Supplementary Material for Asynchronous Methods for Deep Reinforcement Learning
|
|
|
- Cleopatra Flowers
- 6 years ago
- Views:
Transcription
1 Supplementary Material for Asynchronous Methods for Deep Reinforcement Learning May 2, Optimization Details We investigated two different optimization algorithms with our asynchronous framework stochastic gradient descent and RMSProp. Our implementations of these algorithms do not use any locking in order to maximize throughput when using a large number of threads. Momentum SGD: The implementation of SGD in an asynchronous setting is relatively straightforward and well studied [Recht et al., 211]. Let θ be the parameter vector that is shared across all threads and let θ i be the accumulated gradients of the loss with respect to parameters θ computed by thread number i. Each thread i independently applies the standard momentum SGD update m i = αm i + (1 α) θ i followed by θ θ ηm i with learning rate η, momentum α and without any locks. Note that in this setting, each thread maintains its own separate gradient and momentum vector. RMSProp: While RMSProp [Tieleman and Hinton, 212] has been widely used in the deep learning literature, it has not been extensively studied in the asynchronous optimization setting. The standard noncentered RMSProp update is given by g = αg + (1 α) θ 2 θ θ η θ, g + ɛ (S1) (S2) where all operations are performed elementwise. In order to apply RMSProp in the asynchronous optimization setting one must decide whether the moving average of elementwise squared gradients g is shared or per-thread. We experimented with two versions of the algorithm. In one version, which we refer to as RM- SProp, each thread maintains its own g shown in Equation S1. In the other version, which we call Shared RMSProp, the vector g is shared among threads and is updated asynchronously and without locking. Sharing statistics among threads also reduces memory requirements by using one fewer copy of the parameter vector per thread. We compared these three asynchronous optimization algorithms in terms of their sensitivity to different learning rates and random network initializations. Figure S1 shows a comparison of the methods for two different reinforcement learning methods (Async n-step Q and Async Advantage Actor-Critic) on four different games (Breakout, Beamrider, Seaquest and Space Invaders). Each curve shows the scores for experiments that correspond to different random learning rates and initializations. The x-axis shows the rank of the model after sorting in descending order by final average score and the y-axis shows the final average score achieved by the corresponding model. In this representation, the algorithm that performs better would achieve higher maximum rewards on the y-axis and the algorithm that is most robust would have its slope closest to horizontal, thus maximizing the area under the curve. RMSProp with shared statistics tends to be more robust than RMSProp with per-thread statistics, which is in turn more robust than Momentum SGD. 1
2 2 Experimental Setup The experiments performed on a subset of Atari games (Figures 1, 3, 4 and Table 2) as well as the TORCS experiments (Figure S2) used the following setup. Each experiment used 16 actor-learner threads running on a single machine and no GPUs. All methods performed updates after every actions (t max = and I Update = ) and shared RMSProp was used for optimization. The three asynchronous value-based methods used a shared target network that was updated every 4 frames. The Atari experiments used the same input preprocessing as Mnih et al. [21] and an action repeat of 4. The agents used the network architecture from Mnih et al. [213]. The network used a convolutional layer with 16 filters of size 8 8 with stride 4, followed by a convolutional layer with with 32 filters of size 4 4 with stride 2, followed by a fully connected layer with 26 hidden units. All three hidden layers were followed by a rectifier nonlinearity. The value-based methods had a single linear output unit for each action representing the action-value. The model used by actor-critic agents had two set of outputs a softmax output with one entry per action representing the probability of selecting the action, and a single linear output representing the value function. All experiments used a discount of γ =.99 and an RMSProp decay factor of α =.99. The value based methods sampled the exploration rate ɛ from a distribution taking three values ɛ 1, ɛ 2, ɛ 3 with probabilities.4,.3,.3. The values of ɛ 1, ɛ 2, ɛ 3 were annealed from 1 to.1,.1,. respectively over the first four million frames. Advantage actor-critic used entropy regularization with a weight β =.1 for all Atari and TORCS experiments. We performed a set of experiments for five Atari games and every TORCS level, each using a different random initialization and initial learning rate. The initial learning rate was sampled from a LogUniform(1 4, 1 2 ) distribution and annealed to over the course of training. Note that in comparisons to prior work (Tables 1 and S1) we followed standard evaluation protocol and used fixed hyperparameters. 3 Continuous Action Control Using the MuJoCo Physics Simulator To apply the asynchronous advantage actor-critic algorithm to the Mujoco tasks the necessary setup is nearly identical to that used in the discrete action domains, so here we enumerate only the differences required for the continuous action domains. The essential elements for many of the tasks (i.e. the physics models and task objectives) are near identical to the tasks examined in [Lillicrap et al., 21]. However, the rewards and thus performance are not comparable for most of the tasks due to changes made by the developers of Mujoco which altered the contact model. For all the domains we attempted to learn the task using the physical state as input. The physical state consisted of the joint positions and velocities as well as the target position if the task required a target. In addition, for three of the tasks (pendulum, pointmass2d, and gripper) we also examined training directly from RGB pixel inputs. In the low dimensional physical state case, the inputs are mapped to a hidden state using one hidden layer with 2 ReLU units. In the cases where we used pixels, the input was passed through two layers of spatial convolutions without any non-linearity or pooling. In either case, the output of the encoder layers were fed to a single layer of 128 LSTM cells. The most important difference in the architecture is in the the output layer of the policy network. Unlike the discrete action domain where the action output is a Softmax, here the two outputs of the policy network are two real number vectors which we treat as the mean vector µ and scalar variance σ 2 of a multidimensional normal distribution with a spherical covariance. To act, the input is passed through the model to the output layer where we sample from the normal distribution determined by µ and σ 2. In practice, µ is modeled by a linear layer and σ 2 by a SoftPlus operation, log(1 + exp(x)), as the activation computed as a function of the output of a linear layer. In our experiments with continuous control problems the networks for policy network and value network do not share any parameters, though this detail is unlikely to be crucial. Finally, since the episodes were typically at most several hundred time steps long, we did not use any bootstrapping in the policy or value function updates and batched each episode into a single update. As in the discrete action case, we included an entropy cost which encouraged exploration. In the continu- 2
3 ous case the we used a cost on the differential entropy of the normal distribution defined by the output of the actor network, 1 2 (log(2πσ2 ) + 1), we used a constant multiplier of 1 4 for this cost across all of the tasks examined. The asynchronous advantage actor-critic algorithm finds solutions for all the domains. Figure S4 shows learning curves against wall-clock time, and demonstrates that most of the domains from states can be solved within a few hours. All of the experiments, including those done from pixel based observations, were run on CPU. Even in the case of solving the domains directly from pixel inputs we found that it was possible to reliably discover solutions within 24 hours. Figure S3 shows scatter plots of the top scores against the sampled learning rates. In most of the domains there is large range of learning rates that consistently achieve good performance on the task. Algorithm S1 Asynchronous n-step Q-learning - pseudocode for each actor-learner thread. // Assume global shared parameter vector θ. // Assume global shared target parameter vector θ. // Assume global shared counter T =. Initialize thread step counter t 1 Initialize target network parameters θ θ Initialize thread-specific parameters θ = θ Initialize network gradients dθ repeat Clear gradients dθ Synchronize thread-specific parameters θ = θ t start = t Get state s t repeat Take action a t according to the ɛ-greedy policy based on Q(s t, a; θ ) Receive reward r t and new state s t+1 t t + 1 T T + 1 until { terminal s t or t t start == t max for terminal st R = max a Q(s t, a; θ ) for non-terminal s t for i {t 1,..., t start} do R r i + γr Accumulate gradients wrt θ : dθ dθ + (R Q(s i,a i ;θ )) 2 θ end for Perform asynchronous update of θ using dθ. if T mod I target == then θ θ end if until T > T max 3
4 Algorithm S2 Asynchronous advantage actor-critic - pseudocode for each actor-learner thread. // Assume global shared parameter vectors θ and θ v and global shared counter T = // Assume thread-specific parameter vectors θ and θ v Initialize thread step counter t 1 repeat Reset gradients: dθ and dθ v. Synchronize thread-specific parameters θ = θ and θ v = θ v t start = t Get state s t repeat Perform a t according to policy π(a t s t; θ ) Receive reward r t and new state s t+1 t t + 1 T T + 1 until { terminal s t or t t start == t max for terminal st R = V (s t, θ v) for non-terminal s t// Bootstrap from last state for i {t 1,..., t start} do R r i + γr Accumulate gradients wrt θ : dθ dθ + θ log π(a i s i; θ )(R V (s i; θ v)) Accumulate gradients wrt θ v: dθ v dθ v + (R V (s i; θ v)) 2 / θ v end for Perform asynchronous update of θ using dθ and of θ v using dθ v. until T > T max 4
5 4 3 3 Breakout n-step Q, SGD n-step Q, RMSProp n-step Q, Shared RMSProp 2 2 Beamrider n-step Q, SGD n-step Q, RMSProp n-step Q, Shared RMSProp 6 Seaquest n-step Q, SGD n-step Q, RMSProp n-step Q, Shared RMSProp Space Invaders n-step Q, SGD n-step Q, RMSProp n-step Q, Shared RMSProp Breakout A3C, SGD A3C, RMSProp A3C, Shared RMSProp 2 2 Beamrider A3C, SGD A3C, RMSProp A3C, Shared RMSProp Seaquest A3C, SGD A3C, RMSProp A3C, Shared RMSProp Space Invaders A3C, SGD A3C, RMSProp A3C, Shared RMSProp Figure S1: Comparison of three different optimization methods (Momentum SGD, RMSProp, Shared RM- SProp) tested using two different algorithms (Async n-step Q and Async Advantage Actor-Critic) on four different Atari games (Breakout, Beamrider, Seaquest and Space Invaders). Each curve shows the final scores for experiments sorted in descending order that covers a search over random initializations and learning rates. The top row shows results using Async n-step Q algorithm and bottom row shows results with Async Advantage Actor-Critic. Each individual graph shows results for one of the four games and three different optimization methods. Shared RMSProp tends to be more robust to different learning rates and random initializations than Momentum SGD and RMSProp without sharing. Slow car, no bots Slow car, bots Async 1-step Q Async SARSA Async n-step Q Async actor-critic Human tester Async 1-step Q Async SARSA Async n-step Q Async actor-critic Human tester Fast car, no bots 6 Fast car, bots Async 1-step Q Async SARSA Async n-step Q Async actor-critic Human tester Async 1-step Q Async SARSA Async n-step Q Async actor-critic Human tester Figure S2: Comparison of algorithms on the TORCS car racing simulator. Four different configurations of car speed and opponent presence or absence are shown. In each plot, all four algorithms (one-step Q, one-step Sarsa, n-step Q and Advantage Actor-Critic) are compared on score vs training time in wall clock hours. Multi-step algorithms achieve better policies much faster than one-step algorithms on all four levels. The curves show averages over the best runs from experiments with learning rates sampled from LogUniform(1 4, 1 2 ) and all other hyperparameters fixed.









6 Figure S3: Performance for the Mujoco continuous action domains. Scatter plot of the best score obtained against learning rates sampled from LogUniform(1, 1 1 ). For nearly all of the tasks there is a wide range of learning rates that lead to good performance on the task. 6









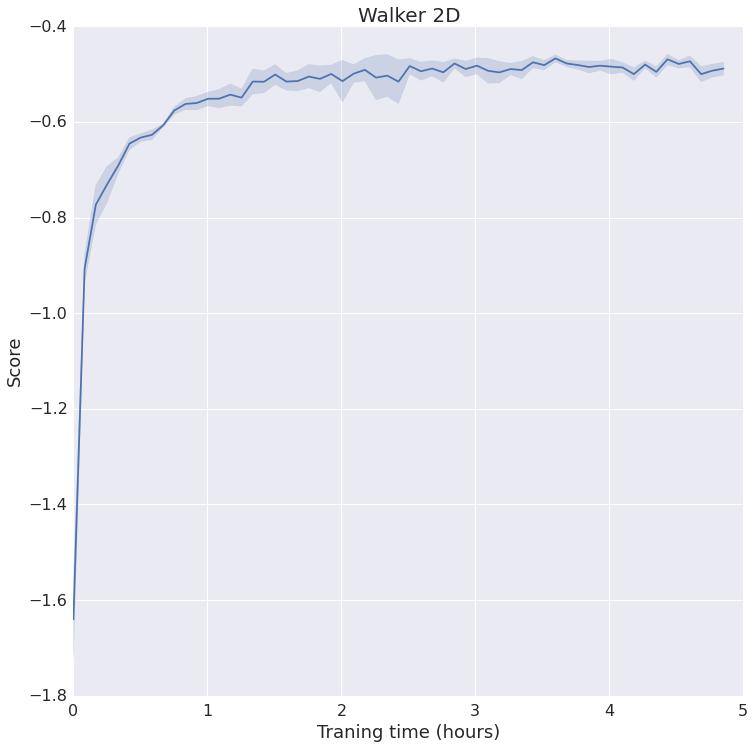




7 Figure S4: per episode vs wall-clock time plots for the Mujoco domains. Each plot shows error bars for the top experiments. 7

8 Beamrider Training epochs Breakout Training epochs Pong Training epochs Q*bert Training epochs Space Invaders Training epochs Figure S: Data efficiency comparison of different numbers of actor-learners one-step Sarsa on five Atari games. The x-axis shows the total number of training epochs where an epoch corresponds to four million frames (across all threads). The y-axis shows the average score. Each curve shows the average of the three best performing agents from a search over random learning rates. Sarsa shows increased data efficiency with increased numbers of parallel workers Beamrider Breakout Pong Q*bert Space Invaders Figure S6: Training speed comparison of different numbers of actor-learners for all one-step Sarsa on five Atari games. The x-axis shows training time in hours while the y-axis shows the average score. Each curve shows the average of the three best performing agents from a search over random learning rates. Sarsa shows significant speedups from using greater numbers of parallel actor-learners step SARSA, Beamrider 4 1-step SARSA, Breakout 2 1-step SARSA, Pong 1-step SARSA, Q*bert 9 1-step SARSA, Space Invaders n-step Q, Beamrider 4 n-step Q, Breakout 3 n-step Q, Pong n-step Q, Q*bert 1 n-step Q, Space Invaders Figure S7: Scatter plots of scores obtained by one-step Q, one-step Sarsa, and n-step Q on five games (Beamrider, Breakout, Pong, Q*bert, Space Invaders) for different learning rates and random initializations. All algorithms exhibit some level of robustness to the choice of learning rate. 8
9 Game DQN Gorila Double Dueling Prioritized A3C FF, 1 day A3C FF A3C LSTM Alien Amidar Assault Asterix Asteroids Atlantis Bank Heist Battle Zone Beam Rider Berzerk Bowling Boxing Breakout Centipede Chopper Comman Crazy Climber Defender Demon Attack Double Dunk Enduro Fishing Derby Freeway Frostbite Gopher Gravitar H.E.R.O Ice Hockey James Bond Kangaroo Krull Kung-Fu Master Montezuma s Revenge Ms. Pacman Name This Game Phoenix Pit Fall Pong Private Eye Q*Bert River Raid Road Runner Robotank Seaquest Skiing Solaris Space Invaders Star Gunner Surround Tennis Time Pilot Tutankham Up and Down Venture Video Pinball Wizard of Wor Yars Revenge Zaxxon Table S1: Raw scores for the human start condition (3 minutes emulator time). DQN scores taken from Nair et al. [21]. Double DQN scores taken from Van Hasselt et al. [21], Dueling scores from Wang et al. [21] and Prioritized scores taken from Schaul et al. [21] 9
10 References Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. arxiv preprint arxiv: , 21. Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. In NIPS Deep Learning Workshop Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement learning. Nature, 18(74):29 33, URL Arun Nair, Praveen Srinivasan, Sam Blackwell, Cagdas Alcicek, Rory Fearon, Alessandro De Maria, Vedavyas Panneershelvam, Mustafa Suleyman, Charles Beattie, Stig Petersen, Shane Legg, Volodymyr Mnih, Koray Kavukcuoglu, and David Silver. Massively parallel methods for deep reinforcement learning. In ICML Deep Learning Workshop. 21. Benjamin Recht, Christopher Re, Stephen Wright, and Feng Niu. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in Neural Information Processing Systems, pages , 211. Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. arxiv preprint arxiv:111.92, 21. Tijmen Tieleman and Geoffrey Hinton. Lecture 6.-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 4, 212. Hado Van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. arxiv preprint arxiv: , 21. Z. Wang, N. de Freitas, and M. Lanctot. Dueling Network Architectures for Deep Reinforcement Learning. ArXiv e-prints, November 21. 1
Reinforcement Learning. Odelia Schwartz 2016
 Reinforcement Learning Odelia Schwartz 2016 Forms of learning? Forms of learning Unsupervised learning Supervised learning Reinforcement learning Forms of learning Unsupervised learning Supervised learning
Reinforcement Learning Odelia Schwartz 2016 Forms of learning? Forms of learning Unsupervised learning Supervised learning Reinforcement learning Forms of learning Unsupervised learning Supervised learning
Deep Q-Learning with Recurrent Neural Networks
 Deep Q-Learning with Recurrent Neural Networks Clare Chen cchen9@stanford.edu Vincent Ying vincenthying@stanford.edu Dillon Laird dalaird@cs.stanford.edu Abstract Deep reinforcement learning models have
Deep Q-Learning with Recurrent Neural Networks Clare Chen cchen9@stanford.edu Vincent Ying vincenthying@stanford.edu Dillon Laird dalaird@cs.stanford.edu Abstract Deep reinforcement learning models have
Deep reinforcement learning. Dialogue Systems Group, Cambridge University Engineering Department
 Deep reinforcement learning Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 25 In this lecture... Introduction to deep reinforcement learning Value-based Deep RL Deep
Deep reinforcement learning Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department 1 / 25 In this lecture... Introduction to deep reinforcement learning Value-based Deep RL Deep
SAMPLE-EFFICIENT DEEP REINFORCEMENT LEARN-
 SAMPLE-EFFICIENT DEEP REINFORCEMENT LEARN- ING VIA EPISODIC BACKWARD UPDATE Anonymous authors Paper under double-blind review ABSTRACT We propose Episodic Backward Update - a new algorithm to boost the
SAMPLE-EFFICIENT DEEP REINFORCEMENT LEARN- ING VIA EPISODIC BACKWARD UPDATE Anonymous authors Paper under double-blind review ABSTRACT We propose Episodic Backward Update - a new algorithm to boost the
Natural Value Approximators: Learning when to Trust Past Estimates
 Natural Value Approximators: Learning when to Trust Past Estimates Zhongwen Xu zhongwen@google.com Joseph Modayil modayil@google.com Hado van Hasselt hado@google.com Andre Barreto andrebarreto@google.com
Natural Value Approximators: Learning when to Trust Past Estimates Zhongwen Xu zhongwen@google.com Joseph Modayil modayil@google.com Hado van Hasselt hado@google.com Andre Barreto andrebarreto@google.com
arxiv: v1 [cs.lg] 5 Dec 2015
![arxiv: v1 [cs.lg] 5 Dec 2015](/thumbs/82/85482236.jpg "arxiv: v1 [cs.lg] 5 Dec 2015") Deep Attention Recurrent Q-Network Ivan Sorokin, Alexey Seleznev, Mikhail Pavlov, Aleksandr Fedorov, Anastasiia Ignateva 5vision 5visionteam@gmail.com arxiv:1512.1693v1 [cs.lg] 5 Dec 215 Abstract A deep
Deep Attention Recurrent Q-Network Ivan Sorokin, Alexey Seleznev, Mikhail Pavlov, Aleksandr Fedorov, Anastasiia Ignateva 5vision 5visionteam@gmail.com arxiv:1512.1693v1 [cs.lg] 5 Dec 215 Abstract A deep
arxiv: v1 [cs.ne] 4 Dec 2015
![arxiv: v1 [cs.ne] 4 Dec 2015](/thumbs/74/70189552.jpg "arxiv: v1 [cs.ne] 4 Dec 2015") Q-Networks for Binary Vector Actions arxiv:1512.01332v1 [cs.ne] 4 Dec 2015 Naoto Yoshida Tohoku University Aramaki Aza Aoba 6-6-01 Sendai 980-8579, Miyagi, Japan naotoyoshida@pfsl.mech.tohoku.ac.jp Abstract
Q-Networks for Binary Vector Actions arxiv:1512.01332v1 [cs.ne] 4 Dec 2015 Naoto Yoshida Tohoku University Aramaki Aza Aoba 6-6-01 Sendai 980-8579, Miyagi, Japan naotoyoshida@pfsl.mech.tohoku.ac.jp Abstract
Multiagent (Deep) Reinforcement Learning
 Reinforcement Learning") Multiagent (Deep) Reinforcement Learning MARTIN PILÁT (MARTIN.PILAT@MFF.CUNI.CZ) Reinforcement learning The agent needs to learn to perform tasks in environment No prior knowledge about the effects of
Multiagent (Deep) Reinforcement Learning MARTIN PILÁT (MARTIN.PILAT@MFF.CUNI.CZ) Reinforcement learning The agent needs to learn to perform tasks in environment No prior knowledge about the effects of
Policy Gradient Methods. February 13, 2017
 Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Supplementary Material: Control of Memory, Active Perception, and Action in Minecraft
 Supplementary Material: Control of Memory, Active Perception, and Action in Minecraft Junhyuk Oh Valliappa Chockalingam Satinder Singh Honglak Lee Computer Science & Engineering, University of Michigan
Supplementary Material: Control of Memory, Active Perception, and Action in Minecraft Junhyuk Oh Valliappa Chockalingam Satinder Singh Honglak Lee Computer Science & Engineering, University of Michigan
Count-Based Exploration in Feature Space for Reinforcement Learning
 Count-Based Exploration in Feature Space for Reinforcement Learning Jarryd Martin, Suraj Narayanan S., Tom Everitt, Marcus Hutter Research School of Computer Science, Australian National University, Canberra
Count-Based Exploration in Feature Space for Reinforcement Learning Jarryd Martin, Suraj Narayanan S., Tom Everitt, Marcus Hutter Research School of Computer Science, Australian National University, Canberra
COMBINING POLICY GRADIENT AND Q-LEARNING
 COMBINING POLICY GRADIENT AND Q-LEARNING Brendan O Donoghue, Rémi Munos, Koray Kavukcuoglu & Volodymyr Mnih Deepmind {bodonoghue,munos,korayk,vmnih}@google.com ABSTRACT Policy gradient is an efficient
COMBINING POLICY GRADIENT AND Q-LEARNING Brendan O Donoghue, Rémi Munos, Koray Kavukcuoglu & Volodymyr Mnih Deepmind {bodonoghue,munos,korayk,vmnih}@google.com ABSTRACT Policy gradient is an efficient
Driving a car with low dimensional input features
 December 2016 Driving a car with low dimensional input features Jean-Claude Manoli jcma@stanford.edu Abstract The aim of this project is to train a Deep Q-Network to drive a car on a race track using only
December 2016 Driving a car with low dimensional input features Jean-Claude Manoli jcma@stanford.edu Abstract The aim of this project is to train a Deep Q-Network to drive a car on a race track using only
Proximal Policy Optimization Algorithms
 Proximal Policy Optimization Algorithms John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov OpenAI {joschu, filip, prafulla, alec, oleg}@openai.com arxiv:177.6347v2 [cs.lg] 28 Aug
Proximal Policy Optimization Algorithms John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov OpenAI {joschu, filip, prafulla, alec, oleg}@openai.com arxiv:177.6347v2 [cs.lg] 28 Aug
Reinforcement. Function Approximation. Learning with KATJA HOFMANN. Researcher, MSR Cambridge
 Reinforcement Learning with Function Approximation KATJA HOFMANN Researcher, MSR Cambridge Representation and Generalization in RL Focus on training stability Learning generalizable value functions Navigating
Reinforcement Learning with Function Approximation KATJA HOFMANN Researcher, MSR Cambridge Representation and Generalization in RL Focus on training stability Learning generalizable value functions Navigating
arxiv: v3 [cs.ai] 19 Jun 2018
![arxiv: v3 [cs.ai] 19 Jun 2018](/thumbs/83/87162495.jpg "arxiv: v3 [cs.ai] 19 Jun 2018") Brendan O Donoghue 1 Ian Osband 1 Remi Munos 1 Volodymyr Mnih 1 arxiv:1709.05380v3 [cs.ai] 19 Jun 2018 Abstract We consider the exploration/exploitation problem in reinforcement learning. For exploitation,
Brendan O Donoghue 1 Ian Osband 1 Remi Munos 1 Volodymyr Mnih 1 arxiv:1709.05380v3 [cs.ai] 19 Jun 2018 Abstract We consider the exploration/exploitation problem in reinforcement learning. For exploitation,
Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control
 Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control Shangtong Zhang Dept. of Computing Science University of Alberta shangtong.zhang@ualberta.ca Osmar R. Zaiane Dept. of
Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control Shangtong Zhang Dept. of Computing Science University of Alberta shangtong.zhang@ualberta.ca Osmar R. Zaiane Dept. of
arxiv: v1 [cs.lg] 30 Jun 2017
![arxiv: v1 [cs.lg] 30 Jun 2017](/thumbs/93/112527827.jpg "arxiv: v1 [cs.lg] 30 Jun 2017") Noisy Networks for Exploration arxiv:176.129v1 [cs.lg] 3 Jun 217 Meire Fortunato Mohammad Gheshlaghi Azar Bilal Piot Jacob Menick Ian Osband Alex Graves Vlad Mnih Remi Munos Demis Hassabis Olivier Pietquin
Noisy Networks for Exploration arxiv:176.129v1 [cs.lg] 3 Jun 217 Meire Fortunato Mohammad Gheshlaghi Azar Bilal Piot Jacob Menick Ian Osband Alex Graves Vlad Mnih Remi Munos Demis Hassabis Olivier Pietquin
Reinforcement Learning
 Reinforcement Learning From the basics to Deep RL Olivier Sigaud ISIR, UPMC + INRIA http://people.isir.upmc.fr/sigaud September 14, 2017 1 / 54 Introduction Outline Some quick background about discrete
Reinforcement Learning From the basics to Deep RL Olivier Sigaud ISIR, UPMC + INRIA http://people.isir.upmc.fr/sigaud September 14, 2017 1 / 54 Introduction Outline Some quick background about discrete
Weighted Double Q-learning
 Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-7) Weighted Double Q-learning Zongzhang Zhang Soochow University Suzhou, Jiangsu 56 China zzzhang@suda.edu.cn
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-7) Weighted Double Q-learning Zongzhang Zhang Soochow University Suzhou, Jiangsu 56 China zzzhang@suda.edu.cn
arxiv: v4 [cs.ai] 10 Mar 2017
![arxiv: v4 [cs.ai] 10 Mar 2017](/thumbs/78/78516979.jpg "arxiv: v4 [cs.ai] 10 Mar 2017") Averaged-DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning Oron Anschel 1 Nir Baram 1 Nahum Shimkin 1 arxiv:1611.1929v4 [cs.ai] 1 Mar 217 Abstract Instability and variability of
Averaged-DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning Oron Anschel 1 Nir Baram 1 Nahum Shimkin 1 arxiv:1611.1929v4 [cs.ai] 1 Mar 217 Abstract Instability and variability of
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
The Predictron: End-To-End Learning and Planning
 David Silver * 1 Hado van Hasselt * 1 Matteo Hessel * 1 Tom Schaul * 1 Arthur Guez * 1 Tim Harley 1 Gabriel Dulac-Arnold 1 David Reichert 1 Neil Rabinowitz 1 Andre Barreto 1 Thomas Degris 1 Abstract One
David Silver * 1 Hado van Hasselt * 1 Matteo Hessel * 1 Tom Schaul * 1 Arthur Guez * 1 Tim Harley 1 Gabriel Dulac-Arnold 1 David Reichert 1 Neil Rabinowitz 1 Andre Barreto 1 Thomas Degris 1 Abstract One
Averaged-DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning
 Averaged-DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning Oron Anschel 1 Nir Baram 1 Nahum Shimkin 1 Abstract Instability and variability of Deep Reinforcement Learning (DRL) algorithms
Averaged-DQN: Variance Reduction and Stabilization for Deep Reinforcement Learning Oron Anschel 1 Nir Baram 1 Nahum Shimkin 1 Abstract Instability and variability of Deep Reinforcement Learning (DRL) algorithms
arxiv: v1 [cs.lg] 28 Dec 2016
![arxiv: v1 [cs.lg] 28 Dec 2016](/thumbs/96/127561464.jpg "arxiv: v1 [cs.lg] 28 Dec 2016") THE PREDICTRON: END-TO-END LEARNING AND PLANNING David Silver*, Hado van Hasselt*, Matteo Hessel*, Tom Schaul*, Arthur Guez*, Tim Harley, Gabriel Dulac-Arnold, David Reichert, Neil Rabinowitz, Andre Barreto,
THE PREDICTRON: END-TO-END LEARNING AND PLANNING David Silver*, Hado van Hasselt*, Matteo Hessel*, Tom Schaul*, Arthur Guez*, Tim Harley, Gabriel Dulac-Arnold, David Reichert, Neil Rabinowitz, Andre Barreto,
Variance Reduction for Policy Gradient Methods. March 13, 2017
 Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Variance Reduction for Policy Gradient Methods March 13, 2017 Reward Shaping Reward Shaping Reward Shaping Reward shaping: r(s, a, s ) = r(s, a, s ) + γφ(s ) Φ(s) for arbitrary potential Φ Theorem: r admits
Deep Reinforcement Learning: Policy Gradients and Q-Learning
 Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
David Silver, Google DeepMind
 Tutorial: Deep Reinforcement Learning David Silver, Google DeepMind Outline Introduction to Deep Learning Introduction to Reinforcement Learning Value-Based Deep RL Policy-Based Deep RL Model-Based Deep
Tutorial: Deep Reinforcement Learning David Silver, Google DeepMind Outline Introduction to Deep Learning Introduction to Reinforcement Learning Value-Based Deep RL Policy-Based Deep RL Model-Based Deep
Variational Deep Q Network
 Variational Deep Q Network Yunhao Tang Department of IEOR Columbia University yt2541@columbia.edu Alp Kucukelbir Department of Computer Science Columbia University alp@cs.columbia.edu Abstract We propose
Variational Deep Q Network Yunhao Tang Department of IEOR Columbia University yt2541@columbia.edu Alp Kucukelbir Department of Computer Science Columbia University alp@cs.columbia.edu Abstract We propose
Deep Reinforcement Learning. Scratching the surface
 Deep Reinforcement Learning Scratching the surface Deep Reinforcement Learning Scenario of Reinforcement Learning Observation State Agent Action Change the environment Don t do that Reward Environment
Deep Reinforcement Learning Scratching the surface Deep Reinforcement Learning Scenario of Reinforcement Learning Observation State Agent Action Change the environment Don t do that Reward Environment
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
THE PREDICTRON: END-TO-END LEARNING AND PLANNING
 THE PREDICTRON: END-TO-END LEARNING AND PLANNING David Silver*, Hado van Hasselt*, Matteo Hessel*, Tom Schaul*, Arthur Guez*, Tim Harley, Gabriel Dulac-Arnold, David Reichert, Neil Rabinowitz, Andre Barreto,
THE PREDICTRON: END-TO-END LEARNING AND PLANNING David Silver*, Hado van Hasselt*, Matteo Hessel*, Tom Schaul*, Arthur Guez*, Tim Harley, Gabriel Dulac-Arnold, David Reichert, Neil Rabinowitz, Andre Barreto,
arxiv: v2 [cs.lg] 10 Jul 2017
![arxiv: v2 [cs.lg] 10 Jul 2017](/thumbs/74/70170832.jpg "arxiv: v2 [cs.lg] 10 Jul 2017") SAMPLE EFFICIENT ACTOR-CRITIC WITH EXPERIENCE REPLAY Ziyu Wang DeepMind ziyu@google.com Victor Bapst DeepMind vbapst@google.com Nicolas Heess DeepMind heess@google.com arxiv:1611.1224v2 [cs.lg] 1 Jul 217
SAMPLE EFFICIENT ACTOR-CRITIC WITH EXPERIENCE REPLAY Ziyu Wang DeepMind ziyu@google.com Victor Bapst DeepMind vbapst@google.com Nicolas Heess DeepMind heess@google.com arxiv:1611.1224v2 [cs.lg] 1 Jul 217
arxiv: v2 [cs.lg] 2 Oct 2018
![arxiv: v2 [cs.lg] 2 Oct 2018](/thumbs/87/96205093.jpg "arxiv: v2 [cs.lg] 2 Oct 2018") AMBER: Adaptive Multi-Batch Experience Replay for Continuous Action Control arxiv:171.4423v2 [cs.lg] 2 Oct 218 Seungyul Han Dept. of Electrical Engineering KAIST Daejeon, South Korea 34141 sy.han@kaist.ac.kr
AMBER: Adaptive Multi-Batch Experience Replay for Continuous Action Control arxiv:171.4423v2 [cs.lg] 2 Oct 218 Seungyul Han Dept. of Electrical Engineering KAIST Daejeon, South Korea 34141 sy.han@kaist.ac.kr
Decoupling deep learning and reinforcement learning for stable and efficient deep policy gradient algorithms
 Decoupling deep learning and reinforcement learning for stable and efficient deep policy gradient algorithms Alfredo Vicente Clemente Master of Science in Computer Science Submission date: August 2017
Decoupling deep learning and reinforcement learning for stable and efficient deep policy gradient algorithms Alfredo Vicente Clemente Master of Science in Computer Science Submission date: August 2017
(Deep) Reinforcement Learning
 Reinforcement Learning") Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
arxiv: v3 [cs.lg] 7 Nov 2017
![arxiv: v3 [cs.lg] 7 Nov 2017](/thumbs/91/107267231.jpg "arxiv: v3 [cs.lg] 7 Nov 2017") UCB Exploration via Q-Ensembles arxiv:176.152v3 [cs.lg] 7 Nov 217 Richard Y. Chen OpenAI richardchen@openai.com Szymon Sidor OpenAI szymon@openai.com John Schulman OpenAI joschu@openai.com Abstract Pieter
UCB Exploration via Q-Ensembles arxiv:176.152v3 [cs.lg] 7 Nov 217 Richard Y. Chen OpenAI richardchen@openai.com Szymon Sidor OpenAI szymon@openai.com John Schulman OpenAI joschu@openai.com Abstract Pieter
Approximation Methods in Reinforcement Learning
 2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
1 Introduction 2. 4 Q-Learning The Q-value The Temporal Difference The whole Q-Learning process... 5
 Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
The Predictron: End-To-End Learning and Planning
 David Silver * 1 Hado van Hasselt * 1 Matteo Hessel * 1 Tom Schaul * 1 Arthur Guez * 1 Tim Harley 1 Gabriel Dulac-Arnold 1 David Reichert 1 Neil Rabinowitz 1 Andre Barreto 1 Thomas Degris 1 We applied
David Silver * 1 Hado van Hasselt * 1 Matteo Hessel * 1 Tom Schaul * 1 Arthur Guez * 1 Tim Harley 1 Gabriel Dulac-Arnold 1 David Reichert 1 Neil Rabinowitz 1 Andre Barreto 1 Thomas Degris 1 We applied
arxiv: v2 [cs.lg] 7 Mar 2018
![arxiv: v2 [cs.lg] 7 Mar 2018](/thumbs/76/73786584.jpg "arxiv: v2 [cs.lg] 7 Mar 2018") Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control arxiv:1712.00006v2 [cs.lg] 7 Mar 2018 Shangtong Zhang 1, Osmar R. Zaiane 2 12 Dept. of Computing Science, University
Comparing Deep Reinforcement Learning and Evolutionary Methods in Continuous Control arxiv:1712.00006v2 [cs.lg] 7 Mar 2018 Shangtong Zhang 1, Osmar R. Zaiane 2 12 Dept. of Computing Science, University
arxiv: v3 [cs.lg] 4 Jun 2016 Abstract
![arxiv: v3 [cs.lg] 4 Jun 2016 Abstract](/thumbs/91/106938439.jpg "arxiv: v3 [cs.lg] 4 Jun 2016 Abstract") Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks Tim Salimans OpenAI tim@openai.com Diederik P. Kingma OpenAI dpkingma@openai.com arxiv:1602.07868v3 [cs.lg]
Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks Tim Salimans OpenAI tim@openai.com Diederik P. Kingma OpenAI dpkingma@openai.com arxiv:1602.07868v3 [cs.lg]
arxiv: v2 [cs.ai] 7 Nov 2016
![arxiv: v2 [cs.ai] 7 Nov 2016](/thumbs/78/78478145.jpg "arxiv: v2 [cs.ai] 7 Nov 2016") Unifying Count-Based Exploration and Intrinsic Motivation Marc G. Bellemare bellemare@google.com Sriram Srinivasan srsrinivasan@google.com Georg Ostrovski ostrovski@google.com arxiv:1606.01868v2 [cs.ai]
Unifying Count-Based Exploration and Intrinsic Motivation Marc G. Bellemare bellemare@google.com Sriram Srinivasan srsrinivasan@google.com Georg Ostrovski ostrovski@google.com arxiv:1606.01868v2 [cs.ai]
Deep Reinforcement Learning via Policy Optimization
 Deep Reinforcement Learning via Policy Optimization John Schulman July 3, 2017 Introduction Deep Reinforcement Learning: What to Learn? Policies (select next action) Deep Reinforcement Learning: What to
Deep Reinforcement Learning via Policy Optimization John Schulman July 3, 2017 Introduction Deep Reinforcement Learning: What to Learn? Policies (select next action) Deep Reinforcement Learning: What to
Human-level control through deep reinforcement. Liia Butler
 Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Reinforcement Learning
 Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
arxiv: v4 [cs.lg] 14 Oct 2018
![arxiv: v4 [cs.lg] 14 Oct 2018](/thumbs/93/111782749.jpg "arxiv: v4 [cs.lg] 14 Oct 2018") Equivalence Between Policy Gradients and Soft -Learning John Schulman 1, Xi Chen 1,2, and Pieter Abbeel 1,2 1 OpenAI 2 UC Berkeley, EECS Dept. {joschu, peter, pieter}@openai.com arxiv:174.644v4 cs.lg 14
Equivalence Between Policy Gradients and Soft -Learning John Schulman 1, Xi Chen 1,2, and Pieter Abbeel 1,2 1 OpenAI 2 UC Berkeley, EECS Dept. {joschu, peter, pieter}@openai.com arxiv:174.644v4 cs.lg 14
Deep Reinforcement Learning SISL. Jeremy Morton (jmorton2) November 7, Stanford Intelligent Systems Laboratory
 November 7, Stanford Intelligent Systems Laboratory") Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
The Supervised Learning Approach To Estimating Heterogeneous Causal Regime Effects
 The Supervised Learning Approach To Estimating Heterogeneous Causal Regime Effects Thai T. Pham Stanford Graduate School of Business thaipham@stanford.edu May, 2016 Introduction Observations Many sequential
The Supervised Learning Approach To Estimating Heterogeneous Causal Regime Effects Thai T. Pham Stanford Graduate School of Business thaipham@stanford.edu May, 2016 Introduction Observations Many sequential
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Stochastic Video Prediction with Deep Conditional Generative Models
 Stochastic Video Prediction with Deep Conditional Generative Models Rui Shu Stanford University ruishu@stanford.edu Abstract Frame-to-frame stochasticity remains a big challenge for video prediction. The
Stochastic Video Prediction with Deep Conditional Generative Models Rui Shu Stanford University ruishu@stanford.edu Abstract Frame-to-frame stochasticity remains a big challenge for video prediction. The
An Off-policy Policy Gradient Theorem Using Emphatic Weightings
 An Off-policy Policy Gradient Theorem Using Emphatic Weightings Ehsan Imani, Eric Graves, Martha White Reinforcement Learning and Artificial Intelligence Laboratory Department of Computing Science University
An Off-policy Policy Gradient Theorem Using Emphatic Weightings Ehsan Imani, Eric Graves, Martha White Reinforcement Learning and Artificial Intelligence Laboratory Department of Computing Science University
A Distributional Perspective on Reinforcement Learning
 Marc G. Bellemare * 1 Will Dabney * 1 Rémi Munos 1 Abstract In this paper we argue for the fundamental importance of the value distribution: the distribution of the random return received by a reinforcement
Marc G. Bellemare * 1 Will Dabney * 1 Rémi Munos 1 Abstract In this paper we argue for the fundamental importance of the value distribution: the distribution of the random return received by a reinforcement
Approximate Q-Learning. Dan Weld / University of Washington
 Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Reinforcement Learning for NLP
 Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Efficient Exploration through Bayesian Deep Q-Networks
 Efficient Exploration through Bayesian Deep Q-Networks Kamyar Azizzadenesheli UCI, Stanford Email:kazizzad@uci.edu Emma Brunskill Stanford Email:ebrun@cs.stanford.edu Animashree Anandkumar Caltech, Amazon
Efficient Exploration through Bayesian Deep Q-Networks Kamyar Azizzadenesheli UCI, Stanford Email:kazizzad@uci.edu Emma Brunskill Stanford Email:ebrun@cs.stanford.edu Animashree Anandkumar Caltech, Amazon
Notes on Tabular Methods
 Notes on Tabular ethods Nan Jiang September 28, 208 Overview of the methods. Tabular certainty-equivalence Certainty-equivalence is a model-based RL algorithm, that is, it first estimates an DP model from
Notes on Tabular ethods Nan Jiang September 28, 208 Overview of the methods. Tabular certainty-equivalence Certainty-equivalence is a model-based RL algorithm, that is, it first estimates an DP model from
RECURRENT ENVIRONMENT SIMULATORS
 Published as a conference paper at ICLR 7 RECURRENT ENVIRONMENT SIMULATORS Silvia Chiappa, Sébastien Racaniere, Daan Wierstra & Shakir Mohamed DeepMind, London, UK {csilvia, sracaniere, wierstra, shakir}@google.com
Published as a conference paper at ICLR 7 RECURRENT ENVIRONMENT SIMULATORS Silvia Chiappa, Sébastien Racaniere, Daan Wierstra & Shakir Mohamed DeepMind, London, UK {csilvia, sracaniere, wierstra, shakir}@google.com
Introduction of Reinforcement Learning
 Introduction of Reinforcement Learning Deep Reinforcement Learning Reference Textbook: Reinforcement Learning: An Introduction http://incompleteideas.net/sutton/book/the-book.html Lectures of David Silver
Introduction of Reinforcement Learning Deep Reinforcement Learning Reference Textbook: Reinforcement Learning: An Introduction http://incompleteideas.net/sutton/book/the-book.html Lectures of David Silver
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016)
") Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016) Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology October 11, 2016 Outline
Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016) Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology October 11, 2016 Outline
LEARNING FINITE STATE REPRESENTATIONS OF RECURRENT POLICY NETWORKS
 LEARNING FINITE STATE REPRESENTATIONS OF RECURRENT POLICY NETWORKS Anurag Koul & Alan Fern School of EECS Oregon State University Corvallis, Oregon, USA {koula,alan.fern}@oregonstate.edu Sam Greydanus
LEARNING FINITE STATE REPRESENTATIONS OF RECURRENT POLICY NETWORKS Anurag Koul & Alan Fern School of EECS Oregon State University Corvallis, Oregon, USA {koula,alan.fern}@oregonstate.edu Sam Greydanus
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
arxiv: v2 [cs.ai] 23 Nov 2018
![arxiv: v2 [cs.ai] 23 Nov 2018](/thumbs/95/124394332.jpg "arxiv: v2 [cs.ai] 23 Nov 2018") Simulated Autonomous Driving in a Realistic Driving Environment using Deep Reinforcement Learning and a Deterministic Finite State Machine arxiv:1811.07868v2 [cs.ai] 23 Nov 2018 Patrick Klose Visual Sensorics
Simulated Autonomous Driving in a Realistic Driving Environment using Deep Reinforcement Learning and a Deterministic Finite State Machine arxiv:1811.07868v2 [cs.ai] 23 Nov 2018 Patrick Klose Visual Sensorics
Multi-Batch Experience Replay for Fast Convergence of Continuous Action Control
 1 Multi-Batch Experience Replay for Fast Convergence of Continuous Action Control Seungyul Han and Youngchul Sung Abstract arxiv:1710.04423v1 [cs.lg] 12 Oct 2017 Policy gradient methods for direct policy
1 Multi-Batch Experience Replay for Fast Convergence of Continuous Action Control Seungyul Han and Youngchul Sung Abstract arxiv:1710.04423v1 [cs.lg] 12 Oct 2017 Policy gradient methods for direct policy
REGRET MINIMIZATION FOR PARTIALLY OBSERVABLE DEEP REINFORCEMENT LEARNING
 REGRET MINIMIZATION FOR PARTIALLY OBSERVABLE DEEP REINFORCEMENT LEARNING Peter Jin, Sergey Levine, and Kurt Keutzer Berkeley AI Research Lab, Department of Electrical Engineering and Computer Sciences
REGRET MINIMIZATION FOR PARTIALLY OBSERVABLE DEEP REINFORCEMENT LEARNING Peter Jin, Sergey Levine, and Kurt Keutzer Berkeley AI Research Lab, Department of Electrical Engineering and Computer Sciences
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
Branes with Brains. Reinforcement learning in the landscape of intersecting brane worlds. String_Data 2017, Boston 11/30/2017
 Branes with Brains Reinforcement learning in the landscape of intersecting brane worlds FABIAN RUEHLE (UNIVERSITY OF OXFORD) String_Data 2017, Boston 11/30/2017 Based on [work in progress] with Brent Nelson
Branes with Brains Reinforcement learning in the landscape of intersecting brane worlds FABIAN RUEHLE (UNIVERSITY OF OXFORD) String_Data 2017, Boston 11/30/2017 Based on [work in progress] with Brent Nelson
Value-Aware Loss Function for Model Learning in Reinforcement Learning
 Journal of Machine Learning Research (EWRL Series) (2016) Submitted 9/16; Published 12/16 Value-Aware Loss Function for Model Learning in Reinforcement Learning Amir-massoud Farahmand farahmand@merl.com
Journal of Machine Learning Research (EWRL Series) (2016) Submitted 9/16; Published 12/16 Value-Aware Loss Function for Model Learning in Reinforcement Learning Amir-massoud Farahmand farahmand@merl.com
arxiv: v1 [cs.lg] 21 Jul 2017
![arxiv: v1 [cs.lg] 21 Jul 2017](/thumbs/78/78750808.jpg "arxiv: v1 [cs.lg] 21 Jul 2017") Marc G. Bellemare * 1 Will Dabney * 1 Rémi Munos 1 arxiv:1707.06887v1 [cs.lg] 21 Jul 2017 Abstract In this paper we argue for the fundamental importance of the value distribution: the distribution of the
Marc G. Bellemare * 1 Will Dabney * 1 Rémi Munos 1 arxiv:1707.06887v1 [cs.lg] 21 Jul 2017 Abstract In this paper we argue for the fundamental importance of the value distribution: the distribution of the
arxiv: v2 [cs.lg] 8 Aug 2018
![arxiv: v2 [cs.lg] 8 Aug 2018](/thumbs/83/87242799.jpg "arxiv: v2 [cs.lg] 8 Aug 2018") : Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor Tuomas Haarnoja 1 Aurick Zhou 1 Pieter Abbeel 1 Sergey Levine 1 arxiv:181.129v2 [cs.lg] 8 Aug 218 Abstract Model-free deep
: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor Tuomas Haarnoja 1 Aurick Zhou 1 Pieter Abbeel 1 Sergey Levine 1 arxiv:181.129v2 [cs.lg] 8 Aug 218 Abstract Model-free deep
Artificial Neural Networks. Introduction to Computational Neuroscience Tambet Matiisen
 Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Tambet Matiisen 2.04.2018 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Learning Control for Air Hockey Striking using Deep Reinforcement Learning
 Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Transfer of Value Functions via Variational Methods
 Transfer of Value Functions via Variational Methods Andrea Tirinzoni Politecnico di Milano andrea.tirinzoni@polimi.it Rafael Rodriguez Sanchez Politecnico di Milano rafaelalberto.rodriguez@polimi.it Marcello
Transfer of Value Functions via Variational Methods Andrea Tirinzoni Politecnico di Milano andrea.tirinzoni@polimi.it Rafael Rodriguez Sanchez Politecnico di Milano rafaelalberto.rodriguez@polimi.it Marcello
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
 Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel & Sergey Levine Department of Electrical Engineering and Computer
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel & Sergey Levine Department of Electrical Engineering and Computer
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
Autonomous Braking System via Deep Reinforcement Learning
 Autonomous Braking System via Deep Reinforcement Learning Hyunmin Chae, Chang Mook Kang, ByeoungDo Kim, Jaekyum Kim, Chung Choo Chung, and Jun Won Choi Hanyang University, Seoul, Korea Email: hmchae@spo.hanyang.ac.kr,
Autonomous Braking System via Deep Reinforcement Learning Hyunmin Chae, Chang Mook Kang, ByeoungDo Kim, Jaekyum Kim, Chung Choo Chung, and Jun Won Choi Hanyang University, Seoul, Korea Email: hmchae@spo.hanyang.ac.kr,
INTRODUCTION TO EVOLUTION STRATEGY ALGORITHMS. James Gleeson Eric Langlois William Saunders
 INTRODUCTION TO EVOLUTION STRATEGY ALGORITHMS James Gleeson Eric Langlois William Saunders REINFORCEMENT LEARNING CHALLENGES f(θ) is a discrete function of theta How do we get a gradient θ f? Credit assignment
INTRODUCTION TO EVOLUTION STRATEGY ALGORITHMS James Gleeson Eric Langlois William Saunders REINFORCEMENT LEARNING CHALLENGES f(θ) is a discrete function of theta How do we get a gradient θ f? Credit assignment
arxiv: v2 [cs.lg] 9 Feb 2018
![arxiv: v2 [cs.lg] 9 Feb 2018](/thumbs/75/72502786.jpg "arxiv: v2 [cs.lg] 9 Feb 2018") IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures Lasse Espeholt * Hubert Soyer * Remi Munos * Karen Simonyan Volodymir Mnih Tom Ward Yotam Doron Vlad Firoiu Tim
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures Lasse Espeholt * Hubert Soyer * Remi Munos * Karen Simonyan Volodymir Mnih Tom Ward Yotam Doron Vlad Firoiu Tim
Forward Actor-Critic for Nonlinear Function Approximation in Reinforcement Learning
 Forward Actor-Critic for Nonlinear Function Approximation in Reinforcement Learning Vivek Veeriah Dept. of Computing Science University of Alberta Edmonton, Canada vivekveeriah@ualberta.ca Harm van Seijen
Forward Actor-Critic for Nonlinear Function Approximation in Reinforcement Learning Vivek Veeriah Dept. of Computing Science University of Alberta Edmonton, Canada vivekveeriah@ualberta.ca Harm van Seijen
Combining PPO and Evolutionary Strategies for Better Policy Search
 Combining PPO and Evolutionary Strategies for Better Policy Search Jennifer She 1 Abstract A good policy search algorithm needs to strike a balance between being able to explore candidate policies and
Combining PPO and Evolutionary Strategies for Better Policy Search Jennifer She 1 Abstract A good policy search algorithm needs to strike a balance between being able to explore candidate policies and
Lecture 10 - Planning under Uncertainty (III)
") Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
COMP9444 Neural Networks and Deep Learning 10. Deep Reinforcement Learning. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 10. Deep Reinforcement Learning COMP9444 17s2 Deep Reinforcement Learning 1 Outline History of Reinforcement Learning Deep Q-Learning for Atari Games Actor-Critic
COMP9444 Neural Networks and Deep Learning 10. Deep Reinforcement Learning COMP9444 17s2 Deep Reinforcement Learning 1 Outline History of Reinforcement Learning Deep Q-Learning for Atari Games Actor-Critic
Stein Variational Policy Gradient
 Stein Variational Policy Gradient Yang Liu UIUC liu301@illinois.edu Prajit Ramachandran UIUC prajitram@gmail.com Qiang Liu Dartmouth qiang.liu@dartmouth.edu Jian Peng UIUC jianpeng@illinois.edu Abstract
Stein Variational Policy Gradient Yang Liu UIUC liu301@illinois.edu Prajit Ramachandran UIUC prajitram@gmail.com Qiang Liu Dartmouth qiang.liu@dartmouth.edu Jian Peng UIUC jianpeng@illinois.edu Abstract
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
arxiv: v1 [cs.lg] 1 Jun 2017
![arxiv: v1 [cs.lg] 1 Jun 2017](/thumbs/74/70663683.jpg "arxiv: v1 [cs.lg] 1 Jun 2017") Interpolated Policy Gradient: Merging On-Policy and Off-Policy Gradient Estimation for Deep Reinforcement Learning arxiv:706.00387v [cs.lg] Jun 207 Shixiang Gu University of Cambridge Max Planck Institute
Interpolated Policy Gradient: Merging On-Policy and Off-Policy Gradient Estimation for Deep Reinforcement Learning arxiv:706.00387v [cs.lg] Jun 207 Shixiang Gu University of Cambridge Max Planck Institute
arxiv: v3 [cs.lg] 28 Jun 2018
![arxiv: v3 [cs.lg] 28 Jun 2018](/thumbs/83/87242823.jpg "arxiv: v3 [cs.lg] 28 Jun 2018") IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures Lasse Espeholt * Hubert Soyer * Remi Munos * Karen Simonyan Volodymyr Mnih Tom Ward Yotam Doron Vlad Firoiu Tim
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures Lasse Espeholt * Hubert Soyer * Remi Munos * Karen Simonyan Volodymyr Mnih Tom Ward Yotam Doron Vlad Firoiu Tim
arxiv: v1 [cs.ai] 19 May 2017
![arxiv: v1 [cs.ai] 19 May 2017](/thumbs/74/70608829.jpg "arxiv: v1 [cs.ai] 19 May 2017") Model-Based Planning in Discrete Action Spaces Mikael Henaff Courant Institute, New York University mbh305@nyu.edu William F. Whitney Courant Institute, New York University ww1114@nyu.edu arxiv:1705.07177v1
Model-Based Planning in Discrete Action Spaces Mikael Henaff Courant Institute, New York University mbh305@nyu.edu William F. Whitney Courant Institute, New York University ww1114@nyu.edu arxiv:1705.07177v1
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Introduction to Deep Neural Networks
 Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
Introduction to Deep Neural Networks Presenter: Chunyuan Li Pattern Classification and Recognition (ECE 681.01) Duke University April, 2016 Outline 1 Background and Preliminaries Why DNNs? Model: Logistic
arxiv: v1 [cs.ai] 27 Oct 2017
![arxiv: v1 [cs.ai] 27 Oct 2017](/thumbs/92/109545789.jpg "arxiv: v1 [cs.ai] 27 Oct 2017") Distributional Reinforcement Learning with Quantile Regression Will Dabney DeepMind Mark Rowland University of Cambridge Marc G. Bellemare Google Brain Rémi Munos DeepMind arxiv:1710.10044v1 [cs.ai] 27
Distributional Reinforcement Learning with Quantile Regression Will Dabney DeepMind Mark Rowland University of Cambridge Marc G. Bellemare Google Brain Rémi Munos DeepMind arxiv:1710.10044v1 [cs.ai] 27
arxiv: v1 [cs.ai] 5 Nov 2017
![arxiv: v1 [cs.ai] 5 Nov 2017](/thumbs/96/129180284.jpg "arxiv: v1 [cs.ai] 5 Nov 2017") arxiv:1711.01569v1 [cs.ai] 5 Nov 2017 Markus Dumke Department of Statistics Ludwig-Maximilians-Universität München markus.dumke@campus.lmu.de Abstract Temporal-difference (TD) learning is an important
arxiv:1711.01569v1 [cs.ai] 5 Nov 2017 Markus Dumke Department of Statistics Ludwig-Maximilians-Universität München markus.dumke@campus.lmu.de Abstract Temporal-difference (TD) learning is an important
Deep Reinforcement Learning
 Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 50 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 50 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
arxiv: v2 [cs.lg] 7 Nov 2016
![arxiv: v2 [cs.lg] 7 Nov 2016](/thumbs/89/98424036.jpg "arxiv: v2 [cs.lg] 7 Nov 2016") Safe and efficient off-policy reinforcement learning Rémi Munos munos@google.com Google DeepMind Thomas Stepleton stepleton@google.com Google DeepMind arxiv:1606.02647v2 [cs.lg] 7 Nov 2016 Anna Harutyunyan
Safe and efficient off-policy reinforcement learning Rémi Munos munos@google.com Google DeepMind Thomas Stepleton stepleton@google.com Google DeepMind arxiv:1606.02647v2 [cs.lg] 7 Nov 2016 Anna Harutyunyan