(Advances in) Quantum Reinforcement Learning. Vedran Dunjko
|
|
|
- Ashley Allen
- 5 years ago
- Views:
Transcription



1 (Advances in) Quantum Reinforcement Learning Vedran Dunjko 2017








2 Acknowledgements: Briegel Melnikov Tiersch theoretical physics Makmal Friis Piater Hangl intelligent & interactive systems Boyajian Orsucci Poulsen Nautrup Paparo Martin-Delgado Taylor Krenn Zeilinger Liu Wu
3 Part 1: Intro Machine learning, Reinforcement learning (and AI) Quantum machine learning Part 2: (a perspective on) Quantum Reinforcement Learning Quantum-enhanced agents and quantum-accesible environments Quantum enhancements of learning agents: oraculization, and three flavours of improvements
4 Part 1: Quantum information and machine learning
![Quantum machine learning (plus) QIP ML (quantum-enhanced ML) [ 94; 12] ML QIP (ML applied to QIP problems) [70](/docs-images/86/93321121/images/5-0.jpg "s? 10] QIP ML (generalizations of learning concepts) [ 00? 06] ML-insipred QIP QIP/QM inspired ML beyond (Q.")
5 Quantum machine learning (plus) QIP ML (quantum-enhanced ML) [ 94; 12] ML QIP (ML applied to QIP problems) [70 s? 10] QIP ML (generalizations of learning concepts) [ 00? 06] ML-insipred QIP QIP/QM inspired ML beyond (Q. AI)?
6 But what is Machine Learning? Learning structure in P(data), give samples from P(data) Learning P(labels data) given samples from P(data,labels) mostly about inferring information from data (about the source) medicine stock markets climate/weather

7 Who cares? Unsupervised learning Supervised learning Learning structure in P(data), give samples from P(data) ML/Data mining in the spotlight industry 4.0 This Is the Year of the Machine Learning Revolution To predict the future, we look at the data we have about the past. Learning P(labels data) given samples from P(data,labels) mostly about inferring information from data (about the source) -medicine -stock-markets -climate/weather Citation from
8 Figures taken from Wikipedia





9 Figures taken from Wikipedia



10


11 Reinforcement learning in the spotlight MIT technology review: one of 10 breakthrough technologies in 2017 The New Stack: AI s Next Big Step: Reinforcement learning E.g. AlphaGo Zero: superhuman Go performance with no human supervision: pure RL self-play Figures taken from Wikipedia


12 Towards AI? Supervised reinforcement Knowledge representation OCR&Vision reasoning & inference
13 What do agents learn? Corner for the serious (PO) Markov Decision Process
14 RL glossary Figures of merit: finite-horizon history of interaction learning model/agent no-free lunch: metaparameters computational complexity model complexity infinite-horizon
15 What do agents learn? Corner for the serious (PO) Markov Decision Process RL vs. (data-driven) ML Learning behavior vs. learning about data In RL, the agent changes the environment In ML the agent does not change P(x y)
16 What [ ] Quantum Reinforcement Learning RL in QIP/QM (natural, related to feedback and control) Quantum-enhanced ML Q. enhancements for specific algorithms Q. enhancements via q. interaction (quantum computational learning theory) Q. generalizations Learning for and in quantum experiments ML building a QC? QRL in Q. systems enabling QRL? 16
![What [ ] Quantum Reinforcement Learning RL in QIP/QM (natural, related to feedback and control) Quantum-enhanced ML Q. enhancements for specific algorithms Q.](/docs-images/86/93321121/images/17-0.jpg "enhancements via q. interaction (quantum computational learning theory) Q. generalizations Learning for and in quantum experiments ML building a QC? QRL in Q.")
17 What [ ] Quantum Reinforcement Learning RL in QIP/QM (natural, related to feedback and control) Quantum-enhanced ML Q. enhancements for specific algorithms Q. enhancements via q. interaction (quantum computational learning theory) Q. generalizations Learning for and in quantum experiments ML building a QC? QRL in Q. systems enabling QRL? 17
18 Part 2: Quantum information and reinforcement learning
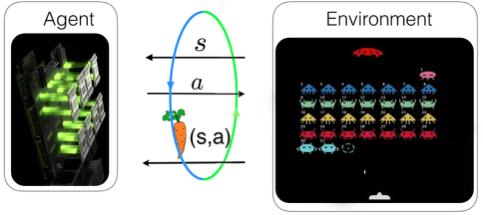
19 Quantum Agent - Environment paradigm? Want something like: Agent C or Q s a s a Environment C or Q V. Dunjko, J. M. Taylor, H. J. Briegel Quantum-enhanced learning In preparation (2016) V. Dunjko, J. M. Taylor, H. J. Briegel Framework for learning agents in quantum environments arxiv: (2015)


20 Flavors or RL what are agents, environments? CS: MDPs, POMDPs, Turing machines Robotics: Real environments Image: Sebastian Thrun & Chris Urmson/Google QIP/QML:? systems
21 Quantum Agent - Environment paradigm is equivalent to Agent Envir. Agents (environments) are sequences of CPTP maps, acting on a private and a common register - the memory and the interface, respectively. Memory channels = combs = quantum strategies
22 But. why go there? Fundamental meaning and role of learning in the quantum world Speed-ups! faster, better learning What can we make better? a) computational complexity b) learning efficiency 22
 computational complexity b) learning efficiency ( genuine learning-related figures of merit ) success probability related to query complexity")
23 But. why go there? Fundamental meaning and role of learning in the quantum world Speed-ups! faster, better learning What can we make better? a) computational complexity b) learning efficiency ( genuine learning-related figures of merit ) success probability related to query complexity time-steps 23

 V. Dunjko, J. M. Taylor, H. J. Briegel Framework for learning agents in quantum environments arxiv:1507.08482 (2015)")
24 Quantum Agent - Environment paradigm Classical (in a formal, well-defined sense) All improvements are consequences of computational improvements intuition: cannot run Grover s search on a classical phonebook Not classical More radical computational improvements More interesting quantum effects may me exploitable Oracular quantum computation: exponential separations in principle possible V. Dunjko, J. M. Taylor, H. J. Briegel Quantum-enhanced machine learning Phys. Rev. Lett. 117, (2016) V. Dunjko, J. M. Taylor, H. J. Briegel Framework for learning agents in quantum environments arxiv: (2015)
25 Q Q s Agent a s Environment Agent Q Q Environment Q a V. Dunjko, J. M. Taylor, H. J. Briegel Quantum-enhanced machine learning Phys. Rev. Lett. 117, (2016)
26 Inspiration from oracular quantum computation
27 Inspiration from oracular quantum computation Agent-like Environment-like
28 Inspiration from oracular quantum computation Agent-like Environment-like think of Environment as oracle

29 How could one use that E.g. oracle identification! Large set of environments If E is chosen at random, on average all agents perform equally (NFL)
30 A An A1 A2 A3

31 (meta) A A1 An A1 A2 A2 A3 A3 An think of Environment as oracle identify faster using QC
32 But environments are not like standard oracles Oraculization (taming the open environment) (blocking, accessing purification and recycling)
33 Oraculization (blocking) (taming the open environment) 1) quantum comb 2) causal network 3) blocking
34 Oraculization (recovery and recycling) (taming the open environment) Classically specified oracle quantization f 34
35 Oraculization (continued) (taming the open environment) 4)
36 Oraculization (continued) (taming the open environment) 4) Relevant information about (aspect of) environment accessible encoded in effective quantum oracle
37 Oraculization in data-driven ML? RL: 37
38 Result schemata: for every A we construct A q s.t. A q > A find useful info using quantum access optimize a (given) learning mechanism compare to given (best) classical agent


39 First result: quantum upgrade of a learning model polynomial improvements for a broad class of task environments by using Grover-like amplification 1. Grover finds rewarding sequences 2. Algorithm is pre-trained to focus more on rewarding space of policies 3. Works whenever algorithm makes sense, and environment s.t. it prefers winners V. Dunjko, J. M. Taylor, H. J. Briegel Quantum-enhanced machine learning Phys. Rev. Lett. 117, (2016)
 given quantum-accessible environment V. Dunjko, J. M. Taylor, H. J. Briegel Advances in Quantum Reinforcement Learning IEEE SMC 2017")
40 Second result: quantum speedup of meta-learning polynomial improvements for meta-learning settings by using quantum optimization methods given a fixed model and environment, the joint AE interaction can be oracularized model parameters can be quantum-optimized in (any) given quantum-accessible environment V. Dunjko, J. M. Taylor, H. J. Briegel Advances in Quantum Reinforcement Learning IEEE SMC 2017

41 quantum upgrade of a learning model underlying Quant. alg.: Grover-based optimization oraculization of Environment 0 r quantum speedup of meta-learning underlying Quant. alg.: Grover-based optimization oraculization of Agent-Env. interaction Ranc ~ ~ oracle encoding properties of environment oracle encoding performance of Agent-Environment interaction
42 Quantum folklore: quadratic improvements a-plenty, super-polynomial hard to come by What about reinforcement learning?
43 Third result: absolute separation of classical & quantum learning RL is VERY BIG. Trivial answers aplenty Given oracular problem, construct MDPs which 1) have generic RL properties : delayed rewards, genuine actions, controlled amount degeneracy in optimal policies (stochasticity) 2) Are hard to learn for any classical agent 3) Oraculization possible, and reduces to oracles which allow superpolynomial speed-ups
44 super-polynomial improvements possible for a class of genuine RL task environments via reduction to (generalized) Recursive Fourier Sampling Complicated, and genuine RL problem RFS-type oracle hiding a necessary key oraculization process super-polynomial separations known V. Dunjko, Y. Liu, X. Wu, J. M. Taylor Super-polynomial separations for quantum reinforcement learning (in preparation)
 Recursive Fourier Sampling")


45 super-polynomial improvements possible for a class of genuine RL task environments via reduction to (generalized) Recursive Fourier Sampling Complicated, and genuine RL problem RFS-type oracle hiding a necessary key oraculization process super-polynomial separations known can be adapted to e.g. Simon s problem: strict exponential separation possible! V. Dunjko, Y. Liu, X. Wu, J. M. Taylor Super-polynomial separations for quantum reinforcement learning (in preparation)
46 quantum upgrade of a learning model natural environments: mazes oraculization to most natural info: rewarding sequences Grover is (almost always) applicable: large natural class of settings where improvements possible absolute separation c & q learning Start with solution; oracle problems with separation reverse-enigneered matching environments identify generalizations/deformations which a) maintain classical hardness b) allow for meaningful oraculization and application of known q. algorithms (shhh: call those above the generic ones!)
47 Perspectives of (this type of) Quantum Reinforcement learning QAE: fundamental questions of learnability Quantum AI and quantum Turing test (behavioral intelligence) QRL-enhancements (theory): connections to oracular models. Elitzur-Vaidman & counterfactual computation. Q. Metrology, q. illumination. Making it concrete: connection to QML! QIP overlaps: generalization of standard oracular models QRL-enhancements: Minimal oraculizations. Quantum agents in quantum systems (quantum experiments, QQ ML). Model-based agents. Quantum behavioral databases. 47
48 The end 48
A route towards quantum-enhanced artificial intelligence
 (x kinda 1 _ in the x 4 direction _ x 10 of ) {z } A route towards quantum-enhanced artificial intelligence Vedran Dunjko v.dunjko@liacs.leidenuniv.nl What is AI Justus Piater Piater: An unsuccessful meta-science
(x kinda 1 _ in the x 4 direction _ x 10 of ) {z } A route towards quantum-enhanced artificial intelligence Vedran Dunjko v.dunjko@liacs.leidenuniv.nl What is AI Justus Piater Piater: An unsuccessful meta-science
Advances in Quantum Reinforcement Learning
 Advances in Quantum Reinforcement Learning Vedran Dunjko Institute for Theoretical Physics, University of Innsbruck, Innsbruck 6020, Austria now at: Max Planck Institute of Quantum Optics Garching 85748,
Advances in Quantum Reinforcement Learning Vedran Dunjko Institute for Theoretical Physics, University of Innsbruck, Innsbruck 6020, Austria now at: Max Planck Institute of Quantum Optics Garching 85748,
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
RL 14: POMDPs continued
 RL 14: POMDPs continued Michael Herrmann University of Edinburgh, School of Informatics 06/03/2015 POMDPs: Points to remember Belief states are probability distributions over states Even if computationally
RL 14: POMDPs continued Michael Herrmann University of Edinburgh, School of Informatics 06/03/2015 POMDPs: Points to remember Belief states are probability distributions over states Even if computationally
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Exponential algorithmic speedup by quantum walk
 Exponential algorithmic speedup by quantum walk Andrew Childs MIT Center for Theoretical Physics joint work with Richard Cleve Enrico Deotto Eddie Farhi Sam Gutmann Dan Spielman quant-ph/0209131 Motivation
Exponential algorithmic speedup by quantum walk Andrew Childs MIT Center for Theoretical Physics joint work with Richard Cleve Enrico Deotto Eddie Farhi Sam Gutmann Dan Spielman quant-ph/0209131 Motivation
Reinforcement Learning
 Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Reinforcement Learning Cyber Rodent Project Some slides from: David Silver, Radford Neal CSC411: Machine Learning and Data Mining, Winter 2017 Michael Guerzhoy 1 Reinforcement Learning Supervised learning:
Partially observable Markov decision processes. Department of Computer Science, Czech Technical University in Prague
 Partially observable Markov decision processes Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Partially observable Markov decision processes Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
Einführung in die Quanteninformation
 Einführung in die Quanteninformation Hans J. Briegel Theoretical Physics, U Innsbruck Department of Philosophy, U Konstanz* *MWK Baden-Württemberg Quanteninformationsverarbeitung Untersuchung grundlegender
Einführung in die Quanteninformation Hans J. Briegel Theoretical Physics, U Innsbruck Department of Philosophy, U Konstanz* *MWK Baden-Württemberg Quanteninformationsverarbeitung Untersuchung grundlegender
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Experiments on the Consciousness Prior
 Yoshua Bengio and William Fedus UNIVERSITÉ DE MONTRÉAL, MILA Abstract Experiments are proposed to explore a novel prior for representation learning, which can be combined with other priors in order to
Yoshua Bengio and William Fedus UNIVERSITÉ DE MONTRÉAL, MILA Abstract Experiments are proposed to explore a novel prior for representation learning, which can be combined with other priors in order to
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Physics and Machine Learning: Emerging Paradigms
 Physics and Machine Learning: Emerging Paradigms Jose D. Martı n-guerrero1, Paulo J. G. Lisboa2, Alfredo Vellido3 1- Dept. of Electronic Engineering - Universitat de Vale ncia Av. de la Universitat, s/n,
Physics and Machine Learning: Emerging Paradigms Jose D. Martı n-guerrero1, Paulo J. G. Lisboa2, Alfredo Vellido3 1- Dept. of Electronic Engineering - Universitat de Vale ncia Av. de la Universitat, s/n,
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning. Hanna Kurniawati
 COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
MS&E338 Reinforcement Learning Lecture 1 - April 2, Introduction
 MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
Bayesian Networks Inference with Probabilistic Graphical Models
 4190.408 2016-Spring Bayesian Networks Inference with Probabilistic Graphical Models Byoung-Tak Zhang intelligence Lab Seoul National University 4190.408 Artificial (2016-Spring) 1 Machine Learning? Learning
4190.408 2016-Spring Bayesian Networks Inference with Probabilistic Graphical Models Byoung-Tak Zhang intelligence Lab Seoul National University 4190.408 Artificial (2016-Spring) 1 Machine Learning? Learning
Introduction to Sequential Teams
 Introduction to Sequential Teams Aditya Mahajan McGill University Joint work with: Ashutosh Nayyar and Demos Teneketzis, UMichigan MITACS Workshop on Fusion and Inference in Networks, 2011 Decentralized
Introduction to Sequential Teams Aditya Mahajan McGill University Joint work with: Ashutosh Nayyar and Demos Teneketzis, UMichigan MITACS Workshop on Fusion and Inference in Networks, 2011 Decentralized
Markov Models and Reinforcement Learning. Stephen G. Ware CSCI 4525 / 5525
 Markov Models and Reinforcement Learning Stephen G. Ware CSCI 4525 / 5525 Camera Vacuum World (CVW) 2 discrete rooms with cameras that detect dirt. A mobile robot with a vacuum. The goal is to ensure both
Markov Models and Reinforcement Learning Stephen G. Ware CSCI 4525 / 5525 Camera Vacuum World (CVW) 2 discrete rooms with cameras that detect dirt. A mobile robot with a vacuum. The goal is to ensure both
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Autonomous Helicopter Flight via Reinforcement Learning
 Autonomous Helicopter Flight via Reinforcement Learning Authors: Andrew Y. Ng, H. Jin Kim, Michael I. Jordan, Shankar Sastry Presenters: Shiv Ballianda, Jerrolyn Hebert, Shuiwang Ji, Kenley Malveaux, Huy
Autonomous Helicopter Flight via Reinforcement Learning Authors: Andrew Y. Ng, H. Jin Kim, Michael I. Jordan, Shankar Sastry Presenters: Shiv Ballianda, Jerrolyn Hebert, Shuiwang Ji, Kenley Malveaux, Huy
Reinforcement Learning Wrap-up
 Reinforcement Learning Wrap-up Slides courtesy of Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Reinforcement Learning Wrap-up Slides courtesy of Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Neural Map. Structured Memory for Deep RL. Emilio Parisotto
 Neural Map Structured Memory for Deep RL Emilio Parisotto eparisot@andrew.cmu.edu PhD Student Machine Learning Department Carnegie Mellon University Supervised Learning Most deep learning problems are
Neural Map Structured Memory for Deep RL Emilio Parisotto eparisot@andrew.cmu.edu PhD Student Machine Learning Department Carnegie Mellon University Supervised Learning Most deep learning problems are
Deep Reinforcement Learning. STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017
 Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
Today s Outline. Recap: MDPs. Bellman Equations. Q-Value Iteration. Bellman Backup 5/7/2012. CSE 473: Artificial Intelligence Reinforcement Learning
 CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CS 570: Machine Learning Seminar. Fall 2016
 CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
RL 3: Reinforcement Learning
 RL 3: Reinforcement Learning Q-Learning Michael Herrmann University of Edinburgh, School of Informatics 20/01/2015 Last time: Multi-Armed Bandits (10 Points to remember) MAB applications do exist (e.g.
RL 3: Reinforcement Learning Q-Learning Michael Herrmann University of Edinburgh, School of Informatics 20/01/2015 Last time: Multi-Armed Bandits (10 Points to remember) MAB applications do exist (e.g.
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Natural Language Processing. Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu
 Natural Language Processing Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu Projects Project descriptions due today! Last class Sequence to sequence models Attention Pointer networks Today Weak
Natural Language Processing Slides from Andreas Vlachos, Chris Manning, Mihai Surdeanu Projects Project descriptions due today! Last class Sequence to sequence models Attention Pointer networks Today Weak
Approximate Q-Learning. Dan Weld / University of Washington
 Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
arxiv: v1 [cs.ai] 21 May 2014
![arxiv: v1 [cs.ai] 21 May 2014](/thumbs/76/74277676.jpg "arxiv: v1 [cs.ai] 21 May 2014") Projective simulation applied to the grid-world and the mountain-car problem Alexey A. Melnikov, Adi Makmal, and Hans J. Briegel Institut für Theoretische Physik, Universität Innsbruck, Technikerstraße
Projective simulation applied to the grid-world and the mountain-car problem Alexey A. Melnikov, Adi Makmal, and Hans J. Briegel Institut für Theoretische Physik, Universität Innsbruck, Technikerstraße
Optimal Control of Partiality Observable Markov. Processes over a Finite Horizon
 Optimal Control of Partiality Observable Markov Processes over a Finite Horizon Report by Jalal Arabneydi 04/11/2012 Taken from Control of Partiality Observable Markov Processes over a finite Horizon by
Optimal Control of Partiality Observable Markov Processes over a Finite Horizon Report by Jalal Arabneydi 04/11/2012 Taken from Control of Partiality Observable Markov Processes over a finite Horizon by
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Dual Memory Model for Using Pre-Existing Knowledge in Reinforcement Learning Tasks
 Dual Memory Model for Using Pre-Existing Knowledge in Reinforcement Learning Tasks Kary Främling Helsinki University of Technology, PL 55, FI-25 TKK, Finland Kary.Framling@hut.fi Abstract. Reinforcement
Dual Memory Model for Using Pre-Existing Knowledge in Reinforcement Learning Tasks Kary Främling Helsinki University of Technology, PL 55, FI-25 TKK, Finland Kary.Framling@hut.fi Abstract. Reinforcement
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
Quantum Artificial Intelligence and Machine Learning: The Path to Enterprise Deployments. Randall Correll. +1 (703) Palo Alto, CA
 Palo Alto, CA") Quantum Artificial Intelligence and Machine : The Path to Enterprise Deployments Randall Correll randall.correll@qcware.com +1 (703) 867-2395 Palo Alto, CA 1 Bundled software and services Professional
Quantum Artificial Intelligence and Machine : The Path to Enterprise Deployments Randall Correll randall.correll@qcware.com +1 (703) 867-2395 Palo Alto, CA 1 Bundled software and services Professional
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes
 CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Sequential decision making under uncertainty. Department of Computer Science, Czech Technical University in Prague
 Sequential decision making under uncertainty Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Sequential decision making under uncertainty Jiří Kléma Department of Computer Science, Czech Technical University in Prague https://cw.fel.cvut.cz/wiki/courses/b4b36zui/prednasky pagenda Previous lecture:
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Optimal Control. McGill COMP 765 Oct 3 rd, 2017
 Optimal Control McGill COMP 765 Oct 3 rd, 2017 Classical Control Quiz Question 1: Can a PID controller be used to balance an inverted pendulum: A) That starts upright? B) That must be swung-up (perhaps
Optimal Control McGill COMP 765 Oct 3 rd, 2017 Classical Control Quiz Question 1: Can a PID controller be used to balance an inverted pendulum: A) That starts upright? B) That must be swung-up (perhaps
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Factored State Spaces 3/2/178
 Factored State Spaces 3/2/178 Converting POMDPs to MDPs In a POMDP: Action + observation updates beliefs Value is a function of beliefs. Instead we can view this as an MDP where: There is a state for every
Factored State Spaces 3/2/178 Converting POMDPs to MDPs In a POMDP: Action + observation updates beliefs Value is a function of beliefs. Instead we can view this as an MDP where: There is a state for every
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
CS 598 Statistical Reinforcement Learning. Nan Jiang
 CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
Lecture 3: The Reinforcement Learning Problem
 Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
CS 6375: Machine Learning Computational Learning Theory
 CS 6375: Machine Learning Computational Learning Theory Vibhav Gogate The University of Texas at Dallas Many slides borrowed from Ray Mooney 1 Learning Theory Theoretical characterizations of Difficulty
CS 6375: Machine Learning Computational Learning Theory Vibhav Gogate The University of Texas at Dallas Many slides borrowed from Ray Mooney 1 Learning Theory Theoretical characterizations of Difficulty
15-780: Graduate Artificial Intelligence. Reinforcement learning (RL)
") 15-780: Graduate Artificial Intelligence Reinforcement learning (RL) From MDPs to RL We still use the same Markov model with rewards and actions But there are a few differences: 1. We do not assume we
15-780: Graduate Artificial Intelligence Reinforcement learning (RL) From MDPs to RL We still use the same Markov model with rewards and actions But there are a few differences: 1. We do not assume we
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Reasoning Under Uncertainty Over Time. CS 486/686: Introduction to Artificial Intelligence
 Reasoning Under Uncertainty Over Time CS 486/686: Introduction to Artificial Intelligence 1 Outline Reasoning under uncertainty over time Hidden Markov Models Dynamic Bayes Nets 2 Introduction So far we
Reasoning Under Uncertainty Over Time CS 486/686: Introduction to Artificial Intelligence 1 Outline Reasoning under uncertainty over time Hidden Markov Models Dynamic Bayes Nets 2 Introduction So far we
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Introduction to Artificial Intelligence (AI)
") Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
Temporal Difference Learning & Policy Iteration
 Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Compute the Fourier transform on the first register to get x {0,1} n x 0.
 CS 94 Recursive Fourier Sampling, Simon s Algorithm /5/009 Spring 009 Lecture 3 1 Review Recall that we can write any classical circuit x f(x) as a reversible circuit R f. We can view R f as a unitary
CS 94 Recursive Fourier Sampling, Simon s Algorithm /5/009 Spring 009 Lecture 3 1 Review Recall that we can write any classical circuit x f(x) as a reversible circuit R f. We can view R f as a unitary
RL 14: Simplifications of POMDPs
 RL 14: Simplifications of POMDPs Michael Herrmann University of Edinburgh, School of Informatics 04/03/2016 POMDPs: Points to remember Belief states are probability distributions over states Even if computationally
RL 14: Simplifications of POMDPs Michael Herrmann University of Edinburgh, School of Informatics 04/03/2016 POMDPs: Points to remember Belief states are probability distributions over states Even if computationally
A Tour of Reinforcement Learning The View from Continuous Control. Benjamin Recht University of California, Berkeley
 A Tour of Reinforcement Learning The View from Continuous Control Benjamin Recht University of California, Berkeley trustable, scalable, predictable Control Theory! Reinforcement Learning is the study
A Tour of Reinforcement Learning The View from Continuous Control Benjamin Recht University of California, Berkeley trustable, scalable, predictable Control Theory! Reinforcement Learning is the study
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Human-level control through deep reinforcement. Liia Butler
 Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Artificial Intelligence & Sequential Decision Problems
 Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Artificial Intelligence & Sequential Decision Problems (CIV6540 - Machine Learning for Civil Engineers) Professor: James-A. Goulet Département des génies civil, géologique et des mines Chapter 15 Goulet
Quantum machine learning, reinforcement learning, quantum information and computation,
 Alexey Melnikov +43 512 507 52246 alexey.melnikov@uibk.ac.at melnikov.info Name Personal Data Alexey A. Melnikov Date of Birth December 7, 1989 Place of Birth Citizenship City of Vladimir, Russia Russian
Alexey Melnikov +43 512 507 52246 alexey.melnikov@uibk.ac.at melnikov.info Name Personal Data Alexey A. Melnikov Date of Birth December 7, 1989 Place of Birth Citizenship City of Vladimir, Russia Russian
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer.
 This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Course 395: Machine Learning
 Course 395: Machine Learning Lecturers: Maja Pantic (maja@doc.ic.ac.uk) Stavros Petridis (sp104@doc.ic.ac.uk) Goal (Lectures): To present basic theoretical concepts and key algorithms that form the core
Course 395: Machine Learning Lecturers: Maja Pantic (maja@doc.ic.ac.uk) Stavros Petridis (sp104@doc.ic.ac.uk) Goal (Lectures): To present basic theoretical concepts and key algorithms that form the core
CSE250A Fall 12: Discussion Week 9
 CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
A reinforcement learning scheme for a multi-agent card game with Monte Carlo state estimation
 A reinforcement learning scheme for a multi-agent card game with Monte Carlo state estimation Hajime Fujita and Shin Ishii, Nara Institute of Science and Technology 8916 5 Takayama, Ikoma, 630 0192 JAPAN
A reinforcement learning scheme for a multi-agent card game with Monte Carlo state estimation Hajime Fujita and Shin Ishii, Nara Institute of Science and Technology 8916 5 Takayama, Ikoma, 630 0192 JAPAN
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
Markov Decision Processes
 Markov Decision Processes Noel Welsh 11 November 2010 Noel Welsh () Markov Decision Processes 11 November 2010 1 / 30 Annoucements Applicant visitor day seeks robot demonstrators for exciting half hour
Markov Decision Processes Noel Welsh 11 November 2010 Noel Welsh () Markov Decision Processes 11 November 2010 1 / 30 Annoucements Applicant visitor day seeks robot demonstrators for exciting half hour
An Introduction to Reinforcement Learning
 1 / 58 An Introduction to Reinforcement Learning Lecture 01: Introduction Dr. Johannes A. Stork School of Computer Science and Communication KTH Royal Institute of Technology January 19, 2017 2 / 58 ../fig/reward-00.jpg
1 / 58 An Introduction to Reinforcement Learning Lecture 01: Introduction Dr. Johannes A. Stork School of Computer Science and Communication KTH Royal Institute of Technology January 19, 2017 2 / 58 ../fig/reward-00.jpg
An Adaptive Clustering Method for Model-free Reinforcement Learning
 An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
CS 4649/7649 Robot Intelligence: Planning
 CS 4649/7649 Robot Intelligence: Planning Probability Primer Sungmoon Joo School of Interactive Computing College of Computing Georgia Institute of Technology S. Joo (sungmoon.joo@cc.gatech.edu) 1 *Slides
CS 4649/7649 Robot Intelligence: Planning Probability Primer Sungmoon Joo School of Interactive Computing College of Computing Georgia Institute of Technology S. Joo (sungmoon.joo@cc.gatech.edu) 1 *Slides
STATE GENERALIZATION WITH SUPPORT VECTOR MACHINES IN REINFORCEMENT LEARNING. Ryo Goto, Toshihiro Matsui and Hiroshi Matsuo
 STATE GENERALIZATION WITH SUPPORT VECTOR MACHINES IN REINFORCEMENT LEARNING Ryo Goto, Toshihiro Matsui and Hiroshi Matsuo Department of Electrical and Computer Engineering, Nagoya Institute of Technology
STATE GENERALIZATION WITH SUPPORT VECTOR MACHINES IN REINFORCEMENT LEARNING Ryo Goto, Toshihiro Matsui and Hiroshi Matsuo Department of Electrical and Computer Engineering, Nagoya Institute of Technology
Reinforcement Learning
 Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Outline. CSE 573: Artificial Intelligence Autumn Agent. Partial Observability. Markov Decision Process (MDP) 10/31/2012
 10/31/2012") CSE 573: Artificial Intelligence Autumn 2012 Reasoning about Uncertainty & Hidden Markov Models Daniel Weld Many slides adapted from Dan Klein, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 Outline
CSE 573: Artificial Intelligence Autumn 2012 Reasoning about Uncertainty & Hidden Markov Models Daniel Weld Many slides adapted from Dan Klein, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 Outline
Deep Learning Autoencoder Models
 Deep Learning Autoencoder Models Davide Bacciu Dipartimento di Informatica Università di Pisa Intelligent Systems for Pattern Recognition (ISPR) Generative Models Wrap-up Deep Learning Module Lecture Generative
Deep Learning Autoencoder Models Davide Bacciu Dipartimento di Informatica Università di Pisa Intelligent Systems for Pattern Recognition (ISPR) Generative Models Wrap-up Deep Learning Module Lecture Generative
Chapter 1. Introduction
 Chapter 1 Introduction Symbolical artificial intelligence is a field of computer science that is highly related to quantum computation. At first glance, this statement appears to be a contradiction. However,
Chapter 1 Introduction Symbolical artificial intelligence is a field of computer science that is highly related to quantum computation. At first glance, this statement appears to be a contradiction. However,
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Artificial Intelligence
 Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
Artificial Intelligence Dynamic Programming Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: So far we focussed on tree search-like solvers for decision problems. There is a second important
A Gentle Introduction to Reinforcement Learning
 A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
The Reinforcement Learning Problem
 The Reinforcement Learning Problem Slides based on the book Reinforcement Learning by Sutton and Barto Formalizing Reinforcement Learning Formally, the agent and environment interact at each of a sequence
The Reinforcement Learning Problem Slides based on the book Reinforcement Learning by Sutton and Barto Formalizing Reinforcement Learning Formally, the agent and environment interact at each of a sequence