Boosting. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL , 10.7, 10.13
|
|
|
- Pierce Payne
- 6 years ago
- Views:
Transcription
1 Boosting Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL , 10.7,
2 Reminder: classification trees Suppose that we are given training data (x i, y i ), i = 1,... n, with y i {1,... K} the class label and x i R p the associated features Recall that the CART algorithm to fit a classification tree starts by considering splitting on variable j and split point s, and defines the regions R 1 = {X R p : X j s}, R 2 = {X R p : X j > s} Within each region the proportion of points of class k is ˆp k (R m ) = 1 n m x i R m 1{y i = k} with n m the number of points in R m. The most common class is c m = argmax k=1,...k ˆp k (R m ) 2
3 The feature and split point j, s are chosen greedily by minimizing the misclassification error ( [1 argmin ˆpc1 (R 1 ) ] + [ 1 ˆp c2 (R 2 ) ]) j,s This strategy is repeated within each of the newly formed regions 3
4 Classification trees with observation weights Now suppose that we are are additionally given observation weights w i, i = 1,... n. Each w i 0, and a higher value means that we place a higher importance in correctly classifying this observation The CART algorithm can be easily adapted to use the weights. All that changes is that our sums become weighted sums. I.e., we now use the weighted proportion of points of class k in region R m : x ˆp k (R m ) = i R m w i 1{y i = k} x i R m w i As before, we let c m = argmax k=1,...k ˆp k (R m ) and hence 1 ˆp cm (R m ) is the weighted misclassification error 4
5 Boosting Boosting 1 is similar to bagging in that we combine the results of several classification trees. However, boosting does something fundamentally different, and can work a lot better As usual, we start with training data (x i, y i ), i = 1,... n. We ll assume that y i { 1, 1} and x i R p. Hence we suppose that a classification tree (fit, e.g., to the training data) will return a prediction of the form ˆf tree (x) { 1, 1} for an input x R p In boosting we combine a weighted sum of B different tree classifiers, ( B ) ˆf boost (x) = sign α b ˆf tree,b (x) b=1 1 Freund and Schapire (1995), A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. Similar ideas were around earlier 5
6 One of the key differences between boosting and bagging is how the individual classifiers ˆf tree,b are fit. Unlike in bagging, in boosting we fit the tree to the entire training set, but adaptively weight the observations to encourage better predictions for points that were previously misclassified (From ESL page 338) 6
7 The basic boosting algorithm (AdaBoost) Given training data (x i, y i ), i = 1,... n, the basic boosting method is called AdaBoost, and can be described as: Initialize the weights by w i = 1/n for each i For b = 1,... B: 1. Fit a classification tree ˆf tree,b to the training data with weights w 1,... w n 2. Compute the weighted misclassification error n i=1 e b = w i1{y i ˆf tree,b (x i )} n i=1 w i 3. Let α b = log{(1 e b )/e b } 4. Update the weights as w i w i exp(α b 1{y i ˆf tree,b (x i )}) for each i Return ˆf B boost (x) = sign( b=1 α b ˆf ) tree,b (x) 7
8 Example: boosting stumps Example (from ESL page 339): here n = 1000 points were drawn from the model { 1 if 10 j=1 Y i = X2 ij > χ2 10 (0.5), for i = 1,... n 1 otherwise where each X ij N(0, 1) independently, j = 1, A stump classifier was computed: this is just a classification tree with one split (two leaves). This has a bad misclassification rate on independent test data, of about 45.8%. (Why is this not surprising?) On the other hand, boosting stumps achieves an excellent error rate of about 5.8% after B = 400 iterations. This is much better than, e.g., a single large tree (error rate 24.7%) 8
9 9
10 Why does boosting work? The intution beyond boosting is simple: we weight misclassified observations in such a way that they get properly classified in future iterations. But there are many ways to do this why does the particular weighting seem to work so well? One nice discovery was the connection between boosting and forward stepwise modeling. 2 To understand this connection, it helps to recall forward stepwise linear regression. Given a continuous response y R n and predictors X 1,... X p R n, we: Choose the predictor X j giving the smallest squared error loss n i=1 (y i ˆβ j X ij ) 2 ( ˆβ j is obtained by regressing y on X j ) Choose the predictor X k giving the smallest additional loss n i=1 (r i ˆβ k X ik ) 2 ( ˆβ k is obtained by regressing r on X k ), where r is the residual r = y ˆβ j X j Repeat the last step 2 Friedman et al. (2000), Additive Logistic Regression: A Statistical View of Boosting 10
11 Boosting fits an additive model In the classification setting, y i is not continuous but discrete, taking values in { 1, 1}. Therefore squared error loss is not appropriate. Instead we use exponential loss: L(y i, f(x i )) = exp( y i f(x i )) Furthermore, boosting doesn t model f(x i ) as a linear function of the variables x i1,... x ip, but rather as a linear function of trees T 1 (x i ),... T M (x i ) of a certain size. (Note that the number M of trees of a given size is finite.) Hence the analogous forward stepwise modeling is as follows: Choose the tree T j and coefficient β j giving the smallest exponential loss n i=1 exp( y iβ j T j (x i )) Choose the tree T k and coefficient β k giving the smallest additional loss n i=1 exp( y i{β j T j (x i ) + β k T k (x i )}) = n i=1 exp( y iβ j T j (x i )) exp( y i β k T k (x i )) Repeat the last step 11
12 12 This forward stepwise procedure can be tied concretely to the AdaBoost algorithm that we just learned (see ESL 10.4 for details) This connection brought boosting from an unfamiliar algorithm to a more-or-less familiar statistical concept. Consequently, there were many suggested ways to extend boosting: Other losses: exponential loss is not really used anywhere else. It leads to a computationally efficient boosting algorithm (AdaBoost), but binomial deviance and SVM loss are two alternatives that can work better. (Algorithms for boosting are now called gradient boosting) Shrinkage: instead of adding one tree at a time (thinking in the forward stepwise perspective), why don t we add a small multiple of a tree? This is called shrinkage a form of regularization for the model building process. This can also be very helpful in terms of prediction accuracy
13 13 Choosing the size of the trees How big should the trees be used in the boosting procedure? Remember that in bagging we grew large trees, and then either stopped (no pruning) or pruned back using the original training data as a validation set. In boosting, actually, the best methods if to grow small trees with no pruning In ESL 10.11, it is argued that right size actually depends on the level of the iteractions between the predictor variables. Generally trees with 2 8 leaves work well; rarely more than 10 leaves are needed
14 14 Disadvantages As with bagging, a major downside is that we lose the simple interpretability of classification trees. The final classifier is a weighted sum of trees, which cannot necessarily be represented by a single tree. Computation is also somewhat more difficult. However, with AdaBoost, the computation is straightforward (moreso than gradient boosting). Further, because we are growing small trees, each step can be done relatively quickly (compared to say, bagging) To deal with the first downside, a measure of variable importance has been developed for boosting (and it can be applied to bagging, also)
15 15 Variable importance for trees For a single decision tree ˆf tree, we define the squared importance for variable j as Imp 2 j( ˆf m tree ) = ˆd k 1{split at node k is on variable j} k=1 where m is the number of internal nodes (non-leaves), and ˆd k is the improvement in training misclassification error from making the kth split
16 16 Variable importance for boosting For boosting, we define the squared importance for a variable j by simplying averaging the squared importance over all of the fitted trees: Imp 2 j( ˆf boost ) = 1 B Imp 2 B j( ˆf tree,b ) (To get the importance, we just take the squared root.) We also usually set the largest importance to 100, and scale all of the other variable importances accordingly, which are then called relative importances This averaging stabilizes the variable importances, which means that they tend to be much more accurate for boosting than they do for any single tree b=1
17 17 Example: spam data Example from ESL 10.8: recall the spam data set, with n = s (1813 spam s), and given p = 58 attributes on each A classification tree, grown by CART and pruned to 15 leaves, had a classification error of 8.7% on an independent test set. Gradient boosting with stumps (only two leaves per tree) achieved an error rate of 4.7% on an independent test set. This is nearly an improvement by a factor of 2! (It also outperforms additive logistic regression and MARS) So what does the boosting classifier look like? This question is hard to answer, because it s not a tree, but we can look at the relative variable importances
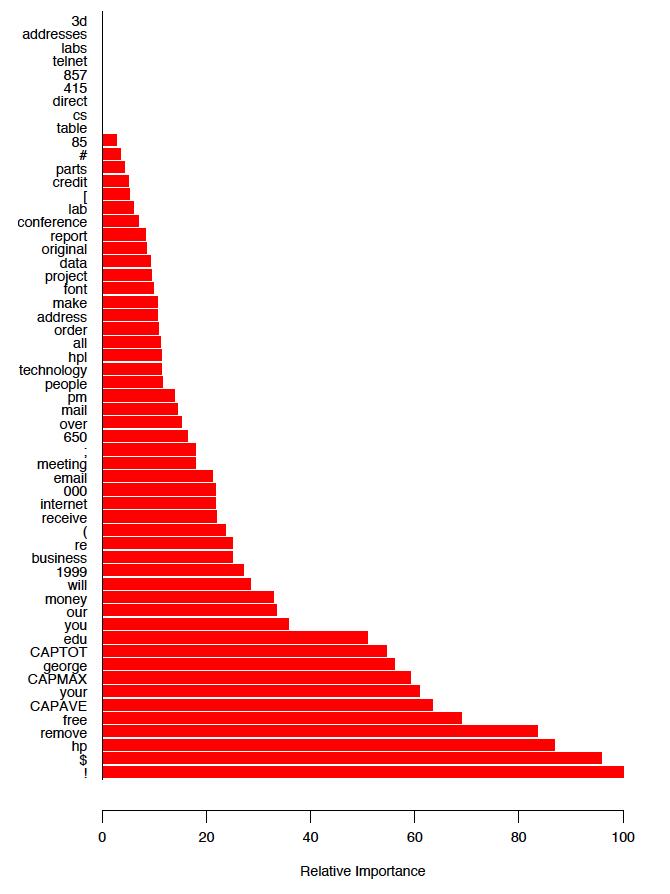
18 18
19 19 Bagging and boosting in R The package adabag implements both bagging and boosting (AdaBoost) for trees, via the functions bagging and boosting The package ipred also performs bagging with the bagging function. The package gbm implements both AdaBoost and gradient boosting; see the function gbm and its distribution option The package mboost is an alternative for boosting, that is quite flexible; see the function blackboost for boosting trees, and the function mboost for boosting arbitrary base learners
20 20 Recap: boosting In this lecture we learned boosting in the context of classification via decision trees. The basic concept is to repeatedly fit classification trees to weighted versions of the training data. In each iteration we update the weights in order to better classify previously misclassified observations. The final classifier is a weighted sum of the decisions made by the trees Boosting shares a close connection to forward stepwise model building. In a precise way, it can be viewed as forward stepwise model building where the base learners are trees, and the loss is exponential. Using other losses can improve performance, as can employing shrinkage. Boosting is a very general, powerful tool Although the final classifier is not as simple as a tree itself, relative variable importances can be computed by looking at how many times a given variable contributes to a split, across all trees

21 21 Next time: final projects! The final project has you perform crime mining (data mining on a crime data set)
Bagging. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL 8.7
 Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions. f(x) = c m 1(x R m )
 = c m 1(x R m )") CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions with R 1,..., R m R p disjoint. f(x) = M c m 1(x R m ) m=1 The CART algorithm is a heuristic, adaptive
CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions with R 1,..., R m R p disjoint. f(x) = M c m 1(x R m ) m=1 The CART algorithm is a heuristic, adaptive
CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions
 CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions f (x) = M c m 1(x R m ) m=1 with R 1,..., R m R p disjoint. The CART algorithm is a heuristic, adaptive
CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions f (x) = M c m 1(x R m ) m=1 with R 1,..., R m R p disjoint. The CART algorithm is a heuristic, adaptive
Ensemble Methods. Charles Sutton Data Mining and Exploration Spring Friday, 27 January 12
 Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Chapter 6. Ensemble Methods
 Chapter 6. Ensemble Methods Wei Pan Division of Biostatistics, School of Public Health, University of Minnesota, Minneapolis, MN 55455 Email: weip@biostat.umn.edu PubH 7475/8475 c Wei Pan Introduction
Chapter 6. Ensemble Methods Wei Pan Division of Biostatistics, School of Public Health, University of Minnesota, Minneapolis, MN 55455 Email: weip@biostat.umn.edu PubH 7475/8475 c Wei Pan Introduction
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
Announcements Kevin Jamieson
 Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Classification 2: Linear discriminant analysis (continued); logistic regression
; logistic regression") Classification 2: Linear discriminant analysis (continued); logistic regression Ryan Tibshirani Data Mining: 36-462/36-662 April 4 2013 Optional reading: ISL 4.4, ESL 4.3; ISL 4.3, ESL 4.4 1 Reminder:
Classification 2: Linear discriminant analysis (continued); logistic regression Ryan Tibshirani Data Mining: 36-462/36-662 April 4 2013 Optional reading: ISL 4.4, ESL 4.3; ISL 4.3, ESL 4.4 1 Reminder:
Gradient Boosting (Continued)
") Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
Regularization Paths
 December 2005 Trevor Hastie, Stanford Statistics 1 Regularization Paths Trevor Hastie Stanford University drawing on collaborations with Brad Efron, Saharon Rosset, Ji Zhu, Hui Zhou, Rob Tibshirani and
December 2005 Trevor Hastie, Stanford Statistics 1 Regularization Paths Trevor Hastie Stanford University drawing on collaborations with Brad Efron, Saharon Rosset, Ji Zhu, Hui Zhou, Rob Tibshirani and
Classification 1: Linear regression of indicators, linear discriminant analysis
 Classification 1: Linear regression of indicators, linear discriminant analysis Ryan Tibshirani Data Mining: 36-462/36-662 April 2 2013 Optional reading: ISL 4.1, 4.2, 4.4, ESL 4.1 4.3 1 Classification
Classification 1: Linear regression of indicators, linear discriminant analysis Ryan Tibshirani Data Mining: 36-462/36-662 April 2 2013 Optional reading: ISL 4.1, 4.2, 4.4, ESL 4.1 4.3 1 Classification
Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes. December 2, 2012
 Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Neural networks Neural network Another classifier (or regression technique)
Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Neural networks Neural network Another classifier (or regression technique)
CS229 Supplemental Lecture notes
 CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes
 Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes Support Vector Machine, Random Forests, Boosting December 2, 2012 1 / 1 2 / 1 Neural networks Artificial Neural networks: Networks
Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes Support Vector Machine, Random Forests, Boosting December 2, 2012 1 / 1 2 / 1 Neural networks Artificial Neural networks: Networks
Convex Optimization / Homework 1, due September 19
 Convex Optimization 1-725/36-725 Homework 1, due September 19 Instructions: You must complete Problems 1 3 and either Problem 4 or Problem 5 (your choice between the two). When you submit the homework,
Convex Optimization 1-725/36-725 Homework 1, due September 19 Instructions: You must complete Problems 1 3 and either Problem 4 or Problem 5 (your choice between the two). When you submit the homework,
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
Gradient descent. Barnabas Poczos & Ryan Tibshirani Convex Optimization /36-725
 Gradient descent Barnabas Poczos & Ryan Tibshirani Convex Optimization 10-725/36-725 1 Gradient descent First consider unconstrained minimization of f : R n R, convex and differentiable. We want to solve
Gradient descent Barnabas Poczos & Ryan Tibshirani Convex Optimization 10-725/36-725 1 Gradient descent First consider unconstrained minimization of f : R n R, convex and differentiable. We want to solve
Lecture 8. Instructor: Haipeng Luo
 Lecture 8 Instructor: Haipeng Luo Boosting and AdaBoost In this lecture we discuss the connection between boosting and online learning. Boosting is not only one of the most fundamental theories in machine
Lecture 8 Instructor: Haipeng Luo Boosting and AdaBoost In this lecture we discuss the connection between boosting and online learning. Boosting is not only one of the most fundamental theories in machine
CSE 151 Machine Learning. Instructor: Kamalika Chaudhuri
 CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees: Overfitting
 Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Statistics and learning: Big Data
 Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Why does boosting work from a statistical view
 Why does boosting work from a statistical view Jialin Yi Applied Mathematics and Computational Science University of Pennsylvania Philadelphia, PA 939 jialinyi@sas.upenn.edu Abstract We review boosting
Why does boosting work from a statistical view Jialin Yi Applied Mathematics and Computational Science University of Pennsylvania Philadelphia, PA 939 jialinyi@sas.upenn.edu Abstract We review boosting
Ensembles of Classifiers.
 Ensembles of Classifiers www.biostat.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts ensemble bootstrap sample bagging boosting random forests error correcting
Ensembles of Classifiers www.biostat.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts ensemble bootstrap sample bagging boosting random forests error correcting
The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m
 At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m") ) Set W () i The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m m =.5 1 n W (m 1) i y i h(x i ; 2 ˆθ
) Set W () i The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m m =.5 1 n W (m 1) i y i h(x i ; 2 ˆθ
Boosting Methods: Why They Can Be Useful for High-Dimensional Data
 New URL: http://www.r-project.org/conferences/dsc-2003/ Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003) March 20 22, Vienna, Austria ISSN 1609-395X Kurt Hornik,
New URL: http://www.r-project.org/conferences/dsc-2003/ Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003) March 20 22, Vienna, Austria ISSN 1609-395X Kurt Hornik,
Generalized Boosted Models: A guide to the gbm package
 Generalized Boosted Models: A guide to the gbm package Greg Ridgeway April 15, 2006 Boosting takes on various forms with different programs using different loss functions, different base models, and different
Generalized Boosted Models: A guide to the gbm package Greg Ridgeway April 15, 2006 Boosting takes on various forms with different programs using different loss functions, different base models, and different
Gradient Descent. Ryan Tibshirani Convex Optimization /36-725
 Gradient Descent Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: canonical convex programs Linear program (LP): takes the form min x subject to c T x Gx h Ax = b Quadratic program (QP): like
Gradient Descent Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: canonical convex programs Linear program (LP): takes the form min x subject to c T x Gx h Ax = b Quadratic program (QP): like
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Regularization Paths. Theme
 June 00 Trevor Hastie, Stanford Statistics June 00 Trevor Hastie, Stanford Statistics Theme Regularization Paths Trevor Hastie Stanford University drawing on collaborations with Brad Efron, Mee-Young Park,
June 00 Trevor Hastie, Stanford Statistics June 00 Trevor Hastie, Stanford Statistics Theme Regularization Paths Trevor Hastie Stanford University drawing on collaborations with Brad Efron, Mee-Young Park,
10701/15781 Machine Learning, Spring 2007: Homework 2
 070/578 Machine Learning, Spring 2007: Homework 2 Due: Wednesday, February 2, beginning of the class Instructions There are 4 questions on this assignment The second question involves coding Do not attach
070/578 Machine Learning, Spring 2007: Homework 2 Due: Wednesday, February 2, beginning of the class Instructions There are 4 questions on this assignment The second question involves coding Do not attach
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c /9/9 page 331 le-tex
 Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
STK-IN4300 Statistical Learning Methods in Data Science
 Outline of the lecture STK-IN4300 Statistical Learning Methods in Data Science Riccardo De Bin debin@math.uio.no AdaBoost Introduction algorithm Statistical Boosting Boosting as a forward stagewise additive
Outline of the lecture STK-IN4300 Statistical Learning Methods in Data Science Riccardo De Bin debin@math.uio.no AdaBoost Introduction algorithm Statistical Boosting Boosting as a forward stagewise additive
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Big Data Analytics. Special Topics for Computer Science CSE CSE Feb 24
 Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Proteomics and Variable Selection
 Proteomics and Variable Selection p. 1/55 Proteomics and Variable Selection Alex Lewin With thanks to Paul Kirk for some graphs Department of Epidemiology and Biostatistics, School of Public Health, Imperial
Proteomics and Variable Selection p. 1/55 Proteomics and Variable Selection Alex Lewin With thanks to Paul Kirk for some graphs Department of Epidemiology and Biostatistics, School of Public Health, Imperial
Non-linear Supervised High Frequency Trading Strategies with Applications in US Equity Markets
 Non-linear Supervised High Frequency Trading Strategies with Applications in US Equity Markets Nan Zhou, Wen Cheng, Ph.D. Associate, Quantitative Research, J.P. Morgan nan.zhou@jpmorgan.com The 4th Annual
Non-linear Supervised High Frequency Trading Strategies with Applications in US Equity Markets Nan Zhou, Wen Cheng, Ph.D. Associate, Quantitative Research, J.P. Morgan nan.zhou@jpmorgan.com The 4th Annual
Delta Boosting Machine and its application in Actuarial Modeling Simon CK Lee, Sheldon XS Lin KU Leuven, University of Toronto
 Delta Boosting Machine and its application in Actuarial Modeling Simon CK Lee, Sheldon XS Lin KU Leuven, University of Toronto This presentation has been prepared for the Actuaries Institute 2015 ASTIN
Delta Boosting Machine and its application in Actuarial Modeling Simon CK Lee, Sheldon XS Lin KU Leuven, University of Toronto This presentation has been prepared for the Actuaries Institute 2015 ASTIN
Learning Ensembles. 293S T. Yang. UCSB, 2017.
 Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Lecture 13: Ensemble Methods
 Lecture 13: Ensemble Methods Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu 1 / 71 Outline 1 Bootstrap
Lecture 13: Ensemble Methods Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu 1 / 71 Outline 1 Bootstrap
Boosting. Acknowledgment Slides are based on tutorials from Robert Schapire and Gunnar Raetsch
 . Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
COMS 4771 Lecture Boosting 1 / 16
 COMS 4771 Lecture 12 1. Boosting 1 / 16 Boosting What is boosting? Boosting: Using a learning algorithm that provides rough rules-of-thumb to construct a very accurate predictor. 3 / 16 What is boosting?
COMS 4771 Lecture 12 1. Boosting 1 / 16 Boosting What is boosting? Boosting: Using a learning algorithm that provides rough rules-of-thumb to construct a very accurate predictor. 3 / 16 What is boosting?
CMSC858P Supervised Learning Methods
 CMSC858P Supervised Learning Methods Hector Corrada Bravo March, 2010 Introduction Today we discuss the classification setting in detail. Our setting is that we observe for each subject i a set of p predictors
CMSC858P Supervised Learning Methods Hector Corrada Bravo March, 2010 Introduction Today we discuss the classification setting in detail. Our setting is that we observe for each subject i a set of p predictors
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
Learning theory. Ensemble methods. Boosting. Boosting: history
 Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
BAGGING PREDICTORS AND RANDOM FOREST
 BAGGING PREDICTORS AND RANDOM FOREST DANA KANER M.SC. SEMINAR IN STATISTICS, MAY 2017 BAGIGNG PREDICTORS / LEO BREIMAN, 1996 RANDOM FORESTS / LEO BREIMAN, 2001 THE ELEMENTS OF STATISTICAL LEARNING (CHAPTERS
BAGGING PREDICTORS AND RANDOM FOREST DANA KANER M.SC. SEMINAR IN STATISTICS, MAY 2017 BAGIGNG PREDICTORS / LEO BREIMAN, 1996 RANDOM FORESTS / LEO BREIMAN, 2001 THE ELEMENTS OF STATISTICAL LEARNING (CHAPTERS
SPECIAL INVITED PAPER
 The Annals of Statistics 2000, Vol. 28, No. 2, 337 407 SPECIAL INVITED PAPER ADDITIVE LOGISTIC REGRESSION: A STATISTICAL VIEW OF BOOSTING By Jerome Friedman, 1 Trevor Hastie 2 3 and Robert Tibshirani 2
The Annals of Statistics 2000, Vol. 28, No. 2, 337 407 SPECIAL INVITED PAPER ADDITIVE LOGISTIC REGRESSION: A STATISTICAL VIEW OF BOOSTING By Jerome Friedman, 1 Trevor Hastie 2 3 and Robert Tibshirani 2
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Harrison B. Prosper. Bari Lectures
 Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
LEAST ANGLE REGRESSION 469
 LEAST ANGLE REGRESSION 469 Specifically for the Lasso, one alternative strategy for logistic regression is to use a quadratic approximation for the log-likelihood. Consider the Bayesian version of Lasso
LEAST ANGLE REGRESSION 469 Specifically for the Lasso, one alternative strategy for logistic regression is to use a quadratic approximation for the log-likelihood. Consider the Bayesian version of Lasso
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Minimax risk bounds for linear threshold functions
 CS281B/Stat241B (Spring 2008) Statistical Learning Theory Lecture: 3 Minimax risk bounds for linear threshold functions Lecturer: Peter Bartlett Scribe: Hao Zhang 1 Review We assume that there is a probability
CS281B/Stat241B (Spring 2008) Statistical Learning Theory Lecture: 3 Minimax risk bounds for linear threshold functions Lecturer: Peter Bartlett Scribe: Hao Zhang 1 Review We assume that there is a probability
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Boosting: Foundations and Algorithms. Rob Schapire
 Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Logistic Regression and Boosting for Labeled Bags of Instances
 Logistic Regression and Boosting for Labeled Bags of Instances Xin Xu and Eibe Frank Department of Computer Science University of Waikato Hamilton, New Zealand {xx5, eibe}@cs.waikato.ac.nz Abstract. In
Logistic Regression and Boosting for Labeled Bags of Instances Xin Xu and Eibe Frank Department of Computer Science University of Waikato Hamilton, New Zealand {xx5, eibe}@cs.waikato.ac.nz Abstract. In
Boosting. CAP5610: Machine Learning Instructor: Guo-Jun Qi
 Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Ensemble Methods: Jay Hyer
 Ensemble Methods: committee-based learning Jay Hyer linkedin.com/in/jayhyer @adatahead Overview Why Ensemble Learning? What is learning? How is ensemble learning different? Boosting Weak and Strong Learners
Ensemble Methods: committee-based learning Jay Hyer linkedin.com/in/jayhyer @adatahead Overview Why Ensemble Learning? What is learning? How is ensemble learning different? Boosting Weak and Strong Learners
Decision Tree Learning Lecture 2
 Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Introduction to Machine Learning Lecture 11. Mehryar Mohri Courant Institute and Google Research
 Introduction to Machine Learning Lecture 11 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Boosting Mehryar Mohri - Introduction to Machine Learning page 2 Boosting Ideas Main idea:
Introduction to Machine Learning Lecture 11 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Boosting Mehryar Mohri - Introduction to Machine Learning page 2 Boosting Ideas Main idea:
Evidence Contrary to the Statistical View of Boosting
 University of Pennsylvania ScholarlyCommons Statistics Papers Wharton Faculty Research 2-2008 Evidence Contrary to the Statistical View of Boosting David Mease San Jose State University Abraham J. Wyner
University of Pennsylvania ScholarlyCommons Statistics Papers Wharton Faculty Research 2-2008 Evidence Contrary to the Statistical View of Boosting David Mease San Jose State University Abraham J. Wyner
Ensemble learning 11/19/13. The wisdom of the crowds. Chapter 11. Ensemble methods. Ensemble methods
 The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
AdaBoost. Lecturer: Authors: Center for Machine Perception Czech Technical University, Prague
 AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
Boosting as a Regularized Path to a Maximum Margin Classifier
 Journal of Machine Learning Research () Submitted 5/03; Published Boosting as a Regularized Path to a Maximum Margin Classifier Saharon Rosset Data Analytics Research Group IBM T.J. Watson Research Center
Journal of Machine Learning Research () Submitted 5/03; Published Boosting as a Regularized Path to a Maximum Margin Classifier Saharon Rosset Data Analytics Research Group IBM T.J. Watson Research Center
the tree till a class assignment is reached
 Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Evidence Contrary to the Statistical View of Boosting
 Journal of Machine Learning Research 9 (2008) 131-156 Submitted 10/05; Revised 7/07; Published 2/08 Evidence Contrary to the Statistical View of Boosting David Mease Department of Marketing and Decision
Journal of Machine Learning Research 9 (2008) 131-156 Submitted 10/05; Revised 7/07; Published 2/08 Evidence Contrary to the Statistical View of Boosting David Mease Department of Marketing and Decision
ABC-LogitBoost for Multi-Class Classification
 Ping Li, Cornell University ABC-Boost BTRY 6520 Fall 2012 1 ABC-LogitBoost for Multi-Class Classification Ping Li Department of Statistical Science Cornell University 2 4 6 8 10 12 14 16 2 4 6 8 10 12
Ping Li, Cornell University ABC-Boost BTRY 6520 Fall 2012 1 ABC-LogitBoost for Multi-Class Classification Ping Li Department of Statistical Science Cornell University 2 4 6 8 10 12 14 16 2 4 6 8 10 12
Machine Learning. Ensemble Methods. Manfred Huber
 Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Ordinal Classification with Decision Rules
 Ordinal Classification with Decision Rules Krzysztof Dembczyński 1, Wojciech Kotłowski 1, and Roman Słowiński 1,2 1 Institute of Computing Science, Poznań University of Technology, 60-965 Poznań, Poland
Ordinal Classification with Decision Rules Krzysztof Dembczyński 1, Wojciech Kotłowski 1, and Roman Słowiński 1,2 1 Institute of Computing Science, Poznań University of Technology, 60-965 Poznań, Poland
Importance Sampling: An Alternative View of Ensemble Learning. Jerome H. Friedman Bogdan Popescu Stanford University
 Importance Sampling: An Alternative View of Ensemble Learning Jerome H. Friedman Bogdan Popescu Stanford University 1 PREDICTIVE LEARNING Given data: {z i } N 1 = {y i, x i } N 1 q(z) y = output or response
Importance Sampling: An Alternative View of Ensemble Learning Jerome H. Friedman Bogdan Popescu Stanford University 1 PREDICTIVE LEARNING Given data: {z i } N 1 = {y i, x i } N 1 q(z) y = output or response
Boosting with decision stumps and binary features
 Boosting with decision stumps and binary features Jason Rennie jrennie@ai.mit.edu April 10, 2003 1 Introduction A special case of boosting is when features are binary and the base learner is a decision
Boosting with decision stumps and binary features Jason Rennie jrennie@ai.mit.edu April 10, 2003 1 Introduction A special case of boosting is when features are binary and the base learner is a decision
Decision trees COMS 4771
 Decision trees COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random pairs (i.e., labeled examples).
Decision trees COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random pairs (i.e., labeled examples).
Introduction to Machine Learning
 1, DATA11002 Introduction to Machine Learning Lecturer: Teemu Roos TAs: Ville Hyvönen and Janne Leppä-aho Department of Computer Science University of Helsinki (based in part on material by Patrik Hoyer
1, DATA11002 Introduction to Machine Learning Lecturer: Teemu Roos TAs: Ville Hyvönen and Janne Leppä-aho Department of Computer Science University of Helsinki (based in part on material by Patrik Hoyer
Online Advertising is Big Business
 Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers
 Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
PDEEC Machine Learning 2016/17
 PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
Day 3: Classification, logistic regression
 Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
Neural Networks and Ensemble Methods for Classification
 Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
LogitBoost with Trees Applied to the WCCI 2006 Performance Prediction Challenge Datasets
 Applied to the WCCI 2006 Performance Prediction Challenge Datasets Roman Lutz Seminar für Statistik, ETH Zürich, Switzerland 18. July 2006 Overview Motivation 1 Motivation 2 The logistic framework The
Applied to the WCCI 2006 Performance Prediction Challenge Datasets Roman Lutz Seminar für Statistik, ETH Zürich, Switzerland 18. July 2006 Overview Motivation 1 Motivation 2 The logistic framework The
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Generalized Boosted Models: A guide to the gbm package
 Generalized Boosted Models: A guide to the gbm package Greg Ridgeway May 23, 202 Boosting takes on various forms th different programs using different loss functions, different base models, and different
Generalized Boosted Models: A guide to the gbm package Greg Ridgeway May 23, 202 Boosting takes on various forms th different programs using different loss functions, different base models, and different
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
The Boosting Approach to. Machine Learning. Maria-Florina Balcan 10/31/2016
 The Boosting Approach to Machine Learning Maria-Florina Balcan 10/31/2016 Boosting General method for improving the accuracy of any given learning algorithm. Works by creating a series of challenge datasets
The Boosting Approach to Machine Learning Maria-Florina Balcan 10/31/2016 Boosting General method for improving the accuracy of any given learning algorithm. Works by creating a series of challenge datasets
Generalized Linear Models
 Generalized Linear Models Advanced Methods for Data Analysis (36-402/36-608 Spring 2014 1 Generalized linear models 1.1 Introduction: two regressions So far we ve seen two canonical settings for regression.
Generalized Linear Models Advanced Methods for Data Analysis (36-402/36-608 Spring 2014 1 Generalized linear models 1.1 Introduction: two regressions So far we ve seen two canonical settings for regression.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Decision Trees. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Ensemble Methods for Machine Learning
 Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof. Ganesh Ramakrishnan
 Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof. Ganesh Ramakrishnan") Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof Ganesh Ramakrishnan October 20, 2016 1 / 25 Decision Trees: Cascade of step
Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof Ganesh Ramakrishnan October 20, 2016 1 / 25 Decision Trees: Cascade of step
Data Mining. CS57300 Purdue University. Bruno Ribeiro. February 8, 2018
 Data Mining CS57300 Purdue University Bruno Ribeiro February 8, 2018 Decision trees Why Trees? interpretable/intuitive, popular in medical applications because they mimic the way a doctor thinks model
Data Mining CS57300 Purdue University Bruno Ribeiro February 8, 2018 Decision trees Why Trees? interpretable/intuitive, popular in medical applications because they mimic the way a doctor thinks model
Gradient Boosting, Continued
 Gradient Boosting, Continued David Rosenberg New York University December 26, 2016 David Rosenberg (New York University) DS-GA 1003 December 26, 2016 1 / 16 Review: Gradient Boosting Review: Gradient Boosting
Gradient Boosting, Continued David Rosenberg New York University December 26, 2016 David Rosenberg (New York University) DS-GA 1003 December 26, 2016 1 / 16 Review: Gradient Boosting Review: Gradient Boosting
Multivariate Analysis Techniques in HEP
 Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees: