DATA MINING: NAÏVE BAYES
|
|
|
- Edmund O’Neal’
- 6 years ago
- Views:
Transcription
1 DATA MINING: NAÏVE BAYES 1

2 Naïve Bayes Classifier Thomas Bayes We will start off with some mathematical background. But first we start with some visual intuition. 2
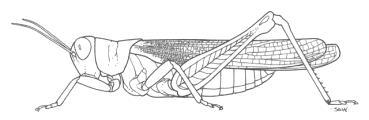
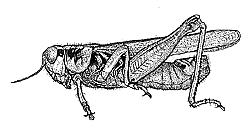
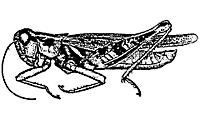

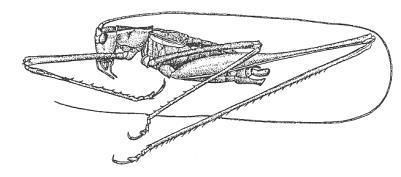


3 Grasshoppers Antenna Length Katydids Abdomen Length Remember this example? Let s get lots more data 3
4 Antenna Length With a lot of data, we can build a histogram. Let us just build one for Antenna Length for now Katydids Grasshoppers 4
5 We can leave the histograms as they are, or we can summarize them with two normal distributions. Let us us two normal distributions for ease of visualization in the following slides 5
6 We want to classify an insect we have found. Its antennae are 3 units long. How can we classify it? We can just ask ourselves, give the distributions of antennae lengths we have seen, is it more probable that our insect is a Grasshopper or a Katydid. There is a formal way to discuss the most probable classification P(c j d) = probability of c j given that we have observed d 3 Antennae length is 3 6
7 P(c j d) = probability of c j given that we have observed d P(Grasshopper 3 ) = 10 / (10 + 2) = P(Katydid 3 ) = 2 / (10 + 2) = Antennae length is 3 7
8 P(c j d) = probability of c j given that we have observed d P(Grasshopper 7 ) = 3 / (3 + 9) = P(Katydid 7 ) = 9 / (3 + 9) = Antennae length is 7 8
9 P(c j d) = probability of c j given that we have observed d P(Grasshopper 5 ) = 6 / (6 + 6) = P(Katydid 5 ) = 6 / (6 + 6) = Antennae length is 5 9
10 Bayes Classifier A probabilistic framework for classification problems Often appropriate because the world is noisy and also some relationships are probabilistic in nature Is predicting who will win a baseball game probabilistic in nature? Before getting the heart of the matter, we will go over some basic probability. We will review the concept of reasoning with uncertainty, which is based on probability theory Should be review for many of you 10
11 Discrete Random Variables A is a Boolean-valued random variable if A denotes an event, and there is some degree of uncertainty as to whether A occurs. Examples A = The next patient you examine is suffering from inhalational anthrax A = The next patient you examine has a cough A = There is an active terrorist cell in your city We view P(A) as the fraction of possible worlds in which A is true 11
12 Visualizing A Event space of all possible worlds Worlds in which A is true P(A) = Area of reddish oval Its area is 1 Worlds in which A is False 12
13 The Axioms Of Probability 0 <= P(A) <= 1 P(True) = 1 P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) The area of A can t get any smaller than 0 And a zero area would mean no world could ever have A true 13
14 Interpreting the axioms 0 <= P(A) <= 1 P(True) = 1 P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) The area of A can t get any bigger than 1 And an area of 1 would mean all worlds will have A true 14
15 Interpreting the axioms 0 <= P(A) <= 1 P(True) = 1 P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) A P(A or B) B P(A and B) B Simple addition and subtraction 15
16 Another Important Theorem 0 <= P(A) <= 1, P(True) = 1, P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) From these we can prove: P(A) = P(A and B) + P(A and not B) A B 16
17 Conditional Probability P(A B) = Fraction of worlds in which B is true that also have A true H = Have a headache F = Coming down with Flu F P(H) = 1/10 P(F) = 1/40 P(H F) = 1/2 H Headaches are rare and flu is rarer, but if you re coming down with flu there s a chance you ll have a headache. 17
18 Conditional Probability F P(H F) = Fraction of flu-inflicted worlds in which you have a headache H = Have a headache F = Coming down with Flu P(H) = 1/10 P(F) = 1/40 P(H F) = 1/2 H = #worlds with flu and headache #worlds with flu = Area of H and F region Area of F region = P(H and F) P(F) 18
19 Definition of Conditional Probability P(A and B) P(A B) = P(B) Corollary: The Chain Rule P(A and B) = P(A B) P(B) 19
20 Probabilistic Inference F H = Have a headache F = Coming down with Flu H P(H) = 1/10 P(F) = 1/40 P(H F) = 1/2 One day you wake up with a headache. You think: Drat! 50% of flus are associated with headaches so I must have a chance of coming down with flu Is this reasoning good? 20
21 Probabilistic Inference F H = Have a headache F = Coming down with Flu H P(H) = 1/10 P(F) = 1/40 P(H F) = 1/2 P(F and H) = P(F H) = 21
22 Probabilistic Inference F H = Have a headache F = Coming down with Flu H P(H) = 1/10 P(F) = 1/40 P(H F) = 1/2 1 1 P( F and H) P( H F) P( F) P( F and H ) P( F H ) 1 80 P( H )
23 What we just did P(A & B) P(A B) P(B) P(B A) = = P(A) P(A) This is Bayes Rule Bayes, Thomas (1763) An essay towards solving a problem in the doctrine of chances. Philosophical Transactions of the Royal Society of London, 53:
24 More Terminology The Prior Probability is the probability assuming no specific information. Thus we would refer to P(A) as the prior probability of even A occurring We would not say that P(A C) is the prior probability of A occurring The Posterior probability is the probability given that we know something We would say that P(A C) is the posterior probability of A (given that C occurs) 24
25 Example of Bayes Theorem Given: A doctor knows that meningitis causes stiff neck 50% of the time Prior probability of any patient having meningitis is 1/50,000 Prior probability of any patient having stiff neck is 1/20 If a patient has stiff neck, what s the probability he/she has meningitis? P( S M ) P( M ) 0.51/ P( M S) P( S) 1/
26 Why Bayes Theorem at All? P( C A) P( A C) P( C) P( A) Why model P(C A) via P(A C) We will see it is easier, but only with significant assumptions In classification, what is C and what is A? C is class and A is the example, a vector of attribute values Why not model P(C A) directly? How would we compute it? We would need to observe A at least once and probably many times in order to come up with reasonable probability estimates. If we observe it once, we would have a probability of 1 for some C and 0 for rest. We cannot expect to see every attribute vector even once! 26
27 Bayes Classifiers That was a visual intuition for a simple case of the Bayes classifier, also called: Idiot Bayes Naïve Bayes Simple Bayes We are about to see some of the mathematical formalisms, and more examples, but keep in mind the basic idea. Find out the probability of the previously unseen instance belonging to each class, then simply pick the most probable class. 27
28 Bayesian Classifiers Bayesian classifiers use Bayes theorem, which says p(c j d ) = p(d c j ) p(c j ) p(d) p(c j d) = probability of instance d being in class c j, This is what we are trying to compute p(d c j ) = probability of generating instance d given class c j, We can imagine that being in class c j, causes you to have feature d with some probability p(c j ) = probability of occurrence of class c j, This is just how frequent the class c j, is in our database p(d) = probability of instance d occurring This can actually be ignored, since it is the same for all classes 28
29 Bayesian Classifiers Given a record with attributes (A 1, A 2,,A n ) The goal is to predict class C Actually, we want to find the value of C that maximizes P(C A 1, A 2,,A n ) Can we estimate P(C A 1, A 2,,A n ) directly (w/o Bayes)? Yes, we simply need to count up the number of times we see A 1, A 2,,A n and then see what fraction belongs to each class For example, if n=3 and the feature vector 4,3,2 occurs 10 times and 4 of these belong to C1 and 6 to C2, then: What is P(C1 4,3,2 )? What is P(C2 4,3,2 )? Unfortunately, this is generally not feasible since not every feature vector will be found in the training set (as we just said) 29
30 Bayesian Classifiers Indirect Approach: Use Bayes Theorem compute the posterior probability P(C A 1, A 2,, A n ) for all values of C using the Bayes theorem P( C A A 1 2 A n ) P( A A A C) P( C) 1 2 n P( A A A ) 1 2 n Choose value of C that maximizes P(C A 1, A 2,, A n ) Equivalent to choosing value of C that maximizes P(A 1, A 2,, A n C) P(C) Since the denominator is the same for all values of C 30
31 Naïve Bayes Classifier How can we estimate P(A 1, A 2,, A n C)? We can measure it directly, but only if the training set samples every feature vector. Not practical! Not easier than measuring P(C P(A 1, A 2,, A n ) So, we must assume independence among attributes A i when class is given: P(A 1, A 2,, A n C) = P(A 1 C j ) P(A 2 C j ) P(A n C j ) Then can we directly estimate P(A i C j ) for all A i and C j? Yes because we are looking only at one feature at a time. We can expect each feature value to appear many times in training data. New point is classified to C j if P(C j ) P(A i C j ) is maximal. 31


32 Assume that we have two classes c 1 = male, and c 2 = female. We have a person whose sex we do not know, say drew or d. Classifying drew as male or female is equivalent to asking is it more probable that drew is male or female, I.e which is greater p(male drew) or p(female drew) (Note: Drew can be a male or female name ) Drew Barrymore What is the probability of being called drew given that you are a male? Drew Carey What is the probability of being a male? p(male drew) = p(drew male ) p(male) p(drew) What is the probability of being named drew? (actually irrelevant, since it is that same for all classes) 32
33 This is Officer Drew (who arrested me in 1997). Is Officer Drew a Male or Female? Luckily, we have a small database with names and sex. Officer Drew p(c j d) = p(d c j ) p(c j ) p(d) We can use it to apply Bayes rule Name Drew Sex Male Claudia Female Drew Drew Female Female Alberto Male Karin Nina Sergio Female Female Male 33
34 Officer Drew p(c j d) = p(d c j ) p(c j ) p(d) p(male drew) = 1/3 * 3/8 = = /8 3/8 p(female drew) = 2/5 * 5/8 = =.666 3/8 3/8 Name Drew Sex Male Claudia Female Drew Drew Female Female Alberto Male Karin Nina Sergio Female Female Male Officer Drew is more likely to be a Female. 34
35 Officer Drew IS a female! So far we have only considered Bayes Classification when we have one attribute (the antennae length, or the name ). In this case there is no real benefit for using Naïve Bayes. But in classification we usually have many features. How do we use all the features? Officer Drew 35
36 p(c j d) = p(d c j ) p(c j ) p(d) Name Over 170CM Eye Hair length Sex Drew No Blue Short Male Claudia Yes Brown Long Female Drew No Blue Long Female Drew No Blue Long Female Alberto Yes Brown Short Male Karin No Blue Long Female Nina Yes Brown Short Female Sergio Yes Blue Long Male 36
37 To simplify the task, naïve Bayesian classifiers assume attributes have independent distributions, and thereby estimate p(d c j ) = p(d 1 c j ) * p(d 2 c j ) *.* p(d n c j ) The probability of class c j generating instance d, equals. The probability of class c j generating the observed value for feature 1, multiplied by.. The probability of class c j generating the observed value for feature 2, multiplied by.. 37
 = p(d 1 c j ) * p(d 2 c j ) *.")
 = 2/5 *")
38 To simplify the task, naïve Bayesian classifiers assume attributes have independent distributions, and thereby estimate p(d c j ) = p(d 1 c j ) * p(d 2 c j ) *.* p(d n c j ) p(officer drew c j ) = p(over_170 cm = yes c j ) * p(eye =blue c j ) *. Officer Drew is blue-eyed, over 170 cm tall, and has long hair p(officer drew Female) = 2/5 * 3/5 *. p(officer drew Male) = 2/3 * 2/3 *. 38
39 Naïve Bayes is fast and space efficient We can look up all the probabilities with a single scan of the database and store them in a (small) table Sex Over190 cm Male Yes 0.15 No 0.85 Female Yes 0.01 No 0.99 Sex Long Hair Male Yes 0.05 No 0.95 Female Yes 0.70 No 0.30 Sex Male Female 39
40 Naïve Bayes is NOT sensitive to irrelevant features... Suppose we are trying to classify a persons sex based on several features, including eye color. (eye color is irrelevant to a persons gender) p(jessica c j ) = p(eye = brown c j ) * p( wears_dress = yes c j ) *. p(jessica Female) = 9,000/10,000 * 9,975/10,000 *. p(jessica Male) = 9,001/10,000 * 2/10,000 *. Almost the same! However, this assumes that we have good enough estimates of the probabilities, so the more data the better. 40
41 An obvious point. I have used a simple two class problem, and two possible values for each example, for my previous examples. However we can have an arbitrary number of classes, or feature values Animal Mass >10 kg Cat Yes 0.15 No 0.85 Dog Yes 0.91 No 0.09 Pig Yes 0.99 No 0.01 Animal Color Cat Black 0.33 White 0.23 Brown 0.44 Dog Black 0.97 White 0.03 Brown 0.90 Pig Black 0.04 White 0.01 Brown 0.95 Animal Cat Dog Pig 41
42 Naïve Bayesian Classifier Problem! Naïve Bayes assumes independence of features Are height and weight independent? Naïve Bayes tends to work well anyway and is competitive with other methods Sex Over 6 foot Male Yes 0.15 No 0.85 Female Yes 0.01 No 0.99 Sex Over 200 pounds Male Yes 0.20 No 0.80 Female Yes 0.05 No
43 The Naïve Bayesian Classifier has a quadratic decision boundary
44 10 How to Estimate Probabilities from Data? categorica l Tid Refund Marital Status categorica l Taxable Income continuous 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No Evade 5 No Divorced 95K Yes 6 No Married 60K No 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes class Class: P(C) = N c /N e.g., P(No) = 7/10, P(Yes) = 3/10 For discrete attributes: P(A i C k ) = A ik / N c where A ik is number of instances having attribute A i and belongs to class C k Examples: P(Status=Married No) = 4/7 P(Refund=Yes Yes)=0 k 44
45 How to Estimate Probabilities from Data? For continuous attributes: Discretize the range into bins Two-way split: (A < v) or (A > v) choose only one of the two splits as new attribute Creates a binary feature k Probability density estimation: Assume attribute follows a normal distribution and use the data to fit this distribution Once probability distribution is known, can use it to estimate the conditional probability P(A i c) We will not deal with continuous values on HW or exam Just understand the general ideas above 45
46 Example of Naïve Bayes We start with a test example and want to know its class. Does this individual evade their taxes: Yes or No? Here is the feature vector: Refund = No, Married, Income = 120K Now what do we do? First try writing out the thing we want to measure 46
47 Example of Naïve Bayes We start with a test example and want to know its class. Does this individual evade their taxes: Yes or No? Here is the feature vector: Refund = No, Married, Income = 120K Now what do we do? First try writing out the thing we want to measure P(Evade [No, Married, Income=120K]) Next, what do we need to maximize? 47
48 Example of Naïve Bayes We start with a test example and want to know its class. Does this individual evade their taxes: Yes or No? Here is the feature vector: Refund = No, Married, Income = 120K Now what do we do? First try writing out the thing we want to measure P(Evade [No, Married, Income=120K]) Next, what do we need to maximize? P(C j ) P(A i C j ) 48
49 Example of Naïve Bayes Since we want to maximize P(C j ) P(A i C j ) What quantities do we need to calculate in order to use this equation? Someone come up to the board and write them out, without calculating them Recall that we have three attributes: Refund: Yes, No Marital Status: Single, Married, Divorced Taxable Income: 10 different discrete values While we could compute every P(A i C j ) for all A i, we only need to do it for the attribute values in the test example 49
50 Values to Compute Given we need to compute P(C j ) P(A i C j ) We need to compute the class probabilities P(Evade=No) P(Evade=Yes) We need to compute the conditional probabilities P(Refund=No Evade=No) P(Refund=No Evade=Yes) P(Marital Status=Married Evade=No) P(Marital Status=Married Evade=Yes) P(Income=120K Evade=No) P(Income=120K Evade=Yes) 50
51 Computed Values Given we need to compute P(C j ) P(A i C j ) We need to compute the class probabilities P(Evade=No) = 7/10 =.7 P(Evade=Yes) = 3/10 =.3 We need to compute the conditional probabilities P(Refund=No Evade=No) = 4/7 P(Refund=No Evade=Yes) 3/3 = 1.0 P(Marital Status=Married Evade=No) = 4/7 P(Marital Status=Married Evade=Yes) =0/3 = 0 P(Income=120K Evade=No) = 1/7 P(Income=120K Evade=Yes) = 0/7 = 0 51
52 Finding the Class Now compute P(C j ) P(A i C j ) for both classes for the test example [No, Married, Income = 120K] For Class Evade=No we get:.7 x 4/7 x 4/7 x 1/7 = For Class Evade=Yes we get:.3 x 1 x 0 x 0 = 0 Which one is best? Clearly we would select No for the class value Note that these are not the actual probabilities of each class, since we did not divide by P([No, Married, Income = 120K]) 52
53 Naïve Bayes Classifier If one of the conditional probability is zero, then the entire expression becomes zero This is not ideal, especially since probability estimates may not be very precise for rarely occurring values We use the Laplace estimate to improve things. Without a lot of observations, the Laplace estimate moves the probability towards the value assuming all classes equally likely Solution smoothing 53
54 Smoothing To account for estimation from small samples, probability estimates are adjusted or smoothed. Laplace smoothing using an m-estimate assumes that each feature is given a prior probability, p, that is assumed to have been previously observed in a virtual sample of size m. P( X i x Y y ) ij k n ijk n k mp m For binary classes, p is assumed to be 0.5 (equal probability) The value of m determines how much of a push there is to the prior probability. We usually use m=1. 54
55 Laplace Smothing Example Assume training set contains 10 positive examples: 4: small 0: medium 6: large Estimate parameters as follows Let m = 1; p = prior probability = 1/3 (all equally likely) Smoothed estimates P(small positive) = (4 + 1/3) / (10 + 1) = P(medium positive) = (0 + 1/3) / (10 + 1) = 0.03 P(large positive) = (6 + 1/3) / (10 + 1) = P(small or medium or large positive) =
56 Naïve Bayes Classifier(Summary) Description Statistical method for classification based on Bayes theorem Advantages Robust to isolated noise points Robust to irrelevant attributes Fast to train and to apply Can handle high dimensionality problems Generally does not require a lot of training data to estimate values Appropriate for problems that may be inherently probabilistic Disadvantages Independence assumption will not always hold But works surprisingly well in practice for many problems Modest expressive power Not very interpretable 56
57 More Examples There are several detailed examples provided Go over them before trying the HW, unless you are clear on Bayesian Classifiers 57
58 Play-tennis example: estimate P(x i C) Outlook Temperature Humidity Windy Class sunny hot high false N sunny hot high true N overcast hot high false P rain mild high false P rain cool normal false P rain cool normal true N overcast cool normal true P sunny mild high false N sunny cool normal false P rain mild normal false P sunny mild normal true P overcast mild high true P overcast hot normal false P rain mild high true N P(p) = 9/14 P(n) = 5/14 outlook P(sunny p) = 2/9 P(sunny n) = 3/5 P(overcast p) = 4/9 P(overcast n) = 0 P(rain p) = 3/9 P(rain n) = 2/5 Temperature P(hot p) = 2/9 P(hot n) = 2/5 P(mild p) = 4/9 P(mild n) = 2/5 P(cool p) = 3/9 P(cool n) = 1/5 Humidity P(high p) = 3/9 P(high n) = 4/5 P(normal p) = 6/9 P(normal n) = 2/5 windy P(true p) = 3/9 P(true n) = 3/5 P(false p) = 6/9 P(false n) = 2/5 58
59 Play-tennis example: classifying X An unseen sample X = <rain, hot, high, false> <outlook, temp, humid, wind> P(X p) P(p) = P(rain p) P(hot p) P(high p) P(false p) P(p) = 3/9 2/9 3/9 6/9 9/14 = P(X n) P(n) = P(rain n) P(hot n) P(high n) P(false n) P(n) = 2/5 2/5 4/5 2/5 5/14 = Sample X is classified in class n (don t play) 59
60 Example of Naïve Bayes Classifier Name Give Birth Can Fly Live in Water Have Legs Class human yes no no yes mammals python no no no no non-mammals salmon no no yes no non-mammals whale yes no yes no mammals frog no no sometimes yes non-mammals komodo no no no yes non-mammals bat yes yes no yes mammals pigeon no yes no yes non-mammals cat yes no no yes mammals leopard shark yes no yes no non-mammals turtle no no sometimes yes non-mammals penguin no no sometimes yes non-mammals porcupine yes no no yes mammals eel no no yes no non-mammals salamander no no sometimes yes non-mammals gila monster no no no yes non-mammals platypus no no no yes mammals owl no yes no yes non-mammals dolphin yes no yes no mammals eagle no yes no yes non-mammals A: attributes M: mammals N: non-mammals P( A M ) P( A N) P( A M ) P( M ) P( A N) P( N) Give Birth Can Fly Live in Water Have Legs Class yes no yes no? P(A M)P(M) > P(A N)P(N) => Mammals 60
61 Advantages/Disadvantages of Naïve Bayes Advantages: Fast to train (single scan). Fast to classify Not sensitive to irrelevant features Handles real and discrete data Handles streaming data well Disadvantages: Assumes independence of features 61
Uncertainty. Yeni Herdiyeni Departemen Ilmu Komputer IPB. The World is very Uncertain Place
 Uncertainty Yeni Herdiyeni Departemen Ilmu Komputer IPB The World is very Uncertain Place 1 Ketidakpastian Presiden Indonesia tahun 2014 adalah Perempuan Tahun depan saya akan lulus Jumlah penduduk Indonesia
Uncertainty Yeni Herdiyeni Departemen Ilmu Komputer IPB The World is very Uncertain Place 1 Ketidakpastian Presiden Indonesia tahun 2014 adalah Perempuan Tahun depan saya akan lulus Jumlah penduduk Indonesia
CISC 4631 Data Mining
 CISC 4631 Data Mining Lecture 06: ayes Theorem Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Eamonn Koegh (UC Riverside) Andrew Moore (CMU/Google) 1 Naïve ayes Classifier
CISC 4631 Data Mining Lecture 06: ayes Theorem Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Eamonn Koegh (UC Riverside) Andrew Moore (CMU/Google) 1 Naïve ayes Classifier
Advanced classifica-on methods
 Advanced classifica-on methods Instance-based classifica-on Bayesian classifica-on Instance-Based Classifiers Set of Stored Cases Atr1... AtrN Class A B B C A C B Store the training records Use training
Advanced classifica-on methods Instance-based classifica-on Bayesian classifica-on Instance-Based Classifiers Set of Stored Cases Atr1... AtrN Class A B B C A C B Store the training records Use training
7 Classification: Naïve Bayes Classifier
 CSE4334/5334 Data Mining 7 Classifiation: Naïve Bayes Classifier Chengkai Li Department of Computer Siene and Engineering University of Texas at rlington Fall 017 Slides ourtesy of ang-ning Tan, Mihael
CSE4334/5334 Data Mining 7 Classifiation: Naïve Bayes Classifier Chengkai Li Department of Computer Siene and Engineering University of Texas at rlington Fall 017 Slides ourtesy of ang-ning Tan, Mihael
Data Analysis. Santiago González
 Santiago González Contents Introduction CRISP-DM (1) Tools Data understanding Data preparation Modeling (2) Association rules? Supervised classification Clustering Assesment & Evaluation
Santiago González Contents Introduction CRISP-DM (1) Tools Data understanding Data preparation Modeling (2) Association rules? Supervised classification Clustering Assesment & Evaluation
Lecture Notes for Chapter 5 (PART 1)
") Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 5 (PART 1) 1 Agenda Rule Based Classifier PART 1 Bayesian Classifier Artificial Neural Network Support Vector Machine PART 2
Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 5 (PART 1) 1 Agenda Rule Based Classifier PART 1 Bayesian Classifier Artificial Neural Network Support Vector Machine PART 2
Classification Lecture 2: Methods
 Classification Lecture 2: Methods Jing Gao SUNY Buffalo 1 Outline Basics Problem, goal, evaluation Methods Nearest Neighbor Decision Tree Naïve Bayes Rule-based Classification Logistic Regression Support
Classification Lecture 2: Methods Jing Gao SUNY Buffalo 1 Outline Basics Problem, goal, evaluation Methods Nearest Neighbor Decision Tree Naïve Bayes Rule-based Classification Logistic Regression Support
Lecture Notes for Chapter 5. Introduction to Data Mining
 Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 5 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Rule-Based
Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 5 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Rule-Based
Lets start off with a visual intuition
 Naïve Bayes Classifier (pages 231 238 on text book) Lets start off with a visual intuition Adapted from Dr. Eamonn Keogh s lecture UCR 1 Body length Data 2 Alligators 10 9 8 7 6 5 4 3 2 1 1 2 3 4 5 6 7
Naïve Bayes Classifier (pages 231 238 on text book) Lets start off with a visual intuition Adapted from Dr. Eamonn Keogh s lecture UCR 1 Body length Data 2 Alligators 10 9 8 7 6 5 4 3 2 1 1 2 3 4 5 6 7
Probabilistic Methods in Bioinformatics. Pabitra Mitra
 Probabilistic Methods in Bioinformatics Pabitra Mitra pabitra@cse.iitkgp.ernet.in Probability in Bioinformatics Classification Categorize a new object into a known class Supervised learning/predictive
Probabilistic Methods in Bioinformatics Pabitra Mitra pabitra@cse.iitkgp.ernet.in Probability in Bioinformatics Classification Categorize a new object into a known class Supervised learning/predictive
Classification Part 2. Overview
 Classification Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Overview Rule based Classifiers Nearest-neighbor Classifiers Data Mining
Classification Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Overview Rule based Classifiers Nearest-neighbor Classifiers Data Mining
DATA MINING LECTURE 10
 DATA MINING LECTURE 10 Classification Nearest Neighbor Classification Support Vector Machines Logistic Regression Naïve Bayes Classifier Supervised Learning 10 10 Illustrating Classification Task Tid Attrib1
DATA MINING LECTURE 10 Classification Nearest Neighbor Classification Support Vector Machines Logistic Regression Naïve Bayes Classifier Supervised Learning 10 10 Illustrating Classification Task Tid Attrib1
Data Mining Classification: Alternative Techniques. Lecture Notes for Chapter 5. Introduction to Data Mining
 Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 5 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Neural networks
Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 5 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Neural networks
Probabilistic and Bayesian Analytics
 Probabilistic and Bayesian Analytics Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to use these
Probabilistic and Bayesian Analytics Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to use these
Machine Learning 2nd Edition
 ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://wwwcstauacil/~apartzin/machinelearning/ and wwwcsprincetonedu/courses/archive/fall01/cs302 /notes/11/emppt The MIT Press, 2010
ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://wwwcstauacil/~apartzin/machinelearning/ and wwwcsprincetonedu/courses/archive/fall01/cs302 /notes/11/emppt The MIT Press, 2010
Bayesian Learning. Artificial Intelligence Programming. 15-0: Learning vs. Deduction
 15-0: Learning vs. Deduction Artificial Intelligence Programming Bayesian Learning Chris Brooks Department of Computer Science University of San Francisco So far, we ve seen two types of reasoning: Deductive
15-0: Learning vs. Deduction Artificial Intelligence Programming Bayesian Learning Chris Brooks Department of Computer Science University of San Francisco So far, we ve seen two types of reasoning: Deductive
Introduction to Machine Learning
 Introduction to Machine Learning CS4375 --- Fall 2018 Bayesian a Learning Reading: Sections 13.1-13.6, 20.1-20.2, R&N Sections 6.1-6.3, 6.7, 6.9, Mitchell 1 Uncertainty Most real-world problems deal with
Introduction to Machine Learning CS4375 --- Fall 2018 Bayesian a Learning Reading: Sections 13.1-13.6, 20.1-20.2, R&N Sections 6.1-6.3, 6.7, 6.9, Mitchell 1 Uncertainty Most real-world problems deal with
COMP61011 : Machine Learning. Probabilis*c Models + Bayes Theorem
 COMP61011 : Machine Learning Probabilis*c Models + Bayes Theorem Probabilis*c Models - one of the most active areas of ML research in last 15 years - foundation of numerous new technologies - enables decision-making
COMP61011 : Machine Learning Probabilis*c Models + Bayes Theorem Probabilis*c Models - one of the most active areas of ML research in last 15 years - foundation of numerous new technologies - enables decision-making
Introduction to Machine Learning
 Uncertainty Introduction to Machine Learning CS4375 --- Fall 2018 a Bayesian Learning Reading: Sections 13.1-13.6, 20.1-20.2, R&N Sections 6.1-6.3, 6.7, 6.9, Mitchell Most real-world problems deal with
Uncertainty Introduction to Machine Learning CS4375 --- Fall 2018 a Bayesian Learning Reading: Sections 13.1-13.6, 20.1-20.2, R&N Sections 6.1-6.3, 6.7, 6.9, Mitchell Most real-world problems deal with
Algorithms for Classification: The Basic Methods
 Algorithms for Classification: The Basic Methods Outline Simplicity first: 1R Naïve Bayes 2 Classification Task: Given a set of pre-classified examples, build a model or classifier to classify new cases.
Algorithms for Classification: The Basic Methods Outline Simplicity first: 1R Naïve Bayes 2 Classification Task: Given a set of pre-classified examples, build a model or classifier to classify new cases.
COMP61011! Probabilistic Classifiers! Part 1, Bayes Theorem!
 COMP61011 Probabilistic Classifiers Part 1, Bayes Theorem Reverend Thomas Bayes, 1702-1761 p ( T W ) W T ) T ) W ) Bayes Theorem forms the backbone of the past 20 years of ML research into probabilistic
COMP61011 Probabilistic Classifiers Part 1, Bayes Theorem Reverend Thomas Bayes, 1702-1761 p ( T W ) W T ) T ) W ) Bayes Theorem forms the backbone of the past 20 years of ML research into probabilistic
The Naïve Bayes Classifier. Machine Learning Fall 2017
 The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
Classification. Classification. What is classification. Simple methods for classification. Classification by decision tree induction
 Classification What is classification Classification Simple methods for classification Classification by decision tree induction Classification evaluation Classification in Large Databases Classification
Classification What is classification Classification Simple methods for classification Classification by decision tree induction Classification evaluation Classification in Large Databases Classification
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation
 Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Part I Introduction to Data Mining by Tan, Steinbach, Kumar Adapted by Qiang Yang (2010) Tan,Steinbach,
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Part I Introduction to Data Mining by Tan, Steinbach, Kumar Adapted by Qiang Yang (2010) Tan,Steinbach,
Artificial Intelligence Programming Probability
 Artificial Intelligence Programming Probability Chris Brooks Department of Computer Science University of San Francisco Department of Computer Science University of San Francisco p.1/?? 13-0: Uncertainty
Artificial Intelligence Programming Probability Chris Brooks Department of Computer Science University of San Francisco Department of Computer Science University of San Francisco p.1/?? 13-0: Uncertainty
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 13, 2011 Today: The Big Picture Overfitting Review: probability Readings: Decision trees, overfiting
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 13, 2011 Today: The Big Picture Overfitting Review: probability Readings: Decision trees, overfiting
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 23. Decision Trees Barnabás Póczos Contents Decision Trees: Definition + Motivation Algorithm for Learning Decision Trees Entropy, Mutual Information, Information
Introduction to Machine Learning CMU-10701 23. Decision Trees Barnabás Póczos Contents Decision Trees: Definition + Motivation Algorithm for Learning Decision Trees Entropy, Mutual Information, Information
Inteligência Artificial (SI 214) Aula 15 Algoritmo 1R e Classificador Bayesiano
 Aula 15 Algoritmo 1R e Classificador Bayesiano") Inteligência Artificial (SI 214) Aula 15 Algoritmo 1R e Classificador Bayesiano Prof. Josenildo Silva jcsilva@ifma.edu.br 2015 2012-2015 Josenildo Silva (jcsilva@ifma.edu.br) Este material é derivado dos
Inteligência Artificial (SI 214) Aula 15 Algoritmo 1R e Classificador Bayesiano Prof. Josenildo Silva jcsilva@ifma.edu.br 2015 2012-2015 Josenildo Silva (jcsilva@ifma.edu.br) Este material é derivado dos
Insect ID. Antennae Length. Insect Class. Abdomen Length
 We have seen that we can do machine learning on data that is in the nice flat file format Rows are objects Columns are features Taking a real problem and massaging it into this format is domain dependent,
We have seen that we can do machine learning on data that is in the nice flat file format Rows are objects Columns are features Taking a real problem and massaging it into this format is domain dependent,
Stephen Scott.
 1 / 28 ian ian Optimal (Adapted from Ethem Alpaydin and Tom Mitchell) Naïve Nets sscott@cse.unl.edu 2 / 28 ian Optimal Naïve Nets Might have reasons (domain information) to favor some hypotheses/predictions
1 / 28 ian ian Optimal (Adapted from Ethem Alpaydin and Tom Mitchell) Naïve Nets sscott@cse.unl.edu 2 / 28 ian Optimal Naïve Nets Might have reasons (domain information) to favor some hypotheses/predictions
A.I. in health informatics lecture 3 clinical reasoning & probabilistic inference, II *
 A.I. in health informatics lecture 3 clinical reasoning & probabilistic inference, II * kevin small & byron wallace * Slides borrow heavily from Andrew Moore, Weng- Keen Wong and Longin Jan Latecki today
A.I. in health informatics lecture 3 clinical reasoning & probabilistic inference, II * kevin small & byron wallace * Slides borrow heavily from Andrew Moore, Weng- Keen Wong and Longin Jan Latecki today
Machine Learning. CS Spring 2015 a Bayesian Learning (I) Uncertainty
 Uncertainty") Machine Learning CS6375 --- Spring 2015 a Bayesian Learning (I) 1 Uncertainty Most real-world problems deal with uncertain information Diagnosis: Likely disease given observed symptoms Equipment repair:
Machine Learning CS6375 --- Spring 2015 a Bayesian Learning (I) 1 Uncertainty Most real-world problems deal with uncertain information Diagnosis: Likely disease given observed symptoms Equipment repair:
Basic Probability and Statistics
 Basic Probability and Statistics Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Jerry Zhu, Mark Craven] slide 1 Reasoning with Uncertainty
Basic Probability and Statistics Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Jerry Zhu, Mark Craven] slide 1 Reasoning with Uncertainty
CSCE 478/878 Lecture 6: Bayesian Learning and Graphical Models. Stephen Scott. Introduction. Outline. Bayes Theorem. Formulas
 ian ian ian Might have reasons (domain information) to favor some hypotheses/predictions over others a priori ian methods work with probabilities, and have two main roles: Naïve Nets (Adapted from Ethem
ian ian ian Might have reasons (domain information) to favor some hypotheses/predictions over others a priori ian methods work with probabilities, and have two main roles: Naïve Nets (Adapted from Ethem
Uncertainty. Chapter 13
 Uncertainty Chapter 13 Uncertainty Let action A t = leave for airport t minutes before flight Will A t get me there on time? Problems: 1. partial observability (road state, other drivers' plans, noisy
Uncertainty Chapter 13 Uncertainty Let action A t = leave for airport t minutes before flight Will A t get me there on time? Problems: 1. partial observability (road state, other drivers' plans, noisy
Bayesian Classification. Bayesian Classification: Why?
 Bayesian Classification http://css.engineering.uiowa.edu/~comp/ Bayesian Classification: Why? Probabilistic learning: Computation of explicit probabilities for hypothesis, among the most practical approaches
Bayesian Classification http://css.engineering.uiowa.edu/~comp/ Bayesian Classification: Why? Probabilistic learning: Computation of explicit probabilities for hypothesis, among the most practical approaches
Probability Basics. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Probability Basics These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Probability Basics These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these
Bayesian Learning Features of Bayesian learning methods:
 Bayesian Learning Features of Bayesian learning methods: Each observed training example can incrementally decrease or increase the estimated probability that a hypothesis is correct. This provides a more
Bayesian Learning Features of Bayesian learning methods: Each observed training example can incrementally decrease or increase the estimated probability that a hypothesis is correct. This provides a more
Soft Computing. Lecture Notes on Machine Learning. Matteo Mattecci.
 Soft Computing Lecture Notes on Machine Learning Matteo Mattecci matteucci@elet.polimi.it Department of Electronics and Information Politecnico di Milano Matteo Matteucci c Lecture Notes on Machine Learning
Soft Computing Lecture Notes on Machine Learning Matteo Mattecci matteucci@elet.polimi.it Department of Electronics and Information Politecnico di Milano Matteo Matteucci c Lecture Notes on Machine Learning
Classification and Regression Trees
 Classification and Regression Trees Ryan P Adams So far, we have primarily examined linear classifiers and regressors, and considered several different ways to train them When we ve found the linearity
Classification and Regression Trees Ryan P Adams So far, we have primarily examined linear classifiers and regressors, and considered several different ways to train them When we ve found the linearity
Machine Learning. Yuh-Jye Lee. March 1, Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU
 Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU March 1, 2017 1 / 13 Bayes Rule Bayes Rule Assume that {B 1, B 2,..., B k } is a partition of S
Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU March 1, 2017 1 / 13 Bayes Rule Bayes Rule Assume that {B 1, B 2,..., B k } is a partition of S
Probability Review Lecturer: Ji Liu Thank Jerry Zhu for sharing his slides
 Probability Review Lecturer: Ji Liu Thank Jerry Zhu for sharing his slides slide 1 Inference with Bayes rule: Example In a bag there are two envelopes one has a red ball (worth $100) and a black ball one
Probability Review Lecturer: Ji Liu Thank Jerry Zhu for sharing his slides slide 1 Inference with Bayes rule: Example In a bag there are two envelopes one has a red ball (worth $100) and a black ball one
COMP 328: Machine Learning
 COMP 328: Machine Learning Lecture 2: Naive Bayes Classifiers Nevin L. Zhang Department of Computer Science and Engineering The Hong Kong University of Science and Technology Spring 2010 Nevin L. Zhang
COMP 328: Machine Learning Lecture 2: Naive Bayes Classifiers Nevin L. Zhang Department of Computer Science and Engineering The Hong Kong University of Science and Technology Spring 2010 Nevin L. Zhang
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
CS 331: Artificial Intelligence Probability I. Dealing with Uncertainty
 CS 331: Artificial Intelligence Probability I Thanks to Andrew Moore for some course material 1 Dealing with Uncertainty We want to get to the point where we can reason with uncertainty This will require
CS 331: Artificial Intelligence Probability I Thanks to Andrew Moore for some course material 1 Dealing with Uncertainty We want to get to the point where we can reason with uncertainty This will require
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 14, 2015 Today: The Big Picture Overfitting Review: probability Readings: Decision trees, overfiting
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 14, 2015 Today: The Big Picture Overfitting Review: probability Readings: Decision trees, overfiting
Generative Learning. INFO-4604, Applied Machine Learning University of Colorado Boulder. November 29, 2018 Prof. Michael Paul
 Generative Learning INFO-4604, Applied Machine Learning University of Colorado Boulder November 29, 2018 Prof. Michael Paul Generative vs Discriminative The classification algorithms we have seen so far
Generative Learning INFO-4604, Applied Machine Learning University of Colorado Boulder November 29, 2018 Prof. Michael Paul Generative vs Discriminative The classification algorithms we have seen so far
Uncertainty. Variables. assigns to each sentence numerical degree of belief between 0 and 1. uncertainty
 Bayes Classification n Uncertainty & robability n Baye's rule n Choosing Hypotheses- Maximum a posteriori n Maximum Likelihood - Baye's concept learning n Maximum Likelihood of real valued function n Bayes
Bayes Classification n Uncertainty & robability n Baye's rule n Choosing Hypotheses- Maximum a posteriori n Maximum Likelihood - Baye's concept learning n Maximum Likelihood of real valued function n Bayes
Supervised Learning! Algorithm Implementations! Inferring Rudimentary Rules and Decision Trees!
 Supervised Learning! Algorithm Implementations! Inferring Rudimentary Rules and Decision Trees! Summary! Input Knowledge representation! Preparing data for learning! Input: Concept, Instances, Attributes"
Supervised Learning! Algorithm Implementations! Inferring Rudimentary Rules and Decision Trees! Summary! Input Knowledge representation! Preparing data for learning! Input: Concept, Instances, Attributes"
Naive Bayes Classifier. Danushka Bollegala
 Naive Bayes Classifier Danushka Bollegala Bayes Rule The probability of hypothesis H, given evidence E P(H E) = P(E H)P(H)/P(E) Terminology P(E): Marginal probability of the evidence E P(H): Prior probability
Naive Bayes Classifier Danushka Bollegala Bayes Rule The probability of hypothesis H, given evidence E P(H E) = P(E H)P(H)/P(E) Terminology P(E): Marginal probability of the evidence E P(H): Prior probability
Bayesian Networks. Distinguished Prof. Dr. Panos M. Pardalos
 Distinguished Prof. Dr. Panos M. Pardalos Center for Applied Optimization Department of Industrial & Systems Engineering Computer & Information Science & Engineering Department Biomedical Engineering Program,
Distinguished Prof. Dr. Panos M. Pardalos Center for Applied Optimization Department of Industrial & Systems Engineering Computer & Information Science & Engineering Department Biomedical Engineering Program,
Sources of Uncertainty
 Probability Basics Sources of Uncertainty The world is a very uncertain place... Uncertain inputs Missing data Noisy data Uncertain knowledge Mul>ple causes lead to mul>ple effects Incomplete enumera>on
Probability Basics Sources of Uncertainty The world is a very uncertain place... Uncertain inputs Missing data Noisy data Uncertain knowledge Mul>ple causes lead to mul>ple effects Incomplete enumera>on
ARTIFICIAL INTELLIGENCE. Supervised learning: classification
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Supervised learning: classification Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Supervised learning: classification Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from
A [somewhat] Quick Overview of Probability. Shannon Quinn CSCI 6900
![A [somewhat] Quick Overview of Probability. Shannon Quinn CSCI 6900](/thumbs/90/102647206.jpg "A [somewhat] Quick Overview of Probability. Shannon Quinn CSCI 6900") A [somewhat] Quick Overview of Probability Shannon Quinn CSCI 6900 [Some material pilfered from http://www.cs.cmu.edu/~awm/tutorials] Probabilistic and Bayesian Analytics Note to other teachers and users
A [somewhat] Quick Overview of Probability Shannon Quinn CSCI 6900 [Some material pilfered from http://www.cs.cmu.edu/~awm/tutorials] Probabilistic and Bayesian Analytics Note to other teachers and users
Bayesian Classification
 Bayesian Classification CSE634: Data Mining Concepts and Techniques Professor Anita Wasilewska TEAM 14 1 References Links http://www.simafore.com/blog/3-challenges-with-naive-bayes-classifiers-and-how-to-overcome
Bayesian Classification CSE634: Data Mining Concepts and Techniques Professor Anita Wasilewska TEAM 14 1 References Links http://www.simafore.com/blog/3-challenges-with-naive-bayes-classifiers-and-how-to-overcome
Data classification (II)
") Lecture 4: Data classification (II) Data Mining - Lecture 4 (2016) 1 Outline Decision trees Choice of the splitting attribute ID3 C4.5 Classification rules Covering algorithms Naïve Bayes Classification
Lecture 4: Data classification (II) Data Mining - Lecture 4 (2016) 1 Outline Decision trees Choice of the splitting attribute ID3 C4.5 Classification rules Covering algorithms Naïve Bayes Classification
Artificial Intelligence
 Artificial Intelligence Dr Ahmed Rafat Abas Computer Science Dept, Faculty of Computers and Informatics, Zagazig University arabas@zu.edu.eg http://www.arsaliem.faculty.zu.edu.eg/ Uncertainty Chapter 13
Artificial Intelligence Dr Ahmed Rafat Abas Computer Science Dept, Faculty of Computers and Informatics, Zagazig University arabas@zu.edu.eg http://www.arsaliem.faculty.zu.edu.eg/ Uncertainty Chapter 13
Probability Based Learning
 Probability Based Learning Lecture 7, DD2431 Machine Learning J. Sullivan, A. Maki September 2013 Advantages of Probability Based Methods Work with sparse training data. More powerful than deterministic
Probability Based Learning Lecture 7, DD2431 Machine Learning J. Sullivan, A. Maki September 2013 Advantages of Probability Based Methods Work with sparse training data. More powerful than deterministic
Uncertainty. Chapter 13
 Uncertainty Chapter 13 Outline Uncertainty Probability Syntax and Semantics Inference Independence and Bayes Rule Uncertainty Let s say you want to get to the airport in time for a flight. Let action A
Uncertainty Chapter 13 Outline Uncertainty Probability Syntax and Semantics Inference Independence and Bayes Rule Uncertainty Let s say you want to get to the airport in time for a flight. Let action A
Bayesian Learning. Reading: Tom Mitchell, Generative and discriminative classifiers: Naive Bayes and logistic regression, Sections 1-2.
 Bayesian Learning Reading: Tom Mitchell, Generative and discriminative classifiers: Naive Bayes and logistic regression, Sections 1-2. (Linked from class website) Conditional Probability Probability of
Bayesian Learning Reading: Tom Mitchell, Generative and discriminative classifiers: Naive Bayes and logistic regression, Sections 1-2. (Linked from class website) Conditional Probability Probability of
Building Bayesian Networks. Lecture3: Building BN p.1
 Building Bayesian Networks Lecture3: Building BN p.1 The focus today... Problem solving by Bayesian networks Designing Bayesian networks Qualitative part (structure) Quantitative part (probability assessment)
Building Bayesian Networks Lecture3: Building BN p.1 The focus today... Problem solving by Bayesian networks Designing Bayesian networks Qualitative part (structure) Quantitative part (probability assessment)
Lecture VII: Classification I. Dr. Ouiem Bchir
 Lecture VII: Classification I Dr. Ouiem Bchir 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find
Lecture VII: Classification I Dr. Ouiem Bchir 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Naïve Bayes. Jia-Bin Huang. Virginia Tech Spring 2019 ECE-5424G / CS-5824
 Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Text Categorization CSE 454. (Based on slides by Dan Weld, Tom Mitchell, and others)
") Text Categorization CSE 454 (Based on slides by Dan Weld, Tom Mitchell, and others) 1 Given: Categorization A description of an instance, x X, where X is the instance language or instance space. A fixed
Text Categorization CSE 454 (Based on slides by Dan Weld, Tom Mitchell, and others) 1 Given: Categorization A description of an instance, x X, where X is the instance language or instance space. A fixed
Data Mining vs Statistics
 Data Mining Data mining emerged in the 1980 s when the amount of data generated and stored became overwhelming. Data mining is strongly influenced by other disciplines such as mathematics, statistics,
Data Mining Data mining emerged in the 1980 s when the amount of data generated and stored became overwhelming. Data mining is strongly influenced by other disciplines such as mathematics, statistics,
CSCE 478/878 Lecture 6: Bayesian Learning
 Bayesian Methods Not all hypotheses are created equal (even if they are all consistent with the training data) Outline CSCE 478/878 Lecture 6: Bayesian Learning Stephen D. Scott (Adapted from Tom Mitchell
Bayesian Methods Not all hypotheses are created equal (even if they are all consistent with the training data) Outline CSCE 478/878 Lecture 6: Bayesian Learning Stephen D. Scott (Adapted from Tom Mitchell
CS 4649/7649 Robot Intelligence: Planning
 CS 4649/7649 Robot Intelligence: Planning Probability Primer Sungmoon Joo School of Interactive Computing College of Computing Georgia Institute of Technology S. Joo (sungmoon.joo@cc.gatech.edu) 1 *Slides
CS 4649/7649 Robot Intelligence: Planning Probability Primer Sungmoon Joo School of Interactive Computing College of Computing Georgia Institute of Technology S. Joo (sungmoon.joo@cc.gatech.edu) 1 *Slides
Induction on Decision Trees
 Séance «IDT» de l'ue «apprentissage automatique» Bruno Bouzy bruno.bouzy@parisdescartes.fr www.mi.parisdescartes.fr/~bouzy Outline Induction task ID3 Entropy (disorder) minimization Noise Unknown attribute
Séance «IDT» de l'ue «apprentissage automatique» Bruno Bouzy bruno.bouzy@parisdescartes.fr www.mi.parisdescartes.fr/~bouzy Outline Induction task ID3 Entropy (disorder) minimization Noise Unknown attribute
Decision Trees. Gavin Brown
 Decision Trees Gavin Brown Every Learning Method has Limitations Linear model? KNN? SVM? Explain your decisions Sometimes we need interpretable results from our techniques. How do you explain the above
Decision Trees Gavin Brown Every Learning Method has Limitations Linear model? KNN? SVM? Explain your decisions Sometimes we need interpretable results from our techniques. How do you explain the above
UVA CS / Introduc8on to Machine Learning and Data Mining
 UVA CS 4501-001 / 6501 007 Introduc8on to Machine Learning and Data Mining Lecture 13: Probability and Sta3s3cs Review (cont.) + Naïve Bayes Classifier Yanjun Qi / Jane, PhD University of Virginia Department
UVA CS 4501-001 / 6501 007 Introduc8on to Machine Learning and Data Mining Lecture 13: Probability and Sta3s3cs Review (cont.) + Naïve Bayes Classifier Yanjun Qi / Jane, PhD University of Virginia Department
Supervised Learning: Regression & Classifiers. Fall 2010
 Supervised Learning: Regression & Classifiers Fall 2010 Problem Statement Given training data of the form: {( xi, yi)...( xm, ym)} X: the space of input features/attributes Y: the space of output values
Supervised Learning: Regression & Classifiers Fall 2010 Problem Statement Given training data of the form: {( xi, yi)...( xm, ym)} X: the space of input features/attributes Y: the space of output values
Behavioral Data Mining. Lecture 2
 Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Naïve Bayes Lecture 6: Self-Study -----
 Naïve Bayes Lecture 6: Self-Study ----- Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 6: Required Reading Daumé III (015:
Naïve Bayes Lecture 6: Self-Study ----- Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 6: Required Reading Daumé III (015:
3 PROBABILITY TOPICS
 Chapter 3 Probability Topics 135 3 PROBABILITY TOPICS Figure 3.1 Meteor showers are rare, but the probability of them occurring can be calculated. (credit: Navicore/flickr) Introduction It is often necessary
Chapter 3 Probability Topics 135 3 PROBABILITY TOPICS Figure 3.1 Meteor showers are rare, but the probability of them occurring can be calculated. (credit: Navicore/flickr) Introduction It is often necessary
T Machine Learning: Basic Principles
 Machine Learning: Basic Principles Bayesian Networks Laboratory of Computer and Information Science (CIS) Department of Computer Science and Engineering Helsinki University of Technology (TKK) Autumn 2007
Machine Learning: Basic Principles Bayesian Networks Laboratory of Computer and Information Science (CIS) Department of Computer Science and Engineering Helsinki University of Technology (TKK) Autumn 2007
Intuition Bayesian Classification
 Intuition Bayesian Classification More ockey fans in Canada tan in US Wic country is Tom, a ockey ball fan, from? Predicting Canada as a better cance to be rigt Prior probability P(Canadian=5%: reflect
Intuition Bayesian Classification More ockey fans in Canada tan in US Wic country is Tom, a ockey ball fan, from? Predicting Canada as a better cance to be rigt Prior probability P(Canadian=5%: reflect
Lecture 9: Naive Bayes, SVM, Kernels. Saravanan Thirumuruganathan
 Lecture 9: Naive Bayes, SVM, Kernels Instructor: Outline 1 Probability basics 2 Probabilistic Interpretation of Classification 3 Bayesian Classifiers, Naive Bayes 4 Support Vector Machines Probability
Lecture 9: Naive Bayes, SVM, Kernels Instructor: Outline 1 Probability basics 2 Probabilistic Interpretation of Classification 3 Bayesian Classifiers, Naive Bayes 4 Support Vector Machines Probability
Numerical Learning Algorithms
 Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Data Mining and Machine Learning (Machine Learning: Symbolische Ansätze)
") Data Mining and Machine Learning (Machine Learning: Symbolische Ansätze) Learning Individual Rules and Subgroup Discovery Introduction Batch Learning Terminology Coverage Spaces Descriptive vs. Predictive
Data Mining and Machine Learning (Machine Learning: Symbolische Ansätze) Learning Individual Rules and Subgroup Discovery Introduction Batch Learning Terminology Coverage Spaces Descriptive vs. Predictive
Why Probability? It's the right way to look at the world.
 Probability Why Probability? It's the right way to look at the world. Discrete Random Variables We denote discrete random variables with capital letters. A boolean random variable may be either true or
Probability Why Probability? It's the right way to look at the world. Discrete Random Variables We denote discrete random variables with capital letters. A boolean random variable may be either true or
Bayes and Naïve Bayes Classifiers CS434
 Bayes and Naïve Bayes Classifiers CS434 In this lectre 1. Review some basic probability concepts 2. Introdce a sefl probabilistic rle - Bayes rle 3. Introdce the learning algorithm based on Bayes rle (ths
Bayes and Naïve Bayes Classifiers CS434 In this lectre 1. Review some basic probability concepts 2. Introdce a sefl probabilistic rle - Bayes rle 3. Introdce the learning algorithm based on Bayes rle (ths
CS 6375 Machine Learning
 CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Handling Uncertainty
 Handling Unertainty Unertain knowledge Typial example: Diagnosis. Name Toothahe Cavity Can we ertainly derive the diagnosti rule: if Toothahe=true then Cavity=true? The problem is that this rule isn t
Handling Unertainty Unertain knowledge Typial example: Diagnosis. Name Toothahe Cavity Can we ertainly derive the diagnosti rule: if Toothahe=true then Cavity=true? The problem is that this rule isn t
Decision Tree Analysis for Classification Problems. Entscheidungsunterstützungssysteme SS 18
 Decision Tree Analysis for Classification Problems Entscheidungsunterstützungssysteme SS 18 Supervised segmentation An intuitive way of thinking about extracting patterns from data in a supervised manner
Decision Tree Analysis for Classification Problems Entscheidungsunterstützungssysteme SS 18 Supervised segmentation An intuitive way of thinking about extracting patterns from data in a supervised manner
In today s lecture. Conditional probability and independence. COSC343: Artificial Intelligence. Curse of dimensionality.
 In today s lecture COSC343: Artificial Intelligence Lecture 5: Bayesian Reasoning Conditional probability independence Curse of dimensionality Lech Szymanski Dept. of Computer Science, University of Otago
In today s lecture COSC343: Artificial Intelligence Lecture 5: Bayesian Reasoning Conditional probability independence Curse of dimensionality Lech Szymanski Dept. of Computer Science, University of Otago
Fundamentals to Biostatistics. Prof. Chandan Chakraborty Associate Professor School of Medical Science & Technology IIT Kharagpur
 Fundamentals to Biostatistics Prof. Chandan Chakraborty Associate Professor School of Medical Science & Technology IIT Kharagpur Statistics collection, analysis, interpretation of data development of new
Fundamentals to Biostatistics Prof. Chandan Chakraborty Associate Professor School of Medical Science & Technology IIT Kharagpur Statistics collection, analysis, interpretation of data development of new
Einführung in Web- und Data-Science
 Einführung in Web- und Data-Science Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Tanya Braun (Übungen) Inductive Learning Chapter 18/19 Chapters 3 and 4 Material adopted
Einführung in Web- und Data-Science Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Tanya Braun (Übungen) Inductive Learning Chapter 18/19 Chapters 3 and 4 Material adopted
CS 188: Artificial Intelligence Spring Today
 CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
Recall from last time: Conditional probabilities. Lecture 2: Belief (Bayesian) networks. Bayes ball. Example (continued) Example: Inference problem
 networks. Bayes ball. Example (continued) Example: Inference problem") Recall from last time: Conditional probabilities Our probabilistic models will compute and manipulate conditional probabilities. Given two random variables X, Y, we denote by Lecture 2: Belief (Bayesian)
Recall from last time: Conditional probabilities Our probabilistic models will compute and manipulate conditional probabilities. Given two random variables X, Y, we denote by Lecture 2: Belief (Bayesian)
Naïve Bayes Classifiers
 Naïve Bayes Classifiers Example: PlayTennis (6.9.1) Given a new instance, e.g. (Outlook = sunny, Temperature = cool, Humidity = high, Wind = strong ), we want to compute the most likely hypothesis: v NB
Naïve Bayes Classifiers Example: PlayTennis (6.9.1) Given a new instance, e.g. (Outlook = sunny, Temperature = cool, Humidity = high, Wind = strong ), we want to compute the most likely hypothesis: v NB
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
Machine Learning Algorithm. Heejun Kim
 Machine Learning Algorithm Heejun Kim June 12, 2018 Machine Learning Algorithms Machine Learning algorithm: a procedure in developing computer programs that improve their performance with experience. Types
Machine Learning Algorithm Heejun Kim June 12, 2018 Machine Learning Algorithms Machine Learning algorithm: a procedure in developing computer programs that improve their performance with experience. Types
Consider an experiment that may have different outcomes. We are interested to know what is the probability of a particular set of outcomes.
 CMSC 310 Artificial Intelligence Probabilistic Reasoning and Bayesian Belief Networks Probabilities, Random Variables, Probability Distribution, Conditional Probability, Joint Distributions, Bayes Theorem
CMSC 310 Artificial Intelligence Probabilistic Reasoning and Bayesian Belief Networks Probabilities, Random Variables, Probability Distribution, Conditional Probability, Joint Distributions, Bayes Theorem
The Solution to Assignment 6
 The Solution to Assignment 6 Problem 1: Use the 2-fold cross-validation to evaluate the Decision Tree Model for trees up to 2 levels deep (that is, the maximum path length from the root to the leaves is
The Solution to Assignment 6 Problem 1: Use the 2-fold cross-validation to evaluate the Decision Tree Model for trees up to 2 levels deep (that is, the maximum path length from the root to the leaves is
Decision Trees. Tirgul 5
 Decision Trees Tirgul 5 Using Decision Trees It could be difficult to decide which pet is right for you. We ll find a nice algorithm to help us decide what to choose without having to think about it. 2
Decision Trees Tirgul 5 Using Decision Trees It could be difficult to decide which pet is right for you. We ll find a nice algorithm to help us decide what to choose without having to think about it. 2
Learning Decision Trees
 Learning Decision Trees Machine Learning Spring 2018 1 This lecture: Learning Decision Trees 1. Representation: What are decision trees? 2. Algorithm: Learning decision trees The ID3 algorithm: A greedy
Learning Decision Trees Machine Learning Spring 2018 1 This lecture: Learning Decision Trees 1. Representation: What are decision trees? 2. Algorithm: Learning decision trees The ID3 algorithm: A greedy