A first model of learning
|
|
|
- Kristin Patrick
- 5 years ago
- Views:
Transcription
1 A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) We observe the data where each Suppose we are given an ensemble of possible hypotheses / classifiers From the training data possible classifier from, we would like to select the best


")
2 Empirical risk minimization (ERM) Recall the definitions of risk/empirical risk Ideally, we would like to choose Since is supposed to be a good estimate of, an incredibly natural (and common) strategy is to pick
3 The excess risk Note that by definition, we must have We would like to guarantee that is small Last time we took an extended detour through the exciting world of concentration inequalities to show (using Hoeffding) that for any fixed or equivalently, that with probability at least

4 Getting a uniform guarantee We would like to get a bound on Since the choice of depends on the empirical risk of all the classifiers in, one way to do this is to ensure that is small for every That is, we want to show that with probability at least for some suitable choice of We do this using the union bound

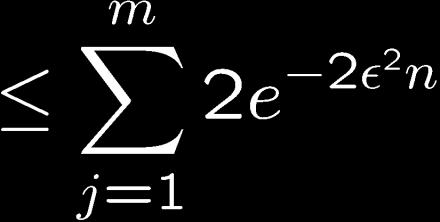

5 Result of the union bound
6 Bounding the excess risk Note that when we have a bound such as we can not only make guarantees about, but can also relate the performance of to : Note that Thus
7 The upshot As long as isn t too big ( ) then we can be reasonably confident that and furthermore that isn t too much larger than Of course, the trick in a doing a good job of learning is ensure that is actually small To achieve this, we need a rich set of possible hypotheses unfortunately
8 Fundamental tradeoff More hypotheses ultimately sacrifices our guarantee that Richer set of hypotheses Error Richness of hypothesis set
9 What is a good hypothesis? Ideally, we would like to have a small number of hypotheses, so that, while also being lucky (or smart) enough to have In general, this may not be possible, since there may not be any function with Why not? Noise: Suppose we knew the joint distribution of our data what is the optimal classification rule? what are the fundamental limits on how small can be?
10 Known distribution case Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by Denote the a posteriori class probabilities by for

11 The Bayes classifier Theorem The classifier satisfies for any possible classifier Terminology: is called a Bayes classifier is called the Bayes risk
12 Proof For convenience, assume variable with density is a continuous random Let denote the a priori class probabilities Consider an arbitrary classifier. Denote the decision regions


13 Proof (Part 2) We can write We want to maximize this expression, we should design our classifier such that is maximal


14 Proof (Part 3) Therefore, the optimal has Bayes rule! Note that in addition to our rigorous derivation, this classifier also coincides with common sense


15 Variations Different ways of expressing the Bayes classifier When likelihood ratio test When maximum likelihood classifier/detector
16 Example Suppose that and that If





17 Example How do we calculate the Bayes risk? In the case where declaring 1 iff, thus, our test reduced to
18 Alternative cost/loss functions So far we have focused on minimizing the risk There are many situations where this is not appropriate cost-sensitive classification type I/type II errors or misses/false alarms may have very different costs, in which case a loss function of the form alternatively, it may be better to focus on them directly a la Neyman-Pearson classification unbalanced datasets when one class dominates the other, the probability of error will place less emphasis on the smaller class the class proportions in our dataset may not be representative of the wild
19 What about learning? We have just seen that when we know the true distribution underlying our dataset, solving the classification problem is straightforward In practical learning problems, all we have is the data One natural approach is to use the data to estimate the distribution, and then just plug this into the formula for the Bayes classifier Plugin methods Before we get to these, we will first talk about what is quite possibly the absolute simplest learning algorithm there is


20 Nearest neighbor classifier The nearest neighbor classifier is easiest to state in words: Assign the same label as the closest training point to The nearest neighbor rule defines a Vornoi partition of the input space

21 Risk of the nearest neighbor classifier Recall that the Bayes classifier simply chooses the maximizes that If, then the risk of the Bayes classifier at is If denotes the nearest neighbor to and has label, then the risk of the nearest neighbor classifier at is given by
 that Bayes risk: NN risk: Asymptotically, the risk of the nearest neighbor classifier is at most twice the")
22 Intuition from asymptotics In the limit as Thus, as we have, we can assume that Consider the binary classification case and suppose (without loss of generality) that Bayes risk: NN risk: Asymptotically, the risk of the nearest neighbor classifier is at most twice the Bayes risk

23 -nearest neighbors We can drive the factor of 2 in this result down to 1 by generalizing the nearest neighbor rule to the -nearest neighbor rule as follows: Assign a label to training points by taking a majority vote over the closest to How do we define this more mathematically? indices of the training points closest to If, then we can write the -nearest neighbor classifier as
24 Example
25 Example
26 Example
27 Example
28 Example
29 Example
30 Example
31 Example

32 Choosing the size of the neighborhood Setting the parameter is a problem of model selection Setting by trying to minimize the training error is a particularly bad idea What is? No matter what, we always have Not much practical guidance from the theory, so we typically must rely on estimates based on holdout sets or more sophisticated model selection techniques


33 Consistency We say that a classification algorithm is consistent if when the size of the training set, we have that where and is a classifier learned from a training set of size is the Bayes risk Theorem Let denote the -nearest neighbor rule with a training set of size. If,, and, then is consistent, i.e.,
34 Summary Given enough data, the -nearest neighbor classifier will do just as well as pretty much any other method Catch The amount of required data can be huge, especially if our feature space is high-dimensional The parameter can matter a lot, so model selection will can be very important Finding the nearest neighbors out of a set of millions of examples is still pretty hard can be sped up using k-d trees, but can still be relatively expensive to apply in contrast, many of the other algorithms we will study have an expensive training phase, but application is cheap
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
A Posteriori Corrections to Classification Methods.
 A Posteriori Corrections to Classification Methods. Włodzisław Duch and Łukasz Itert Department of Informatics, Nicholas Copernicus University, Grudziądzka 5, 87-100 Toruń, Poland; http://www.phys.uni.torun.pl/kmk
A Posteriori Corrections to Classification Methods. Włodzisław Duch and Łukasz Itert Department of Informatics, Nicholas Copernicus University, Grudziądzka 5, 87-100 Toruń, Poland; http://www.phys.uni.torun.pl/kmk
FORMULATION OF THE LEARNING PROBLEM
 FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
Machine Learning. Model Selection and Validation. Fabio Vandin November 7, 2017
 Machine Learning Model Selection and Validation Fabio Vandin November 7, 2017 1 Model Selection When we have to solve a machine learning task: there are different algorithms/classes algorithms have parameters
Machine Learning Model Selection and Validation Fabio Vandin November 7, 2017 1 Model Selection When we have to solve a machine learning task: there are different algorithms/classes algorithms have parameters
The classifier. Theorem. where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know
 The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The classifier. Linear discriminant analysis (LDA) Example. Challenges for LDA
 Example. Challenges for LDA") The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 4771
 Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW2 due now! Project proposal due on tomorrow Midterm next lecture! HW3 posted Last time Linear Regression Parametric vs Nonparametric
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW2 due now! Project proposal due on tomorrow Midterm next lecture! HW3 posted Last time Linear Regression Parametric vs Nonparametric
Lecture 7 Introduction to Statistical Decision Theory
 Lecture 7 Introduction to Statistical Decision Theory I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw December 20, 2016 1 / 55 I-Hsiang Wang IT Lecture 7
Lecture 7 Introduction to Statistical Decision Theory I-Hsiang Wang Department of Electrical Engineering National Taiwan University ihwang@ntu.edu.tw December 20, 2016 1 / 55 I-Hsiang Wang IT Lecture 7
Bayesian Learning Extension
 Bayesian Learning Extension This document will go over one of the most useful forms of statistical inference known as Baye s Rule several of the concepts that extend from it. Named after Thomas Bayes this
Bayesian Learning Extension This document will go over one of the most useful forms of statistical inference known as Baye s Rule several of the concepts that extend from it. Named after Thomas Bayes this
Holdout and Cross-Validation Methods Overfitting Avoidance
 Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Bayes Classifiers. CAP5610 Machine Learning Instructor: Guo-Jun QI
 Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
CS340 Machine learning Lecture 5 Learning theory cont'd. Some slides are borrowed from Stuart Russell and Thorsten Joachims
 CS340 Machine learning Lecture 5 Learning theory cont'd Some slides are borrowed from Stuart Russell and Thorsten Joachims Inductive learning Simplest form: learn a function from examples f is the target
CS340 Machine learning Lecture 5 Learning theory cont'd Some slides are borrowed from Stuart Russell and Thorsten Joachims Inductive learning Simplest form: learn a function from examples f is the target
Machine Learning, Midterm Exam: Spring 2008 SOLUTIONS. Q Topic Max. Score Score. 1 Short answer questions 20.
 10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
Lecture 3: Empirical Risk Minimization
 Lecture 3: Empirical Risk Minimization Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 3 1 / 11 A more general approach We saw the learning algorithms Memorize and
Lecture 3: Empirical Risk Minimization Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 3 1 / 11 A more general approach We saw the learning algorithms Memorize and
Randomized Decision Trees
 Randomized Decision Trees compiled by Alvin Wan from Professor Jitendra Malik s lecture Discrete Variables First, let us consider some terminology. We have primarily been dealing with real-valued data,
Randomized Decision Trees compiled by Alvin Wan from Professor Jitendra Malik s lecture Discrete Variables First, let us consider some terminology. We have primarily been dealing with real-valued data,
Machine Learning. Theory of Classification and Nonparametric Classifier. Lecture 2, January 16, What is theoretically the best classifier
 Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Learning Theory. Machine Learning CSE546 Carlos Guestrin University of Washington. November 25, Carlos Guestrin
 Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Computational Learning Theory
 Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Machine Learning for Signal Processing Bayes Classification
 Machine Learning for Signal Processing Bayes Classification Class 16. 24 Oct 2017 Instructor: Bhiksha Raj - Abelino Jimenez 11755/18797 1 Recap: KNN A very effective and simple way of performing classification
Machine Learning for Signal Processing Bayes Classification Class 16. 24 Oct 2017 Instructor: Bhiksha Raj - Abelino Jimenez 11755/18797 1 Recap: KNN A very effective and simple way of performing classification
Variance Reduction and Ensemble Methods
 Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Consistency of Nearest Neighbor Methods
 E0 370 Statistical Learning Theory Lecture 16 Oct 25, 2011 Consistency of Nearest Neighbor Methods Lecturer: Shivani Agarwal Scribe: Arun Rajkumar 1 Introduction In this lecture we return to the study
E0 370 Statistical Learning Theory Lecture 16 Oct 25, 2011 Consistency of Nearest Neighbor Methods Lecturer: Shivani Agarwal Scribe: Arun Rajkumar 1 Introduction In this lecture we return to the study
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
Learning Theory Continued
 Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Statistical Machine Learning
 Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 2: Introduction to statistical learning theory. 1 / 22 Goals of statistical learning theory SLT aims at studying the performance of
Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 2: Introduction to statistical learning theory. 1 / 22 Goals of statistical learning theory SLT aims at studying the performance of
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Decision Trees. Nicholas Ruozzi University of Texas at Dallas. Based on the slides of Vibhav Gogate and David Sontag
 Decision Trees Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Supervised Learning Input: labelled training data i.e., data plus desired output Assumption:
Decision Trees Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Supervised Learning Input: labelled training data i.e., data plus desired output Assumption:
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Introduction to Machine Learning
 Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
Introduction to Machine Learning Vapnik Chervonenkis Theory Barnabás Póczos Empirical Risk and True Risk 2 Empirical Risk Shorthand: True risk of f (deterministic): Bayes risk: Let us use the empirical
PAC Learning. prof. dr Arno Siebes. Algorithmic Data Analysis Group Department of Information and Computing Sciences Universiteit Utrecht
 PAC Learning prof. dr Arno Siebes Algorithmic Data Analysis Group Department of Information and Computing Sciences Universiteit Utrecht Recall: PAC Learning (Version 1) A hypothesis class H is PAC learnable
PAC Learning prof. dr Arno Siebes Algorithmic Data Analysis Group Department of Information and Computing Sciences Universiteit Utrecht Recall: PAC Learning (Version 1) A hypothesis class H is PAC learnable
IFT Lecture 7 Elements of statistical learning theory
 IFT 6085 - Lecture 7 Elements of statistical learning theory This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s): Brady Neal and
IFT 6085 - Lecture 7 Elements of statistical learning theory This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s): Brady Neal and
Linear and Logistic Regression. Dr. Xiaowei Huang
 Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Classification and Regression Trees
 Classification and Regression Trees Ryan P Adams So far, we have primarily examined linear classifiers and regressors, and considered several different ways to train them When we ve found the linearity
Classification and Regression Trees Ryan P Adams So far, we have primarily examined linear classifiers and regressors, and considered several different ways to train them When we ve found the linearity
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Stephen Scott.
 1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
Lecture 3: Introduction to Complexity Regularization
 ECE90 Spring 2007 Statistical Learning Theory Instructor: R. Nowak Lecture 3: Introduction to Complexity Regularization We ended the previous lecture with a brief discussion of overfitting. Recall that,
ECE90 Spring 2007 Statistical Learning Theory Instructor: R. Nowak Lecture 3: Introduction to Complexity Regularization We ended the previous lecture with a brief discussion of overfitting. Recall that,
Recap from previous lecture
 Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Chapter 2. Binary and M-ary Hypothesis Testing 2.1 Introduction (Levy 2.1)
") Chapter 2. Binary and M-ary Hypothesis Testing 2.1 Introduction (Levy 2.1) Detection problems can usually be casted as binary or M-ary hypothesis testing problems. Applications: This chapter: Simple hypothesis
Chapter 2. Binary and M-ary Hypothesis Testing 2.1 Introduction (Levy 2.1) Detection problems can usually be casted as binary or M-ary hypothesis testing problems. Applications: This chapter: Simple hypothesis
An Introduction to Statistical Theory of Learning. Nakul Verma Janelia, HHMI
 An Introduction to Statistical Theory of Learning Nakul Verma Janelia, HHMI Towards formalizing learning What does it mean to learn a concept? Gain knowledge or experience of the concept. The basic process
An Introduction to Statistical Theory of Learning Nakul Verma Janelia, HHMI Towards formalizing learning What does it mean to learn a concept? Gain knowledge or experience of the concept. The basic process
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Slide Set 3: Detection Theory January 2018 Heikki Huttunen heikki.huttunen@tut.fi Department of Signal Processing Tampere University of Technology Detection theory
PATTERN RECOGNITION AND MACHINE LEARNING Slide Set 3: Detection Theory January 2018 Heikki Huttunen heikki.huttunen@tut.fi Department of Signal Processing Tampere University of Technology Detection theory
Machine Learning. Linear Models. Fabio Vandin October 10, 2017
 Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Machine Learning. Computational Learning Theory. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Computational Learning Theory Le Song Lecture 11, September 20, 2012 Based on Slides from Eric Xing, CMU Reading: Chap. 7 T.M book 1 Complexity of Learning
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Computational Learning Theory Le Song Lecture 11, September 20, 2012 Based on Slides from Eric Xing, CMU Reading: Chap. 7 T.M book 1 Complexity of Learning
Introduction to Machine Learning
 Introduction to Machine Learning 3. Instance Based Learning Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Parzen Windows Kernels, algorithm Model selection
Introduction to Machine Learning 3. Instance Based Learning Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Parzen Windows Kernels, algorithm Model selection
Discriminative v. generative
 Discriminative v. generative Naive Bayes 2 Naive Bayes P (x ij,y i )= Y i P (y i ) Y j P (x ij y i ) P (y i =+)=p MLE: max P (x ij,y i ) a j,b j,p p = 1 N P [yi =+] P (x ij =1 y i = ) = a j P (x ij =1
Discriminative v. generative Naive Bayes 2 Naive Bayes P (x ij,y i )= Y i P (y i ) Y j P (x ij y i ) P (y i =+)=p MLE: max P (x ij,y i ) a j,b j,p p = 1 N P [yi =+] P (x ij =1 y i = ) = a j P (x ij =1
CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors. Furong Huang /
 CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors Furong Huang / furongh@cs.umd.edu What we know so far Decision Trees What is a decision tree, and how to induce it from
CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors Furong Huang / furongh@cs.umd.edu What we know so far Decision Trees What is a decision tree, and how to induce it from
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 8 Feb. 12, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
ECE521 Lecture7. Logistic Regression
 ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
ECE521 Lecture7 Logistic Regression Outline Review of decision theory Logistic regression A single neuron Multi-class classification 2 Outline Decision theory is conceptually easy and computationally hard
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Learning Theory. Piyush Rai. CS5350/6350: Machine Learning. September 27, (CS5350/6350) Learning Theory September 27, / 14
 Learning Theory September 27, / 14") Learning Theory Piyush Rai CS5350/6350: Machine Learning September 27, 2011 (CS5350/6350) Learning Theory September 27, 2011 1 / 14 Why Learning Theory? We want to have theoretical guarantees about our
Learning Theory Piyush Rai CS5350/6350: Machine Learning September 27, 2011 (CS5350/6350) Learning Theory September 27, 2011 1 / 14 Why Learning Theory? We want to have theoretical guarantees about our
Geometric View of Machine Learning Nearest Neighbor Classification. Slides adapted from Prof. Carpuat
 Geometric View of Machine Learning Nearest Neighbor Classification Slides adapted from Prof. Carpuat What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental
Geometric View of Machine Learning Nearest Neighbor Classification Slides adapted from Prof. Carpuat What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
The PAC Learning Framework -II
 The PAC Learning Framework -II Prof. Dan A. Simovici UMB 1 / 1 Outline 1 Finite Hypothesis Space - The Inconsistent Case 2 Deterministic versus stochastic scenario 3 Bayes Error and Noise 2 / 1 Outline
The PAC Learning Framework -II Prof. Dan A. Simovici UMB 1 / 1 Outline 1 Finite Hypothesis Space - The Inconsistent Case 2 Deterministic versus stochastic scenario 3 Bayes Error and Noise 2 / 1 Outline
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Computational and Statistical Learning theory
 Computational and Statistical Learning theory Problem set 2 Due: January 31st Email solutions to : karthik at ttic dot edu Notation : Input space : X Label space : Y = {±1} Sample : (x 1, y 1,..., (x n,
Computational and Statistical Learning theory Problem set 2 Due: January 31st Email solutions to : karthik at ttic dot edu Notation : Input space : X Label space : Y = {±1} Sample : (x 1, y 1,..., (x n,
MLCC 2017 Regularization Networks I: Linear Models
 MLCC 2017 Regularization Networks I: Linear Models Lorenzo Rosasco UNIGE-MIT-IIT June 27, 2017 About this class We introduce a class of learning algorithms based on Tikhonov regularization We study computational
MLCC 2017 Regularization Networks I: Linear Models Lorenzo Rosasco UNIGE-MIT-IIT June 27, 2017 About this class We introduce a class of learning algorithms based on Tikhonov regularization We study computational
Lecture 3: Multiclass Classification
 Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Decision Tree Learning Lecture 2
 Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
An Introduction to No Free Lunch Theorems
 February 2, 2012 Table of Contents Induction Learning without direct observation. Generalising from data. Modelling physical phenomena. The Problem of Induction David Hume (1748) How do we know an induced
February 2, 2012 Table of Contents Induction Learning without direct observation. Generalising from data. Modelling physical phenomena. The Problem of Induction David Hume (1748) How do we know an induced
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Relationship between Least Squares Approximation and Maximum Likelihood Hypotheses
 Relationship between Least Squares Approximation and Maximum Likelihood Hypotheses Steven Bergner, Chris Demwell Lecture notes for Cmpt 882 Machine Learning February 19, 2004 Abstract In these notes, a
Relationship between Least Squares Approximation and Maximum Likelihood Hypotheses Steven Bergner, Chris Demwell Lecture notes for Cmpt 882 Machine Learning February 19, 2004 Abstract In these notes, a
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Sample Complexity of Learning Mahalanobis Distance Metrics. Nakul Verma Janelia, HHMI
 Sample Complexity of Learning Mahalanobis Distance Metrics Nakul Verma Janelia, HHMI feature 2 Mahalanobis Metric Learning Comparing observations in feature space: x 1 [sq. Euclidean dist] x 2 (all features
Sample Complexity of Learning Mahalanobis Distance Metrics Nakul Verma Janelia, HHMI feature 2 Mahalanobis Metric Learning Comparing observations in feature space: x 1 [sq. Euclidean dist] x 2 (all features
Solving Classification Problems By Knowledge Sets
 Solving Classification Problems By Knowledge Sets Marcin Orchel a, a Department of Computer Science, AGH University of Science and Technology, Al. A. Mickiewicza 30, 30-059 Kraków, Poland Abstract We propose
Solving Classification Problems By Knowledge Sets Marcin Orchel a, a Department of Computer Science, AGH University of Science and Technology, Al. A. Mickiewicza 30, 30-059 Kraków, Poland Abstract We propose
PDEEC Machine Learning 2016/17
 PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Chapter ML:II (continued)
") Chapter ML:II (continued) II. Machine Learning Basics Regression Concept Learning: Search in Hypothesis Space Concept Learning: Search in Version Space Measuring Performance ML:II-96 Basics STEIN/LETTMANN
Chapter ML:II (continued) II. Machine Learning Basics Regression Concept Learning: Search in Hypothesis Space Concept Learning: Search in Version Space Measuring Performance ML:II-96 Basics STEIN/LETTMANN
Generalization bounds
 Advanced Course in Machine Learning pring 200 Generalization bounds Handouts are jointly prepared by hie Mannor and hai halev-hwartz he problem of characterizing learnability is the most basic question
Advanced Course in Machine Learning pring 200 Generalization bounds Handouts are jointly prepared by hie Mannor and hai halev-hwartz he problem of characterizing learnability is the most basic question
Chapter 6 Classification and Prediction (2)
") Chapter 6 Classification and Prediction (2) Outline Classification and Prediction Decision Tree Naïve Bayes Classifier Support Vector Machines (SVM) K-nearest Neighbors Accuracy and Error Measures Feature
Chapter 6 Classification and Prediction (2) Outline Classification and Prediction Decision Tree Naïve Bayes Classifier Support Vector Machines (SVM) K-nearest Neighbors Accuracy and Error Measures Feature
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Large-Scale Nearest Neighbor Classification with Statistical Guarantees
 Large-Scale Nearest Neighbor Classification with Statistical Guarantees Guang Cheng Big Data Theory Lab Department of Statistics Purdue University Joint Work with Xingye Qiao and Jiexin Duan July 3, 2018
Large-Scale Nearest Neighbor Classification with Statistical Guarantees Guang Cheng Big Data Theory Lab Department of Statistics Purdue University Joint Work with Xingye Qiao and Jiexin Duan July 3, 2018
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
Bayesian Learning. Artificial Intelligence Programming. 15-0: Learning vs. Deduction
 15-0: Learning vs. Deduction Artificial Intelligence Programming Bayesian Learning Chris Brooks Department of Computer Science University of San Francisco So far, we ve seen two types of reasoning: Deductive
15-0: Learning vs. Deduction Artificial Intelligence Programming Bayesian Learning Chris Brooks Department of Computer Science University of San Francisco So far, we ve seen two types of reasoning: Deductive
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 9
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 9 Slides adapted from Jordan Boyd-Graber Machine Learning: Chenhao Tan Boulder 1 of 39 Recap Supervised learning Previously: KNN, naïve
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 9 Slides adapted from Jordan Boyd-Graber Machine Learning: Chenhao Tan Boulder 1 of 39 Recap Supervised learning Previously: KNN, naïve
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Bayesian Learning. Bayesian Learning Criteria
 Bayesian Learning In Bayesian learning, we are interested in the probability of a hypothesis h given the dataset D. By Bayes theorem: P (h D) = P (D h)p (h) P (D) Other useful formulas to remember are:
Bayesian Learning In Bayesian learning, we are interested in the probability of a hypothesis h given the dataset D. By Bayes theorem: P (h D) = P (D h)p (h) P (D) Other useful formulas to remember are:
Learning Theory. Aar$ Singh and Barnabas Poczos. Machine Learning / Apr 17, Slides courtesy: Carlos Guestrin
 Learning Theory Aar$ Singh and Barnabas Poczos Machine Learning 10-701/15-781 Apr 17, 2014 Slides courtesy: Carlos Guestrin Learning Theory We have explored many ways of learning from data But How good
Learning Theory Aar$ Singh and Barnabas Poczos Machine Learning 10-701/15-781 Apr 17, 2014 Slides courtesy: Carlos Guestrin Learning Theory We have explored many ways of learning from data But How good
CLUe Training An Introduction to Machine Learning in R with an example from handwritten digit recognition
 CLUe Training An Introduction to Machine Learning in R with an example from handwritten digit recognition Ad Feelders Universiteit Utrecht Department of Information and Computing Sciences Algorithmic Data
CLUe Training An Introduction to Machine Learning in R with an example from handwritten digit recognition Ad Feelders Universiteit Utrecht Department of Information and Computing Sciences Algorithmic Data
Machine Learning Gaussian Naïve Bayes Big Picture
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 27, 2011 Today: Naïve Bayes Big Picture Logistic regression Gradient ascent Generative discriminative
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 27, 2011 Today: Naïve Bayes Big Picture Logistic regression Gradient ascent Generative discriminative