Chapter 11. Regression with a Binary Dependent Variable
|
|
|
- Jerome Waters
- 5 years ago
- Views:
Transcription

1 Chapter 11 Regression with a Binary Dependent Variable
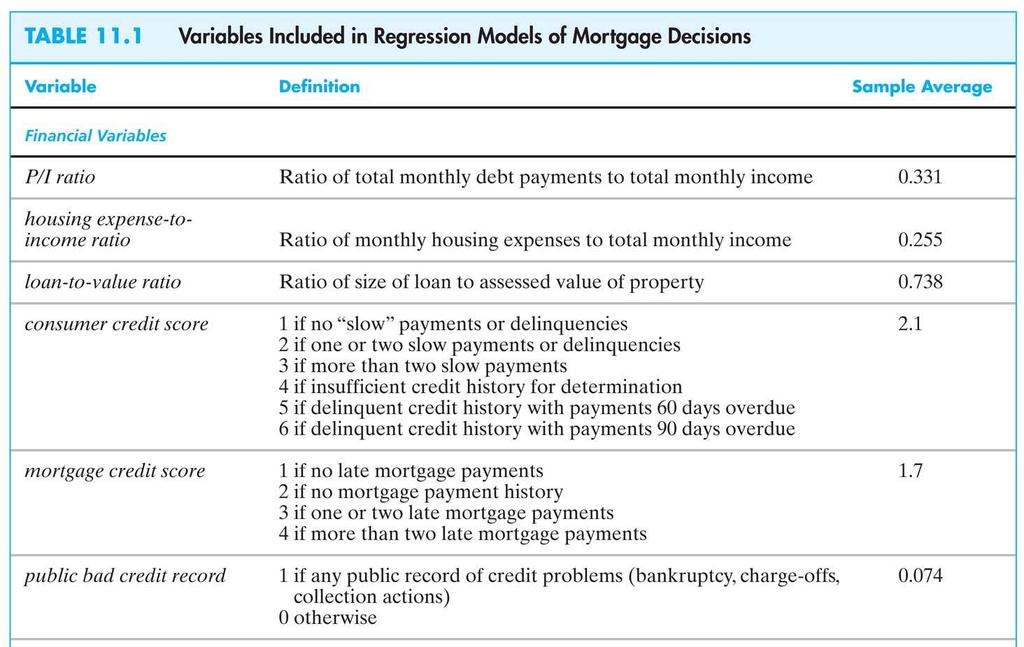
2 2 Regression with a Binary Dependent Variable (SW Chapter 11) So far the dependent variable (Y) has been continuous: district-wide average test score traffic fatality rate What if Y is binary? Y = get into college, or not; X = years of education Y = person smokes, or not; X = income Y = mortgage application is accepted, or not; X = income, house characteristics, marital status, race
3 Example: Mortgage denial and race The Boston Fed HMDA data set Individual applications for single-family mortgages made in 1990 in the greater Boston area 2380 observations, collected under Home Mortgage Disclosure Act (HMDA) Variables Dependent variable: Is the mortgage denied or accepted? Independent variables: income, wealth, employment status other loan, property characteristics race of applicant 3
4 4 The Linear Probability Model (SW Section 11.1) A natural starting point is the linear regression model with a single regressor: Y i = β 0 + β 1 X i + u i But: ΔY What does β 1 mean when Y is binary? Is β 1 = Δ X? What does the line β 0 + β 1 X mean when Y is binary? What does the predicted value Y ˆ mean when Y is binary? For example, what does Y ˆ = 0.26 mean?
5 5 The linear probability model, ctd. Y i = β 0 + β 1 X i + u i Recall assumption #1: E(u i X i ) = 0, so E(Y i X i ) = E(β 0 + β 1 X i + u i X i ) = β 0 + β 1 X i When Y is binary, E(Y) = 1 Pr(Y=1) + 0 Pr(Y=0) = Pr(Y=1) so E(Y X) = Pr(Y=1 X)
6 The linear probability model, ctd. When Y is binary, the linear regression model Y i = β 0 + β 1 X i + u i is called the linear probability model. The predicted value is a probability: E(Y X=x) = Pr(Y=1 X=x) = prob. that Y = 1 given x Y ˆ = the predicted probability that Y i = 1, given X β 1 = change in probability that Y = 1 for a given Δx: Pr( 1 ) Pr( 1 ) β 1 = Y = X = x +Δ x Y = X = x Δx 6
7 7 Example: linear probability model, HMDA data Mortgage denial v. ratio of debt payments to income (P/I ratio) in the HMDA data set (subset)
8 8 Linear probability model: HMDA data, ctd. deny = P/I ratio (n = 2380) (.032) (.098) What is the predicted value for P/I ratio =.3? Pr( deny = 1 P / Iratio =.3) = =.151 Calculating effects: increase P/I ratio from.3 to.4: Pr( deny = 1 P / Iratio =.4) = =.212 The effect on the probability of denial of an increase in P/I ratio from.3 to.4 is to increase the probability by.061, that is, by 6.1 percentage points (what?).
9 9 Linear probability model: HMDA data, ctd Next include black as a regressor: deny = P/I ratio +.177black (.032) (.098) (.025) Predicted probability of denial: for black applicant with P/I ratio =.3: Pr( deny = 1) = =.254 for white applicant, P/I ratio =.3: Pr( deny = 1) = =.077 difference =.177 = 17.7 percentage points Coefficient on black is significant at the 5% level Still plenty of room for omitted variable bias
10 10 The linear probability model: Summary Models Pr(Y=1 X) as a linear function of X Advantages: simple to estimate and to interpret inference is the same as for multiple regression (need heteroskedasticity-robust standard errors) Disadvantages: Does it make sense that the probability should be linear in X? Predicted probabilities can be <0 or >1! These disadvantages can be solved by using a nonlinear probability model: probit and logit regression
11 11 Probit and Logit Regression (SW Section 11.2) The problem with the linear probability model is that it models the probability of Y=1 as being linear: Pr(Y = 1 X) = β 0 + β 1 X Instead, we want: 0 Pr(Y = 1 X) 1 for all X Pr(Y = 1 X) to be increasing in X (for β 1 >0) This requires a nonlinear functional form for the probability. How about an S-curve
12 12 The probit model satisfies these conditions: 0 Pr(Y = 1 X) 1 for all X Pr(Y = 1 X) to be increasing in X (for β 1 >0)
13 13 Probit regression models the probability that Y=1 using the cumulative standard normal distribution function, evaluated at z = β 0 + β 1 X: Pr(Y = 1 X) = Φ(β 0 + β 1 X) Φ is the cumulative normal distribution function. z = β 0 + β 1 X is the z-value or z-index of the probit model. Example: Suppose β 0 = -2, β 1 = 3, X =.4, so Pr(Y = 1 X=.4) = Φ( ) = Φ(-0.8) Pr(Y = 1 X=.4) = area under the standard normal density to left of z = -.8, which is
 =.2119")
14 Pr(Z -0.8) =
15 15 Probit regression, ctd. Why use the cumulative normal probability distribution? The S-shape gives us what we want: 0 Pr(Y = 1 X) 1 for all X Pr(Y = 1 X) to be increasing in X (for β 1 >0) Easy to use the probabilities are tabulated in the cumulative normal tables Relatively straightforward interpretation: z-value = β 0 + β 1 X ˆ β 0 + ˆ β 1 X is the predicted z-value, given X β 1 is the change in the z-value for a unit change in X
16 STATA Example: HMDA data. probit deny p_irat, r; Iteration 0: log likelihood = Iteration 1: log likelihood = Iteration 2: log likelihood = Iteration 3: log likelihood = We ll discuss this later Probit estimates Number of obs = 2380 Wald chi2(1) = Prob > chi2 = Log likelihood = Pseudo R2 = Robust deny Coef. Std. Err. z P> z [95% Conf. Interval] p_irat _cons Pr( deny = 1 P / Iratio) = Φ( P/I ratio) (.16) (.47) 16
17 STATA Example: HMDA data, ctd. Pr( deny = 1 P / Iratio) = Φ( P/I ratio) (.16) (.47) Positive coefficient: does this make sense? Standard errors have the usual interpretation Predicted probabilities: Pr( deny = 1 P / Iratio =.3) = Φ( ) = Φ(-1.30) =.097 Effect of change in P/I ratio from.3 to.4: Pr( deny = 1 P / Iratio =.4) = Φ( ) =.159 Predicted probability of denial rises from.097 to
18 18 Probit regression with multiple regressors Pr(Y = 1 X 1, X 2 ) = Φ(β 0 + β 1 X 1 + β 2 X 2 ) Φ is the cumulative normal distribution function. z = β 0 + β 1 X 1 + β 2 X 2 is the z-value or z-index of the probit model. β 1 is the effect on the z-score of a unit change in X 1, holding constant X 2
19 19 STATA Example: HMDA data. probit deny p_irat black, r; Iteration 0: log likelihood = Iteration 1: log likelihood = Iteration 2: log likelihood = Iteration 3: log likelihood = Probit estimates Number of obs = 2380 Wald chi2(2) = Prob > chi2 = Log likelihood = Pseudo R2 = Robust deny Coef. Std. Err. z P> z [95% Conf. Interval] p_irat black _cons We ll go through the estimation details later
