LECTURER: BURCU CAN Spring
|
|
|
- Reynard Flowers
- 5 years ago
- Views:
Transcription




1 LECTURER: BURCU CAN Spring
2 Open class (lexical) words Nouns Verbs Adjectives yellow Proper Common Main Adverbs slowly IBM Italy cat / cats snow see registered Numbers more 122,312 Closed class (functional) Modals one Determiners the some can Prepositions to with Conjunctions and or had Particles off up Pronouns he its more
3 English PoS Tags CC conjunction, coordinating and both but either or CD numeral, cardinal mid-1890 nine-thirty 0.5 one DT determiner a all an every no that the EX existential there there FW foreign word gemeinschaft hund ich jeux IN preposition or conjunction, subordinating among whether out on by if JJ adjective or numeral, ordinal third ill-mannered regrettable JJR adjective, comparative braver cheaper taller JJS adjective, superlative bravest cheapest tallest MD modal auxiliary can may might will would NN noun, common, singular or mass cabbage thermostat investment subhumanity NNP noun, proper, singular Motown Cougar Yvette Liverpool NNPS noun, proper, plural Americans Materials States NNS noun, common, plural undergraduates bric-a-brac averages POS genitive marker ' 's PRP pronoun, personal hers himself it we them PRP$ pronoun, possessive her his mine my our ours their thy your RB adverb occasionally maddeningly adventurously RBR adverb, comparative further gloomier heavier less-perfectly RBS adverb, superlative best biggest nearest worst RP particle aboard away back by on open through TO "to" as preposition or infinitive marker to UH interjection huh howdy uh whammo shucks heck VB verb, base form ask bring fire see take VBD verb, past tense pleaded swiped registered saw VBG verb, present participle or gerund stirring focusing approaching erasing VBN verb, past participle dilapidated imitated reunifed unsettled VBP verb, present tense, not 3rd person singular twist appear comprise mold postpone VBZ verb, present tense, 3rd person singular bases reconstructs marks uses WDT WH-determiner that what whatever which whichever WP WH-pronoun that what whatever which who whom WP$ WH-pronoun, possessive whose WRB Wh-adverb however whenever where why

4 TURKISH PoS Tags Disambiguating Main POS tags for Turkish, Ehsani et al. 2012
5 Input: the lead paint is unsafe Output: the/det lead/n paint/n is/v unsafe/adj Uses: text-to-speech (how do we pronounce lead?) can write regexps like (Det) Adj* N+ over the output if you know the tag, you can back off to it in other tasks 5
6 Useful: Text-to-speech: record, lead (in English); yüz, bodrum (in Turkish) Lemmatization: saw[v] see, saw[n] saw Useful as a pre-processing step for parsing Less tag ambiguity means fewer parses However, some tag choices are better decided by parsers
7 Supervised Rule-based systems Statistical PoS Tagging Neural Networks (RNNs) Unsupervised Statistical PoS Tagging Neural Networks (RNNs) Partly-supervised
8 Classification Decision Trees Naïve Bayes Logistic Regression / Maximum Entropy (MaxEnt) Perceptron or Neural Networks Support Vector Machines Nearest-Neighbour
9 Sequence Labelling Labels of tokens are dependent on the labels of other tokens Two standard models: Hidden Markov Models Conditional Random Field (CRF)
10 Input: the lead paint is unsafe Output: the/det lead/n paint/n is/v unsafe/adj How many tags are correct? About 97% currently But baseline is already 90% Baseline is the stupidest possible method Tag every word with its most frequent tag Tag unknown words as nouns 10
11 Example VBD VB VBN VBZ VBP VBZ NNP NNS NN NNS CD NN Fed raises interest rates 0.5 percent
12 correct tags PN Verb Det Noun Prep Noun Prep Det Noun Bill directed a cortege of autos through the dunes PN Adj Det Noun Prep Noun Prep Det Noun Verb Verb Noun Verb Adj some possible tags for Prep each word (maybe more)? Each unknown tag is constrained by its word and by the tags to its immediate left and right. But those tags are unknown too 12
13 What Should We Look At? correct tags PN Verb Det Noun Prep Noun Prep Det Noun Bill directed a cortege of autos through the dunes PN Adj Det Noun Prep Noun Prep Det Noun Verb Verb Noun Verb Adj some possible tags for Prep each word (maybe more)? Each unknown tag is constrained by its word and by the tags to its immediate left and right. But those tags are unknown too Intro to NLP - J. Eisner 13
14 What Should We Look At? correct tags PN Verb Det Noun Prep Noun Prep Det Noun Bill directed a cortege of autos through the dunes PN Adj Det Noun Prep Noun Prep Det Noun Verb Verb Noun Verb Adj some possible tags for Prep each word (maybe more)? Each unknown tag is constrained by its word and by the tags to its immediate left and right. But those tags are unknown too 14
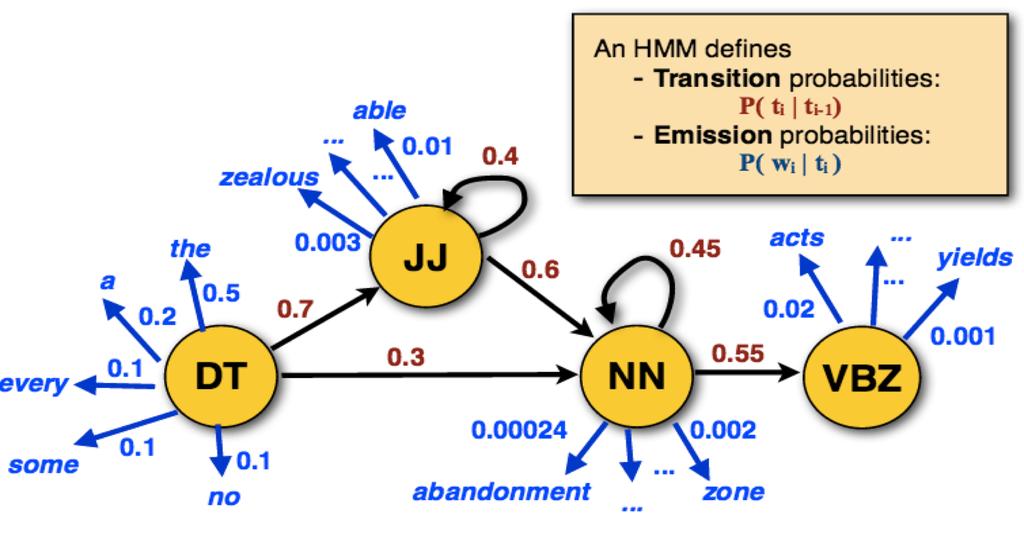
15 Introduce Hidden Markov Models (HMMs) for part-of-speech tagging/sequence classification Cover the three fundamental questions of HMMs: How do we fit the model parameters of an HMM? Given an HMM, how do we efficiently calculate the likelihood of an observation w? Given an HMM and an observation w, how do we efficiently calculate the most likely state sequence for w?
16
17 Green circles are hidden states Dependent only on the previous state (bigram)
18 Purple nodes are observed states Dependent only on their corresponding hidden state
19 S S S S S K K K K K {S, K, P, A, B} S : {s 1 s N } are the values for the hidden states K : {k 1 k M } are the values for the observations
20 S A S A S A S A S B B B K K K K K {S, K, P, A, B} P = {p i } are the initial state probabilities A = {a ij } are the state transition probabilities B = {b ik } are the observation state probabilities
21 Det 0.95 Noun start 0.4 PropNoun Verb stop
22 0.5 start 22 Det Noun Verb 0.25 PropNoun P(PropNoun Verb Det Noun) = 0.4*0.8*0.25*0.95*= stop
23 the a a the the a the that Det start Tom John Mary Alice Jerry PropNoun cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
24 the a a the the a the that Det start Tom John Mary Alice Jerry PropNoun cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
25 0.5 the a a the the a the that Det Tom John Mary Alice Jerry PropNoun cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop start 25
26 the a a the the a the that Det start 26 John 0.95 Tom John Mary Alice Jerry PropNoun cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
27 the a a the the a the that Det start 27 John 0.95 Tom John Mary Alice Jerry PropNoun cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
28 0.5 start 28 the a a the the a the that Det 0.4 John bit 0.95 Tom John Mary Alice Jerry PropNoun cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
29 0.5 start 29 the a a the the a the that Det 0.4 John bit 0.95 Tom John Mary Alice Jerry PropNoun cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
30 0.5 start 30 the a a the the a the that Det Tom John Mary Alice Jerry PropNoun John bit the cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
31 0.5 start 31 the a a the the a the that Det Tom John Mary Alice Jerry PropNoun John bit the cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
32 0.5 start 32 the a a the the a the that Det Tom John Mary Alice Jerry PropNoun John bit the apple cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
33 0.5 start 33 the a a the the a the that Det Tom John Mary Alice Jerry PropNoun John bit the apple cat dog car pen bed apple Noun bit ate played saw hit gave Verb 0.5 stop
34
35
36 We want a model of sequences s and observations w s 0 s 1 s 2 s n w 1 w 2 w n Assumptions: States are tag n-grams Usually a dedicated start and end state / word Tag/state sequence is generated by a Markov model Words are chosen independently, conditioned only on the tag/state These are totally broken assumptions: why?
37 Transitions P(s s ) encode well-formed tag sequences In a bigram tagger, states = tags < > s 0 < t 1 > < t 2 > < t n > s 1 s 2 s n w 1 w 2 w n
38 Use standard smoothing methods to estimate transitions: ) ˆ( ) (1 ) ˆ( ), ˆ( ), ( i i i i i i i i i t P t t P t t t P t t t P l l l l =
39 Emissions are trickier: Words we ve never seen before Words which occur with tags we ve never seen Issue: words aren t black boxes: 343, year Minteria reintroducibly
40 Can do surprisingly well just looking at a word by itself: Word the: the DT Lowercased word Importantly: importantly RB Prefixes unfathomable: un- JJ Suffixes Importantly: -ly RB Capitalization Meridian: CAP NNP Word shapes 35-year: d-x JJ Then build a MaxEnt (or whatever) model to predict tag Maxent P(t w): 93.7% / 82.6% (See the next class for Maxent models)
41 Consider all possible state sequences, Q, of length T that the model could have traversed in generating the given observation sequence. Compute the probability of a given state sequence from A, and multiply it by the probabilities of generating each of given observations in each of the corresponding states in this sequence to get P(O,Q λ) = P(O Q, λ) P(Q λ). Sum this over all possible state sequences to get P(O λ). 41 Computationally complex: O(TN T )
42 Due to the Markov assumption, the probability of being in any state at any given time t only relies on the probability of being in each of the possible states at time t 1. Forward Algorithm: Uses dynamic programming to exploit this fact to efficiently compute observation likelihood in O(TN 2 ) time. Compute a forward trellis that compactly and implicitly encodes information about all possible state paths.
43 s 1 s 2 s 0 s F s N t 1 t 2 t 3 t T-1 t T Continue forward in time until reaching final time point and sum probability of ending in final state.
44 Let a t (j) be the probability of being in state j after seeing the first t observations (by summing over all initial paths leading to j). a ( ) (,,..., l t j = P o1 o2 ot qt = s j )
45 s 1 s 2 s N a t-1 (i) a 1j a 2j a 2j a Nj s j a t (i) Consider all possible ways of getting to s j at time t by coming from all possible states s i and determine probability of each. Sum these to get the total probability of being in state s j at time t while accounting for the first t 1 observations. Then multiply by the probability of actually observing o t in s j.
46 Initialization Recursion Termination N j o b a j j j = 1 ) ( ) ( 1 0 a 1 T t N j o b a i j t j N i ij t t < ú û ù ê ë é = å = - 1, 1 ) ( ) ( ) ( 1 1 a a å = + = = N i if T F T a i s O P 1 1 ) ( ) ( ) ( a a l
47 Requires only O(TN 2 ) time to compute the probability of an observed sequence given a model. Exploits the fact that all state sequences must merge into one of the N possible states at any point in time and the Markov assumption that only the last state effects the next one.
48 What is the most likely sequence of tags t for the given sequence of words w?
49 What is the most likely sequence of tags t for the given sequence of words w? Choosing the best tag sequence T=t 1,t 2,,t n for a given word sequence W = w 1,w 2,,w n (sentence): By Bayes Rule: ^ T = arg max P( T ^ T = TÎt arg max TÎt W ) P( W T ) P( T ) P( W ) Since P(W) will be the same for each tag sequence: ^ T = arg max P( W TÎt T ) P( T )
50 If we assume a tagged corpus and a trigram language model, then P(T) can be approximated as: To evaluate this formula is simple, we get from simple word counting (and smoothing). Õ = - - n i i i i t t t P t t P t P ) ( ) ( ) (
51 To evaluate P(W T), we will make the simplifying assumption that the word depends only on its tag: So, we want the tag sequence that maximizes the following quantity. The best tag sequence can be found by Viterbi algorithm. Õ = n i w i t i P 1 ) ( ú û ù ê ë é Õ Õ = = - - n i i i n i i i i t w P t t t P t t P t P ) ( ) ( ) ( ) (
52
53 Given these two multinomials, we can score any word / tag sequence pair <, > <,NNP> <NNP, VBZ> <VBZ, NN> <NN, NNS> <NNS, CD> <CD, NN> <STOP> NNP VBZ NN NNS CD NN. Fed raises interest rates 0.5 percent. P(NNP <, >) P(Fed NNP) P(VBZ <NNP, >) P(raises VBZ) P(NN VBZ,NNP).. In principle, we re done list all possible tag sequences, score each one, pick the best one (the Viterbi state sequence) NNP VBZ NN NNS CD NN NNP NNS NN NNS CD NN NNP VBZ VB NNS CD NN logp = -23 logp = -29 logp = -27
54 Too many trajectories (state sequences) to list Option 1: Beam Search <> Fed:NNP Fed:VBN Fed:VBD Fed:NNP raises:nns Fed:NNP raises:vbz Fed:VBN raises:nns Fed:VBN raises:vbz A beam is a set of partial hypotheses Start with just the single empty trajectory At each derivation step: Consider all continuations of previous hypotheses Discard most, keep top k, or those within a factor of the best, (or some combination)
55 We want a way of computing exactly: -Most likely state sequence given the model and some w BUT! There are exponentially many possible state sequences T n We can, however efficiently calculate using dynamic programming (DP) The DP algorithm used for efficient state-sequence inference uses a trellis of paths through state space It is an instance of what in NLP is called the Viterbi Algorithm
56
57 Dynamic program for computing di( s) = max P( s0... si- 1s, w1... wi -1) s0... si -1s The score of a best path up to position i ending in state s d 0 ( s) δ i (s) = max s' ì 1 if s =<, > = í î0 otherwise P(s s')p(w i 1 s')δ i 1 (s') Also store a back-trace: most likely previous state for each state y i( s) = arg max P( s s' ) P( w s' ) di- 1( s' ) s' Iterate on i, storing partial results as you go
58
59
60
61
62
63
64
65 Fish sleep.
66 start noun verb end 0.2
67 A two-word language: fish and sleep Suppose in our training corpus, fish appears 8 times as a noun and 5 times as a verb sleep appears 2 as a noun and 5 times as a verb Emission probabilities: Noun P(fish noun) : 0.8 P(sleep noun) : 0.2 Verb P(fish verb) : 0.5 P(sleep verb) :0.5
68 start verb noun end
69 0.2 start noun verb 0.7 end start 1 verb 0 noun 0 end 0
70 0.2 start noun verb 0.7 end 0.2 Token 1: fish start 1 0 verb 0.2 *.5 noun 0.8 *.8 end 0 0
71 0.2 start noun verb 0.7 end 0.2 Token 1: fish start 1 0 verb 0.1 noun 0.64 end 0 0
72 0.2 Token 2: sleep (if fish is verb) start noun verb 0.7 end start verb 0.1.1*.1*.5 noun *.2*.2 end 0 0 -
73 0.2 Token 2: sleep (if fish is verb) start noun verb 0.7 end start verb noun end 0 0 -
74 0.2 Token 2: sleep (if fish is a noun) start noun verb 0.7 end start verb *.8*.5 noun *.1*.2 end 0 0 -
75 0.2 Token 2: sleep (if fish is a noun) start noun verb 0.7 end start verb noun end 0 0 -
76 0.2 Token 2: sleep take maximum, set back pointers start noun verb 0.7 end start verb noun end 0 0 -
77 0.2 Token 2: sleep take maximum, set back pointers start noun verb 0.7 end start verb noun end 0 0 -
78 0.2 start noun verb 0.7 end 0.2 Token 3: end start verb noun end * *.1
79 0.2 Token 3: end take maximum, set back pointers start noun verb 0.7 end start verb noun end * *.1
80 0.2 Decode: fish = noun sleep = verb start noun verb 0.7 end start verb noun end *.7
81 Choose the most common tag 90.3% with a bad unknown word model 93.7% with a good one TnT (Brants, 2000): A carefully smoothed trigram tagger Suffix trees for emissions 96.7% on WSJ text A Fully Bayesian Approach to Unsupervised PoS Tagging (Goldwater, 2007) Painless Unsupervised Learning with Features (Berg et al., 2010) Unsupervised PoS Tagging with Anchor HMMs (Stratos et al., 2016) Noise in the data Many errors in the training and test corpora Probably about 2% guaranteed error from noise
82 Roadmap of (known / unknown) accuracies: Most freq tag: ~90% / ~50% Trigram HMM: ~95% / ~55% Maxent P(t w): 93.7% / 82.6% TnT (HMM++): 96.2% / 86.0% MEMM tagger: 96.9% / 86.9% Bidirectional dependencies: 97.2% / 89.0% Most errors on unknown words Upper bound: ~98% (human agreement)
83 Better features! RB PRP VBD IN RB IN PRP VBD. They left as soon as he arrived. We could fix this with a feature that looked at the next word JJ NNP NNS VBD VBN. Intrinsic flaws remained undetected. We could fix this by linking capitalized words to their lowercase versions More general solution: Maximum-entropy Markov models Reality check: Taggers are already pretty good on WSJ journal text What the world needs is taggers that work on other text!
84 Dan Klein, Chris Manning, Jason Eisner slides Heng Ji, POS Tagging and Syntactic Parsing Raymond Mooney, POS Tagging and HMMs
Natural Language Processing
 Natural Language Processing Part of Speech Tagging Dan Klein UC Berkeley 1 Parts of Speech 2 Parts of Speech (English) One basic kind of linguistic structure: syntactic word classes Open class (lexical)
Natural Language Processing Part of Speech Tagging Dan Klein UC Berkeley 1 Parts of Speech 2 Parts of Speech (English) One basic kind of linguistic structure: syntactic word classes Open class (lexical)
Parts-of-Speech (English) Statistical NLP Spring Part-of-Speech Ambiguity. Why POS Tagging? Classic Solution: HMMs. Lecture 6: POS / Phrase MT
 Statistical NLP Spring Part-of-Speech Ambiguity. Why POS Tagging? Classic Solution: HMMs. Lecture 6: POS / Phrase MT") Statistical LP Spring 2011 Lecture 6: POS / Phrase MT an Klein UC Berkeley Parts-of-Speech (English) One basic kind of linguistic structure: syntactic word classes Open class (lexical) words ouns Proper
Statistical LP Spring 2011 Lecture 6: POS / Phrase MT an Klein UC Berkeley Parts-of-Speech (English) One basic kind of linguistic structure: syntactic word classes Open class (lexical) words ouns Proper
Hidden Markov Models
 CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
CSE 490 U Natural Language Processing Spring 2016
 CSE 490 U atural Language Processing Spring 2016 Parts of Speech Yejin Choi [Slides adapted from an Klein, Luke Zettlemoyer] Overview POS Tagging Feature Rich Techniques Maximum Entropy Markov Models (MEMMs)
CSE 490 U atural Language Processing Spring 2016 Parts of Speech Yejin Choi [Slides adapted from an Klein, Luke Zettlemoyer] Overview POS Tagging Feature Rich Techniques Maximum Entropy Markov Models (MEMMs)
Statistical NLP Spring Parts-of-Speech (English)
") Statistical LP Spring 2009 Lecture 6: Parts-of-Speech an Klein UC Berkeley Parts-of-Speech (English) One basic kind of linguistic structure: syntactic word classes Open class (lexical) words ouns erbs
Statistical LP Spring 2009 Lecture 6: Parts-of-Speech an Klein UC Berkeley Parts-of-Speech (English) One basic kind of linguistic structure: syntactic word classes Open class (lexical) words ouns erbs
Hidden Markov Models (HMMs)
") Hidden Markov Models HMMs Raymond J. Mooney University of Texas at Austin 1 Part Of Speech Tagging Annotate each word in a sentence with a part-of-speech marker. Lowest level of syntactic analysis. John
Hidden Markov Models HMMs Raymond J. Mooney University of Texas at Austin 1 Part Of Speech Tagging Annotate each word in a sentence with a part-of-speech marker. Lowest level of syntactic analysis. John
CSE 517 Natural Language Processing Winter2015
 CSE 517 Natural Language Processing Winter2015 Feature Rich Models Sameer Singh Guest lecture for Yejin Choi - University of Washington [Slides from Jason Eisner, Dan Klein, Luke ZeLlemoyer] Outline POS
CSE 517 Natural Language Processing Winter2015 Feature Rich Models Sameer Singh Guest lecture for Yejin Choi - University of Washington [Slides from Jason Eisner, Dan Klein, Luke ZeLlemoyer] Outline POS
Probabilistic Graphical Models
 CS 1675: Intro to Machine Learning Probabilistic Graphical Models Prof. Adriana Kovashka University of Pittsburgh November 27, 2018 Plan for This Lecture Motivation for probabilistic graphical models Directed
CS 1675: Intro to Machine Learning Probabilistic Graphical Models Prof. Adriana Kovashka University of Pittsburgh November 27, 2018 Plan for This Lecture Motivation for probabilistic graphical models Directed
10/17/04. Today s Main Points
 Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
Part-of-speech Tagging & Hidden Markov Model Intro Lecture #10 Introduction to Natural Language Processing CMPSCI 585, Fall 2004 University of Massachusetts Amherst Andrew McCallum Today s Main Points
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs
 Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 18, 2017 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 18, 2017 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Hidden Markov Models
 INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Hidden Markov Models Murhaf Fares & Stephan Oepen Language Technology Group (LTG) October 27, 2016 Recap: Probabilistic Language
LECTURER: BURCU CAN Spring
 LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
LECTURER: BURCU CAN 2017-2018 Spring Regular Language Hidden Markov Model (HMM) Context Free Language Context Sensitive Language Probabilistic Context Free Grammar (PCFG) Unrestricted Language PCFGs can
CS838-1 Advanced NLP: Hidden Markov Models
 CS838-1 Advanced NLP: Hidden Markov Models Xiaojin Zhu 2007 Send comments to jerryzhu@cs.wisc.edu 1 Part of Speech Tagging Tag each word in a sentence with its part-of-speech, e.g., The/AT representative/nn
CS838-1 Advanced NLP: Hidden Markov Models Xiaojin Zhu 2007 Send comments to jerryzhu@cs.wisc.edu 1 Part of Speech Tagging Tag each word in a sentence with its part-of-speech, e.g., The/AT representative/nn
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Posterior vs. Parameter Sparsity in Latent Variable Models Supplementary Material
 Posterior vs. Parameter Sparsity in Latent Variable Models Supplementary Material João V. Graça L 2 F INESC-ID Lisboa, Portugal Kuzman Ganchev Ben Taskar University of Pennsylvania Philadelphia, PA, USA
Posterior vs. Parameter Sparsity in Latent Variable Models Supplementary Material João V. Graça L 2 F INESC-ID Lisboa, Portugal Kuzman Ganchev Ben Taskar University of Pennsylvania Philadelphia, PA, USA
HMM and Part of Speech Tagging. Adam Meyers New York University
 HMM and Part of Speech Tagging Adam Meyers New York University Outline Parts of Speech Tagsets Rule-based POS Tagging HMM POS Tagging Transformation-based POS Tagging Part of Speech Tags Standards There
HMM and Part of Speech Tagging Adam Meyers New York University Outline Parts of Speech Tagsets Rule-based POS Tagging HMM POS Tagging Transformation-based POS Tagging Part of Speech Tags Standards There
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
INF4820: Algorithms for Artificial Intelligence and Natural Language Processing. Language Models & Hidden Markov Models
 1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
1 University of Oslo : Department of Informatics INF4820: Algorithms for Artificial Intelligence and Natural Language Processing Language Models & Hidden Markov Models Stephan Oepen & Erik Velldal Language
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging
 Tagging") ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
Recap: HMM. ANLP Lecture 9: Algorithms for HMMs. More general notation. Recap: HMM. Elements of HMM: Sharon Goldwater 4 Oct 2018.
 Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
Recap: HMM ANLP Lecture 9: Algorithms for HMMs Sharon Goldwater 4 Oct 2018 Elements of HMM: Set of states (tags) Output alphabet (word types) Start state (beginning of sentence) State transition probabilities
CSE 490 U Natural Language Processing Spring 2016
 CSE 490 U Natural Language Processing Spring 2016 Feature Rich Models Yejin Choi - University of Washington [Many slides from Dan Klein, Luke Zettlemoyer] Structure in the output variable(s)? What is the
CSE 490 U Natural Language Processing Spring 2016 Feature Rich Models Yejin Choi - University of Washington [Many slides from Dan Klein, Luke Zettlemoyer] Structure in the output variable(s)? What is the
Statistical methods in NLP, lecture 7 Tagging and parsing
 Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Statistical methods in NLP, lecture 7 Tagging and parsing Richard Johansson February 25, 2014 overview of today's lecture HMM tagging recap assignment 3 PCFG recap dependency parsing VG assignment 1 overview
Part-of-Speech Tagging + Neural Networks CS 287
 Part-of-Speech Tagging + Neural Networks CS 287 Quiz Last class we focused on hinge loss. L hinge = max{0, 1 (ŷ c ŷ c )} Consider now the squared hinge loss, (also called l 2 SVM) L hinge 2 = max{0, 1
Part-of-Speech Tagging + Neural Networks CS 287 Quiz Last class we focused on hinge loss. L hinge = max{0, 1 (ŷ c ŷ c )} Consider now the squared hinge loss, (also called l 2 SVM) L hinge 2 = max{0, 1
Sequence Labeling: HMMs & Structured Perceptron
 Sequence Labeling: HMMs & Structured Perceptron CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu HMM: Formal Specification Q: a finite set of N states Q = {q 0, q 1, q 2, q 3, } N N Transition
Sequence Labeling: HMMs & Structured Perceptron CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu HMM: Formal Specification Q: a finite set of N states Q = {q 0, q 1, q 2, q 3, } N N Transition
Part-of-Speech Tagging
 Part-of-Speech Tagging Informatics 2A: Lecture 17 Adam Lopez School of Informatics University of Edinburgh 27 October 2016 1 / 46 Last class We discussed the POS tag lexicon When do words belong to the
Part-of-Speech Tagging Informatics 2A: Lecture 17 Adam Lopez School of Informatics University of Edinburgh 27 October 2016 1 / 46 Last class We discussed the POS tag lexicon When do words belong to the
 > > > > < 0.05 θ = 1.96 = 1.64 = 1.66 = 0.96 = 0.82 Geographical distribution of English tweets (gender-induced data) Proportion of gendered tweets in English, May 2016 1 Contexts of the Present Research
> > > > < 0.05 θ = 1.96 = 1.64 = 1.66 = 0.96 = 0.82 Geographical distribution of English tweets (gender-induced data) Proportion of gendered tweets in English, May 2016 1 Contexts of the Present Research
Natural Language Processing CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
Natural Language Processing CS 6840 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Statistical Parsing Define a probabilistic model of syntax P(T S):
Lecture 13: Structured Prediction
 Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Statistical Methods for NLP
 Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Lecture 9: Hidden Markov Model
 Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501 Natural Language Processing 1 This lecture v Hidden Markov
CS388: Natural Language Processing Lecture 4: Sequence Models I
 CS388: Natural Language Processing Lecture 4: Sequence Models I Greg Durrett Mini 1 due today Administrivia Project 1 out today, due September 27 Viterbi algorithm, CRF NER system, extension Extension
CS388: Natural Language Processing Lecture 4: Sequence Models I Greg Durrett Mini 1 due today Administrivia Project 1 out today, due September 27 Viterbi algorithm, CRF NER system, extension Extension
CSE 447/547 Natural Language Processing Winter 2018
 CSE 447/547 Natural Language Processing Winter 2018 Feature Rich Models (Log Linear Models) Yejin Choi University of Washington [Many slides from Dan Klein, Luke Zettlemoyer] Announcements HW #3 Due Feb
CSE 447/547 Natural Language Processing Winter 2018 Feature Rich Models (Log Linear Models) Yejin Choi University of Washington [Many slides from Dan Klein, Luke Zettlemoyer] Announcements HW #3 Due Feb
Natural Language Processing Winter 2013
 Natural Language Processing Winter 2013 Hidden Markov Models Luke Zettlemoyer - University of Washington [Many slides from Dan Klein and Michael Collins] Overview Hidden Markov Models Learning Supervised:
Natural Language Processing Winter 2013 Hidden Markov Models Luke Zettlemoyer - University of Washington [Many slides from Dan Klein and Michael Collins] Overview Hidden Markov Models Learning Supervised:
Lecture 7: Sequence Labeling
 http://courses.engr.illinois.edu/cs447 Lecture 7: Sequence Labeling Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Recap: Statistical POS tagging with HMMs (J. Hockenmaier) 2 Recap: Statistical
http://courses.engr.illinois.edu/cs447 Lecture 7: Sequence Labeling Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Recap: Statistical POS tagging with HMMs (J. Hockenmaier) 2 Recap: Statistical
Maxent Models and Discriminative Estimation
 Maxent Models and Discriminative Estimation Generative vs. Discriminative models (Reading: J+M Ch6) Introduction So far we ve looked at generative models Language models, Naive Bayes But there is now much
Maxent Models and Discriminative Estimation Generative vs. Discriminative models (Reading: J+M Ch6) Introduction So far we ve looked at generative models Language models, Naive Bayes But there is now much
Parsing with Context-Free Grammars
 Parsing with Context-Free Grammars CS 585, Fall 2017 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp2017 Brendan O Connor College of Information and Computer Sciences
Parsing with Context-Free Grammars CS 585, Fall 2017 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp2017 Brendan O Connor College of Information and Computer Sciences
CSCI 5832 Natural Language Processing. Today 2/19. Statistical Sequence Classification. Lecture 9
 CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
CSCI 5832 Natural Language Processing Jim Martin Lecture 9 1 Today 2/19 Review HMMs for POS tagging Entropy intuition Statistical Sequence classifiers HMMs MaxEnt MEMMs 2 Statistical Sequence Classification
Sequence Prediction and Part-of-speech Tagging
 CS5740: atural Language Processing Spring 2017 Sequence Prediction and Part-of-speech Tagging Instructor: Yoav Artzi Slides adapted from Dan Klein, Dan Jurafsky, Chris Manning, Michael Collins, Luke Zettlemoyer,
CS5740: atural Language Processing Spring 2017 Sequence Prediction and Part-of-speech Tagging Instructor: Yoav Artzi Slides adapted from Dan Klein, Dan Jurafsky, Chris Manning, Michael Collins, Luke Zettlemoyer,
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models in Language Processing
 Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Degree in Mathematics
 Degree in Mathematics Title: Introduction to Natural Language Understanding and Chatbots. Author: Víctor Cristino Marcos Advisor: Jordi Saludes Department: Matemàtiques (749) Academic year: 2017-2018 Introduction
Degree in Mathematics Title: Introduction to Natural Language Understanding and Chatbots. Author: Víctor Cristino Marcos Advisor: Jordi Saludes Department: Matemàtiques (749) Academic year: 2017-2018 Introduction
Log-Linear Models, MEMMs, and CRFs
 Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
Fun with weighted FSTs
 Fun with weighted FSTs Informatics 2A: Lecture 18 Shay Cohen School of Informatics University of Edinburgh 29 October 2018 1 / 35 Kedzie et al. (2018) - Content Selection in Deep Learning Models of Summarization
Fun with weighted FSTs Informatics 2A: Lecture 18 Shay Cohen School of Informatics University of Edinburgh 29 October 2018 1 / 35 Kedzie et al. (2018) - Content Selection in Deep Learning Models of Summarization
Text Mining. March 3, March 3, / 49
 Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Midterm sample questions
 Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Probabilistic Context Free Grammars. Many slides from Michael Collins
 Probabilistic Context Free Grammars Many slides from Michael Collins Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Probabilistic Context Free Grammars Many slides from Michael Collins Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Part-of-Speech Tagging
 Part-of-Speech Tagging Informatics 2A: Lecture 17 Shay Cohen School of Informatics University of Edinburgh 26 October 2018 1 / 48 Last class We discussed the POS tag lexicon When do words belong to the
Part-of-Speech Tagging Informatics 2A: Lecture 17 Shay Cohen School of Informatics University of Edinburgh 26 October 2018 1 / 48 Last class We discussed the POS tag lexicon When do words belong to the
10 : HMM and CRF. 1 Case Study: Supervised Part-of-Speech Tagging
 10-708: Probabilistic Graphical Models 10-708, Spring 2018 10 : HMM and CRF Lecturer: Kayhan Batmanghelich Scribes: Ben Lengerich, Michael Kleyman 1 Case Study: Supervised Part-of-Speech Tagging We will
10-708: Probabilistic Graphical Models 10-708, Spring 2018 10 : HMM and CRF Lecturer: Kayhan Batmanghelich Scribes: Ben Lengerich, Michael Kleyman 1 Case Study: Supervised Part-of-Speech Tagging We will
CSE 447 / 547 Natural Language Processing Winter 2018
 CSE 447 / 547 Natural Language Processing Winter 2018 Hidden Markov Models Yejin Choi University of Washington [Many slides from Dan Klein, Michael Collins, Luke Zettlemoyer] Overview Hidden Markov Models
CSE 447 / 547 Natural Language Processing Winter 2018 Hidden Markov Models Yejin Choi University of Washington [Many slides from Dan Klein, Michael Collins, Luke Zettlemoyer] Overview Hidden Markov Models
A Context-Free Grammar
 Statistical Parsing A Context-Free Grammar S VP VP Vi VP Vt VP VP PP DT NN PP PP P Vi sleeps Vt saw NN man NN dog NN telescope DT the IN with IN in Ambiguity A sentence of reasonable length can easily
Statistical Parsing A Context-Free Grammar S VP VP Vi VP Vt VP VP PP DT NN PP PP P Vi sleeps Vt saw NN man NN dog NN telescope DT the IN with IN in Ambiguity A sentence of reasonable length can easily
Structured Output Prediction: Generative Models
 Structured Output Prediction: Generative Models CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 17.3, 17.4, 17.5.1 Structured Output Prediction Supervised
Structured Output Prediction: Generative Models CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 17.3, 17.4, 17.5.1 Structured Output Prediction Supervised
IN FALL NATURAL LANGUAGE PROCESSING. Jan Tore Lønning
 1 IN4080 2018 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning 2 Logistic regression Lecture 8, 26 Sept Today 3 Recap: HMM-tagging Generative and discriminative classifiers Linear classifiers Logistic
1 IN4080 2018 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning 2 Logistic regression Lecture 8, 26 Sept Today 3 Recap: HMM-tagging Generative and discriminative classifiers Linear classifiers Logistic
Hidden Markov Models, Part 1. Steven Bedrick CS/EE 5/655, 10/22/14
 idden Markov Models, Part 1 Steven Bedrick S/EE 5/655, 10/22/14 Plan for the day: 1. Quick Markov hain review 2. Motivation: Part-of-Speech Tagging 3. idden Markov Models 4. Forward algorithm Refresher:
idden Markov Models, Part 1 Steven Bedrick S/EE 5/655, 10/22/14 Plan for the day: 1. Quick Markov hain review 2. Motivation: Part-of-Speech Tagging 3. idden Markov Models 4. Forward algorithm Refresher:
COMP (Fall 2017) Natural Language Processing (with deep learning and connections to vision/robotics)
 Natural Language Processing (with deep learning and connections to vision/robotics)") COMP 790.139 (Fall 2017) Natural Language Processing (with deep learning and connections to vision/robotics) Lecture 3: POS-Tagging, NER, Seq Labeling, Coreference Mohit Bansal (various slides adapted/borrowed
COMP 790.139 (Fall 2017) Natural Language Processing (with deep learning and connections to vision/robotics) Lecture 3: POS-Tagging, NER, Seq Labeling, Coreference Mohit Bansal (various slides adapted/borrowed
Probabilistic Context-free Grammars
 Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
Probabilistic Context-free Grammars Computational Linguistics Alexander Koller 24 November 2017 The CKY Recognizer S NP VP NP Det N VP V NP V ate NP John Det a N sandwich i = 1 2 3 4 k = 2 3 4 5 S NP John
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models. The ischool University of Maryland. Wednesday, September 30, 2009
 CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
Noisy Channel and Hidden Markov Models
 Noisy Channel and Hidden Markov Models Natural Language Processing CS 6120 Spring 2014 Northeastern University David Smith with material from Jason Eisner & Andrew McCallum! Warren Weaver to Norbert Wiener
Noisy Channel and Hidden Markov Models Natural Language Processing CS 6120 Spring 2014 Northeastern University David Smith with material from Jason Eisner & Andrew McCallum! Warren Weaver to Norbert Wiener
TnT Part of Speech Tagger
 TnT Part of Speech Tagger By Thorsten Brants Presented By Arghya Roy Chaudhuri Kevin Patel Satyam July 29, 2014 1 / 31 Outline 1 Why Then? Why Now? 2 Underlying Model Other technicalities 3 Evaluation
TnT Part of Speech Tagger By Thorsten Brants Presented By Arghya Roy Chaudhuri Kevin Patel Satyam July 29, 2014 1 / 31 Outline 1 Why Then? Why Now? 2 Underlying Model Other technicalities 3 Evaluation
Lecture 6: Part-of-speech tagging
 CS447: Natural Language Processing http://courses.engr.illinois.edu/cs447 Lecture 6: Part-of-speech tagging Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Smoothing: Reserving mass in P(X Y)
CS447: Natural Language Processing http://courses.engr.illinois.edu/cs447 Lecture 6: Part-of-speech tagging Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Smoothing: Reserving mass in P(X Y)
Probabilistic Context-Free Grammars. Michael Collins, Columbia University
 Probabilistic Context-Free Grammars Michael Collins, Columbia University Overview Probabilistic Context-Free Grammars (PCFGs) The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Probabilistic Context-Free Grammars Michael Collins, Columbia University Overview Probabilistic Context-Free Grammars (PCFGs) The CKY Algorithm for parsing with PCFGs A Probabilistic Context-Free Grammar
Neural POS-Tagging with Julia
 Neural POS-Tagging with Julia Hiroyuki Shindo 2015-12-19 Julia Tokyo Why Julia? NLP の基礎解析 ( 研究レベル ) ベクトル演算以外の計算も多い ( 探索など ) Java, Scala, C++ Python-like な文法で, 高速なプログラミング言語 Julia, Nim, Crystal? 1 Part-of-Speech
Neural POS-Tagging with Julia Hiroyuki Shindo 2015-12-19 Julia Tokyo Why Julia? NLP の基礎解析 ( 研究レベル ) ベクトル演算以外の計算も多い ( 探索など ) Java, Scala, C++ Python-like な文法で, 高速なプログラミング言語 Julia, Nim, Crystal? 1 Part-of-Speech
Graphical models for part of speech tagging
 Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 8 POS tagset) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th Jan, 2012
 Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th Jan, 2012") CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 8 POS tagset) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th Jan, 2012 HMM: Three Problems Problem Problem 1: Likelihood of a
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 8 POS tagset) Pushpak Bhattacharyya CSE Dept., IIT Bombay 17 th Jan, 2012 HMM: Three Problems Problem Problem 1: Likelihood of a
Natural Language Processing
 Natural Language Processing Info 159/259 Lecture 15: Review (Oct 11, 2018) David Bamman, UC Berkeley Big ideas Classification Naive Bayes, Logistic regression, feedforward neural networks, CNN. Where does
Natural Language Processing Info 159/259 Lecture 15: Review (Oct 11, 2018) David Bamman, UC Berkeley Big ideas Classification Naive Bayes, Logistic regression, feedforward neural networks, CNN. Where does
Natural Language Processing
 Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Lab 12: Structured Prediction
 December 4, 2014 Lecture plan structured perceptron application: confused messages application: dependency parsing structured SVM Class review: from modelization to classification What does learning mean?
December 4, 2014 Lecture plan structured perceptron application: confused messages application: dependency parsing structured SVM Class review: from modelization to classification What does learning mean?
NLP Programming Tutorial 11 - The Structured Perceptron
 NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
Parsing. Based on presentations from Chris Manning s course on Statistical Parsing (Stanford)
") Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Parsing Based on presentations from Chris Manning s course on Statistical Parsing (Stanford) S N VP V NP D N John hit the ball Levels of analysis Level Morphology/Lexical POS (morpho-synactic), WSD Elements
Sequence Modelling with Features: Linear-Chain Conditional Random Fields. COMP-599 Oct 6, 2015
 Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
POS-Tagging. Fabian M. Suchanek
 POS-Tagging Fabian M. Suchanek 100 Def: POS A Part-of-Speech (also: POS, POS-tag, word class, lexical class, lexical category) is a set of words with the same grammatical role. Alizée wrote a really great
POS-Tagging Fabian M. Suchanek 100 Def: POS A Part-of-Speech (also: POS, POS-tag, word class, lexical class, lexical category) is a set of words with the same grammatical role. Alizée wrote a really great
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields
 Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Language Processing with Perl and Prolog
 Language Processing with Perl and Prolog es Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ Pierre Nugues Language Processing with Perl and Prolog 1 / 12 Training
Language Processing with Perl and Prolog es Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ Pierre Nugues Language Processing with Perl and Prolog 1 / 12 Training
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Constituency Parsing
 CS5740: Natural Language Processing Spring 2017 Constituency Parsing Instructor: Yoav Artzi Slides adapted from Dan Klein, Dan Jurafsky, Chris Manning, Michael Collins, Luke Zettlemoyer, Yejin Choi, and
CS5740: Natural Language Processing Spring 2017 Constituency Parsing Instructor: Yoav Artzi Slides adapted from Dan Klein, Dan Jurafsky, Chris Manning, Michael Collins, Luke Zettlemoyer, Yejin Choi, and
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
LING 473: Day 10. START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars
 LING 473: Day 10 START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars 1 Issues with Projects 1. *.sh files must have #!/bin/sh at the top (to run on Condor) 2. If run.sh is supposed
LING 473: Day 10 START THE RECORDING Coding for Probability Hidden Markov Models Formal Grammars 1 Issues with Projects 1. *.sh files must have #!/bin/sh at the top (to run on Condor) 2. If run.sh is supposed
Today s Agenda. Need to cover lots of background material. Now on to the Map Reduce stuff. Rough conceptual sketch of unsupervised training using EM
 Today s Agenda Need to cover lots of background material l Introduction to Statistical Models l Hidden Markov Models l Part of Speech Tagging l Applying HMMs to POS tagging l Expectation-Maximization (EM)
Today s Agenda Need to cover lots of background material l Introduction to Statistical Models l Hidden Markov Models l Part of Speech Tagging l Applying HMMs to POS tagging l Expectation-Maximization (EM)
CSC401/2511 Spring CSC401/2511 Natural Language Computing Spring 2019 Lecture 5 Frank Rudzicz and Chloé Pou-Prom University of Toronto
 CSC401/2511 Natural Language Computing Spring 2019 Lecture 5 Frank Rudzicz and Chloé Pou-Prom University of Toronto Revisiting PoS tagging Will/MD the/dt chair/nn chair/?? the/dt meeting/nn from/in that/dt
CSC401/2511 Natural Language Computing Spring 2019 Lecture 5 Frank Rudzicz and Chloé Pou-Prom University of Toronto Revisiting PoS tagging Will/MD the/dt chair/nn chair/?? the/dt meeting/nn from/in that/dt
Probabilistic Context Free Grammars. Many slides from Michael Collins and Chris Manning
 Probabilistic Context Free Grammars Many slides from Michael Collins and Chris Manning Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic
Probabilistic Context Free Grammars Many slides from Michael Collins and Chris Manning Overview I Probabilistic Context-Free Grammars (PCFGs) I The CKY Algorithm for parsing with PCFGs A Probabilistic
Natural Language Processing Prof. Pawan Goyal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 Natural Language Processing Prof. Pawan Goyal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 18 Maximum Entropy Models I Welcome back for the 3rd module
Natural Language Processing Prof. Pawan Goyal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 18 Maximum Entropy Models I Welcome back for the 3rd module
Lecture 4: Smoothing, Part-of-Speech Tagging. Ivan Titov Institute for Logic, Language and Computation Universiteit van Amsterdam
 Lecture 4: Smoothing, Part-of-Speech Tagging Ivan Titov Institute for Logic, Language and Computation Universiteit van Amsterdam Language Models from Corpora We want a model of sentence probability P(w
Lecture 4: Smoothing, Part-of-Speech Tagging Ivan Titov Institute for Logic, Language and Computation Universiteit van Amsterdam Language Models from Corpora We want a model of sentence probability P(w
Time Zones - KET Grammar
 Inventory of grammatical areas Verbs Regular and irregular forms Pages 104-105 (Unit 1 Modals can (ability; requests; permission) could (ability; polite requests) Page 3 (Getting Started) Pages 45-47,
Inventory of grammatical areas Verbs Regular and irregular forms Pages 104-105 (Unit 1 Modals can (ability; requests; permission) could (ability; polite requests) Page 3 (Getting Started) Pages 45-47,
Sequential Supervised Learning
 Sequential Supervised Learning Many Application Problems Require Sequential Learning Part-of of-speech Tagging Information Extraction from the Web Text-to to-speech Mapping Part-of of-speech Tagging Given
Sequential Supervised Learning Many Application Problems Require Sequential Learning Part-of of-speech Tagging Information Extraction from the Web Text-to to-speech Mapping Part-of of-speech Tagging Given
Lecture 3: ASR: HMMs, Forward, Viterbi
 Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Conditional Random Fields for Sequential Supervised Learning
 Conditional Random Fields for Sequential Supervised Learning Thomas G. Dietterich Adam Ashenfelter Department of Computer Science Oregon State University Corvallis, Oregon 97331 http://www.eecs.oregonstate.edu/~tgd
Conditional Random Fields for Sequential Supervised Learning Thomas G. Dietterich Adam Ashenfelter Department of Computer Science Oregon State University Corvallis, Oregon 97331 http://www.eecs.oregonstate.edu/~tgd
Natural Language Processing
 SFU NatLangLab Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class Simon Fraser University October 20, 2017 0 Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class
SFU NatLangLab Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class Simon Fraser University October 20, 2017 0 Natural Language Processing Anoop Sarkar anoopsarkar.github.io/nlp-class
N-grams. Motivation. Simple n-grams. Smoothing. Backoff. N-grams L545. Dept. of Linguistics, Indiana University Spring / 24
 L545 Dept. of Linguistics, Indiana University Spring 2013 1 / 24 Morphosyntax We just finished talking about morphology (cf. words) And pretty soon we re going to discuss syntax (cf. sentences) In between,
L545 Dept. of Linguistics, Indiana University Spring 2013 1 / 24 Morphosyntax We just finished talking about morphology (cf. words) And pretty soon we re going to discuss syntax (cf. sentences) In between,
Machine Learning for natural language processing
 Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
lecture 6: modeling sequences (final part)
") Natural Language Processing 1 lecture 6: modeling sequences (final part) Ivan Titov Institute for Logic, Language and Computation Outline After a recap: } Few more words about unsupervised estimation of
Natural Language Processing 1 lecture 6: modeling sequences (final part) Ivan Titov Institute for Logic, Language and Computation Outline After a recap: } Few more words about unsupervised estimation of
Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013
 Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative Chain CRF General
Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative Chain CRF General
Dynamic Programming: Hidden Markov Models
 University of Oslo : Department of Informatics Dynamic Programming: Hidden Markov Models Rebecca Dridan 16 October 2013 INF4820: Algorithms for AI and NLP Topics Recap n-grams Parts-of-speech Hidden Markov
University of Oslo : Department of Informatics Dynamic Programming: Hidden Markov Models Rebecca Dridan 16 October 2013 INF4820: Algorithms for AI and NLP Topics Recap n-grams Parts-of-speech Hidden Markov
Statistical Methods for NLP
 Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Natural Language Processing 1. lecture 7: constituent parsing. Ivan Titov. Institute for Logic, Language and Computation
 atural Language Processing 1 lecture 7: constituent parsing Ivan Titov Institute for Logic, Language and Computation Outline Syntax: intro, CFGs, PCFGs PCFGs: Estimation CFGs: Parsing PCFGs: Parsing Parsing
atural Language Processing 1 lecture 7: constituent parsing Ivan Titov Institute for Logic, Language and Computation Outline Syntax: intro, CFGs, PCFGs PCFGs: Estimation CFGs: Parsing PCFGs: Parsing Parsing