Lecture II. Mathematical preliminaries
|
|
|
- Ashlee Boone
- 5 years ago
- Views:
Transcription
1 Lecture II Ivica Kopriva Ruđer Bošković Institute 1/58
2 Course outline Motivation with illustration of applications (lecture I) with principal component analysis (PCA)? (lecture II) Independent component analysis (ICA) for linear static problems: information-theoretic approaches (lecture III) ICA for linear static problems: algebraic approaches (lecture IV) ICA for linear static problems with noise (lecture V) Dependent component analysis (DCA) (lecture VI) 2/58
3 Course outline Underdetermined blind source separation (BSS) and sparse component analysis (SCA) (lecture VII/VIII) Nonnegative matrix factorization (NMF) for determined and underdetermined BSS problems (lecture VIII/IX) BSS from linear convolutive (dynamic) mixtures (lecture X/XI) Nonlinear BSS (lecture XI/XII) Tensor factorization (TF): BSS of multidimensional sources and feature extraction (lecture XIII/XIV) 3/58
4 Expectations, moments, cumulants, kurtosis Gradient and optimization: vector gradient, Jacobian, matrix gradient natural and relative gradient, gradient descent, stochastic gradient descent (batch and online) Estimation theory Information theory: entropy, differential entropy, entropy of a transformation, mutual information, distributions with maximum entropy, negentropy, entropy approximation: Gram-Charlier expansion PCA and whitening (batch and online) 4/58
5 The r th order moment of the scalar stochastic process z is defined as r r 1 T r M r ( z) = E z = z f ( zdz ) z( t) t= 1 T where f(z) is pdf of random variable z and T represents sample size. For real stochastic processes z 1 and z 2 the cross-moment is defined as 1 M rp ( z, z ) E z z z ( t) z ( t) r p T r p 1 2 = 1 2 t= T Cross-moment can be defined for nonzero time shifts as i, j, k, l,.. M τ1 τ2 τr 1 = E zi t zj t+ τ1 zk t+ τ2 zl t+ τr 1 rz, (,,..., ) ( ) ( ) ( )... ( ) 1 T z ( ) ( 1 i t zj t+ τ1) zk( t+ τ2)... zl( t+ τr 1) t= T 5/58
6 The first characteristic function of the random process z is defined as jωz jωz Ψ z ( ω) = E e = e f ( zdz ) Power series expansion of ψ z (ω) is obtained as 2 n ( jω) 2 ( jω) n Ψ z ( ω) = E 1 + jωz+ z z ! n! ω ω = + [ ] ! n! 2 n 2 ( j ) n ( j ) 1 E z jω E z... E z... Moments of the random process z are defined as n n 1 d Ψ z( ω) E z = atω 0. n = n j dω 6/58
7 The second characteristic function of the random process z is defined as K ( ω) = ln Ψ ( ω) z Power series expansion of K z (ω) is obtained as z 2 n ( jω) ( jω) n Kz( ω) = C1( z)( jω) + C2( z) C ( z) ! n! where C 1,C 2,.., C n are cumulants of the appropriate order and are defined as C n 1 d Kz ( ω) ( z) = atω = 0. j dω n n n 7/58
8 In practice cumulants, as well as moments, must be estimated from data. For that purpose relations between cumulants and moments are important. It follows from the definition of the first and second characteristic function { K ω } exp ( ) =Ψ ( ω) After Taylor series expansion the following is obtained z z 2 n ( jω) ( jω) exp { Kz ( ω) } = exp [ C1( z)( jω) ] exp C2( z)...exp Cn ( z)... 2! n! 2 n 2 ( jω) n ( jω) 1 E z jω E z... E z... [ ] = ! n! After exponential function is Taylor series expanded relations between cumulants and moments are obtained by equating coefficients with the same power of jω. 8/58
9 Relation between moments and cumulants: 1-3 Ez [ ] = C( z) 1 Ez [ ] = C( z) + C( z) Ez [ ] = C( z) + 3 C( zc ) ( z) + C( z) E[ z ] = C ( z) + 4 C ( z) C ( z) + 3 C ( z) + 6 C ( z) C ( z) + C ( z) For zero mean process relations simplify to: Ez C z 2 [ ] = 2( ) Ez C z 3 [ ] = 3( ) Ez [ ] = C( z) + 3 C( z) K.S. Shanmugan, A.M. Breiphol, Random Signals Detection, Estimation and Data Analysis, J.Wiley, D.R. Brillinger, Time Series Data Analysis and Theory, McGraw-Hill, /58 3 P. McCullagh, Tensor Methods in Statistics, Chapman & Hall, 1995.
10 Relations between cumulants and moments follow from previous expressions as C ( z) = E[ z] 1 C z E z E z 2 2 2( ) = [ ] [ ] C z Ez EzEz E z ( ) = [ ] 3 [ ] [ ] + 2 [ ] C z Ez EzEz E z E zez E z ( ) = [ ] 4 [ ] [ ] 3 [ ] + 12 [ ] [ ] 6 [ ] and for zero mean processes relations simplify to C z E z 2 2( ) = [ ] C z E z 3 3( ) = [ ] C z E z E z ( ) = [ ] 3 [ ] 10/58
11 As it is the case with cross-moments it is possible to define the cross-cumulants. They are useful in measuring statistical dependence between the random processes. For zero mean processes second order cross-cumulants are defined as C (, i j) = E[ z () t z ( t+ τ )] z i j third order cross-cumulants are defined as Cz(, i j, k) = E zi() t zj( t+ τ1) zk( t+ τ 2) several third order cross-cumulants could be computed such as for example C 111 zz z i j k ( τ, τ ) C ( τ, τ ) C ( τ, τ ) C ( τ, τ ) zz i j zz i j 1 2 z i /58
12 fourth order cross-cumulants are defined as Cz( i, j, k, l) = cum zi( t), zj( t+ τ1), zk( t+ τ2), zl( t+ τ3) = E zi(), t zj( t+ τ1), zk( t+ τ2), zl( t+ τ3) [ ] [ ] [ ] E zi() t zj( t+ τ1) E zl( t+ τ3) zk( t+ τ2) E zi() t zk( t+ τ2) E zl( t+ τ3) zj( t+ τ1) E zi() t zl( t+ τ3) E zj( t+ τ1) zk( t+ τ2) Several fourth order cross-cumulants could be computed such as for example C 1111 zz z z i j k l ( τ, τ, τ ) C 22 zz i j ( τ, τ, τ ) C 13 zz i j ( τ, τ, τ ) C 31 zz i j ( τ, τ, τ ) C τ1 τ2 τ3 z i (,, ) 12/58
13 If two random processes z 1 (t) and z 2 (t) are mutually independent then [ ] E gz ( ) hz ( ) = Egz [ ( )] Ehz [ ( )] Proof: [ ] E g( z ) h( z ) = g( z ) h( z ) p ( z, z ) dz dz = = zz gz ( ) p( z) dz hz ( ) p ( z) dz 1 z z2 2 2 [ ( )] E[ h( z )] E g z /58
14 Operator properties of the cumulants. Cumulants have certain properties that make them very useful in various computations with stochastic processes. Most of these properties will be stated without proofs which can be found in 2,4. n { i} i 1 n z i= α = { i} 1 [CP1] If are constants and are random variables then n cum z z z = cum z z z [CP2]- Cumulants are additive in their arguments ( α, α,..., α ) α (,,..., ) n n i 1 2 n i= 1 ( 1+ 1, 2,.., n ) = cum( x, z,..., z ) + cum( y, z,..., z ) cum x y z z 1 2 n J. Mendel, Tutorial on Higher-Order Statistics (Spectra) in Signal Processing and System Theory: Theoretical 14/58 Results and Some Applications, Proc. IEEE, vol. 79, no.3, March 1991, pp n
15 [CP3] Cumulants are symmetric in their arguments i.e. ( ) ( ) 1, 2,..., =,,..., cum z z z cum z z z k i1 i2 i k where (i 1,i 2,,i k ) is any permutation of (1,2,,k). [CP4] If α is constant then ( α +,,..., ) = (,,..., ) cum z z z cum z z z 1 2 k 1 2 [CP5] If random processes (z 1,z 2,,z k ) and (y 1,y 2,,y k ) are independent then ( +, +,..., + ) = (,,..., ) + (,,..., ) cum y z y z y z cum y y y cum z z z k k 1 2 k 1 2 k k 15/58
16 k { z i} i= 1 [CP6] If any subset of k random variables is statistically independent from the rest then ( ) cum z, z,..., z = k [CP7] Cumulants of independent identically distributed (i.i.d.) random processes are delta functions i.e. where γ, = C,. kz kz Ckz, ( 1, 2,..., k 1 ) = kz, ττ... τ τ τ τ γ δ 1 2 k 1 16/58
17 [CP8] - If random process is Gaussian N(µ,σ 2 ) then C k,z =0 for k>2. Proof. Let f(z) be p.d.f. of the normally distributed random process z 1 ( z µ ) f( z) = exp 2 σ 2π 2σ 2 where µ=e(z)=c 1 (z) is the mean value or the first order cumulant of the random process z and σ 2 =E[z 2 ]-E 2 [z]=c 2 (z) is the variance or the second order cumulant of the random process z. According to the definition of the first characteristic function jωz jωz Ψ z ( ω) = E e = f( z) e dz = ( σ jω ) 1 ( z ˆ µ ) 2 2 = exp jµω + exp dz 2 2 σ 2π 2σ =1 17/58
18 ˆ 2 µ = µ + σ ω j where. By definition of the second characteristic function K z 2 ( jω ) ( ω) = ln Ψ z( ω ) = µ ( jω) + σ 2 when compared with Taylor series expansion of K z (ω) it follows that C k (z)=0 for k>2. 2 The complexity for the cumulants of the order higher than 4 is very high. An important question that has to be answered from the application point of view is what statistics of the order higher than 2 should be used? Because symmetrically distributed random processes, which occur very often in engineering applications, have odd order statistics equal to zero the third order statistics are not used. So, the first statistics of the order higher than 2 that are used are the fourth order statistics. 18/58
19 Another natural question that should be answered is: why and when cumulants are better than moments? Computation with cumulants is simpler than by using moments. For independent random variables cumulant of the sum equals the sum of the cumulants. Cross-cumulants of the independent random processes are zero what does not apply for moments. For normally distributed processes cumulants of order greater than 2 vanish what does not apply for moments. Blind identification of the LTI systems (MA, AR and ARMA) is possible to formulate using cumulants provided that input signal is non-gaussian i.i.d. random process. 19/58
20 Density of transformation. Assume that both x and y are n-dimensional random vectors related through the vector mapping y=g(x). It is assumed that inverse mapping x=g -1 (y) exists and is unique. Density p y (y) is obtained from density p x (x) as follows 5 1 py( y) = p ( ) x x 1 det Jg g y ( ( )) Where Jg is the Jacobian matrix representing the gradient of the vector-valued function Jgx ( ) g1( x) g2( x) gn ( x)... x1 x1 x 1 g ( x) g ( x) g ( x) n = x2 x2 x g1( x) g2( x) gn ( x)... xn xn x n For linear nonsingular transformation y=ax the relation between densities becomes 1 py( y) = px( x) det A 5 A. Papoulis, Probability, Random Variables, and Stochastic Processes, McGraw-Hill, 3 rd ed., /58
21 Kurtosis. Based on the measure called kurtosis it is possible to measure how far certain stochastic process is from Gaussian distribution. The kurtosis is defined as κ ( z ) = i C C ( z ) i ( z ) i where C 4 (z i ) is the FO and C 2 (z i ) is the SO cumulant of the signal z i. For the zero mean signals kurtosis becomes κ Ez ( zi ) = 3 E [ ] 4 [ i ] 2 2 zi 21/58
22 According to cumulant property [CP8] the FO cumulant of the Gaussian process is zero. Signals with positive kurtosis are classified as super-gaussian and signals with negative kurtosis as sub- Gaussian. Most of the communication signals are sub-gaussian processes. Speech and music signals are super-gaussian processes. Uniformly distributed noise is sub-gaussian process. Impulsive noise (with Laplacian or Lorentz distribution) is highly super-gaussian process. 22/58
23 Gradients and optimization (learning) methods. Gradients are used in minimization or maximization of the cost functions. This process is called learning. Solution of the ICA problem is also obtained as a solution of the minimization or maximization problem of the scalar cost function w.r.t. matrix argument. Scalar function g with vector argument is defined as g=g(w 1,w 2,,w m )=g(w). Vector gradient w.r.t. w is defined as g w 1 g =... w g w m Another commonly used notation for vector gradient is g or w g. 23/58
24 Gradients and optimization (learning) methods. Vector valued function is defined as g( 1 w) gw ( ) =... g n ( ) w Gradient of the vector valued function is called Jacobian matrix of g and is defined as Jgw ( ) g1( w) g2( w) gn ( w)... w1 w1 w 1 g ( w) g ( w) g ( w) n = w2 w2 w g1( w) g2( w) gn ( w)... wm wm w m 24/58
25 Gradients and optimization (learning) methods. In solving ICA problem a scalar-valued function g with matrix argument W is defined as g=g(w)=g(w 11,,w ij,,w mn ). The matrix gradient is defined as g g... w11 w 1n g = W g g... wm 1 w mn 25/58
26 Example matrix gradient of the determinant of a matrix (necessary in some ICA algorithms). For invertible square matrix W gradient of the determinant of a matrix is obtained as T det W = ( W ) 1 det W W Proof. The following definition for inverse matrix is used W 1 1 = adj( W) det W where adj(w) stands for adjoint of W and is defined as adj( W) W... W 11 n1 = W1 n... Wnn and scalars W ij are called cofactors. 26/58
27 Determinant can be expressed in terms of cofactors as It follows det W w ij det W = ww n k=1 ik ik det W = Wij = adj = W T T ( W) ( det W)( W ) 1 The previous result also implies log det det w ij W 1 = W = W det W W T ( ) 1 27/58
28 Natural or relative gradient. 6,7 Parameter space of the square matrices has Riemannian metric structure and Euclidean gradient does not point into steepest direction of the cost function J(W). T It has to be corrected in order to obtain natural or relative gradient i.e. ( J W) W W i.e. correction term is given by W T W. 6 S. Amari, Natural gradient works efficiently in learning, Neural Computation 10(2), pp , /58 J. F. Cardoso, and B. Laheld, Equivariant adaptive source separation, IEEE Trans. Signal Processing 44(12), pp , 1996.
29 Proof. We shall follow derivation given by Cardoso in 7. Let us write the Taylor series of J(W + δw): J J W ( W+ δw) = J( W) + trace δw +... Let us require that displacement δw is always proportional to W itself, δw = DW. Then T J J W ( W+ DW) = J( W) + trace DW +... T J = J ( W) + trace DW +... W T 29/58
30 Using the property of the trace operator trace(m 1 M 2 )= trace(m 2 M 1 ) we can write T T J T J T trace D = trace W W W W D We seek for the largest decrement in the value of J(W+DW)-J(W) that is obtained when term T J T J T is minimized. That will happen when D is proportional to. Because trace W W D δw=dw we obtain the gradient descent learning rule J W implying that correction term is W T W. J W T T W W W = W W W W 30/58
31 Exercise. Let the scalar function with matrix argument be defined as f(a)=(y-ax) T (y-ax) where y and x are vectors. Euclidean gradient is given with: f/ A=-2(y-Ax)x T. Riemannian gradient is given with ( f/ A)A T A==-2(y-Ax)x T A T A. Euclidean gradient based learning equation: A(k+1)=A(k)-µ( f/ A) Riemannian gradient based learning equation: A(k+1)=A(k)-µ( f/ A) A T A Evaluate convergence properties of these two learning equations starting with the initial condition A 0 =I. Assume the true values as: A=[2 1;1 2], x=[1 1] T, y=ax=[3 3] T. 31/58
32 Gradient descent and stochastic gradient descent. ICA like in many other statistical and neural network techniques is data driven i.e. we need observation data (x) in order to solve the problem. Typical cost function has the form { ( W x) } J( W) = E g, where expectation is defined w.r.t. some unknown density f(x). The steepest descent learning rule becomes W() t = W( t 1) µ () t E g( W, x()) t W { } W= W( t 1) In practice expectation has to be approximated by the sample mean of function g over the sample x(1), x(2),, x(t). The algorithm where entire training set is used at every iteration step is called batch learning. 32/58
33 Gradient descent and stochastic gradient descent. Sometimes not all the observation could be known in advance but only the latest x(t) could be used. This is called on-line or adaptive learning. The on-line learning rule is obtained by dropping expectation operator from the batch learning i.e. W() t = W( t 1) µ () t g( W, x) W W= W( t 1) Parameter µ(t) is called the learning gain and regulates smoothness and speed of convergence. On-line and batch algorithms converge toward the same solution that represents fixed point of the first order autonomous differential equation dw dt = { ( Wx, )} E g W The learning rate µ(t) should be chosen as µ () t = β β + t where β is an appropriate constant (e.g. β =100). 33/58
34 Information theory entropy, negentropy and mutual information. Entropy of a random variable can be interpreted as the degree of information that the observation of the variable gives. For discrete random variable X entropy H is defined as ( ) H( X) = P( X = a )log P( X = a ) = f PX ( = a) i i i i i Entropy could be generalized for continuous random variables and vectors in which case it is called the differential entropy. [ ] H ( x) = p ( ξ)log p ( ξ) dξ = E log p ( x) x x x Unlike discrete entropy, differential entropy can be negative. Entropy is small when variable is not very random i.e. when it is contained in some limited intervals with high probabilities. 34/58
35 Maximum entropy distributions finite support case. Uniform distribution in the interval [0,a]. Density is given with p Differential entropy is evaluated as x 1/ a for 0 ξ a ( ξ ) = 0 otherwise a 1 1 H( x) = log d loga 0 a a ξ = Entropy is small (in a sense of negative numbers) or large in absolute value sense when a is small In limit lim H( x) = a 0 Uniform distribution is the maximum entropy distribution among the finite support distributions. 35/58
36 Maximum entropy distributions infinite support case. What is distributions that is compatible with the measurements (c i =E{F i (x)}) and makes minimum number of assumptions on the data maximum entropy distributions? p( ξ) F i ( ξ) dξ = c i = 1,..., m i It has been shown in 5 that density p 0 (ξ) which satisfies previous constraint and has maximum entropy is of the form ( ) exp i ( ) p0 ξ = A aif ξ i For set of random variables that take all the values on the real line and have zero mean and fixed variance, say 1, maximum entropy distribution takes the form ( 2 ) p ( ξ ) = Aexp aξ + a ξ that is recognized as Gaussian variable. It has the largest entropy among all random variables of finite (unit) variance with infinite support. 5 A. Papoulis, Probability, Random Variables, and Stochastic Processes, McGraw-Hill, 3 rd ed., /58
37 Entropy of a transformation. Consider an invertible transformation of the random vector x y = f( x) Relation between densities is given by p p J Expressing entropy as expectation we obtain 1 1 y( η) = x( f ( η)) det ff ( ( η)) { } { 1 } y x H( y) = E log p ( y) = E log p ( x) det Jf( x) 1 { log det fx ( ) } { log x( x) } ( x) { log det f( x) } = E J E p = H + E J Entropy is increased by transformation. For the linear transform y=ax we obtain H( y) = H( x) + log deta Differential entropy is not scale invariant i.e. H(αx)=H(x) + log α. Scale must be fixed before differential entropy is measured. 37/58
38 Mutual information is a measure of the information that members of a set of random variables have on the other random variables in the set (vector). One measure of mutual information is a distance between components of the set (vector) measured by Kullback-Leibler divergence: N p( y) MI( y) = D p( y), p( yi ) = p( y)log dy N i= 1 py ( ) N = H( y ) H( y) i= 1 Using Jensen s inequality 8 it can be shown MI(y) 0. i MI( y) = 0 p( y) = p( yi ) Mutual information can be used as a measure of statistical (in)dependence. N i= 1 i= 1 i 8 T. M. Cover and J.A. Thomas, Elements of Information Theory, Wiley, /58
39 Negentropy. The fact that Gaussian variable has maximum entropy enables to use entropy as a measure of non-gaussianity. A measure called negentropy is defined to be zero for Gaussian variable and positive otherwise: J( x) = H( x ) H( x) gauss Where x gauss is a Gaussian random vector of the same covariance matrix Σ as x. Entropy of Gaussian random vector can be evaluated as 1 N H ( xgauss ) = log detσ + 1+ log2 2 2 [ π ] Negentropy has an additional property to be invariant for invertible linear transformation y=ax 1 T N J( Ax) = log det( AΣA ) + [ 1+ log2 π ] ( H( x) + log A) N = log det Σ + 2 log det A + [ 1+ log 2 π ] H ( x) log det A N = log det Σ + [ 1 + log 2 π ] H ( x ) 2 2 = H( x ) H( x) = J( x) 39/58 gauss
40 Approximation of entropy by cumulants. Entropy and negentropy are important measures of non-gaussianity and thus very important for the ICA. However, computation of entropy involves evaluation of integral that include density function. This is computationally very difficult and would limit the use of entropy/negentropy in the algorithm design. To obtain computationally tractable algorithms density function used in entropy integral is approximated using either Edgeworth or Gram-Charlier expansion which are Taylor series-like expansions around Gaussian density. Gram-Charlie expansion of the standardized random variable x with non-gaussian density is obtained as H3( ξ ) H 4( ξ ) p ( ) ˆ x ξ px( ξ) = ϕ( ξ) 1 + C3( x) + C4( x) ! 4! where C 3 (x) and C 4 (x) are cumulants of order 3 and 4, ϕ(ξ) is Gaussian density and H 3 (ξ), H 4 (ξ) are Hermite polynomials defined as i 1 i ϕ( ξ ) ( ξ ) = ( 1) ϕ( ξ) ξ H i i 40/58
41 Entropy can now be estimated from H( x) pˆ ( )log ˆ x ξ px( ξ) dξ Assuming small deviation from Gaussianity we obtain H3( ξ ) H 4( ξ ) H( x) ϕξ ( ) 1 + C3( x) + C4( x) dξ 3! 4! 2 H3( ξ ) H 4( ξ ) H3( ξ ) H 4( ξ ) log ϕ( ξ) + C3( x) + C4( x) C3( x) + C4( x) 2 dξ 3! 4! 3! 4! C ( x) C ( x) ϕξ ( )log ϕξ ( ) dξ 2 3! 2 4! and computationally simple approximation of negentropy is obtained as 1 { } 2 1 J ( x) E x + kurt( x) /58
42 Principal Component Analysis (PCA) and whitening (batch and online). PCA is basically decorellation based transform used in multivariate data analysis. In connection with ICA it is very often a useful preprocessing step used in the whitening transformation after which multivariate data become uncorrelated with unit variance. PCA and/or whitening transform are designed on the basis of the eigenvector decomposition of the sample data covariance matrix ( 1 T K) K ( k ) ( k ) R x x xx k = 1 It is assumed data x is zero mean. If not this is achieved by x x- E{x}. Eigendecomposition of R xx is obtained as Rxx = EΛE Where E is matrix of eigenvectors and Λ is diagonal matrix of eigenvalues of R xx. T 42/58
43 Batch form of PCA/whitening transform is obtained as and one verifies 1/2 T z = Vx= Λ Ex E zz = E Λ ExxEΛ = Λ E E xx EΛ an adaptive whitening transform is obtained as z = T 1/2 T T 1/2 1/2 T T 1/2 k k k 1/2 T T 1/2 1/2 1/2 = Λ EEΛ EEΛ = Λ ΛΛ = I V x V = V µ z z I V T k+ 1 k k k k k where µ is small learning gain and V 0 =I. I I 43/58

; x 2 = N(0,9) z 1 =x 1 + x 2 z 2 =x 1 + 2x 2 y=λ -1/2 E T z")
44 Scatter plots of two uncorrelated Gaussian signals (left); two correlated signals obtained as linear combinations of the uncorrelated Gaussian signals (center); two signals after PCA/whitening transform (right). x 1 =N(0,4); x 2 = N(0,9) z 1 =x 1 + x 2 z 2 =x 1 + 2x 2 y=λ -1/2 E T z z=[z 1 ;z 2 ] 44/58

 y 2 s 2 (?")
45 s 1 s 2 x 1 = 2s 1 + s 2 x 2 = s 1 + s 2 y 1 s 1 (?) y 2 s 2 (?) x 1 x 2 45/58
46 What is ICA? Imagine situation in which two microphones recording weighted sums of the two signals emitted by the speaker and background noise. x 1 = a 11 s 1 + a 12 s 2 x 2 = a 21 s 1 + a 22 s 2 The problems is to estimated the speech signal (s 1 ) and noise signal (s 2 ) from observations x 1 and x 2. If mixing coefficients a 11, a 12, a 21 and a 22 are known problem would be solvable by simple matrix inversion. ICA enables to estimated speech signal (s 1 ) and noise signal (s 2 ) without knowing the mixing coefficients a 11, a 12, a 21 and a 22. This is why the problem of recovering source signals s 1 and s 2 is called blind source separation problem. 46/58
47 What is ICA? 9 ICA is the most frequently used method to solve the BSS problem. ICA could be considered as theory for multichannel blind signal recovery requiring minimum of a priori information. Problem: x=as or x=a*s or x=f(as) or x=f(a*s) Goal: find s based on x only (A is unknown). W can be found such that: y s=wx or y s=w*x y PΛs 9 Ch. Jutten, J. Herault, Blind separation of sources, part I: An adaptive algorithm based on neuromimetic architecture, Sig. Proc., 24(1):1-10, /58
48 What is ICA? Environment x = As y = Wx s 1 s 2 s N x 1 y 1 x 2... x N Source Separation Algorithm W y 2.. y N Sources Sensors Observations 48/58


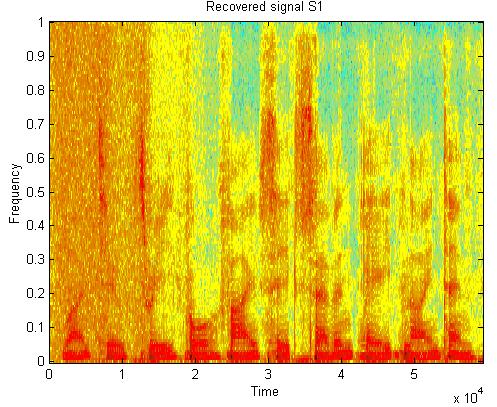

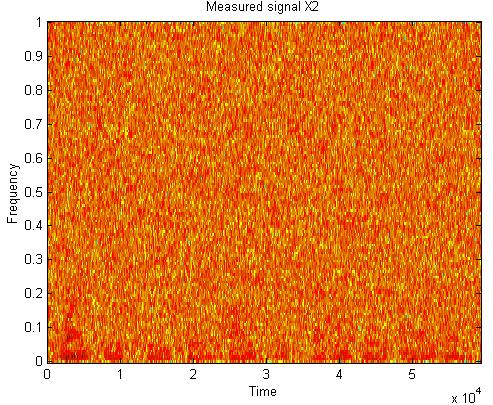

49 Speech from noise separation s x y 49/58
50 When does ICA work!? source signals s i (t) must be statistically independent. p ( s) = pi( si) source signals s i (t), except one, must be non-gaussian. mixing matrix A must be nonsingular and square. N i= C ( s ) 0 n> 2 n W i A 1 Knowledge of the physical interpretation of the mixing matrix is of crucial importance. 50/58
51 When does ICA work!? Ambiguities of ICA. a) Variances (energies) of the independent components can not be determined. This is called scaling indeterminacy. The reason is that both s and A being unknown any scalar multiplier in one of the sources can always be canceled by dividing the corresponding column of A by the same multiplier: 1 x= i a αi ( sα ) i i i b) Order of the independent components can not be determined. This is called permutation indeterminacy. The reason is that components of the source vector s and columns of the mixing matrix A could be freely changed in such that x=ap -1 Ps where P permutation matrix, Ps is new source vector with original components but in different order and AP -1 is a new unknown mixing matrix. 51/58

![Right picture shows mixed signals obtained according to x=as where A=[5 10;10 2]. Obviously there is dependence between x 1 and x 2.](/docs-images/88/115991025/images/52-1.jpg "Knowing maximum or minimum of x 1 enables to know x 2 A could be estimated. But what if sources signals have different statistics?")
52 When does ICA work!? To illustrate ICA model in statistical terms we consider two independent uniformly distribute signals s 1 and s 2. Scatter plot on the left picture shows that there is no redundancy between them i.e. no knowledge could be gained about s 2 from s 1. Right picture shows mixed signals obtained according to x=as where A=[5 10;10 2]. Obviously there is dependence between x 1 and x 2. Knowing maximum or minimum of x 1 enables to know x 2 A could be estimated. But what if sources signals have different statistics? Source signals Mixed signals 52/58

![But distribution is different i.e. sparse. Right picture shows mixed signals obtained according to x=as where A=[5 10;10 2].](/docs-images/88/115991025/images/53-1.jpg "Obviously there is dependence between x 1 and x 2. But edges are at different positions this time. Estimated A from the scatter plot would be very unreliable.")
53 When does ICA work!? Consider two independent source signals s 1 and s 2 generated by the truck and tank engines. Scatter plot on the left picture shows that there is again no redundancy between them i.e. no knowledge could be gained about s 2 from s 1. But distribution is different i.e. sparse. Right picture shows mixed signals obtained according to x=as where A=[5 10;10 2]. Obviously there is dependence between x 1 and x 2. But edges are at different positions this time. Estimated A from the scatter plot would be very unreliable. ICA can do that for different signal statistics without knowing that in advance. Source signals Mixed signals 53/58


54 When does ICA work!? Whitening is only half of the ICA. Whitening transform decorrelates signals. If signals are non-gaussian it does not make them independent. Whitening transform is usually useful first processing step in ICA. A second rotation stage achieved by an unitary matrix can be obtained by ICA exploiting non-gaussianity of the signals. Source signals Mixed signals Whitened signals 54/58
55 When does ICA work!? Why Gaussian variables are forbidden? Suppose two independent components s 1 and s 2 are Gaussian. Their joint density is given by s1 + s 2 1 s ps ( 1, s2) = exp = exp 2π 2 2π 2 Assume that source signals are mixed with orthogonal mixing matrix i.e. A -1 =A T. Their joint density is given by T 2 1 Ax T T 2 2 px ( 1, x2) = exp det A = A x = x anddet A = 1 2π x = exp 2π 2 Original and mixing distributions are identical there is no way that we could infer mixing matrix from the mixtures. 55/58

.")

56 When does ICA work!? Why Gaussian variables are forbidden? Consider mixture of two Gaussian signals s 1 =N(0,4) and s 2 =N(0,9). After whitening stage scatter plot is the same as for source signals. There is no redundancy left after the whitening stage nothing for ICA to do. Source signals Mixed signals Whitened signals 56/58
; % estimate of the data covariance matrix [E,D] = eig(r x ); % eigen-decomposition of the data covariance matrix Z = E *X; %")
57 When does ICA work!? PCA applied to blind image separation: z 1 z 2 MATLAB code: R x =cov(x ); % estimate of the data covariance matrix [E,D] = eig(r x ); % eigen-decomposition of the data covariance matrix Z = E *X; % PCA transform z =reshape(z(1,:),p,q); 1 % transforming vector into image figure(1); imagesc(z 1 ); % show first PCA image z 2 =reshape(z(2,:),p,q); % transforming vector into image figure(2); imagesc(z 2 ); % show second PCA image 57/58



58 Histograms of source, mixed and PCA extracted images Source image Mixed images PCA extracted images 58/58
Fundamentals of Principal Component Analysis (PCA), Independent Component Analysis (ICA), and Independent Vector Analysis (IVA)
, Independent Component Analysis (ICA), and Independent Vector Analysis (IVA)") Fundamentals of Principal Component Analysis (PCA),, and Independent Vector Analysis (IVA) Dr Mohsen Naqvi Lecturer in Signal and Information Processing, School of Electrical and Electronic Engineering,
Fundamentals of Principal Component Analysis (PCA),, and Independent Vector Analysis (IVA) Dr Mohsen Naqvi Lecturer in Signal and Information Processing, School of Electrical and Electronic Engineering,
Natural Gradient Learning for Over- and Under-Complete Bases in ICA
 NOTE Communicated by Jean-François Cardoso Natural Gradient Learning for Over- and Under-Complete Bases in ICA Shun-ichi Amari RIKEN Brain Science Institute, Wako-shi, Hirosawa, Saitama 351-01, Japan Independent
NOTE Communicated by Jean-François Cardoso Natural Gradient Learning for Over- and Under-Complete Bases in ICA Shun-ichi Amari RIKEN Brain Science Institute, Wako-shi, Hirosawa, Saitama 351-01, Japan Independent
Independent Component Analysis. Contents
 Contents Preface xvii 1 Introduction 1 1.1 Linear representation of multivariate data 1 1.1.1 The general statistical setting 1 1.1.2 Dimension reduction methods 2 1.1.3 Independence as a guiding principle
Contents Preface xvii 1 Introduction 1 1.1 Linear representation of multivariate data 1 1.1.1 The general statistical setting 1 1.1.2 Dimension reduction methods 2 1.1.3 Independence as a guiding principle
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts I-II
 Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts I-II Gatsby Unit University College London 27 Feb 2017 Outline Part I: Theory of ICA Definition and difference
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts I-II Gatsby Unit University College London 27 Feb 2017 Outline Part I: Theory of ICA Definition and difference
CIFAR Lectures: Non-Gaussian statistics and natural images
 CIFAR Lectures: Non-Gaussian statistics and natural images Dept of Computer Science University of Helsinki, Finland Outline Part I: Theory of ICA Definition and difference to PCA Importance of non-gaussianity
CIFAR Lectures: Non-Gaussian statistics and natural images Dept of Computer Science University of Helsinki, Finland Outline Part I: Theory of ICA Definition and difference to PCA Importance of non-gaussianity
Massoud BABAIE-ZADEH. Blind Source Separation (BSS) and Independent Componen Analysis (ICA) p.1/39
 and Independent Componen Analysis (ICA) p.1/39") Blind Source Separation (BSS) and Independent Componen Analysis (ICA) Massoud BABAIE-ZADEH Blind Source Separation (BSS) and Independent Componen Analysis (ICA) p.1/39 Outline Part I Part II Introduction
Blind Source Separation (BSS) and Independent Componen Analysis (ICA) Massoud BABAIE-ZADEH Blind Source Separation (BSS) and Independent Componen Analysis (ICA) p.1/39 Outline Part I Part II Introduction
Independent Component Analysis
 Independent Component Analysis Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr March 4, 2009 1 / 78 Outline Theory and Preliminaries
Independent Component Analysis Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr March 4, 2009 1 / 78 Outline Theory and Preliminaries
HST.582J/6.555J/16.456J
 Blind Source Separation: PCA & ICA HST.582J/6.555J/16.456J Gari D. Clifford gari [at] mit. edu http://www.mit.edu/~gari G. D. Clifford 2005-2009 What is BSS? Assume an observation (signal) is a linear
Blind Source Separation: PCA & ICA HST.582J/6.555J/16.456J Gari D. Clifford gari [at] mit. edu http://www.mit.edu/~gari G. D. Clifford 2005-2009 What is BSS? Assume an observation (signal) is a linear
Lecture III. Independent component analysis (ICA) for linear static problems: information- theoretic approaches
 for linear static problems: information- theoretic approaches") Lecture III Independent component analysis (ICA) for linear static problems: information- theoretic approaches Ivica Kopriva Ruđer Bošković Institute e-mail: ikopriva@irb.hr ikopriva@gmail.com Web: http://www.lair.irb.hr/ikopriva/
Lecture III Independent component analysis (ICA) for linear static problems: information- theoretic approaches Ivica Kopriva Ruđer Bošković Institute e-mail: ikopriva@irb.hr ikopriva@gmail.com Web: http://www.lair.irb.hr/ikopriva/
1 Introduction Independent component analysis (ICA) [10] is a statistical technique whose main applications are blind source separation, blind deconvo
![1 Introduction Independent component analysis (ICA) [10] is a statistical technique whose main applications are blind source separation, blind deconvo](/thumbs/72/66692794.jpg "1 Introduction Independent component analysis (ICA) [10] is a statistical technique whose main applications are blind source separation, blind deconvo") The Fixed-Point Algorithm and Maximum Likelihood Estimation for Independent Component Analysis Aapo Hyvarinen Helsinki University of Technology Laboratory of Computer and Information Science P.O.Box 5400,
The Fixed-Point Algorithm and Maximum Likelihood Estimation for Independent Component Analysis Aapo Hyvarinen Helsinki University of Technology Laboratory of Computer and Information Science P.O.Box 5400,
Tutorial on Blind Source Separation and Independent Component Analysis
 Tutorial on Blind Source Separation and Independent Component Analysis Lucas Parra Adaptive Image & Signal Processing Group Sarnoff Corporation February 09, 2002 Linear Mixtures... problem statement...
Tutorial on Blind Source Separation and Independent Component Analysis Lucas Parra Adaptive Image & Signal Processing Group Sarnoff Corporation February 09, 2002 Linear Mixtures... problem statement...
Different Estimation Methods for the Basic Independent Component Analysis Model
 Washington University in St. Louis Washington University Open Scholarship Arts & Sciences Electronic Theses and Dissertations Arts & Sciences Winter 12-2018 Different Estimation Methods for the Basic Independent
Washington University in St. Louis Washington University Open Scholarship Arts & Sciences Electronic Theses and Dissertations Arts & Sciences Winter 12-2018 Different Estimation Methods for the Basic Independent
HST.582J / 6.555J / J Biomedical Signal and Image Processing Spring 2007
 MIT OpenCourseWare http://ocw.mit.edu HST.582J / 6.555J / 16.456J Biomedical Signal and Image Processing Spring 2007 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
MIT OpenCourseWare http://ocw.mit.edu HST.582J / 6.555J / 16.456J Biomedical Signal and Image Processing Spring 2007 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
Semi-Blind approaches to source separation: introduction to the special session
 Semi-Blind approaches to source separation: introduction to the special session Massoud BABAIE-ZADEH 1 Christian JUTTEN 2 1- Sharif University of Technology, Tehran, IRAN 2- Laboratory of Images and Signals
Semi-Blind approaches to source separation: introduction to the special session Massoud BABAIE-ZADEH 1 Christian JUTTEN 2 1- Sharif University of Technology, Tehran, IRAN 2- Laboratory of Images and Signals
Nonnegative matrix factorization (NMF) for determined and underdetermined BSS problems
 for determined and underdetermined BSS problems") Nonnegative matrix factorization (NMF) for determined and underdetermined BSS problems Ivica Kopriva Ruđer Bošković Institute e-mail: ikopriva@irb.hr ikopriva@gmail.com Web: http://www.lair.irb.hr/ikopriva/
Nonnegative matrix factorization (NMF) for determined and underdetermined BSS problems Ivica Kopriva Ruđer Bošković Institute e-mail: ikopriva@irb.hr ikopriva@gmail.com Web: http://www.lair.irb.hr/ikopriva/
Independent component analysis: algorithms and applications
 PERGAMON Neural Networks 13 (2000) 411 430 Invited article Independent component analysis: algorithms and applications A. Hyvärinen, E. Oja* Neural Networks Research Centre, Helsinki University of Technology,
PERGAMON Neural Networks 13 (2000) 411 430 Invited article Independent component analysis: algorithms and applications A. Hyvärinen, E. Oja* Neural Networks Research Centre, Helsinki University of Technology,
Independent Component Analysis
 1 Independent Component Analysis Background paper: http://www-stat.stanford.edu/ hastie/papers/ica.pdf 2 ICA Problem X = AS where X is a random p-vector representing multivariate input measurements. S
1 Independent Component Analysis Background paper: http://www-stat.stanford.edu/ hastie/papers/ica.pdf 2 ICA Problem X = AS where X is a random p-vector representing multivariate input measurements. S
Blind separation of instantaneous mixtures of dependent sources
 Blind separation of instantaneous mixtures of dependent sources Marc Castella and Pierre Comon GET/INT, UMR-CNRS 7, 9 rue Charles Fourier, 9 Évry Cedex, France marc.castella@int-evry.fr, CNRS, I3S, UMR
Blind separation of instantaneous mixtures of dependent sources Marc Castella and Pierre Comon GET/INT, UMR-CNRS 7, 9 rue Charles Fourier, 9 Évry Cedex, France marc.castella@int-evry.fr, CNRS, I3S, UMR
Independent Component Analysis and Its Applications. By Qing Xue, 10/15/2004
 Independent Component Analysis and Its Applications By Qing Xue, 10/15/2004 Outline Motivation of ICA Applications of ICA Principles of ICA estimation Algorithms for ICA Extensions of basic ICA framework
Independent Component Analysis and Its Applications By Qing Xue, 10/15/2004 Outline Motivation of ICA Applications of ICA Principles of ICA estimation Algorithms for ICA Extensions of basic ICA framework
A Canonical Genetic Algorithm for Blind Inversion of Linear Channels
 A Canonical Genetic Algorithm for Blind Inversion of Linear Channels Fernando Rojas, Jordi Solé-Casals, Enric Monte-Moreno 3, Carlos G. Puntonet and Alberto Prieto Computer Architecture and Technology
A Canonical Genetic Algorithm for Blind Inversion of Linear Channels Fernando Rojas, Jordi Solé-Casals, Enric Monte-Moreno 3, Carlos G. Puntonet and Alberto Prieto Computer Architecture and Technology
Independent Component Analysis and Unsupervised Learning
 Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien National Cheng Kung University TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent
Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien National Cheng Kung University TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent
Lecture 10: Dimension Reduction Techniques
 Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Independent Component Analysis (ICA) Bhaskar D Rao University of California, San Diego
 Bhaskar D Rao University of California, San Diego") Independent Component Analysis (ICA) Bhaskar D Rao University of California, San Diego Email: brao@ucsdedu References 1 Hyvarinen, A, Karhunen, J, & Oja, E (2004) Independent component analysis (Vol 46)
Independent Component Analysis (ICA) Bhaskar D Rao University of California, San Diego Email: brao@ucsdedu References 1 Hyvarinen, A, Karhunen, J, & Oja, E (2004) Independent component analysis (Vol 46)
Independent Component Analysis (ICA)
") Independent Component Analysis (ICA) Université catholique de Louvain (Belgium) Machine Learning Group http://www.dice.ucl ucl.ac.be/.ac.be/mlg/ 1 Overview Uncorrelation vs Independence Blind source separation
Independent Component Analysis (ICA) Université catholique de Louvain (Belgium) Machine Learning Group http://www.dice.ucl ucl.ac.be/.ac.be/mlg/ 1 Overview Uncorrelation vs Independence Blind source separation
PROPERTIES OF THE EMPIRICAL CHARACTERISTIC FUNCTION AND ITS APPLICATION TO TESTING FOR INDEPENDENCE. Noboru Murata
 ' / PROPERTIES OF THE EMPIRICAL CHARACTERISTIC FUNCTION AND ITS APPLICATION TO TESTING FOR INDEPENDENCE Noboru Murata Waseda University Department of Electrical Electronics and Computer Engineering 3--
' / PROPERTIES OF THE EMPIRICAL CHARACTERISTIC FUNCTION AND ITS APPLICATION TO TESTING FOR INDEPENDENCE Noboru Murata Waseda University Department of Electrical Electronics and Computer Engineering 3--
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Dimensionality Reduction. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Dimensionality Reduction CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Visualize high dimensional data (and understand its Geometry) } Project the data into lower dimensional spaces }
Dimensionality Reduction CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Visualize high dimensional data (and understand its Geometry) } Project the data into lower dimensional spaces }
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Independent Component Analysis and Unsupervised Learning. Jen-Tzung Chien
 Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent voices Nonparametric likelihood
Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent voices Nonparametric likelihood
Review (Probability & Linear Algebra)
") Review (Probability & Linear Algebra) CE-725 : Statistical Pattern Recognition Sharif University of Technology Spring 2013 M. Soleymani Outline Axioms of probability theory Conditional probability, Joint
Review (Probability & Linear Algebra) CE-725 : Statistical Pattern Recognition Sharif University of Technology Spring 2013 M. Soleymani Outline Axioms of probability theory Conditional probability, Joint
where A 2 IR m n is the mixing matrix, s(t) is the n-dimensional source vector (n» m), and v(t) is additive white noise that is statistically independ
 is the n-dimensional source vector (n» m), and v(t) is additive white noise that is statistically independ") BLIND SEPARATION OF NONSTATIONARY AND TEMPORALLY CORRELATED SOURCES FROM NOISY MIXTURES Seungjin CHOI x and Andrzej CICHOCKI y x Department of Electrical Engineering Chungbuk National University, KOREA
BLIND SEPARATION OF NONSTATIONARY AND TEMPORALLY CORRELATED SOURCES FROM NOISY MIXTURES Seungjin CHOI x and Andrzej CICHOCKI y x Department of Electrical Engineering Chungbuk National University, KOREA
Unsupervised learning: beyond simple clustering and PCA
 Unsupervised learning: beyond simple clustering and PCA Liza Rebrova Self organizing maps (SOM) Goal: approximate data points in R p by a low-dimensional manifold Unlike PCA, the manifold does not have
Unsupervised learning: beyond simple clustering and PCA Liza Rebrova Self organizing maps (SOM) Goal: approximate data points in R p by a low-dimensional manifold Unlike PCA, the manifold does not have
Independent Component Analysis. PhD Seminar Jörgen Ungh
 Independent Component Analysis PhD Seminar Jörgen Ungh Agenda Background a motivater Independence ICA vs. PCA Gaussian data ICA theory Examples Background & motivation The cocktail party problem Bla bla
Independent Component Analysis PhD Seminar Jörgen Ungh Agenda Background a motivater Independence ICA vs. PCA Gaussian data ICA theory Examples Background & motivation The cocktail party problem Bla bla
5. Random Vectors. probabilities. characteristic function. cross correlation, cross covariance. Gaussian random vectors. functions of random vectors
 EE401 (Semester 1) 5. Random Vectors Jitkomut Songsiri probabilities characteristic function cross correlation, cross covariance Gaussian random vectors functions of random vectors 5-1 Random vectors we
EE401 (Semester 1) 5. Random Vectors Jitkomut Songsiri probabilities characteristic function cross correlation, cross covariance Gaussian random vectors functions of random vectors 5-1 Random vectors we
An Improved Cumulant Based Method for Independent Component Analysis
 An Improved Cumulant Based Method for Independent Component Analysis Tobias Blaschke and Laurenz Wiskott Institute for Theoretical Biology Humboldt University Berlin Invalidenstraße 43 D - 0 5 Berlin Germany
An Improved Cumulant Based Method for Independent Component Analysis Tobias Blaschke and Laurenz Wiskott Institute for Theoretical Biology Humboldt University Berlin Invalidenstraße 43 D - 0 5 Berlin Germany
Robust extraction of specific signals with temporal structure
 Robust extraction of specific signals with temporal structure Zhi-Lin Zhang, Zhang Yi Computational Intelligence Laboratory, School of Computer Science and Engineering, University of Electronic Science
Robust extraction of specific signals with temporal structure Zhi-Lin Zhang, Zhang Yi Computational Intelligence Laboratory, School of Computer Science and Engineering, University of Electronic Science
BLIND DECONVOLUTION ALGORITHMS FOR MIMO-FIR SYSTEMS DRIVEN BY FOURTH-ORDER COLORED SIGNALS
 BLIND DECONVOLUTION ALGORITHMS FOR MIMO-FIR SYSTEMS DRIVEN BY FOURTH-ORDER COLORED SIGNALS M. Kawamoto 1,2, Y. Inouye 1, A. Mansour 2, and R.-W. Liu 3 1. Department of Electronic and Control Systems Engineering,
BLIND DECONVOLUTION ALGORITHMS FOR MIMO-FIR SYSTEMS DRIVEN BY FOURTH-ORDER COLORED SIGNALS M. Kawamoto 1,2, Y. Inouye 1, A. Mansour 2, and R.-W. Liu 3 1. Department of Electronic and Control Systems Engineering,
An Introduction to Independent Components Analysis (ICA)
") An Introduction to Independent Components Analysis (ICA) Anish R. Shah, CFA Northfield Information Services Anish@northinfo.com Newport Jun 6, 2008 1 Overview of Talk Review principal components Introduce
An Introduction to Independent Components Analysis (ICA) Anish R. Shah, CFA Northfield Information Services Anish@northinfo.com Newport Jun 6, 2008 1 Overview of Talk Review principal components Introduce
A GUIDE TO INDEPENDENT COMPONENT ANALYSIS Theory and Practice
 CONTROL ENGINEERING LABORATORY A GUIDE TO INDEPENDENT COMPONENT ANALYSIS Theory and Practice Jelmer van Ast and Mika Ruusunen Report A No 3, March 004 University of Oulu Control Engineering Laboratory
CONTROL ENGINEERING LABORATORY A GUIDE TO INDEPENDENT COMPONENT ANALYSIS Theory and Practice Jelmer van Ast and Mika Ruusunen Report A No 3, March 004 University of Oulu Control Engineering Laboratory
INDEPENDENT COMPONENT ANALYSIS
 INDEPENDENT COMPONENT ANALYSIS A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF Bachelor of Technology in Electronics and Communication Engineering Department By P. SHIVA
INDEPENDENT COMPONENT ANALYSIS A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF Bachelor of Technology in Electronics and Communication Engineering Department By P. SHIVA
Statistics for scientists and engineers
 Statistics for scientists and engineers February 0, 006 Contents Introduction. Motivation - why study statistics?................................... Examples..................................................3
Statistics for scientists and engineers February 0, 006 Contents Introduction. Motivation - why study statistics?................................... Examples..................................................3
An Iterative Blind Source Separation Method for Convolutive Mixtures of Images
 An Iterative Blind Source Separation Method for Convolutive Mixtures of Images Marc Castella and Jean-Christophe Pesquet Université de Marne-la-Vallée / UMR-CNRS 8049 5 bd Descartes, Champs-sur-Marne 77454
An Iterative Blind Source Separation Method for Convolutive Mixtures of Images Marc Castella and Jean-Christophe Pesquet Université de Marne-la-Vallée / UMR-CNRS 8049 5 bd Descartes, Champs-sur-Marne 77454
ON SOME EXTENSIONS OF THE NATURAL GRADIENT ALGORITHM. Brain Science Institute, RIKEN, Wako-shi, Saitama , Japan
 ON SOME EXTENSIONS OF THE NATURAL GRADIENT ALGORITHM Pando Georgiev a, Andrzej Cichocki b and Shun-ichi Amari c Brain Science Institute, RIKEN, Wako-shi, Saitama 351-01, Japan a On leave from the Sofia
ON SOME EXTENSIONS OF THE NATURAL GRADIENT ALGORITHM Pando Georgiev a, Andrzej Cichocki b and Shun-ichi Amari c Brain Science Institute, RIKEN, Wako-shi, Saitama 351-01, Japan a On leave from the Sofia
New Approximations of Differential Entropy for Independent Component Analysis and Projection Pursuit
 New Approximations of Differential Entropy for Independent Component Analysis and Projection Pursuit Aapo Hyvarinen Helsinki University of Technology Laboratory of Computer and Information Science P.O.
New Approximations of Differential Entropy for Independent Component Analysis and Projection Pursuit Aapo Hyvarinen Helsinki University of Technology Laboratory of Computer and Information Science P.O.
1 Introduction Blind source separation (BSS) is a fundamental problem which is encountered in a variety of signal processing problems where multiple s
 is a fundamental problem which is encountered in a variety of signal processing problems where multiple s") Blind Separation of Nonstationary Sources in Noisy Mixtures Seungjin CHOI x1 and Andrzej CICHOCKI y x Department of Electrical Engineering Chungbuk National University 48 Kaeshin-dong, Cheongju Chungbuk
Blind Separation of Nonstationary Sources in Noisy Mixtures Seungjin CHOI x1 and Andrzej CICHOCKI y x Department of Electrical Engineering Chungbuk National University 48 Kaeshin-dong, Cheongju Chungbuk
Blind Signal Separation: Statistical Principles
 Blind Signal Separation: Statistical Principles JEAN-FRANÇOIS CARDOSO, MEMBER, IEEE Invited Paper Blind signal separation (BSS) and independent component analysis (ICA) are emerging techniques of array
Blind Signal Separation: Statistical Principles JEAN-FRANÇOIS CARDOSO, MEMBER, IEEE Invited Paper Blind signal separation (BSS) and independent component analysis (ICA) are emerging techniques of array
POLYNOMIAL SINGULAR VALUES FOR NUMBER OF WIDEBAND SOURCES ESTIMATION AND PRINCIPAL COMPONENT ANALYSIS
 POLYNOMIAL SINGULAR VALUES FOR NUMBER OF WIDEBAND SOURCES ESTIMATION AND PRINCIPAL COMPONENT ANALYSIS Russell H. Lambert RF and Advanced Mixed Signal Unit Broadcom Pasadena, CA USA russ@broadcom.com Marcel
POLYNOMIAL SINGULAR VALUES FOR NUMBER OF WIDEBAND SOURCES ESTIMATION AND PRINCIPAL COMPONENT ANALYSIS Russell H. Lambert RF and Advanced Mixed Signal Unit Broadcom Pasadena, CA USA russ@broadcom.com Marcel
ORIENTED PCA AND BLIND SIGNAL SEPARATION
 ORIENTED PCA AND BLIND SIGNAL SEPARATION K. I. Diamantaras Department of Informatics TEI of Thessaloniki Sindos 54101, Greece kdiamant@it.teithe.gr Th. Papadimitriou Department of Int. Economic Relat.
ORIENTED PCA AND BLIND SIGNAL SEPARATION K. I. Diamantaras Department of Informatics TEI of Thessaloniki Sindos 54101, Greece kdiamant@it.teithe.gr Th. Papadimitriou Department of Int. Economic Relat.
Independent Components Analysis
 CS229 Lecture notes Andrew Ng Part XII Independent Components Analysis Our next topic is Independent Components Analysis (ICA). Similar to PCA, this will find a new basis in which to represent our data.
CS229 Lecture notes Andrew Ng Part XII Independent Components Analysis Our next topic is Independent Components Analysis (ICA). Similar to PCA, this will find a new basis in which to represent our data.
One-unit Learning Rules for Independent Component Analysis
 One-unit Learning Rules for Independent Component Analysis Aapo Hyvarinen and Erkki Oja Helsinki University of Technology Laboratory of Computer and Information Science Rakentajanaukio 2 C, FIN-02150 Espoo,
One-unit Learning Rules for Independent Component Analysis Aapo Hyvarinen and Erkki Oja Helsinki University of Technology Laboratory of Computer and Information Science Rakentajanaukio 2 C, FIN-02150 Espoo,
Recursive Generalized Eigendecomposition for Independent Component Analysis
 Recursive Generalized Eigendecomposition for Independent Component Analysis Umut Ozertem 1, Deniz Erdogmus 1,, ian Lan 1 CSEE Department, OGI, Oregon Health & Science University, Portland, OR, USA. {ozertemu,deniz}@csee.ogi.edu
Recursive Generalized Eigendecomposition for Independent Component Analysis Umut Ozertem 1, Deniz Erdogmus 1,, ian Lan 1 CSEE Department, OGI, Oregon Health & Science University, Portland, OR, USA. {ozertemu,deniz}@csee.ogi.edu
Blind Machine Separation Te-Won Lee
 Blind Machine Separation Te-Won Lee University of California, San Diego Institute for Neural Computation Blind Machine Separation Problem we want to solve: Single microphone blind source separation & deconvolution
Blind Machine Separation Te-Won Lee University of California, San Diego Institute for Neural Computation Blind Machine Separation Problem we want to solve: Single microphone blind source separation & deconvolution
Artificial Intelligence Module 2. Feature Selection. Andrea Torsello
 Artificial Intelligence Module 2 Feature Selection Andrea Torsello We have seen that high dimensional data is hard to classify (curse of dimensionality) Often however, the data does not fill all the space
Artificial Intelligence Module 2 Feature Selection Andrea Torsello We have seen that high dimensional data is hard to classify (curse of dimensionality) Often however, the data does not fill all the space
Lecture 3: Central Limit Theorem
 Lecture 3: Central Limit Theorem Scribe: Jacy Bird (Division of Engineering and Applied Sciences, Harvard) February 8, 003 The goal of today s lecture is to investigate the asymptotic behavior of P N (
Lecture 3: Central Limit Theorem Scribe: Jacy Bird (Division of Engineering and Applied Sciences, Harvard) February 8, 003 The goal of today s lecture is to investigate the asymptotic behavior of P N (
ON-LINE BLIND SEPARATION OF NON-STATIONARY SIGNALS
 Yugoslav Journal of Operations Research 5 (25), Number, 79-95 ON-LINE BLIND SEPARATION OF NON-STATIONARY SIGNALS Slavica TODOROVIĆ-ZARKULA EI Professional Electronics, Niš, bssmtod@eunet.yu Branimir TODOROVIĆ,
Yugoslav Journal of Operations Research 5 (25), Number, 79-95 ON-LINE BLIND SEPARATION OF NON-STATIONARY SIGNALS Slavica TODOROVIĆ-ZARKULA EI Professional Electronics, Niš, bssmtod@eunet.yu Branimir TODOROVIĆ,
Principal Component Analysis
 Principal Component Analysis Introduction Consider a zero mean random vector R n with autocorrelation matri R = E( T ). R has eigenvectors q(1),,q(n) and associated eigenvalues λ(1) λ(n). Let Q = [ q(1)
Principal Component Analysis Introduction Consider a zero mean random vector R n with autocorrelation matri R = E( T ). R has eigenvectors q(1),,q(n) and associated eigenvalues λ(1) λ(n). Let Q = [ q(1)
Introduction to Independent Component Analysis. Jingmei Lu and Xixi Lu. Abstract
 Final Project 2//25 Introduction to Independent Component Analysis Abstract Independent Component Analysis (ICA) can be used to solve blind signal separation problem. In this article, we introduce definition
Final Project 2//25 Introduction to Independent Component Analysis Abstract Independent Component Analysis (ICA) can be used to solve blind signal separation problem. In this article, we introduce definition
Independent Component Analysis and FastICA. Copyright Changwei Xiong June last update: July 7, 2016
 Independent Component Analysis and FastICA Copyright Changwei Xiong 016 June 016 last update: July 7, 016 TABLE OF CONTENTS Table of Contents...1 1. Introduction.... Independence by Non-gaussianity....1.
Independent Component Analysis and FastICA Copyright Changwei Xiong 016 June 016 last update: July 7, 016 TABLE OF CONTENTS Table of Contents...1 1. Introduction.... Independence by Non-gaussianity....1.
Analytical solution of the blind source separation problem using derivatives
 Analytical solution of the blind source separation problem using derivatives Sebastien Lagrange 1,2, Luc Jaulin 2, Vincent Vigneron 1, and Christian Jutten 1 1 Laboratoire Images et Signaux, Institut National
Analytical solution of the blind source separation problem using derivatives Sebastien Lagrange 1,2, Luc Jaulin 2, Vincent Vigneron 1, and Christian Jutten 1 1 Laboratoire Images et Signaux, Institut National
Review (probability, linear algebra) CE-717 : Machine Learning Sharif University of Technology
 CE-717 : Machine Learning Sharif University of Technology") Review (probability, linear algebra) CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adopted from Prof. H.R. Rabiee s and also Prof. R. Gutierrez-Osuna
Review (probability, linear algebra) CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adopted from Prof. H.R. Rabiee s and also Prof. R. Gutierrez-Osuna
On Information Maximization and Blind Signal Deconvolution
 On Information Maximization and Blind Signal Deconvolution A Röbel Technical University of Berlin, Institute of Communication Sciences email: roebel@kgwtu-berlinde Abstract: In the following paper we investigate
On Information Maximization and Blind Signal Deconvolution A Röbel Technical University of Berlin, Institute of Communication Sciences email: roebel@kgwtu-berlinde Abstract: In the following paper we investigate
EEL 5544 Noise in Linear Systems Lecture 30. X (s) = E [ e sx] f X (x)e sx dx. Moments can be found from the Laplace transform as
![EEL 5544 Noise in Linear Systems Lecture 30. X (s) = E [ e sx] f X (x)e sx dx. Moments can be found from the Laplace transform as](/thumbs/85/92409620.jpg "EEL 5544 Noise in Linear Systems Lecture 30. X (s) = E [ e sx] f X (x)e sx dx. Moments can be found from the Laplace transform as") L30-1 EEL 5544 Noise in Linear Systems Lecture 30 OTHER TRANSFORMS For a continuous, nonnegative RV X, the Laplace transform of X is X (s) = E [ e sx] = 0 f X (x)e sx dx. For a nonnegative RV, the Laplace
L30-1 EEL 5544 Noise in Linear Systems Lecture 30 OTHER TRANSFORMS For a continuous, nonnegative RV X, the Laplace transform of X is X (s) = E [ e sx] = 0 f X (x)e sx dx. For a nonnegative RV, the Laplace
OR MSc Maths Revision Course
 OR MSc Maths Revision Course Tom Byrne School of Mathematics University of Edinburgh t.m.byrne@sms.ed.ac.uk 15 September 2017 General Information Today JCMB Lecture Theatre A, 09:30-12:30 Mathematics revision
OR MSc Maths Revision Course Tom Byrne School of Mathematics University of Edinburgh t.m.byrne@sms.ed.ac.uk 15 September 2017 General Information Today JCMB Lecture Theatre A, 09:30-12:30 Mathematics revision
Information geometry for bivariate distribution control
 Information geometry for bivariate distribution control C.T.J.Dodson + Hong Wang Mathematics + Control Systems Centre, University of Manchester Institute of Science and Technology Optimal control of stochastic
Information geometry for bivariate distribution control C.T.J.Dodson + Hong Wang Mathematics + Control Systems Centre, University of Manchester Institute of Science and Technology Optimal control of stochastic
STATS 306B: Unsupervised Learning Spring Lecture 12 May 7
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 12 May 7 Lecturer: Lester Mackey Scribe: Lan Huong, Snigdha Panigrahi 12.1 Beyond Linear State Space Modeling Last lecture we completed our discussion
STATS 306B: Unsupervised Learning Spring 2014 Lecture 12 May 7 Lecturer: Lester Mackey Scribe: Lan Huong, Snigdha Panigrahi 12.1 Beyond Linear State Space Modeling Last lecture we completed our discussion
Simultaneous Diagonalization in the Frequency Domain (SDIF) for Source Separation
 for Source Separation") Simultaneous Diagonalization in the Frequency Domain (SDIF) for Source Separation Hsiao-Chun Wu and Jose C. Principe Computational Neuro-Engineering Laboratory Department of Electrical and Computer Engineering
Simultaneous Diagonalization in the Frequency Domain (SDIF) for Source Separation Hsiao-Chun Wu and Jose C. Principe Computational Neuro-Engineering Laboratory Department of Electrical and Computer Engineering
Independent Component Analysis
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 1 Introduction Indepent
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 1 Introduction Indepent
To appear in Proceedings of the ICA'99, Aussois, France, A 2 R mn is an unknown mixture matrix of full rank, v(t) is the vector of noises. The
 is the vector of noises. The") To appear in Proceedings of the ICA'99, Aussois, France, 1999 1 NATURAL GRADIENT APPROACH TO BLIND SEPARATION OF OVER- AND UNDER-COMPLETE MIXTURES L.-Q. Zhang, S. Amari and A. Cichocki Brain-style Information
To appear in Proceedings of the ICA'99, Aussois, France, 1999 1 NATURAL GRADIENT APPROACH TO BLIND SEPARATION OF OVER- AND UNDER-COMPLETE MIXTURES L.-Q. Zhang, S. Amari and A. Cichocki Brain-style Information
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
Whitening and Coloring Transformations for Multivariate Gaussian Data. A Slecture for ECE 662 by Maliha Hossain
 Whitening and Coloring Transformations for Multivariate Gaussian Data A Slecture for ECE 662 by Maliha Hossain Introduction This slecture discusses how to whiten data that is normally distributed. Data
Whitening and Coloring Transformations for Multivariate Gaussian Data A Slecture for ECE 662 by Maliha Hossain Introduction This slecture discusses how to whiten data that is normally distributed. Data
From independent component analysis to score matching
 From independent component analysis to score matching Aapo Hyvärinen Dept of Computer Science & HIIT Dept of Mathematics and Statistics University of Helsinki Finland 1 Abstract First, short introduction
From independent component analysis to score matching Aapo Hyvärinen Dept of Computer Science & HIIT Dept of Mathematics and Statistics University of Helsinki Finland 1 Abstract First, short introduction
Independent Component Analysis and Blind Source Separation
 Independent Component Analysis and Blind Source Separation Aapo Hyvärinen University of Helsinki and Helsinki Institute of Information Technology 1 Blind source separation Four source signals : 1.5 2 3
Independent Component Analysis and Blind Source Separation Aapo Hyvärinen University of Helsinki and Helsinki Institute of Information Technology 1 Blind source separation Four source signals : 1.5 2 3
APPENDIX A. Background Mathematics. A.1 Linear Algebra. Vector algebra. Let x denote the n-dimensional column vector with components x 1 x 2.
 APPENDIX A Background Mathematics A. Linear Algebra A.. Vector algebra Let x denote the n-dimensional column vector with components 0 x x 2 B C @. A x n Definition 6 (scalar product). The scalar product
APPENDIX A Background Mathematics A. Linear Algebra A.. Vector algebra Let x denote the n-dimensional column vector with components 0 x x 2 B C @. A x n Definition 6 (scalar product). The scalar product
Independent Component Analysis and Its Application on Accelerator Physics
 Independent Component Analysis and Its Application on Accelerator Physics Xiaoying Pang LA-UR-12-20069 ICA and PCA Similarities: Blind source separation method (BSS) no model Observed signals are linear
Independent Component Analysis and Its Application on Accelerator Physics Xiaoying Pang LA-UR-12-20069 ICA and PCA Similarities: Blind source separation method (BSS) no model Observed signals are linear
MINIMIZATION-PROJECTION (MP) APPROACH FOR BLIND SOURCE SEPARATION IN DIFFERENT MIXING MODELS
 APPROACH FOR BLIND SOURCE SEPARATION IN DIFFERENT MIXING MODELS") MINIMIZATION-PROJECTION (MP) APPROACH FOR BLIND SOURCE SEPARATION IN DIFFERENT MIXING MODELS Massoud Babaie-Zadeh ;2, Christian Jutten, Kambiz Nayebi 2 Institut National Polytechnique de Grenoble (INPG),
MINIMIZATION-PROJECTION (MP) APPROACH FOR BLIND SOURCE SEPARATION IN DIFFERENT MIXING MODELS Massoud Babaie-Zadeh ;2, Christian Jutten, Kambiz Nayebi 2 Institut National Polytechnique de Grenoble (INPG),
ECE 636: Systems identification
 ECE 636: Systems identification Lectures 3 4 Random variables/signals (continued) Random/stochastic vectors Random signals and linear systems Random signals in the frequency domain υ ε x S z + y Experimental
ECE 636: Systems identification Lectures 3 4 Random variables/signals (continued) Random/stochastic vectors Random signals and linear systems Random signals in the frequency domain υ ε x S z + y Experimental
Independent Component Analysis (ICA)
") Independent Component Analysis (ICA) Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Independent Component Analysis (ICA) Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Lecture 3: Central Limit Theorem
 Lecture 3: Central Limit Theorem Scribe: Jacy Bird (Division of Engineering and Applied Sciences, Harvard) February 8, 003 The goal of today s lecture is to investigate the asymptotic behavior of P N (εx)
Lecture 3: Central Limit Theorem Scribe: Jacy Bird (Division of Engineering and Applied Sciences, Harvard) February 8, 003 The goal of today s lecture is to investigate the asymptotic behavior of P N (εx)
Feature Extraction with Weighted Samples Based on Independent Component Analysis
 Feature Extraction with Weighted Samples Based on Independent Component Analysis Nojun Kwak Samsung Electronics, Suwon P.O. Box 105, Suwon-Si, Gyeonggi-Do, KOREA 442-742, nojunk@ieee.org, WWW home page:
Feature Extraction with Weighted Samples Based on Independent Component Analysis Nojun Kwak Samsung Electronics, Suwon P.O. Box 105, Suwon-Si, Gyeonggi-Do, KOREA 442-742, nojunk@ieee.org, WWW home page:
Fourier PCA. Navin Goyal (MSR India), Santosh Vempala (Georgia Tech) and Ying Xiao (Georgia Tech)
, Santosh Vempala (Georgia Tech) and Ying Xiao (Georgia Tech)") Fourier PCA Navin Goyal (MSR India), Santosh Vempala (Georgia Tech) and Ying Xiao (Georgia Tech) Introduction 1. Describe a learning problem. 2. Develop an efficient tensor decomposition. Independent component
Fourier PCA Navin Goyal (MSR India), Santosh Vempala (Georgia Tech) and Ying Xiao (Georgia Tech) Introduction 1. Describe a learning problem. 2. Develop an efficient tensor decomposition. Independent component
Independent Component Analysis of Incomplete Data
 Independent Component Analysis of Incomplete Data Max Welling Markus Weber California Institute of Technology 136-93 Pasadena, CA 91125 fwelling,rmwg@vision.caltech.edu Keywords: EM, Missing Data, ICA
Independent Component Analysis of Incomplete Data Max Welling Markus Weber California Institute of Technology 136-93 Pasadena, CA 91125 fwelling,rmwg@vision.caltech.edu Keywords: EM, Missing Data, ICA
Principal Component Analysis CS498
 Principal Component Analysis CS498 Today s lecture Adaptive Feature Extraction Principal Component Analysis How, why, when, which A dual goal Find a good representation The features part Reduce redundancy
Principal Component Analysis CS498 Today s lecture Adaptive Feature Extraction Principal Component Analysis How, why, when, which A dual goal Find a good representation The features part Reduce redundancy
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Independent Component Analysis Barnabás Póczos Independent Component Analysis 2 Independent Component Analysis Model original signals Observations (Mixtures)
Advanced Introduction to Machine Learning CMU-10715 Independent Component Analysis Barnabás Póczos Independent Component Analysis 2 Independent Component Analysis Model original signals Observations (Mixtures)
Statistical signal processing
 Statistical signal processing Short overview of the fundamentals Outline Random variables Random processes Stationarity Ergodicity Spectral analysis Random variable and processes Intuition: A random variable
Statistical signal processing Short overview of the fundamentals Outline Random variables Random processes Stationarity Ergodicity Spectral analysis Random variable and processes Intuition: A random variable
ICA. Independent Component Analysis. Zakariás Mátyás
 ICA Independent Component Analysis Zakariás Mátyás Contents Definitions Introduction History Algorithms Code Uses of ICA Definitions ICA Miture Separation Signals typical signals Multivariate statistics
ICA Independent Component Analysis Zakariás Mátyás Contents Definitions Introduction History Algorithms Code Uses of ICA Definitions ICA Miture Separation Signals typical signals Multivariate statistics
Lecture'12:' SSMs;'Independent'Component'Analysis;' Canonical'Correla;on'Analysis'
 Lecture'12:' SSMs;'Independent'Component'Analysis;' Canonical'Correla;on'Analysis' Lester'Mackey' May'7,'2014' ' Stats'306B:'Unsupervised'Learning' Beyond'linearity'in'state'space'modeling' Credit:'Alex'Simma'
Lecture'12:' SSMs;'Independent'Component'Analysis;' Canonical'Correla;on'Analysis' Lester'Mackey' May'7,'2014' ' Stats'306B:'Unsupervised'Learning' Beyond'linearity'in'state'space'modeling' Credit:'Alex'Simma'
Linear Regression and Its Applications
 Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
c c c c c c c c c c a 3x3 matrix C= has a determinant determined by
 Linear Algebra Determinants and Eigenvalues Introduction: Many important geometric and algebraic properties of square matrices are associated with a single real number revealed by what s known as the determinant.
Linear Algebra Determinants and Eigenvalues Introduction: Many important geometric and algebraic properties of square matrices are associated with a single real number revealed by what s known as the determinant.
I R MASTER'S THESIS. Gradient Flow Based Matrix Joint Diagonalization for Independent Component Analysis
 MASTER'S THESIS Gradient Flow Based Matrix Joint Diagonalization for Independent Component Analysis by Bijan Afsari Advisor: Professor P. S. Krishnaprasad MS 2004-4 I R INSTITUTE FOR SYSTEMS RESEARCH ISR
MASTER'S THESIS Gradient Flow Based Matrix Joint Diagonalization for Independent Component Analysis by Bijan Afsari Advisor: Professor P. S. Krishnaprasad MS 2004-4 I R INSTITUTE FOR SYSTEMS RESEARCH ISR
Transformation of Probability Densities
 Transformation of Probability Densities This Wikibook shows how to transform the probability density of a continuous random variable in both the one-dimensional and multidimensional case. In other words,
Transformation of Probability Densities This Wikibook shows how to transform the probability density of a continuous random variable in both the one-dimensional and multidimensional case. In other words,
Stochastic Spectral Approaches to Bayesian Inference
 Stochastic Spectral Approaches to Bayesian Inference Prof. Nathan L. Gibson Department of Mathematics Applied Mathematics and Computation Seminar March 4, 2011 Prof. Gibson (OSU) Spectral Approaches to
Stochastic Spectral Approaches to Bayesian Inference Prof. Nathan L. Gibson Department of Mathematics Applied Mathematics and Computation Seminar March 4, 2011 Prof. Gibson (OSU) Spectral Approaches to
SENSITIVITY ANALYSIS OF BLIND SEPARATION OF SPEECH MIXTURES. Savaskan Bulek. A Dissertation Submitted to the Faculty of
 SENSITIVITY ANALYSIS OF BLIND SEPARATION OF SPEECH MIXTURES by Savaskan Bulek A Dissertation Submitted to the Faculty of The College of Engineering & Computer Science in Partial Fulfillment of the Requirements
SENSITIVITY ANALYSIS OF BLIND SEPARATION OF SPEECH MIXTURES by Savaskan Bulek A Dissertation Submitted to the Faculty of The College of Engineering & Computer Science in Partial Fulfillment of the Requirements
x. Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ 2 ).
.") .8.6 µ =, σ = 1 µ = 1, σ = 1 / µ =, σ =.. 3 1 1 3 x Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ ). The Gaussian distribution Probably the most-important distribution in all of statistics
.8.6 µ =, σ = 1 µ = 1, σ = 1 / µ =, σ =.. 3 1 1 3 x Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ ). The Gaussian distribution Probably the most-important distribution in all of statistics
Random Matrix Eigenvalue Problems in Probabilistic Structural Mechanics
 Random Matrix Eigenvalue Problems in Probabilistic Structural Mechanics S Adhikari Department of Aerospace Engineering, University of Bristol, Bristol, U.K. URL: http://www.aer.bris.ac.uk/contact/academic/adhikari/home.html
Random Matrix Eigenvalue Problems in Probabilistic Structural Mechanics S Adhikari Department of Aerospace Engineering, University of Bristol, Bristol, U.K. URL: http://www.aer.bris.ac.uk/contact/academic/adhikari/home.html
Gaussian processes. Chuong B. Do (updated by Honglak Lee) November 22, 2008
 November 22, 2008") Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Dependence, correlation and Gaussianity in independent component analysis
 Dependence, correlation and Gaussianity in independent component analysis Jean-François Cardoso ENST/TSI 46, rue Barrault, 75634, Paris, France cardoso@tsi.enst.fr Editor: Te-Won Lee Abstract Independent
Dependence, correlation and Gaussianity in independent component analysis Jean-François Cardoso ENST/TSI 46, rue Barrault, 75634, Paris, France cardoso@tsi.enst.fr Editor: Te-Won Lee Abstract Independent
Matrix Derivatives and Descent Optimization Methods
 Matrix Derivatives and Descent Optimization Methods 1 Qiang Ning Department of Electrical and Computer Engineering Beckman Institute for Advanced Science and Techonology University of Illinois at Urbana-Champaign
Matrix Derivatives and Descent Optimization Methods 1 Qiang Ning Department of Electrical and Computer Engineering Beckman Institute for Advanced Science and Techonology University of Illinois at Urbana-Champaign
Problems in Linear Algebra and Representation Theory
 Problems in Linear Algebra and Representation Theory (Most of these were provided by Victor Ginzburg) The problems appearing below have varying level of difficulty. They are not listed in any specific
Problems in Linear Algebra and Representation Theory (Most of these were provided by Victor Ginzburg) The problems appearing below have varying level of difficulty. They are not listed in any specific
Unsupervised Learning: Dimensionality Reduction
 Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,