Chapter 8: Generalization and Function Approximation
|
|
|
- Eustacia Hancock
- 5 years ago
- Views:
Transcription
1 Chapter 8: Generalization and Function Approximation Objectives of this chapter: Look at how experience with a limited part of the state set be used to produce good behavior over a much larger part. Overview of function approximation (FA) methods and how they can be adapted to RL
2 Any FA Method? In principle, yes: artificial neural networks decision trees multivariate regression methods etc. But RL has some special requirements: usually want to learn while interacting ability to handle nonstationarity other? R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 2
3 Gradient Descent Methods t t (1), t (2),, t (n) T transpose Assume V t is a (sufficiently smooth) differentiable function of t, for all s S. Assume, for now, training examples of this form : description of s t, V (s t ) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 3
4 Performance Measures Many are applicable but a common and simple one is the mean-squared error (MSE) over a distribution P : Why P? MSE( t ) Why minimize MSE? s S P(s) V (s) V t (s) Let us assume that P is always the distribution of states at which backups are done. The on-policy distribution: the distribution created while following the policy being evaluated. Stronger results are available for this distribution. 2 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 4
5 Gradient Descent Let f be any function of the parameter space. Its gradient at any point t in this space is: f ( t ) f () t (1), f () t (2),, f () T t. (n) (2) Iteratively move down the gradient: t 1 t f ( t ) t t (1), t (2) T (1) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 5
6 On-Line Gradient-Descent TD(l) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 6
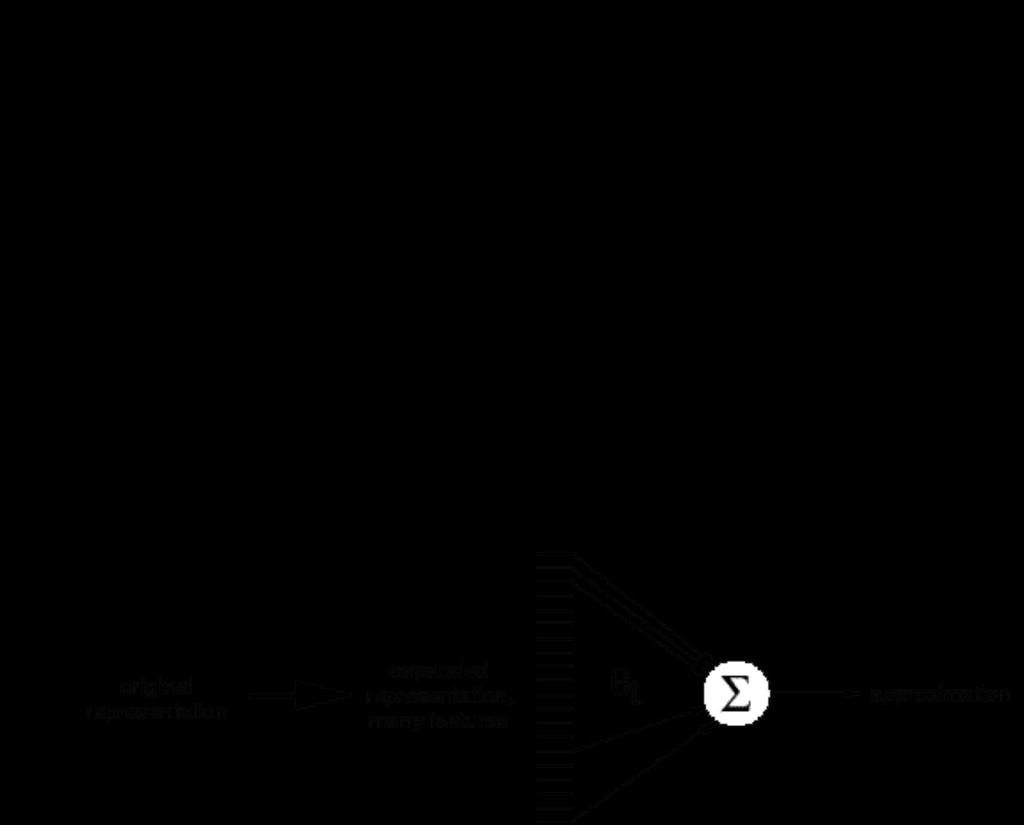
7 Linear Methods Represent states as feature vectors: for each s S : s s (1), s (2),, s (n) T V t (s) tt s V t (s)? n i 1 t (i) s (i) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 7
8 Nice Properties of Linear FA Methods The gradient is very simple: V t (s) s For MSE, the error surface is simple: quadratic surface with a single minumum. Linear gradient descent TD(l) converges: Step size decreases appropriately On-line sampling (states sampled from the on-policy distribution) Converges to parameter vector with property: MSE( ) 1 l 1 MSE( ) (Tsitsiklis & Van Roy, 1997) best parameter vector R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 8


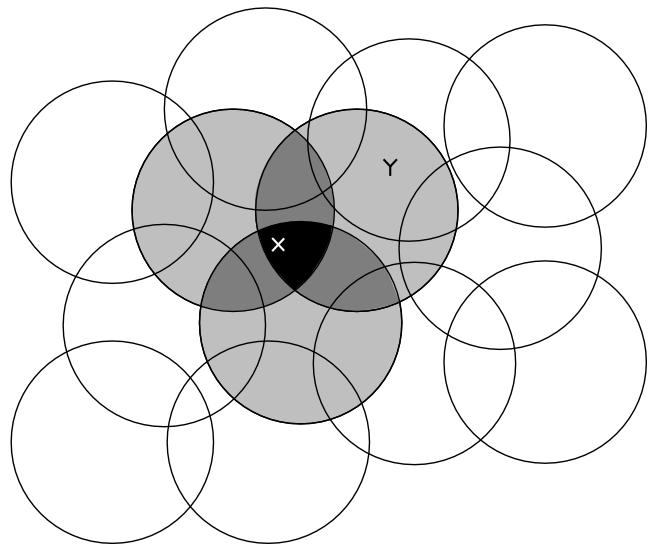
9 Coarse Coding R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 9

10 Shaping Generalization in Coarse Coding R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 10

11 Learning and Coarse Coding R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 11



12 Tile Coding Binary feature for each tile Number of features present at any one time is constant Binary features means weighted sum easy to compute Easy to compute indices of the freatures present R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 12



13 Tile Coding Cont. Irregular tilings Hashing CMAC Cerebellar model arithmetic computer Albus 1971 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 13
 exp s c i 2 2 i 2 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 14")
14 Radial Basis Functions (RBFs) e.g., Gaussians s (i) exp s c i 2 2 i 2 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 14
15 Can you beat the curse of dimensionality? Can you keep the number of features from going up exponentially with the dimension? Function complexity, not dimensionality, is the problem. Kanerva coding: Select a bunch of binary prototypes Use hamming distance as distance measure Dimensionality is no longer a problem, only complexity Lazy learning schemes: Remember all the data To get new value, find nearest neighbors and interpolate e.g., locally-weighted regression R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 15
16 Control with FA Learning state-action values Training examples of the form: description of (s t, a t ), v t The general gradient-descent rule: t 1 t v t Q t (s t,a t ) Q(s t,a t ) Gradient-descent Sarsa(l) (backward view): t 1 t t e t where t r t 1 Q t (s t 1,a t 1 ) Q t (s t,a t ) e t le t 1 Q t (s t,a t ) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 16
17 GPI Linear Gradient Descent Watkins Q(l) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 17
18 GPI with Linear Gradient Descent Sarsa(l) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 18

19 Mountain-Car Task R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 19

20 Mountain Car with Radial Basis Functions R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 20
21 Mountain-Car Results R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 21
22 Baird s Counterexample R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 22
23 Baird s Counterexample Cont. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 23

24 Should We Bootstrap? R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 24
25 Summary Generalization Adapting supervised-learning function approximation methods Gradient-descent methods Linear gradient-descent methods Radial basis functions Tile coding Kanerva coding Nonlinear gradient-descent methods? Backpropation? Subtleties involving function approximation, bootstrapping and the on-policy/off-policy distinction R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 25
26 Value Prediction with FA As usual: Policy Evaluation (the prediction problem): for a given policy, compute the state-value function V In earlier chapters, value functions were stored in lookup tables. Here, the value function estimate at time t, V t, depends on a parameter vector t, and only the parameter vector is updated. e.g., t could be the vector of connection weights of a neural network. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 26
27 Adapt Supervised Learning Algorithms Training Info = desired (target) outputs Inputs Supervised Learning System Outputs Training example = {input, target output} Error = (target output actual output) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 27
28 Backups as Training Examples e.g., the TD(0) backup: V(s t ) V(s t ) r t 1 V(s t 1 ) V(s t ) As a training example: description of s t, r t 1 V(s t 1 ) input target output R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 28
29 Gradient Descent Cont. For the MSE given above and using the chain rule: t 1 t 1 2 MSE( t) t 1 2 t s S s S P(s) P(s) V (s) V t (s) 2 V (s) V t (s) V t (s) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 29
30 Gradient Descent Cont. Use just the sample gradient instead: t 1 t 1 2 V (s t ) V t (s t ) 2 t V (s t ) V t (s t ) V t (s t ), Since each sample gradient is an unbiased estimate of the true gradient, this converges to a local minimum of the MSE if decreases appropriately with t. E V (s t ) V t (s t ) V t (s t ) P(s) V (s) V t (s) V t (s) s S R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 30
31 But We Don t have these Targets Suppose we just have targets v t instead : t 1 t v t V t (s t ) V t (s t ) If each v t is an unbiased estimate of V (s t ), i.e., E v t V (s t ), then gradient descent converges to a local minimum (provided decreases appropriately). e.g., the Monte Carlo target v t R t : t 1 t R t V t (s t ) V t (s t ) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 31
32 What about TD(l) Targets? t 1 t R l t V t (s t ) V t (s t ) Not for l 1 But we do it anyway, using the backwards view : t 1 t t e t, where : t r t 1 V t (s t 1 ) V t (s t ), as usual, and e t le t 1 V t (s t ) R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 32
CSE 190: Reinforcement Learning: An Introduction. Chapter 8: Generalization and Function Approximation. Pop Quiz: What Function Are We Approximating?
 CSE 190: Reinforcement Learning: An Introduction Chapter 8: Generalization and Function Approximation Objectives of this chapter: Look at how experience with a limited part of the state set be used to
CSE 190: Reinforcement Learning: An Introduction Chapter 8: Generalization and Function Approximation Objectives of this chapter: Look at how experience with a limited part of the state set be used to
CSE 190: Reinforcement Learning: An Introduction. Chapter 8: Generalization and Function Approximation. Pop Quiz: What Function Are We Approximating?
 CSE 190: Reinforcement Learning: An Introduction Chapter 8: Generalization and Function Approximation Objectives of this chapter: Look at how experience with a limited part of the state set be used to
CSE 190: Reinforcement Learning: An Introduction Chapter 8: Generalization and Function Approximation Objectives of this chapter: Look at how experience with a limited part of the state set be used to
CS599 Lecture 2 Function Approximation in RL
 CS599 Lecture 2 Function Approximation in RL Look at how experience with a limited part of the state set be used to produce good behavior over a much larger part. Overview of function approximation (FA)
CS599 Lecture 2 Function Approximation in RL Look at how experience with a limited part of the state set be used to produce good behavior over a much larger part. Overview of function approximation (FA)
Generalization and Function Approximation
 Generalization and Function Approximation 0 Generalization and Function Approximation Suggested reading: Chapter 8 in R. S. Sutton, A. G. Barto: Reinforcement Learning: An Introduction MIT Press, 1998.
Generalization and Function Approximation 0 Generalization and Function Approximation Suggested reading: Chapter 8 in R. S. Sutton, A. G. Barto: Reinforcement Learning: An Introduction MIT Press, 1998.
Chapter 8: Generalization and Function Approximation
 Chapte 8: Genealization and Function Appoximation Objectives of this chapte: Look at how expeience with a limited pat of the state set be used to poduce good behavio ove a much lage pat. Oveview of function
Chapte 8: Genealization and Function Appoximation Objectives of this chapte: Look at how expeience with a limited pat of the state set be used to poduce good behavio ove a much lage pat. Oveview of function
Value Prediction with FA. Chapter 8: Generalization and Function Approximation. Adapt Supervised Learning Algorithms. Backups as Training Examples [ ]
![Value Prediction with FA. Chapter 8: Generalization and Function Approximation. Adapt Supervised Learning Algorithms. Backups as Training Examples [ ]](/thumbs/86/93229856.jpg "Value Prediction with FA. Chapter 8: Generalization and Function Approximation. Adapt Supervised Learning Algorithms. Backups as Training Examples [ ]") Chapte 8: Genealization and Function Appoximation Objectives of this chapte:! Look at how expeience with a limited pat of the state set be used to poduce good behavio ove a much lage pat.! Oveview of function
Chapte 8: Genealization and Function Appoximation Objectives of this chapte:! Look at how expeience with a limited pat of the state set be used to poduce good behavio ove a much lage pat.! Oveview of function
Reinforcement Learning
 Reinforcement Learning RL in continuous MDPs March April, 2015 Large/Continuous MDPs Large/Continuous state space Tabular representation cannot be used Large/Continuous action space Maximization over action
Reinforcement Learning RL in continuous MDPs March April, 2015 Large/Continuous MDPs Large/Continuous state space Tabular representation cannot be used Large/Continuous action space Maximization over action
Reinforcement Learning
 Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning: An Introduction. ****Draft****
 i Reinforcement Learning: An Introduction Second edition, in progress ****Draft**** Richard S. Sutton and Andrew G. Barto c 2014, 2015 A Bradford Book The MIT Press Cambridge, Massachusetts London, England
i Reinforcement Learning: An Introduction Second edition, in progress ****Draft**** Richard S. Sutton and Andrew G. Barto c 2014, 2015 A Bradford Book The MIT Press Cambridge, Massachusetts London, England
Lecture 7: Value Function Approximation
 Lecture 7: Value Function Approximation Joseph Modayil Outline 1 Introduction 2 3 Batch Methods Introduction Large-Scale Reinforcement Learning Reinforcement learning can be used to solve large problems,
Lecture 7: Value Function Approximation Joseph Modayil Outline 1 Introduction 2 3 Batch Methods Introduction Large-Scale Reinforcement Learning Reinforcement learning can be used to solve large problems,
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Replacing eligibility trace for action-value learning with function approximation
 Replacing eligibility trace for action-value learning with function approximation Kary FRÄMLING Helsinki University of Technology PL 5500, FI-02015 TKK - Finland Abstract. The eligibility trace is one
Replacing eligibility trace for action-value learning with function approximation Kary FRÄMLING Helsinki University of Technology PL 5500, FI-02015 TKK - Finland Abstract. The eligibility trace is one
Reinforcement Learning with Function Approximation. Joseph Christian G. Noel
 Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
CS 287: Advanced Robotics Fall Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study
 CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
CS 287: Advanced Robotics Fall 2009 Lecture 14: Reinforcement Learning with Function Approximation and TD Gammon case study Pieter Abbeel UC Berkeley EECS Assignment #1 Roll-out: nice example paper: X.
ROB 537: Learning-Based Control. Announcements: Project background due Today. HW 3 Due on 10/30 Midterm Exam on 11/6.
 ROB 537: Learning-Based Control Week 5, Lecture 1 Policy Gradient, Eligibility Traces, Transfer Learning (MaC Taylor Announcements: Project background due Today HW 3 Due on 10/30 Midterm Exam on 11/6 Reading:
ROB 537: Learning-Based Control Week 5, Lecture 1 Policy Gradient, Eligibility Traces, Transfer Learning (MaC Taylor Announcements: Project background due Today HW 3 Due on 10/30 Midterm Exam on 11/6 Reading:
Week 6, Lecture 1. Reinforcement Learning (part 3) Announcements: HW 3 due on 11/5 at NOON Midterm Exam 11/8 Project draft due 11/15
 Announcements: HW 3 due on 11/5 at NOON Midterm Exam 11/8 Project draft due 11/15") ME 537: Learning Based Control Week 6, Lecture 1 Reinforcement Learning (part 3 Announcements: HW 3 due on 11/5 at NOON Midterm Exam 11/8 Project draft due 11/15 Suggested reading : Chapters 7-8 in Reinforcement
ME 537: Learning Based Control Week 6, Lecture 1 Reinforcement Learning (part 3 Announcements: HW 3 due on 11/5 at NOON Midterm Exam 11/8 Project draft due 11/15 Suggested reading : Chapters 7-8 in Reinforcement
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Reinforcement Learning
 Reinforcement Learning Function Approximation Continuous state/action space, mean-square error, gradient temporal difference learning, least-square temporal difference, least squares policy iteration Vien
Reinforcement Learning Function Approximation Continuous state/action space, mean-square error, gradient temporal difference learning, least-square temporal difference, least squares policy iteration Vien
Machine Learning I Continuous Reinforcement Learning
 Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Reinforcement Learning
 Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Overview Example (TD-Gammon) Admission Why approximate RL is hard TD() Fitted value iteration (collocation) Example (k-nn for hill-car)
 Admission Why approximate RL is hard TD() Fitted value iteration (collocation) Example (k-nn for hill-car)") Function Approximation in Reinforcement Learning Gordon Geo ggordon@cs.cmu.edu November 5, 999 Overview Example (TD-Gammon) Admission Why approximate RL is hard TD() Fitted value iteration (collocation)
Function Approximation in Reinforcement Learning Gordon Geo ggordon@cs.cmu.edu November 5, 999 Overview Example (TD-Gammon) Admission Why approximate RL is hard TD() Fitted value iteration (collocation)
Chapter 13 Wow! Least Squares Methods in Batch RL
 Chapter 13 Wow! Least Squares Methods in Batch RL Objectives of this chapter: Introduce batch RL Tradeoffs: Least squares vs. gradient methods Evaluating policies: Fitted value iteration Bellman residual
Chapter 13 Wow! Least Squares Methods in Batch RL Objectives of this chapter: Introduce batch RL Tradeoffs: Least squares vs. gradient methods Evaluating policies: Fitted value iteration Bellman residual
Open Theoretical Questions in Reinforcement Learning
 Open Theoretical Questions in Reinforcement Learning Richard S. Sutton AT&T Labs, Florham Park, NJ 07932, USA, sutton@research.att.com, www.cs.umass.edu/~rich Reinforcement learning (RL) concerns the problem
Open Theoretical Questions in Reinforcement Learning Richard S. Sutton AT&T Labs, Florham Park, NJ 07932, USA, sutton@research.att.com, www.cs.umass.edu/~rich Reinforcement learning (RL) concerns the problem
Introduction to Reinforcement Learning. Part 6: Core Theory II: Bellman Equations and Dynamic Programming
 Introduction to Reinforcement Learning Part 6: Core Theory II: Bellman Equations and Dynamic Programming Bellman Equations Recursive relationships among values that can be used to compute values The tree
Introduction to Reinforcement Learning Part 6: Core Theory II: Bellman Equations and Dynamic Programming Bellman Equations Recursive relationships among values that can be used to compute values The tree
Approximation Methods in Reinforcement Learning
 2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer.
 This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Fast Gradient-Descent Methods for Temporal-Difference Learning with Linear Function Approximation
 Fast Gradient-Descent Methods for Temporal-Difference Learning with Linear Function Approximation Rich Sutton, University of Alberta Hamid Maei, University of Alberta Doina Precup, McGill University Shalabh
Fast Gradient-Descent Methods for Temporal-Difference Learning with Linear Function Approximation Rich Sutton, University of Alberta Hamid Maei, University of Alberta Doina Precup, McGill University Shalabh
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Grundlagen der Künstlichen Intelligenz Reinforcement learning II Daniel Hennes 11.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns
Introduction. Reinforcement Learning
 Introduction Reinforcement Learning Learn Act Sense Scott Sanner NICTA / ANU First.Last@nicta.com.au Lecture Goals 1) To understand formal models for decisionmaking under uncertainty and their properties
Introduction Reinforcement Learning Learn Act Sense Scott Sanner NICTA / ANU First.Last@nicta.com.au Lecture Goals 1) To understand formal models for decisionmaking under uncertainty and their properties
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Sample questions for Fundamentals of Machine Learning 2018
 Sample questions for Fundamentals of Machine Learning 2018 Teacher: Mohammad Emtiyaz Khan A few important informations: In the final exam, no electronic devices are allowed except a calculator. Make sure
Sample questions for Fundamentals of Machine Learning 2018 Teacher: Mohammad Emtiyaz Khan A few important informations: In the final exam, no electronic devices are allowed except a calculator. Make sure
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
(Deep) Reinforcement Learning
 Reinforcement Learning") Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
 https://www.youtube.com/watch?v=ymvi1l746us Eligibility traces Chapter 12, plus some extra stuff! Like n-step methods, but better! Eligibility traces A mechanism that allow TD, Sarsa and Q-learning to
https://www.youtube.com/watch?v=ymvi1l746us Eligibility traces Chapter 12, plus some extra stuff! Like n-step methods, but better! Eligibility traces A mechanism that allow TD, Sarsa and Q-learning to
6 Reinforcement Learning
 6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
Temporal difference learning
 Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Lecture 25: Learning 4. Victor R. Lesser. CMPSCI 683 Fall 2010
 Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
CSE446: non-parametric methods Spring 2017
 CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
ilstd: Eligibility Traces and Convergence Analysis
 ilstd: Eligibility Traces and Convergence Analysis Alborz Geramifard Michael Bowling Martin Zinkevich Richard S. Sutton Department of Computing Science University of Alberta Edmonton, Alberta {alborz,bowling,maz,sutton}@cs.ualberta.ca
ilstd: Eligibility Traces and Convergence Analysis Alborz Geramifard Michael Bowling Martin Zinkevich Richard S. Sutton Department of Computing Science University of Alberta Edmonton, Alberta {alborz,bowling,maz,sutton}@cs.ualberta.ca
Value Function Methods. CS : Deep Reinforcement Learning Sergey Levine
 Value Function Methods CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 2 is due in one week 2. Remember to start forming final project groups and writing your proposal! Proposal
Value Function Methods CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 2 is due in one week 2. Remember to start forming final project groups and writing your proposal! Proposal
On and Off-Policy Relational Reinforcement Learning
 On and Off-Policy Relational Reinforcement Learning Christophe Rodrigues, Pierre Gérard, and Céline Rouveirol LIPN, UMR CNRS 73, Institut Galilée - Université Paris-Nord first.last@lipn.univ-paris13.fr
On and Off-Policy Relational Reinforcement Learning Christophe Rodrigues, Pierre Gérard, and Céline Rouveirol LIPN, UMR CNRS 73, Institut Galilée - Université Paris-Nord first.last@lipn.univ-paris13.fr
Machine Learning. Nonparametric Methods. Space of ML Problems. Todo. Histograms. Instance-Based Learning (aka non-parametric methods)
") Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Machine Learning InstanceBased Learning (aka nonparametric methods) Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Non parametric CSE 446 Machine Learning Daniel Weld March
Chapter 7: Eligibility Traces. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
 Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Reinforcement learning
 Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
Reinforcement Learning for Continuous. Action using Stochastic Gradient Ascent. Hajime KIMURA, Shigenobu KOBAYASHI JAPAN
 Reinforcement Learning for Continuous Action using Stochastic Gradient Ascent Hajime KIMURA, Shigenobu KOBAYASHI Tokyo Institute of Technology, 4259 Nagatsuda, Midori-ku Yokohama 226-852 JAPAN Abstract:
Reinforcement Learning for Continuous Action using Stochastic Gradient Ascent Hajime KIMURA, Shigenobu KOBAYASHI Tokyo Institute of Technology, 4259 Nagatsuda, Midori-ku Yokohama 226-852 JAPAN Abstract:
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]
![Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]](/thumbs/94/119187228.jpg "Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]") Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Reinforcement Learning
 Reinforcement Learning Value Function Approximation Continuous state/action space, mean-square error, gradient temporal difference learning, least-square temporal difference, least squares policy iteration
Reinforcement Learning Value Function Approximation Continuous state/action space, mean-square error, gradient temporal difference learning, least-square temporal difference, least squares policy iteration
Deep Reinforcement Learning SISL. Jeremy Morton (jmorton2) November 7, Stanford Intelligent Systems Laboratory
 November 7, Stanford Intelligent Systems Laboratory") Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning
 Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 50 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 50 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo MLR, University of Stuttgart
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo MLR, University of Stuttgart
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Payments System Design Using Reinforcement Learning: A Progress Report
 Payments System Design Using Reinforcement Learning: A Progress Report A. Desai 1 H. Du 1 R. Garratt 2 F. Rivadeneyra 1 1 Bank of Canada 2 University of California Santa Barbara 16th Payment and Settlement
Payments System Design Using Reinforcement Learning: A Progress Report A. Desai 1 H. Du 1 R. Garratt 2 F. Rivadeneyra 1 1 Bank of Canada 2 University of California Santa Barbara 16th Payment and Settlement
An online kernel-based clustering approach for value function approximation
 An online kernel-based clustering approach for value function approximation N. Tziortziotis and K. Blekas Department of Computer Science, University of Ioannina P.O.Box 1186, Ioannina 45110 - Greece {ntziorzi,kblekas}@cs.uoi.gr
An online kernel-based clustering approach for value function approximation N. Tziortziotis and K. Blekas Department of Computer Science, University of Ioannina P.O.Box 1186, Ioannina 45110 - Greece {ntziorzi,kblekas}@cs.uoi.gr
Approximate Dynamic Programming
 Approximate Dynamic Programming A. LAZARIC (SequeL Team @INRIA-Lille) Ecole Centrale - Option DAD SequeL INRIA Lille EC-RL Course Value Iteration: the Idea 1. Let V 0 be any vector in R N A. LAZARIC Reinforcement
Approximate Dynamic Programming A. LAZARIC (SequeL Team @INRIA-Lille) Ecole Centrale - Option DAD SequeL INRIA Lille EC-RL Course Value Iteration: the Idea 1. Let V 0 be any vector in R N A. LAZARIC Reinforcement
Least-Squares Temporal Difference Learning based on Extreme Learning Machine
 Least-Squares Temporal Difference Learning based on Extreme Learning Machine Pablo Escandell-Montero, José M. Martínez-Martínez, José D. Martín-Guerrero, Emilio Soria-Olivas, Juan Gómez-Sanchis IDAL, Intelligent
Least-Squares Temporal Difference Learning based on Extreme Learning Machine Pablo Escandell-Montero, José M. Martínez-Martínez, José D. Martín-Guerrero, Emilio Soria-Olivas, Juan Gómez-Sanchis IDAL, Intelligent
Reinforcement Learning In Continuous Time and Space
 Reinforcement Learning In Continuous Time and Space presentation of paper by Kenji Doya Leszek Rybicki lrybicki@mat.umk.pl 18.07.2008 Leszek Rybicki lrybicki@mat.umk.pl Reinforcement Learning In Continuous
Reinforcement Learning In Continuous Time and Space presentation of paper by Kenji Doya Leszek Rybicki lrybicki@mat.umk.pl 18.07.2008 Leszek Rybicki lrybicki@mat.umk.pl Reinforcement Learning In Continuous
State Space Abstractions for Reinforcement Learning
 State Space Abstractions for Reinforcement Learning Rowan McAllister and Thang Bui MLG RCC 6 November 24 / 24 Outline Introduction Markov Decision Process Reinforcement Learning State Abstraction 2 Abstraction
State Space Abstractions for Reinforcement Learning Rowan McAllister and Thang Bui MLG RCC 6 November 24 / 24 Outline Introduction Markov Decision Process Reinforcement Learning State Abstraction 2 Abstraction
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
CS325 Artificial Intelligence Chs. 18 & 4 Supervised Machine Learning (cont)
") CS325 Artificial Intelligence Cengiz Spring 2013 Model Complexity in Learning f(x) x Model Complexity in Learning f(x) x Let s start with the linear case... Linear Regression Linear Regression price =
CS325 Artificial Intelligence Cengiz Spring 2013 Model Complexity in Learning f(x) x Model Complexity in Learning f(x) x Let s start with the linear case... Linear Regression Linear Regression price =
Value Function Approximation in Reinforcement Learning using the Fourier Basis
 Value Function Approximation in Reinforcement Learning using the Fourier Basis George Konidaris Sarah Osentoski Technical Report UM-CS-28-19 Autonomous Learning Laboratory Computer Science Department University
Value Function Approximation in Reinforcement Learning using the Fourier Basis George Konidaris Sarah Osentoski Technical Report UM-CS-28-19 Autonomous Learning Laboratory Computer Science Department University
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Lecture 9: Policy Gradient II (Post lecture) 2
 2") Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Off-Policy Actor-Critic
 Off-Policy Actor-Critic Ludovic Trottier Laval University July 25 2012 Ludovic Trottier (DAMAS Laboratory) Off-Policy Actor-Critic July 25 2012 1 / 34 Table of Contents 1 Reinforcement Learning Theory
Off-Policy Actor-Critic Ludovic Trottier Laval University July 25 2012 Ludovic Trottier (DAMAS Laboratory) Off-Policy Actor-Critic July 25 2012 1 / 34 Table of Contents 1 Reinforcement Learning Theory
Chapter 6: Temporal Difference Learning
 Chapter 6: emporal Difference Learning Objectives of this chapter: Introduce emporal Difference (D) learning Focus first on policy evaluation, or prediction, methods Compare efficiency of D learning with
Chapter 6: emporal Difference Learning Objectives of this chapter: Introduce emporal Difference (D) learning Focus first on policy evaluation, or prediction, methods Compare efficiency of D learning with
Elements of Reinforcement Learning
 Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
CPSC 340: Machine Learning and Data Mining. Gradient Descent Fall 2016
 CPSC 340: Machine Learning and Data Mining Gradient Descent Fall 2016 Admin Assignment 1: Marks up this weekend on UBC Connect. Assignment 2: 3 late days to hand it in Monday. Assignment 3: Due Wednesday
CPSC 340: Machine Learning and Data Mining Gradient Descent Fall 2016 Admin Assignment 1: Marks up this weekend on UBC Connect. Assignment 2: 3 late days to hand it in Monday. Assignment 3: Due Wednesday
Reinforcement Learning
 Reinforcement Learning Policy gradients Daniel Hennes 26.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Policy based reinforcement learning So far we approximated the action value
Reinforcement Learning Policy gradients Daniel Hennes 26.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Policy based reinforcement learning So far we approximated the action value
Reinforcement Learning using Continuous Actions. Hado van Hasselt
 Reinforcement Learning using Continuous Actions Hado van Hasselt 2005 Concluding thesis for Cognitive Artificial Intelligence University of Utrecht First supervisor: Dr. Marco A. Wiering, University of
Reinforcement Learning using Continuous Actions Hado van Hasselt 2005 Concluding thesis for Cognitive Artificial Intelligence University of Utrecht First supervisor: Dr. Marco A. Wiering, University of
Chapter 6: Temporal Difference Learning
 Chapter 6: emporal Difference Learning Objectives of this chapter: Introduce emporal Difference (D) learning Focus first on policy evaluation, or prediction, methods hen extend to control methods R. S.
Chapter 6: emporal Difference Learning Objectives of this chapter: Introduce emporal Difference (D) learning Focus first on policy evaluation, or prediction, methods hen extend to control methods R. S.
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Lecture XI Learning with Distal Teachers (Forward and Inverse Models)
") Lecture XI Learning with Distal eachers (Forward and Inverse Models) Contents: he Distal eacher Problem Distal Supervised Learning Direct Inverse Modeling Forward Models Jacobian Combined Inverse & Forward
Lecture XI Learning with Distal eachers (Forward and Inverse Models) Contents: he Distal eacher Problem Distal Supervised Learning Direct Inverse Modeling Forward Models Jacobian Combined Inverse & Forward
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
CSC321 Lecture 6: Backpropagation
 CSC321 Lecture 6: Backpropagation Roger Grosse Roger Grosse CSC321 Lecture 6: Backpropagation 1 / 21 Overview We ve seen that multilayer neural networks are powerful. But how can we actually learn them?
CSC321 Lecture 6: Backpropagation Roger Grosse Roger Grosse CSC321 Lecture 6: Backpropagation 1 / 21 Overview We ve seen that multilayer neural networks are powerful. But how can we actually learn them?
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Machine Learning. Reinforcement learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
Temporal Difference Learning & Policy Iteration
 Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Regularization and Feature Selection in. the Least-Squares Temporal Difference
 Regularization and Feature Selection in Least-Squares Temporal Difference Learning J. Zico Kolter kolter@cs.stanford.edu Andrew Y. Ng ang@cs.stanford.edu Computer Science Department, Stanford University,
Regularization and Feature Selection in Least-Squares Temporal Difference Learning J. Zico Kolter kolter@cs.stanford.edu Andrew Y. Ng ang@cs.stanford.edu Computer Science Department, Stanford University,
A Convergent O(n) Algorithm for Off-policy Temporal-difference Learning with Linear Function Approximation
 Algorithm for Off-policy Temporal-difference Learning with Linear Function Approximation") A Convergent O(n) Algorithm for Off-policy Temporal-difference Learning with Linear Function Approximation Richard S. Sutton, Csaba Szepesvári, Hamid Reza Maei Reinforcement Learning and Artificial Intelligence
A Convergent O(n) Algorithm for Off-policy Temporal-difference Learning with Linear Function Approximation Richard S. Sutton, Csaba Szepesvári, Hamid Reza Maei Reinforcement Learning and Artificial Intelligence
Introduction to Reinforcement Learning. Part 5: Temporal-Difference Learning
 Introduction to Reinforcement Learning Part 5: emporal-difference Learning What everybody should know about emporal-difference (D) learning Used to learn value functions without human input Learns a guess
Introduction to Reinforcement Learning Part 5: emporal-difference Learning What everybody should know about emporal-difference (D) learning Used to learn value functions without human input Learns a guess
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms *
 Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms