Data-Intensive Distributed Computing
|
|
|
- Dennis Gibbs
- 5 years ago
- Views:
Transcription


1 Data-Intensive Distributed Computing CS 451/ /631 (Winter 2018) Part 9: Real-Time Data Analytics (2/2) March 29, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are available at This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States See for details
2 Since last time Storm/Heron Gives you pipes, but you gotta connect everything up yourself Spark Streaming Gives you RDDs, transformations and windowing but no event/processing time distinction Beam Gives you transformations and windowing, event/processing time distinction but too complex
3 Spark Structured Streaming Stream Processing Frameworks Source: Wikipedia (River)

4 Step 1: From RDDs to DataFrames Step 2: From bounded to unbounded tables Source: Spark Structured Streaming Documentation


5 Source: Spark Structured Streaming Documentation

6 Source: Spark Structured Streaming Documentation

7 Source: Spark Structured Streaming Documentation

8 Source: Spark Structured Streaming Documentation
9 Interlude Source: Wikipedia (River)
10 Streams Processing Challenges Inherent challenges Latency requirements Space bounds System challenges Bursty behavior and load balancing Out-of-order message delivery and non-determinism Consistency semantics (at most once, exactly once, at least once)
11 Algorithmic Solutions Throw away data Sampling Accepting some approximations Hashing
12 Reservoir Sampling Task: select s elements from a stream of size N with uniform probability N can be very very large We might not even know what N is! (infinite stream) Solution: Reservoir sampling Store first s elements For the k-th element thereafter, keep with probability s/k (randomly discard an existing element) Example: s = 10 Keep first 10 elements 11th element: keep with 10/11 12th element: keep with 10/12
13 Reservoir Sampling: How does it work? Example: s = 10 Keep first 10 elements 11th element: keep with 10/11 If we decide to keep it: sampled uniformly by definition probability existing item is discarded: 10/11 1/10 = 1/11 probability existing item survives: 10/11 General case: at the (k + 1)th element Probability of selecting each item up until now is s/k Probability existing item is discarded: s/(k+1) 1/s = 1/(k + 1) Probability existing item survives: k/(k + 1) Probability each item survives to (k + 1)th round: (s/k) k/(k + 1) = s/(k + 1)
14 Hashing for Three Common Tasks Cardinality estimation What s the cardinality of set S? How many unique visitors to this page? HashSet Set membership Is x a member of set S? Has this user seen this ad before? HashSet Frequency estimation How many times have we observed x? How many queries has this user issued? HashMap HLL counter Bloom Filter CMS
15 HyperLogLog Counter Task: cardinality estimation of set size() number of unique elements in the set Observation: hash each item and examine the hash code On expectation, 1/2 of the hash codes will start with 0 On expectation, 1/4 of the hash codes will start with 00 On expectation, 1/8 of the hash codes will start with 000 On expectation, 1/16 of the hash codes will start with 0000 How do we take advantage of this observation?
16 Bloom Filters Task: keep track of set membership put(x) insert x into the set contains(x) yes if x is a member of the set Components m-bit bit vector k hash functions: h 1 h k
17 Bloom Filters: put put x h 1 (x) = 2 h 2 (x) = 5 h 3 (x) =
18 Bloom Filters: put put x
19 Bloom Filters: contains contains x h 1 (x) = 2 h 2 (x) = 5 h 3 (x) =
20 Bloom Filters: contains contains x h 1 (x) = 2 h 2 (x) = 5 h 3 (x) = 11 AND A[h 1 (x)] A[h 2 (x)] A[h 3 (x)] = YES
21 Bloom Filters: contains contains y h 1 (y) = 2 h 2 (y) = 6 h 3 (y) =
22 Bloom Filters: contains contains y h 1 (y) = 2 h 2 (y) = 6 h 3 (y) = 9 AND A[h 1 (y)] A[h 2 (y)] A[h 3 (y)] = NO What s going on here?
23 Bloom Filters Error properties: contains(x) False positives possible No false negatives Usage Constraints: capacity, error probability Tunable parameters: size of bit vector m, number of hash functions k
24 Count-Min Sketches Task: frequency estimation put(x) increment count of x by one get(x) returns the frequency of x Components m by k array of counters k hash functions: h 1 h k m k
25 Count-Min Sketches: put put x h 1 (x) = 2 h 2 (x) = 5 h 3 (x) = 11 h 4 (x) =
26 Count-Min Sketches: put put x
27 Count-Min Sketches: put put x h 1 (x) = 2 h 2 (x) = 5 h 3 (x) = 11 h 4 (x) =
28 Count-Min Sketches: put put x
29 Count-Min Sketches: put put y h 1 (y) = 6 h 2 (y) = 5 h 3 (y) = 12 h 4 (y) =
30 Count-Min Sketches: put put y
31 Count-Min Sketches: get get x h 1 (x) = 2 h 2 (x) = 5 h 3 (x) = 11 h 4 (x) =
32 Count-Min Sketches: get get x h 1 (x) = 2 h 2 (x) = 5 h 3 (x) = 11 h 4 (x) = 4 A[h 1 (x)] MIN A[h 2 (x)] A[h 3 (x)] = 2 A[h 4 (x)]
33 Count-Min Sketches: get get y h 1 (y) = 6 h 2 (y) = 5 h 3 (y) = 12 h 4 (y) =
34 Count-Min Sketches: get get y h 1 (y) = 6 h 2 (y) = 5 h 3 (y) = 12 h 4 (y) = 2 A[h 1 (y)] MIN A[h 2 (y)] A[h 3 (y)] = 1 A[h 4 (y)]
35 Count-Min Sketches Error properties: get(x) Reasonable estimation of heavy-hitters Frequent over-estimation of tail Usage Constraints: number of distinct events, distribution of events, error bounds Tunable parameters: number of counters m and hash functions k, size of counters
36 Hashing for Three Common Tasks Cardinality estimation What s the cardinality of set S? How many unique visitors to this page? HashSet Set membership Is x a member of set S? Has this user seen this ad before? HashSet Frequency estimation How many times have we observed x? How many queries has this user issued? HashMap HLL counter Bloom Filter CMS

37 Stream Processing Frameworks Source: Wikipedia (River)




 My data")

38 users Frontend Backend OLTP database Kafka, Heron, Spark Streaming, Spark Structured Streaming, ETL (Extract, Transform, and Load) My data is a day old Data Warehouse BI tools analysts Yay!
 What about our")
39 Source: Wikipedia (Cake) What about our cake?
40 Hybrid Online/Batch Processing Example: count historical clicks and clicks in real time Kafka Online processing Online results online batch merging client HDFS Batch processing Batch results
41 Hybrid Online/Batch Processing Example: count historical clicks and clicks in real time Kafka read Storm topology write Online results query online batch client library client Hadoop job Batch results query ingest HDFS read source 1 write source 2 source 3 store 1 store 2 store 3
42 λ (I hate this.)
43 Hybrid Online/Batch Processing Example: count historical clicks and clicks in real time Kafka read Storm topology write Online results query online batch client library client Hadoop job Batch results query ingest HDFS read source 1 write source 2 source 3 store 1 store 2 store 3
44 Summingbird A domain-specific language (in Scala) designed to integrate batch and online MapReduce computations Idea #1:Algebraic structures provide the basis for seamless integration of batch and online processing Idea #2: For many tasks, close enough is good enough Probabilistic data structures as monoids Boykin, Ritchie, O Connell, and Lin. Summingbird: A Framework for Integrating Batch and Online MapReduce Computations. PVLDB 7(13): , 2014.
45 Batch and Online MapReduce map flatmap[t, U](fn: T => List[U]): List[U] map[t, U](fn: T => U): List[U] filter[t](fn: T => Boolean): List[T] reduce sumbykey
46 Idea #1:Algebraic structures provide the basis for seamless integration of batch and online processing Semigroup = ( M, ) : M M M, s.t., m 1, m 2, m 3 M (m 1 m 2 ) m 3 = m 1 (m 2 m 3 ) Monoid = Semigroup + identity ε s.t., ε m = m ε = m, m M Commutative Monoid = Monoid + commutativity m 1, m 2 M, m 1 m 2 = m 2 m 1 Simplest example: integers with + (addition)
47 Idea #1:Algebraic structures provide the basis for seamless integration of batch and online processing Summingbird values must be at least semigroups (most are commutative monoids in practice) Power of associativity = You can put the parentheses anywhere! ( a b c d e f ) ((((( a b ) c ) d ) e ) f ) (( a b c ) ( d e f )) Batch = Hadoop Online = Storm Mini-batches
![Summingbird Word Count def wordcount[p <: Platform[P]] (source: Producer[P, String], store: P#Store[String, Long]) = source.](/docs-images/95/122522080/images/48-0.jpg "flatmap { sentence => towords(sentence).map(_ -> 1L) }.")
, Scalding.")
48 Summingbird Word Count def wordcount[p <: Platform[P]] (source: Producer[P, String], store: P#Store[String, Long]) = source.flatmap { sentence => towords(sentence).map(_ -> 1L) }.sumbykey(store) where data comes from where data goes map reduce Run on Scalding (Cascading/Hadoop) Scalding.run { read from HDFS wordcount[scalding]( Scalding.source[Tweet]("source_data"), Scalding.store[String, Long]("count_out") ) } write to HDFS Run on Storm Storm.run { read from message queue wordcount[storm]( new TweetSpout(), new MemcacheStore[String, Long] ) write to KV store }


49 Input Input Input Spout Map Map Map Bolt Bolt Bolt Reduce Reduce Bolt Bolt Output Output memcached
50 Boring monoids addition, multiplication, max, min moments (mean, variance, etc.) sets tuples of monoids hashmaps with monoid values
51 Interesting monoids Bloom filters (set membership) HyperLogLog counters (cardinality estimation) Count-min sketches (event counts) Idea #2: For many tasks, close enough is good enough!
52 Cheat Sheet Set membership Set cardinality Frequency count Exact set set hashmap Approximate Bloom filter hyperloglog counter count-min sketches
53 Example: Count queries by hour Exact with hashmaps def wordcount[p <: Platform[P]] (source: Producer[P, Query], store: P#Store[Long, Map[String, Long]]) = source.flatmap { query => (query.gethour, Map(query.getQuery -> 1L)) }.sumbykey(store) Approximate with CMS def wordcount[p <: Platform[P]] (source: Producer[P, Query], store: P#Store[Long, SketchMap[String, Long]]) (implicit countmonoid: SketchMapMonoid[String, Long]) = source.flatmap { query => (query.gethour, countmonoid.create((query.getquery, 1L))) }.sumbykey(store)
54 Hybrid Online/Batch Processing Example: count historical clicks and clicks in real time Kafka read Storm topology write Online results query online batch Summingbird program client library client Hadoop job Batch results query ingest HDFS read source 1 write source 2 source 3 store 1 store 2 store 3
55 TSAR, a TimeSeries AggregatoR! Source:
56 Hybrid Online/Batch Processing Example: count historical clicks and clicks in real time Kafka Online processing Online results online batch Summingbird program merging client HDFS Batch processing Batch results
57 Hybrid Online/Batch Processing Example: count historical clicks and clicks in real time Kafka Online processing Online results client Idea: everything is streaming Batch processing is just streaming through a historic dataset!
58 Everything is Streaming! Kafka Kafka Streams Results client StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> textlines = builder.stream("textlinestopic"); KTable<String, Long> wordcounts = textlines.flatmapvalues(textline -> Arrays.asList(textLine.toLowerCase().split("\\W+"))).groupBy((key, word) -> word).count(materialized.<string, Long, KeyValueStore<Bytes, byte[]>>as("counts-store")); wordcounts.tostream().to("wordswithcountstopic", Produced.with(Serdes.String(), Serdes.Long())); KafkaStreams streams = new KafkaStreams(builder.build(), config); streams.start();
59 κ (I hate this too.)
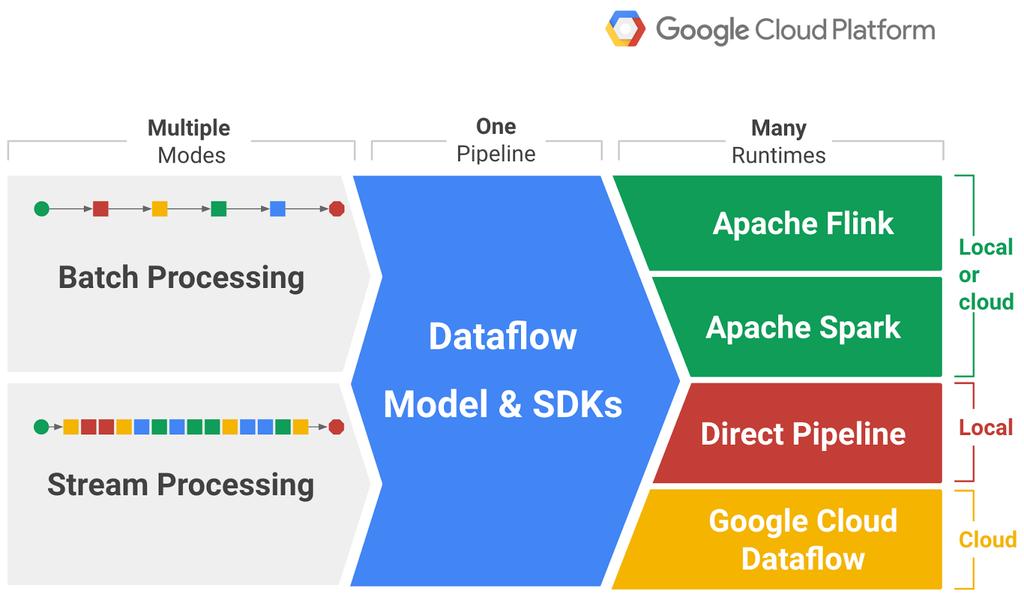
60 The Vision Source:
61 Processing Bounded Datasets Pipeline p = Pipeline.create(options); p.apply(textio.read.from("gs://your/input/")).apply(flatmapelements.via((string word) -> Arrays.asList(word.split("[^a-zA-Z']+")))).apply(Filter.by((String word) ->!word.isempty())).apply(count.perelement()).apply(mapelements.via((kv<string, Long> wordcount) -> wordcount.getkey() + ": " + wordcount.getvalue())).apply(textio.write.to("gs://your/output/"));
62 Processing Unbounded Datasets Pipeline p = Pipeline.create(options); p.apply(kafkaio.read("tweets").withtimestampfn(new TweetTimestampFunction()).withWatermarkFn(kv -> Instant.now().minus(Duration.standardMinutes(2)))).apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))).triggering(AtWatermark().withEarlyFirings(AtPeriod(Duration.standardMinutes(1))).withLateFirings(AtCount(1))).accumulatingAndRetractingFiredPanes()).apply(FlatMapElements.via((String word) -> Arrays.asList(word.split("[^a-zA-Z']+")))).apply(Filter.by((String word) ->!word.isempty())).apply(count.perelement()).apply(kafkaio.write("counts")) Where in event time? When in processing time? How do refines relate?

63 Source: flickr
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 12: Real-Time Data Analytics (2/2) March 31, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 12: Real-Time Data Analytics (2/2) March 31, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/26/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 More algorithms
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/26/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 More algorithms
Acceptably inaccurate. Probabilistic data structures
 Acceptably inaccurate Probabilistic data structures Hello Today's talk Motivation Bloom filters Count-Min Sketch HyperLogLog Motivation Tape HDD SSD Memory Tape HDD SSD Memory Speed Tape HDD SSD Memory
Acceptably inaccurate Probabilistic data structures Hello Today's talk Motivation Bloom filters Count-Min Sketch HyperLogLog Motivation Tape HDD SSD Memory Tape HDD SSD Memory Speed Tape HDD SSD Memory
Introduction to Randomized Algorithms III
 Introduction to Randomized Algorithms III Joaquim Madeira Version 0.1 November 2017 U. Aveiro, November 2017 1 Overview Probabilistic counters Counting with probability 1 / 2 Counting with probability
Introduction to Randomized Algorithms III Joaquim Madeira Version 0.1 November 2017 U. Aveiro, November 2017 1 Overview Probabilistic counters Counting with probability 1 / 2 Counting with probability
4/26/2017. More algorithms for streams: Each element of data stream is a tuple Given a list of keys S Determine which tuples of stream are in S
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
12 Count-Min Sketch and Apriori Algorithm (and Bloom Filters)
") 12 Count-Min Sketch and Apriori Algorithm (and Bloom Filters) Many streaming algorithms use random hashing functions to compress data. They basically randomly map some data items on top of each other.
12 Count-Min Sketch and Apriori Algorithm (and Bloom Filters) Many streaming algorithms use random hashing functions to compress data. They basically randomly map some data items on top of each other.
CS341 info session is on Thu 3/1 5pm in Gates415. CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS341 info session is on Thu 3/1 5pm in Gates415 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/28/18 Jure Leskovec, Stanford CS246: Mining Massive Datasets,
CS341 info session is on Thu 3/1 5pm in Gates415 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/28/18 Jure Leskovec, Stanford CS246: Mining Massive Datasets,
15-451/651: Design & Analysis of Algorithms September 13, 2018 Lecture #6: Streaming Algorithms last changed: August 30, 2018
 15-451/651: Design & Analysis of Algorithms September 13, 2018 Lecture #6: Streaming Algorithms last changed: August 30, 2018 Today we ll talk about a topic that is both very old (as far as computer science
15-451/651: Design & Analysis of Algorithms September 13, 2018 Lecture #6: Streaming Algorithms last changed: August 30, 2018 Today we ll talk about a topic that is both very old (as far as computer science
MapReduce in Spark. Krzysztof Dembczyński. Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland
 Poznań University of Technology, Poland") MapReduce in Spark Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Software Development Technologies Master studies, second semester
MapReduce in Spark Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Software Development Technologies Master studies, second semester
An Optimal Algorithm for l 1 -Heavy Hitters in Insertion Streams and Related Problems
 An Optimal Algorithm for l 1 -Heavy Hitters in Insertion Streams and Related Problems Arnab Bhattacharyya, Palash Dey, and David P. Woodruff Indian Institute of Science, Bangalore {arnabb,palash}@csa.iisc.ernet.in
An Optimal Algorithm for l 1 -Heavy Hitters in Insertion Streams and Related Problems Arnab Bhattacharyya, Palash Dey, and David P. Woodruff Indian Institute of Science, Bangalore {arnabb,palash}@csa.iisc.ernet.in
Window-aware Load Shedding for Aggregation Queries over Data Streams
 Window-aware Load Shedding for Aggregation Queries over Data Streams Nesime Tatbul Stan Zdonik Talk Outline Background Load shedding in Aurora Windowed aggregation queries Window-aware load shedding Experimental
Window-aware Load Shedding for Aggregation Queries over Data Streams Nesime Tatbul Stan Zdonik Talk Outline Background Load shedding in Aurora Windowed aggregation queries Window-aware load shedding Experimental
CS246 Final Exam. March 16, :30AM - 11:30AM
 CS246 Final Exam March 16, 2016 8:30AM - 11:30AM Name : SUID : I acknowledge and accept the Stanford Honor Code. I have neither given nor received unpermitted help on this examination. (signed) Directions
CS246 Final Exam March 16, 2016 8:30AM - 11:30AM Name : SUID : I acknowledge and accept the Stanford Honor Code. I have neither given nor received unpermitted help on this examination. (signed) Directions
Distributed Architectures
 Distributed Architectures Software Architecture VO/KU (707023/707024) Roman Kern KTI, TU Graz 2015-01-21 Roman Kern (KTI, TU Graz) Distributed Architectures 2015-01-21 1 / 64 Outline 1 Introduction 2 Independent
Distributed Architectures Software Architecture VO/KU (707023/707024) Roman Kern KTI, TU Graz 2015-01-21 Roman Kern (KTI, TU Graz) Distributed Architectures 2015-01-21 1 / 64 Outline 1 Introduction 2 Independent
Lecture and notes by: Alessio Guerrieri and Wei Jin Bloom filters and Hashing
 Bloom filters and Hashing 1 Introduction The Bloom filter, conceived by Burton H. Bloom in 1970, is a space-efficient probabilistic data structure that is used to test whether an element is a member of
Bloom filters and Hashing 1 Introduction The Bloom filter, conceived by Burton H. Bloom in 1970, is a space-efficient probabilistic data structure that is used to test whether an element is a member of
MapReduce in Spark. Krzysztof Dembczyński. Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland
 Poznań University of Technology, Poland") MapReduce in Spark Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Software Development Technologies Master studies, first semester
MapReduce in Spark Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Software Development Technologies Master studies, first semester
CS5314 Randomized Algorithms. Lecture 15: Balls, Bins, Random Graphs (Hashing)
") CS5314 Randomized Algorithms Lecture 15: Balls, Bins, Random Graphs (Hashing) 1 Objectives Study various hashing schemes Apply balls-and-bins model to analyze their performances 2 Chain Hashing Suppose
CS5314 Randomized Algorithms Lecture 15: Balls, Bins, Random Graphs (Hashing) 1 Objectives Study various hashing schemes Apply balls-and-bins model to analyze their performances 2 Chain Hashing Suppose
ECEN 689 Special Topics in Data Science for Communications Networks
 ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 5 Optimizing Fixed Size Samples Sampling as
ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 5 Optimizing Fixed Size Samples Sampling as
Part 1: Hashing and Its Many Applications
 1 Part 1: Hashing and Its Many Applications Sid C-K Chau Chi-Kin.Chau@cl.cam.ac.u http://www.cl.cam.ac.u/~cc25/teaching Why Randomized Algorithms? 2 Randomized Algorithms are algorithms that mae random
1 Part 1: Hashing and Its Many Applications Sid C-K Chau Chi-Kin.Chau@cl.cam.ac.u http://www.cl.cam.ac.u/~cc25/teaching Why Randomized Algorithms? 2 Randomized Algorithms are algorithms that mae random
Lecture 2. Frequency problems
 1 / 43 Lecture 2. Frequency problems Ricard Gavaldà MIRI Seminar on Data Streams, Spring 2015 Contents 2 / 43 1 Frequency problems in data streams 2 Approximating inner product 3 Computing frequency moments
1 / 43 Lecture 2. Frequency problems Ricard Gavaldà MIRI Seminar on Data Streams, Spring 2015 Contents 2 / 43 1 Frequency problems in data streams 2 Approximating inner product 3 Computing frequency moments
Data Intensive Computing Handout 11 Spark: Transitive Closure
 Data Intensive Computing Handout 11 Spark: Transitive Closure from random import Random spark/transitive_closure.py num edges = 3000 num vertices = 500 rand = Random(42) def generate g raph ( ) : edges
Data Intensive Computing Handout 11 Spark: Transitive Closure from random import Random spark/transitive_closure.py num edges = 3000 num vertices = 500 rand = Random(42) def generate g raph ( ) : edges
CS 591, Lecture 7 Data Analytics: Theory and Applications Boston University
 CS 591, Lecture 7 Data Analytics: Theory and Applications Boston University Babis Tsourakakis February 13th, 2017 Bloom Filter Approximate membership problem Highly space-efficient randomized data structure
CS 591, Lecture 7 Data Analytics: Theory and Applications Boston University Babis Tsourakakis February 13th, 2017 Bloom Filter Approximate membership problem Highly space-efficient randomized data structure
Ad Placement Strategies
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
CSCB63 Winter Week 11 Bloom Filters. Anna Bretscher. March 30, / 13
 CSCB63 Winter 2019 Week 11 Bloom Filters Anna Bretscher March 30, 2019 1 / 13 Today Bloom Filters Definition Expected Complexity Applications 2 / 13 Bloom Filters (Specification) A bloom filter is a probabilistic
CSCB63 Winter 2019 Week 11 Bloom Filters Anna Bretscher March 30, 2019 1 / 13 Today Bloom Filters Definition Expected Complexity Applications 2 / 13 Bloom Filters (Specification) A bloom filter is a probabilistic
Algorithms for Data Science
 Algorithms for Data Science CSOR W4246 Eleni Drinea Computer Science Department Columbia University Tuesday, December 1, 2015 Outline 1 Recap Balls and bins 2 On randomized algorithms 3 Saving space: hashing-based
Algorithms for Data Science CSOR W4246 Eleni Drinea Computer Science Department Columbia University Tuesday, December 1, 2015 Outline 1 Recap Balls and bins 2 On randomized algorithms 3 Saving space: hashing-based
1 Probability Review. CS 124 Section #8 Hashing, Skip Lists 3/20/17. Expectation (weighted average): the expectation of a random quantity X is:
: the expectation of a random quantity X is:") CS 24 Section #8 Hashing, Skip Lists 3/20/7 Probability Review Expectation (weighted average): the expectation of a random quantity X is: x= x P (X = x) For each value x that X can take on, we look at
CS 24 Section #8 Hashing, Skip Lists 3/20/7 Probability Review Expectation (weighted average): the expectation of a random quantity X is: x= x P (X = x) For each value x that X can take on, we look at
University of New Mexico Department of Computer Science. Final Examination. CS 561 Data Structures and Algorithms Fall, 2013
 University of New Mexico Department of Computer Science Final Examination CS 561 Data Structures and Algorithms Fall, 2013 Name: Email: This exam lasts 2 hours. It is closed book and closed notes wing
University of New Mexico Department of Computer Science Final Examination CS 561 Data Structures and Algorithms Fall, 2013 Name: Email: This exam lasts 2 hours. It is closed book and closed notes wing
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 3: Query Processing Query Processing Decomposition Localization Optimization CS 347 Notes 3 2 Decomposition Same as in centralized system
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 3: Query Processing Query Processing Decomposition Localization Optimization CS 347 Notes 3 2 Decomposition Same as in centralized system
How Philippe Flipped Coins to Count Data
 1/18 How Philippe Flipped Coins to Count Data Jérémie Lumbroso LIP6 / INRIA Rocquencourt December 16th, 2011 0. DATA STREAMING ALGORITHMS Stream: a (very large) sequence S over (also very large) domain
1/18 How Philippe Flipped Coins to Count Data Jérémie Lumbroso LIP6 / INRIA Rocquencourt December 16th, 2011 0. DATA STREAMING ALGORITHMS Stream: a (very large) sequence S over (also very large) domain
Lecture Note 2. 1 Bonferroni Principle. 1.1 Idea. 1.2 Want. Material covered today is from Chapter 1 and chapter 4
 Lecture Note 2 Material covere toay is from Chapter an chapter 4 Bonferroni Principle. Iea Get an iea the frequency of events when things are ranom billion = 0 9 Each person has a % chance to stay in a
Lecture Note 2 Material covere toay is from Chapter an chapter 4 Bonferroni Principle. Iea Get an iea the frequency of events when things are ranom billion = 0 9 Each person has a % chance to stay in a
CS246 Final Exam, Winter 2011
 CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
CS246 Final Exam, Winter 2011 1. Your name and student ID. Name:... Student ID:... 2. I agree to comply with Stanford Honor Code. Signature:... 3. There should be 17 numbered pages in this exam (including
RAPPOR: Randomized Aggregatable Privacy- Preserving Ordinal Response
 RAPPOR: Randomized Aggregatable Privacy- Preserving Ordinal Response Úlfar Erlingsson, Vasyl Pihur, Aleksandra Korolova Google & USC Presented By: Pat Pannuto RAPPOR, What is is good for? (Absolutely something!)
RAPPOR: Randomized Aggregatable Privacy- Preserving Ordinal Response Úlfar Erlingsson, Vasyl Pihur, Aleksandra Korolova Google & USC Presented By: Pat Pannuto RAPPOR, What is is good for? (Absolutely something!)
Bloom Filter Redux. CS 270 Combinatorial Algorithms and Data Structures. UC Berkeley, Spring 2011
 Bloom Filter Redux Matthias Vallentin Gene Pang CS 270 Combinatorial Algorithms and Data Structures UC Berkeley, Spring 2011 Inspiration Our background: network security, databases We deal with massive
Bloom Filter Redux Matthias Vallentin Gene Pang CS 270 Combinatorial Algorithms and Data Structures UC Berkeley, Spring 2011 Inspiration Our background: network security, databases We deal with massive
B669 Sublinear Algorithms for Big Data
 B669 Sublinear Algorithms for Big Data Qin Zhang 1-1 2-1 Part 1: Sublinear in Space The model and challenge The data stream model (Alon, Matias and Szegedy 1996) a n a 2 a 1 RAM CPU Why hard? Cannot store
B669 Sublinear Algorithms for Big Data Qin Zhang 1-1 2-1 Part 1: Sublinear in Space The model and challenge The data stream model (Alon, Matias and Szegedy 1996) a n a 2 a 1 RAM CPU Why hard? Cannot store
CS425: Algorithms for Web Scale Data
 CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org Challenges
CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org Challenges
A General-Purpose Counting Filter: Making Every Bit Count. Prashant Pandey, Michael A. Bender, Rob Johnson, Rob Patro Stony Brook University, NY
 A General-Purpose Counting Filter: Making Every Bit Count Prashant Pandey, Michael A. Bender, Rob Johnson, Rob Patro Stony Brook University, NY Approximate Membership Query (AMQ) insert(x) ismember(x)
A General-Purpose Counting Filter: Making Every Bit Count Prashant Pandey, Michael A. Bender, Rob Johnson, Rob Patro Stony Brook University, NY Approximate Membership Query (AMQ) insert(x) ismember(x)
Lecture 10. Sublinear Time Algorithms (contd) CSC2420 Allan Borodin & Nisarg Shah 1
 CSC2420 Allan Borodin & Nisarg Shah 1") Lecture 10 Sublinear Time Algorithms (contd) CSC2420 Allan Borodin & Nisarg Shah 1 Recap Sublinear time algorithms Deterministic + exact: binary search Deterministic + inexact: estimating diameter in a
Lecture 10 Sublinear Time Algorithms (contd) CSC2420 Allan Borodin & Nisarg Shah 1 Recap Sublinear time algorithms Deterministic + exact: binary search Deterministic + inexact: estimating diameter in a
Data Sketches for Disaggregated Subset Sum and Frequent Item Estimation
 Data Sketches for Disaggregated Subset Sum and Frequent Item Estimation Daniel Ting Tableau Software Seattle, Washington dting@tableau.com ABSTRACT We introduce and study a new data sketch for processing
Data Sketches for Disaggregated Subset Sum and Frequent Item Estimation Daniel Ting Tableau Software Seattle, Washington dting@tableau.com ABSTRACT We introduce and study a new data sketch for processing
CS 347. Parallel and Distributed Data Processing. Spring Notes 11: MapReduce
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 11: MapReduce Motivation Distribution makes simple computations complex Communication Load balancing Fault tolerance Not all applications
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 11: MapReduce Motivation Distribution makes simple computations complex Communication Load balancing Fault tolerance Not all applications
Project 2: Hadoop PageRank Cloud Computing Spring 2017
 Project 2: Hadoop PageRank Cloud Computing Spring 2017 Professor Judy Qiu Goal This assignment provides an illustration of PageRank algorithms and Hadoop. You will then blend these applications by implementing
Project 2: Hadoop PageRank Cloud Computing Spring 2017 Professor Judy Qiu Goal This assignment provides an illustration of PageRank algorithms and Hadoop. You will then blend these applications by implementing
CS 473: Algorithms. Ruta Mehta. Spring University of Illinois, Urbana-Champaign. Ruta (UIUC) CS473 1 Spring / 32
 CS473 1 Spring / 32") CS 473: Algorithms Ruta Mehta University of Illinois, Urbana-Champaign Spring 2018 Ruta (UIUC) CS473 1 Spring 2018 1 / 32 CS 473: Algorithms, Spring 2018 Universal Hashing Lecture 10 Feb 15, 2018 Most
CS 473: Algorithms Ruta Mehta University of Illinois, Urbana-Champaign Spring 2018 Ruta (UIUC) CS473 1 Spring 2018 1 / 32 CS 473: Algorithms, Spring 2018 Universal Hashing Lecture 10 Feb 15, 2018 Most
CS5112: Algorithms and Data Structures for Applications
 CS5112: Algorithms and Data Structures for Applications Lecture 14: Exponential decay; convolution Ramin Zabih Some content from: Piotr Indyk; Wikipedia/Google image search; J. Leskovec, A. Rajaraman,
CS5112: Algorithms and Data Structures for Applications Lecture 14: Exponential decay; convolution Ramin Zabih Some content from: Piotr Indyk; Wikipedia/Google image search; J. Leskovec, A. Rajaraman,
Big Data. Big data arises in many forms: Common themes:
 Big Data Big data arises in many forms: Physical Measurements: from science (physics, astronomy) Medical data: genetic sequences, detailed time series Activity data: GPS location, social network activity
Big Data Big data arises in many forms: Physical Measurements: from science (physics, astronomy) Medical data: genetic sequences, detailed time series Activity data: GPS location, social network activity
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Approximate counting: count-min data structure. Problem definition
 Approximate counting: count-min data structure G. Cormode and S. Muthukrishhan: An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms 55 (2005) 58-75. Problem
Approximate counting: count-min data structure G. Cormode and S. Muthukrishhan: An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms 55 (2005) 58-75. Problem
Multi-join Query Evaluation on Big Data Lecture 2
 Multi-join Query Evaluation on Big Data Lecture 2 Dan Suciu March, 2015 Dan Suciu Multi-Joins Lecture 2 March, 2015 1 / 34 Multi-join Query Evaluation Outline Part 1 Optimal Sequential Algorithms. Thursday
Multi-join Query Evaluation on Big Data Lecture 2 Dan Suciu March, 2015 Dan Suciu Multi-Joins Lecture 2 March, 2015 1 / 34 Multi-join Query Evaluation Outline Part 1 Optimal Sequential Algorithms. Thursday
As mentioned, we will relax the conditions of our dictionary data structure. The relaxations we
 CSE 203A: Advanced Algorithms Prof. Daniel Kane Lecture : Dictionary Data Structures and Load Balancing Lecture Date: 10/27 P Chitimireddi Recap This lecture continues the discussion of dictionary data
CSE 203A: Advanced Algorithms Prof. Daniel Kane Lecture : Dictionary Data Structures and Load Balancing Lecture Date: 10/27 P Chitimireddi Recap This lecture continues the discussion of dictionary data
Lecture 3 Sept. 4, 2014
 CS 395T: Sublinear Algorithms Fall 2014 Prof. Eric Price Lecture 3 Sept. 4, 2014 Scribe: Zhao Song In today s lecture, we will discuss the following problems: 1. Distinct elements 2. Turnstile model 3.
CS 395T: Sublinear Algorithms Fall 2014 Prof. Eric Price Lecture 3 Sept. 4, 2014 Scribe: Zhao Song In today s lecture, we will discuss the following problems: 1. Distinct elements 2. Turnstile model 3.
Computing the Entropy of a Stream
 Computing the Entropy of a Stream To appear in SODA 2007 Graham Cormode graham@research.att.com Amit Chakrabarti Dartmouth College Andrew McGregor U. Penn / UCSD Outline Introduction Entropy Upper Bound
Computing the Entropy of a Stream To appear in SODA 2007 Graham Cormode graham@research.att.com Amit Chakrabarti Dartmouth College Andrew McGregor U. Penn / UCSD Outline Introduction Entropy Upper Bound
Bloom Filters, general theory and variants
 Bloom Filters: general theory and variants G. Caravagna caravagn@cli.di.unipi.it Information Retrieval Wherever a list or set is used, and space is a consideration, a Bloom Filter should be considered.
Bloom Filters: general theory and variants G. Caravagna caravagn@cli.di.unipi.it Information Retrieval Wherever a list or set is used, and space is a consideration, a Bloom Filter should be considered.
Count-Min Tree Sketch: Approximate counting for NLP
 Count-Min Tree Sketch: Approximate counting for NLP Guillaume Pitel, Geoffroy Fouquier, Emmanuel Marchand and Abdul Mouhamadsultane exensa firstname.lastname@exensa.com arxiv:64.5492v [cs.ir] 9 Apr 26
Count-Min Tree Sketch: Approximate counting for NLP Guillaume Pitel, Geoffroy Fouquier, Emmanuel Marchand and Abdul Mouhamadsultane exensa firstname.lastname@exensa.com arxiv:64.5492v [cs.ir] 9 Apr 26
Foundations of Query Languages
 Foundations of Query Languages SS 2011 2. 2. Foundations of Query Languages Dr. Fang Wei Lehrstuhl für Datenbanken und Informationssysteme Universität Freiburg SS 2011 Dr. Fang Wei 30. Mai 2011 Seite 1
Foundations of Query Languages SS 2011 2. 2. Foundations of Query Languages Dr. Fang Wei Lehrstuhl für Datenbanken und Informationssysteme Universität Freiburg SS 2011 Dr. Fang Wei 30. Mai 2011 Seite 1
Problem 1: (Chernoff Bounds via Negative Dependence - from MU Ex 5.15)
") Problem 1: Chernoff Bounds via Negative Dependence - from MU Ex 5.15) While deriving lower bounds on the load of the maximum loaded bin when n balls are thrown in n bins, we saw the use of negative dependence.
Problem 1: Chernoff Bounds via Negative Dependence - from MU Ex 5.15) While deriving lower bounds on the load of the maximum loaded bin when n balls are thrown in n bins, we saw the use of negative dependence.
V.4 MapReduce. 1. System Architecture 2. Programming Model 3. Hadoop. Based on MRS Chapter 4 and RU Chapter 2 IR&DM 13/ 14 !74
 V.4 MapReduce. System Architecture 2. Programming Model 3. Hadoop Based on MRS Chapter 4 and RU Chapter 2!74 Why MapReduce? Large clusters of commodity computers (as opposed to few supercomputers) Challenges:
V.4 MapReduce. System Architecture 2. Programming Model 3. Hadoop Based on MRS Chapter 4 and RU Chapter 2!74 Why MapReduce? Large clusters of commodity computers (as opposed to few supercomputers) Challenges:
CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #15: Mining Streams 2
 Data Management Systems. B. Aditya Prakash Lecture #15: Mining Streams 2") CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #15: Mining Streams 2 Today s Lecture More algorithms for streams: (1) Filtering a data stream: Bloom filters Select elements with property
CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #15: Mining Streams 2 Today s Lecture More algorithms for streams: (1) Filtering a data stream: Bloom filters Select elements with property
Topics in Computer Mathematics
 Random Number Generation (Uniform random numbers) Introduction We frequently need some way to generate numbers that are random (by some criteria), especially in computer science. Simulations of natural
Random Number Generation (Uniform random numbers) Introduction We frequently need some way to generate numbers that are random (by some criteria), especially in computer science. Simulations of natural
6 Filtering and Streaming
 Casus ubique valet; semper tibi pendeat hamus: Quo minime credas gurgite, piscis erit. [Luck affects everything. Let your hook always be cast. Where you least expect it, there will be a fish.] Publius
Casus ubique valet; semper tibi pendeat hamus: Quo minime credas gurgite, piscis erit. [Luck affects everything. Let your hook always be cast. Where you least expect it, there will be a fish.] Publius
Frequent Itemsets and Association Rule Mining. Vinay Setty Slides credit:
 Frequent Itemsets and Association Rule Mining Vinay Setty vinay.j.setty@uis.no Slides credit: http://www.mmds.org/ Association Rule Discovery Supermarket shelf management Market-basket model: Goal: Identify
Frequent Itemsets and Association Rule Mining Vinay Setty vinay.j.setty@uis.no Slides credit: http://www.mmds.org/ Association Rule Discovery Supermarket shelf management Market-basket model: Goal: Identify
Distributed Summaries
 Distributed Summaries Graham Cormode graham@research.att.com Pankaj Agarwal(Duke) Zengfeng Huang (HKUST) Jeff Philips (Utah) Zheiwei Wei (HKUST) Ke Yi (HKUST) Summaries Summaries allow approximate computations:
Distributed Summaries Graham Cormode graham@research.att.com Pankaj Agarwal(Duke) Zengfeng Huang (HKUST) Jeff Philips (Utah) Zheiwei Wei (HKUST) Ke Yi (HKUST) Summaries Summaries allow approximate computations:
Streaming - 2. Bloom Filters, Distinct Item counting, Computing moments. credits:www.mmds.org.
 Streaming - 2 Bloom Filters, Distinct Item counting, Computing moments credits:www.mmds.org http://www.mmds.org Outline More algorithms for streams: 2 Outline More algorithms for streams: (1) Filtering
Streaming - 2 Bloom Filters, Distinct Item counting, Computing moments credits:www.mmds.org http://www.mmds.org Outline More algorithms for streams: 2 Outline More algorithms for streams: (1) Filtering
Lecture 24: Bloom Filters. Wednesday, June 2, 2010
 Lecture 24: Bloom Filters Wednesday, June 2, 2010 1 Topics for the Final SQL Conceptual Design (BCNF) Transactions Indexes Query execution and optimization Cardinality Estimation Parallel Databases 2 Lecture
Lecture 24: Bloom Filters Wednesday, June 2, 2010 1 Topics for the Final SQL Conceptual Design (BCNF) Transactions Indexes Query execution and optimization Cardinality Estimation Parallel Databases 2 Lecture
Lecture 1 September 3, 2013
 CS 229r: Algorithms for Big Data Fall 2013 Prof. Jelani Nelson Lecture 1 September 3, 2013 Scribes: Andrew Wang and Andrew Liu 1 Course Logistics The problem sets can be found on the course website: http://people.seas.harvard.edu/~minilek/cs229r/index.html
CS 229r: Algorithms for Big Data Fall 2013 Prof. Jelani Nelson Lecture 1 September 3, 2013 Scribes: Andrew Wang and Andrew Liu 1 Course Logistics The problem sets can be found on the course website: http://people.seas.harvard.edu/~minilek/cs229r/index.html
Chapter Summary. Sets The Language of Sets Set Operations Set Identities Functions Types of Functions Operations on Functions Computability
 Chapter 2 1 Chapter Summary Sets The Language of Sets Set Operations Set Identities Functions Types of Functions Operations on Functions Computability Sequences and Summations Types of Sequences Summation
Chapter 2 1 Chapter Summary Sets The Language of Sets Set Operations Set Identities Functions Types of Functions Operations on Functions Computability Sequences and Summations Types of Sequences Summation
Some notes on streaming algorithms continued
 U.C. Berkeley CS170: Algorithms Handout LN-11-9 Christos Papadimitriou & Luca Trevisan November 9, 016 Some notes on streaming algorithms continued Today we complete our quick review of streaming algorithms.
U.C. Berkeley CS170: Algorithms Handout LN-11-9 Christos Papadimitriou & Luca Trevisan November 9, 016 Some notes on streaming algorithms continued Today we complete our quick review of streaming algorithms.
Bloom Filters and Locality-Sensitive Hashing
 Randomized Algorithms, Summer 2016 Bloom Filters and Locality-Sensitive Hashing Instructor: Thomas Kesselheim and Kurt Mehlhorn 1 Notation Lecture 4 (6 pages) When e talk about the probability of an event,
Randomized Algorithms, Summer 2016 Bloom Filters and Locality-Sensitive Hashing Instructor: Thomas Kesselheim and Kurt Mehlhorn 1 Notation Lecture 4 (6 pages) When e talk about the probability of an event,
Research Collection. JSONiq on Spark. Master Thesis. ETH Library. Author(s): Irimescu, Stefan. Publication Date: 2018
: Irimescu, Stefan. Publication Date: 2018") Research Collection Master Thesis JSONiq on Spark Author(s): Irimescu, Stefan Publication Date: 2018 Permanent Link: https://doi.org/10.3929/ethz-b-000272416 Rights / License: In Copyright - Non-Commercial
Research Collection Master Thesis JSONiq on Spark Author(s): Irimescu, Stefan Publication Date: 2018 Permanent Link: https://doi.org/10.3929/ethz-b-000272416 Rights / License: In Copyright - Non-Commercial
CSE 190, Great ideas in algorithms: Pairwise independent hash functions
 CSE 190, Great ideas in algorithms: Pairwise independent hash functions 1 Hash functions The goal of hash functions is to map elements from a large domain to a small one. Typically, to obtain the required
CSE 190, Great ideas in algorithms: Pairwise independent hash functions 1 Hash functions The goal of hash functions is to map elements from a large domain to a small one. Typically, to obtain the required
REVIEW QUESTIONS. Chapter 1: Foundations: Sets, Logic, and Algorithms
 REVIEW QUESTIONS Chapter 1: Foundations: Sets, Logic, and Algorithms 1. Why can t a Venn diagram be used to prove a statement about sets? 2. Suppose S is a set with n elements. Explain why the power set
REVIEW QUESTIONS Chapter 1: Foundations: Sets, Logic, and Algorithms 1. Why can t a Venn diagram be used to prove a statement about sets? 2. Suppose S is a set with n elements. Explain why the power set
Data Analytics Beyond OLAP. Prof. Yanlei Diao
 Data Analytics Beyond OLAP Prof. Yanlei Diao OPERATIONAL DBs DB 1 DB 2 DB 3 EXTRACT TRANSFORM LOAD (ETL) METADATA STORE DATA WAREHOUSE SUPPORTS OLAP DATA MINING INTERACTIVE DATA EXPLORATION Overview of
Data Analytics Beyond OLAP Prof. Yanlei Diao OPERATIONAL DBs DB 1 DB 2 DB 3 EXTRACT TRANSFORM LOAD (ETL) METADATA STORE DATA WAREHOUSE SUPPORTS OLAP DATA MINING INTERACTIVE DATA EXPLORATION Overview of
Causal Consistency for Geo-Replicated Cloud Storage under Partial Replication
 Causal Consistency for Geo-Replicated Cloud Storage under Partial Replication Min Shen, Ajay D. Kshemkalyani, TaYuan Hsu University of Illinois at Chicago Min Shen, Ajay D. Kshemkalyani, TaYuan Causal
Causal Consistency for Geo-Replicated Cloud Storage under Partial Replication Min Shen, Ajay D. Kshemkalyani, TaYuan Hsu University of Illinois at Chicago Min Shen, Ajay D. Kshemkalyani, TaYuan Causal
Bloom Filters, Minhashes, and Other Random Stuff
 Bloom Filters, Minhashes, and Other Random Stuff Brian Brubach University of Maryland, College Park StringBio 2018, University of Central Florida What? Probabilistic Space-efficient Fast Not exact Why?
Bloom Filters, Minhashes, and Other Random Stuff Brian Brubach University of Maryland, College Park StringBio 2018, University of Central Florida What? Probabilistic Space-efficient Fast Not exact Why?
Introduction to Algorithms March 10, 2010 Massachusetts Institute of Technology Spring 2010 Professors Piotr Indyk and David Karger Quiz 1
 Introduction to Algorithms March 10, 2010 Massachusetts Institute of Technology 6.006 Spring 2010 Professors Piotr Indyk and David Karger Quiz 1 Quiz 1 Do not open this quiz booklet until directed to do
Introduction to Algorithms March 10, 2010 Massachusetts Institute of Technology 6.006 Spring 2010 Professors Piotr Indyk and David Karger Quiz 1 Quiz 1 Do not open this quiz booklet until directed to do
A Deterministic Algorithm for Summarizing Asynchronous Streams over a Sliding Window
 A Deterministic Algorithm for Summarizing Asynchronous Streams over a Sliding Window Costas Busch 1 and Srikanta Tirthapura 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY
A Deterministic Algorithm for Summarizing Asynchronous Streams over a Sliding Window Costas Busch 1 and Srikanta Tirthapura 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY
2.6 Complexity Theory for Map-Reduce. Star Joins 2.6. COMPLEXITY THEORY FOR MAP-REDUCE 51
 2.6. COMPLEXITY THEORY FOR MAP-REDUCE 51 Star Joins A common structure for data mining of commercial data is the star join. For example, a chain store like Walmart keeps a fact table whose tuples each
2.6. COMPLEXITY THEORY FOR MAP-REDUCE 51 Star Joins A common structure for data mining of commercial data is the star join. For example, a chain store like Walmart keeps a fact table whose tuples each
1 Approximate Quantiles and Summaries
 CS 598CSC: Algorithms for Big Data Lecture date: Sept 25, 2014 Instructor: Chandra Chekuri Scribe: Chandra Chekuri Suppose we have a stream a 1, a 2,..., a n of objects from an ordered universe. For simplicity
CS 598CSC: Algorithms for Big Data Lecture date: Sept 25, 2014 Instructor: Chandra Chekuri Scribe: Chandra Chekuri Suppose we have a stream a 1, a 2,..., a n of objects from an ordered universe. For simplicity
Algorithms for NLP. Language Modeling III. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
11 Heavy Hitters Streaming Majority
 11 Heavy Hitters A core mining problem is to find items that occur more than one would expect. These may be called outliers, anomalies, or other terms. Statistical models can be layered on top of or underneath
11 Heavy Hitters A core mining problem is to find items that occur more than one would expect. These may be called outliers, anomalies, or other terms. Statistical models can be layered on top of or underneath
A Cloud Computing Workflow for Scalable Integration of Remote Sensing and Social Media Data in Urban Studies
 A Cloud Computing Workflow for Scalable Integration of Remote Sensing and Social Media Data in Urban Studies Aiman Soliman1, Kiumars Soltani1, Junjun Yin1, Balaji Subramaniam2, Pierre Riteau2, Kate Keahey2,
A Cloud Computing Workflow for Scalable Integration of Remote Sensing and Social Media Data in Urban Studies Aiman Soliman1, Kiumars Soltani1, Junjun Yin1, Balaji Subramaniam2, Pierre Riteau2, Kate Keahey2,
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Global Grids and the Future of Geospatial Computing. Kevin M. Sahr Department of Computer Science Southern Oregon University
 Global Grids and the Future of Geospatial Computing Kevin M. Sahr Department of Computer Science Southern Oregon University 1 Kevin Sahr - November 11, 2013 The Situation Geospatial computing has achieved
Global Grids and the Future of Geospatial Computing Kevin M. Sahr Department of Computer Science Southern Oregon University 1 Kevin Sahr - November 11, 2013 The Situation Geospatial computing has achieved
Query Analyzer for Apache Pig
 Imperial College London Department of Computing Individual Project: Final Report Query Analyzer for Apache Pig Author: Robert Yau Zhou 00734205 (robert.zhou12@imperial.ac.uk) Supervisor: Dr Peter McBrien
Imperial College London Department of Computing Individual Project: Final Report Query Analyzer for Apache Pig Author: Robert Yau Zhou 00734205 (robert.zhou12@imperial.ac.uk) Supervisor: Dr Peter McBrien
Communication-Efficient Computation on Distributed Noisy Datasets. Qin Zhang Indiana University Bloomington
 Communication-Efficient Computation on Distributed Noisy Datasets Qin Zhang Indiana University Bloomington SPAA 15 June 15, 2015 1-1 Model of computation The coordinator model: k sites and 1 coordinator.
Communication-Efficient Computation on Distributed Noisy Datasets Qin Zhang Indiana University Bloomington SPAA 15 June 15, 2015 1-1 Model of computation The coordinator model: k sites and 1 coordinator.
2 How many distinct elements are in a stream?
 Dealing with Massive Data January 31, 2011 Lecture 2: Distinct Element Counting Lecturer: Sergei Vassilvitskii Scribe:Ido Rosen & Yoonji Shin 1 Introduction We begin by defining the stream formally. Definition
Dealing with Massive Data January 31, 2011 Lecture 2: Distinct Element Counting Lecturer: Sergei Vassilvitskii Scribe:Ido Rosen & Yoonji Shin 1 Introduction We begin by defining the stream formally. Definition
Large-Scale Behavioral Targeting
 Large-Scale Behavioral Targeting Ye Chen, Dmitry Pavlov, John Canny ebay, Yandex, UC Berkeley (This work was conducted at Yahoo! Labs.) June 30, 2009 Chen et al. (KDD 09) Large-Scale Behavioral Targeting
Large-Scale Behavioral Targeting Ye Chen, Dmitry Pavlov, John Canny ebay, Yandex, UC Berkeley (This work was conducted at Yahoo! Labs.) June 30, 2009 Chen et al. (KDD 09) Large-Scale Behavioral Targeting
Introduction to Hashtables
 Introduction to HashTables Boise State University March 5th 2015 Hash Tables: What Problem Do They Solve What Problem Do They Solve? Why not use arrays for everything? 1 Arrays can be very wasteful: Example
Introduction to HashTables Boise State University March 5th 2015 Hash Tables: What Problem Do They Solve What Problem Do They Solve? Why not use arrays for everything? 1 Arrays can be very wasteful: Example
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Foundations of Data Mining
 Foundations of Data Mining http://www.cohenwang.com/edith/dataminingclass2017 Instructors: Haim Kaplan Amos Fiat Lecture 1 1 Course logistics Tuesdays 16:00-19:00, Sherman 002 Slides for (most or all)
Foundations of Data Mining http://www.cohenwang.com/edith/dataminingclass2017 Instructors: Haim Kaplan Amos Fiat Lecture 1 1 Course logistics Tuesdays 16:00-19:00, Sherman 002 Slides for (most or all)
Automata-Based String Analysis
 1 / 46 Automata-Based String Analysis Model Counting Tevfik Bultan, Abdulbaki Aydin, Lucas Bang Verification Laboratory http://vlab.cs.ucsb.edu Department of Computer Science Overview Overview String Constraints
1 / 46 Automata-Based String Analysis Model Counting Tevfik Bultan, Abdulbaki Aydin, Lucas Bang Verification Laboratory http://vlab.cs.ucsb.edu Department of Computer Science Overview Overview String Constraints
Evaluating Physical, Chemical, and Biological Impacts from the Savannah Harbor Expansion Project Cooperative Agreement Number W912HZ
 Evaluating Physical, Chemical, and Biological Impacts from the Savannah Harbor Expansion Project Cooperative Agreement Number W912HZ-13-2-0013 Annual Report FY 2018 Submitted by Sergio Bernardes and Marguerite
Evaluating Physical, Chemical, and Biological Impacts from the Savannah Harbor Expansion Project Cooperative Agreement Number W912HZ-13-2-0013 Annual Report FY 2018 Submitted by Sergio Bernardes and Marguerite
Locally Differentially Private Protocols for Frequency Estimation. Tianhao Wang, Jeremiah Blocki, Ninghui Li, Somesh Jha
 Locally Differentially Private Protocols for Frequency Estimation Tianhao Wang, Jeremiah Blocki, Ninghui Li, Somesh Jha Differential Privacy Differential Privacy Classical setting Differential Privacy
Locally Differentially Private Protocols for Frequency Estimation Tianhao Wang, Jeremiah Blocki, Ninghui Li, Somesh Jha Differential Privacy Differential Privacy Classical setting Differential Privacy
Mining Data Streams. The Stream Model. The Stream Model Sliding Windows Counting 1 s
 Mining Data Streams The Stream Model Sliding Windows Counting 1 s 1 The Stream Model Data enters at a rapid rate from one or more input ports. The system cannot store the entire stream. How do you make
Mining Data Streams The Stream Model Sliding Windows Counting 1 s 1 The Stream Model Data enters at a rapid rate from one or more input ports. The system cannot store the entire stream. How do you make
Lower Bound Techniques for Multiparty Communication Complexity
 Lower Bound Techniques for Multiparty Communication Complexity Qin Zhang Indiana University Bloomington Based on works with Jeff Phillips, Elad Verbin and David Woodruff 1-1 The multiparty number-in-hand
Lower Bound Techniques for Multiparty Communication Complexity Qin Zhang Indiana University Bloomington Based on works with Jeff Phillips, Elad Verbin and David Woodruff 1-1 The multiparty number-in-hand
Arthur-Merlin Streaming Complexity
 Weizmann Institute of Science Joint work with Ran Raz Data Streams The data stream model is an abstraction commonly used for algorithms that process network traffic using sublinear space. A data stream
Weizmann Institute of Science Joint work with Ran Raz Data Streams The data stream model is an abstraction commonly used for algorithms that process network traffic using sublinear space. A data stream
:s ej2mttlm-(iii+j2mlnm )(J21nm/m-lnm/m)
(J21nm/m-lnm/m)") BALLS, BINS, AND RANDOM GRAPHS We use the Chernoff bound for the Poisson distribution (Theorem 5.4) to bound this probability, writing the bound as Pr(X 2: x) :s ex-ill-x In(x/m). For x = m + J2m In m,
BALLS, BINS, AND RANDOM GRAPHS We use the Chernoff bound for the Poisson distribution (Theorem 5.4) to bound this probability, writing the bound as Pr(X 2: x) :s ex-ill-x In(x/m). For x = m + J2m In m,
Random Sampling on Big Data: Techniques and Applications Ke Yi
 : Techniques and Applications Ke Yi Hong Kong University of Science and Technology yike@ust.hk Big Data in one slide The 3 V s: Volume Velocity Variety Integers, real numbers Points in a multi-dimensional
: Techniques and Applications Ke Yi Hong Kong University of Science and Technology yike@ust.hk Big Data in one slide The 3 V s: Volume Velocity Variety Integers, real numbers Points in a multi-dimensional
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Map-Reduce Denis Helic KTI, TU Graz Oct 24, 2013 Denis Helic (KTI, TU Graz) KDDM1 Oct 24, 2013 1 / 82 Big picture: KDDM Probability Theory Linear Algebra
Knowledge Discovery and Data Mining 1 (VO) (707.003) Map-Reduce Denis Helic KTI, TU Graz Oct 24, 2013 Denis Helic (KTI, TU Graz) KDDM1 Oct 24, 2013 1 / 82 Big picture: KDDM Probability Theory Linear Algebra
CS 347 Distributed Databases and Transaction Processing Notes03: Query Processing
 CS 347 Distributed Databases and Transaction Processing Notes03: Query Processing Hector Garcia-Molina Zoltan Gyongyi CS 347 Notes 03 1 Query Processing! Decomposition! Localization! Optimization CS 347
CS 347 Distributed Databases and Transaction Processing Notes03: Query Processing Hector Garcia-Molina Zoltan Gyongyi CS 347 Notes 03 1 Query Processing! Decomposition! Localization! Optimization CS 347
9 Nondeterministic Turing Machines
 Caveat lector: This is the zeroth (draft) edition of this lecture note. In particular, some topics still need to be written. Please send bug reports and suggestions to jeffe@illinois.edu. If first you
Caveat lector: This is the zeroth (draft) edition of this lecture note. In particular, some topics still need to be written. Please send bug reports and suggestions to jeffe@illinois.edu. If first you
CS 125 Section #12 (More) Probability and Randomized Algorithms 11/24/14. For random numbers X which only take on nonnegative integer values, E(X) =
 Probability and Randomized Algorithms 11/24/14. For random numbers X which only take on nonnegative integer values, E(X) =") CS 125 Section #12 (More) Probability and Randomized Algorithms 11/24/14 1 Probability First, recall a couple useful facts from last time about probability: Linearity of expectation: E(aX + by ) = ae(x)
CS 125 Section #12 (More) Probability and Randomized Algorithms 11/24/14 1 Probability First, recall a couple useful facts from last time about probability: Linearity of expectation: E(aX + by ) = ae(x)
Meelis Kull Autumn Meelis Kull - Autumn MTAT Data Mining - Lecture 05
 Meelis Kull meelis.kull@ut.ee Autumn 2017 1 Sample vs population Example task with red and black cards Statistical terminology Permutation test and hypergeometric test Histogram on a sample vs population
Meelis Kull meelis.kull@ut.ee Autumn 2017 1 Sample vs population Example task with red and black cards Statistical terminology Permutation test and hypergeometric test Histogram on a sample vs population
Complete Faceting. code4lib, Feb Toke Eskildsen Mikkel Kamstrup Erlandsen
 Complete Faceting code4lib, Feb. 2009 Toke Eskildsen te@statsbiblioteket.dk Mikkel Kamstrup Erlandsen mke@statsbiblioteket.dk Battle Plan Terminology (geek level: 1) History (geek level: 3) Data Structures
Complete Faceting code4lib, Feb. 2009 Toke Eskildsen te@statsbiblioteket.dk Mikkel Kamstrup Erlandsen mke@statsbiblioteket.dk Battle Plan Terminology (geek level: 1) History (geek level: 3) Data Structures