Computational Learning Theory
|
|
|
- Vanessa Bond
- 5 years ago
- Views:
Transcription
1 Computational Learning Theory Slides by and Nathalie Japkowicz (Reading: R&N AIMA 3 rd ed., Chapter 18.5)
2 Computational Learning Theory Inductive learning: given the training set, a learning algorithm generates a hypothesis. Run hypothesis on the test set. The results say something about how good our hypothesis is. But how much do the results really tell you? Can we be certain about how the learning algorithm generalizes? We would have to see all the examples. Insight: introduce probabilities to measure degree of certainty and correctness (Valiant 1984).
3 Computational Learning Theory Example: We want to use height to distinguish men and women drawing people from the same distribution for training and testing. We can never be absolutely certain that we have learned correctly our target (hidden) concept function. (E.g., there is a non-zero chance that, so far, we have only seen a sequence of bad examples) E.g., relatively tall women and relatively short men We ll see that it s generally highly unlikely to see a long series of bad examples!
4 Aside: flipping a coin
5 Experimental data C program simulation of flips of a fair coin:
6 Experimental Data Contd. With a sufficient number of flips (set of flips=example of coin bias), large outliers become quite rare. Coin example is the key to computational learning theory!
7 Computational Learning Theory Intersection of AI, statistics, and theory of computation. Introduce Probably Approximately Correct Learning concerning efficient learning For our learning procedures we would like to prove that: With high probability an (efficient) learning algorithm will find a hypothesis that is approximately identical to the hidden target concept. Note the double hedging probably and approximately. Why do we need both levels of uncertainty (in general)?
8 Probably Approximately Correct Learning Underlying principle: Seriously wrong hypotheses can be found out almost certainly (with high probability) using a small number of examples Any hypothesis that is consistent with a significantly large set of training examples is unlikely to be seriously wrong: it must be probably approximately correct. Any (efficient) algorithm that returns hypotheses that are PAC is called a PAC-learning algorithm
9 Probably Approximately Correct Learning How many examples are needed to guarantee correctness? Sample complexity (# of examples to guarantee correctness) grows with the size of the Hypothesis space Stationarity assumption: Training set and test sets are drawn from the same distribution
10 Notations Notations: X: set of all possible examples D: distribution from which examples are drawn H: set of all possible hypotheses N: the number of examples in the training set f: the true function to be learned Assume: the true function f is in H. Error of a hypothesis h wrt f : Probability that h differs from f on a randomly picked example: error(h) = P(h(x) f(x) x drawn from D) Exactly what we are trying to measure with our test set.
11 Approximately Correct A hypothesis h is approximately correct if: error(h) ε, where ε is a given threshold, a small constant Goal: Show that after seeing a small (poly) number of examples N, with high probability, all consistent hypotheses will be approximately correct. I.e, chance of bad hypothesis, (high error but consistent with examples) is small (i.e, less than δ)
12 Approximately Correct Approximately correct hypotheses lie inside the ε -ball around f; Those hypotheses that are seriously wrong (h b HBad) are outside the ε -ball, Error(h bad )= P(h b (x) f(x) x drawn from D) > ε, Thus the probability that the h bad (a seriously wrong hypothesis) disagrees with one example is at least ε (definition of error). Thus the probability that the h bad (a seriously wrong hypothesis) agrees with one example is no more than (1- ε). So for N examples, P(h b agrees with N examples) (1- ε ) N.
13 Approximately Correct Hypothesis The probability that H Bad contains at least one consistent hypothesis is bounded by the sum of the individual probabilities. P(H bad contains a consistent hypothesis, agreeing with all the examples) H bad (1- ε ) N H (1- ε ) N h bad agrees with one example is no more than (1- ε).
14 P(H bad contains a consistent hypothesis) H bad (1- ε ) N H (1- ε ) N Goal Bound the probability of learning a bad hypothesis below some small number δ. Note: P(H bad contains a consistent hypothesis) The more accuracy (smaller ε), and the more certainty (with smaller δ) one wants, the more examples one needs. What is the probability P(H good ) of learning a good hypothesis? How large should N be? Derivation: see blackboard Sample Complexity: Number of examples to guarantee a PAC learnable function class If the learning algorithm returns a hypothesis that is consistent with this many examples, then with probability at least (1-δ) the learning algorithm has an error of at most ε. and the hypothesis is Probably Approximately Correct.
15 Probably Approximately correct hypothesis h: If the probability of a small error (error(h) ε ) is greater than or equal to a given threshold 1 - δ A bound on the number of examples (sample complexity) needed to guarantee PAC, that is polynomial (The more accuracy (with smaller ε), and the more certainty desired (with smaller δ), the more examples one needs.) An efficient learning algorithm Theoretical results apply to fairly simple learning models (e.g., decision list learning)
16 PAC Learning Two steps: Sample complexity a polynomial number of examples suffices to specify a good consistent hypothesis (error(h) ε ) with high probability ( 1 δ). Computational complexity there is an efficient algorithm for learning a consistent hypothesis from the small sample. Let s be more specific with examples.
17 Example: Boolean Functions Consider H the set of all Boolean function on n attributesà 1 N (ln + ln H ) = O(2 ε δ 1 n So the sample complexity grows as 2 n L! (same as the number of all possible examples) Not PAC-Learnable! ) H = So, any learning algorithm will do not better than a lookup table if it merely returns a hypothesis that is consistent with all known examples! Intuitively what does it say about H? Finite H required! 2 2 n
18 Coping With Learning Complexity 1. Force learning algorithm to look for smallest consistent hypothesis. We considered that for Decision Tree Learning, often worst case intractable though.. 2. Restrict size of hypothesis space. e.g., Decision Lists à restricted form of Boolean Functions: Hypotheses correspond to a series of tests, each of which a conjunction of literals Good news: only a poly size number of examples is required for guaranteeing PAC learning K-DL functions and there are efficient algorithms for learning K-DL
19 Decision Lists Resemble Decision Trees, but with simpler structure: Series of tests, each test a conjunction of literals; If a test succeeds, decision list specifies value to return; If test fails, processing continues with the next test in the list. No a=patrons(x,some) b=patrons(x,full) c=fri/sat(x) (a) (b c) Y Y N Note: if we allow arbitrarily many literals per test, decision list can express all Boolean functions.
20 (a) No (b) Yes ( d) No (e) Yes (f) No (h) Yes (i) Yes No a=patrons(x,none) d=hungry(x) b=patrons(x,some) e=type(x,french) f=type(x,italian) g=type(x,thai) h=type(x,burger) i=fri/sat(x)
21 K Decision Lists Decision Lists with limited expressiveness (K-DL) at most k literals per test 2-DL (a) (b c) Y Y N K-DL is PAC learnable!!! For fixed k literals, the number of examples needed for PAC learning a K-DL function is polynomial in the number of attributes n. : There are efficient algorithms for learning K-DL functions. So how do we show K-DL is PAC-learnable?
22 2-DL (x) No (y) Yes (w v) No (u b) Yes No K Decision Lists: Sample Complexity N 1 1 (ln + ln H ) What s the size of the hypothesis space H, ε δ i.e, K-DL(n)? K-Decision Lists à set of tests: each test is a conjunct of at most k literals How many possible tests (conjuncts) of length at most k, given n literals, conj(n,k)? 2n 2n 2n Conj ( n, k) 2n + ( ) + ( )! + ( ) = O( n 2 3 A conjunct (or test) can appear in the list as: Yes, No, absent from list So we have at most 3 Conj(n,k) different K-DL lists (ignoring order) But the order of the tests (or conjuncts) in a list matters. k k ) k-dl(n) 3 Conj(n,k) Conj(n,k)!
23 After some work, we get (useful exercise!; try mathematica or maple) K DL( n) = 2 k O( n log2 ( n k )) 1 - Sample Complexity of K-DL is: : 1 1 N (ln + O( n ε δ k log For fixed k literals, the number of examples needed for PAC learning a K-DL function is polynomial in the number of attributes n, J! 2 ( n k ))) So K-DL is PAC learnable!!! Recall sample complexity formula 1 1 N (ln + ln H ) ε δ 2 Efficient learning algorithm a decision list of length k can be learned in polynomial time.
24 Decision-List-Learning Algorithm Greedy algorithm for learning decisions lists: à repeatedly finds a test that agrees with some subset of the training set; à adds test to the decision list under construction and removes the corresponding examples. à uses the remaining examples, until there are no examples left, for constructing the rest of the decision list. (see R&N, page 672. for details on algorithm).
25 Decision-List-Learning Algorithm Greedy algorithm for learning decisions lists:
26 Decision-List-Learning Algorithm Restaurant data.
27 Examples 1. H space of Boolean functions Not PAC Learnable, hypothesis space too big: need too many examples (sample complexity not polynomial)! 2. K-DL PAC learnable 3. Conjunction of literals PAC learnable
28 Probably Approximately Correct Learning (PAC)Learning (summary) A class of functions is said to be PAC-learnable if there exists an efficient learning algorithm such that for all functions in the class, and for all probability distributions on the function's domain, and for any values of epsilon and delta (0 < epsilon, delta <1), using a polynomial number of examples, the algorithm will produce a hypothesis whose error is smaller than ε with probability at least δ. The error of a hypothesis is the probability that it will differ from the target function on a random element from its domain, drawn according to the given probability distribution. Basically, this means that: there is some way to learn efficiently a "pretty good approximation of the target function. the probability is as big as you like that the error is as small as you like. (Of course, the tighter you make the bounds, the harder the learning algorithm is likely to have to work).
29 Discussion Computational Learning Theory studies the tradeoffs between the expressiveness of the hypothesis language and the complexity of learning Probably Approximately Correct learning concerns efficient learning Sample complexity --- polynomial number of examples Efficient Learning Algorithm Word of caution: PAC learning results à worst case complexity results.
30 Sample Complexity for Infinite Hypothesis Spaces I: VC-Dimension The PAC Learning framework has 2 disadvantages: It can lead to weak bounds Sample Complexity bound cannot be established for infinite hypothesis spaces We introduce new ideas for dealing with these problems: A set of instances S is shattered by hypothesis space H iff for every dichotomy of S there exists some hypothesis in H consistent with this dichotomy. 30 Nathalie Japkowicz

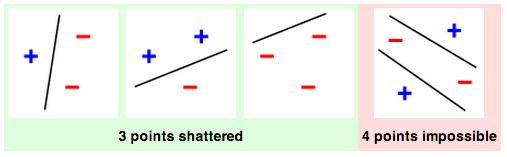

31 VC Dimension: Example
32 Sample Complexity for Infinite Hypothesis Spaces I: VC-Dimension The Vapnik-Chervonenkis dimension, VC(H), of hypothesis space H defined over instance space X is the size of the largest finite subset of X shattered by H. If arbitrarily large finite sets of X can be shattered by H, then VC(H)= 32 Nathalie Japkowicz
33 VC Dimension: Example 2 H = Axis parallel rectangles in R 2 What is the VC dimension of H Can we PAC learn? whesse@clarkson.edu 33
34 Learning Rectangles Consider axis parallel rectangles in the real plane Can we PAC learn it? (1) What is the VC dimension? Some four instances (points on the rectangle) can be shattered Shows that VC(H)>=4 34
35 Learning Rectangles Consider axis parallel rectangles in the real plane Can we PAC learn it? (1) What is the VC dimension? But, no five instances can be shattered Two points must share a line, and if we take 4 points from different lines, there is no rectangle that separates the 4 points from the remaining one. Therefore VC(H) = 4 whesse@clarkson.edu 35
36 Learning Rectangles Consider axis parallel rectangles in the real plane Can we PAC learn it? (1) What is the VC dimension? (2) Can we give an efficient algorithm? 36
37 Learning Rectangles Consider axis parallel rectangles in the real plane Can we PAC learn it? (1) What is the VC dimension? (2) Can we give an efficient algorithm? Find the smallest rectangle that contains the positive examples (necessarily, it will not contain any negative example, and the hypothesis is consistent. Axis parallel rectangles are efficiently PAC learnable. 37
38 The Mistake Bound Model of Learning The Mistake Bound framework is different from the PAC framework as it considers learners that receive a sequence of training examples and that predict, upon receiving each example, what its target value is. The question asked in this setting is: How many mistakes will the learner make in its predictions before it learns the target concept? This question is significant in practical settings where learning must be done while the system is in actual use. 38 Nathalie Japkowicz
39 Optimal Mistake Bounds Definition: Let C be an arbitrary nonempty concept class. The optimal mistake bound for C, denoted Opt(C), is the minimum over all possible learning algorithms A of M A (C). Opt(C)=min A Learning_Algorithms M A (C) Proposition: For any concept class C, the optimal mistake bound is bound as follows: VC(C) Opt(C) log 2 ( C ) 39 Nathalie Japkowicz
Web-Mining Agents Computational Learning Theory
 Web-Mining Agents Computational Learning Theory Prof. Dr. Ralf Möller Dr. Özgür Özcep Universität zu Lübeck Institut für Informationssysteme Tanya Braun (Exercise Lab) Computational Learning Theory (Adapted)
Web-Mining Agents Computational Learning Theory Prof. Dr. Ralf Möller Dr. Özgür Özcep Universität zu Lübeck Institut für Informationssysteme Tanya Braun (Exercise Lab) Computational Learning Theory (Adapted)
CS340 Machine learning Lecture 4 Learning theory. Some slides are borrowed from Sebastian Thrun and Stuart Russell
 CS340 Machine learning Lecture 4 Learning theory Some slides are borrowed from Sebastian Thrun and Stuart Russell Announcement What: Workshop on applying for NSERC scholarships and for entry to graduate
CS340 Machine learning Lecture 4 Learning theory Some slides are borrowed from Sebastian Thrun and Stuart Russell Announcement What: Workshop on applying for NSERC scholarships and for entry to graduate
CS 6375: Machine Learning Computational Learning Theory
 CS 6375: Machine Learning Computational Learning Theory Vibhav Gogate The University of Texas at Dallas Many slides borrowed from Ray Mooney 1 Learning Theory Theoretical characterizations of Difficulty
