Radial-Basis Function Networks
|
|
|
- Ella Greer
- 6 years ago
- Views:
Transcription
1 Radal-Bass uncton Networs v.0 March 00 Mchel Verleysen Radal-Bass uncton Networs - Radal-Bass uncton Networs p Orgn: Cover s theorem p Interpolaton problem p Regularzaton theory p Generalzed RBN p Unversal approxmaton p Comparson wth MLP p RBN = ernel regresson p Learnng p Centers p Wdths p Multplyng factors p Other forms Mchel Verleysen Radal-Bass uncton Networs -
2 Orgn: Covers theorem p Covers theorem on separablty of patterns (965 p x, x,, x P assgned to two classes C C p -separablty: w p Cover s theorem: T w T w ( x ( x > 0 < 0 x C x C p non-lnear functons (x p dmenson hdden space > dmenson nput space probablty of separablty closer to p Example lnear quadratc Mchel Verleysen Radal-Bass uncton Networs - 3 Interpolaton problem p Gven ponts (x, t, x R d, t R, P : p nd : R d Rthat satsfes p RB technque (Powell, 988: p ( x x ( x = t, = K P ( = P x ( x x w = are arbtrary non-lnear functons (RB p as many functons as data ponts p centers fxed at nown ponts x Mchel Verleysen Radal-Bass uncton Networs - 4
3 Interpolaton problem ( x ( = P x ( x x = t w = M P M P L L O L P w t P w = t M M M P PP wp t where l = l ( x x p Into matrx form: Φw = x w = Φ x p Vtal queston: s Φ non-sngular? Mchel Verleysen Radal-Bass uncton Networs - 5 Mchell s theorem p If ponts x are dstnct, Φ s non-sngular (regardless of the dmenson of the nput space p Vald for a large class of RB functons: ( x = x c + ( x = x c + ( > 0 ( x c x = exp (σ > 0 σ non-localzed functon localzed functons Mchel Verleysen Radal-Bass uncton Networs - 6 3
4 Learnng: ll-posed problem t x p Necessty for regularzaton p Error crteron: E P ( ( t ( x + λ C( w = P = MSE regularzaton Mchel Verleysen Radal-Bass uncton Networs - 7 Soluton to the regularzaton problem p Poggo & Gros (990: p f C(w s a (problem-dependent lnear dfferental operator, the soluton to s of the followng form: where E P ( ( t ( x + λ C( w = P = ( = P x ( x, x G( s a Green s functon, G l = G(x,x l w G = w = ( G + λi t Mchel Verleysen Radal-Bass uncton Networs - 8 4
5 Interpolaton - Regularzaton p Interpolaton ( = P x ( x x w = Φ w = x p Exact nterpolator p Possble RB: x x ( x, x = exp σ p Regularzaton ( = P x ( x, x w G = w = ( G + λi t p Exact nterpolator p Equal to the «nterpolaton» soluton ff λ=0 p Example of Green s functon: G ( x, x x x = exp σ One RB / Green s functon for each learnng pattern! Mchel Verleysen Radal-Bass uncton Networs - 9 Generalzed RBN (GRBN RBN p As many radal functons as learnng patterns: p computatonally (too ntensve (nverson of PxP matrx grows wth P 3 p ll-condtoned matrx p regularzaton not easy (problem-specfc Generalzed RBN approach! Typcally: p K << P p ( x w ( x c = K = ( x c = exp x c σ Parameters: c, σ, w Mchel Verleysen Radal-Bass uncton Networs - 0 5
6 Radal-Bass uncton Networs (RBN ( x w ( x c = K = x 0 (bas x ( x c σ w (x ( x c = exp x c σ c j σk f several outputs x d st layer nd layer p Possbltes: p several outputs (common hdden layer p bas (recommended (see extensons Mchel Verleysen Radal-Bass uncton Networs - RBN: unversal approxmaton p Par & Sandberg 99: p or any contnuous nput-output mappng functon f(x K ( x = w( x c Lp ( f ( x, ( x < ε ( ε > 0,p [, ] = p The theorem s stronger (radal summetry not needed p K not specfed p Provdes a theoretcal bass for practcal RBN! Mchel Verleysen Radal-Bass uncton Networs - 6
7 RBN and ernel regresson p non-lnear regresson model t ( x + ε = y + ε, P = f p estmaton of f(x: average of t around x. More precsely: f ( x = E[ y x] = = yf yf Y ( y x X,Y f x dy ( x,y ( x dy p Need for estmates of fx, Y ( x,y and f X ( x Parzen-Rosenblatt densty estmator Mchel Verleysen Radal-Bass uncton Networs - 3 Parzen-Rosenblatt densty estmator fˆ x P x x K d Ph = h ( x = wth K( contnuous, bounded, symmetrc about the orgn, wth maxmum value at 0, and wth unt ntegral, s consstent (asymptotcally unbased. (,y p Estmaton of fx, Y x P ( x x fˆ X,Y x,y = K d Ph = h y y K + h Mchel Verleysen Radal-Bass uncton Networs - 4 7
8 RBN and ernel regresson fˆ ( x = = P = P yfˆ = X,Y fˆ X ( x,y ( x dy x x y K h x x K h f ( x = yfx,y fx ( x,y ( x dy p Weghted average of y p called Nadaraya-Watson estmator (964 p equvalent to Normalzed RBN n the unregularzed context Mchel Verleysen Radal-Bass uncton Networs - 5 RBN MLP p RBN p sngle hdden layer p non-lnear hdden layer lnear output layer p argument of hdden unts: Eucldean norm p unversal approxmaton property p local approxmators p spltted learnng p MLP p sngle or multple hdden layers p non-lnear hdden layer lnear or non-lnear output layer p argument of hdden unts: scalar product p unversal approxmaton property p global approxmators p global learnng Mchel Verleysen Radal-Bass uncton Networs - 6 8
9 RBN: learnng strateges ( x w ( x c ( x c = K = = exp x c σ p Parameters to be determned: c, σ, w p Tradtonal learnng strategy: spltted computaton. centers c. wdths σ 3. weghts w Mchel Verleysen Radal-Bass uncton Networs - 7 RBN: computaton of centers p Idea: centers c must have the (densty propertes of learnng ponts x vector quantzaton p selected at random (n learnng set p compettve learnng p frequency-senstve learnng p Kohonen maps p Ths phase only uses the x nformaton, not the t Mchel Verleysen Radal-Bass uncton Networs - 8 9
10 RBN: computaton of wdths p Unversal approxmaton property: vald wth dentcal wdths p In practce (lmted learnng set: varable wdths σ p Idea: RBN use local clusters p choose σ accordng to standard devaton of clusters Mchel Verleysen Radal-Bass uncton Networs - 9 RBN: computaton of weghts ( x w ( x c = K = ( x c = exp x c σ p Problem becomes lnear! p Soluton of least square crteron leads to where w = Φ + t = Φ = T T ( Φ Φ Φ ( x c p In practse: use SVD! constants! E P ( = ( t ( x P = Mchel Verleysen Radal-Bass uncton Networs - 0 0
11 p 3-steps method: RBN: gradent descent ( x = K w exp = 3 supervsed x c σ unsupervsed p Once c, σ, w have been set by the prevous method, possblty of gradent descent on all parameters p Some mprovement, but p learnng speed p local mnma p rs of non-local bass functons p etc. Mchel Verleysen Radal-Bass uncton Networs - More elaborated models p Add constant and lnear terms K d ( w exp x c x = + w' x w' + 0 = σ = good dea (very dffcult to approxmate a constant wth ernels p Use normalzed RBN x c exp K ( σ x = w = K x c j exp = σ j j bass functons are bouded [0,] can be nterpreted as probablty values (classfcaton Mchel Verleysen Radal-Bass uncton Networs -
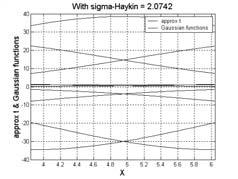
![Bac to the wdths p choose σ accordng to standard devaton of clusters p In the lterature: p σ = d K where d max = maxmum dstance between centrods [] max p p σ = c c where ndex j scans the p nearest](/docs-images/77/74649334/images/12-0.jpg "centrods to c [] p j = ( j p σ = r mn c c j where r s an overlap constant [3] j p.. [] S. Hayn, \"Neural Networs a Comprehensve oundaton\", Prentce-Hall Inc, second edton, 999. [] J.")
12 Bac to the wdths p choose σ accordng to standard devaton of clusters p In the lterature: p σ = d K where d max = maxmum dstance between centrods [] max p p σ = c c where ndex j scans the p nearest centrods to c [] p j = ( j p σ = r mn c c j where r s an overlap constant [3] j p.. [] S. Hayn, "Neural Networs a Comprehensve oundaton", Prentce-Hall Inc, second edton, 999. [] J. Moody and C. J. Daren, "ast learnng n networs of locally-tuned processng unts", Neural Computaton, pp. 8-94, 989. [3] A. Saha and J. D. Keeler, ''Algorthms for Better Representaton and aster Learnng n Radal Bass uncton Networs", Advances n Neural Informaton Processng Systems, Edted by Davd S. Touretzy, pp , 989. Mchel Verleysen Radal-Bass uncton Networs - 3 Basc example p Approxmaton of f(x = wth a d-dmensonal RBN p In theory: dentcal w p Expermentally: sde effects only mddle taen nto account p Error versus wdth Mchel Verleysen Radal-Bass uncton Networs - 4





13 Basc example: erros vs space dmenson Mchel Verleysen Radal-Bass uncton Networs - 5 Basc example: local decomposton? Mchel Verleysen Radal-Bass uncton Networs - 6 3

14 Multple local mnma n error curve p Choose the frst mnmum to preserve the localty of clusters p The frst local mnmum s usually less senstve to varablty Mchel Verleysen Radal-Bass uncton Networs - 7 Some concludng comments p RBN: easy learnng (compared to MLP p n a cross-valdaton scheme: mportant! p Many RBN models p Even more RBN learnng schemes p Results not very senstve to unsupervsed part of learnng (c, σ p Open wor for a pror (proble-dependent choce of wdths σ Mchel Verleysen Radal-Bass uncton Networs - 8 4
15 Sources and references p Most of the basc concepts developed n these sldes come from the excellent boo: p Neural networs a comprehensve foundaton, S. Hayn, Macmllan College Publshng Company, 994. p Some supplementary comments come from the tutoral on RB: p An overvew of Radal Bass uncton Networs, J. Ghosh & A. Nag, n: Radal Bass uncton Networs, R.J. Howlett & L.C. Jan eds., Physca-Verlag, 00. p The results on the basc exemple were generated by my colleague N. Benoudjt, and are submtted for publcaton. Mchel Verleysen Radal-Bass uncton Networs - 9 5
Radial-Basis Function Networks. Radial-Basis Function Networks
 Radial-Basis Function Networks November 00 Michel Verleysen Radial-Basis Function Networks - Radial-Basis Function Networks p Origin: Cover s theorem p Interpolation problem p Regularization theory p Generalized
Radial-Basis Function Networks November 00 Michel Verleysen Radial-Basis Function Networks - Radial-Basis Function Networks p Origin: Cover s theorem p Interpolation problem p Regularization theory p Generalized
Generalized Linear Methods
 Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
Generalzed Lnear Methods 1 Introducton In the Ensemble Methods the general dea s that usng a combnaton of several weak learner one could make a better learner. More formally, assume that we have a set
For now, let us focus on a specific model of neurons. These are simplified from reality but can achieve remarkable results.
 Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Neural Networks : Dervaton compled by Alvn Wan from Professor Jtendra Malk s lecture Ths type of computaton s called deep learnng and s the most popular method for many problems, such as computer vson
Lecture Notes on Linear Regression
 Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Lecture Notes on Lnear Regresson Feng L fl@sdueducn Shandong Unversty, Chna Lnear Regresson Problem In regresson problem, we am at predct a contnuous target value gven an nput feature vector We assume
Other NN Models. Reinforcement learning (RL) Probabilistic neural networks
 Probabilistic neural networks") Other NN Models Renforcement learnng (RL) Probablstc neural networks Support vector machne (SVM) Renforcement learnng g( (RL) Basc deas: Supervsed dlearnng: (delta rule, BP) Samples (x, f(x)) to learn
Other NN Models Renforcement learnng (RL) Probablstc neural networks Support vector machne (SVM) Renforcement learnng g( (RL) Basc deas: Supervsed dlearnng: (delta rule, BP) Samples (x, f(x)) to learn
Pattern Classification
 Pattern Classfcaton All materals n these sldes ere taken from Pattern Classfcaton (nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wley & Sons, 000 th the permsson of the authors and the publsher
Pattern Classfcaton All materals n these sldes ere taken from Pattern Classfcaton (nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wley & Sons, 000 th the permsson of the authors and the publsher
Linear Approximation with Regularization and Moving Least Squares
 Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Lnear Approxmaton wth Regularzaton and Movng Least Squares Igor Grešovn May 007 Revson 4.6 (Revson : March 004). 5 4 3 0.5 3 3.5 4 Contents: Lnear Fttng...4. Weghted Least Squares n Functon Approxmaton...
Multilayer Perceptron (MLP)
") Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
Multlayer Perceptron (MLP) Seungjn Cho Department of Computer Scence and Engneerng Pohang Unversty of Scence and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjn@postech.ac.kr 1 / 20 Outlne
Report on Image warping
 Report on Image warpng Xuan Ne, Dec. 20, 2004 Ths document summarzed the algorthms of our mage warpng soluton for further study, and there s a detaled descrpton about the mplementaton of these algorthms.
Report on Image warpng Xuan Ne, Dec. 20, 2004 Ths document summarzed the algorthms of our mage warpng soluton for further study, and there s a detaled descrpton about the mplementaton of these algorthms.
Lecture 12: Classification
 Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Lecture : Classfcaton g Dscrmnant functons g The optmal Bayes classfer g Quadratc classfers g Eucldean and Mahalanobs metrcs g K Nearest Neghbor Classfers Intellgent Sensor Systems Rcardo Guterrez-Osuna
Neural Networks & Learning
 Neural Netorks & Learnng. Introducton The basc prelmnares nvolved n the Artfcal Neural Netorks (ANN) are descrbed n secton. An Artfcal Neural Netorks (ANN) s an nformaton-processng paradgm that nspred
Neural Netorks & Learnng. Introducton The basc prelmnares nvolved n the Artfcal Neural Netorks (ANN) are descrbed n secton. An Artfcal Neural Netorks (ANN) s an nformaton-processng paradgm that nspred
MLE and Bayesian Estimation. Jie Tang Department of Computer Science & Technology Tsinghua University 2012
 MLE and Bayesan Estmaton Je Tang Department of Computer Scence & Technology Tsnghua Unversty 01 1 Lnear Regresson? As the frst step, we need to decde how we re gong to represent the functon f. One example:
MLE and Bayesan Estmaton Je Tang Department of Computer Scence & Technology Tsnghua Unversty 01 1 Lnear Regresson? As the frst step, we need to decde how we re gong to represent the functon f. One example:
ADVANCED MACHINE LEARNING ADVANCED MACHINE LEARNING
 1 ADVANCED ACHINE LEARNING ADVANCED ACHINE LEARNING Non-lnear regresson technques 2 ADVANCED ACHINE LEARNING Regresson: Prncple N ap N-dm. nput x to a contnuous output y. Learn a functon of the type: N
1 ADVANCED ACHINE LEARNING ADVANCED ACHINE LEARNING Non-lnear regresson technques 2 ADVANCED ACHINE LEARNING Regresson: Prncple N ap N-dm. nput x to a contnuous output y. Learn a functon of the type: N
Feature Selection: Part 1
 CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
CSE 546: Machne Learnng Lecture 5 Feature Selecton: Part 1 Instructor: Sham Kakade 1 Regresson n the hgh dmensonal settng How do we learn when the number of features d s greater than the sample sze n?
Lectures - Week 4 Matrix norms, Conditioning, Vector Spaces, Linear Independence, Spanning sets and Basis, Null space and Range of a Matrix
 Lectures - Week 4 Matrx norms, Condtonng, Vector Spaces, Lnear Independence, Spannng sets and Bass, Null space and Range of a Matrx Matrx Norms Now we turn to assocatng a number to each matrx. We could
Lectures - Week 4 Matrx norms, Condtonng, Vector Spaces, Lnear Independence, Spannng sets and Bass, Null space and Range of a Matrx Matrx Norms Now we turn to assocatng a number to each matrx. We could
Inner Product. Euclidean Space. Orthonormal Basis. Orthogonal
 Inner Product Defnton 1 () A Eucldean space s a fnte-dmensonal vector space over the reals R, wth an nner product,. Defnton 2 (Inner Product) An nner product, on a real vector space X s a symmetrc, blnear,
Inner Product Defnton 1 () A Eucldean space s a fnte-dmensonal vector space over the reals R, wth an nner product,. Defnton 2 (Inner Product) An nner product, on a real vector space X s a symmetrc, blnear,
Errors for Linear Systems
 Errors for Lnear Systems When we solve a lnear system Ax b we often do not know A and b exactly, but have only approxmatons  and ˆb avalable. Then the best thng we can do s to solve ˆx ˆb exactly whch
Errors for Lnear Systems When we solve a lnear system Ax b we often do not know A and b exactly, but have only approxmatons  and ˆb avalable. Then the best thng we can do s to solve ˆx ˆb exactly whch
Week 5: Neural Networks
 Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
Week 5: Neural Networks Instructor: Sergey Levne Neural Networks Summary In the prevous lecture, we saw how we can construct neural networks by extendng logstc regresson. Neural networks consst of multple
p 1 c 2 + p 2 c 2 + p 3 c p m c 2
 Where to put a faclty? Gven locatons p 1,..., p m n R n of m houses, want to choose a locaton c n R n for the fre staton. Want c to be as close as possble to all the house. We know how to measure dstance
Where to put a faclty? Gven locatons p 1,..., p m n R n of m houses, want to choose a locaton c n R n for the fre staton. Want c to be as close as possble to all the house. We know how to measure dstance
Instance-Based Learning (a.k.a. memory-based learning) Part I: Nearest Neighbor Classification
 Part I: Nearest Neighbor Classification") Instance-Based earnng (a.k.a. memory-based learnng) Part I: Nearest Neghbor Classfcaton Note to other teachers and users of these sldes. Andrew would be delghted f you found ths source materal useful n
Instance-Based earnng (a.k.a. memory-based learnng) Part I: Nearest Neghbor Classfcaton Note to other teachers and users of these sldes. Andrew would be delghted f you found ths source materal useful n
EEE 241: Linear Systems
 EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
EEE : Lnear Systems Summary #: Backpropagaton BACKPROPAGATION The perceptron rule as well as the Wdrow Hoff learnng were desgned to tran sngle layer networks. They suffer from the same dsadvantage: they
Multilayer neural networks
 Lecture Multlayer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Mdterm exam Mdterm Monday, March 2, 205 In-class (75 mnutes) closed book materal covered by February 25, 205 Multlayer
Lecture Multlayer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Mdterm exam Mdterm Monday, March 2, 205 In-class (75 mnutes) closed book materal covered by February 25, 205 Multlayer
Supporting Information
 Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
Supportng Informaton The neural network f n Eq. 1 s gven by: f x l = ReLU W atom x l + b atom, 2 where ReLU s the element-wse rectfed lnear unt, 21.e., ReLUx = max0, x, W atom R d d s the weght matrx to
AN IMPROVED PARTICLE FILTER ALGORITHM BASED ON NEURAL NETWORK FOR TARGET TRACKING
 AN IMPROVED PARTICLE FILTER ALGORITHM BASED ON NEURAL NETWORK FOR TARGET TRACKING Qn Wen, Peng Qcong 40 Lab, Insttuton of Communcaton and Informaton Engneerng,Unversty of Electronc Scence and Technology
AN IMPROVED PARTICLE FILTER ALGORITHM BASED ON NEURAL NETWORK FOR TARGET TRACKING Qn Wen, Peng Qcong 40 Lab, Insttuton of Communcaton and Informaton Engneerng,Unversty of Electronc Scence and Technology
Support Vector Machines
 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x n class
Multi-layer neural networks
 Lecture 0 Mult-layer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Lnear regresson w Lnear unts f () Logstc regresson T T = w = p( y =, w) = g( w ) w z f () = p ( y = ) w d w d Gradent
Lecture 0 Mult-layer neural networks Mlos Hauskrecht mlos@cs.ptt.edu 5329 Sennott Square Lnear regresson w Lnear unts f () Logstc regresson T T = w = p( y =, w) = g( w ) w z f () = p ( y = ) w d w d Gradent
Why Bayesian? 3. Bayes and Normal Models. State of nature: class. Decision rule. Rev. Thomas Bayes ( ) Bayes Theorem (yes, the famous one)
 Bayes Theorem (yes, the famous one)") Why Bayesan? 3. Bayes and Normal Models Alex M. Martnez alex@ece.osu.edu Handouts Handoutsfor forece ECE874 874Sp Sp007 If all our research (n PR was to dsappear and you could only save one theory, whch
Why Bayesan? 3. Bayes and Normal Models Alex M. Martnez alex@ece.osu.edu Handouts Handoutsfor forece ECE874 874Sp Sp007 If all our research (n PR was to dsappear and you could only save one theory, whch
Evaluation of classifiers MLPs
 Lecture Evaluaton of classfers MLPs Mlos Hausrecht mlos@cs.ptt.edu 539 Sennott Square Evaluaton For any data set e use to test the model e can buld a confuson matrx: Counts of examples th: class label
Lecture Evaluaton of classfers MLPs Mlos Hausrecht mlos@cs.ptt.edu 539 Sennott Square Evaluaton For any data set e use to test the model e can buld a confuson matrx: Counts of examples th: class label
Lossy Compression. Compromise accuracy of reconstruction for increased compression.
 Lossy Compresson Compromse accuracy of reconstructon for ncreased compresson. The reconstructon s usually vsbly ndstngushable from the orgnal mage. Typcally, one can get up to 0:1 compresson wth almost
Lossy Compresson Compromse accuracy of reconstructon for ncreased compresson. The reconstructon s usually vsbly ndstngushable from the orgnal mage. Typcally, one can get up to 0:1 compresson wth almost
Uncertainty as the Overlap of Alternate Conditional Distributions
 Uncertanty as the Overlap of Alternate Condtonal Dstrbutons Olena Babak and Clayton V. Deutsch Centre for Computatonal Geostatstcs Department of Cvl & Envronmental Engneerng Unversty of Alberta An mportant
Uncertanty as the Overlap of Alternate Condtonal Dstrbutons Olena Babak and Clayton V. Deutsch Centre for Computatonal Geostatstcs Department of Cvl & Envronmental Engneerng Unversty of Alberta An mportant
CIS526: Machine Learning Lecture 3 (Sept 16, 2003) Linear Regression. Preparation help: Xiaoying Huang. x 1 θ 1 output... θ M x M
 Linear Regression. Preparation help: Xiaoying Huang. x 1 θ 1 output... θ M x M") CIS56: achne Learnng Lecture 3 (Sept 6, 003) Preparaton help: Xaoyng Huang Lnear Regresson Lnear regresson can be represented by a functonal form: f(; θ) = θ 0 0 +θ + + θ = θ = 0 ote: 0 s a dummy attrbute
CIS56: achne Learnng Lecture 3 (Sept 6, 003) Preparaton help: Xaoyng Huang Lnear Regresson Lnear regresson can be represented by a functonal form: f(; θ) = θ 0 0 +θ + + θ = θ = 0 ote: 0 s a dummy attrbute
Natural Language Processing and Information Retrieval
 Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Natural Language Processng and Informaton Retreval Support Vector Machnes Alessandro Moschtt Department of nformaton and communcaton technology Unversty of Trento Emal: moschtt@ds.untn.t Summary Support
Maximum Likelihood Estimation (MLE)
") Maxmum Lkelhood Estmaton (MLE) Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 01 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Maxmum Lkelhood Estmaton (MLE) Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 01 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
VQ widely used in coding speech, image, and video
 at Scalar quantzers are specal cases of vector quantzers (VQ): they are constraned to look at one sample at a tme (memoryless) VQ does not have such constrant better RD perfomance expected Source codng
at Scalar quantzers are specal cases of vector quantzers (VQ): they are constraned to look at one sample at a tme (memoryless) VQ does not have such constrant better RD perfomance expected Source codng
Kernels in Support Vector Machines. Based on lectures of Martin Law, University of Michigan
 Kernels n Support Vector Machnes Based on lectures of Martn Law, Unversty of Mchgan Non Lnear separable problems AND OR NOT() The XOR problem cannot be solved wth a perceptron. XOR Per Lug Martell - Systems
Kernels n Support Vector Machnes Based on lectures of Martn Law, Unversty of Mchgan Non Lnear separable problems AND OR NOT() The XOR problem cannot be solved wth a perceptron. XOR Per Lug Martell - Systems
RBF Neural Network Model Training by Unscented Kalman Filter and Its Application in Mechanical Fault Diagnosis
 Appled Mechancs and Materals Submtted: 24-6-2 ISSN: 662-7482, Vols. 62-65, pp 2383-2386 Accepted: 24-6- do:.428/www.scentfc.net/amm.62-65.2383 Onlne: 24-8- 24 rans ech Publcatons, Swtzerland RBF Neural
Appled Mechancs and Materals Submtted: 24-6-2 ISSN: 662-7482, Vols. 62-65, pp 2383-2386 Accepted: 24-6- do:.428/www.scentfc.net/amm.62-65.2383 Onlne: 24-8- 24 rans ech Publcatons, Swtzerland RBF Neural
Neural networks. Nuno Vasconcelos ECE Department, UCSD
 Neural networs Nuno Vasconcelos ECE Department, UCSD Classfcaton a classfcaton problem has two types of varables e.g. X - vector of observatons (features) n the world Y - state (class) of the world x X
Neural networs Nuno Vasconcelos ECE Department, UCSD Classfcaton a classfcaton problem has two types of varables e.g. X - vector of observatons (features) n the world Y - state (class) of the world x X
Topic 5: Non-Linear Regression
 Topc 5: Non-Lnear Regresson The models we ve worked wth so far have been lnear n the parameters. They ve been of the form: y = Xβ + ε Many models based on economc theory are actually non-lnear n the parameters.
Topc 5: Non-Lnear Regresson The models we ve worked wth so far have been lnear n the parameters. They ve been of the form: y = Xβ + ε Many models based on economc theory are actually non-lnear n the parameters.
A Bayes Algorithm for the Multitask Pattern Recognition Problem Direct Approach
 A Bayes Algorthm for the Multtask Pattern Recognton Problem Drect Approach Edward Puchala Wroclaw Unversty of Technology, Char of Systems and Computer etworks, Wybrzeze Wyspanskego 7, 50-370 Wroclaw, Poland
A Bayes Algorthm for the Multtask Pattern Recognton Problem Drect Approach Edward Puchala Wroclaw Unversty of Technology, Char of Systems and Computer etworks, Wybrzeze Wyspanskego 7, 50-370 Wroclaw, Poland
Classification as a Regression Problem
 Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
Target varable y C C, C,, ; Classfcaton as a Regresson Problem { }, 3 L C K To treat classfcaton as a regresson problem we should transform the target y nto numercal values; The choce of numercal class
Lecture 3: Dual problems and Kernels
 Lecture 3: Dual problems and Kernels C4B Machne Learnng Hlary 211 A. Zsserman Prmal and dual forms Lnear separablty revsted Feature mappng Kernels for SVMs Kernel trck requrements radal bass functons SVM
Lecture 3: Dual problems and Kernels C4B Machne Learnng Hlary 211 A. Zsserman Prmal and dual forms Lnear separablty revsted Feature mappng Kernels for SVMs Kernel trck requrements radal bass functons SVM
Chapter 15 Student Lecture Notes 15-1
 Chapter 15 Student Lecture Notes 15-1 Basc Busness Statstcs (9 th Edton) Chapter 15 Multple Regresson Model Buldng 004 Prentce-Hall, Inc. Chap 15-1 Chapter Topcs The Quadratc Regresson Model Usng Transformatons
Chapter 15 Student Lecture Notes 15-1 Basc Busness Statstcs (9 th Edton) Chapter 15 Multple Regresson Model Buldng 004 Prentce-Hall, Inc. Chap 15-1 Chapter Topcs The Quadratc Regresson Model Usng Transformatons
Kernel Methods and SVMs Extension
 Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
Kernel Methods and SVMs Extenson The purpose of ths document s to revew materal covered n Machne Learnng 1 Supervsed Learnng regardng support vector machnes (SVMs). Ths document also provdes a general
2 STATISTICALLY OPTIMAL TRAINING DATA 2.1 A CRITERION OF OPTIMALITY We revew the crteron of statstcally optmal tranng data (Fukumzu et al., 1994). We
. We") Advances n Neural Informaton Processng Systems 8 Actve Learnng n Multlayer Perceptrons Kenj Fukumzu Informaton and Communcaton R&D Center, Rcoh Co., Ltd. 3-2-3, Shn-yokohama, Yokohama, 222 Japan E-mal:
Advances n Neural Informaton Processng Systems 8 Actve Learnng n Multlayer Perceptrons Kenj Fukumzu Informaton and Communcaton R&D Center, Rcoh Co., Ltd. 3-2-3, Shn-yokohama, Yokohama, 222 Japan E-mal:
Chapter 11: Simple Linear Regression and Correlation
 Chapter 11: Smple Lnear Regresson and Correlaton 11-1 Emprcal Models 11-2 Smple Lnear Regresson 11-3 Propertes of the Least Squares Estmators 11-4 Hypothess Test n Smple Lnear Regresson 11-4.1 Use of t-tests
Chapter 11: Smple Lnear Regresson and Correlaton 11-1 Emprcal Models 11-2 Smple Lnear Regresson 11-3 Propertes of the Least Squares Estmators 11-4 Hypothess Test n Smple Lnear Regresson 11-4.1 Use of t-tests
Support Vector Machines. Vibhav Gogate The University of Texas at dallas
 Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Support Vector Machnes Vbhav Gogate he Unversty of exas at dallas What We have Learned So Far? 1. Decson rees. Naïve Bayes 3. Lnear Regresson 4. Logstc Regresson 5. Perceptron 6. Neural networks 7. K-Nearest
Fundamentals of Neural Networks
 Fundamentals of Neural Networks Xaodong Cu IBM T. J. Watson Research Center Yorktown Heghts, NY 10598 Fall, 2018 Outlne Feedforward neural networks Forward propagaton Neural networks as unversal approxmators
Fundamentals of Neural Networks Xaodong Cu IBM T. J. Watson Research Center Yorktown Heghts, NY 10598 Fall, 2018 Outlne Feedforward neural networks Forward propagaton Neural networks as unversal approxmators
Linear Regression Analysis: Terminology and Notation
 ECON 35* -- Secton : Basc Concepts of Regresson Analyss (Page ) Lnear Regresson Analyss: Termnology and Notaton Consder the generc verson of the smple (two-varable) lnear regresson model. It s represented
ECON 35* -- Secton : Basc Concepts of Regresson Analyss (Page ) Lnear Regresson Analyss: Termnology and Notaton Consder the generc verson of the smple (two-varable) lnear regresson model. It s represented
CSci 6974 and ECSE 6966 Math. Tech. for Vision, Graphics and Robotics Lecture 21, April 17, 2006 Estimating A Plane Homography
 CSc 6974 and ECSE 6966 Math. Tech. for Vson, Graphcs and Robotcs Lecture 21, Aprl 17, 2006 Estmatng A Plane Homography Overvew We contnue wth a dscusson of the major ssues, usng estmaton of plane projectve
CSc 6974 and ECSE 6966 Math. Tech. for Vson, Graphcs and Robotcs Lecture 21, Aprl 17, 2006 Estmatng A Plane Homography Overvew We contnue wth a dscusson of the major ssues, usng estmaton of plane projectve
10-701/ Machine Learning, Fall 2005 Homework 3
 10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
10-701/15-781 Machne Learnng, Fall 2005 Homework 3 Out: 10/20/05 Due: begnnng of the class 11/01/05 Instructons Contact questons-10701@autonlaborg for queston Problem 1 Regresson and Cross-valdaton [40
Clustering & Unsupervised Learning
 Clusterng & Unsupervsed Learnng Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 2012 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
Clusterng & Unsupervsed Learnng Ken Kreutz-Delgado (Nuno Vasconcelos) ECE 175A Wnter 2012 UCSD Statstcal Learnng Goal: Gven a relatonshp between a feature vector x and a vector y, and d data samples (x,y
CSE 252C: Computer Vision III
 CSE 252C: Computer Vson III Lecturer: Serge Belonge Scrbe: Catherne Wah LECTURE 15 Kernel Machnes 15.1. Kernels We wll study two methods based on a specal knd of functon k(x, y) called a kernel: Kernel
CSE 252C: Computer Vson III Lecturer: Serge Belonge Scrbe: Catherne Wah LECTURE 15 Kernel Machnes 15.1. Kernels We wll study two methods based on a specal knd of functon k(x, y) called a kernel: Kernel
Matrix Approximation via Sampling, Subspace Embedding. 1 Solving Linear Systems Using SVD
 Matrx Approxmaton va Samplng, Subspace Embeddng Lecturer: Anup Rao Scrbe: Rashth Sharma, Peng Zhang 0/01/016 1 Solvng Lnear Systems Usng SVD Two applcatons of SVD have been covered so far. Today we loo
Matrx Approxmaton va Samplng, Subspace Embeddng Lecturer: Anup Rao Scrbe: Rashth Sharma, Peng Zhang 0/01/016 1 Solvng Lnear Systems Usng SVD Two applcatons of SVD have been covered so far. Today we loo
Some Comments on Accelerating Convergence of Iterative Sequences Using Direct Inversion of the Iterative Subspace (DIIS)
") Some Comments on Acceleratng Convergence of Iteratve Sequences Usng Drect Inverson of the Iteratve Subspace (DIIS) C. Davd Sherrll School of Chemstry and Bochemstry Georga Insttute of Technology May 1998
Some Comments on Acceleratng Convergence of Iteratve Sequences Usng Drect Inverson of the Iteratve Subspace (DIIS) C. Davd Sherrll School of Chemstry and Bochemstry Georga Insttute of Technology May 1998
Estimating the Fundamental Matrix by Transforming Image Points in Projective Space 1
 Estmatng the Fundamental Matrx by Transformng Image Ponts n Projectve Space 1 Zhengyou Zhang and Charles Loop Mcrosoft Research, One Mcrosoft Way, Redmond, WA 98052, USA E-mal: fzhang,cloopg@mcrosoft.com
Estmatng the Fundamental Matrx by Transformng Image Ponts n Projectve Space 1 Zhengyou Zhang and Charles Loop Mcrosoft Research, One Mcrosoft Way, Redmond, WA 98052, USA E-mal: fzhang,cloopg@mcrosoft.com
Econ107 Applied Econometrics Topic 3: Classical Model (Studenmund, Chapter 4)
") I. Classcal Assumptons Econ7 Appled Econometrcs Topc 3: Classcal Model (Studenmund, Chapter 4) We have defned OLS and studed some algebrac propertes of OLS. In ths topc we wll study statstcal propertes
I. Classcal Assumptons Econ7 Appled Econometrcs Topc 3: Classcal Model (Studenmund, Chapter 4) We have defned OLS and studed some algebrac propertes of OLS. In ths topc we wll study statstcal propertes
Classification. Representing data: Hypothesis (classifier) Lecture 2, September 14, Reading: Eric CMU,
 Lecture 2, September 14, Reading: Eric CMU,") Machne Learnng 10-701/15-781, 781, Fall 2011 Nonparametrc methods Erc Xng Lecture 2, September 14, 2011 Readng: 1 Classfcaton Representng data: Hypothess (classfer) 2 1 Clusterng 3 Supervsed vs. Unsupervsed
Machne Learnng 10-701/15-781, 781, Fall 2011 Nonparametrc methods Erc Xng Lecture 2, September 14, 2011 Readng: 1 Classfcaton Representng data: Hypothess (classfer) 2 1 Clusterng 3 Supervsed vs. Unsupervsed
18-660: Numerical Methods for Engineering Design and Optimization
 8-66: Numercal Methods for Engneerng Desgn and Optmzaton n L Department of EE arnege Mellon Unversty Pttsburgh, PA 53 Slde Overve lassfcaton Support vector machne Regularzaton Slde lassfcaton Predct categorcal
8-66: Numercal Methods for Engneerng Desgn and Optmzaton n L Department of EE arnege Mellon Unversty Pttsburgh, PA 53 Slde Overve lassfcaton Support vector machne Regularzaton Slde lassfcaton Predct categorcal
P R. Lecture 4. Theory and Applications of Pattern Recognition. Dept. of Electrical and Computer Engineering /
 Theory and Applcatons of Pattern Recognton 003, Rob Polkar, Rowan Unversty, Glassboro, NJ Lecture 4 Bayes Classfcaton Rule Dept. of Electrcal and Computer Engneerng 0909.40.0 / 0909.504.04 Theory & Applcatons
Theory and Applcatons of Pattern Recognton 003, Rob Polkar, Rowan Unversty, Glassboro, NJ Lecture 4 Bayes Classfcaton Rule Dept. of Electrcal and Computer Engneerng 0909.40.0 / 0909.504.04 Theory & Applcatons
Originated from experimental optimization where measurements are very noisy Approximation can be actually more accurate than
 Surrogate (approxmatons) Orgnated from expermental optmzaton where measurements are ver nos Approxmaton can be actuall more accurate than data! Great nterest now n applng these technques to computer smulatons
Surrogate (approxmatons) Orgnated from expermental optmzaton where measurements are ver nos Approxmaton can be actuall more accurate than data! Great nterest now n applng these technques to computer smulatons
Multigradient for Neural Networks for Equalizers 1
 Multgradent for Neural Netorks for Equalzers 1 Chulhee ee, Jnook Go and Heeyoung Km Department of Electrcal and Electronc Engneerng Yonse Unversty 134 Shnchon-Dong, Seodaemun-Ku, Seoul 1-749, Korea ABSTRACT
Multgradent for Neural Netorks for Equalzers 1 Chulhee ee, Jnook Go and Heeyoung Km Department of Electrcal and Electronc Engneerng Yonse Unversty 134 Shnchon-Dong, Seodaemun-Ku, Seoul 1-749, Korea ABSTRACT
Lecture 10 Support Vector Machines II
 Lecture 10 Support Vector Machnes II 22 February 2016 Taylor B. Arnold Yale Statstcs STAT 365/665 1/28 Notes: Problem 3 s posted and due ths upcomng Frday There was an early bug n the fake-test data; fxed
Lecture 10 Support Vector Machnes II 22 February 2016 Taylor B. Arnold Yale Statstcs STAT 365/665 1/28 Notes: Problem 3 s posted and due ths upcomng Frday There was an early bug n the fake-test data; fxed
Lecture 12: Discrete Laplacian
 Lecture 12: Dscrete Laplacan Scrbe: Tanye Lu Our goal s to come up wth a dscrete verson of Laplacan operator for trangulated surfaces, so that we can use t n practce to solve related problems We are mostly
Lecture 12: Dscrete Laplacan Scrbe: Tanye Lu Our goal s to come up wth a dscrete verson of Laplacan operator for trangulated surfaces, so that we can use t n practce to solve related problems We are mostly
Logistic Regression. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
Logstc Regresson CAP 561: achne Learnng Instructor: Guo-Jun QI Bayes Classfer: A Generatve model odel the posteror dstrbuton P(Y X) Estmate class-condtonal dstrbuton P(X Y) for each Y Estmate pror dstrbuton
ρ some λ THE INVERSE POWER METHOD (or INVERSE ITERATION) , for , or (more usually) to
 , for , or (more usually) to") THE INVERSE POWER METHOD (or INVERSE ITERATION) -- applcaton of the Power method to A some fxed constant ρ (whch s called a shft), x λ ρ If the egenpars of A are { ( λ, x ) } ( ), or (more usually) to,
THE INVERSE POWER METHOD (or INVERSE ITERATION) -- applcaton of the Power method to A some fxed constant ρ (whch s called a shft), x λ ρ If the egenpars of A are { ( λ, x ) } ( ), or (more usually) to,
Support Vector Machines
 /14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
/14/018 Separatng boundary, defned by w Support Vector Machnes CISC 5800 Professor Danel Leeds Separatng hyperplane splts class 0 and class 1 Plane s defned by lne w perpendcular to plan Is data pont x
Using T.O.M to Estimate Parameter of distributions that have not Single Exponential Family
 IOSR Journal of Mathematcs IOSR-JM) ISSN: 2278-5728. Volume 3, Issue 3 Sep-Oct. 202), PP 44-48 www.osrjournals.org Usng T.O.M to Estmate Parameter of dstrbutons that have not Sngle Exponental Famly Jubran
IOSR Journal of Mathematcs IOSR-JM) ISSN: 2278-5728. Volume 3, Issue 3 Sep-Oct. 202), PP 44-48 www.osrjournals.org Usng T.O.M to Estmate Parameter of dstrbutons that have not Sngle Exponental Famly Jubran
10) Activity analysis
 Activity analysis") 3C3 Mathematcal Methods for Economsts (6 cr) 1) Actvty analyss Abolfazl Keshvar Ph.D. Aalto Unversty School of Busness Sldes orgnally by: Tmo Kuosmanen Updated by: Abolfazl Keshvar 1 Outlne Hstorcal development
3C3 Mathematcal Methods for Economsts (6 cr) 1) Actvty analyss Abolfazl Keshvar Ph.D. Aalto Unversty School of Busness Sldes orgnally by: Tmo Kuosmanen Updated by: Abolfazl Keshvar 1 Outlne Hstorcal development
ORIGIN 1. PTC_CE_BSD_3.2_us_mp.mcdx. Mathcad Enabled Content 2011 Knovel Corp.
 Clck to Vew Mathcad Document 2011 Knovel Corp. Buldng Structural Desgn. homas P. Magner, P.E. 2011 Parametrc echnology Corp. Chapter 3: Renforced Concrete Slabs and Beams 3.2 Renforced Concrete Beams -
Clck to Vew Mathcad Document 2011 Knovel Corp. Buldng Structural Desgn. homas P. Magner, P.E. 2011 Parametrc echnology Corp. Chapter 3: Renforced Concrete Slabs and Beams 3.2 Renforced Concrete Beams -
The Geometry of Logit and Probit
 The Geometry of Logt and Probt Ths short note s meant as a supplement to Chapters and 3 of Spatal Models of Parlamentary Votng and the notaton and reference to fgures n the text below s to those two chapters.
The Geometry of Logt and Probt Ths short note s meant as a supplement to Chapters and 3 of Spatal Models of Parlamentary Votng and the notaton and reference to fgures n the text below s to those two chapters.
Limited Dependent Variables
 Lmted Dependent Varables. What f the left-hand sde varable s not a contnuous thng spread from mnus nfnty to plus nfnty? That s, gven a model = f (, β, ε, where a. s bounded below at zero, such as wages
Lmted Dependent Varables. What f the left-hand sde varable s not a contnuous thng spread from mnus nfnty to plus nfnty? That s, gven a model = f (, β, ε, where a. s bounded below at zero, such as wages
De-noising Method Based on Kernel Adaptive Filtering for Telemetry Vibration Signal of the Vehicle Test Kejun ZENG
 6th Internatonal Conference on Mechatroncs, Materals, Botechnology and Envronment (ICMMBE 6) De-nosng Method Based on Kernel Adaptve Flterng for elemetry Vbraton Sgnal of the Vehcle est Kejun ZEG PLA 955
6th Internatonal Conference on Mechatroncs, Materals, Botechnology and Envronment (ICMMBE 6) De-nosng Method Based on Kernel Adaptve Flterng for elemetry Vbraton Sgnal of the Vehcle est Kejun ZEG PLA 955
Multilayer Perceptrons and Backpropagation. Perceptrons. Recap: Perceptrons. Informatics 1 CG: Lecture 6. Mirella Lapata
 Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Multlayer Perceptrons and Informatcs CG: Lecture 6 Mrella Lapata School of Informatcs Unversty of Ednburgh mlap@nf.ed.ac.uk Readng: Kevn Gurney s Introducton to Neural Networks, Chapters 5 6.5 January,
Feb 14: Spatial analysis of data fields
 Feb 4: Spatal analyss of data felds Mappng rregularly sampled data onto a regular grd Many analyss technques for geophyscal data requre the data be located at regular ntervals n space and/or tme. hs s
Feb 4: Spatal analyss of data felds Mappng rregularly sampled data onto a regular grd Many analyss technques for geophyscal data requre the data be located at regular ntervals n space and/or tme. hs s
Which Separator? Spring 1
 Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Whch Separator? 6.034 - Sprng 1 Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng Whch Separator? Mamze the margn to closest ponts 6.034 - Sprng 3 Margn of a pont " # y (w $ + b) proportonal
Module 3 LOSSY IMAGE COMPRESSION SYSTEMS. Version 2 ECE IIT, Kharagpur
 Module 3 LOSSY IMAGE COMPRESSION SYSTEMS Verson ECE IIT, Kharagpur Lesson 6 Theory of Quantzaton Verson ECE IIT, Kharagpur Instructonal Objectves At the end of ths lesson, the students should be able to:
Module 3 LOSSY IMAGE COMPRESSION SYSTEMS Verson ECE IIT, Kharagpur Lesson 6 Theory of Quantzaton Verson ECE IIT, Kharagpur Instructonal Objectves At the end of ths lesson, the students should be able to:
Chapter 5. Solution of System of Linear Equations. Module No. 6. Solution of Inconsistent and Ill Conditioned Systems
 Numercal Analyss by Dr. Anta Pal Assstant Professor Department of Mathematcs Natonal Insttute of Technology Durgapur Durgapur-713209 emal: anta.bue@gmal.com 1 . Chapter 5 Soluton of System of Lnear Equatons
Numercal Analyss by Dr. Anta Pal Assstant Professor Department of Mathematcs Natonal Insttute of Technology Durgapur Durgapur-713209 emal: anta.bue@gmal.com 1 . Chapter 5 Soluton of System of Lnear Equatons
Homework Assignment 3 Due in class, Thursday October 15
 Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Homework Assgnment 3 Due n class, Thursday October 15 SDS 383C Statstcal Modelng I 1 Rdge regresson and Lasso 1. Get the Prostrate cancer data from http://statweb.stanford.edu/~tbs/elemstatlearn/ datasets/prostate.data.
Common loop optimizations. Example to improve locality. Why Dependence Analysis. Data Dependence in Loops. Goal is to find best schedule:
 15-745 Lecture 6 Data Dependence n Loops Copyrght Seth Goldsten, 2008 Based on sldes from Allen&Kennedy Lecture 6 15-745 2005-8 1 Common loop optmzatons Hostng of loop-nvarant computatons pre-compute before
15-745 Lecture 6 Data Dependence n Loops Copyrght Seth Goldsten, 2008 Based on sldes from Allen&Kennedy Lecture 6 15-745 2005-8 1 Common loop optmzatons Hostng of loop-nvarant computatons pre-compute before
Singular Value Decomposition: Theory and Applications
 Sngular Value Decomposton: Theory and Applcatons Danel Khashab Sprng 2015 Last Update: March 2, 2015 1 Introducton A = UDV where columns of U and V are orthonormal and matrx D s dagonal wth postve real
Sngular Value Decomposton: Theory and Applcatons Danel Khashab Sprng 2015 Last Update: March 2, 2015 1 Introducton A = UDV where columns of U and V are orthonormal and matrx D s dagonal wth postve real
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far Supervsed machne learnng Lnear models Least squares regresson Fsher s dscrmnant, Perceptron, Logstc model Non-lnear
UNIVERSITY OF TORONTO Faculty of Arts and Science. December 2005 Examinations STA437H1F/STA1005HF. Duration - 3 hours
 UNIVERSITY OF TORONTO Faculty of Arts and Scence December 005 Examnatons STA47HF/STA005HF Duraton - hours AIDS ALLOWED: (to be suppled by the student) Non-programmable calculator One handwrtten 8.5'' x
UNIVERSITY OF TORONTO Faculty of Arts and Scence December 005 Examnatons STA47HF/STA005HF Duraton - hours AIDS ALLOWED: (to be suppled by the student) Non-programmable calculator One handwrtten 8.5'' x
A METHOD FOR DETECTING OUTLIERS IN FUZZY REGRESSION
 OPERATIONS RESEARCH AND DECISIONS No. 2 21 Barbara GŁADYSZ* A METHOD FOR DETECTING OUTLIERS IN FUZZY REGRESSION In ths artcle we propose a method for dentfyng outlers n fuzzy regresson. Outlers n a sample
OPERATIONS RESEARCH AND DECISIONS No. 2 21 Barbara GŁADYSZ* A METHOD FOR DETECTING OUTLIERS IN FUZZY REGRESSION In ths artcle we propose a method for dentfyng outlers n fuzzy regresson. Outlers n a sample
APPENDIX A Some Linear Algebra
 APPENDIX A Some Lnear Algebra The collecton of m, n matrces A.1 Matrces a 1,1,..., a 1,n A = a m,1,..., a m,n wth real elements a,j s denoted by R m,n. If n = 1 then A s called a column vector. Smlarly,
APPENDIX A Some Lnear Algebra The collecton of m, n matrces A.1 Matrces a 1,1,..., a 1,n A = a m,1,..., a m,n wth real elements a,j s denoted by R m,n. If n = 1 then A s called a column vector. Smlarly,
Solving Nonlinear Differential Equations by a Neural Network Method
 Solvng Nonlnear Dfferental Equatons by a Neural Network Method Luce P. Aarts and Peter Van der Veer Delft Unversty of Technology, Faculty of Cvlengneerng and Geoscences, Secton of Cvlengneerng Informatcs,
Solvng Nonlnear Dfferental Equatons by a Neural Network Method Luce P. Aarts and Peter Van der Veer Delft Unversty of Technology, Faculty of Cvlengneerng and Geoscences, Secton of Cvlengneerng Informatcs,
Lecture 3: Shannon s Theorem
 CSE 533: Error-Correctng Codes (Autumn 006 Lecture 3: Shannon s Theorem October 9, 006 Lecturer: Venkatesan Guruswam Scrbe: Wdad Machmouch 1 Communcaton Model The communcaton model we are usng conssts
CSE 533: Error-Correctng Codes (Autumn 006 Lecture 3: Shannon s Theorem October 9, 006 Lecturer: Venkatesan Guruswam Scrbe: Wdad Machmouch 1 Communcaton Model The communcaton model we are usng conssts
Non-linear Canonical Correlation Analysis Using a RBF Network
 ESANN' proceedngs - European Smposum on Artfcal Neural Networks Bruges (Belgum), 4-6 Aprl, d-sde publ., ISBN -97--, pp. 57-5 Non-lnear Canoncal Correlaton Analss Usng a RBF Network Sukhbnder Kumar, Elane
ESANN' proceedngs - European Smposum on Artfcal Neural Networks Bruges (Belgum), 4-6 Aprl, d-sde publ., ISBN -97--, pp. 57-5 Non-lnear Canoncal Correlaton Analss Usng a RBF Network Sukhbnder Kumar, Elane
Support Vector Machines
 Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
Support Vector Machnes Konstantn Tretyakov (kt@ut.ee) MTAT.03.227 Machne Learnng So far So far Supervsed machne learnng Lnear models Non-lnear models Unsupervsed machne learnng Generc scaffoldng So far
The Gaussian classifier. Nuno Vasconcelos ECE Department, UCSD
 he Gaussan classfer Nuno Vasconcelos ECE Department, UCSD Bayesan decson theory recall that we have state of the world X observatons g decson functon L[g,y] loss of predctng y wth g Bayes decson rule s
he Gaussan classfer Nuno Vasconcelos ECE Department, UCSD Bayesan decson theory recall that we have state of the world X observatons g decson functon L[g,y] loss of predctng y wth g Bayes decson rule s
Why feed-forward networks are in a bad shape
 Why feed-forward networks are n a bad shape Patrck van der Smagt, Gerd Hrznger Insttute of Robotcs and System Dynamcs German Aerospace Center (DLR Oberpfaffenhofen) 82230 Wesslng, GERMANY emal smagt@dlr.de
Why feed-forward networks are n a bad shape Patrck van der Smagt, Gerd Hrznger Insttute of Robotcs and System Dynamcs German Aerospace Center (DLR Oberpfaffenhofen) 82230 Wesslng, GERMANY emal smagt@dlr.de
K means B d ase Consensus Cluste i r ng Dr. Dr Junjie Wu Beihang University
 K means Based dconsensus Clusterng Dr. Junje Wu Dr. Junje Wu Behang Unversty Outlne Motvatons Pont to Centrod to Dstance Utlty Functons for KCC Expermental Results Concludng remarks Cluster Analyss Clusterng
K means Based dconsensus Clusterng Dr. Junje Wu Dr. Junje Wu Behang Unversty Outlne Motvatons Pont to Centrod to Dstance Utlty Functons for KCC Expermental Results Concludng remarks Cluster Analyss Clusterng
U.C. Berkeley CS294: Beyond Worst-Case Analysis Luca Trevisan September 5, 2017
 U.C. Berkeley CS94: Beyond Worst-Case Analyss Handout 4s Luca Trevsan September 5, 07 Summary of Lecture 4 In whch we ntroduce semdefnte programmng and apply t to Max Cut. Semdefnte Programmng Recall that
U.C. Berkeley CS94: Beyond Worst-Case Analyss Handout 4s Luca Trevsan September 5, 07 Summary of Lecture 4 In whch we ntroduce semdefnte programmng and apply t to Max Cut. Semdefnte Programmng Recall that
Composite Hypotheses testing
 Composte ypotheses testng In many hypothess testng problems there are many possble dstrbutons that can occur under each of the hypotheses. The output of the source s a set of parameters (ponts n a parameter
Composte ypotheses testng In many hypothess testng problems there are many possble dstrbutons that can occur under each of the hypotheses. The output of the source s a set of parameters (ponts n a parameter
Internet Engineering. Jacek Mazurkiewicz, PhD Softcomputing. Part 3: Recurrent Artificial Neural Networks Self-Organising Artificial Neural Networks
 Internet Engneerng Jacek Mazurkewcz, PhD Softcomputng Part 3: Recurrent Artfcal Neural Networks Self-Organsng Artfcal Neural Networks Recurrent Artfcal Neural Networks Feedback sgnals between neurons Dynamc
Internet Engneerng Jacek Mazurkewcz, PhD Softcomputng Part 3: Recurrent Artfcal Neural Networks Self-Organsng Artfcal Neural Networks Recurrent Artfcal Neural Networks Feedback sgnals between neurons Dynamc
Outline. Multivariate Parametric Methods. Multivariate Data. Basic Multivariate Statistics. Steven J Zeil
 Outlne Multvarate Parametrc Methods Steven J Zel Old Domnon Unv. Fall 2010 1 Multvarate Data 2 Multvarate ormal Dstrbuton 3 Multvarate Classfcaton Dscrmnants Tunng Complexty Dscrete Features 4 Multvarate
Outlne Multvarate Parametrc Methods Steven J Zel Old Domnon Unv. Fall 2010 1 Multvarate Data 2 Multvarate ormal Dstrbuton 3 Multvarate Classfcaton Dscrmnants Tunng Complexty Dscrete Features 4 Multvarate
An (almost) unbiased estimator for the S-Gini index
 unbiased estimator for the S-Gini index") An (almost unbased estmator for the S-Gn ndex Thomas Demuynck February 25, 2009 Abstract Ths note provdes an unbased estmator for the absolute S-Gn and an almost unbased estmator for the relatve S-Gn for
An (almost unbased estmator for the S-Gn ndex Thomas Demuynck February 25, 2009 Abstract Ths note provdes an unbased estmator for the absolute S-Gn and an almost unbased estmator for the relatve S-Gn for
The big picture. Outline
 The bg pcture Vncent Claveau IRISA - CNRS, sldes from E. Kjak INSA Rennes Notatons classes: C = {ω = 1,.., C} tranng set S of sze m, composed of m ponts (x, ω ) per class ω representaton space: R d (=
The bg pcture Vncent Claveau IRISA - CNRS, sldes from E. Kjak INSA Rennes Notatons classes: C = {ω = 1,.., C} tranng set S of sze m, composed of m ponts (x, ω ) per class ω representaton space: R d (=
Fuzzy Boundaries of Sample Selection Model
 Proceedngs of the 9th WSES Internatonal Conference on ppled Mathematcs, Istanbul, Turkey, May 7-9, 006 (pp309-34) Fuzzy Boundares of Sample Selecton Model L. MUHMD SFIIH, NTON BDULBSH KMIL, M. T. BU OSMN
Proceedngs of the 9th WSES Internatonal Conference on ppled Mathematcs, Istanbul, Turkey, May 7-9, 006 (pp309-34) Fuzzy Boundares of Sample Selecton Model L. MUHMD SFIIH, NTON BDULBSH KMIL, M. T. BU OSMN
Curve Fitting with the Least Square Method
 WIKI Document Number 5 Interpolaton wth Least Squares Curve Fttng wth the Least Square Method Mattheu Bultelle Department of Bo-Engneerng Imperal College, London Context We wsh to model the postve feedback
WIKI Document Number 5 Interpolaton wth Least Squares Curve Fttng wth the Least Square Method Mattheu Bultelle Department of Bo-Engneerng Imperal College, London Context We wsh to model the postve feedback
Neural Networks. Perceptrons and Backpropagation. Silke Bussen-Heyen. 5th of Novemeber Universität Bremen Fachbereich 3. Neural Networks 1 / 17
 Neural Networks Perceptrons and Backpropagaton Slke Bussen-Heyen Unverstät Bremen Fachberech 3 5th of Novemeber 2012 Neural Networks 1 / 17 Contents 1 Introducton 2 Unts 3 Network structure 4 Snglelayer
Neural Networks Perceptrons and Backpropagaton Slke Bussen-Heyen Unverstät Bremen Fachberech 3 5th of Novemeber 2012 Neural Networks 1 / 17 Contents 1 Introducton 2 Unts 3 Network structure 4 Snglelayer