : limited to rigidly structured shapes. System 2 : recognition of a class of varying shapes. Need to:
 : limited to rigidly structured shapes. System 2 : recognition of a class of varying shapes. Need to:") System 2 : Modelling & Recognising Modelling and Recognising Classes of Classes of Shapes Shape : PDM & PCA All the same shape? System 1 (last lecture) : limited to rigidly structured shapes System 2 :
System 2 : Modelling & Recognising Modelling and Recognising Classes of Classes of Shapes Shape : PDM & PCA All the same shape? System 1 (last lecture) : limited to rigidly structured shapes System 2 :
COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017
 COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University PRINCIPAL COMPONENT ANALYSIS DIMENSIONALITY
COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University PRINCIPAL COMPONENT ANALYSIS DIMENSIONALITY
Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization
 Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization Haiping Lu 1 K. N. Plataniotis 1 A. N. Venetsanopoulos 1,2 1 Department of Electrical & Computer Engineering,
Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization Haiping Lu 1 K. N. Plataniotis 1 A. N. Venetsanopoulos 1,2 1 Department of Electrical & Computer Engineering,
HST.582J / 6.555J / J Biomedical Signal and Image Processing Spring 2007
 MIT OpenCourseWare http://ocw.mit.edu HST.582J / 6.555J / 16.456J Biomedical Signal and Image Processing Spring 2007 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
MIT OpenCourseWare http://ocw.mit.edu HST.582J / 6.555J / 16.456J Biomedical Signal and Image Processing Spring 2007 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
DS-GA 1002 Lecture notes 12 Fall Linear regression
 DS-GA Lecture notes 1 Fall 16 1 Linear models Linear regression In statistics, regression consists of learning a function relating a certain quantity of interest y, the response or dependent variable,
DS-GA Lecture notes 1 Fall 16 1 Linear models Linear regression In statistics, regression consists of learning a function relating a certain quantity of interest y, the response or dependent variable,
Notes on singular value decomposition for Math 54. Recall that if A is a symmetric n n matrix, then A has real eigenvalues A = P DP 1 A = P DP T.
 Notes on singular value decomposition for Math 54 Recall that if A is a symmetric n n matrix, then A has real eigenvalues λ 1,, λ n (possibly repeated), and R n has an orthonormal basis v 1,, v n, where
Notes on singular value decomposition for Math 54 Recall that if A is a symmetric n n matrix, then A has real eigenvalues λ 1,, λ n (possibly repeated), and R n has an orthonormal basis v 1,, v n, where
Tutorial on Blind Source Separation and Independent Component Analysis
 Tutorial on Blind Source Separation and Independent Component Analysis Lucas Parra Adaptive Image & Signal Processing Group Sarnoff Corporation February 09, 2002 Linear Mixtures... problem statement...
Tutorial on Blind Source Separation and Independent Component Analysis Lucas Parra Adaptive Image & Signal Processing Group Sarnoff Corporation February 09, 2002 Linear Mixtures... problem statement...
Problem # Max points possible Actual score Total 120
 FINAL EXAMINATION - MATH 2121, FALL 2017. Name: ID#: Email: Lecture & Tutorial: Problem # Max points possible Actual score 1 15 2 15 3 10 4 15 5 15 6 15 7 10 8 10 9 15 Total 120 You have 180 minutes to
FINAL EXAMINATION - MATH 2121, FALL 2017. Name: ID#: Email: Lecture & Tutorial: Problem # Max points possible Actual score 1 15 2 15 3 10 4 15 5 15 6 15 7 10 8 10 9 15 Total 120 You have 180 minutes to
Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes. October 3, Statistics 202: Data Mining
 Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Combinations of features Given a data matrix X n p with p fairly large, it can
Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Combinations of features Given a data matrix X n p with p fairly large, it can
CSE 494/598 Lecture-6: Latent Semantic Indexing. **Content adapted from last year s slides
 CSE 494/598 Lecture-6: Latent Semantic Indexing LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Homework-1 and Quiz-1 Project part-2 released
CSE 494/598 Lecture-6: Latent Semantic Indexing LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Homework-1 and Quiz-1 Project part-2 released
Exercise Set 7.2. Skills
 Orthogonally diagonalizable matrix Spectral decomposition (or eigenvalue decomposition) Schur decomposition Subdiagonal Upper Hessenburg form Upper Hessenburg decomposition Skills Be able to recognize
Orthogonally diagonalizable matrix Spectral decomposition (or eigenvalue decomposition) Schur decomposition Subdiagonal Upper Hessenburg form Upper Hessenburg decomposition Skills Be able to recognize
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis. Massimiliano Pontil
 2. Least Squares and Principal Components Analysis. Massimiliano Pontil") GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
Using SVD to Recommend Movies
 Michael Percy University of California, Santa Cruz Last update: December 12, 2009 Last update: December 12, 2009 1 / Outline 1 Introduction 2 Singular Value Decomposition 3 Experiments 4 Conclusion Last
Michael Percy University of California, Santa Cruz Last update: December 12, 2009 Last update: December 12, 2009 1 / Outline 1 Introduction 2 Singular Value Decomposition 3 Experiments 4 Conclusion Last
Math 307 Learning Goals. March 23, 2010
 Math 307 Learning Goals March 23, 2010 Course Description The course presents core concepts of linear algebra by focusing on applications in Science and Engineering. Examples of applications from recent
Math 307 Learning Goals March 23, 2010 Course Description The course presents core concepts of linear algebra by focusing on applications in Science and Engineering. Examples of applications from recent
Digital Image Processing
 Digital Image Processing, 2nd ed. Digital Image Processing Chapter 7 Wavelets and Multiresolution Processing Dr. Kai Shuang Department of Electronic Engineering China University of Petroleum shuangkai@cup.edu.cn
Digital Image Processing, 2nd ed. Digital Image Processing Chapter 7 Wavelets and Multiresolution Processing Dr. Kai Shuang Department of Electronic Engineering China University of Petroleum shuangkai@cup.edu.cn
Principal Component Analysis
 B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
Singular Value Decomposition and Digital Image Compression
 Singular Value Decomposition and Digital Image Compression Chris Bingham December 1, 016 Page 1 of Abstract The purpose of this document is to be a very basic introduction to the singular value decomposition
Singular Value Decomposition and Digital Image Compression Chris Bingham December 1, 016 Page 1 of Abstract The purpose of this document is to be a very basic introduction to the singular value decomposition
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
15 Singular Value Decomposition
 15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
LECTURE NOTE #10 PROF. ALAN YUILLE
 LECTURE NOTE #10 PROF. ALAN YUILLE 1. Principle Component Analysis (PCA) One way to deal with the curse of dimensionality is to project data down onto a space of low dimensions, see figure (1). Figure
LECTURE NOTE #10 PROF. ALAN YUILLE 1. Principle Component Analysis (PCA) One way to deal with the curse of dimensionality is to project data down onto a space of low dimensions, see figure (1). Figure
Gopalkrishna Veni. Project 4 (Active Shape Models)
") Gopalkrishna Veni Project 4 (Active Shape Models) Introduction Active shape Model (ASM) is a technique of building a model by learning the variability patterns from training datasets. ASMs try to deform
Gopalkrishna Veni Project 4 (Active Shape Models) Introduction Active shape Model (ASM) is a technique of building a model by learning the variability patterns from training datasets. ASMs try to deform
Learning gradients: prescriptive models
 Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Singular Value Decomposition. 1 Singular Value Decomposition and the Four Fundamental Subspaces
 Singular Value Decomposition This handout is a review of some basic concepts in linear algebra For a detailed introduction, consult a linear algebra text Linear lgebra and its pplications by Gilbert Strang
Singular Value Decomposition This handout is a review of some basic concepts in linear algebra For a detailed introduction, consult a linear algebra text Linear lgebra and its pplications by Gilbert Strang
Regularized Discriminant Analysis and Reduced-Rank LDA
 Regularized Discriminant Analysis and Reduced-Rank LDA Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu Regularized Discriminant Analysis A compromise between LDA and
Regularized Discriminant Analysis and Reduced-Rank LDA Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu Regularized Discriminant Analysis A compromise between LDA and
A NO-REFERENCE SHARPNESS METRIC SENSITIVE TO BLUR AND NOISE. Xiang Zhu and Peyman Milanfar
 A NO-REFERENCE SARPNESS METRIC SENSITIVE TO BLUR AND NOISE Xiang Zhu and Peyman Milanfar Electrical Engineering Department University of California at Santa Cruz, CA, 9564 xzhu@soeucscedu ABSTRACT A no-reference
A NO-REFERENCE SARPNESS METRIC SENSITIVE TO BLUR AND NOISE Xiang Zhu and Peyman Milanfar Electrical Engineering Department University of California at Santa Cruz, CA, 9564 xzhu@soeucscedu ABSTRACT A no-reference
SPEECH ENHANCEMENT USING PCA AND VARIANCE OF THE RECONSTRUCTION ERROR IN DISTRIBUTED SPEECH RECOGNITION
 SPEECH ENHANCEMENT USING PCA AND VARIANCE OF THE RECONSTRUCTION ERROR IN DISTRIBUTED SPEECH RECOGNITION Amin Haji Abolhassani 1, Sid-Ahmed Selouani 2, Douglas O Shaughnessy 1 1 INRS-Energie-Matériaux-Télécommunications,
SPEECH ENHANCEMENT USING PCA AND VARIANCE OF THE RECONSTRUCTION ERROR IN DISTRIBUTED SPEECH RECOGNITION Amin Haji Abolhassani 1, Sid-Ahmed Selouani 2, Douglas O Shaughnessy 1 1 INRS-Energie-Matériaux-Télécommunications,
Principal Component Analysis
 Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Statistical Geometry Processing Winter Semester 2011/2012
 Statistical Geometry Processing Winter Semester 2011/2012 Linear Algebra, Function Spaces & Inverse Problems Vector and Function Spaces 3 Vectors vectors are arrows in space classically: 2 or 3 dim. Euclidian
Statistical Geometry Processing Winter Semester 2011/2012 Linear Algebra, Function Spaces & Inverse Problems Vector and Function Spaces 3 Vectors vectors are arrows in space classically: 2 or 3 dim. Euclidian
Independent Component Analysis and Its Application on Accelerator Physics
 Independent Component Analysis and Its Application on Accelerator Physics Xiaoying Pang LA-UR-12-20069 ICA and PCA Similarities: Blind source separation method (BSS) no model Observed signals are linear
Independent Component Analysis and Its Application on Accelerator Physics Xiaoying Pang LA-UR-12-20069 ICA and PCA Similarities: Blind source separation method (BSS) no model Observed signals are linear
Dimensionality Reduction. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Dimensionality Reduction CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Visualize high dimensional data (and understand its Geometry) } Project the data into lower dimensional spaces }
Dimensionality Reduction CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Visualize high dimensional data (and understand its Geometry) } Project the data into lower dimensional spaces }
Exercise Sheet 1. 1 Probability revision 1: Student-t as an infinite mixture of Gaussians
 Exercise Sheet 1 1 Probability revision 1: Student-t as an infinite mixture of Gaussians Show that an infinite mixture of Gaussian distributions, with Gamma distributions as mixing weights in the following
Exercise Sheet 1 1 Probability revision 1: Student-t as an infinite mixture of Gaussians Show that an infinite mixture of Gaussian distributions, with Gamma distributions as mixing weights in the following
Linear Subspace Models
 Linear Subspace Models Goal: Explore linear models of a data set. Motivation: A central question in vision concerns how we represent a collection of data vectors. The data vectors may be rasterized images,
Linear Subspace Models Goal: Explore linear models of a data set. Motivation: A central question in vision concerns how we represent a collection of data vectors. The data vectors may be rasterized images,
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Principal Components Analysis
 Principal Components Analysis Santiago Paternain, Aryan Mokhtari and Alejandro Ribeiro March 29, 2018 At this point we have already seen how the Discrete Fourier Transform and the Discrete Cosine Transform
Principal Components Analysis Santiago Paternain, Aryan Mokhtari and Alejandro Ribeiro March 29, 2018 At this point we have already seen how the Discrete Fourier Transform and the Discrete Cosine Transform