Cognitive Cyber-Physical System
|
|
|
- Emerald Grant
- 5 years ago
- Views:
Transcription
1 Cognitive Cyber-Physical System
2 Physical to Cyber-Physical The emergence of non-trivial embedded sensor units, networked embedded systems and sensor/actuator networks has made possible the design and implementation of several sophisticated applications Main characteristic: large amounts of real-ÿtime data are collected to constitute a big data picture as time passes. Acquired data are then processed at local, cluster-of-units or at server level to take the appropriate actions or make the most appropriate decision.

3 Cyber-Physical Embedded Systems
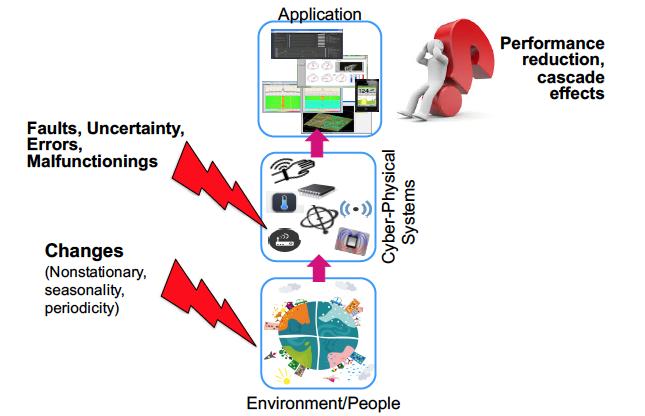
4 CHALLENGES

5 Applications

6

7

8

9 Environmental Monitoring A clinometer or inclinomet er is an instrument for measuring angles of slope (or tilt), elevation or depression of an object with respect to gravity. Rock collapse forecasting pluviometer - gauge consisting of an i nstrument to measure the quantity of precipitation

10 Measurement

11 Properties
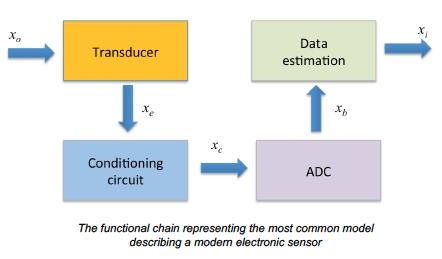
12 Measurement Chain
13 Transducer

14 Transduction

15 Conditioning Circuit

16 ADC
17

18 Data Estimation Module

19

20 Estimation Scheme
21

22 Abstracting Measurement Chain

23 Modeling the measurement process: the additive or signal plus noise model

24 Multiplicative Model

25
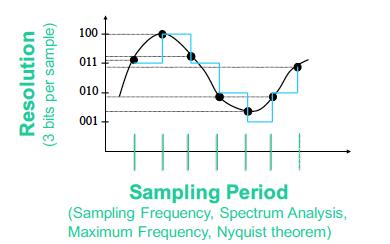
26 Accuracy

27 How to remove bias?

28 Sensor Calibration

29 Precision

30 Example of Precision

31 Precision: Unknown Distribution
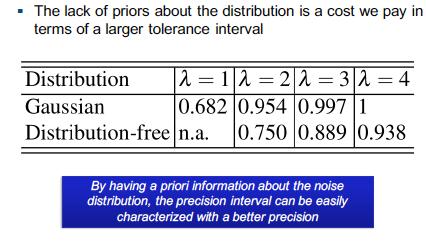
32 Unknown Distribution

33 Resolution

34 Resolution

35 Example Sensor

36 Uncertainty

37 From errors to perturbation

38 Errors to Perturbation
39 Modeling Uncertainty
40 General Signals and Perturbations

41 Perturbations
42 Uncertainty and Learning The real world is prone to uncertainty At different level of the data analysis process Acquiring data Representing information Processing the information Learning mechanisms vtwo questions: üwhy do we need learning mechanisms? üwhich are basics of supervised statistical learning?
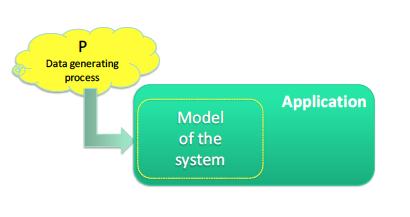
43 Modeling

44 System Modeling

45 System Modeling
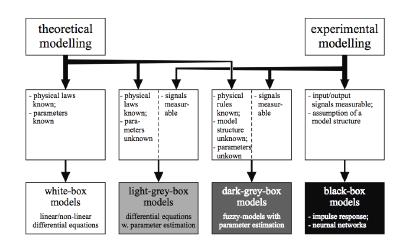
46

47 Learning the System Model

48 Designing a Classifier
49 Regression

50 Non-linear Regression: Statistical Framework

51 Exploit Available Information
52 Learning Parameterized models are built from a series of noisy data. The use of a limited number of data to estimate the model, i.e., to determine an estimate of the optimal parameter configuration, introduces an extra source of uncertainty on the estimated parameters in addition to the noise What happens when we select a non-optimal ( wrong ) model to describe the data? What is the relationship between the optimal parameter configuration, constrained by the selected model family, and the current one configured on a limited data set? Since the estimated parameter vector is a realization of a random variable centered on the optimal one, the model we obtain from the available data can be seen as a perturbed model induced by perturbations affecting the parameter vector. Which are then the effects of this perturbation on the performance of the model?

53 Basics of Learning where Eta is a noise term modeling the existing uncertainty affecting the unknown nonlinear function g(x), if any
54 Learning The ultimate goal of learning is to build an approximation of g(x) based on the information present in dataset Z N through model family f (λ, x) parameterized in the parameter vector λ Θ Rp. Selection of a suitable family of models f (λ, x) can be driven by some a priori available information about the system model. If data are likely to be generated by a linear model or a linear model suffices then this type of model should be considered. Accuracy of model with the learned parameter to be asssesed
55 Structural Risk
56
57

58 Risk

59 Risk Types

60 Risk Types

61 Risk Type
62 The Problem Asymptotically with the number of available data N, the approximation and the estimation errors can both be controlled if the learning method has some basic consistency When the available data set is small, the dominating component of the learning error is determined by the approximation error How well the model family f (λ, x) is close to the process generating the data g(x). In other words, the model risk is mainly determined by the choice of the approximating function f (λ, x), rather than by the training procedure. In the absence of a priori information, we have no basis to prefer a consistent learning method to another one.
63 Bias-Variance Learning is minimization of the following error:
64
65
66
67 Error The first one is the variance of the intrinsic noise and cannot be canceled, independently of how good our approximation is.
68 The second term is the square of the bias and represents the quadratic error we have in approximating the true function g(x) when our model generation procedure is able to provide the best model of the model family f (λo, x) (recall again that the best model is the one that minimizes the distance between the true function and the optimal approximation built in a noise-free environment having an infinite number of training points). Bias represents a discrepancy between the two functions according to the SEPE figure of merit. The last term is known as variance and it represents the variance introduced by having considered the approximating model instead of the optimal one within the family f (λo, x).
69 Example Recall that the SE is the integral of the quadratic point-wise discrepancy only in the case that the distribution of the inputs is uniform. When this is not the case, the quadratic discrepancy is weighted by the pdf f x to differentiate the interest of the error toward more likely inputs. For instance, if we consider interval X = [0, 1], g(x) = x 2 and the approximating function f ( ˆ λ, x) = x then the quadratic discrepancy is SE = 1/30. Differently, if we induce the probability density function f x = 2 if x 0.25, f x = 2/3 if x > 0.25, then the SE 0.027
70 Measuring Model Complexity Given two hypotheses (models) that correctly classify the training data, we should select the less complex one. But how do we measure model complexity in a comparable way for any hypothesis? A general framework: Let X be a space of instances, and let H be a space of hypothesis (e.g., all linear decision surfaces in two dimensions). We will measure the complexity of hîh using VC Dimension.
71 Vapnik-Chervonenkis (VC) Dimension Denoted VC(H) Measures the largest subset S of distinct instances x Î X that can be represented using H. Represented using H means: For each dichotomy of S, $ hîh such that h classifies x Î S perfectly according to this dichotomy.
72 Dichotomies Let S be a subset of instances, S Í X. Each hî H partitions S into two subsets: {xî S h(x) = 1} {xî S h(x) = 0} This partition is called a dichotomy.
73 Example Let X = {(0,0), (0, 1), (1,0), (1,1)}. Let S = X What are the dichotomies of S? In general, given S Í X, how many possible dichotomies are there of S?
74 Shattering a Set of Instances Definition : H shatters S if and only if H can represent all dichotomies of S. That is, H shatters S if and only if for all dichotomies of S, $ hîh that is consistent with that dichotomy. Example: Let S be as on the previous slide, and let H be the set of all linear decision surfaces in two dimensions. Does H shatter S? Let H be the set of all binary decision trees. Does H shatter S?
75 Comments on the notion of shattering: Ability of H to shatter a set of instances S is measure of Hʼs capacity to represent target concepts defined over these instances. Intuition: The larger the subset of X that can be shattered, the more expressive H is. This is what VC dimension measures.
76 VC Dimension Definition: VC(H), defined over X, is the size of the largest finite subset S Í X shattered by H.
77 Examples of VC Dimension 1. Let X = Â (e.g., x = height of some person), and H = set of intervals on the real number line: H = {a < x < b a, bî Â }. What is VC(H)?
78 Need to find largest subset of X that can be shattered by H. Consider subset of X containing two instances: S = {2.2, 4.5} Can S be shattered by H? Yes. Write down different dichotomies of S and the hypotheses that are consistent with them. This shows VC(H) ³ 2. Is there a subset, S = {x 0, x 1, x 2 }, of size 3 that can be shattered? Show that the answer is no. Thus VC(H) = 2.
79 2. Let X={(x,y) x, y Î Â}. Let H = set of all linear decision surfaces in the plane (i.e., lines that separate examples into positive and negative classifications). What is VC(H)?
80 Show that there is a set of two points that can be shattered by constructing all dichotomies and showing that there is a h Î H that represents each one. Is there a set of three points that can be shattered? Yes, if not co-linear. Is there a set of four points that can be shattered? Why or why not? More generally: the VC dimension of linear decision surfaces in an r-dimensional space (i.e., the VC dimension of a perceptron with r inputs) is r + 1.
81 4. If H is finite, prove that VC(H) log 2 H. Proof: Let VC(H) = d. This means that H can shatter a subset S of size d instances. Then H has to have at least 2 d distinct hypotheses. Thus: so, 2 d H VC( H ) = d log 2 H
82 Finding VC dimension General approach: To show that VC(H) ³ m, show that there exists a subset of m instances that is shattered by H. Then, to show that VC(H) = m, show that no subset of m+1 instances is shattered by H.
83 Can we use VC dimension to design better learning algorithms? Vapnik proved: Given a target function t and a sample S of m training examples drawn independently using D, for any h between 0 and 1, with probability 1-h: VC( H )(log (2m / VC( H )) + 1) - log 2 error( h) errors ( h) + m This gives an upper bound on true error as a function of training error, number of training examples, VC dimension of H, and h. Thus, for a given h, we can compute tradeoff among expected true error, number of training examples needed, and VC dimension. 2 ( h / 4)
84 VC dimension is controlled by number of free parameters in the model (e.g., hidden units in a neural network). Need VC(H) high enough so that H can represent target concept, but not so high that the learner will overfit.
85 Structural Risk Minimization Principle Principle: A function that fits the training data and minimizes VC dimension will generalize well. In other words, to minimize true error, both training error and the VCdimension term should be small Large model complexity can lead to overfitting and high generalization error.
86 A machine with too much capacity is like a botanist with a photographic memory who, when presented with a new tree, concludes that it is not a tree because it has a different number of leaves from anything she has seen before; a machine with too little capacity is like the botanistʼs lazy brother, who declares that if itʼs green, itʼs a tree. Neither can generalize well. (C. Burges, A tutorial on support vector machines for pattern recognition). The exploration and formalization of these concepts has resulted in one of the shining peaks of the theory of statistical learning. (Ibid.)
87 error D ( h) error S ( h) + VC( H )(log 2 (2m / VC( H )) + 1) - log m 2 ( h / 4) actual risk empirical risk VC confidence If we have a set of different hypothesis spaces, {H i }, which one should we choose for learning? We want the one that will minimize the bound on the actual risk. Structural risk minimization principle: choose H i that minimizes the right hand side. This requires trade-off: need large enough VC(H) so that error S (h) will be small, but need to minimize VC(H) for second term.

88 Approximation and Estimation Risks
89 Randomized Algorithms Needed to handle real-time and resource constraints on embedded platforms
90 Motivation There exists a very large class of problems that are computationally prohibitive when formalized in deterministic terms. Become manageable when a probabilistic formulation can be derived and considered instead. Not to find the perfect solution but a solution that, according to some probabilistic figure of merit, solves the problem
91
92 We point out that no functions generated by a finitestep, finite-time algorithm, such as any engineeringrelated mathematical computations, can be Lebesgue non-measurable. Under the Lebesgue measurability hypothesis and by defining a probability density function f ψ with support Ψ, it comes out that we can transform computationally hard problems into manageable problems by sampling from Ψ and resorting to probability. All useful algorithms to be executed on embedded systems can be described as Lebesgue measurable functions and many interesting problems can be cast in the same formalism.
93 Monte Carlo Method Monte Carlo methods constitute a class of algorithms that use a repeated random sampling approach and a probabilistic framework to compute the target output.
94 Monte Carlo Method Consider a square S of side length 2r and a circle C inscribed within the square. Assume that a uniform distribution is induced on the square so that each sample drawn from there is equiprobable.
95 Draw then n points inside the square and observe, for each point, whether it belongs to the circle or not. In doing this a straight question would be to ask which is the probability PrC of extracting a point belonging to the circle. The answer is that such a probability is simply the ratio between the area of the circle and that of the square, i.e., its value is π/4; Then, 4 PrC is exactly π: We found a way to compute π with a probabilistic approach
96 To Estimate PrC
97 By extracting n samples from S it is possible to build sequence ˆπ 1, ˆπ 2,..., ˆπ n ; it would be appreciable to discover that such a sequence converges to the expected value π as the second example showed provided that n tends to infinity. Law of large numbers

98 Estimation of Probability function
99 Scheme
100 Bounds on the Number of Samples With Monte Carlo it is difficult to estimate the number of samples n we should consider to solve a given problem. Bounds under specific conditions
101 Bernoulli Process
102 Bernoulli Bound
103
104 Observations The Bernoulli bound shows that the number of required samples grows quadratically (inversely proportional) with the requested accuracy for the estimate ε and linearly (inversely proportional) with the requested confidence δ. We can obtain a good estimate of ˆE n with a polynomial sampling of the space. For instance with the choice of ε = 0.05, δ = 0.01 we need to extract at least n = samples; with the choice of ε = 0.02, δ = 0.01 we need to extract at least n = samples.
105

106 Randomized Algorithms
107 Learning in Non-Stationary Environment Motivation Classical learning systems are built upon the assumption that the input data distribution for the training and testing are same. Real-world environments are often non-stationary (e.g., EEG-based BCI) So, learning in real-time environments is difficult due to the nonstationarity effects and the performance of system degrades with time. So, predictors need to adapt online. However, online adaptation particularly for classifiers is difficult to perform and should be avoided as far as possible and this requires performing in real-time: ü Non-stationary shift-detection test. Inputs x1 x2 Target t + y - Error e 107
108 Background Supervised learning Non-stationary environments Dataset shift Dataset shift-detection Supervised learning (Mitchell, 1997) (Sugiyama et al. 2009) Dataset shift-detection (Shewhart 1939), (Page 1954), (Roberts 1959), (Alippi et al. 2011b), (Alippi & Roveri 2008a; Alippi & Roveri 2008b) Dataset shift (Torres et al. 2012), Non-stationary environments (M Krauledat 2008), (Sugiyama 2012). 108
*+,- y, x = P )/0) y, x ) Is this assumption really true? No.!!! Not always true L Reason :- Non-Stationary Environments!")
109 Supervised Learning Training samples: Input (x) and output (y) Learn input-output rule: y = f'(x) Assumption: Training and test samples are drawn from same probability distribution i.e., (P )*+,- y, x = P )/0) y, x ) Is this assumption really true? No.!!! Not always true L Reason :- Non-Stationary Environments! 109
110 Non-Stationarity Definition: Let be a multivariate time-series, where is an index set. Then is called stationary timeseries, if the probability distribution does not change over time, i.e., for all. A time-series is called non-stationary, if it is not stationary. For examples: N(μ, σ 2 ) Learning from past only is of limited use L Brain-computer interface Robot control Remote sensing application Network intrusion detection What is the challenge? 110
111 Dataset Shift Dataset Shift appears when training and test joint distributions are different. That is, when (P )*+,- y, x P )/0) y, x ) (Torres, 2012) *Note : Relationship between covariates (x) and class label (y) XàY: Predictive model (e.g., spam filtering) YàX: Generative model (e.g., Fault detection ) Types of Dataset Shift Covariate Shift Prior Probability Shift Concept Shift Concept Prior probability shifts appears shift appears only in Covariate shift appears only in XàY problems p )*+,- y x = p )/0) y x, & YàX p )*+,- problems y x p )/0) y x, & p )*+,- (x) p )/0) (x) p p )*+,- )*+,- x y x = p p )/0) )/0) xx y in, & p X )*+,- (y) Y p )/0) (y) 111
112 Dataset Shift-Detection Detecting abrupt and gradual shifts in time-series data is called the data shift-detection. Types of Shift-Detection Retrospective/offline-detection: (i.e., Shift-point analysis) Real-time/online-detection: (i.e., Control charts) 112
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
COMP9444: Neural Networks. Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization
 : Neural Networks Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization 11s2 VC-dimension and PAC-learning 1 How good a classifier does a learner produce? Training error is the precentage
: Neural Networks Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization 11s2 VC-dimension and PAC-learning 1 How good a classifier does a learner produce? Training error is the precentage
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
Machine Learning. VC Dimension and Model Complexity. Eric Xing , Fall 2015
 Machine Learning 10-701, Fall 2015 VC Dimension and Model Complexity Eric Xing Lecture 16, November 3, 2015 Reading: Chap. 7 T.M book, and outline material Eric Xing @ CMU, 2006-2015 1 Last time: PAC and
Machine Learning 10-701, Fall 2015 VC Dimension and Model Complexity Eric Xing Lecture 16, November 3, 2015 Reading: Chap. 7 T.M book, and outline material Eric Xing @ CMU, 2006-2015 1 Last time: PAC and
Lecture Slides for INTRODUCTION TO. Machine Learning. By: Postedited by: R.
 Lecture Slides for INTRODUCTION TO Machine Learning By: alpaydin@boun.edu.tr http://www.cmpe.boun.edu.tr/~ethem/i2ml Postedited by: R. Basili Learning a Class from Examples Class C of a family car Prediction:
Lecture Slides for INTRODUCTION TO Machine Learning By: alpaydin@boun.edu.tr http://www.cmpe.boun.edu.tr/~ethem/i2ml Postedited by: R. Basili Learning a Class from Examples Class C of a family car Prediction:
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Computational Learning Theory
 Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
Statistical and Computational Learning Theory
 Statistical and Computational Learning Theory Fundamental Question: Predict Error Rates Given: Find: The space H of hypotheses The number and distribution of the training examples S The complexity of the
Statistical and Computational Learning Theory Fundamental Question: Predict Error Rates Given: Find: The space H of hypotheses The number and distribution of the training examples S The complexity of the
Does Unlabeled Data Help?
 Does Unlabeled Data Help? Worst-case Analysis of the Sample Complexity of Semi-supervised Learning. Ben-David, Lu and Pal; COLT, 2008. Presentation by Ashish Rastogi Courant Machine Learning Seminar. Outline
Does Unlabeled Data Help? Worst-case Analysis of the Sample Complexity of Semi-supervised Learning. Ben-David, Lu and Pal; COLT, 2008. Presentation by Ashish Rastogi Courant Machine Learning Seminar. Outline
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
PAC Learning Introduction to Machine Learning. Matt Gormley Lecture 14 March 5, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
Linear Classifiers. Michael Collins. January 18, 2012
 Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 4, 2015 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 4, 2015 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Generalization and Overfitting
 Generalization and Overfitting Model Selection Maria-Florina (Nina) Balcan February 24th, 2016 PAC/SLT models for Supervised Learning Data Source Distribution D on X Learning Algorithm Expert / Oracle
Generalization and Overfitting Model Selection Maria-Florina (Nina) Balcan February 24th, 2016 PAC/SLT models for Supervised Learning Data Source Distribution D on X Learning Algorithm Expert / Oracle
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
CS340 Machine learning Lecture 4 Learning theory. Some slides are borrowed from Sebastian Thrun and Stuart Russell
 CS340 Machine learning Lecture 4 Learning theory Some slides are borrowed from Sebastian Thrun and Stuart Russell Announcement What: Workshop on applying for NSERC scholarships and for entry to graduate
CS340 Machine learning Lecture 4 Learning theory Some slides are borrowed from Sebastian Thrun and Stuart Russell Announcement What: Workshop on applying for NSERC scholarships and for entry to graduate
VC-dimension for characterizing classifiers
 VC-dimension for characterizing classifiers Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to
VC-dimension for characterizing classifiers Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to
Active Learning and Optimized Information Gathering
 Active Learning and Optimized Information Gathering Lecture 7 Learning Theory CS 101.2 Andreas Krause Announcements Project proposal: Due tomorrow 1/27 Homework 1: Due Thursday 1/29 Any time is ok. Office
Active Learning and Optimized Information Gathering Lecture 7 Learning Theory CS 101.2 Andreas Krause Announcements Project proposal: Due tomorrow 1/27 Homework 1: Due Thursday 1/29 Any time is ok. Office
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
Web-Mining Agents Computational Learning Theory
 Web-Mining Agents Computational Learning Theory Prof. Dr. Ralf Möller Dr. Özgür Özcep Universität zu Lübeck Institut für Informationssysteme Tanya Braun (Exercise Lab) Computational Learning Theory (Adapted)
Web-Mining Agents Computational Learning Theory Prof. Dr. Ralf Möller Dr. Özgür Özcep Universität zu Lübeck Institut für Informationssysteme Tanya Braun (Exercise Lab) Computational Learning Theory (Adapted)
Computational Learning Theory
 Computational Learning Theory Slides by and Nathalie Japkowicz (Reading: R&N AIMA 3 rd ed., Chapter 18.5) Computational Learning Theory Inductive learning: given the training set, a learning algorithm
Computational Learning Theory Slides by and Nathalie Japkowicz (Reading: R&N AIMA 3 rd ed., Chapter 18.5) Computational Learning Theory Inductive learning: given the training set, a learning algorithm
VC-dimension for characterizing classifiers
 VC-dimension for characterizing classifiers Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to
VC-dimension for characterizing classifiers Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to
Computational Learning Theory (VC Dimension)
") Computational Learning Theory (VC Dimension) 1 Difficulty of machine learning problems 2 Capabilities of machine learning algorithms 1 Version Space with associated errors error is the true error, r is
Computational Learning Theory (VC Dimension) 1 Difficulty of machine learning problems 2 Capabilities of machine learning algorithms 1 Version Space with associated errors error is the true error, r is
Learning Theory Continued
 Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Introduction. Chapter 1
 Chapter 1 Introduction In this book we will be concerned with supervised learning, which is the problem of learning input-output mappings from empirical data (the training dataset). Depending on the characteristics
Chapter 1 Introduction In this book we will be concerned with supervised learning, which is the problem of learning input-output mappings from empirical data (the training dataset). Depending on the characteristics
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
Towards Lifelong Machine Learning Multi-Task and Lifelong Learning with Unlabeled Tasks Christoph Lampert
 Towards Lifelong Machine Learning Multi-Task and Lifelong Learning with Unlabeled Tasks Christoph Lampert HSE Computer Science Colloquium September 6, 2016 IST Austria (Institute of Science and Technology
Towards Lifelong Machine Learning Multi-Task and Lifelong Learning with Unlabeled Tasks Christoph Lampert HSE Computer Science Colloquium September 6, 2016 IST Austria (Institute of Science and Technology
Hypothesis Testing and Computational Learning Theory. EECS 349 Machine Learning With slides from Bryan Pardo, Tom Mitchell
 Hypothesis Testing and Computational Learning Theory EECS 349 Machine Learning With slides from Bryan Pardo, Tom Mitchell Overview Hypothesis Testing: How do we know our learners are good? What does performance
Hypothesis Testing and Computational Learning Theory EECS 349 Machine Learning With slides from Bryan Pardo, Tom Mitchell Overview Hypothesis Testing: How do we know our learners are good? What does performance
Introduction to Machine Learning
 Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Learning Theory, Overfi1ng, Bias Variance Decomposi9on
 Learning Theory, Overfi1ng, Bias Variance Decomposi9on Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- 1 Bar Joseph. Thanks! Any(!) learner that outputs a
Learning Theory, Overfi1ng, Bias Variance Decomposi9on Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- 1 Bar Joseph. Thanks! Any(!) learner that outputs a
Learning theory Lecture 4
 Learning theory Lecture 4 David Sontag New York University Slides adapted from Carlos Guestrin & Luke Zettlemoyer What s next We gave several machine learning algorithms: Perceptron Linear support vector
Learning theory Lecture 4 David Sontag New York University Slides adapted from Carlos Guestrin & Luke Zettlemoyer What s next We gave several machine learning algorithms: Perceptron Linear support vector
Introduction to Machine Learning
 Introduction to Machine Learning Thomas G. Dietterich tgd@eecs.oregonstate.edu 1 Outline What is Machine Learning? Introduction to Supervised Learning: Linear Methods Overfitting, Regularization, and the
Introduction to Machine Learning Thomas G. Dietterich tgd@eecs.oregonstate.edu 1 Outline What is Machine Learning? Introduction to Supervised Learning: Linear Methods Overfitting, Regularization, and the
Intelligent Embedded Systems Uncertainty, Information and Learning Mechanisms (Part 1)
") Advanced Research Intelligent Embedded Systems Uncertainty, Information and Learning Mechanisms (Part 1) Intelligence for Embedded Systems Ph. D. and Master Course Manuel Roveri Politecnico di Milano,
Advanced Research Intelligent Embedded Systems Uncertainty, Information and Learning Mechanisms (Part 1) Intelligence for Embedded Systems Ph. D. and Master Course Manuel Roveri Politecnico di Milano,
Supervised Learning. George Konidaris
 Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Computational Learning Theory. CS534 - Machine Learning
 Computational Learning Theory CS534 Machine Learning Introduction Computational learning theory Provides a theoretical analysis of learning Shows when a learning algorithm can be expected to succeed Shows
Computational Learning Theory CS534 Machine Learning Introduction Computational learning theory Provides a theoretical analysis of learning Shows when a learning algorithm can be expected to succeed Shows
Computational Learning Theory. CS 486/686: Introduction to Artificial Intelligence Fall 2013
 Computational Learning Theory CS 486/686: Introduction to Artificial Intelligence Fall 2013 1 Overview Introduction to Computational Learning Theory PAC Learning Theory Thanks to T Mitchell 2 Introduction
Computational Learning Theory CS 486/686: Introduction to Artificial Intelligence Fall 2013 1 Overview Introduction to Computational Learning Theory PAC Learning Theory Thanks to T Mitchell 2 Introduction
VC Dimension Review. The purpose of this document is to review VC dimension and PAC learning for infinite hypothesis spaces.
 VC Dimension Review The purpose of this document is to review VC dimension and PAC learning for infinite hypothesis spaces. Previously, in discussing PAC learning, we were trying to answer questions about
VC Dimension Review The purpose of this document is to review VC dimension and PAC learning for infinite hypothesis spaces. Previously, in discussing PAC learning, we were trying to answer questions about
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Machine Learning! in just a few minutes. Jan Peters Gerhard Neumann
 Machine Learning! in just a few minutes Jan Peters Gerhard Neumann 1 Purpose of this Lecture Foundations of machine learning tools for robotics We focus on regression methods and general principles Often
Machine Learning! in just a few minutes Jan Peters Gerhard Neumann 1 Purpose of this Lecture Foundations of machine learning tools for robotics We focus on regression methods and general principles Often
Part of the slides are adapted from Ziko Kolter
 Part of the slides are adapted from Ziko Kolter OUTLINE 1 Supervised learning: classification........................................................ 2 2 Non-linear regression/classification, overfitting,
Part of the slides are adapted from Ziko Kolter OUTLINE 1 Supervised learning: classification........................................................ 2 2 Non-linear regression/classification, overfitting,
The Perceptron algorithm
 The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
Lecture 29: Computational Learning Theory
 CS 710: Complexity Theory 5/4/2010 Lecture 29: Computational Learning Theory Instructor: Dieter van Melkebeek Scribe: Dmitri Svetlov and Jake Rosin Today we will provide a brief introduction to computational
CS 710: Complexity Theory 5/4/2010 Lecture 29: Computational Learning Theory Instructor: Dieter van Melkebeek Scribe: Dmitri Svetlov and Jake Rosin Today we will provide a brief introduction to computational
Computational Learning Theory
 1 Computational Learning Theory 2 Computational learning theory Introduction Is it possible to identify classes of learning problems that are inherently easy or difficult? Can we characterize the number
1 Computational Learning Theory 2 Computational learning theory Introduction Is it possible to identify classes of learning problems that are inherently easy or difficult? Can we characterize the number
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning (CS 567) Lecture 2
 Lecture 2") Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Variance Reduction and Ensemble Methods
 Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
On the Sample Complexity of Noise-Tolerant Learning
 On the Sample Complexity of Noise-Tolerant Learning Javed A. Aslam Department of Computer Science Dartmouth College Hanover, NH 03755 Scott E. Decatur Laboratory for Computer Science Massachusetts Institute
On the Sample Complexity of Noise-Tolerant Learning Javed A. Aslam Department of Computer Science Dartmouth College Hanover, NH 03755 Scott E. Decatur Laboratory for Computer Science Massachusetts Institute
Computational Learning Theory
 Computational Learning Theory Sinh Hoa Nguyen, Hung Son Nguyen Polish-Japanese Institute of Information Technology Institute of Mathematics, Warsaw University February 14, 2006 inh Hoa Nguyen, Hung Son
Computational Learning Theory Sinh Hoa Nguyen, Hung Son Nguyen Polish-Japanese Institute of Information Technology Institute of Mathematics, Warsaw University February 14, 2006 inh Hoa Nguyen, Hung Son
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning (CS 567) Lecture 3
 Lecture 3") Machine Learning (CS 567) Lecture 3 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 3 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Solving Classification Problems By Knowledge Sets
 Solving Classification Problems By Knowledge Sets Marcin Orchel a, a Department of Computer Science, AGH University of Science and Technology, Al. A. Mickiewicza 30, 30-059 Kraków, Poland Abstract We propose
Solving Classification Problems By Knowledge Sets Marcin Orchel a, a Department of Computer Science, AGH University of Science and Technology, Al. A. Mickiewicza 30, 30-059 Kraków, Poland Abstract We propose
References for online kernel methods
 References for online kernel methods W. Liu, J. Principe, S. Haykin Kernel Adaptive Filtering: A Comprehensive Introduction. Wiley, 2010. W. Liu, P. Pokharel, J. Principe. The kernel least mean square
References for online kernel methods W. Liu, J. Principe, S. Haykin Kernel Adaptive Filtering: A Comprehensive Introduction. Wiley, 2010. W. Liu, P. Pokharel, J. Principe. The kernel least mean square
Machine Learning 4771
 Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
An Introduction to Statistical Theory of Learning. Nakul Verma Janelia, HHMI
 An Introduction to Statistical Theory of Learning Nakul Verma Janelia, HHMI Towards formalizing learning What does it mean to learn a concept? Gain knowledge or experience of the concept. The basic process
An Introduction to Statistical Theory of Learning Nakul Verma Janelia, HHMI Towards formalizing learning What does it mean to learn a concept? Gain knowledge or experience of the concept. The basic process
Support Vector Machines
 Support Vector Machines Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Overview Motivation
Support Vector Machines Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Overview Motivation
Foundations of Machine Learning
 Introduction to ML Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu page 1 Logistics Prerequisites: basics in linear algebra, probability, and analysis of algorithms. Workload: about
Introduction to ML Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu page 1 Logistics Prerequisites: basics in linear algebra, probability, and analysis of algorithms. Workload: about
6.036 midterm review. Wednesday, March 18, 15
 6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Machine Learning, Midterm Exam: Spring 2008 SOLUTIONS. Q Topic Max. Score Score. 1 Short answer questions 20.
 10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
VC dimension, Model Selection and Performance Assessment for SVM and Other Machine Learning Algorithms
 03/Feb/2010 VC dimension, Model Selection and Performance Assessment for SVM and Other Machine Learning Algorithms Presented by Andriy Temko Department of Electrical and Electronic Engineering Page 2 of
03/Feb/2010 VC dimension, Model Selection and Performance Assessment for SVM and Other Machine Learning Algorithms Presented by Andriy Temko Department of Electrical and Electronic Engineering Page 2 of
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 9
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 9 Slides adapted from Jordan Boyd-Graber Machine Learning: Chenhao Tan Boulder 1 of 39 Recap Supervised learning Previously: KNN, naïve
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 9 Slides adapted from Jordan Boyd-Graber Machine Learning: Chenhao Tan Boulder 1 of 39 Recap Supervised learning Previously: KNN, naïve
Learning Theory. Machine Learning B Seyoung Kim. Many of these slides are derived from Tom Mitchell, Ziv- Bar Joseph. Thanks!
 Learning Theory Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- Bar Joseph. Thanks! Computa2onal Learning Theory What general laws constrain inducgve learning?
Learning Theory Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- Bar Joseph. Thanks! Computa2onal Learning Theory What general laws constrain inducgve learning?
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification MariaFlorina (Nina) Balcan 10/05/2016 Reminders Midterm Exam Mon, Oct. 10th Midterm Review Session
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification MariaFlorina (Nina) Balcan 10/05/2016 Reminders Midterm Exam Mon, Oct. 10th Midterm Review Session
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
Computational Learning Theory
 09s1: COMP9417 Machine Learning and Data Mining Computational Learning Theory May 20, 2009 Acknowledgement: Material derived from slides for the book Machine Learning, Tom M. Mitchell, McGraw-Hill, 1997
09s1: COMP9417 Machine Learning and Data Mining Computational Learning Theory May 20, 2009 Acknowledgement: Material derived from slides for the book Machine Learning, Tom M. Mitchell, McGraw-Hill, 1997
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
Learning Theory. Piyush Rai. CS5350/6350: Machine Learning. September 27, (CS5350/6350) Learning Theory September 27, / 14
 Learning Theory September 27, / 14") Learning Theory Piyush Rai CS5350/6350: Machine Learning September 27, 2011 (CS5350/6350) Learning Theory September 27, 2011 1 / 14 Why Learning Theory? We want to have theoretical guarantees about our
Learning Theory Piyush Rai CS5350/6350: Machine Learning September 27, 2011 (CS5350/6350) Learning Theory September 27, 2011 1 / 14 Why Learning Theory? We want to have theoretical guarantees about our
Computational Learning Theory
 0. Computational Learning Theory Based on Machine Learning, T. Mitchell, McGRAW Hill, 1997, ch. 7 Acknowledgement: The present slides are an adaptation of slides drawn by T. Mitchell 1. Main Questions
0. Computational Learning Theory Based on Machine Learning, T. Mitchell, McGRAW Hill, 1997, ch. 7 Acknowledgement: The present slides are an adaptation of slides drawn by T. Mitchell 1. Main Questions
Computational Learning Theory: Probably Approximately Correct (PAC) Learning. Machine Learning. Spring The slides are mainly from Vivek Srikumar
 Learning. Machine Learning. Spring The slides are mainly from Vivek Srikumar") Computational Learning Theory: Probably Approximately Correct (PAC) Learning Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 This lecture: Computational Learning Theory The Theory
Computational Learning Theory: Probably Approximately Correct (PAC) Learning Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 This lecture: Computational Learning Theory The Theory
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Machine Learning. Computational Learning Theory. Eric Xing , Fall Lecture 9, October 5, 2016
 Machine Learning 10-701, Fall 2016 Computational Learning Theory Eric Xing Lecture 9, October 5, 2016 Reading: Chap. 7 T.M book Eric Xing @ CMU, 2006-2016 1 Generalizability of Learning In machine learning
Machine Learning 10-701, Fall 2016 Computational Learning Theory Eric Xing Lecture 9, October 5, 2016 Reading: Chap. 7 T.M book Eric Xing @ CMU, 2006-2016 1 Generalizability of Learning In machine learning
6.867 Machine learning
 6.867 Machine learning Mid-term eam October 8, 6 ( points) Your name and MIT ID: .5.5 y.5 y.5 a).5.5 b).5.5.5.5 y.5 y.5 c).5.5 d).5.5 Figure : Plots of linear regression results with different types of
6.867 Machine learning Mid-term eam October 8, 6 ( points) Your name and MIT ID: .5.5 y.5 y.5 a).5.5 b).5.5.5.5 y.5 y.5 c).5.5 d).5.5 Figure : Plots of linear regression results with different types of
Computational Learning Theory
 CS 446 Machine Learning Fall 2016 OCT 11, 2016 Computational Learning Theory Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes 1 PAC Learning We want to develop a theory to relate the probability of successful
CS 446 Machine Learning Fall 2016 OCT 11, 2016 Computational Learning Theory Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes 1 PAC Learning We want to develop a theory to relate the probability of successful
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
FORMULATION OF THE LEARNING PROBLEM
 FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
Data Mining. Supervised Learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Supervised Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 15 Table of contents 1 Introduction 2 Supervised
Data Mining Supervised Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 15 Table of contents 1 Introduction 2 Supervised
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
MODULE -4 BAYEIAN LEARNING
 MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
Learning Theory. Machine Learning CSE546 Carlos Guestrin University of Washington. November 25, Carlos Guestrin
 Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Lecture 3: Introduction to Complexity Regularization
 ECE90 Spring 2007 Statistical Learning Theory Instructor: R. Nowak Lecture 3: Introduction to Complexity Regularization We ended the previous lecture with a brief discussion of overfitting. Recall that,
ECE90 Spring 2007 Statistical Learning Theory Instructor: R. Nowak Lecture 3: Introduction to Complexity Regularization We ended the previous lecture with a brief discussion of overfitting. Recall that,
Classifier Complexity and Support Vector Classifiers
 Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl