Information Geometry
|
|
|
- Susanna May
- 6 years ago
- Views:
Transcription
1 2015 Workshop on High-Dimensional Statistical Analysis Dec.11 (Friday) ~15 (Tuesday) Humanities and Social Sciences Center, Academia Sinica, Taiwan Information Geometry and Spontaneous Data Learning Shinto Shinto Eguchi Institute Institute Statistical Mathematics, Japan This talk is based on a joint work with Osamu Komori and Atsumi Ohara, University of Fukui
2 Outline Short review for Information geometry Kolmogorov-Nagumo mean -path in a function space Generalized mean and variance divergence geometry U-divergence geometry Minimum U-divergence and density estimation 2
3 A short review of IG Nonparametric space Space of statistics Information geometry is discussed on the product space 3
4 Bartlett s identity Parametric model Bartlett s first identity Bartlett s second identity 4
5 Metric and connections Information metric Mixture connection Exponential connection Rao (1945), Dawid (1975), Amari (1982) 5
6 Geodesic curves and surfaces in IG m-geodesic curve e-geodesic curve m-geodesic surface e-geodesic surface 6
7 Kullback-Leibler K-L divergence 1. KL divergence is the expected log-likelihood ratio 2. Maximum likelihood is minimum KL divergence. Akaike (1974) 3. KL divergence induces to the m-connection and e-connection Eguchi (1983) 7
8 Pythagoras Thm Amari-Nagaoka (2001) Pf 8
9 Exponential model Exponential model Mean parameter For For Amari (1982) Degenerated Bartlett identity 9


10 Exponential model Mean equal space Minimum KL leaf 10

11 Pythagoras foliation 11
12 log + exp log & exp Bartlett identities KL-divergence e-connection m-connection e-geodesic m-geodesic Pythagoras identity exponential model mean equal space Pythagoras foliation 12


13 Path geometry { m-geodesic, e-geodesic, } 13
14 Kolmogorov-Nagumo mean K-N mean is for positive numbers 14

15 K-N mean in Y Def. K-N mean Cf. Naudts (2009) 15
16 -path Def. -path connecting f and g Thm (Pf ) lim c 1 ( c )
17 Examples of -path Exm 0 Exm 1 Exm 2 Exm 3 17
18 Identities of -density Model 1st identity 2nd identity because 18
19 Generalized mean and variance Def Note
20 Generalized mean and variance Exm 20
21 Bartlett Identity Model Bartlett identity Bartlett identities 21
22 Tangent space of Y Tangent space Riemannian metric Expectation gives the tangent space Topological properties of T f depend on If = log, then T f is too large to do statistics on Y Cf. Pistone (1992) 22
23 Def Parallel transport A vector field is parallel along a curve A curve is -geodesic Cf. Amari (1982). 23
24 -geodesic Thm If is the -geodesic curve Proof. 24
25 -divergence -cross entropy -entropy -divergence Note: -divergence is KL-divergence if = log 25
26 Divergence geometry Def. Let be a statistical model. with the Riemannian metric on M : the pair of affine connections on M: 26
27 -divergence geometry The metric Affine connection pair 27
28 Pythagorean theorem Thm -geodesic -geodesic h Pf f g 28

29 -Pythagorean foliation -mean equal space 29
30 -mean -Bartlett identities - divergence - connection - connection - geodesic - geodesic - Pythagoras identity - model - Pythagoras foliation - mean equal space What is a statistical meaning of -mean and -variance? 30
31 U-divergence U-cross-entropy U-entropy U-divergence Note Exm 31
32 U-divergence geometry The metric associated with U-divergence: Affine connections associated with U-divergence: Thm (i) U-geodesic is mixture geodesic. (ii) U*-geodesic is geodesic 32
33 U-geometry = -geometry / -metric on a model M U-metric on a model M -connection U*-connection 33
34 Triangle with D U Thm mixture geodesic -geodesic h Pf f g 34

35 U-loss function U-estimation Let g(x) be a data density function with statistical model U-empirical loss function U-estimator for 35
36 U-estimator under -model -model U-empirical loss function U-estimator for U-estimator under -model has analogy with MLE under exponential model 36
37 Potential function Def We call the potential function on -model Note We define the mean parameter by Cf. mean parameter Thm U-estimator for is given by the sample mean 37
38 Pythagoras foliation Thm Pf 38

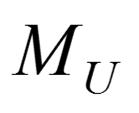
39 Pythagoras foliation 39
40 U-Boost learning for density estimation U-loss function L U n 1 ( f ) ( f ( xi )) U( ( f ( x)))dx n p i 1 Dictionary of density functions RI W { g ( x) : g ( x) 0, g ( x)dx 1, } Learning space = -model W * 1 ( co( ( W ))) { 1 ( ( g ( x)))} Let f ( x, π) W * W ( ( g ( x)). Then f ( x,(0,,1, 0)) g ( x) 1 ) ( ) Goal : find f * argmin f W * U L U ( f )
41 U-Boost algorithm ( A) Find f1 arg min L ( g) g W U (B) Update f k f k 1 1 ((1 k 1 ) ( f k ) k 1 ( g k 1 )) st ( k 1, g k 1 ) arg min, g) (0,1) ( W L U ( 1 ((1 ) ( f k ) ( g))) ˆ 1 ( C) Select K, and f ((1 K ) ( fk 1) K ( g K )) Example 2. Power entropy ( f 1 * ) ( x) ( k gk ( x) k k log gk ( x) k k * If 0, f ( x) exp ) g ( x) If * 1, f ( x) ( x) Klemela (2007) k k g k k k Friedman et al (1984)
) * * 1 Goal : f argmin L ( f ) f (")
 g 4 g 6 g 3 g 2 f (x) g")
42 Inner step in the convex hull W { t( x, ) : } W * U 1 (co ( W )) * * 1 Goal : f argmin L ( f ) f ( x) ( ˆ ( fˆ ( x)) ˆ ( ˆ ˆ f ˆ( x))) f W * U U 1 1 k k W g 7 g 5 * W U f (x) g 4 g 6 g 3 g 2 f (x) g 1
43 Non-asymptotic bound Theorem. Assume that a data distribution has a density g(x) and that ( A) sup U''( ){ ( ) ( )} Then we have where FA( g, W EE( g, W IE( K, W ) (,, ) co( ( W )) W W EI D ( g, fˆ ) FA( g, W * ) EE( g, W ) IE( K, W g U = U K ) inf f WU= D U n ( g, f ) ) 2 EI { sup f g f W 2 2 U c b K c 1 1 ( f ( x )) EI ( ) } n i 1 U i ( c:step- lengthconstant) p 2 b U ), (Functional approximation) (Estimation error) (Iteration effect) Remark. Trade between FA( p, W * U ) and EE( p, W ) 43
 C")
 L")
44 -Boost -Boost KDE RSDE (Girolami-He, 2004) C (skewed-unimodal) H (bimodal) L (quadrimodal) 44
45 Conclusion K-N mean E ( ), Cov ( ) -path = -geodesic -divergence (G ( ),* ( ), ( ) ) -geodesic, -geodesic ) U U-divergence (G (U),* (U), (U) ) -geodesic, m-geodesic ) -path W * U 1 (co ( W )) 45
46 Future problems Tangent space Path space 46
47 Future problems -mean, -variance, -divergence These are natural ideas from IG view point We can build -efficiency in estimation theory, but What is a statistical meaning of -mean and -variance? Can we define a random sample of -version? 47
48 Thank you 48
Information Geometric Structure on Positive Definite Matrices and its Applications
 Information Geometric Structure on Positive Definite Matrices and its Applications Atsumi Ohara Osaka University 2010 Feb. 21 at Osaka City University 大阪市立大学数学研究所情報幾何関連分野研究会 2010 情報工学への幾何学的アプローチ 1 Outline
Information Geometric Structure on Positive Definite Matrices and its Applications Atsumi Ohara Osaka University 2010 Feb. 21 at Osaka City University 大阪市立大学数学研究所情報幾何関連分野研究会 2010 情報工学への幾何学的アプローチ 1 Outline
Distributed Estimation, Information Loss and Exponential Families. Qiang Liu Department of Computer Science Dartmouth College
 Distributed Estimation, Information Loss and Exponential Families Qiang Liu Department of Computer Science Dartmouth College Statistical Learning / Estimation Learning generative models from data Topic
Distributed Estimation, Information Loss and Exponential Families Qiang Liu Department of Computer Science Dartmouth College Statistical Learning / Estimation Learning generative models from data Topic
Information Geometric view of Belief Propagation
 Information Geometric view of Belief Propagation Yunshu Liu 2013-10-17 References: [1]. Shiro Ikeda, Toshiyuki Tanaka and Shun-ichi Amari, Stochastic reasoning, Free energy and Information Geometry, Neural
Information Geometric view of Belief Propagation Yunshu Liu 2013-10-17 References: [1]. Shiro Ikeda, Toshiyuki Tanaka and Shun-ichi Amari, Stochastic reasoning, Free energy and Information Geometry, Neural
Information geometry of Bayesian statistics
 Information geometry of Bayesian statistics Hiroshi Matsuzoe Department of Computer Science and Engineering, Graduate School of Engineering, Nagoya Institute of Technology, Nagoya 466-8555, Japan Abstract.
Information geometry of Bayesian statistics Hiroshi Matsuzoe Department of Computer Science and Engineering, Graduate School of Engineering, Nagoya Institute of Technology, Nagoya 466-8555, Japan Abstract.
Information geometry of mirror descent
 Information geometry of mirror descent Geometric Science of Information Anthea Monod Department of Statistical Science Duke University Information Initiative at Duke G. Raskutti (UW Madison) and S. Mukherjee
Information geometry of mirror descent Geometric Science of Information Anthea Monod Department of Statistical Science Duke University Information Initiative at Duke G. Raskutti (UW Madison) and S. Mukherjee
Entropy and Divergence Associated with Power Function and the Statistical Application
 Entropy 200, 2, 262-274; doi:0.3390/e2020262 Article OPEN ACCESS entropy ISSN 099-4300 www.mdpi.com/journal/entropy Entropy and Divergence Associated with Power Function and the Statistical Application
Entropy 200, 2, 262-274; doi:0.3390/e2020262 Article OPEN ACCESS entropy ISSN 099-4300 www.mdpi.com/journal/entropy Entropy and Divergence Associated with Power Function and the Statistical Application
Chapter 2 Exponential Families and Mixture Families of Probability Distributions
 Chapter 2 Exponential Families and Mixture Families of Probability Distributions The present chapter studies the geometry of the exponential family of probability distributions. It is not only a typical
Chapter 2 Exponential Families and Mixture Families of Probability Distributions The present chapter studies the geometry of the exponential family of probability distributions. It is not only a typical
Geometry of U-Boost Algorithms
 Geometry of U-Boost Algorithms Noboru Murata 1, Takashi Takenouchi 2, Takafumi Kanamori 3, Shinto Eguchi 2,4 1 School of Science and Engineering, Waseda University 2 Department of Statistical Science,
Geometry of U-Boost Algorithms Noboru Murata 1, Takashi Takenouchi 2, Takafumi Kanamori 3, Shinto Eguchi 2,4 1 School of Science and Engineering, Waseda University 2 Department of Statistical Science,
Spatially Smoothed Kernel Density Estimation via Generalized Empirical Likelihood
 Spatially Smoothed Kernel Density Estimation via Generalized Empirical Likelihood Kuangyu Wen & Ximing Wu Texas A&M University Info-Metrics Institute Conference: Recent Innovations in Info-Metrics October
Spatially Smoothed Kernel Density Estimation via Generalized Empirical Likelihood Kuangyu Wen & Ximing Wu Texas A&M University Info-Metrics Institute Conference: Recent Innovations in Info-Metrics October
Surrogate loss functions, divergences and decentralized detection
 Surrogate loss functions, divergences and decentralized detection XuanLong Nguyen Department of Electrical Engineering and Computer Science U.C. Berkeley Advisors: Michael Jordan & Martin Wainwright 1
Surrogate loss functions, divergences and decentralized detection XuanLong Nguyen Department of Electrical Engineering and Computer Science U.C. Berkeley Advisors: Michael Jordan & Martin Wainwright 1
Bootstrap prediction and Bayesian prediction under misspecified models
 Bernoulli 11(4), 2005, 747 758 Bootstrap prediction and Bayesian prediction under misspecified models TADAYOSHI FUSHIKI Institute of Statistical Mathematics, 4-6-7 Minami-Azabu, Minato-ku, Tokyo 106-8569,
Bernoulli 11(4), 2005, 747 758 Bootstrap prediction and Bayesian prediction under misspecified models TADAYOSHI FUSHIKI Institute of Statistical Mathematics, 4-6-7 Minami-Azabu, Minato-ku, Tokyo 106-8569,
Bayesian estimation of the discrepancy with misspecified parametric models
 Bayesian estimation of the discrepancy with misspecified parametric models Pierpaolo De Blasi University of Torino & Collegio Carlo Alberto Bayesian Nonparametrics workshop ICERM, 17-21 September 2012
Bayesian estimation of the discrepancy with misspecified parametric models Pierpaolo De Blasi University of Torino & Collegio Carlo Alberto Bayesian Nonparametrics workshop ICERM, 17-21 September 2012
Applications of Information Geometry to Hypothesis Testing and Signal Detection
 CMCAA 2016 Applications of Information Geometry to Hypothesis Testing and Signal Detection Yongqiang Cheng National University of Defense Technology July 2016 Outline 1. Principles of Information Geometry
CMCAA 2016 Applications of Information Geometry to Hypothesis Testing and Signal Detection Yongqiang Cheng National University of Defense Technology July 2016 Outline 1. Principles of Information Geometry
Bregman divergence and density integration Noboru Murata and Yu Fujimoto
 Journal of Math-for-industry, Vol.1(2009B-3), pp.97 104 Bregman divergence and density integration Noboru Murata and Yu Fujimoto Received on August 29, 2009 / Revised on October 4, 2009 Abstract. In this
Journal of Math-for-industry, Vol.1(2009B-3), pp.97 104 Bregman divergence and density integration Noboru Murata and Yu Fujimoto Received on August 29, 2009 / Revised on October 4, 2009 Abstract. In this
AN AFFINE EMBEDDING OF THE GAMMA MANIFOLD
 AN AFFINE EMBEDDING OF THE GAMMA MANIFOLD C.T.J. DODSON AND HIROSHI MATSUZOE Abstract. For the space of gamma distributions with Fisher metric and exponential connections, natural coordinate systems, potential
AN AFFINE EMBEDDING OF THE GAMMA MANIFOLD C.T.J. DODSON AND HIROSHI MATSUZOE Abstract. For the space of gamma distributions with Fisher metric and exponential connections, natural coordinate systems, potential
STATISTICAL CURVATURE AND STOCHASTIC COMPLEXITY
 2nd International Symposium on Information Geometry and its Applications December 2-6, 2005, Tokyo Pages 000 000 STATISTICAL CURVATURE AND STOCHASTIC COMPLEXITY JUN-ICHI TAKEUCHI, ANDREW R. BARRON, AND
2nd International Symposium on Information Geometry and its Applications December 2-6, 2005, Tokyo Pages 000 000 STATISTICAL CURVATURE AND STOCHASTIC COMPLEXITY JUN-ICHI TAKEUCHI, ANDREW R. BARRON, AND
Lecture 8: Information Theory and Statistics
 Lecture 8: Information Theory and Statistics Part II: Hypothesis Testing and I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw December 23, 2015 1 / 50 I-Hsiang
Lecture 8: Information Theory and Statistics Part II: Hypothesis Testing and I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw December 23, 2015 1 / 50 I-Hsiang
Information Geometry on Hierarchy of Probability Distributions
 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 47, NO. 5, JULY 2001 1701 Information Geometry on Hierarchy of Probability Distributions Shun-ichi Amari, Fellow, IEEE Abstract An exponential family or mixture
IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 47, NO. 5, JULY 2001 1701 Information Geometry on Hierarchy of Probability Distributions Shun-ichi Amari, Fellow, IEEE Abstract An exponential family or mixture
The information complexity of best-arm identification
 The information complexity of best-arm identification Emilie Kaufmann, joint work with Olivier Cappé and Aurélien Garivier MAB workshop, Lancaster, January th, 206 Context: the multi-armed bandit model
The information complexity of best-arm identification Emilie Kaufmann, joint work with Olivier Cappé and Aurélien Garivier MAB workshop, Lancaster, January th, 206 Context: the multi-armed bandit model
Information geometry for bivariate distribution control
 Information geometry for bivariate distribution control C.T.J.Dodson + Hong Wang Mathematics + Control Systems Centre, University of Manchester Institute of Science and Technology Optimal control of stochastic
Information geometry for bivariate distribution control C.T.J.Dodson + Hong Wang Mathematics + Control Systems Centre, University of Manchester Institute of Science and Technology Optimal control of stochastic
Bias-Variance Trade-Off in Hierarchical Probabilistic Models Using Higher-Order Feature Interactions
 - Trade-Off in Hierarchical Probabilistic Models Using Higher-Order Feature Interactions Simon Luo The University of Sydney Data61, CSIRO simon.luo@data61.csiro.au Mahito Sugiyama National Institute of
- Trade-Off in Hierarchical Probabilistic Models Using Higher-Order Feature Interactions Simon Luo The University of Sydney Data61, CSIRO simon.luo@data61.csiro.au Mahito Sugiyama National Institute of
Quantifying Stochastic Model Errors via Robust Optimization
 Quantifying Stochastic Model Errors via Robust Optimization IPAM Workshop on Uncertainty Quantification for Multiscale Stochastic Systems and Applications Jan 19, 2016 Henry Lam Industrial & Operations
Quantifying Stochastic Model Errors via Robust Optimization IPAM Workshop on Uncertainty Quantification for Multiscale Stochastic Systems and Applications Jan 19, 2016 Henry Lam Industrial & Operations
l 1 -Regularized Linear Regression: Persistence and Oracle Inequalities
 l -Regularized Linear Regression: Persistence and Oracle Inequalities Peter Bartlett EECS and Statistics UC Berkeley slides at http://www.stat.berkeley.edu/ bartlett Joint work with Shahar Mendelson and
l -Regularized Linear Regression: Persistence and Oracle Inequalities Peter Bartlett EECS and Statistics UC Berkeley slides at http://www.stat.berkeley.edu/ bartlett Joint work with Shahar Mendelson and
Introduction to Information Geometry
 Introduction to Information Geometry based on the book Methods of Information Geometry written by Shun-Ichi Amari and Hiroshi Nagaoka Yunshu Liu 2012-02-17 Outline 1 Introduction to differential geometry
Introduction to Information Geometry based on the book Methods of Information Geometry written by Shun-Ichi Amari and Hiroshi Nagaoka Yunshu Liu 2012-02-17 Outline 1 Introduction to differential geometry
Uncertainty. Jayakrishnan Unnikrishnan. CSL June PhD Defense ECE Department
 Decision-Making under Statistical Uncertainty Jayakrishnan Unnikrishnan PhD Defense ECE Department University of Illinois at Urbana-Champaign CSL 141 12 June 2010 Statistical Decision-Making Relevant in
Decision-Making under Statistical Uncertainty Jayakrishnan Unnikrishnan PhD Defense ECE Department University of Illinois at Urbana-Champaign CSL 141 12 June 2010 Statistical Decision-Making Relevant in
Learning Binary Classifiers for Multi-Class Problem
 Research Memorandum No. 1010 September 28, 2006 Learning Binary Classifiers for Multi-Class Problem Shiro Ikeda The Institute of Statistical Mathematics 4-6-7 Minami-Azabu, Minato-ku, Tokyo, 106-8569,
Research Memorandum No. 1010 September 28, 2006 Learning Binary Classifiers for Multi-Class Problem Shiro Ikeda The Institute of Statistical Mathematics 4-6-7 Minami-Azabu, Minato-ku, Tokyo, 106-8569,
Information Projection Algorithms and Belief Propagation
 χ 1 π(χ 1 ) Information Projection Algorithms and Belief Propagation Phil Regalia Department of Electrical Engineering and Computer Science Catholic University of America Washington, DC 20064 with J. M.
χ 1 π(χ 1 ) Information Projection Algorithms and Belief Propagation Phil Regalia Department of Electrical Engineering and Computer Science Catholic University of America Washington, DC 20064 with J. M.
LECTURE 15: COMPLETENESS AND CONVEXITY
 LECTURE 15: COMPLETENESS AND CONVEXITY 1. The Hopf-Rinow Theorem Recall that a Riemannian manifold (M, g) is called geodesically complete if the maximal defining interval of any geodesic is R. On the other
LECTURE 15: COMPLETENESS AND CONVEXITY 1. The Hopf-Rinow Theorem Recall that a Riemannian manifold (M, g) is called geodesically complete if the maximal defining interval of any geodesic is R. On the other
Information Measure Estimation and Applications: Boosting the Effective Sample Size from n to n ln n
 Information Measure Estimation and Applications: Boosting the Effective Sample Size from n to n ln n Jiantao Jiao (Stanford EE) Joint work with: Kartik Venkat Yanjun Han Tsachy Weissman Stanford EE Tsinghua
Information Measure Estimation and Applications: Boosting the Effective Sample Size from n to n ln n Jiantao Jiao (Stanford EE) Joint work with: Kartik Venkat Yanjun Han Tsachy Weissman Stanford EE Tsinghua
A minimalist s exposition of EM
 A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
Consistency of the maximum likelihood estimator for general hidden Markov models
 Consistency of the maximum likelihood estimator for general hidden Markov models Jimmy Olsson Centre for Mathematical Sciences Lund University Nordstat 2012 Umeå, Sweden Collaborators Hidden Markov models
Consistency of the maximum likelihood estimator for general hidden Markov models Jimmy Olsson Centre for Mathematical Sciences Lund University Nordstat 2012 Umeå, Sweden Collaborators Hidden Markov models
An Information Geometry Perspective on Estimation of Distribution Algorithms: Boundary Analysis
 An Information Geometry Perspective on Estimation of Distribution Algorithms: Boundary Analysis Luigi Malagò Department of Electronics and Information Politecnico di Milano Via Ponzio, 34/5 20133 Milan,
An Information Geometry Perspective on Estimation of Distribution Algorithms: Boundary Analysis Luigi Malagò Department of Electronics and Information Politecnico di Milano Via Ponzio, 34/5 20133 Milan,
Machine learning - HT Maximum Likelihood
 Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework Formulate linear regression in the language of probability Introduce
Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework Formulate linear regression in the language of probability Introduce
Characterizing the Region of Entropic Vectors via Information Geometry
 Characterizing the Region of Entropic Vectors via Information Geometry John MacLaren Walsh Department of Electrical and Computer Engineering Drexel University Philadelphia, PA jwalsh@ece.drexel.edu Thanks
Characterizing the Region of Entropic Vectors via Information Geometry John MacLaren Walsh Department of Electrical and Computer Engineering Drexel University Philadelphia, PA jwalsh@ece.drexel.edu Thanks
Bayes spaces: use of improper priors and distances between densities
 Bayes spaces: use of improper priors and distances between densities J. J. Egozcue 1, V. Pawlowsky-Glahn 2, R. Tolosana-Delgado 1, M. I. Ortego 1 and G. van den Boogaart 3 1 Universidad Politécnica de
Bayes spaces: use of improper priors and distances between densities J. J. Egozcue 1, V. Pawlowsky-Glahn 2, R. Tolosana-Delgado 1, M. I. Ortego 1 and G. van den Boogaart 3 1 Universidad Politécnica de
2.1 Optimization formulation of k-means
 MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016 Lecture 2: k-means Clustering Lecturer: Jiaming Xu Scribe: Jiaming Xu, September 2, 2016 Outline Optimization formulation of k-means Convergence
MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016 Lecture 2: k-means Clustering Lecturer: Jiaming Xu Scribe: Jiaming Xu, September 2, 2016 Outline Optimization formulation of k-means Convergence
Methods of Estimation
 Methods of Estimation MIT 18.655 Dr. Kempthorne Spring 2016 1 Outline Methods of Estimation I 1 Methods of Estimation I 2 X X, X P P = {P θ, θ Θ}. Problem: Finding a function θˆ(x ) which is close to θ.
Methods of Estimation MIT 18.655 Dr. Kempthorne Spring 2016 1 Outline Methods of Estimation I 1 Methods of Estimation I 2 X X, X P P = {P θ, θ Θ}. Problem: Finding a function θˆ(x ) which is close to θ.
Bregman Divergences for Data Mining Meta-Algorithms
 p.1/?? Bregman Divergences for Data Mining Meta-Algorithms Joydeep Ghosh University of Texas at Austin ghosh@ece.utexas.edu Reflects joint work with Arindam Banerjee, Srujana Merugu, Inderjit Dhillon,
p.1/?? Bregman Divergences for Data Mining Meta-Algorithms Joydeep Ghosh University of Texas at Austin ghosh@ece.utexas.edu Reflects joint work with Arindam Banerjee, Srujana Merugu, Inderjit Dhillon,
Hessian Riemannian Gradient Flows in Convex Programming
 Hessian Riemannian Gradient Flows in Convex Programming Felipe Alvarez, Jérôme Bolte, Olivier Brahic INTERNATIONAL CONFERENCE ON MODELING AND OPTIMIZATION MODOPT 2004 Universidad de La Frontera, Temuco,
Hessian Riemannian Gradient Flows in Convex Programming Felipe Alvarez, Jérôme Bolte, Olivier Brahic INTERNATIONAL CONFERENCE ON MODELING AND OPTIMIZATION MODOPT 2004 Universidad de La Frontera, Temuco,
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
Bounding the Entropic Region via Information Geometry
 Bounding the ntropic Region via Information Geometry Yunshu Liu John MacLaren Walsh Dept. of C, Drexel University, Philadelphia, PA 19104, USA yunshu.liu@drexel.edu jwalsh@coe.drexel.edu Abstract This
Bounding the ntropic Region via Information Geometry Yunshu Liu John MacLaren Walsh Dept. of C, Drexel University, Philadelphia, PA 19104, USA yunshu.liu@drexel.edu jwalsh@coe.drexel.edu Abstract This
Statistical physics models belonging to the generalised exponential family
 Statistical physics models belonging to the generalised exponential family Jan Naudts Universiteit Antwerpen 1. The generalized exponential family 6. The porous media equation 2. Theorem 7. The microcanonical
Statistical physics models belonging to the generalised exponential family Jan Naudts Universiteit Antwerpen 1. The generalized exponential family 6. The porous media equation 2. Theorem 7. The microcanonical
Lecture 7 Introduction to Statistical Decision Theory
 Lecture 7 Introduction to Statistical Decision Theory I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw December 20, 2016 1 / 55 I-Hsiang Wang IT Lecture 7
Lecture 7 Introduction to Statistical Decision Theory I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw December 20, 2016 1 / 55 I-Hsiang Wang IT Lecture 7
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Manifold Monte Carlo Methods
 Manifold Monte Carlo Methods Mark Girolami Department of Statistical Science University College London Joint work with Ben Calderhead Research Section Ordinary Meeting The Royal Statistical Society October
Manifold Monte Carlo Methods Mark Girolami Department of Statistical Science University College London Joint work with Ben Calderhead Research Section Ordinary Meeting The Royal Statistical Society October
Revisiting the Exploration-Exploitation Tradeoff in Bandit Models
 Revisiting the Exploration-Exploitation Tradeoff in Bandit Models joint work with Aurélien Garivier (IMT, Toulouse) and Tor Lattimore (University of Alberta) Workshop on Optimization and Decision-Making
Revisiting the Exploration-Exploitation Tradeoff in Bandit Models joint work with Aurélien Garivier (IMT, Toulouse) and Tor Lattimore (University of Alberta) Workshop on Optimization and Decision-Making
A PARAMETRIC MODEL FOR DISCRETE-VALUED TIME SERIES. 1. Introduction
 tm Tatra Mt. Math. Publ. 00 (XXXX), 1 10 A PARAMETRIC MODEL FOR DISCRETE-VALUED TIME SERIES Martin Janžura and Lucie Fialová ABSTRACT. A parametric model for statistical analysis of Markov chains type
tm Tatra Mt. Math. Publ. 00 (XXXX), 1 10 A PARAMETRIC MODEL FOR DISCRETE-VALUED TIME SERIES Martin Janžura and Lucie Fialová ABSTRACT. A parametric model for statistical analysis of Markov chains type
Information Geometry of Positive Measures and Positive-Definite Matrices: Decomposable Dually Flat Structure
 Entropy 014, 16, 131-145; doi:10.3390/e1604131 OPEN ACCESS entropy ISSN 1099-4300 www.mdpi.com/journal/entropy Article Information Geometry of Positive Measures and Positive-Definite Matrices: Decomposable
Entropy 014, 16, 131-145; doi:10.3390/e1604131 OPEN ACCESS entropy ISSN 1099-4300 www.mdpi.com/journal/entropy Article Information Geometry of Positive Measures and Positive-Definite Matrices: Decomposable
11. Learning graphical models
 Learning graphical models 11-1 11. Learning graphical models Maximum likelihood Parameter learning Structural learning Learning partially observed graphical models Learning graphical models 11-2 statistical
Learning graphical models 11-1 11. Learning graphical models Maximum likelihood Parameter learning Structural learning Learning partially observed graphical models Learning graphical models 11-2 statistical
Covariance function estimation in Gaussian process regression
 Covariance function estimation in Gaussian process regression François Bachoc Department of Statistics and Operations Research, University of Vienna WU Research Seminar - May 2015 François Bachoc Gaussian
Covariance function estimation in Gaussian process regression François Bachoc Department of Statistics and Operations Research, University of Vienna WU Research Seminar - May 2015 François Bachoc Gaussian
Gaussian Mixture Models
 Gaussian Mixture Models David Rosenberg, Brett Bernstein New York University April 26, 2017 David Rosenberg, Brett Bernstein (New York University) DS-GA 1003 April 26, 2017 1 / 42 Intro Question Intro
Gaussian Mixture Models David Rosenberg, Brett Bernstein New York University April 26, 2017 David Rosenberg, Brett Bernstein (New York University) DS-GA 1003 April 26, 2017 1 / 42 Intro Question Intro
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
PROBABILITY AND INFORMATION THEORY. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
Nonparametric estimation: s concave and log-concave densities: alternatives to maximum likelihood
 Nonparametric estimation: s concave and log-concave densities: alternatives to maximum likelihood Jon A. Wellner University of Washington, Seattle Statistics Seminar, York October 15, 2015 Statistics Seminar,
Nonparametric estimation: s concave and log-concave densities: alternatives to maximum likelihood Jon A. Wellner University of Washington, Seattle Statistics Seminar, York October 15, 2015 Statistics Seminar,
Lecture 5 Channel Coding over Continuous Channels
 Lecture 5 Channel Coding over Continuous Channels I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw November 14, 2014 1 / 34 I-Hsiang Wang NIT Lecture 5 From
Lecture 5 Channel Coding over Continuous Channels I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw November 14, 2014 1 / 34 I-Hsiang Wang NIT Lecture 5 From
Journée Interdisciplinaire Mathématiques Musique
 Journée Interdisciplinaire Mathématiques Musique Music Information Geometry Arnaud Dessein 1,2 and Arshia Cont 1 1 Institute for Research and Coordination of Acoustics and Music, Paris, France 2 Japanese-French
Journée Interdisciplinaire Mathématiques Musique Music Information Geometry Arnaud Dessein 1,2 and Arshia Cont 1 1 Institute for Research and Coordination of Acoustics and Music, Paris, France 2 Japanese-French
Relative Loss Bounds for Multidimensional Regression Problems
 Relative Loss Bounds for Multidimensional Regression Problems Jyrki Kivinen and Manfred Warmuth Presented by: Arindam Banerjee A Single Neuron For a training example (x, y), x R d, y [0, 1] learning solves
Relative Loss Bounds for Multidimensional Regression Problems Jyrki Kivinen and Manfred Warmuth Presented by: Arindam Banerjee A Single Neuron For a training example (x, y), x R d, y [0, 1] learning solves
Nonparametric estimation of log-concave densities
 Nonparametric estimation of log-concave densities Jon A. Wellner University of Washington, Seattle Northwestern University November 5, 2010 Conference on Shape Restrictions in Non- and Semi-Parametric
Nonparametric estimation of log-concave densities Jon A. Wellner University of Washington, Seattle Northwestern University November 5, 2010 Conference on Shape Restrictions in Non- and Semi-Parametric
Nishant Gurnani. GAN Reading Group. April 14th, / 107
 Nishant Gurnani GAN Reading Group April 14th, 2017 1 / 107 Why are these Papers Important? 2 / 107 Why are these Papers Important? Recently a large number of GAN frameworks have been proposed - BGAN, LSGAN,
Nishant Gurnani GAN Reading Group April 14th, 2017 1 / 107 Why are these Papers Important? 2 / 107 Why are these Papers Important? Recently a large number of GAN frameworks have been proposed - BGAN, LSGAN,
Welcome to Copenhagen!
 Welcome to Copenhagen! Schedule: Monday Tuesday Wednesday Thursday Friday 8 Registration and welcome 9 Crash course on Crash course on Introduction to Differential and Differential and Information Geometry
Welcome to Copenhagen! Schedule: Monday Tuesday Wednesday Thursday Friday 8 Registration and welcome 9 Crash course on Crash course on Introduction to Differential and Differential and Information Geometry
Information Geometry: Background and Applications in Machine Learning
 Geometry and Computer Science Information Geometry: Background and Applications in Machine Learning Giovanni Pistone www.giannidiorestino.it Pescara IT), February 8 10, 2017 Abstract Information Geometry
Geometry and Computer Science Information Geometry: Background and Applications in Machine Learning Giovanni Pistone www.giannidiorestino.it Pescara IT), February 8 10, 2017 Abstract Information Geometry
Variations. ECE 6540, Lecture 10 Maximum Likelihood Estimation
 Variations ECE 6540, Lecture 10 Last Time BLUE (Best Linear Unbiased Estimator) Formulation Advantages Disadvantages 2 The BLUE A simplification Assume the estimator is a linear system For a single parameter
Variations ECE 6540, Lecture 10 Last Time BLUE (Best Linear Unbiased Estimator) Formulation Advantages Disadvantages 2 The BLUE A simplification Assume the estimator is a linear system For a single parameter
Lecture 17: Density Estimation Lecturer: Yihong Wu Scribe: Jiaqi Mu, Mar 31, 2016 [Ed. Apr 1]
![Lecture 17: Density Estimation Lecturer: Yihong Wu Scribe: Jiaqi Mu, Mar 31, 2016 [Ed. Apr 1]](/thumbs/93/114381334.jpg "Lecture 17: Density Estimation Lecturer: Yihong Wu Scribe: Jiaqi Mu, Mar 31, 2016 [Ed. Apr 1]") ECE598: Information-theoretic methods in high-dimensional statistics Spring 06 Lecture 7: Density Estimation Lecturer: Yihong Wu Scribe: Jiaqi Mu, Mar 3, 06 [Ed. Apr ] In last lecture, we studied the minimax
ECE598: Information-theoretic methods in high-dimensional statistics Spring 06 Lecture 7: Density Estimation Lecturer: Yihong Wu Scribe: Jiaqi Mu, Mar 3, 06 [Ed. Apr ] In last lecture, we studied the minimax
Nonparametric estimation of log-concave densities
 Nonparametric estimation of log-concave densities Jon A. Wellner University of Washington, Seattle Seminaire, Institut de Mathématiques de Toulouse 5 March 2012 Seminaire, Toulouse Based on joint work
Nonparametric estimation of log-concave densities Jon A. Wellner University of Washington, Seattle Seminaire, Institut de Mathématiques de Toulouse 5 March 2012 Seminaire, Toulouse Based on joint work
F -Geometry and Amari s α Geometry on a Statistical Manifold
 Entropy 014, 16, 47-487; doi:10.3390/e160547 OPEN ACCESS entropy ISSN 1099-4300 www.mdpi.com/journal/entropy Article F -Geometry and Amari s α Geometry on a Statistical Manifold Harsha K. V. * and Subrahamanian
Entropy 014, 16, 47-487; doi:10.3390/e160547 OPEN ACCESS entropy ISSN 1099-4300 www.mdpi.com/journal/entropy Article F -Geometry and Amari s α Geometry on a Statistical Manifold Harsha K. V. * and Subrahamanian
Probability and Statistics
 Kristel Van Steen, PhD 2 Montefiore Institute - Systems and Modeling GIGA - Bioinformatics ULg kristel.vansteen@ulg.ac.be Chapter 3: Parametric families of univariate distributions CHAPTER 3: PARAMETRIC
Kristel Van Steen, PhD 2 Montefiore Institute - Systems and Modeling GIGA - Bioinformatics ULg kristel.vansteen@ulg.ac.be Chapter 3: Parametric families of univariate distributions CHAPTER 3: PARAMETRIC
Statistical inference on Lévy processes
 Alberto Coca Cabrero University of Cambridge - CCA Supervisors: Dr. Richard Nickl and Professor L.C.G.Rogers Funded by Fundación Mutua Madrileña and EPSRC MASDOC/CCA student workshop 2013 26th March Outline
Alberto Coca Cabrero University of Cambridge - CCA Supervisors: Dr. Richard Nickl and Professor L.C.G.Rogers Funded by Fundación Mutua Madrileña and EPSRC MASDOC/CCA student workshop 2013 26th March Outline
Econometrics I, Estimation
 Econometrics I, Estimation Department of Economics Stanford University September, 2008 Part I Parameter, Estimator, Estimate A parametric is a feature of the population. An estimator is a function of the
Econometrics I, Estimation Department of Economics Stanford University September, 2008 Part I Parameter, Estimator, Estimate A parametric is a feature of the population. An estimator is a function of the
f-divergence Estimation and Two-Sample Homogeneity Test under Semiparametric Density-Ratio Models
 IEEE Transactions on Information Theory, vol.58, no.2, pp.708 720, 2012. 1 f-divergence Estimation and Two-Sample Homogeneity Test under Semiparametric Density-Ratio Models Takafumi Kanamori Nagoya University,
IEEE Transactions on Information Theory, vol.58, no.2, pp.708 720, 2012. 1 f-divergence Estimation and Two-Sample Homogeneity Test under Semiparametric Density-Ratio Models Takafumi Kanamori Nagoya University,
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
Statistics 612: L p spaces, metrics on spaces of probabilites, and connections to estimation
 Statistics 62: L p spaces, metrics on spaces of probabilites, and connections to estimation Moulinath Banerjee December 6, 2006 L p spaces and Hilbert spaces We first formally define L p spaces. Consider
Statistics 62: L p spaces, metrics on spaces of probabilites, and connections to estimation Moulinath Banerjee December 6, 2006 L p spaces and Hilbert spaces We first formally define L p spaces. Consider
Asymptotic results for empirical measures of weighted sums of independent random variables
 Asymptotic results for empirical measures of weighted sums of independent random variables B. Bercu and W. Bryc University Bordeaux 1, France Workshop on Limit Theorems, University Paris 1 Paris, January
Asymptotic results for empirical measures of weighted sums of independent random variables B. Bercu and W. Bryc University Bordeaux 1, France Workshop on Limit Theorems, University Paris 1 Paris, January
Persistent homology and nonparametric regression
 Cleveland State University March 10, 2009, BIRS: Data Analysis using Computational Topology and Geometric Statistics joint work with Gunnar Carlsson (Stanford), Moo Chung (Wisconsin Madison), Peter Kim
Cleveland State University March 10, 2009, BIRS: Data Analysis using Computational Topology and Geometric Statistics joint work with Gunnar Carlsson (Stanford), Moo Chung (Wisconsin Madison), Peter Kim
Nonparametric estimation under Shape Restrictions
 Nonparametric estimation under Shape Restrictions Jon A. Wellner University of Washington, Seattle Statistical Seminar, Frejus, France August 30 - September 3, 2010 Outline: Five Lectures on Shape Restrictions
Nonparametric estimation under Shape Restrictions Jon A. Wellner University of Washington, Seattle Statistical Seminar, Frejus, France August 30 - September 3, 2010 Outline: Five Lectures on Shape Restrictions
Stat410 Probability and Statistics II (F16)
") Stat4 Probability and Statistics II (F6 Exponential, Poisson and Gamma Suppose on average every /λ hours, a Stochastic train arrives at the Random station. Further we assume the waiting time between two
Stat4 Probability and Statistics II (F6 Exponential, Poisson and Gamma Suppose on average every /λ hours, a Stochastic train arrives at the Random station. Further we assume the waiting time between two
Statistical Estimation: Data & Non-data Information
 Statistical Estimation: Data & Non-data Information Roger J-B Wets University of California, Davis & M.Casey @ Raytheon G.Pflug @ U. Vienna, X. Dong @ EpiRisk, G-M You @ EpiRisk. a little background Decision
Statistical Estimation: Data & Non-data Information Roger J-B Wets University of California, Davis & M.Casey @ Raytheon G.Pflug @ U. Vienna, X. Dong @ EpiRisk, G-M You @ EpiRisk. a little background Decision
An Introduction to Expectation-Maximization
 An Introduction to Expectation-Maximization Dahua Lin Abstract This notes reviews the basics about the Expectation-Maximization EM) algorithm, a popular approach to perform model estimation of the generative
An Introduction to Expectation-Maximization Dahua Lin Abstract This notes reviews the basics about the Expectation-Maximization EM) algorithm, a popular approach to perform model estimation of the generative
Lecture 1: Derivatives
 Lecture 1: Derivatives Steven Hurder University of Illinois at Chicago www.math.uic.edu/ hurder/talks/ Steven Hurder (UIC) Dynamics of Foliations May 3, 2010 1 / 19 Some basic examples Many talks on with
Lecture 1: Derivatives Steven Hurder University of Illinois at Chicago www.math.uic.edu/ hurder/talks/ Steven Hurder (UIC) Dynamics of Foliations May 3, 2010 1 / 19 Some basic examples Many talks on with
Information Theory. David Rosenberg. June 15, New York University. David Rosenberg (New York University) DS-GA 1003 June 15, / 18
 DS-GA 1003 June 15, / 18") Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
G8325: Variational Bayes
 G8325: Variational Bayes Vincent Dorie Columbia University Wednesday, November 2nd, 2011 bridge Variational University Bayes Press 2003. On-screen viewing permitted. Printing not permitted. http://www.c
G8325: Variational Bayes Vincent Dorie Columbia University Wednesday, November 2nd, 2011 bridge Variational University Bayes Press 2003. On-screen viewing permitted. Printing not permitted. http://www.c
Nonparametric estimation of. s concave and log-concave densities: alternatives to maximum likelihood
 Nonparametric estimation of s concave and log-concave densities: alternatives to maximum likelihood Jon A. Wellner University of Washington, Seattle Cowles Foundation Seminar, Yale University November
Nonparametric estimation of s concave and log-concave densities: alternatives to maximum likelihood Jon A. Wellner University of Washington, Seattle Cowles Foundation Seminar, Yale University November
Lecture 1: Derivatives
 Lecture 1: Derivatives Steven Hurder University of Illinois at Chicago www.math.uic.edu/ hurder/talks/ Steven Hurder (UIC) Dynamics of Foliations May 3, 2010 1 / 19 Some basic examples Many talks on with
Lecture 1: Derivatives Steven Hurder University of Illinois at Chicago www.math.uic.edu/ hurder/talks/ Steven Hurder (UIC) Dynamics of Foliations May 3, 2010 1 / 19 Some basic examples Many talks on with
Generative Models and Optimal Transport
 Generative Models and Optimal Transport Marco Cuturi Joint work / work in progress with G. Peyré, A. Genevay (ENS), F. Bach (INRIA), G. Montavon, K-R Müller (TU Berlin) Statistics 0.1 : Density Fitting
Generative Models and Optimal Transport Marco Cuturi Joint work / work in progress with G. Peyré, A. Genevay (ENS), F. Bach (INRIA), G. Montavon, K-R Müller (TU Berlin) Statistics 0.1 : Density Fitting
Semi-Parametric Importance Sampling for Rare-event probability Estimation
 Semi-Parametric Importance Sampling for Rare-event probability Estimation Z. I. Botev and P. L Ecuyer IMACS Seminar 2011 Borovets, Bulgaria Semi-Parametric Importance Sampling for Rare-event probability
Semi-Parametric Importance Sampling for Rare-event probability Estimation Z. I. Botev and P. L Ecuyer IMACS Seminar 2011 Borovets, Bulgaria Semi-Parametric Importance Sampling for Rare-event probability
Inference. Data. Model. Variates
 Data Inference Variates Model ˆθ (,..., ) mˆθn(d) m θ2 M m θ1 (,, ) (,,, ) (,, ) α = :=: (, ) F( ) = = {(, ),, } F( ) X( ) = Γ( ) = Σ = ( ) = ( ) ( ) = { = } :=: (U, ) , = { = } = { = } x 2 e i, e j
Data Inference Variates Model ˆθ (,..., ) mˆθn(d) m θ2 M m θ1 (,, ) (,,, ) (,, ) α = :=: (, ) F( ) = = {(, ),, } F( ) X( ) = Γ( ) = Σ = ( ) = ( ) ( ) = { = } :=: (U, ) , = { = } = { = } x 2 e i, e j
Nonparametric estimation under Shape Restrictions
 Nonparametric estimation under Shape Restrictions Jon A. Wellner University of Washington, Seattle Statistical Seminar, Frejus, France August 30 - September 3, 2010 Outline: Five Lectures on Shape Restrictions
Nonparametric estimation under Shape Restrictions Jon A. Wellner University of Washington, Seattle Statistical Seminar, Frejus, France August 30 - September 3, 2010 Outline: Five Lectures on Shape Restrictions
Asymptotics for posterior hazards
 Asymptotics for posterior hazards Pierpaolo De Blasi University of Turin 10th August 2007, BNR Workshop, Isaac Newton Intitute, Cambridge, UK Joint work with Giovanni Peccati (Université Paris VI) and
Asymptotics for posterior hazards Pierpaolo De Blasi University of Turin 10th August 2007, BNR Workshop, Isaac Newton Intitute, Cambridge, UK Joint work with Giovanni Peccati (Université Paris VI) and
June 21, Peking University. Dual Connections. Zhengchao Wan. Overview. Duality of connections. Divergence: general contrast functions
 Dual Peking University June 21, 2016 Divergences: Riemannian connection Let M be a manifold on which there is given a Riemannian metric g =,. A connection satisfying Z X, Y = Z X, Y + X, Z Y (1) for all
Dual Peking University June 21, 2016 Divergences: Riemannian connection Let M be a manifold on which there is given a Riemannian metric g =,. A connection satisfying Z X, Y = Z X, Y + X, Z Y (1) for all
Legendre-Fenchel transforms in a nutshell
 1 2 3 Legendre-Fenchel transforms in a nutshell Hugo Touchette School of Mathematical Sciences, Queen Mary, University of London, London E1 4NS, UK Started: July 11, 2005; last compiled: October 16, 2014
1 2 3 Legendre-Fenchel transforms in a nutshell Hugo Touchette School of Mathematical Sciences, Queen Mary, University of London, London E1 4NS, UK Started: July 11, 2005; last compiled: October 16, 2014
6.1 Variational representation of f-divergences
 ECE598: Information-theoretic methods in high-dimensional statistics Spring 2016 Lecture 6: Variational representation, HCR and CR lower bounds Lecturer: Yihong Wu Scribe: Georgios Rovatsos, Feb 11, 2016
ECE598: Information-theoretic methods in high-dimensional statistics Spring 2016 Lecture 6: Variational representation, HCR and CR lower bounds Lecturer: Yihong Wu Scribe: Georgios Rovatsos, Feb 11, 2016
Series 7, May 22, 2018 (EM Convergence)
") Exercises Introduction to Machine Learning SS 2018 Series 7, May 22, 2018 (EM Convergence) Institute for Machine Learning Dept. of Computer Science, ETH Zürich Prof. Dr. Andreas Krause Web: https://las.inf.ethz.ch/teaching/introml-s18
Exercises Introduction to Machine Learning SS 2018 Series 7, May 22, 2018 (EM Convergence) Institute for Machine Learning Dept. of Computer Science, ETH Zürich Prof. Dr. Andreas Krause Web: https://las.inf.ethz.ch/teaching/introml-s18
Mean-field equations for higher-order quantum statistical models : an information geometric approach
 Mean-field equations for higher-order quantum statistical models : an information geometric approach N Yapage Department of Mathematics University of Ruhuna, Matara Sri Lanka. arxiv:1202.5726v1 [quant-ph]
Mean-field equations for higher-order quantum statistical models : an information geometric approach N Yapage Department of Mathematics University of Ruhuna, Matara Sri Lanka. arxiv:1202.5726v1 [quant-ph]
Legendre-Fenchel transforms in a nutshell
 1 2 3 Legendre-Fenchel transforms in a nutshell Hugo Touchette School of Mathematical Sciences, Queen Mary, University of London, London E1 4NS, UK Started: July 11, 2005; last compiled: August 14, 2007
1 2 3 Legendre-Fenchel transforms in a nutshell Hugo Touchette School of Mathematical Sciences, Queen Mary, University of London, London E1 4NS, UK Started: July 11, 2005; last compiled: August 14, 2007
SUBTANGENT-LIKE STATISTICAL MANIFOLDS. 1. Introduction
 SUBTANGENT-LIKE STATISTICAL MANIFOLDS A. M. BLAGA Abstract. Subtangent-like statistical manifolds are introduced and characterization theorems for them are given. The special case when the conjugate connections
SUBTANGENT-LIKE STATISTICAL MANIFOLDS A. M. BLAGA Abstract. Subtangent-like statistical manifolds are introduced and characterization theorems for them are given. The special case when the conjugate connections
Decentralized decision making with spatially distributed data
 Decentralized decision making with spatially distributed data XuanLong Nguyen Department of Statistics University of Michigan Acknowledgement: Michael Jordan, Martin Wainwright, Ram Rajagopal, Pravin Varaiya
Decentralized decision making with spatially distributed data XuanLong Nguyen Department of Statistics University of Michigan Acknowledgement: Michael Jordan, Martin Wainwright, Ram Rajagopal, Pravin Varaiya
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Geometry and Optimization of Relative Arbitrage
 Geometry and Optimization of Relative Arbitrage Ting-Kam Leonard Wong joint work with Soumik Pal Department of Mathematics, University of Washington Financial/Actuarial Mathematic Seminar, University of
Geometry and Optimization of Relative Arbitrage Ting-Kam Leonard Wong joint work with Soumik Pal Department of Mathematics, University of Washington Financial/Actuarial Mathematic Seminar, University of
Scalable Hash-Based Estimation of Divergence Measures
 Scalable Hash-Based Estimation of Divergence easures orteza oshad and Alfred O. Hero III Electrical Engineering and Computer Science University of ichigan Ann Arbor, I 4805, USA {noshad,hero} @umich.edu
Scalable Hash-Based Estimation of Divergence easures orteza oshad and Alfred O. Hero III Electrical Engineering and Computer Science University of ichigan Ann Arbor, I 4805, USA {noshad,hero} @umich.edu
Robust Independent Component Analysis via Minimum -Divergence Estimation
 614 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 7, NO. 4, AUGUST 2013 Robust Independent Component Analysis via Minimum -Divergence Estimation Pengwen Chen, Hung Hung, Osamu Komori, Su-Yun
614 IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, VOL. 7, NO. 4, AUGUST 2013 Robust Independent Component Analysis via Minimum -Divergence Estimation Pengwen Chen, Hung Hung, Osamu Komori, Su-Yun
Strong Converse and Stein s Lemma in the Quantum Hypothesis Testing
 Strong Converse and Stein s Lemma in the Quantum Hypothesis Testing arxiv:uant-ph/9906090 v 24 Jun 999 Tomohiro Ogawa and Hiroshi Nagaoka Abstract The hypothesis testing problem of two uantum states is
Strong Converse and Stein s Lemma in the Quantum Hypothesis Testing arxiv:uant-ph/9906090 v 24 Jun 999 Tomohiro Ogawa and Hiroshi Nagaoka Abstract The hypothesis testing problem of two uantum states is