Large-scale Collaborative Ranking in Near-Linear Time
|
|
|
- Beatrix Holt
- 5 years ago
- Views:
Transcription
1 Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack

2 Recommender Systems: Netflix Problem
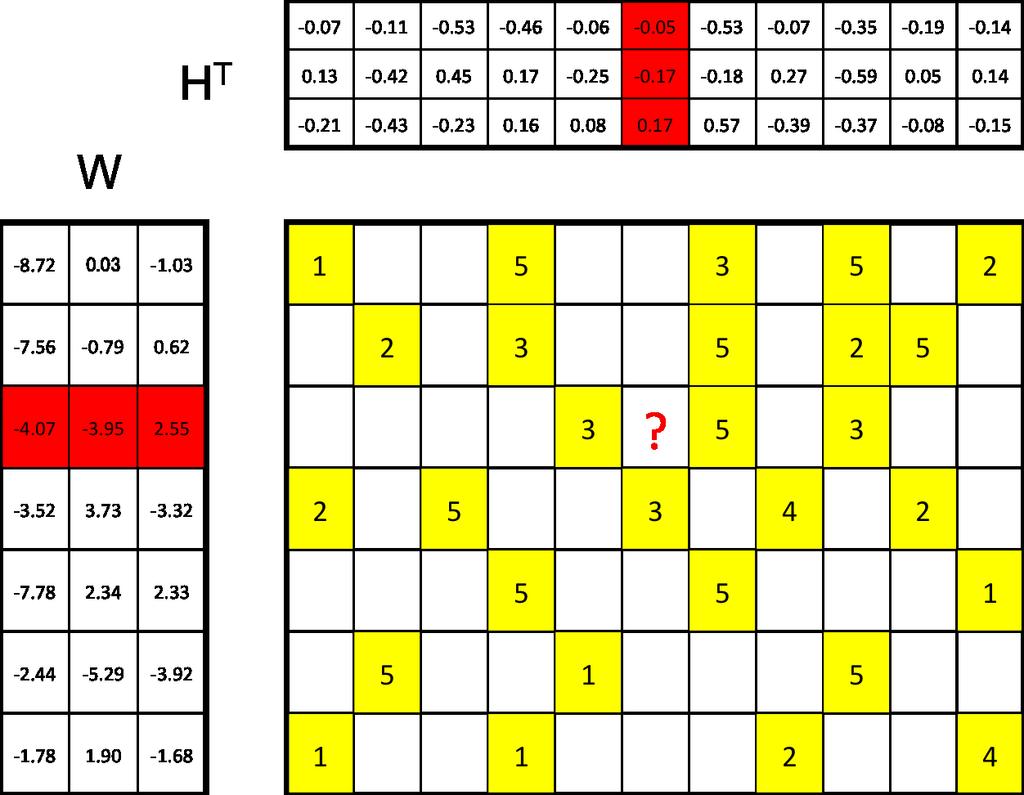

3 Matrix Factorization Approach R WH T

4 Collaborative Filtering: Latent Factor Model
5 Collaborative Filtering: Matrix Factorization Approach Latent Factor model fit the ratings directly in the objective function: min W R d 1 r H R d 2 r (i,j) Ω Ω = {(i, j) R ij is observed} (R ij wi T h j ) 2 + λ 2 Regularized terms to avoid over-fitting Criticisms: ( W 2 F + H 2 ) F, Calibration drawback: users have different standards for their ratings Performance measured by quality of rating prediction, not the ranking of items for each user
6 Collaborative Filtering: Collaborative Ranking Approach Focus on ranking of items rather than ratings in the model Performance measured by ranking order of top k items for each user How?
7 Collaborative Filtering: Collaborative Ranking Approach Focus on ranking of items rather than ratings in the model Performance measured by ranking order of top k items for each user How? Given d 1 users, d 2 movies Each user has a subset of observed movie comparisons Goal: predict movie rankings for each user
8 Collaborative Ranking: Applications Collaborative Ranking can be applied to classical recommender system For classical data (e.g., Netflix), we can transform original ratings to pairwise comparisons With the same data size, ranking loss outperforms point-wise loss

9 Collaborative Ranking: Assumption Assumption: the underlying scoring matrix is low-rank X = UV T
10 Collaborative Ranking: Model Collaborative Ranking: ( l Y i,j,k min U,V (i,j,k) Ω [ (UV T ) ij (UV T ) ik ] ) + λ( U 2 F + V 2 F ) The loss function l we used is L 2 hinge loss l(a) = max(0, 1 a) 2 The set (i, j, k) Ω: User i rates item j > item k Y i,j,k = 1 If user i rates d 2 movies, there will be O( d 2 2 ) pairs per user.
11 Collaborative Ranking: Model Collaborative Ranking: ( l Y i,j,k min U,V (i,j,k) Ω [ (UV T ) ij (UV T ) ik ] ) + λ( U 2 F + V 2 F ) The loss function l we used is L 2 hinge loss l(a) = max(0, 1 a) 2 The set (i, j, k) Ω: User i rates item j > item k Y i,j,k = 1 If user i rates d 2 movies, there will be O( d 2 2 ) pairs per user. Pros and Cons + better prediction and recommendation - slow, since it involves O( Ω ) = O(d 1 d 2 2 ) loss terms (original matrix completion only has O(d 1 d 2 ) terms)
12 Collaborative Ranking: Existing methods State-of-the-art algorithms CollRank (Park et al., ICML 2015): similar problem formulation RobiRank (Yun et al., NIPS 2014): focus on binary observations All of them need O(d 1 d2 2 r) time and O(d1 d2 2 ) memory where d 1 is number of users, d2 is averaged ratings per user, r is the target rank. In full Netflix dataset: d million, d 2 200, if r = 100 Time per iteration: d 1 d 2 2 r Memory: d 1 d GB memory Can t scale to full Netflix data need days to train
13 Our Algorithms: Primal-CR and Primal-CR++ Classical matrix factorization: O(d 1 d2 r) time, O(d 1 d2 ) memory Previous collaborative ranking: O(d 1 d 2 2 r) time, O(d1 d 2 2 ) memory Primal-CR: O(d 1 d d1 d 2 r) time, O(d 1 d 2 ) memory Primal-CR++: O(d 1 d 2 (r + log( d 2 ))) time, O(d 1 d 2 ) memory
14 General Framework: Alternating Minimization Consider the L2-hinge loss: ( 2 min max 0, 1 Y U,V i,j,k (ui T v j ui T v k )) + λ U 2 F + λ V 2 F (i,j,k) Ω := f (U, V ) Use alternating minimization. For t = 1, 2,... Fix V and update U by Fix U and update V by U arg min U f (U, V ) V arg min V f (U, V )
15 Update V Approach: Newton s method + conjugate gradient. Step 1: Compute gradient and Hessian: g = f (V ) R d 1r H = 2 f (V ) R d 1r d 1 r Update V V ηh 1 g (η is the step size) However, H is a huge matrix (d 1 r can be millions) Cannot inverse H Use Conjugate Gradient (CG) to iteratively solve Hx = g. Each iteration of CG only needs a matrix-vector product Hp Questions: (1) How to compute g? (2) How to compute Hp
16 Compute Gradient How to compute the gradient? V f (V ) = d 1 i=1 (j,k) Ω i 2 max Naive computation: O( Ω r) = O(d 1 d2 2 r) But d 1 d 2 2 r ( ) 0, 1 (ui T v j ui T v k ) (u i ek T u iej T ) + λv for Netflix
17 Compute Gradient How to compute the gradient? V f (V ) = d 1 i=1 (j,k) Ω i 2 max Naive computation: O( Ω r) = O(d 1 d2 2 r) But d 1 d 2 2 r ( ) 0, 1 (ui T v j ui T v k ) (u i ek T u iej T ) + λv for Netflix Idea (Primal-CR++): Fix k, do a linear scan of j after sorting For simplicity in illustation: assume at k, observed rating is 1 ignore constant 1 in L 2 hinge loss ignore u i ej T in gradient equation
18 Even better way (Rethinking the main computation) Consider all the items for a user Sort items based on predictive values u T v j (O( d 2 log( d 2 )) time) Now assume observed ratings can only be 0 or 1

19 Even better way (Rethinking the main computation) Look at item 2 and sum over all items with larger predictive value but smaller observed ratings

20 Even better way (Rethinking the main computation) Look at item 1 and sum over all items with larger predictive value but smaller observed ratings
21 Even better way (Rethinking the main computation) Look at item 6 and sum over all items with larger predictive value but smaller observed ratings
22 The linear-time algorithm for 0/1 ratings Let s k = u T v k (current prediction) Maintain prefix-sum at k: P = j:s j >s k and R j =0 Linea-scan algorithm: Initially P = j:r j =0 s j For j = π(1), π(2), If R j = 0: Update P P s j If R j = 1: Add P u to g j s j

23 General case: For T levels of ratings
24 General case: For T levels of ratings Each step needs two operations: (1) Compute P P l for some l (2) Update one of P j
25 General case: For T levels of ratings Each step needs two operations: (1) Compute P P l for some l (2) Update one of P j Can be done in O(log(T )) time per query using Segment tree or Fenwick tree!
26 General case: For T levels of ratings Each step needs two operations: (1) Compute P P l for some l (2) Update one of P j Can be done in O(log(T )) time per query using Segment tree or Fenwick tree! 2 Overall time complexity: d 1 d 2 r d 1 d 2 r + d 1 d 2 log( d 2 ) Order of 3 Speed-up!! Time complexity for standard matrix factorization: d 1 d 2 r
27 Experiments measuring the quality of top-10 recommendations where i represents i-th user and Comparisons NDCG@10 = 1 d 1 DCG@10(i, π i ) d 1 DCG@10(i, πi (1) ), DCG@10(i, π i ) = 1 Single core subsampled data 2 Parallelization 3 Single core full data i=1 10 k=1 2 M i π i (k) 1 log 2 (k + 1). (2)

 Netflix (2, 649, 430 17,")
28 Comparisons: Single Core Subsampled Data We subsampled each user to have exactly 200 ratings in training set and used the rest of ratings as test set, since previous approaches cannot scale up Users with fewer than ratings not included MoviLens1M (6, 040 3, 952) Netflix (2, 649, , 771)
29 Comparisons: Parallelization Our algorithm scales up well (see comparisons for 1 core, 4 cores and 8 cores) in the multi-core shared memory setting Primal-CR still much faster than Collrank when 8 cores are used MoviLens10M (71, , 134) MoviLens10M (71, , 134)
30 Comparisons: Single Core Full Data Due to the O( Ω r) complexity, existing algorithms always sub-sample a limited number of pairs per user Our algorithm is the first ranking-based algorithm that can scale to full Netflix data set using a single machine, and without sub-sampling A natural question: Does using more training data help us predict and recommend better?
31 Comparisons: Single Core Full Data Due to the O( Ω r) complexity, existing algorithms always sub-sample a limited number of pairs per user Our algorithm is the first ranking-based algorithm that can scale to full Netflix data set using a single machine, and without sub-sampling A natural question: Does using more training data help us predict and recommend better? The answer is yes!
 Netflix (2, 649, 430")
32 Comparisons: Single Core Full Data Randomly choose 10 ratings as test data and out of the rest ratings randomly choose up to C ratings per user as training data Users with fewer than 20 ratings not included Comparing NDCG@10 when C = 100, 200, d 2 MoviLens1M (6, 040 3, 952) Netflix (2, 649, , 771)
33 Conclusions We show that CR can be used to replace matrix factorization in recommender systems We show that CR can be solved efficiently (almost same time complexity as matrix factorization) We show that it is always best to use all available pairwise comparisons if possible (subsampling gives suboptimal recommender results for top k items) Julia codes: C++ codes (2x faster than Julia codes, with support for multithreading): Thank You!
SQL-Rank: A Listwise Approach to Collaborative Ranking
 SQL-Rank: A Listwise Approach to Collaborative Ranking Liwei Wu Depts of Statistics and Computer Science UC Davis ICML 18, Stockholm, Sweden July 10-15, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
SQL-Rank: A Listwise Approach to Collaborative Ranking Liwei Wu Depts of Statistics and Computer Science UC Davis ICML 18, Stockholm, Sweden July 10-15, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 18, 2016 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 18, 2016 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
Large-scale Collaborative Ranking in Near-Linear Time
 Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts. of Statistics and Computer Science University of California, Davis liwu@ucdavis.edu ABSTRACT In this paper, we consider the Collaborative
Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts. of Statistics and Computer Science University of California, Davis liwu@ucdavis.edu ABSTRACT In this paper, we consider the Collaborative
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 11, 2016 Paper presentations and final project proposal Send me the names of your group member (2 or 3 students) before October 15 (this Friday)
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 11, 2016 Paper presentations and final project proposal Send me the names of your group member (2 or 3 students) before October 15 (this Friday)
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 27, 2015 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 27, 2015 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
Decoupled Collaborative Ranking
 Decoupled Collaborative Ranking Jun Hu, Ping Li April 24, 2017 Jun Hu, Ping Li WWW2017 April 24, 2017 1 / 36 Recommender Systems Recommendation system is an information filtering technique, which provides
Decoupled Collaborative Ranking Jun Hu, Ping Li April 24, 2017 Jun Hu, Ping Li WWW2017 April 24, 2017 1 / 36 Recommender Systems Recommendation system is an information filtering technique, which provides
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
A Gradient-based Adaptive Learning Framework for Efficient Personal Recommendation
 A Gradient-based Adaptive Learning Framework for Efficient Personal Recommendation Yue Ning 1 Yue Shi 2 Liangjie Hong 2 Huzefa Rangwala 3 Naren Ramakrishnan 1 1 Virginia Tech 2 Yahoo Research. Yue Shi
A Gradient-based Adaptive Learning Framework for Efficient Personal Recommendation Yue Ning 1 Yue Shi 2 Liangjie Hong 2 Huzefa Rangwala 3 Naren Ramakrishnan 1 1 Virginia Tech 2 Yahoo Research. Yue Shi
Preliminaries. Data Mining. The art of extracting knowledge from large bodies of structured data. Let s put it to use!
 Data Mining The art of extracting knowledge from large bodies of structured data. Let s put it to use! 1 Recommendations 2 Basic Recommendations with Collaborative Filtering Making Recommendations 4 The
Data Mining The art of extracting knowledge from large bodies of structured data. Let s put it to use! 1 Recommendations 2 Basic Recommendations with Collaborative Filtering Making Recommendations 4 The
Scaling Neighbourhood Methods
 Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Quick Recap Scaling Neighbourhood Methods Collaborative Filtering m = #items n = #users Complexity : m * m * n Comparative Scale of Signals ~50 M users ~25 M items Explicit Ratings ~ O(1M) (1 per billion)
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent
 Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
CS260: Machine Learning Algorithms
 CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
PU Learning for Matrix Completion
 Cho-Jui Hsieh Dept of Computer Science UT Austin ICML 2015 Joint work with N. Natarajan and I. S. Dhillon Matrix Completion Example: movie recommendation Given a set Ω and the values M Ω, how to predict
Cho-Jui Hsieh Dept of Computer Science UT Austin ICML 2015 Joint work with N. Natarajan and I. S. Dhillon Matrix Completion Example: movie recommendation Given a set Ω and the values M Ω, how to predict
Convex Optimization Algorithms for Machine Learning in 10 Slides
 Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
Optimization Methods for Machine Learning
 Optimization Methods for Machine Learning Sathiya Keerthi Microsoft Talks given at UC Santa Cruz February 21-23, 2017 The slides for the talks will be made available at: http://www.keerthis.com/ Introduction
Optimization Methods for Machine Learning Sathiya Keerthi Microsoft Talks given at UC Santa Cruz February 21-23, 2017 The slides for the talks will be made available at: http://www.keerthis.com/ Introduction
Maximum Margin Matrix Factorization for Collaborative Ranking
 Maximum Margin Matrix Factorization for Collaborative Ranking Joint work with Quoc Le, Alexandros Karatzoglou and Markus Weimer Alexander J. Smola sml.nicta.com.au Statistical Machine Learning Program
Maximum Margin Matrix Factorization for Collaborative Ranking Joint work with Quoc Le, Alexandros Karatzoglou and Markus Weimer Alexander J. Smola sml.nicta.com.au Statistical Machine Learning Program
Large-scale Linear RankSVM
 Large-scale Linear RankSVM Ching-Pei Lee Department of Computer Science National Taiwan University Joint work with Chih-Jen Lin Ching-Pei Lee (National Taiwan Univ.) 1 / 41 Outline 1 Introduction 2 Our
Large-scale Linear RankSVM Ching-Pei Lee Department of Computer Science National Taiwan University Joint work with Chih-Jen Lin Ching-Pei Lee (National Taiwan Univ.) 1 / 41 Outline 1 Introduction 2 Our
Large-scale Matrix Factorization. Kijung Shin Ph.D. Student, CSD
 Large-scale Matrix Factorization Kijung Shin Ph.D. Student, CSD Roadmap Matrix Factorization (review) Algorithms Distributed SGD: DSGD Alternating Least Square: ALS Cyclic Coordinate Descent: CCD++ Experiments
Large-scale Matrix Factorization Kijung Shin Ph.D. Student, CSD Roadmap Matrix Factorization (review) Algorithms Distributed SGD: DSGD Alternating Least Square: ALS Cyclic Coordinate Descent: CCD++ Experiments
Click-Through Rate prediction: TOP-5 solution for the Avazu contest
 Click-Through Rate prediction: TOP-5 solution for the Avazu contest Dmitry Efimov Petrovac, Montenegro June 04, 2015 Outline Provided data Likelihood features FTRL-Proximal Batch algorithm Factorization
Click-Through Rate prediction: TOP-5 solution for the Avazu contest Dmitry Efimov Petrovac, Montenegro June 04, 2015 Outline Provided data Likelihood features FTRL-Proximal Batch algorithm Factorization
Restricted Boltzmann Machines for Collaborative Filtering
 Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Lecture 9: September 28
 0-725/36-725: Convex Optimization Fall 206 Lecturer: Ryan Tibshirani Lecture 9: September 28 Scribes: Yiming Wu, Ye Yuan, Zhihao Li Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These
0-725/36-725: Convex Optimization Fall 206 Lecturer: Ryan Tibshirani Lecture 9: September 28 Scribes: Yiming Wu, Ye Yuan, Zhihao Li Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These
A Simple Algorithm for Nuclear Norm Regularized Problems
 A Simple Algorithm for Nuclear Norm Regularized Problems ICML 00 Martin Jaggi, Marek Sulovský ETH Zurich Matrix Factorizations for recommender systems Y = Customer Movie UV T = u () The Netflix challenge:
A Simple Algorithm for Nuclear Norm Regularized Problems ICML 00 Martin Jaggi, Marek Sulovský ETH Zurich Matrix Factorizations for recommender systems Y = Customer Movie UV T = u () The Netflix challenge:
Mixed Membership Matrix Factorization
 Mixed Membership Matrix Factorization Lester Mackey 1 David Weiss 2 Michael I. Jordan 1 1 University of California, Berkeley 2 University of Pennsylvania International Conference on Machine Learning, 2010
Mixed Membership Matrix Factorization Lester Mackey 1 David Weiss 2 Michael I. Jordan 1 1 University of California, Berkeley 2 University of Pennsylvania International Conference on Machine Learning, 2010
Mixed Membership Matrix Factorization
 Mixed Membership Matrix Factorization Lester Mackey University of California, Berkeley Collaborators: David Weiss, University of Pennsylvania Michael I. Jordan, University of California, Berkeley 2011
Mixed Membership Matrix Factorization Lester Mackey University of California, Berkeley Collaborators: David Weiss, University of Pennsylvania Michael I. Jordan, University of California, Berkeley 2011
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Andriy Mnih and Ruslan Salakhutdinov
 MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
Nonnegative Matrix Factorization
 Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Recommender Systems EE448, Big Data Mining, Lecture 10. Weinan Zhang Shanghai Jiao Tong University
 2018 EE448, Big Data Mining, Lecture 10 Recommender Systems Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of This Course Overview of
2018 EE448, Big Data Mining, Lecture 10 Recommender Systems Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html Content of This Course Overview of
Big & Quic: Sparse Inverse Covariance Estimation for a Million Variables
 for a Million Variables Cho-Jui Hsieh The University of Texas at Austin NIPS Lake Tahoe, Nevada Dec 8, 2013 Joint work with M. Sustik, I. Dhillon, P. Ravikumar and R. Poldrack FMRI Brain Analysis Goal:
for a Million Variables Cho-Jui Hsieh The University of Texas at Austin NIPS Lake Tahoe, Nevada Dec 8, 2013 Joint work with M. Sustik, I. Dhillon, P. Ravikumar and R. Poldrack FMRI Brain Analysis Goal:
Algorithms for Collaborative Filtering
 Algorithms for Collaborative Filtering or How to Get Half Way to Winning $1million from Netflix Todd Lipcon Advisor: Prof. Philip Klein The Real-World Problem E-commerce sites would like to make personalized
Algorithms for Collaborative Filtering or How to Get Half Way to Winning $1million from Netflix Todd Lipcon Advisor: Prof. Philip Klein The Real-World Problem E-commerce sites would like to make personalized
Ad Placement Strategies
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox 2014 Emily Fox January
Review: Probabilistic Matrix Factorization. Probabilistic Matrix Factorization (PMF)
") Case Study 4: Collaborative Filtering Review: Probabilistic Matrix Factorization Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 2 th, 214 Emily Fox 214 1 Probabilistic
Case Study 4: Collaborative Filtering Review: Probabilistic Matrix Factorization Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 2 th, 214 Emily Fox 214 1 Probabilistic
Using SVD to Recommend Movies
 Michael Percy University of California, Santa Cruz Last update: December 12, 2009 Last update: December 12, 2009 1 / Outline 1 Introduction 2 Singular Value Decomposition 3 Experiments 4 Conclusion Last
Michael Percy University of California, Santa Cruz Last update: December 12, 2009 Last update: December 12, 2009 1 / Outline 1 Introduction 2 Singular Value Decomposition 3 Experiments 4 Conclusion Last
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
Semestrial Project - Expedia Hotel Ranking
 1 Many customers search and purchase hotels online. Companies such as Expedia make their profit from purchases made through their sites. The ultimate goal top of the list are the hotels that are most likely
1 Many customers search and purchase hotels online. Companies such as Expedia make their profit from purchases made through their sites. The ultimate goal top of the list are the hotels that are most likely
Chapter 2. Optimization. Gradients, convexity, and ALS
 Chapter 2 Optimization Gradients, convexity, and ALS Contents Background Gradient descent Stochastic gradient descent Newton s method Alternating least squares KKT conditions 2 Motivation We can solve
Chapter 2 Optimization Gradients, convexity, and ALS Contents Background Gradient descent Stochastic gradient descent Newton s method Alternating least squares KKT conditions 2 Motivation We can solve
Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM
 Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM Lee, Ching-pei University of Illinois at Urbana-Champaign Joint work with Dan Roth ICML 2015 Outline Introduction Algorithm Experiments
Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM Lee, Ching-pei University of Illinois at Urbana-Champaign Joint work with Dan Roth ICML 2015 Outline Introduction Algorithm Experiments
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task
 Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Binary Principal Component Analysis in the Netflix Collaborative Filtering Task László Kozma, Alexander Ilin, Tapani Raiko first.last@tkk.fi Helsinki University of Technology Adaptive Informatics Research
Recommender Systems. Dipanjan Das Language Technologies Institute Carnegie Mellon University. 20 November, 2007
 Recommender Systems Dipanjan Das Language Technologies Institute Carnegie Mellon University 20 November, 2007 Today s Outline What are Recommender Systems? Two approaches Content Based Methods Collaborative
Recommender Systems Dipanjan Das Language Technologies Institute Carnegie Mellon University 20 November, 2007 Today s Outline What are Recommender Systems? Two approaches Content Based Methods Collaborative
Kaggle.
 Administrivia Mini-project 2 due April 7, in class implement multi-class reductions, naive bayes, kernel perceptron, multi-class logistic regression and two layer neural networks training set: Project
Administrivia Mini-project 2 due April 7, in class implement multi-class reductions, naive bayes, kernel perceptron, multi-class logistic regression and two layer neural networks training set: Project
A Learning-rate Schedule for Stochastic Gradient Methods to Matrix Factorization
 A Learning-rate Schedule for Stochastic Gradient Methods to Matrix Factorization Wei-Sheng Chin, Yong Zhuang, Yu-Chin Juan, and Chih-Jen Lin Department of Computer Science National Taiwan University, Taipei,
A Learning-rate Schedule for Stochastic Gradient Methods to Matrix Factorization Wei-Sheng Chin, Yong Zhuang, Yu-Chin Juan, and Chih-Jen Lin Department of Computer Science National Taiwan University, Taipei,
Presentation in Convex Optimization
 Dec 22, 2014 Introduction Sample size selection in optimization methods for machine learning Introduction Sample size selection in optimization methods for machine learning Main results: presents a methodology
Dec 22, 2014 Introduction Sample size selection in optimization methods for machine learning Introduction Sample size selection in optimization methods for machine learning Main results: presents a methodology
An Ensemble Ranking Solution for the Yahoo! Learning to Rank Challenge
 An Ensemble Ranking Solution for the Yahoo! Learning to Rank Challenge Ming-Feng Tsai Department of Computer Science University of Singapore 13 Computing Drive, Singapore Shang-Tse Chen Yao-Nan Chen Chun-Sung
An Ensemble Ranking Solution for the Yahoo! Learning to Rank Challenge Ming-Feng Tsai Department of Computer Science University of Singapore 13 Computing Drive, Singapore Shang-Tse Chen Yao-Nan Chen Chun-Sung
Matrix Factorization Techniques for Recommender Systems
 Matrix Factorization Techniques for Recommender Systems Patrick Seemann, December 16 th, 2014 16.12.2014 Fachbereich Informatik Recommender Systems Seminar Patrick Seemann Topics Intro New-User / New-Item
Matrix Factorization Techniques for Recommender Systems Patrick Seemann, December 16 th, 2014 16.12.2014 Fachbereich Informatik Recommender Systems Seminar Patrick Seemann Topics Intro New-User / New-Item
Collaborative Recommendation with Multiclass Preference Context
 Collaborative Recommendation with Multiclass Preference Context Weike Pan and Zhong Ming {panweike,mingz}@szu.edu.cn College of Computer Science and Software Engineering Shenzhen University Pan and Ming
Collaborative Recommendation with Multiclass Preference Context Weike Pan and Zhong Ming {panweike,mingz}@szu.edu.cn College of Computer Science and Software Engineering Shenzhen University Pan and Ming
Binary Classification, Multi-label Classification and Ranking: A Decision-theoretic Approach
 Binary Classification, Multi-label Classification and Ranking: A Decision-theoretic Approach Krzysztof Dembczyński and Wojciech Kot lowski Intelligent Decision Support Systems Laboratory (IDSS) Poznań
Binary Classification, Multi-label Classification and Ranking: A Decision-theoretic Approach Krzysztof Dembczyński and Wojciech Kot lowski Intelligent Decision Support Systems Laboratory (IDSS) Poznań
Statistical Ranking Problem
 Statistical Ranking Problem Tong Zhang Statistics Department, Rutgers University Ranking Problems Rank a set of items and display to users in corresponding order. Two issues: performance on top and dealing
Statistical Ranking Problem Tong Zhang Statistics Department, Rutgers University Ranking Problems Rank a set of items and display to users in corresponding order. Two issues: performance on top and dealing
A Parallel SGD method with Strong Convergence
 A Parallel SGD method with Strong Convergence Dhruv Mahajan Microsoft Research India dhrumaha@microsoft.com S. Sundararajan Microsoft Research India ssrajan@microsoft.com S. Sathiya Keerthi Microsoft Corporation,
A Parallel SGD method with Strong Convergence Dhruv Mahajan Microsoft Research India dhrumaha@microsoft.com S. Sundararajan Microsoft Research India ssrajan@microsoft.com S. Sathiya Keerthi Microsoft Corporation,
StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory
 StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory S.V. N. (vishy) Vishwanathan Purdue University and Microsoft vishy@purdue.edu October 9, 2012 S.V. N. Vishwanathan (Purdue,
StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory S.V. N. (vishy) Vishwanathan Purdue University and Microsoft vishy@purdue.edu October 9, 2012 S.V. N. Vishwanathan (Purdue,
1 [15 points] Frequent Itemsets Generation With Map-Reduce
![1 [15 points] Frequent Itemsets Generation With Map-Reduce](/thumbs/72/67172903.jpg "1 [15 points] Frequent Itemsets Generation With Map-Reduce") Data Mining Learning from Large Data Sets Final Exam Date: 15 August 2013 Time limit: 120 minutes Number of pages: 11 Maximum score: 100 points You can use the back of the pages if you run out of space.
Data Mining Learning from Large Data Sets Final Exam Date: 15 August 2013 Time limit: 120 minutes Number of pages: 11 Maximum score: 100 points You can use the back of the pages if you run out of space.
Collaborative Filtering Applied to Educational Data Mining
 Journal of Machine Learning Research (200) Submitted ; Published Collaborative Filtering Applied to Educational Data Mining Andreas Töscher commendo research 8580 Köflach, Austria andreas.toescher@commendo.at
Journal of Machine Learning Research (200) Submitted ; Published Collaborative Filtering Applied to Educational Data Mining Andreas Töscher commendo research 8580 Köflach, Austria andreas.toescher@commendo.at
Spectral k-support Norm Regularization
 Spectral k-support Norm Regularization Andrew McDonald Department of Computer Science, UCL (Joint work with Massimiliano Pontil and Dimitris Stamos) 25 March, 2015 1 / 19 Problem: Matrix Completion Goal:
Spectral k-support Norm Regularization Andrew McDonald Department of Computer Science, UCL (Joint work with Massimiliano Pontil and Dimitris Stamos) 25 March, 2015 1 / 19 Problem: Matrix Completion Goal:
Variables. Cho-Jui Hsieh The University of Texas at Austin. ICML workshop on Covariance Selection Beijing, China June 26, 2014
 for a Million Variables Cho-Jui Hsieh The University of Texas at Austin ICML workshop on Covariance Selection Beijing, China June 26, 2014 Joint work with M. Sustik, I. Dhillon, P. Ravikumar, R. Poldrack,
for a Million Variables Cho-Jui Hsieh The University of Texas at Austin ICML workshop on Covariance Selection Beijing, China June 26, 2014 Joint work with M. Sustik, I. Dhillon, P. Ravikumar, R. Poldrack,
A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices
 A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices Ryota Tomioka 1, Taiji Suzuki 1, Masashi Sugiyama 2, Hisashi Kashima 1 1 The University of Tokyo 2 Tokyo Institute of Technology 2010-06-22
A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices Ryota Tomioka 1, Taiji Suzuki 1, Masashi Sugiyama 2, Hisashi Kashima 1 1 The University of Tokyo 2 Tokyo Institute of Technology 2010-06-22
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
Fast Coordinate Descent methods for Non-Negative Matrix Factorization
 Fast Coordinate Descent methods for Non-Negative Matrix Factorization Inderjit S. Dhillon University of Texas at Austin SIAM Conference on Applied Linear Algebra Valencia, Spain June 19, 2012 Joint work
Fast Coordinate Descent methods for Non-Negative Matrix Factorization Inderjit S. Dhillon University of Texas at Austin SIAM Conference on Applied Linear Algebra Valencia, Spain June 19, 2012 Joint work
Matrix Factorization and Factorization Machines for Recommender Systems
 Talk at SDM workshop on Machine Learning Methods on Recommender Systems, May 2, 215 Chih-Jen Lin (National Taiwan Univ.) 1 / 54 Matrix Factorization and Factorization Machines for Recommender Systems Chih-Jen
Talk at SDM workshop on Machine Learning Methods on Recommender Systems, May 2, 215 Chih-Jen Lin (National Taiwan Univ.) 1 / 54 Matrix Factorization and Factorization Machines for Recommender Systems Chih-Jen
Large-Scale Social Network Data Mining with Multi-View Information. Hao Wang
 Large-Scale Social Network Data Mining with Multi-View Information Hao Wang Dept. of Computer Science and Engineering Shanghai Jiao Tong University Supervisor: Wu-Jun Li 2013.6.19 Hao Wang Multi-View Social
Large-Scale Social Network Data Mining with Multi-View Information Hao Wang Dept. of Computer Science and Engineering Shanghai Jiao Tong University Supervisor: Wu-Jun Li 2013.6.19 Hao Wang Multi-View Social
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Recommendation. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Recommendation Tobias Scheffer Recommendation Engines Recommendation of products, music, contacts,.. Based on user features, item
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Recommendation Tobias Scheffer Recommendation Engines Recommendation of products, music, contacts,.. Based on user features, item
Scalable Coordinate Descent Approaches to Parallel Matrix Factorization for Recommender Systems
 Scalable Coordinate Descent Approaches to Parallel Matrix Factorization for Recommender Systems Hsiang-Fu Yu, Cho-Jui Hsieh, Si Si, and Inderjit Dhillon Department of Computer Science University of Texas
Scalable Coordinate Descent Approaches to Parallel Matrix Factorization for Recommender Systems Hsiang-Fu Yu, Cho-Jui Hsieh, Si Si, and Inderjit Dhillon Department of Computer Science University of Texas
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Numerical Linear Algebra Background Cho-Jui Hsieh UC Davis May 15, 2018 Linear Algebra Background Vectors A vector has a direction and a magnitude
STA141C: Big Data & High Performance Statistical Computing Numerical Linear Algebra Background Cho-Jui Hsieh UC Davis May 15, 2018 Linear Algebra Background Vectors A vector has a direction and a magnitude
Gradient Boosting, Continued
 Gradient Boosting, Continued David Rosenberg New York University December 26, 2016 David Rosenberg (New York University) DS-GA 1003 December 26, 2016 1 / 16 Review: Gradient Boosting Review: Gradient Boosting
Gradient Boosting, Continued David Rosenberg New York University December 26, 2016 David Rosenberg (New York University) DS-GA 1003 December 26, 2016 1 / 16 Review: Gradient Boosting Review: Gradient Boosting
Low Rank Matrix Completion Formulation and Algorithm
 1 2 Low Rank Matrix Completion and Algorithm Jian Zhang Department of Computer Science, ETH Zurich zhangjianthu@gmail.com March 25, 2014 Movie Rating 1 2 Critic A 5 5 Critic B 6 5 Jian 9 8 Kind Guy B 9
1 2 Low Rank Matrix Completion and Algorithm Jian Zhang Department of Computer Science, ETH Zurich zhangjianthu@gmail.com March 25, 2014 Movie Rating 1 2 Critic A 5 5 Critic B 6 5 Jian 9 8 Kind Guy B 9
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Approximation. Inderjit S. Dhillon Dept of Computer Science UT Austin. SAMSI Massive Datasets Opening Workshop Raleigh, North Carolina.
 Using Quadratic Approximation Inderjit S. Dhillon Dept of Computer Science UT Austin SAMSI Massive Datasets Opening Workshop Raleigh, North Carolina Sept 12, 2012 Joint work with C. Hsieh, M. Sustik and
Using Quadratic Approximation Inderjit S. Dhillon Dept of Computer Science UT Austin SAMSI Massive Datasets Opening Workshop Raleigh, North Carolina Sept 12, 2012 Joint work with C. Hsieh, M. Sustik and
Relational Stacked Denoising Autoencoder for Tag Recommendation. Hao Wang
 Relational Stacked Denoising Autoencoder for Tag Recommendation Hao Wang Dept. of Computer Science and Engineering Hong Kong University of Science and Technology Joint work with Xingjian Shi and Dit-Yan
Relational Stacked Denoising Autoencoder for Tag Recommendation Hao Wang Dept. of Computer Science and Engineering Hong Kong University of Science and Technology Joint work with Xingjian Shi and Dit-Yan
Parallel Matrix Factorization for Recommender Systems
 Under consideration for publication in Knowledge and Information Systems Parallel Matrix Factorization for Recommender Systems Hsiang-Fu Yu, Cho-Jui Hsieh, Si Si, and Inderjit S. Dhillon Department of
Under consideration for publication in Knowledge and Information Systems Parallel Matrix Factorization for Recommender Systems Hsiang-Fu Yu, Cho-Jui Hsieh, Si Si, and Inderjit S. Dhillon Department of
Neural Word Embeddings from Scratch
 Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
CS-E4830 Kernel Methods in Machine Learning
 CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
What is Happening Right Now... That Interests Me?
 What is Happening Right Now... That Interests Me? Online Topic Discovery and Recommendation in Twitter Ernesto Diaz-Aviles 1, Lucas Drumond 2, Zeno Gantner 2, Lars Schmidt-Thieme 2, and Wolfgang Nejdl
What is Happening Right Now... That Interests Me? Online Topic Discovery and Recommendation in Twitter Ernesto Diaz-Aviles 1, Lucas Drumond 2, Zeno Gantner 2, Lars Schmidt-Thieme 2, and Wolfgang Nejdl
Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization
 Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization Jialin Dong ShanghaiTech University 1 Outline Introduction FourVignettes: System Model and Problem Formulation Problem Analysis
Ranking from Crowdsourced Pairwise Comparisons via Matrix Manifold Optimization Jialin Dong ShanghaiTech University 1 Outline Introduction FourVignettes: System Model and Problem Formulation Problem Analysis
Matrix Factorization Techniques For Recommender Systems. Collaborative Filtering
 Matrix Factorization Techniques For Recommender Systems Collaborative Filtering Markus Freitag, Jan-Felix Schwarz 28 April 2011 Agenda 2 1. Paper Backgrounds 2. Latent Factor Models 3. Overfitting & Regularization
Matrix Factorization Techniques For Recommender Systems Collaborative Filtering Markus Freitag, Jan-Felix Schwarz 28 April 2011 Agenda 2 1. Paper Backgrounds 2. Latent Factor Models 3. Overfitting & Regularization
Circle-based Recommendation in Online Social Networks
 Circle-based Recommendation in Online Social Networks Xiwang Yang, Harald Steck*, and Yong Liu Polytechnic Institute of NYU * Bell Labs/Netflix 1 Outline q Background & Motivation q Circle-based RS Trust
Circle-based Recommendation in Online Social Networks Xiwang Yang, Harald Steck*, and Yong Liu Polytechnic Institute of NYU * Bell Labs/Netflix 1 Outline q Background & Motivation q Circle-based RS Trust
* Matrix Factorization and Recommendation Systems
 Matrix Factorization and Recommendation Systems Originally presented at HLF Workshop on Matrix Factorization with Loren Anderson (University of Minnesota Twin Cities) on 25 th September, 2017 15 th March,
Matrix Factorization and Recommendation Systems Originally presented at HLF Workshop on Matrix Factorization with Loren Anderson (University of Minnesota Twin Cities) on 25 th September, 2017 15 th March,
Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs
 information Article Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs Lei Guo 1, *, Haoran Jiang 2, Xinhua Wang 3 and Fangai Liu 3 1 School of Management
information Article Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs Lei Guo 1, *, Haoran Jiang 2, Xinhua Wang 3 and Fangai Liu 3 1 School of Management
Collaborative topic models: motivations cont
 Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Collaborative topic models: motivations cont Two topics: machine learning social network analysis Two people: " boy Two articles: article A! girl article B Preferences: The boy likes A and B --- no problem.
Fast Logistic Regression for Text Categorization with Variable-Length N-grams
 Fast Logistic Regression for Text Categorization with Variable-Length N-grams Georgiana Ifrim *, Gökhan Bakır +, Gerhard Weikum * * Max-Planck Institute for Informatics Saarbrücken, Germany + Google Switzerland
Fast Logistic Regression for Text Categorization with Variable-Length N-grams Georgiana Ifrim *, Gökhan Bakır +, Gerhard Weikum * * Max-Planck Institute for Informatics Saarbrücken, Germany + Google Switzerland
A Statistical View of Ranking: Midway between Classification and Regression
 A Statistical View of Ranking: Midway between Classification and Regression Yoonkyung Lee* 1 Department of Statistics The Ohio State University *joint work with Kazuki Uematsu June 4-6, 2014 Conference
A Statistical View of Ranking: Midway between Classification and Regression Yoonkyung Lee* 1 Department of Statistics The Ohio State University *joint work with Kazuki Uematsu June 4-6, 2014 Conference
RETRIEVAL MODELS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
Principal Component Analysis (PCA) for Sparse High-Dimensional Data
 for Sparse High-Dimensional Data") AB Principal Component Analysis (PCA) for Sparse High-Dimensional Data Tapani Raiko, Alexander Ilin, and Juha Karhunen Helsinki University of Technology, Finland Adaptive Informatics Research Center Principal
AB Principal Component Analysis (PCA) for Sparse High-Dimensional Data Tapani Raiko, Alexander Ilin, and Juha Karhunen Helsinki University of Technology, Finland Adaptive Informatics Research Center Principal
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
a Short Introduction
 Collaborative Filtering in Recommender Systems: a Short Introduction Norm Matloff Dept. of Computer Science University of California, Davis matloff@cs.ucdavis.edu December 3, 2016 Abstract There is a strong
Collaborative Filtering in Recommender Systems: a Short Introduction Norm Matloff Dept. of Computer Science University of California, Davis matloff@cs.ucdavis.edu December 3, 2016 Abstract There is a strong
Sparse Linear Programming via Primal and Dual Augmented Coordinate Descent
 Sparse Linear Programg via Primal and Dual Augmented Coordinate Descent Presenter: Joint work with Kai Zhong, Cho-Jui Hsieh, Pradeep Ravikumar and Inderjit Dhillon. Sparse Linear Program Given vectors
Sparse Linear Programg via Primal and Dual Augmented Coordinate Descent Presenter: Joint work with Kai Zhong, Cho-Jui Hsieh, Pradeep Ravikumar and Inderjit Dhillon. Sparse Linear Program Given vectors
CS60021: Scalable Data Mining. Large Scale Machine Learning
 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 CS60021: Scalable Data Mining Large Scale Machine Learning Sourangshu Bhattacharya Example: Spam filtering Instance
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 CS60021: Scalable Data Mining Large Scale Machine Learning Sourangshu Bhattacharya Example: Spam filtering Instance
Factor Modeling for Advertisement Targeting
 Ye Chen 1, Michael Kapralov 2, Dmitry Pavlov 3, John F. Canny 4 1 ebay Inc, 2 Stanford University, 3 Yandex Labs, 4 UC Berkeley NIPS-2009 Presented by Miao Liu May 27, 2010 Introduction GaP model Sponsored
Ye Chen 1, Michael Kapralov 2, Dmitry Pavlov 3, John F. Canny 4 1 ebay Inc, 2 Stanford University, 3 Yandex Labs, 4 UC Berkeley NIPS-2009 Presented by Miao Liu May 27, 2010 Introduction GaP model Sponsored
Collaborative Filtering via Ensembles of Matrix Factorizations
 Collaborative Ftering via Ensembles of Matrix Factorizations Mingrui Wu Max Planck Institute for Biological Cybernetics Spemannstrasse 38, 72076 Tübingen, Germany mingrui.wu@tuebingen.mpg.de ABSTRACT We
Collaborative Ftering via Ensembles of Matrix Factorizations Mingrui Wu Max Planck Institute for Biological Cybernetics Spemannstrasse 38, 72076 Tübingen, Germany mingrui.wu@tuebingen.mpg.de ABSTRACT We
Collaborative Filtering. Radek Pelánek
 Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 5: Numerical Linear Algebra Cho-Jui Hsieh UC Davis April 20, 2017 Linear Algebra Background Vectors A vector has a direction and a magnitude
STA141C: Big Data & High Performance Statistical Computing Lecture 5: Numerical Linear Algebra Cho-Jui Hsieh UC Davis April 20, 2017 Linear Algebra Background Vectors A vector has a direction and a magnitude
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 27, 2015 Outline Linear regression Ridge regression and Lasso Time complexity (closed form solution) Iterative Solvers Regression Input: training
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 27, 2015 Outline Linear regression Ridge regression and Lasso Time complexity (closed form solution) Iterative Solvers Regression Input: training
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
A Unified Algorithm for One-class Structured Matrix Factorization with Side Information
 A Unified Algorithm for One-class Structured Matrix Factorization with Side Information Hsiang-Fu Yu University of Texas at Austin rofuyu@cs.utexas.edu Hsin-Yuan Huang National Taiwan University momohuang@gmail.com
A Unified Algorithm for One-class Structured Matrix Factorization with Side Information Hsiang-Fu Yu University of Texas at Austin rofuyu@cs.utexas.edu Hsin-Yuan Huang National Taiwan University momohuang@gmail.com
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Improved Bounded Matrix Completion for Large-Scale Recommender Systems
 Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-7) Improved Bounded Matrix Completion for Large-Scale Recommender Systems Huang Fang, Zhen Zhang, Yiqun
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-7) Improved Bounded Matrix Completion for Large-Scale Recommender Systems Huang Fang, Zhen Zhang, Yiqun
Machine Learning Techniques
 Machine Learning Techniques ( 機器學習技法 ) Lecture 15: Matrix Factorization Hsuan-Tien Lin ( 林軒田 ) htlin@csie.ntu.edu.tw Department of Computer Science & Information Engineering National Taiwan University
Machine Learning Techniques ( 機器學習技法 ) Lecture 15: Matrix Factorization Hsuan-Tien Lin ( 林軒田 ) htlin@csie.ntu.edu.tw Department of Computer Science & Information Engineering National Taiwan University