CS 591, Lecture 2 Data Analytics: Theory and Applications Boston University
|
|
|
- Adelia Baldwin
- 5 years ago
- Views:
Transcription
1 CS 591, Lecture 2 Data Analytics: Theory and Applications Boston University Charalampos E. Tsourakakis January 25rd, 2017
2 Probability Theory
3 The theory of probability is a system for making better guesses. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 3 / 36
4 By the probability of a particular outcome of an observation we mean our estimate for the most likely fraction of a number of repeated observations that will yield that particular outcome. p(a) = N A N Babis Tsourakakis CS 591 Data Analytics, Lecture 2 4 / 36
5 Inclusion Exclusion theorem Theorem Suppose n N and A i is a finite set for 1 i n. It follows that A i = A i1 A i1 A i2 1 i n 1 i 1 n + 1 i 1 i 2 i 3 n 1 i 1 i 2 n n A i1 A i2 A i ( 1) n+1 A i i=1 Application (aka matching hat problem): Deal two packs of shuffled cards simultaneously. What is the probability that no pair of identical cards will be exposed simultaneously? Babis Tsourakakis CS 591 Data Analytics, Lecture 2 5 / 36
6 Inclusion Exclusion theorem Fix the first pack Let A i be the set of all possible arrangements of the second pack which match the card in position i of the first pack. X = i A i Details on whiteboard. X /52! = (52!) ( 1 ( 52 1)51! ( 52 2)50! + ( 52 3)49!.. ( 52 52)0! ) = 1 1/2! + 1/3!... 1/52! 1 ( ( 1) i /i!) i=0 = 1 1/e. Thus the desired probability is 1/e as n +. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 6 / 36
7 Fundamental Rules Pr [X Y ] = Pr [X ] + Pr [Y ] Pr [X Y ] (1) Pr [X ] = y Pr [X, Y = y] = y Pr [X Y = y]pr [Y = y] (2) Sum Rule Pr [X, Y ] = Pr [X Y ] = Pr [X ]Pr [Y X ] = Pr [Y ]Pr [X Y ] (3) Product Rule Babis Tsourakakis CS 591 Data Analytics, Lecture 2 7 / 36
8 Fundamental Rules By applying the product rule multiple times we obtain the chain rule: Pr [X 1, X 2,..., X n ] = Pr [X 1 ]Pr [X 2,..., X n X 1 ] =.. = Pr [X 1 ]Pr [X 2 X 1 ]Pr [X 3 X 2, X 1 ]... Pr [X n X 1,..., X n 1 ] (4) Chain Rule Pr [X Y ] = Pr [X Y ] (5) Pr [Y ] Conditional probability Babis Tsourakakis CS 591 Data Analytics, Lecture 2 8 / 36

9 Reminder: Bayes rule Bayes rule is a direct application of conditional probabilities. Pr [H D] = Pr [D H]Pr [H], and Pr [D] > 0, or... Pr [D] posterior likelihood prior. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 9 / 36
10 Independence and Conditional Independence We say X and Y are unconditionally independent or marginally independent, or just independent if As a result Notation: X Y Pr [X Y ] = Pr [X ],Pr [Y X ] = Pr [Y ] Pr [X, Y ] = Pr [X ]Pr [Y ]. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 10 / 36



11 Independence and Conditional Independence Source: Visual-Information/ Babis Tsourakakis CS 591 Data Analytics, Lecture 2 11 / 36


12 Independence and Conditional Independence Independence visualized Babis Tsourakakis CS 591 Data Analytics, Lecture 2 12 / 36

13 Independence and Conditional Independence Closer to reality Babis Tsourakakis CS 591 Data Analytics, Lecture 2 13 / 36


14 Independence and Conditional Independence Closer to reality... Babis Tsourakakis CS 591 Data Analytics, Lecture 2 14 / 36


15 Independence and Conditional Independence... or alternatively... Babis Tsourakakis CS 591 Data Analytics, Lecture 2 15 / 36


16 Independence and Conditional Independence... or alternatively... Babis Tsourakakis CS 591 Data Analytics, Lecture 2 16 / 36
17 Independence and Conditional Independence We say X and Y are conditionally independent given Z if Pr [X, Y Z] = Pr [X Z]Pr [Y Z]. Joint distribution factorizes as Pr [X, Y, Z] = Pr [X Z]Pr [Y Z]Pr [Z]. Notation: X Y Z Babis Tsourakakis CS 591 Data Analytics, Lecture 2 17 / 36
18 Mean, variance, covariance For discrete RVs E [X ] = x xpr [X = x] and for continuous E [X ] = x xp(x)dx The variance and the standard deviation std[x ] = σ are defined as Var [X ] = σ 2 = E [ (X E [X ]) 2] = E [ X 2] E [X ] 2. Reminder: Jensen s inequality states that if f is convex, then f (E [X ]) E [f (X )]. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 18 / 36
19 Mean, variance, covariance Covariance of two random variables X, Y cov[x, Y ] = E [(X E [X ])(Y E [Y ])] = = E [XY ] E [X ] E [Y ]. In general, if x is a d-dimensional random vector, the covariance is defined as cov[x] = E [ (x E [x])(x E [x]) T ]. Pearson correlation coefficient: corr[x, Y ] = cov[x, Y ] Var [X ] Var [Y ]. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 19 / 36
20 Mean, variance, covariance Correlation examples, Wikipedia Babis Tsourakakis CS 591 Data Analytics, Lecture 2 20 / 36
21 Probability distributions Source We will go over few important ones. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 21 / 36
22 Discrete distributions Details on whiteboard. Bernoulli: X Ber(p) Binomial: X Bin(n, p) Multinomial: x Mu(n, θ) Poisson: X Po(λ) Babis Tsourakakis CS 591 Data Analytics, Lecture 2 22 / 36
23 Continuous Univariate distributions Normal: X N(x; µ, σ 2 ) Student t distribution: X T (x; µ, σ 2, ν) Laplace: X Lap(x; µ, β) Gamma: X Ga(x; α, β) Pareto: Pareto(x k, m) Babis Tsourakakis CS 591 Data Analytics, Lecture 2 23 / 36
![Multivariate normal distribution Isotropic, i.e., Σ = σ 2 I N (x; µ, Σ) = 1 { exp 1 } (2π) D 2 Σ 1/2 2 (x µ)t Σ 1 (x µ) where µ = E [x], Σ = Cov[x].](/docs-images/95/124575358/images/24-0.jpg "Σ 1 = Λ is also known as the precision matrix. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 24 / 36")
24 Multivariate normal distribution Isotropic, i.e., Σ = σ 2 I N (x; µ, Σ) = 1 { exp 1 } (2π) D 2 Σ 1/2 2 (x µ)t Σ 1 (x µ) where µ = E [x], Σ = Cov[x]. Σ 1 = Λ is also known as the precision matrix. Babis Tsourakakis CS 591 Data Analytics, Lecture 2 24 / 36

25 Multivariate normal distribution µ = (0, 0), Σ = [21.8; 1.82] Contour plot Babis Tsourakakis CS 591 Data Analytics, Lecture 2 25 / 36
26 Linear transformations of Random Variables Suppose f is a linear function: Then, y = f (x) = Ax + b E [y] = AE [x] + b (6) by Linearity of Expectation Cov[y] = ACov[x]A T (7) Covariance Cov[y] = Var [ a T x + b ] = a T Cov[x]a (8) if f() scalar valued Babis Tsourakakis CS 591 Data Analytics, Lecture 2 26 / 36
27 Information Theory




28 Information Theory Suppose Bob wants to communicate with Alice by sending her bits. Example: Babis Tsourakakis CS 591 Data Analytics, Lecture 2 28 / 36




29 Information Theory Can we use fewer than 2 bits? Babis Tsourakakis CS 591 Data Analytics, Lecture 2 29 / 36


30 Information Theory Can we use fewer than 1.75 bits? Babis Tsourakakis CS 591 Data Analytics, Lecture 2 30 / 36
 = n p k log 2 ( 1 ).")
31 Information Theory Suppose there are n events, the k-th event with probability p k Shannon entropy, or just entropy is defined as: H(p 1,..., p n ) = n p k log 2 ( 1 ). p k k=1 Babis Tsourakakis CS 591 Data Analytics, Lecture 2 31 / 36
32 Information Theory Intuition: When the k-th event happends, we receive log( 1 p k ) bits of information. Therefore, H(p 1,..., p n ) is the expected number of bits in a random event. If p k = 0, we define p k log( 1 p k ) = 0 To see why: lim ɛ log( 1 ) = 0. ɛ 0+ p k Question: For what values p 1,..., p n is the entropy maximized? Babis Tsourakakis CS 591 Data Analytics, Lecture 2 32 / 36

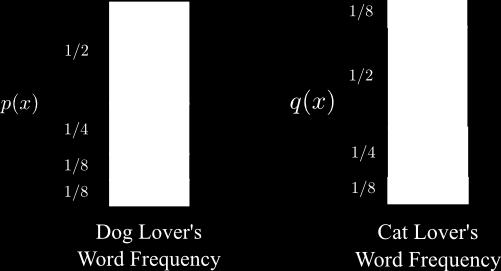


33 Information Theory Cross-entropy: Babis Tsourakakis CS 591 Data Analytics, Lecture 2 33 / 36
34 Information Theory Cross-entropy: H p (q) = x 1 q(x) log( p(x) ). H(p) = 1.75 H(q) = 1.75 H p (q) = = H q (p) Cross-entropy isnt symmetric! For the interested: Cross entropy and neural networks Babis Tsourakakis CS 591 Data Analytics, Lecture 2 34 / 36
35 Information Theory Kullback-Leibler divergence (aka as relative entropy): KL(p, q) = k p k log( p k q k ). KL(p, q) = H(p) + H q (p). Theorem with equality iff p = q. KL(p, q) 0 (9) Information Inequality Babis Tsourakakis CS 591 Data Analytics, Lecture 2 35 / 36
36 Information Theory How similar is the joint probability distribution p(x, Y ) to the factorization p(x )p(y )? I (X ; Y ) = KL(p(X, Y ) p(x )p(y )) = p(x, y) p(x, y) log( p(x)p(y) ) x,y (10) Mutual information Babis Tsourakakis CS 591 Data Analytics, Lecture 2 36 / 36
Introduction to Machine Learning
 Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
Introduction to Machine Learning
 What does this mean? Outline Contents Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola December 26, 2017 1 Introduction to Probability 1 2 Random Variables 3 3 Bayes
What does this mean? Outline Contents Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola December 26, 2017 1 Introduction to Probability 1 2 Random Variables 3 3 Bayes
Lecture 3. Probability - Part 2. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. October 19, 2016
 Lecture 3 Probability - Part 2 Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza October 19, 2016 Luigi Freda ( La Sapienza University) Lecture 3 October 19, 2016 1 / 46 Outline 1 Common Continuous
Lecture 3 Probability - Part 2 Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza October 19, 2016 Luigi Freda ( La Sapienza University) Lecture 3 October 19, 2016 1 / 46 Outline 1 Common Continuous
PROBABILITY AND INFORMATION THEORY. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
Hands-On Learning Theory Fall 2016, Lecture 3
 Hands-On Learning Theory Fall 016, Lecture 3 Jean Honorio jhonorio@purdue.edu 1 Information Theory First, we provide some information theory background. Definition 3.1 (Entropy). The entropy of a discrete
Hands-On Learning Theory Fall 016, Lecture 3 Jean Honorio jhonorio@purdue.edu 1 Information Theory First, we provide some information theory background. Definition 3.1 (Entropy). The entropy of a discrete
3. If a choice is broken down into two successive choices, the original H should be the weighted sum of the individual values of H.
 Appendix A Information Theory A.1 Entropy Shannon (Shanon, 1948) developed the concept of entropy to measure the uncertainty of a discrete random variable. Suppose X is a discrete random variable that
Appendix A Information Theory A.1 Entropy Shannon (Shanon, 1948) developed the concept of entropy to measure the uncertainty of a discrete random variable. Suppose X is a discrete random variable that
CS 630 Basic Probability and Information Theory. Tim Campbell
 CS 630 Basic Probability and Information Theory Tim Campbell 21 January 2003 Probability Theory Probability Theory is the study of how best to predict outcomes of events. An experiment (or trial or event)
CS 630 Basic Probability and Information Theory Tim Campbell 21 January 2003 Probability Theory Probability Theory is the study of how best to predict outcomes of events. An experiment (or trial or event)
Information Theory Primer:
 Information Theory Primer: Entropy, KL Divergence, Mutual Information, Jensen s inequality Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Information Theory Primer: Entropy, KL Divergence, Mutual Information, Jensen s inequality Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Machine learning - HT Maximum Likelihood
 Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework Formulate linear regression in the language of probability Introduce
Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework Formulate linear regression in the language of probability Introduce
Machine Learning. Lecture 02.2: Basics of Information Theory. Nevin L. Zhang
 Machine Learning Lecture 02.2: Basics of Information Theory Nevin L. Zhang lzhang@cse.ust.hk Department of Computer Science and Engineering The Hong Kong University of Science and Technology Nevin L. Zhang
Machine Learning Lecture 02.2: Basics of Information Theory Nevin L. Zhang lzhang@cse.ust.hk Department of Computer Science and Engineering The Hong Kong University of Science and Technology Nevin L. Zhang
Lecture 5 - Information theory
 Lecture 5 - Information theory Jan Bouda FI MU May 18, 2012 Jan Bouda (FI MU) Lecture 5 - Information theory May 18, 2012 1 / 42 Part I Uncertainty and entropy Jan Bouda (FI MU) Lecture 5 - Information
Lecture 5 - Information theory Jan Bouda FI MU May 18, 2012 Jan Bouda (FI MU) Lecture 5 - Information theory May 18, 2012 1 / 42 Part I Uncertainty and entropy Jan Bouda (FI MU) Lecture 5 - Information
Chapter 5 continued. Chapter 5 sections
 Chapter 5 sections Discrete univariate distributions: 5.2 Bernoulli and Binomial distributions Just skim 5.3 Hypergeometric distributions 5.4 Poisson distributions Just skim 5.5 Negative Binomial distributions
Chapter 5 sections Discrete univariate distributions: 5.2 Bernoulli and Binomial distributions Just skim 5.3 Hypergeometric distributions 5.4 Poisson distributions Just skim 5.5 Negative Binomial distributions
Probability reminders
 CS246 Winter 204 Mining Massive Data Sets Probability reminders Sammy El Ghazzal selghazz@stanfordedu Disclaimer These notes may contain typos, mistakes or confusing points Please contact the author so
CS246 Winter 204 Mining Massive Data Sets Probability reminders Sammy El Ghazzal selghazz@stanfordedu Disclaimer These notes may contain typos, mistakes or confusing points Please contact the author so
Recitation 2: Probability
 Recitation 2: Probability Colin White, Kenny Marino January 23, 2018 Outline Facts about sets Definitions and facts about probability Random Variables and Joint Distributions Characteristics of distributions
Recitation 2: Probability Colin White, Kenny Marino January 23, 2018 Outline Facts about sets Definitions and facts about probability Random Variables and Joint Distributions Characteristics of distributions
Expectation Maximization
 Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
Chapter 2: Entropy and Mutual Information. University of Illinois at Chicago ECE 534, Natasha Devroye
 Chapter 2: Entropy and Mutual Information Chapter 2 outline Definitions Entropy Joint entropy, conditional entropy Relative entropy, mutual information Chain rules Jensen s inequality Log-sum inequality
Chapter 2: Entropy and Mutual Information Chapter 2 outline Definitions Entropy Joint entropy, conditional entropy Relative entropy, mutual information Chain rules Jensen s inequality Log-sum inequality
Lecture 1: Introduction, Entropy and ML estimation
 0-704: Information Processing and Learning Spring 202 Lecture : Introduction, Entropy and ML estimation Lecturer: Aarti Singh Scribes: Min Xu Disclaimer: These notes have not been subjected to the usual
0-704: Information Processing and Learning Spring 202 Lecture : Introduction, Entropy and ML estimation Lecturer: Aarti Singh Scribes: Min Xu Disclaimer: These notes have not been subjected to the usual
Statistical Machine Learning Lectures 4: Variational Bayes
 1 / 29 Statistical Machine Learning Lectures 4: Variational Bayes Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 29 Synonyms Variational Bayes Variational Inference Variational Bayesian Inference
1 / 29 Statistical Machine Learning Lectures 4: Variational Bayes Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 29 Synonyms Variational Bayes Variational Inference Variational Bayesian Inference
Lecture 1: August 28
 36-705: Intermediate Statistics Fall 2017 Lecturer: Siva Balakrishnan Lecture 1: August 28 Our broad goal for the first few lectures is to try to understand the behaviour of sums of independent random
36-705: Intermediate Statistics Fall 2017 Lecturer: Siva Balakrishnan Lecture 1: August 28 Our broad goal for the first few lectures is to try to understand the behaviour of sums of independent random
ECE 4400:693 - Information Theory
 ECE 4400:693 - Information Theory Dr. Nghi Tran Lecture 8: Differential Entropy Dr. Nghi Tran (ECE-University of Akron) ECE 4400:693 Lecture 1 / 43 Outline 1 Review: Entropy of discrete RVs 2 Differential
ECE 4400:693 - Information Theory Dr. Nghi Tran Lecture 8: Differential Entropy Dr. Nghi Tran (ECE-University of Akron) ECE 4400:693 Lecture 1 / 43 Outline 1 Review: Entropy of discrete RVs 2 Differential
Review of probability
 Review of probability Computer Sciences 760 Spring 2014 http://pages.cs.wisc.edu/~dpage/cs760/ Goals for the lecture you should understand the following concepts definition of probability random variables
Review of probability Computer Sciences 760 Spring 2014 http://pages.cs.wisc.edu/~dpage/cs760/ Goals for the lecture you should understand the following concepts definition of probability random variables
01 Probability Theory and Statistics Review
 NAVARCH/EECS 568, ROB 530 - Winter 2018 01 Probability Theory and Statistics Review Maani Ghaffari January 08, 2018 Last Time: Bayes Filters Given: Stream of observations z 1:t and action data u 1:t Sensor/measurement
NAVARCH/EECS 568, ROB 530 - Winter 2018 01 Probability Theory and Statistics Review Maani Ghaffari January 08, 2018 Last Time: Bayes Filters Given: Stream of observations z 1:t and action data u 1:t Sensor/measurement
Lecture 6: Gaussian Channels. Copyright G. Caire (Sample Lectures) 157
 157") Lecture 6: Gaussian Channels Copyright G. Caire (Sample Lectures) 157 Differential entropy (1) Definition 18. The (joint) differential entropy of a continuous random vector X n p X n(x) over R is: Z h(x
Lecture 6: Gaussian Channels Copyright G. Caire (Sample Lectures) 157 Differential entropy (1) Definition 18. The (joint) differential entropy of a continuous random vector X n p X n(x) over R is: Z h(x
Part IA Probability. Definitions. Based on lectures by R. Weber Notes taken by Dexter Chua. Lent 2015
 Part IA Probability Definitions Based on lectures by R. Weber Notes taken by Dexter Chua Lent 2015 These notes are not endorsed by the lecturers, and I have modified them (often significantly) after lectures.
Part IA Probability Definitions Based on lectures by R. Weber Notes taken by Dexter Chua Lent 2015 These notes are not endorsed by the lecturers, and I have modified them (often significantly) after lectures.
Part IA Probability. Theorems. Based on lectures by R. Weber Notes taken by Dexter Chua. Lent 2015
 Part IA Probability Theorems Based on lectures by R. Weber Notes taken by Dexter Chua Lent 2015 These notes are not endorsed by the lecturers, and I have modified them (often significantly) after lectures.
Part IA Probability Theorems Based on lectures by R. Weber Notes taken by Dexter Chua Lent 2015 These notes are not endorsed by the lecturers, and I have modified them (often significantly) after lectures.
Formulas for probability theory and linear models SF2941
 Formulas for probability theory and linear models SF2941 These pages + Appendix 2 of Gut) are permitted as assistance at the exam. 11 maj 2008 Selected formulae of probability Bivariate probability Transforms
Formulas for probability theory and linear models SF2941 These pages + Appendix 2 of Gut) are permitted as assistance at the exam. 11 maj 2008 Selected formulae of probability Bivariate probability Transforms
COMPSCI 650 Applied Information Theory Jan 21, Lecture 2
 COMPSCI 650 Applied Information Theory Jan 21, 2016 Lecture 2 Instructor: Arya Mazumdar Scribe: Gayane Vardoyan, Jong-Chyi Su 1 Entropy Definition: Entropy is a measure of uncertainty of a random variable.
COMPSCI 650 Applied Information Theory Jan 21, 2016 Lecture 2 Instructor: Arya Mazumdar Scribe: Gayane Vardoyan, Jong-Chyi Su 1 Entropy Definition: Entropy is a measure of uncertainty of a random variable.
CS37300 Class Notes. Jennifer Neville, Sebastian Moreno, Bruno Ribeiro
 CS37300 Class Notes Jennifer Neville, Sebastian Moreno, Bruno Ribeiro 2 Background on Probability and Statistics These are basic definitions, concepts, and equations that should have been covered in your
CS37300 Class Notes Jennifer Neville, Sebastian Moreno, Bruno Ribeiro 2 Background on Probability and Statistics These are basic definitions, concepts, and equations that should have been covered in your
Lecture 2: August 31
 0-704: Information Processing and Learning Fall 206 Lecturer: Aarti Singh Lecture 2: August 3 Note: These notes are based on scribed notes from Spring5 offering of this course. LaTeX template courtesy
0-704: Information Processing and Learning Fall 206 Lecturer: Aarti Singh Lecture 2: August 3 Note: These notes are based on scribed notes from Spring5 offering of this course. LaTeX template courtesy
Basics on Probability. Jingrui He 09/11/2007
 Basics on Probability Jingrui He 09/11/2007 Coin Flips You flip a coin Head with probability 0.5 You flip 100 coins How many heads would you expect Coin Flips cont. You flip a coin Head with probability
Basics on Probability Jingrui He 09/11/2007 Coin Flips You flip a coin Head with probability 0.5 You flip 100 coins How many heads would you expect Coin Flips cont. You flip a coin Head with probability
Introduction to Statistical Learning Theory
 Introduction to Statistical Learning Theory In the last unit we looked at regularization - adding a w 2 penalty. We add a bias - we prefer classifiers with low norm. How to incorporate more complicated
Introduction to Statistical Learning Theory In the last unit we looked at regularization - adding a w 2 penalty. We add a bias - we prefer classifiers with low norm. How to incorporate more complicated
Quantitative Biology II Lecture 4: Variational Methods
 10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
Gaussian discriminant analysis Naive Bayes
 DM825 Introduction to Machine Learning Lecture 7 Gaussian discriminant analysis Marco Chiarandini Department of Mathematics & Computer Science University of Southern Denmark Outline 1. is 2. Multi-variate
DM825 Introduction to Machine Learning Lecture 7 Gaussian discriminant analysis Marco Chiarandini Department of Mathematics & Computer Science University of Southern Denmark Outline 1. is 2. Multi-variate
Probability Theory Review Reading Assignments
 Probability Theory Review Reading Assignments R. Duda, P. Hart, and D. Stork, Pattern Classification, John-Wiley, 2nd edition, 2001 (appendix A.4, hard-copy). "Everything I need to know about Probability"
Probability Theory Review Reading Assignments R. Duda, P. Hart, and D. Stork, Pattern Classification, John-Wiley, 2nd edition, 2001 (appendix A.4, hard-copy). "Everything I need to know about Probability"
DEEP LEARNING CHAPTER 3 PROBABILITY & INFORMATION THEORY
 DEEP LEARNING CHAPTER 3 PROBABILITY & INFORMATION THEORY OUTLINE 3.1 Why Probability? 3.2 Random Variables 3.3 Probability Distributions 3.4 Marginal Probability 3.5 Conditional Probability 3.6 The Chain
DEEP LEARNING CHAPTER 3 PROBABILITY & INFORMATION THEORY OUTLINE 3.1 Why Probability? 3.2 Random Variables 3.3 Probability Distributions 3.4 Marginal Probability 3.5 Conditional Probability 3.6 The Chain
Cheng Soon Ong & Christian Walder. Canberra February June 2017
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2017 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 679 Part XIX
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2017 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 679 Part XIX
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Generative and Discriminative Approaches to Graphical Models CMSC Topics in AI
 Generative and Discriminative Approaches to Graphical Models CMSC 35900 Topics in AI Lecture 2 Yasemin Altun January 26, 2007 Review of Inference on Graphical Models Elimination algorithm finds single
Generative and Discriminative Approaches to Graphical Models CMSC 35900 Topics in AI Lecture 2 Yasemin Altun January 26, 2007 Review of Inference on Graphical Models Elimination algorithm finds single
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Uncertainty & Probabilities & Bandits Daniel Hennes 16.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Uncertainty Probability
Grundlagen der Künstlichen Intelligenz Uncertainty & Probabilities & Bandits Daniel Hennes 16.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Uncertainty Probability
Random Variables and Their Distributions
 Chapter 3 Random Variables and Their Distributions A random variable (r.v.) is a function that assigns one and only one numerical value to each simple event in an experiment. We will denote r.vs by capital
Chapter 3 Random Variables and Their Distributions A random variable (r.v.) is a function that assigns one and only one numerical value to each simple event in an experiment. We will denote r.vs by capital
Machine Learning Srihari. Information Theory. Sargur N. Srihari
 Information Theory Sargur N. Srihari 1 Topics 1. Entropy as an Information Measure 1. Discrete variable definition Relationship to Code Length 2. Continuous Variable Differential Entropy 2. Maximum Entropy
Information Theory Sargur N. Srihari 1 Topics 1. Entropy as an Information Measure 1. Discrete variable definition Relationship to Code Length 2. Continuous Variable Differential Entropy 2. Maximum Entropy
Homework 1 Due: Thursday 2/5/2015. Instructions: Turn in your homework in class on Thursday 2/5/2015
 10-704 Homework 1 Due: Thursday 2/5/2015 Instructions: Turn in your homework in class on Thursday 2/5/2015 1. Information Theory Basics and Inequalities C&T 2.47, 2.29 (a) A deck of n cards in order 1,
10-704 Homework 1 Due: Thursday 2/5/2015 Instructions: Turn in your homework in class on Thursday 2/5/2015 1. Information Theory Basics and Inequalities C&T 2.47, 2.29 (a) A deck of n cards in order 1,
Bioinformatics: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Bayesian Interpretation of Probabilities 2 Where (or of what)
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Bayesian Interpretation of Probabilities 2 Where (or of what)
Bivariate distributions
 Bivariate distributions 3 th October 017 lecture based on Hogg Tanis Zimmerman: Probability and Statistical Inference (9th ed.) Bivariate Distributions of the Discrete Type The Correlation Coefficient
Bivariate distributions 3 th October 017 lecture based on Hogg Tanis Zimmerman: Probability and Statistical Inference (9th ed.) Bivariate Distributions of the Discrete Type The Correlation Coefficient
Quick Tour of Basic Probability Theory and Linear Algebra
 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra CS224w: Social and Information Network Analysis Fall 2011 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra Outline Definitions
Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra CS224w: Social and Information Network Analysis Fall 2011 Quick Tour of and Linear Algebra Quick Tour of and Linear Algebra Outline Definitions
Lecture 2: Repetition of probability theory and statistics
 Algorithms for Uncertainty Quantification SS8, IN2345 Tobias Neckel Scientific Computing in Computer Science TUM Lecture 2: Repetition of probability theory and statistics Concept of Building Block: Prerequisites:
Algorithms for Uncertainty Quantification SS8, IN2345 Tobias Neckel Scientific Computing in Computer Science TUM Lecture 2: Repetition of probability theory and statistics Concept of Building Block: Prerequisites:
Some Concepts of Probability (Review) Volker Tresp Summer 2018
 Volker Tresp Summer 2018") Some Concepts of Probability (Review) Volker Tresp Summer 2018 1 Definition There are different way to define what a probability stands for Mathematically, the most rigorous definition is based on Kolmogorov
Some Concepts of Probability (Review) Volker Tresp Summer 2018 1 Definition There are different way to define what a probability stands for Mathematically, the most rigorous definition is based on Kolmogorov
Fundamentals. CS 281A: Statistical Learning Theory. Yangqing Jia. August, Based on tutorial slides by Lester Mackey and Ariel Kleiner
 Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
CS Lecture 19. Exponential Families & Expectation Propagation
 CS 6347 Lecture 19 Exponential Families & Expectation Propagation Discrete State Spaces We have been focusing on the case of MRFs over discrete state spaces Probability distributions over discrete spaces
CS 6347 Lecture 19 Exponential Families & Expectation Propagation Discrete State Spaces We have been focusing on the case of MRFs over discrete state spaces Probability distributions over discrete spaces
Advanced topics from statistics
 Advanced topics from statistics Anders Ringgaard Kristensen Advanced Herd Management Slide 1 Outline Covariance and correlation Random vectors and multivariate distributions The multinomial distribution
Advanced topics from statistics Anders Ringgaard Kristensen Advanced Herd Management Slide 1 Outline Covariance and correlation Random vectors and multivariate distributions The multinomial distribution
Review (Probability & Linear Algebra)
") Review (Probability & Linear Algebra) CE-725 : Statistical Pattern Recognition Sharif University of Technology Spring 2013 M. Soleymani Outline Axioms of probability theory Conditional probability, Joint
Review (Probability & Linear Algebra) CE-725 : Statistical Pattern Recognition Sharif University of Technology Spring 2013 M. Soleymani Outline Axioms of probability theory Conditional probability, Joint
Computational Systems Biology: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA L#8:(November-08-2010) Cancer and Signals Outline 1 Bayesian Interpretation of Probabilities Information Theory Outline Bayesian
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA L#8:(November-08-2010) Cancer and Signals Outline 1 Bayesian Interpretation of Probabilities Information Theory Outline Bayesian
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Basic Statistics and Probability Theory
 0. Basic Statistics and Probability Theory Based on Foundations of Statistical NLP C. Manning & H. Schütze, ch. 2, MIT Press, 2002 Probability theory is nothing but common sense reduced to calculation.
0. Basic Statistics and Probability Theory Based on Foundations of Statistical NLP C. Manning & H. Schütze, ch. 2, MIT Press, 2002 Probability theory is nothing but common sense reduced to calculation.
Information geometry for bivariate distribution control
 Information geometry for bivariate distribution control C.T.J.Dodson + Hong Wang Mathematics + Control Systems Centre, University of Manchester Institute of Science and Technology Optimal control of stochastic
Information geometry for bivariate distribution control C.T.J.Dodson + Hong Wang Mathematics + Control Systems Centre, University of Manchester Institute of Science and Technology Optimal control of stochastic
Maximum likelihood estimation
 Maximum likelihood estimation Guillaume Obozinski Ecole des Ponts - ParisTech Master MVA Maximum likelihood estimation 1/26 Outline 1 Statistical concepts 2 A short review of convex analysis and optimization
Maximum likelihood estimation Guillaume Obozinski Ecole des Ponts - ParisTech Master MVA Maximum likelihood estimation 1/26 Outline 1 Statistical concepts 2 A short review of convex analysis and optimization
Lecture 11. Probability Theory: an Overveiw
 Math 408 - Mathematical Statistics Lecture 11. Probability Theory: an Overveiw February 11, 2013 Konstantin Zuev (USC) Math 408, Lecture 11 February 11, 2013 1 / 24 The starting point in developing the
Math 408 - Mathematical Statistics Lecture 11. Probability Theory: an Overveiw February 11, 2013 Konstantin Zuev (USC) Math 408, Lecture 11 February 11, 2013 1 / 24 The starting point in developing the
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Review of Probabilities and Basic Statistics
 Alex Smola Barnabas Poczos TA: Ina Fiterau 4 th year PhD student MLD Review of Probabilities and Basic Statistics 10-701 Recitations 1/25/2013 Recitation 1: Statistics Intro 1 Overview Introduction to
Alex Smola Barnabas Poczos TA: Ina Fiterau 4 th year PhD student MLD Review of Probabilities and Basic Statistics 10-701 Recitations 1/25/2013 Recitation 1: Statistics Intro 1 Overview Introduction to
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
A Few Special Distributions and Their Properties
 A Few Special Distributions and Their Properties Econ 690 Purdue University Justin L. Tobias (Purdue) Distributional Catalog 1 / 20 Special Distributions and Their Associated Properties 1 Uniform Distribution
A Few Special Distributions and Their Properties Econ 690 Purdue University Justin L. Tobias (Purdue) Distributional Catalog 1 / 20 Special Distributions and Their Associated Properties 1 Uniform Distribution
Lecture 1a: Basic Concepts and Recaps
 Lecture 1a: Basic Concepts and Recaps Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Lecture 1a: Basic Concepts and Recaps Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Stat 5101 Notes: Brand Name Distributions
 Stat 5101 Notes: Brand Name Distributions Charles J. Geyer September 5, 2012 Contents 1 Discrete Uniform Distribution 2 2 General Discrete Uniform Distribution 2 3 Uniform Distribution 3 4 General Uniform
Stat 5101 Notes: Brand Name Distributions Charles J. Geyer September 5, 2012 Contents 1 Discrete Uniform Distribution 2 2 General Discrete Uniform Distribution 2 3 Uniform Distribution 3 4 General Uniform
Information theory and decision tree
 Information theory and decision tree Jianxin Wu LAMDA Group National Key Lab for Novel Software Technology Nanjing University, China wujx2001@gmail.com June 14, 2018 Contents 1 Prefix code and Huffman
Information theory and decision tree Jianxin Wu LAMDA Group National Key Lab for Novel Software Technology Nanjing University, China wujx2001@gmail.com June 14, 2018 Contents 1 Prefix code and Huffman
Chapter 5. Chapter 5 sections
 1 / 43 sections Discrete univariate distributions: 5.2 Bernoulli and Binomial distributions Just skim 5.3 Hypergeometric distributions 5.4 Poisson distributions Just skim 5.5 Negative Binomial distributions
1 / 43 sections Discrete univariate distributions: 5.2 Bernoulli and Binomial distributions Just skim 5.3 Hypergeometric distributions 5.4 Poisson distributions Just skim 5.5 Negative Binomial distributions
Introduction to Bayesian Statistics
 School of Computing & Communication, UTS January, 207 Random variables Pre-university: A number is just a fixed value. When we talk about probabilities: When X is a continuous random variable, it has a
School of Computing & Communication, UTS January, 207 Random variables Pre-university: A number is just a fixed value. When we talk about probabilities: When X is a continuous random variable, it has a
5 Mutual Information and Channel Capacity
 5 Mutual Information and Channel Capacity In Section 2, we have seen the use of a quantity called entropy to measure the amount of randomness in a random variable. In this section, we introduce several
5 Mutual Information and Channel Capacity In Section 2, we have seen the use of a quantity called entropy to measure the amount of randomness in a random variable. In this section, we introduce several
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Lecture 1 October 9, 2013
 Probabilistic Graphical Models Fall 2013 Lecture 1 October 9, 2013 Lecturer: Guillaume Obozinski Scribe: Huu Dien Khue Le, Robin Bénesse The web page of the course: http://www.di.ens.fr/~fbach/courses/fall2013/
Probabilistic Graphical Models Fall 2013 Lecture 1 October 9, 2013 Lecturer: Guillaume Obozinski Scribe: Huu Dien Khue Le, Robin Bénesse The web page of the course: http://www.di.ens.fr/~fbach/courses/fall2013/
Information Theory. David Rosenberg. June 15, New York University. David Rosenberg (New York University) DS-GA 1003 June 15, / 18
 DS-GA 1003 June 15, / 18") Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
(Multivariate) Gaussian (Normal) Probability Densities
 Gaussian (Normal) Probability Densities") (Multivariate) Gaussian (Normal) Probability Densities Carl Edward Rasmussen, José Miguel Hernández-Lobato & Richard Turner April 20th, 2018 Rasmussen, Hernàndez-Lobato & Turner Gaussian Densities April
(Multivariate) Gaussian (Normal) Probability Densities Carl Edward Rasmussen, José Miguel Hernández-Lobato & Richard Turner April 20th, 2018 Rasmussen, Hernàndez-Lobato & Turner Gaussian Densities April
Covariance. Lecture 20: Covariance / Correlation & General Bivariate Normal. Covariance, cont. Properties of Covariance
 Covariance Lecture 0: Covariance / Correlation & General Bivariate Normal Sta30 / Mth 30 We have previously discussed Covariance in relation to the variance of the sum of two random variables Review Lecture
Covariance Lecture 0: Covariance / Correlation & General Bivariate Normal Sta30 / Mth 30 We have previously discussed Covariance in relation to the variance of the sum of two random variables Review Lecture
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Some Basic Concepts of Probability and Information Theory: Pt. 2
 Some Basic Concepts of Probability and Information Theory: Pt. 2 PHYS 476Q - Southern Illinois University January 22, 2018 PHYS 476Q - Southern Illinois University Some Basic Concepts of Probability and
Some Basic Concepts of Probability and Information Theory: Pt. 2 PHYS 476Q - Southern Illinois University January 22, 2018 PHYS 476Q - Southern Illinois University Some Basic Concepts of Probability and
Data Mining Techniques. Lecture 3: Probability
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 3: Probability Jan-Willem van de Meent (credit: Zhao, CS 229, Bishop) Project Vote 1. Freeform: Develop your own project proposals 30% of
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 3: Probability Jan-Willem van de Meent (credit: Zhao, CS 229, Bishop) Project Vote 1. Freeform: Develop your own project proposals 30% of
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability. Machine Learning and Pattern Recognition. Chris Williams. School of Informatics, University of Edinburgh. August 2014
 Probability Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh August 2014 (All of the slides in this course have been adapted from previous versions
Probability Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh August 2014 (All of the slides in this course have been adapted from previous versions
Series 7, May 22, 2018 (EM Convergence)
") Exercises Introduction to Machine Learning SS 2018 Series 7, May 22, 2018 (EM Convergence) Institute for Machine Learning Dept. of Computer Science, ETH Zürich Prof. Dr. Andreas Krause Web: https://las.inf.ethz.ch/teaching/introml-s18
Exercises Introduction to Machine Learning SS 2018 Series 7, May 22, 2018 (EM Convergence) Institute for Machine Learning Dept. of Computer Science, ETH Zürich Prof. Dr. Andreas Krause Web: https://las.inf.ethz.ch/teaching/introml-s18
Dependence. Practitioner Course: Portfolio Optimization. John Dodson. September 10, Dependence. John Dodson. Outline.
 Practitioner Course: Portfolio Optimization September 10, 2008 Before we define dependence, it is useful to define Random variables X and Y are independent iff For all x, y. In particular, F (X,Y ) (x,
Practitioner Course: Portfolio Optimization September 10, 2008 Before we define dependence, it is useful to define Random variables X and Y are independent iff For all x, y. In particular, F (X,Y ) (x,
Signal Processing - Lecture 7
 1 Introduction Signal Processing - Lecture 7 Fitting a function to a set of data gathered in time sequence can be viewed as signal processing or learning, and is an important topic in information theory.
1 Introduction Signal Processing - Lecture 7 Fitting a function to a set of data gathered in time sequence can be viewed as signal processing or learning, and is an important topic in information theory.
Lecture 5: Moment Generating Functions
 Lecture 5: Moment Generating Functions IB Paper 7: Probability and Statistics Carl Edward Rasmussen Department of Engineering, University of Cambridge February 28th, 2018 Rasmussen (CUED) Lecture 5: Moment
Lecture 5: Moment Generating Functions IB Paper 7: Probability and Statistics Carl Edward Rasmussen Department of Engineering, University of Cambridge February 28th, 2018 Rasmussen (CUED) Lecture 5: Moment
MATH c UNIVERSITY OF LEEDS Examination for the Module MATH2715 (January 2015) STATISTICAL METHODS. Time allowed: 2 hours
 STATISTICAL METHODS. Time allowed: 2 hours") MATH2750 This question paper consists of 8 printed pages, each of which is identified by the reference MATH275. All calculators must carry an approval sticker issued by the School of Mathematics. c UNIVERSITY
MATH2750 This question paper consists of 8 printed pages, each of which is identified by the reference MATH275. All calculators must carry an approval sticker issued by the School of Mathematics. c UNIVERSITY
Stat 5101 Lecture Notes
 Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Expectation. DS GA 1002 Statistical and Mathematical Models. Carlos Fernandez-Granda
 Expectation DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Aim Describe random variables with a few numbers: mean, variance,
Expectation DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Aim Describe random variables with a few numbers: mean, variance,
Multiple Random Variables
 Multiple Random Variables This Version: July 30, 2015 Multiple Random Variables 2 Now we consider models with more than one r.v. These are called multivariate models For instance: height and weight An
Multiple Random Variables This Version: July 30, 2015 Multiple Random Variables 2 Now we consider models with more than one r.v. These are called multivariate models For instance: height and weight An
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Topic 2: Probability & Distributions. Road Map Probability & Distributions. ECO220Y5Y: Quantitative Methods in Economics. Dr.
 Topic 2: Probability & Distributions ECO220Y5Y: Quantitative Methods in Economics Dr. Nick Zammit University of Toronto Department of Economics Room KN3272 n.zammit utoronto.ca November 21, 2017 Dr. Nick
Topic 2: Probability & Distributions ECO220Y5Y: Quantitative Methods in Economics Dr. Nick Zammit University of Toronto Department of Economics Room KN3272 n.zammit utoronto.ca November 21, 2017 Dr. Nick
COM336: Neural Computing
 COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
Machine Learning using Bayesian Approaches
 Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Machine Learning using Bayesian Approaches Sargur N. Srihari University at Buffalo, State University of New York 1 Outline 1. Progress in ML and PR 2. Fully Bayesian Approach 1. Probability theory Bayes
Department of Large Animal Sciences. Outline. Slide 2. Department of Large Animal Sciences. Slide 4. Department of Large Animal Sciences
 Outline Advanced topics from statistics Anders Ringgaard Kristensen Covariance and correlation Random vectors and multivariate distributions The multinomial distribution The multivariate normal distribution
Outline Advanced topics from statistics Anders Ringgaard Kristensen Covariance and correlation Random vectors and multivariate distributions The multinomial distribution The multivariate normal distribution
CS 109 Review. CS 109 Review. Julia Daniel, 12/3/2018. Julia Daniel
 CS 109 Review CS 109 Review Julia Daniel, 12/3/2018 Julia Daniel Dec. 3, 2018 Where we re at Last week: ML wrap-up, theoretical background for modern ML This week: course overview, open questions after
CS 109 Review CS 109 Review Julia Daniel, 12/3/2018 Julia Daniel Dec. 3, 2018 Where we re at Last week: ML wrap-up, theoretical background for modern ML This week: course overview, open questions after
Artificial Intelligence
 Artificial Intelligence Probabilities Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: AI systems need to reason about what they know, or not know. Uncertainty may have so many sources:
Artificial Intelligence Probabilities Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: AI systems need to reason about what they know, or not know. Uncertainty may have so many sources:
Probability Theory for Machine Learning. Chris Cremer September 2015
 Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Probability Theory for Machine Learning Chris Cremer September 2015 Outline Motivation Probability Definitions and Rules Probability Distributions MLE for Gaussian Parameter Estimation MLE and Least Squares
Expectation. DS GA 1002 Probability and Statistics for Data Science. Carlos Fernandez-Granda
 Expectation DS GA 1002 Probability and Statistics for Data Science http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall17 Carlos Fernandez-Granda Aim Describe random variables with a few numbers: mean,
Expectation DS GA 1002 Probability and Statistics for Data Science http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall17 Carlos Fernandez-Granda Aim Describe random variables with a few numbers: mean,
G8325: Variational Bayes
 G8325: Variational Bayes Vincent Dorie Columbia University Wednesday, November 2nd, 2011 bridge Variational University Bayes Press 2003. On-screen viewing permitted. Printing not permitted. http://www.c
G8325: Variational Bayes Vincent Dorie Columbia University Wednesday, November 2nd, 2011 bridge Variational University Bayes Press 2003. On-screen viewing permitted. Printing not permitted. http://www.c
Week 3: The EM algorithm
 Week 3: The EM algorithm Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Term 1, Autumn 2005 Mixtures of Gaussians Data: Y = {y 1... y N } Latent
Week 3: The EM algorithm Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Term 1, Autumn 2005 Mixtures of Gaussians Data: Y = {y 1... y N } Latent
Lecture 1: Review on Probability and Statistics
 STAT 516: Stochastic Modeling of Scientific Data Autumn 2018 Instructor: Yen-Chi Chen Lecture 1: Review on Probability and Statistics These notes are partially based on those of Mathias Drton. 1.1 Motivating
STAT 516: Stochastic Modeling of Scientific Data Autumn 2018 Instructor: Yen-Chi Chen Lecture 1: Review on Probability and Statistics These notes are partially based on those of Mathias Drton. 1.1 Motivating
Application of Information Theory, Lecture 7. Relative Entropy. Handout Mode. Iftach Haitner. Tel Aviv University.
 Application of Information Theory, Lecture 7 Relative Entropy Handout Mode Iftach Haitner Tel Aviv University. December 1, 2015 Iftach Haitner (TAU) Application of Information Theory, Lecture 7 December
Application of Information Theory, Lecture 7 Relative Entropy Handout Mode Iftach Haitner Tel Aviv University. December 1, 2015 Iftach Haitner (TAU) Application of Information Theory, Lecture 7 December
U Logo Use Guidelines
 Information Theory Lecture 3: Applications to Machine Learning U Logo Use Guidelines Mark Reid logo is a contemporary n of our heritage. presents our name, d and our motto: arn the nature of things. authenticity
Information Theory Lecture 3: Applications to Machine Learning U Logo Use Guidelines Mark Reid logo is a contemporary n of our heritage. presents our name, d and our motto: arn the nature of things. authenticity