Machine Learning A Geometric Approach
|
|
|
- Poppy Hubbard
- 6 years ago
- Views:
Transcription
1 Machine Learning A Geometric Approach Linear Classification: Perceptron Professor Liang Huang some slides from Alex Smola (CMU)


2 Perceptron Frank Rosenblatt
3 deep learning multilayer perceptron linear regression perceptron SVM CRF structured perceptron
4 Brief History of Perceptron 1959 osenblatt invention batch +max margin online 1962 Novikoff proof +kernels 1969* Minsky/Papert book killed it +soft-margin minibatch conservative updates DEAD inseparable case 1997 Cortes/Vapnik SVM online approx. max margin 1999 Freund/Schapire voted/avg: revived subgradient descent 2003 Crammer/Singer MIRA minibatch * Singer group Pegasos 2006 Singer group aggressive *mentioned in lectures but optional (others papers all covered in detail) AT&T Research 2002 Collins structured 2005* McDonald/Crammer/Pereira structured MIRA ex-at&t and students
 May be up to 1m long and will transport the activation signal to neurons at different")
5 Neurons Soma (CPU) Cell body - combines signals Dendrite (input bus) Combines the inputs from several other nerve cells Synapse (interface) Interface and parameter store between neurons Axon (output cable) May be up to 1m long and will transport the activation signal to neurons at different locations
6 Neurons x 1 x 2 x 3... x n w 1 w n synaptic weights output X f(x) = σ( w i x i = hw, xi) i


7 Frank Rosenblatt s Perceptron
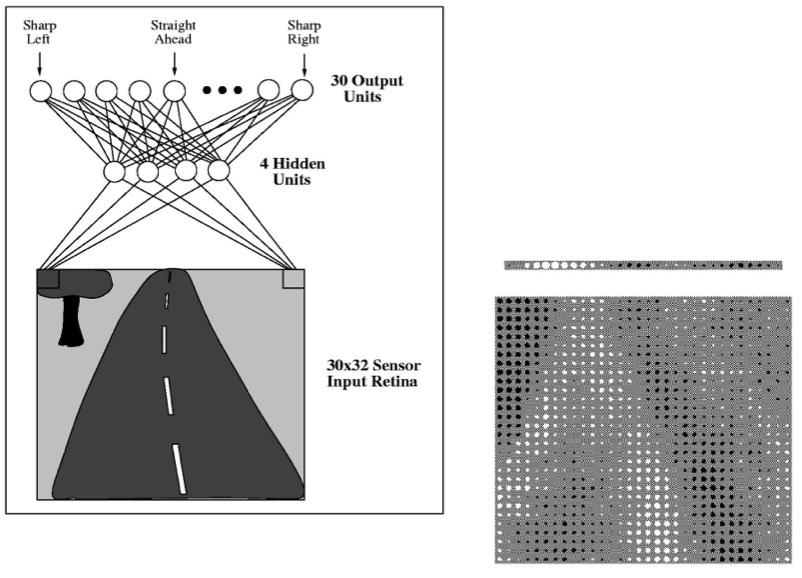

8 Multilayer Perceptron (Neural Net)
9 Perceptron w/ bias Weighted linear x 1 x 2 x 3... x n combination Nonlinear decision function Linear offset (bias) synaptic weights w 1 output w n f(x) = (hw, xi + b) Linear separating hyperplanes Learning: w and b
10 Perceptron w/o bias Weighted linear x 0 = 1 x 1 x 2 x 3... x n combination w 0 w 1 w n Nonlinear decision function synaptic weights No Linear offset (bias): hyperplane through the origin output f(x) = (hw, xi + b) Linear separating hyperplanes Learning: w
11 Augmented Space 1 O can separate in 2D from the origin can t separate in 1D from the origin can separate in 3D from the origin can t separate in 2D from the origin
12 Perceptron Ham Spam
13 The Perceptron w/o bias initialize w = 0 and b =0 repeat if y i [hw, x i i + b] apple 0 then w w + y i x i and b b + y i end if until all classified correctly Nothing happens if classified correctly Weight vector is linear combination Classifier is linear combination of w = X i2i y i x i inner products f(x) = X i2i y i hx i,xi + b σ( )
14 The Perceptron w/ bias initialize w = 0 and b =0 repeat if y i [hw, x i i + b] apple 0 then w w + y i x i and b b + y i end if until all classified correctly Nothing happens if classified correctly Weight vector is linear combination Classifier is linear combination of w = X i2i y i x i inner products f(x) = X i2i y i hx i,xi + b σ( )
15 Demo x i w (bias=0)
16 Demo
17 Demo
18 Demo
19
20 Convergence Theorem If there exists some oracle unit vector u : kuk = 1 y i (u x i ) for all i then the perceptron converges to a linear separator after a number of updates bounded by R 2 / 2 where R = maxkx i k i Dimensionality independent Order independent (but order matters in output) Dataset size independent Scales with difficulty of problem
21 Geometry of the Proof part 1: progress (alignment) on oracle projection assume w i is the weight vector before the ith update (on hx i, y i i) and assume initial w 0 = 0 w i+1 = w i + y i x i u w i+1 = u w i + y i (u x i ) u w i+1 u w i + u w i+1 i projection on u increases! y i (u x i ) x i w i+1 for all i (more agreement w/ oracle) u : kuk = 1 kw i+1 k = kukkw i+1 k u w i+1 i w i
22 Geometry of the Proof part 2: bound the norm of the weight vector w i+1 = w i + y i x i kw i+1 k 2 = kw i + y i x i k 2 = kw i k 2 + kx i k 2 + 2y i (w i x i ) apple kw i k 2 + R 2 mistake on x_i apple ir 2 (radius) x i w i+1 Combine with part 1 kw i+1 k = kukkw i+1 k u w i+1 i u : kuk = 1 i apple R 2 / 2 w i
23 Convergence Bound R 2 / 2 w is independent of: dimensionality number of examples starting weight vector order of examples constant learning rate and is dependent of: but test accuracy is dependent of: order of examples (shuffling helps) variable learning rate (1/total#error helps) can you still prove convergence? separation difficulty feature scale
24 Hardness margin vs. size hard easy
25 XOR XOR - not linearly separable Nonlinear separation is trivial Caveat from Perceptrons (Minsky & Papert, 1969) Finding the minimum error linear separator is NP hard (this killed Neural Networks in the 70s).
26 Brief History of Perceptron 1959 osenblatt invention batch +max margin online 1962 Novikoff proof +kernels 1969* Minsky/Papert book killed it +soft-margin minibatch conservative updates DEAD inseparable case 1997 Cortes/Vapnik SVM online approx. max margin 1999 Freund/Schapire voted/avg: revived subgradient descent 2003 Crammer/Singer MIRA minibatch * Singer group Pegasos 2006 Singer group aggressive *mentioned in lectures but optional (others papers all covered in detail) AT&T Research 2002 Collins structured 2005* McDonald/Crammer/Pereira structured MIRA ex-at&t and students
27 Extensions of Perceptron Problems with Perceptron doesn t converge with inseparable data update might often be too bold doesn t optimize margin is sensitive to the order of examples Ways to alleviate these problems voted perceptron and average perceptron MIRA (margin-infused relaxation algorithm)
28 Voted/Avged Perceptron motivation: updates on later examples taking over! voted perceptron (Freund and Schapire, 1999) record the weight vector after each example in D (not just after each update) and vote on a new example using D models shown to have better generalization power averaged perceptron (from the same paper) an approximation of voted perceptron just use the average of all weight vectors can be implemented efficiently
29 Voted Perceptron
30 Voted/Avged Perceptron (low dim - less separable) test error
31 Voted/Avged Perceptron (high dim - more separable) test error
32 Averaged Perceptron voted perceptron is not scalable and does not output a single model avg perceptron is an approximation of voted perceptron initialize w = 0 and w 0 b =0 repeat c c +1 if y i [hw, x i i + b] apple 0 then w w + y i x i and b b + y i wend 0 ifw 0 + w until all classified correctly output w 0 /c after each example, not each update 32
33 Efficient Implementation of Averaging naive implementation (running sum) doesn t scale very clever trick from Daume (2006, PhD thesis) initialize w = 0 and w a b =0 repeat c c +1 if y i [hw, x i i + b] apple 0 then w w + y i x i and b b + y i end w a if w a + cy i x i until all classified correctly output w w a /c w t w (0) = w (1) = w (2) = w (3) = w (1) w (1) w (2) w (1) w (2) w (3) t w w (4) = w (1) w (2) w (3) w (4) 33
34 MIRA perceptron often makes too bold updates but hard to tune learning rate the smallest update to correct the mistake? w i+1 = w i + y i w i x i kx i k 2 x i easy to show: y i (w i+1 x i ) = y i (w i + y i margin-infused relaxation algorithm (MIRA) w i x i kx i k 2 x i ) x i = 1 kx i k w i x i 1 kx i k perceptron overcorrects this mistake w i x i perceptron MIRA 1 w i x i kx i k
35 Perceptron x i perceptron w perceptron undercorrects this mistake (bias=0)
36 MIRA min kw 0 wk 2 w 0 s.t. w 0 x 1 minimal change to ensure margin MIRA x i MIRA makes sure after update, dotproduct w x_i = 1 MIRA 1-step SVM perceptron margin of 1/ x_i w perceptron undercorrects this mistake (bias=0)
37 Aggressive MIRA aggressive version of MIRA also update if correct but margin isn t big enough functional margin: y i (w x i ) geometric margin: y i (w x i ) kwk update if functional margin is <=p (0<=p<1) update rule is same as MIRA called p-aggressive MIRA (MIRA: p=0) larger p leads to a larger geometric margin but slower convergence

38 Aggressive MIRA p=0.2 perceptron p=0.9
39 Demo perceptron vs. 0.2-aggressive vs. 0.9-aggressive p=0.2 perceptron p=0.9
40 Demo perceptron vs. 0.2-aggressive vs. 0.9-aggressive why does this dataset so slow to converge? perceptron: 22, p=0.2: 87, p=0.9: 2,518 epochs answer: margin shrinks in augmented space! 1 small margin in 2D O big margin in 1D
41 Demo perceptron vs. 0.2-aggressive vs. 0.9-aggressive why does this dataset so fast to converge? perceptron: 3, p=0.2: 1, p=0.9: 5 epochs answer: margin shrinks in augmented space! 1 ok margin in 2D O big margin in 1D
 weights will remain bounded and not diverge use dev set for when to stop (prevents overfitting) higher-order features by")
42 What if data is not separable in practice, data is almost always inseparable wait, what does that mean?? perceptron cycling theorem (1970) weights will remain bounded and not diverge use dev set for when to stop (prevents overfitting) higher-order features by combining atomic ones kernels => separable in higher dimensions

43
44 Solving XOR (x 1,x 2 ) (x 1,x 2,x 1 x 2 ) XOR not linearly separable Mapping into 3 dimensions makes it easily solvable
45 Useful Engineering Tips: averaging, shuffling, variable learning rate, fixing feature scale averaging helps significantly; MIRA helps a tiny little bit perceptron < MIRA < avg. perceptron avg. MIRA shuffling the data helps hugely if classes were ordered shuffling before each epoch helps a little bit variable learning rate often helps a little 1/(total#updates) or 1/(total#examples) helps any requirement in order to converge? how to prove convergence now? centering of each feature dim helps why? => R smaller, margin bigger unit variance also helps (why?) 0-mean, 1-var => each feature a unit Gaussian 1 O 1 O
46 Useful Engineering Tips: categorical=>binary, feature bucketing (binning/quantization) Age, Workclass, Education, Marital_Status, Occupation, Race, Sex, Hours, Country, Target 40, Private, Doctorate, Married-civ-spouse, Prof-specialty, White, Male, 60, United-States, >50K HW1 Adult income dataset: <=50K, or >50K? 2 numerical features age and hours-per-week option 1: treat them as numerical features but is older and more hours always better? option 2: treat them as binary features e.g., age=22, hours=38,... option 3: bin them (e.g., age=0-25, hours= ) 7 categorical features: convert to binary features country, race, occupation, etc. e.g., country:united_states, education:doctorate,... optional: you can probably add a numerical feature edu_level perceptron: ~20% error, avg. perceptron: ~16% error
47 Brief History of Perceptron 1959 osenblatt invention batch +max margin online 1962 Novikoff proof +kernels 1969* Minsky/Papert book killed it +soft-margin minibatch conservative updates DEAD inseparable case 1997 Cortes/Vapnik SVM online approx. max margin 1999 Freund/Schapire voted/avg: revived subgradient descent 2003 Crammer/Singer MIRA minibatch * Singer group Pegasos 2006 Singer group aggressive *mentioned in lectures but optional (others papers all covered in detail) AT&T Research 2002 Collins structured 2005* McDonald/Crammer/Pereira structured MIRA ex-at&t and students
Machine Learning A Geometric Approach
 Machine Learning A Geometric Approach CIML book Chap 7.7 Linear Classification: Support Vector Machines (SVM) Professor Liang Huang some slides from Alex Smola (CMU) Linear Separator Ham Spam From Perceptron
Machine Learning A Geometric Approach CIML book Chap 7.7 Linear Classification: Support Vector Machines (SVM) Professor Liang Huang some slides from Alex Smola (CMU) Linear Separator Ham Spam From Perceptron
Structured Prediction
 Machine Learning Fall 2017 (structured perceptron, HMM, structured SVM) Professor Liang Huang (Chap. 17 of CIML) x x the man bit the dog x the man bit the dog x DT NN VBD DT NN S =+1 =-1 the man bit the
Machine Learning Fall 2017 (structured perceptron, HMM, structured SVM) Professor Liang Huang (Chap. 17 of CIML) x x the man bit the dog x the man bit the dog x DT NN VBD DT NN S =+1 =-1 the man bit the
Multi-class SVMs. Lecture 17: Aykut Erdem April 2016 Hacettepe University
 Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Perceptron. Subhransu Maji. CMPSCI 689: Machine Learning. 3 February February 2015
 Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Machine Learning. Kernels. Fall (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang. (Chap. 12 of CIML)
 Professor Liang Huang. (Chap. 12 of CIML)") Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
The Perceptron Algorithm
 The Perceptron Algorithm Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Outline The Perceptron Algorithm Perceptron Mistake Bound Variants of Perceptron 2 Where are we? The Perceptron
The Perceptron Algorithm Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Outline The Perceptron Algorithm Perceptron Mistake Bound Variants of Perceptron 2 Where are we? The Perceptron
Perceptron (Theory) + Linear Regression
 + Linear Regression") 10601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron (Theory) Linear Regression Matt Gormley Lecture 6 Feb. 5, 2018 1 Q&A
10601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron (Theory) Linear Regression Matt Gormley Lecture 6 Feb. 5, 2018 1 Q&A
Introduction to Machine Learning
 Introduction to Machine Learning 4. Perceptron and Kernels Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Perceptron Hebbian learning & biology Algorithm
Introduction to Machine Learning 4. Perceptron and Kernels Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Perceptron Hebbian learning & biology Algorithm
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
CS 188: Artificial Intelligence. Outline
 CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
Linear models: the perceptron and closest centroid algorithms. D = {(x i,y i )} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.
} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.") Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Introduction To Artificial Neural Networks
 Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Introduction To Artificial Neural Networks Machine Learning Supervised circle square circle square Unsupervised group these into two categories Supervised Machine Learning Supervised Machine Learning Supervised
Linear discriminant functions
 Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
L5 Support Vector Classification
 L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Vote. Vote on timing for night section: Option 1 (what we have now) Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9
 Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9") Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
More about the Perceptron
 More about the Perceptron CMSC 422 MARINE CARPUAT marine@cs.umd.edu Credit: figures by Piyush Rai and Hal Daume III Recap: Perceptron for binary classification Classifier = hyperplane that separates positive
More about the Perceptron CMSC 422 MARINE CARPUAT marine@cs.umd.edu Credit: figures by Piyush Rai and Hal Daume III Recap: Perceptron for binary classification Classifier = hyperplane that separates positive
The Perceptron Algorithm, Margins
 The Perceptron Algorithm, Margins MariaFlorina Balcan 08/29/2018 The Perceptron Algorithm Simple learning algorithm for supervised classification analyzed via geometric margins in the 50 s [Rosenblatt
The Perceptron Algorithm, Margins MariaFlorina Balcan 08/29/2018 The Perceptron Algorithm Simple learning algorithm for supervised classification analyzed via geometric margins in the 50 s [Rosenblatt
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
The Perceptron. Volker Tresp Summer 2016
 The Perceptron Volker Tresp Summer 2016 1 Elements in Learning Tasks Collection, cleaning and preprocessing of training data Definition of a class of learning models. Often defined by the free model parameters
The Perceptron Volker Tresp Summer 2016 1 Elements in Learning Tasks Collection, cleaning and preprocessing of training data Definition of a class of learning models. Often defined by the free model parameters
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Brief Introduction to Machine Learning
 Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
6.036 midterm review. Wednesday, March 18, 15
 6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
Simple Neural Nets For Pattern Classification
 CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
Supervised Learning (contd) Decision Trees. Mausam (based on slides by UW-AI faculty)
 Decision Trees. Mausam (based on slides by UW-AI faculty)") Supervised Learning (contd) Decision Trees Mausam (based on slides by UW-AI faculty) Decision Trees To play or not to play? http://www.sfgate.com/blogs/images/sfgate/sgreen/2007/09/05/2240773250x321.jpg
Supervised Learning (contd) Decision Trees Mausam (based on slides by UW-AI faculty) Decision Trees To play or not to play? http://www.sfgate.com/blogs/images/sfgate/sgreen/2007/09/05/2240773250x321.jpg
Logistic Regression Logistic
 Case Study 1: Estimating Click Probabilities L2 Regularization for Logistic Regression Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 10 th,
Case Study 1: Estimating Click Probabilities L2 Regularization for Logistic Regression Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 10 th,
Lecture 12. Neural Networks Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 12 Neural Networks 10.12.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 12 Neural Networks 10.12.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Preliminaries. Definition: The Euclidean dot product between two vectors is the expression. i=1
 90 8 80 7 70 6 60 0 8/7/ Preliminaries Preliminaries Linear models and the perceptron algorithm Chapters, T x + b < 0 T x + b > 0 Definition: The Euclidean dot product beteen to vectors is the expression
90 8 80 7 70 6 60 0 8/7/ Preliminaries Preliminaries Linear models and the perceptron algorithm Chapters, T x + b < 0 T x + b > 0 Definition: The Euclidean dot product beteen to vectors is the expression
COMP9444 Neural Networks and Deep Learning 2. Perceptrons. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 2. Perceptrons COMP9444 17s2 Perceptrons 1 Outline Neurons Biological and Artificial Perceptron Learning Linear Separability Multi-Layer Networks COMP9444 17s2
COMP9444 Neural Networks and Deep Learning 2. Perceptrons COMP9444 17s2 Perceptrons 1 Outline Neurons Biological and Artificial Perceptron Learning Linear Separability Multi-Layer Networks COMP9444 17s2
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning
 CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning 0.1 Linear Functions So far, we have been looking at Linear Functions { as a class of functions which can 1 if W1 X separate some data and not
CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning 0.1 Linear Functions So far, we have been looking at Linear Functions { as a class of functions which can 1 if W1 X separate some data and not
Pattern Recognition and Machine Learning. Perceptrons and Support Vector machines
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Linear Classifiers. Michael Collins. January 18, 2012
 Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
EE 511 Online Learning Perceptron
 Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Kevin Jamison EE 511 Online Learning Perceptron Instructor: Hanna Hajishirzi hannaneh@washington.edu
Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Kevin Jamison EE 511 Online Learning Perceptron Instructor: Hanna Hajishirzi hannaneh@washington.edu
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
The Perceptron algorithm
 The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
Support Vector Machine II
 Support Vector Machine II Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 due tonight HW 2 released. Online Scalable Learning Adaptive to Unknown Dynamics and Graphs Yanning
Support Vector Machine II Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 due tonight HW 2 released. Online Scalable Learning Adaptive to Unknown Dynamics and Graphs Yanning
Support Vector Machines
 Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
CSE 151 Machine Learning. Instructor: Kamalika Chaudhuri
 CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Linear Classification Given labeled data: (xi, feature vector yi) label i=1,..,n where y is 1 or 1, find a hyperplane to separate from Linear Classification
CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Linear Classification Given labeled data: (xi, feature vector yi) label i=1,..,n where y is 1 or 1, find a hyperplane to separate from Linear Classification
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Linear models and the perceptron algorithm
 8/5/6 Preliminaries Linear models and the perceptron algorithm Chapters, 3 Definition: The Euclidean dot product beteen to vectors is the expression dx T x = i x i The dot product is also referred to as
8/5/6 Preliminaries Linear models and the perceptron algorithm Chapters, 3 Definition: The Euclidean dot product beteen to vectors is the expression dx T x = i x i The dot product is also referred to as
HOMEWORK 4: SVMS AND KERNELS
 HOMEWORK 4: SVMS AND KERNELS CMU 060: MACHINE LEARNING (FALL 206) OUT: Sep. 26, 206 DUE: 5:30 pm, Oct. 05, 206 TAs: Simon Shaolei Du, Tianshu Ren, Hsiao-Yu Fish Tung Instructions Homework Submission: Submit
HOMEWORK 4: SVMS AND KERNELS CMU 060: MACHINE LEARNING (FALL 206) OUT: Sep. 26, 206 DUE: 5:30 pm, Oct. 05, 206 TAs: Simon Shaolei Du, Tianshu Ren, Hsiao-Yu Fish Tung Instructions Homework Submission: Submit
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
LINEAR CLASSIFIERS Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification, the input
Linear Classifiers and the Perceptron
 Linear Classifiers and the Perceptron William Cohen February 4, 2008 1 Linear classifiers Let s assume that every instance is an n-dimensional vector of real numbers x R n, and there are only two possible
Linear Classifiers and the Perceptron William Cohen February 4, 2008 1 Linear classifiers Let s assume that every instance is an n-dimensional vector of real numbers x R n, and there are only two possible
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Support Vector Machine I
 Support Vector Machine I Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Please use piazza. No emails. HW 0 grades are back. Re-grade request for one week. HW 1 due soon. HW
Support Vector Machine I Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Please use piazza. No emails. HW 0 grades are back. Re-grade request for one week. HW 1 due soon. HW
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Natural Language Processing. Classification. Features. Some Definitions. Classification. Feature Vectors. Classification I. Dan Klein UC Berkeley
 Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Perceptron & Neural Networks
 School of Computer Science 10-701 Introduction to Machine Learning Perceptron & Neural Networks Readings: Bishop Ch. 4.1.7, Ch. 5 Murphy Ch. 16.5, Ch. 28 Mitchell Ch. 4 Matt Gormley Lecture 12 October
School of Computer Science 10-701 Introduction to Machine Learning Perceptron & Neural Networks Readings: Bishop Ch. 4.1.7, Ch. 5 Murphy Ch. 16.5, Ch. 28 Mitchell Ch. 4 Matt Gormley Lecture 12 October
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Errors, and What to Do. CS 188: Artificial Intelligence Fall What to Do About Errors. Later On. Some (Simplified) Biology
 Biology") CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
The Perceptron Algorithm
 The Perceptron Algorithm Greg Grudic Greg Grudic Machine Learning Questions? Greg Grudic Machine Learning 2 Binary Classification A binary classifier is a mapping from a set of d inputs to a single output
The Perceptron Algorithm Greg Grudic Greg Grudic Machine Learning Questions? Greg Grudic Machine Learning 2 Binary Classification A binary classifier is a mapping from a set of d inputs to a single output
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
Lecture 10: Linear Discriminant Functions Perceptron. Aykut Erdem March 2016 Hacettepe University
 Lecture 10: Linear Discriminant Functions Perceptron Aykut Erdem March 2016 Hacettepe University Administrative Project proposal due today! a half page description problem to be investigated, why it is
Lecture 10: Linear Discriminant Functions Perceptron Aykut Erdem March 2016 Hacettepe University Administrative Project proposal due today! a half page description problem to be investigated, why it is
Kernels. Machine Learning CSE446 Carlos Guestrin University of Washington. October 28, Carlos Guestrin
 Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Support Vector Machines
 Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
The Perceptron Algorithm 1
 CS 64: Machine Learning Spring 5 College of Computer and Information Science Northeastern University Lecture 5 March, 6 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu Introduction The Perceptron
CS 64: Machine Learning Spring 5 College of Computer and Information Science Northeastern University Lecture 5 March, 6 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu Introduction The Perceptron
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining Linear Classifiers: predictions Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due Friday of next
CPSC 340: Machine Learning and Data Mining Linear Classifiers: predictions Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due Friday of next
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Single layer NN. Neuron Model
 Single layer NN We consider the simple architecture consisting of just one neuron. Generalization to a single layer with more neurons as illustrated below is easy because: M M The output units are independent
Single layer NN We consider the simple architecture consisting of just one neuron. Generalization to a single layer with more neurons as illustrated below is easy because: M M The output units are independent
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
Machine Learning (CSE 446): Neural Networks
: Neural Networks") Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Machine Learning (CSE 446): Neural Networks Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 6, 2017 1 / 22 Admin No Wednesday office hours for Noah; no lecture Friday. 2 /
Numerical Learning Algorithms
 Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt.
 1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
CPSC 340: Machine Learning and Data Mining. Stochastic Gradient Fall 2017
 CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
Artificial Neural Networks The Introduction
 Artificial Neural Networks The Introduction 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001 00100000
Artificial Neural Networks The Introduction 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001 00100000
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Lecture 12. Neural Networks Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 12 Neural Networks 24.11.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de Talk Announcement Yann LeCun (NYU & FaceBook AI)
Advanced Machine Learning Lecture 12 Neural Networks 24.11.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de Talk Announcement Yann LeCun (NYU & FaceBook AI)
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning
 SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
SVAN 2016 Mini Course: Stochastic Convex Optimization Methods in Machine Learning Mark Schmidt University of British Columbia, May 2016 www.cs.ubc.ca/~schmidtm/svan16 Some images from this lecture are
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation