BRUTE FORCE AND INTELLIGENT METHODS OF LEARNING. Vladimir Vapnik. Columbia University, New York Facebook AI Research, New York
|
|
|
- Aldous Piers McKinney
- 6 years ago
- Views:
Transcription
1 1 BRUTE FORCE AND INTELLIGENT METHODS OF LEARNING Vladimir Vapnik Columbia University, New York Facebook AI Research, New York
2 2 PART 1 BASIC LINE OF REASONING Problem of pattern recognition can be formulated as the basic problem of Information Theory: Using l bits of information that contains training data find in a given set of functions the desired one.
3 BASIC SETTING OF LEARNING PROBLEM 3 Learning is defined as the problem of estimating a function from a given collection of functions based on finite number of observations (y i, x i ), i = 1,..., l To extract the conceptual part of the problem let us simplify the setting: Consider set of indicator functions containing finite number N of elements. ( The generalization to infinite number of real valued functions is given by the VC theory is just technical result.)
4 SHANNON S IDEA OF INFORMATION 4 THE PROBLEM: How many questions that require answers YES or NO one has to ask Query to find the desired object among N objects. THE ANSWER: l = log 2 N = ln N ln 2. One has to split N objects into 2 equal subsets and ask Query is the desired object in the first subset. After Query s answer one removes subset which does not contains desired object, splits remaining part into two subsets and ask the same question. After log 2 N answers of Query one find the desired object (log 2 N answers defines log 2 N bits of information). This is the smallest number of questions that is guarantee to find the desired object among N objects.
5 INTERPRETATION FOR PATTERN RECOGNITION 5 THE QUESTION: How many examples (x i, y i ), x X, y {0, 1} is required to find among N indicator functions (f(x) {0, 1}) the desired one. THE ANSWER: l = log 2 N = ln N ln 2. One has to find vector x i for which half of functions take value 1 and half take value 0 and ask Query which value takes the desired indicator function for vector x i. Then remove the half of functions that disagree with Query and do it log 2 N times.
6 STATISTICAL PATTERN RECOGNITION MODEL-1 6 Since it is difficult to find vector x that splits N functions into two equal parts, consider the model where training examples x 1,..., x l are (iid) generated according to some unknown generator P (x). THE QUESTION: How many training examples is required to find among N indicator functions the one that with probability 1 η is ε-close to the desired function. THE ANSWER: l = ln N ln η ε, 0 < ε < 1 THIS BOUND CANNOT BE IMPROVED
7 PATTERN RECOGNITION MODEL-2 7 Let among N functions there is NO function that does not commit errors. THE QUESTION: How many training examples is required to find among N indicator functions the one that with probability 1 η is ε-close to the best function in the set. ln N ln η THE ANSWER: l = ε 2 0 < ε < 1 THIS BOUND CANNOT BE IMPROVED
8 THREE CATEGORY OF NUMBERS 8 Let us distinguish three category of integers: 1. ORDINARY numbers l. Say 1 l 1, 000, 000. The number of objects we deal with during life time 2. BIG numbers B. Say B = 2 l. The number of objects from which we can choose the desired one (using l = log 2 B bits of Query information obtained during life time). 3. HUGE numbers H. Say, H = 2 B = 2 2l. Generally speaking, using Ordinary number of observations one can NOT choose the desired function from a set with Huge numbers H of elements.
9 9 BRUTE FORCE AND INTELLIGENT LEARNING In classical machine learning models Teacher supplies any training vector x with one bit of information y, generated according to some (unknown) conditional probability function P (y x). The goal is to find the desired function using order of log 2 N examples. The corresponding methods we call BRUTE FORCE methods. The new approach considers an Intelligent Teacher which supplies any vector x with more than one bit of information (x, y) using some (unknown) Intelligence Generator P (x, y x). The goal is to find the desired function using less than log 2 N examples. The corresponding methods we call INTELLIGENT methods and vector x we call the PRIVILEGED information.
10 GENERALIZATION FOR INFINITE SET: VC DIMENSION 10 Let N F (x 1,..., x l ) be the number of different separations of set x 1,..., x l into two classes using indicator functions from the set F. We call the Growth-function of set F the function G(l) = sup x 1,...,x l log 2 N(x 1,..., x l ) THEOREM (VC 1968) Growth function either linear function G(l) = l or bounded by the logarithmic function G(l) h ln l, where h is the smallest l for which G(h) h VALUE h IS CALLED VC DIMENSION OF THE SET F.
11 PATTERN RECOGNITION (VC MODEL) 11 Consider an infinite set of functions f(x, α), α Λ which VC dimension is V C dim. QUESTION: How many examples one has to see to find among these functions the function that with probability 1 η is ε-close to the best function in the set.. ANSWER: l V C dim ln η ε if in the set of functions there exist one that does not commit errors on training set. l V C dim ln η ε 2 if in the set of functions there are NO function that does not commit errors on training set. IN THESE BOUNDS V C dim REPLACES ln N.
12 12 INTELLIGENT AND ADVANCED METHODS OF LEARNING Bounds obtained by VC theory are: ( ) V l = O Cdim, (k = 1 or k = 2), ε < 1. ε k To improve learning rate one must either: 1. To improve statistical part of method increasing the denominator (obtaining k < k in the bound) or 2. To decrease the numerator of bound (obtaining h < V C dim in the bound). Methods designed to decrees the numerator is called Intelligent Methods of Learning Methods designed to increase the denominator is called Advanced Statistical Methods of Learning
13 13 PART 2 ELEMENTS OF VC THEORY VC theory analyze Brute Force methods of learning. It provides: 1. The necessary and sufficient conditions of consistency of learning processes. 2. The bound on convergence rate of learning processes. 3. Universally consistent principle of learning (Structural Risk Minimization (SRM) principle). 4. Efficient algorithms realizing SRM principle (SVM)
14 RISK MINIMIZATION PROBLEM 14 THE PROBLEM: Given iid observation of pairs (x 1, y 1 ),..., (x l, y l ), x X R n, y {0, 1} generated according to unknown probability measure P (x, y), find in the given set of functions f(x, α), α Λ, the one that minimizes the expected loss E(α) = ρ(y, f(x, α))dp (x, y), α Λ. THE SOLUTION: Approximate the function that minimizes expected loss f(x, α 0 ) with the function that minimizes empirical loss: E l (α) = 1 l ρ(y i, f(x i, α)). l i=1 THE THEORY: Answers the question: When this works?
15 VC-THEORY OF EMPIRICAL RISK MINIMIZATION 15 THEOREM 1. For consistency of ERM principle convergence lim P {sup E(α) E l (α) ε} = 0, ε > 0. l α Λ (the uniform law of large numbers) is necessary and sufficient. THEOREM 2. For existence of uniform convergence independently of probability measure P (x, y), it is necessary and sufficient that set r(x, α), α Λ has a finite VC-dimension (to be explained). THEOREM 3. For existence of uniform convergence given probability measure P (x, y), it is necessary and sufficient that set r(x, α), α Λ has a VC-entropy (to be explained) which ratio to the number of observations converges to zero. THEOREM 4. If ratio of VC-entropy to the number of observations converges to µ > 0, then there exist X X, P (X ) = µ such that almost any l examples from X can be shattered.
16 VC BOUNDS 16 THEOREM 5. Let VC dimension of the set of indicator functions f(x, α), α Λ be h. Then with probability 1 η simultaneously for all rules f(x, α), α Λ the inequality h ln l ln η E(α) E l (α) + C, α Λ l holds true. If among rules f(x, α), α Λ there exist rules f(x, α), α Λ such that E l (α) = 0, α Λ, then the better bound holds true. E(α) 0 + C h ln l ln η, α Λ l Both bounds are achievable.
17 STRUCTURAL RISK MINIMIZATION (SRM) PRINCIPLE. 17 Let a structure S on a set of rules f(x, α), α Λ be defined Λ 1 Λ 2... Λ n... such that VC dimension of the rules of subset are h 1 < h 2 <... < h n <... SRM PRINCIPLE: Given set of rules f(x, α), α Λ and the structure S on it find, for any fixed number l of observations, the function f(x, α l ) that minimizes the r.h.s. of VC bound hk ln l ln η W (α) = E l (α) + C, α Λ k l choosing both the element k of the structure S and the best rule belonging to this element f(x, α l ), α Λ k.
18 CORE MECHANISM OF LEARNING: SRM PRINCIPLE 18 Let S k be elements of the structure and S = k=1 S k be the closure of this structure. Let the minimum of risk be achieved on the element f(x, α 0 ) of the closure. Consider the sequence of solutions of SRM method f(x, α 1 ), f(x, α 2 ),..., f(x, α l ),... obtained using samples of different size l. THEOREM 6. With increasing number of observations l, sequence f(x, α l ) converges uniformly to f(x, α 0 ) with probability one: P {sup f(x, α 0 ) f(x, α l ) l 0} = 1. x
19 STRUCTURE IN HILBERT SPACES 19 Let vectors x i R n is mapped into Hilbert space z i Z THEOREM 8. Let z 2 1. The VC dimension of subset of hyperplanes (w, z) + b = 0 for which is bounded as (w, w) h + 1.
20 REALIZATION OF SRM PRINCIPLE: SVM 20 Let vectors x i R n is mapped into Hilbert space z i Z. Consider element of the structure on hyperplanes in Hilbert space (w, z) + b = 0 for which (w, w). Choose the hyperplane that minimizes the empirical loss. That is, minimizes the functional l R(α) = ξ i, subject to the constraints i=1 y i ((w, z i ) + b) 1 ξ i, ξ i 0, i = 1,..., l, (w, w). The SVM algorithm is the solution of this problem.
21 21 PART 3. TEACHER-STUDENT INTERACTION To accelerate speed of learning one includes in the learning process Intelligent Teacher. There are two mechanisms of Teacher-Student interaction: 1) Similarity Control between training examples ( ). 2) Knowledge Transfer from Teacher to Student (2015).
22 BACK TO SHANNON To choose the desired indicator function from N functions one has to ask Query at least l questions and get l YES-NO (1,0) answers, where l = log 2 N. 2. To choose the desired indicator function asking less than log 2 N questions is possible only if Query provides x i with the answer more that has more one bit of information. That is if on question x i Query answering (y i, x i ) where, y i {0, 1}, x i X. We call x i the privileged information.
23 TWO LEARNING MODELS 23 THE CLASSICAL MODEL: Given iid training pairs (x 1, y 1 ),..., (x l, y l ), x i X, y i {0, 1}, i = 1,..., l, where x i is generated by unknown P (x) and y i by unknown P (y i x i ), find in a given set of functions f(x, α), α Λ the one y = f(x, α l ) that minimizes the probability of error. THE LUPI MODEL: Given iid training triplets (x 1, x 1, y 1 ),..., (x l, x l, y l ), x i X, x i X, y i {0, 1}, where x generated by unknown P (x) and y i, x i by unknown P (y i, x i x i), find in a given set of functions f(x, α), α Λ the function y = f(x, α l ) that minimizes the probability of error.
24 SVM FOR SEPARABLE CASE 24 Minimize the functional subject to the constraints Generalization 1: Large margin. R = (w, w) y i [(w, z i ) + b] 1, i = 1,..., l. The solution (w l, b l ) with probability 1 η has the bound ( ) V Cdim ln η P test O. l
25 SVM FOR NON-SEPARABLE CASE Minimize the functional subject to constraints Generalization 2: Nonseparable case. R(w, b) = (w, w) + C l i=1 y i [(w, z i ) + b] 1 ξ i, ξ i 0, i = 1,..., l. The solution (w l, b l ) with probability 1 η has the bound ( ) V Cdim ln η P test ν train + O. l ξ i
26 WHY WE HAVE SO BIG DIFFERENCE? 26 In the separable case, one estimates n parameters of vector w using l examples. In the non-separable case, one estimates n + l parameters (n parameters of vector w and l parameters of slacks). Suppose that we know a set of functions ξ(x, δ) 0, δ D with finite V Cdim (let δ be an m-dimensional vector) such that ξ = ξ(x) = ξ(x, δ 0 ). In this setting to find optimal hyperplane in non-separable case one needs to estimate n + m parameters using l observations. Can the rate of convergence in new setting be faster?
27 THE KEY OBSERVATION: ORACLE SVM 27 Suppose we are given triplets (x 1, ξ 0 1, y 1 ),..., (x l, ξ 0 l, y l ), where ξi 0 = ξ 0 (x i ), i = 1,..., l are the slack values with respect to the best hyperplane. Then to find the approximation (w best, b best ) we minimize the functional subject to constraints R(w, b) = (w, w) y i [(w, x i ) + b] r i, r i = 1 ξ 0 (x i ), i = 1,..., l. Proposition 1. With probability 1 η the bound holds ( ) V Cdim ln η P test ν train + O. l
28 ILLUSTRATION I class II class I Sample Training Data 6 x x 1
29 ILLUSTRATION II K : linear SVM Oracle SVM Bayes error 20% % 17 Error rate Error Rate 14 14% % Training Data Size
30 WHAT CAN A REAL TEACHER DO 30 Teacher does not know values of slacks. However he can: Supply students with a correcting space X and a set of functions ξ(x, δ), δ D, with VC dimension h which contains a function ξ i = ξ(x i, δ best ) that approximates the oracle slack function ξ 0 = ξ 0 (x ) well. During training process teacher supplies students with triplets (x 1, x 1, y 1 ),..., (x l, x l, y l ) in order to estimate simultaneously both the correcting (slack) function ξ = ξ(x, δ l ) and the decision hyperplane (pair (w l, b l )).
31 IDEA OF SVM ALGORITHM 31 Generalization of Perceptron 3: Mercer Kernels 1. Transform the training pairs (x 1, y 1 ),..., (x l, y l ) into the training pairs (z 1, y 1 ),..., (z l, y l ) by mapping vectors x X into vectors z Z. 2. Find in Z the hyperplane that minimizes the functional subject to the constraints R(w, b) = (w, w) + C l i=1 y i [(w, z i ) + b] 1 ξ i, ξ i 0, i = 1,..., l. 3. Define the inner product in Z space using Mercer Kernels (z i, z j ) = K(x i, x j ). ξ i
32 DUAL SPACE SOLUTION FOR SVM 32 The decision function has the form [ l ] r(x, α) = sgn α i y i K(x i, x) + b, (1) i=1 where α i 0, i = 1,..., l are values which maximize the functional l W (α) = α i 1 l α i α j y i y j K(x i, x j ), (2) 2 i=1 i,j=1 subject to the constraints l α i y i = 0, 0 α i C, i = 1,..., l. i=1 Here kernel K(, ) is used for two different purposes: 1. In (1), to define a set of expansion-functions K(x i, x). 2. In (2), to define similarity between vectors x i and x j.
33 IDEA OF SVM+ ALGORITHM 33 Transform the training triplets (x 1, x 1, y 1 ),..., (x l, x l, y l) into the triplets (z 1, z 1, y 1 ),..., (z l, z l, y l) by mapping x X into z Z and x X into z Z. Define the slack-function in the form ξ i = y i [(w, z i ) + b ] and find in space Z the hyperplane that minimizes the functional l W (w, b, w, b ) = (w, w) + γ(w, w ) + C (y i [(w, zi ) + b ]) +, subject to the constraints i=1 y i [(w, z i ) + b] 1 (y i [(w, z i ) + b ]) +, i = 1,..., l. Use inner products in Z and Z spaces in the kernel form (z i, z j ) = K(x i, x j ), (z i, z j ) = K (x i, x j).
34 DUAL SPACE SOLUTION FOR SVM+ 34 The decision function has the form ( l ) r(x, α) = θ α i y i K(x i, x) + b, i=1 where α i, i = 1,..., l are values that maximize the functional l α i 1 2 i=1 W (α, β) = l α i α j y i y j K(x i, x j ) 1 l (α i β i )(α j β j )y i y j K (x i, x 2γ j), i,j=1 subject to the constraints l α i y i = 0, and the constraints i=1 i,j=1 l y i β i = 0. i=1 0 α i β i, 0 β i C.

35 ADVANCED TECHNICAL MODEL AS PRIVILEGED INFORMATION 35 Classification of proteins into families The problem is: Given amino-acid sequences of proteins construct a rule to classify families of proteins. The decision space X is the space of amino-acid sequences. The privileged information space X is the space of 3D structures of the proteins.
36 36 CLASSIFICATION OF PROTEINS (FRAGMENT) Protein SVM SVM+ SVM Protein SVM SVM+ SVM superfamily pair (3D) superfamily pair (3D) a.26.1-vs-c b.29.1-vs-c a.26.1-vs-g b.30.5-vs-b a vs-b b b vs-b b a vs-d b.55.1-vs-b a vs-d b.55.1-vs-d a vs-e b.55.1-vs-d b.1.18-vs-b b.80.1-vs-b b.18.1-vs-b b.82.1-vs-b b.18.1-vs-c b vs-d b.18.1-vs-c b vs-d b.18.1-vs-d c.36.1-vs-c b.29.1-vs-b c.36.1-vs-e b.29.1-vs-b.55.1 b c471-vs-c c.47.1 c b.29.1-vs-b c.52.1-vs-b b.29.1-vs-b c.55.1-vs-c D structure is essential for classification; SVM+ does not improve classification of SVM SVM+ provides significant improvement over SVM (several times)
37 FUTURE EVENTS AS PRIVILEGED INFORMATION 37 Time series prediction Given pairs (x 1, y 1 )..., (x l, y l ), find the rule y t = f(x t+ ), where x t = (x(t),..., x(t m)). For regression model of time series: y t = x(t + ). For classification model of time series: y t = { 1, if x(t + ) > x(t), 1, if x(t + ) x(t).
,.")
38 MACKEY-GLASS TIME SERIES PREDICTION 38 Let data be generated by the Mackey-Glass equation: dx(t) dt = ax(t) + bx(t τ) 1 + x 10 (t τ), where a, b, and τ (delay) are parameters. The training triplets (x 1,, x 1, y 1 ),..., (x l, x l, y l) are defined as follows: x t = (x(t), x(t 1), x(t 2), x(t 3)) x t = (x(t + 1), x(t + 2), x(t + + 1), x(t + + 2))

39 INTERPOLATION AND EXTRAPOLATION 39


40 ILLUSTRATION 40
41 HOLISTIC DESCRIPTION AS PRIVILEGED INFORMATION 41 Classification of digit 5 and digit 8 from the NIST database. Given triplets (x i, x i, y i), i = 1,..., l find the classification rule y = f(x), where x i is the holistic description of the digit x i.
42 HOLISTIC DESCRIPTIONS 42 Straightforward, very active, hard, very masculine with rather clear intention. A sportsman or a warrior. Aggressive and ruthless, eager to dominate everybody, clever and accurate, more emotional than rational, very resolute. No compromise accepted. Strong individuality, egoistic. Honest. Hot, able to give much pain. Hard. Belongs to surface. Individual, no desire to be sociable. First moving second thinking. Will never give a second thought to whatever. Upward-seeking. 40 years old. A young man is energetic and seriously absorbed in his career. He is not absolutely precise and accurate. He seems a bit aggressive mostly due to lack of sense of humor. He is too busy with himself to be open to the world. He has simple mind and evident plans connected with everyday needs. He feels good in familiar surroundings. Solid soil and earth are his native space. He is upward seeking but does not understand air.
43 CODES FOR HOLISTIC DESCRIPTION 43 1.Active (0 5), 2.Passive (0 5), 3.Feminine (0 5), 4.Masculine (0 5), 5.Hard (0 5), 6.Soft (0 5), 7.Occupancy (0 3), 8.Strength (0 3), 9.Hot (0 3), 10.Cold (0 3), 11.Aggressive (0 3), 12.Controlling (0 3), 13.Mysterious (0 3), 14.Clear (0 3), 15.Emotional (0 3), 16.Rational (0 3), 17.Collective (0 3), 18.Individual (0 3), 19.Serious (0 3), 20.Light-minded (0 3), 21.Hidden (0 3), 22.Evident (0 3), 23.Light (0 3), 24.Dark (0 3), 25.Upward-seeking (0 3), 26.Downward-seeking (0 3), 27.Water flowing (0 3), 28.Solid earth (0 3), 29.Interior (0 2), 30.Surface (0 2), 31.Air (0 3).

44 RESULTS 44
45 45 PART 4. TEACHER-STUDENT INTERACTION: KNOWLEDGE TRANSFER Knowledge transfer is the most important element of Teacher- Student interactions. According to Japanese proverb: Better than a thousand days of diligent study is one day with a great teacher.
46 KNOWLEDGE TRANSFER MECHANISM 46 Given examples with privileged information (x 1, x 1, y 1 ),..., (x l, x l, y l ), x i X, x i X, consider two pattern recognition problems: 1. Using data, (x 1, y 1 ),..., (x l, y l ), find a rule y = sgn{f l (x)} 2. Using data, (x 1, y 1 ),..., (x l, y l), find a rule y = sgn{f l (x )}. Suppose that the best rule y = sgn{f 0 (x )} in space X can be as good as the best rule y = sgn{f 0 (x)} in space X. Can knowledge of a good rule in X space l fl (x ) = y i αi K (x i, x ) + b i=1 help to construct a good rule y = f l (x) in X space? WHY CAN IT HELP?
