Reinforcement Learning. Yishay Mansour Tel-Aviv University
|
|
|
- Pearl Eugenia Wilkinson
- 6 years ago
- Views:
Transcription
1 Reinforcement Learning Yishay Mansour Tel-Aviv University 1
2 Reinforcement Learning: Course Information Classes: Wednesday Lecture Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak Course Web site: rl-tau-2018.wikidot.com Resources: Markov Decision Processes Puterman Reinforcement Learning Sutton and Barto Neuro-dynamic Programming Bertsekas and Tsitsiklis 2
3 Reinforcement Learning: Course requirements Homework: Every two week: Theory and Programming Project: Near the end of the term Deep RL/Atari Final Exam Grade: 60% Final exam Have to pass 20% HW 20% project 3


4 Playing Board Games AlphaGo, DeepMind Gerald Tesauro, TD-gammon


5 Other notable board games Arthur Samuel 1962 Deep Blue1996 5


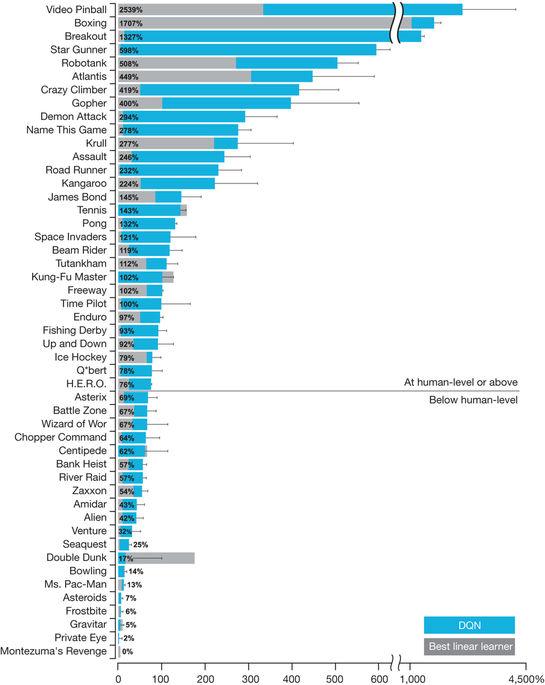
6 Playing Atari Games 6




7 Controlling Robots 7
8 Today Outline: Overview Basics Goal of Reinforcement Learning Mathematical Model (MDP) Planning Value iteration Policy iteration Learning Algorithms Model based Model Free Large state space Function approx Policy gradient 8
9 Goal of Reinforcement Learning Goal oriented learning through interaction Control of large scale stochastic environments with partial knowledge. Supervised / Unsupervised Learning Learn from labeled / unlabeled examples 9

10 10
11 Mathematical Model - Motivation Model of uncertainty: Environment, actions, our knowledge. Focus on decision making. Maximize long term reward. Markov Decision Process (MDP) 11
12 Contrast with Supervised Learning The system has a state. The algorithm influences the state distribution. Inherent Tradeoff: Exploration versus Exploitation. * There is a cost to discover information! 12
13 Mathematical Model - MDP Markov Decision Processes S- set of states A- set of actions d - Transition probability R - Reward function Similar to DFA! 13
14 MDP model - states and actions Environment = states action a Actions = transitions d ( s, a, s ' ) 14
15 MDP model - rewards R(s,a) = reward at state s for doing action a (a random variable). Example: R(s,a) = -1 with probability with probability with probability
16 MDP model - trajectories trajectory: s 0 a 0 r 0 s 1 a 1 r 1 s 2 a 2 r 2 16
17 MDP - Return function. Combining all the immediate rewards to a single value. Modeling issues: Are early rewards more valuable than later rewards? Is the system terminating or continuous? Usually the return is linear in the immediate rewards. 17
18 MDP model - return functions Finite Horizon - parameter H return = å R( s i, ai ) Infinite Horizon 1 i H i discounted - parameter g<1. return = å γ R(si,ai ) i=0 undiscounted 1 N N -1 å i= 0 R(s i,a i ) ¾ N ¾ return Terminating MDP 18
19 MDP Example: Inventory P= Price/item, J(.)=order cost C(.)=inventory cost - " = min (! " + # ", $ " ) ) " =, - " +. # " /! "%& # " $ "! "! "%& =! " + # " $ " % 19
20 MDP model - action selection AIM: Maximize the expected return. This talk: discounted return Fully Observable - can see the exact state. Policy - mapping from states to actions Optimal policy: optimal from any start state. THEOREM: There exists a deterministic optimal policy 20
21 MDP model - summary s Î S a Î A d ( s1, a, s2 ) p : R(s,a) S å i = 0 g i ri A - set of states, S =n. - set of k actions, A =k. - transition function. - immediate reward function. - policy. - discounted cumulative return. 21
22 Contrast with Supervised Learning Supervised Learning: Fixed distribution on examples. Reinforcement Learning: The state distribution is policy dependent!!! A small local change in the policy can make a huge global change in the return. 22
23 Simple setting: Multi-armed bandit Single state. Goal: Maximize sum of immediate rewards. a 1 s a 2 Given the model: Greedy action. a 3 Difficulty: unknown rewards. 23
24 Today Outline: Overview Basics Goal of Reinforcement Learning Mathematical Model (MDP) Planning Value iteration Policy iteration Learning Algorithms Model based Model Free Large state space Function Approx Policy gradient 24
25 Planning - Basic Problems. Given a complete MDP model. Policy evaluation - Given a policy p, evaluate its return. Optimal control - Find an optimal policy p * (maximizes the return from any start state). 25
26 Planning - Value Functions V p (s) The expected return starting at state s following p. Q p (s,a) The expected return starting at state s with action a and then following p. V * (s) and Q * (s,a) are define using an optimal policy p *. V * (s) = max p V p (s) 26
27 Planning - Policy Evaluation Discounted infinite horizon (Bellman Eq.) V p (s) = E s ~ p (s) [ R(s,p (s)) + g V p (s )] Rewrite the expectation V p ( s) = E[ R( s, p ( s))] + g å s ' d ( s, p ( s), s') V p ( s') Linear system of equations. 27
28 Algorithms -Policy Evaluation Example A={+1,-1} g = 1/2 d(s i,a)= s i+a p random "a: R(s i,a) = i s 0 s s 3 s 2 V p (s 0 ) = 0 +g [p(s 0,+1)V p (s 1 ) + p(s 0,-1) V p (s 3 ) ] 28
29 Algorithms -Policy Evaluation Example A={+1,-1} g = 1/2 d(s i,a)= s i+a p random "a: R(s i,a) = i s 0 s s 3 s 2 V p (s 0 ) = 5/3 V p (s 1 ) = 7/3 V p (s 2 ) = 11/3 V p (s 3 ) = 13/3 V p (s 0 ) = 0 + (V p (s 1 ) + V p (s 3 ) )/4 V p (s 1 ) = 1 + (V p (s 0 ) + V p (s 2 ) )/4 V p (s 2 ) = 2 + (V p (s 1 ) + V p (s 3 ) )/4 V p (s 3 ) = 3 + (V p (s 0 ) + V p (s 2 ) )/4 29
30 Algorithms - optimal control State-Action Value function: Q p (s,a) = E [ R(s,a)] + ge s ~ p (s) [ V p (s )] p p Note V ( s) = Q ( s, p ( s)) For a deterministic policy p. 30
31 Algorithms -Optimal control Example A={+1,-1} g = 1/2 d(s i,a)= s i+a p random R(s i,a) = i s 0 s s 3 s 2 Q p (s 0,+1) = 7/6 Q p (s 0,-1) = 13/6 Q p (s 0,+1) = 0 +g V p (s 1 ) 31
32 Algorithms - optimal control CLAIM: A policy p is optimal if and only if at each state s: V p (s) = MAX a {Q p (s,a)} (Bellman Eq.) PROOF: (only if) Assume there is a state s and action a s.t., V p (s) < Q p (s,a). Then the strategy of performing a at state s (the first time) is better than p. This is true each time we visit s, so the policy that performs action a at state s is better than p. p 32
33 Algorithms -optimal control Example A={+1,-1} g = 1/2 d(s i,a)= s i+a p random R(s i,a) = i s 0 s s 3 s 2 Changing the policy using the state-action value function. 33
34 MDP - computing optimal policy 1. Linear Programming 2. Value Iteration method. )}, ( arg max{ ) ( 1 a s Q s i a i - = p p ')} ( '),, ( ), ( max{ ) ( ' 1 s V s a s a s R s V s t a t å + + d g 3. Policy Iteration method. 34


35 Example: Grid world ACTIONS Initial State = Red Final State = Blue COST = steps to target (blue) 35
36 Example: Grid world 0 Initial Values t=0 36
37 Example: Grid world One Iteration t=1 37
38 Example: Grid world Two Iterations t=2 38
 39")
39 Example: Grid world Optimal Policy Q(s,à)= walk à and add distance to target Optimal policy Derive from Q(s, - ) 39
40 Convergence Value Iteration Decrease the distance from optimal By a factor of 1-γ Policy Iteration Policy improves Number of iteration less than Value Iteration 40
41 Today Outline: Overview Basics Goal of Reinforcement Learning Mathematical Model (MDP) Planning Value iteration Policy iteration Learning Algorithms Model based Model Free Large state space Function approx Policy gradient 41
42 Learning Algorithms Given access only to actions perform: 1. policy evaluation. 2. control - find optimal policy. Two approaches: 1. Model based. 2. Model free. 42
43 Learning - Model Based Estimate the model from the observation. (Both transition probability and rewards.) Use the estimated model as a true model, and find a near optimal policy. If we have a good estimated model, we should have a good estimation. 43
44 Learning - Model Based: off policy Let the policy run for a long time. o what is long?! o Assuming some exploration Build an observed model : o Transition probabilities o Rewards Both are independent! Use the observed model learn optimal policy. 44
45 Learning - Model Based off-policy algorithm Observe a trajectory generated by a policy π o off-policy: not need to control For every!,! # & and ' (: o ) (!, ',! ) = #(!, ',! ) / #(!, ', ) o 2 (!, ') = (34(5!, ') Find an optimal policy for (&, ', ), 2 ) 45
46 Learning - Model Based Claim: if the model is accurate we will compute a near-optimal policy. Hidden assumption: o Each (s,a, ) is sampled many times. o This is the responsibility of the policy π Off-policy Simple question: How many samples we need for each (s,a, ) 46
47 Learning - Model Based: on policy The learner has control over the action. o The immediate goal is to learn a model As before: o Build an observed model : Transition probabilities and Rewards o Use the observed model to estimate value of the policy. Accelerating the learning: o How to reach unexplored states?! 47
48 Learning - Model Based: on policy Well sampled states Relatively unknown states 48
49 Learning - Model Based: on policy HIGH REAWRD Well sampled states Relatively unknown states Exploration à Planning in new MDP 49
50 Learning: Policy improvement Assume that we can perform: Given a policy p, Compute V π and Q π functions of p Can run policy improvement: p = Greedy (Q π ) Process converges if estimates are accurate. 50
51 Model-Free learning 53
52 Q-Learning: off policy Basic Idea: Learn the Q-function. On a move (s,a) s update: Old estimate Q ( t+ 1 s, a) = (1 -a ( s, a)) Q a ( s, a)[ R t t t t ( s, a) + ( s, a) + g max u Q t ( s', u)] Learning rate a t (s,a)=1/t w New estimate 54
53 55 Q-Learning: update equation Old estimate New estimate update learning rate ) ', ( max ), ( ), ( ), ( ), ( ), 1( u s Q a s R a s Q a s a s Q a s Q t u t t t t t g a + - D = D - = +
54 Q-Learning: Intuition Updates based on the difference: D = Q t ( s, u) -[ R ( s, a) + g max Q ( s', u)] t u t Assume we have the right Q function Good news: The expectation is Zero!!! Challenge: understand the dynamics stochastic process 56
55 Learning - Model Free Policy evaluation: TD(0) An online view: At state s t we performed action a t, received reward r t and moved to state s t+1. Our estimation error is Err t =r t +gv(s t+1 )-V(s t ), The update: V t +1 (s t ) = V t (s t ) + a Err t Note that for the correct value function we have: E[r+gV(s )-V(s)] =E[Err t ]=0 57
56 Learning - Model Free Policy evaluation: TD(l) Again: At state s t we performed action a t, received reward r t and moved to state s t+1. Our estimation error Err t =r t +gv(s t+1 )-V(s t ), Update every state s: V t +1 (s) = V t (s ) + a Err t e(s) Update of e(s) : When visiting s: incremented by 1: e(s) = e(s)+1 For all other s : decremented by g l factor: e(s ) = g l e(s ) 58
57 Different Model-Free Algorithms On-policy versus Off-policy The function approximated (V vs Q) Fairly similar general methodologies Challenges: controlling stochastic process 59
58 Today Outline: Overview Basics Goal of Reinforcement Learning Mathematical Model (MDP) Planning Value iteration Policy iteration Learning Algorithms Model based Model Free Large state space Function approx Policy gradient 60
59 Large state MDP Previous Methods: Tabular. (small state space). Large state Exponential size. Similar to basic view of learning. 61
60 Large scale MDP Approaches: 1. Restricted Value function. 2. Restricted policy class. 3. Restricted model of MDP. 4. Different MDP representation: Generative Model 62
61 Large MDP - Restricted Value Function (Value) Function Approximation: Use a limited class of functions to estimate the value function. Given a good approximation of the value function, we can estimate the optimal policy. Vague Idea: reduce to a supervised (deep) learning. applications: most of the recent work (AlphaGo, Atari etc.) 63
62 Large MDP: Restricted Policy Fix a policy class Π = {$: & (} Given a policy $ Π Approximate V π and Q π Run policy improvement: p = Greedy (Q π ) Quality depends on approximation. Convergence not guaranteed. 64
63 Large MDP: Policy Gradient Improving the parameter of a policy Taking the gradient Challenge: The update impacts both: Action probabilities Distribution over states Use off-policy compute the gradient from policy history 65
64 Large MDP: Generative Model. Clearly we can not use matrix representation. Generator representation: s a Generator s r Algorithm for estimating optimal policy (for discounted infinite horizon) in time independent of the number of states 66
65 Large state MDP: Generative Model. Use generative model for look ahead Sample a tree of a shallow depth Using generative model Compute optimal policy on the tree Result in approximate optimal policy in the MDP 67
66 Today Outline: Overview Basics Goal of Reinforcement Learning Mathematical Model (MDP) Planning Value iteration Policy iteration Learning Algorithms Model based Model Free Large state space Function approx Policy gradient 68
67 Course (tentative) Outline Part 1: MDP basics and planning Part 2: MDP learning Model Based and Model free Part 3: Large state MDP Policy Gradient, Deep Q-Network Part 4: Special MDPs Bandits and Partially Observable MDP Part 5: Advanced topics 69
Lecture 1: March 7, 2018
 Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning Spring Semester, 2017/8 Lecture 1: March 7, 2018 Lecturer: Yishay Mansour Scribe: ym DISCLAIMER: Based on Learning and Planning in Dynamical Systems by Shie Mannor c, all rights
Reinforcement Learning
 Reinforcement Learning Yihay Manour Google Inc. & Tel-Aviv Univerity Outline Goal of Reinforcement Learning Mathematical Model (MDP) Planning Learning Current Reearch iue 2 Goal of Reinforcement Learning
Reinforcement Learning Yihay Manour Google Inc. & Tel-Aviv Univerity Outline Goal of Reinforcement Learning Mathematical Model (MDP) Planning Learning Current Reearch iue 2 Goal of Reinforcement Learning
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
CS 570: Machine Learning Seminar. Fall 2016
 CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
CS 570: Machine Learning Seminar Fall 2016 Class Information Class web page: http://web.cecs.pdx.edu/~mm/mlseminar2016-2017/fall2016/ Class mailing list: cs570@cs.pdx.edu My office hours: T,Th, 2-3pm or
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Lecture 25: Learning 4. Victor R. Lesser. CMPSCI 683 Fall 2010
 Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
Lecture 25: Learning 4 Victor R. Lesser CMPSCI 683 Fall 2010 Final Exam Information Final EXAM on Th 12/16 at 4:00pm in Lederle Grad Res Ctr Rm A301 2 Hours but obviously you can leave early! Open Book
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CMU Lecture 12: Reinforcement Learning. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Markov Decision Processes and Solving Finite Problems. February 8, 2017
 Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
CS 598 Statistical Reinforcement Learning. Nan Jiang
 CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
CS 598 Statistical Reinforcement Learning Nan Jiang Overview What s this course about? A grad-level seminar course on theory of RL 3 What s this course about? A grad-level seminar course on theory of RL
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
6 Reinforcement Learning
 6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Administration. CSCI567 Machine Learning (Fall 2018) Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.
 Outline. Outline. HW5 is available, due on 11/18. Practice final will also be available soon.") Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Administration CSCI567 Machine Learning Fall 2018 Prof. Haipeng Luo U of Southern California Nov 7, 2018 HW5 is available, due on 11/18. Practice final will also be available soon. Remaining weeks: 11/14,
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement Learning with Function Approximation. Joseph Christian G. Noel
 Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
MDP Preliminaries. Nan Jiang. February 10, 2019
 MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Open Theoretical Questions in Reinforcement Learning
 Open Theoretical Questions in Reinforcement Learning Richard S. Sutton AT&T Labs, Florham Park, NJ 07932, USA, sutton@research.att.com, www.cs.umass.edu/~rich Reinforcement learning (RL) concerns the problem
Open Theoretical Questions in Reinforcement Learning Richard S. Sutton AT&T Labs, Florham Park, NJ 07932, USA, sutton@research.att.com, www.cs.umass.edu/~rich Reinforcement learning (RL) concerns the problem
Reinforcement Learning and Control
 CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
CS9 Lecture notes Andrew Ng Part XIII Reinforcement Learning and Control We now begin our study of reinforcement learning and adaptive control. In supervised learning, we saw algorithms that tried to make
Temporal difference learning
 Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Deep Reinforcement Learning. STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017
 Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
Deep Reinforcement Learning STAT946 Deep Learning Guest Lecture by Pascal Poupart University of Waterloo October 19, 2017 Outline Introduction to Reinforcement Learning AlphaGo (Deep RL for Computer Go)
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes
 CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Reinforcement Learning: An Introduction
 Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction to Reinforcement Learning
 Introduction to Reinforcement Learning Rémi Munos SequeL project: Sequential Learning http://researchers.lille.inria.fr/ munos/ INRIA Lille - Nord Europe Machine Learning Summer School, September 2011,
Introduction to Reinforcement Learning Rémi Munos SequeL project: Sequential Learning http://researchers.lille.inria.fr/ munos/ INRIA Lille - Nord Europe Machine Learning Summer School, September 2011,
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]
![Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]](/thumbs/94/119187228.jpg "Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]") Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Elements of Reinforcement Learning
 Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Elements of Reinforcement Learning Policy: way learning algorithm behaves (mapping from state to action) Reward function: Mapping of state action pair to reward or cost Value function: long term reward,
Lecture 10 - Planning under Uncertainty (III)
") Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Today s Outline. Recap: MDPs. Bellman Equations. Q-Value Iteration. Bellman Backup 5/7/2012. CSE 473: Artificial Intelligence Reinforcement Learning
 CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
CSE 473: Artificial Intelligence Reinforcement Learning Dan Weld Today s Outline Reinforcement Learning Q-value iteration Q-learning Exploration / exploitation Linear function approximation Many slides
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Machine Learning. Reinforcement learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning. Hanna Kurniawati
 COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
COMP3702/7702 Artificial Intelligence Lecture 11: Introduction to Machine Learning and Reinforcement Learning Hanna Kurniawati Today } What is machine learning? } Where is it used? } Types of machine learning
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Lecture 23: Reinforcement Learning
 Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 23: Reinforcement Learning MDPs revisited Model-based learning Monte Carlo value function estimation Temporal-difference (TD) learning Exploration November 23, 2006 1 COMP-424 Lecture 23 Recall:
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
University of Alberta
 University of Alberta NEW REPRESENTATIONS AND APPROXIMATIONS FOR SEQUENTIAL DECISION MAKING UNDER UNCERTAINTY by Tao Wang A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment
University of Alberta NEW REPRESENTATIONS AND APPROXIMATIONS FOR SEQUENTIAL DECISION MAKING UNDER UNCERTAINTY by Tao Wang A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer.
 This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
CS 7180: Behavioral Modeling and Decisionmaking
 CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
An Adaptive Clustering Method for Model-free Reinforcement Learning
 An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
Lecture 3: Markov Decision Processes
 Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
15-780: ReinforcementLearning
 15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
An Introduction to Reinforcement Learning
 1 / 58 An Introduction to Reinforcement Learning Lecture 01: Introduction Dr. Johannes A. Stork School of Computer Science and Communication KTH Royal Institute of Technology January 19, 2017 2 / 58 ../fig/reward-00.jpg
1 / 58 An Introduction to Reinforcement Learning Lecture 01: Introduction Dr. Johannes A. Stork School of Computer Science and Communication KTH Royal Institute of Technology January 19, 2017 2 / 58 ../fig/reward-00.jpg
Markov Decision Processes Chapter 17. Mausam
 Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Optimal Control. McGill COMP 765 Oct 3 rd, 2017
 Optimal Control McGill COMP 765 Oct 3 rd, 2017 Classical Control Quiz Question 1: Can a PID controller be used to balance an inverted pendulum: A) That starts upright? B) That must be swung-up (perhaps
Optimal Control McGill COMP 765 Oct 3 rd, 2017 Classical Control Quiz Question 1: Can a PID controller be used to balance an inverted pendulum: A) That starts upright? B) That must be swung-up (perhaps
Approximation Methods in Reinforcement Learning
 2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Reinforcement Learning Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Reinforcement Learning Double
CS 188: Artificial Intelligence Reinforcement Learning Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Reinforcement Learning Double
Deep Reinforcement Learning SISL. Jeremy Morton (jmorton2) November 7, Stanford Intelligent Systems Laboratory
 November 7, Stanford Intelligent Systems Laboratory") Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
(Deep) Reinforcement Learning
 Reinforcement Learning") Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
Planning in Markov Decision Processes
 Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Planning in Markov Decision Processes Lecture 3, CMU 10703 Katerina Fragkiadaki Markov Decision Process (MDP) A Markov
Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Planning in Markov Decision Processes Lecture 3, CMU 10703 Katerina Fragkiadaki Markov Decision Process (MDP) A Markov
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
CMU Lecture 11: Markov Decision Processes II. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 11: Markov Decision Processes II Teacher: Gianni A. Di Caro RECAP: DEFINING MDPS Markov decision processes: o Set of states S o Start state s 0 o Set of actions A o Transitions P(s s,a)
CMU 15-781 Lecture 11: Markov Decision Processes II Teacher: Gianni A. Di Caro RECAP: DEFINING MDPS Markov decision processes: o Set of states S o Start state s 0 o Set of actions A o Transitions P(s s,a)
Markov Decision Processes (and a small amount of reinforcement learning)
") Markov Decision Processes (and a small amount of reinforcement learning) Slides adapted from: Brian Williams, MIT Manuela Veloso, Andrew Moore, Reid Simmons, & Tom Mitchell, CMU Nicholas Roy 16.4/13 Session
Markov Decision Processes (and a small amount of reinforcement learning) Slides adapted from: Brian Williams, MIT Manuela Veloso, Andrew Moore, Reid Simmons, & Tom Mitchell, CMU Nicholas Roy 16.4/13 Session
The Simplex and Policy Iteration Methods are Strongly Polynomial for the Markov Decision Problem with Fixed Discount
 The Simplex and Policy Iteration Methods are Strongly Polynomial for the Markov Decision Problem with Fixed Discount Yinyu Ye Department of Management Science and Engineering and Institute of Computational
The Simplex and Policy Iteration Methods are Strongly Polynomial for the Markov Decision Problem with Fixed Discount Yinyu Ye Department of Management Science and Engineering and Institute of Computational
Deep Reinforcement Learning: Policy Gradients and Q-Learning
 Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Reinforcement Learning
 Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Lecture 3: The Reinforcement Learning Problem
 Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Course basics. CSE 190: Reinforcement Learning: An Introduction. Last Time. Course goals. The website for the class is linked off my homepage.
 Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Course basics CSE 190: Reinforcement Learning: An Introduction The website for the class is linked off my homepage. Grades will be based on programming assignments, homeworks, and class participation.
Reinforcement Learning II
 Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
1 MDP Value Iteration Algorithm
 CS 0. - Active Learning Problem Set Handed out: 4 Jan 009 Due: 9 Jan 009 MDP Value Iteration Algorithm. Implement the value iteration algorithm given in the lecture. That is, solve Bellman s equation using
CS 0. - Active Learning Problem Set Handed out: 4 Jan 009 Due: 9 Jan 009 MDP Value Iteration Algorithm. Implement the value iteration algorithm given in the lecture. That is, solve Bellman s equation using
CSE250A Fall 12: Discussion Week 9
 CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
CSE250A Fall 12: Discussion Week 9 Aditya Menon (akmenon@ucsd.edu) December 4, 2012 1 Schedule for today Recap of Markov Decision Processes. Examples: slot machines and maze traversal. Planning and learning.
Reinforcement Learning
 1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Prioritized Sweeping Converges to the Optimal Value Function
 Technical Report DCS-TR-631 Prioritized Sweeping Converges to the Optimal Value Function Lihong Li and Michael L. Littman {lihong,mlittman}@cs.rutgers.edu RL 3 Laboratory Department of Computer Science
Technical Report DCS-TR-631 Prioritized Sweeping Converges to the Optimal Value Function Lihong Li and Michael L. Littman {lihong,mlittman}@cs.rutgers.edu RL 3 Laboratory Department of Computer Science
Some AI Planning Problems
 Course Logistics CS533: Intelligent Agents and Decision Making M, W, F: 1:00 1:50 Instructor: Alan Fern (KEC2071) Office hours: by appointment (see me after class or send email) Emailing me: include CS533
Course Logistics CS533: Intelligent Agents and Decision Making M, W, F: 1:00 1:50 Instructor: Alan Fern (KEC2071) Office hours: by appointment (see me after class or send email) Emailing me: include CS533
Markov Decision Processes Chapter 17. Mausam
 Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Markov Decision Processes Chapter 17 Mausam Planning Agent Static vs. Dynamic Fully vs. Partially Observable Environment What action next? Deterministic vs. Stochastic Perfect vs. Noisy Instantaneous vs.
Chapter 7: Eligibility Traces. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
 Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
MS&E338 Reinforcement Learning Lecture 1 - April 2, Introduction
 MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
MS&E338 Reinforcement Learning Lecture 1 - April 2, 2018 Introduction Lecturer: Ben Van Roy Scribe: Gabriel Maher 1 Reinforcement Learning Introduction In reinforcement learning (RL) we consider an agent
An Introduction to Markov Decision Processes. MDP Tutorial - 1
 An Introduction to Markov Decision Processes Bob Givan Purdue University Ron Parr Duke University MDP Tutorial - 1 Outline Markov Decision Processes defined (Bob) Objective functions Policies Finding Optimal
An Introduction to Markov Decision Processes Bob Givan Purdue University Ron Parr Duke University MDP Tutorial - 1 Outline Markov Decision Processes defined (Bob) Objective functions Policies Finding Optimal
A Gentle Introduction to Reinforcement Learning
 A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,
A Gentle Introduction to Reinforcement Learning Alexander Jung 2018 1 Introduction and Motivation Consider the cleaning robot Rumba which has to clean the office room B329. In order to keep things simple,