2018 EE448, Big Data Mining, Lecture 4. (Part I) Weinan Zhang Shanghai Jiao Tong University
|
|
|
- Julius Hamilton
- 5 years ago
- Views:
Transcription
1 2018 EE448, Big Data Mining, Lecture 4 Supervised Learning (Part I) Weinan Zhang Shanghai Jiao Tong University
2 Content of Supervised Learning Introduction to Machine Learning Linear Models Support Vector Machines Neural Networks Tree Models Ensemble Methods
3 Content of This Lecture Introduction to Machine Learning Linear Models
 artificial intelligence, the psychology of human cognition Nobel Prize in Economics (1978) decision-making")
4 What is Machine Learning Learning Learning is any process by which a system improves performance from experience. --- Herbert Simon Turing Award (1975) artificial intelligence, the psychology of human cognition Nobel Prize in Economics (1978) decision-making process within economic organizations
5 What is Machine Learning A more mathematical definition by Tom Mitchell Machine learning is the study of algorithms that improvement their performance P at some task T based on experience E with non-explicit programming A well-defined learning task is given by <P, T, E>
6 Programming vs. Machine Learning Traditional Programming Input Human Programmer Machine Learning Program Input Output Data Learning Algorithm Program Output Slide credit: Feifei Li
7 When does ML Make Advantages ML is used when Models are based on a huge amount of data Examples: Google web search, Facebook news feed Output must be customized Examples: News / item / ads recommendation Humans cannot explain the expertise Examples: Speech / face recognition, game of Go Human expertise does not exist Examples: Navigating on Mars
8 Machine Learning Categories Supervised Learning To perform the desired output given the data and labels Unsupervised Learning To analyze and make use of the underlying data patterns/structures Reinforcement Learning To learn a policy of taking actions in a dynamic environment and acquire rewards
9 Machine Learning Process Raw Data Raw Data Data Formalization Training Data Test Data Model Evaluation Basic assumption: there exist the same patterns across training and test data
10 Supervised Learning Given the training dataset of (data, label) pairs, let the machine learn a function from data to label Function set is called hypothesis space Learning is referred to as updating the parameter How to learn? Update the parameter to make the prediction close to the corresponding label What is the learning objective? How to update the parameters?
11 Learning Objective Make the prediction close to the corresponding label Loss function measures the error between the label and prediction The definition of loss function depends on the data and task Most popular loss function: squared loss
12 Squared Loss Penalty much more on larger distances Accept small distance (error) Observation noise etc. Generalization
13 Gradient Learning Methods
14 A Simple Example Observing the data, we can use different models (hypothesis spaces) to learn First, model selection (linear or quadratic) Then, learn the parameters An example from Andrew Ng
15 Learning Linear Model - Curve
16 Learning Linear Model - Weights
17 Learning Quadratic Model
18 Learning Cubic Model
19 Model Selection Which model is the best? Linear model: underfitting Quadratic model: well fitting 5 th -order model: overfitting Underfitting occurs when a statistical model or machine learning algorithm cannot capture the underlying trend of the data. Overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship
20 Model Selection Which model is the best? Linear model: underfitting 4 th -order model: well fitting 15 th -order model: overfitting Underfitting occurs when a statistical model or machine learning algorithm cannot capture the underlying trend of the data. Overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship
21 Regularization Add a penalty term of the parameters to prevent the model from overfitting the data
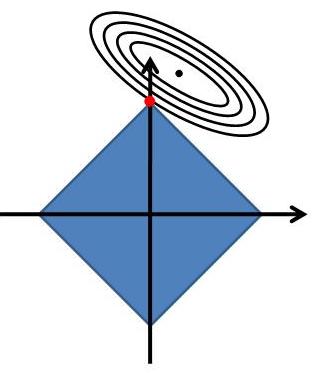
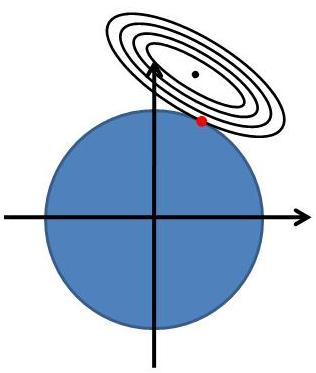
22 Typical Regularization L2-Norm (Ridge) L1-Norm (LASSO)
23 More Normal-Form Regularization Contours of constant value of Ridge LASSO Sparse model learning with q not higher than 1 Seldom use of q > 2 Actually, 99% cases use q = 1 or 2
24 Principle of Occam's razor Among competing hypotheses, the one with the fewest assumptions should be selected. Recall the function set is called hypothesis space Original loss Penalty on assumptions
25 Model Selection An ML solution has model parameters and optimization hyperparameters Hyperparameters Define higher level concepts about the model such as complexity, or capacity to learn. Cannot be learned directly from the data in the standard model training process and need to be predefined. Can be decided by setting different values, training different models, and choosing the values that test better Model selection (or hyperparameter optimization) cares how to select the optimal hyperparameters.
26 Cross Validation for Model Selection Original Training Data Random Split Training Data Validation Data Model Evaluation K-fold Cross Validation 1. Set hyperparameters 2. For K times repeat: Randomly split the original training data into training and validation datasets Train the model on training data and evaluate it on validation data, leading to an evaluation score 3. Average the K evaluation scores as the model performance
27 Machine Learning Process Raw Data Raw Data Data Formalization Training Data Test Data Model Evaluation After selecting good hyperparameters, we train the model over the whole training data and the model can be used on test data.
28 Generalization Ability Generalization Ability is the model prediction capacity on unobserved data Can be evaluated by Generalization Error, defined by where is the underlying (probably unknown) joint data distribution Empirical estimation of GA on a training dataset is
29 A Simple Case Study on Generalization Error Finite hypothesis set Theorem of generalization error bound: For any function, with probability no less than, it satisfies where N: number of training instances d: number of functions in the hypothesis set Section 1.7 in Dr. Hang Li s text book.
30 Content of This Lecture Introduction to Machine Learning Linear Models Linear regression, linear classification, applications
31 Linear Regression Linear Models for Supervised Learning
32 Linear Discriminative Models Discriminative model modeling the dependence of unobserved variables on observed ones also called conditional models. Deterministic: Probabilistic: Focus of this course Linear regression model Linear classification model
33 Linear Discriminative Models Discriminative model modeling the dependence of unobserved variables on observed ones also called conditional models. Deterministic: Probabilistic: Linear regression model
34 Linear Regression One-dimensional linear & quadratic regression Linear Regression Quadratic Regression (A kind of generalized linear model)
35 Linear Regression Two-dimensional linear regression
36 Learning Objective Make the prediction close to the corresponding label Loss function measures the error between the label and prediction The definition of loss function depends on the data and task Most popular loss function: squared loss
37 Squared Loss Penalty much more on larger distances Accept small distance (error) Observation noise etc. Generalization
38 Least Square Linear Regression Objective function to minimize

39 Minimize the Objective Function Let N=1 for a simple case, for (x,y)=(2,1)
40 Gradient Learning Methods
41 Batch Gradient Descent Update for the whole batch
42 Learning Linear Model - Curve
43 Learning Linear Model - Weights
44 Stochastic Gradient Descent Update for every single instance Compare with BGD Faster learning Uncertainty or fluctuation in learning
45 Linear Classification Model
46 Mini-Batch Gradient Descent A combination of batch GD and stochastic GD Split the whole dataset into K mini-batches For each mini-batch k, perform one-step BGD toward minimizing Update for each mini-batch
47 Mini-Batch Gradient Descent Good learning stability (BGD) Good convergence rate (SGD) Easy to be parallelized Parallelization within a mini-batch Map Worker 1 Parallelized Gradient Reduce Gradient Sum Minibatch Worker 2 Worker 3

48 Basic Search Procedure Choose an initial value for μ Update iteratively with the data Until we research a minimum μ
49 Basic Search Procedure Choose a new initial value for μ Update iteratively with the data Until we research a minimum μ
50 Unique Minimum for Convex Objective Different initial parameters and different learning algorithm lead to the same optimum


51 Convex Set A convex set S is a set of points such that, given any two points A, B in that set, the line AB joining them lies entirely within S. tx 1 +(1 t)x 2 2 S for all x 1 ;x 2 2 S; 0 t 1 A B A B Convex set Non-convex set [Boyd, Stephen, and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004.]
52 Convex Function f : R n! R for all is convex if dom f is a convex set and f(tx 1 +(1 t)x 2 ) tf(x 1 )+(1 t)f(x 2 ) x 1 ;x 2 2 dom f;0 t 1
53 Choosing Learning Rate too small slow convergence too large Increasing value of The initial point may be too far away from the optimal solution, which takes much time to converge May overshoot the minimum May fail to converge May even diverge To see if gradient descent is working, print out for each or every several iterations. If does not drop properly, adjust Slide credit Eric Eaton
54 Algebra Perspective 2 X = 6 4 x (1) x (2). x (n) 3 Prediction = ::: x (1) 3 d 3 ::: x (2) d μ. 5 = 3 ::: x (n) d 2 x (1) 3 μ x (2) μ ^y = Xμ = x (n) μ x (1) 1 x (1) 2 x (1) x (2) 1 x (2) 2 x (2) x (n) 1 x (n) 2 x (n) 2 μ 1 μ μ d 3 7 y 5 = y 1 y 2. y n Objective J(μ) = 1 2 (y ^y)> (y ^y) = 1 2 (y Xμ)> (y Xμ)
55 Matrix Form Objective J(μ) = 1 2 (y Xμ)> (y Xμ) minj(μ) = X > (y Xμ) = 0 ) X > (y Xμ) =0 ) X > y = X > Xμ ) ^μ =(X > X) 1 X > y
![Matrix Form Then the predicted values are ^y = X(X > X) 1 X > y = Hy H: hat matrix Geometrical Explanation The column vectors [x 1 ; x 2 ;:::;x d ] form a subspace of H is a least square projection X](/docs-images/83/87232118/images/56-0.jpg "= 2 6 4 x (1) 1 x (1) 2 x (1) x (2) 1 x (2) 2 x (2).. x (n) 1 x (n) 2 x (n) 3 ::: x (1) 3 2 d 3 ::: x (2) d.... 7.")
56 Matrix Form Then the predicted values are ^y = X(X > X) 1 X > y = Hy H: hat matrix Geometrical Explanation The column vectors [x 1 ; x 2 ;:::;x d ] form a subspace of H is a least square projection X = x (1) 1 x (1) 2 x (1) x (2) 1 x (2) 2 x (2).. x (n) 1 x (n) 2 x (n) 3 ::: x (1) 3 2 d 3 ::: x (2) d =[x 1; x 2 ;:::;x d ] y = ::: x (n) d Second column First column [x 1 ; x 2 ;:::;x d ] R n More details refer to Sec 3.2. Hastie et al. The elements of statistical learning. jjy Xμjj 2 y 1 y 2. y n R n
57 X > X Might be Singular When some column vectors are not independent For example, x 2 =3x 1 then X > X is singular, thus cannot be directly calculated. ^μ =(X > X) 1 X > y Solution: regularization J(μ) = 1 2 (y Xμ)> (y Xμ)+ 2 jjμjj2 2
58 Matrix Form with Regularization Objective J(μ) = 1 2 (y Xμ)> (y Xμ)+ 2 jjμjj2 2 min J(μ) Gradient = X > (y = 0! X > (y Xμ)+ μ = X > y =(X > X + I)μ! ^μ =(X > X + I) 1 X > y
59 Linear Discriminative Models Discriminative model modeling the dependence of unobserved variables on observed ones also called conditional models. Deterministic: Probabilistic: Linear regression with Gaussian noise model
60 Objective: Likelihood Data likelihood
61 Learning Maximize the data likelihood max μ NY i=1 Maximize the data log-likelihood NY log min μ i=1 1 p (y 2¼¾ 2 e i μ> x i ) 2 1 p (y 2¼¾ 2 e i μ> x i ) 2 2¾ 2¾ = NX log i=1 = i=1 1 p (y 2¼¾ 2 e i μ> x i ) 2 2¾ NX (y i μ > x i ) 2 2¾ +const NX (y i μ > x i ) 2 Equivalent to least square error learning i=1
62 Linear Classification Linear Models for Supervised Learning
63 Classification Problem Given: A description of an instance, x 2 X, where X is the instance space. A fixed set of categories: C = fc 1 ;c 2 ;:::;c m g Determine: The category of x : f(x) 2 C, where f(x) is a categorization function whose domain is X and whose range is C If the category set binary, i.e. C = f0; 1g ({false, true}, {negative, positive}) then it is called binary classification.
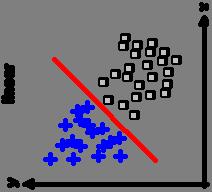
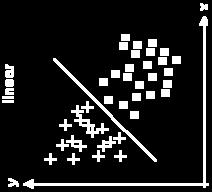
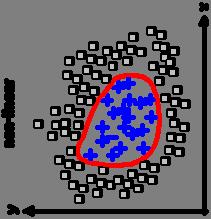
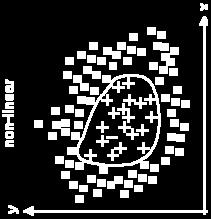
64 Binary Classification Linearly inseparable Non-linearly inseparable
65 Linear Discriminative Models Discriminative model modeling the dependence of unobserved variables on observed ones also called conditional models. Deterministic: y = f μ (x) Non-differentiable Probabilistic: p μ (yjx) Differentiable For binary classification p μ (y =1jx) p μ (y =0jx) =1 p μ (y =1jx)
66 Loss Function Cross entropy loss Discrete case: Continuous case: H(p; q) = X x Z H(p; q) = For classification problem x p(x)logq(x) p(x)logq(x)dx Ground Truth Prediction L(y;x; p μ )= X ±(y = c k )logp μ (y = c k jx) ( k 1; z is true ±(z) = 0; otherwise
67 Cross Entropy for Binary Classification Class 1 Class 2 Ground Truth 0 1 Prediction Loss function L(y; x; p μ )= ±(y =1)logp μ (y =1jx) ±(y =0)logp μ (y =0jx) = y log p μ (y =1jx) (1 y)log(1 p μ (y =1jx))
= p μ (y =0jx) = e μ> x 1+e μ> x 1 1+e μ> x Cross entropy loss function Gradient L(y;x; p")
 1 1 ¾(μ > ¾(z)(1 ¾(z))x x) =(¾(μ > x) y)x @¾(z) μ Ã μ + (y ¾(μ > x))x = ¾(z)(1 ¾(z))")
68 Logistic Regression Logistic regression is a binary classification model p μ (y =1jx) =¾(μ > x)= p μ (y =0jx) = e μ> x 1+e μ> x 1 1+e μ> x Cross entropy loss function Gradient L(y;x; p μ )= ylog ¾(μ > x) (1 y)log(1 ¾(μ > x)) x; p μ ) 1 = ¾(μ > x) ¾(z)(1 ¾(z))x (1 y) 1 1 ¾(μ > ¾(z)(1 ¾(z))x x) =(¾(μ > x) μ Ã μ + (y ¾(μ > x))x = ¾(z)(1 x
69 Label Decision Logistic regression provides the probability p μ (y =1jx) =¾(μ > x)= p μ (y =0jx) = e μ> x 1+e μ> x The final label of an instance is decided by setting a threshold h ^y = ( 1; p μ (y =1jx) >h 0; otherwise 1 1+e μ> x
70 Evaluation Measures Prediction 1 0 Label 1 0 True Positive False Positive False Negative True Negative True / False True: prediction = label False: prediction label Positive / Negative Positive: predict y = 1 Negative: predict y = 0 Class 1 TP: if predicting 1 FN: if predicting 0 Class 0 FP: if predicting 1 TN: if predicting 0
71 Evaluation Measures Prediction 1 0 Label 1 0 True Positive False Positive False Negative True Negative Accuracy: the ratio of cases when prediction = label Acc = TP + TN TP+TN+FP+FN
72 Evaluation Measures Prediction 1 0 Prediction 1 0 Label 1 True Positive False Negative Label 1 True Positive False Negative 0 False Positive True Negative 0 False Positive True Negative Precision: the ratio of true class 1 cases in those with prediction 1 Recall: the ratio of cases with prediction 1 in all true class 1 cases Prec = TP TP + FP Rec = TP TP + FN

73 Evaluation Measures Precision-recall tradeoff ^y = ( 1; p μ (y =1jx) >h 0; otherwise Higher threshold, higher precision, lower recall Extreme case: threshold = 0.99 Lower threshold, lower precision, higher recall Extreme case: threshold = 0 F1 Measure F1 = 2 Prec Recall Prec + Rec
74 Evaluation Measures Ranking-based measure: Area Under ROC Curve (AUC)
 Perfect Prediction AUC = 1 Random Prediction AUC")
75 Evaluation Measures Ranking-based measure: Area Under ROC Curve (AUC) Perfect Prediction AUC = 1 Random Prediction AUC = 0.5
76 Evaluation Measures A simple example of Area Under ROC Curve (AUC) True Positive Ratio False Positive Ratio AUC = 0.75 Prediction Label
77 Multi-Class Classification Still cross entropy loss Ground Truth Prediction L(y;x; p μ )= X k ±(y = c k )logp μ (y = c k jx) ±(z) = ( 1; z is true 0; otherwise
78 Multi-Class Logistic Regression Class set C = fc 1 ;c 2 ;:::;c m g Predicting the probability of p μ (y = c j jx) Softmax Parameters e μ> j x P m k=1 eμ> k x p μ μ(y = c j jx) =P m for j =1;:::;m k=1 eμ> k x μ = fμ 1 ; μ 2 ;:::;μ m g Can be normalized with m-1 groups of parameters
79 Multi-Class Logistic Regression Learning on one instance Maximize log-likelihood Gradient max log p μ (y = c j jx) log p μ (y = c j jx) j (x; y = c j ) = j = x eμ> j x x e μ> j x P m k=1 eμ> k x mx k=1 P m k=1 eμ> k x e μ> k x
80 Application Case Study: Click-Through Rate (CTR) Estimation in Online Advertising Linear Models for Supervised Learning


81 Ad Click-Through Rate Estimation Click or not? [
82 User response estimation problem Problem definition One instance data Date: Hour: 14 Weekday: 7 IP: * Region: England City: London Country: UK Ad Exchange: Google Domain: yahoo.co.uk URL: OS: Windows Browser: Chrome Ad size: 300*250 Ad ID: a1890 User occupation: Student User tags: Sports, Electronics Corresponding label Click (1) or not (0)? Predicted CTR (0.15)
83 One-Hot Binary Encoding A standard feature engineering paradigm x=[weekday=friday, Gender=Male, City=Shanghai] x=[0,0,0,0,1,0,0 0,1 0,0,1,0 0] Sparse representation: x=[5:1 9:1 12:1] High dimensional sparse binary feature vector Usually higher than 1M dimensions, even 1B dimensions Extremely sparse
84 Training/Validation/Test Data Examples (in LibSVM format) 1 5:1 9:1 12:1 45:1 154:1 509:1 4089: : :1 0 2:1 7:1 18:1 34:1 176:1 510:1 3879: : :1 Training/Validation/Test data split Sort data by time Train:validation:test = 8:1:1 Shuffle training data
85 Training Logistic Regression Logistic regression is a binary classification model p μ (y =1jx) =¾(μ > x)= 1 1+e μ> x Cross entropy loss function with L2 regularization L(y; x; p μ )= ylog ¾(μ > x) (1 y)log(1 ¾(μ > x)) + 2 jjμjj2 2 Parameter learning μ Ã (1 )μ + (y ¾(μ > x))x Only update non-zero entries
86 Experimental Results Datasets Criteo Terabyte Dataset 13 numerical fields, 26 categorical fields 7 consecutive days out of 24 days in total (about 300 GB) during M impressions, 1.6M clicks after negative down sampling ipinyou Dataset 65 categorical fields 10 consecutive days during M impressions, 937.7K clicks without negative down sampling
87 Performance Model Logistic Regression Factorization Machine Deep Neural Networks Linearity AUC Log Loss Criteo ipinyou Criteo ipinyou Linear 71.48% 73.43% e-3 Bi-linear 72.20% 75.52% e-3 Nonlinear 75.66% 76.19% e-3 Compared with non-linear models, linear models Pros: standardized, easily understood and implemented, efficient and scalable Cons: modeling limit (feature independent assumption), cannot explore feature interactions [Yanru Qu et al. Product-based Neural Networks for User Response Prediction. ICDM 2016.]
88 For more machine learning materials, you can check out my machine learning course at Zhiyuan College CS420 Machine Learning Weinan Zhang Course webpage:
2018 CS420, Machine Learning, Lecture 5. Tree Models. Weinan Zhang Shanghai Jiao Tong University
 2018 CS420, Machine Learning, Lecture 5 Tree Models Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html ML Task: Function Approximation Problem setting
2018 CS420, Machine Learning, Lecture 5 Tree Models Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html ML Task: Function Approximation Problem setting
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION
 SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Logistic Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
2018 EE448, Big Data Mining, Lecture 5. (Part II) Weinan Zhang Shanghai Jiao Tong University
 Weinan Zhang Shanghai Jiao Tong University") 2018 EE448, Big Data Mining, Lecture 5 Supervised Learning (Part II) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
2018 EE448, Big Data Mining, Lecture 5 Supervised Learning (Part II) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
CSC2515 Winter 2015 Introduction to Machine Learning. Lecture 2: Linear regression
 CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Introduction to Logistic Regression
 Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Summary and discussion of: Dropout Training as Adaptive Regularization
 Summary and discussion of: Dropout Training as Adaptive Regularization Statistics Journal Club, 36-825 Kirstin Early and Calvin Murdock November 21, 2014 1 Introduction Multi-layered (i.e. deep) artificial
Summary and discussion of: Dropout Training as Adaptive Regularization Statistics Journal Club, 36-825 Kirstin Early and Calvin Murdock November 21, 2014 1 Introduction Multi-layered (i.e. deep) artificial
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS16
 SS16") COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS6 Lecture 3: Classification with Logistic Regression Advanced optimization techniques Underfitting & Overfitting Model selection (Training-
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS6 Lecture 3: Classification with Logistic Regression Advanced optimization techniques Underfitting & Overfitting Model selection (Training-
CS60021: Scalable Data Mining. Large Scale Machine Learning
 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 CS60021: Scalable Data Mining Large Scale Machine Learning Sourangshu Bhattacharya Example: Spam filtering Instance
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 CS60021: Scalable Data Mining Large Scale Machine Learning Sourangshu Bhattacharya Example: Spam filtering Instance
Introduction to Gaussian Process
 Introduction to Gaussian Process CS 778 Chris Tensmeyer CS 478 INTRODUCTION 1 What Topic? Machine Learning Regression Bayesian ML Bayesian Regression Bayesian Non-parametric Gaussian Process (GP) GP Regression
Introduction to Gaussian Process CS 778 Chris Tensmeyer CS 478 INTRODUCTION 1 What Topic? Machine Learning Regression Bayesian ML Bayesian Regression Bayesian Non-parametric Gaussian Process (GP) GP Regression
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data
 Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data DD2424 March 23, 2017 Binary classification problem given labelled training data Have labelled training examples? Given
Lecture 2 - Learning Binary & Multi-class Classifiers from Labelled Training Data DD2424 March 23, 2017 Binary classification problem given labelled training data Have labelled training examples? Given
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Lecture 2 Machine Learning Review
 Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Classification Based on Probability
 Logistic Regression These slides were assembled by Byron Boots, with only minor modifications from Eric Eaton s slides and grateful acknowledgement to the many others who made their course materials freely
Logistic Regression These slides were assembled by Byron Boots, with only minor modifications from Eric Eaton s slides and grateful acknowledgement to the many others who made their course materials freely
Linear Regression. Aarti Singh. Machine Learning / Sept 27, 2010
 Linear Regression Aarti Singh Machine Learning 10-701/15-781 Sept 27, 2010 Discrete to Continuous Labels Classification Sports Science News Anemic cell Healthy cell Regression X = Document Y = Topic X
Linear Regression Aarti Singh Machine Learning 10-701/15-781 Sept 27, 2010 Discrete to Continuous Labels Classification Sports Science News Anemic cell Healthy cell Regression X = Document Y = Topic X
Selected Topics in Optimization. Some slides borrowed from
 Selected Topics in Optimization Some slides borrowed from http://www.stat.cmu.edu/~ryantibs/convexopt/ Overview Optimization problems are almost everywhere in statistics and machine learning. Input Model