20 STATA Example, ctd.: predicted probit probabilities. probit deny p_irat black, r; Probit estimates Number of obs = 2380 Wald chi2(2) = Prob > chi2 = Log likelihood = Pseudo R2 = Robust deny Coef. Std. Err. z P> z [95% Conf. Interval] p_irat black _cons sca z1 = _b[_cons]+_b[p_irat]*.3+_b[black]*0;. display "Pred prob, p_irat=.3, white: " normprob(z1); Pred prob, p_irat=.3, white: NOTE _b[_cons] is the estimated intercept ( ) _b[p_irat] is the coefficient on p_irat ( ) sca creates a new scalar which is the result of a calculation display prints the indicated information to the screen 20
21 21 STATA Example, ctd. Pr( deny = 1 P / I, black) = Φ( P/I ratio +.71 black) (.16) (.44) (.08) Is the coefficient on black statistically significant? Estimated effect of race for P/I ratio =.3: Pr( deny = 1.3,1) = Φ( ) =.233 Pr( deny = 1.3,0) = Φ( ) =.075 Difference in rejection probabilities =.158 (15.8 percentage points) Still plenty of room still for omitted variable bias
22 Logit Regression Logit regression models the probability of Y=1 as the cumulative standard logistic distribution function, evaluated at z = β 0 + β 1 X: Pr(Y = 1 X) = F(β 0 + β 1 X) F is the cumulative logistic distribution function: F(β 0 + β 1 X) = 1+ 1 ( 0 1X ) e β + β 22
23 Logit regression, ctd. Pr(Y = 1 X) = F(β 0 + β 1 X) where F(β 0 + β 1 X) = 1+ 1 ( 0 1X ) e β + β. Example: β 0 = -3, β 1 = 2, X =.4, so β 0 + β 1 X = = -2.2 so Pr(Y = 1 X=.4) = 1/(1+e ( 2.2) ) =.0998 Why bother with logit if we have probit? Historically, logit is more convenient computationally In practice, logit and probit are very similar 23
24 24 STATA Example: HMDA data. logit deny p_irat black, r; Iteration 0: log likelihood = Later Iteration 1: log likelihood = Iteration 2: log likelihood = Iteration 3: log likelihood = Iteration 4: log likelihood = Logit estimates Number of obs = 2380 Wald chi2(2) = Prob > chi2 = Log likelihood = Pseudo R2 = Robust deny Coef. Std. Err. z P> z [95% Conf. Interval] p_irat black _cons dis "Pred prob, p_irat=.3, white: " > 1/(1+exp(-(_b[_cons]+_b[p_irat]*.3+_b[black]*0))); Pred prob, p_irat=.3, white: NOTE: the probit predicted probability is
25 Predicted probabilities from estimated probit and logit models usually are (as usual) very close in this application. 25
26 26 Example for class discussion: Characterizing the Background of Hezbollah Militants Source: Alan Krueger and Jitka Maleckova, Education, Poverty and Terrorism: Is There a Causal Connection? Journal of Economic Perspectives, Fall 2003, Logit regression: 1 = died in Hezbollah military event Table of logit results:
27 27
28 28
29 29 Hezbollah militants example, ctd. Compute the effect of schooling by comparing predicted probabilities using the logit regression in column (3): Pr(Y=1 secondary = 1, poverty = 0, age = 20) Pr(Y=0 secondary = 0, poverty = 0, age = 20): Pr(Y=1 secondary = 1, poverty = 0, age = 20) = 1/[1+e ( ) ] = 1/[1 + e ] = does this make sense? Pr(Y=1 secondary = 0, poverty = 0, age = 20) = 1/[1+e ( ) ] = 1/[1 + e ] = does this make sense?
30 30 Predicted change in probabilities: Pr(Y=1 secondary = 1, poverty = 0, age = 20) Pr(Y=1 secondary = 1, poverty = 0, age = 20) = = Both these statements are true: The probability of being a Hezbollah militant increases by percentage points, if secondary school is attended. The probability of being a Hezbollah militant increases by 32%, if secondary school is attended ( / =.32). These sound so different! what is going on?
31 31 Estimation and Inference in Probit (and Logit) Models (SW Section 11.3) Probit model: Pr(Y = 1 X) = Φ(β 0 + β 1 X) Estimation and inference How can we estimate β 0 and β 1? What is the sampling distribution of the estimators? Why can we use the usual methods of inference? First motivate via nonlinear least squares Then discuss maximum likelihood estimation (what is actually done in practice)
32 Probit estimation by nonlinear least squares Recall OLS: n min [ Y ( b + b X )] b0, b1 i 0 1 i i= 1 The result is the OLS estimators ˆ β 0 and ˆ β 1 Nonlinear least squares estimator of probit coefficients: n min [ Y Φ ( b + b X )] b0, b1 i 0 1 i i= 1 How to solve this minimization problem? Calculus doesn t give and explicit solution. Solved numerically using the computer(specialized minimization algorithms) In practice, nonlinear least squares isn t used because it isn t efficient an estimator with a smaller variance is
33 33 Probit estimation by maximum likelihood The likelihood function is the conditional density of Y 1,,Y n given X 1,,X n, treated as a function of the unknown parameters β 0 and β 1. The maximum likelihood estimator (MLE) is the value of (β 0, β 1 ) that maximize the likelihood function. The MLE is the value of (β 0, β 1 ) that best describe the full distribution of the data. In large samples, the MLE is: consistent normally distributed efficient (has the smallest variance of all estimators)
34 34 Special case: the probit MLE with no X Y = 1 with probability p 0 with probability 1 p (Bernoulli distribution) Data: Y 1,,Y n, i.i.d. Derivation of the likelihood starts with the density of Y 1 : so Pr(Y 1 = 1) = p and Pr(Y 1 = 0) = 1 p y1 1 y1 Pr(Y 1 = y 1 ) = p (1 p) (verify this for y 1 =0, 1!)
35 35 Joint density of (Y 1,Y 2 ): Because Y 1 and Y 2 are independent, Pr(Y 1 = y 1,Y 2 = y 2 ) = Pr(Y 1 = y 1 ) Pr(Y 2 = y 2 ) y1 1 y1 = [ p (1 p) y2 1 y2 ] [ p (1 p) ] = Joint density of (Y 1,..,Y n ): p ( y + y ) [ 2 ( y + y )] (1 p) Pr(Y 1 = y 1,Y 2 = y 2,,Y n = y n ) y1 1 y1 = [ p (1 p) y2 1 y2 ] [ p (1 p) ] [ n n y ( n y 1 i ) i 1 i i = p = = (1 p) p y n (1 ) 1 yn p ]
36 36 The likelihood is the joint density, treated as a function of the unknown parameters, which here is p: ( ) n n Y n Y 1 i i 1 i i f(p;y 1,,Y n ) = p = = (1 p) The MLE maximizes the likelihood. Its easier to work with the logarithm of the likelihood, ln[f(p;y 1,,Y n )]: ln[f(p;y 1,,Y n )] = ( n ) ( n ) i i Y ln( p) + n Y ln(1 p) i= 1 i= 1 Maximize the likelihood by setting the derivative = 0: dln f( p; Y1,..., Y n ) = ( n ) 1 ( n ) 1 Y i 1 i + n Y = i= 1 i dp p 1 p Solving for p yields the MLE; that is, p ˆ MLE satisfies, = 0
37 37 or or or MLE pˆ 1 pˆ ( n ) ( n Y ) 1 i n Y i= MLE i= 1 i = pˆ 1 pˆ ( n ) ( n Y ) 1 i = n Y i= MLE i= 1 i Y pˆ = 1 Y 1 pˆ MLE MLE MLE ˆ MLE p = Y = fraction of 1 s whew a lot of work to get back to the first thing you would think of using but the nice thing is that this whole approach generalizes to more complicated models...
38 38 The MLE in the no-x case (Bernoulli distribution), ctd.: ˆ MLE p = Y = fraction of 1 s For Y i i.i.d. Bernoulli, the MLE is the natural estimator of p, the fraction of 1 s, which is Y We already know the essentials of inference: In large n, the sampling distribution of p ˆ MLE = Y is normally distributed Thus inference is as usual: hypothesis testing via t- statistic, confidence interval as ± 1.96SE
39 39 The MLE in the no-x case (Bernoulli distribution), ctd: The theory of maximum likelihood estimation says that p ˆ MLE is the most efficient estimator of p of all possible estimators at least for large n. (Much stronger than the Gauss-Markov theorem). This is why people use the MLE. STATA note: to emphasize requirement of large-n, the printout calls the t-statistic the z-statistic; instead of the F- statistic, the chi-squared statistic (= q F). Now we extend this to probit in which the probability is conditional on X the MLE of the probit coefficients.
40 40 The probit likelihood with one X The derivation starts with the density of Y 1, given X 1 : Pr(Y 1 = 1 X 1 ) = Φ(β 0 + β 1 X 1 ) Pr(Y 1 = 0 X 1 ) = 1 Φ(β 0 + β 1 X 1 ) so y1 1 y1 Pr(Y 1 = y 1 X 1 ) = Φ ( β + β X ) [1 Φ ( β + β X )] The probit likelihood function is the joint density of Y 1,,Y n given X 1,,X n, treated as a function of β 0, β 1 : f(β 0,β 1 ; Y 1,,Y n X 1,,X n ) Y1 1 = { ( ) [1 ( )] 1 Y Φ β + β X Φ β + β X } Yn 1 Yn { Φ ( β + β X ) [1 Φ ( β + β X )] } 0 1 n 0 1 n
41 41 The probit likelihood function: f(β 0,β 1 ; Y 1,,Y n X 1,,X n ) Y1 1 Y1 = { Φ ( β + β X ) [1 Φ ( β + β X )] } Yn 1 Yn { Φ ( β + β X ) [1 Φ ( β + β X )] } 0 1 n 0 1 Can t solve for the maximum explicitly Must maximize using numerical methods As in the case of no X, in large samples: ˆ MLE 0 ˆ MLE 0 ˆ MLE 0 ˆ MLE β, β 1 are consistent β, ˆ β MLE 1 are normally distributed β, ˆ β MLE 1 are asymptotically efficient among all estimators (assuming the probit model is the correct model) n
42 42 The Probit MLE, ctd. Standard errors of ˆ β MLE 0, ˆ β MLE 1 are computed automatically Testing, confidence intervals proceeds as usual For multiple X s, see SW App. 11.2
43 43 The logit likelihood with one X The only difference between probit and logit is the functional form used for the probability: Φ is replaced by the cumulative logistic function. Otherwise, the likelihood is similar; for details see SW App As with probit, ˆ β MLE 0, ˆ β MLE 1 are consistent ˆ β MLE 0, ˆ β MLE 1 are normally distributed Their standard errors can be computed Testing, confidence intervals proceeds as usual
44 44 Measures of fit for logit and probit The R 2 2 and R don t make sense here (why?). So, two other specialized measures are used: 1. The fraction correctly predicted = fraction of Y s for which predicted probability is >50% (if Y i =1) or is <50% (if Y i =0). 2. The pseudo-r 2 measure the fit using the likelihood function: measures the improvement in the value of the log likelihood, relative to having no X s (see SW App. 11.2). This simplifies to the R 2 in the linear model with normally distributed errors.
45 45 Application to the Boston HMDA Data (SW Section 11.4) Mortgages (home loans) are an essential part of buying a home. Is there differential access to home loans by race? If two otherwise identical individuals, one white and one black, applied for a home loan, is there a difference in the probability of denial?
46 46 The HMDA Data Set Data on individual characteristics, property characteristics, and loan denial/acceptance The mortgage application process circa : Go to a bank or mortgage company Fill out an application (personal+financial info) Meet with the loan officer Then the loan officer decides by law, in a race-blind way. Presumably, the bank wants to make profitable loans, and the loan officer doesn t want to originate defaults.
47 47 The loan officer s decision Loan officer uses key financial variables: P/I ratio housing expense-to-income ratio loan-to-value ratio personal credit history The decision rule is nonlinear: loan-to-value ratio > 80% loan-to-value ratio > 95% (what happens in default?) credit score
48 48 Regression specifications Pr(deny=1 black, other X s) = linear probability model probit Main problem with the regressions so far: potential omitted variable bias. All these (i) enter the loan officer decision function, all (ii) are or could be correlated with race: wealth, type of employment credit history family status The HMDA data set is very rich
49 49
50 50
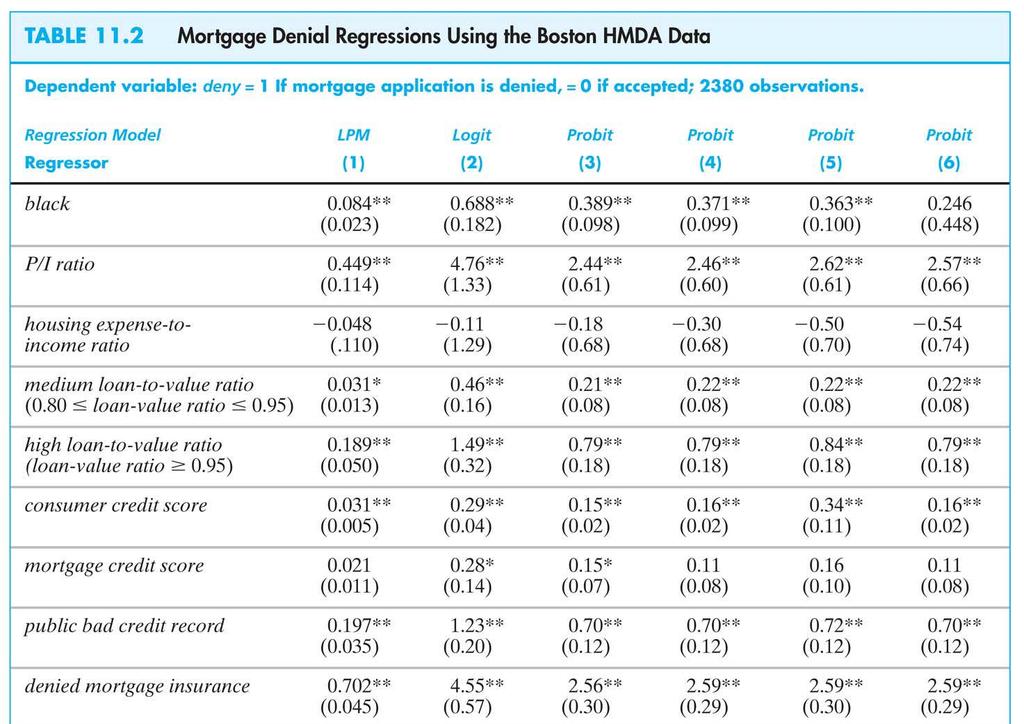
51 51
52 Table 11.2, ctd. 52
53 Table 11.2, ctd. 53
54 54 Summary of Empirical Results Coefficients on the financial variables make sense. Black is statistically significant in all specifications Race-financial variable interactions aren t significant. Including the covariates sharply reduces the effect of race on denial probability. LPM, probit, logit: similar estimates of effect of race on the probability of denial. Estimated effects are large in a real world sense.
55 55 Remaining threats to internal, external validity Internal validity 1. omitted variable bias what else is learned in the in-person interviews? 2. functional form misspecification (no ) 3. measurement error (originally, yes; now, no ) 4. selection random sample of loan applications define population to be loan applicants 5. simultaneous causality (no) External validity This is for Boston in What about today?
56 56 Summary (SW Section 11.5) If Y i is binary, then E(Y X) = Pr(Y=1 X) Three models: linear probability model (linear multiple regression) probit (cumulative standard normal distribution) logit (cumulative standard logistic distribution) LPM, probit, logit all produce predicted probabilities Effect of ΔX is change in conditional probability that Y=1. For logit and probit, this depends on the initial X Probit and logit are estimated via maximum likelihood Coefficients are normally distributed for large n Large-n hypothesis testing, conf. intervals is as usual
Binary Dependent Variable. Regression with a
 Beykent University Faculty of Business and Economics Department of Economics Econometrics II Yrd.Doç.Dr. Özgür Ömer Ersin Regression with a Binary Dependent Variable (SW Chapter 11) SW Ch. 11 1/59 Regression
Beykent University Faculty of Business and Economics Department of Economics Econometrics II Yrd.Doç.Dr. Özgür Ömer Ersin Regression with a Binary Dependent Variable (SW Chapter 11) SW Ch. 11 1/59 Regression
Regression with a Binary Dependent Variable (SW Ch. 9)
") Regression with a Binary Dependent Variable (SW Ch. 9) So far the dependent variable (Y) has been continuous: district-wide average test score traffic fatality rate But we might want to understand the
Regression with a Binary Dependent Variable (SW Ch. 9) So far the dependent variable (Y) has been continuous: district-wide average test score traffic fatality rate But we might want to understand the
ECON Introductory Econometrics. Lecture 11: Binary dependent variables
 ECON4150 - Introductory Econometrics Lecture 11: Binary dependent variables Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 11 Lecture Outline 2 The linear probability model Nonlinear probability
ECON4150 - Introductory Econometrics Lecture 11: Binary dependent variables Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 11 Lecture Outline 2 The linear probability model Nonlinear probability
Applied Economics. Regression with a Binary Dependent Variable. Department of Economics Universidad Carlos III de Madrid
 Applied Economics Regression with a Binary Dependent Variable Department of Economics Universidad Carlos III de Madrid See Stock and Watson (chapter 11) 1 / 28 Binary Dependent Variables: What is Different?
Applied Economics Regression with a Binary Dependent Variable Department of Economics Universidad Carlos III de Madrid See Stock and Watson (chapter 11) 1 / 28 Binary Dependent Variables: What is Different?
2. We care about proportion for categorical variable, but average for numerical one.
 Probit Model 1. We apply Probit model to Bank data. The dependent variable is deny, a dummy variable equaling one if a mortgage application is denied, and equaling zero if accepted. The key regressor is
Probit Model 1. We apply Probit model to Bank data. The dependent variable is deny, a dummy variable equaling one if a mortgage application is denied, and equaling zero if accepted. The key regressor is
Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals
 Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals (SW Chapter 5) Outline. The standard error of ˆ. Hypothesis tests concerning β 3. Confidence intervals for β 4. Regression
Regression with a Single Regressor: Hypothesis Tests and Confidence Intervals (SW Chapter 5) Outline. The standard error of ˆ. Hypothesis tests concerning β 3. Confidence intervals for β 4. Regression
Chapter 9 Regression with a Binary Dependent Variable. Multiple Choice. 1) The binary dependent variable model is an example of a
 The binary dependent variable model is an example of a") Chapter 9 Regression with a Binary Dependent Variable Multiple Choice ) The binary dependent variable model is an example of a a. regression model, which has as a regressor, among others, a binary variable.
Chapter 9 Regression with a Binary Dependent Variable Multiple Choice ) The binary dependent variable model is an example of a a. regression model, which has as a regressor, among others, a binary variable.
Chapter 7. Hypothesis Tests and Confidence Intervals in Multiple Regression
 Chapter 7 Hypothesis Tests and Confidence Intervals in Multiple Regression Outline 1. Hypothesis tests and confidence intervals for a single coefficie. Joint hypothesis tests on multiple coefficients 3.
Chapter 7 Hypothesis Tests and Confidence Intervals in Multiple Regression Outline 1. Hypothesis tests and confidence intervals for a single coefficie. Joint hypothesis tests on multiple coefficients 3.
Econometrics Honor s Exam Review Session. Spring 2012 Eunice Han
 Econometrics Honor s Exam Review Session Spring 2012 Eunice Han Topics 1. OLS The Assumptions Omitted Variable Bias Conditional Mean Independence Hypothesis Testing and Confidence Intervals Homoskedasticity
Econometrics Honor s Exam Review Session Spring 2012 Eunice Han Topics 1. OLS The Assumptions Omitted Variable Bias Conditional Mean Independence Hypothesis Testing and Confidence Intervals Homoskedasticity
Hypothesis Tests and Confidence Intervals in Multiple Regression
 Hypothesis Tests and Confidence Intervals in Multiple Regression (SW Chapter 7) Outline 1. Hypothesis tests and confidence intervals for one coefficient. Joint hypothesis tests on multiple coefficients
Hypothesis Tests and Confidence Intervals in Multiple Regression (SW Chapter 7) Outline 1. Hypothesis tests and confidence intervals for one coefficient. Joint hypothesis tests on multiple coefficients
Nonlinear Regression Functions
 Nonlinear Regression Functions (SW Chapter 8) Outline 1. Nonlinear regression functions general comments 2. Nonlinear functions of one variable 3. Nonlinear functions of two variables: interactions 4.
Nonlinear Regression Functions (SW Chapter 8) Outline 1. Nonlinear regression functions general comments 2. Nonlinear functions of one variable 3. Nonlinear functions of two variables: interactions 4.
ECONOMETRICS HONOR S EXAM REVIEW SESSION
 ECONOMETRICS HONOR S EXAM REVIEW SESSION Eunice Han ehan@fas.harvard.edu March 26 th, 2013 Harvard University Information 2 Exam: April 3 rd 3-6pm @ Emerson 105 Bring a calculator and extra pens. Notes
ECONOMETRICS HONOR S EXAM REVIEW SESSION Eunice Han ehan@fas.harvard.edu March 26 th, 2013 Harvard University Information 2 Exam: April 3 rd 3-6pm @ Emerson 105 Bring a calculator and extra pens. Notes
Econ 371 Problem Set #6 Answer Sheet. deaths per 10,000. The 90% confidence interval for the change in death rate is 1.81 ±
 Econ 371 Problem Set #6 Answer Sheet 10.1 This question focuses on the regression model results in Table 10.1. a. The first part of this question asks you to predict the number of lives that would be saved
Econ 371 Problem Set #6 Answer Sheet 10.1 This question focuses on the regression model results in Table 10.1. a. The first part of this question asks you to predict the number of lives that would be saved
Econometrics Problem Set 10
 Econometrics Problem Set 0 WISE, Xiamen University Spring 207 Conceptual Questions Dependent variable: P ass Probit Logit LPM Probit Logit LPM Probit () (2) (3) (4) (5) (6) (7) Experience 0.03 0.040 0.006
Econometrics Problem Set 0 WISE, Xiamen University Spring 207 Conceptual Questions Dependent variable: P ass Probit Logit LPM Probit Logit LPM Probit () (2) (3) (4) (5) (6) (7) Experience 0.03 0.040 0.006
Introduction to Econometrics
 Introduction to Econometrics T H I R D E D I T I O N Global Edition James H. Stock Harvard University Mark W. Watson Princeton University Boston Columbus Indianapolis New York San Francisco Upper Saddle
Introduction to Econometrics T H I R D E D I T I O N Global Edition James H. Stock Harvard University Mark W. Watson Princeton University Boston Columbus Indianapolis New York San Francisco Upper Saddle
Logit regression Logit regression
 Logit regressio Logit regressio models the probability of Y= as the cumulative stadard logistic distributio fuctio, evaluated at z = β 0 + β X: Pr(Y = X) = F(β 0 + β X) F is the cumulative logistic distributio
Logit regressio Logit regressio models the probability of Y= as the cumulative stadard logistic distributio fuctio, evaluated at z = β 0 + β X: Pr(Y = X) = F(β 0 + β X) F is the cumulative logistic distributio
Binary Dependent Variables
 Binary Dependent Variables In some cases the outcome of interest rather than one of the right hand side variables - is discrete rather than continuous Binary Dependent Variables In some cases the outcome
Binary Dependent Variables In some cases the outcome of interest rather than one of the right hand side variables - is discrete rather than continuous Binary Dependent Variables In some cases the outcome
Extensions to the Basic Framework II
 Topic 7 Extensions to the Basic Framework II ARE/ECN 240 A Graduate Econometrics Professor: Òscar Jordà Outline of this topic Nonlinear regression Limited Dependent Variable regression Applications of
Topic 7 Extensions to the Basic Framework II ARE/ECN 240 A Graduate Econometrics Professor: Òscar Jordà Outline of this topic Nonlinear regression Limited Dependent Variable regression Applications of
Lecture 12: Effect modification, and confounding in logistic regression
 Lecture 12: Effect modification, and confounding in logistic regression Ani Manichaikul amanicha@jhsph.edu 4 May 2007 Today Categorical predictor create dummy variables just like for linear regression
Lecture 12: Effect modification, and confounding in logistic regression Ani Manichaikul amanicha@jhsph.edu 4 May 2007 Today Categorical predictor create dummy variables just like for linear regression
Linear Regression with Multiple Regressors
 Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Binomial Model. Lecture 10: Introduction to Logistic Regression. Logistic Regression. Binomial Distribution. n independent trials
 Lecture : Introduction to Logistic Regression Ani Manichaikul amanicha@jhsph.edu 2 May 27 Binomial Model n independent trials (e.g., coin tosses) p = probability of success on each trial (e.g., p =! =
Lecture : Introduction to Logistic Regression Ani Manichaikul amanicha@jhsph.edu 2 May 27 Binomial Model n independent trials (e.g., coin tosses) p = probability of success on each trial (e.g., p =! =
Lecture 10: Introduction to Logistic Regression
 Lecture 10: Introduction to Logistic Regression Ani Manichaikul amanicha@jhsph.edu 2 May 2007 Logistic Regression Regression for a response variable that follows a binomial distribution Recall the binomial
Lecture 10: Introduction to Logistic Regression Ani Manichaikul amanicha@jhsph.edu 2 May 2007 Logistic Regression Regression for a response variable that follows a binomial distribution Recall the binomial
Homework Solutions Applied Logistic Regression
 Homework Solutions Applied Logistic Regression WEEK 6 Exercise 1 From the ICU data, use as the outcome variable vital status (STA) and CPR prior to ICU admission (CPR) as a covariate. (a) Demonstrate that
Homework Solutions Applied Logistic Regression WEEK 6 Exercise 1 From the ICU data, use as the outcome variable vital status (STA) and CPR prior to ICU admission (CPR) as a covariate. (a) Demonstrate that
Statistical Inference with Regression Analysis
 Introductory Applied Econometrics EEP/IAS 118 Spring 2015 Steven Buck Lecture #13 Statistical Inference with Regression Analysis Next we turn to calculating confidence intervals and hypothesis testing
Introductory Applied Econometrics EEP/IAS 118 Spring 2015 Steven Buck Lecture #13 Statistical Inference with Regression Analysis Next we turn to calculating confidence intervals and hypothesis testing
Nonlinear Econometric Analysis (ECO 722) : Homework 2 Answers. (1 θ) if y i = 0. which can be written in an analytically more convenient way as
 : Homework 2 Answers. (1 θ) if y i = 0. which can be written in an analytically more convenient way as") Nonlinear Econometric Analysis (ECO 722) : Homework 2 Answers 1. Consider a binary random variable y i that describes a Bernoulli trial in which the probability of observing y i = 1 in any draw is given
Nonlinear Econometric Analysis (ECO 722) : Homework 2 Answers 1. Consider a binary random variable y i that describes a Bernoulli trial in which the probability of observing y i = 1 in any draw is given
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 6 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 53 Outline of Lecture 6 1 Omitted variable bias (SW 6.1) 2 Multiple
Applied Statistics and Econometrics Lecture 6 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 53 Outline of Lecture 6 1 Omitted variable bias (SW 6.1) 2 Multiple
ECON Introductory Econometrics. Lecture 5: OLS with One Regressor: Hypothesis Tests
 ECON4150 - Introductory Econometrics Lecture 5: OLS with One Regressor: Hypothesis Tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 5 Lecture outline 2 Testing Hypotheses about one
ECON4150 - Introductory Econometrics Lecture 5: OLS with One Regressor: Hypothesis Tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 5 Lecture outline 2 Testing Hypotheses about one
Linear Regression with one Regressor
 1 Linear Regression with one Regressor Covering Chapters 4.1 and 4.2. We ve seen the California test score data before. Now we will try to estimate the marginal effect of STR on SCORE. To motivate these
1 Linear Regression with one Regressor Covering Chapters 4.1 and 4.2. We ve seen the California test score data before. Now we will try to estimate the marginal effect of STR on SCORE. To motivate these
Sociology 362 Data Exercise 6 Logistic Regression 2
 Sociology 362 Data Exercise 6 Logistic Regression 2 The questions below refer to the data and output beginning on the next page. Although the raw data are given there, you do not have to do any Stata runs
Sociology 362 Data Exercise 6 Logistic Regression 2 The questions below refer to the data and output beginning on the next page. Although the raw data are given there, you do not have to do any Stata runs
Introduction to Econometrics. Multiple Regression
 Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Multiple Regression Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 OLS estimate of the TS/STR
Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Multiple Regression Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 OLS estimate of the TS/STR
Introduction to Econometrics. Multiple Regression (2016/2017)
") Introduction to Econometrics STAT-S-301 Multiple Regression (016/017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 OLS estimate of the TS/STR relation: OLS estimate of the Test Score/STR relation:
Introduction to Econometrics STAT-S-301 Multiple Regression (016/017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 OLS estimate of the TS/STR relation: OLS estimate of the Test Score/STR relation:
Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data
 data") Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data 1/2/3-1 1/2/3-2 Brief Overview of the Course Economics suggests important
Introduction to Econometrics Third Edition James H. Stock Mark W. Watson The statistical analysis of economic (and related) data 1/2/3-1 1/2/3-2 Brief Overview of the Course Economics suggests important
Exam ECON3150/4150: Introductory Econometrics. 18 May 2016; 09:00h-12.00h.
 Exam ECON3150/4150: Introductory Econometrics. 18 May 2016; 09:00h-12.00h. This is an open book examination where all printed and written resources, in addition to a calculator, are allowed. If you are
Exam ECON3150/4150: Introductory Econometrics. 18 May 2016; 09:00h-12.00h. This is an open book examination where all printed and written resources, in addition to a calculator, are allowed. If you are
7/28/15. Review Homework. Overview. Lecture 6: Logistic Regression Analysis
 Lecture 6: Logistic Regression Analysis Christopher S. Hollenbeak, PhD Jane R. Schubart, PhD The Outcomes Research Toolbox Review Homework 2 Overview Logistic regression model conceptually Logistic regression
Lecture 6: Logistic Regression Analysis Christopher S. Hollenbeak, PhD Jane R. Schubart, PhD The Outcomes Research Toolbox Review Homework 2 Overview Logistic regression model conceptually Logistic regression
Immigration attitudes (opposes immigration or supports it) it may seriously misestimate the magnitude of the effects of IVs
 it may seriously misestimate the magnitude of the effects of IVs") Logistic Regression, Part I: Problems with the Linear Probability Model (LPM) Richard Williams, University of Notre Dame, https://www3.nd.edu/~rwilliam/ Last revised February 22, 2015 This handout steals
Logistic Regression, Part I: Problems with the Linear Probability Model (LPM) Richard Williams, University of Notre Dame, https://www3.nd.edu/~rwilliam/ Last revised February 22, 2015 This handout steals
EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7
 Introduction to Generalized Univariate Models: Models for Binary Outcomes EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7 EPSY 905: Intro to Generalized In This Lecture A short review
Introduction to Generalized Univariate Models: Models for Binary Outcomes EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7 EPSY 905: Intro to Generalized In This Lecture A short review
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 5 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 44 Outline of Lecture 5 Now that we know the sampling distribution
Applied Statistics and Econometrics Lecture 5 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 44 Outline of Lecture 5 Now that we know the sampling distribution
ECON 594: Lecture #6
 ECON 594: Lecture #6 Thomas Lemieux Vancouver School of Economics, UBC May 2018 1 Limited dependent variables: introduction Up to now, we have been implicitly assuming that the dependent variable, y, was
ECON 594: Lecture #6 Thomas Lemieux Vancouver School of Economics, UBC May 2018 1 Limited dependent variables: introduction Up to now, we have been implicitly assuming that the dependent variable, y, was
Lecture 3.1 Basic Logistic LDA
 y Lecture.1 Basic Logistic LDA 0.2.4.6.8 1 Outline Quick Refresher on Ordinary Logistic Regression and Stata Women s employment example Cross-Over Trial LDA Example -100-50 0 50 100 -- Longitudinal Data
y Lecture.1 Basic Logistic LDA 0.2.4.6.8 1 Outline Quick Refresher on Ordinary Logistic Regression and Stata Women s employment example Cross-Over Trial LDA Example -100-50 0 50 100 -- Longitudinal Data
Assessing Studies Based on Multiple Regression
 Assessing Studies Based on Multiple Regression Outline 1. Internal and External Validity 2. Threats to Internal Validity a. Omitted variable bias b. Functional form misspecification c. Errors-in-variables
Assessing Studies Based on Multiple Regression Outline 1. Internal and External Validity 2. Threats to Internal Validity a. Omitted variable bias b. Functional form misspecification c. Errors-in-variables
ECON Introductory Econometrics. Lecture 7: OLS with Multiple Regressors Hypotheses tests
 ECON4150 - Introductory Econometrics Lecture 7: OLS with Multiple Regressors Hypotheses tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 7 Lecture outline 2 Hypothesis test for single
ECON4150 - Introductory Econometrics Lecture 7: OLS with Multiple Regressors Hypotheses tests Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 7 Lecture outline 2 Hypothesis test for single
Introduction to Regression Analysis. Dr. Devlina Chatterjee 11 th August, 2017
 Introduction to Regression Analysis Dr. Devlina Chatterjee 11 th August, 2017 What is regression analysis? Regression analysis is a statistical technique for studying linear relationships. One dependent
Introduction to Regression Analysis Dr. Devlina Chatterjee 11 th August, 2017 What is regression analysis? Regression analysis is a statistical technique for studying linear relationships. One dependent
Introduction to Maximum Likelihood Estimation
 Introduction to Maximum Likelihood Estimation Eric Zivot July 26, 2012 The Likelihood Function Let 1 be an iid sample with pdf ( ; ) where is a ( 1) vector of parameters that characterize ( ; ) Example:
Introduction to Maximum Likelihood Estimation Eric Zivot July 26, 2012 The Likelihood Function Let 1 be an iid sample with pdf ( ; ) where is a ( 1) vector of parameters that characterize ( ; ) Example:
Quiz 1. Name: Instructions: Closed book, notes, and no electronic devices.
 Quiz 1. Name: Instructions: Closed book, notes, and no electronic devices. 1. What is the difference between a deterministic model and a probabilistic model? (Two or three sentences only). 2. What is the
Quiz 1. Name: Instructions: Closed book, notes, and no electronic devices. 1. What is the difference between a deterministic model and a probabilistic model? (Two or three sentences only). 2. What is the
Econometrics Homework 1
 Econometrics Homework Due Date: March, 24. by This problem set includes questions for Lecture -4 covered before midterm exam. Question Let z be a random column vector of size 3 : z = @ (a) Write out z
Econometrics Homework Due Date: March, 24. by This problem set includes questions for Lecture -4 covered before midterm exam. Question Let z be a random column vector of size 3 : z = @ (a) Write out z
5. Let W follow a normal distribution with mean of μ and the variance of 1. Then, the pdf of W is
 Practice Final Exam Last Name:, First Name:. Please write LEGIBLY. Answer all questions on this exam in the space provided (you may use the back of any page if you need more space). Show all work but do
Practice Final Exam Last Name:, First Name:. Please write LEGIBLY. Answer all questions on this exam in the space provided (you may use the back of any page if you need more space). Show all work but do
ECON Introductory Econometrics. Lecture 17: Experiments
 ECON4150 - Introductory Econometrics Lecture 17: Experiments Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 13 Lecture outline 2 Why study experiments? The potential outcome framework.
ECON4150 - Introductory Econometrics Lecture 17: Experiments Monique de Haan (moniqued@econ.uio.no) Stock and Watson Chapter 13 Lecture outline 2 Why study experiments? The potential outcome framework.
Generalized Linear Models for Non-Normal Data
 Generalized Linear Models for Non-Normal Data Today s Class: 3 parts of a generalized model Models for binary outcomes Complications for generalized multivariate or multilevel models SPLH 861: Lecture
Generalized Linear Models for Non-Normal Data Today s Class: 3 parts of a generalized model Models for binary outcomes Complications for generalized multivariate or multilevel models SPLH 861: Lecture
CRE METHODS FOR UNBALANCED PANELS Correlated Random Effects Panel Data Models IZA Summer School in Labor Economics May 13-19, 2013 Jeffrey M.
 CRE METHODS FOR UNBALANCED PANELS Correlated Random Effects Panel Data Models IZA Summer School in Labor Economics May 13-19, 2013 Jeffrey M. Wooldridge Michigan State University 1. Introduction 2. Linear
CRE METHODS FOR UNBALANCED PANELS Correlated Random Effects Panel Data Models IZA Summer School in Labor Economics May 13-19, 2013 Jeffrey M. Wooldridge Michigan State University 1. Introduction 2. Linear
Binary Logistic Regression
 The coefficients of the multiple regression model are estimated using sample data with k independent variables Estimated (or predicted) value of Y Estimated intercept Estimated slope coefficients Ŷ = b
The coefficients of the multiple regression model are estimated using sample data with k independent variables Estimated (or predicted) value of Y Estimated intercept Estimated slope coefficients Ŷ = b
Using the same data as before, here is part of the output we get in Stata when we do a logistic regression of Grade on Gpa, Tuce and Psi.
 Logistic Regression, Part III: Hypothesis Testing, Comparisons to OLS Richard Williams, University of Notre Dame, https://www3.nd.edu/~rwilliam/ Last revised January 14, 2018 This handout steals heavily
Logistic Regression, Part III: Hypothesis Testing, Comparisons to OLS Richard Williams, University of Notre Dame, https://www3.nd.edu/~rwilliam/ Last revised January 14, 2018 This handout steals heavily
i (x i x) 2 1 N i x i(y i y) Var(x) = P (x 1 x) Var(x)
 2 1 N i x i(y i y) Var(x) = P (x 1 x) Var(x)") ECO 6375 Prof Millimet Problem Set #2: Answer Key Stata problem 2 Q 3 Q (a) The sample average of the individual-specific marginal effects is 0039 for educw and -0054 for white Thus, on average, an extra
ECO 6375 Prof Millimet Problem Set #2: Answer Key Stata problem 2 Q 3 Q (a) The sample average of the individual-specific marginal effects is 0039 for educw and -0054 for white Thus, on average, an extra
Introduction to Econometrics
 Introduction to Econometrics STAT-S-301 Panel Data (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Regression with Panel Data A panel dataset contains observations on multiple entities
Introduction to Econometrics STAT-S-301 Panel Data (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Regression with Panel Data A panel dataset contains observations on multiple entities
Consider Table 1 (Note connection to start-stop process).
.") Discrete-Time Data and Models Discretized duration data are still duration data! Consider Table 1 (Note connection to start-stop process). Table 1: Example of Discrete-Time Event History Data Case Event
Discrete-Time Data and Models Discretized duration data are still duration data! Consider Table 1 (Note connection to start-stop process). Table 1: Example of Discrete-Time Event History Data Case Event
Ch 7: Dummy (binary, indicator) variables
 variables") Ch 7: Dummy (binary, indicator) variables :Examples Dummy variable are used to indicate the presence or absence of a characteristic. For example, define female i 1 if obs i is female 0 otherwise or male
Ch 7: Dummy (binary, indicator) variables :Examples Dummy variable are used to indicate the presence or absence of a characteristic. For example, define female i 1 if obs i is female 0 otherwise or male
Applied Statistics and Econometrics
 Applied Statistics and Econometrics Lecture 7 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 68 Outline of Lecture 7 1 Empirical example: Italian labor force
Applied Statistics and Econometrics Lecture 7 Saul Lach September 2017 Saul Lach () Applied Statistics and Econometrics September 2017 1 / 68 Outline of Lecture 7 1 Empirical example: Italian labor force
Truncation and Censoring
 Truncation and Censoring Laura Magazzini laura.magazzini@univr.it Laura Magazzini (@univr.it) Truncation and Censoring 1 / 35 Truncation and censoring Truncation: sample data are drawn from a subset of
Truncation and Censoring Laura Magazzini laura.magazzini@univr.it Laura Magazzini (@univr.it) Truncation and Censoring 1 / 35 Truncation and censoring Truncation: sample data are drawn from a subset of
Lecture notes to Chapter 11, Regression with binary dependent variables - probit and logit regression
 Lecture notes to Chapter 11, Regression with binary dependent variables - probit and logit regression Tore Schweder October 28, 2011 Outline Examples of binary respons variables Probit and logit - examples
Lecture notes to Chapter 11, Regression with binary dependent variables - probit and logit regression Tore Schweder October 28, 2011 Outline Examples of binary respons variables Probit and logit - examples
Discrete Dependent Variable Models
 Discrete Dependent Variable Models James J. Heckman University of Chicago This draft, April 10, 2006 Here s the general approach of this lecture: Economic model Decision rule (e.g. utility maximization)
Discrete Dependent Variable Models James J. Heckman University of Chicago This draft, April 10, 2006 Here s the general approach of this lecture: Economic model Decision rule (e.g. utility maximization)
Essential of Simple regression
 Essential of Simple regression We use simple regression when we are interested in the relationship between two variables (e.g., x is class size, and y is student s GPA). For simplicity we assume the relationship
Essential of Simple regression We use simple regression when we are interested in the relationship between two variables (e.g., x is class size, and y is student s GPA). For simplicity we assume the relationship
ECON3150/4150 Spring 2015
 ECON3150/4150 Spring 2015 Lecture 3&4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo January 29, 2015 1 / 67 Chapter 4 in S&W Section 17.1 in S&W (extended OLS assumptions) 2
ECON3150/4150 Spring 2015 Lecture 3&4 - The linear regression model Siv-Elisabeth Skjelbred University of Oslo January 29, 2015 1 / 67 Chapter 4 in S&W Section 17.1 in S&W (extended OLS assumptions) 2
Final Exam. Question 1 (20 points) 2 (25 points) 3 (30 points) 4 (25 points) 5 (10 points) 6 (40 points) Total (150 points) Bonus question (10)
 2 (25 points) 3 (30 points) 4 (25 points) 5 (10 points) 6 (40 points) Total (150 points) Bonus question (10)") Name Economics 170 Spring 2004 Honor pledge: I have neither given nor received aid on this exam including the preparation of my one page formula list and the preparation of the Stata assignment for the
Name Economics 170 Spring 2004 Honor pledge: I have neither given nor received aid on this exam including the preparation of my one page formula list and the preparation of the Stata assignment for the
h=1 exp (X : J h=1 Even the direction of the e ect is not determined by jk. A simpler interpretation of j is given by the odds-ratio
 Multivariate Response Models The response variable is unordered and takes more than two values. The term unordered refers to the fact that response 3 is not more favored than response 2. One choice from
Multivariate Response Models The response variable is unordered and takes more than two values. The term unordered refers to the fact that response 3 is not more favored than response 2. One choice from
WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, Academic Year Exam Version: A
 WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, 2015-16 Academic Year Exam Version: A INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This
WISE MA/PhD Programs Econometrics Instructor: Brett Graham Spring Semester, 2015-16 Academic Year Exam Version: A INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This
WISE International Masters
 WISE International Masters ECONOMETRICS Instructor: Brett Graham INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This examination paper contains 32 questions. You are
WISE International Masters ECONOMETRICS Instructor: Brett Graham INSTRUCTIONS TO STUDENTS 1 The time allowed for this examination paper is 2 hours. 2 This examination paper contains 32 questions. You are
6. Assessing studies based on multiple regression
 6. Assessing studies based on multiple regression Questions of this section: What makes a study using multiple regression (un)reliable? When does multiple regression provide a useful estimate of the causal
6. Assessing studies based on multiple regression Questions of this section: What makes a study using multiple regression (un)reliable? When does multiple regression provide a useful estimate of the causal
Multivariate Regression: Part I
 Topic 1 Multivariate Regression: Part I ARE/ECN 240 A Graduate Econometrics Professor: Òscar Jordà Outline of this topic Statement of the objective: we want to explain the behavior of one variable as a
Topic 1 Multivariate Regression: Part I ARE/ECN 240 A Graduate Econometrics Professor: Òscar Jordà Outline of this topic Statement of the objective: we want to explain the behavior of one variable as a
Econometrics I KS. Module 2: Multivariate Linear Regression. Alexander Ahammer. This version: April 16, 2018
 Econometrics I KS Module 2: Multivariate Linear Regression Alexander Ahammer Department of Economics Johannes Kepler University of Linz This version: April 16, 2018 Alexander Ahammer (JKU) Module 2: Multivariate
Econometrics I KS Module 2: Multivariate Linear Regression Alexander Ahammer Department of Economics Johannes Kepler University of Linz This version: April 16, 2018 Alexander Ahammer (JKU) Module 2: Multivariate
Non-linear panel data modeling
 Non-linear panel data modeling Laura Magazzini University of Verona laura.magazzini@univr.it http://dse.univr.it/magazzini May 2010 Laura Magazzini (@univr.it) Non-linear panel data modeling May 2010 1
Non-linear panel data modeling Laura Magazzini University of Verona laura.magazzini@univr.it http://dse.univr.it/magazzini May 2010 Laura Magazzini (@univr.it) Non-linear panel data modeling May 2010 1
Exam ECON5106/9106 Fall 2018
 Exam ECO506/906 Fall 208. Suppose you observe (y i,x i ) for i,2,, and you assume f (y i x i ;α,β) γ i exp( γ i y i ) where γ i exp(α + βx i ). ote that in this case, the conditional mean of E(y i X x
Exam ECO506/906 Fall 208. Suppose you observe (y i,x i ) for i,2,, and you assume f (y i x i ;α,β) γ i exp( γ i y i ) where γ i exp(α + βx i ). ote that in this case, the conditional mean of E(y i X x
Lecture 4: Multivariate Regression, Part 2
 Lecture 4: Multivariate Regression, Part 2 Gauss-Markov Assumptions 1) Linear in Parameters: Y X X X i 0 1 1 2 2 k k 2) Random Sampling: we have a random sample from the population that follows the above
Lecture 4: Multivariate Regression, Part 2 Gauss-Markov Assumptions 1) Linear in Parameters: Y X X X i 0 1 1 2 2 k k 2) Random Sampling: we have a random sample from the population that follows the above
POLI 8501 Introduction to Maximum Likelihood Estimation
 POLI 8501 Introduction to Maximum Likelihood Estimation Maximum Likelihood Intuition Consider a model that looks like this: Y i N(µ, σ 2 ) So: E(Y ) = µ V ar(y ) = σ 2 Suppose you have some data on Y,
POLI 8501 Introduction to Maximum Likelihood Estimation Maximum Likelihood Intuition Consider a model that looks like this: Y i N(µ, σ 2 ) So: E(Y ) = µ V ar(y ) = σ 2 Suppose you have some data on Y,
Hypothesis Tests and Confidence Intervals. in Multiple Regression
 ECON4135, LN6 Hypothesis Tests and Confidence Intervals Outline 1. Why multipple regression? in Multiple Regression (SW Chapter 7) 2. Simpson s paradox (omitted variables bias) 3. Hypothesis tests and
ECON4135, LN6 Hypothesis Tests and Confidence Intervals Outline 1. Why multipple regression? in Multiple Regression (SW Chapter 7) 2. Simpson s paradox (omitted variables bias) 3. Hypothesis tests and
Econ 371 Problem Set #6 Answer Sheet In this first question, you are asked to consider the following equation:
 Econ 37 Problem Set #6 Answer Sheet 0. In this first question, you are asked to consider the following equation: Y it = β 0 + β X it + β 3 S t + u it. () You are asked how you might time-demean the data
Econ 37 Problem Set #6 Answer Sheet 0. In this first question, you are asked to consider the following equation: Y it = β 0 + β X it + β 3 S t + u it. () You are asked how you might time-demean the data
Recent Advances in the Field of Trade Theory and Policy Analysis Using Micro-Level Data
 Recent Advances in the Field of Trade Theory and Policy Analysis Using Micro-Level Data July 2012 Bangkok, Thailand Cosimo Beverelli (World Trade Organization) 1 Content a) Classical regression model b)
Recent Advances in the Field of Trade Theory and Policy Analysis Using Micro-Level Data July 2012 Bangkok, Thailand Cosimo Beverelli (World Trade Organization) 1 Content a) Classical regression model b)
Linear Regression with Multiple Regressors
 Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Linear Regression with Multiple Regressors (SW Chapter 6) Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
ESTIMATING AVERAGE TREATMENT EFFECTS: REGRESSION DISCONTINUITY DESIGNS Jeff Wooldridge Michigan State University BGSE/IZA Course in Microeconometrics
 ESTIMATING AVERAGE TREATMENT EFFECTS: REGRESSION DISCONTINUITY DESIGNS Jeff Wooldridge Michigan State University BGSE/IZA Course in Microeconometrics July 2009 1. Introduction 2. The Sharp RD Design 3.
ESTIMATING AVERAGE TREATMENT EFFECTS: REGRESSION DISCONTINUITY DESIGNS Jeff Wooldridge Michigan State University BGSE/IZA Course in Microeconometrics July 2009 1. Introduction 2. The Sharp RD Design 3.
Introduction to Econometrics
 Introduction to Econometrics STAT-S-301 Introduction to Time Series Regression and Forecasting (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Introduction to Time Series Regression
Introduction to Econometrics STAT-S-301 Introduction to Time Series Regression and Forecasting (2016/2017) Lecturer: Yves Dominicy Teaching Assistant: Elise Petit 1 Introduction to Time Series Regression
4. Nonlinear regression functions
 4. Nonlinear regression functions Up to now: Population regression function was assumed to be linear The slope(s) of the population regression function is (are) constant The effect on Y of a unit-change
4. Nonlinear regression functions Up to now: Population regression function was assumed to be linear The slope(s) of the population regression function is (are) constant The effect on Y of a unit-change
Chapter 6: Linear Regression With Multiple Regressors
 Chapter 6: Linear Regression With Multiple Regressors 1-1 Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Chapter 6: Linear Regression With Multiple Regressors 1-1 Outline 1. Omitted variable bias 2. Causality and regression analysis 3. Multiple regression and OLS 4. Measures of fit 5. Sampling distribution
Empirical Application of Simple Regression (Chapter 2)
") Empirical Application of Simple Regression (Chapter 2) 1. The data file is House Data, which can be downloaded from my webpage. 2. Use stata menu File Import Excel Spreadsheet to read the data. Don t forget
Empirical Application of Simple Regression (Chapter 2) 1. The data file is House Data, which can be downloaded from my webpage. 2. Use stata menu File Import Excel Spreadsheet to read the data. Don t forget
Lecture#12. Instrumental variables regression Causal parameters III
 Lecture#12 Instrumental variables regression Causal parameters III 1 Demand experiment, market data analysis & simultaneous causality 2 Simultaneous causality Your task is to estimate the demand function
Lecture#12 Instrumental variables regression Causal parameters III 1 Demand experiment, market data analysis & simultaneous causality 2 Simultaneous causality Your task is to estimate the demand function
Lecture 4: Multivariate Regression, Part 2
 Lecture 4: Multivariate Regression, Part 2 Gauss-Markov Assumptions 1) Linear in Parameters: Y X X X i 0 1 1 2 2 k k 2) Random Sampling: we have a random sample from the population that follows the above
Lecture 4: Multivariate Regression, Part 2 Gauss-Markov Assumptions 1) Linear in Parameters: Y X X X i 0 1 1 2 2 k k 2) Random Sampling: we have a random sample from the population that follows the above
 STOCKHOLM UNIVERSITY Department of Economics Course name: Empirical Methods Course code: EC40 Examiner: Lena Nekby Number of credits: 7,5 credits Date of exam: Saturday, May 9, 008 Examination time: 3
STOCKHOLM UNIVERSITY Department of Economics Course name: Empirical Methods Course code: EC40 Examiner: Lena Nekby Number of credits: 7,5 credits Date of exam: Saturday, May 9, 008 Examination time: 3
ECO220Y Simple Regression: Testing the Slope
 ECO220Y Simple Regression: Testing the Slope Readings: Chapter 18 (Sections 18.3-18.5) Winter 2012 Lecture 19 (Winter 2012) Simple Regression Lecture 19 1 / 32 Simple Regression Model y i = β 0 + β 1 x
ECO220Y Simple Regression: Testing the Slope Readings: Chapter 18 (Sections 18.3-18.5) Winter 2012 Lecture 19 (Winter 2012) Simple Regression Lecture 19 1 / 32 Simple Regression Model y i = β 0 + β 1 x
Econ 583 Homework 7 Suggested Solutions: Wald, LM and LR based on GMM and MLE
 Econ 583 Homework 7 Suggested Solutions: Wald, LM and LR based on GMM and MLE Eric Zivot Winter 013 1 Wald, LR and LM statistics based on generalized method of moments estimation Let 1 be an iid sample
Econ 583 Homework 7 Suggested Solutions: Wald, LM and LR based on GMM and MLE Eric Zivot Winter 013 1 Wald, LR and LM statistics based on generalized method of moments estimation Let 1 be an iid sample
1 Motivation for Instrumental Variable (IV) Regression
 Regression") ECON 370: IV & 2SLS 1 Instrumental Variables Estimation and Two Stage Least Squares Econometric Methods, ECON 370 Let s get back to the thiking in terms of cross sectional (or pooled cross sectional) data
ECON 370: IV & 2SLS 1 Instrumental Variables Estimation and Two Stage Least Squares Econometric Methods, ECON 370 Let s get back to the thiking in terms of cross sectional (or pooled cross sectional) data
The F distribution. If: 1. u 1,,u n are normally distributed; and 2. X i is distributed independently of u i (so in particular u i is homoskedastic)
") The F distribution If: 1. u 1,,u n are normally distributed; and. X i is distributed independently of u i (so in particular u i is homoskedastic) then the homoskedasticity-only F-statistic has the F q,n-k
The F distribution If: 1. u 1,,u n are normally distributed; and. X i is distributed independently of u i (so in particular u i is homoskedastic) then the homoskedasticity-only F-statistic has the F q,n-k
Applied Health Economics (for B.Sc.)
") Applied Health Economics (for B.Sc.) Helmut Farbmacher Department of Economics University of Mannheim Autumn Semester 2017 Outlook 1 Linear models (OLS, Omitted variables, 2SLS) 2 Limited and qualitative
Applied Health Economics (for B.Sc.) Helmut Farbmacher Department of Economics University of Mannheim Autumn Semester 2017 Outlook 1 Linear models (OLS, Omitted variables, 2SLS) 2 Limited and qualitative
Ninth ARTNeT Capacity Building Workshop for Trade Research "Trade Flows and Trade Policy Analysis"
 Ninth ARTNeT Capacity Building Workshop for Trade Research "Trade Flows and Trade Policy Analysis" June 2013 Bangkok, Thailand Cosimo Beverelli and Rainer Lanz (World Trade Organization) 1 Selected econometric
Ninth ARTNeT Capacity Building Workshop for Trade Research "Trade Flows and Trade Policy Analysis" June 2013 Bangkok, Thailand Cosimo Beverelli and Rainer Lanz (World Trade Organization) 1 Selected econometric
ECON3150/4150 Spring 2016
 ECON3150/4150 Spring 2016 Lecture 6 Multiple regression model Siv-Elisabeth Skjelbred University of Oslo February 5th Last updated: February 3, 2016 1 / 49 Outline Multiple linear regression model and
ECON3150/4150 Spring 2016 Lecture 6 Multiple regression model Siv-Elisabeth Skjelbred University of Oslo February 5th Last updated: February 3, 2016 1 / 49 Outline Multiple linear regression model and
Control Function and Related Methods: Nonlinear Models
 Control Function and Related Methods: Nonlinear Models Jeff Wooldridge Michigan State University Programme Evaluation for Policy Analysis Institute for Fiscal Studies June 2012 1. General Approach 2. Nonlinear
Control Function and Related Methods: Nonlinear Models Jeff Wooldridge Michigan State University Programme Evaluation for Policy Analysis Institute for Fiscal Studies June 2012 1. General Approach 2. Nonlinear
Limited Dependent Variable Models II
 Limited Dependent Variable Models II Fall 2008 Environmental Econometrics (GR03) LDV Fall 2008 1 / 15 Models with Multiple Choices The binary response model was dealing with a decision problem with two
Limited Dependent Variable Models II Fall 2008 Environmental Econometrics (GR03) LDV Fall 2008 1 / 15 Models with Multiple Choices The binary response model was dealing with a decision problem with two
Introduction to Econometrics. Regression with Panel Data
 Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Regression with Panel Data Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 Regression with Panel
Introduction to Econometrics The statistical analysis of economic (and related) data STATS301 Regression with Panel Data Titulaire: Christopher Bruffaerts Assistant: Lorenzo Ricci 1 Regression with Panel
L6: Regression II. JJ Chen. July 2, 2015
 L6: Regression II JJ Chen July 2, 2015 Today s Plan Review basic inference based on Sample average Difference in sample average Extrapolate the knowledge to sample regression coefficients Standard error,
L6: Regression II JJ Chen July 2, 2015 Today s Plan Review basic inference based on Sample average Difference in sample average Extrapolate the knowledge to sample regression coefficients Standard error,
Recent Developments in Multilevel Modeling
 Recent Developments in Multilevel Modeling Roberto G. Gutierrez Director of Statistics StataCorp LP 2007 North American Stata Users Group Meeting, Boston R. Gutierrez (StataCorp) Multilevel Modeling August
Recent Developments in Multilevel Modeling Roberto G. Gutierrez Director of Statistics StataCorp LP 2007 North American Stata Users Group Meeting, Boston R. Gutierrez (StataCorp) Multilevel Modeling August
Lab 11 - Heteroskedasticity
 Lab 11 - Heteroskedasticity Spring 2017 Contents 1 Introduction 2 2 Heteroskedasticity 2 3 Addressing heteroskedasticity in Stata 3 4 Testing for heteroskedasticity 4 5 A simple example 5 1 1 Introduction
Lab 11 - Heteroskedasticity Spring 2017 Contents 1 Introduction 2 2 Heteroskedasticity 2 3 Addressing heteroskedasticity in Stata 3 4 Testing for heteroskedasticity 4 5 A simple example 5 1 1 Introduction
Binary Choice Models Probit & Logit. = 0 with Pr = 0 = 1. decision-making purchase of durable consumer products unemployment
 BINARY CHOICE MODELS Y ( Y ) ( Y ) 1 with Pr = 1 = P = 0 with Pr = 0 = 1 P Examples: decision-making purchase of durable consumer products unemployment Estimation with OLS? Yi = Xiβ + εi Problems: nonsense
BINARY CHOICE MODELS Y ( Y ) ( Y ) 1 with Pr = 1 = P = 0 with Pr = 0 = 1 P Examples: decision-making purchase of durable consumer products unemployment Estimation with OLS? Yi = Xiβ + εi Problems: nonsense
Practice exam questions
 Practice exam questions Nathaniel Higgins nhiggins@jhu.edu, nhiggins@ers.usda.gov 1. The following question is based on the model y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + u. Discuss the following two hypotheses.
Practice exam questions Nathaniel Higgins nhiggins@jhu.edu, nhiggins@ers.usda.gov 1. The following question is based on the model y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + u. Discuss the following two hypotheses.
Problem Set 1 ANSWERS
 Economics 20 Prof. Patricia M. Anderson Problem Set 1 ANSWERS Part I. Multiple Choice Problems 1. If X and Z are two random variables, then E[X-Z] is d. E[X] E[Z] This is just a simple application of one
Economics 20 Prof. Patricia M. Anderson Problem Set 1 ANSWERS Part I. Multiple Choice Problems 1. If X and Z are two random variables, then E[X-Z] is d. E[X] E[Z] This is just a simple application of one