The intersection axiom of
|
|
|
- Erick Webb
- 5 years ago
- Views:
Transcription
1 The intersection axiom of conditional independence: some new [?] results Richard D. Gill Mathematical Institute, University Leiden This version: 26 March, 2019 (X Y Z) & (X Z Y) X (Y, Z) Presented at Algebraic Statistics seminar, Leiden, 27 February 2019 The best-laid plans of mice and men often go awry No matter how carefully a project is planned, something may still go wrong with it. The saying is adapted from a line in To a Mouse, by Robert Burns: The best laid schemes o' mice an' men / Gang aft a-gley.
2 Algebraic Statistics Seth Sullivant North Carolina State University address: 2010 Mathematics Subject Classification. Primary 62-01, 14-01, 13P10, 13P15, 14M12, 14M25, 14P10, 14T05, 52B20, 60J10, 62F03, 62H17, 90C10, 92D15 Key words and phrases. algebraic statistics, graphical models, contingency tables, conditional independence, phylogenetic models, design of experiments, Gröbner bases, real algebraic geometry, exponential families, exact test, maximum likelihood degree, Markov basis, disclosure limitation, random graph models, model selection, identifiability Abstract. Algebraic statistics uses tools from algebraic geometry, commutative algebra, combinatorics, and their computational sides to address problems in statistics and its applications. The starting point for this connection is the observation that many statistical models are semialgebraic sets. The algebra/statistics connection is now over twenty years old this book presents the first comprehensive and introductory treatment of the subject. After background material in probability, algebra, and statistics, the book covers a range of topics in algebraic statistics including algebraic exponential families, likelihood inference, Fisher s exact test, bounds on entries of contingency tables, design of experiments, identifiability of hidden variable models, phylogenetic models, and model selection. The book is suitable for both classroom use and independent study, as it has numerous examples, references, and over 150 exercises.
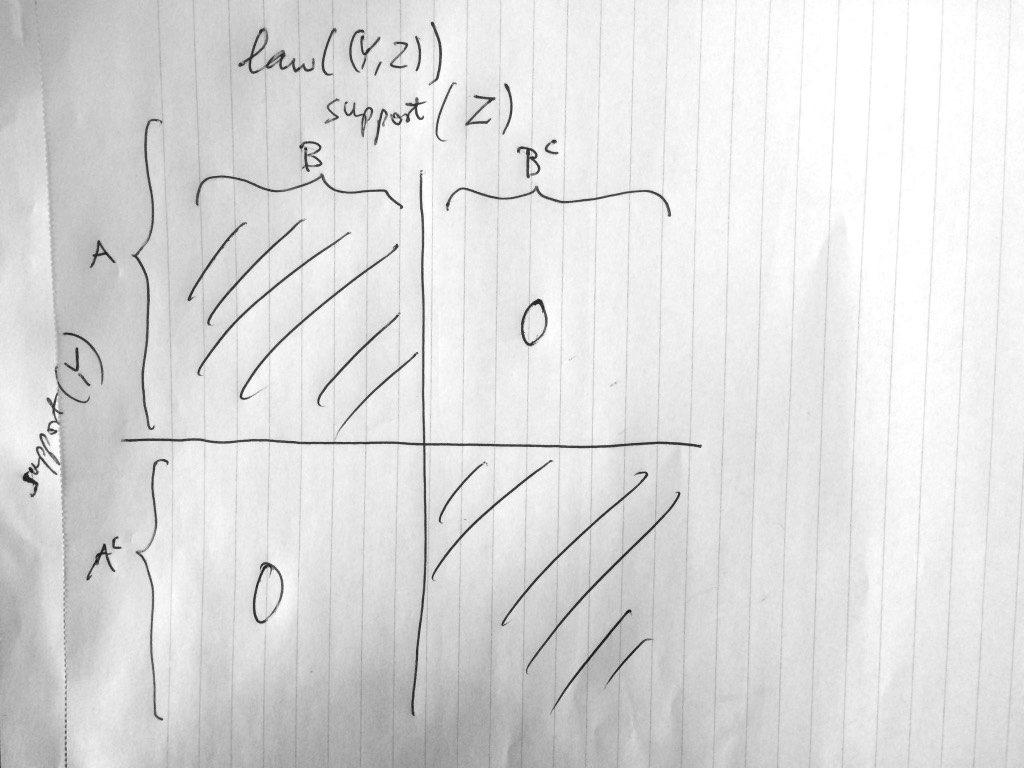
3 The intersection axiom: New result: (X Y Z) & (X Z Y) X (Y, Z) (X Y Z) & (X Z Y) X (Y, Z) W where W:= f(y) = g(z) for some f, g In particular, we can take W = Law((Y, Z) X) If f and g are trivial (constant) we obtain axiom 5 Also new : Nontrivial f, g exist such that f(y) = g(z) a.e. iff A, B exist with probabilities strictly between 0 and 1 s.t. Pr(Y A & Z B c ) = 0 = Pr(Y A c & Z B) Call such a joint law decomposable
4
5
6
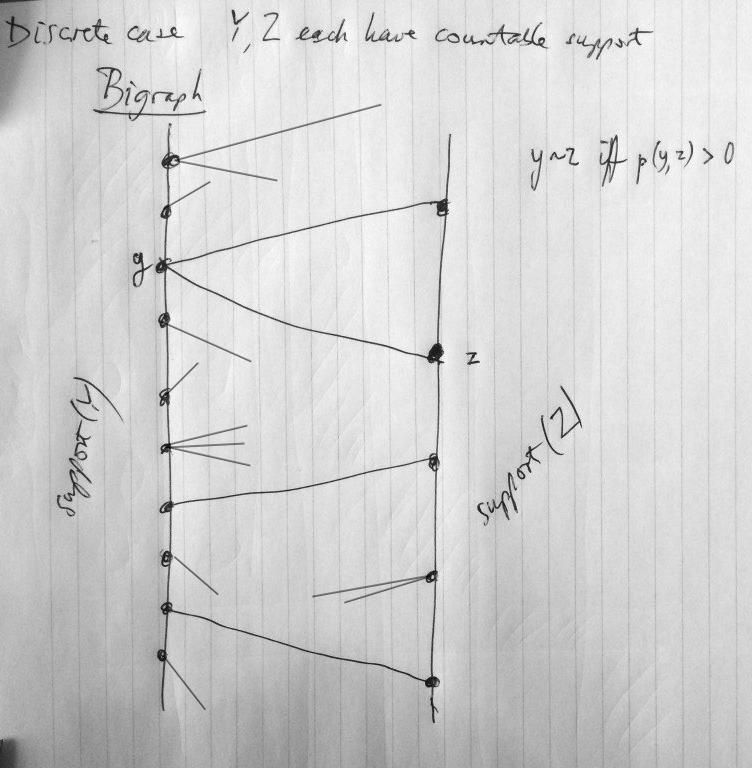
7 Comfort zones All variables have finite support (Algebraic Geometry) All variables have countable support All variables have continuous joint probability densities (many applied statisticians) All densities are strictly positive All distributions are non-degenerate Gaussian All variables take values in Polish spaces (My favourite)
8 Please recall The joint probability distribution of X and Y can be disintegrated into the marginal distribution of X and a family of conditional distributions of Y given X = x The disintegration is unique up to almost everywhere equivalence Conditional independence of X and Y given Z is just ordinary independence within each of the joint laws of X and Y conditional on Z = z For me, 0/0 = undefined and 0 x undefined = 0 In other words: conditional distributions do exist even if we condition on zero probability events; they just fail to be uniquely defined. The non-uniqueness is harmless
9 Some new notation I ll denote by law(x) the probability distribution of X on X In the finite, discrete case, a law is just a vector of real numbers, non-negative, adding to one. In the Polish case, the set of probability laws on a given Polish space is itself a Polish space under an appropriate metric. One can moreover take convex combinations. The family of conditional distributions of X given Y, (law(x Y = y))y Y can be thought of as a function of y Y. The function in question is Borel measurable. As a function of the random variable Y, we can consider it as a random variable!!!! By Law(X Y) I ll denote that random variable, taking values in the space of probability laws on X.
10 Crucial lemma X Y Law(X Y)
11 Lemma: X Y Law(X Y) Proof of lemma, discrete case Recall, X Y Z p(x, y, z) = g(x, z) h(y, z) Thus X Y L we can factor p(x, y, l) this way Given function p(x, y), pick any x X, y Y, l Δ X 1 p(x, y, l) = p(x, y) 1{l = p(, y)/p(y)} = l(x)p(y)1{l = p(, y)/p(y)} = Eval(l, x). p(y)1{l = p(, y)/p(y)} Proof of lemma, Polish case Similar, but different we don t assume existence of joint densities!
12 Proof of forwards implication X Y Z Law(X Y, Z) = Law(X Z) X Z Y Law(X Y, Z) = Law(X Y) So we have w(y, Z) = g(z) = f(y) =: W for some functions w, g, f By our lemma, X (Y, Z) Law(X (Y, Z)) We found functions g, f such that g(z) = f(y) and, with W:= w(y, Z) = g(z) = f(y), X (Y, Z) W
13 Proof of reverse implication Suppose X (Y, Z) W where W = g(z) = f(y) for some functions g, f By axiom, X Y (W, Z) So X Y (g(z), Z) So X Y Z Similarly, X Z Y
14 Sullivant Uses primary decomposition of toric ideals to come up with a nice parametrisation of the model Axiom 5 Given: finite sets X, Y, Z, what is the set of all probability measures on their product satisfying Axiom 5, and with p(y) > 0, p(z) > 0, for all y, z? Answer: pick partitions of Y, Z which are in 1-1 correspondence with one another. Call one of them W. Pick a positive probability distribution on W. Pick indecomposable probability distributions on the products of corresponding partition elements of Y and Z. Pick probability distributions on X, also corresponding to the preceding, not necessarily all different Now put them together: in simulation terms: generate r.v. W = w W. Generate (Y,Z) given W =w and independently thereof generate X given W = w.
15 Polish spaces Exactly same construction just replace partition by a Borel measurable map onto another Polish space Corresponding partitions Borel measurable maps onto same Polish space
16 Questions Does algebraic geometry provide any further statistical insights? Can some of you join me to turn all these ideas into a nice joint paper? Could there be a category theoretical meta-theorem?
17 References SS07] Sullivant, book, ch. 4, esp. section Mathias Drton, Bernd Sturmfels, and Seth Sullivant, Algebraic factor analysis: tetrads, pentads and beyond, Probab. Theory Related Fields 138 (2007), no. 3-4, SS09], Lectures on Algebraic Statistics, Oberwolfach Seminars, vol. 39, Birkhäuser Verlag, Basel, MR in11] Alex Fink, The binomial ideal of the intersection axiom for conditional probabilities, J. Algebraic Combin. 33 (2011), no. 3, MR et14] Jonas Peters, On the intersection property of conditional independence and its application to causal discovery, Journal of Causal Inference 3 (2014),
18 References (cont.) van der Vaart & Wellner (1996), Weak Convergence and Empirical Processes Ghosal & van der Vaart (2017), Fundamentals of Nonparametric Bayesian Inference Aad van der Vaart (2019), personal communication
19 The (semi-)graphoid axioms of (conditional) independence Symmetry Decomposition Weak union Contraction X Y Y X X (Y, Z) X Y X (Y, Z) X Y Z ( X Z Y & X Y ) X (Y, Z) Intersection ( X Y Z & X Z Y ) X (Y, Z)
![Comfort zones All variables have: Finite outcome space [Nice for algebraic geometry] Countable outcome space Continuous joint density with respect to sigma-finite](/docs-images/95/122760272/images/20-0.jpg "product measures [?")
20 Comfort zones All variables have: Finite outcome space [Nice for algebraic geometry] Countable outcome space Continuous joint density with respect to sigma-finite product measures [?] Outcome spaces are Polish Other convenience assumptions: Strictly positive joint density Multivariate normal also allows algebraic geometry approach
Toric Varieties in Statistics
 Toric Varieties in Statistics Daniel Irving Bernstein and Seth Sullivant North Carolina State University dibernst@ncsu.edu http://www4.ncsu.edu/~dibernst/ http://arxiv.org/abs/50.063 http://arxiv.org/abs/508.0546
Toric Varieties in Statistics Daniel Irving Bernstein and Seth Sullivant North Carolina State University dibernst@ncsu.edu http://www4.ncsu.edu/~dibernst/ http://arxiv.org/abs/50.063 http://arxiv.org/abs/508.0546
PRIMARY DECOMPOSITION FOR THE INTERSECTION AXIOM
 PRIMARY DECOMPOSITION FOR THE INTERSECTION AXIOM ALEX FINK 1. Introduction and background Consider the discrete conditional independence model M given by {X 1 X 2 X 3, X 1 X 3 X 2 }. The intersection axiom
PRIMARY DECOMPOSITION FOR THE INTERSECTION AXIOM ALEX FINK 1. Introduction and background Consider the discrete conditional independence model M given by {X 1 X 2 X 3, X 1 X 3 X 2 }. The intersection axiom
Algebraic Statistics. Seth Sullivant. North Carolina State University address:
 Algebraic Statistics Seth Sullivant North Carolina State University E-mail address: smsulli2@ncsu.edu 2010 Mathematics Subject Classification. Primary 62-01, 14-01, 13P10, 13P15, 14M12, 14M25, 14P10, 14T05,
Algebraic Statistics Seth Sullivant North Carolina State University E-mail address: smsulli2@ncsu.edu 2010 Mathematics Subject Classification. Primary 62-01, 14-01, 13P10, 13P15, 14M12, 14M25, 14P10, 14T05,
Testing Algebraic Hypotheses
 Testing Algebraic Hypotheses Mathias Drton Department of Statistics University of Chicago 1 / 18 Example: Factor analysis Multivariate normal model based on conditional independence given hidden variable:
Testing Algebraic Hypotheses Mathias Drton Department of Statistics University of Chicago 1 / 18 Example: Factor analysis Multivariate normal model based on conditional independence given hidden variable:
Causal Models with Hidden Variables
 Causal Models with Hidden Variables Robin J. Evans www.stats.ox.ac.uk/ evans Department of Statistics, University of Oxford Quantum Networks, Oxford August 2017 1 / 44 Correlation does not imply causation
Causal Models with Hidden Variables Robin J. Evans www.stats.ox.ac.uk/ evans Department of Statistics, University of Oxford Quantum Networks, Oxford August 2017 1 / 44 Correlation does not imply causation
Mixture Models and Representational Power of RBM s, DBN s and DBM s
 Mixture Models and Representational Power of RBM s, DBN s and DBM s Guido Montufar Max Planck Institute for Mathematics in the Sciences, Inselstraße 22, D-04103 Leipzig, Germany. montufar@mis.mpg.de Abstract
Mixture Models and Representational Power of RBM s, DBN s and DBM s Guido Montufar Max Planck Institute for Mathematics in the Sciences, Inselstraße 22, D-04103 Leipzig, Germany. montufar@mis.mpg.de Abstract
Tutorial: Gaussian conditional independence and graphical models. Thomas Kahle Otto-von-Guericke Universität Magdeburg
 Tutorial: Gaussian conditional independence and graphical models Thomas Kahle Otto-von-Guericke Universität Magdeburg The central dogma of algebraic statistics Statistical models are varieties The central
Tutorial: Gaussian conditional independence and graphical models Thomas Kahle Otto-von-Guericke Universität Magdeburg The central dogma of algebraic statistics Statistical models are varieties The central
Lecture 4 October 18th
 Directed and undirected graphical models Fall 2017 Lecture 4 October 18th Lecturer: Guillaume Obozinski Scribe: In this lecture, we will assume that all random variables are discrete, to keep notations
Directed and undirected graphical models Fall 2017 Lecture 4 October 18th Lecturer: Guillaume Obozinski Scribe: In this lecture, we will assume that all random variables are discrete, to keep notations
Likelihood Analysis of Gaussian Graphical Models
 Faculty of Science Likelihood Analysis of Gaussian Graphical Models Ste en Lauritzen Department of Mathematical Sciences Minikurs TUM 2016 Lecture 2 Slide 1/43 Overview of lectures Lecture 1 Markov Properties
Faculty of Science Likelihood Analysis of Gaussian Graphical Models Ste en Lauritzen Department of Mathematical Sciences Minikurs TUM 2016 Lecture 2 Slide 1/43 Overview of lectures Lecture 1 Markov Properties
Theorem 2.1 (Caratheodory). A (countably additive) probability measure on a field has an extension. n=1
. A (countably additive) probability measure on a field has an extension. n=1") Chapter 2 Probability measures 1. Existence Theorem 2.1 (Caratheodory). A (countably additive) probability measure on a field has an extension to the generated σ-field Proof of Theorem 2.1. Let F 0 be
Chapter 2 Probability measures 1. Existence Theorem 2.1 (Caratheodory). A (countably additive) probability measure on a field has an extension to the generated σ-field Proof of Theorem 2.1. Let F 0 be
Based on slides by Richard Zemel
 CSC 412/2506 Winter 2018 Probabilistic Learning and Reasoning Lecture 3: Directed Graphical Models and Latent Variables Based on slides by Richard Zemel Learning outcomes What aspects of a model can we
CSC 412/2506 Winter 2018 Probabilistic Learning and Reasoning Lecture 3: Directed Graphical Models and Latent Variables Based on slides by Richard Zemel Learning outcomes What aspects of a model can we
Analysis of Probabilistic Systems
 Analysis of Probabilistic Systems Bootcamp Lecture 2: Measure and Integration Prakash Panangaden 1 1 School of Computer Science McGill University Fall 2016, Simons Institute Panangaden (McGill) Analysis
Analysis of Probabilistic Systems Bootcamp Lecture 2: Measure and Integration Prakash Panangaden 1 1 School of Computer Science McGill University Fall 2016, Simons Institute Panangaden (McGill) Analysis
Discrete Mathematics and Probability Theory Spring 2016 Rao and Walrand Note 26. Estimation: Regression and Least Squares
 CS 70 Discrete Mathematics and Probability Theory Spring 2016 Rao and Walrand Note 26 Estimation: Regression and Least Squares This note explains how to use observations to estimate unobserved random variables.
CS 70 Discrete Mathematics and Probability Theory Spring 2016 Rao and Walrand Note 26 Estimation: Regression and Least Squares This note explains how to use observations to estimate unobserved random variables.
18.175: Lecture 2 Extension theorems, random variables, distributions
 18.175: Lecture 2 Extension theorems, random variables, distributions Scott Sheffield MIT Outline Extension theorems Characterizing measures on R d Random variables Outline Extension theorems Characterizing
18.175: Lecture 2 Extension theorems, random variables, distributions Scott Sheffield MIT Outline Extension theorems Characterizing measures on R d Random variables Outline Extension theorems Characterizing
Lecture Notes 1 Probability and Random Variables. Conditional Probability and Independence. Functions of a Random Variable
 Lecture Notes 1 Probability and Random Variables Probability Spaces Conditional Probability and Independence Random Variables Functions of a Random Variable Generation of a Random Variable Jointly Distributed
Lecture Notes 1 Probability and Random Variables Probability Spaces Conditional Probability and Independence Random Variables Functions of a Random Variable Generation of a Random Variable Jointly Distributed
Lecture Notes 1 Probability and Random Variables. Conditional Probability and Independence. Functions of a Random Variable
 Lecture Notes 1 Probability and Random Variables Probability Spaces Conditional Probability and Independence Random Variables Functions of a Random Variable Generation of a Random Variable Jointly Distributed
Lecture Notes 1 Probability and Random Variables Probability Spaces Conditional Probability and Independence Random Variables Functions of a Random Variable Generation of a Random Variable Jointly Distributed
int cl int cl A = int cl A.
 BAIRE CATEGORY CHRISTIAN ROSENDAL 1. THE BAIRE CATEGORY THEOREM Theorem 1 (The Baire category theorem. Let (D n n N be a countable family of dense open subsets of a Polish space X. Then n N D n is dense
BAIRE CATEGORY CHRISTIAN ROSENDAL 1. THE BAIRE CATEGORY THEOREM Theorem 1 (The Baire category theorem. Let (D n n N be a countable family of dense open subsets of a Polish space X. Then n N D n is dense
STAT 7032 Probability Spring Wlodek Bryc
 STAT 7032 Probability Spring 2018 Wlodek Bryc Created: Friday, Jan 2, 2014 Revised for Spring 2018 Printed: January 9, 2018 File: Grad-Prob-2018.TEX Department of Mathematical Sciences, University of Cincinnati,
STAT 7032 Probability Spring 2018 Wlodek Bryc Created: Friday, Jan 2, 2014 Revised for Spring 2018 Printed: January 9, 2018 File: Grad-Prob-2018.TEX Department of Mathematical Sciences, University of Cincinnati,
Markov properties for undirected graphs
 Graphical Models, Lecture 2, Michaelmas Term 2011 October 12, 2011 Formal definition Fundamental properties Random variables X and Y are conditionally independent given the random variable Z if L(X Y,
Graphical Models, Lecture 2, Michaelmas Term 2011 October 12, 2011 Formal definition Fundamental properties Random variables X and Y are conditionally independent given the random variable Z if L(X Y,
Lecture 2 One too many inequalities
 University of Illinois Department of Economics Spring 2017 Econ 574 Roger Koenker Lecture 2 One too many inequalities In lecture 1 we introduced some of the basic conceptual building materials of the course.
University of Illinois Department of Economics Spring 2017 Econ 574 Roger Koenker Lecture 2 One too many inequalities In lecture 1 we introduced some of the basic conceptual building materials of the course.
The Multivariate Gaussian Distribution [DRAFT]
![The Multivariate Gaussian Distribution [DRAFT]](/thumbs/90/102238180.jpg "The Multivariate Gaussian Distribution [DRAFT]") The Multivariate Gaussian Distribution DRAFT David S. Rosenberg Abstract This is a collection of a few key and standard results about multivariate Gaussian distributions. I have not included many proofs,
The Multivariate Gaussian Distribution DRAFT David S. Rosenberg Abstract This is a collection of a few key and standard results about multivariate Gaussian distributions. I have not included many proofs,
Chris Bishop s PRML Ch. 8: Graphical Models
 Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Chris Bishop s PRML Ch. 8: Graphical Models January 24, 2008 Introduction Visualize the structure of a probabilistic model Design and motivate new models Insights into the model s properties, in particular
Total positivity in Markov structures
 1 based on joint work with Shaun Fallat, Kayvan Sadeghi, Caroline Uhler, Nanny Wermuth, and Piotr Zwiernik (arxiv:1510.01290) Faculty of Science Total positivity in Markov structures Steffen Lauritzen
1 based on joint work with Shaun Fallat, Kayvan Sadeghi, Caroline Uhler, Nanny Wermuth, and Piotr Zwiernik (arxiv:1510.01290) Faculty of Science Total positivity in Markov structures Steffen Lauritzen
Introduction to Empirical Processes and Semiparametric Inference Lecture 08: Stochastic Convergence
 Introduction to Empirical Processes and Semiparametric Inference Lecture 08: Stochastic Convergence Michael R. Kosorok, Ph.D. Professor and Chair of Biostatistics Professor of Statistics and Operations
Introduction to Empirical Processes and Semiparametric Inference Lecture 08: Stochastic Convergence Michael R. Kosorok, Ph.D. Professor and Chair of Biostatistics Professor of Statistics and Operations
Open Problems in Algebraic Statistics
 Open Problems inalgebraic Statistics p. Open Problems in Algebraic Statistics BERND STURMFELS UNIVERSITY OF CALIFORNIA, BERKELEY and TECHNISCHE UNIVERSITÄT BERLIN Advertisement Oberwolfach Seminar Algebraic
Open Problems inalgebraic Statistics p. Open Problems in Algebraic Statistics BERND STURMFELS UNIVERSITY OF CALIFORNIA, BERKELEY and TECHNISCHE UNIVERSITÄT BERLIN Advertisement Oberwolfach Seminar Algebraic
The binomial ideal of the intersection axiom for conditional probabilities
 J Algebr Comb (2011) 33: 455 463 DOI 10.1007/s10801-010-0253-5 The binomial ideal of the intersection axiom for conditional probabilities Alex Fink Received: 10 February 2009 / Accepted: 27 August 2010
J Algebr Comb (2011) 33: 455 463 DOI 10.1007/s10801-010-0253-5 The binomial ideal of the intersection axiom for conditional probabilities Alex Fink Received: 10 February 2009 / Accepted: 27 August 2010
STAT 598L Probabilistic Graphical Models. Instructor: Sergey Kirshner. Probability Review
 STAT 598L Probabilistic Graphical Models Instructor: Sergey Kirshner Probability Review Some slides are taken (or modified) from Carlos Guestrin s 10-708 Probabilistic Graphical Models Fall 2008 at CMU
STAT 598L Probabilistic Graphical Models Instructor: Sergey Kirshner Probability Review Some slides are taken (or modified) from Carlos Guestrin s 10-708 Probabilistic Graphical Models Fall 2008 at CMU
Fusion in simple models
 Fusion in simple models Peter Antal antal@mit.bme.hu A.I. February 8, 2018 1 Basic concepts of probability theory Joint distribution Conditional probability Bayes rule Chain rule Marginalization General
Fusion in simple models Peter Antal antal@mit.bme.hu A.I. February 8, 2018 1 Basic concepts of probability theory Joint distribution Conditional probability Bayes rule Chain rule Marginalization General
SDS 321: Introduction to Probability and Statistics
 SDS 321: Introduction to Probability and Statistics Lecture 13: Expectation and Variance and joint distributions Purnamrita Sarkar Department of Statistics and Data Science The University of Texas at Austin
SDS 321: Introduction to Probability and Statistics Lecture 13: Expectation and Variance and joint distributions Purnamrita Sarkar Department of Statistics and Data Science The University of Texas at Austin
STATISTICAL METHODS IN AI/ML Vibhav Gogate The University of Texas at Dallas. Bayesian networks: Representation
 STATISTICAL METHODS IN AI/ML Vibhav Gogate The University of Texas at Dallas Bayesian networks: Representation Motivation Explicit representation of the joint distribution is unmanageable Computationally:
STATISTICAL METHODS IN AI/ML Vibhav Gogate The University of Texas at Dallas Bayesian networks: Representation Motivation Explicit representation of the joint distribution is unmanageable Computationally:
Toric statistical models: parametric and binomial representations
 AISM (2007) 59:727 740 DOI 10.1007/s10463-006-0079-z Toric statistical models: parametric and binomial representations Fabio Rapallo Received: 21 February 2005 / Revised: 1 June 2006 / Published online:
AISM (2007) 59:727 740 DOI 10.1007/s10463-006-0079-z Toric statistical models: parametric and binomial representations Fabio Rapallo Received: 21 February 2005 / Revised: 1 June 2006 / Published online:
Causal Discovery with Latent Variables: the Measurement Problem
 Causal Discovery with Latent Variables: the Measurement Problem Richard Scheines Carnegie Mellon University Peter Spirtes, Clark Glymour, Ricardo Silva, Steve Riese, Erich Kummerfeld, Renjie Yang, Max
Causal Discovery with Latent Variables: the Measurement Problem Richard Scheines Carnegie Mellon University Peter Spirtes, Clark Glymour, Ricardo Silva, Steve Riese, Erich Kummerfeld, Renjie Yang, Max
Introduction to Graphical Models
 Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
CS434a/541a: Pattern Recognition Prof. Olga Veksler. Lecture 1
 CS434a/541a: Pattern Recognition Prof. Olga Veksler Lecture 1 1 Outline of the lecture Syllabus Introduction to Pattern Recognition Review of Probability/Statistics 2 Syllabus Prerequisite Analysis of
CS434a/541a: Pattern Recognition Prof. Olga Veksler Lecture 1 1 Outline of the lecture Syllabus Introduction to Pattern Recognition Review of Probability/Statistics 2 Syllabus Prerequisite Analysis of
Prof. Dr. Lars Schmidt-Thieme, L. B. Marinho, K. Buza Information Systems and Machine Learning Lab (ISMLL), University of Hildesheim, Germany, Course
, University of Hildesheim, Germany, Course") Course on Bayesian Networks, winter term 2007 0/31 Bayesian Networks Bayesian Networks I. Bayesian Networks / 1. Probabilistic Independence and Separation in Graphs Prof. Dr. Lars Schmidt-Thieme, L. B.
Course on Bayesian Networks, winter term 2007 0/31 Bayesian Networks Bayesian Networks I. Bayesian Networks / 1. Probabilistic Independence and Separation in Graphs Prof. Dr. Lars Schmidt-Thieme, L. B.
Commuting birth-and-death processes
 Commuting birth-and-death processes Caroline Uhler Department of Statistics UC Berkeley (joint work with Steven N. Evans and Bernd Sturmfels) MSRI Workshop on Algebraic Statistics December 18, 2008 Birth-and-death
Commuting birth-and-death processes Caroline Uhler Department of Statistics UC Berkeley (joint work with Steven N. Evans and Bernd Sturmfels) MSRI Workshop on Algebraic Statistics December 18, 2008 Birth-and-death
Algebraic Classification of Small Bayesian Networks
 GROSTAT VI, Menton IUT STID p. 1 Algebraic Classification of Small Bayesian Networks Luis David Garcia, Michael Stillman, and Bernd Sturmfels lgarcia@math.vt.edu Virginia Tech GROSTAT VI, Menton IUT STID
GROSTAT VI, Menton IUT STID p. 1 Algebraic Classification of Small Bayesian Networks Luis David Garcia, Michael Stillman, and Bernd Sturmfels lgarcia@math.vt.edu Virginia Tech GROSTAT VI, Menton IUT STID
Bayesian Networks Representation
 Bayesian Networks Representation Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University March 19 th, 2007 Handwriting recognition Character recognition, e.g., kernel SVMs a c z rr r r
Bayesian Networks Representation Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University March 19 th, 2007 Handwriting recognition Character recognition, e.g., kernel SVMs a c z rr r r
Basic Sampling Methods
 Basic Sampling Methods Sargur Srihari srihari@cedar.buffalo.edu 1 1. Motivation Topics Intractability in ML How sampling can help 2. Ancestral Sampling Using BNs 3. Transforming a Uniform Distribution
Basic Sampling Methods Sargur Srihari srihari@cedar.buffalo.edu 1 1. Motivation Topics Intractability in ML How sampling can help 2. Ancestral Sampling Using BNs 3. Transforming a Uniform Distribution
Geometry of Phylogenetic Inference
 Geometry of Phylogenetic Inference Matilde Marcolli CS101: Mathematical and Computational Linguistics Winter 2015 References N. Eriksson, K. Ranestad, B. Sturmfels, S. Sullivant, Phylogenetic algebraic
Geometry of Phylogenetic Inference Matilde Marcolli CS101: Mathematical and Computational Linguistics Winter 2015 References N. Eriksson, K. Ranestad, B. Sturmfels, S. Sullivant, Phylogenetic algebraic
MATHEMATICAL ENGINEERING TECHNICAL REPORTS. Markov Bases for Two-way Subtable Sum Problems
 MATHEMATICAL ENGINEERING TECHNICAL REPORTS Markov Bases for Two-way Subtable Sum Problems Hisayuki HARA, Akimichi TAKEMURA and Ruriko YOSHIDA METR 27 49 August 27 DEPARTMENT OF MATHEMATICAL INFORMATICS
MATHEMATICAL ENGINEERING TECHNICAL REPORTS Markov Bases for Two-way Subtable Sum Problems Hisayuki HARA, Akimichi TAKEMURA and Ruriko YOSHIDA METR 27 49 August 27 DEPARTMENT OF MATHEMATICAL INFORMATICS
PROBABILITY THEORY REVIEW
 PROBABILITY THEORY REVIEW CMPUT 466/551 Martha White Fall, 2017 REMINDERS Assignment 1 is due on September 28 Thought questions 1 are due on September 21 Chapters 1-4, about 40 pages If you are printing,
PROBABILITY THEORY REVIEW CMPUT 466/551 Martha White Fall, 2017 REMINDERS Assignment 1 is due on September 28 Thought questions 1 are due on September 21 Chapters 1-4, about 40 pages If you are printing,
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 7 Approximate
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 12 Dynamical Models CS/CNS/EE 155 Andreas Krause Homework 3 out tonight Start early!! Announcements Project milestones due today Please email to TAs 2 Parameter learning
Probabilistic Graphical Models Lecture 12 Dynamical Models CS/CNS/EE 155 Andreas Krause Homework 3 out tonight Start early!! Announcements Project milestones due today Please email to TAs 2 Parameter learning
Review: mostly probability and some statistics
 Review: mostly probability and some statistics C2 1 Content robability (should know already) Axioms and properties Conditional probability and independence Law of Total probability and Bayes theorem Random
Review: mostly probability and some statistics C2 1 Content robability (should know already) Axioms and properties Conditional probability and independence Law of Total probability and Bayes theorem Random
Terminology. Experiment = Prior = Posterior =
 Review: probability RVs, events, sample space! Measures, distributions disjoint union property (law of total probability book calls this sum rule ) Sample v. population Law of large numbers Marginals,
Review: probability RVs, events, sample space! Measures, distributions disjoint union property (law of total probability book calls this sum rule ) Sample v. population Law of large numbers Marginals,
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Machine Learning 4771 Instructor: Tony Jebara Topic 11 Maximum Likelihood as Bayesian Inference Maximum A Posteriori Bayesian Gaussian Estimation Why Maximum Likelihood? So far, assumed max (log) likelihood
Bayesian Nonparametrics
 Bayesian Nonparametrics Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent
Bayesian Nonparametrics Peter Orbanz Columbia University PARAMETERS AND PATTERNS Parameters P(X θ) = Probability[data pattern] 3 2 1 0 1 2 3 5 0 5 Inference idea data = underlying pattern + independent
Axioms of separation
 Axioms of separation These notes discuss the same topic as Sections 31, 32, 33, 34, 35, and also 7, 10 of Munkres book. Some notions (hereditarily normal, perfectly normal, collectionwise normal, monotonically
Axioms of separation These notes discuss the same topic as Sections 31, 32, 33, 34, 35, and also 7, 10 of Munkres book. Some notions (hereditarily normal, perfectly normal, collectionwise normal, monotonically
Algebraic Statistics Tutorial I
 Algebraic Statistics Tutorial I Seth Sullivant North Carolina State University June 9, 2012 Seth Sullivant (NCSU) Algebraic Statistics June 9, 2012 1 / 34 Introduction to Algebraic Geometry Let R[p] =
Algebraic Statistics Tutorial I Seth Sullivant North Carolina State University June 9, 2012 Seth Sullivant (NCSU) Algebraic Statistics June 9, 2012 1 / 34 Introduction to Algebraic Geometry Let R[p] =
One-Parameter Processes, Usually Functions of Time
 Chapter 4 One-Parameter Processes, Usually Functions of Time Section 4.1 defines one-parameter processes, and their variations (discrete or continuous parameter, one- or two- sided parameter), including
Chapter 4 One-Parameter Processes, Usually Functions of Time Section 4.1 defines one-parameter processes, and their variations (discrete or continuous parameter, one- or two- sided parameter), including
CSC 412 (Lecture 4): Undirected Graphical Models
: Undirected Graphical Models") CSC 412 (Lecture 4): Undirected Graphical Models Raquel Urtasun University of Toronto Feb 2, 2016 R Urtasun (UofT) CSC 412 Feb 2, 2016 1 / 37 Today Undirected Graphical Models: Semantics of the graph:
CSC 412 (Lecture 4): Undirected Graphical Models Raquel Urtasun University of Toronto Feb 2, 2016 R Urtasun (UofT) CSC 412 Feb 2, 2016 1 / 37 Today Undirected Graphical Models: Semantics of the graph:
An Introduction to Reversible Jump MCMC for Bayesian Networks, with Application
 An Introduction to Reversible Jump MCMC for Bayesian Networks, with Application, CleverSet, Inc. STARMAP/DAMARS Conference Page 1 The research described in this presentation has been funded by the U.S.
An Introduction to Reversible Jump MCMC for Bayesian Networks, with Application, CleverSet, Inc. STARMAP/DAMARS Conference Page 1 The research described in this presentation has been funded by the U.S.
11. Learning graphical models
 Learning graphical models 11-1 11. Learning graphical models Maximum likelihood Parameter learning Structural learning Learning partially observed graphical models Learning graphical models 11-2 statistical
Learning graphical models 11-1 11. Learning graphical models Maximum likelihood Parameter learning Structural learning Learning partially observed graphical models Learning graphical models 11-2 statistical
CS491/691: Introduction to Aerial Robotics
 CS491/691: Introduction to Aerial Robotics Topic: State Estimation Dr. Kostas Alexis (CSE) World state (or system state) Belief state: Our belief/estimate of the world state World state: Real state of
CS491/691: Introduction to Aerial Robotics Topic: State Estimation Dr. Kostas Alexis (CSE) World state (or system state) Belief state: Our belief/estimate of the world state World state: Real state of
Recall from last time: Conditional probabilities. Lecture 2: Belief (Bayesian) networks. Bayes ball. Example (continued) Example: Inference problem
 networks. Bayes ball. Example (continued) Example: Inference problem") Recall from last time: Conditional probabilities Our probabilistic models will compute and manipulate conditional probabilities. Given two random variables X, Y, we denote by Lecture 2: Belief (Bayesian)
Recall from last time: Conditional probabilities Our probabilistic models will compute and manipulate conditional probabilities. Given two random variables X, Y, we denote by Lecture 2: Belief (Bayesian)
Introduction to Estimation Theory
 Introduction to Statistics IST, the slides, set 1 Introduction to Estimation Theory Richard D. Gill Dept. of Mathematics Leiden University September 18, 2009 Statistical Models Data, Parameters: Maths
Introduction to Statistics IST, the slides, set 1 Introduction to Estimation Theory Richard D. Gill Dept. of Mathematics Leiden University September 18, 2009 Statistical Models Data, Parameters: Maths
Large Deviations for Weakly Dependent Sequences: The Gärtner-Ellis Theorem
 Chapter 34 Large Deviations for Weakly Dependent Sequences: The Gärtner-Ellis Theorem This chapter proves the Gärtner-Ellis theorem, establishing an LDP for not-too-dependent processes taking values in
Chapter 34 Large Deviations for Weakly Dependent Sequences: The Gärtner-Ellis Theorem This chapter proves the Gärtner-Ellis theorem, establishing an LDP for not-too-dependent processes taking values in
Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart
 Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart 1 Motivation Imaging is a stochastic process: If we take all the different sources of
Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart 1 Motivation Imaging is a stochastic process: If we take all the different sources of
Introduction to Probabilistic Graphical Models: Exercises
 Introduction to Probabilistic Graphical Models: Exercises Cédric Archambeau Xerox Research Centre Europe cedric.archambeau@xrce.xerox.com Pascal Bootcamp Marseille, France, July 2010 Exercise 1: basics
Introduction to Probabilistic Graphical Models: Exercises Cédric Archambeau Xerox Research Centre Europe cedric.archambeau@xrce.xerox.com Pascal Bootcamp Marseille, France, July 2010 Exercise 1: basics
Algebraic Statistics progress report
 Algebraic Statistics progress report Joe Neeman December 11, 2008 1 A model for biochemical reaction networks We consider a model introduced by Craciun, Pantea and Rempala [2] for identifying biochemical
Algebraic Statistics progress report Joe Neeman December 11, 2008 1 A model for biochemical reaction networks We consider a model introduced by Craciun, Pantea and Rempala [2] for identifying biochemical
Lecture 10: Probability distributions TUESDAY, FEBRUARY 19, 2019
 Lecture 10: Probability distributions DANIEL WELLER TUESDAY, FEBRUARY 19, 2019 Agenda What is probability? (again) Describing probabilities (distributions) Understanding probabilities (expectation) Partial
Lecture 10: Probability distributions DANIEL WELLER TUESDAY, FEBRUARY 19, 2019 Agenda What is probability? (again) Describing probabilities (distributions) Understanding probabilities (expectation) Partial
Statistical Inference
 Statistical Inference Lecture 1: Probability Theory MING GAO DASE @ ECNU (for course related communications) mgao@dase.ecnu.edu.cn Sep. 11, 2018 Outline Introduction Set Theory Basics of Probability Theory
Statistical Inference Lecture 1: Probability Theory MING GAO DASE @ ECNU (for course related communications) mgao@dase.ecnu.edu.cn Sep. 11, 2018 Outline Introduction Set Theory Basics of Probability Theory
Connectedness. Proposition 2.2. The following are equivalent for a topological space (X, T ).
.") Connectedness 1 Motivation Connectedness is the sort of topological property that students love. Its definition is intuitive and easy to understand, and it is a powerful tool in proofs of well-known results.
Connectedness 1 Motivation Connectedness is the sort of topological property that students love. Its definition is intuitive and easy to understand, and it is a powerful tool in proofs of well-known results.
Basic Definitions: Indexed Collections and Random Functions
 Chapter 1 Basic Definitions: Indexed Collections and Random Functions Section 1.1 introduces stochastic processes as indexed collections of random variables. Section 1.2 builds the necessary machinery
Chapter 1 Basic Definitions: Indexed Collections and Random Functions Section 1.1 introduces stochastic processes as indexed collections of random variables. Section 1.2 builds the necessary machinery
Introduction to Algebraic Statistics
 Introduction to Algebraic Statistics Seth Sullivant North Carolina State University January 5, 2017 Seth Sullivant (NCSU) Algebraic Statistics January 5, 2017 1 / 28 What is Algebraic Statistics? Observation
Introduction to Algebraic Statistics Seth Sullivant North Carolina State University January 5, 2017 Seth Sullivant (NCSU) Algebraic Statistics January 5, 2017 1 / 28 What is Algebraic Statistics? Observation
Stat 643 Review of Probability Results (Cressie)
") Stat 643 Review of Probability Results (Cressie) Probability Space: ( HTT,, ) H is the set of outcomes T is a 5-algebra; subsets of H T is a probability measure mapping from T onto [0,] Measurable Space:
Stat 643 Review of Probability Results (Cressie) Probability Space: ( HTT,, ) H is the set of outcomes T is a 5-algebra; subsets of H T is a probability measure mapping from T onto [0,] Measurable Space:
Empirical Processes: General Weak Convergence Theory
 Empirical Processes: General Weak Convergence Theory Moulinath Banerjee May 18, 2010 1 Extended Weak Convergence The lack of measurability of the empirical process with respect to the sigma-field generated
Empirical Processes: General Weak Convergence Theory Moulinath Banerjee May 18, 2010 1 Extended Weak Convergence The lack of measurability of the empirical process with respect to the sigma-field generated
Axioms of Kleene Algebra
 Introduction to Kleene Algebra Lecture 2 CS786 Spring 2004 January 28, 2004 Axioms of Kleene Algebra In this lecture we give the formal definition of a Kleene algebra and derive some basic consequences.
Introduction to Kleene Algebra Lecture 2 CS786 Spring 2004 January 28, 2004 Axioms of Kleene Algebra In this lecture we give the formal definition of a Kleene algebra and derive some basic consequences.
HYPERBOLIC DYNAMICAL SYSTEMS AND THE NONCOMMUTATIVE INTEGRATION THEORY OF CONNES ABSTRACT
 HYPERBOLIC DYNAMICAL SYSTEMS AND THE NONCOMMUTATIVE INTEGRATION THEORY OF CONNES Jan Segert ABSTRACT We examine hyperbolic differentiable dynamical systems in the context of Connes noncommutative integration
HYPERBOLIC DYNAMICAL SYSTEMS AND THE NONCOMMUTATIVE INTEGRATION THEORY OF CONNES Jan Segert ABSTRACT We examine hyperbolic differentiable dynamical systems in the context of Connes noncommutative integration
Basics on Probability. Jingrui He 09/11/2007
 Basics on Probability Jingrui He 09/11/2007 Coin Flips You flip a coin Head with probability 0.5 You flip 100 coins How many heads would you expect Coin Flips cont. You flip a coin Head with probability
Basics on Probability Jingrui He 09/11/2007 Coin Flips You flip a coin Head with probability 0.5 You flip 100 coins How many heads would you expect Coin Flips cont. You flip a coin Head with probability
Conditional Independence
 H. Nooitgedagt Conditional Independence Bachelorscriptie, 18 augustus 2008 Scriptiebegeleider: prof.dr. R. Gill Mathematisch Instituut, Universiteit Leiden Preface In this thesis I ll discuss Conditional
H. Nooitgedagt Conditional Independence Bachelorscriptie, 18 augustus 2008 Scriptiebegeleider: prof.dr. R. Gill Mathematisch Instituut, Universiteit Leiden Preface In this thesis I ll discuss Conditional
The main results about probability measures are the following two facts:
 Chapter 2 Probability measures The main results about probability measures are the following two facts: Theorem 2.1 (extension). If P is a (continuous) probability measure on a field F 0 then it has a
Chapter 2 Probability measures The main results about probability measures are the following two facts: Theorem 2.1 (extension). If P is a (continuous) probability measure on a field F 0 then it has a
Artificial Intelligence Bayesian Networks
 Artificial Intelligence Bayesian Networks Stephan Dreiseitl FH Hagenberg Software Engineering & Interactive Media Stephan Dreiseitl (Hagenberg/SE/IM) Lecture 11: Bayesian Networks Artificial Intelligence
Artificial Intelligence Bayesian Networks Stephan Dreiseitl FH Hagenberg Software Engineering & Interactive Media Stephan Dreiseitl (Hagenberg/SE/IM) Lecture 11: Bayesian Networks Artificial Intelligence
Probabilistic Graphical Models
 2016 Robert Nowak Probabilistic Graphical Models 1 Introduction We have focused mainly on linear models for signals, in particular the subspace model x = Uθ, where U is a n k matrix and θ R k is a vector
2016 Robert Nowak Probabilistic Graphical Models 1 Introduction We have focused mainly on linear models for signals, in particular the subspace model x = Uθ, where U is a n k matrix and θ R k is a vector
Reminders. Thought questions should be submitted on eclass. Please list the section related to the thought question
 Linear regression Reminders Thought questions should be submitted on eclass Please list the section related to the thought question If it is a more general, open-ended question not exactly related to a
Linear regression Reminders Thought questions should be submitted on eclass Please list the section related to the thought question If it is a more general, open-ended question not exactly related to a
4.1 Notation and probability review
 Directed and undirected graphical models Fall 2015 Lecture 4 October 21st Lecturer: Simon Lacoste-Julien Scribe: Jaime Roquero, JieYing Wu 4.1 Notation and probability review 4.1.1 Notations Let us recall
Directed and undirected graphical models Fall 2015 Lecture 4 October 21st Lecturer: Simon Lacoste-Julien Scribe: Jaime Roquero, JieYing Wu 4.1 Notation and probability review 4.1.1 Notations Let us recall
Examples of Dual Spaces from Measure Theory
 Chapter 9 Examples of Dual Spaces from Measure Theory We have seen that L (, A, µ) is a Banach space for any measure space (, A, µ). We will extend that concept in the following section to identify an
Chapter 9 Examples of Dual Spaces from Measure Theory We have seen that L (, A, µ) is a Banach space for any measure space (, A, µ). We will extend that concept in the following section to identify an
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Multivariate Gaussians Mark Schmidt University of British Columbia Winter 2019 Last Time: Multivariate Gaussian http://personal.kenyon.edu/hartlaub/mellonproject/bivariate2.html
CPSC 540: Machine Learning Multivariate Gaussians Mark Schmidt University of British Columbia Winter 2019 Last Time: Multivariate Gaussian http://personal.kenyon.edu/hartlaub/mellonproject/bivariate2.html
Preliminaries Bayesian Networks Graphoid Axioms d-separation Wrap-up. Bayesian Networks. Brandon Malone
 Preliminaries Graphoid Axioms d-separation Wrap-up Much of this material is adapted from Chapter 4 of Darwiche s book January 23, 2014 Preliminaries Graphoid Axioms d-separation Wrap-up 1 Preliminaries
Preliminaries Graphoid Axioms d-separation Wrap-up Much of this material is adapted from Chapter 4 of Darwiche s book January 23, 2014 Preliminaries Graphoid Axioms d-separation Wrap-up 1 Preliminaries
Example A. Define X = number of heads in ten tosses of a coin. What are the values that X may assume?
 Stat 400, section.1-.2 Random Variables & Probability Distributions notes by Tim Pilachowski For a given situation, or experiment, observations are made and data is recorded. A sample space S must contain
Stat 400, section.1-.2 Random Variables & Probability Distributions notes by Tim Pilachowski For a given situation, or experiment, observations are made and data is recorded. A sample space S must contain
9 Forward-backward algorithm, sum-product on factor graphs
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 9 Forward-backward algorithm, sum-product on factor graphs The previous
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 9 Forward-backward algorithm, sum-product on factor graphs The previous
Review of Probability Mark Craven and David Page Computer Sciences 760.
 Review of Probability Mark Craven and David Page Computer Sciences 760 www.biostat.wisc.edu/~craven/cs760/ Goals for the lecture you should understand the following concepts definition of probability random
Review of Probability Mark Craven and David Page Computer Sciences 760 www.biostat.wisc.edu/~craven/cs760/ Goals for the lecture you should understand the following concepts definition of probability random
Chapter 6 Expectation and Conditional Expectation. Lectures Definition 6.1. Two random variables defined on a probability space are said to be
 Chapter 6 Expectation and Conditional Expectation Lectures 24-30 In this chapter, we introduce expected value or the mean of a random variable. First we define expectation for discrete random variables
Chapter 6 Expectation and Conditional Expectation Lectures 24-30 In this chapter, we introduce expected value or the mean of a random variable. First we define expectation for discrete random variables
7 Gaussian Discriminant Analysis (including QDA and LDA)
") 36 Jonathan Richard Shewchuk 7 Gaussian Discriminant Analysis (including QDA and LDA) GAUSSIAN DISCRIMINANT ANALYSIS Fundamental assumption: each class comes from normal distribution (Gaussian). X N(µ,
36 Jonathan Richard Shewchuk 7 Gaussian Discriminant Analysis (including QDA and LDA) GAUSSIAN DISCRIMINANT ANALYSIS Fundamental assumption: each class comes from normal distribution (Gaussian). X N(µ,
Motivation. Bayesian Networks in Epistemology and Philosophy of Science Lecture. Overview. Organizational Issues
 Bayesian Networks in Epistemology and Philosophy of Science Lecture 1: Bayesian Networks Center for Logic and Philosophy of Science Tilburg University, The Netherlands Formal Epistemology Course Northern
Bayesian Networks in Epistemology and Philosophy of Science Lecture 1: Bayesian Networks Center for Logic and Philosophy of Science Tilburg University, The Netherlands Formal Epistemology Course Northern
Toric Fiber Products
 Toric Fiber Products Seth Sullivant North Carolina State University June 8, 2011 Seth Sullivant (NCSU) Toric Fiber Products June 8, 2011 1 / 26 Families of Ideals Parametrized by Graphs Let G be a finite
Toric Fiber Products Seth Sullivant North Carolina State University June 8, 2011 Seth Sullivant (NCSU) Toric Fiber Products June 8, 2011 1 / 26 Families of Ideals Parametrized by Graphs Let G be a finite
The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Randomized Algorithms
 Randomized Algorithms Prof. Tapio Elomaa tapio.elomaa@tut.fi Course Basics A new 4 credit unit course Part of Theoretical Computer Science courses at the Department of Mathematics There will be 4 hours
Randomized Algorithms Prof. Tapio Elomaa tapio.elomaa@tut.fi Course Basics A new 4 credit unit course Part of Theoretical Computer Science courses at the Department of Mathematics There will be 4 hours
Introduction to the Mathematical and Statistical Foundations of Econometrics Herman J. Bierens Pennsylvania State University
 Introduction to the Mathematical and Statistical Foundations of Econometrics 1 Herman J. Bierens Pennsylvania State University November 13, 2003 Revised: March 15, 2004 2 Contents Preface Chapter 1: Probability
Introduction to the Mathematical and Statistical Foundations of Econometrics 1 Herman J. Bierens Pennsylvania State University November 13, 2003 Revised: March 15, 2004 2 Contents Preface Chapter 1: Probability
Section 10: Counting the Elements of a Finite Group
 Section 10: Counting the Elements of a Finite Group Let G be a group and H a subgroup. Because the right cosets are the family of equivalence classes with respect to an equivalence relation on G, it follows
Section 10: Counting the Elements of a Finite Group Let G be a group and H a subgroup. Because the right cosets are the family of equivalence classes with respect to an equivalence relation on G, it follows
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Fall 2017 STAT 532 Homework Peter Hoff. 1. Let P be a probability measure on a collection of sets A.
 1. Let P be a probability measure on a collection of sets A. (a) For each n N, let H n be a set in A such that H n H n+1. Show that P (H n ) monotonically converges to P ( k=1 H k) as n. (b) For each n
1. Let P be a probability measure on a collection of sets A. (a) For each n N, let H n be a set in A such that H n H n+1. Show that P (H n ) monotonically converges to P ( k=1 H k) as n. (b) For each n
Preliminary draft only: please check for final version
 ARE211, Fall2012 CALCULUS4: THU, OCT 11, 2012 PRINTED: AUGUST 22, 2012 (LEC# 15) Contents 3. Univariate and Multivariate Differentiation (cont) 1 3.6. Taylor s Theorem (cont) 2 3.7. Applying Taylor theory:
ARE211, Fall2012 CALCULUS4: THU, OCT 11, 2012 PRINTED: AUGUST 22, 2012 (LEC# 15) Contents 3. Univariate and Multivariate Differentiation (cont) 1 3.6. Taylor s Theorem (cont) 2 3.7. Applying Taylor theory:
Polyhedral Conditions for the Nonexistence of the MLE for Hierarchical Log-linear Models
 Polyhedral Conditions for the Nonexistence of the MLE for Hierarchical Log-linear Models Nicholas Eriksson Department of Mathematics University of California, Berkeley Alessandro Rinaldo Department of
Polyhedral Conditions for the Nonexistence of the MLE for Hierarchical Log-linear Models Nicholas Eriksson Department of Mathematics University of California, Berkeley Alessandro Rinaldo Department of
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
ECE 275B Homework # 1 Solutions Winter 2018
 ECE 275B Homework # 1 Solutions Winter 2018 1. (a) Because x i are assumed to be independent realizations of a continuous random variable, it is almost surely (a.s.) 1 the case that x 1 < x 2 < < x n Thus,
ECE 275B Homework # 1 Solutions Winter 2018 1. (a) Because x i are assumed to be independent realizations of a continuous random variable, it is almost surely (a.s.) 1 the case that x 1 < x 2 < < x n Thus,
Nonparametric Bayesian Methods (Gaussian Processes)
") [70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
[70240413 Statistical Machine Learning, Spring, 2015] Nonparametric Bayesian Methods (Gaussian Processes) Jun Zhu dcszj@mail.tsinghua.edu.cn http://bigml.cs.tsinghua.edu.cn/~jun State Key Lab of Intelligent
Solutions Homework 6
 1 Solutions Homework 6 October 26, 2015 Solution to Exercise 1.5.9: Part (a) is easy: we know E[X Y ] = k if X = k, a.s. The function φ(y) k is Borel measurable from the range space of Y to, and E[X Y
1 Solutions Homework 6 October 26, 2015 Solution to Exercise 1.5.9: Part (a) is easy: we know E[X Y ] = k if X = k, a.s. The function φ(y) k is Borel measurable from the range space of Y to, and E[X Y