CS 6375: Machine Learning Computational Learning Theory Vibhav Gogate The University of Texas at Dallas Many slides borrowed from Ray Mooney 1 Learning Theory Theoretical characterizations of Difficulty
Computational Learning Theory
 1 Computational Learning Theory 2 Computational learning theory Introduction Is it possible to identify classes of learning problems that are inherently easy or difficult? Can we characterize the number
1 Computational Learning Theory 2 Computational learning theory Introduction Is it possible to identify classes of learning problems that are inherently easy or difficult? Can we characterize the number
Computational Learning Theory (VC Dimension)
") Computational Learning Theory (VC Dimension) 1 Difficulty of machine learning problems 2 Capabilities of machine learning algorithms 1 Version Space with associated errors error is the true error, r is
Computational Learning Theory (VC Dimension) 1 Difficulty of machine learning problems 2 Capabilities of machine learning algorithms 1 Version Space with associated errors error is the true error, r is
Computational Learning Theory. CS 486/686: Introduction to Artificial Intelligence Fall 2013
 Computational Learning Theory CS 486/686: Introduction to Artificial Intelligence Fall 2013 1 Overview Introduction to Computational Learning Theory PAC Learning Theory Thanks to T Mitchell 2 Introduction
Computational Learning Theory CS 486/686: Introduction to Artificial Intelligence Fall 2013 1 Overview Introduction to Computational Learning Theory PAC Learning Theory Thanks to T Mitchell 2 Introduction
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Lecture 25 of 42. PAC Learning, VC Dimension, and Mistake Bounds
 Lecture 25 of 42 PAC Learning, VC Dimension, and Mistake Bounds Thursday, 15 March 2007 William H. Hsu, KSU http://www.kddresearch.org/courses/spring2007/cis732 Readings: Sections 7.4.17.4.3, 7.5.17.5.3,
Lecture 25 of 42 PAC Learning, VC Dimension, and Mistake Bounds Thursday, 15 March 2007 William H. Hsu, KSU http://www.kddresearch.org/courses/spring2007/cis732 Readings: Sections 7.4.17.4.3, 7.5.17.5.3,
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Computational Learning Theory
 CS 446 Machine Learning Fall 2016 OCT 11, 2016 Computational Learning Theory Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes 1 PAC Learning We want to develop a theory to relate the probability of successful
CS 446 Machine Learning Fall 2016 OCT 11, 2016 Computational Learning Theory Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes 1 PAC Learning We want to develop a theory to relate the probability of successful
Computational Learning Theory (COLT)
") Computational Learning Theory (COLT) Goals: Theoretical characterization of 1 Difficulty of machine learning problems Under what conditions is learning possible and impossible? 2 Capabilities of machine
Computational Learning Theory (COLT) Goals: Theoretical characterization of 1 Difficulty of machine learning problems Under what conditions is learning possible and impossible? 2 Capabilities of machine
Computational Learning Theory
 Computational Learning Theory Sinh Hoa Nguyen, Hung Son Nguyen Polish-Japanese Institute of Information Technology Institute of Mathematics, Warsaw University February 14, 2006 inh Hoa Nguyen, Hung Son
Computational Learning Theory Sinh Hoa Nguyen, Hung Son Nguyen Polish-Japanese Institute of Information Technology Institute of Mathematics, Warsaw University February 14, 2006 inh Hoa Nguyen, Hung Son
VC Dimension Review. The purpose of this document is to review VC dimension and PAC learning for infinite hypothesis spaces.
 VC Dimension Review The purpose of this document is to review VC dimension and PAC learning for infinite hypothesis spaces. Previously, in discussing PAC learning, we were trying to answer questions about
VC Dimension Review The purpose of this document is to review VC dimension and PAC learning for infinite hypothesis spaces. Previously, in discussing PAC learning, we were trying to answer questions about
Computational Learning Theory. CS534 - Machine Learning
 Computational Learning Theory CS534 Machine Learning Introduction Computational learning theory Provides a theoretical analysis of learning Shows when a learning algorithm can be expected to succeed Shows
Computational Learning Theory CS534 Machine Learning Introduction Computational learning theory Provides a theoretical analysis of learning Shows when a learning algorithm can be expected to succeed Shows
Statistical and Computational Learning Theory
 Statistical and Computational Learning Theory Fundamental Question: Predict Error Rates Given: Find: The space H of hypotheses The number and distribution of the training examples S The complexity of the
Statistical and Computational Learning Theory Fundamental Question: Predict Error Rates Given: Find: The space H of hypotheses The number and distribution of the training examples S The complexity of the
Introduction to Machine Learning
 Introduction to Machine Learning PAC Learning and VC Dimension Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE
Introduction to Machine Learning PAC Learning and VC Dimension Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE
Computational Learning Theory
 0. Computational Learning Theory Based on Machine Learning, T. Mitchell, McGRAW Hill, 1997, ch. 7 Acknowledgement: The present slides are an adaptation of slides drawn by T. Mitchell 1. Main Questions
0. Computational Learning Theory Based on Machine Learning, T. Mitchell, McGRAW Hill, 1997, ch. 7 Acknowledgement: The present slides are an adaptation of slides drawn by T. Mitchell 1. Main Questions
CS340 Machine learning Lecture 5 Learning theory cont'd. Some slides are borrowed from Stuart Russell and Thorsten Joachims
 CS340 Machine learning Lecture 5 Learning theory cont'd Some slides are borrowed from Stuart Russell and Thorsten Joachims Inductive learning Simplest form: learn a function from examples f is the target
CS340 Machine learning Lecture 5 Learning theory cont'd Some slides are borrowed from Stuart Russell and Thorsten Joachims Inductive learning Simplest form: learn a function from examples f is the target
Computational Learning Theory
 Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
Computational Learning Theory Pardis Noorzad Department of Computer Engineering and IT Amirkabir University of Technology Ordibehesht 1390 Introduction For the analysis of data structures and algorithms
A Tutorial on Computational Learning Theory Presented at Genetic Programming 1997 Stanford University, July 1997
 A Tutorial on Computational Learning Theory Presented at Genetic Programming 1997 Stanford University, July 1997 Vasant Honavar Artificial Intelligence Research Laboratory Department of Computer Science
A Tutorial on Computational Learning Theory Presented at Genetic Programming 1997 Stanford University, July 1997 Vasant Honavar Artificial Intelligence Research Laboratory Department of Computer Science
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Computational Learning Theory
 09s1: COMP9417 Machine Learning and Data Mining Computational Learning Theory May 20, 2009 Acknowledgement: Material derived from slides for the book Machine Learning, Tom M. Mitchell, McGraw-Hill, 1997
09s1: COMP9417 Machine Learning and Data Mining Computational Learning Theory May 20, 2009 Acknowledgement: Material derived from slides for the book Machine Learning, Tom M. Mitchell, McGraw-Hill, 1997
Computational learning theory. PAC learning. VC dimension.
 Computational learning theory. PAC learning. VC dimension. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics COLT 2 Concept...........................................................................................................
Computational learning theory. PAC learning. VC dimension. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics COLT 2 Concept...........................................................................................................
COMP9444: Neural Networks. Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization
 : Neural Networks Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization 11s2 VC-dimension and PAC-learning 1 How good a classifier does a learner produce? Training error is the precentage
: Neural Networks Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization 11s2 VC-dimension and PAC-learning 1 How good a classifier does a learner produce? Training error is the precentage
Learning Theory. Machine Learning CSE546 Carlos Guestrin University of Washington. November 25, Carlos Guestrin
 Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Hypothesis Testing and Computational Learning Theory. EECS 349 Machine Learning With slides from Bryan Pardo, Tom Mitchell
 Hypothesis Testing and Computational Learning Theory EECS 349 Machine Learning With slides from Bryan Pardo, Tom Mitchell Overview Hypothesis Testing: How do we know our learners are good? What does performance
Hypothesis Testing and Computational Learning Theory EECS 349 Machine Learning With slides from Bryan Pardo, Tom Mitchell Overview Hypothesis Testing: How do we know our learners are good? What does performance
Computational Learning Theory. Definitions
 Computational Learning Theory Computational learning theory is interested in theoretical analyses of the following issues. What is needed to learn effectively? Sample complexity. How many examples? Computational
Computational Learning Theory Computational learning theory is interested in theoretical analyses of the following issues. What is needed to learn effectively? Sample complexity. How many examples? Computational
Introduction to Algorithms / Algorithms I Lecturer: Michael Dinitz Topic: Intro to Learning Theory Date: 12/8/16
 600.463 Introduction to Algorithms / Algorithms I Lecturer: Michael Dinitz Topic: Intro to Learning Theory Date: 12/8/16 25.1 Introduction Today we re going to talk about machine learning, but from an
600.463 Introduction to Algorithms / Algorithms I Lecturer: Michael Dinitz Topic: Intro to Learning Theory Date: 12/8/16 25.1 Introduction Today we re going to talk about machine learning, but from an
Learning Theory. Aar$ Singh and Barnabas Poczos. Machine Learning / Apr 17, Slides courtesy: Carlos Guestrin
 Learning Theory Aar$ Singh and Barnabas Poczos Machine Learning 10-701/15-781 Apr 17, 2014 Slides courtesy: Carlos Guestrin Learning Theory We have explored many ways of learning from data But How good
Learning Theory Aar$ Singh and Barnabas Poczos Machine Learning 10-701/15-781 Apr 17, 2014 Slides courtesy: Carlos Guestrin Learning Theory We have explored many ways of learning from data But How good
Online Learning, Mistake Bounds, Perceptron Algorithm
 Online Learning, Mistake Bounds, Perceptron Algorithm 1 Online Learning So far the focus of the course has been on batch learning, where algorithms are presented with a sample of training data, from which
Online Learning, Mistake Bounds, Perceptron Algorithm 1 Online Learning So far the focus of the course has been on batch learning, where algorithms are presented with a sample of training data, from which
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
Computational Learning Theory: Probably Approximately Correct (PAC) Learning. Machine Learning. Spring The slides are mainly from Vivek Srikumar
 Learning. Machine Learning. Spring The slides are mainly from Vivek Srikumar") Computational Learning Theory: Probably Approximately Correct (PAC) Learning Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 This lecture: Computational Learning Theory The Theory
Computational Learning Theory: Probably Approximately Correct (PAC) Learning Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 This lecture: Computational Learning Theory The Theory
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
PAC Learning. prof. dr Arno Siebes. Algorithmic Data Analysis Group Department of Information and Computing Sciences Universiteit Utrecht
 PAC Learning prof. dr Arno Siebes Algorithmic Data Analysis Group Department of Information and Computing Sciences Universiteit Utrecht Recall: PAC Learning (Version 1) A hypothesis class H is PAC learnable
PAC Learning prof. dr Arno Siebes Algorithmic Data Analysis Group Department of Information and Computing Sciences Universiteit Utrecht Recall: PAC Learning (Version 1) A hypothesis class H is PAC learnable
Machine Learning. Computational Learning Theory. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Computational Learning Theory Le Song Lecture 11, September 20, 2012 Based on Slides from Eric Xing, CMU Reading: Chap. 7 T.M book 1 Complexity of Learning
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Computational Learning Theory Le Song Lecture 11, September 20, 2012 Based on Slides from Eric Xing, CMU Reading: Chap. 7 T.M book 1 Complexity of Learning
Learning Theory Continued
 Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Learning Theory. Machine Learning B Seyoung Kim. Many of these slides are derived from Tom Mitchell, Ziv- Bar Joseph. Thanks!
 Learning Theory Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- Bar Joseph. Thanks! Computa2onal Learning Theory What general laws constrain inducgve learning?
Learning Theory Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- Bar Joseph. Thanks! Computa2onal Learning Theory What general laws constrain inducgve learning?
Machine Learning. VC Dimension and Model Complexity. Eric Xing , Fall 2015
 Machine Learning 10-701, Fall 2015 VC Dimension and Model Complexity Eric Xing Lecture 16, November 3, 2015 Reading: Chap. 7 T.M book, and outline material Eric Xing @ CMU, 2006-2015 1 Last time: PAC and
Machine Learning 10-701, Fall 2015 VC Dimension and Model Complexity Eric Xing Lecture 16, November 3, 2015 Reading: Chap. 7 T.M book, and outline material Eric Xing @ CMU, 2006-2015 1 Last time: PAC and
Computational Learning Theory
 Computational Learning Theory [read Chapter 7] [Suggested exercises: 7.1, 7.2, 7.5, 7.8] Computational learning theory Setting 1: learner poses queries to teacher Setting 2: teacher chooses examples Setting
Computational Learning Theory [read Chapter 7] [Suggested exercises: 7.1, 7.2, 7.5, 7.8] Computational learning theory Setting 1: learner poses queries to teacher Setting 2: teacher chooses examples Setting
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
10.1 The Formal Model
 67577 Intro. to Machine Learning Fall semester, 2008/9 Lecture 10: The Formal (PAC) Learning Model Lecturer: Amnon Shashua Scribe: Amnon Shashua 1 We have see so far algorithms that explicitly estimate
67577 Intro. to Machine Learning Fall semester, 2008/9 Lecture 10: The Formal (PAC) Learning Model Lecturer: Amnon Shashua Scribe: Amnon Shashua 1 We have see so far algorithms that explicitly estimate
Lecture 5: Efficient PAC Learning. 1 Consistent Learning: a Bound on Sample Complexity
 Universität zu Lübeck Institut für Theoretische Informatik Lecture notes on Knowledge-Based and Learning Systems by Maciej Liśkiewicz Lecture 5: Efficient PAC Learning 1 Consistent Learning: a Bound on
Universität zu Lübeck Institut für Theoretische Informatik Lecture notes on Knowledge-Based and Learning Systems by Maciej Liśkiewicz Lecture 5: Efficient PAC Learning 1 Consistent Learning: a Bound on
Computational Learning Theory: Shattering and VC Dimensions. Machine Learning. Spring The slides are mainly from Vivek Srikumar
 Computational Learning Theory: Shattering and VC Dimensions Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 This lecture: Computational Learning Theory The Theory of Generalization
Computational Learning Theory: Shattering and VC Dimensions Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 This lecture: Computational Learning Theory The Theory of Generalization
THE VAPNIK- CHERVONENKIS DIMENSION and LEARNABILITY
 THE VAPNIK- CHERVONENKIS DIMENSION and LEARNABILITY Dan A. Simovici UMB, Doctoral Summer School Iasi, Romania What is Machine Learning? The Vapnik-Chervonenkis Dimension Probabilistic Learning Potential
THE VAPNIK- CHERVONENKIS DIMENSION and LEARNABILITY Dan A. Simovici UMB, Doctoral Summer School Iasi, Romania What is Machine Learning? The Vapnik-Chervonenkis Dimension Probabilistic Learning Potential
Part of the slides are adapted from Ziko Kolter
 Part of the slides are adapted from Ziko Kolter OUTLINE 1 Supervised learning: classification........................................................ 2 2 Non-linear regression/classification, overfitting,
Part of the slides are adapted from Ziko Kolter OUTLINE 1 Supervised learning: classification........................................................ 2 2 Non-linear regression/classification, overfitting,
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
6.045: Automata, Computability, and Complexity (GITCS) Class 17 Nancy Lynch
 Class 17 Nancy Lynch") 6.045: Automata, Computability, and Complexity (GITCS) Class 17 Nancy Lynch Today Probabilistic Turing Machines and Probabilistic Time Complexity Classes Now add a new capability to standard TMs: random
6.045: Automata, Computability, and Complexity (GITCS) Class 17 Nancy Lynch Today Probabilistic Turing Machines and Probabilistic Time Complexity Classes Now add a new capability to standard TMs: random
The Vapnik-Chervonenkis Dimension
 The Vapnik-Chervonenkis Dimension Prof. Dan A. Simovici UMB 1 / 91 Outline 1 Growth Functions 2 Basic Definitions for Vapnik-Chervonenkis Dimension 3 The Sauer-Shelah Theorem 4 The Link between VCD and
The Vapnik-Chervonenkis Dimension Prof. Dan A. Simovici UMB 1 / 91 Outline 1 Growth Functions 2 Basic Definitions for Vapnik-Chervonenkis Dimension 3 The Sauer-Shelah Theorem 4 The Link between VCD and
COMPUTATIONAL LEARNING THEORY
 COMPUTATIONAL LEARNING THEORY XIAOXU LI Abstract. This paper starts with basic concepts of computational learning theory and moves on with examples in monomials and learning rays to the final discussion
COMPUTATIONAL LEARNING THEORY XIAOXU LI Abstract. This paper starts with basic concepts of computational learning theory and moves on with examples in monomials and learning rays to the final discussion
Machine Learning. Computational Learning Theory. Eric Xing , Fall Lecture 9, October 5, 2016
 Machine Learning 10-701, Fall 2016 Computational Learning Theory Eric Xing Lecture 9, October 5, 2016 Reading: Chap. 7 T.M book Eric Xing @ CMU, 2006-2016 1 Generalizability of Learning In machine learning
Machine Learning 10-701, Fall 2016 Computational Learning Theory Eric Xing Lecture 9, October 5, 2016 Reading: Chap. 7 T.M book Eric Xing @ CMU, 2006-2016 1 Generalizability of Learning In machine learning
Learning Theory. Piyush Rai. CS5350/6350: Machine Learning. September 27, (CS5350/6350) Learning Theory September 27, / 14
 Learning Theory September 27, / 14") Learning Theory Piyush Rai CS5350/6350: Machine Learning September 27, 2011 (CS5350/6350) Learning Theory September 27, 2011 1 / 14 Why Learning Theory? We want to have theoretical guarantees about our
Learning Theory Piyush Rai CS5350/6350: Machine Learning September 27, 2011 (CS5350/6350) Learning Theory September 27, 2011 1 / 14 Why Learning Theory? We want to have theoretical guarantees about our
Lecture Learning infinite hypothesis class via VC-dimension and Rademacher complexity;
 CSCI699: Topics in Learning and Game Theory Lecture 2 Lecturer: Ilias Diakonikolas Scribes: Li Han Today we will cover the following 2 topics: 1. Learning infinite hypothesis class via VC-dimension and
CSCI699: Topics in Learning and Game Theory Lecture 2 Lecturer: Ilias Diakonikolas Scribes: Li Han Today we will cover the following 2 topics: 1. Learning infinite hypothesis class via VC-dimension and
FORMULATION OF THE LEARNING PROBLEM
 FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
Lecture 29: Computational Learning Theory
 CS 710: Complexity Theory 5/4/2010 Lecture 29: Computational Learning Theory Instructor: Dieter van Melkebeek Scribe: Dmitri Svetlov and Jake Rosin Today we will provide a brief introduction to computational
CS 710: Complexity Theory 5/4/2010 Lecture 29: Computational Learning Theory Instructor: Dieter van Melkebeek Scribe: Dmitri Svetlov and Jake Rosin Today we will provide a brief introduction to computational
Statistical Learning Learning From Examples
 Statistical Learning Learning From Examples We want to estimate the working temperature range of an iphone. We could study the physics and chemistry that affect the performance of the phone too hard We
Statistical Learning Learning From Examples We want to estimate the working temperature range of an iphone. We could study the physics and chemistry that affect the performance of the phone too hard We
Generalization theory
 Generalization theory Chapter 4 T.P. Runarsson (tpr@hi.is) and S. Sigurdsson (sven@hi.is) Introduction Suppose you are given the empirical observations, (x 1, y 1 ),..., (x l, y l ) (X Y) l. Consider the
Generalization theory Chapter 4 T.P. Runarsson (tpr@hi.is) and S. Sigurdsson (sven@hi.is) Introduction Suppose you are given the empirical observations, (x 1, y 1 ),..., (x l, y l ) (X Y) l. Consider the
Learning theory Lecture 4
 Learning theory Lecture 4 David Sontag New York University Slides adapted from Carlos Guestrin & Luke Zettlemoyer What s next We gave several machine learning algorithms: Perceptron Linear support vector
Learning theory Lecture 4 David Sontag New York University Slides adapted from Carlos Guestrin & Luke Zettlemoyer What s next We gave several machine learning algorithms: Perceptron Linear support vector
[read Chapter 2] [suggested exercises 2.2, 2.3, 2.4, 2.6] General-to-specific ordering over hypotheses
![[read Chapter 2] [suggested exercises 2.2, 2.3, 2.4, 2.6] General-to-specific ordering over hypotheses](/thumbs/86/94586808.jpg "[read Chapter 2] [suggested exercises 2.2, 2.3, 2.4, 2.6] General-to-specific ordering over hypotheses") 1 CONCEPT LEARNING AND THE GENERAL-TO-SPECIFIC ORDERING [read Chapter 2] [suggested exercises 2.2, 2.3, 2.4, 2.6] Learning from examples General-to-specific ordering over hypotheses Version spaces and
1 CONCEPT LEARNING AND THE GENERAL-TO-SPECIFIC ORDERING [read Chapter 2] [suggested exercises 2.2, 2.3, 2.4, 2.6] Learning from examples General-to-specific ordering over hypotheses Version spaces and
Computational and Statistical Learning theory
 Computational and Statistical Learning theory Problem set 2 Due: January 31st Email solutions to : karthik at ttic dot edu Notation : Input space : X Label space : Y = {±1} Sample : (x 1, y 1,..., (x n,
Computational and Statistical Learning theory Problem set 2 Due: January 31st Email solutions to : karthik at ttic dot edu Notation : Input space : X Label space : Y = {±1} Sample : (x 1, y 1,..., (x n,
Linear Classifiers: Expressiveness
 Linear Classifiers: Expressiveness Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture outline Linear classifiers: Introduction What functions do linear classifiers express?
Linear Classifiers: Expressiveness Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture outline Linear classifiers: Introduction What functions do linear classifiers express?
Cognitive Cyber-Physical System
 Cognitive Cyber-Physical System Physical to Cyber-Physical The emergence of non-trivial embedded sensor units, networked embedded systems and sensor/actuator networks has made possible the design and implementation
Cognitive Cyber-Physical System Physical to Cyber-Physical The emergence of non-trivial embedded sensor units, networked embedded systems and sensor/actuator networks has made possible the design and implementation
CS 543 Page 1 John E. Boon, Jr.
 CS 543 Machine Learning Spring 2010 Lecture 05 Evaluating Hypotheses I. Overview A. Given observed accuracy of a hypothesis over a limited sample of data, how well does this estimate its accuracy over
CS 543 Machine Learning Spring 2010 Lecture 05 Evaluating Hypotheses I. Overview A. Given observed accuracy of a hypothesis over a limited sample of data, how well does this estimate its accuracy over
MACHINE LEARNING. Probably Approximately Correct (PAC) Learning. Alessandro Moschitti
 Learning. Alessandro Moschitti") MACHINE LEARNING Probably Approximately Correct (PAC) Learning Alessandro Moschitti Department of Information Engineering and Computer Science University of Trento Email: moschitti@disi.unitn.it Objectives:
MACHINE LEARNING Probably Approximately Correct (PAC) Learning Alessandro Moschitti Department of Information Engineering and Computer Science University of Trento Email: moschitti@disi.unitn.it Objectives:
PAC Learning Introduction to Machine Learning. Matt Gormley Lecture 14 March 5, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University PAC Learning Matt Gormley Lecture 14 March 5, 2018 1 ML Big Picture Learning Paradigms:
PAC Model and Generalization Bounds
 PAC Model and Generalization Bounds Overview Probably Approximately Correct (PAC) model Basic generalization bounds finite hypothesis class infinite hypothesis class Simple case More next week 2 Motivating
PAC Model and Generalization Bounds Overview Probably Approximately Correct (PAC) model Basic generalization bounds finite hypothesis class infinite hypothesis class Simple case More next week 2 Motivating
Discrete Mathematics and Probability Theory Spring 2016 Rao and Walrand Note 14
 CS 70 Discrete Mathematics and Probability Theory Spring 2016 Rao and Walrand Note 14 Introduction One of the key properties of coin flips is independence: if you flip a fair coin ten times and get ten
CS 70 Discrete Mathematics and Probability Theory Spring 2016 Rao and Walrand Note 14 Introduction One of the key properties of coin flips is independence: if you flip a fair coin ten times and get ten
CS173 Strong Induction and Functions. Tandy Warnow
 CS173 Strong Induction and Functions Tandy Warnow CS 173 Introduction to Strong Induction (also Functions) Tandy Warnow Preview of the class today What are functions? Weak induction Strong induction A
CS173 Strong Induction and Functions Tandy Warnow CS 173 Introduction to Strong Induction (also Functions) Tandy Warnow Preview of the class today What are functions? Weak induction Strong induction A
1 More finite deterministic automata
 CS 125 Section #6 Finite automata October 18, 2016 1 More finite deterministic automata Exercise. Consider the following game with two players: Repeatedly flip a coin. On heads, player 1 gets a point.
CS 125 Section #6 Finite automata October 18, 2016 1 More finite deterministic automata Exercise. Consider the following game with two players: Repeatedly flip a coin. On heads, player 1 gets a point.
The Power of Random Counterexamples
 Proceedings of Machine Learning Research 76:1 14, 2017 Algorithmic Learning Theory 2017 The Power of Random Counterexamples Dana Angluin DANA.ANGLUIN@YALE.EDU and Tyler Dohrn TYLER.DOHRN@YALE.EDU Department
Proceedings of Machine Learning Research 76:1 14, 2017 Algorithmic Learning Theory 2017 The Power of Random Counterexamples Dana Angluin DANA.ANGLUIN@YALE.EDU and Tyler Dohrn TYLER.DOHRN@YALE.EDU Department
Active Learning and Optimized Information Gathering
 Active Learning and Optimized Information Gathering Lecture 7 Learning Theory CS 101.2 Andreas Krause Announcements Project proposal: Due tomorrow 1/27 Homework 1: Due Thursday 1/29 Any time is ok. Office
Active Learning and Optimized Information Gathering Lecture 7 Learning Theory CS 101.2 Andreas Krause Announcements Project proposal: Due tomorrow 1/27 Homework 1: Due Thursday 1/29 Any time is ok. Office
Introduction to Machine Learning
 Introduction to Machine Learning 236756 Prof. Nir Ailon Lecture 4: Computational Complexity of Learning & Surrogate Losses Efficient PAC Learning Until now we were mostly worried about sample complexity
Introduction to Machine Learning 236756 Prof. Nir Ailon Lecture 4: Computational Complexity of Learning & Surrogate Losses Efficient PAC Learning Until now we were mostly worried about sample complexity
Polynomial time Prediction Strategy with almost Optimal Mistake Probability
 Polynomial time Prediction Strategy with almost Optimal Mistake Probability Nader H. Bshouty Department of Computer Science Technion, 32000 Haifa, Israel bshouty@cs.technion.ac.il Abstract We give the
Polynomial time Prediction Strategy with almost Optimal Mistake Probability Nader H. Bshouty Department of Computer Science Technion, 32000 Haifa, Israel bshouty@cs.technion.ac.il Abstract We give the
Machine Learning, Midterm Exam: Spring 2008 SOLUTIONS. Q Topic Max. Score Score. 1 Short answer questions 20.
 10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
A Course in Machine Learning
 A Course in Machine Learning Hal Daumé III 10 LEARNING THEORY For nothing ought to be posited without a reason given, unless it is self-evident or known by experience or proved by the authority of Sacred
A Course in Machine Learning Hal Daumé III 10 LEARNING THEORY For nothing ought to be posited without a reason given, unless it is self-evident or known by experience or proved by the authority of Sacred
Learning Theory, Overfi1ng, Bias Variance Decomposi9on
 Learning Theory, Overfi1ng, Bias Variance Decomposi9on Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- 1 Bar Joseph. Thanks! Any(!) learner that outputs a
Learning Theory, Overfi1ng, Bias Variance Decomposi9on Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- 1 Bar Joseph. Thanks! Any(!) learner that outputs a
Computational Learning Theory - Hilary Term : Introduction to the PAC Learning Framework
 Computational Learning Theory - Hilary Term 2018 1 : Introduction to the PAC Learning Framework Lecturer: Varun Kanade 1 What is computational learning theory? Machine learning techniques lie at the heart
Computational Learning Theory - Hilary Term 2018 1 : Introduction to the PAC Learning Framework Lecturer: Varun Kanade 1 What is computational learning theory? Machine learning techniques lie at the heart
A Theoretical and Empirical Study of a Noise-Tolerant Algorithm to Learn Geometric Patterns
 Machine Learning, 37, 5 49 (1999) c 1999 Kluwer Academic Publishers. Manufactured in The Netherlands. A Theoretical and Empirical Study of a Noise-Tolerant Algorithm to Learn Geometric Patterns SALLY A.
Machine Learning, 37, 5 49 (1999) c 1999 Kluwer Academic Publishers. Manufactured in The Netherlands. A Theoretical and Empirical Study of a Noise-Tolerant Algorithm to Learn Geometric Patterns SALLY A.
TTIC An Introduction to the Theory of Machine Learning. Learning from noisy data, intro to SQ model
 TTIC 325 An Introduction to the Theory of Machine Learning Learning from noisy data, intro to SQ model Avrim Blum 4/25/8 Learning when there is no perfect predictor Hoeffding/Chernoff bounds: minimizing
TTIC 325 An Introduction to the Theory of Machine Learning Learning from noisy data, intro to SQ model Avrim Blum 4/25/8 Learning when there is no perfect predictor Hoeffding/Chernoff bounds: minimizing
The Decision List Machine
 The Decision List Machine Marina Sokolova SITE, University of Ottawa Ottawa, Ont. Canada,K1N-6N5 sokolova@site.uottawa.ca Nathalie Japkowicz SITE, University of Ottawa Ottawa, Ont. Canada,K1N-6N5 nat@site.uottawa.ca
The Decision List Machine Marina Sokolova SITE, University of Ottawa Ottawa, Ont. Canada,K1N-6N5 sokolova@site.uottawa.ca Nathalie Japkowicz SITE, University of Ottawa Ottawa, Ont. Canada,K1N-6N5 nat@site.uottawa.ca
1 Randomized Computation
 CS 6743 Lecture 17 1 Fall 2007 1 Randomized Computation Why is randomness useful? Imagine you have a stack of bank notes, with very few counterfeit ones. You want to choose a genuine bank note to pay at
CS 6743 Lecture 17 1 Fall 2007 1 Randomized Computation Why is randomness useful? Imagine you have a stack of bank notes, with very few counterfeit ones. You want to choose a genuine bank note to pay at
The Vapnik-Chervonenkis Dimension: Information versus Complexity in Learning
 REVlEW The Vapnik-Chervonenkis Dimension: Information versus Complexity in Learning Yaser S. Abu-Mostafa California Institute of Terhnohgy, Pasadcna, CA 91 125 USA When feasible, learning is a very attractive
REVlEW The Vapnik-Chervonenkis Dimension: Information versus Complexity in Learning Yaser S. Abu-Mostafa California Institute of Terhnohgy, Pasadcna, CA 91 125 USA When feasible, learning is a very attractive
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Probability and Statistics
 Probability and Statistics Kristel Van Steen, PhD 2 Montefiore Institute - Systems and Modeling GIGA - Bioinformatics ULg kristel.vansteen@ulg.ac.be CHAPTER 4: IT IS ALL ABOUT DATA 4a - 1 CHAPTER 4: IT
Probability and Statistics Kristel Van Steen, PhD 2 Montefiore Institute - Systems and Modeling GIGA - Bioinformatics ULg kristel.vansteen@ulg.ac.be CHAPTER 4: IT IS ALL ABOUT DATA 4a - 1 CHAPTER 4: IT
Qualifying Exam in Machine Learning
 Qualifying Exam in Machine Learning October 20, 2009 Instructions: Answer two out of the three questions in Part 1. In addition, answer two out of three questions in two additional parts (choose two parts
Qualifying Exam in Machine Learning October 20, 2009 Instructions: Answer two out of the three questions in Part 1. In addition, answer two out of three questions in two additional parts (choose two parts
ICML '97 and AAAI '97 Tutorials
 A Short Course in Computational Learning Theory: ICML '97 and AAAI '97 Tutorials Michael Kearns AT&T Laboratories Outline Sample Complexity/Learning Curves: nite classes, Occam's VC dimension Razor, Best
A Short Course in Computational Learning Theory: ICML '97 and AAAI '97 Tutorials Michael Kearns AT&T Laboratories Outline Sample Complexity/Learning Curves: nite classes, Occam's VC dimension Razor, Best
12.1 A Polynomial Bound on the Sample Size m for PAC Learning
 67577 Intro. to Machine Learning Fall semester, 2008/9 Lecture 12: PAC III Lecturer: Amnon Shashua Scribe: Amnon Shashua 1 In this lecture will use the measure of VC dimension, which is a combinatorial
67577 Intro. to Machine Learning Fall semester, 2008/9 Lecture 12: PAC III Lecturer: Amnon Shashua Scribe: Amnon Shashua 1 In this lecture will use the measure of VC dimension, which is a combinatorial
Learning Decision Trees
 Learning Decision Trees CS194-10 Fall 2011 Lecture 8 CS194-10 Fall 2011 Lecture 8 1 Outline Decision tree models Tree construction Tree pruning Continuous input features CS194-10 Fall 2011 Lecture 8 2
Learning Decision Trees CS194-10 Fall 2011 Lecture 8 CS194-10 Fall 2011 Lecture 8 1 Outline Decision tree models Tree construction Tree pruning Continuous input features CS194-10 Fall 2011 Lecture 8 2
Learning from Examples
 Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
On the Sample Complexity of Noise-Tolerant Learning
 On the Sample Complexity of Noise-Tolerant Learning Javed A. Aslam Department of Computer Science Dartmouth College Hanover, NH 03755 Scott E. Decatur Laboratory for Computer Science Massachusetts Institute
On the Sample Complexity of Noise-Tolerant Learning Javed A. Aslam Department of Computer Science Dartmouth College Hanover, NH 03755 Scott E. Decatur Laboratory for Computer Science Massachusetts Institute
Introduction to Machine Learning
 Introduction to Machine Learning Slides adapted from Eli Upfal Machine Learning: Jordan Boyd-Graber University of Maryland FEATURE ENGINEERING Machine Learning: Jordan Boyd-Graber UMD Introduction to Machine
Introduction to Machine Learning Slides adapted from Eli Upfal Machine Learning: Jordan Boyd-Graber University of Maryland FEATURE ENGINEERING Machine Learning: Jordan Boyd-Graber UMD Introduction to Machine
Introduction to Computational Complexity
 Introduction to Computational Complexity Tandy Warnow October 30, 2018 CS 173, Introduction to Computational Complexity Tandy Warnow Overview Topics: Solving problems using oracles Proving the answer to
Introduction to Computational Complexity Tandy Warnow October 30, 2018 CS 173, Introduction to Computational Complexity Tandy Warnow Overview Topics: Solving problems using oracles Proving the answer to
SAT, NP, NP-Completeness
 CS 473: Algorithms, Spring 2018 SAT, NP, NP-Completeness Lecture 22 April 13, 2018 Most slides are courtesy Prof. Chekuri Ruta (UIUC) CS473 1 Spring 2018 1 / 57 Part I Reductions Continued Ruta (UIUC)
CS 473: Algorithms, Spring 2018 SAT, NP, NP-Completeness Lecture 22 April 13, 2018 Most slides are courtesy Prof. Chekuri Ruta (UIUC) CS473 1 Spring 2018 1 / 57 Part I Reductions Continued Ruta (UIUC)
Introduction to Computational Learning Theory
 Introduction to Computational Learning Theory The classification problem Consistent Hypothesis Model Probably Approximately Correct (PAC) Learning c Hung Q. Ngo (SUNY at Buffalo) CSE 694 A Fun Course 1
Introduction to Computational Learning Theory The classification problem Consistent Hypothesis Model Probably Approximately Correct (PAC) Learning c Hung Q. Ngo (SUNY at Buffalo) CSE 694 A Fun Course 1
Computational and Statistical Learning Theory
 Computational and Statistical Learning Theory TTIC 31120 Prof. Nati Srebro Lecture 7: Computational Complexity of Learning Agnostic Learning Hardness of Learning via Crypto Assumption: No poly-time algorithm
Computational and Statistical Learning Theory TTIC 31120 Prof. Nati Srebro Lecture 7: Computational Complexity of Learning Agnostic Learning Hardness of Learning via Crypto Assumption: No poly-time algorithm
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
New Algorithms for Contextual Bandits
 New Algorithms for Contextual Bandits Lev Reyzin Georgia Institute of Technology Work done at Yahoo! 1 S A. Beygelzimer, J. Langford, L. Li, L. Reyzin, R.E. Schapire Contextual Bandit Algorithms with Supervised
New Algorithms for Contextual Bandits Lev Reyzin Georgia Institute of Technology Work done at Yahoo! 1 S A. Beygelzimer, J. Langford, L. Li, L. Reyzin, R.E. Schapire Contextual Bandit Algorithms with Supervised
Stephen Scott.
 1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
Chapter 11 - Sequences and Series
 Calculus and Analytic Geometry II Chapter - Sequences and Series. Sequences Definition. A sequence is a list of numbers written in a definite order, We call a n the general term of the sequence. {a, a
Calculus and Analytic Geometry II Chapter - Sequences and Series. Sequences Definition. A sequence is a list of numbers written in a definite order, We call a n the general term of the sequence. {a, a
1 Review of The Learning Setting
 COS 5: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #8 Scribe: Changyan Wang February 28, 208 Review of The Learning Setting Last class, we moved beyond the PAC model: in the PAC model we
COS 5: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #8 Scribe: Changyan Wang February 28, 208 Review of The Learning Setting Last class, we moved beyond the PAC model: in the PAC model we
Lecture 7: Passive Learning
 CS 880: Advanced Complexity Theory 2/8/2008 Lecture 7: Passive Learning Instructor: Dieter van Melkebeek Scribe: Tom Watson In the previous lectures, we studied harmonic analysis as a tool for analyzing
CS 880: Advanced Complexity Theory 2/8/2008 Lecture 7: Passive Learning Instructor: Dieter van Melkebeek Scribe: Tom Watson In the previous lectures, we studied harmonic analysis as a tool for analyzing