Multivariate Gaussians. Sargur Srihari
|
|
|
- Piers Dixon
- 6 years ago
- Views:
Transcription
1 Multivariate Gaussians Sargur 1
2 Topics 1. Multivariate Gaussian: Basic Parameterization 2. Covariance and Information Form 3. Operations on Gaussians 4. Independencies in Gaussians 2
3 Three Representations of Multivariate Gaussian Equivalent representations: 1. Basic parameterization 1. Covariance form, 2. Information (or precision ) form 2. Gaussian Bayesian network Information form captures conditional independencies needed for BN 3. Gaussian Markov Random Field Easiest conversion 3
4 Parameterizing Multivariate Gaussian 1. Basic parameterization: covariance form 2. Multivariate Gaussian distribution over X 1,..,X n is characterized by an n-dimensional mean vector μ and a symmetric n x n covariance matrix Σ 3. The density function is defined as p( x) = 1 ( 2π ) d/2 Σ exp (x 1/2 µ)t Σ 1 (x µ) 4
 with X 3 X 2 is negatively")
5 Covariance Intuition in Gaussian The pdf specifies a set of ellipsoidal contours around the mean vector µ Contours are parallel Each corresponds to a value of the density function Shape of ellipsoid and steepness of contour are determined by Σ μ=e[x] Σ=E[xx t ]-E[x]E[x] t X,Y uncorrelated X,Y Correlated µ = Σ = X 1 is negatively correlated (-2) with X 3 X 2 is negatively correlated (-5) with X 3

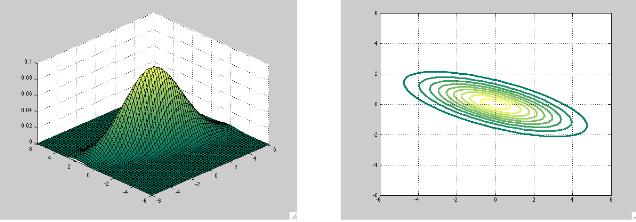
6 Multivariate Gaussian examples 6
7 Deriving the Information Form Covariance Form of multivariate Gaussian is: p( x) = 1 ( 2π ) d/2 Σ exp (x 1/2 µ)t Σ 1 (x µ) Using inverse covariance matrix Precision J=Σ -1 1 ( 2 x µ )t Σ 1 ( x µ ) = 1 ( 2 x µ )t J ( x µ ) = 1 2 xt Jx 2x t Jµ + µ t Jµ Since last term is constant, we get information form ( ) α exp 1 2 x t Jx + (J µ) t x p x Jμ is called the potential vector
8 Information form of Gaussian Since Σ is invertible we can also define the Gaussian in terms of the inverse covariance matrix J=Σ -1 Called the information matrix or precision matrix It induces an alternate form of the Gaussian density ( ) α exp 1 2 x t Jx + (J µ) t x p x Jµ is called the potential vector 8
9 Operations on Gaussians There are two main operations we wish to perform on a distribution: 1. Compute marginal distribution over some subset Y 2. Conditioning the distribution on some Z=z Each operation is very easy in one of the two ways of encoding a Gaussian 1. Marginalization is trivial in the covariance form 2. Conditioning a Gaussian is very easy to perform in the information form 9
10 Marginalization in Covariance Form Marginal distribution of any subset of variables Trivially read from the mean and covariance matrix p(x 1,X 2,X 3 ) = N(µ, Σ) p(x 2,X 3 ) = Σ X1 p(x 1,X 2,X 3 ) =N(µ,Σ ) µ = Σ = More generally, if we have a joint distribution over {X,Y}, XεR n, YεR m then we can decompose mean and covariance of joint as: p(x, Y) = N µ X µ Y where µ X εr n, µ Y εr m, Σ XX is nxn, Σ XY is nxm, Σ YX =Σ T XY is mxn, Σ YY is mxm Lemma: If {X,Y} have a joint normal distribution then marginal of Y is a normal distribution N(μ Y ;Σ YY ) 10 ; Σ XX Σ YX then µ'= Σ XY Σ YY 3 4 Σ'=
11 Conditioning in Information Form Conditioning on an observation Z=z is very easy to perform in the information form Simply assign Z=z in the equation p x ( ) α exp 1 2 x t Jx + (J µ) t x It turns some of the quadratic terms into linear terms or even constant terms Expression has same form with fewer terms Not so straightforward in covariance form 11
12 Summary of Marginalization & Conditioning To marginalize a Gaussian over a subset of variables: Compute pairwise covariances Which is precisely generating the distribution in its covariance form To condition a Gaussian on an observation: Invert covariance matrix to obtain information form Inversion feasible for small matrices Too costly for high-dimensional space 12
13 Independencies in Gaussians Theorem: If X=X 1,..,X n have a joint normal distribution N(µ,Σ) then X i and X j are independent if and only if Σ i,j =0 This property does not hold in general If p(x,y) is not Gaussian then it is possible that Cov[X;Y]=0 while X and Y are still dependent in p 13
14 Independencies from Information Matrix Theorem: Consider a Gaussian distribution p(x 1,..,X n )=N(μ,Σ) and let J=Σ -1 be the information matrix. Then J ij =0 if and only if Example: p ( X i X j χ {X i, X j }) µ = Σ = then J = Then X 1,X 3 are conditionally independent given X 2
15 Information matrix defines an I-map Information matrix J captures independencies between pairs of variables conditioned on all the remaining variables Can use J to construct unique minimal I-map for p Definition of I-map I independence assertion set of form (X Y/ Z), which are true of distribution P G is an I-map of P implies: I G I» Minimal I-map: removal of a single edge renders the graph not an I-map Introduce an edge between X i and X j whenever ( X i X j χ {X i, X j }) does not hold in p This is precisely when J ij 0 15
From Distributions to Markov Networks. Sargur Srihari
 From Distributions to Markov Networks Sargur srihari@cedar.buffalo.edu 1 Topics The task: How to encode independencies in given distribution P in a graph structure G Theorems concerning What type of Independencies?
From Distributions to Markov Networks Sargur srihari@cedar.buffalo.edu 1 Topics The task: How to encode independencies in given distribution P in a graph structure G Theorems concerning What type of Independencies?
A Probability Review
 A Probability Review Outline: A probability review Shorthand notation: RV stands for random variable EE 527, Detection and Estimation Theory, # 0b 1 A Probability Review Reading: Go over handouts 2 5 in
A Probability Review Outline: A probability review Shorthand notation: RV stands for random variable EE 527, Detection and Estimation Theory, # 0b 1 A Probability Review Reading: Go over handouts 2 5 in
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
01 Probability Theory and Statistics Review
 NAVARCH/EECS 568, ROB 530 - Winter 2018 01 Probability Theory and Statistics Review Maani Ghaffari January 08, 2018 Last Time: Bayes Filters Given: Stream of observations z 1:t and action data u 1:t Sensor/measurement
NAVARCH/EECS 568, ROB 530 - Winter 2018 01 Probability Theory and Statistics Review Maani Ghaffari January 08, 2018 Last Time: Bayes Filters Given: Stream of observations z 1:t and action data u 1:t Sensor/measurement
5. Random Vectors. probabilities. characteristic function. cross correlation, cross covariance. Gaussian random vectors. functions of random vectors
 EE401 (Semester 1) 5. Random Vectors Jitkomut Songsiri probabilities characteristic function cross correlation, cross covariance Gaussian random vectors functions of random vectors 5-1 Random vectors we
EE401 (Semester 1) 5. Random Vectors Jitkomut Songsiri probabilities characteristic function cross correlation, cross covariance Gaussian random vectors functions of random vectors 5-1 Random vectors we
Probability Background
 Probability Background Namrata Vaswani, Iowa State University August 24, 2015 Probability recap 1: EE 322 notes Quick test of concepts: Given random variables X 1, X 2,... X n. Compute the PDF of the second
Probability Background Namrata Vaswani, Iowa State University August 24, 2015 Probability recap 1: EE 322 notes Quick test of concepts: Given random variables X 1, X 2,... X n. Compute the PDF of the second
Lecture Note 1: Probability Theory and Statistics
 Univ. of Michigan - NAME 568/EECS 568/ROB 530 Winter 2018 Lecture Note 1: Probability Theory and Statistics Lecturer: Maani Ghaffari Jadidi Date: April 6, 2018 For this and all future notes, if you would
Univ. of Michigan - NAME 568/EECS 568/ROB 530 Winter 2018 Lecture Note 1: Probability Theory and Statistics Lecturer: Maani Ghaffari Jadidi Date: April 6, 2018 For this and all future notes, if you would
Alternative Parameterizations of Markov Networks. Sargur Srihari
 Alternative Parameterizations of Markov Networks Sargur srihari@cedar.buffalo.edu 1 Topics Three types of parameterization 1. Gibbs Parameterization 2. Factor Graphs 3. Log-linear Models Features (Ising,
Alternative Parameterizations of Markov Networks Sargur srihari@cedar.buffalo.edu 1 Topics Three types of parameterization 1. Gibbs Parameterization 2. Factor Graphs 3. Log-linear Models Features (Ising,
Two Posts to Fill On School Board
 Y Y 9 86 4 4 qz 86 x : ( ) z 7 854 Y x 4 z z x x 4 87 88 Y 5 x q x 8 Y 8 x x : 6 ; : 5 x ; 4 ( z ; ( ) ) x ; z 94 ; x 3 3 3 5 94 ; ; ; ; 3 x : 5 89 q ; ; x ; x ; ; x : ; ; ; ; ; ; 87 47% : () : / : 83
Y Y 9 86 4 4 qz 86 x : ( ) z 7 854 Y x 4 z z x x 4 87 88 Y 5 x q x 8 Y 8 x x : 6 ; : 5 x ; 4 ( z ; ( ) ) x ; z 94 ; x 3 3 3 5 94 ; ; ; ; 3 x : 5 89 q ; ; x ; x ; ; x : ; ; ; ; ; ; 87 47% : () : / : 83
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 12: Gaussian Belief Propagation, State Space Models and Kalman Filters Guest Kalman Filter Lecture by
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 12: Gaussian Belief Propagation, State Space Models and Kalman Filters Guest Kalman Filter Lecture by
Probability and Information Theory. Sargur N. Srihari
 Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
Probability and Information Theory Sargur N. srihari@cedar.buffalo.edu 1 Topics in Probability and Information Theory Overview 1. Why Probability? 2. Random Variables 3. Probability Distributions 4. Marginal
UCSD ECE153 Handout #30 Prof. Young-Han Kim Thursday, May 15, Homework Set #6 Due: Thursday, May 22, 2011
 UCSD ECE153 Handout #30 Prof. Young-Han Kim Thursday, May 15, 2014 Homework Set #6 Due: Thursday, May 22, 2011 1. Linear estimator. Consider a channel with the observation Y = XZ, where the signal X and
UCSD ECE153 Handout #30 Prof. Young-Han Kim Thursday, May 15, 2014 Homework Set #6 Due: Thursday, May 22, 2011 1. Linear estimator. Consider a channel with the observation Y = XZ, where the signal X and
16.584: Random Vectors
 1 16.584: Random Vectors Define X : (X 1, X 2,..X n ) T : n-dimensional Random Vector X 1 : X(t 1 ): May correspond to samples/measurements Generalize definition of PDF: F X (x) = P[X 1 x 1, X 2 x 2,...X
1 16.584: Random Vectors Define X : (X 1, X 2,..X n ) T : n-dimensional Random Vector X 1 : X(t 1 ): May correspond to samples/measurements Generalize definition of PDF: F X (x) = P[X 1 x 1, X 2 x 2,...X
Introduction to Probabilistic Graphical Models
 Introduction to Probabilistic Graphical Models Sargur Srihari srihari@cedar.buffalo.edu 1 Topics 1. What are probabilistic graphical models (PGMs) 2. Use of PGMs Engineering and AI 3. Directionality in
Introduction to Probabilistic Graphical Models Sargur Srihari srihari@cedar.buffalo.edu 1 Topics 1. What are probabilistic graphical models (PGMs) 2. Use of PGMs Engineering and AI 3. Directionality in
x. Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ 2 ).
.") .8.6 µ =, σ = 1 µ = 1, σ = 1 / µ =, σ =.. 3 1 1 3 x Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ ). The Gaussian distribution Probably the most-important distribution in all of statistics
.8.6 µ =, σ = 1 µ = 1, σ = 1 / µ =, σ =.. 3 1 1 3 x Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ ). The Gaussian distribution Probably the most-important distribution in all of statistics
Chapter 5 continued. Chapter 5 sections
 Chapter 5 sections Discrete univariate distributions: 5.2 Bernoulli and Binomial distributions Just skim 5.3 Hypergeometric distributions 5.4 Poisson distributions Just skim 5.5 Negative Binomial distributions
Chapter 5 sections Discrete univariate distributions: 5.2 Bernoulli and Binomial distributions Just skim 5.3 Hypergeometric distributions 5.4 Poisson distributions Just skim 5.5 Negative Binomial distributions
Basic Sampling Methods
 Basic Sampling Methods Sargur Srihari srihari@cedar.buffalo.edu 1 1. Motivation Topics Intractability in ML How sampling can help 2. Ancestral Sampling Using BNs 3. Transforming a Uniform Distribution
Basic Sampling Methods Sargur Srihari srihari@cedar.buffalo.edu 1 1. Motivation Topics Intractability in ML How sampling can help 2. Ancestral Sampling Using BNs 3. Transforming a Uniform Distribution
Independencies. Undirected Graphical Models 2: Independencies. Independencies (Markov networks) Independencies (Bayesian Networks)
 Independencies (Bayesian Networks)") (Bayesian Networks) Undirected Graphical Models 2: Use d-separation to read off independencies in a Bayesian network Takes a bit of effort! 1 2 (Markov networks) Use separation to determine independencies
(Bayesian Networks) Undirected Graphical Models 2: Use d-separation to read off independencies in a Bayesian network Takes a bit of effort! 1 2 (Markov networks) Use separation to determine independencies
The Multivariate Gaussian Distribution
 The Multivariate Gaussian Distribution Chuong B. Do October, 8 A vector-valued random variable X = T X X n is said to have a multivariate normal or Gaussian) distribution with mean µ R n and covariance
The Multivariate Gaussian Distribution Chuong B. Do October, 8 A vector-valued random variable X = T X X n is said to have a multivariate normal or Gaussian) distribution with mean µ R n and covariance
[POLS 8500] Review of Linear Algebra, Probability and Information Theory
![[POLS 8500] Review of Linear Algebra, Probability and Information Theory](/thumbs/72/67586683.jpg "[POLS 8500] Review of Linear Algebra, Probability and Information Theory") [POLS 8500] Review of Linear Algebra, Probability and Information Theory Professor Jason Anastasopoulos ljanastas@uga.edu January 12, 2017 For today... Basic linear algebra. Basic probability. Programming
[POLS 8500] Review of Linear Algebra, Probability and Information Theory Professor Jason Anastasopoulos ljanastas@uga.edu January 12, 2017 For today... Basic linear algebra. Basic probability. Programming
Partitioned Covariance Matrices and Partial Correlations. Proposition 1 Let the (p + q) (p + q) covariance matrix C > 0 be partitioned as C = C11 C 12
 (p + q) covariance matrix C > 0 be partitioned as C = C11 C 12") Partitioned Covariance Matrices and Partial Correlations Proposition 1 Let the (p + q (p + q covariance matrix C > 0 be partitioned as ( C11 C C = 12 C 21 C 22 Then the symmetric matrix C > 0 has the following
Partitioned Covariance Matrices and Partial Correlations Proposition 1 Let the (p + q (p + q covariance matrix C > 0 be partitioned as ( C11 C C = 12 C 21 C 22 Then the symmetric matrix C > 0 has the following
Using Graphs to Describe Model Structure. Sargur N. Srihari
 Using Graphs to Describe Model Structure Sargur N. srihari@cedar.buffalo.edu 1 Topics in Structured PGMs for Deep Learning 0. Overview 1. Challenge of Unstructured Modeling 2. Using graphs to describe
Using Graphs to Describe Model Structure Sargur N. srihari@cedar.buffalo.edu 1 Topics in Structured PGMs for Deep Learning 0. Overview 1. Challenge of Unstructured Modeling 2. Using graphs to describe
Chapter 5. The multivariate normal distribution. Probability Theory. Linear transformations. The mean vector and the covariance matrix
 Probability Theory Linear transformations A transformation is said to be linear if every single function in the transformation is a linear combination. Chapter 5 The multivariate normal distribution When
Probability Theory Linear transformations A transformation is said to be linear if every single function in the transformation is a linear combination. Chapter 5 The multivariate normal distribution When
Latent Variable View of EM. Sargur Srihari
 Latent Variable View of EM Sargur srihari@cedar.buffalo.edu 1 Examples of latent variables 1. Mixture Model Joint distribution is p(x,z) We don t have values for z 2. Hidden Markov Model A single time
Latent Variable View of EM Sargur srihari@cedar.buffalo.edu 1 Examples of latent variables 1. Mixture Model Joint distribution is p(x,z) We don t have values for z 2. Hidden Markov Model A single time
Inverse of a Square Matrix. For an N N square matrix A, the inverse of A, 1
 Inverse of a Square Matrix For an N N square matrix A, the inverse of A, 1 A, exists if and only if A is of full rank, i.e., if and only if no column of A is a linear combination 1 of the others. A is
Inverse of a Square Matrix For an N N square matrix A, the inverse of A, 1 A, exists if and only if A is of full rank, i.e., if and only if no column of A is a linear combination 1 of the others. A is
OWELL WEEKLY JOURNAL
 Y \»< - } Y Y Y & #»»» q ] q»»»>) & - - - } ) x ( - { Y» & ( x - (» & )< - Y X - & Q Q» 3 - x Q Y 6 \Y > Y Y X 3 3-9 33 x - - / - -»- --
Y \»< - } Y Y Y & #»»» q ] q»»»>) & - - - } ) x ( - { Y» & ( x - (» & )< - Y X - & Q Q» 3 - x Q Y 6 \Y > Y Y X 3 3-9 33 x - - / - -»- --
CMPE 58K Bayesian Statistics and Machine Learning Lecture 5
