Some Problems from Enzyme Families
|
|
|
- Barnaby O’Connor’
- 5 years ago
- Views:
Transcription
1 Some Problems from Enzyme Families Greg Butler Department of Computer Science Concordia University, Montreal Abstract I will discuss some problems from bioinformatics and related areas that we encounter in applying knowledge of families of enzymes during our search of fungal genomes (actually ESTs) for more effective enzymes. These include multiple sequence alignments, scoping the boundaries between families and subfamilies, constructing classifiers for family membership, and predicting enzymatic activity of new sequences/enzymes.
2 Aims of Talk introduce some problems in bioinformatics All are open research problems! give some pointers to solutions Outline Enzymes and Enzyme Families Problem: Determine Properties of a New Enzyme SubProblem: Multiple Sequence Algnment SubProblem: Splitting Families and Subfamilies SubProblem: Building Classifiers SubProblem: Predicting Enzymatic Activity Some Literature References
3 What is an Enzyme? Enzyme is a protein that catalyses a reaction.
4 Enzymes are very specific. What is an Enzyme? Enzymes are very efficient catalysts.
5 Enzyme Families Aim: To classify and organize enzymes. Some Example Classification Schemes EC (Enzyme Commission) numbers To consider the classification and nomenclature of enzymes and coenzymes, their units of activity and standard methods of assay, together with the symbols used in the description of enzyme kinetics. GO (Gene Ontology) three classifications of gene products molecular function biological process cellular component CATH: Class, Architecture, Topology, Homology There is no objective definition. a family is clearly related by sequence similarity, a superfamily is composed of families whose sequence relationship isn t clear, but which are believed on structural and functional grounds to be homologous, and a fold is a group of superfamilies that share a common structural topology but are not necessarily homologous. InterPro combination of many classification schemes

6 Gene Ontology Entry

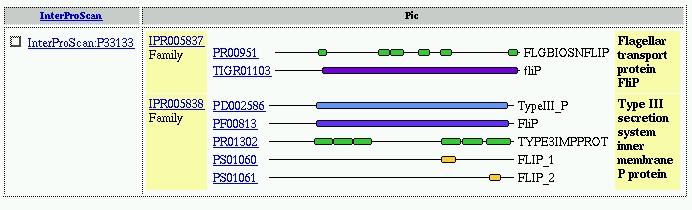
7 InterPro
8 The Fungal Genomics Project

9 Multiple Sequence Alignment (MSA) Problem: Given a set of protein sequences, and an objective function, determine the optimal alignment of the sequences. Why? Amino acid sequence determines protein structure determines enzyme function
10 MSA Issues Multiple sequence alignment is a complicated task choice of the sequences choice of an objective function the optimization of the objective function Issues math vs biology (optimal MSA not necessarily good MSA for biologist) outliers affect results divergence can affect choice of parameters/algorithms multi-domain sequences are problems many sequences, long sequences costly Ideal align closely related sequences trim so only one domain present feed in lots of constraints eg, structural information...
11 Progressive Approaches to MSA sequences are added one by one to the multiple alignment according to a precomputed order Iterative iteratively modify a sub-optimal solution Stochastic iterative randomly modify result is either kept or discarded dependent on an acceptance function convergence via more stringent acceptance function Consistency-based given a set of independent observations, the most consistent are often closer to the truth optimal MSA is one that agrees the most with all the possible optimal pair-wise alignments Constraint-based use prior information as constraints on the alignment

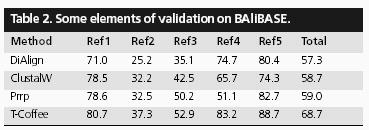
12
13 Splitting Families into Subfamilies Problem: Given the sequences for a family of enzymes, determine how to delineate cohesive subfamilies. Why?: more homologous means easier to study easier to build better alignments easier to build better classifiers Subproblem: remove outliers from the set of sequences
14 Building Classifiers for Enzyme Families Problem: Given the sequences for a family of enzymes, determine how to decide membership in the family. In some cases the sequence of an unknown protein is too distantly related to any protein of known structure to detect its resemblance by overall sequence alignment, but it can be identified by the occurrence in its sequence of a particular cluster of residue types which is variously known as a pattern, motif, signature, or fingerprint. A profile or weight matrix is a table of position-specific amino acid weights and gap costs. A domain is a conserved protein region. independently folding structural unit A fingerprint is a group of conserved motifs used to characterise a protein family.
15 Predicting Enzyme Activity Problem: Given the sequences for a family of enzymes, with (quantitative) information about their enzymatic activity, and given a new sequence in the family, predict the (quantitative) enzymatic activity of the new protein. Why?: quantitative aspect of enzyme function Subproblem: understand known enzymes in (sub)family
16 Measuring Enzyme Kinetic Activity
17 Panther System from Celera The PANTHER database was designed for high-throughput analysis of protein sequences. One of the key features is a simplified ontology of protein function, which allows browsing of the database by biological functions. Biologist curators have associated the ontology terms with groups of protein sequences rather than individual sequences. Statistical models (Hidden Markov Models, or HMMs) are built from each of these groups. The advantage of this approach is that new sequences can be automatically classified as they become available. To ensure accurate functional classification, HMMs are constructed not only for families, but also for functionally distinct subfamilies. Multiple sequence alignments and phylogenetic trees, including curator-assigned information, are available for each family. The current version of the PANTHER database includes training sequences from all organisms in the Gen- Bank non-redundant protein database, and the HMMs have been used to classify gene products across the entire genomes of human, and Drosophila melanogaster.

18 Panther System from Celera

19 Panther System from Celera

20 PipeAlign System from Strasbourg
21 Some Solutions Multiple Sequence Alignment many ClustalW most widely used POA seems best compromise of speed vs quality Splitting a Family into Subfamilies Panther PipeAlign Classifiers of an Enzyme Family many, but HMMer is most widely used Predicting Kinetic Activity???
22 Acknowledgements
23 References L. Duret and S. Abdeddaim, Multiple alignments for structural, functional, or phylogenetic analyses of homologous sequences. In Bioinformatics: Sequence, Structure and Databanks, editted by D. Higgins and W. Taylor, Oxford University Press, C. Notredame, Recent progresses in multiple sequence alignment: a survey, Pharmacogenomics 3(1) (2002) J.D. Thompson, F. Plewniak, O. Poch, A comprehensive comparison of multiple sequence alignment programs, Nucleic Acids Research, 27, 13 (1999) Timo Lassmann and Erik L.L. Sonnhammer, Quality assessment of multiple alignment programs, FEBS Letters 529: (2002). Paul D. Thomas et al, PANTHER: a browsable database of gene products organized by biological function, using curated protein family and subfamily classification. Nucl. Acids. Res., 31 (2003) F. Plewniak et al, PipeAlign : a new toolkit for protein family analysis. Nucleic Acids Research, 2003, Vol.31, 13: N. Wicker, G.R. Perrin, J.C. Thierry and O. Poch. Secator: a program for inferring protein subfamilies from phylogenetic trees. Mol.Biol.Evol., 2001, 8:
Statistical Machine Learning Methods for Biomedical Informatics II. Hidden Markov Model for Biological Sequences
 Statistical Machine Learning Methods for Biomedical Informatics II. Hidden Markov Model for Biological Sequences Jianlin Cheng, PhD William and Nancy Thompson Missouri Distinguished Professor Department
Statistical Machine Learning Methods for Biomedical Informatics II. Hidden Markov Model for Biological Sequences Jianlin Cheng, PhD William and Nancy Thompson Missouri Distinguished Professor Department
Bioinformatics. Proteins II. - Pattern, Profile, & Structure Database Searching. Robert Latek, Ph.D. Bioinformatics, Biocomputing
 Bioinformatics Proteins II. - Pattern, Profile, & Structure Database Searching Robert Latek, Ph.D. Bioinformatics, Biocomputing WIBR Bioinformatics Course, Whitehead Institute, 2002 1 Proteins I.-III.
Bioinformatics Proteins II. - Pattern, Profile, & Structure Database Searching Robert Latek, Ph.D. Bioinformatics, Biocomputing WIBR Bioinformatics Course, Whitehead Institute, 2002 1 Proteins I.-III.
Statistical Machine Learning Methods for Bioinformatics II. Hidden Markov Model for Biological Sequences
 Statistical Machine Learning Methods for Bioinformatics II. Hidden Markov Model for Biological Sequences Jianlin Cheng, PhD Department of Computer Science University of Missouri 2008 Free for Academic
Statistical Machine Learning Methods for Bioinformatics II. Hidden Markov Model for Biological Sequences Jianlin Cheng, PhD Department of Computer Science University of Missouri 2008 Free for Academic
CSCE555 Bioinformatics. Protein Function Annotation
 CSCE555 Bioinformatics Protein Function Annotation Why we need to do function annotation? Fig from: Network-based prediction of protein function. Molecular Systems Biology 3:88. 2007 What s function? The
CSCE555 Bioinformatics Protein Function Annotation Why we need to do function annotation? Fig from: Network-based prediction of protein function. Molecular Systems Biology 3:88. 2007 What s function? The
Introduction to Bioinformatics Online Course: IBT
 Introduction to Bioinformatics Online Course: IBT Multiple Sequence Alignment Building Multiple Sequence Alignment Lec1 Building a Multiple Sequence Alignment Learning Outcomes 1- Understanding Why multiple
Introduction to Bioinformatics Online Course: IBT Multiple Sequence Alignment Building Multiple Sequence Alignment Lec1 Building a Multiple Sequence Alignment Learning Outcomes 1- Understanding Why multiple
CS612 - Algorithms in Bioinformatics
 Fall 2017 Databases and Protein Structure Representation October 2, 2017 Molecular Biology as Information Science > 12, 000 genomes sequenced, mostly bacterial (2013) > 5x10 6 unique sequences available
Fall 2017 Databases and Protein Structure Representation October 2, 2017 Molecular Biology as Information Science > 12, 000 genomes sequenced, mostly bacterial (2013) > 5x10 6 unique sequences available
Computational methods for predicting protein-protein interactions
 Computational methods for predicting protein-protein interactions Tomi Peltola T-61.6070 Special course in bioinformatics I 3.4.2008 Outline Biological background Protein-protein interactions Computational
Computational methods for predicting protein-protein interactions Tomi Peltola T-61.6070 Special course in bioinformatics I 3.4.2008 Outline Biological background Protein-protein interactions Computational
CMPS 6630: Introduction to Computational Biology and Bioinformatics. Structure Comparison
 CMPS 6630: Introduction to Computational Biology and Bioinformatics Structure Comparison Protein Structure Comparison Motivation Understand sequence and structure variability Understand Domain architecture
CMPS 6630: Introduction to Computational Biology and Bioinformatics Structure Comparison Protein Structure Comparison Motivation Understand sequence and structure variability Understand Domain architecture
EBI web resources II: Ensembl and InterPro
 EBI web resources II: Ensembl and InterPro Yanbin Yin http://www.ebi.ac.uk/training/online/course/ 1 Homework 3 Go to http://www.ebi.ac.uk/interpro/training.htmland finish the second online training course
EBI web resources II: Ensembl and InterPro Yanbin Yin http://www.ebi.ac.uk/training/online/course/ 1 Homework 3 Go to http://www.ebi.ac.uk/interpro/training.htmland finish the second online training course
Multiple Sequence Alignment, Gunnar Klau, December 9, 2005, 17:
 Multiple Sequence Alignment, Gunnar Klau, December 9, 2005, 17:50 5001 5 Multiple Sequence Alignment The first part of this exposition is based on the following sources, which are recommended reading:
Multiple Sequence Alignment, Gunnar Klau, December 9, 2005, 17:50 5001 5 Multiple Sequence Alignment The first part of this exposition is based on the following sources, which are recommended reading:
Protein Bioinformatics. Rickard Sandberg Dept. of Cell and Molecular Biology Karolinska Institutet sandberg.cmb.ki.
 Protein Bioinformatics Rickard Sandberg Dept. of Cell and Molecular Biology Karolinska Institutet rickard.sandberg@ki.se sandberg.cmb.ki.se Outline Protein features motifs patterns profiles signals 2 Protein
Protein Bioinformatics Rickard Sandberg Dept. of Cell and Molecular Biology Karolinska Institutet rickard.sandberg@ki.se sandberg.cmb.ki.se Outline Protein features motifs patterns profiles signals 2 Protein
Motifs, Profiles and Domains. Michael Tress Protein Design Group Centro Nacional de Biotecnología, CSIC
 Motifs, Profiles and Domains Michael Tress Protein Design Group Centro Nacional de Biotecnología, CSIC Comparing Two Proteins Sequence Alignment Determining the pattern of evolution and identifying conserved
Motifs, Profiles and Domains Michael Tress Protein Design Group Centro Nacional de Biotecnología, CSIC Comparing Two Proteins Sequence Alignment Determining the pattern of evolution and identifying conserved
A profile-based protein sequence alignment algorithm for a domain clustering database
 A profile-based protein sequence alignment algorithm for a domain clustering database Lin Xu,2 Fa Zhang and Zhiyong Liu 3, Key Laboratory of Computer System and architecture, the Institute of Computing
A profile-based protein sequence alignment algorithm for a domain clustering database Lin Xu,2 Fa Zhang and Zhiyong Liu 3, Key Laboratory of Computer System and architecture, the Institute of Computing
EBI web resources II: Ensembl and InterPro. Yanbin Yin Spring 2013
 EBI web resources II: Ensembl and InterPro Yanbin Yin Spring 2013 1 Outline Intro to genome annotation Protein family/domain databases InterPro, Pfam, Superfamily etc. Genome browser Ensembl Hands on Practice
EBI web resources II: Ensembl and InterPro Yanbin Yin Spring 2013 1 Outline Intro to genome annotation Protein family/domain databases InterPro, Pfam, Superfamily etc. Genome browser Ensembl Hands on Practice
CISC 636 Computational Biology & Bioinformatics (Fall 2016)
") CISC 636 Computational Biology & Bioinformatics (Fall 2016) Predicting Protein-Protein Interactions CISC636, F16, Lec22, Liao 1 Background Proteins do not function as isolated entities. Protein-Protein
CISC 636 Computational Biology & Bioinformatics (Fall 2016) Predicting Protein-Protein Interactions CISC636, F16, Lec22, Liao 1 Background Proteins do not function as isolated entities. Protein-Protein
HMM applications. Applications of HMMs. Gene finding with HMMs. Using the gene finder
 HMM applications Applications of HMMs Gene finding Pairwise alignment (pair HMMs) Characterizing protein families (profile HMMs) Predicting membrane proteins, and membrane protein topology Gene finding
HMM applications Applications of HMMs Gene finding Pairwise alignment (pair HMMs) Characterizing protein families (profile HMMs) Predicting membrane proteins, and membrane protein topology Gene finding
Sequence Alignment Techniques and Their Uses
 Sequence Alignment Techniques and Their Uses Sarah Fiorentino Since rapid sequencing technology and whole genomes sequencing, the amount of sequence information has grown exponentially. With all of this
Sequence Alignment Techniques and Their Uses Sarah Fiorentino Since rapid sequencing technology and whole genomes sequencing, the amount of sequence information has grown exponentially. With all of this
Week 10: Homology Modelling (II) - HHpred
 - HHpred") Week 10: Homology Modelling (II) - HHpred Course: Tools for Structural Biology Fabian Glaser BKU - Technion 1 2 Identify and align related structures by sequence methods is not an easy task All comparative
Week 10: Homology Modelling (II) - HHpred Course: Tools for Structural Biology Fabian Glaser BKU - Technion 1 2 Identify and align related structures by sequence methods is not an easy task All comparative
Structure to Function. Molecular Bioinformatics, X3, 2006
 Structure to Function Molecular Bioinformatics, X3, 2006 Structural GeNOMICS Structural Genomics project aims at determination of 3D structures of all proteins: - organize known proteins into families
Structure to Function Molecular Bioinformatics, X3, 2006 Structural GeNOMICS Structural Genomics project aims at determination of 3D structures of all proteins: - organize known proteins into families
Objectives. Comparison and Analysis of Heat Shock Proteins in Organisms of the Kingdom Viridiplantae. Emily Germain 1,2 Mentor Dr.
 Comparison and Analysis of Heat Shock Proteins in Organisms of the Kingdom Viridiplantae Emily Germain 1,2 Mentor Dr. Hugh Nicholas 3 1 Bioengineering & Bioinformatics Summer Institute, Department of Computational
Comparison and Analysis of Heat Shock Proteins in Organisms of the Kingdom Viridiplantae Emily Germain 1,2 Mentor Dr. Hugh Nicholas 3 1 Bioengineering & Bioinformatics Summer Institute, Department of Computational
Research Proposal. Title: Multiple Sequence Alignment used to investigate the co-evolving positions in OxyR Protein family.
 Research Proposal Title: Multiple Sequence Alignment used to investigate the co-evolving positions in OxyR Protein family. Name: Minjal Pancholi Howard University Washington, DC. June 19, 2009 Research
Research Proposal Title: Multiple Sequence Alignment used to investigate the co-evolving positions in OxyR Protein family. Name: Minjal Pancholi Howard University Washington, DC. June 19, 2009 Research
EECS730: Introduction to Bioinformatics
 EECS730: Introduction to Bioinformatics Lecture 07: profile Hidden Markov Model http://bibiserv.techfak.uni-bielefeld.de/sadr2/databasesearch/hmmer/profilehmm.gif Slides adapted from Dr. Shaojie Zhang
EECS730: Introduction to Bioinformatics Lecture 07: profile Hidden Markov Model http://bibiserv.techfak.uni-bielefeld.de/sadr2/databasesearch/hmmer/profilehmm.gif Slides adapted from Dr. Shaojie Zhang
Bioinformatics. Dept. of Computational Biology & Bioinformatics
 Bioinformatics Dept. of Computational Biology & Bioinformatics 3 Bioinformatics - play with sequences & structures Dept. of Computational Biology & Bioinformatics 4 ORGANIZATION OF LIFE ROLE OF BIOINFORMATICS
Bioinformatics Dept. of Computational Biology & Bioinformatics 3 Bioinformatics - play with sequences & structures Dept. of Computational Biology & Bioinformatics 4 ORGANIZATION OF LIFE ROLE OF BIOINFORMATICS
08/21/2017 BLAST. Multiple Sequence Alignments: Clustal Omega
 BLAST Multiple Sequence Alignments: Clustal Omega What does basic BLAST do (e.g. what is input sequence and how does BLAST look for matches?) Susan Parrish McDaniel College Multiple Sequence Alignments
BLAST Multiple Sequence Alignments: Clustal Omega What does basic BLAST do (e.g. what is input sequence and how does BLAST look for matches?) Susan Parrish McDaniel College Multiple Sequence Alignments
Multiple sequence alignment
 Multiple sequence alignment Multiple sequence alignment: today s goals to define what a multiple sequence alignment is and how it is generated; to describe profile HMMs to introduce databases of multiple
Multiple sequence alignment Multiple sequence alignment: today s goals to define what a multiple sequence alignment is and how it is generated; to describe profile HMMs to introduce databases of multiple
An Introduction to Bioinformatics Algorithms Hidden Markov Models
 Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
PANTHER: a browsable database of gene products organized by biological function, using curated protein family and subfamily classification
 334 341 Nucleic Acids Research, 2003, Vol. 31, No. 1 # 2003 Oxford University Press DOI: 10.1093/nar/gkg115 PANTHER: a browsable database of gene products organized by biological function, using curated
334 341 Nucleic Acids Research, 2003, Vol. 31, No. 1 # 2003 Oxford University Press DOI: 10.1093/nar/gkg115 PANTHER: a browsable database of gene products organized by biological function, using curated
Introductory course on Multiple Sequence Alignment Part I: Theoretical foundations
 Sequence Analysis and Structure Prediction Service Centro Nacional de Biotecnología CSIC 8-10 May, 2013 Introductory course on Multiple Sequence Alignment Part I: Theoretical foundations Course Notes Instructor:
Sequence Analysis and Structure Prediction Service Centro Nacional de Biotecnología CSIC 8-10 May, 2013 Introductory course on Multiple Sequence Alignment Part I: Theoretical foundations Course Notes Instructor:
Syllabus of BIOINF 528 (2017 Fall, Bioinformatics Program)
") Syllabus of BIOINF 528 (2017 Fall, Bioinformatics Program) Course Name: Structural Bioinformatics Course Description: Instructor: This course introduces fundamental concepts and methods for structural
Syllabus of BIOINF 528 (2017 Fall, Bioinformatics Program) Course Name: Structural Bioinformatics Course Description: Instructor: This course introduces fundamental concepts and methods for structural
Computational Analysis of the Fungal and Metazoan Groups of Heat Shock Proteins
 Computational Analysis of the Fungal and Metazoan Groups of Heat Shock Proteins Introduction: Benjamin Cooper, The Pennsylvania State University Advisor: Dr. Hugh Nicolas, Biomedical Initiative, Carnegie
Computational Analysis of the Fungal and Metazoan Groups of Heat Shock Proteins Introduction: Benjamin Cooper, The Pennsylvania State University Advisor: Dr. Hugh Nicolas, Biomedical Initiative, Carnegie
Subfamily HMMS in Functional Genomics. D. Brown, N. Krishnamurthy, J.M. Dale, W. Christopher, and K. Sjölander
 Subfamily HMMS in Functional Genomics D. Brown, N. Krishnamurthy, J.M. Dale, W. Christopher, and K. Sjölander Pacific Symposium on Biocomputing 10:322-333(2005) SUBFAMILY HMMS IN FUNCTIONAL GENOMICS DUNCAN
Subfamily HMMS in Functional Genomics D. Brown, N. Krishnamurthy, J.M. Dale, W. Christopher, and K. Sjölander Pacific Symposium on Biocomputing 10:322-333(2005) SUBFAMILY HMMS IN FUNCTIONAL GENOMICS DUNCAN
BMD645. Integration of Omics
 BMD645 Integration of Omics Shu-Jen Chen, Chang Gung University Dec. 11, 2009 1 Traditional Biology vs. Systems Biology Traditional biology : Single genes or proteins Systems biology: Simultaneously study
BMD645 Integration of Omics Shu-Jen Chen, Chang Gung University Dec. 11, 2009 1 Traditional Biology vs. Systems Biology Traditional biology : Single genes or proteins Systems biology: Simultaneously study
Prediction of protein function from sequence analysis
 Prediction of protein function from sequence analysis Rita Casadio BIOCOMPUTING GROUP University of Bologna, Italy The omic era Genome Sequencing Projects: Archaea: 74 species In Progress:52 Bacteria:
Prediction of protein function from sequence analysis Rita Casadio BIOCOMPUTING GROUP University of Bologna, Italy The omic era Genome Sequencing Projects: Archaea: 74 species In Progress:52 Bacteria:
Information content of sets of biological sequences revisited
 Information content of sets of biological sequences revisited Alessandra Carbone and Stefan Engelen Génomique Analytique, Université Pierre et Marie Curie, INSERM UMRS511, 91, Bd de l Hôpital, 75013 Paris,
Information content of sets of biological sequences revisited Alessandra Carbone and Stefan Engelen Génomique Analytique, Université Pierre et Marie Curie, INSERM UMRS511, 91, Bd de l Hôpital, 75013 Paris,
Quantifying sequence similarity
 Quantifying sequence similarity Bas E. Dutilh Systems Biology: Bioinformatic Data Analysis Utrecht University, February 16 th 2016 After this lecture, you can define homology, similarity, and identity
Quantifying sequence similarity Bas E. Dutilh Systems Biology: Bioinformatic Data Analysis Utrecht University, February 16 th 2016 After this lecture, you can define homology, similarity, and identity
2MHR. Protein structure classification is important because it organizes the protein structure universe that is independent of sequence similarity.
 Protein structure classification is important because it organizes the protein structure universe that is independent of sequence similarity. A global picture of the protein universe will help us to understand
Protein structure classification is important because it organizes the protein structure universe that is independent of sequence similarity. A global picture of the protein universe will help us to understand
Homology and Information Gathering and Domain Annotation for Proteins
 Homology and Information Gathering and Domain Annotation for Proteins Outline Homology Information Gathering for Proteins Domain Annotation for Proteins Examples and exercises The concept of homology The
Homology and Information Gathering and Domain Annotation for Proteins Outline Homology Information Gathering for Proteins Domain Annotation for Proteins Examples and exercises The concept of homology The
STRUCTURAL BIOINFORMATICS I. Fall 2015
 STRUCTURAL BIOINFORMATICS I Fall 2015 Info Course Number - Classification: Biology 5411 Class Schedule: Monday 5:30-7:50 PM, SERC Room 456 (4 th floor) Instructors: Vincenzo Carnevale - SERC, Room 704C;
STRUCTURAL BIOINFORMATICS I Fall 2015 Info Course Number - Classification: Biology 5411 Class Schedule: Monday 5:30-7:50 PM, SERC Room 456 (4 th floor) Instructors: Vincenzo Carnevale - SERC, Room 704C;
BIOINFORMATICS: An Introduction
 BIOINFORMATICS: An Introduction What is Bioinformatics? The term was first coined in 1988 by Dr. Hwa Lim The original definition was : a collective term for data compilation, organisation, analysis and
BIOINFORMATICS: An Introduction What is Bioinformatics? The term was first coined in 1988 by Dr. Hwa Lim The original definition was : a collective term for data compilation, organisation, analysis and
Genome Annotation. Bioinformatics and Computational Biology. Genome sequencing Assembly. Gene prediction. Protein targeting.
 Genome Annotation Bioinformatics and Computational Biology Genome Annotation Frank Oliver Glöckner 1 Genome Analysis Roadmap Genome sequencing Assembly Gene prediction Protein targeting trna prediction
Genome Annotation Bioinformatics and Computational Biology Genome Annotation Frank Oliver Glöckner 1 Genome Analysis Roadmap Genome sequencing Assembly Gene prediction Protein targeting trna prediction
Hidden Markov Models
 Hidden Markov Models A selection of slides taken from the following: Chris Bystroff Protein Folding Initiation Site Motifs Iosif Vaisman Bioinformatics and Gene Discovery Colin Cherry Hidden Markov Models
Hidden Markov Models A selection of slides taken from the following: Chris Bystroff Protein Folding Initiation Site Motifs Iosif Vaisman Bioinformatics and Gene Discovery Colin Cherry Hidden Markov Models
Jeremy Chang Identifying protein protein interactions with statistical coupling analysis
 Jeremy Chang Identifying protein protein interactions with statistical coupling analysis Abstract: We used an algorithm known as statistical coupling analysis (SCA) 1 to create a set of features for building
Jeremy Chang Identifying protein protein interactions with statistical coupling analysis Abstract: We used an algorithm known as statistical coupling analysis (SCA) 1 to create a set of features for building
Introduction to Evolutionary Concepts
 Introduction to Evolutionary Concepts and VMD/MultiSeq - Part I Zaida (Zan) Luthey-Schulten Dept. Chemistry, Beckman Institute, Biophysics, Institute of Genomics Biology, & Physics NIH Workshop 2009 VMD/MultiSeq
Introduction to Evolutionary Concepts and VMD/MultiSeq - Part I Zaida (Zan) Luthey-Schulten Dept. Chemistry, Beckman Institute, Biophysics, Institute of Genomics Biology, & Physics NIH Workshop 2009 VMD/MultiSeq
Sequence Analysis '17- lecture 8. Multiple sequence alignment
 Sequence Analysis '17- lecture 8 Multiple sequence alignment Ex5 explanation How many random database search scores have e-values 10? (Answer: 10!) Why? e-value of x = m*p(s x), where m is the database
Sequence Analysis '17- lecture 8 Multiple sequence alignment Ex5 explanation How many random database search scores have e-values 10? (Answer: 10!) Why? e-value of x = m*p(s x), where m is the database
Computational Genomics and Molecular Biology, Fall
 Computational Genomics and Molecular Biology, Fall 2011 1 HMM Lecture Notes Dannie Durand and Rose Hoberman October 11th 1 Hidden Markov Models In the last few lectures, we have focussed on three problems
Computational Genomics and Molecular Biology, Fall 2011 1 HMM Lecture Notes Dannie Durand and Rose Hoberman October 11th 1 Hidden Markov Models In the last few lectures, we have focussed on three problems
Today. Last time. Secondary structure Transmembrane proteins. Domains Hidden Markov Models. Structure prediction. Secondary structure
 Last time Today Domains Hidden Markov Models Structure prediction NAD-specific glutamate dehydrogenase Hard Easy >P24295 DHE2_CLOSY MSKYVDRVIAEVEKKYADEPEFVQTVEEVL SSLGPVVDAHPEYEEVALLERMVIPERVIE FRVPWEDDNGKVHVNTGYRVQFNGAIGPYK
Last time Today Domains Hidden Markov Models Structure prediction NAD-specific glutamate dehydrogenase Hard Easy >P24295 DHE2_CLOSY MSKYVDRVIAEVEKKYADEPEFVQTVEEVL SSLGPVVDAHPEYEEVALLERMVIPERVIE FRVPWEDDNGKVHVNTGYRVQFNGAIGPYK
An Introduction to Sequence Similarity ( Homology ) Searching
 Searching") An Introduction to Sequence Similarity ( Homology ) Searching Gary D. Stormo 1 UNIT 3.1 1 Washington University, School of Medicine, St. Louis, Missouri ABSTRACT Homologous sequences usually have the same,
An Introduction to Sequence Similarity ( Homology ) Searching Gary D. Stormo 1 UNIT 3.1 1 Washington University, School of Medicine, St. Louis, Missouri ABSTRACT Homologous sequences usually have the same,
Christian Sigrist. November 14 Protein Bioinformatics: Sequence-Structure-Function 2018 Basel
 Christian Sigrist General Definition on Conserved Regions Conserved regions in proteins can be classified into 5 different groups: Domains: specific combination of secondary structures organized into a
Christian Sigrist General Definition on Conserved Regions Conserved regions in proteins can be classified into 5 different groups: Domains: specific combination of secondary structures organized into a
Intro Secondary structure Transmembrane proteins Function End. Last time. Domains Hidden Markov Models
 Last time Domains Hidden Markov Models Today Secondary structure Transmembrane proteins Structure prediction NAD-specific glutamate dehydrogenase Hard Easy >P24295 DHE2_CLOSY MSKYVDRVIAEVEKKYADEPEFVQTVEEVL
Last time Domains Hidden Markov Models Today Secondary structure Transmembrane proteins Structure prediction NAD-specific glutamate dehydrogenase Hard Easy >P24295 DHE2_CLOSY MSKYVDRVIAEVEKKYADEPEFVQTVEEVL
O 3 O 4 O 5. q 3. q 4. Transition
 Hidden Markov Models Hidden Markov models (HMM) were developed in the early part of the 1970 s and at that time mostly applied in the area of computerized speech recognition. They are first described in
Hidden Markov Models Hidden Markov models (HMM) were developed in the early part of the 1970 s and at that time mostly applied in the area of computerized speech recognition. They are first described in
Update on human genome completion and annotations: Protein information resource
 UPDATE ON GENOME COMPLETION AND ANNOTATIONS Update on human genome completion and annotations: Protein information resource Cathy Wu 1 and Daniel W. Nebert 2 * 1 Director of PIR, Department of Biochemistry
UPDATE ON GENOME COMPLETION AND ANNOTATIONS Update on human genome completion and annotations: Protein information resource Cathy Wu 1 and Daniel W. Nebert 2 * 1 Director of PIR, Department of Biochemistry
hsnim: Hyper Scalable Network Inference Machine for Scale-Free Protein-Protein Interaction Networks Inference
 CS 229 Project Report (TR# MSB2010) Submitted 12/10/2010 hsnim: Hyper Scalable Network Inference Machine for Scale-Free Protein-Protein Interaction Networks Inference Muhammad Shoaib Sehgal Computer Science
CS 229 Project Report (TR# MSB2010) Submitted 12/10/2010 hsnim: Hyper Scalable Network Inference Machine for Scale-Free Protein-Protein Interaction Networks Inference Muhammad Shoaib Sehgal Computer Science
Protein Structure: Data Bases and Classification Ingo Ruczinski
 Protein Structure: Data Bases and Classification Ingo Ruczinski Department of Biostatistics, Johns Hopkins University Reference Bourne and Weissig Structural Bioinformatics Wiley, 2003 More References
Protein Structure: Data Bases and Classification Ingo Ruczinski Department of Biostatistics, Johns Hopkins University Reference Bourne and Weissig Structural Bioinformatics Wiley, 2003 More References
Gene function annotation
 Gene function annotation Paul D. Thomas, Ph.D. University of Southern California What is function annotation? The formal answer to the question: what does this gene do? The association between: a description
Gene function annotation Paul D. Thomas, Ph.D. University of Southern California What is function annotation? The formal answer to the question: what does this gene do? The association between: a description
Heteropolymer. Mostly in regular secondary structure
 Heteropolymer - + + - Mostly in regular secondary structure 1 2 3 4 C >N trace how you go around the helix C >N C2 >N6 C1 >N5 What s the pattern? Ci>Ni+? 5 6 move around not quite 120 "#$%&'!()*(+2!3/'!4#5'!1/,#64!#6!,6!
Heteropolymer - + + - Mostly in regular secondary structure 1 2 3 4 C >N trace how you go around the helix C >N C2 >N6 C1 >N5 What s the pattern? Ci>Ni+? 5 6 move around not quite 120 "#$%&'!()*(+2!3/'!4#5'!1/,#64!#6!,6!
Copyright 2000 N. AYDIN. All rights reserved. 1
 Introduction to Bioinformatics Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr Multiple Sequence Alignment Outline Multiple sequence alignment introduction to msa methods of msa progressive global alignment
Introduction to Bioinformatics Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr Multiple Sequence Alignment Outline Multiple sequence alignment introduction to msa methods of msa progressive global alignment
Protein Families. João C. Setubal University of São Paulo Agosto /23/2012 J. C. Setubal
 Protein Families João C. Setubal University of São Paulo Agosto 2012 8/23/2012 J. C. Setubal 1 Motivation Phytophthora Science paper [Tyler et al., 2006] Comparison of the [P. sojae and P. ramorum] genomes
Protein Families João C. Setubal University of São Paulo Agosto 2012 8/23/2012 J. C. Setubal 1 Motivation Phytophthora Science paper [Tyler et al., 2006] Comparison of the [P. sojae and P. ramorum] genomes
A Protein Ontology from Large-scale Textmining?
 A Protein Ontology from Large-scale Textmining? Protege-Workshop Manchester, 07-07-2003 Kai Kumpf, Juliane Fluck and Martin Hofmann Instructive mistakes: a narrative Aim: Protein ontology that supports
A Protein Ontology from Large-scale Textmining? Protege-Workshop Manchester, 07-07-2003 Kai Kumpf, Juliane Fluck and Martin Hofmann Instructive mistakes: a narrative Aim: Protein ontology that supports
Pairwise & Multiple sequence alignments
 Pairwise & Multiple sequence alignments Urmila Kulkarni-Kale Bioinformatics Centre 411 007 urmila@bioinfo.ernet.in Basis for Sequence comparison Theory of evolution: gene sequences have evolved/derived
Pairwise & Multiple sequence alignments Urmila Kulkarni-Kale Bioinformatics Centre 411 007 urmila@bioinfo.ernet.in Basis for Sequence comparison Theory of evolution: gene sequences have evolved/derived
Outline. Terminologies and Ontologies. Communication and Computation. Communication. Outline. Terminologies and Vocabularies.
 Page 1 Outline 1. Why do we need terminologies and ontologies? Terminologies and Ontologies Iwei Yeh yeh@smi.stanford.edu 04/16/2002 2. Controlled Terminologies Enzyme Classification Gene Ontology 3. Ontologies
Page 1 Outline 1. Why do we need terminologies and ontologies? Terminologies and Ontologies Iwei Yeh yeh@smi.stanford.edu 04/16/2002 2. Controlled Terminologies Enzyme Classification Gene Ontology 3. Ontologies
Hidden Markov Models
 Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Genomics and bioinformatics summary. Finding genes -- computer searches
 Genomics and bioinformatics summary 1. Gene finding: computer searches, cdnas, ESTs, 2. Microarrays 3. Use BLAST to find homologous sequences 4. Multiple sequence alignments (MSAs) 5. Trees quantify sequence
Genomics and bioinformatics summary 1. Gene finding: computer searches, cdnas, ESTs, 2. Microarrays 3. Use BLAST to find homologous sequences 4. Multiple sequence alignments (MSAs) 5. Trees quantify sequence
Mining and classification of repeat protein structures
 Mining and classification of repeat protein structures Ian Walsh Ph.D. BioComputing UP, Department of Biology, University of Padova, Italy URL: http://protein.bio.unipd.it/ Repeat proteins Why are they
Mining and classification of repeat protein structures Ian Walsh Ph.D. BioComputing UP, Department of Biology, University of Padova, Italy URL: http://protein.bio.unipd.it/ Repeat proteins Why are they
Multiple Sequence Alignment: A Critical Comparison of Four Popular Programs
 Multiple Sequence Alignment: A Critical Comparison of Four Popular Programs Shirley Sutton, Biochemistry 218 Final Project, March 14, 2008 Introduction For both the computational biologist and the research
Multiple Sequence Alignment: A Critical Comparison of Four Popular Programs Shirley Sutton, Biochemistry 218 Final Project, March 14, 2008 Introduction For both the computational biologist and the research
Giri Narasimhan. CAP 5510: Introduction to Bioinformatics. ECS 254; Phone: x3748
 CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 2/15/07 CAP5510 1 EM Algorithm Goal: Find θ, Z that maximize Pr
CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 2/15/07 CAP5510 1 EM Algorithm Goal: Find θ, Z that maximize Pr
The PRALINE online server: optimising progressive multiple alignment on the web
 Computational Biology and Chemistry 27 (2003) 511 519 Software Note The PRALINE online server: optimising progressive multiple alignment on the web V.A. Simossis a,b, J. Heringa a, a Bioinformatics Unit,
Computational Biology and Chemistry 27 (2003) 511 519 Software Note The PRALINE online server: optimising progressive multiple alignment on the web V.A. Simossis a,b, J. Heringa a, a Bioinformatics Unit,
Hidden Markov Models (HMMs) and Profiles
 and Profiles") Hidden Markov Models (HMMs) and Profiles Swiss Institute of Bioinformatics (SIB) 26-30 November 2001 Markov Chain Models A Markov Chain Model is a succession of states S i (i = 0, 1,...) connected by transitions.
Hidden Markov Models (HMMs) and Profiles Swiss Institute of Bioinformatics (SIB) 26-30 November 2001 Markov Chain Models A Markov Chain Model is a succession of states S i (i = 0, 1,...) connected by transitions.
Simultaneous Sequence Alignment and Tree Construction Using Hidden Markov Models. R.C. Edgar, K. Sjölander
 Simultaneous Sequence Alignment and Tree Construction Using Hidden Markov Models R.C. Edgar, K. Sjölander Pacific Symposium on Biocomputing 8:180-191(2003) SIMULTANEOUS SEQUENCE ALIGNMENT AND TREE CONSTRUCTION
Simultaneous Sequence Alignment and Tree Construction Using Hidden Markov Models R.C. Edgar, K. Sjölander Pacific Symposium on Biocomputing 8:180-191(2003) SIMULTANEOUS SEQUENCE ALIGNMENT AND TREE CONSTRUCTION
THEORY. Based on sequence Length According to the length of sequence being compared it is of following two types
 Exp 11- THEORY Sequence Alignment is a process of aligning two sequences to achieve maximum levels of identity between them. This help to derive functional, structural and evolutionary relationships between
Exp 11- THEORY Sequence Alignment is a process of aligning two sequences to achieve maximum levels of identity between them. This help to derive functional, structural and evolutionary relationships between
K-means-based Feature Learning for Protein Sequence Classification
 K-means-based Feature Learning for Protein Sequence Classification Paul Melman and Usman W. Roshan Department of Computer Science, NJIT Newark, NJ, 07102, USA pm462@njit.edu, usman.w.roshan@njit.edu Abstract
K-means-based Feature Learning for Protein Sequence Classification Paul Melman and Usman W. Roshan Department of Computer Science, NJIT Newark, NJ, 07102, USA pm462@njit.edu, usman.w.roshan@njit.edu Abstract
An Efficient Algorithm for Protein-Protein Interaction Network Analysis to Discover Overlapping Functional Modules
 An Efficient Algorithm for Protein-Protein Interaction Network Analysis to Discover Overlapping Functional Modules Ying Liu 1 Department of Computer Science, Mathematics and Science, College of Professional
An Efficient Algorithm for Protein-Protein Interaction Network Analysis to Discover Overlapping Functional Modules Ying Liu 1 Department of Computer Science, Mathematics and Science, College of Professional
PROTEIN FUNCTION PREDICTION WITH AMINO ACID SEQUENCE AND SECONDARY STRUCTURE ALIGNMENT SCORES
 PROTEIN FUNCTION PREDICTION WITH AMINO ACID SEQUENCE AND SECONDARY STRUCTURE ALIGNMENT SCORES Eser Aygün 1, Caner Kömürlü 2, Zafer Aydin 3 and Zehra Çataltepe 1 1 Computer Engineering Department and 2
PROTEIN FUNCTION PREDICTION WITH AMINO ACID SEQUENCE AND SECONDARY STRUCTURE ALIGNMENT SCORES Eser Aygün 1, Caner Kömürlü 2, Zafer Aydin 3 and Zehra Çataltepe 1 1 Computer Engineering Department and 2
COMP 598 Advanced Computational Biology Methods & Research. Introduction. Jérôme Waldispühl School of Computer Science McGill University
 COMP 598 Advanced Computational Biology Methods & Research Introduction Jérôme Waldispühl School of Computer Science McGill University General informations (1) Office hours: by appointment Office: TR3018
COMP 598 Advanced Computational Biology Methods & Research Introduction Jérôme Waldispühl School of Computer Science McGill University General informations (1) Office hours: by appointment Office: TR3018
Homology Modeling. Roberto Lins EPFL - summer semester 2005
 Homology Modeling Roberto Lins EPFL - summer semester 2005 Disclaimer: course material is mainly taken from: P.E. Bourne & H Weissig, Structural Bioinformatics; C.A. Orengo, D.T. Jones & J.M. Thornton,
Homology Modeling Roberto Lins EPFL - summer semester 2005 Disclaimer: course material is mainly taken from: P.E. Bourne & H Weissig, Structural Bioinformatics; C.A. Orengo, D.T. Jones & J.M. Thornton,
Supplementary text for the section Interactions conserved across species: can one select the conserved interactions?
 1 Supporting Information: What Evidence is There for the Homology of Protein-Protein Interactions? Anna C. F. Lewis, Nick S. Jones, Mason A. Porter, Charlotte M. Deane Supplementary text for the section
1 Supporting Information: What Evidence is There for the Homology of Protein-Protein Interactions? Anna C. F. Lewis, Nick S. Jones, Mason A. Porter, Charlotte M. Deane Supplementary text for the section
A bioinformatics approach to the structural and functional analysis of the glycogen phosphorylase protein family
 A bioinformatics approach to the structural and functional analysis of the glycogen phosphorylase protein family Jieming Shen 1,2 and Hugh B. Nicholas, Jr. 3 1 Bioengineering and Bioinformatics Summer
A bioinformatics approach to the structural and functional analysis of the glycogen phosphorylase protein family Jieming Shen 1,2 and Hugh B. Nicholas, Jr. 3 1 Bioengineering and Bioinformatics Summer
Similarity searching summary (2)
") Similarity searching / sequence alignment summary Biol4230 Thurs, February 22, 2016 Bill Pearson wrp@virginia.edu 4-2818 Pinn 6-057 What have we covered? Homology excess similiarity but no excess similarity
Similarity searching / sequence alignment summary Biol4230 Thurs, February 22, 2016 Bill Pearson wrp@virginia.edu 4-2818 Pinn 6-057 What have we covered? Homology excess similiarity but no excess similarity
Bioinformatics. Scoring Matrices. David Gilbert Bioinformatics Research Centre
 Bioinformatics Scoring Matrices David Gilbert Bioinformatics Research Centre www.brc.dcs.gla.ac.uk Department of Computing Science, University of Glasgow Learning Objectives To explain the requirement
Bioinformatics Scoring Matrices David Gilbert Bioinformatics Research Centre www.brc.dcs.gla.ac.uk Department of Computing Science, University of Glasgow Learning Objectives To explain the requirement
Homology. and. Information Gathering and Domain Annotation for Proteins
 Homology and Information Gathering and Domain Annotation for Proteins Outline WHAT IS HOMOLOGY? HOW TO GATHER KNOWN PROTEIN INFORMATION? HOW TO ANNOTATE PROTEIN DOMAINS? EXAMPLES AND EXERCISES Homology
Homology and Information Gathering and Domain Annotation for Proteins Outline WHAT IS HOMOLOGY? HOW TO GATHER KNOWN PROTEIN INFORMATION? HOW TO ANNOTATE PROTEIN DOMAINS? EXAMPLES AND EXERCISES Homology
-max_target_seqs: maximum number of targets to report
 Review of exercise 1 tblastn -num_threads 2 -db contig -query DH10B.fasta -out blastout.xls -evalue 1e-10 -outfmt "6 qseqid sseqid qstart qend sstart send length nident pident evalue" Other options: -max_target_seqs:
Review of exercise 1 tblastn -num_threads 2 -db contig -query DH10B.fasta -out blastout.xls -evalue 1e-10 -outfmt "6 qseqid sseqid qstart qend sstart send length nident pident evalue" Other options: -max_target_seqs:
Amino Acid Structures from Klug & Cummings. 10/7/2003 CAP/CGS 5991: Lecture 7 1
 Amino Acid Structures from Klug & Cummings 10/7/2003 CAP/CGS 5991: Lecture 7 1 Amino Acid Structures from Klug & Cummings 10/7/2003 CAP/CGS 5991: Lecture 7 2 Amino Acid Structures from Klug & Cummings
Amino Acid Structures from Klug & Cummings 10/7/2003 CAP/CGS 5991: Lecture 7 1 Amino Acid Structures from Klug & Cummings 10/7/2003 CAP/CGS 5991: Lecture 7 2 Amino Acid Structures from Klug & Cummings
Computational Genomics and Molecular Biology, Fall
 Computational Genomics and Molecular Biology, Fall 2014 1 HMM Lecture Notes Dannie Durand and Rose Hoberman November 6th Introduction In the last few lectures, we have focused on three problems related
Computational Genomics and Molecular Biology, Fall 2014 1 HMM Lecture Notes Dannie Durand and Rose Hoberman November 6th Introduction In the last few lectures, we have focused on three problems related
CAP 5510 Lecture 3 Protein Structures
 CAP 5510 Lecture 3 Protein Structures Su-Shing Chen Bioinformatics CISE 8/19/2005 Su-Shing Chen, CISE 1 Protein Conformation 8/19/2005 Su-Shing Chen, CISE 2 Protein Conformational Structures Hydrophobicity
CAP 5510 Lecture 3 Protein Structures Su-Shing Chen Bioinformatics CISE 8/19/2005 Su-Shing Chen, CISE 1 Protein Conformation 8/19/2005 Su-Shing Chen, CISE 2 Protein Conformational Structures Hydrophobicity
Functional Annotation
 Functional Annotation Outline Introduction Strategy Pipeline Databases Now, what s next? Functional Annotation Adding the layers of analysis and interpretation necessary to extract its biological significance
Functional Annotation Outline Introduction Strategy Pipeline Databases Now, what s next? Functional Annotation Adding the layers of analysis and interpretation necessary to extract its biological significance
NetAffx GPCR annotation database summary December 12, 2001
 NetAffx GPCR annotation database summary December 12, 2001 Introduction Only approximately 51% of the human proteome can be annotated by the standard motif-based recognition systems [1]. These systems,
NetAffx GPCR annotation database summary December 12, 2001 Introduction Only approximately 51% of the human proteome can be annotated by the standard motif-based recognition systems [1]. These systems,
Effects of Gap Open and Gap Extension Penalties
 Brigham Young University BYU ScholarsArchive All Faculty Publications 200-10-01 Effects of Gap Open and Gap Extension Penalties Hyrum Carroll hyrumcarroll@gmail.com Mark J. Clement clement@cs.byu.edu See
Brigham Young University BYU ScholarsArchive All Faculty Publications 200-10-01 Effects of Gap Open and Gap Extension Penalties Hyrum Carroll hyrumcarroll@gmail.com Mark J. Clement clement@cs.byu.edu See
MSAT a Multiple Sequence Alignment tool based on TOPS
 MSAT a Multiple Sequence Alignment tool based on TOPS Te Ren, Mallika Veeramalai, Aik Choon Tan and David Gilbert Bioinformatics Research Centre Department of Computer Science University of Glasgow Glasgow,
MSAT a Multiple Sequence Alignment tool based on TOPS Te Ren, Mallika Veeramalai, Aik Choon Tan and David Gilbert Bioinformatics Research Centre Department of Computer Science University of Glasgow Glasgow,
Neural Networks for Protein Structure Prediction Brown, JMB CS 466 Saurabh Sinha
 Neural Networks for Protein Structure Prediction Brown, JMB 1999 CS 466 Saurabh Sinha Outline Goal is to predict secondary structure of a protein from its sequence Artificial Neural Network used for this
Neural Networks for Protein Structure Prediction Brown, JMB 1999 CS 466 Saurabh Sinha Outline Goal is to predict secondary structure of a protein from its sequence Artificial Neural Network used for this
InDel 3-5. InDel 8-9. InDel 3-5. InDel 8-9. InDel InDel 8-9
 Lecture 5 Alignment I. Introduction. For sequence data, the process of generating an alignment establishes positional homologies; that is, alignment provides the identification of homologous phylogenetic
Lecture 5 Alignment I. Introduction. For sequence data, the process of generating an alignment establishes positional homologies; that is, alignment provides the identification of homologous phylogenetic
Algorithms in Bioinformatics FOUR Pairwise Sequence Alignment. Pairwise Sequence Alignment. Convention: DNA Sequences 5. Sequence Alignment
 Algorithms in Bioinformatics FOUR Sami Khuri Department of Computer Science San José State University Pairwise Sequence Alignment Homology Similarity Global string alignment Local string alignment Dot
Algorithms in Bioinformatics FOUR Sami Khuri Department of Computer Science San José State University Pairwise Sequence Alignment Homology Similarity Global string alignment Local string alignment Dot
Large-Scale Genomic Surveys
 Bioinformatics Subtopics Fold Recognition Secondary Structure Prediction Docking & Drug Design Protein Geometry Protein Flexibility Homology Modeling Sequence Alignment Structure Classification Gene Prediction
Bioinformatics Subtopics Fold Recognition Secondary Structure Prediction Docking & Drug Design Protein Geometry Protein Flexibility Homology Modeling Sequence Alignment Structure Classification Gene Prediction
Sequence Bioinformatics. Multiple Sequence Alignment Waqas Nasir
 Sequence Bioinformatics Multiple Sequence Alignment Waqas Nasir 2010-11-12 Multiple Sequence Alignment One amino acid plays coy; a pair of homologous sequences whisper; many aligned sequences shout out
Sequence Bioinformatics Multiple Sequence Alignment Waqas Nasir 2010-11-12 Multiple Sequence Alignment One amino acid plays coy; a pair of homologous sequences whisper; many aligned sequences shout out
Chemical Data Retrieval and Management
 Chemical Data Retrieval and Management ChEMBL, ChEBI, and the Chemistry Development Kit Stephan A. Beisken What is EMBL-EBI? Part of the European Molecular Biology Laboratory International, non-profit
Chemical Data Retrieval and Management ChEMBL, ChEBI, and the Chemistry Development Kit Stephan A. Beisken What is EMBL-EBI? Part of the European Molecular Biology Laboratory International, non-profit
Probalign: Multiple sequence alignment using partition function posterior probabilities
 Sequence Analysis Probalign: Multiple sequence alignment using partition function posterior probabilities Usman Roshan 1* and Dennis R. Livesay 2 1 Department of Computer Science, New Jersey Institute
Sequence Analysis Probalign: Multiple sequence alignment using partition function posterior probabilities Usman Roshan 1* and Dennis R. Livesay 2 1 Department of Computer Science, New Jersey Institute
Tools and Algorithms in Bioinformatics
 Tools and Algorithms in Bioinformatics GCBA815, Fall 2015 Week-4 BLAST Algorithm Continued Multiple Sequence Alignment Babu Guda, Ph.D. Department of Genetics, Cell Biology & Anatomy Bioinformatics and
Tools and Algorithms in Bioinformatics GCBA815, Fall 2015 Week-4 BLAST Algorithm Continued Multiple Sequence Alignment Babu Guda, Ph.D. Department of Genetics, Cell Biology & Anatomy Bioinformatics and
Practical considerations of working with sequencing data
 Practical considerations of working with sequencing data File Types Fastq ->aligner -> reference(genome) coordinates Coordinate files SAM/BAM most complete, contains all of the info in fastq and more!
Practical considerations of working with sequencing data File Types Fastq ->aligner -> reference(genome) coordinates Coordinate files SAM/BAM most complete, contains all of the info in fastq and more!
Motivating the need for optimal sequence alignments...
 1 Motivating the need for optimal sequence alignments... 2 3 Note that this actually combines two objectives of optimal sequence alignments: (i) use the score of the alignment o infer homology; (ii) use
1 Motivating the need for optimal sequence alignments... 2 3 Note that this actually combines two objectives of optimal sequence alignments: (i) use the score of the alignment o infer homology; (ii) use
Molecular Modeling. Prediction of Protein 3D Structure from Sequence. Vimalkumar Velayudhan. May 21, 2007
 Molecular Modeling Prediction of Protein 3D Structure from Sequence Vimalkumar Velayudhan Jain Institute of Vocational and Advanced Studies May 21, 2007 Vimalkumar Velayudhan Molecular Modeling 1/23 Outline
Molecular Modeling Prediction of Protein 3D Structure from Sequence Vimalkumar Velayudhan Jain Institute of Vocational and Advanced Studies May 21, 2007 Vimalkumar Velayudhan Molecular Modeling 1/23 Outline
Chapter 5. Proteomics and the analysis of protein sequence Ⅱ
 Proteomics Chapter 5. Proteomics and the analysis of protein sequence Ⅱ 1 Pairwise similarity searching (1) Figure 5.5: manual alignment One of the amino acids in the top sequence has no equivalent and
Proteomics Chapter 5. Proteomics and the analysis of protein sequence Ⅱ 1 Pairwise similarity searching (1) Figure 5.5: manual alignment One of the amino acids in the top sequence has no equivalent and
1. Protein Data Bank (PDB) 1. Protein Data Bank (PDB)
 1. Protein Data Bank (PDB)") Protein structure databases; visualization; and classifications 1. Introduction to Protein Data Bank (PDB) 2. Free graphic software for 3D structure visualization 3. Hierarchical classification of protein
Protein structure databases; visualization; and classifications 1. Introduction to Protein Data Bank (PDB) 2. Free graphic software for 3D structure visualization 3. Hierarchical classification of protein