ECS289: Scalable Machine Learning
|
|
|
- Joleen Curtis
- 5 years ago
- Views:
Transcription
1 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 27, 2015
2 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels

3 Multiclass Learning n data points, L labels, d features Input: training data {x i, y i } n i=1 : Each x i is a d dimensional feature vector Each y i {1,..., L} is the corresponding label Each training data belongs to one category Goal: find a function to predict the correct label f (x) y
 Example: y i = [0, 0, 1, 0, 0, 1, 1] (or Y i = {3, 6, 7}) Each training data can belong to multiple categories Goal: Given a testing sample x, predict the correct labels")
4 Multi-label Problems n data points, L labels, d features Input: training data {x i, y i } n i=1 : Each x i is a d dimensional feature vector Each y i {0, 1} L is a label vector (or Y i {1, 2,..., L}) Example: y i = [0, 0, 1, 0, 0, 1, 1] (or Y i = {3, 6, 7}) Each training data can belong to multiple categories Goal: Given a testing sample x, predict the correct labels


5 Illustration Multiclass: each row of L has exact one 1 Multilabel: each row of L can have multiple ones
6 Measure the accuracy (multi-class) Let {x i, y i } m i=1 be a set of testing data for multi-class problems Let z 1,..., z m be the prediction for each testing data Accuracy: 1 m m I (y i = z i ) i=1
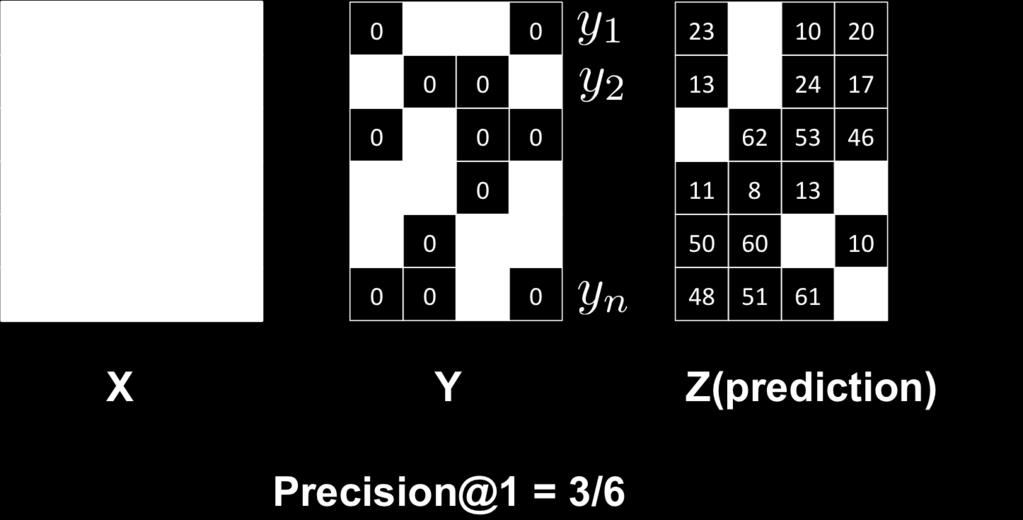
7 Measure the accuracy (multi-class) Let {x i, y i } m i=1 be a set of testing data for multi-class problems Let z 1,..., z m be the prediction for each testing data Accuracy: 1 m m I (y i = z i ) i=1 If the algorithm outputs a set of k potential labels for each sample: Each Z i is a set of k labels Precision@k: Z 1, Z 2,..., Z m 1 m m I (y i Z i ) i=1
8 Example (multiclass)
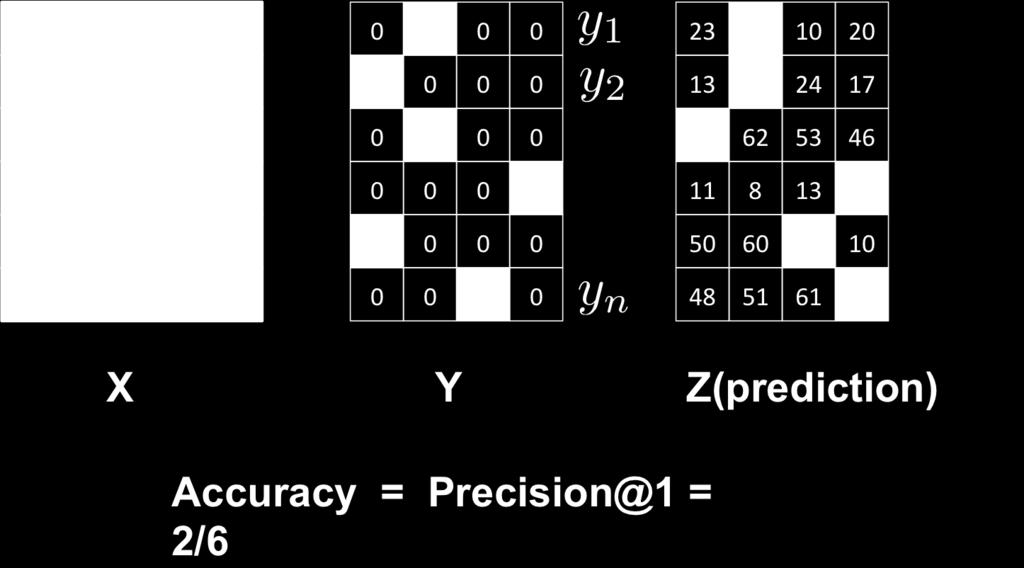
9 Example (multiclass)
10 Example (multiclass)
11 Example (multiclass)
12 Measure the accuracy (multi-label) Let {x i, y i } m i=1 be a set of testing data for multi-label problems For each testing data, the classifier outputs z i {0, 1} L We use Y i = {t : (y i ) t 0} and Z i = {t : (z i ) t 0} to denote the subset of real and predictive labels for the i-th testing data. If each Z i has k elements, then Precision@k is defined by: 1 m m i=1 Z i Y i k Hamming loss: overall classification performance 1 m m d(y i, z i ), i=1 where d(y i, z i ) measures the number of places where y i and z i differ. ROC curve (assume the classifier predicts a ranking of labels for each data point)
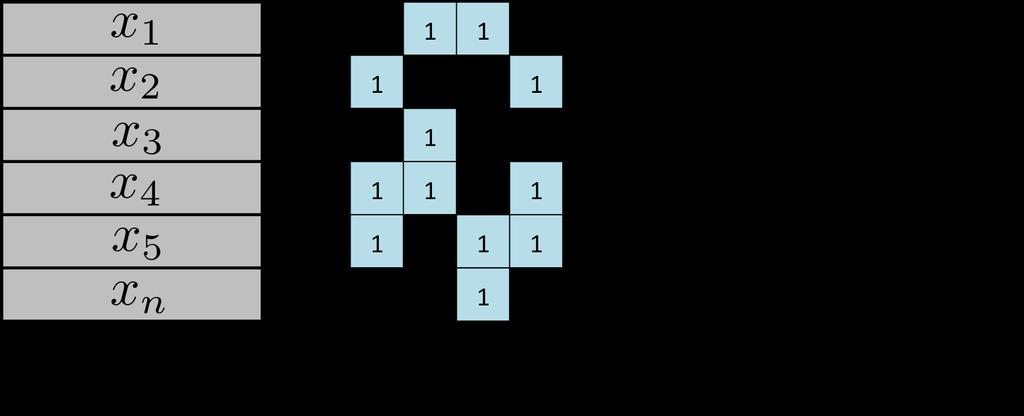
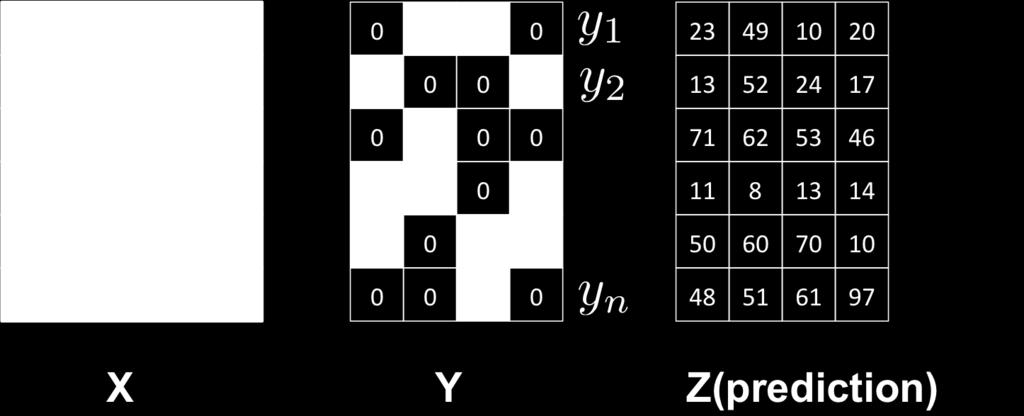
13 Example (multilabel)
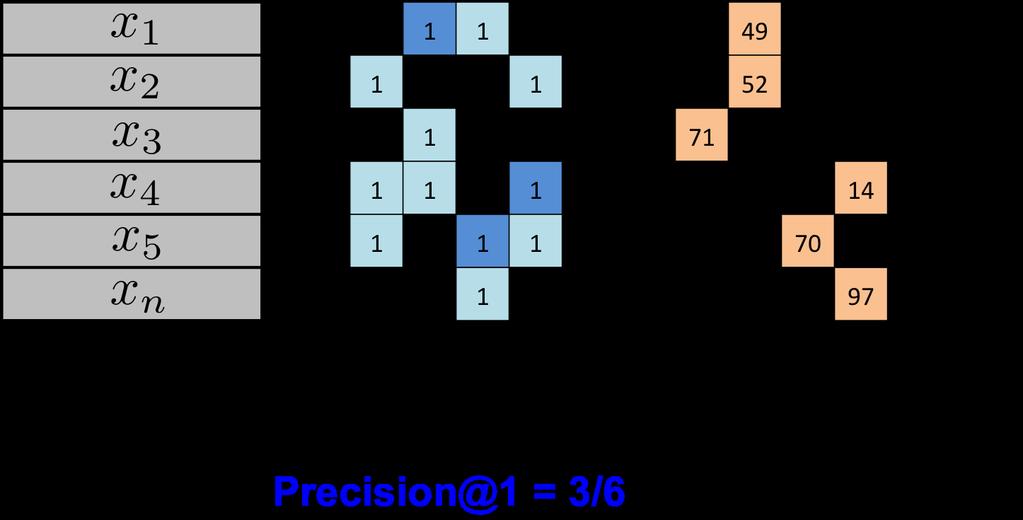
14 Example (multilabel)
15 Example (multilabel)
16 Traditional Approach Many algorithms for binary classification Idea: transform multi-class or multi-label problems to multiple binary classification problems Two approaches: One versus All (OVA) One versus One (OVO)
17 One Versus All (OVA) Multi-class/multi-label problems with L categories Build L different binary classifiers For the t-th classifier: Positive samples: all the points in class t ({x i : t y i }) Negative samples: all the points not in class t ({x i : t / y i }) f t (x): the decision value for the t-th classifier (larger f t higher probability that x in class t) Prediction: f (x) = arg max f t (x) t Example: using SVM to train each binary classifier.
18 One Versus One (OVO) Multi-class/multi-label problems with L categories Build L(L 1) different binary classifiers For the (s, t)-th classifier: Positive samples: all the points in class s ({x i : s y i }) Negative samples: all the points in class t ({x i : t y i }) f s,t (x): the decision value for this classifier (larger f s,t (x) label s has higher probability than label t) f t,s (x) = f s,t (x) Prediction: ( ) f (x) = arg max s t f s,t (x) Example: using SVM to train each binary classifier. Not for multilabel problems.
19 OVA vs OVO Prediction accuracy: depends on datasets Computational time: OVA needs to train L classifiers OVO needs to train L(L 1)/2 classifiers Is OVA always faster than OVO?
20 OVA vs OVO Prediction accuracy: depends on datasets Computational time: OVA needs to train L classifiers OVO needs to train L(L 1)/2 classifiers Is OVA always faster than OVO? NO, depends on the time complexity of the binary classifier If the binary classifier requires O(n) time for n samples: OVA and OVO have similar time complexity If the binary classifier requires O(n 1.xx ) time: OVO is faster than OVA
21 OVA vs OVO Prediction accuracy: depends on datasets Computational time: OVA needs to train L classifiers OVO needs to train L(L 1)/2 classifiers Is OVA always faster than OVO? NO, depends on the time complexity of the binary classifier If the binary classifier requires O(n) time for n samples: OVA and OVO have similar time complexity If the binary classifier requires O(n 1.xx ) time: OVO is faster than OVA LIBSVM (kernel SVM solver): OVO LIBLINEAR (linear SVM solver): OVA
22 Comparisons (accuracy) For kernel SVM with RBF kernel (See A comparison of methods for multiclass support vector machines, 2002)
23 Comparisons (training time) For kernel SVM (with RBF kernel) (See A comparison of methods for multiclass support vector machines, 2002)
24 Methods Using Instance-wise Ranking Loss
25 Main idea OVA and OVO: decompose the problem by labels However, the ranking of the labels for a testing sample is important For multiclass classification, the score of y i should be larger than other labels For multilabel classification, the score of Y i should be larger than other labels Both OVA and OVO decompose the problem into individual labels they cannot capture the ranking information Solve one combined optimization problem by minimizing the ranking loss
26 Main idea For simplicity, we assume a linear model Model parameters: w 1,..., w L For each data point x, compute the decision value for each label: Prediction: w T 1 x, w T 2 x,..., w T L x y = arg max w T t t x For training data x i, y i is the true label, so we want y i arg max w T t t x i i

27 Main idea Question: how to define the distance between XW and Y
28 Weston-Watkins Formulation Proposed in Weston and Watkins, Multi-class support vector machines. In ESANN, min {w t},{ξi t} 2 L w t 2 + C t=1 n L i=1 t=1 s.t. w T y i x i w T t x i 1 ξ t i, ξ t i ξ t i 0 t y i, i = 1,..., n If point i is in class y i, for any other labels (t y i ), we want w T y i x i w T t x i 1 or we pay a penalty ξ t i Prediction: f (x) = arg max w T t t x i
29 Weston-Watkins Formulation (dual) The dual problem of Weston-Watkins formulation: 1 min {α t} 2 L w t (α) + t=1 n αi t i=1 t y i s.t.0 α t i C, t y i, i = 1,..., n α 1,..., α L R n : dual variables for each label w t (α) = i αt i x i, and α y i i = t y i αi t Can be solved by dual (block) coordinate descent
30 Crammer-Singer Formulation Proposed in Carmmer and Singer, On the algorithmic implementation of multiclass kernel-based vector machines. JMLR, min {w t},{ξi t} 2 L w t 2 + C t=1 n i=1 ξ i s.t. w T y i x i w T t x i 1 ξ i, ξ i 0 i = 1,..., n t y i, i = 1,..., n If point i is in class y i, for any other labels (t y i ), we want w T y i x i w T t x i 1 For each point i, we only pay the largest penalty Prediction: f (x) = arg max w T t t x i
31 Crammer-Singer Formulation (dual) The dual problem of Crammer-Singer formulation: 1 L min w t (α) + {α t} 2 t=1 ( s.t. αi t C, t, t n αi t i=1 t y i ) αi t = 0, i = 1, 2,..., n α 1,..., α L R n : dual variables for each label w t (α) = i αt i x i, and α y i i = t y i αi t Can be solved by dual (block) coordinate descent

32 Comparisons (See A Sequential Dual Method for Large Scale Multi-Class Linear SVMs, KDD 2008)
33 Scaling to huge number of labels
 classification with large number")

34 Challenges: large number of categories Multi-label (or multi-class) classification with large number of labels Image classification > labels Recommending tags for articles: millions of labels (tags)
35 Challenges: large number of categories Consider a problem with 1 million labels (L = 1, 000, 000) One versus all: reduce to 1 million binary problems Training: 1 million binary classification problems. Need 694 days if each binary problem can be solved in 1 minute Model size: 1 million models. Need 1 TB if each model requires 1MB. Prediction one testing data: 1 million binary prediction Need 1000 secs if each binary prediction needs 10 3 secs.
36 Several Approaches Label space reduction by Compressed Sensing (CS) Feature space reduction (PCA) Supervised latent feature model by matrix factorization
37 Compressed Sensing If A R n d, w R d, y R n, and Given A and y, can we recover w? Aw = y

38 Compressed Sensing If A R n d, w R d, y R n, and Aw = y Given A and y, can we recover w? When n d: Usually yes, because number of constraints number of variable (over-determined linear system)

39 Compressed Sensing If A R n d, w R d, y R n, and Aw = y Given A and y, can we recover w? When n d: No, because number of constraints number of variable (high dimensional regression, under-determined linear system,... )
, and")

40 Compressed Sensing However, if we know w is a sparse vector (with s nonozero elements), and A satisfies certain condition, then we can recover w even in the high dimensional setting.
41 Compressed Sensing Conditions: w is s-sparse and A satisfies Restricted Isometry Property (RIP) Example: all entries of A are generated i.i.d. from Gaussian N(0, σ)... w can be recoverd by O(s log d) samples Lasso (l 1 -regularized linear regression) Orthogonal Mathcing Pursuit (OMP)... How is this related to multilabel classification?
42 Label Space Reduction by Compressed Sensing Proposed in Hsu et al., Multi-Label Prediction via Compressed Sensing. In NIPS Main idea: reduce the label space from R L to R k, where k L z i = My i where M R k L If we can recover y i by knowing z i and M, then: we only need to learn a function to map x i to z i : f (x i ) z i
43 Label Space Reduction by Compressed Sensing Proposed in Hsu et al., Multi-Label Prediction via Compressed Sensing. In NIPS Main idea: reduce the label space from R L to R k, where k L z i = My i where M R k L If we can recover y i by knowing z i and M, then: we only need to learn a function to map x i to z i : f (x i ) z i By compressed sensing: y i can be recovered given x i and M even when k = O(s log L) s is the number of nonzeroes in y i : usually very small in practice
44 Label Space Reduction by Compressed Sensing Training: Step 1: Construct M by i.i.d. Gaussian Step 2: Compute z i = My i for all i = 1, 2,..., n Step 3: Learn a function f such that f (x i ) z i Prediction for a test sample x Step 1: compute z = f (x) Step 2: compute y R L by solving a Lasso problem Step 3: Threshold y to give the prediction
45 Label Space Reduction by Compressed Sensing Reduce the label size from L to O(s log L) Drawbacks: 1 Slow prediction time (need to solve a Lasso problem for every prediction) 2 Large error in practice

46 Another way to understand this algorithm X R n d : data matrix, each row is a data point x i Y R n L : label matrix, each row is y i M R L k : Gaussian random matrix Goal: find a U matrix such that XU YM

47 Another way to understand this algorithm X R n d : data matrix, each row is a data point x i Y R n L : label matrix, each row is y i M R L k : Gaussian random matrix M : psuedo inverse of M Goal: find a U matrix such that XUM YMM
48 Feature space reduction Another way to improve speed: reduce the feature space Dimension reduction from d dimensional space to k dimensional space x i Nx i = x i, where N R k d and k d Matrix form: X = XN T Multilabel learning on the reduced feature space: Learn V such that X V Y Time complexity: reduced by a factor of n/k Several ways to choose N: PCA, random projection,...

49 Another way to understand this algorithm X R n d : data matrix, each row is a data point x i Y R n L : label matrix, each row is y i N R k d : matrix for dimensional reduction Goal: find a V matrix such that XN T V Y
50 Supervised latent space model (by matrix factorization) Label space reduction: find U such that X UV T Y Feature space reduction: find V such that How to improve? XUV T Y Find best U and V simultaneously Proposed in Chen and Lin, Feature-aware label space dimension reduction for multi-label classification. In NIPS Xu et al., Speedup Matrix Completion with Side Information: Application to Multi-Label Learning. In NIPS Yu et al., Large-scale Multi-label Learning with Missing Labels. In ICML 2014.
51 Low Rank Modeling for Multilabel Classification Let X R n d be the data matrix, Y R n L be the 0-1 label matrix Find U R d k and V R L k such that Y XUV T Obtain U, V by solving the following optimization problem: min U R d k,v R L k Y XUV T 2 F + λ 1 U 2 F + λ 2 V 2 F where λ 1, λ 2 are the regularization parameters Solve by alternating minimization.
 for updating V O(ndk)")
 per")
52 Low Rank Modeling for Multilabel Classification Time complexity: O(nkL) for updating V O(ndk) for updating U Overall: O(nkL + ndk) per iteration Original time complexity: O(ndL) per iteration
53 Extensions Extend to general loss function: min dis(y ij, (XUV T ) ij ) + λ 1 U 2 U R d k,v R L k F + λ 2 V 2 F i,j Can handle problems with missing data: min dis(y ij, (XUV T ) ij ) + λ 1 U 2 U R d k,v R L k F + λ 2 V 2 F i,j Ω Is it similar to inductive matrix completion? What s the time complexity for prediction?
54 Coming up Next class: paper presentations on mutlilabel classification and matrix completion Questions?
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 18, 2016 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 18, 2016 Outline One versus all/one versus one Ranking loss for multiclass/multilabel classification Scaling to millions of labels Multiclass
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 11, 2016 Paper presentations and final project proposal Send me the names of your group member (2 or 3 students) before October 15 (this Friday)
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 11, 2016 Paper presentations and final project proposal Send me the names of your group member (2 or 3 students) before October 15 (this Friday)
Large-scale Collaborative Ranking in Near-Linear Time
 Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
Convex Optimization Algorithms for Machine Learning in 10 Slides
 Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
Lecture 18: Multiclass Support Vector Machines
 Fall, 2017 Outlines Overview of Multiclass Learning Traditional Methods for Multiclass Problems One-vs-rest approaches Pairwise approaches Recent development for Multiclass Problems Simultaneous Classification
Fall, 2017 Outlines Overview of Multiclass Learning Traditional Methods for Multiclass Problems One-vs-rest approaches Pairwise approaches Recent development for Multiclass Problems Simultaneous Classification
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
1 Training and Approximation of a Primal Multiclass Support Vector Machine
 1 Training and Approximation of a Primal Multiclass Support Vector Machine Alexander Zien 1,2 and Fabio De Bona 1 and Cheng Soon Ong 1,2 1 Friedrich Miescher Lab., Max Planck Soc., Spemannstr. 39, Tübingen,
1 Training and Approximation of a Primal Multiclass Support Vector Machine Alexander Zien 1,2 and Fabio De Bona 1 and Cheng Soon Ong 1,2 1 Friedrich Miescher Lab., Max Planck Soc., Spemannstr. 39, Tübingen,
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Compressed Sensing and Neural Networks
 and Jan Vybíral (Charles University & Czech Technical University Prague, Czech Republic) NOMAD Summer Berlin, September 25-29, 2017 1 / 31 Outline Lasso & Introduction Notation Training the network Applications
and Jan Vybíral (Charles University & Czech Technical University Prague, Czech Republic) NOMAD Summer Berlin, September 25-29, 2017 1 / 31 Outline Lasso & Introduction Notation Training the network Applications
PU Learning for Matrix Completion
 Cho-Jui Hsieh Dept of Computer Science UT Austin ICML 2015 Joint work with N. Natarajan and I. S. Dhillon Matrix Completion Example: movie recommendation Given a set Ω and the values M Ω, how to predict
Cho-Jui Hsieh Dept of Computer Science UT Austin ICML 2015 Joint work with N. Natarajan and I. S. Dhillon Matrix Completion Example: movie recommendation Given a set Ω and the values M Ω, how to predict
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
6.036 midterm review. Wednesday, March 18, 15
 6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
Training Support Vector Machines: Status and Challenges
 ICML Workshop on Large Scale Learning Challenge July 9, 2008 Chih-Jen Lin (National Taiwan Univ.) 1 / 34 Training Support Vector Machines: Status and Challenges Chih-Jen Lin Department of Computer Science
ICML Workshop on Large Scale Learning Challenge July 9, 2008 Chih-Jen Lin (National Taiwan Univ.) 1 / 34 Training Support Vector Machines: Status and Challenges Chih-Jen Lin Department of Computer Science
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
Introduction to Machine Learning Lecture 13. Mehryar Mohri Courant Institute and Google Research
 Introduction to Machine Learning Lecture 13 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Multi-Class Classification Mehryar Mohri - Introduction to Machine Learning page 2 Motivation
Introduction to Machine Learning Lecture 13 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Multi-Class Classification Mehryar Mohri - Introduction to Machine Learning page 2 Motivation
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Support Vector Machine. Industrial AI Lab. Prof. Seungchul Lee
 Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Andreas Maletti Technische Universität Dresden Fakultät Informatik June 15, 2006 1 The Problem 2 The Basics 3 The Proposed Solution Learning by Machines Learning
Introduction to Support Vector Machines Andreas Maletti Technische Universität Dresden Fakultät Informatik June 15, 2006 1 The Problem 2 The Basics 3 The Proposed Solution Learning by Machines Learning
StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory
 StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory S.V. N. (vishy) Vishwanathan Purdue University and Microsoft vishy@purdue.edu October 9, 2012 S.V. N. Vishwanathan (Purdue,
StreamSVM Linear SVMs and Logistic Regression When Data Does Not Fit In Memory S.V. N. (vishy) Vishwanathan Purdue University and Microsoft vishy@purdue.edu October 9, 2012 S.V. N. Vishwanathan (Purdue,
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers
 Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Linear and Logistic Regression. Dr. Xiaowei Huang
 Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
CS-E4830 Kernel Methods in Machine Learning
 CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
CS-E4830 Kernel Methods in Machine Learning Lecture 5: Multi-class and preference learning Juho Rousu 11. October, 2017 Juho Rousu 11. October, 2017 1 / 37 Agenda from now on: This week s theme: going
MLCC 2018 Variable Selection and Sparsity. Lorenzo Rosasco UNIGE-MIT-IIT
 MLCC 2018 Variable Selection and Sparsity Lorenzo Rosasco UNIGE-MIT-IIT Outline Variable Selection Subset Selection Greedy Methods: (Orthogonal) Matching Pursuit Convex Relaxation: LASSO & Elastic Net
MLCC 2018 Variable Selection and Sparsity Lorenzo Rosasco UNIGE-MIT-IIT Outline Variable Selection Subset Selection Greedy Methods: (Orthogonal) Matching Pursuit Convex Relaxation: LASSO & Elastic Net
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
SQL-Rank: A Listwise Approach to Collaborative Ranking
 SQL-Rank: A Listwise Approach to Collaborative Ranking Liwei Wu Depts of Statistics and Computer Science UC Davis ICML 18, Stockholm, Sweden July 10-15, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
SQL-Rank: A Listwise Approach to Collaborative Ranking Liwei Wu Depts of Statistics and Computer Science UC Davis ICML 18, Stockholm, Sweden July 10-15, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 27, 2015 Outline Linear regression Ridge regression and Lasso Time complexity (closed form solution) Iterative Solvers Regression Input: training
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 27, 2015 Outline Linear regression Ridge regression and Lasso Time complexity (closed form solution) Iterative Solvers Regression Input: training
Learning SVM Classifiers with Indefinite Kernels
 Learning SVM Classifiers with Indefinite Kernels Suicheng Gu and Yuhong Guo Dept. of Computer and Information Sciences Temple University Support Vector Machines (SVMs) (Kernel) SVMs are widely used in
Learning SVM Classifiers with Indefinite Kernels Suicheng Gu and Yuhong Guo Dept. of Computer and Information Sciences Temple University Support Vector Machines (SVMs) (Kernel) SVMs are widely used in
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
A Dual Coordinate Descent Method for Large-scale Linear SVM
 Cho-Jui Hsieh b92085@csie.ntu.edu.tw Kai-Wei Chang b92084@csie.ntu.edu.tw Chih-Jen Lin cjlin@csie.ntu.edu.tw Department of Computer Science, National Taiwan University, Taipei 106, Taiwan S. Sathiya Keerthi
Cho-Jui Hsieh b92085@csie.ntu.edu.tw Kai-Wei Chang b92084@csie.ntu.edu.tw Chih-Jen Lin cjlin@csie.ntu.edu.tw Department of Computer Science, National Taiwan University, Taipei 106, Taiwan S. Sathiya Keerthi
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc.
 Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Support Vector Machine I
 Support Vector Machine I Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Please use piazza. No emails. HW 0 grades are back. Re-grade request for one week. HW 1 due soon. HW
Support Vector Machine I Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Please use piazza. No emails. HW 0 grades are back. Re-grade request for one week. HW 1 due soon. HW
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Exploiting Primal and Dual Sparsity for Extreme Classification 1
 Exploiting Primal and Dual Sparsity for Extreme Classification 1 Ian E.H. Yen Joint work with Xiangru Huang, Kai Zhong, Pradeep Ravikumar and Inderjit Dhillon Machine Learning Department Carnegie Mellon
Exploiting Primal and Dual Sparsity for Extreme Classification 1 Ian E.H. Yen Joint work with Xiangru Huang, Kai Zhong, Pradeep Ravikumar and Inderjit Dhillon Machine Learning Department Carnegie Mellon
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
An Ensemble Ranking Solution for the Yahoo! Learning to Rank Challenge
 An Ensemble Ranking Solution for the Yahoo! Learning to Rank Challenge Ming-Feng Tsai Department of Computer Science University of Singapore 13 Computing Drive, Singapore Shang-Tse Chen Yao-Nan Chen Chun-Sung
An Ensemble Ranking Solution for the Yahoo! Learning to Rank Challenge Ming-Feng Tsai Department of Computer Science University of Singapore 13 Computing Drive, Singapore Shang-Tse Chen Yao-Nan Chen Chun-Sung
Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM
 Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM Lee, Ching-pei University of Illinois at Urbana-Champaign Joint work with Dan Roth ICML 2015 Outline Introduction Algorithm Experiments
Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM Lee, Ching-pei University of Illinois at Urbana-Champaign Joint work with Dan Roth ICML 2015 Outline Introduction Algorithm Experiments
A Least Squares Formulation for Canonical Correlation Analysis
 A Least Squares Formulation for Canonical Correlation Analysis Liang Sun, Shuiwang Ji, and Jieping Ye Department of Computer Science and Engineering Arizona State University Motivation Canonical Correlation
A Least Squares Formulation for Canonical Correlation Analysis Liang Sun, Shuiwang Ji, and Jieping Ye Department of Computer Science and Engineering Arizona State University Motivation Canonical Correlation
Lecture 7: Kernels for Classification and Regression
 Lecture 7: Kernels for Classification and Regression CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 15, 2011 Outline Outline A linear regression problem Linear auto-regressive
Lecture 7: Kernels for Classification and Regression CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 15, 2011 Outline Outline A linear regression problem Linear auto-regressive
Support Vector and Kernel Methods
 SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence
 Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence oé LAMDA Group H ŒÆOŽÅ Æ EâX ^ #EâI[ : liwujun@nju.edu.cn Dec 10, 2016 Wu-Jun Li (http://cs.nju.edu.cn/lwj)
Parallel and Distributed Stochastic Learning -Towards Scalable Learning for Big Data Intelligence oé LAMDA Group H ŒÆOŽÅ Æ EâX ^ #EâI[ : liwujun@nju.edu.cn Dec 10, 2016 Wu-Jun Li (http://cs.nju.edu.cn/lwj)
Incremental and Decremental Training for Linear Classification
 Incremental and Decremental Training for Linear Classification Authors: Cheng-Hao Tsai, Chieh-Yen Lin, and Chih-Jen Lin Department of Computer Science National Taiwan University Presenter: Ching-Pei Lee
Incremental and Decremental Training for Linear Classification Authors: Cheng-Hao Tsai, Chieh-Yen Lin, and Chih-Jen Lin Department of Computer Science National Taiwan University Presenter: Ching-Pei Lee
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Foundations of Machine Learning Multi-Class Classification. Mehryar Mohri Courant Institute and Google Research
 Foundations of Machine Learning Multi-Class Classification Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Motivation Real-world problems often have multiple classes: text, speech,
Foundations of Machine Learning Multi-Class Classification Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Motivation Real-world problems often have multiple classes: text, speech,
Large-Margin Thresholded Ensembles for Ordinal Regression
 Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin and Ling Li Learning Systems Group, California Institute of Technology, U.S.A. Conf. on Algorithmic Learning Theory, October 9,
Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin and Ling Li Learning Systems Group, California Institute of Technology, U.S.A. Conf. on Algorithmic Learning Theory, October 9,
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text
 Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Lecture 3: Multiclass Classification
 Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
CIS 520: Machine Learning Oct 09, Kernel Methods
 CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
Kaggle.
 Administrivia Mini-project 2 due April 7, in class implement multi-class reductions, naive bayes, kernel perceptron, multi-class logistic regression and two layer neural networks training set: Project
Administrivia Mini-project 2 due April 7, in class implement multi-class reductions, naive bayes, kernel perceptron, multi-class logistic regression and two layer neural networks training set: Project
Foundations of Machine Learning Lecture 9. Mehryar Mohri Courant Institute and Google Research
 Foundations of Machine Learning Lecture 9 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Multi-Class Classification page 2 Motivation Real-world problems often have multiple classes:
Foundations of Machine Learning Lecture 9 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Multi-Class Classification page 2 Motivation Real-world problems often have multiple classes:
MIT 9.520/6.860, Fall 2018 Statistical Learning Theory and Applications. Class 08: Sparsity Based Regularization. Lorenzo Rosasco
 MIT 9.520/6.860, Fall 2018 Statistical Learning Theory and Applications Class 08: Sparsity Based Regularization Lorenzo Rosasco Learning algorithms so far ERM + explicit l 2 penalty 1 min w R d n n l(y
MIT 9.520/6.860, Fall 2018 Statistical Learning Theory and Applications Class 08: Sparsity Based Regularization Lorenzo Rosasco Learning algorithms so far ERM + explicit l 2 penalty 1 min w R d n n l(y
A Parallel SGD method with Strong Convergence
 A Parallel SGD method with Strong Convergence Dhruv Mahajan Microsoft Research India dhrumaha@microsoft.com S. Sundararajan Microsoft Research India ssrajan@microsoft.com S. Sathiya Keerthi Microsoft Corporation,
A Parallel SGD method with Strong Convergence Dhruv Mahajan Microsoft Research India dhrumaha@microsoft.com S. Sundararajan Microsoft Research India ssrajan@microsoft.com S. Sathiya Keerthi Microsoft Corporation,
Midterms. PAC Learning SVM Kernels+Boost Decision Trees. MultiClass CS446 Spring 17
 Midterms PAC Learning SVM Kernels+Boost Decision Trees 1 Grades are on a curve Midterms Will be available at the TA sessions this week Projects feedback has been sent. Recall that this is 25% of your grade!
Midterms PAC Learning SVM Kernels+Boost Decision Trees 1 Grades are on a curve Midterms Will be available at the TA sessions this week Projects feedback has been sent. Recall that this is 25% of your grade!
Machine Learning Lecture 6 Note
 Machine Learning Lecture 6 Note Compiled by Abhi Ashutosh, Daniel Chen, and Yijun Xiao February 16, 2016 1 Pegasos Algorithm The Pegasos Algorithm looks very similar to the Perceptron Algorithm. In fact,
Machine Learning Lecture 6 Note Compiled by Abhi Ashutosh, Daniel Chen, and Yijun Xiao February 16, 2016 1 Pegasos Algorithm The Pegasos Algorithm looks very similar to the Perceptron Algorithm. In fact,
Efficient Maximum Margin Clustering
 Dept. Automation, Tsinghua Univ. MLA, Nov. 8, 2008 Nanjing, China Outline 1 2 3 4 5 Outline 1 2 3 4 5 Support Vector Machine Given X = {x 1,, x n }, y = (y 1,..., y n ) { 1, +1} n, SVM finds a hyperplane
Dept. Automation, Tsinghua Univ. MLA, Nov. 8, 2008 Nanjing, China Outline 1 2 3 4 5 Outline 1 2 3 4 5 Support Vector Machine Given X = {x 1,, x n }, y = (y 1,..., y n ) { 1, +1} n, SVM finds a hyperplane
What is semi-supervised learning?
 What is semi-supervised learning? In many practical learning domains, there is a large supply of unlabeled data but limited labeled data, which can be expensive to generate text processing, video-indexing,
What is semi-supervised learning? In many practical learning domains, there is a large supply of unlabeled data but limited labeled data, which can be expensive to generate text processing, video-indexing,
Linear classifiers: Overfitting and regularization
 Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
A Simple Algorithm for Multilabel Ranking
 A Simple Algorithm for Multilabel Ranking Krzysztof Dembczyński 1 Wojciech Kot lowski 1 Eyke Hüllermeier 2 1 Intelligent Decision Support Systems Laboratory (IDSS), Poznań University of Technology, Poland
A Simple Algorithm for Multilabel Ranking Krzysztof Dembczyński 1 Wojciech Kot lowski 1 Eyke Hüllermeier 2 1 Intelligent Decision Support Systems Laboratory (IDSS), Poznań University of Technology, Poland
Big & Quic: Sparse Inverse Covariance Estimation for a Million Variables
 for a Million Variables Cho-Jui Hsieh The University of Texas at Austin NIPS Lake Tahoe, Nevada Dec 8, 2013 Joint work with M. Sustik, I. Dhillon, P. Ravikumar and R. Poldrack FMRI Brain Analysis Goal:
for a Million Variables Cho-Jui Hsieh The University of Texas at Austin NIPS Lake Tahoe, Nevada Dec 8, 2013 Joint work with M. Sustik, I. Dhillon, P. Ravikumar and R. Poldrack FMRI Brain Analysis Goal:
MULTIPLEKERNELLEARNING CSE902
 MULTIPLEKERNELLEARNING CSE902 Multiple Kernel Learning -keywords Heterogeneous information fusion Feature selection Max-margin classification Multiple kernel learning MKL Convex optimization Kernel classification
MULTIPLEKERNELLEARNING CSE902 Multiple Kernel Learning -keywords Heterogeneous information fusion Feature selection Max-margin classification Multiple kernel learning MKL Convex optimization Kernel classification
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
The role of dimensionality reduction in classification
 The role of dimensionality reduction in classification Weiran Wang and Miguel Á. Carreira-Perpiñán Electrical Engineering and Computer Science University of California, Merced http://eecs.ucmerced.edu
The role of dimensionality reduction in classification Weiran Wang and Miguel Á. Carreira-Perpiñán Electrical Engineering and Computer Science University of California, Merced http://eecs.ucmerced.edu
Midterm exam CS 189/289, Fall 2015
 Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Randomized Algorithms
 Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
CS 231A Section 1: Linear Algebra & Probability Review
 CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
CS 231A Section 1: Linear Algebra & Probability Review. Kevin Tang
 CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent
 Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent KDD 2011 Rainer Gemulla, Peter J. Haas, Erik Nijkamp and Yannis Sismanis Presenter: Jiawen Yao Dept. CSE, UT Arlington 1 1
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Discriminative Learning and Big Data
 AIMS-CDT Michaelmas 2016 Discriminative Learning and Big Data Lecture 2: Other loss functions and ANN Andrew Zisserman Visual Geometry Group University of Oxford http://www.robots.ox.ac.uk/~vgg Lecture
AIMS-CDT Michaelmas 2016 Discriminative Learning and Big Data Lecture 2: Other loss functions and ANN Andrew Zisserman Visual Geometry Group University of Oxford http://www.robots.ox.ac.uk/~vgg Lecture
CS 188: Artificial Intelligence. Outline
 CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
Big Data Analytics: Optimization and Randomization
 Big Data Analytics: Optimization and Randomization Tianbao Yang Tutorial@ACML 2015 Hong Kong Department of Computer Science, The University of Iowa, IA, USA Nov. 20, 2015 Yang Tutorial for ACML 15 Nov.
Big Data Analytics: Optimization and Randomization Tianbao Yang Tutorial@ACML 2015 Hong Kong Department of Computer Science, The University of Iowa, IA, USA Nov. 20, 2015 Yang Tutorial for ACML 15 Nov.
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Learning Classification with Auxiliary Probabilistic Information Quang Nguyen Hamed Valizadegan Milos Hauskrecht
 Learning Classification with Auxiliary Probabilistic Information Quang Nguyen Hamed Valizadegan Milos Hauskrecht Computer Science Department University of Pittsburgh Outline Introduction Learning with
Learning Classification with Auxiliary Probabilistic Information Quang Nguyen Hamed Valizadegan Milos Hauskrecht Computer Science Department University of Pittsburgh Outline Introduction Learning with
CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System
 CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System Yang You 1, James Demmel 1, Kent Czechowski 2, Le Song 2, Richard Vuduc 2 UC Berkeley 1, Georgia Tech 2 Yang You (Speaker) James
CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System Yang You 1, James Demmel 1, Kent Czechowski 2, Le Song 2, Richard Vuduc 2 UC Berkeley 1, Georgia Tech 2 Yang You (Speaker) James
Linear Methods for Regression. Lijun Zhang
 Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Linear Methods for Regression Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Linear Regression Models and Least Squares Subset Selection Shrinkage Methods Methods Using Derived
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
A Study on Trust Region Update Rules in Newton Methods for Large-scale Linear Classification
 JMLR: Workshop and Conference Proceedings 1 16 A Study on Trust Region Update Rules in Newton Methods for Large-scale Linear Classification Chih-Yang Hsia r04922021@ntu.edu.tw Dept. of Computer Science,
JMLR: Workshop and Conference Proceedings 1 16 A Study on Trust Region Update Rules in Newton Methods for Large-scale Linear Classification Chih-Yang Hsia r04922021@ntu.edu.tw Dept. of Computer Science,
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Variables. Cho-Jui Hsieh The University of Texas at Austin. ICML workshop on Covariance Selection Beijing, China June 26, 2014
 for a Million Variables Cho-Jui Hsieh The University of Texas at Austin ICML workshop on Covariance Selection Beijing, China June 26, 2014 Joint work with M. Sustik, I. Dhillon, P. Ravikumar, R. Poldrack,
for a Million Variables Cho-Jui Hsieh The University of Texas at Austin ICML workshop on Covariance Selection Beijing, China June 26, 2014 Joint work with M. Sustik, I. Dhillon, P. Ravikumar, R. Poldrack,
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Machine Learning for Signal Processing Sparse and Overcomplete Representations. Bhiksha Raj (slides from Sourish Chaudhuri) Oct 22, 2013
 Oct 22, 2013") Machine Learning for Signal Processing Sparse and Overcomplete Representations Bhiksha Raj (slides from Sourish Chaudhuri) Oct 22, 2013 1 Key Topics in this Lecture Basics Component-based representations
Machine Learning for Signal Processing Sparse and Overcomplete Representations Bhiksha Raj (slides from Sourish Chaudhuri) Oct 22, 2013 1 Key Topics in this Lecture Basics Component-based representations
Support Vector Machines and Kernel Methods
 Support Vector Machines and Kernel Methods Chih-Jen Lin Department of Computer Science National Taiwan University Talk at International Workshop on Recent Trends in Learning, Computation, and Finance,
Support Vector Machines and Kernel Methods Chih-Jen Lin Department of Computer Science National Taiwan University Talk at International Workshop on Recent Trends in Learning, Computation, and Finance,
 https://goo.gl/kfxweg KYOTO UNIVERSITY Statistical Machine Learning Theory Sparsity Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT OF INTELLIGENCE SCIENCE AND TECHNOLOGY 1 KYOTO UNIVERSITY Topics:
https://goo.gl/kfxweg KYOTO UNIVERSITY Statistical Machine Learning Theory Sparsity Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT OF INTELLIGENCE SCIENCE AND TECHNOLOGY 1 KYOTO UNIVERSITY Topics:
Kernel methods, kernel SVM and ridge regression
 Kernel methods, kernel SVM and ridge regression Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Collaborative Filtering 2 Collaborative Filtering R: rating matrix; U: user factor;
Kernel methods, kernel SVM and ridge regression Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Collaborative Filtering 2 Collaborative Filtering R: rating matrix; U: user factor;
Applied Machine Learning Lecture 5: Linear classifiers, continued. Richard Johansson
 Applied Machine Learning Lecture 5: Linear classifiers, continued Richard Johansson overview preliminaries logistic regression training a logistic regression classifier side note: multiclass linear classifiers
Applied Machine Learning Lecture 5: Linear classifiers, continued Richard Johansson overview preliminaries logistic regression training a logistic regression classifier side note: multiclass linear classifiers
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Infinite Ensemble Learning with Support Vector Machinery
 Infinite Ensemble Learning with Support Vector Machinery Hsuan-Tien Lin and Ling Li Learning Systems Group, California Institute of Technology ECML/PKDD, October 4, 2005 H.-T. Lin and L. Li (Learning Systems
Infinite Ensemble Learning with Support Vector Machinery Hsuan-Tien Lin and Ling Li Learning Systems Group, California Institute of Technology ECML/PKDD, October 4, 2005 H.-T. Lin and L. Li (Learning Systems