Learning from Rational * Behavior
|
|
|
- Naomi Tyler
- 5 years ago
- Views:
Transcription
1 Learning from Rational * Behavior Josef Broder, Olivier Chapelle, Geri Gay, Arpita Ghosh, Laura Granka, Thorsten Joachims, Bobby Kleinberg, Madhu Kurup, Filip Radlinski, Karthik Raman, Tobias Schnabel, Pannaga Shivaswamy, Adith Swaminathan, Yisong Yue Department of Computer Science Department of Information Science Cornell University * ) Restrictions apply. Some modeling required.






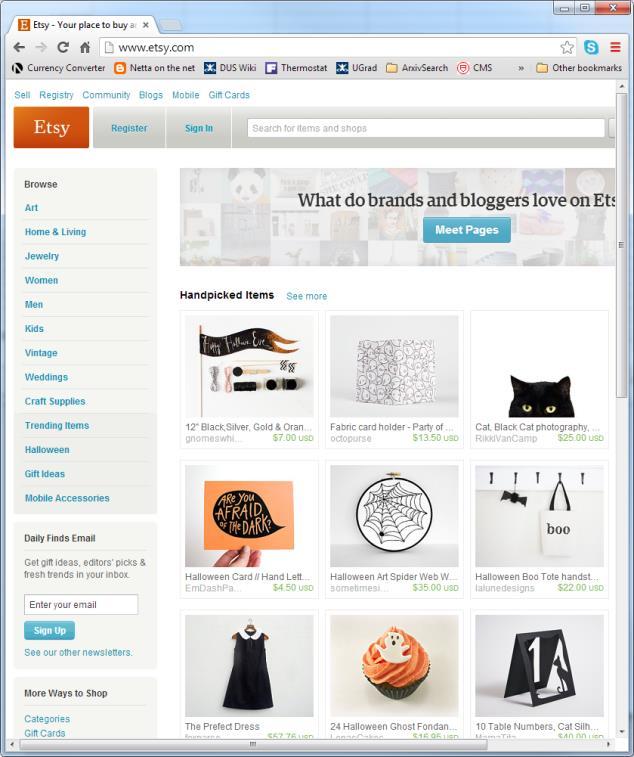

2 Knowledge-Based Systems Users as a Source of Knowledge
3 Supervised Batch Learning Data: x, y P(X, Y ) x is input y is true label Rules: f H Prediction: y = f(x) Loss function: Δ(y, y ) Find f H that minimizes prediction error R f = Δ(f x, y )
4 Interactive Learning System Design! response y t dependent on x t (e.g. ranking for query) Model! System Utility: U(y t ) User command x t and feedback δ t (e.g. query, click given ranking) Observed Data Training Data in Naïve Learning Model Observed data is user s decisions Decisions need proper interpretation New Learning Models that Integrate User and Algorithm Decisions Feedback Learning Algorithm
5 Decide between two Ranking Distribution P(x) of x=(user, query) Functions (tj, SVM ) Retrieval Function 1 Which one Retrieval Function 2 f 1 (x) y 1 is better? f 2 (x) y 2 1. Kernel Machines 2. SVM-Light Support Vector Machine 3. School of Veterinary Medicine at UPenn 4. An Introduction to Support Vector Machines 5. Service Master Company 1. School of Veterinary Medicine at UPenn 2. Service Master Company 3. Support Vector Machine 4. Archives of SUPPORT-VECTOR-MACHINES 5. SVM-Light Support Vector Machine light/ U(tj, SVM,y 1 ) U(tj, SVM,y 2 )
6 Name Description Aggregation Measuring Utility Abandonment Rate % of queries with no click N/A Increase Reformulation Rate Queries per Session % of queries that are followed by reformulation Session = no interruption of more than 30 minutes N/A Mean Hypothesized Change with Decreased Quality Increase Increase Clicks per Query Number of clicks Mean Decrease Click@1 % of queries with clicks at position 1 N/A Decrease Max Reciprocal Rank* 1/rank for highest click Mean Decrease Mean Reciprocal Rank* Mean of 1/rank for all clicks Mean Decrease Time to First Click* Seconds before first click Median Increase Time to Last Click* Seconds before final click Median Decrease (*) only queries with at least one click count


7 ArXiv.org: User Study User Study in ArXiv.org Natural user and query population User in natural context, not lab Live and operational search engine Ground truth by construction ORIG Â SWAP2 Â SWAP4 ORIG: Hand-tuned fielded SWAP2: ORIG with 2 pairs swapped SWAP4: ORIG with 4 pairs swapped ORIG Â FLAT Â RAND ORIG: Hand-tuned fielded FLAT: No field weights RAND : Top 10 of FLAT shuffled [Radlinski et al., 2008]
8 ArXiv.org: Experiment Setup Experiment Setup Phase I: 36 days Users randomly receive ranking from Orig, Flat, Rand Phase II: 30 days Users randomly receive ranking from Orig, Swap2, Swap4 User are permanently assigned to one experimental condition based on IP address and browser. Basic Statistics ~700 queries per day / ~300 distinct users per day Quality Control and Data Cleaning Test run for 32 days Heuristics to identify bots and spammers All evaluation code was written twice and cross-validated
9 Arxiv.org: Results ORIG FLAT RAND ORIG SWAP2 SWAP [Radlinski et al., 2008]
10 Arxiv.org: Results Conclusions ORIG FLAT None of the absolute metrics reflects RAND expected order. ORIG Most differences not significant SWAP2 after SWAP4 one month of data. Analogous results for Yahoo! Search with much more data [Chapelle et al., 2012]. [Radlinski et al., 2008]

11 How about Explicit Feedback? [Sipos et al., WWW14]
12 Interactive Learning System Design! response y t dependent on x t (e.g. ranking for query) Model! System Utility: U(y t ) User command x t and feedback δ t (e.g. query, click given ranking) Observed Data Training Data Decisions Observed data Feedback is user s decisions Learning Algorithm Model Even explicit the users feedback decision reflects process user s to extract decision feedback process Design learning algorithm for this type of feedback
13 Decide between two Ranking Distribution P(x) of x=(user, query) Functions (tj, SVM ) Retrieval Function 1 Which one Retrieval Function 2 f 1 (x) y 1 is better? f 2 (x) y 2 1. Kernel Machines 2. SVM-Light Support Vector Machine 3. School of Veterinary Medicine at UPenn 4. An Introduction to Support Vector Machines 5. Service Master Company 1. School of Veterinary Medicine at UPenn 2. Service Master Company 3. Support Vector Machine 4. Archives of SUPPORT-VECTOR-MACHINES 5. SVM-Light Support Vector Machine light/ U(tj, SVM,y 1 ) U(tj, SVM,y 2 )
14 Economic Models of Rational Choice Alternatives Y Utility function U(y) Decision y * =argmax y2y {U(y)} Bounded Rationality Time constraints Computation constraints Approximate U(y) Behavioral Economics Framing Fairness Loss aversion Handling uncertainty Decision Making Click
 Empirically supported by [Granka et al.")
15 A Model of how Users Click in Search Model of clicking: Users explore ranking to position k Users click on most relevant (looking) links in top k Users stop clicking when time budget up or other action more promising (e.g. reformulation) Empirically supported by [Granka et al., 2004] Click argmax y Top k U(y)
16 Balanced Interleaving x=(u=tj, q= svm ) f 1 (x) y 1 f 2 (x) y 2 1. Kernel Machines 2. Support Vector Machine 3. An Introduction to Support Vector Machines 4. Archives of SUPPORT-VECTOR-MACHINES SVM-Light Support Vector Machine light/ Model of User: Better retrieval functions is more likely to get more clicks. Interleaving(y 1,y 2 ) 1. Kernel Machines Support Vector Machine SVM-Light Support Vector Machine 2 light/ 4. An Introduction to Support Vector Machines Support Vector Machine and Kernel... References Archives of SUPPORT-VECTOR-MACHINES Lucent Technologies: SVM demo applet Kernel Machines 2. SVM-Light Support Vector Machine light/ 3. Support Vector Machine and Kernel... References 4. Lucent Technologies: SVM demo applet 5. Royal Holloway Support Vector Machine Invariant: For all k, top k of balanced interleaving is union of top k 1 of r 1 and top k 2 of r 2 with k 1 =k 2 ± 1. Interpretation: (y 1 Â y 2 ) clicks(topk(y 1 )) > clicks(topk(y 2 )) see also [Radlinski, Craswell, 2012] [Hofmann, 2012] [Joachims, 2001] [Radlinski et al., 2008]
17 Arxiv.org: Interleaving Experiment Experiment Setup Phase I: 36 days Balanced Interleaving of (Orig,Flat) (Flat,Rand) (Orig,Rand) Phase II: 30 days Balanced Interleaving of (Orig,Swap2) (Swap2,Swap4) (Orig,Swap4) Quality Control and Data Cleaning Same as for absolute metrics
18 Percent Wins Arxiv.org: Interleaving Results % wins ORIG % wins RAND
19 Percent Wins Arxiv.org: Interleaving Results % wins ORIG % wins RAND Conclusions All interleaving experiments reflect the expected order. All differences are significant after one month of data. Same results also for alternative data-preprocessing.
20 Yahoo and Bing: Interleaving Results Yahoo Web Search [Chapelle et al., 2012] Four retrieval functions (i.e. 6 paired comparisons) Balanced Interleaving All paired comparisons consistent with ordering by NDCG. Bing Web Search [Radlinski & Craswell, 2010] Five retrieval function pairs Team-Game Interleaving Consistent with ordering by NDGC when NDCG significant.
21 Efficiency: Interleaving vs. Explicit Bing Web Search 4 retrieval function pairs ~12k manually judged queries ~200k interleaved queries Experiment p = probability that NDCG is correct on subsample of size y x = number of queries needed to reach same p-value with interleaving Ten interleaved queries are equivalent to one manually judged query. [Radlinski & Craswell, 2010]
22 Interactive Learning System Design! response y t dependent on x t (e.g. ranking for query) Model! Algorithm Utility: U(y t ) User command x t and feedback δ t (e.g. query, click given ranking) Observed Data Training Data Decisions Feedback Learning Algorithm Model the users decision process to extract feedback Pairwise comparison test P( y i  y j U(y i )>U(y j ) ) Design learning algorithm for this type of feedback
23 Supervised Batch Learning Data: x, y P(X, Y ) x is input y is true label Rules: f H Prediction: y = f(x) Loss function: Δ(y, y ) Find f H that minimizes prediction error R f = Δ(f x, y )
24 Learning on Operational System Example: 4 retrieval functions: A > B >> C > D 10 possible pairs for interactive experiment (A,B) low cost to user (A,C) medium cost to user (C,D) high cost to user (A,A) zero cost to user Minimizing Regret Don t present bad pairs more often than necessary Trade off (long term) informativeness and (short term) cost Definition: Probability of (f t, f t ) losing against the best f Dueling Bandits Problem T R(A) = P f Âf t P f Âf t 0.5 t=1 [Yue, Broder, Kleinberg, Joachims, 2010]
25 First Thought: Tournament Noisy Sorting/Max Algorithms: [Feige et al.]: Triangle Tournament Heap O(n/ 2 log(1/ )) with prob 1- [Adler et al., Karp & Kleinberg]: optimal under weaker assumptions X 1 X 1 X 5 X 1 X 3 X 5 X 7 X 1 X 2 X 3 X 4 X 5 X 6 X 7 X 8
26 Algorithm: Interleaved Filter 2 Algorithm InterleavedFilter1(T,W={f 1 f K }) Pick random f from W =1/(TK 2 ) WHILE W >1 FOR b 2 W DO» duel(f,f)» update P f t=t+1 c t =(log(1/ )/t) 0.5 Remove all f from W with P f < 0.5-c t [WORSE WITH PROB 1- ] IF there exists f with P f > 0.5+c t [BETTER WITH PROB 1- ]» Remove f from W» Remove all f from W that are empirically inferior to f» f =f ; t=0 UNTIL T: duel(f,f ) Related Algorithms: [Hofmann, Whiteson, Rijke, 2011] [Yue, Joachims, 2009] [Yue, Joachims, 2011] f 1 f 2 f =f 3 f 4 f 5 0/0 0/0 0/0 0/0 f 1 f 2 f =f 3 f 4 f 5 8/2 7/3 4/6 1/9 f 1 f 2 f =f 3 f 4 13/2 11/4 7/8 XX f =f 1 f 2 f 4 0/0 0/0 XX XX XX [Yue et al., 2009]

27 Assumptions Preference Relation: f i  f j P(f i  f j ) = 0.5+ i,j > 0.5 Weak Stochastic Transitivity: f i  f j and f j  f k f i  f k Theorem: IF2 incurs expected average regret bounded by f 1  f 2  f 3  f 4  f 5  f 6   f K Strong Stochastic Transitivity: i,k max{ i,j, j,k } 1,4 2,4 3, ,4 6,4 K,4 Stochastic Triangle Inequality: f i  f j  f k i,k i,j + j,k 1,2 = 0.01 and 2,3 = , Winner exists: = max i { P(f 1  f i )-0.5 } = 1,2 > 0 [Yue et al., 2009]
28 Interactive Learning System Design! response y t dependent on x t (e.g. ranking for query) Model! System Utility: U(y t ) User command x t and feedback δ t (e.g. query, click given ranking) Observed Data Training Data Decisions Feedback Learning Algorithm Model the users decision process to extract feedback Pairwise comparison test P( y i  y j U(y i )>U(y j ) ) Design learning algorithm for this type of feedback Dueling Bandits problem and algorithms (e.g. IF2)


29 Who does the exploring? Example 1
30 Who does the exploring? Example 2 Click


31 Who does the exploring? Example 3 Click



32 Interaction: given x Coactive Feedback Model Set of all y for context x Algorithm prediction y User explored y Improved Prediction y Feedback: Optimal Prediction Improved prediction ӯ t U(ӯ t x t ) > U(y t x t ) Supervised learning: optimal prediction y t * y t * = argmax y U(y x t )
33 Machine Translation x t We propose Coactive Learning as a model of interaction between a learning system and a human user, where both have the common goal of providing results of maximum utility to the user. y t Wir schlagen vor, koaktive Learning als ein Modell der Wechselwirkung zwischen einem Lernsystem und menschlichen Benutzer, wobei sowohl die gemeinsame Ziel, die Ergebnisse der maximalen Nutzen für den Benutzer. Á Wir schlagen vor, koaktive Learning als ein Modell der Wechselwirkung des Dialogs zwischen einem Lernsystem und menschlichen Benutzer, wobei sowohl die beide das gemeinsame Ziel haben, die Ergebnisse der maximalen Nutzen für den Benutzer zu liefern. ӯ t
34 Supervised Batch Learning Data: x, y P(X, Y ) x is input y is true label Rules: f H Prediction: y = f(x) Loss function: Δ(y, y ) Find f H that minimizes prediction error R f = Δ(f x, y )
 - (x t,y t ) This may look similar to a multi-class Perceptron, but Feedback ӯ t is different (not get the correct class label) Regret is different (misclassifications")
35 Coactive Preference Perceptron Model Linear model of user utility: U(y x) = w T Á(x,y) Algorithm FOR t = 1 TO T DO Observe x t Present y t = argmax y { w t T (x t,y) } Obtain feedback ӯ t from user Update w t+1 = w t + (x t,ӯ t ) - (x t,y t ) This may look similar to a multi-class Perceptron, but Feedback ӯ t is different (not get the correct class label) Regret is different (misclassifications vs. utility difference) R A = 1 T T t=1 U y t x) U y t x Never revealed: cardinal feedback optimal y * [Shivaswamy, Joachims, 2012]

 U y t x 1 αt T t=1 model error gap to optimal ξ t + 2R w α T model error zero [Shivaswamy,")
36 Coactive Perceptron: Regret Bound Model U(y x) = w T ɸ(x,y), where w is unknown Feedback: ξ-approximately α-informative E U x t, y t U x t, y t + α U x t, y t U x t, y t ξ t Theorem For user feedback ӯ that is α-informative in expectation, the expected average regret of the Preference Perceptron is bounded by E 1 T T t=1 user feedback system prediction U y t x) U y t x 1 αt T t=1 model error gap to optimal ξ t + 2R w α T model error zero [Shivaswamy, Joachims, 2012]
 = i i w T t")
![Á(x,y (i) ) [~1000 features] Computing argmax ranking: sort by w T t Á(x,y (i) ) Feedback](/docs-images/83/88362142/images/37-4.jpg "Construct ӯ t from y t by moving Coactive Coactive clicked links one position higher.")
 Baseline Baseline Evaluation Interleaving of")
37 Cumulative Win Ratio Preference Perceptron: Experiment Experiment: Automatically optimize Arxiv.org Fulltext Search Model Analogous to DCG Utility of ranking y for query x: U t (y x) = i i w T t Á(x,y (i) ) [~1000 features] Computing argmax ranking: sort by w T t Á(x,y (i) ) Feedback Construct ӯ t from y t by moving Coactive Coactive clicked links one position higher. Learning Learning Perturbation [Raman et al., 2013] Baseline Handtuned w base for U base (y x) Baseline Baseline Evaluation Interleaving of ranking from U t (y x) and U base (y x) Number of of Feedback [Raman et al., 2013]
38 Interactive Learning System Design! y t dependent on x t (e.g. ranking for query) Model! Algorithm Utility: U(y t ) User x t+1 dependent on y t (e.g. click given ranking, new query) Observed Data Training Data Decisions Feedback Learning Algorithm Dueling Bandits Model: Pairwise comparison test P( y i  y j U(y i )>U(y j ) ) Algorithm: Interleaved Filter 2, O( Y log(t)) regret Coactive Learning Model: for given y, user provides ӯ with U(ӯ x) > U(y x) Algorithm: Preference Perceptron, O(ǁwǁ T 0.5 ) regret
39 Running Interactive Learning Experiments 1) Build your own system and provide service not your thing too little data 2) Convince others to run your experiments on commercial system good luck with that 3) Use large-scale historical log data from commercial system

 context f 0 action")
40 Information in Interaction Logs Partial Information (aka Bandit ) Feedback News recommender f 0 presents set y of articles for user x and observes that user reads δ minutes Ad system f 0 presents ad y to user x and observes monetary payoff δ Search engine f 0 interleaves ranking y for query x with baseline ranker and observes win/loss δ MT system f 0 predicts translation y for x and receives rating δ Data: S = ( x 1, y 1, δ 1,, x n, y n, δ n ) context f 0 action reward
41 Supervised Batch Learning Data: x, y P(X, Y ) x is input y is true label Rules: f H Prediction: y = f(x) Loss function: Δ(y, y ) Find f H that minimizes prediction error R f = Δ(f x, y )
 Off-Policy Evaluation Given S = ( x 1, y 1, δ 1,, x n, y n, δ n ) collected under f 0, R f = 1 n = 1 n n n i=1 i=1 δ i δ i P(Y x, f) P y i x i, f P y i x i, f 0 Propensity weight [Rubin, 1983]")
42 Changing History Expected Performance of Stochastic Policy f: P y x, f R f On-Policy Evaluation = P δ x, y P y x, f P(x) Given S = ( x 1, y 1, δ 1,, x n, y n, δ n ) collected under f 0, R f 0 P(Y x, f 0 ) Off-Policy Evaluation Given S = ( x 1, y 1, δ 1,, x n, y n, δ n ) collected under f 0, R f = 1 n = 1 n n n i=1 i=1 δ i δ i P(Y x, f) P y i x i, f P y i x i, f 0 Propensity weight [Rubin, 1983] [Langford, Li, 2009.]
43 Setup Partial Information Empirical Risk Minimization Stochastic logging using f 0 with p i = P(y i x i, f 0 ) Data S = x 1, y 1, δ 1, p 1,, x n, y n, δ n, p n Stochastic prediction rules f H: P y i x i, f P(Y x, f 0 ) Training P(Y x, f 1 ) f argmax f H n P(Y x, f 0 ) P y i x i, h p i i δ i P(Y x, f 2 ) [Langford & Li], [Bottou, et al.,2014]
44 Setup Partial Information Empirical Risk Minimization Stochastic logging using f 0 with p i = P(y i x i, f 0 ) Data S = x 1, y 1, δ 1, p 1,, x n, y n, δ n, p n Stochastic prediction rules f H: P y i x i, f Training f argmax f H n i P y i x i, h p i δ i [Langford & Li], [Bottou, et al.,2014]


45 Propensity Risk Minimization Intuition and Learning Theory De-bias estimator through propensity weighting Correct for variance of estimators for different f H Account for capacity of the hypothesis space H Training: optimize generalization error bound Mean P y i x i,f p i δ i Unbiased Estimator f = argmax f H λ 1 Var P y i x i,f p i λ 2 Reg H δ i Variance Control Capacity Control [Swaminathan, Joachims]
46 Hamming Loss Experiment: Propensity Risk Minimization Experiment Setup x: Reuters RCV1 text document y: label vector with 4 binary labels δ: number of correct labels p: propensity under logging with CRF(0) H: CRF with one weight vector per label Results CRF(0) CRF(PRM) CRF(supervised) S = Number of Training Interactions from CRF(0)

47 Summary and Conclusions Design! response y t dependent on x t (e.g. ranking for query) Model! Algorithm Utility: U(y t ) User command x t and feedback δ t (e.g. query, click given ranking) Observed Data Training Data Decisions Feedback Learning Algorithm Dueling Bandits Model: Pairwise comparison test P( y i  y j U(y i )>U(y j ) ) Algorithm: Interleaved Filter 2, O( Y log(t)) regret Coactive Learning Model: for given y, user provides ӯ with U(ӯ x) > U(y x) Algorithm: Preference Perceptron, O(ǁwǁ T 0.5 ) regret Data Propensity Risk Minimization Partial information learning in the Batch setting
48 Learning from Human Decisions Decision Model Learning Algorithm Design Space: Decision Model Utility Model Interaction Experiments Feedback Type Regret Applications Application Related Fields: Micro Economics Decision Theory Econometrics Psychology Communications Cognitive Science Contact: Software + Papers:
Interventions. Online Learning from User Interactions through Interventions. Interactive Learning Systems
 Online Learning from Interactions through Interventions CS 7792 - Fall 2016 horsten Joachims Department of Computer Science & Department of Information Science Cornell University Y. Yue, J. Broder, R.
Online Learning from Interactions through Interventions CS 7792 - Fall 2016 horsten Joachims Department of Computer Science & Department of Information Science Cornell University Y. Yue, J. Broder, R.
Counterfactual Evaluation and Learning
 SIGIR 26 Tutorial Counterfactual Evaluation and Learning Adith Swaminathan, Thorsten Joachims Department of Computer Science & Department of Information Science Cornell University Website: http://www.cs.cornell.edu/~adith/cfactsigir26/
SIGIR 26 Tutorial Counterfactual Evaluation and Learning Adith Swaminathan, Thorsten Joachims Department of Computer Science & Department of Information Science Cornell University Website: http://www.cs.cornell.edu/~adith/cfactsigir26/
Stable Coactive Learning via Perturbation
 Karthik Raman horsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA Pannaga Shivaswamy A& Research, San Francisco, CA, USA obias Schnabel Fachbereich Informatik, Universitaet
Karthik Raman horsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA Pannaga Shivaswamy A& Research, San Francisco, CA, USA obias Schnabel Fachbereich Informatik, Universitaet
Stable Coactive Learning via Perturbation
 Karthik Raman horsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA Pannaga Shivaswamy A& Research, San Francisco, CA, USA obias Schnabel Fachbereich Informatik, Universitaet
Karthik Raman horsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA Pannaga Shivaswamy A& Research, San Francisco, CA, USA obias Schnabel Fachbereich Informatik, Universitaet
Counterfactual Model for Learning Systems
 Counterfactual Model for Learning Systems CS 7792 - Fall 28 Thorsten Joachims Department of Computer Science & Department of Information Science Cornell University Imbens, Rubin, Causal Inference for Statistical
Counterfactual Model for Learning Systems CS 7792 - Fall 28 Thorsten Joachims Department of Computer Science & Department of Information Science Cornell University Imbens, Rubin, Causal Inference for Statistical
The K-armed Dueling Bandits Problem
 The K-armed Dueling Bandits Problem Yisong Yue, Josef Broder, Robert Kleinberg, Thorsten Joachims Abstract We study a partial-information online-learning problem where actions are restricted to noisy comparisons
The K-armed Dueling Bandits Problem Yisong Yue, Josef Broder, Robert Kleinberg, Thorsten Joachims Abstract We study a partial-information online-learning problem where actions are restricted to noisy comparisons
Support Vector and Kernel Methods
 SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
Outline. Offline Evaluation of Online Metrics Counterfactual Estimation Advanced Estimators. Case Studies & Demo Summary
 Outline Offline Evaluation of Online Metrics Counterfactual Estimation Advanced Estimators 1. Self-Normalized Estimator 2. Doubly Robust Estimator 3. Slates Estimator Case Studies & Demo Summary IPS: Issues
Outline Offline Evaluation of Online Metrics Counterfactual Estimation Advanced Estimators 1. Self-Normalized Estimator 2. Doubly Robust Estimator 3. Slates Estimator Case Studies & Demo Summary IPS: Issues
OPTIMIZING SEARCH ENGINES USING CLICKTHROUGH DATA. Paper By: Thorsten Joachims (Cornell University) Presented By: Roy Levin (Technion)
 Presented By: Roy Levin (Technion)") OPTIMIZING SEARCH ENGINES USING CLICKTHROUGH DATA Paper By: Thorsten Joachims (Cornell University) Presented By: Roy Levin (Technion) Outline The idea The model Learning a ranking function Experimental
OPTIMIZING SEARCH ENGINES USING CLICKTHROUGH DATA Paper By: Thorsten Joachims (Cornell University) Presented By: Roy Levin (Technion) Outline The idea The model Learning a ranking function Experimental
New Algorithms for Contextual Bandits
 New Algorithms for Contextual Bandits Lev Reyzin Georgia Institute of Technology Work done at Yahoo! 1 S A. Beygelzimer, J. Langford, L. Li, L. Reyzin, R.E. Schapire Contextual Bandit Algorithms with Supervised
New Algorithms for Contextual Bandits Lev Reyzin Georgia Institute of Technology Work done at Yahoo! 1 S A. Beygelzimer, J. Langford, L. Li, L. Reyzin, R.E. Schapire Contextual Bandit Algorithms with Supervised
Information Retrieval
 Information Retrieval Online Evaluation Ilya Markov i.markov@uva.nl University of Amsterdam Ilya Markov i.markov@uva.nl Information Retrieval 1 Course overview Offline Data Acquisition Data Processing
Information Retrieval Online Evaluation Ilya Markov i.markov@uva.nl University of Amsterdam Ilya Markov i.markov@uva.nl Information Retrieval 1 Course overview Offline Data Acquisition Data Processing
CS-E4830 Kernel Methods in Machine Learning
 CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
Learning Socially Optimal Information Systems from Egoistic Users
 Learning Socially Optimal Information Systems from Egoistic Users Karthik Raman and Thorsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA {karthik,tj}@cs.cornell.edu http://www.cs.cornell.edu
Learning Socially Optimal Information Systems from Egoistic Users Karthik Raman and Thorsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA {karthik,tj}@cs.cornell.edu http://www.cs.cornell.edu
Beat the Mean Bandit
 Yisong Yue H. John Heinz III College, Carnegie Mellon University, Pittsburgh, PA, USA Thorsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA yisongyue@cmu.edu tj@cs.cornell.edu
Yisong Yue H. John Heinz III College, Carnegie Mellon University, Pittsburgh, PA, USA Thorsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA yisongyue@cmu.edu tj@cs.cornell.edu
Recommendations as Treatments: Debiasing Learning and Evaluation
 ICML 2016, NYC Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, Thorsten Joachims Cornell University, Google Funded in part through NSF Awards IIS-1247637, IIS-1217686, IIS-1513692. Romance
ICML 2016, NYC Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, Thorsten Joachims Cornell University, Google Funded in part through NSF Awards IIS-1247637, IIS-1217686, IIS-1513692. Romance
Interactively Optimizing Information Retrieval Systems as a Dueling Bandits Problem
 Interactively Optimizing Information Retrieval Systems as a Dueling Bandits Problem Yisong Yue Thorsten Joachims Department of Computer Science, Cornell University, Ithaca, NY 14853 USA yyue@cs.cornell.edu
Interactively Optimizing Information Retrieval Systems as a Dueling Bandits Problem Yisong Yue Thorsten Joachims Department of Computer Science, Cornell University, Ithaca, NY 14853 USA yyue@cs.cornell.edu
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Ad Placement Strategies
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Doubly Robust Policy Evaluation and Learning
 Doubly Robust Policy Evaluation and Learning Miroslav Dudik, John Langford and Lihong Li Yahoo! Research Discussed by Miao Liu October 9, 2011 October 9, 2011 1 / 17 1 Introduction 2 Problem Definition
Doubly Robust Policy Evaluation and Learning Miroslav Dudik, John Langford and Lihong Li Yahoo! Research Discussed by Miao Liu October 9, 2011 October 9, 2011 1 / 17 1 Introduction 2 Problem Definition
Relative Upper Confidence Bound for the K-Armed Dueling Bandit Problem
 Relative Upper Confidence Bound for the K-Armed Dueling Bandit Problem Masrour Zoghi 1, Shimon Whiteson 1, Rémi Munos 2 and Maarten de Rijke 1 University of Amsterdam 1 ; INRIA Lille / MSR-NE 2 June 24,
Relative Upper Confidence Bound for the K-Armed Dueling Bandit Problem Masrour Zoghi 1, Shimon Whiteson 1, Rémi Munos 2 and Maarten de Rijke 1 University of Amsterdam 1 ; INRIA Lille / MSR-NE 2 June 24,
CS 188: Artificial Intelligence. Outline
 CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
Bandit Algorithms. Zhifeng Wang ... Department of Statistics Florida State University
 Bandit Algorithms Zhifeng Wang Department of Statistics Florida State University Outline Multi-Armed Bandits (MAB) Exploration-First Epsilon-Greedy Softmax UCB Thompson Sampling Adversarial Bandits Exp3
Bandit Algorithms Zhifeng Wang Department of Statistics Florida State University Outline Multi-Armed Bandits (MAB) Exploration-First Epsilon-Greedy Softmax UCB Thompson Sampling Adversarial Bandits Exp3
Bayesian Ranker Comparison Based on Historical User Interactions
 Bayesian Ranker Comparison Based on Historical User Interactions Artem Grotov a.grotov@uva.nl Shimon Whiteson s.a.whiteson@uva.nl University of Amsterdam, Amsterdam, The Netherlands Maarten de Rijke derijke@uva.nl
Bayesian Ranker Comparison Based on Historical User Interactions Artem Grotov a.grotov@uva.nl Shimon Whiteson s.a.whiteson@uva.nl University of Amsterdam, Amsterdam, The Netherlands Maarten de Rijke derijke@uva.nl
Hybrid Machine Learning Algorithms
 Hybrid Machine Learning Algorithms Umar Syed Princeton University Includes joint work with: Rob Schapire (Princeton) Nina Mishra, Alex Slivkins (Microsoft) Common Approaches to Machine Learning!! Supervised
Hybrid Machine Learning Algorithms Umar Syed Princeton University Includes joint work with: Rob Schapire (Princeton) Nina Mishra, Alex Slivkins (Microsoft) Common Approaches to Machine Learning!! Supervised
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Empirical Risk Minimization, Model Selection, and Model Assessment
 Empirical Risk Minimization, Model Selection, and Model Assessment CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 5.7-5.7.2.4, 6.5-6.5.3.1 Dietterich,
Empirical Risk Minimization, Model Selection, and Model Assessment CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 5.7-5.7.2.4, 6.5-6.5.3.1 Dietterich,
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Counterfactual Learning-to-Rank for Additive Metrics and Deep Models
 Counterfactual Learning-to-Rank for Additive Metrics and Deep Models Aman Agarwal Cornell University Ithaca, NY aman@cs.cornell.edu Ivan Zaitsev Cornell University Ithaca, NY iz44@cornell.edu Thorsten
Counterfactual Learning-to-Rank for Additive Metrics and Deep Models Aman Agarwal Cornell University Ithaca, NY aman@cs.cornell.edu Ivan Zaitsev Cornell University Ithaca, NY iz44@cornell.edu Thorsten
An Introduction to Machine Learning
 An Introduction to Machine Learning L6: Structured Estimation Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia Alex.Smola@nicta.com.au Tata Institute, Pune, January
An Introduction to Machine Learning L6: Structured Estimation Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia Alex.Smola@nicta.com.au Tata Institute, Pune, January
NEW LEARNING FRAMEWORKS FOR INFORMATION RETRIEVAL
 NEW LEARNING FRAMEWORKS FOR INFORMATION RETRIEVAL A Dissertation Presented to the Faculty of the Graduate School of Cornell University in Partial Fulfillment of the Requirements for the Degree of Doctor
NEW LEARNING FRAMEWORKS FOR INFORMATION RETRIEVAL A Dissertation Presented to the Faculty of the Graduate School of Cornell University in Partial Fulfillment of the Requirements for the Degree of Doctor
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Semestrial Project - Expedia Hotel Ranking
 1 Many customers search and purchase hotels online. Companies such as Expedia make their profit from purchases made through their sites. The ultimate goal top of the list are the hotels that are most likely
1 Many customers search and purchase hotels online. Companies such as Expedia make their profit from purchases made through their sites. The ultimate goal top of the list are the hotels that are most likely
Case Study 1: Estimating Click Probabilities. Kakade Announcements: Project Proposals: due this Friday!
 Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Web Search and Text Mining. Learning from Preference Data
 Web Search and Text Mining Learning from Preference Data Outline Two-stage algorithm, learning preference functions, and finding a total order that best agrees with a preference function Learning ranking
Web Search and Text Mining Learning from Preference Data Outline Two-stage algorithm, learning preference functions, and finding a total order that best agrees with a preference function Learning ranking
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Learning Socially Optimal Information Systems from Egoistic Users
 Learning Socially Optimal Information Systems from Egoistic Users Karthik Raman and Thorsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA {karthik,tj}@cs.cornell.edu http://www.cs.cornell.edu
Learning Socially Optimal Information Systems from Egoistic Users Karthik Raman and Thorsten Joachims Department of Computer Science, Cornell University, Ithaca, NY, USA {karthik,tj}@cs.cornell.edu http://www.cs.cornell.edu
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
Models, Data, Learning Problems
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Models, Data, Learning Problems Tobias Scheffer Overview Types of learning problems: Supervised Learning (Classification, Regression,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Models, Data, Learning Problems Tobias Scheffer Overview Types of learning problems: Supervised Learning (Classification, Regression,
Sequential and reinforcement learning: Stochastic Optimization I
 1 Sequential and reinforcement learning: Stochastic Optimization I Sequential and reinforcement learning: Stochastic Optimization I Summary This session describes the important and nowadays framework of
1 Sequential and reinforcement learning: Stochastic Optimization I Sequential and reinforcement learning: Stochastic Optimization I Summary This session describes the important and nowadays framework of
Reducing contextual bandits to supervised learning
 Reducing contextual bandits to supervised learning Daniel Hsu Columbia University Based on joint work with A. Agarwal, S. Kale, J. Langford, L. Li, and R. Schapire 1 Learning to interact: example #1 Practicing
Reducing contextual bandits to supervised learning Daniel Hsu Columbia University Based on joint work with A. Agarwal, S. Kale, J. Langford, L. Li, and R. Schapire 1 Learning to interact: example #1 Practicing
arxiv: v2 [cs.lg] 26 Jun 2017
![arxiv: v2 [cs.lg] 26 Jun 2017](/thumbs/96/128495300.jpg "arxiv: v2 [cs.lg] 26 Jun 2017") Effective Evaluation Using Logged Bandit Feedback from Multiple Loggers Aman Agarwal, Soumya Basu, Tobias Schnabel, Thorsten Joachims Cornell University, Dept. of Computer Science Ithaca, NY, USA [aa2398,sb2352,tbs49,tj36]@cornell.edu
Effective Evaluation Using Logged Bandit Feedback from Multiple Loggers Aman Agarwal, Soumya Basu, Tobias Schnabel, Thorsten Joachims Cornell University, Dept. of Computer Science Ithaca, NY, USA [aa2398,sb2352,tbs49,tj36]@cornell.edu
Large-scale Information Processing, Summer Recommender Systems (part 2)
") Large-scale Information Processing, Summer 2015 5 th Exercise Recommender Systems (part 2) Emmanouil Tzouridis tzouridis@kma.informatik.tu-darmstadt.de Knowledge Mining & Assessment SVM question When a
Large-scale Information Processing, Summer 2015 5 th Exercise Recommender Systems (part 2) Emmanouil Tzouridis tzouridis@kma.informatik.tu-darmstadt.de Knowledge Mining & Assessment SVM question When a
Ad Placement Strategies
 Case Study : Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD AdaGrad Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 7 th, 04 Ad
Case Study : Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD AdaGrad Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 7 th, 04 Ad
Foundations of Machine Learning
 Introduction to ML Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu page 1 Logistics Prerequisites: basics in linear algebra, probability, and analysis of algorithms. Workload: about
Introduction to ML Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu page 1 Logistics Prerequisites: basics in linear algebra, probability, and analysis of algorithms. Workload: about
CS 188: Artificial Intelligence. Machine Learning
 CS 188: Artificial Intelligence Review of Machine Learning (ML) DISCLAIMER: It is insufficient to simply study these slides, they are merely meant as a quick refresher of the high-level ideas covered.
CS 188: Artificial Intelligence Review of Machine Learning (ML) DISCLAIMER: It is insufficient to simply study these slides, they are merely meant as a quick refresher of the high-level ideas covered.
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
Natural Language Processing. Classification. Features. Some Definitions. Classification. Feature Vectors. Classification I. Dan Klein UC Berkeley
 Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Administration. CSCI567 Machine Learning (Fall 2018) Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.
 Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.") Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Unbiased Learning to Rank with Unbiased Propensity Estimation
 Unbiased Learning to Rank with Unbiased Propensity Estimation Qingyao Ai CICS, UMass Amherst Amherst, MA, USA aiqy@cs.umass.edu Keping Bi CICS, UMass Amherst Amherst, MA, USA kbi@cs.umass.edu Cheng Luo
Unbiased Learning to Rank with Unbiased Propensity Estimation Qingyao Ai CICS, UMass Amherst Amherst, MA, USA aiqy@cs.umass.edu Keping Bi CICS, UMass Amherst Amherst, MA, USA kbi@cs.umass.edu Cheng Luo
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
Simple Techniques for Improving SGD. CS6787 Lecture 2 Fall 2017
 Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Errors, and What to Do. CS 188: Artificial Intelligence Fall What to Do About Errors. Later On. Some (Simplified) Biology
 Biology") CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
Announcements. CS 188: Artificial Intelligence Spring Classification. Today. Classification overview. Case-Based Reasoning
 CS 188: Artificial Intelligence Spring 21 Lecture 22: Nearest Neighbors, Kernels 4/18/211 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!) Remaining
CS 188: Artificial Intelligence Spring 21 Lecture 22: Nearest Neighbors, Kernels 4/18/211 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!) Remaining
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Offline Evaluation of Ranking Policies with Click Models
 Offline Evaluation of Ranking Policies with Click Models Shuai Li The Chinese University of Hong Kong Joint work with Yasin Abbasi-Yadkori (Adobe Research) Branislav Kveton (Google Research, was in Adobe
Offline Evaluation of Ranking Policies with Click Models Shuai Li The Chinese University of Hong Kong Joint work with Yasin Abbasi-Yadkori (Adobe Research) Branislav Kveton (Google Research, was in Adobe
Learning Binary Classifiers for Multi-Class Problem
 Research Memorandum No. 1010 September 28, 2006 Learning Binary Classifiers for Multi-Class Problem Shiro Ikeda The Institute of Statistical Mathematics 4-6-7 Minami-Azabu, Minato-ku, Tokyo, 106-8569,
Research Memorandum No. 1010 September 28, 2006 Learning Binary Classifiers for Multi-Class Problem Shiro Ikeda The Institute of Statistical Mathematics 4-6-7 Minami-Azabu, Minato-ku, Tokyo, 106-8569,
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 13 Text Classification and Naïve Bayes Dell Zhang Birkbeck, University of London Motivation Relevance Feedback revisited The user marks a number of documents
Information Retrieval and Organisation Chapter 13 Text Classification and Naïve Bayes Dell Zhang Birkbeck, University of London Motivation Relevance Feedback revisited The user marks a number of documents
Stochastic Gradient Descent. CS 584: Big Data Analytics
 Stochastic Gradient Descent CS 584: Big Data Analytics Gradient Descent Recap Simplest and extremely popular Main Idea: take a step proportional to the negative of the gradient Easy to implement Each iteration
Stochastic Gradient Descent CS 584: Big Data Analytics Gradient Descent Recap Simplest and extremely popular Main Idea: take a step proportional to the negative of the gradient Easy to implement Each iteration
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
Markov Models and Reinforcement Learning. Stephen G. Ware CSCI 4525 / 5525
 Markov Models and Reinforcement Learning Stephen G. Ware CSCI 4525 / 5525 Camera Vacuum World (CVW) 2 discrete rooms with cameras that detect dirt. A mobile robot with a vacuum. The goal is to ensure both
Markov Models and Reinforcement Learning Stephen G. Ware CSCI 4525 / 5525 Camera Vacuum World (CVW) 2 discrete rooms with cameras that detect dirt. A mobile robot with a vacuum. The goal is to ensure both
Some Formal Analysis of Rocchio s Similarity-Based Relevance Feedback Algorithm
 Some Formal Analysis of Rocchio s Similarity-Based Relevance Feedback Algorithm Zhixiang Chen (chen@cs.panam.edu) Department of Computer Science, University of Texas-Pan American, 1201 West University
Some Formal Analysis of Rocchio s Similarity-Based Relevance Feedback Algorithm Zhixiang Chen (chen@cs.panam.edu) Department of Computer Science, University of Texas-Pan American, 1201 West University
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
Supervised Learning Coursework
 Supervised Learning Coursework John Shawe-Taylor Tom Diethe Dorota Glowacka November 30, 2009; submission date: noon December 18, 2009 Abstract Using a series of synthetic examples, in this exercise session
Supervised Learning Coursework John Shawe-Taylor Tom Diethe Dorota Glowacka November 30, 2009; submission date: noon December 18, 2009 Abstract Using a series of synthetic examples, in this exercise session
COMS 4721: Machine Learning for Data Science Lecture 20, 4/11/2017
 COMS 4721: Machine Learning for Data Science Lecture 20, 4/11/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SEQUENTIAL DATA So far, when thinking
COMS 4721: Machine Learning for Data Science Lecture 20, 4/11/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SEQUENTIAL DATA So far, when thinking
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
A Relative Exponential Weighing Algorithm for Adversarial Utility-based Dueling Bandits
 A Relative Exponential Weighing Algorithm for Adversarial Utility-based Dueling Bandits Pratik Gajane Tanguy Urvoy Fabrice Clérot Orange-labs, Lannion, France PRATIK.GAJANE@ORANGE.COM TANGUY.URVOY@ORANGE.COM
A Relative Exponential Weighing Algorithm for Adversarial Utility-based Dueling Bandits Pratik Gajane Tanguy Urvoy Fabrice Clérot Orange-labs, Lannion, France PRATIK.GAJANE@ORANGE.COM TANGUY.URVOY@ORANGE.COM
Evaluation. Andrea Passerini Machine Learning. Evaluation
 Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Learning with Exploration
 Learning with Exploration John Langford (Yahoo!) { With help from many } Austin, March 24, 2011 Yahoo! wants to interactively choose content and use the observed feedback to improve future content choices.
Learning with Exploration John Langford (Yahoo!) { With help from many } Austin, March 24, 2011 Yahoo! wants to interactively choose content and use the observed feedback to improve future content choices.
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Large-Scale Behavioral Targeting
 Large-Scale Behavioral Targeting Ye Chen, Dmitry Pavlov, John Canny ebay, Yandex, UC Berkeley (This work was conducted at Yahoo! Labs.) June 30, 2009 Chen et al. (KDD 09) Large-Scale Behavioral Targeting
Large-Scale Behavioral Targeting Ye Chen, Dmitry Pavlov, John Canny ebay, Yandex, UC Berkeley (This work was conducted at Yahoo! Labs.) June 30, 2009 Chen et al. (KDD 09) Large-Scale Behavioral Targeting
Lecture 3: Multiclass Classification
 Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Evaluation requires to define performance measures to be optimized
 Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
arxiv: v2 [cs.lg] 13 Jun 2018
![arxiv: v2 [cs.lg] 13 Jun 2018](/thumbs/93/113672774.jpg "arxiv: v2 [cs.lg] 13 Jun 2018") Offline Evaluation of Ranking Policies with Click odels Shuai Li The Chinese University of Hong Kong shuaili@cse.cuhk.edu.hk S. uthukrishnan Rutgers University muthu@cs.rutgers.edu Yasin Abbasi-Yadkori
Offline Evaluation of Ranking Policies with Click odels Shuai Li The Chinese University of Hong Kong shuaili@cse.cuhk.edu.hk S. uthukrishnan Rutgers University muthu@cs.rutgers.edu Yasin Abbasi-Yadkori
Evaluation Metrics. Jaime Arguello INLS 509: Information Retrieval March 25, Monday, March 25, 13
 Evaluation Metrics Jaime Arguello INLS 509: Information Retrieval jarguell@email.unc.edu March 25, 2013 1 Batch Evaluation evaluation metrics At this point, we have a set of queries, with identified relevant
Evaluation Metrics Jaime Arguello INLS 509: Information Retrieval jarguell@email.unc.edu March 25, 2013 1 Batch Evaluation evaluation metrics At this point, we have a set of queries, with identified relevant
EE 511 Online Learning Perceptron
 Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Kevin Jamison EE 511 Online Learning Perceptron Instructor: Hanna Hajishirzi hannaneh@washington.edu
Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Kevin Jamison EE 511 Online Learning Perceptron Instructor: Hanna Hajishirzi hannaneh@washington.edu
Generative Models for Classification
 Generative Models for Classification CS4780/5780 Machine Learning Fall 2014 Thorsten Joachims Cornell University Reading: Mitchell, Chapter 6.9-6.10 Duda, Hart & Stork, Pages 20-39 Generative vs. Discriminative
Generative Models for Classification CS4780/5780 Machine Learning Fall 2014 Thorsten Joachims Cornell University Reading: Mitchell, Chapter 6.9-6.10 Duda, Hart & Stork, Pages 20-39 Generative vs. Discriminative
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Coactive Learning for Locally Optimal Problem Solving
 Coactive Learning for Locally Optimal Problem Solving Robby Goetschalckx, Alan Fern, Prasad adepalli School of EECS, Oregon State University, Corvallis, Oregon, USA Abstract Coactive learning is an online
Coactive Learning for Locally Optimal Problem Solving Robby Goetschalckx, Alan Fern, Prasad adepalli School of EECS, Oregon State University, Corvallis, Oregon, USA Abstract Coactive learning is an online
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Large-scale Linear RankSVM
 Large-scale Linear RankSVM Ching-Pei Lee Department of Computer Science National Taiwan University Joint work with Chih-Jen Lin Ching-Pei Lee (National Taiwan Univ.) 1 / 41 Outline 1 Introduction 2 Our
Large-scale Linear RankSVM Ching-Pei Lee Department of Computer Science National Taiwan University Joint work with Chih-Jen Lin Ching-Pei Lee (National Taiwan Univ.) 1 / 41 Outline 1 Introduction 2 Our
A Support Vector Method for Multivariate Performance Measures
 A Support Vector Method for Multivariate Performance Measures Thorsten Joachims Cornell University Department of Computer Science Thanks to Rich Caruana, Alexandru Niculescu-Mizil, Pierre Dupont, Jérôme
A Support Vector Method for Multivariate Performance Measures Thorsten Joachims Cornell University Department of Computer Science Thanks to Rich Caruana, Alexandru Niculescu-Mizil, Pierre Dupont, Jérôme
CS6375: Machine Learning Gautam Kunapuli. Decision Trees
 Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
arxiv: v1 [cs.ir] 22 Dec 2012
![arxiv: v1 [cs.ir] 22 Dec 2012](/thumbs/72/67223966.jpg "arxiv: v1 [cs.ir] 22 Dec 2012") Learning the Gain Values and Discount Factors of DCG arxiv:22.5650v [cs.ir] 22 Dec 202 Ke Zhou Dept. of Computer Science and Engineering Shanghai Jiao-Tong University No. 800, Dongchuan Road, Shanghai,
Learning the Gain Values and Discount Factors of DCG arxiv:22.5650v [cs.ir] 22 Dec 202 Ke Zhou Dept. of Computer Science and Engineering Shanghai Jiao-Tong University No. 800, Dongchuan Road, Shanghai,
Stephen Scott.
 1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 15: Learning to Rank Sec. 15.4 Machine learning for IR ranking? We ve looked at methods for ranking
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 15: Learning to Rank Sec. 15.4 Machine learning for IR ranking? We ve looked at methods for ranking
Introduction of Reinforcement Learning
 Introduction of Reinforcement Learning Deep Reinforcement Learning Reference Textbook: Reinforcement Learning: An Introduction http://incompleteideas.net/sutton/book/the-book.html Lectures of David Silver
Introduction of Reinforcement Learning Deep Reinforcement Learning Reference Textbook: Reinforcement Learning: An Introduction http://incompleteideas.net/sutton/book/the-book.html Lectures of David Silver
1 A Support Vector Machine without Support Vectors
 CS/CNS/EE 53 Advanced Topics in Machine Learning Problem Set 1 Handed out: 15 Jan 010 Due: 01 Feb 010 1 A Support Vector Machine without Support Vectors In this question, you ll be implementing an online
CS/CNS/EE 53 Advanced Topics in Machine Learning Problem Set 1 Handed out: 15 Jan 010 Due: 01 Feb 010 1 A Support Vector Machine without Support Vectors In this question, you ll be implementing an online
11. Learning To Rank. Most slides were adapted from Stanford CS 276 course.
 11. Learning To Rank Most slides were adapted from Stanford CS 276 course. 1 Sec. 15.4 Machine learning for IR ranking? We ve looked at methods for ranking documents in IR Cosine similarity, inverse document
11. Learning To Rank Most slides were adapted from Stanford CS 276 course. 1 Sec. 15.4 Machine learning for IR ranking? We ve looked at methods for ranking documents in IR Cosine similarity, inverse document
SVMC An introduction to Support Vector Machines Classification
 SVMC An introduction to Support Vector Machines Classification 6.783, Biomedical Decision Support Lorenzo Rosasco (lrosasco@mit.edu) Department of Brain and Cognitive Science MIT A typical problem We have
SVMC An introduction to Support Vector Machines Classification 6.783, Biomedical Decision Support Lorenzo Rosasco (lrosasco@mit.edu) Department of Brain and Cognitive Science MIT A typical problem We have
Linear classifiers: Overfitting and regularization
 Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Adaptive Sampling Under Low Noise Conditions 1
 Manuscrit auteur, publié dans "41èmes Journées de Statistique, SFdS, Bordeaux (2009)" Adaptive Sampling Under Low Noise Conditions 1 Nicolò Cesa-Bianchi Dipartimento di Scienze dell Informazione Università
Manuscrit auteur, publié dans "41èmes Journées de Statistique, SFdS, Bordeaux (2009)" Adaptive Sampling Under Low Noise Conditions 1 Nicolò Cesa-Bianchi Dipartimento di Scienze dell Informazione Università