CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors. Furong Huang /
|
|
|
- Griffin Evans
- 5 years ago
- Views:
Transcription

1 CMSC 422 Introduction to Machine Learning Lecture 4 Geometry and Nearest Neighbors Furong Huang / furongh@cs.umd.edu
2 What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental Machine Learning Concepts Difference between memorization and generalization What inductive bias is, and what is its role in learning What underfitting and overfitting means How to take a task and cast it as a learning problem Why you should never ever touch your test data!!
3 Today s Topics Nearest Neighbors (NN) algorithms for classification K-NN, Epsilon ball NN Fundamental Machine Learning Concepts Decision boundary
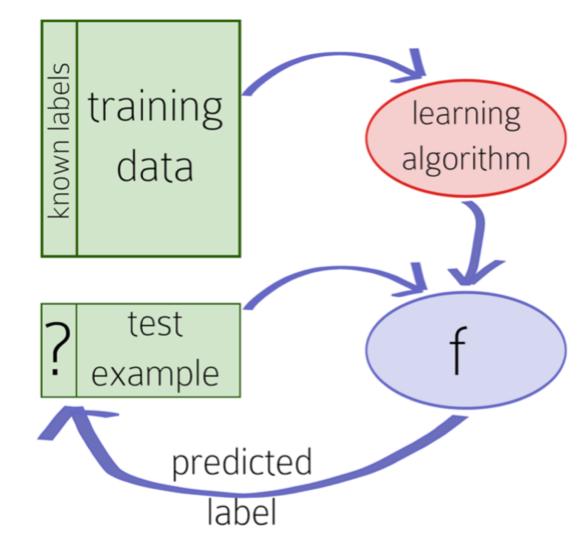
4
5 Linear Algebra Provides compact representation of data For a given example, all its features can be represented as a single vector An entire dataset can be represented as a single matrix Provide ways of manipulating these objects Dot products, vector/matrix operations, etc Provides formal ways of describing and discovering patterns in data Examples are points in a Vector Space We can use Norms and Distances to compare them Some are valid for feature data types Some can be made valid, with generalization...
6 Mathematical view of vectors Ordered set of numbers: (1,2,3,4) Example: (x,y,z) coordinates of a point in space. The pixels in a image of a face List of choices in the tennis example Vectors usually indicated with bold lower case letters. Scalars with lower case Usual mathematical operations with vectors: Addition operation! + $, with: v Zero % $ + % = $ v Inverse $ + $ = % Scalar multiplication: v Distributive rule: (! + $ = (! + ($ (( + *)! = (! + *!
7 Dot Product The dot product or, more generally, inner product of two vectors is a scalar:!!! " = $! $ " + &! & " + '! ' " (in 3D) Useful for many purposes Computing the Euclidean length of a vector: length(v) = sqrt(v v) Normalizing a vector, making it unit-length Computing the angle between two vectors: u v= u v cos(θ) Checking two vectors for orthogonality Projecting one vector onto another Other ways of measuring length and distance are possible
8 Vector Norms! = ($ %, $ ',, $ ) ) Two norm (Euclidean norm) )! ' = + $, ' If! ' = 1,! is a unit vector,-% Infinity norm! / = max $ %, $ ',, $ ) One norm (Manhattan distance) )! % = + $,,-%
9 Law of Large Numbers Suppose that!!,! ",! # are independent and identically distributed random variables The empirical sample average approaches the population average as the number of sample goes to infinity 1 Pr lim # % * +! & = -! = 1 &
10 Nearest Neighbor Intuition points close in a feature space are likely to belong to the same class Choosing right features is very important Nearest Neighbors (NN) algorithms for Classification K-NN, Epsilon ball NN Fundamental Machine Learning Concepts Decision boundary
11 Intuition for Nearest Neighbor Classification This rule of nearest neighbor has considerable elementary intuitive appeal and probably corresponds to practice in many situations. For example, it is possible that much medical diagnosis is influenced by the doctor s recollection of the subsequent history of an earlier patient whose symptoms resemble in some way those of the current patient. (Fix and Hodges, 1952)
12 Intuition for Nearest Neighbor Classification Simple idea Store all training examples Classify new examples based on label for K closest training examples Training may just involve making structures to make computing closest examples cheaper
13 classification is K Nearest Neighbor Classification Training Data K: number of neighbors that based on Test instance with unknown class in { 1; +1 }
14 2 approaches to learning Eager learning (eg decision trees) Learn/Train Induce an abstract model from data Test/Predict/Classify Apply learned model to new data Lazy learning (eg nearest neighbors) Learn Just store data in memory Test/Predict/Classify Compare new data to stored data Properties Retains all information seen in training Complex hypothesis space Classification can be very slow
15 Components of a k-nn Classifier Distance metric How do we measure distance between instances? Determines the layout of the example space The k hyperparameter How large a neighborhood should we consider? Determines the complexity of the hypothesis space
 L1")
16 Distance metrics We can use any distance function to select nearest neighbors. Different distances yield different neighborhoods L2 distance ( = Euclidean distance) L1 distance Max norm
17 K=1 and Voronoi Diagrams Imagine we are given a bunch of training examples Find regions in the feature space which are closest to every training example Algorithm if our test point is in the region corresponding to a given input point return its label
