Natural Language Processing with Deep Learning. CS224N/Ling284
|
|
|
- Alan Berry
- 5 years ago
- Views:
Transcription

1 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher
2 Overview Today: Classifica(on background Upda(ng word vectors for classifica(on Window classifica(on & cross entropy error deriva(on (ps A single layer neural network! Max-Margin loss and backprop This lecture will help a lot with PSet1 :)
3 Classifica6on setup and nota6on Generally we have a training dataset consis(ng of samples {x i,y i } N i=1 x i - inputs, e.g. words (indices or vectors!), context windows, sentences, documents, etc. y i - labels we try to predict, for example class: sen(ment, named en((es, buy/sell decision, other words later: mul(-word sequences
4 Classifica6on intui6on Training data: {x i,y i } N i=1 Simple illustra(on case: Fixed 2d word vectors to classify Using logis(c regression à linear decision boundary à General ML: assume x is fixed, train logis(c regression weights W à only modify the decision boundary Visualiza(ons with ConvNetJS by Karpathy! hzp://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html Goal: predict for each x: where
5 Details of the so=max We can tease apart into two steps: 1. Take the y th row of W and mul(ply that row with x: Compute all f c for c=1,,c 2. Normalize to obtain probability with so^max func(on: =softmax (f) y
6 The so=max and cross-entropy error For each training example {x,y}, our objec(ve is to maximize the probability of the correct class y Hence, we minimize the nega(ve log probability of that class:
7 Background: Why Cross entropy error Assuming a ground truth (or gold or target) probability distribu(on that is 1 at the right class and 0 everywhere else: p = [0,,0,1,0, 0] and our computed probability is q, then the cross entropy is: Because of one-hot p, the only term le= is the nega6ve log probability of the true class
8 Sidenote: The KL divergence Cross-entropy can be re-wrizen in terms of the entropy and Kullback-Leibler divergence between the two distribu(ons: Because H(p) is zero in our case (and even if it wasn t it would be fixed and have no contribu(on to gradient), to minimize this is equal to minimizing the KL divergence between p and q The KL divergence is not a distance but a non-symmetric measure of the difference between two probability distribu(ons p and q
9 Classifica6on over a full dataset Cross entropy loss func(on over full dataset {x i,y i } N i=1 Instead of We will write f in matrix nota(on: We can s(ll index elements of it based on class

 x-axis: more powerful model or")
10 Classifica6on: Regulariza6on! Really full loss func(on over any dataset includes regulariza6on over all parameters θ: Regulariza(on will prevent overfigng when we have a lot of features (or later a very powerful/deep model) x-axis: more powerful model or more training itera(ons Blue: training error, red: test error
11 Details: General ML op6miza6on For general machine learning θusually only consists of columns of W: So we only update the decision boundary Visualiza(ons with ConvNetJS by Karpathy
12 Classifica6on difference with word vectors Common in deep learning: Learn both W and word vectors x Very large! Overfigng Danger!
 What happens when we train the word vectors?")
13 television Losing generaliza6on by re-training word vectors Segng: Training logis(c regression for movie review sen(ment single words and in the training data we have TV and telly In the tes(ng data we have television Originally they were all similar (from pre-training word vectors) What happens when we train the word vectors? telly TV
14 Losing generaliza6on by re-training word vectors What happens when we train the word vectors? Those that are in the training data move around Words from pre-training that do NOT appear in training stay Example: In training data: TV and telly Only in tes(ng data: television telly TV :( television
15 Losing generaliza6on by re-training word vectors Take home message: If you only have a small training data set, don t train the word vectors. If you have have a very large dataset, it may work bezer to train word vectors to the task. telly TV television
16 Side note on word vectors nota6on The word vector matrix L is also called lookup table Word vectors = word embeddings = word representa(ons (mostly) Mostly from methods like word2vec or Glove V [ ] L = d aardvark a meta zebra These are the word features x word from now on New development (later in the class): character models :o
17 Window classifica6on Classifying single words is rarely done. Interes(ng problems like ambiguity arise in context! Example: auto-antonyms: "To sanc(on" can mean "to permit" or "to punish. "To seed" can mean "to place seeds" or "to remove seeds." Example: ambiguous named en((es: Paris à Paris, France vs Paris Hilton Hathaway à Berkshire Hathaway vs Anne Hathaway
18 Window classifica6on Idea: classify a word in its context window of neighboring words. For example named en(ty recogni(on into 4 classes: Person, loca(on, organiza(on, none Many possibili(es exist for classifying one word in context, e.g. averaging all the words in a window but that looses posi(on informa(on
19 Window classifica6on Train so^max classifier by assigning a label to a center word and concatena(ng all word vectors surrounding it Example: Classify Paris in the context of this sentence with window length 2: museums in Paris are amazing. X window = [ x museums x in x Paris x are x amazing ] T Resul(ng vector x window = x R 5d, a column vector!
20 Simplest window classifier: So=max With x = x window we can use the same so^max classifier as before predicted model output probability With cross entropy error as before: same But how do you update the word vectors?
21 Upda6ng concatenated word vectors Short answer: Just take deriva(ves as before Long answer: Let s go over steps together (helpful for PSet 1) Define: : so^max probability output vector (see previous slide) : target probability distribu(on (all 0 s except at ground truth index of class y, where it s 1) and f c = c th element of the f vector Hard, the first (me, hence some (ps now :)
22 Upda6ng concatenated word vectors Tip 1: Carefully define your variables and keep track of their dimensionality! Tip 2: Chain rule! If y = f(u) and u = g(x), i.e. y = f(g(x)), then: Simple example:
23 Upda6ng concatenated word vectors Tip 2 con(nued: Know thy chain rule Don t forget which variables depend on what and that x appears inside all elements of f s Tip 3: For the so^max part of the deriva(ve: First take the deriva(ve wrt f c when c=y (the correct class), then take deriva(ve wrt f c when c y (all the incorrect classes)
24 Upda6ng concatenated word vectors Tip 4: When you take deriva(ve wrt one element of f, try to see if you can create a gradient in the end that includes all par(al deriva(ves: Tip 5: To later not go insane & implementa(on! à results in terms of vector opera(ons and define single index-able vectors:
25 Upda6ng concatenated word vectors Tip 6: When you start with the chain rule, first use explicit sums and look at par(al deriva(ves of e.g. x i or W ij Tip 7: To clean it up for even more complex func(ons later: Know dimensionality of variables &simplify into matrix nota(on Tip 8: Write this out in full sums if it s not clear!
26 Upda6ng concatenated word vectors What is the dimensionality of the window vector gradient? x is the en(re window, 5 d-dimensional word vectors, so the deriva(ve wrt to x has to have the same dimensionality:
27 Upda6ng concatenated word vectors The gradient that arrives at and updates the word vectors can simply be split up for each word vector: Let With x window = [ x museums x in x Paris x are x amazing ] We have
28 Upda6ng concatenated word vectors This will push word vectors into areas such they will be helpful in determining named en((es. For example, the model can learn that seeing x in as the word just before the center word is indica(ve for the center word to be a loca(on
29 What s missing for training the window model? The gradient of J wrt the so^max weights W! Similar steps, write down par(al wrt W ij first! Then we have full
30 A note on matrix implementa6ons There are two expensive opera(ons in the so^max: The matrix mul(plica(on and the exp A for loop is never as efficient when you implement it compared to a large matrix mul(plica(on! Example code à
31 A note on matrix implementa6ons Looping over word vectors instead of concatena(ng them all into one large matrix and then mul(plying the so^max weights with that matrix 1000 loops, best of 3: 639 µs per loop loops, best of 3: 53.8 µs per loop
 Matrices are awesome!")
32 A note on matrix implementa6ons Result of faster method is a C x N matrix: Each column is an f(x) in our nota(on (unnormalized class scores) Matrices are awesome! You should speed test your code a lot too
33 So=max (= logis6c regression) alone not very powerful So^max only gives linear decision boundaries in the original space. With lizle data that can be a good regularizer With more data it is very limi(ng!
34 So=max (= logis6c regression) is not very powerful So^max only linear decision boundaries à Lame when problem is complex Wouldn t it be cool to get these correct?
35 Neural Nets for the Win! Neural networks can learn much more complex func(ons and nonlinear decision boundaries!
36 From logis6c regression to neural nets
37 Demys6fying neural networks Neural networks come with their own terminological baggage A single neuron A computa(onal unit with n (3) inputs and 1 output and parameters W, b But if you understand how so^max models work Then you already understand the opera(on of a basic neuron! Inputs Ac(va(on func(on Output Bias unit corresponds to intercept term
38 A neuron is essen6ally a binary logis6c regression unit h w,b (x) = f (w T x + b) 1 f (z) = 1+ e z b: We can have an always on feature, which gives a class prior, or separate it out, as a bias term w, b are the parameters of this neuron i.e., this logis(c regression model
39 A neural network = running several logis6c regressions at the same 6me If we feed a vector of inputs through a bunch of logis(c regression func(ons, then we get a vector of outputs But we don t have to decide ahead of Ame what variables these logisac regressions are trying to predict!
40 A neural network = running several logis6c regressions at the same 6me which we can feed into another logis(c regression func(on It is the loss funcaon that will direct what the intermediate hidden variables should be, so as to do a good job at predicang the targets for the next layer, etc.
41 A neural network = running several logis6c regressions at the same 6me Before we know it, we have a mul(layer neural network.
42 Matrix nota6on for a layer We have a 1 = f (W 11 x 1 +W 12 x 2 +W 13 x 3 + b 1 ) a 2 = f (W 21 x 1 +W 22 x 2 +W 23 x 3 + b 2 ) etc. In matrix nota(on z = Wx + b a = f (z) where f is applied element-wise: f ([z 1, z 2, z 3 ]) = [ f (z 1 ), f (z 2 ), f (z 3 )] W 12 b 3 a 1 a 2 a 3
43 Non-lineari6es (f): Why they re needed Example: function approximation, e.g., regression or classification Without non-linearities, deep neural networks can t do anything more than a linear transform Extra layers could just be compiled down into a single linear transform: W 1 W 2 x = Wx With more layers, they can approximate more complex functions!
44 A more powerful, neural net window classifier Revisi(ng X window = [ x museums x in x Paris x are x amazing ] Assume we want to classify whether the center word is a loca(on or not Lecture 5, Slide 44 Richard Socher 1/19/17
 Or an unnormalized score (even simpler)")
45 A Single Layer Neural Network A single layer is a combina(on of a linear layer and a nonlinearity: The neural ac(va(ons a can then be used to compute some output For instance, a probability via so^max p y x = softmax(wa) Or an unnormalized score (even simpler) 45


46 Summary: Feed-forward Computa6on Compu(ng a window s score with a 3-layer neural net: s = score(museums in Paris are amazing ) x window = [ x museums x in x Paris x are x amazing ] 46
47 Main intui6on for extra layer The layer learns non-linear interac(ons between the input word vectors. Example: only if museums is first vector should it mazer that in is in the second posi(on X window = [ x museums x in x Paris x are x amazing ] 47
48 The max-margin loss s = score(museums in Paris are amazing) s c = score(not all museums in Paris) Idea for training objec(ve: make score of true window larger and corrupt window s score lower (un(l they re good enough): minimize This is con(nuous --> we can use SGD 48
49 Max-margin Objec6ve func6on Objec(ve for a single window: Each window with a loca(on at its center should have a score +1 higher than any window without a loca(on at its center xxx ß 1 à ooo For full objec(ve func(on: Sample several corrupt windows per true one. Sum over all training windows 49


50 Training with Backpropaga6on Assuming cost J is > 0, compute the deriva(ves of s and s c wrt all the involved variables: U, W, b, x 50
51 Training with Backpropaga6on Let s consider the deriva(ve of a single weight W ij This only appears inside a i s U 2 For example: W 23 is only used to compute a 2 a 1 a 2 W 23 b 2 x 1 x 2 x

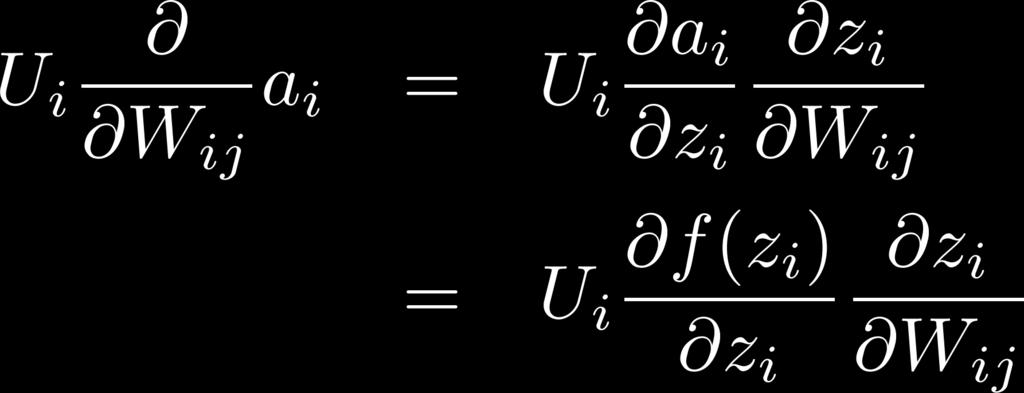
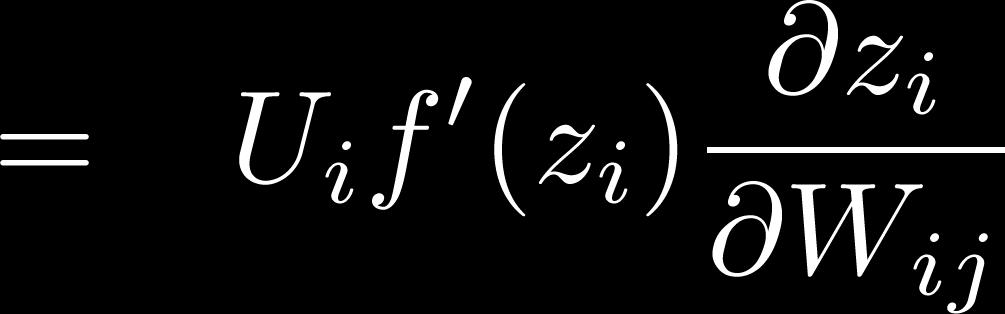
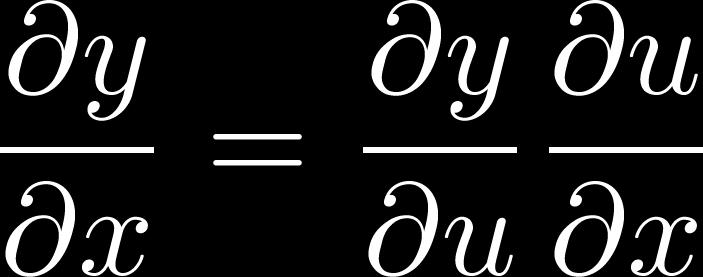
52 Training with Backpropaga6on Deriva(ve of weight W ij : s U 2 a 1 a 2 W 23 x 1 x 2 x



53 Training with Backpropaga6on Deriva(ve of single weight W ij : s U 2 Local error signal Local input signal a 1 a 2 W 23 where for logis(c f x 1 x 2 x


54 Training with Backpropaga6on From single weight W ij to full W: S We want all combina(ons of i = 1, 2 and j = 1, 2, 3 à? Solu(on: Outer product: where is the responsibility or error signal coming from each ac(va(on a s U 2 a 1 a 2 W 23 x 1 x 2 x

55 Training with Backpropaga6on For biases b, we get: s U 2 a 1 a 2 W 23 x 1 x 2 x
56 Training with Backpropaga6on That s almost backpropaga(on It s taking deriva(ves and using the chain rule Remaining trick: we can re-use deriva(ves computed for higher layers in compu(ng deriva(ves for lower layers! Example: last deriva(ves of model, the word vectors in x 56

57 Training with Backpropaga6on Take deriva(ve of score with respect to single element of word vector Now, we cannot just take into considera(on one a i because each x j is connected to all the neurons above and hence x j influences the overall score through all of these, hence: 57 Re-used part of previous deriva(ve
58 Training with Backpropaga6on With,what is the full gradient? à Observa(ons: The error message δ that arrives at a hidden layer has the same dimensionality as that hidden layer 58
59 Pu[ng all gradients together: Remember: Full objec(ve func(on for each window was: For example: gradient for U: 59
60 Summary Congrats! Super useful basic components and real model Word vector training Windows So^max and cross entropy error à PSet1 Scores and max-margin loss Neural network à PSet1 One more half of a math-heavy lecture Then the rest will be easier and more applied :)
61 Next lecture: Project advice Taking more and deeper deriva6ves à Full Backprop Then we have all the basic tools in place to learn about more complex models and have some fun :)
Natural Language Processing with Deep Learning. CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Classifica6on setup and nota6on Generally
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Classifica6on setup and nota6on Generally
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Christopher Manning Lecture 3: Word Window Classification, Neural Networks, and Matrix Calculus 1. Course plan: coming up Week 2: We learn
Natural Language Processing with Deep Learning CS224N/Ling284 Christopher Manning Lecture 3: Word Window Classification, Neural Networks, and Matrix Calculus 1. Course plan: coming up Week 2: We learn
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
COMP 562: Introduction to Machine Learning
 COMP 562: Introduction to Machine Learning Lecture 20 : Support Vector Machines, Kernels Mahmoud Mostapha 1 Department of Computer Science University of North Carolina at Chapel Hill mahmoudm@cs.unc.edu
COMP 562: Introduction to Machine Learning Lecture 20 : Support Vector Machines, Kernels Mahmoud Mostapha 1 Department of Computer Science University of North Carolina at Chapel Hill mahmoudm@cs.unc.edu
Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]
![Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]](/thumbs/88/117565192.jpg "Neural Networks. William Cohen [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ]") Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Neural Networks William Cohen 10-601 [pilfered from: Ziv; Geoff Hinton; Yoshua Bengio; Yann LeCun; Hongkak Lee - NIPs 2010 tutorial ] WHAT ARE NEURAL NETWORKS? William s notation Logis;c regression + 1
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012
 CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
Least Mean Squares Regression. Machine Learning Fall 2017
 Least Mean Squares Regression Machine Learning Fall 2017 1 Lecture Overview Linear classifiers What func?ons do linear classifiers express? Least Squares Method for Regression 2 Where are we? Linear classifiers
Least Mean Squares Regression Machine Learning Fall 2017 1 Lecture Overview Linear classifiers What func?ons do linear classifiers express? Least Squares Method for Regression 2 Where are we? Linear classifiers
Last Lecture Recap UVA CS / Introduc8on to Machine Learning and Data Mining. Lecture 3: Linear Regression
 UVA CS 4501-001 / 6501 007 Introduc8on to Machine Learning and Data Mining Lecture 3: Linear Regression Yanjun Qi / Jane University of Virginia Department of Computer Science 1 Last Lecture Recap q Data
UVA CS 4501-001 / 6501 007 Introduc8on to Machine Learning and Data Mining Lecture 3: Linear Regression Yanjun Qi / Jane University of Virginia Department of Computer Science 1 Last Lecture Recap q Data
Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop
 Different descriptions and viewpoints of backprop") Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips Announcement: Hint for PSet1: Understand
Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips Announcement: Hint for PSet1: Understand
CS 6140: Machine Learning Spring What We Learned Last Week 2/26/16
 Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Sign
Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Sign
Part 2. Representation Learning Algorithms
 53 Part 2 Representation Learning Algorithms 54 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logis;c regression func;ons, then
53 Part 2 Representation Learning Algorithms 54 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logis;c regression func;ons, then
C4 Phenomenological Modeling - Regression & Neural Networks : Computational Modeling and Simulation Instructor: Linwei Wang
 C4 Phenomenological Modeling - Regression & Neural Networks 4040-849-03: Computational Modeling and Simulation Instructor: Linwei Wang Recall.. The simple, multiple linear regression function ŷ(x) = a
C4 Phenomenological Modeling - Regression & Neural Networks 4040-849-03: Computational Modeling and Simulation Instructor: Linwei Wang Recall.. The simple, multiple linear regression function ŷ(x) = a
Logis&c Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Logis&c Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Logis&c Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
CS 6140: Machine Learning Spring What We Learned Last Week. Survey 2/26/16. VS. Model
 Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Assignment
Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Assignment
CS 6140: Machine Learning Spring 2016
 CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa?on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis?cs Assignment
CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa?on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis?cs Assignment
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
UVA CS 4501: Machine Learning. Lecture 6: Linear Regression Model with Dr. Yanjun Qi. University of Virginia
 UVA CS 4501: Machine Learning Lecture 6: Linear Regression Model with Regulariza@ons Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sec@ons of this course
UVA CS 4501: Machine Learning Lecture 6: Linear Regression Model with Regulariza@ons Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sec@ons of this course
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015
 CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015 Luke ZeElemoyer Slides adapted from Carlos Guestrin Predic5on of con5nuous variables Billionaire says: Wait, that s not what
CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015 Luke ZeElemoyer Slides adapted from Carlos Guestrin Predic5on of con5nuous variables Billionaire says: Wait, that s not what
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Regression.
 Regression www.biostat.wisc.edu/~dpage/cs760/ Goals for the lecture you should understand the following concepts linear regression RMSE, MAE, and R-square logistic regression convex functions and sets
Regression www.biostat.wisc.edu/~dpage/cs760/ Goals for the lecture you should understand the following concepts linear regression RMSE, MAE, and R-square logistic regression convex functions and sets
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
Machine Learning and Data Mining. Multi-layer Perceptrons & Neural Networks: Basics. Prof. Alexander Ihler
 + Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
+ Machine Learning and Data Mining Multi-layer Perceptrons & Neural Networks: Basics Prof. Alexander Ihler Linear Classifiers (Perceptrons) Linear Classifiers a linear classifier is a mapping which partitions
Recurrent Neural Networks. Dr. Kira Radinsky CTO SalesPredict Visi8ng Professor/Scien8st Technion. Slides were adapted from lectures by Richard Socher
 Recurrent Neural Networks Dr. Kira Radinsky CTO SalesPredict Visi8ng Professor/Scien8st Technion Slides were adapted from lectures by Richard Socher Overview Tradi8onal language models RNNs RNN language
Recurrent Neural Networks Dr. Kira Radinsky CTO SalesPredict Visi8ng Professor/Scien8st Technion Slides were adapted from lectures by Richard Socher Overview Tradi8onal language models RNNs RNN language
Neural Networks in Structured Prediction. November 17, 2015
 Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
Neural Networks in Structured Prediction November 17, 2015 HWs and Paper Last homework is going to be posted soon Neural net NER tagging model This is a new structured model Paper - Thursday after Thanksgiving
Machine Learning 2nd Edi7on
 Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Discrimina)ve Latent Variable Models. SPFLODD November 15, 2011
ve Latent Variable Models. SPFLODD November 15, 2011") Discrimina)ve Latent Variable Models SPFLODD November 15, 2011 Lecture Plan 1. Latent variables in genera)ve models (review) 2. Latent variables in condi)onal models 3. Latent variables in structural SVMs
Discrimina)ve Latent Variable Models SPFLODD November 15, 2011 Lecture Plan 1. Latent variables in genera)ve models (review) 2. Latent variables in condi)onal models 3. Latent variables in structural SVMs
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Natural Language Processing with Deep Learning CS224N/Ling284. Richard Socher Lecture 2: Word Vectors
 Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Deep Learning for NLP Part 2
 Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on
 CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 13.1 and 13.2 1 Status Check Extra credits? Announcement Evalua/on process will start soon
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 13.1 and 13.2 1 Status Check Extra credits? Announcement Evalua/on process will start soon
Deep neural networks
 Deep neural networks On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo - of convolutions
Deep neural networks On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo - of convolutions
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Feedforward Networks. Sargur N. Srihari
 Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Deep Feedforward Networks Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation and Other Differentiation
Homework 3 COMS 4705 Fall 2017 Prof. Kathleen McKeown
 Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Lecture 35: Optimization and Neural Nets
 Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
Lecture 4 Backpropagation
 Lecture 4 Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 5, 2017 Things we will look at today More Backpropagation Still more backpropagation Quiz
Lecture 4 Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 5, 2017 Things we will look at today More Backpropagation Still more backpropagation Quiz
CSE 473: Ar+ficial Intelligence. Hidden Markov Models. Bayes Nets. Two random variable at each +me step Hidden state, X i Observa+on, E i
 CSE 473: Ar+ficial Intelligence Bayes Nets Daniel Weld [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at hnp://ai.berkeley.edu.]
CSE 473: Ar+ficial Intelligence Bayes Nets Daniel Weld [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at hnp://ai.berkeley.edu.]
Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data
 Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data DD2424 March 23, 2017 Binary classification problem given labelled training data Have labelled training examples? Given
Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data DD2424 March 23, 2017 Binary classification problem given labelled training data Have labelled training examples? Given
Neural Networks for Machine Learning. Lecture 2a An overview of the main types of neural network architecture
 Neural Networks for Machine Learning Lecture 2a An overview of the main types of neural network architecture Geoffrey Hinton with Nitish Srivastava Kevin Swersky Feed-forward neural networks These are
Neural Networks for Machine Learning Lecture 2a An overview of the main types of neural network architecture Geoffrey Hinton with Nitish Srivastava Kevin Swersky Feed-forward neural networks These are
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Deep Feedforward Networks
 Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Deep Feedforward Networks Yongjin Park 1 Goal of Feedforward Networks Deep Feedforward Networks are also called as Feedforward neural networks or Multilayer Perceptrons Their Goal: approximate some function
Natural Language Processing
 Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Machine Learning (CSE 446): Backpropagation
: Backpropagation") Machine Learning (CSE 446): Backpropagation Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 8, 2017 1 / 32 Neuron-Inspired Classifiers correct output y n L n loss hidden units
Machine Learning (CSE 446): Backpropagation Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 8, 2017 1 / 32 Neuron-Inspired Classifiers correct output y n L n loss hidden units
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Backpropagation Introduction to Machine Learning. Matt Gormley Lecture 12 Feb 23, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Artificial Neural Networks
 Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Natural Language Processing
 Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
CSC321 Lecture 2: Linear Regression
 CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
The connection of dropout and Bayesian statistics
 The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
8-1: Backpropagation Prof. J.C. Kao, UCLA. Backpropagation. Chain rule for the derivatives Backpropagation graphs Examples
 8-1: Backpropagation Prof. J.C. Kao, UCLA Backpropagation Chain rule for the derivatives Backpropagation graphs Examples 8-2: Backpropagation Prof. J.C. Kao, UCLA Motivation for backpropagation To do gradient
8-1: Backpropagation Prof. J.C. Kao, UCLA Backpropagation Chain rule for the derivatives Backpropagation graphs Examples 8-2: Backpropagation Prof. J.C. Kao, UCLA Motivation for backpropagation To do gradient
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Seman&cs with Dense Vectors. Dorota Glowacka
 Semancs with Dense Vectors Dorota Glowacka dorota.glowacka@ed.ac.uk Previous lectures: - how to represent a word as a sparse vector with dimensions corresponding to the words in the vocabulary - the values
Semancs with Dense Vectors Dorota Glowacka dorota.glowacka@ed.ac.uk Previous lectures: - how to represent a word as a sparse vector with dimensions corresponding to the words in the vocabulary - the values
Algorithms for NLP. Classifica(on III. Taylor Berg- Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Classifica(on III Taylor Berg- Kirkpatrick CMU Slides: Dan Klein UC Berkeley The Perceptron, Again Start with zero weights Visit training instances one by one Try to classify If correct,
Algorithms for NLP Classifica(on III Taylor Berg- Kirkpatrick CMU Slides: Dan Klein UC Berkeley The Perceptron, Again Start with zero weights Visit training instances one by one Try to classify If correct,
Boos$ng Can we make dumb learners smart?
 Boos$ng Can we make dumb learners smart? Aarti Singh Machine Learning 10-601 Nov 29, 2011 Slides Courtesy: Carlos Guestrin, Freund & Schapire 1 Why boost weak learners? Goal: Automa'cally categorize type
Boos$ng Can we make dumb learners smart? Aarti Singh Machine Learning 10-601 Nov 29, 2011 Slides Courtesy: Carlos Guestrin, Freund & Schapire 1 Why boost weak learners? Goal: Automa'cally categorize type
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling