Dan Roth 461C, 3401 Walnut
|
|
|
- Mark Hunt
- 5 years ago
- Views:
Transcription
1 CIS 519/419 Applied Machine Learning Dan Roth 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn or CS446 at UIUC), Eric Eaton for CIS519/419 at Penn, or from other authors who have made their ML slides available.


2 Overall (142): Mean: Std Dev: 14.9 Max: 98.5, Min: 1 Midterm Exams Undergrads Grads Solutions will be available tomorrow. Midterms will be made available at the recitations, Wednesday and Thursday. This will also be a good opportunity to ask the TAs questions about the grading. Questions? Class is curved; B+ will be around here 2
3 Projects Please start working! Come to my office hours at least once in the next 3 weeks to discuss the project. HW2 Grades are out too. PDF (40) Code (60) Total (100) EC (10) Mean Stdev Max Min # submissions HW3 is out. You can only do part of it now. Hopefully can do it all by Wednesday. 3
4 COLT approach to explaining Learning No Distributional Assumption Training Distribution is the same as the Test Distribution Generalization bounds depend on this view and affects model selection. Err D (h) < Err TR (h) + P(VC(H), log(1/ϒ),1/m) This is also called the Structural Risk Minimization principle. 4
5 COLT approach to explaining Learning No Distributional Assumption Training Distribution is the same as the Test Distribution Generalization bounds depend on this view and affect model selection. Err D (h) < Err TR (h) + P(VC(H), log(1/ϒ),1/m) As presented, the VC dimension is a combinatorial parameter that is associated with a class of functions. We know that the class of linear functions has a lower VC dimension than the class of quadratic functions. But, this notion can be refined to depend on a given data set, and this way directly affect the hypothesis chosen for a given data set. 5
6 Data Dependent VC dimension So far we discussed VC dimension in the context of a fixed class of functions. We can also parameterize the class of functions in interesting ways. Consider the class of linear functions, parameterized by their margin. Note that this is a data dependent notion. 6
7 Linear Classification Let X = R 2, Y = {+1, -1} Which of these classifiers would be likely to generalize better? h 1 h 2 7
8 VC and Linear Classification Recall the VC based generalization bound: Err(h) err TR (h) + Poly{VC(H), 1/m, log(1/ϒ)} Here we get the same bound for both classifiers: Err TR (h 1 ) = Err TR (h 2 )= 0 h 1, h 2 2 H lin(2), VC(H lin(2) ) = 3 How, then, can we explain our intuition that h 2 should give better generalization than h 1? 8
9 Linear Classification Although both classifiers separate the data, the distance with which the separation is achieved is different: h 1 h 2 9
10 Concept of Margin The margin ϒ i of a point x i Є R n with respect to a linear classifier h(x) = sign(w T x +b) is defined as the distance of x i from the hyperplane w T x +b = 0: ϒ i = (w T x i +b)/ w The margin of a set of points {x 1, x m } with respect to a hyperplane w, is defined as the margin of the point closest to the hyperplane: ϒ = min i ϒ i = min i (w T x i +b)/ w 10
11 VC and Linear Classification Theorem: If H ϒ is the space of all linear classifiers in R n that separate the training data with margin at least ϒ, then: VC(H ϒ ) min(r 2 / ϒ 2, n) +1, Where R is the radius of the smallest sphere (in R n ) that contains the data. Thus, for such classifiers, we have a bound of the form: Err(h) err TR (h) + { (O(R 2 /ϒ 2 ) + log(4/δ))/m } 1/2 11
12 Towards Max Margin Classifiers First observation: When we consider the class H ϒ of linear hypotheses that separate a given data set with a margin ϒ, We see that Large Margin ϒ Small VC dimension of H ϒ Consequently, our goal could be to find a separating hyperplane w that maximizes the margin of the set S of examples. But, how can we do it algorithmically? A second observation that drives an algorithmic approach is that: Small w Large Margin Together, this leads to an algorithm: from among all those w s that agree with the data, find the one with the minimal size w But, if w separates the data, so does w/7. We need to better understand the relations between w and the margin 12
13 The distance between a point x and the hyperplane defined by (w; b) is: w T x + b / w Maximal Margin A hypothesis (w,b) has many names This discussion motivates the notion of a maximal margin. The maximal margin of a data set S is define as: ϒ(S) = max w =1 min (x,y) Є S y w T x 1. For a given w: Find the closest point. 2. Then, find the point that gives the maximal margin value across all w s (of size 1). Note: the selection of the point is in the min and therefore the max does not change if we scale w, so it s okay to only deal with normalized w s. Interpretation 1: among all w s, choose the one that maximizes the margin. How does it help us to derive these h s? argmax w =1 min (x,y) Є S y w T x 13
14 Recap: Margin and VC dimension Believe We ll show Theorem (Vapnik): If H ϒ is the space of all linear classifiers in R n that separate the training data with margin at least ϒ, then VC(H ϒ ) R 2 /ϒ 2 where R is the radius of the smallest sphere (in R n ) that contains the data. This is the first observation that will lead to an algorithmic approach. The second observation is that: Small w Large Margin Consequently: the algorithm will be: from among all those w s that agree with the data, find the one with the minimal size w 14
15 From Margin to W We want to choose the hyperplane that achieves the largest margin. That is, given a data set S, find: w * = argmax w =1 min (x,y) Є S y w T x How to find this w *? Interpretation 2: among all w s that separate the data with margin 1, choose the one with minimal size. Claim: Define w 0 to be the solution of the optimization problem: w 0 = argmin { w 2 : (x,y) Є S, y w T x 1 }. Then: w 0 / w 0 = argmax w =1 min (x,y) Є S y w T x That is, the normalization of w 0 corresponds to the largest margin separating hyperplane. The next slide will show that the two interpretations are equivalent 15
16 From Margin to W (2) Def. of w 0 Claim: Define w 0 to be the solution of the optimization problem: w 0 = argmin { w 2 : (x,y) Є S, y w T x 1 } (**) Then: w 0 / w 0 = argmax w =1 min (x,y) Є S y w T x That is, the normalization of w 0 corresponds to the largest margin separating hyperplane. Proof: Define w = w 0 / w 0 and let w * be the largest-margin separating hyperplane of size 1. We need to show that w = w *. Note first that w * /ϒ(S) satisfies the constraints in (**); therefore: w 0 w * / ϒ(S) = 1/ ϒ(S). Consequently: Def. of w Def. of w 0 Prev. ineq. (x,y) Є S y w T x = 1/ w 0 y w 0T x 1/ w 0 ϒ(S) But since w = 1 this implies that w corresponds to the largest margin, that is w = w * 16
17 Margin of a Separating Hyperplane A separating hyperplane: w T x+b = 0 Assumption: data is linearly separable Let (x 0, y 0 ) be a point on w T x+b = 1 Then its distance to the separating plane w T x+b = 0 is: w T x 0 +b / w = 1/ w Distance between w T x+b = +1 and -1 is 2 / w What we did: 1. Consider all possible w with different angles 2. Scale w such that the constraints are tight 3. Pick the one with largest margin/minimal size w T x i +b 1 if y i = 1 w T x i +b -1 if y i = -1 => yy ii (ww TT xx ii + bb) 1 w T x+b = 0 w T x+b = -1 17
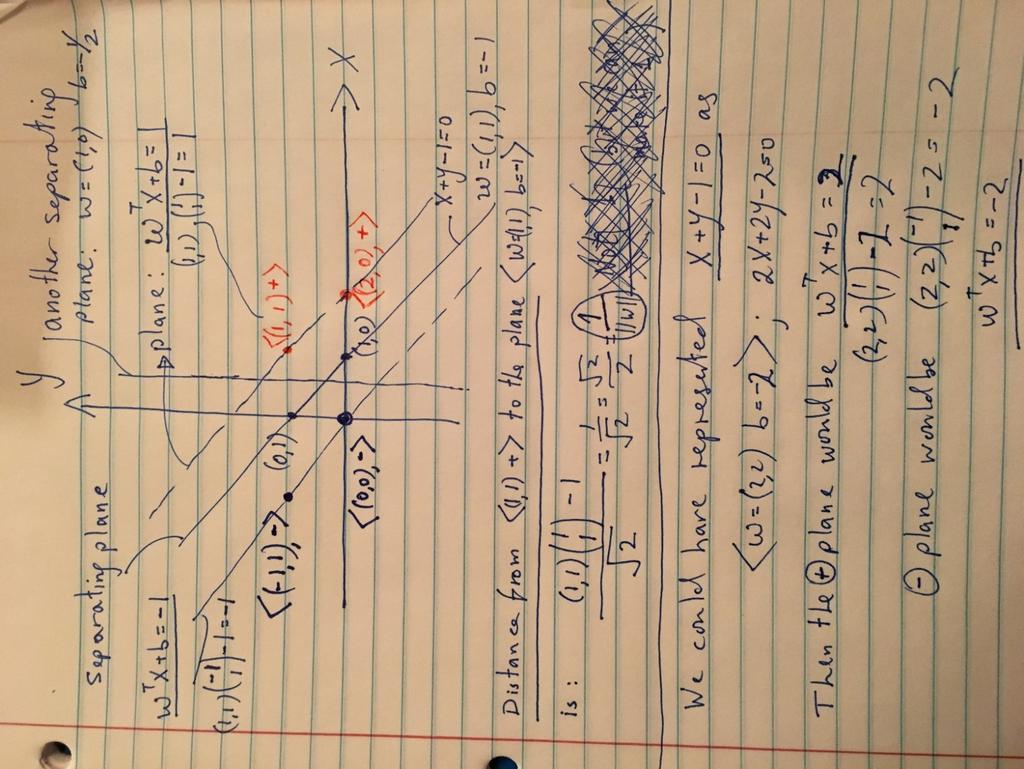
18 18
19 Hard SVM Optimization We have shown that the sought after weight vector w is the solution of the following optimization problem: SVM Optimization: (***) Minimize: ½ w 2 Subject to: (x,y) Є S: y w T x 1 This is a quadratic optimization problem in (n+1) variables, with S =m inequality constraints. It has a unique solution. 19
20 Maximal Margin The margin of a linear separator w T x+b = 0 is 2 / w max 2 / w = min w = min ½ w T w min ww,bb 1 2 wwtt ww s.t y i (w T x i + bb) 1, xx ii, yy ii SS 20
21 Support Vector Machines The name Support Vector Machine stems from the fact that w* is supported by (i.e. is the linear span of) the examples that are exactly at a distance 1/ w* from the separating hyperplane. These vectors are therefore called support vectors. Theorem: Let w* be the minimizer of the SVM optimization problem (***) for S = {(x i, y i )}. Let I= {i: w *T x i = 1}. Then there exists coefficients i >0 such that: w * = i Є I α i y i x i This representation should ring a bell 21
 for S = {(x i, y i )}. Let I= {i: y i (w *T x i +b)= 1}.")
22 Duality This, and other properties of Support Vector Machines are shown by moving to the dual problem. Theorem: Let w* be the minimizer of the SVM optimization problem (***) for S = {(x i, y i )}. Let I= {i: y i (w *T x i +b)= 1}. Then there exists coefficients α i >0 such that: w * = i Є I α i y i x i 22
23 Footnote about the threshold Similar to Perceptron, we can augment vectors to handle the bias term xx xx, 1 ; ww ww, bb so that ww TT xx = ww TT xx + bb Then consider the following formulation 1 min ww 2 wwtt ww s.t y i ww T xx i 1, xx ii, yy ii S However, this formulation is slightly different from (***), because it is equivalent to min ww,bb 1 2 wwtt ww bb2 s.t y i (ww T x i + bb) 1, xx ii, yy ii S The bias term is included in the regularization. This usually doesn t matter For simplicity, we ignore the bias term 25
24 Key Issues Computational Issues Training of an SVM used to be is very time consuming solving quadratic program. Modern methods are based on Stochastic Gradient Descent and Coordinate Descent and are much faster. Is it really optimal? Is the objective function we are optimizing the right one? 26
25 Real Data 17,000 dimensional context sensitive spelling Histogram of distance of points from the hyperplane In practice, even in the separable case, we may not want to depend on the points closest to the hyperplane but rather on the distribution of the distance. If only a few are close, maybe we can dismiss them. 27
26 Soft SVM The hard SVM formulation assumes linearly separable data. A natural relaxation: maximize the margin while minimizing the # of examples that violate the margin (separability) constraints. However, this leads to non-convex problem that is hard to solve. Instead, we relax in a different way, that results in optimizing a surrogate loss function that is convex. 28
27 Soft SVM Notice that the relaxation of the constraint: y i w T x i 1 Can be done by introducing a slack variable ξξ ii (per example) and requiring: Now, we want to solve: y i w T x i 1 ξξ ii ; ξξ ii 0 1 min ww,ξξ ii 2 wwtt ww + CC ii ξξ ii s.t y i w T x i 1 ξξ ii ; ξξ ii 0 ii A large value of C means that misclassifications are bad we focus on a small training error (at the expense of margin). A small C results in more training error, but hopefully better true error. 29
28 Soft SVM (2) Now, we want to solve: min 1 ww,ξξ ii Which can be written as: 1 min ww 2 wwtt ww + CC 2 wwtt ww + CC ii ξξ ii s.t ξξy i w T ii 1x i y1 i w T xξξ i ii ;; ξξ iiii 0 ii What is the interpretation of this? ii In optimum, ξ i = max(0, 1 y i w T x i ) max(0, 1 yy ii ww TT xx ii ). 30
29 SVM Objective Function The problem we solved is: Min ½ w 2 + c ξξ ii Where ξξ ii > 0 is called a slack variable, and is defined by: ξξ ii = max(0, 1 y i w t x i ) Equivalently, we can say that: y i w t x i 1 - ξξ ii ; ξξ ii 0 And this can be written as: Min ½ w 2 + c ξξ ii Regularization term Can be replaced by other regularization functions Empirical loss Can be replaced by other loss functions General Form of a learning algorithm: Minimize empirical loss, and Regularize (to avoid over fitting) Theoretically motivated improvement over the original algorithm we ve seen at the beginning of the semester. 31
30 Balance between regularization and empirical loss 32
31 Balance between regularization and empirical loss (DEMO) 33


32 Underfitting and Overfitting Expected Error Underfitting Overfitting Variance Bias Model complexity Simple models: High bias and low variance Smaller C Complex models: High variance and low bias Larger C 34
33 What Do We Optimize? 35
34 What Do We Optimize(2)? We get an unconstrained problem. We can use the gradient descent algorithm! However, it is quite slow. Many other methods Iterative scaling; non-linear conjugate gradient; quasi-newton methods; truncated Newton methods; trust-region newton method. All methods are iterative methods, that generate a sequence w k that converges to the optimal solution of the optimization problem above. Currently: Limited memory BFGS is very popular 36
35 Optimization: How to Solve 1. Earlier methods used Quadratic Programming. Very slow. 2. The soft SVM problem is an unconstrained optimization problems. It is possible to use the gradient descent algorithm. Many options within this category: Iterative scaling; non-linear conjugate gradient; quasi-newton methods; truncated Newton methods; trust-region newton method. All methods are iterative methods, that generate a sequence w k that converges to the optimal solution of the optimization problem above. Currently: Limited memory BFGS is very popular 3. 3 rd generation algorithms are based on Stochastic Gradient Decent The runtime does not depend on n=#(examples); advantage when n is very large. Stopping criteria is a problem: method tends to be too aggressive at the beginning and reaches a moderate accuracy quite fast, but it s convergence becomes slow if we are interested in more accurate solutions. 4. Dual Coordinated Descent (& Stochastic Version) 37
36 SGD for SVM Goal: min ww ff ww 1 2 wwtt ww + CC mm ii max 0, 1 yy ii ww TT xx ii. m: data size Compute sub-gradient of ff ww : ff ww = ww CCyy ii xx ii if 1 yy ii ww TT xx ii 0 ; otherwise ff ww = ww 1. Initialize ww = 0 RR nn 2. For every example x i, y i DD If yy ii ww TT xx ii 1 update the weight vector to ww 1 γγ ww + γγccyy ii xx ii Otherwise ww (1 γγ)ww 3. Continue until convergence is achieved Convergence can be proved for a slightly complicated version of SGD (e.g, Pegasos) m is here for mathematical correctness, it doesn t matter in the view of modeling. (γγ - learning rate) This algorithm should ring a bell 38
37 Nonlinear SVM We can map data to a high dimensional space: x φφ xx (DEMO) Then use Kernel trick: KK xx ii, xx jj = φφ xx TT ii φφ xx jj (DEMO2) Primal: Dual: 1 min ww,ξξ ii 2 wwtt ww + CC ii ξξ ii 1 min αα 2 ααtt Qαα ee TT αα s.t y i w T φφ xx ii 1 ξξ ii s.t 0 αα CC ii ξξ ii 0 ii Q iiii = yy ii yy jj KK xx ii, xx jj Theorem: Let w* be the minimizer of the primal problem, αα be the minimizer of the dual problem. Then w = ii αα y i x i 39
38 Nonlinear SVM Tradeoff between training time and accuracy Complex model v.s. simple model From: 40
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Support Vector Machines. CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Topics we covered. Machine Learning. Statistics. Optimization. Systems! Basics of probability Tail bounds Density Estimation Exponential Families
 Midterm Review Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines
Midterm Review Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Machine Learning Basics Lecture 4: SVM I. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
 Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Lecture 11. Kernel Methods
 Lecture 11. Kernel Methods COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture The kernel trick Efficient computation of a dot product
Lecture 11. Kernel Methods COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture The kernel trick Efficient computation of a dot product
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
Support Vector Machines, Kernel SVM
 Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Linear classifiers Lecture 3
 Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Kernels. Machine Learning CSE446 Carlos Guestrin University of Washington. October 28, Carlos Guestrin
 Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Support Vector Machines
 Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Support Vector Machines for Classification and Regression
 CIS 520: Machine Learning Oct 04, 207 Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may
CIS 520: Machine Learning Oct 04, 207 Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Machine Learning A Geometric Approach
 Machine Learning A Geometric Approach CIML book Chap 7.7 Linear Classification: Support Vector Machines (SVM) Professor Liang Huang some slides from Alex Smola (CMU) Linear Separator Ham Spam From Perceptron
Machine Learning A Geometric Approach CIML book Chap 7.7 Linear Classification: Support Vector Machines (SVM) Professor Liang Huang some slides from Alex Smola (CMU) Linear Separator Ham Spam From Perceptron
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machines for Classification and Regression. 1 Linearly Separable Data: Hard Margin SVMs
 E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Statistical and Computational Learning Theory
 Statistical and Computational Learning Theory Fundamental Question: Predict Error Rates Given: Find: The space H of hypotheses The number and distribution of the training examples S The complexity of the
Statistical and Computational Learning Theory Fundamental Question: Predict Error Rates Given: Find: The space H of hypotheses The number and distribution of the training examples S The complexity of the
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012
 CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
Support Vector and Kernel Methods
 SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
Learning From Data Lecture 25 The Kernel Trick
 Learning From Data Lecture 25 The Kernel Trick Learning with only inner products The Kernel M. Magdon-Ismail CSCI 400/600 recap: Large Margin is Better Controling Overfitting Non-Separable Data 0.08 random
Learning From Data Lecture 25 The Kernel Trick Learning with only inner products The Kernel M. Magdon-Ismail CSCI 400/600 recap: Large Margin is Better Controling Overfitting Non-Separable Data 0.08 random
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Statistical Pattern Recognition
 Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
Lecture 4: Linear predictors and the Perceptron
 Lecture 4: Linear predictors and the Perceptron Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 4 1 / 34 Inductive Bias Inductive bias is critical to prevent overfitting.
Lecture 4: Linear predictors and the Perceptron Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 4 1 / 34 Inductive Bias Inductive bias is critical to prevent overfitting.
Loss Functions, Decision Theory, and Linear Models
 Loss Functions, Decision Theory, and Linear Models CMSC 678 UMBC January 31 st, 2018 Some slides adapted from Hamed Pirsiavash Logistics Recap Piazza (ask & answer questions): https://piazza.com/umbc/spring2018/cmsc678
Loss Functions, Decision Theory, and Linear Models CMSC 678 UMBC January 31 st, 2018 Some slides adapted from Hamed Pirsiavash Logistics Recap Piazza (ask & answer questions): https://piazza.com/umbc/spring2018/cmsc678
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
The Perceptron Algorithm, Margins
 The Perceptron Algorithm, Margins MariaFlorina Balcan 08/29/2018 The Perceptron Algorithm Simple learning algorithm for supervised classification analyzed via geometric margins in the 50 s [Rosenblatt
The Perceptron Algorithm, Margins MariaFlorina Balcan 08/29/2018 The Perceptron Algorithm Simple learning algorithm for supervised classification analyzed via geometric margins in the 50 s [Rosenblatt
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining Linear Classifiers: predictions Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due Friday of next
CPSC 340: Machine Learning and Data Mining Linear Classifiers: predictions Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due Friday of next
Computational and Statistical Learning Theory
 Computational and Statistical Learning Theory TTIC 31120 Prof. Nati Srebro Lecture 17: Stochastic Optimization Part II: Realizable vs Agnostic Rates Part III: Nearest Neighbor Classification Stochastic
Computational and Statistical Learning Theory TTIC 31120 Prof. Nati Srebro Lecture 17: Stochastic Optimization Part II: Realizable vs Agnostic Rates Part III: Nearest Neighbor Classification Stochastic
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie
 A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
Modelli Lineari (Generalizzati) e SVM
 e SVM") Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Machine Learning 4771
 Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
Machine Learning 477 Instructor: Tony Jebara Topic 5 Generalization Guarantees VC-Dimension Nearest Neighbor Classification (infinite VC dimension) Structural Risk Minimization Support Vector Machines
FIND A FUNCTION TO CLASSIFY HIGH VALUE CUSTOMERS
 LINEAR CLASSIFIER 1 FIND A FUNCTION TO CLASSIFY HIGH VALUE CUSTOMERS x f y High Value Customers Salary Task: Find Nb Orders 150 70 300 100 200 80 120 100 Low Value Customers Salary Nb Orders 40 80 220
LINEAR CLASSIFIER 1 FIND A FUNCTION TO CLASSIFY HIGH VALUE CUSTOMERS x f y High Value Customers Salary Task: Find Nb Orders 150 70 300 100 200 80 120 100 Low Value Customers Salary Nb Orders 40 80 220
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Natural Language Processing. Classification. Features. Some Definitions. Classification. Feature Vectors. Classification I. Dan Klein UC Berkeley
 Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Lecture 18: Kernels Risk and Loss Support Vector Regression. Aykut Erdem December 2016 Hacettepe University
 Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Multi-class SVMs. Lecture 17: Aykut Erdem April 2016 Hacettepe University
 Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Support Vector Machines
 Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
CS269: Machine Learning Theory Lecture 16: SVMs and Kernels November 17, 2010
 CS269: Machine Learning Theory Lecture 6: SVMs and Kernels November 7, 200 Lecturer: Jennifer Wortman Vaughan Scribe: Jason Au, Ling Fang, Kwanho Lee Today, we will continue on the topic of support vector
CS269: Machine Learning Theory Lecture 6: SVMs and Kernels November 7, 200 Lecturer: Jennifer Wortman Vaughan Scribe: Jason Au, Ling Fang, Kwanho Lee Today, we will continue on the topic of support vector
Outline. Basic concepts: SVM and kernels SVM primal/dual problems. Chih-Jen Lin (National Taiwan Univ.) 1 / 22
 1 / 22") Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Incorporating detractors into SVM classification
 Incorporating detractors into SVM classification AGH University of Science and Technology 1 2 3 4 5 (SVM) SVM - are a set of supervised learning methods used for classification and regression SVM maximal
Incorporating detractors into SVM classification AGH University of Science and Technology 1 2 3 4 5 (SVM) SVM - are a set of supervised learning methods used for classification and regression SVM maximal
Simple Techniques for Improving SGD. CS6787 Lecture 2 Fall 2017
 Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Support Vector Machine and Neural Network Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 1 Announcements Due end of the day of this Friday (11:59pm) Reminder
CS249: ADVANCED DATA MINING Support Vector Machine and Neural Network Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 1 Announcements Due end of the day of this Friday (11:59pm) Reminder
Machine Learning and Data Mining. Support Vector Machines. Kalev Kask
 Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Homework 2 Solutions Kernel SVM and Perceptron
 Homework 2 Solutions Kernel SVM and Perceptron CMU 1-71: Machine Learning (Fall 21) https://piazza.com/cmu/fall21/17115781/home OUT: Sept 25, 21 DUE: Oct 8, 11:59 PM Problem 1: SVM decision boundaries
Homework 2 Solutions Kernel SVM and Perceptron CMU 1-71: Machine Learning (Fall 21) https://piazza.com/cmu/fall21/17115781/home OUT: Sept 25, 21 DUE: Oct 8, 11:59 PM Problem 1: SVM decision boundaries
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
COMP 652: Machine Learning. Lecture 12. COMP Lecture 12 1 / 37
 COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Training Support Vector Machines: Status and Challenges
 ICML Workshop on Large Scale Learning Challenge July 9, 2008 Chih-Jen Lin (National Taiwan Univ.) 1 / 34 Training Support Vector Machines: Status and Challenges Chih-Jen Lin Department of Computer Science
ICML Workshop on Large Scale Learning Challenge July 9, 2008 Chih-Jen Lin (National Taiwan Univ.) 1 / 34 Training Support Vector Machines: Status and Challenges Chih-Jen Lin Department of Computer Science
SVMs, Duality and the Kernel Trick
 SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
COMP 875 Announcements
 Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
CS446: Machine Learning Spring Problem Set 4
 CS446: Machine Learning Spring 2017 Problem Set 4 Handed Out: February 27 th, 2017 Due: March 11 th, 2017 Feel free to talk to other members of the class in doing the homework. I am more concerned that
CS446: Machine Learning Spring 2017 Problem Set 4 Handed Out: February 27 th, 2017 Due: March 11 th, 2017 Feel free to talk to other members of the class in doing the homework. I am more concerned that
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Support Vector Machine I
 Support Vector Machine I Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Please use piazza. No emails. HW 0 grades are back. Re-grade request for one week. HW 1 due soon. HW
Support Vector Machine I Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Please use piazza. No emails. HW 0 grades are back. Re-grade request for one week. HW 1 due soon. HW
UVA CS 4501: Machine Learning
 UVA CS 4501: Machine Learning Lecture 16 Extra: Support Vector Machine Optimization with Dual Dr. Yanjun Qi University of Virginia Department of Computer Science Today Extra q Optimization of SVM ü SVM
UVA CS 4501: Machine Learning Lecture 16 Extra: Support Vector Machine Optimization with Dual Dr. Yanjun Qi University of Virginia Department of Computer Science Today Extra q Optimization of SVM ü SVM
Day 4: Classification, support vector machines
 Day 4: Classification, support vector machines Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 21 June 2018 Topics so far
Day 4: Classification, support vector machines Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 21 June 2018 Topics so far
LECTURE 7 Support vector machines
 LECTURE 7 Support vector machines SVMs have been used in a multitude of applications and are one of the most popular machine learning algorithms. We will derive the SVM algorithm from two perspectives:
LECTURE 7 Support vector machines SVMs have been used in a multitude of applications and are one of the most popular machine learning algorithms. We will derive the SVM algorithm from two perspectives:
LECTURE NOTE #8 PROF. ALAN YUILLE. Can we find a linear classifier that separates the position and negative examples?
 LECTURE NOTE #8 PROF. ALAN YUILLE 1. Linear Classifiers and Perceptrons A dataset contains N samples: { (x µ, y µ ) : µ = 1 to N }, y µ {±1} Can we find a linear classifier that separates the position
LECTURE NOTE #8 PROF. ALAN YUILLE 1. Linear Classifiers and Perceptrons A dataset contains N samples: { (x µ, y µ ) : µ = 1 to N }, y µ {±1} Can we find a linear classifier that separates the position
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
Lecture 3: Multiclass Classification
 Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
Cutting Plane Training of Structural SVM
 Cutting Plane Training of Structural SVM Seth Neel University of Pennsylvania sethneel@wharton.upenn.edu September 28, 2017 Seth Neel (Penn) Short title September 28, 2017 1 / 33 Overview Structural SVMs
Cutting Plane Training of Structural SVM Seth Neel University of Pennsylvania sethneel@wharton.upenn.edu September 28, 2017 Seth Neel (Penn) Short title September 28, 2017 1 / 33 Overview Structural SVMs
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Active Learning and Optimized Information Gathering
 Active Learning and Optimized Information Gathering Lecture 7 Learning Theory CS 101.2 Andreas Krause Announcements Project proposal: Due tomorrow 1/27 Homework 1: Due Thursday 1/29 Any time is ok. Office
Active Learning and Optimized Information Gathering Lecture 7 Learning Theory CS 101.2 Andreas Krause Announcements Project proposal: Due tomorrow 1/27 Homework 1: Due Thursday 1/29 Any time is ok. Office