Online Advertising is Big Business
|
|
|
- Donald Alexander
- 6 years ago
- Views:
Transcription
1 Online Advertising

2
3

4


5 Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA than cable TV and nearly the same as broadcast TV [PWC, Internet Advertising Bureau, Oct 2013] Large source of revenue for Google and other search engines

![) and by ad campaign, but can be less than 1% [Andrew Stern, imedia Connection, 2010]](/docs-images/76/73100086/images/6-1.jpg "Lots of Data Lots of people use the internet Easy to gathered labeled data A great")
6 Canonical Scalable ML Problem Problem is hard; we need all the data we can get! Success varies by type of online ad (banner, sponsor search, , etc.) and by ad campaign, but can be less than 1% [Andrew Stern, imedia Connection, 2010] Lots of Data Lots of people use the internet Easy to gathered labeled data A great success story for scalable ML
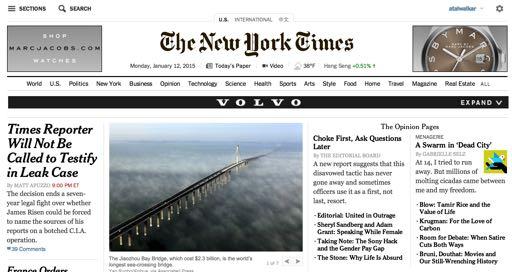
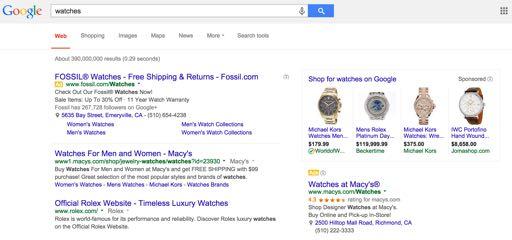
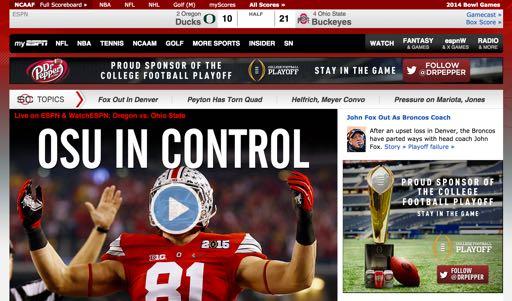
7 The Players Publishers: NYTimes, Google, ESPN Make money displaying ads on their sites Advertisers: Marc Jacobs, Fossil, Macy s, Dr. Pepper Pay for their ads to be displayed on publisher sites They want to attract business Matchmakers: Google, Microsoft, Yahoo Match publishers with advertisers In real-time (i.e., as a specific user visits a website)
8 Why Advertisers Pay? Impressions Get message to target audience e.g., brand awareness campaign Performance Get users to do something e.g., click on ad (pay-per-click) Most common e.g., buy something or join a mailing list
")
9 Efficient Matchmaking Idea: Predict probability that user will click each ad and choose ads to maximize probability Estimate P (click predictive features) Conditional probability: probability given predictive features Predictive features Ad s historical performance Advertiser and ad content info Publisher info User info (e.g., search / click history)
10 Publishers Get Billions of Impressions Per Day But, data is high-dimensional, sparse, and skewed Hundreds of millions of online users Millions of unique publisher pages to display ads Millions of unique ads to display Very few ads get clicked by users Massive datasets are crucial to tease out signal Goal: Estimate P (click user, ad, publisher info) Given: Massive amounts of labeled data
11 Linear Classification and Logistic Regresssion
12 Classification Goal: Learn a mapping from observations to discrete labels given a set of training examples (supervised learning) Example: Spam Classification Observations are s Labels are {spam, not-spam} (Binary Classification) Given a set of labeled s, we want to predict whether a new is spam or not-spam
13 Classification Goal: Learn a mapping from observations to discrete labels given a set of training examples (supervised learning) Example: Click-through Rate Prediction Observations are user-ad-publisher triples Labels are {not-click, click} (Binary Classification) Given a set of labeled observations, we want to predict whether a new user-ad-publisher triple will result in a click
14 Reminder: Linear Regression Example: Predicting shoe size from height, gender, and weight For each observation we have a feature vector, x, and label, y x = x 1 x 2 x 3 We assume a linear mapping between features and label: y w 0 + w 1 x 1 + w 2 x 2 + w 3 x 3
15 Reminder: Linear Regression Example: Predicting shoe size from height, gender, and weight We can augment the feature vector to incorporate offset: x = 1 x 1 x 2 x 3 We can then rewrite this linear mapping as scalar product: 3 y ŷ = w i x i = w x i=0
16 Why a Linear Mapping? Simple Often works well in practice Can introduce complexity via feature extraction Can we do something similar for classification?
17 Linear Regression Linear Classifier Example: Predicting rain from temperature, cloudiness, and humidity Use the same feature representation: x = 1 x 1 x 2 x 3 How can we make class predictions? {not-rain, rain}, {not-spam, spam}, {not-click, click} We can threshold by sign 3 ŷ = w i x i = w x = ŷ = sign(w x) i=0
18 Linear Classifier Decision Boundary Decision 3x 1 Boundary 4x2 Imagine w 1=0 x2 = 1 3 x = :w x= x = :w x=1 x = : w x = 12 x = : w x = x1 y = Let swinterpret x = rule: y = sign(w x) i xi = w this i=0y = 1 : w x > 0 y = 1 : w x < 0 Decision boundary: w x = 0
19 Evaluating Predictions Regression: can measure closeness between label and prediction Song year prediction: better to be off by a year than by 20 years Squared loss: (y ŷ) 2 Classification: Class predictions are discrete 0-1 loss: Penalty is 0 for correct prediction, and 1 otherwise
20 0/1 Loss Minimization 0/1(z) = 1 if z < 0 0 otherwise (z) 0-1 z = y w x Let y { 1, 1} z = y w x and define z is positive if y and w x have same sign, negative otherwise
21 How Can We Learn Model (w)? Assume we have n training points, where x (i) denotes the ith point Recall two earlier points: Linear assumption: ŷ = sign(w x) We use 0-1 loss: 0/1(z) Idea: Find w that minimizes average 0-1 loss over training points: n min w 0/1 y (i) w x (i) i=1
22 0/1 Loss Minimization (z) 0/1(z) = 1 if z < 0 0 otherwise Issue: hard optimization problem, not convex! 0-1 z = y w x Let y { 1, 1} z = y w x and define z is positive if y and w x have same sign, negative otherwise
23 Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge), Logistic regression (logistic), Adaboost (exponential)
24 Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x Logistic loss (logloss): l log (z) = log(1 + e z )
25 Logistic Regression Optimization Logistic Regression: Learn mapping ( ) that minimizes logistic loss on training data with a regularization term w n Training LogLoss Model Complexity min w log y (i) w x (i) + λ w 2 2 i=1 Convex Closed form solution doesn t exist
26 Logistic Regression Optimization f(w) Goal: Find w n that minimizes f(w) = log y (i) w x (i) i=1 Can solve via Gradient Descent Step Size w * w Update Rule: w i+1 = w i α f(w) n 1 1 y (j) x (j) j=1 1 +exp( y (j) w i x (j) ) Gradient
27 Logistic Regression Optimization Regularized Logistic Regression: Learn mapping ( ) that minimizes logistic loss on training data with a regularization term w n Training LogLoss Model Complexity min w log y (i) w x (i) + λ w 2 2 i=1 Convex Closed form solution doesn t exist Can add regularization term (as in ridge regression)
28 Logistic Regression: Probabilistic Interpretation
29 Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge), Logistic regression (logistic), Adaboost (exponential)
30 Probabilistic Interpretation Goal: Model conditional probability: P[ y = 1 x ] Example: Predict rain from temperature, cloudiness, humidity x x P[ y = rain t = 14 F, c = LOW, h = 2%]=.05 P[ y = rain t = 70 F, c = HIGH, h = 95%]=.9 Example: Predict click from ad s historical performance, user s click frequency, and publisher page s relevance x x P[ y = click h = GOOD, f = HIGH, r = HIGH ]=.1 P[ y = click h = BAD, f = LOW, r = LOW ]=.001
31 Probabilistic Interpretation Goal: Model conditional probability: P[ y = 1 x ] First thought: P[ y = 1 x ]=w x Linear regression returns any real number, but probabilities range from 0 to 1! How can we transform or squash its output? Use logistic (or sigmoid) function: P[ y = 1 x ]=σ(w x)
32 Logistic Function σ(z) Maps real numbers to [0, 1] Large positive inputs 1 Large negative inputs 0 z σ(z) = 1 1 +exp( z)
33 Probabilistic Interpretation Goal: Model conditional probability: P[ y = 1 x ] Logistic regression uses logistic function to model this conditional probability P[ y = 1 x ]=σ(w x) P[ y = 0 x ]=1 σ(w x) For notational convenience we now define y {0, 1}
34 How Do We Use Probabilities? To make class predictions, we need to convert probabilities to values in {0, 1} We can do this by setting a threshold on the probabilities Default threshold is 0.5 x P[ y = 1 x ] > 0.5 = ŷ = 1 Example: Predict rain from temperature, cloudiness, humidity P[ y = rain t = 14 F, c = LOW, h = 2%]=.05 ŷ = 0 P[ y = rain t = 70 F, c = HIGH, h = 95%]=.9 ŷ = 1
35 Connection with Decision Boundary? Decision Boundary x 2 predictions: ŷ = sign(w x) Threshold by sign to make class ŷ = 1 : w x > 0 ŷ = 0 : w x < 0 decision boundary: w x = 0 x 1 How does this compare with thresholding probability? P[ y = 1 x ]=σ(w x) > 0.5 = ŷ = 1
36 Connection with Decision Boundary? σ ( z) σ ( 0 ) = y = i=0 z w x=0 σ (w x) = 0.5 Threshold by sign to make class wi xi =predictions: w x = y = sign(w x) y = 1 : w x > 0 y = 0 : w x < 0 decision boundary: w x = 0 How does this compare with thresholding probability? x y = 1 x ]P[ x ] > 0.5 = y = 1 P[ =yσ= (w1 x) With threshold of 0.5, the decision boundaries are identical!
37 Using Probabilistic Predictions
38 How Do We Use Probabilities? To make class predictions, we need to convert probabilities to values in {0, 1} We can do this by setting a threshold on the probabilities Default threshold is 0.5 x P[ y = 1 x ] > 0.5 = ŷ = 1 Example: Predict rain from temperature, cloudiness, humidity P[ y = rain t = 14 F, c = LOW, h = 2%]=.05 ŷ = 0 P[ y = rain t = 70 F, c = HIGH, h = 95%]=.9 ŷ = 1
39 Setting different thresholds In spam detection application, we model P[ y = spam x ] Two types of error Classify a not-spam as spam (false positive, FP) Classify a spam as not-spam (false negative, FN) Can argue that false positives are more harmful than false negatives Worse to miss an important than to have to delete spam We can use a threshold greater than 0.5 to be more conservative
40 ROC Plots: Measuring Varying Thresholds Perfect Classification Threshold = 0 ROC plot displays FPR vs TPR Top left is perfect Dotted Line is random prediction (i.e., biased coin flips) Can classify at various thresholds (T) T = 0: Everything is spam TPR = 1, but FPR = 1 True Positive Rate (TPR) FPR at 0.1 Random Prediction T = 1: Nothing is spam FPR = 0, but TPR = 0 Threshold = 1 False Positive Rate (FPR) We can tradeoff between TPR/FPR FPR: % not-spam predicted as spam TPR: % spam predicted as spam
41 Working Directly with Probabilities Example: Predict click from ad s historical performance, user s click frequency, and publisher page s relevance P[ y = click h = GOOD, f = HIGH, r = HIGH ]=.1 P[ y = click h = BAD, f = LOW, r = LOW ]=.001 ŷ = 0 ŷ = 0 Success can be less than 1% [Andrew Stern, imedia Connection, 2010] Probabilities provide more granular information Confidence of prediction Useful when combining predictions with other information In such cases, we want to evaluate probabilities directly Logistic loss makes sense for evaluation!
42 Logistic Loss log(p, y) = log(p) if y = 1 log(1 p) if y = 0 When y = 1, we want p = 1 No penalty at 1 log(p) log(1 p) Increasing penalty away from 1 Similar logic when y = 0 p
Online Advertising is Big Business
 Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
Introduction to Logistic Regression
 Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Case Study 1: Estimating Click Probabilities. Kakade Announcements: Project Proposals: due this Friday!
 Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels
 SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
Supervised Learning. George Konidaris
 Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Performance Evaluation
 Performance Evaluation David S. Rosenberg Bloomberg ML EDU October 26, 2017 David S. Rosenberg (Bloomberg ML EDU) October 26, 2017 1 / 36 Baseline Models David S. Rosenberg (Bloomberg ML EDU) October 26,
Performance Evaluation David S. Rosenberg Bloomberg ML EDU October 26, 2017 David S. Rosenberg (Bloomberg ML EDU) October 26, 2017 1 / 36 Baseline Models David S. Rosenberg (Bloomberg ML EDU) October 26,
Machine Learning Basics Lecture 2: Linear Classification. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 2: Linear Classification Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d.
Machine Learning Basics Lecture 2: Linear Classification Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d.
ECE521 Lecture7. Logistic Regression
 ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
Logistic Regression Logistic
 Case Study 1: Estimating Click Probabilities L2 Regularization for Logistic Regression Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 10 th,
Case Study 1: Estimating Click Probabilities L2 Regularization for Logistic Regression Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 10 th,
Optimal and Adaptive Algorithms for Online Boosting
 Optimal and Adaptive Algorithms for Online Boosting Alina Beygelzimer 1 Satyen Kale 1 Haipeng Luo 2 1 Yahoo! Labs, NYC 2 Computer Science Department, Princeton University Jul 8, 2015 Boosting: An Example
Optimal and Adaptive Algorithms for Online Boosting Alina Beygelzimer 1 Satyen Kale 1 Haipeng Luo 2 1 Yahoo! Labs, NYC 2 Computer Science Department, Princeton University Jul 8, 2015 Boosting: An Example
Logistic Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Logistic Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Lecture 4 Discriminant Analysis, k-nearest Neighbors
 Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012
 CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Classification objectives COMS 4771
 Classification objectives COMS 4771 1. Recap: binary classification Scoring functions Consider binary classification problems with Y = { 1, +1}. 1 / 22 Scoring functions Consider binary classification
Classification objectives COMS 4771 1. Recap: binary classification Scoring functions Consider binary classification problems with Y = { 1, +1}. 1 / 22 Scoring functions Consider binary classification
Variations of Logistic Regression with Stochastic Gradient Descent
 Variations of Logistic Regression with Stochastic Gradient Descent Panqu Wang(pawang@ucsd.edu) Phuc Xuan Nguyen(pxn002@ucsd.edu) January 26, 2012 Abstract In this paper, we extend the traditional logistic
Variations of Logistic Regression with Stochastic Gradient Descent Panqu Wang(pawang@ucsd.edu) Phuc Xuan Nguyen(pxn002@ucsd.edu) January 26, 2012 Abstract In this paper, we extend the traditional logistic
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Lecture 3 Classification, Logistic Regression
 Lecture 3 Classification, Logistic Regression Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se F. Lindsten Summary
Lecture 3 Classification, Logistic Regression Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se F. Lindsten Summary
Linear classifiers: Logistic regression
 Linear classifiers: Logistic regression STAT/CSE 416: Machine Learning Emily Fox University of Washington April 19, 2018 How confident is your prediction? The sushi & everything else were awesome! The
Linear classifiers: Logistic regression STAT/CSE 416: Machine Learning Emily Fox University of Washington April 19, 2018 How confident is your prediction? The sushi & everything else were awesome! The
Ad Placement Strategies
 Case Study : Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD AdaGrad Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 7 th, 04 Ad
Case Study : Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD AdaGrad Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 7 th, 04 Ad
Linear classifiers: Overfitting and regularization
 Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Boosting. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL , 10.7, 10.13
 Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
CSC 411 Lecture 7: Linear Classification
 CSC 411 Lecture 7: Linear Classification Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 07-Linear Classification 1 / 23 Overview Classification: predicting
CSC 411 Lecture 7: Linear Classification Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 07-Linear Classification 1 / 23 Overview Classification: predicting
Evaluation requires to define performance measures to be optimized
 Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear classifiers Lecture 3
 Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Linear and Logistic Regression. Dr. Xiaowei Huang
 Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Regularization. CSCE 970 Lecture 3: Regularization. Stephen Scott and Vinod Variyam. Introduction. Outline
 Other Measures 1 / 52 sscott@cse.unl.edu learning can generally be distilled to an optimization problem Choose a classifier (function, hypothesis) from a set of functions that minimizes an objective function
Other Measures 1 / 52 sscott@cse.unl.edu learning can generally be distilled to an optimization problem Choose a classifier (function, hypothesis) from a set of functions that minimizes an objective function
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
CPSC 340: Machine Learning and Data Mining. Stochastic Gradient Fall 2017
 CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Kernels. Machine Learning CSE446 Carlos Guestrin University of Washington. October 28, Carlos Guestrin
 Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Evaluation. Andrea Passerini Machine Learning. Evaluation
 Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
2018 EE448, Big Data Mining, Lecture 4. (Part I) Weinan Zhang Shanghai Jiao Tong University
 Weinan Zhang Shanghai Jiao Tong University") 2018 EE448, Big Data Mining, Lecture 4 Supervised Learning (Part I) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
2018 EE448, Big Data Mining, Lecture 4 Supervised Learning (Part I) Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of Supervised Learning
Applied Machine Learning Lecture 5: Linear classifiers, continued. Richard Johansson
 Applied Machine Learning Lecture 5: Linear classifiers, continued Richard Johansson overview preliminaries logistic regression training a logistic regression classifier side note: multiclass linear classifiers
Applied Machine Learning Lecture 5: Linear classifiers, continued Richard Johansson overview preliminaries logistic regression training a logistic regression classifier side note: multiclass linear classifiers
Day 3: Classification, logistic regression
 Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
Performance evaluation of binary classifiers
 Performance evaluation of binary classifiers Kevin P. Murphy Last updated October 10, 2007 1 ROC curves We frequently design systems to detect events of interest, such as diseases in patients, faces in
Performance evaluation of binary classifiers Kevin P. Murphy Last updated October 10, 2007 1 ROC curves We frequently design systems to detect events of interest, such as diseases in patients, faces in
Performance Evaluation
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Example:
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Example:
Applied Machine Learning Annalisa Marsico
 Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 22 April, SoSe 2015 Goals Feature Selection rather than Feature
Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 22 April, SoSe 2015 Goals Feature Selection rather than Feature
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Classification Based on Probability
 Logistic Regression These slides were assembled by Byron Boots, with only minor modifications from Eric Eaton s slides and grateful acknowledgement to the many others who made their course materials freely
Logistic Regression These slides were assembled by Byron Boots, with only minor modifications from Eric Eaton s slides and grateful acknowledgement to the many others who made their course materials freely
Least Squares Classification
 Least Squares Classification Stephen Boyd EE103 Stanford University November 4, 2017 Outline Classification Least squares classification Multi-class classifiers Classification 2 Classification data fitting
Least Squares Classification Stephen Boyd EE103 Stanford University November 4, 2017 Outline Classification Least squares classification Multi-class classifiers Classification 2 Classification data fitting
CSC 411: Lecture 04: Logistic Regression
 CSC 411: Lecture 04: Logistic Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 23, 2015 Urtasun & Zemel (UofT) CSC 411: 04-Prob Classif Sep 23, 2015 1 / 16 Today Key Concepts: Logistic
CSC 411: Lecture 04: Logistic Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 23, 2015 Urtasun & Zemel (UofT) CSC 411: 04-Prob Classif Sep 23, 2015 1 / 16 Today Key Concepts: Logistic
Methods and Criteria for Model Selection. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Methods and Criteria for Model Selection CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Introduce classifier evaluation criteria } Introduce Bias x Variance duality } Model Assessment }
Methods and Criteria for Model Selection CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Introduce classifier evaluation criteria } Introduce Bias x Variance duality } Model Assessment }
Training the linear classifier
 215, Training the linear classifier A natural way to train the classifier is to minimize the number of classification errors on the training data, i.e. choosing w so that the training error is minimized.
215, Training the linear classifier A natural way to train the classifier is to minimize the number of classification errors on the training data, i.e. choosing w so that the training error is minimized.
Introduction to Machine Learning
 Introduction to Machine Learning Thomas G. Dietterich tgd@eecs.oregonstate.edu 1 Outline What is Machine Learning? Introduction to Supervised Learning: Linear Methods Overfitting, Regularization, and the
Introduction to Machine Learning Thomas G. Dietterich tgd@eecs.oregonstate.edu 1 Outline What is Machine Learning? Introduction to Supervised Learning: Linear Methods Overfitting, Regularization, and the
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Stephen Scott.
 1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Online Learning and Sequential Decision Making
 Online Learning and Sequential Decision Making Emilie Kaufmann CNRS & CRIStAL, Inria SequeL, emilie.kaufmann@univ-lille.fr Research School, ENS Lyon, Novembre 12-13th 2018 Emilie Kaufmann Online Learning
Online Learning and Sequential Decision Making Emilie Kaufmann CNRS & CRIStAL, Inria SequeL, emilie.kaufmann@univ-lille.fr Research School, ENS Lyon, Novembre 12-13th 2018 Emilie Kaufmann Online Learning
Classification: Analyzing Sentiment
 Classification: Analyzing Sentiment STAT/CSE 416: Machine Learning Emily Fox University of Washington April 17, 2018 Predicting sentiment by topic: An intelligent restaurant review system 1 It s a big
Classification: Analyzing Sentiment STAT/CSE 416: Machine Learning Emily Fox University of Washington April 17, 2018 Predicting sentiment by topic: An intelligent restaurant review system 1 It s a big
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
CS229 Supplemental Lecture notes
 CS229 Supplemental Lecture notes John Duchi Binary classification In binary classification problems, the target y can take on at only two values. In this set of notes, we show how to model this problem
CS229 Supplemental Lecture notes John Duchi Binary classification In binary classification problems, the target y can take on at only two values. In this set of notes, we show how to model this problem
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
COMP 875 Announcements
 Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Support Vector Machines, Kernel SVM
 Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Tutorial: PART 1. Online Convex Optimization, A Game- Theoretic Approach to Learning.
 Tutorial: PART 1 Online Convex Optimization, A Game- Theoretic Approach to Learning http://www.cs.princeton.edu/~ehazan/tutorial/tutorial.htm Elad Hazan Princeton University Satyen Kale Yahoo Research
Tutorial: PART 1 Online Convex Optimization, A Game- Theoretic Approach to Learning http://www.cs.princeton.edu/~ehazan/tutorial/tutorial.htm Elad Hazan Princeton University Satyen Kale Yahoo Research
Machine Learning for NLP
 Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Binary Classification / Perceptron
 Binary Classification / Perceptron Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Supervised Learning Input: x 1, y 1,, (x n, y n ) x i is the i th data
Binary Classification / Perceptron Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Supervised Learning Input: x 1, y 1,, (x n, y n ) x i is the i th data
MLCC 2017 Regularization Networks I: Linear Models
 MLCC 2017 Regularization Networks I: Linear Models Lorenzo Rosasco UNIGE-MIT-IIT June 27, 2017 About this class We introduce a class of learning algorithms based on Tikhonov regularization We study computational
MLCC 2017 Regularization Networks I: Linear Models Lorenzo Rosasco UNIGE-MIT-IIT June 27, 2017 About this class We introduce a class of learning algorithms based on Tikhonov regularization We study computational
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
CS221 / Autumn 2017 / Liang & Ermon. Lecture 2: Machine learning I
 CS221 / Autumn 2017 / Liang & Ermon Lecture 2: Machine learning I cs221.stanford.edu/q Question How many parameters (real numbers) can be learned by machine learning algorithms using today s computers?
CS221 / Autumn 2017 / Liang & Ermon Lecture 2: Machine learning I cs221.stanford.edu/q Question How many parameters (real numbers) can be learned by machine learning algorithms using today s computers?
Learning Neural Networks
 Learning Neural Networks Neural Networks can represent complex decision boundaries Variable size. Any boolean function can be represented. Hidden units can be interpreted as new features Deterministic
Learning Neural Networks Neural Networks can represent complex decision boundaries Variable size. Any boolean function can be represented. Hidden units can be interpreted as new features Deterministic
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 7 Unsupervised Learning Statistical Perspective Probability Models Discrete & Continuous: Gaussian, Bernoulli, Multinomial Maimum Likelihood Logistic
Machine Learning 4771 Instructor: Tony Jebara Topic 7 Unsupervised Learning Statistical Perspective Probability Models Discrete & Continuous: Gaussian, Bernoulli, Multinomial Maimum Likelihood Logistic
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Homework 2 Solutions Kernel SVM and Perceptron
 Homework 2 Solutions Kernel SVM and Perceptron CMU 1-71: Machine Learning (Fall 21) https://piazza.com/cmu/fall21/17115781/home OUT: Sept 25, 21 DUE: Oct 8, 11:59 PM Problem 1: SVM decision boundaries
Homework 2 Solutions Kernel SVM and Perceptron CMU 1-71: Machine Learning (Fall 21) https://piazza.com/cmu/fall21/17115781/home OUT: Sept 25, 21 DUE: Oct 8, 11:59 PM Problem 1: SVM decision boundaries
Naïve Bayes Classifiers and Logistic Regression. Doug Downey Northwestern EECS 349 Winter 2014
 Naïve Bayes Classifiers and Logistic Regression Doug Downey Northwestern EECS 349 Winter 2014 Naïve Bayes Classifiers Combines all ideas we ve covered Conditional Independence Bayes Rule Statistical Estimation
Naïve Bayes Classifiers and Logistic Regression Doug Downey Northwestern EECS 349 Winter 2014 Naïve Bayes Classifiers Combines all ideas we ve covered Conditional Independence Bayes Rule Statistical Estimation
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
Optimal and Adaptive Online Learning
 Optimal and Adaptive Online Learning Haipeng Luo Advisor: Robert Schapire Computer Science Department Princeton University Examples of Online Learning (a) Spam detection 2 / 34 Examples of Online Learning
Optimal and Adaptive Online Learning Haipeng Luo Advisor: Robert Schapire Computer Science Department Princeton University Examples of Online Learning (a) Spam detection 2 / 34 Examples of Online Learning
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning. Lecture 04: Logistic and Softmax Regression. Nevin L. Zhang
 Machine Learning Lecture 04: Logistic and Softmax Regression Nevin L. Zhang lzhang@cse.ust.hk Department of Computer Science and Engineering The Hong Kong University of Science and Technology This set
Machine Learning Lecture 04: Logistic and Softmax Regression Nevin L. Zhang lzhang@cse.ust.hk Department of Computer Science and Engineering The Hong Kong University of Science and Technology This set
Day 4: Classification, support vector machines
 Day 4: Classification, support vector machines Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 21 June 2018 Topics so far
Day 4: Classification, support vector machines Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 21 June 2018 Topics so far
Boosting: Foundations and Algorithms. Rob Schapire
 Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Machine Learning Basics Lecture 4: SVM I. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
ML4NLP Multiclass Classification
 ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
Natural Language Processing. Classification. Features. Some Definitions. Classification. Feature Vectors. Classification I. Dan Klein UC Berkeley
 Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Directly and Efficiently Optimizing Prediction Error and AUC of Linear Classifiers
 Directly and Efficiently Optimizing Prediction Error and AUC of Linear Classifiers Hiva Ghanbari Joint work with Prof. Katya Scheinberg Industrial and Systems Engineering Department US & Mexico Workshop
Directly and Efficiently Optimizing Prediction Error and AUC of Linear Classifiers Hiva Ghanbari Joint work with Prof. Katya Scheinberg Industrial and Systems Engineering Department US & Mexico Workshop
Classification Logistic Regression
 Announcements: Classification Logistic Regression Machine Learning CSE546 Sham Kakade University of Washington HW due on Friday. Today: Review: sub-gradients,lasso Logistic Regression October 3, 26 Sham
Announcements: Classification Logistic Regression Machine Learning CSE546 Sham Kakade University of Washington HW due on Friday. Today: Review: sub-gradients,lasso Logistic Regression October 3, 26 Sham
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Classification and Pattern Recognition
 Classification and Pattern Recognition Léon Bottou NEC Labs America COS 424 2/23/2010 The machine learning mix and match Goals Representation Capacity Control Operational Considerations Computational Considerations
Classification and Pattern Recognition Léon Bottou NEC Labs America COS 424 2/23/2010 The machine learning mix and match Goals Representation Capacity Control Operational Considerations Computational Considerations