Chapter 6 The Structural Risk Minimization Principle
|
|
|
- Annice Melanie Thompson
- 5 years ago
- Views:
Transcription
1 Chapter 6 The Structural Risk Minimization Principle Junping Zhang jpzhang@fudan.edu.cn Intelligent Information Processing Laboratory, Fudan University March 23, 2004
2 Objectives
3 Structural risk minimization
4 Two other induction principles
5 The Scheme of the SRM induction principle
6 Real-Valued functions
7
8
9
10
11

12
13 Principle of SRM
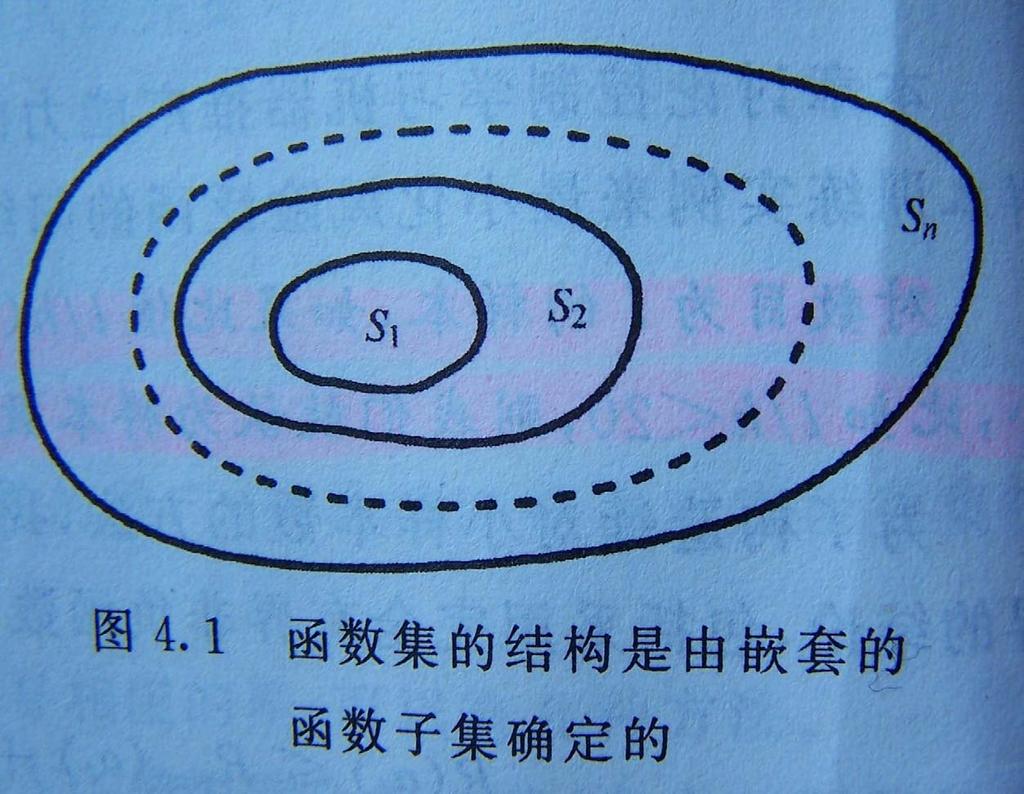
14
15
16
17
18
19

20

21 SRM
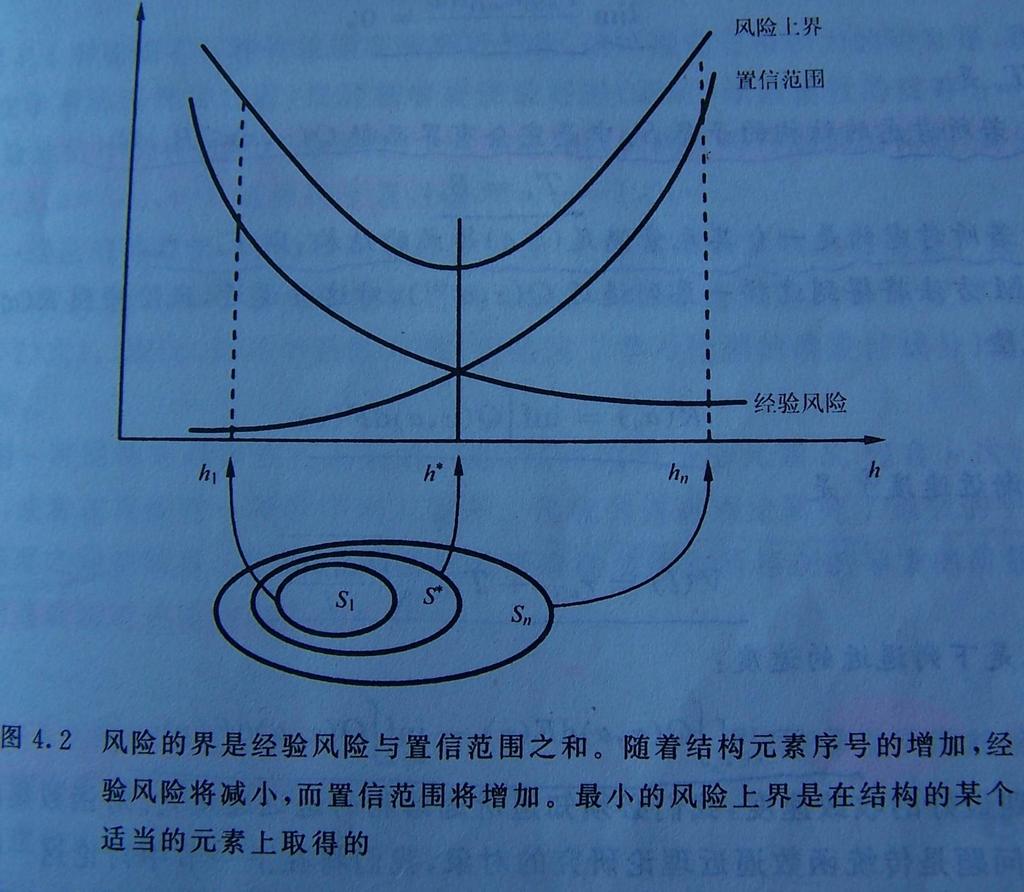
22
23 Minimum Description Length and SRM inductive principles The idea about the Nature of Random Phenomena Minimum Description Length Principle for the Pattern Recognition Problem Bounds for the MDL SRM for the simplest Model and MDL The Shortcoming of the MDL
24 The idea about the Nature of Random Phenomena Probability theory (1930s, Kolmogrov) Formal inference Axiomatization hasn t considered nature of randomness Axioms: given probability measures
25 The idea about the Nature of Random Phenomena The model of randomness Solomonoff (1965), Kolmogrov (1965), Chaitin (1966). Algorithm (descriptive) complexity The length of the shortest binary computer program Up to an additive constant does not depend on the type of computer. Universal characteristic of the object.
26 A relatively large string describing an object is random If algorithm complexity of an object is high If the given description of an object cannot be compressed significantly. MML (Wallace and Boulton, 1968)& MDL (Rissanen, 1978) Algorithm Complexity as a main tool of induction inference of learning machines
27 Minimum Description Length Principle for the Pattern Recognition Problem Given l pairs containing the vector x and the binary value ω Consider two strings: the binary string
28 Question Q: Given (147), is the string (146) a random object? A: to analyze the complexity of the string (146) in the spirit of Solomonoff- Kolmogorov-Chaitin ideas
29 Compress its description Since ω i i=1, l are binary values, the string (146) is described by l bits. Since training pairs were drawn randomly and independently. The value ω i depend on the vector x i but not on the vector x j.
30 Model
31
32
33
34 General Case: not contain the perfect table.
35
36 Randomness
37 Bounds for the MDL Q: A: Does the compression coefficient K(T) determine the probability of the test error in classification (decoding) vectors x by the table T? Yes
38 Comparison between the MDL and ERM in the simplest model
39
40
41 SRM for the simplest Model and MDL
42 SRM for the simplest Model and MDL
43
44 The power of compression coefficient To obtain bound for the probability of error Only information about the coefficient need to be known.
45 The power of compression coefficient How many examples we used How the structure of code books was organized Which code book was used and how many tables were in this code book. How many errors were made by the table from the code book we used.
46 MDL principle To minimize the probability of error One has to minimize the coefficient of compression
47 The shortcoming of the MDL MDL uses code books with a finite number of tables. Continuously depends on parameters, one has to first quantize that set to make the tables.
48 Quantization How do we make the smart quantization for a given number of observations. For a given set of functions, how can we construct a code book with a small number of tables but with good approximation ability?
49 The shortcoming of the MDL Finding a good quantization is extremely difficult and determines the main shortcoming of MDL principle. The MDL principle works well when the problem of constructing reasonable code books has a good solution.
50 Consistency of the SRM principle and asymptotic bounds on the rate of convergence Q: Is the SRM consistent? What is the bound on the (asymptotic) rate of convergence?
51
52
53 Consistency of the SRM principle.
54 Simplification version
55
56
57
58
59 Remark To avoid choosing the minimum of functional (156) over the infinite number of elements of the structure. Additional constraint Choose the minimum from the first l elements of the structure where l is equal to the number of observations.

60
61
62 Discussions and Example
63 The rate of convergence is determined by two contradictory requirements on the rule n=n(l). The first summand: The larger n=n(l), the smaller is the deviation The second summand: The larger n=n(l), the larger deviation For structures with a known bound on the rate of approximation, select the rule that assures the largest rate of convergence.
64
65
66
67
68
69
70 Bounds for the regression estimation problem
71 The model of regression estimation by series expansion
72
73
74
75
76
77 Example
78
79
80 The problem of approximating functions
81
82
83
84
85
86
87
88
89
90
91 To get high asymptotic rate of approximation the only constraint is that the kernel should be a bounded function which can be described as a family of functions possessing finite VC dimension.
92 Problem of local risk minimization
93
94
95
96 Local Risk Minimization Model
97
98
99
100
101
102
103
104
105
106 Note Using local risk minimization methods, one probably does not need rich sets of approximating functions. Whereas the classical semi-local methods are based on using a set of constant functions.
107 Note For local estimation functions in the one-dimensional case, it is probably enough to consider elements S k, k=0,1,2,3 containing the polynomials of degree 0,1,2,3
108 Summary MDL SRM Local Risk Functional
Is there an Elegant Universal Theory of Prediction?
 Is there an Elegant Universal Theory of Prediction? Shane Legg Dalle Molle Institute for Artificial Intelligence Manno-Lugano Switzerland 17th International Conference on Algorithmic Learning Theory Is
Is there an Elegant Universal Theory of Prediction? Shane Legg Dalle Molle Institute for Artificial Intelligence Manno-Lugano Switzerland 17th International Conference on Algorithmic Learning Theory Is
CISC 876: Kolmogorov Complexity
 March 27, 2007 Outline 1 Introduction 2 Definition Incompressibility and Randomness 3 Prefix Complexity Resource-Bounded K-Complexity 4 Incompressibility Method Gödel s Incompleteness Theorem 5 Outline
March 27, 2007 Outline 1 Introduction 2 Definition Incompressibility and Randomness 3 Prefix Complexity Resource-Bounded K-Complexity 4 Incompressibility Method Gödel s Incompleteness Theorem 5 Outline
The Minimum Message Length Principle for Inductive Inference
 The Principle for Inductive Inference Centre for Molecular, Environmental, Genetic & Analytic (MEGA) Epidemiology School of Population Health University of Melbourne University of Helsinki, August 25,
The Principle for Inductive Inference Centre for Molecular, Environmental, Genetic & Analytic (MEGA) Epidemiology School of Population Health University of Melbourne University of Helsinki, August 25,
Information Theory and Coding Techniques: Chapter 1.1. What is Information Theory? Why you should take this course?
 Information Theory and Coding Techniques: Chapter 1.1 What is Information Theory? Why you should take this course? 1 What is Information Theory? Information Theory answers two fundamental questions in
Information Theory and Coding Techniques: Chapter 1.1 What is Information Theory? Why you should take this course? 1 What is Information Theory? Information Theory answers two fundamental questions in
Lecture 3: Introduction to Complexity Regularization
 ECE90 Spring 2007 Statistical Learning Theory Instructor: R. Nowak Lecture 3: Introduction to Complexity Regularization We ended the previous lecture with a brief discussion of overfitting. Recall that,
ECE90 Spring 2007 Statistical Learning Theory Instructor: R. Nowak Lecture 3: Introduction to Complexity Regularization We ended the previous lecture with a brief discussion of overfitting. Recall that,
An Introduction to Statistical Theory of Learning. Nakul Verma Janelia, HHMI
 An Introduction to Statistical Theory of Learning Nakul Verma Janelia, HHMI Towards formalizing learning What does it mean to learn a concept? Gain knowledge or experience of the concept. The basic process
An Introduction to Statistical Theory of Learning Nakul Verma Janelia, HHMI Towards formalizing learning What does it mean to learn a concept? Gain knowledge or experience of the concept. The basic process
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning. VC Dimension and Model Complexity. Eric Xing , Fall 2015
 Machine Learning 10-701, Fall 2015 VC Dimension and Model Complexity Eric Xing Lecture 16, November 3, 2015 Reading: Chap. 7 T.M book, and outline material Eric Xing @ CMU, 2006-2015 1 Last time: PAC and
Machine Learning 10-701, Fall 2015 VC Dimension and Model Complexity Eric Xing Lecture 16, November 3, 2015 Reading: Chap. 7 T.M book, and outline material Eric Xing @ CMU, 2006-2015 1 Last time: PAC and
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Introduction to Machine Learning
 Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Algorithmic Probability
 Algorithmic Probability From Scholarpedia From Scholarpedia, the free peer-reviewed encyclopedia p.19046 Curator: Marcus Hutter, Australian National University Curator: Shane Legg, Dalle Molle Institute
Algorithmic Probability From Scholarpedia From Scholarpedia, the free peer-reviewed encyclopedia p.19046 Curator: Marcus Hutter, Australian National University Curator: Shane Legg, Dalle Molle Institute
Support Vector Machine. Industrial AI Lab. Prof. Seungchul Lee
 Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Compression Complexity
 Compression Complexity Stephen Fenner University of South Carolina Lance Fortnow Georgia Institute of Technology February 15, 2017 Abstract The Kolmogorov complexity of x, denoted C(x), is the length of
Compression Complexity Stephen Fenner University of South Carolina Lance Fortnow Georgia Institute of Technology February 15, 2017 Abstract The Kolmogorov complexity of x, denoted C(x), is the length of
BITS F464: MACHINE LEARNING
 BITS F464: MACHINE LEARNING Lecture-09: Concept Learning Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031 INDIA Jan
BITS F464: MACHINE LEARNING Lecture-09: Concept Learning Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031 INDIA Jan
Computational Learning Theory
 Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
Kolmogorov complexity and its applications
 CS860, Winter, 2010 Kolmogorov complexity and its applications Ming Li School of Computer Science University of Waterloo http://www.cs.uwaterloo.ca/~mli/cs860.html We live in an information society. Information
CS860, Winter, 2010 Kolmogorov complexity and its applications Ming Li School of Computer Science University of Waterloo http://www.cs.uwaterloo.ca/~mli/cs860.html We live in an information society. Information
A Tutorial on Computational Learning Theory Presented at Genetic Programming 1997 Stanford University, July 1997
 A Tutorial on Computational Learning Theory Presented at Genetic Programming 1997 Stanford University, July 1997 Vasant Honavar Artificial Intelligence Research Laboratory Department of Computer Science
A Tutorial on Computational Learning Theory Presented at Genetic Programming 1997 Stanford University, July 1997 Vasant Honavar Artificial Intelligence Research Laboratory Department of Computer Science
FORMAL LANGUAGES, AUTOMATA AND COMPUTABILITY
 15-453 FORMAL LANGUAGES, AUTOMATA AND COMPUTABILITY KOLMOGOROV-CHAITIN (descriptive) COMPLEXITY TUESDAY, MAR 18 CAN WE QUANTIFY HOW MUCH INFORMATION IS IN A STRING? A = 01010101010101010101010101010101
15-453 FORMAL LANGUAGES, AUTOMATA AND COMPUTABILITY KOLMOGOROV-CHAITIN (descriptive) COMPLEXITY TUESDAY, MAR 18 CAN WE QUANTIFY HOW MUCH INFORMATION IS IN A STRING? A = 01010101010101010101010101010101
Computational and Statistical Learning theory
 Computational and Statistical Learning theory Problem set 2 Due: January 31st Email solutions to : karthik at ttic dot edu Notation : Input space : X Label space : Y = {±1} Sample : (x 1, y 1,..., (x n,
Computational and Statistical Learning theory Problem set 2 Due: January 31st Email solutions to : karthik at ttic dot edu Notation : Input space : X Label space : Y = {±1} Sample : (x 1, y 1,..., (x n,
Pattern Recognition and Machine Learning. Perceptrons and Support Vector machines
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW2 due now! Project proposal due on tomorrow Midterm next lecture! HW3 posted Last time Linear Regression Parametric vs Nonparametric
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW2 due now! Project proposal due on tomorrow Midterm next lecture! HW3 posted Last time Linear Regression Parametric vs Nonparametric
Classification. The goal: map from input X to a label Y. Y has a discrete set of possible values. We focused on binary Y (values 0 or 1).
.") Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Minimum Message Length and Kolmogorov Complexity
 Minimum Message Length and Kolmogorov Complexity C. S. WALLACE AND D. L. DOWE Computer Science, Monash University, Clayton Vic 3168 Australia Email: csw@cs.monash.edu.au The notion of algorithmic complexity
Minimum Message Length and Kolmogorov Complexity C. S. WALLACE AND D. L. DOWE Computer Science, Monash University, Clayton Vic 3168 Australia Email: csw@cs.monash.edu.au The notion of algorithmic complexity
From Complexity to Intelligence
 From Complexity to Intelligence Machine Learning and Complexity PAGE 1 / 72 Table of contents Reminder Introduction to Machine Learning What is Machine Learning? Types of Learning Unsupervised Learning
From Complexity to Intelligence Machine Learning and Complexity PAGE 1 / 72 Table of contents Reminder Introduction to Machine Learning What is Machine Learning? Types of Learning Unsupervised Learning
Universal Learning Technology: Support Vector Machines
 Special Issue on Information Utilizing Technologies for Value Creation Universal Learning Technology: Support Vector Machines By Vladimir VAPNIK* This paper describes the Support Vector Machine (SVM) technology,
Special Issue on Information Utilizing Technologies for Value Creation Universal Learning Technology: Support Vector Machines By Vladimir VAPNIK* This paper describes the Support Vector Machine (SVM) technology,
On Computational Limitations of Neural Network Architectures
 On Computational Limitations of Neural Network Architectures Achim Hoffmann + 1 In short A powerful method for analyzing the computational abilities of neural networks based on algorithmic information
On Computational Limitations of Neural Network Architectures Achim Hoffmann + 1 In short A powerful method for analyzing the computational abilities of neural networks based on algorithmic information
Content. Learning. Regression vs Classification. Regression a.k.a. function approximation and Classification a.k.a. pattern recognition
 Content Andrew Kusiak Intelligent Systems Laboratory 239 Seamans Center The University of Iowa Iowa City, IA 52242-527 andrew-kusiak@uiowa.edu http://www.icaen.uiowa.edu/~ankusiak Introduction to learning
Content Andrew Kusiak Intelligent Systems Laboratory 239 Seamans Center The University of Iowa Iowa City, IA 52242-527 andrew-kusiak@uiowa.edu http://www.icaen.uiowa.edu/~ankusiak Introduction to learning
Novel Quantization Strategies for Linear Prediction with Guarantees
 Novel Novel for Linear Simon Du 1/10 Yichong Xu Yuan Li Aarti Zhang Singh Pulkit Background Motivation: Brain Computer Interface (BCI). Predict whether an individual is trying to move his hand towards
Novel Novel for Linear Simon Du 1/10 Yichong Xu Yuan Li Aarti Zhang Singh Pulkit Background Motivation: Brain Computer Interface (BCI). Predict whether an individual is trying to move his hand towards
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Intelligent Data Analysis. Decision Trees
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Intelligent Data Analysis Decision Trees Paul Prasse, Niels Landwehr, Tobias Scheffer Decision Trees One of many applications:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Intelligent Data Analysis Decision Trees Paul Prasse, Niels Landwehr, Tobias Scheffer Decision Trees One of many applications:
Machine Learning. Computational Learning Theory. Eric Xing , Fall Lecture 9, October 5, 2016
 Machine Learning 10-701, Fall 2016 Computational Learning Theory Eric Xing Lecture 9, October 5, 2016 Reading: Chap. 7 T.M book Eric Xing @ CMU, 2006-2016 1 Generalizability of Learning In machine learning
Machine Learning 10-701, Fall 2016 Computational Learning Theory Eric Xing Lecture 9, October 5, 2016 Reading: Chap. 7 T.M book Eric Xing @ CMU, 2006-2016 1 Generalizability of Learning In machine learning
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Risk Minimization Barnabás Póczos What have we seen so far? Several classification & regression algorithms seem to work fine on training datasets: Linear
Advanced Introduction to Machine Learning CMU-10715 Risk Minimization Barnabás Póczos What have we seen so far? Several classification & regression algorithms seem to work fine on training datasets: Linear
Consistency of Nearest Neighbor Methods
 E0 370 Statistical Learning Theory Lecture 16 Oct 25, 2011 Consistency of Nearest Neighbor Methods Lecturer: Shivani Agarwal Scribe: Arun Rajkumar 1 Introduction In this lecture we return to the study
E0 370 Statistical Learning Theory Lecture 16 Oct 25, 2011 Consistency of Nearest Neighbor Methods Lecturer: Shivani Agarwal Scribe: Arun Rajkumar 1 Introduction In this lecture we return to the study
Machine Learning. Computational Learning Theory. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Computational Learning Theory Le Song Lecture 11, September 20, 2012 Based on Slides from Eric Xing, CMU Reading: Chap. 7 T.M book 1 Complexity of Learning
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Computational Learning Theory Le Song Lecture 11, September 20, 2012 Based on Slides from Eric Xing, CMU Reading: Chap. 7 T.M book 1 Complexity of Learning
Convergence and Error Bounds for Universal Prediction of Nonbinary Sequences
 Technical Report IDSIA-07-01, 26. February 2001 Convergence and Error Bounds for Universal Prediction of Nonbinary Sequences Marcus Hutter IDSIA, Galleria 2, CH-6928 Manno-Lugano, Switzerland marcus@idsia.ch
Technical Report IDSIA-07-01, 26. February 2001 Convergence and Error Bounds for Universal Prediction of Nonbinary Sequences Marcus Hutter IDSIA, Galleria 2, CH-6928 Manno-Lugano, Switzerland marcus@idsia.ch
About this class. Maximizing the Margin. Maximum margin classifiers. Picture of large and small margin hyperplanes
 About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
Randomness, probabilities and machines
 1/20 Randomness, probabilities and machines by George Barmpalias and David Dowe Chinese Academy of Sciences - Monash University CCR 2015, Heildeberg 2/20 Concrete examples of random numbers? Chaitin (1975)
1/20 Randomness, probabilities and machines by George Barmpalias and David Dowe Chinese Academy of Sciences - Monash University CCR 2015, Heildeberg 2/20 Concrete examples of random numbers? Chaitin (1975)
DATA MINING LECTURE 9. Minimum Description Length Information Theory Co-Clustering
 DATA MINING LECTURE 9 Minimum Description Length Information Theory Co-Clustering MINIMUM DESCRIPTION LENGTH Occam s razor Most data mining tasks can be described as creating a model for the data E.g.,
DATA MINING LECTURE 9 Minimum Description Length Information Theory Co-Clustering MINIMUM DESCRIPTION LENGTH Occam s razor Most data mining tasks can be described as creating a model for the data E.g.,
Universal probability distributions, two-part codes, and their optimal precision
 Universal probability distributions, two-part codes, and their optimal precision Contents 0 An important reminder 1 1 Universal probability distributions in theory 2 2 Universal probability distributions
Universal probability distributions, two-part codes, and their optimal precision Contents 0 An important reminder 1 1 Universal probability distributions in theory 2 2 Universal probability distributions
Generative Techniques: Bayes Rule and the Axioms of Probability
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2016/2017 Lesson 8 3 March 2017 Generative Techniques: Bayes Rule and the Axioms of Probability Generative
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2016/2017 Lesson 8 3 March 2017 Generative Techniques: Bayes Rule and the Axioms of Probability Generative
Kolmogorov Complexity
 Kolmogorov Complexity Davide Basilio Bartolini University of Illinois at Chicago Politecnico di Milano dbarto3@uic.edu davide.bartolini@mail.polimi.it 1 Abstract What follows is a survey of the field of
Kolmogorov Complexity Davide Basilio Bartolini University of Illinois at Chicago Politecnico di Milano dbarto3@uic.edu davide.bartolini@mail.polimi.it 1 Abstract What follows is a survey of the field of
Kolmogorov complexity and its applications
 Spring, 2009 Kolmogorov complexity and its applications Paul Vitanyi Computer Science University of Amsterdam http://www.cwi.nl/~paulv/course-kc We live in an information society. Information science is
Spring, 2009 Kolmogorov complexity and its applications Paul Vitanyi Computer Science University of Amsterdam http://www.cwi.nl/~paulv/course-kc We live in an information society. Information science is
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Learning Objectives. c D. Poole and A. Mackworth 2010 Artificial Intelligence, Lecture 7.2, Page 1
 Learning Objectives At the end of the class you should be able to: identify a supervised learning problem characterize how the prediction is a function of the error measure avoid mixing the training and
Learning Objectives At the end of the class you should be able to: identify a supervised learning problem characterize how the prediction is a function of the error measure avoid mixing the training and
Introduction to Machine Learning
 Introduction to Machine Learning Kernel Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1 / 21
Introduction to Machine Learning Kernel Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1 / 21
Model Selection Based on Minimum Description Length
 Journal of Mathematical Psychology 44, 133152 (2000) doi:10.1006jmps.1999.1280, available online at http:www.idealibrary.com on Model Selection Based on Minimum Description Length P. Gru nwald CWI We introduce
Journal of Mathematical Psychology 44, 133152 (2000) doi:10.1006jmps.1999.1280, available online at http:www.idealibrary.com on Model Selection Based on Minimum Description Length P. Gru nwald CWI We introduce
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
ECE-271B. Nuno Vasconcelos ECE Department, UCSD
 ECE-271B Statistical ti ti Learning II Nuno Vasconcelos ECE Department, UCSD The course the course is a graduate level course in statistical learning in SLI we covered the foundations of Bayesian or generative
ECE-271B Statistical ti ti Learning II Nuno Vasconcelos ECE Department, UCSD The course the course is a graduate level course in statistical learning in SLI we covered the foundations of Bayesian or generative
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Statistical and Inductive Inference by Minimum Message Length
 C.S. Wallace Statistical and Inductive Inference by Minimum Message Length With 22 Figures Springer Contents Preface 1. Inductive Inference 1 1.1 Introduction 1 1.2 Inductive Inference 5 1.3 The Demise
C.S. Wallace Statistical and Inductive Inference by Minimum Message Length With 22 Figures Springer Contents Preface 1. Inductive Inference 1 1.1 Introduction 1 1.2 Inductive Inference 5 1.3 The Demise
Statistical learning theory, Support vector machines, and Bioinformatics
 1 Statistical learning theory, Support vector machines, and Bioinformatics Jean-Philippe.Vert@mines.org Ecole des Mines de Paris Computational Biology group ENS Paris, november 25, 2003. 2 Overview 1.
1 Statistical learning theory, Support vector machines, and Bioinformatics Jean-Philippe.Vert@mines.org Ecole des Mines de Paris Computational Biology group ENS Paris, november 25, 2003. 2 Overview 1.
Uncertainty & Induction in AGI
 Uncertainty & Induction in AGI Marcus Hutter Canberra, ACT, 0200, Australia http://www.hutter1.net/ ANU AGI ProbOrNot Workshop 31 July 2013 Marcus Hutter - 2 - Uncertainty & Induction in AGI Abstract AGI
Uncertainty & Induction in AGI Marcus Hutter Canberra, ACT, 0200, Australia http://www.hutter1.net/ ANU AGI ProbOrNot Workshop 31 July 2013 Marcus Hutter - 2 - Uncertainty & Induction in AGI Abstract AGI
Classifier Complexity and Support Vector Classifiers
 Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
Bayesian Reasoning and Recognition
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG 2 / osig 1 Second Semester 2013/2014 Lesson 12 28 arch 2014 Bayesian Reasoning and Recognition Notation...2 Pattern Recognition...3
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG 2 / osig 1 Second Semester 2013/2014 Lesson 12 28 arch 2014 Bayesian Reasoning and Recognition Notation...2 Pattern Recognition...3
A statistical mechanical interpretation of algorithmic information theory
 A statistical mechanical interpretation of algorithmic information theory Kohtaro Tadaki Research and Development Initiative, Chuo University 1 13 27 Kasuga, Bunkyo-ku, Tokyo 112-8551, Japan. E-mail: tadaki@kc.chuo-u.ac.jp
A statistical mechanical interpretation of algorithmic information theory Kohtaro Tadaki Research and Development Initiative, Chuo University 1 13 27 Kasuga, Bunkyo-ku, Tokyo 112-8551, Japan. E-mail: tadaki@kc.chuo-u.ac.jp
Computational Learning Theory
 1 Computational Learning Theory 2 Computational learning theory Introduction Is it possible to identify classes of learning problems that are inherently easy or difficult? Can we characterize the number
1 Computational Learning Theory 2 Computational learning theory Introduction Is it possible to identify classes of learning problems that are inherently easy or difficult? Can we characterize the number
Entropy as a measure of surprise
 Entropy as a measure of surprise Lecture 5: Sam Roweis September 26, 25 What does information do? It removes uncertainty. Information Conveyed = Uncertainty Removed = Surprise Yielded. How should we quantify
Entropy as a measure of surprise Lecture 5: Sam Roweis September 26, 25 What does information do? It removes uncertainty. Information Conveyed = Uncertainty Removed = Surprise Yielded. How should we quantify
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
Computational Learning Theory. CS 486/686: Introduction to Artificial Intelligence Fall 2013
 Computational Learning Theory CS 486/686: Introduction to Artificial Intelligence Fall 2013 1 Overview Introduction to Computational Learning Theory PAC Learning Theory Thanks to T Mitchell 2 Introduction
Computational Learning Theory CS 486/686: Introduction to Artificial Intelligence Fall 2013 1 Overview Introduction to Computational Learning Theory PAC Learning Theory Thanks to T Mitchell 2 Introduction
Introduction to Information Theory
 Introduction to Information Theory Impressive slide presentations Radu Trîmbiţaş UBB October 2012 Radu Trîmbiţaş (UBB) Introduction to Information Theory October 2012 1 / 19 Transmission of information
Introduction to Information Theory Impressive slide presentations Radu Trîmbiţaş UBB October 2012 Radu Trîmbiţaş (UBB) Introduction to Information Theory October 2012 1 / 19 Transmission of information
Lecture 3: Decision Trees
 Lecture 3: Decision Trees Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning Lecture 3: Decision Trees p. Decision
Lecture 3: Decision Trees Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning Lecture 3: Decision Trees p. Decision
Minimum message length estimation of mixtures of multivariate Gaussian and von Mises-Fisher distributions
 Minimum message length estimation of mixtures of multivariate Gaussian and von Mises-Fisher distributions Parthan Kasarapu & Lloyd Allison Monash University, Australia September 8, 25 Parthan Kasarapu
Minimum message length estimation of mixtures of multivariate Gaussian and von Mises-Fisher distributions Parthan Kasarapu & Lloyd Allison Monash University, Australia September 8, 25 Parthan Kasarapu
IFT Lecture 7 Elements of statistical learning theory
 IFT 6085 - Lecture 7 Elements of statistical learning theory This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s): Brady Neal and
IFT 6085 - Lecture 7 Elements of statistical learning theory This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s): Brady Neal and
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Measures of relative complexity
 Measures of relative complexity George Barmpalias Institute of Software Chinese Academy of Sciences and Visiting Fellow at the Isaac Newton Institute for the Mathematical Sciences Newton Institute, January
Measures of relative complexity George Barmpalias Institute of Software Chinese Academy of Sciences and Visiting Fellow at the Isaac Newton Institute for the Mathematical Sciences Newton Institute, January
Clustering using the Minimum Message Length Criterion and Simulated Annealing
 Clustering using the Minimum Message Length Criterion and Simulated Annealing Ian Davidson CSIRO Australia, Division of Information Technology, 723 Swanston Street, Carlton, Victoria, Australia 3053, inpd@mel.dit.csiro.au
Clustering using the Minimum Message Length Criterion and Simulated Annealing Ian Davidson CSIRO Australia, Division of Information Technology, 723 Swanston Street, Carlton, Victoria, Australia 3053, inpd@mel.dit.csiro.au
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Machine Learning Theory (CS 6783)
") Machine Learning Theory (CS 6783) Tu-Th 1:25 to 2:40 PM Kimball, B-11 Instructor : Karthik Sridharan ABOUT THE COURSE No exams! 5 assignments that count towards your grades (55%) One term project (40%)
Machine Learning Theory (CS 6783) Tu-Th 1:25 to 2:40 PM Kimball, B-11 Instructor : Karthik Sridharan ABOUT THE COURSE No exams! 5 assignments that count towards your grades (55%) One term project (40%)
CS154, Lecture 12: Kolmogorov Complexity: A Universal Theory of Data Compression
 CS154, Lecture 12: Kolmogorov Complexity: A Universal Theory of Data Compression Rosencrantz & Guildenstern Are Dead (Tom Stoppard) Rigged Lottery? And the winning numbers are: 1, 2, 3, 4, 5, 6 But is
CS154, Lecture 12: Kolmogorov Complexity: A Universal Theory of Data Compression Rosencrantz & Guildenstern Are Dead (Tom Stoppard) Rigged Lottery? And the winning numbers are: 1, 2, 3, 4, 5, 6 But is
Applied Logic. Lecture 4 part 2 Bayesian inductive reasoning. Marcin Szczuka. Institute of Informatics, The University of Warsaw
 Applied Logic Lecture 4 part 2 Bayesian inductive reasoning Marcin Szczuka Institute of Informatics, The University of Warsaw Monographic lecture, Spring semester 2017/2018 Marcin Szczuka (MIMUW) Applied
Applied Logic Lecture 4 part 2 Bayesian inductive reasoning Marcin Szczuka Institute of Informatics, The University of Warsaw Monographic lecture, Spring semester 2017/2018 Marcin Szczuka (MIMUW) Applied
Randomness. What next?
 Randomness What next? Random Walk Attribution These slides were prepared for the New Jersey Governor s School course The Math Behind the Machine taught in the summer of 2012 by Grant Schoenebeck Large
Randomness What next? Random Walk Attribution These slides were prepared for the New Jersey Governor s School course The Math Behind the Machine taught in the summer of 2012 by Grant Schoenebeck Large
Generalization and Overfitting
 Generalization and Overfitting Model Selection Maria-Florina (Nina) Balcan February 24th, 2016 PAC/SLT models for Supervised Learning Data Source Distribution D on X Learning Algorithm Expert / Oracle
Generalization and Overfitting Model Selection Maria-Florina (Nina) Balcan February 24th, 2016 PAC/SLT models for Supervised Learning Data Source Distribution D on X Learning Algorithm Expert / Oracle
A Tutorial Introduction to the Minimum Description Length Principle
 A Tutorial Introduction to the Minimum Description Length Principle Peter Grünwald Centrum voor Wiskunde en Informatica Kruislaan 413, 1098 SJ Amsterdam The Netherlands pdg@cwi.nl www.grunwald.nl Abstract
A Tutorial Introduction to the Minimum Description Length Principle Peter Grünwald Centrum voor Wiskunde en Informatica Kruislaan 413, 1098 SJ Amsterdam The Netherlands pdg@cwi.nl www.grunwald.nl Abstract
Information, Learning and Falsification
 Information, Learning and Falsification David Balduzzi December 17, 2011 Max Planck Institute for Intelligent Systems Tübingen, Germany Three main theories of information: Algorithmic information. Description.
Information, Learning and Falsification David Balduzzi December 17, 2011 Max Planck Institute for Intelligent Systems Tübingen, Germany Three main theories of information: Algorithmic information. Description.
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Linear Algebra. Min Yan
 Linear Algebra Min Yan January 2, 2018 2 Contents 1 Vector Space 7 1.1 Definition................................. 7 1.1.1 Axioms of Vector Space..................... 7 1.1.2 Consequence of Axiom......................
Linear Algebra Min Yan January 2, 2018 2 Contents 1 Vector Space 7 1.1 Definition................................. 7 1.1.1 Axioms of Vector Space..................... 7 1.1.2 Consequence of Axiom......................
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Introduction. Chapter 1
 Chapter 1 Introduction In this book we will be concerned with supervised learning, which is the problem of learning input-output mappings from empirical data (the training dataset). Depending on the characteristics
Chapter 1 Introduction In this book we will be concerned with supervised learning, which is the problem of learning input-output mappings from empirical data (the training dataset). Depending on the characteristics
BRUTE FORCE AND INTELLIGENT METHODS OF LEARNING. Vladimir Vapnik. Columbia University, New York Facebook AI Research, New York
 1 BRUTE FORCE AND INTELLIGENT METHODS OF LEARNING Vladimir Vapnik Columbia University, New York Facebook AI Research, New York 2 PART 1 BASIC LINE OF REASONING Problem of pattern recognition can be formulated
1 BRUTE FORCE AND INTELLIGENT METHODS OF LEARNING Vladimir Vapnik Columbia University, New York Facebook AI Research, New York 2 PART 1 BASIC LINE OF REASONING Problem of pattern recognition can be formulated
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers
 Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Introduction to Machine Learning
 Introduction to Machine Learning CS4731 Dr. Mihail Fall 2017 Slide content based on books by Bishop and Barber. https://www.microsoft.com/en-us/research/people/cmbishop/ http://web4.cs.ucl.ac.uk/staff/d.barber/pmwiki/pmwiki.php?n=brml.homepage
Introduction to Machine Learning CS4731 Dr. Mihail Fall 2017 Slide content based on books by Bishop and Barber. https://www.microsoft.com/en-us/research/people/cmbishop/ http://web4.cs.ucl.ac.uk/staff/d.barber/pmwiki/pmwiki.php?n=brml.homepage
Algorithmic Information Theory
 Algorithmic Information Theory Peter D. Grünwald CWI, P.O. Box 94079 NL-1090 GB Amsterdam, The Netherlands E-mail: pdg@cwi.nl Paul M.B. Vitányi CWI, P.O. Box 94079 NL-1090 GB Amsterdam The Netherlands
Algorithmic Information Theory Peter D. Grünwald CWI, P.O. Box 94079 NL-1090 GB Amsterdam, The Netherlands E-mail: pdg@cwi.nl Paul M.B. Vitányi CWI, P.O. Box 94079 NL-1090 GB Amsterdam The Netherlands
An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme
 An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme Ghassen Jerfel April 2017 As we will see during this talk, the Bayesian and information-theoretic
An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme Ghassen Jerfel April 2017 As we will see during this talk, the Bayesian and information-theoretic
CIS 520: Machine Learning Oct 09, Kernel Methods
 CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
References for online kernel methods
 References for online kernel methods W. Liu, J. Principe, S. Haykin Kernel Adaptive Filtering: A Comprehensive Introduction. Wiley, 2010. W. Liu, P. Pokharel, J. Principe. The kernel least mean square
References for online kernel methods W. Liu, J. Principe, S. Haykin Kernel Adaptive Filtering: A Comprehensive Introduction. Wiley, 2010. W. Liu, P. Pokharel, J. Principe. The kernel least mean square
Machine Learning. Model Selection and Validation. Fabio Vandin November 7, 2017
 Machine Learning Model Selection and Validation Fabio Vandin November 7, 2017 1 Model Selection When we have to solve a machine learning task: there are different algorithms/classes algorithms have parameters
Machine Learning Model Selection and Validation Fabio Vandin November 7, 2017 1 Model Selection When we have to solve a machine learning task: there are different algorithms/classes algorithms have parameters
Statistical Learning Theory
 Statistical Learning Theory Fundamentals Miguel A. Veganzones Grupo Inteligencia Computacional Universidad del País Vasco (Grupo Inteligencia Vapnik Computacional Universidad del País Vasco) UPV/EHU 1
Statistical Learning Theory Fundamentals Miguel A. Veganzones Grupo Inteligencia Computacional Universidad del País Vasco (Grupo Inteligencia Vapnik Computacional Universidad del País Vasco) UPV/EHU 1
Low Bias Bagged Support Vector Machines
 Low Bias Bagged Support Vector Machines Giorgio Valentini Dipartimento di Scienze dell Informazione Università degli Studi di Milano, Italy valentini@dsi.unimi.it Thomas G. Dietterich Department of Computer
Low Bias Bagged Support Vector Machines Giorgio Valentini Dipartimento di Scienze dell Informazione Università degli Studi di Milano, Italy valentini@dsi.unimi.it Thomas G. Dietterich Department of Computer
Introduction to Machine Learning (67577) Lecture 5
 Lecture 5") Introduction to Machine Learning (67577) Lecture 5 Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Nonuniform learning, MDL, SRM, Decision Trees, Nearest Neighbor Shai
Introduction to Machine Learning (67577) Lecture 5 Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Nonuniform learning, MDL, SRM, Decision Trees, Nearest Neighbor Shai
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
CS340 Machine learning Lecture 5 Learning theory cont'd. Some slides are borrowed from Stuart Russell and Thorsten Joachims
 CS340 Machine learning Lecture 5 Learning theory cont'd Some slides are borrowed from Stuart Russell and Thorsten Joachims Inductive learning Simplest form: learn a function from examples f is the target
CS340 Machine learning Lecture 5 Learning theory cont'd Some slides are borrowed from Stuart Russell and Thorsten Joachims Inductive learning Simplest form: learn a function from examples f is the target
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Statistical Learning Learning From Examples
 Statistical Learning Learning From Examples We want to estimate the working temperature range of an iphone. We could study the physics and chemistry that affect the performance of the phone too hard We
Statistical Learning Learning From Examples We want to estimate the working temperature range of an iphone. We could study the physics and chemistry that affect the performance of the phone too hard We
Introduction to Machine Learning
 Introduction to Machine Learning 236756 Prof. Nir Ailon Lecture 4: Computational Complexity of Learning & Surrogate Losses Efficient PAC Learning Until now we were mostly worried about sample complexity
Introduction to Machine Learning 236756 Prof. Nir Ailon Lecture 4: Computational Complexity of Learning & Surrogate Losses Efficient PAC Learning Until now we were mostly worried about sample complexity
Kernel Methods. Foundations of Data Analysis. Torsten Möller. Möller/Mori 1
 Kernel Methods Foundations of Data Analysis Torsten Möller Möller/Mori 1 Reading Chapter 6 of Pattern Recognition and Machine Learning by Bishop Chapter 12 of The Elements of Statistical Learning by Hastie,
Kernel Methods Foundations of Data Analysis Torsten Möller Möller/Mori 1 Reading Chapter 6 of Pattern Recognition and Machine Learning by Bishop Chapter 12 of The Elements of Statistical Learning by Hastie,
Computational learning theory. PAC learning. VC dimension.
 Computational learning theory. PAC learning. VC dimension. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics COLT 2 Concept...........................................................................................................
Computational learning theory. PAC learning. VC dimension. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics COLT 2 Concept...........................................................................................................
MML Mixture Models of Heterogeneous Poisson Processes with Uniform Outliers for Bridge Deterioration
 MML Mixture Models of Heterogeneous Poisson Processes with Uniform Outliers for Bridge Deterioration T. Maheswaran, J.G. Sanjayan 2, David L. Dowe 3 and Peter J. Tan 3 VicRoads, Metro South East Region,
MML Mixture Models of Heterogeneous Poisson Processes with Uniform Outliers for Bridge Deterioration T. Maheswaran, J.G. Sanjayan 2, David L. Dowe 3 and Peter J. Tan 3 VicRoads, Metro South East Region,
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University