18 Decision Boundary of a Classifier It is simply the line that separates positive and negative regions in the feature space Why is it useful? it helps us visualize how examples will be classified for the entire feature space it helps us visualize the complexity of the learned model
19 Decision Boundaries for 1-NN

20 Decision Boundaries change with the distance function
21 Decision Boundaries change with K
22 The k hyperparameter Tunes the complexity of the hypothesis space If k = 1, every training example has its own neighborhood If k = N, the entire feature space is one neighborhood! Higher k yields smoother decision boundaries How would you set k in practice?
23 What is the inductive bias of k-nn? Nearby instances should have the same label All features are equally important Complexity is tuned by the k parameter
24 Variations on k-nn: Weighted voting Weighted voting Default: all neighbors have equal weight Extension: weight neighbors by (inverse) distance
25 Variations on k-nn: Epsilon Ball Nearest Neighbors Same general principle as K-NN, but change the method for selecting which training examples vote Instead of using K nearest neighbors, use all examples x such that!"#$%&'( )*, ).
26 Exercise: How would you modify KNN-Predict to perform Epsilon Ball NN?

27 Furong Huang 3251 A.V. Williams, College Park, MD / furongh@cs.umd.edu
Geometric View of Machine Learning Nearest Neighbor Classification. Slides adapted from Prof. Carpuat
 Geometric View of Machine Learning Nearest Neighbor Classification Slides adapted from Prof. Carpuat What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental
Geometric View of Machine Learning Nearest Neighbor Classification Slides adapted from Prof. Carpuat What we know so far Decision Trees What is a decision tree, and how to induce it from data Fundamental
Linear and Logistic Regression. Dr. Xiaowei Huang
 Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Machine Learning. Kernels. Fall (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang. (Chap. 12 of CIML)
 Professor Liang Huang. (Chap. 12 of CIML)") Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows Kn-Nearest
Nearest Neighbor. Machine Learning CSE546 Kevin Jamieson University of Washington. October 26, Kevin Jamieson 2
 Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
II. Linear Models (pp.47-70)
") Notation: Means pencil-and-paper QUIZ Means coding QUIZ Agree or disagree: Regression can be always reduced to classification. Explain, either way! A certain classifier scores 98% on the training set,
Notation: Means pencil-and-paper QUIZ Means coding QUIZ Agree or disagree: Regression can be always reduced to classification. Explain, either way! A certain classifier scores 98% on the training set,
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
CSC 411 Lecture 6: Linear Regression
 CSC 411 Lecture 6: Linear Regression Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 06-Linear Regression 1 / 37 A Timely XKCD UofT CSC 411: 06-Linear Regression
CSC 411 Lecture 6: Linear Regression Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 06-Linear Regression 1 / 37 A Timely XKCD UofT CSC 411: 06-Linear Regression
Computational Methods CMSC/AMSC/MAPL 460. Linear Systems, Matrices, LU Decomposition, Ramani Duraiswami, Dept. of Computer Science
 Computational ethods CSC/ASC/APL 460 Linear Systems, atrices, LU Decomposition, Ramani Duraiswami, Dept. of Computer Science Class Outline uch of scientific computation involves solution of linear equations
Computational ethods CSC/ASC/APL 460 Linear Systems, atrices, LU Decomposition, Ramani Duraiswami, Dept. of Computer Science Class Outline uch of scientific computation involves solution of linear equations
Tufts COMP 135: Introduction to Machine Learning
 Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2019s/ Logistic Regression Many slides attributable to: Prof. Mike Hughes Erik Sudderth (UCI) Finale Doshi-Velez (Harvard)
Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2019s/ Logistic Regression Many slides attributable to: Prof. Mike Hughes Erik Sudderth (UCI) Finale Doshi-Velez (Harvard)
Brief Introduction to Machine Learning
 Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Lecture 4 Discriminant Analysis, k-nearest Neighbors
 Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
ESS2222. Lecture 4 Linear model
 ESS2222 Lecture 4 Linear model Hosein Shahnas University of Toronto, Department of Earth Sciences, 1 Outline Logistic Regression Predicting Continuous Target Variables Support Vector Machine (Some Details)
ESS2222 Lecture 4 Linear model Hosein Shahnas University of Toronto, Department of Earth Sciences, 1 Outline Logistic Regression Predicting Continuous Target Variables Support Vector Machine (Some Details)
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
Linear models: the perceptron and closest centroid algorithms. D = {(x i,y i )} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.
} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.") Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Decision Trees. Nicholas Ruozzi University of Texas at Dallas. Based on the slides of Vibhav Gogate and David Sontag
 Decision Trees Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Supervised Learning Input: labelled training data i.e., data plus desired output Assumption:
Decision Trees Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Supervised Learning Input: labelled training data i.e., data plus desired output Assumption:
Machine Learning. Theory of Classification and Nonparametric Classifier. Lecture 2, January 16, What is theoretically the best classifier
 Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Theory of Classification and Nonparametric Classifier Eric Xing Lecture 2, January 16, 2006 Reading: Chap. 2,5 CB and handouts Outline What is theoretically
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
Lecture 4: Linear predictors and the Perceptron
 Lecture 4: Linear predictors and the Perceptron Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 4 1 / 34 Inductive Bias Inductive bias is critical to prevent overfitting.
Lecture 4: Linear predictors and the Perceptron Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 4 1 / 34 Inductive Bias Inductive bias is critical to prevent overfitting.
Announcements. CS 188: Artificial Intelligence Spring Classification. Today. Classification overview. Case-Based Reasoning
 CS 188: Artificial Intelligence Spring 21 Lecture 22: Nearest Neighbors, Kernels 4/18/211 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!) Remaining
CS 188: Artificial Intelligence Spring 21 Lecture 22: Nearest Neighbors, Kernels 4/18/211 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!) Remaining
Day 3: Classification, logistic regression
 Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
1 Handling of Continuous Attributes in C4.5. Algorithm
 .. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
.. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Machine Learning. Nonparametric Methods. Space of ML Problems. Todo. Histograms. Instance-Based Learning (aka non-parametric methods)
") Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Lecture Notes 1: Vector spaces
 Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Ridge Regression 1. to which some random noise is added. So that the training labels can be represented as:
 CS 1: Machine Learning Spring 15 College of Computer and Information Science Northeastern University Lecture 3 February, 3 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu 1 Introduction Ridge
CS 1: Machine Learning Spring 15 College of Computer and Information Science Northeastern University Lecture 3 February, 3 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu 1 Introduction Ridge
Contents Lecture 4. Lecture 4 Linear Discriminant Analysis. Summary of Lecture 3 (II/II) Summary of Lecture 3 (I/II)
 Summary of Lecture 3 (I/II)") Contents Lecture Lecture Linear Discriminant Analysis Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University Email: fredriklindsten@ituuse Summary of lecture
Contents Lecture Lecture Linear Discriminant Analysis Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University Email: fredriklindsten@ituuse Summary of lecture
1 Handling of Continuous Attributes in C4.5. Algorithm
 .. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
.. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
LEC1: Instance-based classifiers
 LEC1: Instance-based classifiers Dr. Guangliang Chen February 2, 2016 Outline Having data ready knn kmeans Summary Downloading data Save all the scripts (from course webpage) and raw files (from LeCun
LEC1: Instance-based classifiers Dr. Guangliang Chen February 2, 2016 Outline Having data ready knn kmeans Summary Downloading data Save all the scripts (from course webpage) and raw files (from LeCun
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
Lecture 2: Linear regression
 Lecture 2: Linear regression Roger Grosse 1 Introduction Let s ump right in and look at our first machine learning algorithm, linear regression. In regression, we are interested in predicting a scalar-valued
Lecture 2: Linear regression Roger Grosse 1 Introduction Let s ump right in and look at our first machine learning algorithm, linear regression. In regression, we are interested in predicting a scalar-valued
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
ORIE 4741: Learning with Big Messy Data. Train, Test, Validate
 ORIE 4741: Learning with Big Messy Data Train, Test, Validate Professor Udell Operations Research and Information Engineering Cornell December 4, 2017 1 / 14 Exercise You run a hospital. A vendor wants
ORIE 4741: Learning with Big Messy Data Train, Test, Validate Professor Udell Operations Research and Information Engineering Cornell December 4, 2017 1 / 14 Exercise You run a hospital. A vendor wants
CSE446: non-parametric methods Spring 2017
 CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
CSC321 Lecture 2: Linear Regression
 CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Computational Methods CMSC/AMSC/MAPL 460. Vectors, Matrices, Linear Systems, LU Decomposition, Ramani Duraiswami, Dept. of Computer Science
 Computational ethods CSC/ASC/APL 460 Vectors, atrices, Linear Systems, LU Decomposition, Ramani Duraiswami, Dept. of Computer Science Class Outline uch of scientific computation involves solution of linear
Computational ethods CSC/ASC/APL 460 Vectors, atrices, Linear Systems, LU Decomposition, Ramani Duraiswami, Dept. of Computer Science Class Outline uch of scientific computation involves solution of linear
The Kernel Trick, Gram Matrices, and Feature Extraction. CS6787 Lecture 4 Fall 2017
 The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
A first model of learning
 A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) We observe the data where each Suppose we are given an ensemble of possible hypotheses / classifiers
A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) We observe the data where each Suppose we are given an ensemble of possible hypotheses / classifiers
Vector spaces. DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis.
 Vector spaces DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Vector space Consists of: A set V A scalar
Vector spaces DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Vector space Consists of: A set V A scalar
Machine Learning and Deep Learning! Vincent Lepetit!
 Machine Learning and Deep Learning!! Vincent Lepetit! 1! What is Machine Learning?! 2! Hand-Written Digit Recognition! 2 9 3! Hand-Written Digit Recognition! Formalization! 0 1 x = @ A Images are 28x28
Machine Learning and Deep Learning!! Vincent Lepetit! 1! What is Machine Learning?! 2! Hand-Written Digit Recognition! 2 9 3! Hand-Written Digit Recognition! Formalization! 0 1 x = @ A Images are 28x28
EECS 349:Machine Learning Bryan Pardo
 EECS 349:Machine Learning Bryan Pardo Topic 2: Decision Trees (Includes content provided by: Russel & Norvig, D. Downie, P. Domingos) 1 General Learning Task There is a set of possible examples Each example
EECS 349:Machine Learning Bryan Pardo Topic 2: Decision Trees (Includes content provided by: Russel & Norvig, D. Downie, P. Domingos) 1 General Learning Task There is a set of possible examples Each example
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur
 Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Lecture 21 K - Nearest Neighbor V In this lecture we discuss; how do we evaluate the
Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Lecture 21 K - Nearest Neighbor V In this lecture we discuss; how do we evaluate the
Perceptron. Subhransu Maji. CMPSCI 689: Machine Learning. 3 February February 2015
 Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Metric-based classifiers. Nuno Vasconcelos UCSD
 Metric-based classifiers Nuno Vasconcelos UCSD Statistical learning goal: given a function f. y f and a collection of eample data-points, learn what the function f. is. this is called training. two major
Metric-based classifiers Nuno Vasconcelos UCSD Statistical learning goal: given a function f. y f and a collection of eample data-points, learn what the function f. is. this is called training. two major
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
Consistency of Nearest Neighbor Methods
 E0 370 Statistical Learning Theory Lecture 16 Oct 25, 2011 Consistency of Nearest Neighbor Methods Lecturer: Shivani Agarwal Scribe: Arun Rajkumar 1 Introduction In this lecture we return to the study
E0 370 Statistical Learning Theory Lecture 16 Oct 25, 2011 Consistency of Nearest Neighbor Methods Lecturer: Shivani Agarwal Scribe: Arun Rajkumar 1 Introduction In this lecture we return to the study
Nearest neighbor classification in metric spaces: universal consistency and rates of convergence
 Nearest neighbor classification in metric spaces: universal consistency and rates of convergence Sanjoy Dasgupta University of California, San Diego Nearest neighbor The primeval approach to classification.
Nearest neighbor classification in metric spaces: universal consistency and rates of convergence Sanjoy Dasgupta University of California, San Diego Nearest neighbor The primeval approach to classification.
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Bayes Classifiers. CAP5610 Machine Learning Instructor: Guo-Jun QI
 Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
Bayes Classifiers CAP5610 Machine Learning Instructor: Guo-Jun QI Recap: Joint distributions Joint distribution over Input vector X = (X 1, X 2 ) X 1 =B or B (drinking beer or not) X 2 = H or H (headache
A Course in Machine Learning
 A Course in Machine Learning Hal Daumé III 3 THE PERCEPTRON Learning Objectives: Describe the biological motivation behind the perceptron. Classify learning algorithms based on whether they are error-driven
A Course in Machine Learning Hal Daumé III 3 THE PERCEPTRON Learning Objectives: Describe the biological motivation behind the perceptron. Classify learning algorithms based on whether they are error-driven
Learning Theory Continued
 Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Linear classifiers Lecture 3
 Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Supervised Learning: Non-parametric Estimation
 Supervised Learning: Non-parametric Estimation Edmondo Trentin March 18, 2018 Non-parametric Estimates No assumptions are made on the form of the pdfs 1. There are 3 major instances of non-parametric estimates:
Supervised Learning: Non-parametric Estimation Edmondo Trentin March 18, 2018 Non-parametric Estimates No assumptions are made on the form of the pdfs 1. There are 3 major instances of non-parametric estimates:
Algorithms for Picture Analysis. Lecture 07: Metrics. Axioms of a Metric
 Axioms of a Metric Picture analysis always assumes that pictures are defined in coordinates, and we apply the Euclidean metric as the golden standard for distance (or derived, such as area) measurements.
Axioms of a Metric Picture analysis always assumes that pictures are defined in coordinates, and we apply the Euclidean metric as the golden standard for distance (or derived, such as area) measurements.
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Support Vector Machines
 Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
Probability and Statistical Decision Theory
 Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2019s/ Probability and Statistical Decision Theory Many slides attributable to: Erik Sudderth (UCI) Prof. Mike Hughes
Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2019s/ Probability and Statistical Decision Theory Many slides attributable to: Erik Sudderth (UCI) Prof. Mike Hughes
Applied inductive learning - Lecture 4
 Applied inductive learning - Lecture 4 Louis Wehenkel Department of Electrical Engineering and Computer Science University of Liège Montefiore - Liège - October 10, 2005 Find slides: http://montefiore.ulg.ac.be/
Applied inductive learning - Lecture 4 Louis Wehenkel Department of Electrical Engineering and Computer Science University of Liège Montefiore - Liège - October 10, 2005 Find slides: http://montefiore.ulg.ac.be/
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Machine Learning, Fall 2011: Homework 5
 0-60 Machine Learning, Fall 0: Homework 5 Machine Learning Department Carnegie Mellon University Due:??? Instructions There are 3 questions on this assignment. Please submit your completed homework to
0-60 Machine Learning, Fall 0: Homework 5 Machine Learning Department Carnegie Mellon University Due:??? Instructions There are 3 questions on this assignment. Please submit your completed homework to
More about the Perceptron
 More about the Perceptron CMSC 422 MARINE CARPUAT marine@cs.umd.edu Credit: figures by Piyush Rai and Hal Daume III Recap: Perceptron for binary classification Classifier = hyperplane that separates positive
More about the Perceptron CMSC 422 MARINE CARPUAT marine@cs.umd.edu Credit: figures by Piyush Rai and Hal Daume III Recap: Perceptron for binary classification Classifier = hyperplane that separates positive
DATA MINING LECTURE 10
 DATA MINING LECTURE 10 Classification Nearest Neighbor Classification Support Vector Machines Logistic Regression Naïve Bayes Classifier Supervised Learning 10 10 Illustrating Classification Task Tid Attrib1
DATA MINING LECTURE 10 Classification Nearest Neighbor Classification Support Vector Machines Logistic Regression Naïve Bayes Classifier Supervised Learning 10 10 Illustrating Classification Task Tid Attrib1
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
CS6375: Machine Learning Gautam Kunapuli. Decision Trees
 Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Vote. Vote on timing for night section: Option 1 (what we have now) Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9
 Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9") Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
Lecture 2: Linear Algebra Review
 CS 4980/6980: Introduction to Data Science c Spring 2018 Lecture 2: Linear Algebra Review Instructor: Daniel L. Pimentel-Alarcón Scribed by: Anh Nguyen and Kira Jordan This is preliminary work and has
CS 4980/6980: Introduction to Data Science c Spring 2018 Lecture 2: Linear Algebra Review Instructor: Daniel L. Pimentel-Alarcón Scribed by: Anh Nguyen and Kira Jordan This is preliminary work and has
4 THE PERCEPTRON. 4.1 Bio-inspired Learning. Learning Objectives:
 4 THE PERCEPTRON Algebra is nothing more than geometry, in words; geometry is nothing more than algebra, in pictures. Sophie Germain Learning Objectives: Describe the biological motivation behind the perceptron.
4 THE PERCEPTRON Algebra is nothing more than geometry, in words; geometry is nothing more than algebra, in pictures. Sophie Germain Learning Objectives: Describe the biological motivation behind the perceptron.
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Lecture 3: Empirical Risk Minimization
 Lecture 3: Empirical Risk Minimization Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 3 1 / 11 A more general approach We saw the learning algorithms Memorize and
Lecture 3: Empirical Risk Minimization Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 3 1 / 11 A more general approach We saw the learning algorithms Memorize and
Recap from previous lecture
 Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Distribution-specific analysis of nearest neighbor search and classification
 Distribution-specific analysis of nearest neighbor search and classification Sanjoy Dasgupta University of California, San Diego Nearest neighbor The primeval approach to information retrieval and classification.
Distribution-specific analysis of nearest neighbor search and classification Sanjoy Dasgupta University of California, San Diego Nearest neighbor The primeval approach to information retrieval and classification.
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 8 Feb. 12, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Linear Classifiers and the Perceptron
 Linear Classifiers and the Perceptron William Cohen February 4, 2008 1 Linear classifiers Let s assume that every instance is an n-dimensional vector of real numbers x R n, and there are only two possible
Linear Classifiers and the Perceptron William Cohen February 4, 2008 1 Linear classifiers Let s assume that every instance is an n-dimensional vector of real numbers x R n, and there are only two possible
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
Linear Regression. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Linear Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Linear Regression These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Data Mining algorithms
 Data Mining algorithms 2017-2018 spring 02.07-09.2018 Overview Classification vs. Regression Evaluation I Basics Bálint Daróczy daroczyb@ilab.sztaki.hu Basic reachability: MTA SZTAKI, Lágymányosi str.
Data Mining algorithms 2017-2018 spring 02.07-09.2018 Overview Classification vs. Regression Evaluation I Basics Bálint Daróczy daroczyb@ilab.sztaki.hu Basic reachability: MTA SZTAKI, Lágymányosi str.
Review: Support vector machines. Machine learning techniques and image analysis
 Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Chapter 6 Classification and Prediction (2)
") Chapter 6 Classification and Prediction (2) Outline Classification and Prediction Decision Tree Naïve Bayes Classifier Support Vector Machines (SVM) K-nearest Neighbors Accuracy and Error Measures Feature
Chapter 6 Classification and Prediction (2) Outline Classification and Prediction Decision Tree Naïve Bayes Classifier Support Vector Machines (SVM) K-nearest Neighbors Accuracy and Error Measures Feature
What s Cooking? Predicting Cuisines from Recipe Ingredients
 What s Cooking? Predicting Cuisines from Recipe Ingredients Kevin K. Do Department of Computer Science Duke University Durham, NC 27708 kevin.kydat.do@gmail.com Abstract Kaggle is an online platform for
What s Cooking? Predicting Cuisines from Recipe Ingredients Kevin K. Do Department of Computer Science Duke University Durham, NC 27708 kevin.kydat.do@gmail.com Abstract Kaggle is an online platform for
PAC Learning Introduction to Machine Learning. Matt Gormley Lecture 14 March 5, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms: