INTRODUCTION HIERARCHY OF CLASSIFIERS
|
|
|
- Linda Francis
- 5 years ago
- Views:
Transcription

1 INTRODUCTION DETECTION AND FOLDED HIERARCHIES FOR EFFICIENT DONALD GEMAN JOINT WORK WITH FRANCOIS FLEURET 2 / 35 INTRODUCTION DETECTION (CONT.) HIERARCHY OF CLASSIFIERS Advantages - Highly efficient scene parsing; - Organized focusing on hard examples. Disadvantages Many classifiers to learn; - Inefficient learning (unless training examples can be synthesized). 3 / 35 4 / 35
, - Patchwork of Parts (Y. Amit, A. Trouvé), - Compositional (S. Geman). Wholistic - Convolutional Networks (Y.")

 For faces, typically y = (u c, v c, θ, s). Cats are more complex.")
. for predicting Y k.")
2 INTRODUCTION RELATED WORK Part-based Models - Constellation (M. Weber, M. Welling, P. Perona), - Composite (D. J. Crandall, D. P. Huttenlocher), - Implicit Shape (E. Seemann, M. Fritz, B. Schiele), - Patchwork of Parts (Y. Amit, A. Trouvé), - Compositional (S. Geman). Wholistic - Convolutional Networks (Y. Lecun), - Boosted Cascades (P. Viola, M. Jones), - Bag-of-Features (A.Zisserman, F.F.Li,). INTRODUCTION POSE SPACE Let Y be the space of poses and Y 1,..., Y K a partition. Let I be an image and Y = (Y 1,..., Y K ), where, for each k, Y k is a Boolean variable stating if there is an object in I with pose in Y k. 5 / 35 6 / 35 INTRODUCTION POSE SPACE (CONT.) For faces, typically y = (u c, v c, θ, s). Cats are more complex. TRAINING A DETECTOR FRAGMENTATION Given a training set {( I (t), Y (t))} t, we are interested in building, for each k, a classifier f k : I {0, 1} A coarse description is y = (u h, v h, s h, u b, v b ). for predicting Y k. Without additional knowledge about the relationship between k, Y k and I, we would train f k with {( )} I (t), Y (t) k Hence, each f k is trained with a fragment ( 1/K ) of the positive population. t. 7 / 35 8 / 35
) given Y k = 1 does not depend on k.")

3 TRAINING A DETECTOR AGGREGATION TRAINING A DETECTOR AGGREGATION (CONT.) To avoid fragmentation, samples are often normalized in pose. Let ξ : I R N denote an N-dimensional vector of features. Let ψ : {1,..., K } I I be a transformation such that the conditional distribution of ξ(ψ(k, I)) given Y k = 1 does not depend on k. Then train a single classifier g with the training set {( ( ψ k, I (t)) )}, Y (t) k and define f k (I) = g(ψ(k, I)). t, k Here, samples are aggregated for training: all positive samples are used to build each f k. 9 / / 35 TRAINING A DETECTOR AGGREGATION (CONT.) However: - Evaluating ψ is computationally intensive for any non-trivial transformation. - The mapping ψ does not exist for a complex pose. INTRODUCTION We directly index the features with the pose. {1,..., K } I I ψ X ξ R N Hence, in practice, fragmentation is still the norm to deal with many deformations. But how does on deal with complex poses? 11 / / 35
4 DEFINITION DEFINITION (CONT.) Hence, we define a family of pose-indexed features as a mapping X : {1,..., K } I R N such that they are stationary in the following sense: for every k {1,..., K }, the probability distribution does not depend on k. P(X(k, I) = x Y k = 1), x R N 13 / / 35 TOY EXAMPLE, 1D SIGNAL { } Y = (θ 1, θ 2 ) {1,..., N} 2, 1 < θ 1 < θ 2 < N P(I Y = (θ 1, θ 2 )) = φ 0 (I n ) φ 1 (I n ) φ 0 (I n ) n<θ 1 θ 1 n θ 2 θ 2 <n TRAINING We then define f k (I) = g(x(k, I)), k {1,..., K }, where one single classifier g : R N {0, 1} is trained with {( ( X k, I (t)) )}, Y (t) k t, k X((θ 1, θ 2 ), I) = (I(θ 1 1), I(θ 1 ), I(θ 2 ), I(θ 2 + 1)) Notice that stationarity is the main condition required to ensure that the training samples are identically distributed. P(X = (x 1, x 2, x 3, x 4 ) Y = (θ 1, θ 2 )) = φ 0 (x 1 )φ 1 (x 2 )φ 1 (x 3 )φ 0 (x 4 ) 15 / / 35
5 EDGE DETECTORS EDGE DETECTORS (CONT.) Let e φ,σ (I, u, v) be the presence on an edge in image I at location (u, v) with orientation φ {0,..., 7} at scale σ {1, 2, 4}. σ = 1 17 / / 35 EDGE DETECTORS (CONT.) EDGE DETECTORS (CONT.) σ = 2 σ = 4 19 / / 35
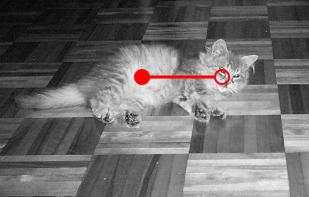
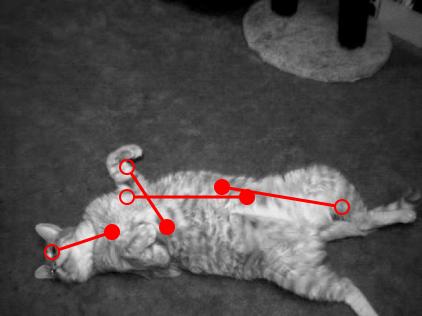
6 BASE FEATURES We use three types of stationary features: The windows W and W are indexed either with respect to the head or with respect to the head-belly. - Proportion of an edge (φ, σ) in a window W. - L 1 -distance between the histograms of orientations at scale σ in two windows W and W. - L 1 -distance between the histograms of gray-levels in two windows W and W. h h Head registration 21 / 35 h h 22 / 35 CLASSIFIER FOLDED HIERARCHIES b SUMMARY b We build classifiers with Adaboost and an asymmetric weighting by sampling. If the weighted error rate is L(h) = t,k ω t,k 1 { }, h(k, I (t) ) Z (t) k we use all the positive samples, and sub-sample negative ones with µ(k, t) ω t,k 1 { Y (t) k =0}. Total of 2327 scenes containing 1683 cats, 85% for training. Experiments (not shown) demonstrate: - Fragmentation applied Head-belly to complex registration poses is disastrous in practice; - Naive, brute-force exploration of the pose space is computationally intractable. Alternatively: - Stationary features largely avoid fragmentation; - Hierarchical search concentrates computation on ambiguous regions. We call this alternative a folded hierarchy of classifiers. 23 / / 35
7 FOLDED HIERARCHIES SUMMARY (CONT.) SCENE PARSING STRATEGY g 1 g 2 25 / / 35 SCENE PARSING ERROR CRITERION SCENE PARSING ERROR RATES TP H B HB 85% (3.61) 80% (3.87) 5.07 (1.08) 70% (2.89) 1.88 (0.32) 60% 7.80 (1.98) 0.95 (0.22) 50% 5.41 (1.62) 0.53 (0.13) Average number of FAs per / / 35



")









 31")































8 S CENE PARSING S CENE PARSING E RROR R ESULTS ( PICKED RATES ( CONT.) AT RANDOM ) 1 H B HB True positive rate Average number of FAs per 640x / / 35 S CENE PARSING S CENE PARSING R ESULTS ( PICKED R ESULTS ( SELECTED AT RANDOM, CONT.) 31 / 35 FALSE ALARMS ) 32 / 35

9 SCENE PARSING SELECTED CONCLUSION A folded hierarchy of classifiers is highly efficient: - For (offline) learning; - For (online) scene processing. It combines the strengths of: - Template matching; - Powerful, wholistic machine learning; - Hierarchical search. However, this is achieved at the expense of - Rich annotation of the training samples. - Designing stationary features. 33 / / 35 ACKNOWLEDGMENT 35 / 35
PROCEEDINGS OF SPIE. , "Front Matter: Volume 6814," Proc. SPIE 6814, Computational Imaging VI, (12 May 2008); doi: /12.
; doi: /12.") PROCEEDINGS OF SPIE SPIEDigitalLibrary.org/conference-proceedings-of-spie Front Matter: Volume 6814, "Front Matter: Volume 6814," Proc. SPIE 6814, Computational Imaging VI, 681401 (12 May 2008); doi: 10.1117/12.796836
PROCEEDINGS OF SPIE SPIEDigitalLibrary.org/conference-proceedings-of-spie Front Matter: Volume 6814, "Front Matter: Volume 6814," Proc. SPIE 6814, Computational Imaging VI, 681401 (12 May 2008); doi: 10.1117/12.796836
Multi-Layer Boosting for Pattern Recognition
 Multi-Layer Boosting for Pattern Recognition François Fleuret IDIAP Research Institute, Centre du Parc, P.O. Box 592 1920 Martigny, Switzerland fleuret@idiap.ch Abstract We extend the standard boosting
Multi-Layer Boosting for Pattern Recognition François Fleuret IDIAP Research Institute, Centre du Parc, P.O. Box 592 1920 Martigny, Switzerland fleuret@idiap.ch Abstract We extend the standard boosting
COS 429: COMPUTER VISON Face Recognition
 COS 429: COMPUTER VISON Face Recognition Intro to recognition PCA and Eigenfaces LDA and Fisherfaces Face detection: Viola & Jones (Optional) generic object models for faces: the Constellation Model Reading:
COS 429: COMPUTER VISON Face Recognition Intro to recognition PCA and Eigenfaces LDA and Fisherfaces Face detection: Viola & Jones (Optional) generic object models for faces: the Constellation Model Reading:
Visual Object Detection
 Visual Object Detection Ying Wu Electrical Engineering and Computer Science Northwestern University, Evanston, IL 60208 yingwu@northwestern.edu http://www.eecs.northwestern.edu/~yingwu 1 / 47 Visual Object
Visual Object Detection Ying Wu Electrical Engineering and Computer Science Northwestern University, Evanston, IL 60208 yingwu@northwestern.edu http://www.eecs.northwestern.edu/~yingwu 1 / 47 Visual Object
A Hierarchy of Support Vector Machines for Pattern Detection
 A Hierarchy of Support Vector Machines for Pattern Detection Hichem Sahbi Imedia research Group INRIA Rocquencourt, BP 105-78153 Le Chesnay cedex, FRANCE Donald Geman Center for Imaging Science 302 Clark
A Hierarchy of Support Vector Machines for Pattern Detection Hichem Sahbi Imedia research Group INRIA Rocquencourt, BP 105-78153 Le Chesnay cedex, FRANCE Donald Geman Center for Imaging Science 302 Clark
Self-Normalized Linear Tests
 Self-Normalized Linear Tests Sachin Gangaputra Dept. of Electrical and Computer Engineering The Johns Hopkins University Baltimore, MD 21218 sachin@jhu.edu Donald Geman Dept. of Applied Mathematics and
Self-Normalized Linear Tests Sachin Gangaputra Dept. of Electrical and Computer Engineering The Johns Hopkins University Baltimore, MD 21218 sachin@jhu.edu Donald Geman Dept. of Applied Mathematics and
Scale-Invariance of Support Vector Machines based on the Triangular Kernel. Abstract
 Scale-Invariance of Support Vector Machines based on the Triangular Kernel François Fleuret Hichem Sahbi IMEDIA Research Group INRIA Domaine de Voluceau 78150 Le Chesnay, France Abstract This paper focuses
Scale-Invariance of Support Vector Machines based on the Triangular Kernel François Fleuret Hichem Sahbi IMEDIA Research Group INRIA Domaine de Voluceau 78150 Le Chesnay, France Abstract This paper focuses
Self-Normalized Linear Tests
 Self-Normalized Linear Tests Sachin Gangaputra Dept. of Electrical and Computer Engineering The Johns Hopkins University Baltimore, MD 21218 sachin@jhu.edu Donald Geman Dept. of Applied Mathematics and
Self-Normalized Linear Tests Sachin Gangaputra Dept. of Electrical and Computer Engineering The Johns Hopkins University Baltimore, MD 21218 sachin@jhu.edu Donald Geman Dept. of Applied Mathematics and
Learning theory. Ensemble methods. Boosting. Boosting: history
 Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Discriminative part-based models. Many slides based on P. Felzenszwalb
 More sliding window detection: ti Discriminative part-based models Many slides based on P. Felzenszwalb Challenge: Generic object detection Pedestrian detection Features: Histograms of oriented gradients
More sliding window detection: ti Discriminative part-based models Many slides based on P. Felzenszwalb Challenge: Generic object detection Pedestrian detection Features: Histograms of oriented gradients
Performance Evaluation and Comparison
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Cross Validation and Resampling 3 Interval Estimation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Cross Validation and Resampling 3 Interval Estimation
End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human Pose Estimation
 End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human Pose Estimation Wei Yang, Wanli Ouyang, Hongsheng Li, and Xiaogang Wang Department of Electronic Engineering,
End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human Pose Estimation Wei Yang, Wanli Ouyang, Hongsheng Li, and Xiaogang Wang Department of Electronic Engineering,
Object Detection Grammars
 Object Detection Grammars Pedro F. Felzenszwalb and David McAllester February 11, 2010 1 Introduction We formulate a general grammar model motivated by the problem of object detection in computer vision.
Object Detection Grammars Pedro F. Felzenszwalb and David McAllester February 11, 2010 1 Introduction We formulate a general grammar model motivated by the problem of object detection in computer vision.
Hierarchical Boosting and Filter Generation
 January 29, 2007 Plan Combining Classifiers Boosting Neural Network Structure of AdaBoost Image processing Hierarchical Boosting Hierarchical Structure Filters Combining Classifiers Combining Classifiers
January 29, 2007 Plan Combining Classifiers Boosting Neural Network Structure of AdaBoost Image processing Hierarchical Boosting Hierarchical Structure Filters Combining Classifiers Combining Classifiers
Introduction to Boosting and Joint Boosting
 Introduction to Boosting and Learning Systems Group, Caltech 2005/04/26, Presentation in EE150 Boosting and Outline Introduction to Boosting 1 Introduction to Boosting Intuition of Boosting Adaptive Boosting
Introduction to Boosting and Learning Systems Group, Caltech 2005/04/26, Presentation in EE150 Boosting and Outline Introduction to Boosting 1 Introduction to Boosting Intuition of Boosting Adaptive Boosting
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2014-2015 Jakob Verbeek, ovember 21, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2014-2015 Jakob Verbeek, ovember 21, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Pictorial Structures Revisited: People Detection and Articulated Pose Estimation. Department of Computer Science TU Darmstadt
 Pictorial Structures Revisited: People Detection and Articulated Pose Estimation Mykhaylo Andriluka Stefan Roth Bernt Schiele Department of Computer Science TU Darmstadt Generic model for human detection
Pictorial Structures Revisited: People Detection and Articulated Pose Estimation Mykhaylo Andriluka Stefan Roth Bernt Schiele Department of Computer Science TU Darmstadt Generic model for human detection
CS 231A Section 1: Linear Algebra & Probability Review
 CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review. Kevin Tang
 CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2012-2013 Jakob Verbeek, ovember 23, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.12.13
Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2012-2013 Jakob Verbeek, ovember 23, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.12.13
Reconnaissance d objetsd et vision artificielle
 Reconnaissance d objetsd et vision artificielle http://www.di.ens.fr/willow/teaching/recvis09 Lecture 6 Face recognition Face detection Neural nets Attention! Troisième exercice de programmation du le
Reconnaissance d objetsd et vision artificielle http://www.di.ens.fr/willow/teaching/recvis09 Lecture 6 Face recognition Face detection Neural nets Attention! Troisième exercice de programmation du le
Modeling Mutual Context of Object and Human Pose in Human-Object Interaction Activities
 Modeling Mutual Context of Object and Human Pose in Human-Object Interaction Activities Bangpeng Yao and Li Fei-Fei Computer Science Department, Stanford University {bangpeng,feifeili}@cs.stanford.edu
Modeling Mutual Context of Object and Human Pose in Human-Object Interaction Activities Bangpeng Yao and Li Fei-Fei Computer Science Department, Stanford University {bangpeng,feifeili}@cs.stanford.edu
Distinguish between different types of scenes. Matching human perception Understanding the environment
 Scene Recognition Adriana Kovashka UTCS, PhD student Problem Statement Distinguish between different types of scenes Applications Matching human perception Understanding the environment Indexing of images
Scene Recognition Adriana Kovashka UTCS, PhD student Problem Statement Distinguish between different types of scenes Applications Matching human perception Understanding the environment Indexing of images
Face detection and recognition. Detection Recognition Sally
 Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
PCA FACE RECOGNITION
 PCA FACE RECOGNITION The slides are from several sources through James Hays (Brown); Srinivasa Narasimhan (CMU); Silvio Savarese (U. of Michigan); Shree Nayar (Columbia) including their own slides. Goal
PCA FACE RECOGNITION The slides are from several sources through James Hays (Brown); Srinivasa Narasimhan (CMU); Silvio Savarese (U. of Michigan); Shree Nayar (Columbia) including their own slides. Goal
Outline: Ensemble Learning. Ensemble Learning. The Wisdom of Crowds. The Wisdom of Crowds - Really? Crowd wiser than any individual
 Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn
, Bayes Rule, knn") Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn CMU 10-701: Machine Learning (Fall 2016) https://piazza.com/class/is95mzbrvpn63d OUT: September 13th DUE: September
Homework 1 Solutions Probability, Maximum Likelihood Estimation (MLE), Bayes Rule, knn CMU 10-701: Machine Learning (Fall 2016) https://piazza.com/class/is95mzbrvpn63d OUT: September 13th DUE: September
Pattern Recognition and Machine Learning. Learning and Evaluation of Pattern Recognition Processes
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lesson 1 5 October 2016 Learning and Evaluation of Pattern Recognition Processes Outline Notation...2 1. The
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lesson 1 5 October 2016 Learning and Evaluation of Pattern Recognition Processes Outline Notation...2 1. The
Boosting: Algorithms and Applications
 Boosting: Algorithms and Applications Lecture 11, ENGN 4522/6520, Statistical Pattern Recognition and Its Applications in Computer Vision ANU 2 nd Semester, 2008 Chunhua Shen, NICTA/RSISE Boosting Definition
Boosting: Algorithms and Applications Lecture 11, ENGN 4522/6520, Statistical Pattern Recognition and Its Applications in Computer Vision ANU 2 nd Semester, 2008 Chunhua Shen, NICTA/RSISE Boosting Definition
Introduction to Machine Learning
 Introduction to Machine Learning Reading for today: R&N 18.1-18.4 Next lecture: R&N 18.6-18.12, 20.1-20.3.2 Outline The importance of a good representation Different types of learning problems Different
Introduction to Machine Learning Reading for today: R&N 18.1-18.4 Next lecture: R&N 18.6-18.12, 20.1-20.3.2 Outline The importance of a good representation Different types of learning problems Different
Presentation in Convex Optimization
 Dec 22, 2014 Introduction Sample size selection in optimization methods for machine learning Introduction Sample size selection in optimization methods for machine learning Main results: presents a methodology
Dec 22, 2014 Introduction Sample size selection in optimization methods for machine learning Introduction Sample size selection in optimization methods for machine learning Main results: presents a methodology
Regularization. CSCE 970 Lecture 3: Regularization. Stephen Scott and Vinod Variyam. Introduction. Outline
 Other Measures 1 / 52 sscott@cse.unl.edu learning can generally be distilled to an optimization problem Choose a classifier (function, hypothesis) from a set of functions that minimizes an objective function
Other Measures 1 / 52 sscott@cse.unl.edu learning can generally be distilled to an optimization problem Choose a classifier (function, hypothesis) from a set of functions that minimizes an objective function
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Object Recognition 2017-2018 Jakob Verbeek Clustering Finding a group structure in the data Data in one cluster similar to
Clustering with k-means and Gaussian mixture distributions Machine Learning and Object Recognition 2017-2018 Jakob Verbeek Clustering Finding a group structure in the data Data in one cluster similar to
Learning Methods for Linear Detectors
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2011/2012 Lesson 20 27 April 2012 Contents Learning Methods for Linear Detectors Learning Linear Detectors...2
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2011/2012 Lesson 20 27 April 2012 Contents Learning Methods for Linear Detectors Learning Linear Detectors...2
AdaBoost. Lecturer: Authors: Center for Machine Perception Czech Technical University, Prague
 AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Learning. CSL603 - Fall 2017 Narayanan C Krishnan
 Bayesian Learning CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Bayes Theorem MAP Learners Bayes optimal classifier Naïve Bayes classifier Example text classification Bayesian networks
Bayesian Learning CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Bayes Theorem MAP Learners Bayes optimal classifier Naïve Bayes classifier Example text classification Bayesian networks
Graphical Object Models for Detection and Tracking
 Graphical Object Models for Detection and Tracking (ls@cs.brown.edu) Department of Computer Science Brown University Joined work with: -Ying Zhu, Siemens Corporate Research, Princeton, NJ -DorinComaniciu,
Graphical Object Models for Detection and Tracking (ls@cs.brown.edu) Department of Computer Science Brown University Joined work with: -Ying Zhu, Siemens Corporate Research, Princeton, NJ -DorinComaniciu,
Probabilistic Graphical Models & Applications
 Probabilistic Graphical Models & Applications Learning of Graphical Models Bjoern Andres and Bernt Schiele Max Planck Institute for Informatics The slides of today s lecture are authored by and shown with
Probabilistic Graphical Models & Applications Learning of Graphical Models Bjoern Andres and Bernt Schiele Max Planck Institute for Informatics The slides of today s lecture are authored by and shown with
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Decision Trees. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Pattern recognition. "To understand is to perceive patterns" Sir Isaiah Berlin, Russian philosopher
 Pattern recognition "To understand is to perceive patterns" Sir Isaiah Berlin, Russian philosopher The more relevant patterns at your disposal, the better your decisions will be. This is hopeful news to
Pattern recognition "To understand is to perceive patterns" Sir Isaiah Berlin, Russian philosopher The more relevant patterns at your disposal, the better your decisions will be. This is hopeful news to
Representing Images Detecting faces in images
 11-755 Machine Learning for Signal Processing Representing Images Detecting faces in images Class 5. 15 Sep 2009 Instructor: Bhiksha Raj Last Class: Representing Audio n Basic DFT n Computing a Spectrogram
11-755 Machine Learning for Signal Processing Representing Images Detecting faces in images Class 5. 15 Sep 2009 Instructor: Bhiksha Raj Last Class: Representing Audio n Basic DFT n Computing a Spectrogram
ABC random forest for parameter estimation. Jean-Michel Marin
 ABC random forest for parameter estimation Jean-Michel Marin Université de Montpellier Institut Montpelliérain Alexander Grothendieck (IMAG) Institut de Biologie Computationnelle (IBC) Labex Numev! joint
ABC random forest for parameter estimation Jean-Michel Marin Université de Montpellier Institut Montpelliérain Alexander Grothendieck (IMAG) Institut de Biologie Computationnelle (IBC) Labex Numev! joint
Models, Data, Learning Problems
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Models, Data, Learning Problems Tobias Scheffer Overview Types of learning problems: Supervised Learning (Classification, Regression,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Models, Data, Learning Problems Tobias Scheffer Overview Types of learning problems: Supervised Learning (Classification, Regression,
Algorithm-Independent Learning Issues
 Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
The state of the art and beyond
 Feature Detectors and Descriptors The state of the art and beyond Local covariant detectors and descriptors have been successful in many applications Registration Stereo vision Motion estimation Matching
Feature Detectors and Descriptors The state of the art and beyond Local covariant detectors and descriptors have been successful in many applications Registration Stereo vision Motion estimation Matching
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Fast Human Detection from Videos Using Covariance Features
 THIS PAPER APPEARED IN THE ECCV VISUAL SURVEILLANCE WORKSHOP (ECCV-VS), MARSEILLE, OCTOBER 2008 Fast Human Detection from Videos Using Covariance Features Jian Yao Jean-Marc Odobez IDIAP Research Institute
THIS PAPER APPEARED IN THE ECCV VISUAL SURVEILLANCE WORKSHOP (ECCV-VS), MARSEILLE, OCTOBER 2008 Fast Human Detection from Videos Using Covariance Features Jian Yao Jean-Marc Odobez IDIAP Research Institute
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Boosting. Acknowledgment Slides are based on tutorials from Robert Schapire and Gunnar Raetsch
 . Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Biometrics: Introduction and Examples. Raymond Veldhuis
 Biometrics: Introduction and Examples Raymond Veldhuis 1 Overview Biometric recognition Face recognition Challenges Transparent face recognition Large-scale identification Watch list Anonymous biometrics
Biometrics: Introduction and Examples Raymond Veldhuis 1 Overview Biometric recognition Face recognition Challenges Transparent face recognition Large-scale identification Watch list Anonymous biometrics
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Machine Learning for Signal Processing Detecting faces in images
 Machine Learning for Signal Processing Detecting faces in images Class 7. 19 Sep 2013 Instructor: Bhiksha Raj 19 Sep 2013 11755/18979 1 Administrivia Project teams? Project proposals? 19 Sep 2013 11755/18979
Machine Learning for Signal Processing Detecting faces in images Class 7. 19 Sep 2013 Instructor: Bhiksha Raj 19 Sep 2013 11755/18979 1 Administrivia Project teams? Project proposals? 19 Sep 2013 11755/18979
Bagging and Other Ensemble Methods
 Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
The Origin of Deep Learning. Lili Mou Jan, 2015
 The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
Diagnostics. Gad Kimmel
 Diagnostics Gad Kimmel Outline Introduction. Bootstrap method. Cross validation. ROC plot. Introduction Motivation Estimating properties of an estimator. Given data samples say the average. x 1, x 2,...,
Diagnostics Gad Kimmel Outline Introduction. Bootstrap method. Cross validation. ROC plot. Introduction Motivation Estimating properties of an estimator. Given data samples say the average. x 1, x 2,...,
Introduction to Supervised Learning. Performance Evaluation
 Introduction to Supervised Learning Performance Evaluation Marcelo S. Lauretto Escola de Artes, Ciências e Humanidades, Universidade de São Paulo marcelolauretto@usp.br Lima - Peru Performance Evaluation
Introduction to Supervised Learning Performance Evaluation Marcelo S. Lauretto Escola de Artes, Ciências e Humanidades, Universidade de São Paulo marcelolauretto@usp.br Lima - Peru Performance Evaluation
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
CIKM 18, October 22-26, 2018, Torino, Italy
 903 Session 6B: Knowledge Modelling 1.1 Entity Typing by Structured Features Existing systems [16, 19, 27] cast entity typing as a single-instance multi-label classification problem. For each entity e,
903 Session 6B: Knowledge Modelling 1.1 Entity Typing by Structured Features Existing systems [16, 19, 27] cast entity typing as a single-instance multi-label classification problem. For each entity e,
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Beyond Spatial Pyramids
 Beyond Spatial Pyramids Receptive Field Learning for Pooled Image Features Yangqing Jia 1 Chang Huang 2 Trevor Darrell 1 1 UC Berkeley EECS 2 NEC Labs America Goal coding pooling Bear Analysis of the pooling
Beyond Spatial Pyramids Receptive Field Learning for Pooled Image Features Yangqing Jia 1 Chang Huang 2 Trevor Darrell 1 1 UC Berkeley EECS 2 NEC Labs America Goal coding pooling Bear Analysis of the pooling
Classifier Performance. Assessment and Improvement
 Classifier Performance Assessment and Improvement Error Rates Define the Error Rate function Q( ω ˆ,ω) = δ( ω ˆ ω) = 1 if ω ˆ ω = 0 0 otherwise When training a classifier, the Apparent error rate (or Test
Classifier Performance Assessment and Improvement Error Rates Define the Error Rate function Q( ω ˆ,ω) = δ( ω ˆ ω) = 1 if ω ˆ ω = 0 0 otherwise When training a classifier, the Apparent error rate (or Test
Gaussian with mean ( µ ) and standard deviation ( σ)
 and standard deviation ( σ)") Slide from Pieter Abbeel Gaussian with mean ( µ ) and standard deviation ( σ) 10/6/16 CSE-571: Robotics X ~ N( µ, σ ) Y ~ N( aµ + b, a σ ) Y = ax + b + + + + 1 1 1 1 1 1 1 1 1 1, ~ ) ( ) ( ), ( ~ ), (
Slide from Pieter Abbeel Gaussian with mean ( µ ) and standard deviation ( σ) 10/6/16 CSE-571: Robotics X ~ N( µ, σ ) Y ~ N( aµ + b, a σ ) Y = ax + b + + + + 1 1 1 1 1 1 1 1 1 1, ~ ) ( ) ( ), ( ~ ), (
Loss Functions and Optimization. Lecture 3-1
 Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative Assignment 1 is released: http://cs231n.github.io/assignments2017/assignment1/ Due Thursday April 20, 11:59pm on Canvas (Extending
Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative Assignment 1 is released: http://cs231n.github.io/assignments2017/assignment1/ Due Thursday April 20, 11:59pm on Canvas (Extending
CS446: Machine Learning Spring Problem Set 4
 CS446: Machine Learning Spring 2017 Problem Set 4 Handed Out: February 27 th, 2017 Due: March 11 th, 2017 Feel free to talk to other members of the class in doing the homework. I am more concerned that
CS446: Machine Learning Spring 2017 Problem Set 4 Handed Out: February 27 th, 2017 Due: March 11 th, 2017 Feel free to talk to other members of the class in doing the homework. I am more concerned that
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Recognition Performance from SAR Imagery Subject to System Resource Constraints
 Recognition Performance from SAR Imagery Subject to System Resource Constraints Michael D. DeVore Advisor: Joseph A. O SullivanO Washington University in St. Louis Electronic Systems and Signals Research
Recognition Performance from SAR Imagery Subject to System Resource Constraints Michael D. DeVore Advisor: Joseph A. O SullivanO Washington University in St. Louis Electronic Systems and Signals Research
Global Scene Representations. Tilke Judd
 Global Scene Representations Tilke Judd Papers Oliva and Torralba [2001] Fei Fei and Perona [2005] Labzebnik, Schmid and Ponce [2006] Commonalities Goal: Recognize natural scene categories Extract features
Global Scene Representations Tilke Judd Papers Oliva and Torralba [2001] Fei Fei and Perona [2005] Labzebnik, Schmid and Ponce [2006] Commonalities Goal: Recognize natural scene categories Extract features
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Not so naive Bayesian classification
 Not so naive Bayesian classification Geoff Webb Monash University, Melbourne, Australia http://www.csse.monash.edu.au/ webb Not so naive Bayesian classification p. 1/2 Overview Probability estimation provides
Not so naive Bayesian classification Geoff Webb Monash University, Melbourne, Australia http://www.csse.monash.edu.au/ webb Not so naive Bayesian classification p. 1/2 Overview Probability estimation provides
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bregman divergence and density integration Noboru Murata and Yu Fujimoto
 Journal of Math-for-industry, Vol.1(2009B-3), pp.97 104 Bregman divergence and density integration Noboru Murata and Yu Fujimoto Received on August 29, 2009 / Revised on October 4, 2009 Abstract. In this
Journal of Math-for-industry, Vol.1(2009B-3), pp.97 104 Bregman divergence and density integration Noboru Murata and Yu Fujimoto Received on August 29, 2009 / Revised on October 4, 2009 Abstract. In this
Roadmap. Introduction to image analysis (computer vision) Theory of edge detection. Applications
 Theory of edge detection. Applications") Edge Detection Roadmap Introduction to image analysis (computer vision) Its connection with psychology and neuroscience Why is image analysis difficult? Theory of edge detection Gradient operator Advanced
Edge Detection Roadmap Introduction to image analysis (computer vision) Its connection with psychology and neuroscience Why is image analysis difficult? Theory of edge detection Gradient operator Advanced
Big Data Analytics. Special Topics for Computer Science CSE CSE Feb 24
 Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Metric Embedding of Task-Specific Similarity. joint work with Trevor Darrell (MIT)
") Metric Embedding of Task-Specific Similarity Greg Shakhnarovich Brown University joint work with Trevor Darrell (MIT) August 9, 2006 Task-specific similarity A toy example: Task-specific similarity A toy
Metric Embedding of Task-Specific Similarity Greg Shakhnarovich Brown University joint work with Trevor Darrell (MIT) August 9, 2006 Task-specific similarity A toy example: Task-specific similarity A toy
Final Examination CS 540-2: Introduction to Artificial Intelligence
 Final Examination CS 540-2: Introduction to Artificial Intelligence May 7, 2017 LAST NAME: SOLUTIONS FIRST NAME: Problem Score Max Score 1 14 2 10 3 6 4 10 5 11 6 9 7 8 9 10 8 12 12 8 Total 100 1 of 11
Final Examination CS 540-2: Introduction to Artificial Intelligence May 7, 2017 LAST NAME: SOLUTIONS FIRST NAME: Problem Score Max Score 1 14 2 10 3 6 4 10 5 11 6 9 7 8 9 10 8 12 12 8 Total 100 1 of 11
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Classification: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
CS6220: DATA MINING TECHNIQUES Matrix Data: Classification: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
Deformable Template As Active Basis
 Deformable Template As Active Basis Ying Nian Wu, Zhangzhang Si, Chuck Fleming, and Song-Chun Zhu UCLA Department of Statistics http://www.stat.ucla.edu/ ywu/activebasis.html Abstract This article proposes
Deformable Template As Active Basis Ying Nian Wu, Zhangzhang Si, Chuck Fleming, and Song-Chun Zhu UCLA Department of Statistics http://www.stat.ucla.edu/ ywu/activebasis.html Abstract This article proposes
Statistical learning. Chapter 20, Sections 1 3 1
 Statistical learning Chapter 20, Sections 1 3 Chapter 20, Sections 1 3 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 3 Chapter 20, Sections 1 3 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Linear Classifiers as Pattern Detectors
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2014/2015 Lesson 16 8 April 2015 Contents Linear Classifiers as Pattern Detectors Notation...2 Linear
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2014/2015 Lesson 16 8 April 2015 Contents Linear Classifiers as Pattern Detectors Notation...2 Linear
PDEEC Machine Learning 2016/17
 PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
Part I. Linear regression & LASSO. Linear Regression. Linear Regression. Week 10 Based in part on slides from textbook, slides of Susan Holmes
 Week 10 Based in part on slides from textbook, slides of Susan Holmes Part I Linear regression & December 5, 2012 1 / 1 2 / 1 We ve talked mostly about classification, where the outcome categorical. If
Week 10 Based in part on slides from textbook, slides of Susan Holmes Part I Linear regression & December 5, 2012 1 / 1 2 / 1 We ve talked mostly about classification, where the outcome categorical. If
DynamicBoost: Boosting Time Series Generated by Dynamical Systems
 DynamicBoost: Boosting Time Series Generated by Dynamical Systems René Vidal Center for Imaging Science, Dept. of BME, Johns Hopkins University, Baltimore MD, USA rvidal@cis.jhu.edu http://www.vision.jhu.edu
DynamicBoost: Boosting Time Series Generated by Dynamical Systems René Vidal Center for Imaging Science, Dept. of BME, Johns Hopkins University, Baltimore MD, USA rvidal@cis.jhu.edu http://www.vision.jhu.edu
Lecture 13 Visual recognition
 Lecture 13 Visual recognition Announcements Silvio Savarese Lecture 13-20-Feb-14 Lecture 13 Visual recognition Object classification bag of words models Discriminative methods Generative methods Object
Lecture 13 Visual recognition Announcements Silvio Savarese Lecture 13-20-Feb-14 Lecture 13 Visual recognition Object classification bag of words models Discriminative methods Generative methods Object
Machine Learning (CS 567) Lecture 3
 Lecture 3") Machine Learning (CS 567) Lecture 3 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 3 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Boosting. CAP5610: Machine Learning Instructor: Guo-Jun Qi
 Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Region Covariance: A Fast Descriptor for Detection and Classification
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Region Covariance: A Fast Descriptor for Detection and Classification Oncel Tuzel, Fatih Porikli, Peter Meer TR2005-111 May 2006 Abstract We
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Region Covariance: A Fast Descriptor for Detection and Classification Oncel Tuzel, Fatih Porikli, Peter Meer TR2005-111 May 2006 Abstract We
Advanced statistical methods for data analysis Lecture 2
 Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Estimating Parameters
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 13, 2012 Today: Bayes Classifiers Naïve Bayes Gaussian Naïve Bayes Readings: Mitchell: Naïve Bayes
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 13, 2012 Today: Bayes Classifiers Naïve Bayes Gaussian Naïve Bayes Readings: Mitchell: Naïve Bayes
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Stephen Scott.
 1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
Information Theory in Computer Vision and Pattern Recognition
 Francisco Escolano Pablo Suau Boyan Bonev Information Theory in Computer Vision and Pattern Recognition Foreword by Alan Yuille ~ Springer Contents 1 Introduction...............................................
Francisco Escolano Pablo Suau Boyan Bonev Information Theory in Computer Vision and Pattern Recognition Foreword by Alan Yuille ~ Springer Contents 1 Introduction...............................................