 CMPE 58K Bayesian Statistics and Machine Learning Lecture 5 Multivariate distributions: Gaussian, Bernoulli, Probability tables Department of Computer Engineering, Boğaziçi University, Istanbul, Turkey
CMPE 58K Bayesian Statistics and Machine Learning Lecture 5 Multivariate distributions: Gaussian, Bernoulli, Probability tables Department of Computer Engineering, Boğaziçi University, Istanbul, Turkey
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science Algorithms For Inference Fall 2014
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 Problem Set 3 Issued: Thursday, September 25, 2014 Due: Thursday,
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 Problem Set 3 Issued: Thursday, September 25, 2014 Due: Thursday,
A DARK GREY P O N T, with a Switch Tail, and a small Star on the Forehead. Any
 Y Y Y X X «/ YY Y Y ««Y x ) & \ & & } # Y \#$& / Y Y X» \\ / X X X x & Y Y X «q «z \x» = q Y # % \ & [ & Z \ & { + % ) / / «q zy» / & / / / & x x X / % % ) Y x X Y $ Z % Y Y x x } / % «] «] # z» & Y X»
Y Y Y X X «/ YY Y Y ««Y x ) & \ & & } # Y \#$& / Y Y X» \\ / X X X x & Y Y X «q «z \x» = q Y # % \ & [ & Z \ & { + % ) / / «q zy» / & / / / & x x X / % % ) Y x X Y $ Z % Y Y x x } / % «] «] # z» & Y X»
Alternative Parameterizations of Markov Networks. Sargur Srihari
 Alternative Parameterizations of Markov Networks Sargur srihari@cedar.buffalo.edu 1 Topics Three types of parameterization 1. Gibbs Parameterization 2. Factor Graphs 3. Log-linear Models with Energy functions
Alternative Parameterizations of Markov Networks Sargur srihari@cedar.buffalo.edu 1 Topics Three types of parameterization 1. Gibbs Parameterization 2. Factor Graphs 3. Log-linear Models with Energy functions
Review of Probability Theory
 Review of Probability Theory Arian Maleki and Tom Do Stanford University Probability theory is the study of uncertainty Through this class, we will be relying on concepts from probability theory for deriving
Review of Probability Theory Arian Maleki and Tom Do Stanford University Probability theory is the study of uncertainty Through this class, we will be relying on concepts from probability theory for deriving
Introduction to Graphical Models
 Introduction to Graphical Models STA 345: Multivariate Analysis Department of Statistical Science Duke University, Durham, NC, USA Robert L. Wolpert 1 Conditional Dependence Two real-valued or vector-valued
Introduction to Graphical Models STA 345: Multivariate Analysis Department of Statistical Science Duke University, Durham, NC, USA Robert L. Wolpert 1 Conditional Dependence Two real-valued or vector-valued
MAP Examples. Sargur Srihari
 MAP Examples Sargur srihari@cedar.buffalo.edu 1 Potts Model CRF for OCR Topics Image segmentation based on energy minimization 2 Examples of MAP Many interesting examples of MAP inference are instances
MAP Examples Sargur srihari@cedar.buffalo.edu 1 Potts Model CRF for OCR Topics Image segmentation based on energy minimization 2 Examples of MAP Many interesting examples of MAP inference are instances
Bayesian Network Representation
 Bayesian Network Representation Sargur Srihari srihari@cedar.buffalo.edu 1 Topics Joint and Conditional Distributions I-Maps I-Map to Factorization Factorization to I-Map Perfect Map Knowledge Engineering
Bayesian Network Representation Sargur Srihari srihari@cedar.buffalo.edu 1 Topics Joint and Conditional Distributions I-Maps I-Map to Factorization Factorization to I-Map Perfect Map Knowledge Engineering
From Bayesian Networks to Markov Networks. Sargur Srihari
 From Bayesian Networks to Markov Networks Sargur srihari@cedar.buffalo.edu 1 Topics Bayesian Networks and Markov Networks From BN to MN: Moralized graphs From MN to BN: Chordal graphs 2 Bayesian Networks
From Bayesian Networks to Markov Networks Sargur srihari@cedar.buffalo.edu 1 Topics Bayesian Networks and Markov Networks From BN to MN: Moralized graphs From MN to BN: Chordal graphs 2 Bayesian Networks
Multivariate probability distributions and linear regression
 Multivariate probability distributions and linear regression Patrik Hoyer 1 Contents: Random variable, probability distribution Joint distribution Marginal distribution Conditional distribution Independence,
Multivariate probability distributions and linear regression Patrik Hoyer 1 Contents: Random variable, probability distribution Joint distribution Marginal distribution Conditional distribution Independence,
Chapter 17: Undirected Graphical Models
 Chapter 17: Undirected Graphical Models The Elements of Statistical Learning Biaobin Jiang Department of Biological Sciences Purdue University bjiang@purdue.edu October 30, 2014 Biaobin Jiang (Purdue)
Chapter 17: Undirected Graphical Models The Elements of Statistical Learning Biaobin Jiang Department of Biological Sciences Purdue University bjiang@purdue.edu October 30, 2014 Biaobin Jiang (Purdue)
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
Continuous Random Variables
 1 / 24 Continuous Random Variables Saravanan Vijayakumaran sarva@ee.iitb.ac.in Department of Electrical Engineering Indian Institute of Technology Bombay February 27, 2013 2 / 24 Continuous Random Variables
1 / 24 Continuous Random Variables Saravanan Vijayakumaran sarva@ee.iitb.ac.in Department of Electrical Engineering Indian Institute of Technology Bombay February 27, 2013 2 / 24 Continuous Random Variables
8 - Continuous random vectors
 8-1 Continuous random vectors S. Lall, Stanford 2011.01.25.01 8 - Continuous random vectors Mean-square deviation Mean-variance decomposition Gaussian random vectors The Gamma function The χ 2 distribution
8-1 Continuous random vectors S. Lall, Stanford 2011.01.25.01 8 - Continuous random vectors Mean-square deviation Mean-variance decomposition Gaussian random vectors The Gamma function The χ 2 distribution
BN Semantics 3 Now it s personal!
 Readings: K&F: 3.3, 3.4 BN Semantics 3 Now it s personal! Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 22 nd, 2008 10-708 Carlos Guestrin 2006-2008 1 Independencies encoded
Readings: K&F: 3.3, 3.4 BN Semantics 3 Now it s personal! Graphical Models 10708 Carlos Guestrin Carnegie Mellon University September 22 nd, 2008 10-708 Carlos Guestrin 2006-2008 1 Independencies encoded
Gaussian Models (9/9/13)
") STA561: Probabilistic machine learning Gaussian Models (9/9/13) Lecturer: Barbara Engelhardt Scribes: Xi He, Jiangwei Pan, Ali Razeen, Animesh Srivastava 1 Multivariate Normal Distribution The multivariate
STA561: Probabilistic machine learning Gaussian Models (9/9/13) Lecturer: Barbara Engelhardt Scribes: Xi He, Jiangwei Pan, Ali Razeen, Animesh Srivastava 1 Multivariate Normal Distribution The multivariate
Introduction to Probability and Stocastic Processes - Part I
 Introduction to Probability and Stocastic Processes - Part I Lecture 2 Henrik Vie Christensen vie@control.auc.dk Department of Control Engineering Institute of Electronic Systems Aalborg University Denmark
Introduction to Probability and Stocastic Processes - Part I Lecture 2 Henrik Vie Christensen vie@control.auc.dk Department of Control Engineering Institute of Electronic Systems Aalborg University Denmark
Statistical Techniques in Robotics (16-831, F12) Lecture#17 (Wednesday October 31) Kalman Filters. Lecturer: Drew Bagnell Scribe:Greydon Foil 1
 Lecture#17 (Wednesday October 31) Kalman Filters. Lecturer: Drew Bagnell Scribe:Greydon Foil 1") Statistical Techniques in Robotics (16-831, F12) Lecture#17 (Wednesday October 31) Kalman Filters Lecturer: Drew Bagnell Scribe:Greydon Foil 1 1 Gauss Markov Model Consider X 1, X 2,...X t, X t+1 to be
Statistical Techniques in Robotics (16-831, F12) Lecture#17 (Wednesday October 31) Kalman Filters Lecturer: Drew Bagnell Scribe:Greydon Foil 1 1 Gauss Markov Model Consider X 1, X 2,...X t, X t+1 to be
Introduction to Probabilistic Graphical Models: Exercises
 Introduction to Probabilistic Graphical Models: Exercises Cédric Archambeau Xerox Research Centre Europe cedric.archambeau@xrce.xerox.com Pascal Bootcamp Marseille, France, July 2010 Exercise 1: basics
Introduction to Probabilistic Graphical Models: Exercises Cédric Archambeau Xerox Research Centre Europe cedric.archambeau@xrce.xerox.com Pascal Bootcamp Marseille, France, July 2010 Exercise 1: basics
The Gaussian distribution
 The Gaussian distribution Probability density function: A continuous probability density function, px), satisfies the following properties:. The probability that x is between two points a and b b P a
The Gaussian distribution Probability density function: A continuous probability density function, px), satisfies the following properties:. The probability that x is between two points a and b b P a
Eigenvectors and SVD 1
 Eigenvectors and SVD 1 Definition Eigenvectors of a square matrix Ax=λx, x=0. Intuition: x is unchanged by A (except for scaling) Examples: axis of rotation, stationary distribution of a Markov chain 2
Eigenvectors and SVD 1 Definition Eigenvectors of a square matrix Ax=λx, x=0. Intuition: x is unchanged by A (except for scaling) Examples: axis of rotation, stationary distribution of a Markov chain 2
Data Analysis and Uncertainty Part 1: Random Variables
 Data Analysis and Uncertainty Part 1: Random Variables Instructor: Sargur N. University at Buffalo The State University of New York srihari@cedar.buffalo.edu 1 Topics 1. Why uncertainty exists? 2. Dealing
Data Analysis and Uncertainty Part 1: Random Variables Instructor: Sargur N. University at Buffalo The State University of New York srihari@cedar.buffalo.edu 1 Topics 1. Why uncertainty exists? 2. Dealing
STAT 100C: Linear models
 STAT 100C: Linear models Arash A. Amini June 9, 2018 1 / 56 Table of Contents Multiple linear regression Linear model setup Estimation of β Geometric interpretation Estimation of σ 2 Hat matrix Gram matrix
STAT 100C: Linear models Arash A. Amini June 9, 2018 1 / 56 Table of Contents Multiple linear regression Linear model setup Estimation of β Geometric interpretation Estimation of σ 2 Hat matrix Gram matrix
Physics 403. Segev BenZvi. Parameter Estimation, Correlations, and Error Bars. Department of Physics and Astronomy University of Rochester
 Physics 403 Parameter Estimation, Correlations, and Error Bars Segev BenZvi Department of Physics and Astronomy University of Rochester Table of Contents 1 Review of Last Class Best Estimates and Reliability
Physics 403 Parameter Estimation, Correlations, and Error Bars Segev BenZvi Department of Physics and Astronomy University of Rochester Table of Contents 1 Review of Last Class Best Estimates and Reliability
EE4601 Communication Systems
 EE4601 Communication Systems Week 2 Review of Probability, Important Distributions 0 c 2011, Georgia Institute of Technology (lect2 1) Conditional Probability Consider a sample space that consists of two
EE4601 Communication Systems Week 2 Review of Probability, Important Distributions 0 c 2011, Georgia Institute of Technology (lect2 1) Conditional Probability Consider a sample space that consists of two
3. Probability and Statistics
 FE661 - Statistical Methods for Financial Engineering 3. Probability and Statistics Jitkomut Songsiri definitions, probability measures conditional expectations correlation and covariance some important
FE661 - Statistical Methods for Financial Engineering 3. Probability and Statistics Jitkomut Songsiri definitions, probability measures conditional expectations correlation and covariance some important
Machine Learning (CS 567) Lecture 5
 Lecture 5") Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Elliptically Contoured Distributions
 Elliptically Contoured Distributions Recall: if X N p µ, Σ), then { 1 f X x) = exp 1 } det πσ x µ) Σ 1 x µ) So f X x) depends on x only through x µ) Σ 1 x µ), and is therefore constant on the ellipsoidal
Elliptically Contoured Distributions Recall: if X N p µ, Σ), then { 1 f X x) = exp 1 } det πσ x µ) Σ 1 x µ) So f X x) depends on x only through x µ) Σ 1 x µ), and is therefore constant on the ellipsoidal
Gaussian Processes. Le Song. Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012
 Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Gaussian Processes Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 01 Pictorial view of embedding distribution Transform the entire distribution to expected features Feature space Feature
Random Vectors and Multivariate Normal Distributions
 Chapter 3 Random Vectors and Multivariate Normal Distributions 3.1 Random vectors Definition 3.1.1. Random vector. Random vectors are vectors of random 75 variables. For instance, X = X 1 X 2., where each
Chapter 3 Random Vectors and Multivariate Normal Distributions 3.1 Random vectors Definition 3.1.1. Random vector. Random vectors are vectors of random 75 variables. For instance, X = X 1 X 2., where each
MCMC and Gibbs Sampling. Sargur Srihari
 MCMC and Gibbs Sampling Sargur srihari@cedar.buffalo.edu 1 Topics 1. Markov Chain Monte Carlo 2. Markov Chains 3. Gibbs Sampling 4. Basic Metropolis Algorithm 5. Metropolis-Hastings Algorithm 6. Slice
MCMC and Gibbs Sampling Sargur srihari@cedar.buffalo.edu 1 Topics 1. Markov Chain Monte Carlo 2. Markov Chains 3. Gibbs Sampling 4. Basic Metropolis Algorithm 5. Metropolis-Hastings Algorithm 6. Slice
Directed Graphical Models or Bayesian Networks
 Directed Graphical Models or Bayesian Networks Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Bayesian Networks One of the most exciting recent advancements in statistical AI Compact
Directed Graphical Models or Bayesian Networks Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Bayesian Networks One of the most exciting recent advancements in statistical AI Compact
EEL 5544 Noise in Linear Systems Lecture 30. X (s) = E [ e sx] f X (x)e sx dx. Moments can be found from the Laplace transform as
![EEL 5544 Noise in Linear Systems Lecture 30. X (s) = E [ e sx] f X (x)e sx dx. Moments can be found from the Laplace transform as](/thumbs/85/92409620.jpg "EEL 5544 Noise in Linear Systems Lecture 30. X (s) = E [ e sx] f X (x)e sx dx. Moments can be found from the Laplace transform as") L30-1 EEL 5544 Noise in Linear Systems Lecture 30 OTHER TRANSFORMS For a continuous, nonnegative RV X, the Laplace transform of X is X (s) = E [ e sx] = 0 f X (x)e sx dx. For a nonnegative RV, the Laplace
L30-1 EEL 5544 Noise in Linear Systems Lecture 30 OTHER TRANSFORMS For a continuous, nonnegative RV X, the Laplace transform of X is X (s) = E [ e sx] = 0 f X (x)e sx dx. For a nonnegative RV, the Laplace
MAS223 Statistical Inference and Modelling Exercises
 MAS223 Statistical Inference and Modelling Exercises The exercises are grouped into sections, corresponding to chapters of the lecture notes Within each section exercises are divided into warm-up questions,
MAS223 Statistical Inference and Modelling Exercises The exercises are grouped into sections, corresponding to chapters of the lecture notes Within each section exercises are divided into warm-up questions,
Random vectors X 1 X 2. Recall that a random vector X = is made up of, say, k. X k. random variables.
 Random vectors Recall that a random vector X = X X 2 is made up of, say, k random variables X k A random vector has a joint distribution, eg a density f(x), that gives probabilities P(X A) = f(x)dx Just
Random vectors Recall that a random vector X = X X 2 is made up of, say, k random variables X k A random vector has a joint distribution, eg a density f(x), that gives probabilities P(X A) = f(x)dx Just
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout 2:. The Multivariate Gaussian & Decision Boundaries
 University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
UCSD ECE153 Handout #34 Prof. Young-Han Kim Tuesday, May 27, Solutions to Homework Set #6 (Prepared by TA Fatemeh Arbabjolfaei)
") UCSD ECE53 Handout #34 Prof Young-Han Kim Tuesday, May 7, 04 Solutions to Homework Set #6 (Prepared by TA Fatemeh Arbabjolfaei) Linear estimator Consider a channel with the observation Y XZ, where the
UCSD ECE53 Handout #34 Prof Young-Han Kim Tuesday, May 7, 04 Solutions to Homework Set #6 (Prepared by TA Fatemeh Arbabjolfaei) Linear estimator Consider a channel with the observation Y XZ, where the
Linear Algebra for Machine Learning. Sargur N. Srihari
 Linear Algebra for Machine Learning Sargur N. srihari@cedar.buffalo.edu 1 Overview Linear Algebra is based on continuous math rather than discrete math Computer scientists have little experience with it
Linear Algebra for Machine Learning Sargur N. srihari@cedar.buffalo.edu 1 Overview Linear Algebra is based on continuous math rather than discrete math Computer scientists have little experience with it
The generative approach to classification. A classification problem. Generative models CSE 250B
 The generative approach to classification The generative approach to classification CSE 250B The learning process: Fit a probability distribution to each class, individually To classify a new point: Which
The generative approach to classification The generative approach to classification CSE 250B The learning process: Fit a probability distribution to each class, individually To classify a new point: Which
1 Data Arrays and Decompositions
 1 Data Arrays and Decompositions 1.1 Variance Matrices and Eigenstructure Consider a p p positive definite and symmetric matrix V - a model parameter or a sample variance matrix. The eigenstructure is
1 Data Arrays and Decompositions 1.1 Variance Matrices and Eigenstructure Consider a p p positive definite and symmetric matrix V - a model parameter or a sample variance matrix. The eigenstructure is
1. Density and properties Brief outline 2. Sampling from multivariate normal and MLE 3. Sampling distribution and large sample behavior of X and S 4.
 Multivariate normal distribution Reading: AMSA: pages 149-200 Multivariate Analysis, Spring 2016 Institute of Statistics, National Chiao Tung University March 1, 2016 1. Density and properties Brief outline
Multivariate normal distribution Reading: AMSA: pages 149-200 Multivariate Analysis, Spring 2016 Institute of Statistics, National Chiao Tung University March 1, 2016 1. Density and properties Brief outline
11 : Gaussian Graphic Models and Ising Models
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 11 : Gaussian Graphic Models and Ising Models Lecturer: Bryon Aragam Scribes: Chao-Ming Yen 1 Introduction Different from previous maximum likelihood
10-708: Probabilistic Graphical Models 10-708, Spring 2017 11 : Gaussian Graphic Models and Ising Models Lecturer: Bryon Aragam Scribes: Chao-Ming Yen 1 Introduction Different from previous maximum likelihood
Bayesian Machine Learning - Lecture 7
 Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Bayesian Networks Representation
 Bayesian Networks Representation Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University March 19 th, 2007 Handwriting recognition Character recognition, e.g., kernel SVMs a c z rr r r
Bayesian Networks Representation Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University March 19 th, 2007 Handwriting recognition Character recognition, e.g., kernel SVMs a c z rr r r
Variational Inference and Learning. Sargur N. Srihari
 Variational Inference and Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics in Approximate Inference Task of Inference Intractability in Inference 1. Inference as Optimization 2. Expectation Maximization
Variational Inference and Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics in Approximate Inference Task of Inference Intractability in Inference 1. Inference as Optimization 2. Expectation Maximization
CS Lecture 3. More Bayesian Networks
 CS 6347 Lecture 3 More Bayesian Networks Recap Last time: Complexity challenges Representing distributions Computing probabilities/doing inference Introduction to Bayesian networks Today: D-separation,
CS 6347 Lecture 3 More Bayesian Networks Recap Last time: Complexity challenges Representing distributions Computing probabilities/doing inference Introduction to Bayesian networks Today: D-separation,
Gaussian Process Regression
 Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
1 Undirected Graphical Models. 2 Markov Random Fields (MRFs)
") Machine Learning (ML, F16) Lecture#07 (Thursday Nov. 3rd) Lecturer: Byron Boots Undirected Graphical Models 1 Undirected Graphical Models In the previous lecture, we discussed directed graphical models.
Machine Learning (ML, F16) Lecture#07 (Thursday Nov. 3rd) Lecturer: Byron Boots Undirected Graphical Models 1 Undirected Graphical Models In the previous lecture, we discussed directed graphical models.
Lecture 4: Least Squares (LS) Estimation
 Estimation") ME 233, UC Berkeley, Spring 2014 Xu Chen Lecture 4: Least Squares (LS) Estimation Background and general solution Solution in the Gaussian case Properties Example Big picture general least squares estimation:
ME 233, UC Berkeley, Spring 2014 Xu Chen Lecture 4: Least Squares (LS) Estimation Background and general solution Solution in the Gaussian case Properties Example Big picture general least squares estimation:
Appendix A : Introduction to Probability and stochastic processes
 A-1 Mathematical methods in communication July 5th, 2009 Appendix A : Introduction to Probability and stochastic processes Lecturer: Haim Permuter Scribe: Shai Shapira and Uri Livnat The probability of
A-1 Mathematical methods in communication July 5th, 2009 Appendix A : Introduction to Probability and stochastic processes Lecturer: Haim Permuter Scribe: Shai Shapira and Uri Livnat The probability of
Chris Bishop s PRML Ch. 8: Graphical Models
 Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
1.12 Multivariate Random Variables
 112 MULTIVARIATE RANDOM VARIABLES 59 112 Multivariate Random Variables We will be using matrix notation to denote multivariate rvs and their distributions Denote by X (X 1,,X n ) T an n-dimensional random
112 MULTIVARIATE RANDOM VARIABLES 59 112 Multivariate Random Variables We will be using matrix notation to denote multivariate rvs and their distributions Denote by X (X 1,,X n ) T an n-dimensional random
11 - The linear model
 11-1 The linear model S. Lall, Stanford 2011.02.15.01 11 - The linear model The linear model The joint pdf and covariance Example: uniform pdfs The importance of the prior Linear measurements with Gaussian
11-1 The linear model S. Lall, Stanford 2011.02.15.01 11 - The linear model The linear model The joint pdf and covariance Example: uniform pdfs The importance of the prior Linear measurements with Gaussian
Joint p.d.f. and Independent Random Variables
 1 Joint p.d.f. and Independent Random Variables Let X and Y be two discrete r.v. s and let R be the corresponding space of X and Y. The joint p.d.f. of X = x and Y = y, denoted by f(x, y) = P(X = x, Y
1 Joint p.d.f. and Independent Random Variables Let X and Y be two discrete r.v. s and let R be the corresponding space of X and Y. The joint p.d.f. of X = x and Y = y, denoted by f(x, y) = P(X = x, Y
P (x). all other X j =x j. If X is a continuous random vector (see p.172), then the marginal distributions of X i are: f(x)dx 1 dx n
. all other X j =x j. If X is a continuous random vector (see p.172), then the marginal distributions of X i are: f(x)dx 1 dx n") JOINT DENSITIES - RANDOM VECTORS - REVIEW Joint densities describe probability distributions of a random vector X: an n-dimensional vector of random variables, ie, X = (X 1,, X n ), where all X is are
JOINT DENSITIES - RANDOM VECTORS - REVIEW Joint densities describe probability distributions of a random vector X: an n-dimensional vector of random variables, ie, X = (X 1,, X n ), where all X is are
Computational Complexity of Inference
 Computational Complexity of Inference Sargur srihari@cedar.buffalo.edu 1 Topics 1. What is Inference? 2. Complexity Classes 3. Exact Inference 1. Variable Elimination Sum-Product Algorithm 2. Factor Graphs
Computational Complexity of Inference Sargur srihari@cedar.buffalo.edu 1 Topics 1. What is Inference? 2. Complexity Classes 3. Exact Inference 1. Variable Elimination Sum-Product Algorithm 2. Factor Graphs
Basics on Probability. Jingrui He 09/11/2007
 Basics on Probability Jingrui He 09/11/2007 Coin Flips You flip a coin Head with probability 0.5 You flip 100 coins How many heads would you expect Coin Flips cont. You flip a coin Head with probability
Basics on Probability Jingrui He 09/11/2007 Coin Flips You flip a coin Head with probability 0.5 You flip 100 coins How many heads would you expect Coin Flips cont. You flip a coin Head with probability
Gaussian random variables inr n
 Gaussian vectors Lecture 5 Gaussian random variables inr n One-dimensional case One-dimensional Gaussian density with mean and standard deviation (called N, ): fx x exp. Proposition If X N,, then ax b
Gaussian vectors Lecture 5 Gaussian random variables inr n One-dimensional case One-dimensional Gaussian density with mean and standard deviation (called N, ): fx x exp. Proposition If X N,, then ax b
Multiple Random Variables
 Multiple Random Variables This Version: July 30, 2015 Multiple Random Variables 2 Now we consider models with more than one r.v. These are called multivariate models For instance: height and weight An
Multiple Random Variables This Version: July 30, 2015 Multiple Random Variables 2 Now we consider models with more than one r.v. These are called multivariate models For instance: height and weight An
2.3. The Gaussian Distribution
 78 2. PROBABILITY DISTRIBUTIONS Figure 2.5 Plots of the Dirichlet distribution over three variables, where the two horizontal axes are coordinates in the plane of the simplex and the vertical axis corresponds
78 2. PROBABILITY DISTRIBUTIONS Figure 2.5 Plots of the Dirichlet distribution over three variables, where the two horizontal axes are coordinates in the plane of the simplex and the vertical axis corresponds
MIT Spring 2015
 Regression Analysis MIT 18.472 Dr. Kempthorne Spring 2015 1 Outline Regression Analysis 1 Regression Analysis 2 Multiple Linear Regression: Setup Data Set n cases i = 1, 2,..., n 1 Response (dependent)
Regression Analysis MIT 18.472 Dr. Kempthorne Spring 2015 1 Outline Regression Analysis 1 Regression Analysis 2 Multiple Linear Regression: Setup Data Set n cases i = 1, 2,..., n 1 Response (dependent)
Lecture 15: Multivariate normal distributions
 Lecture 15: Multivariate normal distributions Normal distributions with singular covariance matrices Consider an n-dimensional X N(µ,Σ) with a positive definite Σ and a fixed k n matrix A that is not of
Lecture 15: Multivariate normal distributions Normal distributions with singular covariance matrices Consider an n-dimensional X N(µ,Σ) with a positive definite Σ and a fixed k n matrix A that is not of
Dynamic models 1 Kalman filters, linearization,
 Koller & Friedman: Chapter 16 Jordan: Chapters 13, 15 Uri Lerner s Thesis: Chapters 3,9 Dynamic models 1 Kalman filters, linearization, Switching KFs, Assumed density filters Probabilistic Graphical Models
Koller & Friedman: Chapter 16 Jordan: Chapters 13, 15 Uri Lerner s Thesis: Chapters 3,9 Dynamic models 1 Kalman filters, linearization, Switching KFs, Assumed density filters Probabilistic Graphical Models
CDA5530: Performance Models of Computers and Networks. Chapter 2: Review of Practical Random Variables
 CDA5530: Performance Models of Computers and Networks Chapter 2: Review of Practical Random Variables Definition Random variable (R.V.) X: A function on sample space X: S R Cumulative distribution function
CDA5530: Performance Models of Computers and Networks Chapter 2: Review of Practical Random Variables Definition Random variable (R.V.) X: A function on sample space X: S R Cumulative distribution function
MATH 829: Introduction to Data Mining and Analysis Graphical Models I
 MATH 829: Introduction to Data Mining and Analysis Graphical Models I Dominique Guillot Departments of Mathematical Sciences University of Delaware May 2, 2016 1/12 Independence and conditional independence:
MATH 829: Introduction to Data Mining and Analysis Graphical Models I Dominique Guillot Departments of Mathematical Sciences University of Delaware May 2, 2016 1/12 Independence and conditional independence:
Copula Regression RAHUL A. PARSA DRAKE UNIVERSITY & STUART A. KLUGMAN SOCIETY OF ACTUARIES CASUALTY ACTUARIAL SOCIETY MAY 18,2011
 Copula Regression RAHUL A. PARSA DRAKE UNIVERSITY & STUART A. KLUGMAN SOCIETY OF ACTUARIES CASUALTY ACTUARIAL SOCIETY MAY 18,2011 Outline Ordinary Least Squares (OLS) Regression Generalized Linear Models
Copula Regression RAHUL A. PARSA DRAKE UNIVERSITY & STUART A. KLUGMAN SOCIETY OF ACTUARIES CASUALTY ACTUARIAL SOCIETY MAY 18,2011 Outline Ordinary Least Squares (OLS) Regression Generalized Linear Models
CSC 412 (Lecture 4): Undirected Graphical Models
: Undirected Graphical Models") CSC 412 (Lecture 4): Undirected Graphical Models Raquel Urtasun University of Toronto Feb 2, 2016 R Urtasun (UofT) CSC 412 Feb 2, 2016 1 / 37 Today Undirected Graphical Models: Semantics of the graph:
CSC 412 (Lecture 4): Undirected Graphical Models Raquel Urtasun University of Toronto Feb 2, 2016 R Urtasun (UofT) CSC 412 Feb 2, 2016 1 / 37 Today Undirected Graphical Models: Semantics of the graph:
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Gaussian Processes Barnabás Póczos http://www.gaussianprocess.org/ 2 Some of these slides in the intro are taken from D. Lizotte, R. Parr, C. Guesterin
Advanced Introduction to Machine Learning CMU-10715 Gaussian Processes Barnabás Póczos http://www.gaussianprocess.org/ 2 Some of these slides in the intro are taken from D. Lizotte, R. Parr, C. Guesterin
Partially Directed Graphs and Conditional Random Fields. Sargur Srihari
 Partially Directed Graphs and Conditional Random Fields Sargur srihari@cedar.buffalo.edu 1 Topics Conditional Random Fields Gibbs distribution and CRF Directed and Undirected Independencies View as combination
Partially Directed Graphs and Conditional Random Fields Sargur srihari@cedar.buffalo.edu 1 Topics Conditional Random Fields Gibbs distribution and CRF Directed and Undirected Independencies View as combination
Undirected Graphical Models: Markov Random Fields
 Undirected Graphical Models: Markov Random Fields 40-956 Advanced Topics in AI: Probabilistic Graphical Models Sharif University of Technology Soleymani Spring 2015 Markov Random Field Structure: undirected
Undirected Graphical Models: Markov Random Fields 40-956 Advanced Topics in AI: Probabilistic Graphical Models Sharif University of Technology Soleymani Spring 2015 Markov Random Field Structure: undirected
18 Bivariate normal distribution I
 8 Bivariate normal distribution I 8 Example Imagine firing arrows at a target Hopefully they will fall close to the target centre As we fire more arrows we find a high density near the centre and fewer
8 Bivariate normal distribution I 8 Example Imagine firing arrows at a target Hopefully they will fall close to the target centre As we fire more arrows we find a high density near the centre and fewer
CS 340 Lec. 18: Multivariate Gaussian Distributions and Linear Discriminant Analysis
 CS 3 Lec. 18: Multivariate Gaussian Distributions and Linear Discriminant Analysis AD March 11 AD ( March 11 1 / 17 Multivariate Gaussian Consider data { x i } N i=1 where xi R D and we assume they are
CS 3 Lec. 18: Multivariate Gaussian Distributions and Linear Discriminant Analysis AD March 11 AD ( March 11 1 / 17 Multivariate Gaussian Consider data { x i } N i=1 where xi R D and we assume they are
Bayesian Inference. Chapter 9. Linear models and regression
 Bayesian Inference Chapter 9. Linear models and regression M. Concepcion Ausin Universidad Carlos III de Madrid Master in Business Administration and Quantitative Methods Master in Mathematical Engineering
Bayesian Inference Chapter 9. Linear models and regression M. Concepcion Ausin Universidad Carlos III de Madrid Master in Business Administration and Quantitative Methods Master in Mathematical Engineering