DATA ASSIMILATION FOR COMPLEX SUBSURFACE FLOW FIELDS
|
|
|
- Maurice Tucker
- 5 years ago
- Views:
Transcription
1 POLITECNICO DI MILANO Department of Civil and Environmental Engineering Doctoral Programme in Environmental and Infrastructure Engineering XXVI Cycle DATA ASSIMILATION FOR COMPLEX SUBSURFACE FLOW FIELDS Marco PANZERI Tutor: Advisor: Co-advisor: Prof. Alberto GUADAGNINI Prof. Monica RIVA Dr. Ernesto Luigi DELLA ROSSA The Chair of the Doctoral Programme: Prof. Alberto GUADAGNINI 24
2





3 POLITECNICO DI MILANO Department of Civil and Environmental Engineering Doctoral Programme in Environmental and Infrastructure Engineering XXVI Cycle DATA ASSIMILATION FOR COMPLEX SUBSURFACE FLOW FIELDS Doctoral dissertation of: Marco PANZERI Tutor: Prof. Alberto GUADAGNINI Advisor: Prof. Monica RIVA Co-advisor: Dr. Ernesto Luigi DELLA ROSSA The Chair of the Doctoral Programme: Prof. Alberto GUADAGNINI 24
4
5 TABLE OF CONTENTS Abstract... Chapter. Introduction...5. Background Obectives and Outline...3 Chapter 2. Data assimilation with the Kalman Filter The filtering problem Forward step Analysis step...2 Chapter 3. Kalman Filter coupled with stochastic moment equations of transient groundwater flow Extended transient moment equations of groundwater flow Data assimilation of groundwater flow data via KF: MC-based EnKF and MEbased approach Exploratory synthetic example of data assimilation and parameter estimation Comparison between MC-based EnKF and ME-based approach Conclusions...66 Chapter 4. EnKF with complex geology Markov Mesh (MM) model Theoretical formulation Synthetic example Conclusions...4 Appendix A...7 References...5 Acknowledgements...23 Estratto in italiano...25
6
7 Abstract Proper modeling of subsurface flow and transport processes is key to the solution of a wide range of engineering and environmental problems. Relevant applications include, e.g., the supply of fresh water for civil and industrial activities, the remediation of contaminated aquifers or the protection of groundwater sources, the need for enhancing the recovery efficiency of hydrocarbon reservoirs to face the ever increasing demand for energy resources, the quantification of the risk linked to the geological disposals of nuclear wastes. Building a subsurface flow model requires defining the spatial distribution of the input parameters embedded in the underlying governing equations, such as permeability and porosity. Despite the key role played by these petrophysical properties when modeling aquifer and oil reservoirs, our knowledge of the way they are distributed within a domain of interest is scarce in practical applications and often characterized by a high degree of uncertainty. A well-established approach to tackle this problem is to work within a stochastic framework, in which the permeability and the porosity fields are treated as random processes of space. An inverse and/or data assimilation modeling framework is then employed for conditioning these spatial distributions relying on either direct or surrogate measurements. Among the various available inversion (or data assimilation) techniques, we focus on the Ensemble Kalman Filter (EnKF) approach. EnKF is a data assimilation technique which is employed to incorporate data into physical system models sequentially and as soon as they are collected. EnKF is appropriate for large and nonlinear models of the kind required for realistic subsurface fluid flow simulations and has traditionally entailed the use of a (numerical) Monte Carlo (MC) approach to generate a collection of interdependent random model representations. Despite its increasing popularity, there are several drawbacks that undermine the range of scenarios under which EnKF is applicable. A critical factor is the size of the
8 ensemble, i.e., the number of MC simulations employed for (ensemble) moment evaluation. Whereas to estimate mean and covariance accurately requires many simulations, working with large ensemble sizes and assessing MC convergence is computationally demanding. Another common problem is that EnKF performs optimally only if the system variables (i.e., model parameters and state variables) can be described by a oint Gaussian distribution. Modern reservoir models require to explicitly take into account the spatial distribution of facies, which can be defined as distinctive and non-overlapping units forming the internal architecture of the host rock system and which are associated with given attributes such as porosity, permeability, mineralogy. Demarcation of diverse facies in a reservoir model is usually accomplished through indicator functions. Due to the typically non Gaussian nature of the latter, use of EnKF to update complex reservoir models can be fraught with severe challenges. The main obectives of this work are: (a) to couple EnKF with stochastic moment equations (MEs) of transient groundwater flow to circumvent and alleviate problems related to the finiteness of the ensemble employed in the traditional MC-based EnKF; and (b) to develop an assimilation algorithm that is conducive to conditioning on a set of measured production data the spatial distribution of lithofacies and of the associated petrophysical properties for a collection of hydrocarbon reservoirs. We propose to circumvent the need for MC through a direct solution of nonlocal (integrodifferential) stochastic MEs that govern the space-time evolution of conditional ensemble means (statistical expectations) and covariances of hydraulic heads and fluxes. The purpose is to combine an approximate form of the stochastic MEs with EnKF in a way that allows sequential updating of parameters and system states without a need for computationally intensive MC analyses. We explore the resulting combined algorithm on synthetic problems of two-dimensional transient groundwater flow toward a well pumping 2
9 water from a randomly heterogeneous confined aquifer subect to prescribed boundary conditions. We investigate the effect of the error variances linked to available logconductivity data and the impact of assimilating hydraulic heads during the transient or the pseudo-steady state regime on the quality of the calibrated mean of log-conductivity and head fields as well as on the associated estimation variance. We also compare the performances and accuracies of our ME- and MC-based EnKF on synthetic problems differing from each other in the variance and (integral) autocorrelation scale of log-conductivity random fields. We analyze the impact of the number of realizations employed in the MC-based EnKF and the occurrence of filter inbreeding in the assimilations. We show that embedding MEs in the EnKF scheme allows for computationally efficient real time estimation of system states and model parameters avoiding the drawbacks which are commonly encountered in traditional MC-based applications of EnKF. Our results confirm that a few hundred MC simulations are not enough to overcome filter inbreeding issues, which have a negative impact on the quality of log-conductivity estimates as well as on the predicted heads and the associated estimation variances. Contrariwise, ME-based EnKF obviates the need for repeated simulations and is demonstrated to be free of inbreeding issues. We further illustrate a novel data assimilation scheme conducive to updating both facies and petrophysical properties of a reservoir model set characterized by complex geology architecture. The spatial distribution of facies is treated by means of a Markov Mesh (MM) model coupled with a multi-grid approach, according to which geological patterns are initially reproduced at a coarse scale and are subsequently generated on grids with increasing resolution. This allows reproducing detailed facies geometries and spatial patterns distributed on multiple scales. The assimilation algorithm is developed within the context of a history matching procedure and is based on the integration of the MM model within the EnKF workflow. We test the methodology by way of a two-dimensional synthetic reservoir model 3
10 in the presence of two distinct facies and representing a complex meandering channel system. We show that the proposed inversion scheme is conducive to an updated collection of facies and log-permeability fields which maintain the geological architecture displayed by the reference model, as opposed to the standard EnKF. We test the prediction ability of the realizations obtained through our procedure by means of two forecast scenarios, in which diverse flow configurations are considered following the latest assimilation time. In our first scenario, the same flow setting imposed in the course of the assimilation time is maintained also during the additional simulation period. A second study is performed by considering the presence of two additional wells that become operative after the assimilation period. The approaches tested yield a good estimation of the target production values during the first scenario, the predictions provided by standard EnKF being characterized by the highest degree of uncertainty. The performances of the two methodologies are markedly different when considering the second scenario where our proposed algorithm outperforms the standard EnKF by providing a superior match between the reference and the predicted production curves. 4
11 . Introduction. Background Our ability of properly modeling subsurface flow and transport phenomena upon making use of diverse information content associated with the often limited amount of data available has a considerable impact on several engineering, environmental and energy applications. These include, e.g., the supply of fresh water for civil and industrial activities, the remediation of contaminated aquifers or the protection of groundwater sources, the need for enhancing the recovery efficiency in hydrocarbon reservoirs to face the ever increasing demand for energy resources, the quantification of the risk linked to the geological disposals of nuclear wastes. The motion of fluids and contaminants in sedimentary aquifers and fractured rocks is strongly influenced by the spatial distribution of the physical properties of the geological media, such as permeability and porosity, which are often characterized by a high degree of spatial heterogeneity. Despite the key role played by these properties in modeling aquifers and oil reservoirs, in practical applications our knowledge of the way they are distributed within a domain of interest is scarce and often characterized by a high degree of uncertainty. For these reasons, providing reliable predictions of pressure, saturation or solute concentration values at a given location of the considered domain and taking advantage of diverse types of information to quantify the uncertainty associated with such predictions are often complex tasks. In the last decades, several techniques have been developed for estimating the spatial distribution of petrophysical properties of underground reservoirs on the basis of either direct or indirect/surrogate measurements, with the obective of improving our ability of predicting the system response to anthropogenic or natural forcing terms. These techniques are often referred to as inverse modeling approaches in the groundwater hydrology community or 5
12 history matching in the reservoir engineering literature. The quantification of the uncertainty associated with a model prediction requires the adoption of a probabilistic approach. In this context the model parameters are treated as spatially correlated random fields and the resulting governing differential equations become stochastic, thus allowing the quantification of the space-time evolution of the probability density function of a target state variable. There are several flavors of inverse modeling procedures which can be employed in the context of groundwater aquifers and petroleum reservoir modeling. In recent years hydrogeologists and petroleum reservoir engineers have devoted increasing attention to the development of data assimilation techniques based on the concepts embedded in the Kalman Filter (KF) approach. Kalman Filter (KF) is a well-known data assimilation technique used to incorporate data into physical system models sequentially and as they are collected. It was originally introduced by Kalman [Kalman, 96] to integrate data corrupted by white Gaussian noise in linear dynamic models the outputs of which include additive noise which is also modeled as a Gaussian random variable. KF entails two steps: (a) a forward modeling (or forecasting) step that propagates system states in time until new measurements become available, and (b) an updating step that modifies/updates system states optimally in real time on the basis of such measurements. Some modern versions of KF update system states (e.g., hydraulic heads or pressures) and parameters (e.g., permeabilities) ointly based on measurements of one or both variables [e.g., Vrugt et al., 25]. Gelb [974] proposed an Extended Kalman Filter (EKF) to deal with nonlinear system models. EKF linearizes the model and propagates the first two statistical moments of target model variables in time. As such it is not suitable for strongly non-linear systems of the kind encountered in the context of groundwater flow or transport in any but mildly heterogeneous media. EKF further requires large amounts of computer storage which limits its use to relatively small-size problems. Evensen [994] and Burgers et al. [998] proposed 6
13 to overcome these limitations through the use of Monte Carlo (MC) simulation. Their socalled Ensemble Kalman Filter (EnKF) approach utilizes sample mean values and covariances to perform the updating. The development of sensors and measuring devices capable of recording massive amounts of data in real time has rendered EnKF popular among hydrologists, climate modelers and petroleum reservoir engineers [Oliver and Chen, 2; Liu et al., 22]; assimilating such rich data sets in batch rather than sequential mode, as is common with classical inverse frameworks such as Maximum Likelihood, would not be feasible. Applications of EnKF to groundwater and multiphase flow problems include the pioneering works of McLaughlin [22] and Naevdal et al. [25]; recent reviews are presented by Aanonsen et al. [29], Oliver and Chen [2] and Liu et al. [22]. A crucial factor affecting EnKF is the size of the "ensemble", i.e., the number (NMC) of MC simulations (sample size) employed for moment evaluation. Whereas to estimate mean and covariance accurately requires many simulations, working with large NMC tends to be computationally demanding. Chen and Zhang [26] showed that a few hundred NMC appear to provide accurate estimates of mean log-conductivity fields. They pointed out, however, that obtaining covariance estimates of comparable accuracy would require many more simulations, a task they had not carried through. Efforts to reduce the dimensionality of the problem through orthogonal decomposition of state variables have been reported by Zhang et al. [27] and Zeng et al. [2, 22]. Small sample sizes give rise to filter inbreeding [Oliver and Chen, 2] whereby EnKF systematically understates parameter and system state estimation errors; rather than stabilizing as they should, these errors appear to continue decreasing indefinitely with time, giving a false impression that the quality of the parameter and state estimates likewise keeps improving. There is no general theory to assess, a priori, the impact that the number NMC of MC simulations would have on the accuracy of moment estimates. We do know, however, 7
14 that the sample mean of a random variable converges to the population mean at a rate proportional to NMC, the sample width of a normal variable's confidence interval converges at a rate proportional to /NMC for large NMC, and this latter rate is modulated by Chebyshev's inequality as detailed in Ballio and Guadagnini [24] and references therein. This is enough to conclude that increasing NMC by a factor of a few hundred, as is often done, would likely not lead to marked improvements in accuracy. A practical solution is to continue running MC simulations till the sample mean and variance stabilize or, if computer time is at a premium, till their rates of change slow down markedly. van Leeuwen [999] showed theoretically that filter inbreeding is caused by (a) updating a given set ("ensemble" or collection) of model output realizations with a gain computed on the basis of this same set and (b) spurious covariances associated with gains based on finite numbers NMC of realizations. Remedies suggested in the literature are generally ad hoc. Houtkamer and Mitchell [998] proposed splitting the set of MC runs into two groups and updating each subset with a Kalman gain obtained from the other subset. Hendricks Franssen and Kinzelbach [28] proposed alleviating the adverse effects of filter inbreeding by (a) dampening the amplitude of log-conductivity fluctuations, (b) correcting the predicted covariance matrix on the basis of a comparison between the predicted ensemble variance and the average absolute error at measurement locations, and (c) performing a large number of realizations (in their case NMC = ) during the first simulation step and a subset of realizations (NMC = ) thereafter; a procedure similar to the latter was also suggested in Wen and Chen [27]. To select an optimal subset one would minimize some measure of differences between cumulative sample distributions of hydraulic heads obtained in the first step with (say) NMC = and NMC =. This, however, brings about an artificial reduction in variance, as shown by Hendricks Franssen and Kinzelbach [28]. Hendricks Franssen and Kinzelbach [28] obtained best results with a combination of all 8
15 three techniques. Hendricks Franssen et al. [2] observed filter inbreeding when analyzing variably saturated flow through a randomly heterogeneous porous medium with NMC = even after dampening log-conductivity fluctuations by a factor of. Several authors [e.g., Wang et al., 27; Anderson, 27; Liang et al., 22; Xu et al., 23] have noted a reduction in filter inbreeding effects through covariance localization and covariance inflation. Covariance localization is achieved upon multiplying each element of the updated state covariance matrix by an appropriate localization function to reduce the effect of spurious correlations [Houtekamer and Michell, 998; Furrer and Bengtsson, 27]. In the covariance inflation methods, the forecast ensemble is inflated through multiplication of each state by a constant or variable factor [e.g., Wang and Bishop, 23; Liang et al., 22; Xu et al., 23]. Another common problem encountered in the application of the EnKF is related to the assumption that the system variables (i.e., model parameters and state variables) can be described by a oint Gaussian distribution. Most current reservoir models require to explicitly take into account the spatial distribution of facies, which can be defined as distinctive and non-overlapping units of the host rock system with specified characteristics such as porosity, permeability, mineralogy. Like petrophysical properties, facies can often be inferred from well logs at well locations. As is often the case, their spatial distribution between wells is highly uncertain. A common procedure to distinguish between diverse facies in a reservoir model is to employ indicator functions, which by their nature cannot be represented by Gaussian distributions. This implies that using EnKF to update these types of complex reservoir models can be problematic. The common approach which is found in the literature is based on the transformation of the diverse facies types into intermediate random fields that are described by Gaussian distributions. Liu and Oliver [25a, 25b] used a transformation based on the truncated pluri-gaussian method [Le Loc'h and Galli, 997] and focused on the estimation of the 9
16 boundaries between the diverse facies. They did not consider within-facies variability of attributes (i.e., porosity and permeability) and assigned a deterministic value of permeability and porosity to each facies type (thus, considering only across-facies variability). They adopted two Gaussian fields and three thresholds to model the spatial distribution of three geologic units. The key point of the work of Liu and Oliver [25a] is to consider two truncated Gaussian fields with fixed truncation thresholds as static parameters (i.e., parameters that do not vary with time during a flow simulation, such as permeability and porosity in the absence of consolidation processes or geochemical reactions) in the state vector to be estimated through inversion. This would overcome the problem of updating a discrete variable (facies distribution in the domain of interest) by representing the latter by means of two continuously distributed random processes. They applied the truncated pluri- Gaussian method to match both hard (i.e., direct facies observations) and production data. Disadvantages of the truncated pluri-gaussian method include the difficulty in determining truncation maps and structural properties of the Gaussian random fields that are suitable to describe the internal architecture of highly complex reservoirs in terms of a small number of truncation parameters. Moreover, although the underlying model parameters are multivariate Gaussian, the relationship between observations and model parameters is highly non-linear and causes the appearance of apparently unphysical updates during the assimilation step. For this reason, iterative methods, where only the static parameters are updated and the system states are obtained by re-starting the flow simulation from the previous assimilation time, are often employed to alleviate these drawbacks [Aanonsen et al., 29]. Moreno and Aanonsen [27] proposed to combine the level set method with the EnKF. The level set method relies on a suitable level-set function which is an implicit representation of a given surface that is defined as the set of points at which the function vanishes. More specifically, if a given facies in a background medium is defined on a certain
17 domain (support), the level set function is defined as the signed distance to the domain boundary. This distance is positive inside and negative outside of the boundary separating the facies from the background medium. The spatial dynamics of the level set function which is deforming during data acquisition is modeled by the convection equation. Moreno and Aanonsen [27] assumed that the velocity field governing the evolution of the level set was defined as a Gaussian random field and included it in the state vector to be estimated/updated. Chang et al. [2] improved the application of level set functions to EnKF by employing a parameterization based on the concept of representing nodes (i.e., these are also called master points or pilot points in the literature). Contrary to Moreno and Aanonsen [27], they considered only the values of the level set function at a set of so-called representing nodes as variables of the state vector to be estimated. The values of the level set function at grid nodes different from the selected representing nodes are obtained by linear interpolation. This allowed these authors to alleviate the non-uniqueness associated with the identifiability of the level set function. If the distance between representing nodes is properly chosen, these are uncorrelated or weakly correlated and can be treated as independent from each other. The authors applied their methodology to diverse synthetic case studies with two or three different facies units, where the rock properties such as porosity and permeability were assumed as constant within the same unit. Although the work of Chang et al. [2] has introduced important improvements in the application of the level set method to EnKF, it is not clear how level set methodologies enables one to capture complex geological constraints of the kind required for reproducing realistic facies geometries. Jafarpour and McLaughlin [28] introduced the use of the Discrete Cosine Transform (DCT) method to history matching applications in reservoir models with complex geology. The Discrete Cosine Transform (DCT) is a Fourier-related transform. It uses orthonormal cosine basis functions to represent an image that, in the case we examine, can
18 correspond to the spatial distribution of state variables or model parameters. This method has been proposed by Ahmed et al. [974] for signal decorrelation and has been used in the context of several applications in other fields (mostly in the context of audio and image compression, e.g., Rao et al. [99]). The powerful compression property of DCT allows for retaining only a few basis functions in comparison to the total number of grid nodes. The authors modified the EnKF scheme in such a way that the coefficients of the retained cosine basis functions representing the spatial distribution of the state variables and model parameters are updated to describe the distribution of the target quantities. Using DCT parameterization contributes to dramatically reduce the dimension of the state vector and can also mitigate the loss of structural continuity that can be observed in the context of other approaches when the updating step is performed with reference to each node of the numerical grid. This result can be achieved because DCT emphasizes large scale (associated with low frequency component) rather than small scale features. One of the synthetic test cases presented by Jafarpour and McLaughlin [28] was a two-facies reservoir model. In this scenario the methodology was conducive to a correct identification of large scale structures, in the shape of elongated continuous channels, embedded in the reference fields. These results highlighted the ability of this parameterization method to account for relatively complex geological structures within a reservoir model. Other proposed schemes include the work of Dovera and Della Rossa [2], where a composite medium is described through a multimodal density of system parameters. The multimodality of prior parameter fields is taken into account through the theory of Gaussian mixture (GM) models. Gaussian mixture models are based on the idea that the probability density function (pdf) of the model parameters can be parametrically described as weighted sums of Gaussian pdfs. The authors derived a novel set of EnKF updating equations and coupled it with the expectation-maximization (EM) method for the evaluation of the weights 2
19 of the prior GM. The authors compared the performance of their method against the traditional EnKF formulation by means of a synthetic case and concluded that their scheme allowed obtaining an improved evaluation of the posterior distribution of the forecast production. Jafarpour and Khodabakhshi [2] proposed a Probability Conditioning Method (PCM) for conditioning the facies distribution of a collection of reservoir models in which a deterministic value of permeability and porosity is assigned to each facies type. They employed the EnKF scheme to update the sample mean values of the log-permeability field. The updated mean values are then used to infer information about the distribution of facies probabilities through the PCM. This method consists of converting a value of logpermeability mean to a value of probability of facies occurrence through a simple linear mapping function. The updated probability map is then combined with the snesim algorithm [Strebelle, 22] to simulate a new collection of facies realizations. The realizations are therefore conditioned on the updated probability maps as well as on the production data. The updated saturation and pressure fields are obtained by re-running the simulation from the initial time to ensure consistency with the updated permeability fields. This methodology was used to successfully condition the categorical permeability fields in an ensemble of synthetic reservoirs with two or three different facies, and was demonstrated to outperform the EnKF in the quality of the calibrated models and in the accuracy of the model forecast..2 Obectives and outline The main obectives of this work are: (a) to couple the updating step of EnKF with the stochastic moment equations of transient groundwater flow to circumvent and alleviate problems related to the finiteness of the ensemble employed in the traditional MC-based EnKF, and (b) to develop an assimilation algorithm that is conducive to conditioning the spatial distribution of the facies and of the associated petrophysical properties of a collection 3
