Response-Field Dynamics in the Auditory Pathway
|
|
|
- Randolph Smith
- 5 years ago
- Views:
Transcription
1 Response-Field Dynamics in the Auditory Pathway Didier Depireux Powen Ru Shihab Shamma Jonathan Simon Work supported by grants from the Office of Naval Research, a training grant from the National Institute on Deafness and Other Communication Disorders, and the National Science Foundation
2 Abstract We investigated the response properties and functional organization of Primary Auditory Cortex (AI), to determine how the shape of the acoustic spectrum is represented in single-unit responses. The experiments employ broadband stimuli with sinusoidally modulated spectral envelopes (ripples), and systems theoretic methods to derive unit response fields and to characterize their spectro-temporal properties. These methods assume linearity of auditory responses with respect to the stimulus spectral envelope. We also address the degree of separability of response fields with respect to upward and downward moving sounds. We verified that unit responses to complex sounds with both upward and downward components can be predicted from their responses to simple ripples.
3 Introduction Natural sounds are characterized by loudness (intensity), pitch (tonal height) and timbre (the rest, e.g. dynamic envelope of spectrum). Question: How is timbre encoded in primary auditory cortex (AI)? Our Approach: Beyond the sensory epithelium (cochlea or retina), principles used by neural systems are universal. To lowest order, we view the basilar membrane as a -D retina, and use the method of gratings to study single units in AI. Important Concepts: Response Field (RF): the range of frequencies that influence a neuron. In general, RF is a function of time. Ripples: broadband sounds with sinusoidally modulated spectral envelope; i.e. auditory gratings. Data analysis based on linear systems to characterize response field. By varying ripple frequency and velocity, we measure the transfer function. The inverse Fourier transform gives the spectro-temporal RF (STRF). We find: Cells can be characterized by a STRF. The STRF can be separable or non-separable. Cells behave like a linear system: when cells are presented with a sound made of up the sum of several profiles, the response of the cell (assuming a rate code) is the sum of the responses to the individual profiles. We show predictions of single-unit responses in AI to complex spectra, verifying: Linearity of AI responses to all types of dynamic ripples: responses to both upward and downward moving ripples can be superimposed linearly to predict responses to arbitrary combinations of these ripples. Separability of spectral and temporal measurements of the responses: spectral properties can be measured independently of the temporal properties (such as the impulse response). We conclude: The combined spectro-temporal decomposition in AI can be described by an affine wavelet transformation of the input, in concert with a similar temporal decomposition. The auditory profile is the result of a multistage process which occurs early in the pathway. This pattern is projected centrally where a multiscale representation is generated in AI by STRFs with a range of widths, asymmetries, BFs, time lags and directional sensitivities.
4 Captions The next few figures illustrate spectro-temporal functions and their Fourier transforms. Since the cochlea performs (to first order) a Fourier transform along the logarithmic frequency axis, we also measure spectral distance in log(frequency). Since the Fourier transform is time-windowed, we also require a time axis. For this reason we will focus attention on two-dimensional functions of log(frequency) and time. Consider the (Fourier) space dual to this two-dimensional spectro-temporal space. For linear systems, the spectro-temporal domain and its Fourier domain are equivalent. Analysis is often conceptually simpler in the Fourier domain. Note that real functions in the spectro-temporal domain give rise to complex conjugate symmetric functions in the Fourier domain. The next panel Spectro-Temporal Fourier Transform illustrates the envelope of a speech fragment, in both its spectro-temporal and Fourier representations. Notice that in the Fourier representation, the function is highly concentrated. The subsequent panel Spectro-Temporal Fourier Transform Response illustrates the spectrotemporal response field of a neuron, and its Fourier dual, the transfer function. The panel Spectro-Temporal Fourier Transform Stimulus shows an example of the usefulness of the Fourier domain. The envelope of a speech fragment is Fourier transformed. The Fourier transform is then approximated by its largest components and then inverted, giving an excellent approximation to the original envelope. The panel Ripples demonstrates that points in the Fourier space correspond to broadband sounds with a sinusoidally modulated spectral and temporal envelope.




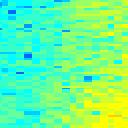



























5 Spectro-Temporal Fourier Transform Spectrogram (log frequency) x = log f w Fourier Tranform ( ) [ ]exp ±π j Ω x ± π jwt Inverse Tranform Ω t 3 ( =*) ( =*) w = ripple velocity Ω = ripple frequency
















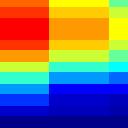





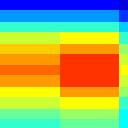










6 Spectro-Temporal Fourier Transform Response Spectrogram (log frequency) x = log f w Fourier Tranform ( ) [ ]exp ±π j Ω x ± π jwt Inverse Tranform Ω Spectro-Temporal Response Function (STRF) of a cortical neuron t Dimensional Transfer Function of a cortical neuron

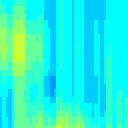









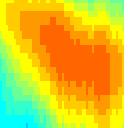






















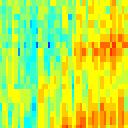















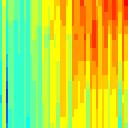










7 water all year Spectro-Temporal Fourier Transform Simulus frequency (khz) Spectrogram (log frequency) frequency (khz) LPC Envelope 5 time (ms) Fourier Transform ( peaks) 5 time (ms) Reconstruction ripple velocity (Hz) ripple frequency (cycles/octave) frequency (khz) 5 time (ms)



.")

8 Ripple in Fourier Space Hz w Ripples The Fourier transform of a ripple has support only on a single point (and its complex conjugate). -. cyc/oct. cyc/oct Ω Hz Ripple in Spectro-Temporal Space (Spectrogram) 5
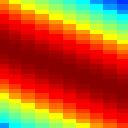
9 Quadrant Separability IR(t) Spectro-Temporal Domain t x o x Fourier Domain w Fully Separable RF x D Fourier Transform Ω t IR(t) w RF x t x D Fourier Transform left-moving right-moving Ω Quadrant Separable t w x D Fourier Transform Ω Inseparable t



















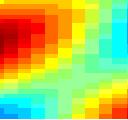



















10 Ripple Spectrogram Linearity STRF Expected Response * t = * t = 5 * t 5 = 5
11 A Ripple Frequency (cyc/oct) Measurements in Ripple Frequency Ripple Velocity is Hz 7 db B -. cyc/oct /3a6 cyc/oct C 6 π π π 6 π Transfer Function Amplitude Transfer Function Phase Ripple Frequeny (cyc/oct) D Amplitude Spike counts 5 5 RF (Negative Freqs) RF (Positive Freqs) RF (Pure Tones) 3 5 Octaves. cyc/oct. cyc/oct
12 A Ripple Velocity (Hz) Measurements in Ripple Velocity Ripple Frequency is. cyc/oct 7 db B -Hz /3a7 6 -Hz C Transfer Function Amplitude Transfer Function Phase π π Ripple velocity (Hz) D 6 IR (positive freqs) -6 -Hz Hz 6 IR (negative freqs)





13 Spectro-Temporal Response Fields frequency (khz) 9/b /a frequency (khz) 6 time (ms) /a time (ms) 7/a
















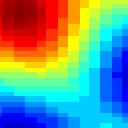









14 Predictions Stimulus Spectrogram Spectro-Temporal Response Field Response * t = - 9/b6() 6 6 * t = 5 /a6(3) time (ms) time (ms) -5 time (ms) Prediction Response No Spikes Spontaneous
15 Response field modeling The response of the spatial filter is H n (Ω) = (Ω / Ωn ) e ( Ω / Ω n ) max(ω,) h n (x) = h n,r(x) + j ˆ h n, r (x) Ripple Decomposition The response of temporal filter is G m (w) = (w / w m ) e (w / w m ) max(sgn(w m )w,) g m (t) = g m, r(t) + j sgn(w m ) g ˆ m,r (t) Direction selectivity The multiscale-multirate response for an auditory spectrogram is p mn (t,x) = p (t, x) * t g m (t)* x h n (x) The composite spatiotemporal impulse response shows the nature of directional selectivity. where h n, r (x) = k n ( (k n x) )e (k n and k n = πωn x) / where g m,r (t) = ω m ( (ωmt) )e (ω m t ) / and ωn = π w n Representation The phase of the complex response is indicated by colors: green =, red = 9, purple = ± and blue = -9. The magnitude is linearly represented by the saturation of the color.
16 Ripple Filters Frequency (octaves) cyc/oct, 3 Hz cyc/oct, Hz cyc/oct, 3 Hz cyc/oct, Hz Frequency (octaves) cyc/oct, - Hz cyc/oct, -3 Hz cyc/oct, - Hz cyc/oct, -3 Hz














17 Ripple Decomposition Example 3 Hz. () cyc/oct, 3 Hz. (.) cyc/oct, 3 Hz. (.).... Hz. (.) Auditory Spectrgram <sentsahm> Come home right away. Hz. (.) cyc/oct, Hz. (.) cyc/oct, Hz. (.3) cyc/oct (.) cyc/oct () cyc/oct, Hz. () cyc/oct, Hz. (.3). 3 Hz. () 3 5 cyc/oct, 3 Hz. (.9) 3 5 cyc/oct, 3 Hz. (.39) 3 5
18 Selected References Dynamical papers Kowalski NA, Depireux DA and Shamma SA, J.Neurophys. 76 (5) (996) , and Stationary papers Shamma SA, Versnel H and Kowalski NA, J. Auditory Neuroscience () (995) 33-5, and 55-7, and 7-5. Schreiner CE and Calhoun BM. Auditory Neurosci., (99) Related analysis techniques and models Kowalski NA, Versnel H and Shamma SA, J. Neurophys. 73() (995) Wang K and Shamma SA, IEEE Trans. on Speech and Audio (3) (99) - 35, and 3() (995) Shamma SA, Fleshman JW, Wiser PR and Versnel H, J. Neurophys 69() (993)
Linear and Non-Linear Responses to Dynamic Broad-Band Spectra in Primary Auditory Cortex
 Linear and Non-Linear Responses to Dynamic Broad-Band Spectra in Primary Auditory Cortex D. J. Klein S. A. Shamma J. Z. Simon D. A. Depireux,2,2 2 Department of Electrical Engineering Supported in part
Linear and Non-Linear Responses to Dynamic Broad-Band Spectra in Primary Auditory Cortex D. J. Klein S. A. Shamma J. Z. Simon D. A. Depireux,2,2 2 Department of Electrical Engineering Supported in part
Functional and Structural Implications of Non-Separability of Spectral and Temporal Responses in AI
 Functional and Structural Implications of Non-Separability of Spectral and Temporal Responses in AI Jonathan Z. Simon David J. Klein Didier A. Depireux Shihab A. Shamma and Dept. of Electrical & Computer
Functional and Structural Implications of Non-Separability of Spectral and Temporal Responses in AI Jonathan Z. Simon David J. Klein Didier A. Depireux Shihab A. Shamma and Dept. of Electrical & Computer
TECHNICAL RESEARCH REPORT
 TECHNICAL RESEARCH REPORT Dynamics of Neural Responses in Ferret Primary Auditory Cortex: I. Spectro-Temporal Response Field Characterization by Dynamic Ripple Spectra by D.A. Depireux, J.Z. Simon, D.J.
TECHNICAL RESEARCH REPORT Dynamics of Neural Responses in Ferret Primary Auditory Cortex: I. Spectro-Temporal Response Field Characterization by Dynamic Ripple Spectra by D.A. Depireux, J.Z. Simon, D.J.
COMP 546. Lecture 21. Cochlea to brain, Source Localization. Tues. April 3, 2018
 COMP 546 Lecture 21 Cochlea to brain, Source Localization Tues. April 3, 2018 1 Ear pinna auditory canal cochlea outer middle inner 2 Eye Ear Lens? Retina? Photoreceptors (light -> chemical) Ganglion cells
COMP 546 Lecture 21 Cochlea to brain, Source Localization Tues. April 3, 2018 1 Ear pinna auditory canal cochlea outer middle inner 2 Eye Ear Lens? Retina? Photoreceptors (light -> chemical) Ganglion cells
Time-Series Analysis for Ear-Related and Psychoacoustic Metrics
 Time-Series Analysis for Ear-Related and Psychoacoustic Metrics V. Mellert, H. Remmers, R. Weber, B. Schulte-Fortkamp how to analyse p(t) to obtain an earrelated parameter? general remarks on acoustical
Time-Series Analysis for Ear-Related and Psychoacoustic Metrics V. Mellert, H. Remmers, R. Weber, B. Schulte-Fortkamp how to analyse p(t) to obtain an earrelated parameter? general remarks on acoustical
Robust Spectrotemporal Reverse Correlation for the Auditory System: Optimizing Stimulus Design
 Journal of Computational Neuroscience 9, 85 111, 2000 c 2000 Kluwer Academic Publishers. Manufactured in The Netherlands. Robust Spectrotemporal Reverse Correlation for the Auditory System: Optimizing
Journal of Computational Neuroscience 9, 85 111, 2000 c 2000 Kluwer Academic Publishers. Manufactured in The Netherlands. Robust Spectrotemporal Reverse Correlation for the Auditory System: Optimizing
Robust spectro-temporal reverse correlation for the auditory system: Optimizing stimulus design
 Robust spectro-temporal reverse correlation for the auditory system: Optimizing stimulus design D. J. Klein Institute for Systems Research Department of Electrical Engineering University of Maryland College
Robust spectro-temporal reverse correlation for the auditory system: Optimizing stimulus design D. J. Klein Institute for Systems Research Department of Electrical Engineering University of Maryland College
LECTURE NOTES IN AUDIO ANALYSIS: PITCH ESTIMATION FOR DUMMIES
 LECTURE NOTES IN AUDIO ANALYSIS: PITCH ESTIMATION FOR DUMMIES Abstract March, 3 Mads Græsbøll Christensen Audio Analysis Lab, AD:MT Aalborg University This document contains a brief introduction to pitch
LECTURE NOTES IN AUDIO ANALYSIS: PITCH ESTIMATION FOR DUMMIES Abstract March, 3 Mads Græsbøll Christensen Audio Analysis Lab, AD:MT Aalborg University This document contains a brief introduction to pitch
Feature extraction 2
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 2 Dr Philip Jackson Linear prediction Perceptual linear prediction Comparison of feature methods
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 2 Dr Philip Jackson Linear prediction Perceptual linear prediction Comparison of feature methods
University of Colorado at Boulder ECEN 4/5532. Lab 2 Lab report due on February 16, 2015
 University of Colorado at Boulder ECEN 4/5532 Lab 2 Lab report due on February 16, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
University of Colorado at Boulder ECEN 4/5532 Lab 2 Lab report due on February 16, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
JOINT TIME-FREQUENCY SCATTERING FOR AUDIO CLASSIFICATION
 2015 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 17 20, 2015, BOSTON, USA JOINT TIME-FREQUENCY SCATTERING FOR AUDIO CLASSIFICATION Joakim Andén PACM Princeton University,
2015 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 17 20, 2015, BOSTON, USA JOINT TIME-FREQUENCY SCATTERING FOR AUDIO CLASSIFICATION Joakim Andén PACM Princeton University,
Last time: small acoustics
 Last time: small acoustics Voice, many instruments, modeled by tubes Traveling waves in both directions yield standing waves Standing waves correspond to resonances Variations from the idealization give
Last time: small acoustics Voice, many instruments, modeled by tubes Traveling waves in both directions yield standing waves Standing waves correspond to resonances Variations from the idealization give
Estimating spatio-temporal receptive fields of auditory and visual neurons from their responses to natural stimuli
 ISTITUTE OF PHYSICS PUBLISHIG ETWORK: COMPUTATIO I EURAL SYSTEMS etwork: Comput eural Syst 1 (001) 89 316 wwwioporg/journals/ne PII: S0954-898X(01)3517-9 Estimating spatio-temporal receptive fields of
ISTITUTE OF PHYSICS PUBLISHIG ETWORK: COMPUTATIO I EURAL SYSTEMS etwork: Comput eural Syst 1 (001) 89 316 wwwioporg/journals/ne PII: S0954-898X(01)3517-9 Estimating spatio-temporal receptive fields of
MULTI-RESOLUTION SIGNAL DECOMPOSITION WITH TIME-DOMAIN SPECTROGRAM FACTORIZATION. Hirokazu Kameoka
 MULTI-RESOLUTION SIGNAL DECOMPOSITION WITH TIME-DOMAIN SPECTROGRAM FACTORIZATION Hiroazu Kameoa The University of Toyo / Nippon Telegraph and Telephone Corporation ABSTRACT This paper proposes a novel
MULTI-RESOLUTION SIGNAL DECOMPOSITION WITH TIME-DOMAIN SPECTROGRAM FACTORIZATION Hiroazu Kameoa The University of Toyo / Nippon Telegraph and Telephone Corporation ABSTRACT This paper proposes a novel
Nonnegative Matrix Factor 2-D Deconvolution for Blind Single Channel Source Separation
 Nonnegative Matrix Factor 2-D Deconvolution for Blind Single Channel Source Separation Mikkel N. Schmidt and Morten Mørup Technical University of Denmark Informatics and Mathematical Modelling Richard
Nonnegative Matrix Factor 2-D Deconvolution for Blind Single Channel Source Separation Mikkel N. Schmidt and Morten Mørup Technical University of Denmark Informatics and Mathematical Modelling Richard
Identification and separation of noises with spectro-temporal patterns
 PROCEEDINGS of the 22 nd International Congress on Acoustics Soundscape, Psychoacoustics and Urban Environment: Paper ICA2016-532 Identification and separation of noises with spectro-temporal patterns
PROCEEDINGS of the 22 nd International Congress on Acoustics Soundscape, Psychoacoustics and Urban Environment: Paper ICA2016-532 Identification and separation of noises with spectro-temporal patterns
Exercises. Chapter 1. of τ approx that produces the most accurate estimate for this firing pattern.
 1 Exercises Chapter 1 1. Generate spike sequences with a constant firing rate r 0 using a Poisson spike generator. Then, add a refractory period to the model by allowing the firing rate r(t) to depend
1 Exercises Chapter 1 1. Generate spike sequences with a constant firing rate r 0 using a Poisson spike generator. Then, add a refractory period to the model by allowing the firing rate r(t) to depend
Limulus. The Neural Code. Response of Visual Neurons 9/21/2011
 Crab cam (Barlow et al., 2001) self inhibition recurrent inhibition lateral inhibition - L16. Neural processing in Linear Systems: Temporal and Spatial Filtering C. D. Hopkins Sept. 21, 2011 The Neural
Crab cam (Barlow et al., 2001) self inhibition recurrent inhibition lateral inhibition - L16. Neural processing in Linear Systems: Temporal and Spatial Filtering C. D. Hopkins Sept. 21, 2011 The Neural
Cepstral Deconvolution Method for Measurement of Absorption and Scattering Coefficients of Materials
 Cepstral Deconvolution Method for Measurement of Absorption and Scattering Coefficients of Materials Mehmet ÇALIŞKAN a) Middle East Technical University, Department of Mechanical Engineering, Ankara, 06800,
Cepstral Deconvolution Method for Measurement of Absorption and Scattering Coefficients of Materials Mehmet ÇALIŞKAN a) Middle East Technical University, Department of Mechanical Engineering, Ankara, 06800,
Neural Encoding Models
 Neural Encoding Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Term 1, Autumn 2011 Studying sensory systems x(t) y(t) Decoding: ˆx(t)= G[y(t)]
Neural Encoding Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Term 1, Autumn 2011 Studying sensory systems x(t) y(t) Decoding: ˆx(t)= G[y(t)]
Single Channel Signal Separation Using MAP-based Subspace Decomposition
 Single Channel Signal Separation Using MAP-based Subspace Decomposition Gil-Jin Jang, Te-Won Lee, and Yung-Hwan Oh 1 Spoken Language Laboratory, Department of Computer Science, KAIST 373-1 Gusong-dong,
Single Channel Signal Separation Using MAP-based Subspace Decomposition Gil-Jin Jang, Te-Won Lee, and Yung-Hwan Oh 1 Spoken Language Laboratory, Department of Computer Science, KAIST 373-1 Gusong-dong,
200Pa 10million. Overview. Acoustics of Speech and Hearing. Loudness. Terms to describe sound. Matching Pressure to Loudness. Loudness vs.
 Overview Acoustics of Speech and Hearing Lecture 1-2 How is sound pressure and loudness related? How can we measure the size (quantity) of a sound? The scale Logarithmic scales in general Decibel scales
Overview Acoustics of Speech and Hearing Lecture 1-2 How is sound pressure and loudness related? How can we measure the size (quantity) of a sound? The scale Logarithmic scales in general Decibel scales
Nonlinear reverse-correlation with synthesized naturalistic noise
 Cognitive Science Online, Vol1, pp1 7, 2003 http://cogsci-onlineucsdedu Nonlinear reverse-correlation with synthesized naturalistic noise Hsin-Hao Yu Department of Cognitive Science University of California
Cognitive Science Online, Vol1, pp1 7, 2003 http://cogsci-onlineucsdedu Nonlinear reverse-correlation with synthesized naturalistic noise Hsin-Hao Yu Department of Cognitive Science University of California
arxiv:math/ v1 [math.na] 12 Feb 2005
![arxiv:math/ v1 [math.na] 12 Feb 2005](/thumbs/90/103872726.jpg "arxiv:math/ v1 [math.na] 12 Feb 2005") arxiv:math/0502252v1 [math.na] 12 Feb 2005 An Orthogonal Discrete Auditory Transform Jack Xin and Yingyong Qi Abstract An orthogonal discrete auditory transform (ODAT) from sound signal to spectrum is
arxiv:math/0502252v1 [math.na] 12 Feb 2005 An Orthogonal Discrete Auditory Transform Jack Xin and Yingyong Qi Abstract An orthogonal discrete auditory transform (ODAT) from sound signal to spectrum is
MULTISCALE SCATTERING FOR AUDIO CLASSIFICATION
 MULTISCALE SCATTERING FOR AUDIO CLASSIFICATION Joakim Andén CMAP, Ecole Polytechnique, 91128 Palaiseau anden@cmappolytechniquefr Stéphane Mallat CMAP, Ecole Polytechnique, 91128 Palaiseau ABSTRACT Mel-frequency
MULTISCALE SCATTERING FOR AUDIO CLASSIFICATION Joakim Andén CMAP, Ecole Polytechnique, 91128 Palaiseau anden@cmappolytechniquefr Stéphane Mallat CMAP, Ecole Polytechnique, 91128 Palaiseau ABSTRACT Mel-frequency
Spike-Frequency Adaptation: Phenomenological Model and Experimental Tests
 Spike-Frequency Adaptation: Phenomenological Model and Experimental Tests J. Benda, M. Bethge, M. Hennig, K. Pawelzik & A.V.M. Herz February, 7 Abstract Spike-frequency adaptation is a common feature of
Spike-Frequency Adaptation: Phenomenological Model and Experimental Tests J. Benda, M. Bethge, M. Hennig, K. Pawelzik & A.V.M. Herz February, 7 Abstract Spike-frequency adaptation is a common feature of
Frequency Domain Speech Analysis
 Frequency Domain Speech Analysis Short Time Fourier Analysis Cepstral Analysis Windowed (short time) Fourier Transform Spectrogram of speech signals Filter bank implementation* (Real) cepstrum and complex
Frequency Domain Speech Analysis Short Time Fourier Analysis Cepstral Analysis Windowed (short time) Fourier Transform Spectrogram of speech signals Filter bank implementation* (Real) cepstrum and complex
The Spectral Differences in Sounds and Harmonics. Through chemical and biological processes, we, as humans, can detect the movement and
 John Chambers Semester Project 5/2/16 The Spectral Differences in Sounds and Harmonics Through chemical and biological processes, we, as humans, can detect the movement and vibrations of molecules through
John Chambers Semester Project 5/2/16 The Spectral Differences in Sounds and Harmonics Through chemical and biological processes, we, as humans, can detect the movement and vibrations of molecules through
Introduction to Biomedical Engineering
 Introduction to Biomedical Engineering Biosignal processing Kung-Bin Sung 6/11/2007 1 Outline Chapter 10: Biosignal processing Characteristics of biosignals Frequency domain representation and analysis
Introduction to Biomedical Engineering Biosignal processing Kung-Bin Sung 6/11/2007 1 Outline Chapter 10: Biosignal processing Characteristics of biosignals Frequency domain representation and analysis
SPEECH ANALYSIS AND SYNTHESIS
 16 Chapter 2 SPEECH ANALYSIS AND SYNTHESIS 2.1 INTRODUCTION: Speech signal analysis is used to characterize the spectral information of an input speech signal. Speech signal analysis [52-53] techniques
16 Chapter 2 SPEECH ANALYSIS AND SYNTHESIS 2.1 INTRODUCTION: Speech signal analysis is used to characterize the spectral information of an input speech signal. Speech signal analysis [52-53] techniques
Sound Recognition in Mixtures
 Sound Recognition in Mixtures Juhan Nam, Gautham J. Mysore 2, and Paris Smaragdis 2,3 Center for Computer Research in Music and Acoustics, Stanford University, 2 Advanced Technology Labs, Adobe Systems
Sound Recognition in Mixtures Juhan Nam, Gautham J. Mysore 2, and Paris Smaragdis 2,3 Center for Computer Research in Music and Acoustics, Stanford University, 2 Advanced Technology Labs, Adobe Systems
Signal Modeling Techniques in Speech Recognition. Hassan A. Kingravi
 Signal Modeling Techniques in Speech Recognition Hassan A. Kingravi Outline Introduction Spectral Shaping Spectral Analysis Parameter Transforms Statistical Modeling Discussion Conclusions 1: Introduction
Signal Modeling Techniques in Speech Recognition Hassan A. Kingravi Outline Introduction Spectral Shaping Spectral Analysis Parameter Transforms Statistical Modeling Discussion Conclusions 1: Introduction
Audio Features. Fourier Transform. Fourier Transform. Fourier Transform. Short Time Fourier Transform. Fourier Transform.
 Advanced Course Computer Science Music Processing Summer Term 2010 Fourier Transform Meinard Müller Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Audio Features Fourier Transform Fourier
Advanced Course Computer Science Music Processing Summer Term 2010 Fourier Transform Meinard Müller Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Audio Features Fourier Transform Fourier
Cochlear modeling and its role in human speech recognition
 Allen/IPAM February 1, 2005 p. 1/3 Cochlear modeling and its role in human speech recognition Miller Nicely confusions and the articulation index Jont Allen Univ. of IL, Beckman Inst., Urbana IL Allen/IPAM
Allen/IPAM February 1, 2005 p. 1/3 Cochlear modeling and its role in human speech recognition Miller Nicely confusions and the articulation index Jont Allen Univ. of IL, Beckman Inst., Urbana IL Allen/IPAM
Audio Features. Fourier Transform. Short Time Fourier Transform. Short Time Fourier Transform. Short Time Fourier Transform
 Advanced Course Computer Science Music Processing Summer Term 2009 Meinard Müller Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Audio Features Fourier Transform Tells which notes (frequencies)
Advanced Course Computer Science Music Processing Summer Term 2009 Meinard Müller Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Audio Features Fourier Transform Tells which notes (frequencies)
encoding and estimation bottleneck and limits to visual fidelity
 Retina Light Optic Nerve photoreceptors encoding and estimation bottleneck and limits to visual fidelity interneurons ganglion cells light The Neural Coding Problem s(t) {t i } Central goals for today:
Retina Light Optic Nerve photoreceptors encoding and estimation bottleneck and limits to visual fidelity interneurons ganglion cells light The Neural Coding Problem s(t) {t i } Central goals for today:
Periodicity and pitch perception
 Periodicity and pitch perception John R. Pierce Center for Computer Research in Music and 4coustics, Department of Music, Stanford University, Stanford, California 94505 (Received 11 December 1990; revised
Periodicity and pitch perception John R. Pierce Center for Computer Research in Music and 4coustics, Department of Music, Stanford University, Stanford, California 94505 (Received 11 December 1990; revised
Analysis of polyphonic audio using source-filter model and non-negative matrix factorization
 Analysis of polyphonic audio using source-filter model and non-negative matrix factorization Tuomas Virtanen and Anssi Klapuri Tampere University of Technology, Institute of Signal Processing Korkeakoulunkatu
Analysis of polyphonic audio using source-filter model and non-negative matrix factorization Tuomas Virtanen and Anssi Klapuri Tampere University of Technology, Institute of Signal Processing Korkeakoulunkatu
Speech Signal Representations
 Speech Signal Representations Berlin Chen 2003 References: 1. X. Huang et. al., Spoken Language Processing, Chapters 5, 6 2. J. R. Deller et. al., Discrete-Time Processing of Speech Signals, Chapters 4-6
Speech Signal Representations Berlin Chen 2003 References: 1. X. Huang et. al., Spoken Language Processing, Chapters 5, 6 2. J. R. Deller et. al., Discrete-Time Processing of Speech Signals, Chapters 4-6
Mel-Generalized Cepstral Representation of Speech A Unified Approach to Speech Spectral Estimation. Keiichi Tokuda
 Mel-Generalized Cepstral Representation of Speech A Unified Approach to Speech Spectral Estimation Keiichi Tokuda Nagoya Institute of Technology Carnegie Mellon University Tamkang University March 13,
Mel-Generalized Cepstral Representation of Speech A Unified Approach to Speech Spectral Estimation Keiichi Tokuda Nagoya Institute of Technology Carnegie Mellon University Tamkang University March 13,
Tutorial on Blind Source Separation and Independent Component Analysis
 Tutorial on Blind Source Separation and Independent Component Analysis Lucas Parra Adaptive Image & Signal Processing Group Sarnoff Corporation February 09, 2002 Linear Mixtures... problem statement...
Tutorial on Blind Source Separation and Independent Component Analysis Lucas Parra Adaptive Image & Signal Processing Group Sarnoff Corporation February 09, 2002 Linear Mixtures... problem statement...
Digital Image Processing Lectures 15 & 16
 Lectures 15 & 16, Professor Department of Electrical and Computer Engineering Colorado State University CWT and Multi-Resolution Signal Analysis Wavelet transform offers multi-resolution by allowing for
Lectures 15 & 16, Professor Department of Electrical and Computer Engineering Colorado State University CWT and Multi-Resolution Signal Analysis Wavelet transform offers multi-resolution by allowing for
Feature extraction 1
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 1 Dr Philip Jackson Cepstral analysis - Real & complex cepstra - Homomorphic decomposition Filter
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Feature extraction 1 Dr Philip Jackson Cepstral analysis - Real & complex cepstra - Homomorphic decomposition Filter
Hammerstein-Wiener Model: A New Approach to the Estimation of Formal Neural Information
 Hammerstein-Wiener Model: A New Approach to the Estimation of Formal Neural Information Reza Abbasi-Asl1, Rahman Khorsandi2, Bijan Vosooghi-Vahdat1 1. Biomedical Signal and Image Processing Laboratory
Hammerstein-Wiener Model: A New Approach to the Estimation of Formal Neural Information Reza Abbasi-Asl1, Rahman Khorsandi2, Bijan Vosooghi-Vahdat1 1. Biomedical Signal and Image Processing Laboratory
Which of the six boxes below cannot be made from this unfolded box? (There may be more than ffi. ffi
 Which of the six boxes below cannot be made from this unfolded box? (There may be more than one.) @ ffi w @ @ ffi c Biophysics @ YORK Peripheral sensory transduction Christopher Bergevin (York University,
Which of the six boxes below cannot be made from this unfolded box? (There may be more than one.) @ ffi w @ @ ffi c Biophysics @ YORK Peripheral sensory transduction Christopher Bergevin (York University,
Introduction Basic Audio Feature Extraction
 Introduction Basic Audio Feature Extraction Vincent Koops (with slides by Meinhard Müller) Sound and Music Technology, December 6th, 2016 1 28 November 2017 Today g Main modules A. Sound and music for
Introduction Basic Audio Feature Extraction Vincent Koops (with slides by Meinhard Müller) Sound and Music Technology, December 6th, 2016 1 28 November 2017 Today g Main modules A. Sound and music for
Linear Systems Theory Handout
 Linear Systems Theory Handout David Heeger, Stanford University Matteo Carandini, ETH/University of Zurich Characterizing the complete input-output properties of a system by exhaustive measurement is usually
Linear Systems Theory Handout David Heeger, Stanford University Matteo Carandini, ETH/University of Zurich Characterizing the complete input-output properties of a system by exhaustive measurement is usually
Computational Auditory Scene Analysis Based on Loudness/Pitch/Timbre Decomposition
 Computational Auditory Scene Analysis Based on Loudness/Pitch/Timbre Decomposition Mototsugu Abe and Shigeru Ando Department of Mathematical Engineering and Information Physics Faculty of Engineering,
Computational Auditory Scene Analysis Based on Loudness/Pitch/Timbre Decomposition Mototsugu Abe and Shigeru Ando Department of Mathematical Engineering and Information Physics Faculty of Engineering,
Non-Negative Matrix Factorization And Its Application to Audio. Tuomas Virtanen Tampere University of Technology
 Non-Negative Matrix Factorization And Its Application to Audio Tuomas Virtanen Tampere University of Technology tuomas.virtanen@tut.fi 2 Contents Introduction to audio signals Spectrogram representation
Non-Negative Matrix Factorization And Its Application to Audio Tuomas Virtanen Tampere University of Technology tuomas.virtanen@tut.fi 2 Contents Introduction to audio signals Spectrogram representation
Signal representations: Cepstrum
 Signal representations: Cepstrum Source-filter separation for sound production For speech, source corresponds to excitation by a pulse train for voiced phonemes and to turbulence (noise) for unvoiced phonemes,
Signal representations: Cepstrum Source-filter separation for sound production For speech, source corresponds to excitation by a pulse train for voiced phonemes and to turbulence (noise) for unvoiced phonemes,
ELEG 3124 SYSTEMS AND SIGNALS Ch. 5 Fourier Transform
 Department of Electrical Engineering University of Arkansas ELEG 3124 SYSTEMS AND SIGNALS Ch. 5 Fourier Transform Dr. Jingxian Wu wuj@uark.edu OUTLINE 2 Introduction Fourier Transform Properties of Fourier
Department of Electrical Engineering University of Arkansas ELEG 3124 SYSTEMS AND SIGNALS Ch. 5 Fourier Transform Dr. Jingxian Wu wuj@uark.edu OUTLINE 2 Introduction Fourier Transform Properties of Fourier
Physical Acoustics. Hearing is the result of a complex interaction of physics, physiology, perception and cognition.
 Physical Acoustics Hearing, auditory perception, or audition is the ability to perceive sound by detecting vibrations, changes in the pressure of the surrounding medium through time, through an organ such
Physical Acoustics Hearing, auditory perception, or audition is the ability to perceive sound by detecting vibrations, changes in the pressure of the surrounding medium through time, through an organ such
Design Criteria for the Quadratically Interpolated FFT Method (I): Bias due to Interpolation
: Bias due to Interpolation") CENTER FOR COMPUTER RESEARCH IN MUSIC AND ACOUSTICS DEPARTMENT OF MUSIC, STANFORD UNIVERSITY REPORT NO. STAN-M-4 Design Criteria for the Quadratically Interpolated FFT Method (I): Bias due to Interpolation
CENTER FOR COMPUTER RESEARCH IN MUSIC AND ACOUSTICS DEPARTMENT OF MUSIC, STANFORD UNIVERSITY REPORT NO. STAN-M-4 Design Criteria for the Quadratically Interpolated FFT Method (I): Bias due to Interpolation
Review: Continuous Fourier Transform
 Review: Continuous Fourier Transform Review: convolution x t h t = x τ h(t τ)dτ Convolution in time domain Derivation Convolution Property Interchange the order of integrals Let Convolution Property By
Review: Continuous Fourier Transform Review: convolution x t h t = x τ h(t τ)dτ Convolution in time domain Derivation Convolution Property Interchange the order of integrals Let Convolution Property By
Membrane equation. VCl. dv dt + V = V Na G Na + V K G K + V Cl G Cl. G total. C m. G total = G Na + G K + G Cl
 Spiking neurons Membrane equation V GNa GK GCl Cm VNa VK VCl dv dt + V = V Na G Na + V K G K + V Cl G Cl G total G total = G Na + G K + G Cl = C m G total Membrane with synaptic inputs V Gleak GNa GK
Spiking neurons Membrane equation V GNa GK GCl Cm VNa VK VCl dv dt + V = V Na G Na + V K G K + V Cl G Cl G total G total = G Na + G K + G Cl = C m G total Membrane with synaptic inputs V Gleak GNa GK
David Weenink. First semester 2007
 Institute of Phonetic Sciences University of Amsterdam First semester 2007 Definition (ANSI: In Psycho-acoustics) is that auditory attribute of sound according to which sounds can be ordered on a scale
Institute of Phonetic Sciences University of Amsterdam First semester 2007 Definition (ANSI: In Psycho-acoustics) is that auditory attribute of sound according to which sounds can be ordered on a scale
Fourier Analysis of Signals
 Chapter 2 Fourier Analysis of Signals As we have seen in the last chapter, music signals are generally complex sound mixtures that consist of a multitude of different sound components. Because of this
Chapter 2 Fourier Analysis of Signals As we have seen in the last chapter, music signals are generally complex sound mixtures that consist of a multitude of different sound components. Because of this
1 Wind Turbine Acoustics. Wind turbines generate sound by both mechanical and aerodynamic
 Wind Turbine Acoustics 1 1 Wind Turbine Acoustics Wind turbines generate sound by both mechanical and aerodynamic sources. Sound remains an important criterion used in the siting of wind farms. Sound emission
Wind Turbine Acoustics 1 1 Wind Turbine Acoustics Wind turbines generate sound by both mechanical and aerodynamic sources. Sound remains an important criterion used in the siting of wind farms. Sound emission
Non-negative Matrix Factor Deconvolution; Extraction of Multiple Sound Sources from Monophonic Inputs
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Non-negative Matrix Factor Deconvolution; Extraction of Multiple Sound Sources from Monophonic Inputs Paris Smaragdis TR2004-104 September
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Non-negative Matrix Factor Deconvolution; Extraction of Multiple Sound Sources from Monophonic Inputs Paris Smaragdis TR2004-104 September
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
Elec4621 Advanced Digital Signal Processing Chapter 11: Time-Frequency Analysis
 Elec461 Advanced Digital Signal Processing Chapter 11: Time-Frequency Analysis Dr. D. S. Taubman May 3, 011 In this last chapter of your notes, we are interested in the problem of nding the instantaneous
Elec461 Advanced Digital Signal Processing Chapter 11: Time-Frequency Analysis Dr. D. S. Taubman May 3, 011 In this last chapter of your notes, we are interested in the problem of nding the instantaneous
SINGLE CHANNEL SPEECH MUSIC SEPARATION USING NONNEGATIVE MATRIX FACTORIZATION AND SPECTRAL MASKS. Emad M. Grais and Hakan Erdogan
 SINGLE CHANNEL SPEECH MUSIC SEPARATION USING NONNEGATIVE MATRIX FACTORIZATION AND SPECTRAL MASKS Emad M. Grais and Hakan Erdogan Faculty of Engineering and Natural Sciences, Sabanci University, Orhanli
SINGLE CHANNEL SPEECH MUSIC SEPARATION USING NONNEGATIVE MATRIX FACTORIZATION AND SPECTRAL MASKS Emad M. Grais and Hakan Erdogan Faculty of Engineering and Natural Sciences, Sabanci University, Orhanli
Chapters 11 and 12. Sound and Standing Waves
 Chapters 11 and 12 Sound and Standing Waves The Nature of Sound Waves LONGITUDINAL SOUND WAVES Speaker making sound waves in a tube The Nature of Sound Waves The distance between adjacent condensations
Chapters 11 and 12 Sound and Standing Waves The Nature of Sound Waves LONGITUDINAL SOUND WAVES Speaker making sound waves in a tube The Nature of Sound Waves The distance between adjacent condensations
L6: Short-time Fourier analysis and synthesis
 L6: Short-time Fourier analysis and synthesis Overview Analysis: Fourier-transform view Analysis: filtering view Synthesis: filter bank summation (FBS) method Synthesis: overlap-add (OLA) method STFT magnitude
L6: Short-time Fourier analysis and synthesis Overview Analysis: Fourier-transform view Analysis: filtering view Synthesis: filter bank summation (FBS) method Synthesis: overlap-add (OLA) method STFT magnitude
The Continuous-time Fourier
 The Continuous-time Fourier Transform Rui Wang, Assistant professor Dept. of Information and Communication Tongji University it Email: ruiwang@tongji.edu.cn Outline Representation of Aperiodic signals:
The Continuous-time Fourier Transform Rui Wang, Assistant professor Dept. of Information and Communication Tongji University it Email: ruiwang@tongji.edu.cn Outline Representation of Aperiodic signals:
Signal Processing COS 323
 Signal Processing COS 323 Digital Signals D: functions of space or time e.g., sound 2D: often functions of 2 spatial dimensions e.g. images 3D: functions of 3 spatial dimensions CAT, MRI scans or 2 space,
Signal Processing COS 323 Digital Signals D: functions of space or time e.g., sound 2D: often functions of 2 spatial dimensions e.g. images 3D: functions of 3 spatial dimensions CAT, MRI scans or 2 space,
ACOUSTICAL MEASUREMENTS BY ADAPTIVE SYSTEM MODELING
 ACOUSTICAL MEASUREMENTS BY ADAPTIVE SYSTEM MODELING PACS REFERENCE: 43.60.Qv Somek, Branko; Dadic, Martin; Fajt, Sinisa Faculty of Electrical Engineering and Computing University of Zagreb Unska 3, 10000
ACOUSTICAL MEASUREMENTS BY ADAPTIVE SYSTEM MODELING PACS REFERENCE: 43.60.Qv Somek, Branko; Dadic, Martin; Fajt, Sinisa Faculty of Electrical Engineering and Computing University of Zagreb Unska 3, 10000
Gaussian Processes for Audio Feature Extraction
 Gaussian Processes for Audio Feature Extraction Dr. Richard E. Turner (ret26@cam.ac.uk) Computational and Biological Learning Lab Department of Engineering University of Cambridge Machine hearing pipeline
Gaussian Processes for Audio Feature Extraction Dr. Richard E. Turner (ret26@cam.ac.uk) Computational and Biological Learning Lab Department of Engineering University of Cambridge Machine hearing pipeline
SPEECH COMMUNICATION 6.541J J-HST710J Spring 2004
 6.541J PS3 02/19/04 1 SPEECH COMMUNICATION 6.541J-24.968J-HST710J Spring 2004 Problem Set 3 Assigned: 02/19/04 Due: 02/26/04 Read Chapter 6. Problem 1 In this problem we examine the acoustic and perceptual
6.541J PS3 02/19/04 1 SPEECH COMMUNICATION 6.541J-24.968J-HST710J Spring 2004 Problem Set 3 Assigned: 02/19/04 Due: 02/26/04 Read Chapter 6. Problem 1 In this problem we examine the acoustic and perceptual
AN INVERTIBLE DISCRETE AUDITORY TRANSFORM
 COMM. MATH. SCI. Vol. 3, No. 1, pp. 47 56 c 25 International Press AN INVERTIBLE DISCRETE AUDITORY TRANSFORM JACK XIN AND YINGYONG QI Abstract. A discrete auditory transform (DAT) from sound signal to
COMM. MATH. SCI. Vol. 3, No. 1, pp. 47 56 c 25 International Press AN INVERTIBLE DISCRETE AUDITORY TRANSFORM JACK XIN AND YINGYONG QI Abstract. A discrete auditory transform (DAT) from sound signal to
Timbral, Scale, Pitch modifications
 Introduction Timbral, Scale, Pitch modifications M2 Mathématiques / Vision / Apprentissage Audio signal analysis, indexing and transformation Page 1 / 40 Page 2 / 40 Modification of playback speed Modifications
Introduction Timbral, Scale, Pitch modifications M2 Mathématiques / Vision / Apprentissage Audio signal analysis, indexing and transformation Page 1 / 40 Page 2 / 40 Modification of playback speed Modifications
+ + ( + ) = Linear recurrent networks. Simpler, much more amenable to analytic treatment E.g. by choosing
 = Linear recurrent networks. Simpler, much more amenable to analytic treatment E.g. by choosing") Linear recurrent networks Simpler, much more amenable to analytic treatment E.g. by choosing + ( + ) = Firing rates can be negative Approximates dynamics around fixed point Approximation often reasonable
Linear recurrent networks Simpler, much more amenable to analytic treatment E.g. by choosing + ( + ) = Firing rates can be negative Approximates dynamics around fixed point Approximation often reasonable
Topic 3: Fourier Series (FS)
") ELEC264: Signals And Systems Topic 3: Fourier Series (FS) o o o o Introduction to frequency analysis of signals CT FS Fourier series of CT periodic signals Signal Symmetry and CT Fourier Series Properties
ELEC264: Signals And Systems Topic 3: Fourier Series (FS) o o o o Introduction to frequency analysis of signals CT FS Fourier series of CT periodic signals Signal Symmetry and CT Fourier Series Properties
Frequency Multiplexing Tickle Tones to Determine Harmonic Coupling Weights in Nonlinear Systems
 Charles Baylis and Robert J. Marks II, "Frequency multiplexing tickle tones to determine harmonic coupling weights in nonlinear systems,'' Microwave Measurement Symposium (ARFTG), 2011 78th ARFTG pp.1-7,
Charles Baylis and Robert J. Marks II, "Frequency multiplexing tickle tones to determine harmonic coupling weights in nonlinear systems,'' Microwave Measurement Symposium (ARFTG), 2011 78th ARFTG pp.1-7,
Exploring Nonlinear Oscillator Models for the Auditory Periphery
 Exploring Nonlinear Oscillator Models for the Auditory Periphery Andrew Binder Dr. Christopher Bergevin, Supervisor October 31, 2008 1 Introduction Sound-induced vibrations are converted into electrical
Exploring Nonlinear Oscillator Models for the Auditory Periphery Andrew Binder Dr. Christopher Bergevin, Supervisor October 31, 2008 1 Introduction Sound-induced vibrations are converted into electrical
Nature Neuroscience: doi: /nn.2283
 Supplemental Material for NN-A2678-T Phase-to-rate transformations encode touch in cortical neurons of a scanning sensorimotor system by John Curtis and David Kleinfeld Figure S. Overall distribution of
Supplemental Material for NN-A2678-T Phase-to-rate transformations encode touch in cortical neurons of a scanning sensorimotor system by John Curtis and David Kleinfeld Figure S. Overall distribution of
Robust regression and non-linear kernel methods for characterization of neuronal response functions from limited data
 Robust regression and non-linear kernel methods for characterization of neuronal response functions from limited data Maneesh Sahani Gatsby Computational Neuroscience Unit University College, London Jennifer
Robust regression and non-linear kernel methods for characterization of neuronal response functions from limited data Maneesh Sahani Gatsby Computational Neuroscience Unit University College, London Jennifer
Sound 2: frequency analysis
 COMP 546 Lecture 19 Sound 2: frequency analysis Tues. March 27, 2018 1 Speed of Sound Sound travels at about 340 m/s, or 34 cm/ ms. (This depends on temperature and other factors) 2 Wave equation Pressure
COMP 546 Lecture 19 Sound 2: frequency analysis Tues. March 27, 2018 1 Speed of Sound Sound travels at about 340 m/s, or 34 cm/ ms. (This depends on temperature and other factors) 2 Wave equation Pressure
Basilar membrane models
 Technical University of Denmark Basilar membrane models 2 nd semester project DTU Electrical Engineering Acoustic Technology Spring semester 2008 Group 5 Troels Schmidt Lindgreen s073081 David Pelegrin
Technical University of Denmark Basilar membrane models 2 nd semester project DTU Electrical Engineering Acoustic Technology Spring semester 2008 Group 5 Troels Schmidt Lindgreen s073081 David Pelegrin
Topic 6. Timbre Representations
 Topic 6 Timbre Representations We often say that singer s voice is magnetic the violin sounds bright this French horn sounds solid that drum sounds dull What aspect(s) of sound are these words describing?
Topic 6 Timbre Representations We often say that singer s voice is magnetic the violin sounds bright this French horn sounds solid that drum sounds dull What aspect(s) of sound are these words describing?
High-dimensional geometry of cortical population activity. Marius Pachitariu University College London
 High-dimensional geometry of cortical population activity Marius Pachitariu University College London Part I: introduction to the brave new world of large-scale neuroscience Part II: large-scale data preprocessing
High-dimensional geometry of cortical population activity Marius Pachitariu University College London Part I: introduction to the brave new world of large-scale neuroscience Part II: large-scale data preprocessing
2A1H Time-Frequency Analysis II
 2AH Time-Frequency Analysis II Bugs/queries to david.murray@eng.ox.ac.uk HT 209 For any corrections see the course page DW Murray at www.robots.ox.ac.uk/ dwm/courses/2tf. (a) A signal g(t) with period
2AH Time-Frequency Analysis II Bugs/queries to david.murray@eng.ox.ac.uk HT 209 For any corrections see the course page DW Murray at www.robots.ox.ac.uk/ dwm/courses/2tf. (a) A signal g(t) with period
Time and Spatial Series and Transforms
 Time and Spatial Series and Transforms Z- and Fourier transforms Gibbs' phenomenon Transforms and linear algebra Wavelet transforms Reading: Sheriff and Geldart, Chapter 15 Z-Transform Consider a digitized
Time and Spatial Series and Transforms Z- and Fourier transforms Gibbs' phenomenon Transforms and linear algebra Wavelet transforms Reading: Sheriff and Geldart, Chapter 15 Z-Transform Consider a digitized
Time-domain representations
 Time-domain representations Speech Processing Tom Bäckström Aalto University Fall 2016 Basics of Signal Processing in the Time-domain Time-domain signals Before we can describe speech signals or modelling
Time-domain representations Speech Processing Tom Bäckström Aalto University Fall 2016 Basics of Signal Processing in the Time-domain Time-domain signals Before we can describe speech signals or modelling
Chapter 9. Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析
 Chapter 9 Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析 1 LPC Methods LPC methods are the most widely used in speech coding, speech synthesis, speech recognition, speaker recognition and verification
Chapter 9 Linear Predictive Analysis of Speech Signals 语音信号的线性预测分析 1 LPC Methods LPC methods are the most widely used in speech coding, speech synthesis, speech recognition, speaker recognition and verification
Automatic Speech Recognition (CS753)
") Automatic Speech Recognition (CS753) Lecture 12: Acoustic Feature Extraction for ASR Instructor: Preethi Jyothi Feb 13, 2017 Speech Signal Analysis Generate discrete samples A frame Need to focus on short
Automatic Speech Recognition (CS753) Lecture 12: Acoustic Feature Extraction for ASR Instructor: Preethi Jyothi Feb 13, 2017 Speech Signal Analysis Generate discrete samples A frame Need to focus on short
Short-Time Fourier Transform and Chroma Features
 Friedrich-Alexander-Universität Erlangen-Nürnberg Lab Course Short-Time Fourier Transform and Chroma Features International Audio Laboratories Erlangen Prof. Dr. Meinard Müller Friedrich-Alexander Universität
Friedrich-Alexander-Universität Erlangen-Nürnberg Lab Course Short-Time Fourier Transform and Chroma Features International Audio Laboratories Erlangen Prof. Dr. Meinard Müller Friedrich-Alexander Universität
Lecture 14 1/38 Phys 220. Final Exam. Wednesday, August 6 th 10:30 am 12:30 pm Phys multiple choice problems (15 points each 300 total)
") Lecture 14 1/38 Phys 220 Final Exam Wednesday, August 6 th 10:30 am 12:30 pm Phys 114 20 multiple choice problems (15 points each 300 total) 75% will be from Chapters 10-16 25% from Chapters 1-9 Students
Lecture 14 1/38 Phys 220 Final Exam Wednesday, August 6 th 10:30 am 12:30 pm Phys 114 20 multiple choice problems (15 points each 300 total) 75% will be from Chapters 10-16 25% from Chapters 1-9 Students
Generative models for amplitude modulation: Gaussian Modulation Cascade Processes
 Generative models for amplitude modulation: Gaussian Modulation Cascade Processes Richard Turner (turner@gatsby.ucl.ac.uk) Maneesh Sahani (maneesh@gatsby.ucl.ac.uk) Gatsby Computational Neuroscience Unit,
Generative models for amplitude modulation: Gaussian Modulation Cascade Processes Richard Turner (turner@gatsby.ucl.ac.uk) Maneesh Sahani (maneesh@gatsby.ucl.ac.uk) Gatsby Computational Neuroscience Unit,
Obtaining objective, content-specific room acoustical parameters using auditory modeling
 Obtaining objective, content-specific room acoustical parameters using auditory modeling Jasper van Dorp Schuitman Philips Research, Digital Signal Processing Group, Eindhoven, The Netherlands Diemer de
Obtaining objective, content-specific room acoustical parameters using auditory modeling Jasper van Dorp Schuitman Philips Research, Digital Signal Processing Group, Eindhoven, The Netherlands Diemer de
A METHOD OF ICA IN TIME-FREQUENCY DOMAIN
 A METHOD OF ICA IN TIME-FREQUENCY DOMAIN Shiro Ikeda PRESTO, JST Hirosawa 2-, Wako, 35-98, Japan Shiro.Ikeda@brain.riken.go.jp Noboru Murata RIKEN BSI Hirosawa 2-, Wako, 35-98, Japan Noboru.Murata@brain.riken.go.jp
A METHOD OF ICA IN TIME-FREQUENCY DOMAIN Shiro Ikeda PRESTO, JST Hirosawa 2-, Wako, 35-98, Japan Shiro.Ikeda@brain.riken.go.jp Noboru Murata RIKEN BSI Hirosawa 2-, Wako, 35-98, Japan Noboru.Murata@brain.riken.go.jp
Lecture 5. The Digital Fourier Transform. (Based, in part, on The Scientist and Engineer's Guide to Digital Signal Processing by Steven Smith)
") Lecture 5 The Digital Fourier Transform (Based, in part, on The Scientist and Engineer's Guide to Digital Signal Processing by Steven Smith) 1 -. 8 -. 6 -. 4 -. 2-1 -. 8 -. 6 -. 4 -. 2 -. 2. 4. 6. 8 1
Lecture 5 The Digital Fourier Transform (Based, in part, on The Scientist and Engineer's Guide to Digital Signal Processing by Steven Smith) 1 -. 8 -. 6 -. 4 -. 2-1 -. 8 -. 6 -. 4 -. 2 -. 2. 4. 6. 8 1
VID3: Sampling and Quantization
 Video Transmission VID3: Sampling and Quantization By Prof. Gregory D. Durgin copyright 2009 all rights reserved Claude E. Shannon (1916-2001) Mathematician and Electrical Engineer Worked for Bell Labs
Video Transmission VID3: Sampling and Quantization By Prof. Gregory D. Durgin copyright 2009 all rights reserved Claude E. Shannon (1916-2001) Mathematician and Electrical Engineer Worked for Bell Labs
The Bayesian Brain. Robert Jacobs Department of Brain & Cognitive Sciences University of Rochester. May 11, 2017
 The Bayesian Brain Robert Jacobs Department of Brain & Cognitive Sciences University of Rochester May 11, 2017 Bayesian Brain How do neurons represent the states of the world? How do neurons represent
The Bayesian Brain Robert Jacobs Department of Brain & Cognitive Sciences University of Rochester May 11, 2017 Bayesian Brain How do neurons represent the states of the world? How do neurons represent
A Nonlinear Psychoacoustic Model Applied to the ISO MPEG Layer 3 Coder
 A Nonlinear Psychoacoustic Model Applied to the ISO MPEG Layer 3 Coder Frank Baumgarte, Charalampos Ferekidis, Hendrik Fuchs Institut für Theoretische Nachrichtentechnik und Informationsverarbeitung Universität
A Nonlinear Psychoacoustic Model Applied to the ISO MPEG Layer 3 Coder Frank Baumgarte, Charalampos Ferekidis, Hendrik Fuchs Institut für Theoretische Nachrichtentechnik und Informationsverarbeitung Universität
CEPSTRAL ANALYSIS SYNTHESIS ON THE MEL FREQUENCY SCALE, AND AN ADAPTATIVE ALGORITHM FOR IT.
 CEPSTRAL ANALYSIS SYNTHESIS ON THE EL FREQUENCY SCALE, AND AN ADAPTATIVE ALGORITH FOR IT. Summarized overview of the IEEE-publicated papers Cepstral analysis synthesis on the mel frequency scale by Satochi
CEPSTRAL ANALYSIS SYNTHESIS ON THE EL FREQUENCY SCALE, AND AN ADAPTATIVE ALGORITH FOR IT. Summarized overview of the IEEE-publicated papers Cepstral analysis synthesis on the mel frequency scale by Satochi
CCNY. BME I5100: Biomedical Signal Processing. Stochastic Processes. Lucas C. Parra Biomedical Engineering Department City College of New York
 BME I5100: Biomedical Signal Processing Stochastic Processes Lucas C. Parra Biomedical Engineering Department CCNY 1 Schedule Week 1: Introduction Linear, stationary, normal - the stuff biology is not
BME I5100: Biomedical Signal Processing Stochastic Processes Lucas C. Parra Biomedical Engineering Department CCNY 1 Schedule Week 1: Introduction Linear, stationary, normal - the stuff biology is not
TIME-FREQUENCY ANALYSIS EE3528 REPORT. N.Krishnamurthy. Department of ECE University of Pittsburgh Pittsburgh, PA 15261
 TIME-FREQUENCY ANALYSIS EE358 REPORT N.Krishnamurthy Department of ECE University of Pittsburgh Pittsburgh, PA 56 ABSTRACT - analysis, is an important ingredient in signal analysis. It has a plethora of
TIME-FREQUENCY ANALYSIS EE358 REPORT N.Krishnamurthy Department of ECE University of Pittsburgh Pittsburgh, PA 56 ABSTRACT - analysis, is an important ingredient in signal analysis. It has a plethora of
Pulse-Code Modulation (PCM) :
 :") PCM & DPCM & DM 1 Pulse-Code Modulation (PCM) : In PCM each sample of the signal is quantized to one of the amplitude levels, where B is the number of bits used to represent each sample. The rate from
PCM & DPCM & DM 1 Pulse-Code Modulation (PCM) : In PCM each sample of the signal is quantized to one of the amplitude levels, where B is the number of bits used to represent each sample. The rate from
Lecture 7: Pitch and Chord (2) HMM, pitch detection functions. Li Su 2016/03/31
 HMM, pitch detection functions. Li Su 2016/03/31") Lecture 7: Pitch and Chord (2) HMM, pitch detection functions Li Su 2016/03/31 Chord progressions Chord progressions are not arbitrary Example 1: I-IV-I-V-I (C-F-C-G-C) Example 2: I-V-VI-III-IV-I-II-V
Lecture 7: Pitch and Chord (2) HMM, pitch detection functions Li Su 2016/03/31 Chord progressions Chord progressions are not arbitrary Example 1: I-IV-I-V-I (C-F-C-G-C) Example 2: I-V-VI-III-IV-I-II-V