47 WHY KNOWLEDGE TRANSFER WORKS 47 Suppose that our goal is to classify images x i of biopsy in pixel space X into two classes: cancer and non-cancer. Suppose that, along with images x i X, we are given description of the images x i X (privileged information), reflecting the existing model of developing cancer: Aggressive proliferation of A-cells into B-cells. Absence of any dynamic in standard picture. Suppose that in space X there exist a rule which can separate training data not much worse than the best rule in space X. Since space X is universal (can be used for many problems) and space X is created just for cancer model, the VC dimension of admissible set of functions in X space has to be much bigger than VC dimension of admissible set of functions in X. Therefore the rule constructed from examples in space X will be more accurate than rule constructed in space X. That is why transfer the rule from space X into space X is useful.
48 48 KNOWLEDGE REPRESENTATION IN X SPACE. Consider three elements of knowledge representation in X : 1. Fundamental elements of the knowledge in space X. 2. Main frames (fragments) of the knowledge in space X. 3. Structure of knowledge: combination of the frames in X. 1. We define as fundamental elements of knowledge in X the support vectors u s X, s = 1,..., k of obtained (in X ) function k fl (x ) = βsk (u s, x ) + b. s=1 2. We define as frames the functions K (u s, x ), s = 1,..., k. 3. We construct in X the images φ s (x) of the frames K (u s, x ) 3. We estimate the desired function f l (x) using expansion on frame images k f l (x) = σ s φ s (x) + b. s=1
49 FRAMES AND THEIR IMAGES 49 Let u 1..., u m be fundamental elements in X and let K (u 1, x ),..., K (u m, x ) be frames of the rule in space X. The images (in X) of the frames K (u k, x ) (in X ) are φ k (x) = K (u k, x )p(x x)dx k = 1,.., m. To find images φ 1 (x),..., φ m (x) of the frames K (u 1, x ),..., K (u m, x ) using triplets (x i, x i, y i), i = 1,..., l one has to: Find m regression functions φ k (x), k = 1,..., m given data (x 1, z k 1),..., (x l, z k l ), k = 1,..., m, z k i = K (u k, x i ), where i = 1,..., l, k = 1,...m.
50 SVM BASED ALGORITHM FOR LUPI 50 THE PROBLEM: Find the desired approximation, given triplets (x 1, x 1, y 1 ),..., (x l, x l, y l ) (1) THE ALGORITHM: 1) Using SVM find the classification rule in X space l s = y i α i K (x i, x ) + b (2) i=1 2) Using RSVM find in space X the images φ 1 (x),..., φ k (x) of the frames K (x 1, x ),..., K (x k, x ) transforming X space as X = FX. 3) Using triplets (1), transformed vectors Fx i, and classification rule (2), construct the triplets (Fx 1, x 1, s 1),..., (Fx l, x l, s l) (3) 4) Using SVM+ obtain the desired rule solving LUPI for (3) l y = c i K(Fx i, Fx) + b i=1

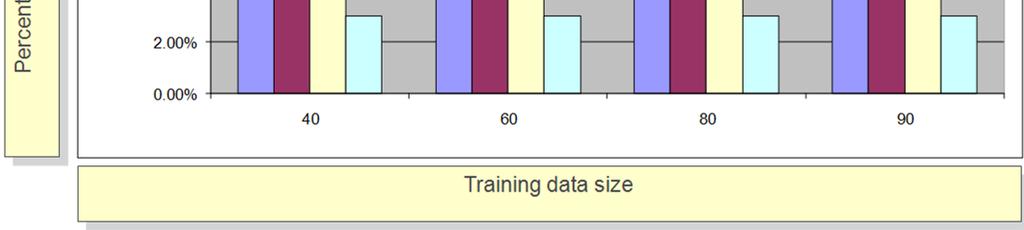
51 EXAMPLE OF KNOWLEDGE TRANSFER 51 Knowledge transfer from space of high resolution images X to space of low resolution images X. Error rate Training data size
52 INTELLIGENCE: REFLECTION IN PHILOSOPHY Both, old Greek philosophy and classical German philosophy use bilingual model of understanding of World: There exist World of Things x X and World of Essences x X. World of Things is reflection of World of Essences. 2. Plato s Cave Allegory describes this model as follows: People in the Cave are illuminated behind them. They can see on the wall only shadow x of reality x. Relation of the reality x to shadow x is defined by (unknown) generator P (x x). 3. The difference between Brute force and Intelligent reasoning depends on information that is used for the inference: shadow information x or also information about reality x. To get information x one needs to have access to an generator of Intelligence P (x x).
53 INTELLIGENCE: REFLECTION IN MATHEMATICS 53 BRUTE FORCE METHODS: using Ordinary number l of examples x i, i = 1,..., l chose the best function from a set of Big number (B 2 l ) of functions. INTELLIGENT METHODS: using Ordinary number l of examples x i, i = 1,..., l AND information x i given by (unknown) Intelligence generator P (x x) chose the best function from a set of Huge number (H >> B) of functions.
Universal Learning Technology: Support Vector Machines
 Special Issue on Information Utilizing Technologies for Value Creation Universal Learning Technology: Support Vector Machines By Vladimir VAPNIK* This paper describes the Support Vector Machine (SVM) technology,
Special Issue on Information Utilizing Technologies for Value Creation Universal Learning Technology: Support Vector Machines By Vladimir VAPNIK* This paper describes the Support Vector Machine (SVM) technology,
Machine Learning. VC Dimension and Model Complexity. Eric Xing , Fall 2015
 Machine Learning 10-701, Fall 2015 VC Dimension and Model Complexity Eric Xing Lecture 16, November 3, 2015 Reading: Chap. 7 T.M book, and outline material Eric Xing @ CMU, 2006-2015 1 Last time: PAC and
Machine Learning 10-701, Fall 2015 VC Dimension and Model Complexity Eric Xing Lecture 16, November 3, 2015 Reading: Chap. 7 T.M book, and outline material Eric Xing @ CMU, 2006-2015 1 Last time: PAC and
Chapter 9. Support Vector Machine. Yongdai Kim Seoul National University
 Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Solving Classification Problems By Knowledge Sets
 Solving Classification Problems By Knowledge Sets Marcin Orchel a, a Department of Computer Science, AGH University of Science and Technology, Al. A. Mickiewicza 30, 30-059 Kraków, Poland Abstract We propose
Solving Classification Problems By Knowledge Sets Marcin Orchel a, a Department of Computer Science, AGH University of Science and Technology, Al. A. Mickiewicza 30, 30-059 Kraków, Poland Abstract We propose
Statistical learning theory, Support vector machines, and Bioinformatics
 1 Statistical learning theory, Support vector machines, and Bioinformatics Jean-Philippe.Vert@mines.org Ecole des Mines de Paris Computational Biology group ENS Paris, november 25, 2003. 2 Overview 1.
1 Statistical learning theory, Support vector machines, and Bioinformatics Jean-Philippe.Vert@mines.org Ecole des Mines de Paris Computational Biology group ENS Paris, november 25, 2003. 2 Overview 1.
Brief Introduction to Machine Learning
 Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
EMPIRICAL INFERENCE SCIENCE. Vladimir Vapnik Columbia University, New York NEC Laboratories America, Princeton
 EMPIRICAL INFERENCE SCIENCE Vladimir Vapnik Columbia University, New York NEC Laboratories America, Princeton CONTENTS 2 Part 1: PROBLEM OF INDUCTION (A FRAMEWORK OF THE CLASSICAL PARADIGM) Part 2: NON-INDUCTIVE
EMPIRICAL INFERENCE SCIENCE Vladimir Vapnik Columbia University, New York NEC Laboratories America, Princeton CONTENTS 2 Part 1: PROBLEM OF INDUCTION (A FRAMEWORK OF THE CLASSICAL PARADIGM) Part 2: NON-INDUCTIVE
About this class. Maximizing the Margin. Maximum margin classifiers. Picture of large and small margin hyperplanes
 About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machines
 Support Vector Machines Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Overview Motivation
Support Vector Machines Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Overview Motivation
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Stat542 (F11) Statistical Learning. First consider the scenario where the two classes of points are separable.
 Statistical Learning. First consider the scenario where the two classes of points are separable.") Linear SVM (separable case) First consider the scenario where the two classes of points are separable. It s desirable to have the width (called margin) between the two dashed lines to be large, i.e., have
Linear SVM (separable case) First consider the scenario where the two classes of points are separable. It s desirable to have the width (called margin) between the two dashed lines to be large, i.e., have
Computational Learning Theory
 Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
Nearest Neighbors Methods for Support Vector Machines
 Nearest Neighbors Methods for Support Vector Machines A. J. Quiroz, Dpto. de Matemáticas. Universidad de Los Andes joint work with María González-Lima, Universidad Simón Boĺıvar and Sergio A. Camelo, Universidad
Nearest Neighbors Methods for Support Vector Machines A. J. Quiroz, Dpto. de Matemáticas. Universidad de Los Andes joint work with María González-Lima, Universidad Simón Boĺıvar and Sergio A. Camelo, Universidad
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Support Vector Machine. Industrial AI Lab. Prof. Seungchul Lee
 Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Math for Machine Learning Open Doors to Data Science and Artificial Intelligence. Richard Han
 Math for Machine Learning Open Doors to Data Science and Artificial Intelligence Richard Han Copyright 05 Richard Han All rights reserved. CONTENTS PREFACE... - INTRODUCTION... LINEAR REGRESSION... 4 LINEAR
Math for Machine Learning Open Doors to Data Science and Artificial Intelligence Richard Han Copyright 05 Richard Han All rights reserved. CONTENTS PREFACE... - INTRODUCTION... LINEAR REGRESSION... 4 LINEAR
Classifier Complexity and Support Vector Classifiers
 Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Generalization and Overfitting
 Generalization and Overfitting Model Selection Maria-Florina (Nina) Balcan February 24th, 2016 PAC/SLT models for Supervised Learning Data Source Distribution D on X Learning Algorithm Expert / Oracle
Generalization and Overfitting Model Selection Maria-Florina (Nina) Balcan February 24th, 2016 PAC/SLT models for Supervised Learning Data Source Distribution D on X Learning Algorithm Expert / Oracle
Generalization theory
 Generalization theory Chapter 4 T.P. Runarsson (tpr@hi.is) and S. Sigurdsson (sven@hi.is) Introduction Suppose you are given the empirical observations, (x 1, y 1 ),..., (x l, y l ) (X Y) l. Consider the
Generalization theory Chapter 4 T.P. Runarsson (tpr@hi.is) and S. Sigurdsson (sven@hi.is) Introduction Suppose you are given the empirical observations, (x 1, y 1 ),..., (x l, y l ) (X Y) l. Consider the
Linear Classification and SVM. Dr. Xin Zhang
 Linear Classification and SVM Dr. Xin Zhang Email: eexinzhang@scut.edu.cn What is linear classification? Classification is intrinsically non-linear It puts non-identical things in the same class, so a
Linear Classification and SVM Dr. Xin Zhang Email: eexinzhang@scut.edu.cn What is linear classification? Classification is intrinsically non-linear It puts non-identical things in the same class, so a
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Linear, Binary SVM Classifiers
 Linear, Binary SVM Classifiers COMPSCI 37D Machine Learning COMPSCI 37D Machine Learning Linear, Binary SVM Classifiers / 6 Outline What Linear, Binary SVM Classifiers Do 2 Margin I 3 Loss and Regularized
Linear, Binary SVM Classifiers COMPSCI 37D Machine Learning COMPSCI 37D Machine Learning Linear, Binary SVM Classifiers / 6 Outline What Linear, Binary SVM Classifiers Do 2 Margin I 3 Loss and Regularized
Support Vector Machine & Its Applications
 Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning
 Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
MACHINE LEARNING. Support Vector Machines. Alessandro Moschitti
 MACHINE LEARNING Support Vector Machines Alessandro Moschitti Department of information and communication technology University of Trento Email: moschitti@dit.unitn.it Summary Support Vector Machines
MACHINE LEARNING Support Vector Machines Alessandro Moschitti Department of information and communication technology University of Trento Email: moschitti@dit.unitn.it Summary Support Vector Machines
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
Support'Vector'Machines. Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan
 Support'Vector'Machines Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan kasthuri.kannan@nyumc.org Overview Support Vector Machines for Classification Linear Discrimination Nonlinear Discrimination
Support'Vector'Machines Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan kasthuri.kannan@nyumc.org Overview Support Vector Machines for Classification Linear Discrimination Nonlinear Discrimination
Support Vector Machines
 Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Machine Learning Basics Lecture 4: SVM I. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Approximation Theoretical Questions for SVMs
 Ingo Steinwart LA-UR 07-7056 October 20, 2007 Statistical Learning Theory: an Overview Support Vector Machines Informal Description of the Learning Goal X space of input samples Y space of labels, usually
Ingo Steinwart LA-UR 07-7056 October 20, 2007 Statistical Learning Theory: an Overview Support Vector Machines Informal Description of the Learning Goal X space of input samples Y space of labels, usually
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Support Vector Machines
 Support Vector Machines Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts Sridhar Mahadevan: CMPSCI 689 p. 1/32 Margin Classifiers margin b = 0 Sridhar Mahadevan: CMPSCI 689 p.
Support Vector Machines Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts Sridhar Mahadevan: CMPSCI 689 p. 1/32 Margin Classifiers margin b = 0 Sridhar Mahadevan: CMPSCI 689 p.
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Support Vector Machines
 Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines. Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Support Vector Machines Explained
 December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Applied Machine Learning Annalisa Marsico
 Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 29 April, SoSe 2015 Support Vector Machines (SVMs) 1. One of
Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 29 April, SoSe 2015 Support Vector Machines (SVMs) 1. One of
Learning Theory. Ingo Steinwart University of Stuttgart. September 4, 2013
 Learning Theory Ingo Steinwart University of Stuttgart September 4, 2013 Ingo Steinwart University of Stuttgart () Learning Theory September 4, 2013 1 / 62 Basics Informal Introduction Informal Description
Learning Theory Ingo Steinwart University of Stuttgart September 4, 2013 Ingo Steinwart University of Stuttgart () Learning Theory September 4, 2013 1 / 62 Basics Informal Introduction Informal Description
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Lecture Notes on Support Vector Machine
 Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Modelli Lineari (Generalizzati) e SVM
 e SVM") Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
Support Vector Machine via Nonlinear Rescaling Method
 Manuscript Click here to download Manuscript: svm-nrm_3.tex Support Vector Machine via Nonlinear Rescaling Method Roman Polyak Department of SEOR and Department of Mathematical Sciences George Mason University
Manuscript Click here to download Manuscript: svm-nrm_3.tex Support Vector Machine via Nonlinear Rescaling Method Roman Polyak Department of SEOR and Department of Mathematical Sciences George Mason University
Support Vector Machines
 Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Support Vector Learning for Ordinal Regression
 Support Vector Learning for Ordinal Regression Ralf Herbrich, Thore Graepel, Klaus Obermayer Technical University of Berlin Department of Computer Science Franklinstr. 28/29 10587 Berlin ralfh graepel2
Support Vector Learning for Ordinal Regression Ralf Herbrich, Thore Graepel, Klaus Obermayer Technical University of Berlin Department of Computer Science Franklinstr. 28/29 10587 Berlin ralfh graepel2
Pattern Recognition and Machine Learning. Perceptrons and Support Vector machines
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Machine Learning 4771
 Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Lecture 3 January 28
 EECS 28B / STAT 24B: Advanced Topics in Statistical LearningSpring 2009 Lecture 3 January 28 Lecturer: Pradeep Ravikumar Scribe: Timothy J. Wheeler Note: These lecture notes are still rough, and have only
EECS 28B / STAT 24B: Advanced Topics in Statistical LearningSpring 2009 Lecture 3 January 28 Lecturer: Pradeep Ravikumar Scribe: Timothy J. Wheeler Note: These lecture notes are still rough, and have only
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Name (NetID): (1 Point)
: (1 Point)") CS446: Machine Learning (D) Spring 2017 March 16 th, 2017 This is a closed book exam. Everything you need in order to solve the problems is supplied in the body of this exam. This exam booklet contains
CS446: Machine Learning (D) Spring 2017 March 16 th, 2017 This is a closed book exam. Everything you need in order to solve the problems is supplied in the body of this exam. This exam booklet contains
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
BINARY CLASSIFICATION
 BINARY CLASSIFICATION MAXIM RAGINSY The problem of binary classification can be stated as follows. We have a random couple Z = X, Y ), where X R d is called the feature vector and Y {, } is called the
BINARY CLASSIFICATION MAXIM RAGINSY The problem of binary classification can be stated as follows. We have a random couple Z = X, Y ), where X R d is called the feature vector and Y {, } is called the
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Empirical Risk Minimization
 Empirical Risk Minimization Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Introduction PAC learning ERM in practice 2 General setting Data X the input space and Y the output space
Empirical Risk Minimization Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Introduction PAC learning ERM in practice 2 General setting Data X the input space and Y the output space
ML (cont.): SUPPORT VECTOR MACHINES
: SUPPORT VECTOR MACHINES") ML (cont.): SUPPORT VECTOR MACHINES CS540 Bryan R Gibson University of Wisconsin-Madison Slides adapted from those used by Prof. Jerry Zhu, CS540-1 1 / 40 Support Vector Machines (SVMs) The No-Math Version
ML (cont.): SUPPORT VECTOR MACHINES CS540 Bryan R Gibson University of Wisconsin-Madison Slides adapted from those used by Prof. Jerry Zhu, CS540-1 1 / 40 Support Vector Machines (SVMs) The No-Math Version
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
Content. Learning. Regression vs Classification. Regression a.k.a. function approximation and Classification a.k.a. pattern recognition
 Content Andrew Kusiak Intelligent Systems Laboratory 239 Seamans Center The University of Iowa Iowa City, IA 52242-527 andrew-kusiak@uiowa.edu http://www.icaen.uiowa.edu/~ankusiak Introduction to learning
Content Andrew Kusiak Intelligent Systems Laboratory 239 Seamans Center The University of Iowa Iowa City, IA 52242-527 andrew-kusiak@uiowa.edu http://www.icaen.uiowa.edu/~ankusiak Introduction to learning
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Generalization theory
 Generalization theory Daniel Hsu Columbia TRIPODS Bootcamp 1 Motivation 2 Support vector machines X = R d, Y = { 1, +1}. Return solution ŵ R d to following optimization problem: λ min w R d 2 w 2 2 + 1
Generalization theory Daniel Hsu Columbia TRIPODS Bootcamp 1 Motivation 2 Support vector machines X = R d, Y = { 1, +1}. Return solution ŵ R d to following optimization problem: λ min w R d 2 w 2 2 + 1
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
FORMULATION OF THE LEARNING PROBLEM
 FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
Randomized Decision Trees
 Randomized Decision Trees compiled by Alvin Wan from Professor Jitendra Malik s lecture Discrete Variables First, let us consider some terminology. We have primarily been dealing with real-valued data,
Randomized Decision Trees compiled by Alvin Wan from Professor Jitendra Malik s lecture Discrete Variables First, let us consider some terminology. We have primarily been dealing with real-valued data,
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
The Perceptron. Volker Tresp Summer 2016
 The Perceptron Volker Tresp Summer 2016 1 Elements in Learning Tasks Collection, cleaning and preprocessing of training data Definition of a class of learning models. Often defined by the free model parameters
The Perceptron Volker Tresp Summer 2016 1 Elements in Learning Tasks Collection, cleaning and preprocessing of training data Definition of a class of learning models. Often defined by the free model parameters
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Machine Learning. Lecture 6: Support Vector Machine. Feng Li.
 Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Midterm exam CS 189/289, Fall 2015
 Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Support Vector Machines for Classification and Regression. 1 Linearly Separable Data: Hard Margin SVMs
 E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
Support Vector Machines with Example Dependent Costs
 Support Vector Machines with Example Dependent Costs Ulf Brefeld, Peter Geibel, and Fritz Wysotzki TU Berlin, Fak. IV, ISTI, AI Group, Sekr. FR5-8 Franklinstr. 8/9, D-0587 Berlin, Germany Email {geibel
Support Vector Machines with Example Dependent Costs Ulf Brefeld, Peter Geibel, and Fritz Wysotzki TU Berlin, Fak. IV, ISTI, AI Group, Sekr. FR5-8 Franklinstr. 8/9, D-0587 Berlin, Germany Email {geibel
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Foundations of Machine Learning
 Introduction to ML Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu page 1 Logistics Prerequisites: basics in linear algebra, probability, and analysis of algorithms. Workload: about
Introduction to ML Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu page 1 Logistics Prerequisites: basics in linear algebra, probability, and analysis of algorithms. Workload: about
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Lecture 18: Kernels Risk and Loss Support Vector Regression. Aykut Erdem December 2016 Hacettepe University
 Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Hilbert Space Methods in Learning
 Hilbert Space Methods in Learning guest lecturer: Risi Kondor 6772 Advanced Machine Learning and Perception (Jebara), Columbia University, October 15, 2003. 1 1. A general formulation of the learning problem
Hilbert Space Methods in Learning guest lecturer: Risi Kondor 6772 Advanced Machine Learning and Perception (Jebara), Columbia University, October 15, 2003. 1 1. A general formulation of the learning problem
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Risk Minimization Barnabás Póczos What have we seen so far? Several classification & regression algorithms seem to work fine on training datasets: Linear
Advanced Introduction to Machine Learning CMU-10715 Risk Minimization Barnabás Póczos What have we seen so far? Several classification & regression algorithms seem to work fine on training datasets: Linear