20 of hydrocarbon reservoirs on a set of measured production data. The dissertation is structured according to the obectives outlined above. In Chapter 2, we cast the updating equations of the Kalman Filter in a Bayesian context. The derivation follows the work of Cohn [997] and provides the theoretical ground on which all KF-based assimilation techniques are based. In this Chapter it is shown that assuming that the prior distribution of the model variables and the distribution of the measurement errors be multivariate normal leads to a Gaussian posterior distribution of the model variables conditioned on the measured data. The mean vector and the covariance matrix of the posterior distribution are precisely those which are determined through the updating equations of the KF. In Chapter 3, we propose to circumvent the need for MC through a direct solution of nonlocal (integrodifferential) stochastic MEs that govern the space-time evolution of conditional ensemble means (statistical expectations) and covariances of hydraulic heads and fluxes [Tartakovsky and Neuman, 998; e et al., 24]. Such MEs have been used successfully to analyze steady state and transient flows in randomly heterogeneous media conditional on measured values of medium properties. Second-order approximations of these equations have yielded accurate predictions of complex flows in heterogeneous media with unconditional variances of (natural) log-hydraulic conductivity as high as 4. [Guadagnini and Neuman, 999]. Hernandez et al. [23, 26] and Riva et al. [29] developed batch geostatistical inverse algorithms that enable one to condition flow predictions further on measured values of state variables (heads and fluxes) for steady state and transient flows, respectively. A field application is described in the work of Bianchi Janetti et al. [2]. This approach yields Maximum Likelihood (ML) estimates of hydraulic conductivity, variogram parameters and measurement error statistics. Parameter estimation entails the minimization of a log- 4
21 likelihood function which in turn requires the computation of a sensitivity matrix. The latter step tends to be computationally intensive, especially in the case of large parameter vectors [e.g., Alcolea et al., 26; Riva et al., 2]. Our purpose is to combine approximate forms of nonlocal, conditional stochastic MEs with EnKF in a way that allows sequential updating of parameters and system states without a need for computationally intensive ML or MC analyses. We extend the ME formulation of e et al. [24] in a way that renders it compatible with EnKF. We explore the resulting combined algorithm on synthetic problems of two-dimensional transient groundwater flow toward a well pumping water from a randomly heterogeneous confined aquifer subect to prescribed head and flux boundary conditions. We investigate the effect of the error variances linked to the measurements of log-conductivities and the impact of assimilating hydraulic heads during the transient or the pseudo-steady state regime on the quality of the calibrated mean of log-conductivity and head fields and on the associated estimation variance. In addition, we compare the performances and accuracies of our ME- and the traditional MCbased EnKF on synthetic problems differing from each other in the variance and (integral) autocorrelation scale of the (natural) logarithm of hydraulic conductivities. We analyze the impact of the number of realizations employed in the MC-based EnKF and the occurrence of filter inbreeding in the performed assimilations. In Chapter 4, we illustrate a novel inversion scheme which allows conditioning the geological and petrophysical properties of a collection of reservoir realizations on the basis of a set of production data. First, we present a Markov Mesh model [Stien and Kolbørnsen, 2] that is used to (a) describe the spatial distribution of the geological properties and (b) reproduce their complex spatial arrangement. The MM model is coupled with a multi-grid approach [Kolbørnsen et al., 23], according to which the geological patterns are initially reproduced at a coarse scale, and are subsequently generated on increasingly finer grids. This 5
22 methodology allows reproducing (geological) patterns distributed on different scales. The proposed inversion scheme is based on a three step algorithm. First, the EnKF scheme is employed to update the sample mean of the lithofacies spatial distribution. A new collection of facies realizations is then generated via a Markov Mesh (MM) model. During this step the equation used to calculate the conditional probability of occurrence of a given lithotype in each element of the computational grid ensures that the mean facies distribution obtained at the previous step is honored. In the third step, the petrophysical properties of each reservoir model in the collection are updated through a proposed modification of the EnKF scheme. The cross-covariance between production data and log-permeabilities is estimated considering the updated spatial distribution of lithofacies computed at the previous step. Updating of log-permeabilities in a given realization relies on the estimation of the sample cross-covariance between production data and log-permeabilities associated with a given reference block in the reservoir upon considering only the members of the collection where the same facies of the reference element considered in the target model realization occurs. We test the proposed methodology by way of a two-dimensional synthetic reservoir model in the presence of two distinct facies and representing a complex meandering channel system. We analyze the accuracy and computational efficiency of our algorithm and demonstrate its benefit with respect to the standard EnKF in terms of improved prediction ability and use of information for the quantification of the uncertainty associated with the forecast production. 6
23 2. Data assimilation with the Kalman Filter In this Chapter we present a derivation of the Kalman Filter (KF) equations in the context of Bayesian inference theory. The obective is to provide a theoretical framework and to introduce the basic concepts that will become useful in the following Chapters. The KF algorithm developed by Kalman [96] considers a linear model dynamic the output of which is corrupted with additive Gaussian noise with zero mean and given covariance matrix. Here we intentionally restrict our discussion to the case of an exact model (i.e., without error) and focus on techniques that extend the classical KF scheme to models characterized by nonlinear dynamics of the kind required to model realistic subsurface fluid flow scenarios. In Section 2. we define the filtering problem in the framework of data assimilation. The solution of this problem is achieved by means of two sequential steps, respectively termed forward and analysis and described in Sections 2.2 and The filtering problem The model dynamics describing groundwater and (in general) subsurface multiphase flow consist of a system of (typically coupled) nonlinear partial differential equations (PDEs). Let y be the vector containing the N y model variables of the system under study evaluated at time T k at a finite number of discretization nodes (or elements) of a numerical grid. This vector can include model parameters (i.e., permeability and porosity), state variables (i.e., pressure, saturation) and production data (i.e., well flow rates, water cut, bottom hole pressure). Model dynamics can be described through the non-linear operator, which yields the solution at time T k, y, given the model state at an earlier time k k T, y T y y (2.) 7
24 Uncertainty associated with model parameters renders the system state y random, and T allows describing it by means of the probability density function (pdf) f y k. The time t evolution of f y within the time interval T T T PDEs associated with (in general) random initial condition k f k k is governed by a set of stochastic y. We introduce the following model governing system observations d H y ε (2.2) d where matrix d is a vector of size d N H of size d y N containing all N d measurements available at time T k, the N is a linear operator mapping the model variables y into their observed counterparts and ε is a random vector containing the N d measurement errors. T k d Typically, ε is assumed to be normally distributed, unbiased and with known covariance T k d matrix ε (2.3) d Nd, d d d d εε ε ε ε ε Σ (2.4) where N d, is a vector of size Nd with all elements equal zero, denotes expectation and the superscript + stands for transpose. A common assumption is that the measurement error vectors at different times are uncorrelated Tl d T k d N, ε ε for k l (2.5) d Nd The filtering problem in data assimilation is posed as the problem of describing the evolution in time of the conditional pdf, all observations available up to time T k, i.e. f y D, where the matrix D denotes the set of T T2 D d, d,, d (2.6) 8
25 The filtering problem is solved by means of two sequential steps. The forward step (Section 2.2) consists on propagating in time the conditional density available at time, f y D, towards the corresponding pdf at time k conditioned on the measurement vector T allowing the evaluation of, k T k T k T k T f f k 2.2 Forward step T, f y D. The latter is then d by means of the analysis step (Section 2.3), y D d y D. Suppose one is given the conditional density f the evaluation of the density f y D. The forward step requires y D. This entails solving a stochastic PDE within the time interval and subect to the random initial conditions embodied in f y D. If the model dynamics are linear, as it is assumed in the classical KF, the evaluation of the mean vector and of the covariance matrix associated with f y D is straightforward [Cohn, 997]. This assumption is generally not valid in the field of groundwater and multiphase flow in porous media, where the model dynamics can be highly non-linear. In these cases, the solution of the forward step requires a diverse approach. A possible strategy is to resort to Monte Carlo (MC) simulation. This technique is based on representing the pdf f y D through a collection of model realizations. Propagating each member of the collection within the time interval using the forward model operator (2.) allows approximating the pdf f estimating its statistical moments through the corresponding sample moments. y D at time T k and Monte Carlo simulations are not the only available strategy for the solution of the forward step in the presence of non-linear system dynamics. As will be explored in this dissertation (Chapter 3), an alternative could be formulating a system of (ensemble) moment 9
26 equations (MEs) which describe the temporal evolution of the statistical moments (typically, t T mean and covariances) of the pdf k f y D, t. The format of these moment equations is determined by the model dynamic expressed by (2.), and should be derived ad hoc depending on the specific context. This issue will be further explored in Chapter 3, where a set of approximated equations describing the temporal evolution of the first and second moment of the target pdf for a groundwater flow model will be presented and embedded in the KF scheme. 2.3 Analysis step The obective of the analysis step is to calculate the conditional pdf the density f y D. Application of Bayes theorem allows writing f y D given f y D f y D, d f y D f d D, y f d D (2.7) Since d (given y ) depends only on d (2.5), the following simplification holds f T, k T k T k T k T f k k ε, which in turn is independent of D T because of d D y d y (2.8) and (2.7) can be rewritten as f y f y ft, k D f y D f d y f d D The function f (2.9) y D is also termed the forward pdf, and is here denoted as. Following the work of [Cohn, 997], we consider this density to be multivariate Gaussian so that it can be parameterized through the corresponding mean vector and the covariance matrix. These are respectively defined as 2
27 f, y D y (2.) f, f, f, f, f, y y y y Σ yy (2.) The density function of f f, T y k is then equal to f, T N 2, 2 k y f T k f, f, f, T k f, f, 2 yy exp yy y Σ y y Σ y y (2.2) 2 where denotes matrix determinant. By virtue of (2.2)-(2.4), the mean vector and the covariance matrix of the likelihood function f d y can be written as d y H y ε y H y (2.3) d T k d d εε d d y d d y y ε ε y Σ (2.4) Since T k ε d is considered to be normally distributed, the density f d y is also Gaussian and given by f 2 2 T k T N k d T k T k T k 2 εε exp εε d y Σ d H y Σ d H y (2.5) 2 We can then employ (2.2) to define the mean vector and the covariance matrix of the pdf f d D as d D H y ε D H y D H y (2.6) f, d d d D d d D D Since,, d d f f H y y ε H y y ε D f, T k yy εε H Σ H Σ (2.7) ε and T k d y were assumed to be normally distributed, the density f d D is also Gaussian and can be written as 2
28 f N 2 d, 2 yy f T k εε 2 d D H Σ H Σ, f f, T k f, yy εε exp d H y H Σ H Σ d H y (2.8) 2 Substitution of (2.2), (2.5) and (2.8) into (2.9) yields the target posterior density function, f, f y D, also termed as the updated pdf and denoted as f y ut k u, T N 2, 2 k y u T k u, u, u, T k u, u, 2 yy exp yy y Σ y y Σ y y (2.9) 2 Here, the mean vector ut, y k and the covariance matrix Σ are evaluated using the ut, k yy following set of equations u, T k f, T k T k T k T k f, T k y y K d H y (2.2) u, f, yy Ny yy Σ I K H Σ (2.2) f, f, T k K Σ yy H H Σ yy H Σ εε (2.22) where I is the identity matrix of size Ny Ny, and the matrix K is called the Kalman N y gain. The complete set of details of the mathematical derivation of (2.2)-(2.22) can be found in Cohn [997] or in Tarantola [25]. The set of equations (2.2)-(2.22) allows defining the updated pdf as a function of the mean vector and of the covariance matrix of the forward and measurement error density functions. The updated moments of the target pdf are then used to characterize the initial conditions in the subsequent forward step, consisting in the evaluation of the density f y D. When KF is coupled with MC simulation, the pdf of f, T y k is approximated through a collection of model realizations, as discussed in Section 2.2. In this case equations (2.2) - (2.22) do not enable one to evaluate directly the updated realizations, which are employed to approximate the posterior pdf at time k, T, f y ut k, and constitute the initial 22
29 conditions to the solution of the flow problem during the subsequent forward step. If we indicate the collection of forward model realizations at time T k as y, i,, NMC f, T k i (NMC being the number of Monte Carlo iteration in the sample), then the updated realizations, y, can be calculated through [Evensen, 994; Burgers et al., 998] ut, k i u, f, f, i i i i y y Kˆ d H y i,, NMC (2.23) Here, d is a randomized measurement vector defined as T k i d d ε i,, NMC (2.24) i d, i where matrix ε is a random vector having a Gaussian distribution with zero mean and covariance T d k, i Σ εε. In (2.24), the empirical Kalman gain matrix ˆ T K k, given by ˆ ˆ f, ˆ f, T k ˆ K Σ yy H H Σ yy H Σ εε (2.25) is evaluated employing the empirical covariance matrices, defined as y y (2.26) NMC f, f, i NMC i ˆ Σ y y y y (2.27) NMC i i f, f, f, f, f, yy NMC i NMC T k d d i (2.28) NMC i NMC ˆ T k T k Σ di d di d (2.29) εε NMC i The system (2.24)-(2.3) yields the updating equations used in the Ensemble Kalman Filter (EnKF). Equations (2.24) - (2.3) ensure that the elements of the collection y, i,, NMC are ut, k i realizations of the posterior distribution defined in (2.9). Evaluating the sample mean, ut, y k, and the sample covariance matrix, Σ ˆ ut, k yy, of the updated model realizations 23
30 ˆ u, T k f, T k T k T k T k f, T k y y K d H y (2.3) ˆ Σ y y y y NMC i i u, u, u, u, u, T k yy NMC i NMC ˆ f, f, ˆ f, IN K H y y i y K di d NMC i ˆ k k, k, k ˆ k k, T T f T f T T T f IN K H y y i y K di d N y Ny Ny I Kˆ H Σˆ I Kˆ H Kˆ Σˆ Kˆ I Kˆ H Σ ˆ (2.3) f, f, yy εε yy and comparing (2.3) - (2.3) with (2.2) - (2.22) show that in the limit of infinite sample size the empirical moments of the updated collection converge to their corresponding theoretical counterparts. The state vector f, T y k contains model parameters, state variables and production data in most of the KF-based applications performed in the context of data assimilation in groundwater and subsurface multiphase flow models. In these cases, assuming that the density of f, T y k is multivariate normal (see (2.2)) is in general sub-optimal because of the non-linear relationship between the elements of the model state vector. For this reason the solution obtained by means of the updating equations (2.2)-(2.22) can be considered only an approximation of the true system state. One of the main drawbacks related to this approximation is the appearance of unphysical updates, for which the updated model variables do not satisfy mass conservation or saturations are associated with values which can be negative or larger than unity. 24
31 3. Kalman Filter coupled with stochastic moment equations of transient groundwater flow This Chapter focuses on data assimilation in models of transient groundwater flow in randomly heterogeneous media via Kalman Filter. We propose to solve the forward step entailed in the Kalman Filter scheme through a direct solution of approximate nonlocal (integrodifferential) moment equations (ME) that govern the space-time evolution of conditional ensemble means (statistical expectations) and covariances of hydraulic heads and fluxes. This procedure allows circumventing the need for computationally intensive Monte Carlo (MC) simulation. In Section 3. we extend the ME formulation of e et al. [24] in a way that renders it compatible with KF. Section 3.2 describes the key steps of the assimilation procedure performed using the common MC-based EnKF as well as our new ME-based version. Section 3.3 explores the feasibility and accuracy of the proposed algorithm on a synthetic problem of two-dimensional transient groundwater flow toward a well pumping water from a randomly heterogeneous confined aquifer subect to prescribed head and flux boundary conditions. In Section 3.4 the same flow setting is considered for nine heterogeneous systems differing from each other in the variance and integral scale of the log-hydraulic conductivity field. A detailed comparison of the performances and accuracies of ME- and MC-based EnKF is presented and results and implications are discussed in Section Extended transient moment equations of groundwater flow We consider transient groundwater flow in a saturated domain governed by stochastic partial differential equations of mass balance and Darcy s law h x, t SS qx, t f x, t x (3.) t 25
32 , t K h, t q x x x x (3.2) subect to initial and boundary conditions, h x t H x x (3.3),, h x t H x t x D (3.4), t Q, t q x n x x x N (3.5) where hx, t is hydraulic head and qx,t the Darcy flux vector at point,t x in spacetime, K x is an autocorrelated random field of scalar hydraulic conductivities, S S is specific storage treated here as a deterministic constant, H x is (generally) a random initial head field, f x, t is (generally) a random source function of space and time, Hx, t and Q, t x are (generally) random head and normal flux conditions on Dirichlet boundaries D and Neumann boundaries The Laplace transform of a function t g e g t dt, respectively, and n is a unit outward normal to. N gt is defined as (3.6) where is a complex Laplace parameter. Taking the Laplace transform of (3.) - (3.5) yields the transformed flow equations S,,, S x h x q x f x S x H x x (3.7), K h, S q x x x x (3.8) h, H, x x x D (3.9), Q, q x n x x x N (3.) N 26
33 Each random quantity in (3.7) - (3.) can be written as the sum of its (conditional) ensemble mean (statistical expectation) and a zero-mean random fluctuation about that mean such that K x K x K x (3.),,, h x h x h x (3.2),,, q x q x q x (3.3) e et al. [24] present and solve numerically non-local conditional stochastic MEs satisfied by the mean and covariance of h and q and by the cross-covariance between h and K for a special case in which all forcing terms ( f, H, H, and Q ) are uncorrelated with each other and/or with K. To embed (3.7) - (3.) in the KF scheme, the total simulation period is segmented into a sequence of time intervals according to the number of time steps at which measurements need to be assimilated. We solve the MEs within each time interval T T k k and treat the updated moments of h (and flux) at time k T as initial condition. The MEs of e et al. are therefore extended in a way that takes these cross-correlations into account. Like e et al. [24], we render the exact MEs workable by expanding them to second-order in, the conditional standard deviation of (natural) log-conductivity x ln Kx, about its conditional mean, x. We adopt the notation of e et al. [24] and approximate the Laplace transform of conditional mean head and flux by their leading terms up to second-order (denoted by parenthetic superscript) in h h h 2 x, x, x, (3.4) 2 q x, q x, q x, (3.5) The system of equations satisfied by the zero-order mean and flux is given by 27
34 x x q x x x x x (3.6) S, S h, f, SS H K G h q x, x x, x (3.7) h x x x D (3.8), H, q x n x x x N (3.9), Q, Here, KG exp x is the conditional geometric mean of K ; f, H, H and Q are ensemble mean (in part Laplace transformed) forcing terms. For simplicity we treat f, H and Q as deterministic. Second-order corrections of head and flux are governed by x , K q x,, G h x h x r x, x (3.2) 2 SS 2 2 x h x, q x, x (3.2) 2 x, D h x (3.22) q x, n x x N (3.23) 2 where 2 x 2 x is the conditional variance of x and the second-order transformed residual flux, 2 2 r x, K x h x,, in (3.2) is evaluated according to 2 KG KG C x y G y h 2 K h SS x G,, d r x, x y x, y y, x, y, dy where C, x y y y x y (3.24) x y x y is the conditional covariance of between points x and y, the superscript + denoting transpose. The zero-order conditional mean random Green s function, G yx,,, associated with (3.7) - (3.) is obtained upon writing (3.6) - 28
35 (3.9) in terms of y, and solving them subect to homogenous boundary conditions and a Dirac delta source at x. The last integral on the right hand side of (3.24), containing the conditional cross-correlation between hydraulic conductivity and initial head fluctuations h, is new and does not appear in equation (39) of e et al. [24]. For reasons explained earlier, this term may vanish during the first time interval T T (in particular when H is deterministic) but not during later intervals. The second-order conditional cross-covariance, u Kh 2 xy,,, between K x and transformed head h, 2 Kh G G z z 2 y is evaluated according to u x, y, K x K z C z, x h z, G z, y, dz SS z K x h z G z, y, dz (3.25) Corresponding equations for the conditional second-moment (variance-covariance) of associated head prediction errors are evaluated according to x KG x xch x, y,, s ukh x, y, s x h x, SS x Ch x, y,, s C h 2 S 2, S x h x h y s x (3.26) xy,,, s x D (3.27) K 2,,, 2,, G x xch x y s ukh x y s x h x, n x x N (3.28) Here, h 2,,,,, C x y s h x h y s is the conditional covariance between transformed and untransformed head fluctuations hx, and hy, s. The term on the right hand side of (3.26) includes the covariance between head hy, s at time s and initial head h covariance is rendered by the inverse Laplace transform with respect to s of 2 2 z 2 h x h y, h z, K z h x G z, y, dz z x. This SS z h x h z G z, y, dz (3.29) 29
36 Like e et al. [24] the above MEs are solved by a Galerkin finite element method using bilinear Lagrange interpolation functions. The finite element equations are shown in Appendix A. Laplace back transformation into the time domain is performed using the quotient difference algorithm of De Hoog et al. [982]. The numerical code has been parallelized to (i) solve (3.4) - (3.24) for different values of simultaneously, and (ii) compute the cross-covariances and covariances (3.25) - (3.29) at subsets of grid nodes which are uniformly distributed among available processors in a cluster. 3.2 Data assimilation of groundwater flow data via KF: MC-based EnKF and ME-based approach We consider the model vector y h (3.3) where the parameter vector contains N log-conductivities and the state vector h includes N h hydraulic head values satisfying (3.) - (3.5), so that y has dimension N y N Nh. In our finite element solver of (3.) - (3.5), described above, N is the number of elements in which hydraulic conductivity is taken to be uniform and N h is the number of nodes at which heads are computed. According to the notations introduced in Chapter 2, we denote the model vector y at, time conditioned on measurements available up to time, by y ut k. In line with ut, Tarantola [25], Cohn [997] and Woodbuty and Ulrych [2] we consider y k to be multivariate Gaussian with mean vector y ut, k h ut, k ut, k (3.3) and covariance matrix 3
37 u, u, C, u ut h k Σ u, T yy (3.32) k u, uh Ch, Here, C ut k, and C ut k, are the conditional covariance matrix of ut k, and h ut k, h, respectively, and u ut k is their cross-covariance matrix. h The forward step entailed in the KF algorithm requires solving the system of stochastic PDEs (3.) - (3.5) within the time interval and with random initial conditions given by (3.3) - (3.32). One way of solving the forward step is to rely on Monte Carlo (MC) simulation. As ut, detailed in Chapter 2, MC requires representing the density function of y k through a, collection of model realizations, ut k y,,, NMC. With this approach equations (3.) - (3.5) are solved within the time interval T T k k for each model realization. This is accomplished by employing the deterministic log-conductivity field and initial head field, contained in ut k y. The MC solution yields the collection of forward realizations at time T k, y,,, NMC. f, T k As an alternative to MC, we propose to solve the forward step directly through the system of moment equations (3.7) - (3.29). These MEs are solved within the time interval T T k k upon setting the mean and the covariance of the log-conductivity field equal to ut, k, in (3.3) and ut k C in (3.32), respectively. This approach requires treating the initial conditions as random. The initial head field is characterized by mean and covariance, matrix equal to ut k, h and C ut k, respectively, while the cross-covariances between h Kh G h u, T, conductivities and initial heads are set to k u u K u. The ME solution yields secondorder approximation of mean and covariance matrix of the forward vector at time T k, f, T y k 3
38 y f, h f, f, (3.33) f, f, C, u f T h k Σ f, T yy (3.34) k f, uh Ch The measurements of and/or h available at time T k and the covariance matrix of the corresponding measurement errors are then used in the analysis step of the KF algorithm. Working with MC, (2.24) - (2.3) allow obtaining the collection of updated model realizations y,,, NMC. In the ME-based approach, (2.2) - (2.22) are used for the ut, k evaluation of the mean, ut, y k, and covariance matrix, Σ of the target updated density ut, k yy function. Figures summarize the assimilation algorithms associated with MC and ME approaches, respectively. T Initial conditions: h T,, NMC Forecast: MC (3.) - (3.5) k = n h f, T k,, NMC d T k T Σ k εε Observed Data Assimilation Updating: EnKF (2.23) - (2.29) h ut, k,, NMC Figure 3.. Flow chart of data assimilation through common MC-based EnKF. 32
39 T Initial conditions: h T C uh u C h h T Forecast: ME (3.7) - (3.29) k = n f, T k C h u h u C h h f, T k d T k T Σ k εε Observed Data Assimilation Updating: KF (2.2) - (2.22) ut, k C h u h uh Ch ut, k Figure 3.2. Flow chart of data assimilation through embedding of stochastic moment equations of transient groundwater flow in the KF scheme. 3.3 Exploratory synthetic example of data assimilation and parameter estimation We explore the feasibility and accuracy of our ME-based approach by way of a twodimensional transient flow example. We consider a square domain measuring 4 4 (all quantities are given in consistent space-time units) discretized into grid cells of size. Each element has uniform hydraulic conductivity, yielding a parameter vector of dimension N 6. Head values are prescribed or computed at Nh 68 nodes, yielding a head vector h of similar dimension. Whereas deterministic head values equal to H. and H2. are prescribed along the left and right boundaries, the top and bottom boundaries are made impervious (Figure 3.3). Storativity is set equal to a uniform deterministic value of.3. Initial hydraulic heads are deterministic and vary linearly between the two constant head boundaries. Superimposed on this background gradient is convergent 33
40 flow to a centrally located well that starts pumping at a deterministic constant rate Qp.3 at reference time f x, t and t. Mathematically the well is simulated by setting f x, t Qp x x w in (3.) where is the Dirac delta function, x w are the Cartesian coordinates of the well and well radius is neglected. 4. Impervious boundary 5 8 x 2 Constant head H Constant head H Impervious boundary x Figure 3.3. Flow domain, nodes of the computational grid (+), boundary conditions, pumping well ( ), log-conductivity ( ) and hydraulic head ( ) measurement locations. Values of in each grid cell are set equal to those generated at element centers using a sequential Gaussian simulator [SGSIM, Deutsch and Journel, 998]. The generated values form a random realization (depicted in Figure 3.4) of a statistically homogeneous and isotropic multivariate Gaussian field having variance 2. and exponential covariance with integral scale 4.. This strongly heterogeneous reference field is characterized by spatial mean and variance equal, respectively, to. and.7. We solve the corresponding deterministic flow problem through the system (3.) - (3.5) for a time period of 8 units 34

41 T 8. to obtain a corresponding reference head distribution in space-time. Figure 3.5 max shows the time evolution of reference head at eight selected measurement points. The vertical line in Figure 3.5 at 3. separates an early transient flow regime from a later pseudo steady state regime during which heads are seen to vary linearly with log-time. x x Figure 3.4. Spatial distribution of log-hydraulic conductivity in the reference model. We sample the reference field, ref, in nine elements uniformly distributed ( m, m,,9 ) across the domain and the reference head values at 2 grid points and N k k observation times ( h T, n,,2, k,, Nk ). The spatial locations of the measurement n points are indicated in Figure 3.3. The and h measurements are corrupted with zero-mean white Gaussian noise, according to m and, having standard deviations E and he, respectively, T k n m m m m,,9 (3.35) h h n,,2 k,, Nk (3.36), T k T k T k n n n 35
42 Head Figure 3.5. Temporal evolution of reference hydraulic head (curves) and noisy measurements (symbols) at seven locations identified in Figure 3.3. T k We consider three case studies (TC, TC2 and TC3) with diverse values of N k and. Test case (TC) considers ten observation times ( T 5.;.; 5.; 2.; 25.; 3.; E k 35.; 4.; 6.; 8.; k =,2, N k ) and E.. In test case 2 (TC2) the measurement error variance of exceeds that in TC by one order of magnitude, the standard deviation being now E.32. The third test case (TC3) differs from TC in that it includes eleven additional observation times ( T k 3.; 7.; 9.;.; 3.; 7.; 9.; 2.; 23.; 27.; 2 29.). All three test cases consider the measurement error variance of heads, he, equal to 4. In our example the vector d introduced in (2.2) contains the perturbed sample of hydraulic head at time T k as defined in (3.36). The corresponding covariance matrix of head measurement errors, Σ εε, is diagonal homoscedastic with entries equal to. Entries H 2 he i 36
43 of H are equal to when the i-th element of d is a measurement of the -th entry of y and otherwise. The elements of the vector containing the measurements of log-conductivity as defined in (3.35) are employed for generating the mean and the covariance matrix of the logconductivity field,, at the initial time T. The perturbed samples of log-conductivity are proected via ordinary kriging onto the centroids of all grid elements assuming knowledge of the corresponding variogram model and parameters. Figures 3.6 and 3.7 respectively depict estimates of and corresponding variances at each assimilation step of TC. The estimates of in Figure 3.6 evolve toward a pattern similar to that of the reference field in Figure 3.4. The rate of evolution is fastest at early time and slowest during the pseudo steady state period at 3. A similar phenomenon was observed by Chen and Zhang [26] when coupling EnKF with standard MC simulation, and by Riva et al. [29] during batch transient inversion of stochastic MEs using maximum likelihood. Prior to the start of assimilation (at ) the estimation variance of in Figure 3.7 is close to the unconditional reference variance everywhere except near the nine measurement points at which it is equal to the error measurement variance. Assimilation brings about a rapid reduction in this estimation variance at early time and a much reduced rate of reduction at later times. 37







44 T k = T k = 5 T k = T k = 5 T k = 2 T k = 25 T k = 3 T k = 35 T k = 4 T k = 6 T k = Figure 3.6. Estimates of log-conductivity at initial times and at ten updating times for test case TC. 38






45 T k = T k = 5 T k = T k = 5 T k = 2 T k = T k = 3 T k = 35 T k = 4 T k = 6 T k = Figure 3.7. Estimation variance of at initial times and at ten updating times for test case TC. 39
46 These phenomena are reflected quantitatively in the temporal behaviors of E, the average absolute difference between estimates ut, k and reference values ref at all element centroids x i, and of V, the average estimation variance N E t x x ut,* i i ref N i 2 ut, at these points, defined as (3.37) N i N i V 2 ut, t x (3.38) where t Tmax is normalized time (assimilation take place at t.625;.25;.875;.25;.325;.375;.4375;.5;.75;.). Indeed, Figure 3.8 demonstrates that E and V decrease more sharply with t at early time than during the later pseudo steady state period E E V V Figure 3.8. Average absolute difference E t between estimated and reference values, and corresponding average estimation variance V t, versus t for test case TC. t 4
47 Figure 3.9 depicts scatter plots of estimated versus reference values at, 5, *, 3, and 8 together with intervals corresponding to ± two standard deviations, 2 ut x, of the estimates about their mean values. More than 9% of the estimates are seen to lie inside these intervals at each time T k, even as the intervals narrow with increasing T k. Linear regression lines fitted in Figure 3. to the data have slopes that increase with time from.4 at to.37 at 3, and coefficients of determination.8 at to.33 at 3. Beyond 3 2 R that likewise increase from, these variations are comparatively small. Figure 3.9 also shows that, due to the relatively small standard deviation of measurement errors, estimates of at the nine measurement points do not change much during the assimilation process. Figures 3. and 3. show that increasing the measurement error variance of by one order of magnitude, as is done in TC2, has only a minor effect on the temporal behavior of of E and V. Including eleven additional observation times (TC3) allows obtaining values E considerably reduced, while V remains virtually unaffected. This behavior indicates that increasing the number of assimilation data at early time improves parameter estimates without underestimating their variance. Figure 3.2 compares slopes of regression lines fitted to scatter plots of estimated versus reference values at various updating times in each test case. The graph shows that whereas adding noise to log-conductivity measurements causes their estimates (in terms of this slope) to deteriorate slightly for the scenarios considered, adding early time measurements renders the estimates markedly more accurate. 4
48 ref.7 2 R.8 (a) ref.7 2 R.3 (b) ref ref. 2 R T k = T k = 5 (c) ref ref.6 2 R (d) ref T k = 3 T k = Figure 3.9. Scatter plots of estimated and reference at four T k values; corresponding intervals of ± two standard deviations of estimates about their mean (gray lines); and linear regression fits to the data (black lines), for test case TC. estimates at the nine measurement locations are highlighted in red. ref 42
49 E TC 7TC2 TC Figure 3.. Average absolute difference E t between estimated and reference values versus t for test cases TC, TC2 and TC3. t.5 2. V TC 7TC2 TC Figure 3.. Average estimation variance V t versus t for test cases TC, TC2 and TC3. t 43
50 Regression line slope Figure Slopes of regression lines fitted to scatter plots of estimated versus reference values at various updating times in each test case. t 5TC 7TC2 TC3 8 44
51 The impact of initial hydraulic heads on estimates of is analyzed by repeating the three test cases described above with stochastic initial heads, the moments of which are obtained by solving the steady-state MEs [Guadagnini and Neuman, 999] with kriged mean permeability and corresponding covariance without pumping. We designate the test cases corresponding to this initial condition as TCi_S ( i, 2, 3 ). It is important to note that in this case the cross-correlation between K and initial heads in (3.24) - (3.29) does not vanish (not even during the first time interval). This cross-correlation is provided by the solution of the steady-state MEs. In all these test cases the average estimation variance is found to remain unaffected by the initial head. On the other hand, depict the temporal behaviors of E is slightly influenced by H. Figures 3.3 and 3.4 E for TC, TC3, and all considered H. Results corresponding to TC2 are qualitatively similar to those of TC and are not shown. The effects of the nature (stochastic or deterministic) of H depend on the frequency of head observation. For TC, the adoption of a stochastic H improves (globally) the estimate field slightly relative to those obtained with a deterministic and linear H. The opposite happens in case TC3 even as the difference in E tends to decrease with time (see Figure 3.4). In the case of random H, increasing the frequency of head observations does not cause E to decrease significantly in comparison to the case of deterministic H (compare Figures 3.3 and 3.4). 45
52 E TC 7TC_S Figure 3.3. Average absolute difference E t between estimated and reference values versus t for test cases TC and TC_S. t.5.5 E TC3 7TC3_S Figure 3.4. Average absolute difference E t between estimated and reference values versus t for test cases TC3 and TC3_S. t 46
53 The analysis illustrated above treats the functional form and parameters of the variograms used to generate the reference field as given. To test the influence of the variogram model and parameters on our estimates, three additional test cases were performed using the same reference log-conductivity and head fields and the same conditioning data set of TC. In one test case (TC4), we increased the unconditional variance and integral scale of to 3 and 6, respectively, and decreased them to and 2, respectively, in another (TC5). In the last test case (TC6), we changed the functional form of the variogram from exponential to Gaussian, without changing the unconditional variance and integral scale of. The results, shown in Figures 3.5 and 3.6 confirm in part the finding due to Chen and Zhang [26] that incorrect initial variance and integral scale values of have no significant adverse effect on E or V, the latter tending to decrease with diminishing initial sill and integral scale values. The effect of incorrect initial variance and integral scale of on V was found to diminish with time. This observation might obviate the need to estimate variogram parameters ointly with, as done in the context of steady state and batch transient geostatistical inversion of MEs by Riva et al. [29, 2]. In contrast, adopting an incorrect variogram model caused the quality of values to deteriorate at all times. E, V, and correlations between estimated and true 47
54 E TC TC4 TC5 TC Figure 3.5. Average absolute difference E t between estimated and reference values versus t for test cases TC, TC4, TC5 and TC6. t Figure 3.6. Average estimation variance V t versus t for test cases TC, TC4, TC5 and TC6. V t TC TC4 TC5 TC
55 3.4 Comparison between MC-based EnKF and ME-based approach We compare the performances and accuracies of MC-based EnKF and our ME-based implementation on nine synthetic problems. We adopt the identical domain and computational grid employed in Section 3.3 and the same flow setting depicted in Figure 3.3. In these synthetic cases deterministic head values of H.8 and H2. are prescribed along the left and right domain boundaries, respectively. These conditions generate a mean hydraulic gradient of 2% aligned along direction x. As in Section 3.3, the bottom and top domain boundaries are taken as impervious. Initial heads are considered as random. Superimposed on this background gradient is convergent flow to a centrally located well that starts pumping at a deterministic constant rate Q p t. 3 at the reference time Storativity is set equal to a uniform deterministic value of -4. The nine problems differ from each other in the variance and integral scale of the reference log-hydraulic conductivity fields, x ln K ref ref x. The latter are generated (Figure 3.7) by sampling statistically homogeneous and isotropic multivariate Gaussian fields having mean equal to 4 ln 9.2 and 9 exponential variograms with different combinations of sill and integral scale, I, as detailed in Table 3.. The reference realizations are generated by the sequential Gaussian simulator SGSIM of Deutsch and Journel [998]. Included in Table 3. are the ratios between domain length scale and I, sample variance, as well as sill and integral scale obtained for each reference realization by fitting, via least squares, an exponential variogram model to the corresponding sample variogram. The least squares variogram parameter estimates are seen to differ, generally, from their original field values. 49
56 Input parameters Least squares fit Ref. case Sill I Domain side / I Sample variance Sill I TC TC TC TC TC TC TC TC TC Table 3.. Variogram input parameters, ratio between domain side and I, sample variance, sill and integral scale obtained by fitting, using least squares, an exponential variogram model to the corresponding sample variogram. Both MC- and ME-based EnKF require specifying the variogram parameters for the initial step. We work with the generating rather than the estimated sill and integral scale to avoid introducing additional sources of uncertainty in the comparison. Chen and Zhang [26] showed that incorrect initial sill and integral scale of have only a secondary effect on the final log-conductivity estimates. On the other hand, Jafarpour and Tarrahi [2] found in analyzing flow through a highly anisotropic system that inaccuracies in prescribed directional integral scales tends to persist throughout MC-based EnKF runs. We solve numerically the groundwater flow equations (3.) - (3.5) for the duration of 2 time units ( Tmax 2. ). Similarly to Section 3.3, we sample each reference field in nine elements uniformly distributed across the domain and the reference head fields at 2 grid points (Figure 3.3) and observation times ( h n, n =, 2, T k =.; 5.; 2.; 25.; 3.; 5.; 8.;.; 5.; 2.; k =, 2,..., ). This selection of observation times enables us to sample transient as well as pseudo steady state flow regimes (during which 5
57 computed heads vary linearly with log-time) the latter of which develop, in these cases, at T 8. The log-conductivity and head samples are turned into measurements by k T corrupting them with white Gaussian noise, ε m and εn k, having zero mean and standard deviations E. and he., respectively, as defined in (3.35) (3.36). The resulting absolute relative differences between reference and measured values range from.% to 2.6% (with mean.8%, mode.7%, 5 th percentile.2% and 95 th percentile 2.5%) for log-conductivity and from.% to 44% (with mean 4.6%, mode.6%, 5 th percentile.% and 95 th percentile 9.4%) for hydraulic head. Large relative errors (> 5%) in head measurement are thus obtained far from the pumping well, at short times T k, where h are close to zero. T k n The elements of d T k, Σ and H are defined in the same way as described in Section T k εε 3.3. The perturbed log-conductivity samples included in the vector initial time T. In the ME-based assimilation are made available at is used for generating the initial mean and the covariance matrix of the model vector. In the MC-based EnKF, the initial collection of T log-conductivity realizations,, i,, NMC, is generated using the true variogram i T model with parameters listed in Table 3.. Each is conditioned on the randomized i measurement vector i, obtained by perturbing each element of with a Gaussian noise T T having standard deviation E. For each MC realization,, the initial head vector, h, is computed by solving the deterministic steady-state flow problem (3.) - (3.5) without pumping. In most previous applications of MC-based EnKF [Chen and Zhang, 26; Hendricks Franssen and Kinzelbach, 28; Schoeniger et al., 22; Xu et al., 23] the number NMC of Monte Carlo runs did not exceed a few hundred. Recognizing that NMC may have an i i 5
58 impact on the results and that estimates of mean and variance of a random variable converge at a rate which diminishes with NMC [Ballio and Guadagnini, 24], we consider here a series of values NMC = ; 5;,; 5,;,; 5,;,. Figures 3.7 and 3.8, respectively, compare the spatial distributions of updated log-conductivity ut, k, and 2 ut, corresponding estimation variances k ut, (diagonal entries of C k ), at the final assimilation time ( 2. ) for all nine reference cases obtained by ME- and MC-based EnKF. Values of ut, k obtained with NMC, exhibit more pronounced spatial variabilities than do those obtained from a larger number of MC realizations. Indeed, as ut, k represents a relatively smooth estimate of, spatial fluctuations are expected to diminish with increasing NMC. Results obtained with NMC, are similar to those obtained with NMC, for all cases examined and therefore not shown. Estimation variance is seen to vary locally with NMC, due most likely to filter inbreeding. The problem seems to disappear at NMC, where the spatial distribution of MC-based variances is quite similar to that of their ME-based counterparts. 52








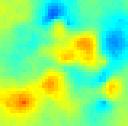














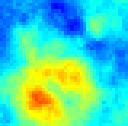








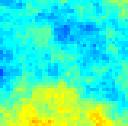

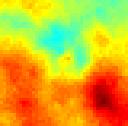



59 TC TC2 TC3 TC4 TC5 TC6 TC7 TC8 TC9 ME NMC =, NMC =, NMC = 5 NMC = Reference field Figure 3.7. Spatial distributions of ut, k at T k = 2 obtained by ME- and MC-based EnKF with diverse values of NMC. Reference fields are also shown. 53

























60 TC TC2 TC3 TC4 TC5 TC6 ME NMC =, NMC =, NMC = 5 NMC = TC7 TC8 TC ut, Figure 3.8. Spatial distributions of k at T k = 2 obtained by ME- and MC-based EnKF with diverse values of NMC. Reference fields are also shown. 54
61 Figures 3.9 and 3.2, respectively, show temporal behaviors of the average absolute difference, E, as well as the average estimation variance, V, defined in (3.37) - (3.38). Assimilation in these cases takes place at t.5,.75,.,.25,.5,.25,.4,.5,.75,.). E and V are seen to increase as the sill of the variogram increases and as I decreases. The largest difference between MC-based values of E and V obtained with NMC and with NMC, occurs in TC3 (Figures 3.2c and 3.2c) where the sill is largest and the integral scale smallest. Figure 3.9 shows that whereas E tends to decrease with NMC, at large NMC its MC- and ME-based values are close. The only exception is TC9 (associated with the largest sill and I, Figure 3.9i) where the curve obtained with NMC, lies slightly below that obtained with ME-based EnKF. In TC9, the relative difference between MC- and ME-based results varies between 8% at small t and % at large t. We ascribe this behavior to approximations required to close what would otherwise be exact moment equations. Inaccuracies associated with these approximations tend to increase with increasing values of I relative to domain size. 55
62 E E E Figure 3.9. E versus t * for the nine test cases. ME-based (solid black) and MC-based results with NMC = (dashed gray), 5 (dashed-dotted gray),, (solid gray), and, (dashed-dotted black) are reported Sill =.5 Sill =. Sill = 2. (a) (b) (c) (d) (e) (f) (g) (h) (i) t t t I 4. I. I 2. Figures 3.9 and 3.2 indicate that assimilations done with NMC are generally associated with (a) large E values that tend to increase with time and (b) small V values that tend to decrease with time. The two phenomena are symptomatic of filter inbreeding. Several authors [Hendricks Franssen and Kinzelbach, 28; Liang et al., 22; Xu et al., 23] suggest to analyze the occurrence of filter inbreeding by plotting the ratio V MSE versus time where 2 N ut,* i i ref N i MSE t x x (3.39) 56
63 V V V Figure 3.2. V versus t * for the nine test cases. ME-based (solid black) and MC-based results with NMC = (dashed gray), 5 (dashed-dotted gray),, (solid gray), and, (dashed-dotted black) are reported Sill =.5 Sill =. Sill = 2. (a) (b) (c) (d) (e) (f) (g) (h) (i) t t t I 4. I. I 2. Under ideal conditions, V MSE should be equal to unity [Liang et al., 22]. Here we explore this issue by considering also the quantity N * u, t u, t P * 2 t H 2 x x x i i i (3.4) ref N i where H is the Heaviside step function, P2 representing percent reference values of * ut, lying inside a confidence interval of width equal to ± 2 x about ut,* x i i. Analyses of how V MSE (Figure 3.2) and P2 (Figure 3.22) evolve with time lead to similar conclusions. When NMC,, V MSE and P2 decrease with time, exhibiting a distinct filter inbreeding effect. 57
64 V V V MSE MSE MSE t Figure 3.2. Ratio between V and t MSE versus t * for the nine test cases. ME-based (solid black) and MC-based results with NMC = (dashed gray), 5 (dashed-dotted gray),, (solid gray), and, (dashed-dotted black) are reported t Sill =.5 Sill =. Sill = 2. (a) (b) (c) (d) (e) (f) (g) (h) (i) I 4. I. I 2. No such deterioration with time is exhibited by either MC-based results with NMC, or by ME-based outcomes where V MSE remains approximately constant and 2 P larger than 9%. The only exception concerns ME-based results associated with TC9 (see Figures 3.2i and 3.22i) where P2 is slightly smaller than 9% ( 88%). However, even here the ME-based values of V MSE and 2 P show no systematic decrease with time (as would happen in the presence of filter inbreeding) but instead diminish rapidly during the first assimilation period and then stay approximately constant. The rapid early decline is likely due to spurious updates caused by second-order approximation of the cross-covariance terms. In contrast to MC-based P2 which, at small NMC, drops down to below 4%, a steep decline in ME-based values is limited to early time. 58
65 P2 P2 P t Figure P2 versus t * for the nine test cases. ME-based (solid black) and MC-based results with NMC = (dashed gray), 5 (dashed-dotted gray),, (solid gray), and, (dashed-dotted black) are reported t t Sill =.5 Sill =. Sill = 2. (a) (b) (c) (d) (e) (f) (g) (h) (i) I 4. I. I 2. 59
66 Black dots in Figure 3.23 indicate the spatial location of the reference values of which, following the last assimilation period at t., lie outside confidence intervals *, having widths equal to 2 ut x about ut,* x i i. This confirms the poor quality of estimates obtained with NMC,, even in the weakly heterogeneous settings of TC, TC4 and TC7. Remarkably, black dots in Figure 3.23 corresponding to MC- (with NMC, ) and ME-based filters have similar spatial distributions. It thus appears that the two approaches behave similarly in a global (as observed in Figures ) and in a local sense when NMC is sufficiently large. This behavior can be quantified by analyzing the percentage of cells in which reference values of lie within the 95% confidence intervals around updated values in both the ME- and MC- based solutions. As expected, this metric is seen to decrease as the number of MC realizations grows in all test cases. In case of the MC approach, average values of in the nine test cases are 94%, 93%, 9%, 87% and 48% for NMC =,,,, 5, and, respectively. 6





 of")



67 ME NMC =, NMC =, NMC = 5 NMC = ME NMC, NMC, NMC 5 NMC TC ME NMC, NMC, NMC 5 NMC TC2 ME NMC, NMC, NMC 5 NMC TC3 ME NMC, NMC, NMC 5 NMC TC4 ME NMC, NMC, NMC 5 NMC TC5 ME NMC, NMC, NMC 5 NMC TC6 ME NMC, NMC, NMC 5 NMC TC7 ME NMC, NMC, NMC 5 NMC TC8 ME NMC, NMC, NMC 5 NMC TC9 Figure Spatial distributions (black squares) of elements in which ref lie outside confidence intervals ut, of width ± 2 k x about x i i ut, k when T 2. for the nine test cases. k 6
68 Figures 3.24 and 3.25 depict temporal behaviors of E h and V h, the hydraulic head analogues of E and V in (3.37) (3.38), defined as N h E t h x h x ut,* h i i ref Nh i (3.4) V N h 2 ut, * t x h h i Nh i 2 where ut, * x h (3.42) is the estimation variance of h at node x i (i.e., a diagonal component of i C ) and ut, h N h is the number of nodes, N h, minus those located on Dirichlet boundaries and at the pumping well where, theoretically, h due to the negligible well radius. Figure 3.24 shows that E h decreases sharply at the first assimilation time to then increase with t *. The largest rate of increase is associated with MC-based values obtained with NMC. MEbased values of E h are in general very close to MC-based values obtained with sufficiently large NMC. On the other hand, the monotonically decreasing temporal trend in V is not mirrored by the mean estimation variance of h in Figure Instead, V h in Figure 3.25 decreases sharply during the first assimilation step and then increases with time. We attribute this to the combination of two contrasting effects: (a) the decrease of V h which is typically associated with the updating step, (b) the temporal increase or decrease (depending on location in the domain; see also Figure 7 of e et al. [24] and results of Riva et al. [29] in head variance during the forward steps. Effect (a) dominates during the first assimilation period, due to the high information content of the measurements (see also Figures ), causing V h to decrease initially with time. As time increases and pseudo-steady state conditions are approached, the conditioning head data become less informative (see also Riva 62
69 et al. [29]). This is reflected in Figure 3.9 where E is seen to be almost constant at large values of t *. Here, effect (b) dominates as manifested by an increase in V h with time. E h Sill =.5 Sill =. Sill = (a) (b) (c) I E.8 h E h Figure E h versus t * for the nine test cases. ME-based (solid black) and MC-based results with NMC = (dashed gray), 5 (dashed-dotted gray),, (solid gray), and, (dashed-dotted black) are reported (d) (e) (f) (g) (h) (i) t t t I. I 2. 63
70 V h V.4 h V h Figure V h versus t * for the nine test cases. ME-based (solid black) and MC-based results with NMC = (dashed gray), 5 (dashed-dotted gray),, (solid gray), and, (dashed-dotted black) are reported Sill =.5 Sill =. Sill = 2. (a) (b) (c) (d) (e) (f) (g) (h) (i) t t t I 4. I. I 2. We close our analysis by plotting in Figure 3.26 the temporal behavior of Nh u, t* u, t* P2 t 2 H x x x h h i h i h i (3.43) ref N h i representing percent reference h values lying inside a confidence interval of width equal to,* 2 ut x about h ut,* x h i i. Figure 3.26 confirms that filter inbreeding associated with small NMC impacts not only but also h. 64
71 P2 h P2 h P2 h t Figure P2 h versus t * for the nine test cases. ME-based (solid black) and MC-based results with NMC = (dashed gray), 5 (dashed-dotted gray),, (solid gray), and, (dashed-dotted black) are reported t t Sill =.5 Sill =. Sill = 2. (a) (b) (c) (d) (e) (f) (g) (h) (i) I 4. I. I 2. e et al. [24] compared the computational time required by ME- and MC-based forward solutions of a transient groundwater flow problem similar to the one we analyze here and within a domain which is half the size of the one we consider. They found that, with NMC 2,, the ME-based method required one quarter to one half the computer time to evaluate mean heads and variances than did the MC-base approach. The authors computed head variances by solving an integral expression (their (47)) in the presence of deterministic sources, boundary and initial conditions, which does not require computing a complete head covariance matrix. To conduct a more comprehensive comparison with the MC-based approach, we opted in this work to compute the complete head covariance matrix at the end of each time interval T k T k. Our updating step requires computing additional terms appearing in (3.24)-(3.26) and (3.29). As recognized by e et al. [24], the computation of 65
72 these terms can have a significant effect on computational time during the forward step. Indeed we find that, in our case, the ME- and MC-based approaches require 3,65 s and.375 NMC s, respectively, of CPU time on parallel 2.8 GHz Intel i7-86 processors. It follows that CPU time associated with ME-based EnKF is comparable to that associated with NMC 35, MC-based assimilations. Considering that in our test cases the MC approach converges within NMC,, which however requires a tenfold increase in NMC to ascertain convergence (i.e., NMC, realizations are required to support convergence at NMC, ), we conclude that ME-based EnKF constitutes a viable alternative to the traditional MC-based approach not only in terms of quality but also in terms of computational efficiency. We believe that it should be possible to improve the computational efficiency of ME-based EnKF further in the future. 3.5 Conclusions In this Chapter we described a novel inversion algorithm for updating in real time model parameters and system states in a groundwater flow model on information about logconductivity and transient head data collected in a randomly heterogeneous aquifer. The methodology combines approximate form of stochastic transient groundwater flow moment equations with the Kalman Filter algorithm and allows sequential updating of parameters and system states without a need for computationally intensive Maximum Likelihood (ML) or Monte Carlo (MC) analyses. We explored the feasibility and accuracy of the novel inversion scheme and compared its performance and computational efficiency against the common MC-based EnKF on nine different synthetic examples characterized by different degree of heterogeneity. We showed that embedding the MEs in the KF scheme allows computationally efficient real time estimation of system states and model parameters avoiding the drawbacks which are commonly encountered in traditional MC-based applications of EnKF. Our results 66
73 confirm an earlier finding by others that a few hundred MC simulations are not enough to overcome filter inbreeding issues, which have a negative impact on the quality of logconductivity estimates as well as predicted heads and associated estimation variances. MEbased EnKF obviates the need for repeated MC simulations and was demonstrated to be free of inbreeding issues. 67
74
75 4. EnKF with complex geology Here we present a methodology conducive to updating geological and petrophysical properties of a collection of reservoir models characterized by a complex structural (geological) architecture within the context of a history matching procedure based on the Ensemble Kalman Filter (EnKF) approach. The associated computational algorithms are illustrated in all their relevant details. The (heterogeneous) spatial distribution of facies is handled by means of a Markov Mesh (MM) model. The latter is adopted because of (a) its ability to reproduce detailed facies geometries and spatial patterns, and (b) its consistency with the probabilistic Bayesian framework at the basis of EnKF. In Section 4. we start by outlining a formal definition of the MM model. Section 4.2 illustrates a novel inversion scheme which allows conditioning the geological and the petrophysical properties of a collection of reservoir realizations on a set of measured production data. The results obtained on a two-dimensional synthetic test case and a comparison with those obtained using a standard EnKF are presented in Section 4.3. In Section 4.4 we discuss our results. 4. Markov Mesh (MM) Model We consider a finite, regular grid G comprising N e elements arranged in two or more dimensions and define a sequence of regular grids G, G 2, G L. Each of these grids is a subset of cells in G such that G G G, G G (4.) L 2 L With this notation, the coarsest and the finest grids are respectively denoted as G and G L. We further introduce the disoint sets of elements, H, H 2, H L, defined as H G l (4.2) l l 69
76 H G \ G l 2,3,, L (4.3) l l l Each set H l, l consists of the cells of G l that are not appearing in the coarser grid level, G l. Figure 4. depicts the grid refinement that has been selected in our implementation. Note that the disoint sets H, l,, L are defined such that l l l G H (4.4) k k G H G H H G3 H H2 H3 G Figure 4.. Sequence of grids (G, G 2 and G 3 ) onto which the rectangular domain G is decomposed within a multi-grid approach. Colors indicate the disoint sets H, H 2 and H 3. Cell numbering corresponds to element indices while arrows indicate the direction followed by the simulation path. : H : H 2 : H3 7
77 We then define a path scanning all the elements of the grid G. This path initially visits all elements of the coarsest subset, H. It then scans all the elements of H 2 and proceeds until the last subset, H L, is reached. Each of the subsets, H, l L, is scanned starting from the elements at the top grid layer and proceeding through all the elements of the underlying layers until the bottom of the domain. In each layer the path starts from the left-bottom corner and proceeds by paths parallel to the domain diagonal. The sequence of elements defined by the scanning path allows assigning a label i N l,, e to each cell of the grid G, as sketched in Figure 4.. Note that the selections of the grid refinement and of the path are not unique, and diverse choices are admissible. We assign an integer value, s,, K i, corresponding to a facies type (K being the number of facies occurring in the domain), to each element of the grid. An indicator variable k s i is then defined as s k i if si k, k,, K otherwise (4.5) Assuming that the vector s containing the facies identifiers, s i, in all grid elements forms a random field, one can describe the probability of observing a given facies distribution within domain G through the discrete oint probability mass function as a product of conditional probabilities N e si i i s. The latter can be written s s (4.6) Here, s i is the vector containing the facies identifiers over all grid elements with index i. Let i be a subset of the cells identified by facies distribution within the elements of is expressed by i and let the vector s denote the i i. Then, the Markov property of the random field s 7
78 s i i si i s s (4.7) and the oint probability distribution defined in (4.6) can be simplified as Ne si i s s (4.8) i In our implementation, the subset i contains all the elements i that are contained in a square of arbitrary size and is centered at i. Figure 4.2 provides a graphical depiction of a snapshot of a simulation at the time element i is visited while the algorithm is progressing. i Figure 4.2. Snapshot of a simulation obtained by freezing the algorithm while grid element i is visited. Colored cells are identified by index < i and have already been visited by the simulation path. Red, yellow and green elements belong to the disoint sets H, H 2 and H 3, respectively. Blocks contoured by the solid line belong to the conditional neighborhood ( i ) of element i. Grey cells are identified by index > i and will be simulated after element i. At the core of the method is the way we express the conditional probability included in (4.8). We employ the method proposed by Stien and Kolbornsen [2] where the target probability is function of a linear combination of coefficients, in the form 72
79 s i s i K k K k2 exp exp s z θ k k i i li z θ i k2 li (4.9) Here, z i is a vector of size P and contains a set of coefficients which depend on the facies distribution over k s i ; li θ is a vector of unknown parameters; and the function li allows identifying the subset of cells H li to which the element with label i belongs to (i.e., i H li ). In our implementation, we follow for the elements of the vector z i the same definitions proposed by Kolbornsen et al. [23], where each coefficient is equal to or depending on whether a predefined pattern of facies is reproduced over i or not. From definition (4.9) it follows that there exists one vector of model parameters for each facies and for each grid level, for a total number of L K vectors. Estimating these parameter vectors is accomplished via Maximum likelihood [Stien and Kolbornsen, 2] by means of an appropriate training image which contains all the important features one desires to preserve in the collection of realizations. The MM model introduced above allows drawing a facies realization by following the sequential path defined previously. For each cell, a value identifying a facies is drawn according to the conditional probability expressed by (4.9). After all elements have been visited, the resulting facies generation follows the oint probability distribution (4.8). Application of the methodology to field settings requires that all members of a collection of generated spatial fields of facies share the same volumetric facies proportions. These values are in fact related to the quantity and mode of displacement of oil in a reservoir and have a significant impact on strategic planning of production. It is well known that the statistical framework offered by the MM (a) does not guarantee that the facies proportion 73
80 observed in the training image is preserved in the generated realizations and (b) does not include any tuning parameters which might allow setting a given value of facies proportions. In this work we propose to overcome this drawback by adopting an acceptance/reection (AR) sampling method. Let s k Ne k si k,, K (4.) N e i be the volumetric proportion of facies k over a field composed by N e elements and characterized by the occurrence of K distinct facies, and let s s (4.) K s be the vector containing all volumetric proportions evaluated through (4.). We note that (k =,..., K) is the sum of N e random correlated variables (see (4.)). Therefore, k s k s is also a random variable, and s is a random vector. Generating a spatial field of facies through the sequential algorithm described above allows obtaining a realization of s, that we interpret as a realization drawn from its prior probability density function. In this framework, we can (a) consider additional information about s in the form of a likelihood function and (b) draw samples from the corresponding posterior density using a traditional AR algorithm. As an example, we consider the case where the additional information (which is available, e.g., in the form of seismic data and/or expert opinion) suggests that s follows a multi-normal distribution with mean vector μ and covariance matrix Σ (i.e., N, s μσ ). Drawing samples from the resulting posterior density can be accomplished using the AR algorithm described according to the following two steps: Step : generate an unconditional realization of a spatial field of facies and compute the corresponding vector s. 74
81 Step 2: Compute the quantity N,, max N,, s μ Σ s μ Σ. Draw a realization u from a uniform distribution over the interval,. Accept the current realization of facies if u Return to Step. 4.2 Theoretical formulation s, otherwise reect it. In this Section we describe a novel inversion scheme for conditioning a collection of facies and log-permeability spatial fields on available production data. For simplicity of notation we limit the illustration to the case where only two fluid phases (oil and water) are displaced in the host porous domain. Note that the methodology can readily be extended to systems characterized by a three-phase fluid flow. We consider the model vector p y Swat w Here,, p, (4.2) S wat are vectors containing static (e.g., the log-permeability values) and dynamic (e.g., pressure and water saturation values) variables at N e numerical block centers, respectively, while w contains N w values of production data (e.g., fluid flow rates at well locations or bottom hole pressure values). Vector y is therefore of size N 3N N. y e w, According to the notation introduced in Chapter 2, we denote by y ut k the model vector y at time conditioned on measurements available up to time. Adoption of a Monte Carlo framework enables one to approximate the probability density function (pdf) of 75
82 ut, k y by means of a collection of NMC equally likely model realizations of the system, defined as y ut, k p Swat w ut, k,, NMC (4.3) The non-linear operator allows calculating the corresponding forward vectors at time T k as f, u, y y,, NMC (4.4) which enables representing the pdf of f, T y k. The function in (4.4) represents a multiphase flow model the solution of which is performed within time interval by, setting the log-permeability field to ut k and considering as initial conditions the pressure, and water saturation fields contained in vectors ut k ut, p and k S, respectively. The boundary conditions for the flow simulation are here assumed to be known without uncertainty. Since we consider the case where the static variables (i.e., the log-permeabilities) do not change f, T, during a flow simulation, equality k u always holds. We also note that the wat,, particular value of the vector ut k w has no effect on the flow simulation. We introduce the collection of vectors s,, NMC (4.5) f, T k describing our knowledge about the spatial distribution of the facies over the domain at time T k conditioned on measurements available up to time k T, and the vector 76
83 v f, s K s w f,,, NMC (4.6) Here, each vector s describes the prior spatial distribution of the indicator variables k, f, T k associated with each facies k,, K in a given realization of the ensemble. The obective of the data assimilation algorithm is to calculate the updated vectors, y and ut, k s, conditioned on measured values of production data, w ut, k, at time T k. Note that these measurements correspond to randomly perturbed values of w and are contained in vector d as defined in (2.2). The data assimilation scheme is the developed through a fourstep algorithm described in details in the following. Step In the first step we consider the sample average of the quantity defined in (4.6) v v (4.7) NMC f, f, NMC and, instead of updating each individual member of the collection, v f, T k, as done in the EnKF context (see (2.23) - (2.29)), we use the corresponding averaged equation defined in (2.3) to evaluate the updated vector ut, v k through u, f, ˆ f, ˆ f, ˆ f, v v Σvv H H Σ vv H Σεε d H v (4.8) Here, the quantities H, d and ˆ Σ follow the same definitions respectively given in εε (2.2), (2.28) and (2.29) of Chapter 2, while Σ ˆ is defined as f, T k vv ˆ Σ v v v v (4.9) NMC i i f, f, f, f, f, vv NMC i 77
84 Step 2 The updated vector ut, v k evaluated at step is now employed to draw a new collection of updated realizations of spatial fields of facies, s,,, NMC. ut, k The updating algorithm visits each element of the grid following the same sequential path used for the generation of each facies field realization. When the algorithm has progressed to reach a generic element i, we assign a new facies identifier to this element for each updated grid of the collection ( s ut, k i, ) according to s s u, u, i i K exp k K k2 s exp z θ λ k, u, k k i i l i l i z θ λ k2 k i l i l i (4.2) where the values of the vectors λ are tuned to satisfy k li NMC,, k,, k s k u T k u T i, si k,, K (4.2) NMC The term appearing on the right hand side of (4.2) is a component of the updated vector ut, v k k (4.8). One can note that (4.2) reduces to (4.9) when li λ equals P,. In practice, (4.2) - (4.2) are used to update the probability of the MM reported in (4.9), s i i u, T, which is not conditioned on the production data, into the probability k u s i i conditioned on the information provided by the measurements available up to time T k. s. s, In our implementation of the algorithm we consider λ as vectors of constant k li k k components, differing from vector to vector (i.e., λ λ l i li P,, λ k li and P, respectively being an unknown scalar and a vector of size P with unit components). Working with this assumption, the conditional probability (4.2) is a monotonic function of λ k li. Estimation of 78
85 λ k li is readily accomplished through a bisection algorithm. This simple strategy has been seen to yield good results, in the sense that the updated spatial distribution of facies maintains spatial correlations which are similar to those observed in the original grids before the assimilation of production data. Forms of λ with increased complexity can be taken into k li account in the procedure. Step 3 Up to this point we have evaluated the vectors s,,, NMC, which are the ut, k realizations of the spatial fields of facies conditioned on the measurements available up to time T k. Before updating the model realizations y,,, NMC, in this third step we iterate the flow simulations performed within the time interval upon replacing the, model parameters and the system states updated at time (namely ut k,, ut k p and f, T k ', S ) through the corresponding auxiliary fields ( ut k ',, ut k ut ', p and S k ) to render them ut, k wat, wat, consistent with the underlying facies fields updated through steps () - (2). Each auxiliary updated realization is then used as input vector in the flow simulation expressed by (4.4) to obtain the auxiliary forward vectors at time T k, y f ', T k. The latter will be further conditioned on the measurements available at time T k during step (4) of our algorithm. In practice, one can note that step 3 allows alleviating the appearance of unphysical updates in the model state vectors. To maintain the same statistics (mean and covariances) of the log-permeability fields, contained in ut k ', also in the auxiliary log-permeability fields, ut k, one employs L L,, NMC (4.22) u', u', u', u, u, u, ut, Entries k, of the vector ut k are computed by m, 79
86 NMC NMC u, T k km, f, T k km, f, u, m, m, l m, l m, l l l m,, Ne s s (4.23) In (4.23), k is the facies identifier at element m of the forward facies grid m s (i.e., f, T k km,, K ) k m s (4.24) ft, k m, It follows that the indicator variable s in (4.23) is equal to or according to whether km, f, ml, the facies identifiers over element m of ensemble members l and coincide or not. ', Similarly, an entry m of vector ut k ut ',, k, is evaluated by m, NMC NMC u', T k km, u, T k km, u, u, m, m, l m, l m, l l l m,, Ne s s (4.25) In (4.25), k m is defined as k s (4.26) m ut, m, k, Matrices ut k ', L and ut k L in (4.22) are the Cholesky decompositions of C ut,, k ut ', and C, respectively (i.e., they satisfy the equalities u', u', T k u',, ut, L L C ). Entries k ut ', C, and k, respectively, are computed by means of mn, mn, u, u, T k u,,, k L L C and C of matrices C ut,, k ut ', and C, NMC NMC u, km, f, kn, f, km, f, kn, f, u, u, u, u, C, sm, l sn, l sm, l sn, l m, l m, n, l n, mn, l l m,, Ne, n,, Ne (4.27) NMC NMC u', km, u, kn, u, km, u, kn, u, u, u ', u, u ', C, sm, l sn, l sm, l sn, l m, l m, n, l n, mn, l l m,, Ne, n,, Ne (4.28), k 8
87 Following the procedure described for log-permeabilities (embodied by (4.22) - (4.28)), we, modify the values of pressure and water saturation in ut k ut, p and k S in the corresponding wat, auxiliary vectors p and ut ', k S. ut ', k wat, The updated auxiliary vectors are then used for the evaluation of the auxiliary forward spatial fields at time T k through f ', u', y y,, NMC (4.29) Step 4 We propose to evaluate the updated state vectors ut, y at time k T by means of ˆ ˆ ˆ u, f ', f ', f ', f ', y y Σyy, H H Σyy, H Σεε d H y,, Ne where the entries ˆ f ', T k Σ, yy H of matrix ˆ f ', yy, mn, Σ H are computed as ˆ Σ H NMC NMC,,,, s k u s k u m, l m, l y y w w f ', m m f ', f ', f ', f ', yy, m, l m n, l n mn, l l (4.3) m,,3n e, n,, Nw (4.3) NMC NMC f ', T k,, k,, k m u T k u T m k f ', m m, l m, l m, l l l m,,3n e y s s y (4.32) NMC NMC f ', T k,, k,, k m u T k u T m k f ', n m, l m, l n, l l l n,, Nw w s s w (4.33) Subscript m in (4.3) - (4.33) indicates the label of the grid element to which the m- entry of the state vector belongs (e.g., consistently with definitions given in (4.2), m* equals m, m Ne or m 2N e according to whether the m-th element of the state vector corresponds to a value of log-permeability, pressures or water saturation, respectively). Equations (4.3) - (4.33) allows updating the model vector of a given realization by estimating the sample crosscovariance between production data and the model variable associated with a given block in 8
88 the reservoir only on the basis of the members of the collection where the very same facies value of the element considered in the target model realization occurs. This strategy is adopted because when the reservoir model is characterized by the presence of distinct facies with unknown spatial distribution the scatter plots between petrophysical parameters (or system state variables) and production data are typically arranged in clusters, each of which is associated with a particular facies identifier. A schematic representation of the data assimilation algorithm described is depicted in Figure
89 Geostatistical tools Equilibrium conditions y T p Swat w T k =T T s T T p T S wat, T v T s K s w T Updated logk, pressure and saturation fields y ut, k p Swat w Flow simulator Input: ut, - logk fields: k - initial conditions: u, u, p, S wat, k = k + ut, k Step 4 Auxiliary forward fields y f ', p Swat w f ', p S Flow simulator Input: ut ', - logk fields: k - initial conditions: u', T u', T p, S ut ', k ut ', k ut ', k wat, wat, Flow simulator Input: T - logk fields: - initial conditions: T T p, S wat, k = k + v f, s K s w f, y f, p Swat w f, Step ut, s k Updated mean facies field Step 2 ut, s k Updated facies fields Step 3 Figure 4.3. Flow chart describing the proposed data assimilation algorithm. 83
.")
90 4.3 Synthetic example We illustrate the data assimilation scheme described in Section 4.2 and explore its feasibility and accuracy by way of a transient three-dimensional flow example. The flow domain is of size 48 m 32 m 5 m along directions x, x 2, and x 3, respectively, and is discretized into grid cells of uniform size of 5 m 5 m 5 m (i.e., blocks, yielding Ne 644 ). Note that the grid blocks in this example are arranged into a single horizontal layer and the ensuing spatial distributions of parameters and state variables are modeled as two-dimensional random fields. The reference model of the reservoir is formed by two different facies (i.e., K 2). The spatial distribution of the facies has been obtained by the Markov Mesh (MM) procedure described in Section 4. and by estimating the parameters of the MM from the training image depicted in Figure Figure 4.4. Training image employed for the estimation of the parameters in the MM model example. The domain is then populated with the petrophysical properties (i.e., the log-permeability), yielding the field depicted in Figure 4.5. Log-permeabilities are generated at element centers 84
 and the corresponding permeability values (k) in the reference field, respectively.")
91 using a sequential Gaussian simulator, with the statistical parameters listed in Table 4.. Figures display the sample histograms of the log-permeability ( ) and the corresponding permeability values (k) in the reference field, respectively. In our example we consider a permeability tensor Κ that is diagonal and displays a vertical anisotropy. It can be written as the product between the scalar permeability k and a scaling tensor Κ k (4.34). Porosity is treated as a deterministic constant over the numerical grid and set equal to.2, yielding a pore volume of m. x2 m I3 Figure 4.5. Log-permeability distribution and well locations in the reference model. Inectors and producers are indicated as I i and P i (i =, 2, 3), respectively. I I x m P P2 P3 ref Mean Covariance function Sill Nugget Range x [m] Range x 2 [m] Facies 7. Exponential Facies Exponential Table 4.. Parameters adopted for the generation of the reference log-permeability field. Permeability values are expressed in mdarcy. 85
92 Relative frequency Relative frequency ln k Figure 4.6. Histogram of the log-permeability values in the reference model Figure 4.7. Histogram of the permeability values in the reference model. k mdarcy We simulate the deterministic transient flow caused by the oint action of 6 wells: 3 producer wells (P, P2 and P3) with constant Bottom Hole Pressure (BHP) equal to 3 bar and three inectors (I, I2 and I3), inecting water at a constant rate of 3, 23 and 3 m 3 /day, respectively. As shown in Figure 4.5, only the two wells I2 and P2 lie in the region of the domain characterized by the highest permeabilities and are connected by high permeability channel. A constant initial oil saturation of.8 is imposed on the system, rendering an initial total volume of oil of m. Initial pressure is set to a uniform value of bar while all external domain boundaries are impervious. Flow is simulated for a time period of 86
93 2 days using the commercial software ECLIPSE developed by Schlumberger. The dynamics of this reference model are strongly influenced by the underlying facies distribution and are typical of a water-flooding environment in which the volume of the inected water is mainly displaced along the meandering channel. We sample the reference production curves at twenty times, separated by a fixed lag of 6 days (i.e., 6, 2, 2 days) and perturb these with a white Gaussian noise having standard deviation 3 d = 5 m day and 5 bar for flow rates and pressures, respectively, reflecting measurement errors as described in (2.2). In our example the vector T d k introduced in (2.2) contains these perturbed data while the covariance matrix of the corresponding measurement errors, Σ εε 2, is diagonal with entries equal to d. The temporal behaviors of the reference production curves and of the corresponding conditioning measurements employed during the assimilation are depicted in Figures Reference values of water production rate are zero at all assimilation steps and therefore are not included in these figures. 2 WBHP bar Figure 4.8. Reference (solid lines) and measured (symbols) values of Well Bottom Hole Pressure (BHP) versus time for inection wells I (blue), I2 (green) and I3 (red). time days 87
94 WOPR m 3 day Figure 4.9. Reference (solid lines) and measured (symbols) values of Well Oil Production Rate (WOPR) versus time for production wells P (blue), P2 (green) and P3 (red). time days At initial time T, we generate a collection of spatial fields of facies through the MM model by using the same parameters employed for the reference field. These realizations are also conditioned on the value of the volumetric proportion of facies observed in the reference model (the latter being equal to.34) following the acceptance/reection procedure described in Section 2.2. Each facies field is then populated by the log-permeability values using a Gaussian simulator with the same variogram functions and parameters used for generating the reference field. Following this procedure, we implicitly assume a perfect knowledge of the statistical models describing the spatial distribution of the geological and of the petrophysical properties in the reservoir. This allows testing the feasibility and accuracy of the proposed algorithm without introducing additional sources of uncertainty in our analysis. We compare the performances and accuracies of the inversion algorithm described in Section 4.2 (denoted in the following as Facies-EnKF) against the traditional EnKF. We consider NMC 5 and start the assimilation with the same collection of model realizations for both methodologies. Figures respectively compare the spatial distribution of the mean and the variance of the log-permeability fields obtained at various assimilation steps using the two 88
95 approaches. During the earliest assimilation steps the estimated mean fields obtained with the two approaches are similar and reflect the plausibility for the meandering channel to occur both within the upper and the lower parts of the domain. During the subsequent updating steps, when additional data are assimilated into the model, estimates of log-permeability obtained with Facies-EnKF evolve toward a pattern which is similar to that of the reference field and enables a correct identification of the position of the channel. Note that the production curves of inectors I and I3 play a key role towards an appropriate facies identification. This is so because these two wells inect the same water flow rate but work at different pressure values, as shown in Figure 4.8, suggesting that one of the two (i.e., I) is characterized by a lower inectivity and should be located further from the high permeable channel. The estimated variance field obtained after the latest assimilation step using Facies- EnKF suggests that the calibrated values of are characterized by the highest uncertainty at locations corresponding to the boundary of the identified channel. These results are not mirrored by the fields calibrated through EnKF, in which the estimated regions associated with highest permeabilities correspond only in part to the high-permeable pattern displayed in the reference field. Figure 4. shows that the EnKF algorithm identifies correctly the presence of high/low permeable regions around each well without capturing the global field architecture. Moreover, EnKF does not allow preserving the correct geological setting in the calibrated realizations. This is evident from Figure 4.2, which displays five selected realizations of log-permeability updated after the latest assimilation step using the two methodologies. On the contrary, the fields estimated through Facies-EnKF preserve the correct architecture. By visual inspection, one can also note that these fields tend to show a degree of spatial variability of log-permeabilities which is similar to the one characterizing the reference model. 89








96 9 Time step Facies-EnKF EnKF Figure 4.. Estimates of mean log-permeability at initial time and at 6 assimilation steps. I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P








97 9 Time step Facies-EnKF EnKF Figure 4.. Estimation variance of log-permeability at initial time and at 6 assimilation steps. I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P I I2 I3 P P2 P3 I I2 I3 P P2 P3 I I2 I3 P P2 P










98 Relization n. Facies-EnKF EnKF I P I I P 8 I3 I2 P2 P3 I3 I2 I3 I2 P2 P3 P I P I I P 8 2 I3 I2 P2 P3 I3 I2 I3 I2 P2 P3 P I P I I P 8 3 I3 I2 P2 P3 I3 I2 I3 I2 P2 P3 P I P I I P 8 4 I3 I2 P2 P3 I3 I2 I3 I2 P2 P3 P I P I I P I2 P2 I2 I2 P2 4 I3 P3 I3 I3 P3 P3 2 Figure 4.2. Five selected realizations of the updated log-permeability field after the latest assimilation step. 92
Ensemble Kalman filter assimilation of transient groundwater flow data via stochastic moment equations
 Ensemble Kalman filter assimilation of transient groundwater flow data via stochastic moment equations Alberto Guadagnini (1,), Marco Panzeri (1), Monica Riva (1,), Shlomo P. Neuman () (1) Department of
Ensemble Kalman filter assimilation of transient groundwater flow data via stochastic moment equations Alberto Guadagnini (1,), Marco Panzeri (1), Monica Riva (1,), Shlomo P. Neuman () (1) Department of
11280 Electrical Resistivity Tomography Time-lapse Monitoring of Three-dimensional Synthetic Tracer Test Experiments
 11280 Electrical Resistivity Tomography Time-lapse Monitoring of Three-dimensional Synthetic Tracer Test Experiments M. Camporese (University of Padova), G. Cassiani* (University of Padova), R. Deiana
11280 Electrical Resistivity Tomography Time-lapse Monitoring of Three-dimensional Synthetic Tracer Test Experiments M. Camporese (University of Padova), G. Cassiani* (University of Padova), R. Deiana
Statistical Rock Physics
 Statistical - Introduction Book review 3.1-3.3 Min Sun March. 13, 2009 Outline. What is Statistical. Why we need Statistical. How Statistical works Statistical Rock physics Information theory Statistics
Statistical - Introduction Book review 3.1-3.3 Min Sun March. 13, 2009 Outline. What is Statistical. Why we need Statistical. How Statistical works Statistical Rock physics Information theory Statistics
A Stochastic Collocation based. for Data Assimilation
 A Stochastic Collocation based Kalman Filter (SCKF) for Data Assimilation Lingzao Zeng and Dongxiao Zhang University of Southern California August 11, 2009 Los Angeles Outline Introduction SCKF Algorithm
A Stochastic Collocation based Kalman Filter (SCKF) for Data Assimilation Lingzao Zeng and Dongxiao Zhang University of Southern California August 11, 2009 Los Angeles Outline Introduction SCKF Algorithm
A008 THE PROBABILITY PERTURBATION METHOD AN ALTERNATIVE TO A TRADITIONAL BAYESIAN APPROACH FOR SOLVING INVERSE PROBLEMS
 A008 THE PROAILITY PERTURATION METHOD AN ALTERNATIVE TO A TRADITIONAL AYESIAN APPROAH FOR SOLVING INVERSE PROLEMS Jef AERS Stanford University, Petroleum Engineering, Stanford A 94305-2220 USA Abstract
A008 THE PROAILITY PERTURATION METHOD AN ALTERNATIVE TO A TRADITIONAL AYESIAN APPROAH FOR SOLVING INVERSE PROLEMS Jef AERS Stanford University, Petroleum Engineering, Stanford A 94305-2220 USA Abstract
Application of the Ensemble Kalman Filter to History Matching
 Application of the Ensemble Kalman Filter to History Matching Presented at Texas A&M, November 16,2010 Outline Philosophy EnKF for Data Assimilation Field History Match Using EnKF with Covariance Localization
Application of the Ensemble Kalman Filter to History Matching Presented at Texas A&M, November 16,2010 Outline Philosophy EnKF for Data Assimilation Field History Match Using EnKF with Covariance Localization
Structural Surface Uncertainty Modeling and Updating Using the Ensemble Kalman Filter
 Structural Surface Uncertainty Modeling and Updating Using the Ensemble Kalman Filter A. Seiler, Nansen Environmental and Remote Sensing Center and Statoil; S.I. Aanonsen, Center for Integrated Petroleum
Structural Surface Uncertainty Modeling and Updating Using the Ensemble Kalman Filter A. Seiler, Nansen Environmental and Remote Sensing Center and Statoil; S.I. Aanonsen, Center for Integrated Petroleum
A Spectral Approach to Linear Bayesian Updating
 A Spectral Approach to Linear Bayesian Updating Oliver Pajonk 1,2, Bojana V. Rosic 1, Alexander Litvinenko 1, and Hermann G. Matthies 1 1 Institute of Scientific Computing, TU Braunschweig, Germany 2 SPT
A Spectral Approach to Linear Bayesian Updating Oliver Pajonk 1,2, Bojana V. Rosic 1, Alexander Litvinenko 1, and Hermann G. Matthies 1 1 Institute of Scientific Computing, TU Braunschweig, Germany 2 SPT
Geostatistical History Matching coupled with Adaptive Stochastic Sampling: A zonation-based approach using Direct Sequential Simulation
 Geostatistical History Matching coupled with Adaptive Stochastic Sampling: A zonation-based approach using Direct Sequential Simulation Eduardo Barrela* Instituto Superior Técnico, Av. Rovisco Pais 1,
Geostatistical History Matching coupled with Adaptive Stochastic Sampling: A zonation-based approach using Direct Sequential Simulation Eduardo Barrela* Instituto Superior Técnico, Av. Rovisco Pais 1,
Deterministic solution of stochastic groundwater flow equations by nonlocalfiniteelements A. Guadagnini^ & S.P. Neuman^
 Deterministic solution of stochastic groundwater flow equations by nonlocalfiniteelements A. Guadagnini^ & S.P. Neuman^ Milano, Italy; ^Department of. Hydrology & Water Resources, The University ofarizona,
Deterministic solution of stochastic groundwater flow equations by nonlocalfiniteelements A. Guadagnini^ & S.P. Neuman^ Milano, Italy; ^Department of. Hydrology & Water Resources, The University ofarizona,
A new Hierarchical Bayes approach to ensemble-variational data assimilation
 A new Hierarchical Bayes approach to ensemble-variational data assimilation Michael Tsyrulnikov and Alexander Rakitko HydroMetCenter of Russia College Park, 20 Oct 2014 Michael Tsyrulnikov and Alexander
A new Hierarchical Bayes approach to ensemble-variational data assimilation Michael Tsyrulnikov and Alexander Rakitko HydroMetCenter of Russia College Park, 20 Oct 2014 Michael Tsyrulnikov and Alexander
New Fast Kalman filter method
 New Fast Kalman filter method Hojat Ghorbanidehno, Hee Sun Lee 1. Introduction Data assimilation methods combine dynamical models of a system with typically noisy observations to obtain estimates of the
New Fast Kalman filter method Hojat Ghorbanidehno, Hee Sun Lee 1. Introduction Data assimilation methods combine dynamical models of a system with typically noisy observations to obtain estimates of the
Integration of seismic and fluid-flow data: a two-way road linked by rock physics
 Integration of seismic and fluid-flow data: a two-way road linked by rock physics Abstract Yunyue (Elita) Li, Yi Shen, and Peter K. Kang Geologic model building of the subsurface is a complicated and lengthy
Integration of seismic and fluid-flow data: a two-way road linked by rock physics Abstract Yunyue (Elita) Li, Yi Shen, and Peter K. Kang Geologic model building of the subsurface is a complicated and lengthy
Excellence. Respect Openness. Trust. History matching and identifying infill targets using an ensemble based method
 Re-thinking the Goliat reservoir models: Trust History matching and identifying infill targets using an ensemble based method Gjertrud Halset, Reservoir geologist Guro Solberg, Reservoir engineer Respect
Re-thinking the Goliat reservoir models: Trust History matching and identifying infill targets using an ensemble based method Gjertrud Halset, Reservoir geologist Guro Solberg, Reservoir engineer Respect
Stochastic Collocation Methods for Polynomial Chaos: Analysis and Applications
 Stochastic Collocation Methods for Polynomial Chaos: Analysis and Applications Dongbin Xiu Department of Mathematics, Purdue University Support: AFOSR FA955-8-1-353 (Computational Math) SF CAREER DMS-64535
Stochastic Collocation Methods for Polynomial Chaos: Analysis and Applications Dongbin Xiu Department of Mathematics, Purdue University Support: AFOSR FA955-8-1-353 (Computational Math) SF CAREER DMS-64535
Parameter Estimation in Reservoir Engineering Models via Data Assimilation Techniques
 Parameter Estimation in Reservoir Engineering Models via Data Assimilation Techniques Mariya V. Krymskaya TU Delft July 6, 2007 Ensemble Kalman Filter (EnKF) Iterative Ensemble Kalman Filter (IEnKF) State
Parameter Estimation in Reservoir Engineering Models via Data Assimilation Techniques Mariya V. Krymskaya TU Delft July 6, 2007 Ensemble Kalman Filter (EnKF) Iterative Ensemble Kalman Filter (IEnKF) State
Net-to-gross from Seismic P and S Impedances: Estimation and Uncertainty Analysis using Bayesian Statistics
 Net-to-gross from Seismic P and S Impedances: Estimation and Uncertainty Analysis using Bayesian Statistics Summary Madhumita Sengupta*, Ran Bachrach, Niranjan Banik, esterngeco. Net-to-gross (N/G ) is
Net-to-gross from Seismic P and S Impedances: Estimation and Uncertainty Analysis using Bayesian Statistics Summary Madhumita Sengupta*, Ran Bachrach, Niranjan Banik, esterngeco. Net-to-gross (N/G ) is
EnKF Applications to Thermal Petroleum Reservoir Characterization
 EnKF Applications to Thermal Petroleum Reservoir Characterization Yevgeniy Zagayevskiy and Clayton V. Deutsch This paper presents a summary of the application of the ensemble Kalman filter (EnKF) to petroleum
EnKF Applications to Thermal Petroleum Reservoir Characterization Yevgeniy Zagayevskiy and Clayton V. Deutsch This paper presents a summary of the application of the ensemble Kalman filter (EnKF) to petroleum
Thomas Bayes versus the wedge model: An example inference using a geostatistical prior function
 Thomas Bayes versus the wedge model: An example inference using a geostatistical prior function Jason M. McCrank, Gary F. Margrave, and Don C. Lawton ABSTRACT The Bayesian inference is used to estimate
Thomas Bayes versus the wedge model: An example inference using a geostatistical prior function Jason M. McCrank, Gary F. Margrave, and Don C. Lawton ABSTRACT The Bayesian inference is used to estimate
INVERSE MODELING AND UNCERTAINTY QUANTIFICATION OF NONLINEAR FLOW IN POROUS MEDIA MODELS
 INVERSE MODELING AND UNCERTAINTY QUANTIFICATION OF NONLINEAR FLOW IN POROUS MEDIA MODELS by Weixuan Li A Dissertation Presented to the FACULTY OF THE USC GRADUATE SCHOOL UNIVERSITY OF SOUTHERN CALIFORNIA
INVERSE MODELING AND UNCERTAINTY QUANTIFICATION OF NONLINEAR FLOW IN POROUS MEDIA MODELS by Weixuan Li A Dissertation Presented to the FACULTY OF THE USC GRADUATE SCHOOL UNIVERSITY OF SOUTHERN CALIFORNIA
Short tutorial on data assimilation
 Mitglied der Helmholtz-Gemeinschaft Short tutorial on data assimilation 23 June 2015 Wolfgang Kurtz & Harrie-Jan Hendricks Franssen Institute of Bio- and Geosciences IBG-3 (Agrosphere), Forschungszentrum
Mitglied der Helmholtz-Gemeinschaft Short tutorial on data assimilation 23 June 2015 Wolfgang Kurtz & Harrie-Jan Hendricks Franssen Institute of Bio- and Geosciences IBG-3 (Agrosphere), Forschungszentrum
Dynamic Data Driven Simulations in Stochastic Environments
 Computing 77, 321 333 (26) Digital Object Identifier (DOI) 1.17/s67-6-165-3 Dynamic Data Driven Simulations in Stochastic Environments C. Douglas, Lexington, Y. Efendiev, R. Ewing, College Station, V.
Computing 77, 321 333 (26) Digital Object Identifier (DOI) 1.17/s67-6-165-3 Dynamic Data Driven Simulations in Stochastic Environments C. Douglas, Lexington, Y. Efendiev, R. Ewing, College Station, V.
Inverting hydraulic heads in an alluvial aquifer constrained with ERT data through MPS and PPM: a case study
 Inverting hydraulic heads in an alluvial aquifer constrained with ERT data through MPS and PPM: a case study Hermans T. 1, Scheidt C. 2, Caers J. 2, Nguyen F. 1 1 University of Liege, Applied Geophysics
Inverting hydraulic heads in an alluvial aquifer constrained with ERT data through MPS and PPM: a case study Hermans T. 1, Scheidt C. 2, Caers J. 2, Nguyen F. 1 1 University of Liege, Applied Geophysics
Ensemble square-root filters
 Ensemble square-root filters MICHAEL K. TIPPETT International Research Institute for climate prediction, Palisades, New Yor JEFFREY L. ANDERSON GFDL, Princeton, New Jersy CRAIG H. BISHOP Naval Research
Ensemble square-root filters MICHAEL K. TIPPETT International Research Institute for climate prediction, Palisades, New Yor JEFFREY L. ANDERSON GFDL, Princeton, New Jersy CRAIG H. BISHOP Naval Research
Development of Stochastic Artificial Neural Networks for Hydrological Prediction
 Development of Stochastic Artificial Neural Networks for Hydrological Prediction G. B. Kingston, M. F. Lambert and H. R. Maier Centre for Applied Modelling in Water Engineering, School of Civil and Environmental
Development of Stochastic Artificial Neural Networks for Hydrological Prediction G. B. Kingston, M. F. Lambert and H. R. Maier Centre for Applied Modelling in Water Engineering, School of Civil and Environmental
Machine Learning Applied to 3-D Reservoir Simulation
 Machine Learning Applied to 3-D Reservoir Simulation Marco A. Cardoso 1 Introduction The optimization of subsurface flow processes is important for many applications including oil field operations and
Machine Learning Applied to 3-D Reservoir Simulation Marco A. Cardoso 1 Introduction The optimization of subsurface flow processes is important for many applications including oil field operations and
A Note on the Particle Filter with Posterior Gaussian Resampling
 Tellus (6), 8A, 46 46 Copyright C Blackwell Munksgaard, 6 Printed in Singapore. All rights reserved TELLUS A Note on the Particle Filter with Posterior Gaussian Resampling By X. XIONG 1,I.M.NAVON 1,2 and
Tellus (6), 8A, 46 46 Copyright C Blackwell Munksgaard, 6 Printed in Singapore. All rights reserved TELLUS A Note on the Particle Filter with Posterior Gaussian Resampling By X. XIONG 1,I.M.NAVON 1,2 and
We LHR3 04 Realistic Uncertainty Quantification in Geostatistical Seismic Reservoir Characterization
 We LHR3 04 Realistic Uncertainty Quantification in Geostatistical Seismic Reservoir Characterization A. Moradi Tehrani* (CGG), A. Stallone (Roma Tre University), R. Bornard (CGG) & S. Boudon (CGG) SUMMARY
We LHR3 04 Realistic Uncertainty Quantification in Geostatistical Seismic Reservoir Characterization A. Moradi Tehrani* (CGG), A. Stallone (Roma Tre University), R. Bornard (CGG) & S. Boudon (CGG) SUMMARY
Reservoir characterization
 1/15 Reservoir characterization This paper gives an overview of the activities in geostatistics for the Petroleum industry in the domain of reservoir characterization. This description has been simplified
1/15 Reservoir characterization This paper gives an overview of the activities in geostatistics for the Petroleum industry in the domain of reservoir characterization. This description has been simplified
IJMGE Int. J. Min. & Geo-Eng. Vol.49, No.1, June 2015, pp
 IJMGE Int. J. Min. & Geo-Eng. Vol.49, No.1, June 2015, pp.131-142 Joint Bayesian Stochastic Inversion of Well Logs and Seismic Data for Volumetric Uncertainty Analysis Moslem Moradi 1, Omid Asghari 1,
IJMGE Int. J. Min. & Geo-Eng. Vol.49, No.1, June 2015, pp.131-142 Joint Bayesian Stochastic Inversion of Well Logs and Seismic Data for Volumetric Uncertainty Analysis Moslem Moradi 1, Omid Asghari 1,
SENSITIVITY ANALYSIS IN NUMERICAL SIMULATION OF MULTIPHASE FLOW FOR CO 2 STORAGE IN SALINE AQUIFERS USING THE PROBABILISTIC COLLOCATION APPROACH
 XIX International Conference on Water Resources CMWR 2012 University of Illinois at Urbana-Champaign June 17-22,2012 SENSITIVITY ANALYSIS IN NUMERICAL SIMULATION OF MULTIPHASE FLOW FOR CO 2 STORAGE IN
XIX International Conference on Water Resources CMWR 2012 University of Illinois at Urbana-Champaign June 17-22,2012 SENSITIVITY ANALYSIS IN NUMERICAL SIMULATION OF MULTIPHASE FLOW FOR CO 2 STORAGE IN
Multiple-Point Geostatistics: from Theory to Practice Sebastien Strebelle 1
 Multiple-Point Geostatistics: from Theory to Practice Sebastien Strebelle 1 Abstract The limitations of variogram-based simulation programs to model complex, yet fairly common, geological elements, e.g.
Multiple-Point Geostatistics: from Theory to Practice Sebastien Strebelle 1 Abstract The limitations of variogram-based simulation programs to model complex, yet fairly common, geological elements, e.g.
Checking up on the neighbors: Quantifying uncertainty in relative event location
 Checking up on the neighbors: Quantifying uncertainty in relative event location The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation
Checking up on the neighbors: Quantifying uncertainty in relative event location The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation
Ensemble Kalman filter for automatic history matching of geologic facies
 Journal of Petroleum Science and Engineering 47 (2005) 147 161 www.elsevier.com/locate/petrol Ensemble Kalman filter for automatic history matching of geologic facies Ning LiuT, Dean S. Oliver School of
Journal of Petroleum Science and Engineering 47 (2005) 147 161 www.elsevier.com/locate/petrol Ensemble Kalman filter for automatic history matching of geologic facies Ning LiuT, Dean S. Oliver School of
Gaussian Filtering Strategies for Nonlinear Systems
 Gaussian Filtering Strategies for Nonlinear Systems Canonical Nonlinear Filtering Problem ~u m+1 = ~ f (~u m )+~ m+1 ~v m+1 = ~g(~u m+1 )+~ o m+1 I ~ f and ~g are nonlinear & deterministic I Noise/Errors
Gaussian Filtering Strategies for Nonlinear Systems Canonical Nonlinear Filtering Problem ~u m+1 = ~ f (~u m )+~ m+1 ~v m+1 = ~g(~u m+1 )+~ o m+1 I ~ f and ~g are nonlinear & deterministic I Noise/Errors
ROBOTICS 01PEEQW. Basilio Bona DAUIN Politecnico di Torino
 ROBOTICS 01PEEQW Basilio Bona DAUIN Politecnico di Torino Probabilistic Fundamentals in Robotics Gaussian Filters Course Outline Basic mathematical framework Probabilistic models of mobile robots Mobile
ROBOTICS 01PEEQW Basilio Bona DAUIN Politecnico di Torino Probabilistic Fundamentals in Robotics Gaussian Filters Course Outline Basic mathematical framework Probabilistic models of mobile robots Mobile
CO 2 storage capacity and injectivity analysis through the integrated reservoir modelling
 CO 2 storage capacity and injectivity analysis through the integrated reservoir modelling Dr. Liuqi Wang Geoscience Australia CO 2 Geological Storage and Technology Training School of CAGS Beijing, P.
CO 2 storage capacity and injectivity analysis through the integrated reservoir modelling Dr. Liuqi Wang Geoscience Australia CO 2 Geological Storage and Technology Training School of CAGS Beijing, P.
Dynamic System Identification using HDMR-Bayesian Technique
 Dynamic System Identification using HDMR-Bayesian Technique *Shereena O A 1) and Dr. B N Rao 2) 1), 2) Department of Civil Engineering, IIT Madras, Chennai 600036, Tamil Nadu, India 1) ce14d020@smail.iitm.ac.in
Dynamic System Identification using HDMR-Bayesian Technique *Shereena O A 1) and Dr. B N Rao 2) 1), 2) Department of Civil Engineering, IIT Madras, Chennai 600036, Tamil Nadu, India 1) ce14d020@smail.iitm.ac.in
Joint inversion of geophysical and hydrological data for improved subsurface characterization
 Joint inversion of geophysical and hydrological data for improved subsurface characterization Michael B. Kowalsky, Jinsong Chen and Susan S. Hubbard, Lawrence Berkeley National Lab., Berkeley, California,
Joint inversion of geophysical and hydrological data for improved subsurface characterization Michael B. Kowalsky, Jinsong Chen and Susan S. Hubbard, Lawrence Berkeley National Lab., Berkeley, California,
Stochastic methods for aquifer protection and management
 Stochastic methods for aquifer protection and management Dr Adrian Butler Department of Civil & Environmental Engineering G-WADI 07 International Workshop on Groundwater Modeling for Arid and Semi-arid
Stochastic methods for aquifer protection and management Dr Adrian Butler Department of Civil & Environmental Engineering G-WADI 07 International Workshop on Groundwater Modeling for Arid and Semi-arid
Optimizing Thresholds in Truncated Pluri-Gaussian Simulation
 Optimizing Thresholds in Truncated Pluri-Gaussian Simulation Samaneh Sadeghi and Jeff B. Boisvert Truncated pluri-gaussian simulation (TPGS) is an extension of truncated Gaussian simulation. This method
Optimizing Thresholds in Truncated Pluri-Gaussian Simulation Samaneh Sadeghi and Jeff B. Boisvert Truncated pluri-gaussian simulation (TPGS) is an extension of truncated Gaussian simulation. This method
Groundwater Resources Management under. Uncertainty Harald Kunstmann*, Wolfgang Kinzelbach* & Gerrit van Tender**
 Groundwater Resources Management under Uncertainty Harald Kunstmann*, Wolfgang Kinzelbach* & Gerrit van Tender**, C/f &OP3 Zwnc/?, Email: kunstmann@ihw. baum. ethz. ch Abstract Groundwater resources and
Groundwater Resources Management under Uncertainty Harald Kunstmann*, Wolfgang Kinzelbach* & Gerrit van Tender**, C/f &OP3 Zwnc/?, Email: kunstmann@ihw. baum. ethz. ch Abstract Groundwater resources and
Assessing the Value of Information from Inverse Modelling for Optimising Long-Term Oil Reservoir Performance
 Assessing the Value of Information from Inverse Modelling for Optimising Long-Term Oil Reservoir Performance Eduardo Barros, TU Delft Paul Van den Hof, TU Eindhoven Jan Dirk Jansen, TU Delft 1 Oil & gas
Assessing the Value of Information from Inverse Modelling for Optimising Long-Term Oil Reservoir Performance Eduardo Barros, TU Delft Paul Van den Hof, TU Eindhoven Jan Dirk Jansen, TU Delft 1 Oil & gas
Hierarchical Bayes Ensemble Kalman Filter
 Hierarchical Bayes Ensemble Kalman Filter M Tsyrulnikov and A Rakitko HydroMetCenter of Russia Wrocław, 7 Sep 2015 M Tsyrulnikov and A Rakitko (HMC) Hierarchical Bayes Ensemble Kalman Filter Wrocław, 7
Hierarchical Bayes Ensemble Kalman Filter M Tsyrulnikov and A Rakitko HydroMetCenter of Russia Wrocław, 7 Sep 2015 M Tsyrulnikov and A Rakitko (HMC) Hierarchical Bayes Ensemble Kalman Filter Wrocław, 7
Multiple Scenario Inversion of Reflection Seismic Prestack Data
 Downloaded from orbit.dtu.dk on: Nov 28, 2018 Multiple Scenario Inversion of Reflection Seismic Prestack Data Hansen, Thomas Mejer; Cordua, Knud Skou; Mosegaard, Klaus Publication date: 2013 Document Version
Downloaded from orbit.dtu.dk on: Nov 28, 2018 Multiple Scenario Inversion of Reflection Seismic Prestack Data Hansen, Thomas Mejer; Cordua, Knud Skou; Mosegaard, Klaus Publication date: 2013 Document Version
Mini-Course 07 Kalman Particle Filters. Henrique Massard da Fonseca Cesar Cunha Pacheco Wellington Bettencurte Julio Dutra
 Mini-Course 07 Kalman Particle Filters Henrique Massard da Fonseca Cesar Cunha Pacheco Wellington Bettencurte Julio Dutra Agenda State Estimation Problems & Kalman Filter Henrique Massard Steady State
Mini-Course 07 Kalman Particle Filters Henrique Massard da Fonseca Cesar Cunha Pacheco Wellington Bettencurte Julio Dutra Agenda State Estimation Problems & Kalman Filter Henrique Massard Steady State
Characterization of reservoir simulation models using a polynomial chaos-based ensemble Kalman filter
 WATER RESOURCES RESEARCH, VOL. 45,, doi:10.1029/2008wr007148, 2009 Characterization of reservoir simulation models using a polynomial chaos-based ensemble Kalman filter George Saad 1 and Roger Ghanem 1
WATER RESOURCES RESEARCH, VOL. 45,, doi:10.1029/2008wr007148, 2009 Characterization of reservoir simulation models using a polynomial chaos-based ensemble Kalman filter George Saad 1 and Roger Ghanem 1
Inverse Modelling for Flow and Transport in Porous Media
 Inverse Modelling for Flow and Transport in Porous Media Mauro Giudici 1 Dipartimento di Scienze della Terra, Sezione di Geofisica, Università degli Studi di Milano, Milano, Italy Lecture given at the
Inverse Modelling for Flow and Transport in Porous Media Mauro Giudici 1 Dipartimento di Scienze della Terra, Sezione di Geofisica, Università degli Studi di Milano, Milano, Italy Lecture given at the
Reliability of Seismic Data for Hydrocarbon Reservoir Characterization
 Reliability of Seismic Data for Hydrocarbon Reservoir Characterization Geetartha Dutta (gdutta@stanford.edu) December 10, 2015 Abstract Seismic data helps in better characterization of hydrocarbon reservoirs.
Reliability of Seismic Data for Hydrocarbon Reservoir Characterization Geetartha Dutta (gdutta@stanford.edu) December 10, 2015 Abstract Seismic data helps in better characterization of hydrocarbon reservoirs.
Seismic reservoir characterization in offshore Nile Delta.
 Seismic reservoir characterization in offshore Nile Delta. Part II: Probabilistic petrophysical-seismic inversion M. Aleardi 1, F. Ciabarri 2, B. Garcea 2, A. Mazzotti 1 1 Earth Sciences Department, University
Seismic reservoir characterization in offshore Nile Delta. Part II: Probabilistic petrophysical-seismic inversion M. Aleardi 1, F. Ciabarri 2, B. Garcea 2, A. Mazzotti 1 1 Earth Sciences Department, University
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Hydraulic tomography: Development of a new aquifer test method
 WATER RESOURCES RESEARCH, VOL. 36, NO. 8, PAGES 2095 2105, AUGUST 2000 Hydraulic tomography: Development of a new aquifer test method T.-C. Jim Yeh and Shuyun Liu Department of Hydrology and Water Resources,
WATER RESOURCES RESEARCH, VOL. 36, NO. 8, PAGES 2095 2105, AUGUST 2000 Hydraulic tomography: Development of a new aquifer test method T.-C. Jim Yeh and Shuyun Liu Department of Hydrology and Water Resources,
Best Practice Reservoir Characterization for the Alberta Oil Sands
 Best Practice Reservoir Characterization for the Alberta Oil Sands Jason A. McLennan and Clayton V. Deutsch Centre for Computational Geostatistics (CCG) Department of Civil and Environmental Engineering
Best Practice Reservoir Characterization for the Alberta Oil Sands Jason A. McLennan and Clayton V. Deutsch Centre for Computational Geostatistics (CCG) Department of Civil and Environmental Engineering
Lagrangian Data Assimilation and Manifold Detection for a Point-Vortex Model. David Darmon, AMSC Kayo Ide, AOSC, IPST, CSCAMM, ESSIC
 Lagrangian Data Assimilation and Manifold Detection for a Point-Vortex Model David Darmon, AMSC Kayo Ide, AOSC, IPST, CSCAMM, ESSIC Background Data Assimilation Iterative process Forecast Analysis Background
Lagrangian Data Assimilation and Manifold Detection for a Point-Vortex Model David Darmon, AMSC Kayo Ide, AOSC, IPST, CSCAMM, ESSIC Background Data Assimilation Iterative process Forecast Analysis Background
Probabilistic Collocation Method for Uncertainty Analysis of Soil Infiltration in Flood Modelling
 Probabilistic Collocation Method for Uncertainty Analysis of Soil Infiltration in Flood Modelling Y. Huang 1,2, and X.S. Qin 1,2* 1 School of Civil & Environmental Engineering, Nanyang Technological University,
Probabilistic Collocation Method for Uncertainty Analysis of Soil Infiltration in Flood Modelling Y. Huang 1,2, and X.S. Qin 1,2* 1 School of Civil & Environmental Engineering, Nanyang Technological University,
Risk Assessment for CO 2 Sequestration- Uncertainty Quantification based on Surrogate Models of Detailed Simulations
 Risk Assessment for CO 2 Sequestration- Uncertainty Quantification based on Surrogate Models of Detailed Simulations Yan Zhang Advisor: Nick Sahinidis Department of Chemical Engineering Carnegie Mellon
Risk Assessment for CO 2 Sequestration- Uncertainty Quantification based on Surrogate Models of Detailed Simulations Yan Zhang Advisor: Nick Sahinidis Department of Chemical Engineering Carnegie Mellon
A hybrid Marquardt-Simulated Annealing method for solving the groundwater inverse problem
 Calibration and Reliability in Groundwater Modelling (Proceedings of the ModelCARE 99 Conference held at Zurich, Switzerland, September 1999). IAHS Publ. no. 265, 2000. 157 A hybrid Marquardt-Simulated
Calibration and Reliability in Groundwater Modelling (Proceedings of the ModelCARE 99 Conference held at Zurich, Switzerland, September 1999). IAHS Publ. no. 265, 2000. 157 A hybrid Marquardt-Simulated
The Inversion Problem: solving parameters inversion and assimilation problems
 The Inversion Problem: solving parameters inversion and assimilation problems UE Numerical Methods Workshop Romain Brossier romain.brossier@univ-grenoble-alpes.fr ISTerre, Univ. Grenoble Alpes Master 08/09/2016
The Inversion Problem: solving parameters inversion and assimilation problems UE Numerical Methods Workshop Romain Brossier romain.brossier@univ-grenoble-alpes.fr ISTerre, Univ. Grenoble Alpes Master 08/09/2016
Gaussian Process Approximations of Stochastic Differential Equations
 Gaussian Process Approximations of Stochastic Differential Equations Cédric Archambeau Dan Cawford Manfred Opper John Shawe-Taylor May, 2006 1 Introduction Some of the most complex models routinely run
Gaussian Process Approximations of Stochastic Differential Equations Cédric Archambeau Dan Cawford Manfred Opper John Shawe-Taylor May, 2006 1 Introduction Some of the most complex models routinely run
Training Venue and Dates Ref # Reservoir Geophysics October, 2019 $ 6,500 London
 Training Title RESERVOIR GEOPHYSICS Training Duration 5 days Training Venue and Dates Ref # Reservoir Geophysics DE035 5 07 11 October, 2019 $ 6,500 London In any of the 5 star hotels. The exact venue
Training Title RESERVOIR GEOPHYSICS Training Duration 5 days Training Venue and Dates Ref # Reservoir Geophysics DE035 5 07 11 October, 2019 $ 6,500 London In any of the 5 star hotels. The exact venue
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Monte Carlo Simulation-based Sensitivity Analysis of the model of a Thermal-Hydraulic Passive System
 Monte Carlo Simulation-based Sensitivity Analysis of the model of a Thermal-Hydraulic Passive System Enrico Zio, Nicola Pedroni To cite this version: Enrico Zio, Nicola Pedroni. Monte Carlo Simulation-based
Monte Carlo Simulation-based Sensitivity Analysis of the model of a Thermal-Hydraulic Passive System Enrico Zio, Nicola Pedroni To cite this version: Enrico Zio, Nicola Pedroni. Monte Carlo Simulation-based
Improved inverse modeling for flow and transport in subsurface media: Combined parameter and state estimation
 GEOPHYSICAL RESEARCH LETTERS, VOL. 32, L18408, doi:10.1029/2005gl023940, 2005 Improved inverse modeling for flow and transport in subsurface media: Combined parameter and state estimation Jasper A. Vrugt,
GEOPHYSICAL RESEARCH LETTERS, VOL. 32, L18408, doi:10.1029/2005gl023940, 2005 Improved inverse modeling for flow and transport in subsurface media: Combined parameter and state estimation Jasper A. Vrugt,
Local Ensemble Transform Kalman Filter
 Local Ensemble Transform Kalman Filter Brian Hunt 11 June 2013 Review of Notation Forecast model: a known function M on a vector space of model states. Truth: an unknown sequence {x n } of model states
Local Ensemble Transform Kalman Filter Brian Hunt 11 June 2013 Review of Notation Forecast model: a known function M on a vector space of model states. Truth: an unknown sequence {x n } of model states
Model Inversion for Induced Seismicity
 Model Inversion for Induced Seismicity David Castiñeira Research Associate Department of Civil and Environmental Engineering In collaboration with Ruben Juanes (MIT) and Birendra Jha (USC) May 30th, 2017
Model Inversion for Induced Seismicity David Castiñeira Research Associate Department of Civil and Environmental Engineering In collaboration with Ruben Juanes (MIT) and Birendra Jha (USC) May 30th, 2017
Probabilistic Fundamentals in Robotics. DAUIN Politecnico di Torino July 2010
 Probabilistic Fundamentals in Robotics Gaussian Filters Basilio Bona DAUIN Politecnico di Torino July 2010 Course Outline Basic mathematical framework Probabilistic models of mobile robots Mobile robot
Probabilistic Fundamentals in Robotics Gaussian Filters Basilio Bona DAUIN Politecnico di Torino July 2010 Course Outline Basic mathematical framework Probabilistic models of mobile robots Mobile robot
Stochastic Spectral Approaches to Bayesian Inference
 Stochastic Spectral Approaches to Bayesian Inference Prof. Nathan L. Gibson Department of Mathematics Applied Mathematics and Computation Seminar March 4, 2011 Prof. Gibson (OSU) Spectral Approaches to
Stochastic Spectral Approaches to Bayesian Inference Prof. Nathan L. Gibson Department of Mathematics Applied Mathematics and Computation Seminar March 4, 2011 Prof. Gibson (OSU) Spectral Approaches to
USING GEOSTATISTICS TO DESCRIBE COMPLEX A PRIORI INFORMATION FOR INVERSE PROBLEMS THOMAS M. HANSEN 1,2, KLAUS MOSEGAARD 2 and KNUD S.
 USING GEOSTATISTICS TO DESCRIBE COMPLEX A PRIORI INFORMATION FOR INVERSE PROBLEMS THOMAS M. HANSEN 1,2, KLAUS MOSEGAARD 2 and KNUD S. CORDUA 1 1 Institute of Geography & Geology, University of Copenhagen,
USING GEOSTATISTICS TO DESCRIBE COMPLEX A PRIORI INFORMATION FOR INVERSE PROBLEMS THOMAS M. HANSEN 1,2, KLAUS MOSEGAARD 2 and KNUD S. CORDUA 1 1 Institute of Geography & Geology, University of Copenhagen,
Efficient Data Assimilation for Spatiotemporal Chaos: a Local Ensemble Transform Kalman Filter
 Efficient Data Assimilation for Spatiotemporal Chaos: a Local Ensemble Transform Kalman Filter arxiv:physics/0511236 v1 28 Nov 2005 Brian R. Hunt Institute for Physical Science and Technology and Department
Efficient Data Assimilation for Spatiotemporal Chaos: a Local Ensemble Transform Kalman Filter arxiv:physics/0511236 v1 28 Nov 2005 Brian R. Hunt Institute for Physical Science and Technology and Department
Non parametric Bayesian belief nets (NPBBNs) versus ensemble Kalman filter (EnKF) in reservoir simulation
 versus ensemble Kalman filter (EnKF) in reservoir simulation") Delft University of Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft Institute of Applied Mathematics Non parametric Bayesian belief nets (NPBBNs) versus ensemble Kalman
Delft University of Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft Institute of Applied Mathematics Non parametric Bayesian belief nets (NPBBNs) versus ensemble Kalman
c 2004 Society for Industrial and Applied Mathematics
 SIAM J. SCI. COMPUT. Vol. 26, No. 2, pp. 558 577 c 2004 Society for Industrial and Applied Mathematics A COMPARATIVE STUDY ON UNCERTAINTY QUANTIFICATION FOR FLOW IN RANDOMLY HETEROGENEOUS MEDIA USING MONTE
SIAM J. SCI. COMPUT. Vol. 26, No. 2, pp. 558 577 c 2004 Society for Industrial and Applied Mathematics A COMPARATIVE STUDY ON UNCERTAINTY QUANTIFICATION FOR FLOW IN RANDOMLY HETEROGENEOUS MEDIA USING MONTE
Sequential Importance Sampling for Rare Event Estimation with Computer Experiments
 Sequential Importance Sampling for Rare Event Estimation with Computer Experiments Brian Williams and Rick Picard LA-UR-12-22467 Statistical Sciences Group, Los Alamos National Laboratory Abstract Importance
Sequential Importance Sampling for Rare Event Estimation with Computer Experiments Brian Williams and Rick Picard LA-UR-12-22467 Statistical Sciences Group, Los Alamos National Laboratory Abstract Importance
Estimation of Relative Permeability Parameters in Reservoir Engineering Applications
 Delft University of Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft Institute of Applied Mathematics Master of Science Thesis Estimation of Relative Permeability Parameters
Delft University of Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft Institute of Applied Mathematics Master of Science Thesis Estimation of Relative Permeability Parameters
EFFICIENT CHARACTERIZATION OF UNCERTAIN MODEL PARAMETERS WITH A REDUCED-ORDER ENSEMBLE KALMAN FILTER
 EFFICIENT CHARACTERIZATION OF UNCERTAIN MODEL PARAMETERS WITH A REDUCED-ORDER ENSEMBLE KALMAN FILTER BINGHUAI LIN AND DENNIS MCLAUGHLIN Abstract. Spatially variable model parameters are often highly uncertain
EFFICIENT CHARACTERIZATION OF UNCERTAIN MODEL PARAMETERS WITH A REDUCED-ORDER ENSEMBLE KALMAN FILTER BINGHUAI LIN AND DENNIS MCLAUGHLIN Abstract. Spatially variable model parameters are often highly uncertain
Localization in the ensemble Kalman Filter
 Department of Meteorology Localization in the ensemble Kalman Filter Ruth Elizabeth Petrie A dissertation submitted in partial fulfilment of the requirement for the degree of MSc. Atmosphere, Ocean and
Department of Meteorology Localization in the ensemble Kalman Filter Ruth Elizabeth Petrie A dissertation submitted in partial fulfilment of the requirement for the degree of MSc. Atmosphere, Ocean and
Simple closed form formulas for predicting groundwater flow model uncertainty in complex, heterogeneous trending media
 WATER RESOURCES RESEARCH, VOL. 4,, doi:0.029/2005wr00443, 2005 Simple closed form formulas for predicting groundwater flow model uncertainty in complex, heterogeneous trending media Chuen-Fa Ni and Shu-Guang
WATER RESOURCES RESEARCH, VOL. 4,, doi:0.029/2005wr00443, 2005 Simple closed form formulas for predicting groundwater flow model uncertainty in complex, heterogeneous trending media Chuen-Fa Ni and Shu-Guang
A Statistical Input Pruning Method for Artificial Neural Networks Used in Environmental Modelling
 A Statistical Input Pruning Method for Artificial Neural Networks Used in Environmental Modelling G. B. Kingston, H. R. Maier and M. F. Lambert Centre for Applied Modelling in Water Engineering, School
A Statistical Input Pruning Method for Artificial Neural Networks Used in Environmental Modelling G. B. Kingston, H. R. Maier and M. F. Lambert Centre for Applied Modelling in Water Engineering, School
Kalman Filter and Ensemble Kalman Filter
 Kalman Filter and Ensemble Kalman Filter 1 Motivation Ensemble forecasting : Provides flow-dependent estimate of uncertainty of the forecast. Data assimilation : requires information about uncertainty
Kalman Filter and Ensemble Kalman Filter 1 Motivation Ensemble forecasting : Provides flow-dependent estimate of uncertainty of the forecast. Data assimilation : requires information about uncertainty
Dynamic Bayesian Networks as a Possible Alternative to the Ensemble Kalman Filter for Parameter Estimation in Reservoir Engineering
 Dynamic Bayesian Networks as a Possible Alternative to the Ensemble Kalman Filter for Parameter Estimation in Reservoir Engineering Anca Hanea a, Remus Hanea a,b, Aurelius Zilko a a Institute of Applied
Dynamic Bayesian Networks as a Possible Alternative to the Ensemble Kalman Filter for Parameter Estimation in Reservoir Engineering Anca Hanea a, Remus Hanea a,b, Aurelius Zilko a a Institute of Applied
BME STUDIES OF STOCHASTIC DIFFERENTIAL EQUATIONS REPRESENTING PHYSICAL LAW
 7 VIII. BME STUDIES OF STOCHASTIC DIFFERENTIAL EQUATIONS REPRESENTING PHYSICAL LAW A wide variety of natural processes are described using physical laws. A physical law may be expressed by means of an
7 VIII. BME STUDIES OF STOCHASTIC DIFFERENTIAL EQUATIONS REPRESENTING PHYSICAL LAW A wide variety of natural processes are described using physical laws. A physical law may be expressed by means of an
Best Unbiased Ensemble Linearization and the Quasi-Linear Kalman Ensemble Generator
 W. Nowak a,b Best Unbiased Ensemble Linearization and the Quasi-Linear Kalman Ensemble Generator Stuttgart, February 2009 a Institute of Hydraulic Engineering (LH 2 ), University of Stuttgart, Pfaffenwaldring
W. Nowak a,b Best Unbiased Ensemble Linearization and the Quasi-Linear Kalman Ensemble Generator Stuttgart, February 2009 a Institute of Hydraulic Engineering (LH 2 ), University of Stuttgart, Pfaffenwaldring
Assessment of Hydraulic Conductivity Upscaling Techniques and. Associated Uncertainty
 CMWRXVI Assessment of Hydraulic Conductivity Upscaling Techniques and Associated Uncertainty FARAG BOTROS,, 4, AHMED HASSAN 3, 4, AND GREG POHLL Division of Hydrologic Sciences, University of Nevada, Reno
CMWRXVI Assessment of Hydraulic Conductivity Upscaling Techniques and Associated Uncertainty FARAG BOTROS,, 4, AHMED HASSAN 3, 4, AND GREG POHLL Division of Hydrologic Sciences, University of Nevada, Reno
DATA ASSIMILATION FOR FLOOD FORECASTING
 DATA ASSIMILATION FOR FLOOD FORECASTING Arnold Heemin Delft University of Technology 09/16/14 1 Data assimilation is the incorporation of measurement into a numerical model to improve the model results
DATA ASSIMILATION FOR FLOOD FORECASTING Arnold Heemin Delft University of Technology 09/16/14 1 Data assimilation is the incorporation of measurement into a numerical model to improve the model results
Downloaded 10/25/16 to Redistribution subject to SEG license or copyright; see Terms of Use at
 Facies modeling in unconventional reservoirs using seismic derived facies probabilities Reinaldo J. Michelena*, Omar G. Angola, and Kevin S. Godbey, ireservoir.com, Inc. Summary We present in this paper
Facies modeling in unconventional reservoirs using seismic derived facies probabilities Reinaldo J. Michelena*, Omar G. Angola, and Kevin S. Godbey, ireservoir.com, Inc. Summary We present in this paper
If we want to analyze experimental or simulated data we might encounter the following tasks:
 Chapter 1 Introduction If we want to analyze experimental or simulated data we might encounter the following tasks: Characterization of the source of the signal and diagnosis Studying dependencies Prediction
Chapter 1 Introduction If we want to analyze experimental or simulated data we might encounter the following tasks: Characterization of the source of the signal and diagnosis Studying dependencies Prediction
Computational Challenges in Reservoir Modeling. Sanjay Srinivasan The Pennsylvania State University
 Computational Challenges in Reservoir Modeling Sanjay Srinivasan The Pennsylvania State University Well Data 3D view of well paths Inspired by an offshore development 4 platforms 2 vertical wells 2 deviated
Computational Challenges in Reservoir Modeling Sanjay Srinivasan The Pennsylvania State University Well Data 3D view of well paths Inspired by an offshore development 4 platforms 2 vertical wells 2 deviated
Fundamentals of Data Assimila1on
 2015 GSI Community Tutorial NCAR Foothills Campus, Boulder, CO August 11-14, 2015 Fundamentals of Data Assimila1on Milija Zupanski Cooperative Institute for Research in the Atmosphere Colorado State University
2015 GSI Community Tutorial NCAR Foothills Campus, Boulder, CO August 11-14, 2015 Fundamentals of Data Assimila1on Milija Zupanski Cooperative Institute for Research in the Atmosphere Colorado State University
SPE History Matching Using the Ensemble Kalman Filter on a North Sea Field Case
 SPE- 1243 History Matching Using the Ensemble Kalman Filter on a North Sea Field Case Vibeke Haugen, SPE, Statoil ASA, Lars-Jørgen Natvik, Statoil ASA, Geir Evensen, Hydro, Aina Berg, IRIS, Kristin Flornes,
SPE- 1243 History Matching Using the Ensemble Kalman Filter on a North Sea Field Case Vibeke Haugen, SPE, Statoil ASA, Lars-Jørgen Natvik, Statoil ASA, Geir Evensen, Hydro, Aina Berg, IRIS, Kristin Flornes,
APPLICATION OF THE TRUNCATED PLURIGAUSSIAN METHOD TO DELINEATE HYDROFACIES DISTRIBUTION IN HETEROGENEOUS AQUIFERS
 XIX International Conference on Water Resources CMWR 2012 University of Illinois at Urbana-Champaign June 17-22, 2012 APPLICATION OF THE TRUNCATED PLURIGAUSSIAN METHOD TO DELINEATE HYDROFACIES DISTRIBUTION
XIX International Conference on Water Resources CMWR 2012 University of Illinois at Urbana-Champaign June 17-22, 2012 APPLICATION OF THE TRUNCATED PLURIGAUSSIAN METHOD TO DELINEATE HYDROFACIES DISTRIBUTION
Monte Carlo Simulation. CWR 6536 Stochastic Subsurface Hydrology
 Monte Carlo Simulation CWR 6536 Stochastic Subsurface Hydrology Steps in Monte Carlo Simulation Create input sample space with known distribution, e.g. ensemble of all possible combinations of v, D, q,
Monte Carlo Simulation CWR 6536 Stochastic Subsurface Hydrology Steps in Monte Carlo Simulation Create input sample space with known distribution, e.g. ensemble of all possible combinations of v, D, q,
Hierarchical sparse Bayesian learning for structural health monitoring. with incomplete modal data
 Hierarchical sparse Bayesian learning for structural health monitoring with incomplete modal data Yong Huang and James L. Beck* Division of Engineering and Applied Science, California Institute of Technology,
Hierarchical sparse Bayesian learning for structural health monitoring with incomplete modal data Yong Huang and James L. Beck* Division of Engineering and Applied Science, California Institute of Technology,
Bayesian Inverse problem, Data assimilation and Localization
 Bayesian Inverse problem, Data assimilation and Localization Xin T Tong National University of Singapore ICIP, Singapore 2018 X.Tong Localization 1 / 37 Content What is Bayesian inverse problem? What is
Bayesian Inverse problem, Data assimilation and Localization Xin T Tong National University of Singapore ICIP, Singapore 2018 X.Tong Localization 1 / 37 Content What is Bayesian inverse problem? What is
PUBLICATIONS. Water Resources Research
 PUBLICATIONS RESEARCH ARTICLE Special Section: Modeling highly heterogeneous aquifers: Lessons learned in the last 3 years from the MADE experiments and others Characterization of non-gaussian conductivities
PUBLICATIONS RESEARCH ARTICLE Special Section: Modeling highly heterogeneous aquifers: Lessons learned in the last 3 years from the MADE experiments and others Characterization of non-gaussian conductivities
Sequential Monte Carlo Samplers for Applications in High Dimensions
 Sequential Monte Carlo Samplers for Applications in High Dimensions Alexandros Beskos National University of Singapore KAUST, 26th February 2014 Joint work with: Dan Crisan, Ajay Jasra, Nik Kantas, Alex
Sequential Monte Carlo Samplers for Applications in High Dimensions Alexandros Beskos National University of Singapore KAUST, 26th February 2014 Joint work with: Dan Crisan, Ajay Jasra, Nik Kantas, Alex
A013 HISTORY MATCHING WITH RESPECT TO RESERVOIR STRUCTURE
 A3 HISTORY MATCHING WITH RESPECT TO RESERVOIR STRUCTURE SIGURD IVAR AANONSEN ; ODDVAR LIA ; AND OLE JAKOB ARNTZEN Centre for Integrated Research, University of Bergen, Allégt. 4, N-7 Bergen, Norway Statoil
A3 HISTORY MATCHING WITH RESPECT TO RESERVOIR STRUCTURE SIGURD IVAR AANONSEN ; ODDVAR LIA ; AND OLE JAKOB ARNTZEN Centre for Integrated Research, University of Bergen, Allégt. 4, N-7 Bergen, Norway Statoil
MULTISCALE FINITE ELEMENT METHODS FOR STOCHASTIC POROUS MEDIA FLOW EQUATIONS AND APPLICATION TO UNCERTAINTY QUANTIFICATION
 MULTISCALE FINITE ELEMENT METHODS FOR STOCHASTIC POROUS MEDIA FLOW EQUATIONS AND APPLICATION TO UNCERTAINTY QUANTIFICATION P. DOSTERT, Y. EFENDIEV, AND T.Y. HOU Abstract. In this paper, we study multiscale
MULTISCALE FINITE ELEMENT METHODS FOR STOCHASTIC POROUS MEDIA FLOW EQUATIONS AND APPLICATION TO UNCERTAINTY QUANTIFICATION P. DOSTERT, Y. EFENDIEV, AND T.Y. HOU Abstract. In this paper, we study multiscale
Fundamentals of Data Assimila1on
 014 GSI Community Tutorial NCAR Foothills Campus, Boulder, CO July 14-16, 014 Fundamentals of Data Assimila1on Milija Zupanski Cooperative Institute for Research in the Atmosphere Colorado State University
014 GSI Community Tutorial NCAR Foothills Campus, Boulder, CO July 14-16, 014 Fundamentals of Data Assimila1on Milija Zupanski Cooperative Institute for Research in the Atmosphere Colorado State University
Applications of Randomized Methods for Decomposing and Simulating from Large Covariance Matrices
 Applications of Randomized Methods for Decomposing and Simulating from Large Covariance Matrices Vahid Dehdari and Clayton V. Deutsch Geostatistical modeling involves many variables and many locations.
Applications of Randomized Methods for Decomposing and Simulating from Large Covariance Matrices Vahid Dehdari and Clayton V. Deutsch Geostatistical modeling involves many variables and many locations.
Quantitative Seismic Interpretation An Earth Modeling Perspective
 Quantitative Seismic Interpretation An Earth Modeling Perspective Damien Thenin*, RPS, Calgary, AB, Canada TheninD@rpsgroup.com Ron Larson, RPS, Calgary, AB, Canada LarsonR@rpsgroup.com Summary Earth models
Quantitative Seismic Interpretation An Earth Modeling Perspective Damien Thenin*, RPS, Calgary, AB, Canada TheninD@rpsgroup.com Ron Larson, RPS, Calgary, AB, Canada LarsonR@rpsgroup.com Summary Earth models
Adaptive Data Assimilation and Multi-Model Fusion
 Adaptive Data Assimilation and Multi-Model Fusion Pierre F.J. Lermusiaux, Oleg G. Logoutov and Patrick J. Haley Jr. Mechanical Engineering and Ocean Science and Engineering, MIT We thank: Allan R. Robinson
Adaptive Data Assimilation and Multi-Model Fusion Pierre F.J. Lermusiaux, Oleg G. Logoutov and Patrick J. Haley Jr. Mechanical Engineering and Ocean Science and Engineering, MIT We thank: Allan R. Robinson