Selected Topics in Optimization Some slides borrowed from http://www.stat.cmu.edu/~ryantibs/convexopt/ Overview Optimization problems are almost everywhere in statistics and machine learning. Input Model
Logistic Regression. William Cohen
 Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Linear classifiers: Overfitting and regularization
 Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Essence of Machine Learning (and Deep Learning) Hoa M. Le Data Science Lab, HUST hoamle.github.io
 Hoa M. Le Data Science Lab, HUST hoamle.github.io") Essence of Machine Learning (and Deep Learning) Hoa M. Le Data Science Lab, HUST hoamle.github.io 1 Examples https://www.youtube.com/watch?v=bmka1zsg2 P4 http://www.r2d3.us/visual-intro-to-machinelearning-part-1/
Essence of Machine Learning (and Deep Learning) Hoa M. Le Data Science Lab, HUST hoamle.github.io 1 Examples https://www.youtube.com/watch?v=bmka1zsg2 P4 http://www.r2d3.us/visual-intro-to-machinelearning-part-1/
PAC Learning Introduction to Machine Learning. Matt Gormley Lecture 14 March 5, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Linear Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Linear Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Linear Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Behavioral Data Mining. Lecture 7 Linear and Logistic Regression
 Behavioral Data Mining Lecture 7 Linear and Logistic Regression Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips Linear Regression
Behavioral Data Mining Lecture 7 Linear and Logistic Regression Outline Linear Regression Regularization Logistic Regression Stochastic Gradient Fast Stochastic Methods Performance tips Linear Regression
Midterm exam CS 189/289, Fall 2015
 Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Lecture 11 Linear regression
 Advanced Algorithms Floriano Zini Free University of Bozen-Bolzano Faculty of Computer Science Academic Year 2013-2014 Lecture 11 Linear regression These slides are taken from Andrew Ng, Machine Learning
Advanced Algorithms Floriano Zini Free University of Bozen-Bolzano Faculty of Computer Science Academic Year 2013-2014 Lecture 11 Linear regression These slides are taken from Andrew Ng, Machine Learning
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Variations of Logistic Regression with Stochastic Gradient Descent
 Variations of Logistic Regression with Stochastic Gradient Descent Panqu Wang(pawang@ucsd.edu) Phuc Xuan Nguyen(pxn002@ucsd.edu) January 26, 2012 Abstract In this paper, we extend the traditional logistic
Variations of Logistic Regression with Stochastic Gradient Descent Panqu Wang(pawang@ucsd.edu) Phuc Xuan Nguyen(pxn002@ucsd.edu) January 26, 2012 Abstract In this paper, we extend the traditional logistic
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Online Advertising is Big Business
 Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Class 4: Classification. Quaid Morris February 11 th, 2011 ML4Bio
 Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
Case Study 1: Estimating Click Probabilities. Kakade Announcements: Project Proposals: due this Friday!
 Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Ridge Regression 1. to which some random noise is added. So that the training labels can be represented as:
 CS 1: Machine Learning Spring 15 College of Computer and Information Science Northeastern University Lecture 3 February, 3 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu 1 Introduction Ridge
CS 1: Machine Learning Spring 15 College of Computer and Information Science Northeastern University Lecture 3 February, 3 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu 1 Introduction Ridge
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Linear Models for Regression CS534
 Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Methods and Criteria for Model Selection. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Methods and Criteria for Model Selection CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Introduce classifier evaluation criteria } Introduce Bias x Variance duality } Model Assessment }
Methods and Criteria for Model Selection CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Introduce classifier evaluation criteria } Introduce Bias x Variance duality } Model Assessment }
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Approximation Methods in Reinforcement Learning
 2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Stochastic Gradient Descent. CS 584: Big Data Analytics
 Stochastic Gradient Descent CS 584: Big Data Analytics Gradient Descent Recap Simplest and extremely popular Main Idea: take a step proportional to the negative of the gradient Easy to implement Each iteration
Stochastic Gradient Descent CS 584: Big Data Analytics Gradient Descent Recap Simplest and extremely popular Main Idea: take a step proportional to the negative of the gradient Easy to implement Each iteration
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Feature Engineering, Model Evaluations
 Feature Engineering, Model Evaluations Giri Iyengar Cornell University gi43@cornell.edu Feb 5, 2018 Giri Iyengar (Cornell Tech) Feature Engineering Feb 5, 2018 1 / 35 Overview 1 ETL 2 Feature Engineering
Feature Engineering, Model Evaluations Giri Iyengar Cornell University gi43@cornell.edu Feb 5, 2018 Giri Iyengar (Cornell Tech) Feature Engineering Feb 5, 2018 1 / 35 Overview 1 ETL 2 Feature Engineering
Machine Learning Linear Models
 Machine Learning Linear Models Outline II - Linear Models 1. Linear Regression (a) Linear regression: History (b) Linear regression with Least Squares (c) Matrix representation and Normal Equation Method
Machine Learning Linear Models Outline II - Linear Models 1. Linear Regression (a) Linear regression: History (b) Linear regression with Least Squares (c) Matrix representation and Normal Equation Method
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Optimization Methods for Machine Learning
 Optimization Methods for Machine Learning Sathiya Keerthi Microsoft Talks given at UC Santa Cruz February 21-23, 2017 The slides for the talks will be made available at: http://www.keerthis.com/ Introduction
Optimization Methods for Machine Learning Sathiya Keerthi Microsoft Talks given at UC Santa Cruz February 21-23, 2017 The slides for the talks will be made available at: http://www.keerthis.com/ Introduction
An Introduction to Statistical and Probabilistic Linear Models
 An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
Introduction to Machine Learning
 Introduction to Machine Learning CS4731 Dr. Mihail Fall 2017 Slide content based on books by Bishop and Barber. https://www.microsoft.com/en-us/research/people/cmbishop/ http://web4.cs.ucl.ac.uk/staff/d.barber/pmwiki/pmwiki.php?n=brml.homepage
Introduction to Machine Learning CS4731 Dr. Mihail Fall 2017 Slide content based on books by Bishop and Barber. https://www.microsoft.com/en-us/research/people/cmbishop/ http://web4.cs.ucl.ac.uk/staff/d.barber/pmwiki/pmwiki.php?n=brml.homepage
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Recap from previous lecture
 Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Machine Learning Basics Lecture 4: SVM I. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Machine Learning (CS 567) Lecture 2
 Lecture 2") Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Classification: Decision Trees
 Classification: Decision Trees These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online. Feel
Classification: Decision Trees These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online. Feel
Course Structure. Psychology 452 Week 12: Deep Learning. Chapter 8 Discussion. Part I: Deep Learning: What and Why? Rufus. Rufus Processed By Fetch
 Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
DATA MINING AND MACHINE LEARNING
 DATA MINING AND MACHINE LEARNING Lecture 5: Regularization and loss functions Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Loss functions Loss functions for regression problems
DATA MINING AND MACHINE LEARNING Lecture 5: Regularization and loss functions Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Loss functions Loss functions for regression problems
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Supervised Learning. George Konidaris
 Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
ECE521 lecture 4: 19 January Optimization, MLE, regularization
 ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
Neural Networks: Optimization & Regularization
 Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
Neural Networks: Optimization & Regularization Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) NN Opt & Reg
DATA MINING AND MACHINE LEARNING. Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
Machine Learning (CS 567) Lecture 3
 Lecture 3") Machine Learning (CS 567) Lecture 3 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 3 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Homework #3 RELEASE DATE: 10/28/2013 DUE DATE: extended to 11/18/2013, BEFORE NOON QUESTIONS ABOUT HOMEWORK MATERIALS ARE WELCOMED ON THE FORUM.
 Homework #3 RELEASE DATE: 10/28/2013 DUE DATE: extended to 11/18/2013, BEFORE NOON QUESTIONS ABOUT HOMEWORK MATERIALS ARE WELCOMED ON THE FORUM. Unless granted by the instructor in advance, you must turn
Homework #3 RELEASE DATE: 10/28/2013 DUE DATE: extended to 11/18/2013, BEFORE NOON QUESTIONS ABOUT HOMEWORK MATERIALS ARE WELCOMED ON THE FORUM. Unless granted by the instructor in advance, you must turn
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011!
 Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning and Data Mining. Linear regression. Kalev Kask
 Machine Learning and Data Mining Linear regression Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ Parameters q Learning algorithm Program ( Learner ) Change q Improve performance
Machine Learning and Data Mining Linear regression Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ Parameters q Learning algorithm Program ( Learner ) Change q Improve performance
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors