Dobbiaco Lectures 2010 (4)Solved and Unsolved Problems in
|
|
|
- Neil Snow
- 6 years ago
- Views:
Transcription
1 Dobbiaco Lectures 2010 (4) Solved and Unsolved Problems in Biology Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Dobbiaco
2 Outline 1 2 3
3 PART IX: Information
4 Main theses Outline There are seven main propositions in the text. These are:... 1 The world is everything that is the case. 2 What is the case (a fact) is the existence of states of affairs. 3 A logical picture of facts is a thought. 4 A thought is a proposition with sense. 5 A proposition is a truth-function of elementary propositions. 6 The general form of a proposition is the general form of a truth function, which is: p, ξ, ξ 7 Where (or of what) one cannot speak, one must pass over in silence. Ludwig Wittgenstein, Tractatus Logico-Philosophicus, 1921.
5 Outline 1 2 3

6
7 Bayesian Interpretation Probability P(e) our certainty about whether event e is true or false in the real world. (Given whatever information we have available.) Degree of Belief. More rigorously, we should write Conditional probability P(e L) Represents a degree of belief with respect to L The background information upon which our belief is based.
8 Probability as a Dynamic Entity We update the degree of belief as more data arrives: using Bayes Theorem: P(e D) = P(D e)p(e). P(D) Posterior is proportional to the prior in a manner that depends on the data P(D e)/p(d). Prior Probability: P(e) is one s belief in the event e before any data is observed. Posterior Probability: P(e D) is one s updated belief in e given the observed data. Likelihood: P(D e) Probability of the data under the assumption e
9 Dynamics Outline Note: P(e D 1, D 2 ) = P(D 2 D 1, e)p(e D 1 ) P(D 2 D 1 ) = P(D 2 D 1, e)p(d 1 e)p(e) P(D 2 D 1 ) Further, note: The effects of prior diminish as the number of data points increase. The Law of Large Number: With large number of data points, Bayesian and frequentist viewpoints become indistinguishable.
10 Parameter Estimation Functional form for a model M 1 Model depends on some parameters Θ 2 What is the best estimation of Θ? Typically the parameters Θ are a set of real-valued numbers Both prior P(Θ) and posterior P(Θ D) are defining probability density functions.
11 MAP Method: Maximum A Posteriori Find the set of parameters Θ 1 Maximizing the posterior P(Θ D) or minimizing a score log P(Θ D) E (Θ) = log P(Θ D) = log P(D Θ) log P(Θ) + log P(D) 2 If prior P(Θ) is uniform over the entire parameter space (i.e., uninformative) min arg Θ E L (Θ) = log P(D Θ). Maximum Likelihood Solution
12 Robustness Outline Find a distribution (pdf) for parameters Θ 1 Maximizing the expectation over parameters E = P(Θ, D) log P(Θ D) = P(Θ) P(Θ D) log P(Θ D) Empirical Bayes Methods: P(Θ) is a compressed (lossy) representation of P(D).

13
14 Information theory Information theory is based on probability theory (and statistics). Basic concepts: Entropy (the information in a random variable) and Mutual Information (the amount of information in common between two random variables). The most common unit of information is the bit (based log 2). Other units include the nat, and the hartley.
15 Entropy Outline The entropy H of a discrete random variable X is a measure of the amount uncertainty associated with the value X. Suppose one transmits 1000 bits (0s and 1s). If these bits are known ahead of transmission (to be a certain value with absolute probability), logic dictates that no information has been transmitted. If, however, each is equally and independently likely to be 0 or 1, 1000 bits (in the information theoretic sense) have been transmitted.
16 Entropy Outline Between these two extremes, information can be quantified as follows. If X is the set of all messages x that X could be, and p(x) is the probability of X given x, then the entropy of X is defined as H(x) = E X [I(x)] = x X p(x) log p(x). Here, I(x) is the self-information, which is the entropy contribution of an individual message, and E X is the expected value.
17 An important property of entropy is that it is maximized when all the messages in the message space are equiprobable p(x) = 1/n, i.e., most unpredictable, in which case H(X) = log n. The binary entropy function (for a random variable with two outcomes {0, 1} or {H, T }: H b (p, q) = p log p q log q, p + q = 1.
18 Joint entropy Outline The joint entropy of two discrete random variables X and Y is merely the entropy of their pairing: X, Y. Thus, if X and Y are independent, then their joint entropy is the sum of their individual entropies. H(X, Y) = E X,Y [ log p(x, y)] = x,y log p(x, y). For example, if (X,Y) represents the position of a chess piece Ñ X the row and Y the column, then the joint entropy of the row of the piece and the column of the piece will be the entropy of the position of the piece.
19 Conditional Entropy or Equivocation The conditional entropy or conditional uncertainty of X given random variable Y (also called the equivocation of X about Y ) is the average conditional entropy over Y : H(X Y) = E Y [H(X y)] = y Y p(y) x X p(x y) log p(x y) = x,y p(x, y) log p(x, y) p(y) A basic property of this form of conditional entropy is that: H(X Y) = H(X, Y) H(Y).
20 Mutual Information (Transinformation) Mutual information measures the amount of information that can be obtained about one random variable by observing another. The mutual information of X relative to Y is given by: I(X; Y) = E X,Y [SI(x, y)] = x,y p(x, y) log p(x, y) p(x)p(y). where SI (Specific mutual Information) is the pointwise mutual information.
21 A basic property of the mutual information is that I(X; Y) = H(X) H(X Y) = H(X)+H(Y) H(X, Y) = I(Y; X). That is, knowing Y, we can save an average of I(X; Y) bits in encoding X compared to not knowing Y. Note that mutual information is symmetric. It is important in communication where it can be used to maximize the amount of information shared between sent and received signals.
22 Kullback-Leibler Divergence (Information Gain) The Kullback-Leibler divergence (or information divergence, information gain, or relative entropy) is a way of comparing two distributions: a true probability distribution p(x), and an arbitrary probability distribution q(x). D KL (p(x) q(x)) = x X p(x) log p(x) q(x) = x X[ p(x) log q(x)] [ p(x) log p(x)]
23 If we compress data in a manner that assumes q(x) is the distribution underlying some data, when, in reality, p(x) is the correct distribution, the Kullback-Leibler divergence is the number of average additional bits per datum necessary for compression. Although it is sometimes used as a distance metric, it is not a true metric since it is not symmetric and does not satisfy the triangle inequality (making it a semi-quasimetric).
24 Mutual information can be expressed as the average Kullback-Leibler divergence (information gain) of the posterior probability distribution of X given the value of Y to the prior distribution on X: I(X; Y) = E p(y) [D KL (p(x Y = y) p(x)] = D KL (p(x, Y) p(x)p(y)). In other words, mutual information I(X, Y) is a measure of how much, on the average, the probability distribution on X will change if we are given the value of Y. This is often recalculated as the divergence from the product of the marginal distributions to the actual joint distribution. Mutual information is closely related to the log-likelihood ratio test in the context of contingency tables and the multinomial distribution and to Pearson s χ 2 test.
25 Source theory Any process that generates successive messages can be considered a source of information. A memoryless source is one in which each message is an independent identically-distributed random variable, whereas the properties of ergodicity and stationarity impose more general constraints. All such sources are stochastic.
26 Information Rate Rate Information rate is the average entropy per symbol. For memoryless sources, this is merely the entropy of each symbol, while, in the case of a stationary stochastic process, it is r = lim n H(X n X n 1, X n 2...) In general (e.g., nonstationary), it is defined as 1 r = lim n n H(X n, X n 1, X n 2...) In information theory, one may thus speak of the rate or entropy of a language.

27
28 Rate Distortion Theory R(D) = Minimum achievable rate under a given constraint on the expected distortion. X = random variable; T = alphabet for a compressed representation. If x X is represented by t T, there is a distortion d(x, t) R(D) = d(x, t) = x,t min I(T,X). {p(t x): d(x,t) D} p(x, t)d(x, t) = x,t p(x)p(t x)d(x, t)
29 Introduce a Lagrange multiplier parameter β and Solve the following variational problem L min [p(t x)] = I(T;X) + β d(x, t) p(x)p(t x). We need L p(t x) = 0. Since L = x p(x) t p(t x) log p(t x) p(t) +β x p(x) t p(t x)d(x, t), we have [ p(x) log p(t x) ] + βd(x, t) = 0. p(t) p(t x) e βd(x,t). p(t)
30 Summary Outline In summary, p(t x) = p(t) Z(x,β) e βd(x,t) p(t) = x p(x)p(t x). Z(x,β) = t p(t) exp[ βd(x, t)] is a Partition Function. The Lagrange parameter in this case is positive; It is determined by the upper bound on distortion: R D = β.
31 Redescription Some hidden object may be observed via two views X and Y (two random variables.) Create a common descriptor T Example X = words, Y = topics. R(D) = L min I(T;X) p(t x):i(t:y) D = I(T : X) βi(t;y)
32 Proceeding as before, we have p(t x) = p(t) = x p(t) Z(x,β) e βd KL[p(y x) p(y t)] p(x)p(t x) p(y t) = p(y x) = 1 p(t) p(x, y)p(t x) x p(x, y) p(x) Information Bottleneck = T.
33 Blahut-Arimoto Algorithm Start with the basic formulation for RDT; Can be changed mutatis mutandis for IB. Input: p(x), T, and β Output: p(t x) Step 1. Randomly initialize p(t) Step 2. loop until p(t x) converges (to a fixed point) Step 3. Step 4. Step 5. endloop p(t x) := p(t) Z(x,β) e βd(x,t) p(t) := x p(x)p(t x) Convex Programming: Optimization of a convex function over a convex set Global optimum exists!
34 PART X: Models
35 Outline 1 2 3
36 Information Bottleneck The computational principle uses Information Bottleneck Theory (a special case of RDT) It creates a Kripke model (with states and state transitions)
37 Data Outline D i = The random variable; Samples are the rows in submatrix of D i
38 States Outline States Cluster D i =; effectively identifying the state variable X i such that the mutual information between D i and X i is minimized min I(D i ; X i ) subj DISTORTION
39 Transitions Outline State-Transitions Preserve ontologies... Relate the conditional distribution P(O X i ) with P(O X i+1 ) (1 i < k) & P(O X i 1 ) (1 < i k) Measure distortions using Kullback-Liebler Distances.
40 Algorithm Outline Cluster the data over time as well as gene sets... Cluster and cluster-edges optimize the mutual information terms I(D i ; X i ) β + D KL (O X i O X i+1 ) β D KL (O X i O X i 1 ) Measure distortions using Kullback-Liebler Distances.

41
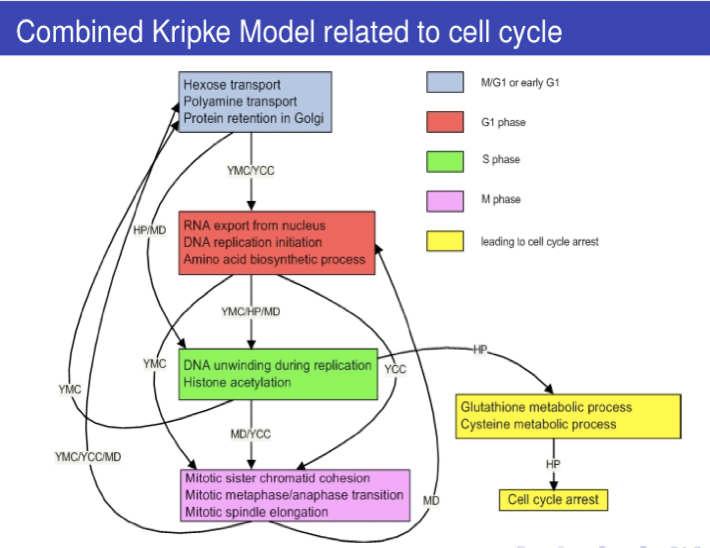
42
43 Cancer Outline What causes cancer? 1 Cancer as a disease of the genomeé 2 Cancer as a somatic evolutionary processé 3 Cancer as a price of symbiosis (mitochondrial)é 4 Cancer as a response to multi-cellularityé 5 Cancer as a price of repair/regeneration (stem cells)é 6 Cancer as a consequence of energy consumption (Anaerobic Glycolysis)É Warburg Effect 7 Cancer as a response to external stressé 8 Cancer as a response to the micro-environment (hyperand hypo-methylation)
44 Processes involved in Cancer Coordination of processes in cancer progression 1 Inflammation 2 Autophagy and mitophagy 3 Apoptosis 4 Hypoxia 5 Anaerobic glycolysis 6 Fibrosis 7 Signaling
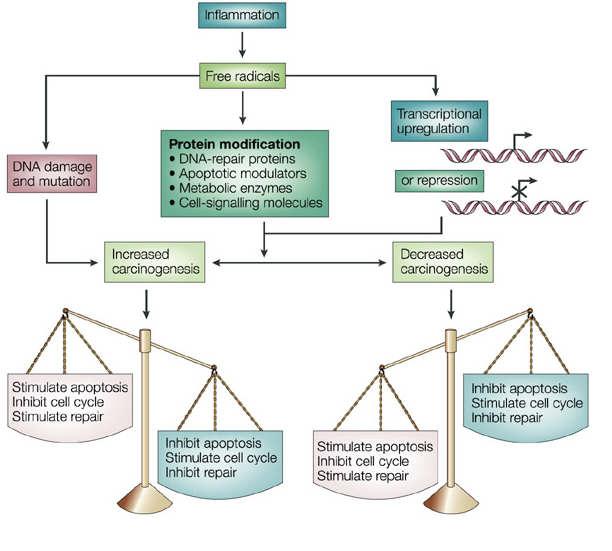
45
46 PART XI: Laws
47 Outline 1 2 3
48 Character of Physical Laws For many philosophers of science, physics is the science and the way in which it has developed forms a model that all other sciences are implicitly expected to follow. But biology is not physics, and there will never be a biological equivalent of the physicists dream of a theory of everything, apart from the modern synthesis of natural selection and population genetics. Making sense of life: explaining biological development with models, metaphors and machines: Reviewed by M. Cobb

49
50 Feynman Outline I want to discuss now the art of guessing nature s laws. It is an art. How is it done? One way you might suggest is to look at history to see ow the other guys did it. So we look at history. We must start with Newton. He had a situation where he had incomplete knowledge, and he was able to guess the laws by putting together ideas which were relatively close to experiment... Feynman: The Character of Physical Law

51
52 Hypotheses non fingo Tycho Brahe s Data. Kepler s Laws: (Especially the Third Law) Galilean Principles: Law of Inertia, Galilean Identity (Inertial Mass = Gravitational Mass)
53
54
55 Idler Wheels and Gears The next guy who did something great was maxwell, who obtained the laws of electricity and magnetism. What he did was this. He put together all the laws of electricity, due to Faraday and other people who came before him, and he looked at them and realized that they were mathematically inconsistent. In order to straighten it out he had to add one term to an equation. He did this by inventing for himself a model of idler wheels and geras and so on in space... So the logic may be wrong, but the answer right... Feynman: The Character of Physical Law
56 Einstein Outline In the case of [Einstein s] relativity the discovery was completely different. There was an accumulation of paradoxes; the known laws gave inconsistent results. This was a new kind of thinking, a thinking in terms of discussing the possible symmetries of laws... Also it was difficult to accept that ordinary ideas of time and space, which seemed so instinctive, could be wrong. Feynman: The Character of Physical Law
57 Thoughts.. Outline Newton Leibnitz Euler Bolzano Weirstrasse Frege Cantor Russell Wittgenstein


58
59 Feynman Outline What is it about nature that lets this happen, that it is possible to guess from one part what the rest is going to do? That is an unscientific question: I do not know how to answer it, and therefore I am going to give an unscientific answer... I think it is because nature has a simplicity and therefore a great beauty. Feynman: The Character of Physical Law
60
61 [End of Lecture #4]
Bioinformatics: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Bayesian Interpretation of Probabilities 2 Where (or of what)
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Bayesian Interpretation of Probabilities 2 Where (or of what)
Computational Systems Biology: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA L#8:(November-08-2010) Cancer and Signals Outline 1 Bayesian Interpretation of Probabilities Information Theory Outline Bayesian
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA L#8:(November-08-2010) Cancer and Signals Outline 1 Bayesian Interpretation of Probabilities Information Theory Outline Bayesian
Computational Biology Lecture #3: Probability and Statistics. Bud Mishra Professor of Computer Science, Mathematics, & Cell Biology Sept
 Computational Biology Lecture #3: Probability and Statistics Bud Mishra Professor of Computer Science, Mathematics, & Cell Biology Sept 26 2005 L2-1 Basic Probabilities L2-2 1 Random Variables L2-3 Examples
Computational Biology Lecture #3: Probability and Statistics Bud Mishra Professor of Computer Science, Mathematics, & Cell Biology Sept 26 2005 L2-1 Basic Probabilities L2-2 1 Random Variables L2-3 Examples
the Information Bottleneck
 the Information Bottleneck Daniel Moyer December 10, 2017 Imaging Genetics Center/Information Science Institute University of Southern California Sorry, no Neuroimaging! (at least not presented) 0 Instead,
the Information Bottleneck Daniel Moyer December 10, 2017 Imaging Genetics Center/Information Science Institute University of Southern California Sorry, no Neuroimaging! (at least not presented) 0 Instead,
Introduction to Information Theory. Uncertainty. Entropy. Surprisal. Joint entropy. Conditional entropy. Mutual information.
 L65 Dept. of Linguistics, Indiana University Fall 205 Information theory answers two fundamental questions in communication theory: What is the ultimate data compression? What is the transmission rate
L65 Dept. of Linguistics, Indiana University Fall 205 Information theory answers two fundamental questions in communication theory: What is the ultimate data compression? What is the transmission rate
Dept. of Linguistics, Indiana University Fall 2015
 L645 Dept. of Linguistics, Indiana University Fall 2015 1 / 28 Information theory answers two fundamental questions in communication theory: What is the ultimate data compression? What is the transmission
L645 Dept. of Linguistics, Indiana University Fall 2015 1 / 28 Information theory answers two fundamental questions in communication theory: What is the ultimate data compression? What is the transmission
Lecture 2: August 31
 0-704: Information Processing and Learning Fall 206 Lecturer: Aarti Singh Lecture 2: August 3 Note: These notes are based on scribed notes from Spring5 offering of this course. LaTeX template courtesy
0-704: Information Processing and Learning Fall 206 Lecturer: Aarti Singh Lecture 2: August 3 Note: These notes are based on scribed notes from Spring5 offering of this course. LaTeX template courtesy
Information Theory in Intelligent Decision Making
 Information Theory in Intelligent Decision Making Adaptive Systems and Algorithms Research Groups School of Computer Science University of Hertfordshire, United Kingdom June 7, 2015 Information Theory
Information Theory in Intelligent Decision Making Adaptive Systems and Algorithms Research Groups School of Computer Science University of Hertfordshire, United Kingdom June 7, 2015 Information Theory
Lecture 1: Introduction, Entropy and ML estimation
 0-704: Information Processing and Learning Spring 202 Lecture : Introduction, Entropy and ML estimation Lecturer: Aarti Singh Scribes: Min Xu Disclaimer: These notes have not been subjected to the usual
0-704: Information Processing and Learning Spring 202 Lecture : Introduction, Entropy and ML estimation Lecturer: Aarti Singh Scribes: Min Xu Disclaimer: These notes have not been subjected to the usual
COMPSCI 650 Applied Information Theory Jan 21, Lecture 2
 COMPSCI 650 Applied Information Theory Jan 21, 2016 Lecture 2 Instructor: Arya Mazumdar Scribe: Gayane Vardoyan, Jong-Chyi Su 1 Entropy Definition: Entropy is a measure of uncertainty of a random variable.
COMPSCI 650 Applied Information Theory Jan 21, 2016 Lecture 2 Instructor: Arya Mazumdar Scribe: Gayane Vardoyan, Jong-Chyi Su 1 Entropy Definition: Entropy is a measure of uncertainty of a random variable.
arxiv:physics/ v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1
![arxiv:physics/ v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1](/thumbs/74/70237419.jpg "arxiv:physics/ v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1") The information bottleneck method arxiv:physics/0004057v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1 1 NEC Research Institute, 4 Independence Way Princeton,
The information bottleneck method arxiv:physics/0004057v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1 1 NEC Research Institute, 4 Independence Way Princeton,
Noisy channel communication
 Information Theory http://www.inf.ed.ac.uk/teaching/courses/it/ Week 6 Communication channels and Information Some notes on the noisy channel setup: Iain Murray, 2012 School of Informatics, University
Information Theory http://www.inf.ed.ac.uk/teaching/courses/it/ Week 6 Communication channels and Information Some notes on the noisy channel setup: Iain Murray, 2012 School of Informatics, University
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
CS 630 Basic Probability and Information Theory. Tim Campbell
 CS 630 Basic Probability and Information Theory Tim Campbell 21 January 2003 Probability Theory Probability Theory is the study of how best to predict outcomes of events. An experiment (or trial or event)
CS 630 Basic Probability and Information Theory Tim Campbell 21 January 2003 Probability Theory Probability Theory is the study of how best to predict outcomes of events. An experiment (or trial or event)
3. If a choice is broken down into two successive choices, the original H should be the weighted sum of the individual values of H.
 Appendix A Information Theory A.1 Entropy Shannon (Shanon, 1948) developed the concept of entropy to measure the uncertainty of a discrete random variable. Suppose X is a discrete random variable that
Appendix A Information Theory A.1 Entropy Shannon (Shanon, 1948) developed the concept of entropy to measure the uncertainty of a discrete random variable. Suppose X is a discrete random variable that
Expectation Maximization
 Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
Classification & Information Theory Lecture #8
 Classification & Information Theory Lecture #8 Introduction to Natural Language Processing CMPSCI 585, Fall 2007 University of Massachusetts Amherst Andrew McCallum Today s Main Points Automatically categorizing
Classification & Information Theory Lecture #8 Introduction to Natural Language Processing CMPSCI 585, Fall 2007 University of Massachusetts Amherst Andrew McCallum Today s Main Points Automatically categorizing
Bioinformatics: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 2 Main theses Outline There are seven main propositions in the
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 2 Main theses Outline There are seven main propositions in the
Quiz 2 Date: Monday, November 21, 2016
 10-704 Information Processing and Learning Fall 2016 Quiz 2 Date: Monday, November 21, 2016 Name: Andrew ID: Department: Guidelines: 1. PLEASE DO NOT TURN THIS PAGE UNTIL INSTRUCTED. 2. Write your name,
10-704 Information Processing and Learning Fall 2016 Quiz 2 Date: Monday, November 21, 2016 Name: Andrew ID: Department: Guidelines: 1. PLEASE DO NOT TURN THIS PAGE UNTIL INSTRUCTED. 2. Write your name,
Series 7, May 22, 2018 (EM Convergence)
") Exercises Introduction to Machine Learning SS 2018 Series 7, May 22, 2018 (EM Convergence) Institute for Machine Learning Dept. of Computer Science, ETH Zürich Prof. Dr. Andreas Krause Web: https://las.inf.ethz.ch/teaching/introml-s18
Exercises Introduction to Machine Learning SS 2018 Series 7, May 22, 2018 (EM Convergence) Institute for Machine Learning Dept. of Computer Science, ETH Zürich Prof. Dr. Andreas Krause Web: https://las.inf.ethz.ch/teaching/introml-s18
5 Mutual Information and Channel Capacity
 5 Mutual Information and Channel Capacity In Section 2, we have seen the use of a quantity called entropy to measure the amount of randomness in a random variable. In this section, we introduce several
5 Mutual Information and Channel Capacity In Section 2, we have seen the use of a quantity called entropy to measure the amount of randomness in a random variable. In this section, we introduce several
Quantitative Biology II Lecture 4: Variational Methods
 10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
Chapter 4. Data Transmission and Channel Capacity. Po-Ning Chen, Professor. Department of Communications Engineering. National Chiao Tung University
 Chapter 4 Data Transmission and Channel Capacity Po-Ning Chen, Professor Department of Communications Engineering National Chiao Tung University Hsin Chu, Taiwan 30050, R.O.C. Principle of Data Transmission
Chapter 4 Data Transmission and Channel Capacity Po-Ning Chen, Professor Department of Communications Engineering National Chiao Tung University Hsin Chu, Taiwan 30050, R.O.C. Principle of Data Transmission
Variable selection and feature construction using methods related to information theory
 Outline Variable selection and feature construction using methods related to information theory Kari 1 1 Intelligent Systems Lab, Motorola, Tempe, AZ IJCNN 2007 Outline Outline 1 Information Theory and
Outline Variable selection and feature construction using methods related to information theory Kari 1 1 Intelligent Systems Lab, Motorola, Tempe, AZ IJCNN 2007 Outline Outline 1 Information Theory and
ELEMENT OF INFORMATION THEORY
 History Table of Content ELEMENT OF INFORMATION THEORY O. Le Meur olemeur@irisa.fr Univ. of Rennes 1 http://www.irisa.fr/temics/staff/lemeur/ October 2010 1 History Table of Content VERSION: 2009-2010:
History Table of Content ELEMENT OF INFORMATION THEORY O. Le Meur olemeur@irisa.fr Univ. of Rennes 1 http://www.irisa.fr/temics/staff/lemeur/ October 2010 1 History Table of Content VERSION: 2009-2010:
The binary entropy function
 ECE 7680 Lecture 2 Definitions and Basic Facts Objective: To learn a bunch of definitions about entropy and information measures that will be useful through the quarter, and to present some simple but
ECE 7680 Lecture 2 Definitions and Basic Facts Objective: To learn a bunch of definitions about entropy and information measures that will be useful through the quarter, and to present some simple but
Probabilistic and Bayesian Machine Learning
 Probabilistic and Bayesian Machine Learning Lecture 1: Introduction to Probabilistic Modelling Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Why a
Probabilistic and Bayesian Machine Learning Lecture 1: Introduction to Probabilistic Modelling Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Why a
Statistical Machine Learning Lectures 4: Variational Bayes
 1 / 29 Statistical Machine Learning Lectures 4: Variational Bayes Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 29 Synonyms Variational Bayes Variational Inference Variational Bayesian Inference
1 / 29 Statistical Machine Learning Lectures 4: Variational Bayes Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 29 Synonyms Variational Bayes Variational Inference Variational Bayesian Inference
3F1 Information Theory, Lecture 1
 3F1 Information Theory, Lecture 1 Jossy Sayir Department of Engineering Michaelmas 2013, 22 November 2013 Organisation History Entropy Mutual Information 2 / 18 Course Organisation 4 lectures Course material:
3F1 Information Theory, Lecture 1 Jossy Sayir Department of Engineering Michaelmas 2013, 22 November 2013 Organisation History Entropy Mutual Information 2 / 18 Course Organisation 4 lectures Course material:
Chapter 2: Entropy and Mutual Information. University of Illinois at Chicago ECE 534, Natasha Devroye
 Chapter 2: Entropy and Mutual Information Chapter 2 outline Definitions Entropy Joint entropy, conditional entropy Relative entropy, mutual information Chain rules Jensen s inequality Log-sum inequality
Chapter 2: Entropy and Mutual Information Chapter 2 outline Definitions Entropy Joint entropy, conditional entropy Relative entropy, mutual information Chain rules Jensen s inequality Log-sum inequality
ECE 4400:693 - Information Theory
 ECE 4400:693 - Information Theory Dr. Nghi Tran Lecture 8: Differential Entropy Dr. Nghi Tran (ECE-University of Akron) ECE 4400:693 Lecture 1 / 43 Outline 1 Review: Entropy of discrete RVs 2 Differential
ECE 4400:693 - Information Theory Dr. Nghi Tran Lecture 8: Differential Entropy Dr. Nghi Tran (ECE-University of Akron) ECE 4400:693 Lecture 1 / 43 Outline 1 Review: Entropy of discrete RVs 2 Differential
Bioinformatics: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Where (or of what) one cannot speak, one must pass over in silence.
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Where (or of what) one cannot speak, one must pass over in silence.
02 Background Minimum background on probability. Random process
 0 Background 0.03 Minimum background on probability Random processes Probability Conditional probability Bayes theorem Random variables Sampling and estimation Variance, covariance and correlation Probability
0 Background 0.03 Minimum background on probability Random processes Probability Conditional probability Bayes theorem Random variables Sampling and estimation Variance, covariance and correlation Probability
PROBABILITY AND INFORMATION THEORY. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
Information Theory Primer:
 Information Theory Primer: Entropy, KL Divergence, Mutual Information, Jensen s inequality Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Information Theory Primer: Entropy, KL Divergence, Mutual Information, Jensen s inequality Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Information Theory. Coding and Information Theory. Information Theory Textbooks. Entropy
 Coding and Information Theory Chris Williams, School of Informatics, University of Edinburgh Overview What is information theory? Entropy Coding Information Theory Shannon (1948): Information theory is
Coding and Information Theory Chris Williams, School of Informatics, University of Edinburgh Overview What is information theory? Entropy Coding Information Theory Shannon (1948): Information theory is
Introduction to Machine Learning
 Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
3F1 Information Theory, Lecture 3
 3F1 Information Theory, Lecture 3 Jossy Sayir Department of Engineering Michaelmas 2011, 28 November 2011 Memoryless Sources Arithmetic Coding Sources with Memory 2 / 19 Summary of last lecture Prefix-free
3F1 Information Theory, Lecture 3 Jossy Sayir Department of Engineering Michaelmas 2011, 28 November 2011 Memoryless Sources Arithmetic Coding Sources with Memory 2 / 19 Summary of last lecture Prefix-free
Information Theory, Statistics, and Decision Trees
 Information Theory, Statistics, and Decision Trees Léon Bottou COS 424 4/6/2010 Summary 1. Basic information theory. 2. Decision trees. 3. Information theory and statistics. Léon Bottou 2/31 COS 424 4/6/2010
Information Theory, Statistics, and Decision Trees Léon Bottou COS 424 4/6/2010 Summary 1. Basic information theory. 2. Decision trees. 3. Information theory and statistics. Léon Bottou 2/31 COS 424 4/6/2010
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Chapter I: Fundamental Information Theory
 ECE-S622/T62 Notes Chapter I: Fundamental Information Theory Ruifeng Zhang Dept. of Electrical & Computer Eng. Drexel University. Information Source Information is the outcome of some physical processes.
ECE-S622/T62 Notes Chapter I: Fundamental Information Theory Ruifeng Zhang Dept. of Electrical & Computer Eng. Drexel University. Information Source Information is the outcome of some physical processes.
Probability, Entropy, and Inference / More About Inference
 Probability, Entropy, and Inference / More About Inference Mário S. Alvim (msalvim@dcc.ufmg.br) Information Theory DCC-UFMG (2018/02) Mário S. Alvim (msalvim@dcc.ufmg.br) Probability, Entropy, and Inference
Probability, Entropy, and Inference / More About Inference Mário S. Alvim (msalvim@dcc.ufmg.br) Information Theory DCC-UFMG (2018/02) Mário S. Alvim (msalvim@dcc.ufmg.br) Probability, Entropy, and Inference
13 : Variational Inference: Loopy Belief Propagation and Mean Field
 10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
Classical Information Theory Notes from the lectures by prof Suhov Trieste - june 2006
 Classical Information Theory Notes from the lectures by prof Suhov Trieste - june 2006 Fabio Grazioso... July 3, 2006 1 2 Contents 1 Lecture 1, Entropy 4 1.1 Random variable...............................
Classical Information Theory Notes from the lectures by prof Suhov Trieste - june 2006 Fabio Grazioso... July 3, 2006 1 2 Contents 1 Lecture 1, Entropy 4 1.1 Random variable...............................
Machine Learning Lecture Notes
 Machine Learning Lecture Notes Predrag Radivojac January 25, 205 Basic Principles of Parameter Estimation In probabilistic modeling, we are typically presented with a set of observations and the objective
Machine Learning Lecture Notes Predrag Radivojac January 25, 205 Basic Principles of Parameter Estimation In probabilistic modeling, we are typically presented with a set of observations and the objective
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Lecture 8: Graphical models for Text
 Lecture 8: Graphical models for Text 4F13: Machine Learning Joaquin Quiñonero-Candela and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/
Lecture 8: Graphical models for Text 4F13: Machine Learning Joaquin Quiñonero-Candela and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
Machine Learning Srihari. Information Theory. Sargur N. Srihari
 Information Theory Sargur N. Srihari 1 Topics 1. Entropy as an Information Measure 1. Discrete variable definition Relationship to Code Length 2. Continuous Variable Differential Entropy 2. Maximum Entropy
Information Theory Sargur N. Srihari 1 Topics 1. Entropy as an Information Measure 1. Discrete variable definition Relationship to Code Length 2. Continuous Variable Differential Entropy 2. Maximum Entropy
Lecture 11: Continuous-valued signals and differential entropy
 Lecture 11: Continuous-valued signals and differential entropy Biology 429 Carl Bergstrom September 20, 2008 Sources: Parts of today s lecture follow Chapter 8 from Cover and Thomas (2007). Some components
Lecture 11: Continuous-valued signals and differential entropy Biology 429 Carl Bergstrom September 20, 2008 Sources: Parts of today s lecture follow Chapter 8 from Cover and Thomas (2007). Some components
CS 591, Lecture 2 Data Analytics: Theory and Applications Boston University
 CS 591, Lecture 2 Data Analytics: Theory and Applications Boston University Charalampos E. Tsourakakis January 25rd, 2017 Probability Theory The theory of probability is a system for making better guesses.
CS 591, Lecture 2 Data Analytics: Theory and Applications Boston University Charalampos E. Tsourakakis January 25rd, 2017 Probability Theory The theory of probability is a system for making better guesses.
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Lecture 5 Channel Coding over Continuous Channels
 Lecture 5 Channel Coding over Continuous Channels I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw November 14, 2014 1 / 34 I-Hsiang Wang NIT Lecture 5 From
Lecture 5 Channel Coding over Continuous Channels I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw November 14, 2014 1 / 34 I-Hsiang Wang NIT Lecture 5 From
Quantitative Biology Lecture 3
 23 nd Sep 2015 Quantitative Biology Lecture 3 Gurinder Singh Mickey Atwal Center for Quantitative Biology Summary Covariance, Correlation Confounding variables (Batch Effects) Information Theory Covariance
23 nd Sep 2015 Quantitative Biology Lecture 3 Gurinder Singh Mickey Atwal Center for Quantitative Biology Summary Covariance, Correlation Confounding variables (Batch Effects) Information Theory Covariance
MAHALAKSHMI ENGINEERING COLLEGE-TRICHY QUESTION BANK UNIT V PART-A. 1. What is binary symmetric channel (AUC DEC 2006)
") MAHALAKSHMI ENGINEERING COLLEGE-TRICHY QUESTION BANK SATELLITE COMMUNICATION DEPT./SEM.:ECE/VIII UNIT V PART-A 1. What is binary symmetric channel (AUC DEC 2006) 2. Define information rate? (AUC DEC 2007)
MAHALAKSHMI ENGINEERING COLLEGE-TRICHY QUESTION BANK SATELLITE COMMUNICATION DEPT./SEM.:ECE/VIII UNIT V PART-A 1. What is binary symmetric channel (AUC DEC 2006) 2. Define information rate? (AUC DEC 2007)
1 Introduction. Sept CS497:Learning and NLP Lec 4: Mathematical and Computational Paradigms Fall Consider the following examples:
 Sept. 20-22 2005 1 CS497:Learning and NLP Lec 4: Mathematical and Computational Paradigms Fall 2005 In this lecture we introduce some of the mathematical tools that are at the base of the technical approaches
Sept. 20-22 2005 1 CS497:Learning and NLP Lec 4: Mathematical and Computational Paradigms Fall 2005 In this lecture we introduce some of the mathematical tools that are at the base of the technical approaches
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
QB LECTURE #4: Motif Finding
 QB LECTURE #4: Motif Finding Adam Siepel Nov. 20, 2015 2 Plan for Today Probability models for binding sites Scoring and detecting binding sites De novo motif finding 3 Transcription Initiation Chromatin
QB LECTURE #4: Motif Finding Adam Siepel Nov. 20, 2015 2 Plan for Today Probability models for binding sites Scoring and detecting binding sites De novo motif finding 3 Transcription Initiation Chromatin
an introduction to bayesian inference
 with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak
 Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
ELEC546 Review of Information Theory
 ELEC546 Review of Information Theory Vincent Lau 1/1/004 1 Review of Information Theory Entropy: Measure of uncertainty of a random variable X. The entropy of X, H(X), is given by: If X is a discrete random
ELEC546 Review of Information Theory Vincent Lau 1/1/004 1 Review of Information Theory Entropy: Measure of uncertainty of a random variable X. The entropy of X, H(X), is given by: If X is a discrete random
MACHINE LEARNING INTRODUCTION: STRING CLASSIFICATION
 MACHINE LEARNING INTRODUCTION: STRING CLASSIFICATION THOMAS MAILUND Machine learning means different things to different people, and there is no general agreed upon core set of algorithms that must be
MACHINE LEARNING INTRODUCTION: STRING CLASSIFICATION THOMAS MAILUND Machine learning means different things to different people, and there is no general agreed upon core set of algorithms that must be
Lecture 7. Union bound for reducing M-ary to binary hypothesis testing
 Lecture 7 Agenda for the lecture M-ary hypothesis testing and the MAP rule Union bound for reducing M-ary to binary hypothesis testing Introduction of the channel coding problem 7.1 M-ary hypothesis testing
Lecture 7 Agenda for the lecture M-ary hypothesis testing and the MAP rule Union bound for reducing M-ary to binary hypothesis testing Introduction of the channel coding problem 7.1 M-ary hypothesis testing
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Capacity of a channel Shannon s second theorem. Information Theory 1/33
 Capacity of a channel Shannon s second theorem Information Theory 1/33 Outline 1. Memoryless channels, examples ; 2. Capacity ; 3. Symmetric channels ; 4. Channel Coding ; 5. Shannon s second theorem,
Capacity of a channel Shannon s second theorem Information Theory 1/33 Outline 1. Memoryless channels, examples ; 2. Capacity ; 3. Symmetric channels ; 4. Channel Coding ; 5. Shannon s second theorem,
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning
 Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Lecture 4 Noisy Channel Coding
 Lecture 4 Noisy Channel Coding I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw October 9, 2015 1 / 56 I-Hsiang Wang IT Lecture 4 The Channel Coding Problem
Lecture 4 Noisy Channel Coding I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw October 9, 2015 1 / 56 I-Hsiang Wang IT Lecture 4 The Channel Coding Problem
Lecture 11: Information theory THURSDAY, FEBRUARY 21, 2019
 Lecture 11: Information theory DANIEL WELLER THURSDAY, FEBRUARY 21, 2019 Agenda Information and probability Entropy and coding Mutual information and capacity Both images contain the same fraction of black
Lecture 11: Information theory DANIEL WELLER THURSDAY, FEBRUARY 21, 2019 Agenda Information and probability Entropy and coding Mutual information and capacity Both images contain the same fraction of black
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Bayesian Inference Course, WTCN, UCL, March 2013
 Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Feature selection. c Victor Kitov August Summer school on Machine Learning in High Energy Physics in partnership with
 Feature selection c Victor Kitov v.v.kitov@yandex.ru Summer school on Machine Learning in High Energy Physics in partnership with August 2015 1/38 Feature selection Feature selection is a process of selecting
Feature selection c Victor Kitov v.v.kitov@yandex.ru Summer school on Machine Learning in High Energy Physics in partnership with August 2015 1/38 Feature selection Feature selection is a process of selecting
Lecture 5 - Information theory
 Lecture 5 - Information theory Jan Bouda FI MU May 18, 2012 Jan Bouda (FI MU) Lecture 5 - Information theory May 18, 2012 1 / 42 Part I Uncertainty and entropy Jan Bouda (FI MU) Lecture 5 - Information
Lecture 5 - Information theory Jan Bouda FI MU May 18, 2012 Jan Bouda (FI MU) Lecture 5 - Information theory May 18, 2012 1 / 42 Part I Uncertainty and entropy Jan Bouda (FI MU) Lecture 5 - Information
Probability and Estimation. Alan Moses
 Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Information in Biology
 Lecture 3: Information in Biology Tsvi Tlusty, tsvi@unist.ac.kr Living information is carried by molecular channels Living systems I. Self-replicating information processors Environment II. III. Evolve
Lecture 3: Information in Biology Tsvi Tlusty, tsvi@unist.ac.kr Living information is carried by molecular channels Living systems I. Self-replicating information processors Environment II. III. Evolve
MAHALAKSHMI ENGINEERING COLLEGE QUESTION BANK. SUBJECT CODE / Name: EC2252 COMMUNICATION THEORY UNIT-V INFORMATION THEORY PART-A
 MAHALAKSHMI ENGINEERING COLLEGE QUESTION BANK DEPARTMENT: ECE SEMESTER: IV SUBJECT CODE / Name: EC2252 COMMUNICATION THEORY UNIT-V INFORMATION THEORY PART-A 1. What is binary symmetric channel (AUC DEC
MAHALAKSHMI ENGINEERING COLLEGE QUESTION BANK DEPARTMENT: ECE SEMESTER: IV SUBJECT CODE / Name: EC2252 COMMUNICATION THEORY UNIT-V INFORMATION THEORY PART-A 1. What is binary symmetric channel (AUC DEC
Information Theory. David Rosenberg. June 15, New York University. David Rosenberg (New York University) DS-GA 1003 June 15, / 18
 DS-GA 1003 June 15, / 18") Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
Introduction to Machine Learning
 What does this mean? Outline Contents Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola December 26, 2017 1 Introduction to Probability 1 2 Random Variables 3 3 Bayes
What does this mean? Outline Contents Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola December 26, 2017 1 Introduction to Probability 1 2 Random Variables 3 3 Bayes
Information. = more information was provided by the outcome in #2
 Outline First part based very loosely on [Abramson 63]. Information theory usually formulated in terms of information channels and coding will not discuss those here.. Information 2. Entropy 3. Mutual
Outline First part based very loosely on [Abramson 63]. Information theory usually formulated in terms of information channels and coding will not discuss those here.. Information 2. Entropy 3. Mutual
A Gentle Tutorial on Information Theory and Learning. Roni Rosenfeld. Carnegie Mellon University
 A Gentle Tutorial on Information Theory and Learning Roni Rosenfeld Mellon University Mellon Outline First part based very loosely on [Abramson 63]. Information theory usually formulated in terms of information
A Gentle Tutorial on Information Theory and Learning Roni Rosenfeld Mellon University Mellon Outline First part based very loosely on [Abramson 63]. Information theory usually formulated in terms of information
Clustering and Gaussian Mixture Models
 Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Homework 1 Due: Thursday 2/5/2015. Instructions: Turn in your homework in class on Thursday 2/5/2015
 10-704 Homework 1 Due: Thursday 2/5/2015 Instructions: Turn in your homework in class on Thursday 2/5/2015 1. Information Theory Basics and Inequalities C&T 2.47, 2.29 (a) A deck of n cards in order 1,
10-704 Homework 1 Due: Thursday 2/5/2015 Instructions: Turn in your homework in class on Thursday 2/5/2015 1. Information Theory Basics and Inequalities C&T 2.47, 2.29 (a) A deck of n cards in order 1,
Probabilistic Graphical Models
 Probabilistic Graphical Models Introduction. Basic Probability and Bayes Volkan Cevher, Matthias Seeger Ecole Polytechnique Fédérale de Lausanne 26/9/2011 (EPFL) Graphical Models 26/9/2011 1 / 28 Outline
Probabilistic Graphical Models Introduction. Basic Probability and Bayes Volkan Cevher, Matthias Seeger Ecole Polytechnique Fédérale de Lausanne 26/9/2011 (EPFL) Graphical Models 26/9/2011 1 / 28 Outline
DEEP LEARNING CHAPTER 3 PROBABILITY & INFORMATION THEORY
 DEEP LEARNING CHAPTER 3 PROBABILITY & INFORMATION THEORY OUTLINE 3.1 Why Probability? 3.2 Random Variables 3.3 Probability Distributions 3.4 Marginal Probability 3.5 Conditional Probability 3.6 The Chain
DEEP LEARNING CHAPTER 3 PROBABILITY & INFORMATION THEORY OUTLINE 3.1 Why Probability? 3.2 Random Variables 3.3 Probability Distributions 3.4 Marginal Probability 3.5 Conditional Probability 3.6 The Chain
Intro to Probability. Andrei Barbu
 Intro to Probability Andrei Barbu Some problems Some problems A means to capture uncertainty Some problems A means to capture uncertainty You have data from two sources, are they different? Some problems
Intro to Probability Andrei Barbu Some problems Some problems A means to capture uncertainty Some problems A means to capture uncertainty You have data from two sources, are they different? Some problems
Robust Monte Carlo Methods for Sequential Planning and Decision Making
 Robust Monte Carlo Methods for Sequential Planning and Decision Making Sue Zheng, Jason Pacheco, & John Fisher Sensing, Learning, & Inference Group Computer Science & Artificial Intelligence Laboratory
Robust Monte Carlo Methods for Sequential Planning and Decision Making Sue Zheng, Jason Pacheco, & John Fisher Sensing, Learning, & Inference Group Computer Science & Artificial Intelligence Laboratory
Information in Biology
 Information in Biology CRI - Centre de Recherches Interdisciplinaires, Paris May 2012 Information processing is an essential part of Life. Thinking about it in quantitative terms may is useful. 1 Living
Information in Biology CRI - Centre de Recherches Interdisciplinaires, Paris May 2012 Information processing is an essential part of Life. Thinking about it in quantitative terms may is useful. 1 Living
4F5: Advanced Communications and Coding Handout 2: The Typical Set, Compression, Mutual Information
 4F5: Advanced Communications and Coding Handout 2: The Typical Set, Compression, Mutual Information Ramji Venkataramanan Signal Processing and Communications Lab Department of Engineering ramji.v@eng.cam.ac.uk
4F5: Advanced Communications and Coding Handout 2: The Typical Set, Compression, Mutual Information Ramji Venkataramanan Signal Processing and Communications Lab Department of Engineering ramji.v@eng.cam.ac.uk
(each row defines a probability distribution). Given n-strings x X n, y Y n we can use the absence of memory in the channel to compute
. Given n-strings x X n, y Y n we can use the absence of memory in the channel to compute") ENEE 739C: Advanced Topics in Signal Processing: Coding Theory Instructor: Alexander Barg Lecture 6 (draft; 9/6/03. Error exponents for Discrete Memoryless Channels http://www.enee.umd.edu/ abarg/enee739c/course.html
ENEE 739C: Advanced Topics in Signal Processing: Coding Theory Instructor: Alexander Barg Lecture 6 (draft; 9/6/03. Error exponents for Discrete Memoryless Channels http://www.enee.umd.edu/ abarg/enee739c/course.html
Ch. 8 Math Preliminaries for Lossy Coding. 8.4 Info Theory Revisited
 Ch. 8 Math Preliminaries for Lossy Coding 8.4 Info Theory Revisited 1 Info Theory Goals for Lossy Coding Again just as for the lossless case Info Theory provides: Basis for Algorithms & Bounds on Performance
Ch. 8 Math Preliminaries for Lossy Coding 8.4 Info Theory Revisited 1 Info Theory Goals for Lossy Coding Again just as for the lossless case Info Theory provides: Basis for Algorithms & Bounds on Performance
Entropies & Information Theory
 Entropies & Information Theory LECTURE I Nilanjana Datta University of Cambridge,U.K. See lecture notes on: http://www.qi.damtp.cam.ac.uk/node/223 Quantum Information Theory Born out of Classical Information
Entropies & Information Theory LECTURE I Nilanjana Datta University of Cambridge,U.K. See lecture notes on: http://www.qi.damtp.cam.ac.uk/node/223 Quantum Information Theory Born out of Classical Information
Expectation Propagation for Approximate Bayesian Inference
 Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Lecture 1: Entropy, convexity, and matrix scaling CSE 599S: Entropy optimality, Winter 2016 Instructor: James R. Lee Last updated: January 24, 2016
 Lecture 1: Entropy, convexity, and matrix scaling CSE 599S: Entropy optimality, Winter 2016 Instructor: James R. Lee Last updated: January 24, 2016 1 Entropy Since this course is about entropy maximization,
Lecture 1: Entropy, convexity, and matrix scaling CSE 599S: Entropy optimality, Winter 2016 Instructor: James R. Lee Last updated: January 24, 2016 1 Entropy Since this course is about entropy maximization,
Complex Systems Methods 2. Conditional mutual information, entropy rate and algorithmic complexity
 Complex Systems Methods 2. Conditional mutual information, entropy rate and algorithmic complexity Eckehard Olbrich MPI MiS Leipzig Potsdam WS 2007/08 Olbrich (Leipzig) 26.10.2007 1 / 18 Overview 1 Summary
Complex Systems Methods 2. Conditional mutual information, entropy rate and algorithmic complexity Eckehard Olbrich MPI MiS Leipzig Potsdam WS 2007/08 Olbrich (Leipzig) 26.10.2007 1 / 18 Overview 1 Summary
Communication Theory II
 Communication Theory II Lecture 15: Information Theory (cont d) Ahmed Elnakib, PhD Assistant Professor, Mansoura University, Egypt March 29 th, 2015 1 Example: Channel Capacity of BSC o Let then: o For
Communication Theory II Lecture 15: Information Theory (cont d) Ahmed Elnakib, PhD Assistant Professor, Mansoura University, Egypt March 29 th, 2015 1 Example: Channel Capacity of BSC o Let then: o For
Bayesian Inference and MCMC
 Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016
 MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016 Lecture 14: Information Theoretic Methods Lecturer: Jiaming Xu Scribe: Hilda Ibriga, Adarsh Barik, December 02, 2016 Outline f-divergence
MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016 Lecture 14: Information Theoretic Methods Lecturer: Jiaming Xu Scribe: Hilda Ibriga, Adarsh Barik, December 02, 2016 Outline f-divergence
Biology as Information Dynamics
 Biology as Information Dynamics John Baez Biological Complexity: Can It Be Quantified? Beyond Center February 2, 2017 IT S ALL RELATIVE EVEN INFORMATION! When you learn something, how much information
Biology as Information Dynamics John Baez Biological Complexity: Can It Be Quantified? Beyond Center February 2, 2017 IT S ALL RELATIVE EVEN INFORMATION! When you learn something, how much information
Bayesian Machine Learning - Lecture 7
 Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1