CS540 Machine learning Lecture 5
|
|
|
- Julius Gordon
- 5 years ago
- Views:
Transcription
1 CS540 Machine learning Lecture 5 1
2 Last time Basis functions for linear regression Normal equations QR SVD - briefly 2
3 This time Geometry of least squares (again) SVD more slowly LMS Ridge regression 3
4 Geometry of least squares Columns of X define a d-dimensional linear subspace in n-dimensions. Yhat is projection of y into that subspace. Here n=3, d=2. Unit norm 4
5 Projection of y onto X Orthogonal projection Let r = y - \hat{y}. Residual must be orthogonal to X. Hence Prediction on training set Hat matrix Residual is orthogonal 5
6 This time Geometry of least squares (again) SVD more slowly LMS Ridge regression 6
7 Eigenvector decomposition (EVD) For any square matrix A, we say λ is an eval and u is its evec if Stacking up all evecs/vals gives If evecs linearly independent diagonalization 7
8 EVD of symmetric matrices If A is symmetric, all its evals are real, and all its evecs are orthonormal, u it u j =δ ij Hence and 8

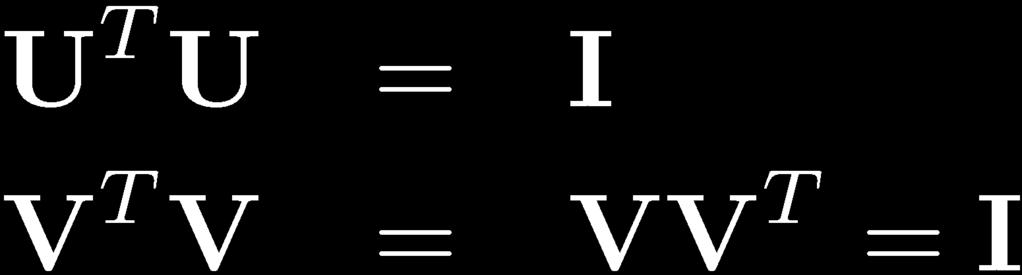
9 SVD For any real matrix 9
10 Truncated SVD Rank k approximation to a matrix Equivalent to PCA 10

11 Truncated SVD 11
12 SVD and EVD If A is symmetric positive definite, then svals(a)=evals(a), leftsvecs(a)=rightsvecs(a)=evecs(a) modulo sign changes 12
13 SVD and EVD For arbitrary real matrix A leftsvecs(a) = evecs(a A ) rightsvecs(a) = evecs(a A) Svals(A)^2 = evals(a A) = evals(a A ) 13
14 SVD for least squares We have What if D j = 0 (so rank of X is less than d)? 14
15 Pseudo inverse If D_j=0, use Of all solutions w that minimize Xw y, the pinv solution also minimizes w 15
16 This time Geometry of least squares (again) SVD more slowly LMS Ridge regression 16
 per step, but may need many steps η=0.1 η=0.")
17 QR and SVD take O(d 3 ) time Gradient descent We can find the MLE by following the gradient O(d) per step, but may need many steps η=0.1 η=0.6 Exact line search 17


18 Stochastic gradient descent Approximate the gradient by looking at a single data case Least Mean Squared Widrow-Hoff Delta-rule Can be used to learn online 18
19 This time Geometry of least squares (again) SVD more slowly LMS Ridge regression 19
20 Ridge regression Minimize penalized negative log likelihood l(w)+λ w 2 2 Weight decay, shrinkage, L2 regularization, ridge regression 20
21 Regularization D=14 λ=0 λ=10-5 λ=
22 Coefficients if λ=0 (MLE) Why it works -0.18, 10.57, , , , , , , , , , 54 Coefficients if λ= , 5.52, 3.66, 17.04, -2.63, , -0.37, , 5.40, 8.29, 7.75, 1.78, 2.03, -8.42, Small weights mean the curve is almost linear (same is true for sigmoid function) 22
23 The objective function is w = argmin w Ridge regression n (y i x T iw w 0 ) 2 +λ i=1 We don t shrink w_0. We should standardize first. Constrained formulation d j=1 w 2 j w = argmin w n (y i x T iw w 0 ) 2 s.t. i=1 Find the penalized MLE d wj 2 t j=1 J(w) = (y Xw) T (y Xw)+λw T w w = (X T X+λI) 1 X T y See book 23
24 Recall w = (X T X+λI) 1 X T y Expanded data: X = ( ) λid X, ỹ= QR ( y 0 d 1 J(w) = (ỹ Xw) T (ỹ Xw)=(y Xw) T (y Xw)+λw T w ŵ ridge = X\ỹ. ) 24
 1 DU T y Cheap to compute for many lambdas (regularization")
25 SVD Recall w = (X T X+λI) 1 X T y Homework: let X=U D V T. w = V(D 2 +λi) 1 DU T y Cheap to compute for many lambdas (regularization path), useful for CV 25
26 We have Ridge and PCA ŷ = Xŵ ridge =UDV T V(D 2 +λi) 1 DU T y d = U DU T y= u j Djj u T j y j=1 D jj def = [D(D 2 +λi) 1 D] jj = d2 j d 2 j +λ ŷ = Xŵ ridge = d j=1 u j d 2 j d 2 j +λut j y ŷ = Xŵ ls =(UDV T )(VD 1 U T y)=uu T y= d u j u T jy j=1 d 2 j/(d 2 j+λ) 1 Filter factors 26


27 Ridge and PCA D j2 are the eigenvalues of empirical cov mat X T X. Small d_j are directions j with small variance: these get shrunk the most, since most ill-determined ŷ = Xŵ ridge = d j=1 u j d 2 j d 2 j +λut jy 27
28 Principal components regression Can set Z=PCA(X,K) then w=regress(x,y) using a pcatransformer object PCR sets (transformed) dimensions K+1,,d to zero, whereas ridge uses all weighted dimensions. Ridge predictions usually more accurate. Feature selection (see later) sets (original) dimensions K+1,,d to zero. Ridge is usually more accurate, but may be less interpretable. 28
29 Degrees of freedom λ=0 λ=10-5 λ=10-3 All have D=14 but clearly differ in their effective complexity ŷ = S(X)y def df(s) = trace(s) d d 2 j df(λ) = d 2 j +λ j=1 29
30 Tikhonov regularization 1 min f (f(x) y(x)) 2 dx+ λ [f (x)] 2 dx 30
31 Discretization 1 min f 2 1 min f min f 2 n (f i y i ) 2 + λ 4 i=1 (f(x) y(x)) 2 dx+ λ 2 n 1 (f i y i ) 2 + λ 2 i=1 n 1 i=1 1 0 [f (x)] 2 dx (f i+1 f i ) 2 n [(f i f i 1 ) 2 +(f i f i+1 ) 2] i=1 Boundary conditions: f 0 =f 1, f n+1 =f n 31
32 Matrix form 1 min f 2 n (f i y i ) 2 + λ 4 i=1 D T D= n [(f i f i 1 ) 2 +(f i f i+1 ) 2] i=1 J(w)= y w 2 +λ Dw D= Dw 2 =w T (D T D)w= 1 1 n 1 (w i+1 w i ) 2 i=
33 QR ( )w ( ) min w λd In y 0 2 Listing 1: : D = spdiags(ones(n-1,1)*[-1 1], [0 1], N-1, N); A = [speye(n); sqrt(lambda)*d]; b = [y; zeros(n-1,1)]; w = A \ b; 33
Linear Regression Linear Regression with Shrinkage
 Linear Regression Linear Regression ith Shrinkage Introduction Regression means predicting a continuous (usually scalar) output y from a vector of continuous inputs (features) x. Example: Predicting vehicle
Linear Regression Linear Regression ith Shrinkage Introduction Regression means predicting a continuous (usually scalar) output y from a vector of continuous inputs (features) x. Example: Predicting vehicle
Linear Regression Linear Regression with Shrinkage
 Linear Regression Linear Regression ith Shrinkage Introduction Regression means predicting a continuous (usually scalar) output y from a vector of continuous inputs (features) x. Example: Predicting vehicle
Linear Regression Linear Regression ith Shrinkage Introduction Regression means predicting a continuous (usually scalar) output y from a vector of continuous inputs (features) x. Example: Predicting vehicle
Learning with Singular Vectors
 Learning with Singular Vectors CIS 520 Lecture 30 October 2015 Barry Slaff Based on: CIS 520 Wiki Materials Slides by Jia Li (PSU) Works cited throughout Overview Linear regression: Given X, Y find w:
Learning with Singular Vectors CIS 520 Lecture 30 October 2015 Barry Slaff Based on: CIS 520 Wiki Materials Slides by Jia Li (PSU) Works cited throughout Overview Linear regression: Given X, Y find w:
Linear Regression. S. Sumitra
 Linear Regression S Sumitra Notations: x i : ith data point; x T : transpose of x; x ij : ith data point s jth attribute Let {(x 1, y 1 ), (x, y )(x N, y N )} be the given data, x i D and y i Y Here D
Linear Regression S Sumitra Notations: x i : ith data point; x T : transpose of x; x ij : ith data point s jth attribute Let {(x 1, y 1 ), (x, y )(x N, y N )} be the given data, x i D and y i Y Here D
Eigenvalues and diagonalization
 Eigenvalues and diagonalization Patrick Breheny November 15 Patrick Breheny BST 764: Applied Statistical Modeling 1/20 Introduction The next topic in our course, principal components analysis, revolves
Eigenvalues and diagonalization Patrick Breheny November 15 Patrick Breheny BST 764: Applied Statistical Modeling 1/20 Introduction The next topic in our course, principal components analysis, revolves
We ve seen today that a square, symmetric matrix A can be written as. A = ODO t
 Lecture 5: Shrinky dink From last time... Inference So far we ve shied away from formal probabilistic arguments (aside from, say, assessing the independence of various outputs of a linear model) -- We
Lecture 5: Shrinky dink From last time... Inference So far we ve shied away from formal probabilistic arguments (aside from, say, assessing the independence of various outputs of a linear model) -- We
Linear Methods for Regression. Lijun Zhang
 Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
Lecture VIII Dim. Reduction (I)
") Lecture VIII Dim. Reduction (I) Contents: Subset Selection & Shrinkage Ridge regression, Lasso PCA, PCR, PLS Lecture VIII: MLSC - Dr. Sethu Viayakumar Data From Human Movement Measure arm movement and
Lecture VIII Dim. Reduction (I) Contents: Subset Selection & Shrinkage Ridge regression, Lasso PCA, PCR, PLS Lecture VIII: MLSC - Dr. Sethu Viayakumar Data From Human Movement Measure arm movement and
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
MA 575 Linear Models: Cedric E. Ginestet, Boston University Regularization: Ridge Regression and Lasso Week 14, Lecture 2
 MA 575 Linear Models: Cedric E. Ginestet, Boston University Regularization: Ridge Regression and Lasso Week 14, Lecture 2 1 Ridge Regression Ridge regression and the Lasso are two forms of regularized
MA 575 Linear Models: Cedric E. Ginestet, Boston University Regularization: Ridge Regression and Lasso Week 14, Lecture 2 1 Ridge Regression Ridge regression and the Lasso are two forms of regularized
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis. Massimiliano Pontil
 2. Least Squares and Principal Components Analysis. Massimiliano Pontil") GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
GI07/COMPM012: Mathematical Programming and Research Methods (Part 2) 2. Least Squares and Principal Components Analysis Massimiliano Pontil 1 Today s plan SVD and principal component analysis (PCA) Connection
Lecture 6: Methods for high-dimensional problems
 Lecture 6: Methods for high-dimensional problems Hector Corrada Bravo and Rafael A. Irizarry March, 2010 In this Section we will discuss methods where data lies on high-dimensional spaces. In particular,
Lecture 6: Methods for high-dimensional problems Hector Corrada Bravo and Rafael A. Irizarry March, 2010 In this Section we will discuss methods where data lies on high-dimensional spaces. In particular,
Lecture 8. Principal Component Analysis. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. December 13, 2016
 Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
1. Background: The SVD and the best basis (questions selected from Ch. 6- Can you fill in the exercises?)
") Math 35 Exam Review SOLUTIONS Overview In this third of the course we focused on linear learning algorithms to model data. summarize: To. Background: The SVD and the best basis (questions selected from
Math 35 Exam Review SOLUTIONS Overview In this third of the course we focused on linear learning algorithms to model data. summarize: To. Background: The SVD and the best basis (questions selected from
Principal Component Analysis and Linear Discriminant Analysis
 Principal Component Analysis and Linear Discriminant Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/29
Principal Component Analysis and Linear Discriminant Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/29
Linear Regression. Volker Tresp 2014
 Linear Regression Volker Tresp 2014 1 Learning Machine: The Linear Model / ADALINE As with the Perceptron we start with an activation functions that is a linearly weighted sum of the inputs h i = M 1 j=0
Linear Regression Volker Tresp 2014 1 Learning Machine: The Linear Model / ADALINE As with the Perceptron we start with an activation functions that is a linearly weighted sum of the inputs h i = M 1 j=0
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Week 3: Linear Regression
 Week 3: Linear Regression Instructor: Sergey Levine Recap In the previous lecture we saw how linear regression can solve the following problem: given a dataset D = {(x, y ),..., (x N, y N )}, learn to
Week 3: Linear Regression Instructor: Sergey Levine Recap In the previous lecture we saw how linear regression can solve the following problem: given a dataset D = {(x, y ),..., (x N, y N )}, learn to
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Models for Regression
 Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
SCMA292 Mathematical Modeling : Machine Learning. Krikamol Muandet. Department of Mathematics Faculty of Science, Mahidol University.
 SCMA292 Mathematical Modeling : Machine Learning Krikamol Muandet Department of Mathematics Faculty of Science, Mahidol University February 9, 2016 Outline Quick Recap of Least Square Ridge Regression
SCMA292 Mathematical Modeling : Machine Learning Krikamol Muandet Department of Mathematics Faculty of Science, Mahidol University February 9, 2016 Outline Quick Recap of Least Square Ridge Regression
Statistical Machine Learning, Part I. Regression 2
 Statistical Machine Learning, Part I Regression 2 mcuturi@i.kyoto-u.ac.jp SML-2015 1 Last Week Regression: highlight a functional relationship between a predicted variable and predictors SML-2015 2 Last
Statistical Machine Learning, Part I Regression 2 mcuturi@i.kyoto-u.ac.jp SML-2015 1 Last Week Regression: highlight a functional relationship between a predicted variable and predictors SML-2015 2 Last
 https://goo.gl/kfxweg KYOTO UNIVERSITY Statistical Machine Learning Theory Sparsity Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT OF INTELLIGENCE SCIENCE AND TECHNOLOGY 1 KYOTO UNIVERSITY Topics:
https://goo.gl/kfxweg KYOTO UNIVERSITY Statistical Machine Learning Theory Sparsity Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT OF INTELLIGENCE SCIENCE AND TECHNOLOGY 1 KYOTO UNIVERSITY Topics:
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
l 1 and l 2 Regularization
 David Rosenberg New York University February 5, 2015 David Rosenberg (New York University) DS-GA 1003 February 5, 2015 1 / 32 Tikhonov and Ivanov Regularization Hypothesis Spaces We ve spoken vaguely about
David Rosenberg New York University February 5, 2015 David Rosenberg (New York University) DS-GA 1003 February 5, 2015 1 / 32 Tikhonov and Ivanov Regularization Hypothesis Spaces We ve spoken vaguely about
Background Mathematics (2/2) 1. David Barber
 1. David Barber") Background Mathematics (2/2) 1 David Barber University College London Modified by Samson Cheung (sccheung@ieee.org) 1 These slides accompany the book Bayesian Reasoning and Machine Learning. The book and
Background Mathematics (2/2) 1 David Barber University College London Modified by Samson Cheung (sccheung@ieee.org) 1 These slides accompany the book Bayesian Reasoning and Machine Learning. The book and
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Regularization: Ridge Regression and the LASSO
 Agenda Wednesday, November 29, 2006 Agenda Agenda 1 The Bias-Variance Tradeoff 2 Ridge Regression Solution to the l 2 problem Data Augmentation Approach Bayesian Interpretation The SVD and Ridge Regression
Agenda Wednesday, November 29, 2006 Agenda Agenda 1 The Bias-Variance Tradeoff 2 Ridge Regression Solution to the l 2 problem Data Augmentation Approach Bayesian Interpretation The SVD and Ridge Regression
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Multivariate Statistical Analysis
 Multivariate Statistical Analysis Fall 2011 C. L. Williams, Ph.D. Lecture 4 for Applied Multivariate Analysis Outline 1 Eigen values and eigen vectors Characteristic equation Some properties of eigendecompositions
Multivariate Statistical Analysis Fall 2011 C. L. Williams, Ph.D. Lecture 4 for Applied Multivariate Analysis Outline 1 Eigen values and eigen vectors Characteristic equation Some properties of eigendecompositions
Singular Value Decomposition and Principal Component Analysis (PCA) I
 I") Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Linear Regression. In this problem sheet, we consider the problem of linear regression with p predictors and one intercept,
 Linear Regression In this problem sheet, we consider the problem of linear regression with p predictors and one intercept, y = Xβ + ɛ, where y t = (y 1,..., y n ) is the column vector of target values,
Linear Regression In this problem sheet, we consider the problem of linear regression with p predictors and one intercept, y = Xβ + ɛ, where y t = (y 1,..., y n ) is the column vector of target values,
CS545 Contents XVI. l Adaptive Control. l Reading Assignment for Next Class
 CS545 Contents XVI Adaptive Control Model Reference Adaptive Control Self-Tuning Regulators Linear Regression Recursive Least Squares Gradient Descent Feedback-Error Learning Reading Assignment for Next
CS545 Contents XVI Adaptive Control Model Reference Adaptive Control Self-Tuning Regulators Linear Regression Recursive Least Squares Gradient Descent Feedback-Error Learning Reading Assignment for Next
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Linear Models for Regression
 Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Linear Algebra Review. Vectors
 Linear Algebra Review 9/4/7 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa (UCSD) Cogsci 8F Linear Algebra review Vectors
Linear Algebra Review 9/4/7 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa (UCSD) Cogsci 8F Linear Algebra review Vectors
Machine Learning. Linear Models. Fabio Vandin October 10, 2017
 Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Machine Learning Linear Models Fabio Vandin October 10, 2017 1 Linear Predictors and Affine Functions Consider X = R d Affine functions: L d = {h w,b : w R d, b R} where ( d ) h w,b (x) = w, x + b = w
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
DATA MINING AND MACHINE LEARNING. Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
Principal Component Analysis
 Principal Component Analysis CS5240 Theoretical Foundations in Multimedia Leow Wee Kheng Department of Computer Science School of Computing National University of Singapore Leow Wee Kheng (NUS) Principal
Principal Component Analysis CS5240 Theoretical Foundations in Multimedia Leow Wee Kheng Department of Computer Science School of Computing National University of Singapore Leow Wee Kheng (NUS) Principal
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Foundation of Intelligent Systems, Part I. Regression 2
 Foundation of Intelligent Systems, Part I Regression 2 mcuturi@i.kyoto-u.ac.jp FIS - 2013 1 Some Words on the Survey Not enough answers to say anything meaningful! Try again: survey. FIS - 2013 2 Last
Foundation of Intelligent Systems, Part I Regression 2 mcuturi@i.kyoto-u.ac.jp FIS - 2013 1 Some Words on the Survey Not enough answers to say anything meaningful! Try again: survey. FIS - 2013 2 Last
CPSC 340 Assignment 4 (due November 17 ATE)
") CPSC 340 Assignment 4 due November 7 ATE) Multi-Class Logistic The function example multiclass loads a multi-class classification datasetwith y i {,, 3, 4, 5} and fits a one-vs-all classification model
CPSC 340 Assignment 4 due November 7 ATE) Multi-Class Logistic The function example multiclass loads a multi-class classification datasetwith y i {,, 3, 4, 5} and fits a one-vs-all classification model
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
A Modern Look at Classical Multivariate Techniques
 A Modern Look at Classical Multivariate Techniques Yoonkyung Lee Department of Statistics The Ohio State University March 16-20, 2015 The 13th School of Probability and Statistics CIMAT, Guanajuato, Mexico
A Modern Look at Classical Multivariate Techniques Yoonkyung Lee Department of Statistics The Ohio State University March 16-20, 2015 The 13th School of Probability and Statistics CIMAT, Guanajuato, Mexico
Foundations of Computer Vision
 Foundations of Computer Vision Wesley. E. Snyder North Carolina State University Hairong Qi University of Tennessee, Knoxville Last Edited February 8, 2017 1 3.2. A BRIEF REVIEW OF LINEAR ALGEBRA Apply
Foundations of Computer Vision Wesley. E. Snyder North Carolina State University Hairong Qi University of Tennessee, Knoxville Last Edited February 8, 2017 1 3.2. A BRIEF REVIEW OF LINEAR ALGEBRA Apply
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Theorems. Least squares regression
 Theorems In this assignment we are trying to classify AML and ALL samples by use of penalized logistic regression. Before we indulge on the adventure of classification we should first explain the most
Theorems In this assignment we are trying to classify AML and ALL samples by use of penalized logistic regression. Before we indulge on the adventure of classification we should first explain the most
Big Data Analytics: Optimization and Randomization
 Big Data Analytics: Optimization and Randomization Tianbao Yang Tutorial@ACML 2015 Hong Kong Department of Computer Science, The University of Iowa, IA, USA Nov. 20, 2015 Yang Tutorial for ACML 15 Nov.
Big Data Analytics: Optimization and Randomization Tianbao Yang Tutorial@ACML 2015 Hong Kong Department of Computer Science, The University of Iowa, IA, USA Nov. 20, 2015 Yang Tutorial for ACML 15 Nov.
Exercises * on Principal Component Analysis
 Exercises * on Principal Component Analysis Laurenz Wiskott Institut für Neuroinformatik Ruhr-Universität Bochum, Germany, EU 4 February 207 Contents Intuition 3. Problem statement..........................................
Exercises * on Principal Component Analysis Laurenz Wiskott Institut für Neuroinformatik Ruhr-Universität Bochum, Germany, EU 4 February 207 Contents Intuition 3. Problem statement..........................................
Lecture 5 : Projections
 Lecture 5 : Projections EE227C. Lecturer: Professor Martin Wainwright. Scribe: Alvin Wan Up until now, we have seen convergence rates of unconstrained gradient descent. Now, we consider a constrained minimization
Lecture 5 : Projections EE227C. Lecturer: Professor Martin Wainwright. Scribe: Alvin Wan Up until now, we have seen convergence rates of unconstrained gradient descent. Now, we consider a constrained minimization
References. Lecture 3: Shrinkage. The Power of Amnesia. Ockham s Razor
 References Lecture 3: Shrinkage Isabelle Guon guoni@inf.ethz.ch Structural risk minimization for character recognition Isabelle Guon et al. http://clopinet.com/isabelle/papers/sr m.ps.z Kernel Ridge Regression
References Lecture 3: Shrinkage Isabelle Guon guoni@inf.ethz.ch Structural risk minimization for character recognition Isabelle Guon et al. http://clopinet.com/isabelle/papers/sr m.ps.z Kernel Ridge Regression
IV. Matrix Approximation using Least-Squares
 IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
IV. Matrix Approximation using Least-Squares The SVD and Matrix Approximation We begin with the following fundamental question. Let A be an M N matrix with rank R. What is the closest matrix to A that
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Today. Calculus. Linear Regression. Lagrange Multipliers
 Today Calculus Lagrange Multipliers Linear Regression 1 Optimization with constraints What if I want to constrain the parameters of the model. The mean is less than 10 Find the best likelihood, subject
Today Calculus Lagrange Multipliers Linear Regression 1 Optimization with constraints What if I want to constrain the parameters of the model. The mean is less than 10 Find the best likelihood, subject
These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
 course textbook Pattern Recognition and Machine Learning by Christopher Bishop") Music and Machine Learning (IFT68 Winter 8) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Music and Machine Learning (IFT68 Winter 8) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Empirical Gramians and Balanced Truncation for Model Reduction of Nonlinear Systems
 Empirical Gramians and Balanced Truncation for Model Reduction of Nonlinear Systems Antoni Ras Departament de Matemàtica Aplicada 4 Universitat Politècnica de Catalunya Lecture goals To review the basic
Empirical Gramians and Balanced Truncation for Model Reduction of Nonlinear Systems Antoni Ras Departament de Matemàtica Aplicada 4 Universitat Politècnica de Catalunya Lecture goals To review the basic
Midterm. Introduction to Machine Learning. CS 189 Spring Please do not open the exam before you are instructed to do so.
 CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
1 = I I I II 1 1 II 2 = normalization constant III 1 1 III 2 2 III 3 = normalization constant...
 Here is a review of some (but not all) of the topics you should know for the midterm. These are things I think are important to know. I haven t seen the test, so there are probably some things on it that
Here is a review of some (but not all) of the topics you should know for the midterm. These are things I think are important to know. I haven t seen the test, so there are probably some things on it that
Linear Regression. Volker Tresp 2018
 Linear Regression Volker Tresp 2018 1 Learning Machine: The Linear Model / ADALINE As with the Perceptron we start with an activation functions that is a linearly weighted sum of the inputs h = M j=0 w
Linear Regression Volker Tresp 2018 1 Learning Machine: The Linear Model / ADALINE As with the Perceptron we start with an activation functions that is a linearly weighted sum of the inputs h = M j=0 w
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Numerical Methods I Singular Value Decomposition
 Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Data Mining Stat 588
 Data Mining Stat 588 Lecture 02: Linear Methods for Regression Department of Statistics & Biostatistics Rutgers University September 13 2011 Regression Problem Quantitative generic output variable Y. Generic
Data Mining Stat 588 Lecture 02: Linear Methods for Regression Department of Statistics & Biostatistics Rutgers University September 13 2011 Regression Problem Quantitative generic output variable Y. Generic
Linear Algebra for Machine Learning. Sargur N. Srihari
 Linear Algebra for Machine Learning Sargur N. srihari@cedar.buffalo.edu 1 Overview Linear Algebra is based on continuous math rather than discrete math Computer scientists have little experience with it
Linear Algebra for Machine Learning Sargur N. srihari@cedar.buffalo.edu 1 Overview Linear Algebra is based on continuous math rather than discrete math Computer scientists have little experience with it
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 9 1 / 23 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 9 1 / 23 Overview
MATH 829: Introduction to Data Mining and Analysis Principal component analysis
 1/11 MATH 829: Introduction to Data Mining and Analysis Principal component analysis Dominique Guillot Departments of Mathematical Sciences University of Delaware April 4, 2016 Motivation 2/11 High-dimensional
1/11 MATH 829: Introduction to Data Mining and Analysis Principal component analysis Dominique Guillot Departments of Mathematical Sciences University of Delaware April 4, 2016 Motivation 2/11 High-dimensional
COMP6237 Data Mining Covariance, EVD, PCA & SVD. Jonathon Hare
 COMP6237 Data Mining Covariance, EVD, PCA & SVD Jonathon Hare jsh2@ecs.soton.ac.uk Variance and Covariance Random Variables and Expected Values Mathematicians talk variance (and covariance) in terms of
COMP6237 Data Mining Covariance, EVD, PCA & SVD Jonathon Hare jsh2@ecs.soton.ac.uk Variance and Covariance Random Variables and Expected Values Mathematicians talk variance (and covariance) in terms of
Mathematical foundations - linear algebra
 Mathematical foundations - linear algebra Andrea Passerini passerini@disi.unitn.it Machine Learning Vector space Definition (over reals) A set X is called a vector space over IR if addition and scalar
Mathematical foundations - linear algebra Andrea Passerini passerini@disi.unitn.it Machine Learning Vector space Definition (over reals) A set X is called a vector space over IR if addition and scalar
Matrix Vector Products
 We covered these notes in the tutorial sessions I strongly recommend that you further read the presented materials in classical books on linear algebra Please make sure that you understand the proofs and
We covered these notes in the tutorial sessions I strongly recommend that you further read the presented materials in classical books on linear algebra Please make sure that you understand the proofs and
Machine Learning for OR & FE
 Machine Learning for OR & FE Regression II: Regularization and Shrinkage Methods Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com
Machine Learning for OR & FE Regression II: Regularization and Shrinkage Methods Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com
Lecture 7. Logistic Regression. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. December 11, 2016
 Lecture 7 Logistic Regression Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 11, 2016 Luigi Freda ( La Sapienza University) Lecture 7 December 11, 2016 1 / 39 Outline 1 Intro Logistic
Lecture 7 Logistic Regression Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 11, 2016 Luigi Freda ( La Sapienza University) Lecture 7 December 11, 2016 1 / 39 Outline 1 Intro Logistic
PCA and admixture models
 PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
A Quick Tour of Linear Algebra and Optimization for Machine Learning
 A Quick Tour of Linear Algebra and Optimization for Machine Learning Masoud Farivar January 8, 2015 1 / 28 Outline of Part I: Review of Basic Linear Algebra Matrices and Vectors Matrix Multiplication Operators
A Quick Tour of Linear Algebra and Optimization for Machine Learning Masoud Farivar January 8, 2015 1 / 28 Outline of Part I: Review of Basic Linear Algebra Matrices and Vectors Matrix Multiplication Operators
Spectral Regularization
 Spectral Regularization Lorenzo Rosasco 9.520 Class 07 February 27, 2008 About this class Goal To discuss how a class of regularization methods originally designed for solving ill-posed inverse problems,
Spectral Regularization Lorenzo Rosasco 9.520 Class 07 February 27, 2008 About this class Goal To discuss how a class of regularization methods originally designed for solving ill-posed inverse problems,
Machine Learning Practice Page 2 of 2 10/28/13
 Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning 10-701 Practice Page 2 of 2 10/28/13 1. True or False Please give an explanation for your answer, this is worth 1 pt/question. (a) (2 points) No classifier can do better than a naive Bayes
Machine Learning. Regression basics. Marc Toussaint University of Stuttgart Summer 2015
 Machine Learning Regression basics Linear regression, non-linear features (polynomial, RBFs, piece-wise), regularization, cross validation, Ridge/Lasso, kernel trick Marc Toussaint University of Stuttgart
Machine Learning Regression basics Linear regression, non-linear features (polynomial, RBFs, piece-wise), regularization, cross validation, Ridge/Lasso, kernel trick Marc Toussaint University of Stuttgart
Orthonormal Bases; Gram-Schmidt Process; QR-Decomposition
 Orthonormal Bases; Gram-Schmidt Process; QR-Decomposition MATH 322, Linear Algebra I J. Robert Buchanan Department of Mathematics Spring 205 Motivation When working with an inner product space, the most
Orthonormal Bases; Gram-Schmidt Process; QR-Decomposition MATH 322, Linear Algebra I J. Robert Buchanan Department of Mathematics Spring 205 Motivation When working with an inner product space, the most
A Least Squares Formulation for Canonical Correlation Analysis
 A Least Squares Formulation for Canonical Correlation Analysis Liang Sun, Shuiwang Ji, and Jieping Ye Department of Computer Science and Engineering Arizona State University Motivation Canonical Correlation
A Least Squares Formulation for Canonical Correlation Analysis Liang Sun, Shuiwang Ji, and Jieping Ye Department of Computer Science and Engineering Arizona State University Motivation Canonical Correlation
Biostatistics Advanced Methods in Biostatistics IV
 Biostatistics 140.754 Advanced Methods in Biostatistics IV Jeffrey Leek Assistant Professor Department of Biostatistics jleek@jhsph.edu Lecture 12 1 / 36 Tip + Paper Tip: As a statistician the results
Biostatistics 140.754 Advanced Methods in Biostatistics IV Jeffrey Leek Assistant Professor Department of Biostatistics jleek@jhsph.edu Lecture 12 1 / 36 Tip + Paper Tip: As a statistician the results
COMS 4771 Lecture Fixed-design linear regression 2. Ridge and principal components regression 3. Sparse regression and Lasso
 COMS 477 Lecture 6. Fixed-design linear regression 2. Ridge and principal components regression 3. Sparse regression and Lasso / 2 Fixed-design linear regression Fixed-design linear regression A simplified
COMS 477 Lecture 6. Fixed-design linear regression 2. Ridge and principal components regression 3. Sparse regression and Lasso / 2 Fixed-design linear regression Fixed-design linear regression A simplified
1 Singular Value Decomposition and Principal Component
 Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Regularization via Spectral Filtering
 Regularization via Spectral Filtering Lorenzo Rosasco MIT, 9.520 Class 7 About this class Goal To discuss how a class of regularization methods originally designed for solving ill-posed inverse problems,
Regularization via Spectral Filtering Lorenzo Rosasco MIT, 9.520 Class 7 About this class Goal To discuss how a class of regularization methods originally designed for solving ill-posed inverse problems,
Signal Analysis. Principal Component Analysis
 Multi dimensional Signal Analysis Lecture 2E Principal Component Analysis Subspace representation Note! Given avector space V of dimension N a scalar product defined by G 0 a subspace U of dimension M
Multi dimensional Signal Analysis Lecture 2E Principal Component Analysis Subspace representation Note! Given avector space V of dimension N a scalar product defined by G 0 a subspace U of dimension M
Linear Algebra & Geometry why is linear algebra useful in computer vision?
 Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
2. Review of Linear Algebra
 2. Review of Linear Algebra ECE 83, Spring 217 In this course we will represent signals as vectors and operators (e.g., filters, transforms, etc) as matrices. This lecture reviews basic concepts from linear
2. Review of Linear Algebra ECE 83, Spring 217 In this course we will represent signals as vectors and operators (e.g., filters, transforms, etc) as matrices. This lecture reviews basic concepts from linear
15 Singular Value Decomposition
 15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
MATH 20F: LINEAR ALGEBRA LECTURE B00 (T. KEMP)
") MATH 20F: LINEAR ALGEBRA LECTURE B00 (T KEMP) Definition 01 If T (x) = Ax is a linear transformation from R n to R m then Nul (T ) = {x R n : T (x) = 0} = Nul (A) Ran (T ) = {Ax R m : x R n } = {b R m
MATH 20F: LINEAR ALGEBRA LECTURE B00 (T KEMP) Definition 01 If T (x) = Ax is a linear transformation from R n to R m then Nul (T ) = {x R n : T (x) = 0} = Nul (A) Ran (T ) = {Ax R m : x R n } = {b R m
Vasil Khalidov & Miles Hansard. C.M. Bishop s PRML: Chapter 5; Neural Networks
 C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
Linear regression methods
 Linear regression methods Most of our intuition about statistical methods stem from linear regression. For observations i = 1,..., n, the model is Y i = p X ij β j + ε i, j=1 where Y i is the response
Linear regression methods Most of our intuition about statistical methods stem from linear regression. For observations i = 1,..., n, the model is Y i = p X ij β j + ε i, j=1 where Y i is the response
COMP 558 lecture 18 Nov. 15, 2010
 Least squares We have seen several least squares problems thus far, and we will see more in the upcoming lectures. For this reason it is good to have a more general picture of these problems and how to
Least squares We have seen several least squares problems thus far, and we will see more in the upcoming lectures. For this reason it is good to have a more general picture of these problems and how to
4 Bias-Variance for Ridge Regression (24 points)
") 2 count = 0 3 for x in self.x_test_ridge: 4 5 prediction = np.matmul(self.w_ridge,x) 6 ###ADD THE COMPUTED MEAN BACK TO THE PREDICTED VECTOR### 7 prediction = self.ss_y.inverse_transform(prediction) 8
2 count = 0 3 for x in self.x_test_ridge: 4 5 prediction = np.matmul(self.w_ridge,x) 6 ###ADD THE COMPUTED MEAN BACK TO THE PREDICTED VECTOR### 7 prediction = self.ss_y.inverse_transform(prediction) 8
Ridge Regression. Flachs, Munkholt og Skotte. May 4, 2009
 Ridge Regression Flachs, Munkholt og Skotte May 4, 2009 As in usual regression we consider a pair of random variables (X, Y ) with values in R p R and assume that for some (β 0, β) R +p it holds that E(Y
Ridge Regression Flachs, Munkholt og Skotte May 4, 2009 As in usual regression we consider a pair of random variables (X, Y ) with values in R p R and assume that for some (β 0, β) R +p it holds that E(Y
STK-IN4300 Statistical Learning Methods in Data Science
 Outline of the lecture STK-I4300 Statistical Learning Methods in Data Science Riccardo De Bin debin@math.uio.no Model Assessment and Selection Cross-Validation Bootstrap Methods Methods using Derived Input
Outline of the lecture STK-I4300 Statistical Learning Methods in Data Science Riccardo De Bin debin@math.uio.no Model Assessment and Selection Cross-Validation Bootstrap Methods Methods using Derived Input
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning
 Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Lecture 3: More on regularization. Bayesian vs maximum likelihood learning L2 and L1 regularization for linear estimators A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting
Fall TMA4145 Linear Methods. Exercise set Given the matrix 1 2
 Norwegian University of Science and Technology Department of Mathematical Sciences TMA445 Linear Methods Fall 07 Exercise set Please justify your answers! The most important part is how you arrive at an
Norwegian University of Science and Technology Department of Mathematical Sciences TMA445 Linear Methods Fall 07 Exercise set Please justify your answers! The most important part is how you arrive at an
Properties of Matrices and Operations on Matrices
 Properties of Matrices and Operations on Matrices A common data structure for statistical analysis is a rectangular array or matris. Rows represent individual observational units, or just observations,
Properties of Matrices and Operations on Matrices A common data structure for statistical analysis is a rectangular array or matris. Rows represent individual observational units, or just observations,