Topics we covered. Machine Learning. Statistics. Optimization. Systems! Basics of probability Tail bounds Density Estimation Exponential Families
|
|
|
- Nickolas Harrington
- 5 years ago
- Views:
Transcription
1 Midterm Review
2 Topics we covered Machine Learning Optimization Basics of optimization Convexity Unconstrained: GD, SGD Constrained: Lagrange, KKT Duality Linear Methods Perceptrons Support Vector Machines Kernels Statistics Basics of probability Tail bounds Density Estimation Exponential Families Graphical Models Systems!
3 Basics of Machine Learning Supervised/Unsupervised Learning? Classification, Regression, Clustering Training error/test error? Model Complexity: Overfitting/Underfitting True error Bayes Optimal Error
4 Bias-Variance Tradeoff When estimating a quantity θ, we evaluate the performance of an estimator by computing its risk expected value of a loss function R θ, θ = E L(θ, θ), where L could be Mean Squared Error Loss 0/1 Loss Hinge Loss (used for SVMs) Bias-Variance Decomposition: Y = f x + ε Err x = E f x f x 2 = (E f x f(x)) 2 +E f x E f x 2 + σε 2 Bias Variance 3/3/2015 4

5 Copied from: Junier Oliva
6 Copied from: Junier Oliva
7 Copied from: Junier Oliva
8 Copied from: Junier Oliva
9 Copied from: Junier Oliva
10 Copied from: Junier Oliva
11 Copied from: Junier Oliva
12 Copied from: Junier Oliva
13 Copied from: Junier Oliva
14 Regression
15 Optimization Copied from: Xuezhi Wang
16 Convex Sets Copied from: Xuezhi Wang
17 Convex Functions Copied from: Xuezhi Wang
18 Convex Functions Examples
19 Useful Observations A function is convex if and only if its epigraph is a convex set. Below-Sets of Convex Functions is a convex set Convex functions cannot have local minima
20 Gradient Descent Copied from: Xuezhi Wang
21 Newton s Method Copied from: Prof Barnabas
22 Newton s Method Copied from: Prof Barnabas

23 Duality

24 Duality

25 KKT Conditions
26 Perceptrons
27 Convergence of Perceptrons
28 Back to Optimization
29 Gradient Descent
30 Stochastic Gradient Descent
31 SGD and Perceptron

32 SVM Primal Find maximum margin hyper-plane Hard Margin Copied from: Junier Oliva 3/3/

33 SVM Primal Find maximum margin hyper-plane Soft Margin Copied from: Junier Oliva 3/3/

34 SVM Dual Find maximum margin hyper-plane Dual for the hard margin SVM Copied from: Junier Oliva 3/3/

35 SVM Dual Find maximum margin hyper-plane Dual for the hard margin SVM Substituting α for w Copied from: Junier Oliva 3/3/
36 SVM Dual Find maximum margin hyper-plane Dual for the hard margin SVM The constraints are active for the support vectors Copied from: Junier Oliva 3/3/
37 SVM Dual Find maximum margin hyper-plane Dual for the hard margin SVM Copied from: Junier Oliva 3/3/

38 SVM Computing w Find maximum margin hyper-plane Dual for the hard margin SVM Copied from: Junier Oliva 3/3/


39 SVM Computing w Find maximum margin hyper-plane Dual for the soft margin SVM only difference from the separable case Copied from: Junier Oliva 3/3/

40 SVM the feature map Find maximum margin hyper-plane But data is not linearly separable We obtain a linear separator in the feature space.!! inputs feature map features is expensive to compute! Copied from: Junier Oliva 3/3/
41 Introducing the kernel The dual formulation no longer depends on w, only on a dot product! We obtain a linear separator in the feature space.!! is expensive to compute! But we don t have to! What we need is the dot product: Let s call this a kernel - 2-variable function - can be written as a dot product Copied from: Junier Oliva 3/3/
42 Kernel SVM The dual formulation no longer depends on w, only on a dot product! closed form This is the famous kernel trick. - never compute the feature map - learn using the closed form K - constant time for HD dot products Copied from: Junier Oliva 3/3/
43 Kernel SVM Run time What happens when we need to classify some x 0? Recall that w depends on α Our classifier for x 0 uses w Copied from: Junier Oliva 3/3/


44 Kernel SVM Run time What happens when we need to classify some x 0? Recall that w depends on α Our classifier for x 0 uses w Who needs w when we ve got dot products? Copied from: Junier Oliva 44



45 Kernel SVM Recap Pick kernel Solve the optimization to get α Classify as Compute b using the support vectors Copied from: Junier Oliva 45
46 Reminder on Kernels Remember Kernels are nothing but implicit feature maps Gram Matrix of a set of vectors x 1 x n in the inner product space defined by the kernel K Gram Matrix is always positive definite 46

47 Bayes Rule

48 Law of Large Numbers

49 Central Limit Theorem

50 Tail Bounds

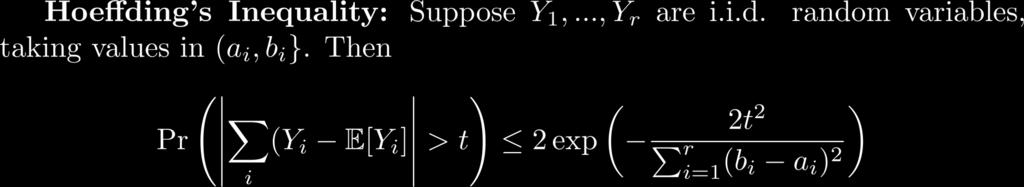
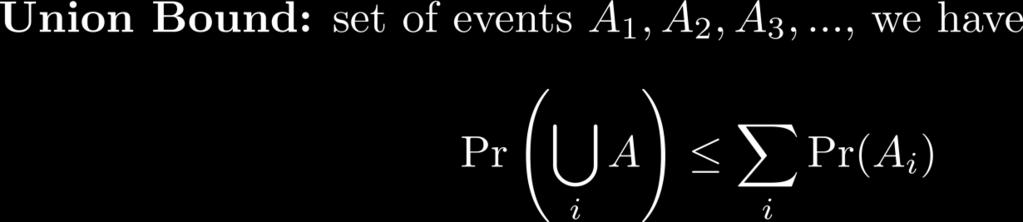
51 More Tail Bounds

52
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
SVMs, Duality and the Kernel Trick
 SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
 Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Machine Learning and Data Mining. Support Vector Machines. Kalev Kask
 Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machines
 Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
Support Vector Machines
 Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
COMS 4771 Regression. Nakul Verma
 COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Kernels. Machine Learning CSE446 Carlos Guestrin University of Washington. October 28, Carlos Guestrin
 Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Kernels Machine Learning CSE446 Carlos Guestrin University of Washington October 28, 2013 Carlos Guestrin 2005-2013 1 Linear Separability: More formally, Using Margin Data linearly separable, if there
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
Support Vector Machines, Kernel SVM
 Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines
 Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
10701 Recitation 5 Duality and SVM. Ahmed Hefny
 10701 Recitation 5 Duality and SVM Ahmed Hefny Outline Langrangian and Duality The Lagrangian Duality Eamples Support Vector Machines Primal Formulation Dual Formulation Soft Margin and Hinge Loss Lagrangian
10701 Recitation 5 Duality and SVM Ahmed Hefny Outline Langrangian and Duality The Lagrangian Duality Eamples Support Vector Machines Primal Formulation Dual Formulation Soft Margin and Hinge Loss Lagrangian
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Machine Learning. Support Vector Machines. Manfred Huber
 Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Support Vector Machines. Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
Kernels and the Kernel Trick. Machine Learning Fall 2017
 Kernels and the Kernel Trick Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem Support vectors, duals and kernels
Kernels and the Kernel Trick Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem Support vectors, duals and kernels
6.036 midterm review. Wednesday, March 18, 15
 6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels
 SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
Machine Learning Basics Lecture 4: SVM I. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Machine Learning Basics Lecture 4: SVM I Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d. from distribution
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machines
 Support Vector Machines Ryan M. Rifkin Google, Inc. 2008 Plan Regularization derivation of SVMs Geometric derivation of SVMs Optimality, Duality and Large Scale SVMs The Regularization Setting (Again)
Support Vector Machines Ryan M. Rifkin Google, Inc. 2008 Plan Regularization derivation of SVMs Geometric derivation of SVMs Optimality, Duality and Large Scale SVMs The Regularization Setting (Again)
Midterm. Introduction to Machine Learning. CS 189 Spring You have 1 hour 20 minutes for the exam.
 CS 189 Spring 2013 Introduction to Machine Learning Midterm You have 1 hour 20 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. Please use non-programmable calculators
CS 189 Spring 2013 Introduction to Machine Learning Midterm You have 1 hour 20 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. Please use non-programmable calculators
CS798: Selected topics in Machine Learning
 CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012
 CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
Lecture Notes on Support Vector Machine
 Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Optimization and Gradient Descent
 Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Machine Learning Basics: Stochastic Gradient Descent. Sargur N. Srihari
 Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 8 Feb. 12, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
Math for Machine Learning Open Doors to Data Science and Artificial Intelligence. Richard Han
 Math for Machine Learning Open Doors to Data Science and Artificial Intelligence Richard Han Copyright 05 Richard Han All rights reserved. CONTENTS PREFACE... - INTRODUCTION... LINEAR REGRESSION... 4 LINEAR
Math for Machine Learning Open Doors to Data Science and Artificial Intelligence Richard Han Copyright 05 Richard Han All rights reserved. CONTENTS PREFACE... - INTRODUCTION... LINEAR REGRESSION... 4 LINEAR
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Pattern Recognition 2018 Support Vector Machines
 Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
COMP 875 Announcements
 Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Multi-class SVMs. Lecture 17: Aykut Erdem April 2016 Hacettepe University
 Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Lecture 3 January 28
 EECS 28B / STAT 24B: Advanced Topics in Statistical LearningSpring 2009 Lecture 3 January 28 Lecturer: Pradeep Ravikumar Scribe: Timothy J. Wheeler Note: These lecture notes are still rough, and have only
EECS 28B / STAT 24B: Advanced Topics in Statistical LearningSpring 2009 Lecture 3 January 28 Lecturer: Pradeep Ravikumar Scribe: Timothy J. Wheeler Note: These lecture notes are still rough, and have only
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
COMP 652: Machine Learning. Lecture 12. COMP Lecture 12 1 / 37
 COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
COMP 652: Machine Learning Lecture 12 COMP 652 Lecture 12 1 / 37 Today Perceptrons Definition Perceptron learning rule Convergence (Linear) support vector machines Margin & max margin classifier Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Numerical Optimization Techniques
 Numerical Optimization Techniques Léon Bottou NEC Labs America COS 424 3/2/2010 Today s Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification,
Numerical Optimization Techniques Léon Bottou NEC Labs America COS 424 3/2/2010 Today s Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification,
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Midterm exam CS 189/289, Fall 2015
 Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Support Vector Machine II
 Support Vector Machine II Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 due tonight HW 2 released. Online Scalable Learning Adaptive to Unknown Dynamics and Graphs Yanning
Support Vector Machine II Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 due tonight HW 2 released. Online Scalable Learning Adaptive to Unknown Dynamics and Graphs Yanning
LECTURE 7 Support vector machines
 LECTURE 7 Support vector machines SVMs have been used in a multitude of applications and are one of the most popular machine learning algorithms. We will derive the SVM algorithm from two perspectives:
LECTURE 7 Support vector machines SVMs have been used in a multitude of applications and are one of the most popular machine learning algorithms. We will derive the SVM algorithm from two perspectives:
COMS 4771 Introduction to Machine Learning. James McInerney Adapted from slides by Nakul Verma
 COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
Support Vector Machines
 Support Vector Machines Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts Sridhar Mahadevan: CMPSCI 689 p. 1/32 Margin Classifiers margin b = 0 Sridhar Mahadevan: CMPSCI 689 p.
Support Vector Machines Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts Sridhar Mahadevan: CMPSCI 689 p. 1/32 Margin Classifiers margin b = 0 Sridhar Mahadevan: CMPSCI 689 p.
Indirect Rule Learning: Support Vector Machines. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
SMO Algorithms for Support Vector Machines without Bias Term
 Institute of Automatic Control Laboratory for Control Systems and Process Automation Prof. Dr.-Ing. Dr. h. c. Rolf Isermann SMO Algorithms for Support Vector Machines without Bias Term Michael Vogt, 18-Jul-2002
Institute of Automatic Control Laboratory for Control Systems and Process Automation Prof. Dr.-Ing. Dr. h. c. Rolf Isermann SMO Algorithms for Support Vector Machines without Bias Term Michael Vogt, 18-Jul-2002
Support Vector Machines
 Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Support Vector Machines and Bayes Regression
 Statistical Techniques in Robotics (16-831, F11) Lecture #14 (Monday ctober 31th) Support Vector Machines and Bayes Regression Lecturer: Drew Bagnell Scribe: Carl Doersch 1 1 Linear SVMs We begin by considering
Statistical Techniques in Robotics (16-831, F11) Lecture #14 (Monday ctober 31th) Support Vector Machines and Bayes Regression Lecturer: Drew Bagnell Scribe: Carl Doersch 1 1 Linear SVMs We begin by considering
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
Support Vector Machines for Classification and Regression. 1 Linearly Separable Data: Hard Margin SVMs
 E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Support Vector Machines and Kernel Methods
 Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
CS269: Machine Learning Theory Lecture 16: SVMs and Kernels November 17, 2010
 CS269: Machine Learning Theory Lecture 6: SVMs and Kernels November 7, 200 Lecturer: Jennifer Wortman Vaughan Scribe: Jason Au, Ling Fang, Kwanho Lee Today, we will continue on the topic of support vector
CS269: Machine Learning Theory Lecture 6: SVMs and Kernels November 7, 200 Lecturer: Jennifer Wortman Vaughan Scribe: Jason Au, Ling Fang, Kwanho Lee Today, we will continue on the topic of support vector
Machine Learning And Applications: Supervised Learning-SVM
 Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
About this class. Maximizing the Margin. Maximum margin classifiers. Picture of large and small margin hyperplanes
 About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
Machine Learning. Lecture 6: Support Vector Machine. Feng Li.
 Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
INTRODUCTION TO DATA SCIENCE
 INTRODUCTION TO DATA SCIENCE JOHN P DICKERSON Lecture #13 3/9/2017 CMSC320 Tuesdays & Thursdays 3:30pm 4:45pm ANNOUNCEMENTS Mini-Project #1 is due Saturday night (3/11): Seems like people are able to do
INTRODUCTION TO DATA SCIENCE JOHN P DICKERSON Lecture #13 3/9/2017 CMSC320 Tuesdays & Thursdays 3:30pm 4:45pm ANNOUNCEMENTS Mini-Project #1 is due Saturday night (3/11): Seems like people are able to do
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Convex Optimization Lecture 16
 Convex Optimization Lecture 16 Today: Projected Gradient Descent Conditional Gradient Descent Stochastic Gradient Descent Random Coordinate Descent Recall: Gradient Descent (Steepest Descent w.r.t Euclidean
Convex Optimization Lecture 16 Today: Projected Gradient Descent Conditional Gradient Descent Stochastic Gradient Descent Random Coordinate Descent Recall: Gradient Descent (Steepest Descent w.r.t Euclidean
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Foundation of Intelligent Systems, Part I. SVM s & Kernel Methods
 Foundation of Intelligent Systems, Part I SVM s & Kernel Methods mcuturi@i.kyoto-u.ac.jp FIS - 2013 1 Support Vector Machines The linearly-separable case FIS - 2013 2 A criterion to select a linear classifier:
Foundation of Intelligent Systems, Part I SVM s & Kernel Methods mcuturi@i.kyoto-u.ac.jp FIS - 2013 1 Support Vector Machines The linearly-separable case FIS - 2013 2 A criterion to select a linear classifier: