A Practical Algorithm for Topic Modeling with Provable Guarantees
|
|
|
- Ethelbert Young
- 5 years ago
- Views:
Transcription
1 1 A Practical Algorithm for Topic Modeling with Provable Guarantees Sanjeev Arora, Rong Ge, Yoni Halpern, David Mimno, Ankur Moitra, David Sontag, Yichen Wu, Michael Zhu Reviewed by Zhao Song December 13, 2013
2 1 1 Background 2 The Proposed Algorithm Word-Word Co-occurences Matrix Construction Topic Recovery via Bayes Rule Anchor Words Search 3 Experimental Results
3 2 Outline 1 Background 2 The Proposed Algorithm Word-Word Co-occurences Matrix Construction Topic Recovery via Bayes Rule Anchor Words Search 3 Experimental Results
4 Topic Modeling Nonnegative Matrix Factorization problem [Arora, Ge, and Moitra 2012]: A: Unknown word-topic matrix with dimension V K. A i,k = p(w 1 = i z 1 = k) = p(w 2 = i z 2 = k) W : Unknown topic-document matrix with dimension K M. W i,k = p(z 1 = i d 1 = k) = p(z 2 = i d 2 = k) R: Unknown topic-topic covariance matrix with dimension K K R = E(W W T ) Q: Word-word co-occurrence matrix with dimension V V. Q = E[AW W T A T ] = ARA T Task : Given Q, recover A and R. 3
5 4 Previous Work [Arora, Ge, and Moitra 2012] presented a provably polynomial-time algorithm learning parameters of topic model provided that every topic contains at least one anchor word. The word-topic matrix A is p separable: For p > 0 and for each topic k, there is some word i such that A i,k p; A i,k = 0, for k k. The word here is called Anchor Word. Two steps: Selection step: Find anchor words. Recovery step: Reconstruct topic distribution.

6 Previous Work (Cont.) 5
7 6 Previous Work (Cont.) Limitations in [Arora, Ge, and Moitra 2012] Unstable and sensitive to noise: Use matrix inversion to recover A. Not sufficient for real data: Only use K rows of the word-word co-occurrence matrix Q, corresponding to the anchor words.
8 7 Outline 1 Background 2 The Proposed Algorithm Word-Word Co-occurences Matrix Construction Topic Recovery via Bayes Rule Anchor Words Search 3 Experimental Results

9 Framework 8
10 9 Outline 1 Background 2 The Proposed Algorithm Word-Word Co-occurences Matrix Construction Topic Recovery via Bayes Rule Anchor Words Search 3 Experimental Results
11 10 Construct Q Matrix Let H d R V where the i th element equals the number of times word i appearing in document d and n d be the length of document. H d Hd = nd (n d 1) Ĥ d = Diag(H d) n d (n d 1) Then, collect all Hd to form H and compute the sum of all Ĥ d to get Ĥ. We can prove E( H H T Ĥ) = Q and use H H T Ĥ to approximate Q and normalize its row to get Q.
12 11 Outline 1 Background 2 The Proposed Algorithm Word-Word Co-occurences Matrix Construction Topic Recovery via Bayes Rule Anchor Words Search 3 Experimental Results
13 12 Interpretations for matrix Q For an anchor word s k Q sk,j = p(z 1 = k w 1 = s k ) p(w 2 = j z 1 = k ) k (1) = p(w 2 = j z 1 = k) (2) For any other word i Q i,j = k = k p(z 1 = k w 1 = i) p(w 2 = j z 1 = k) (3) C i,k Qsk,j (4) Every other rows of Q lies in the Convex Hull of rows corresponding to the anchor words.
14 13 Matrices A and R recovery Bayes rule: p(w 1 = i z 1 = k) = p(z 1 = k w 1 = i) p(w 1 = i) i p(z 1 = k w 1 = i ) p(w 1 = i ) (5) where p(w 1 = i) = j p(w 1 = i, w 2 = j) = j Q i,j (6) How to compute C i = p(z 1 w 1 = i): Defining different loss function 1 KL Divergence: D( Q i k S C i,k Qsk ) 2 Quadratic Loss Q i k S C i,k Qsk 2 Matrix R recovery R = A Q(A ) T (7)
15 RecoverKL Algorithm 14
16 15 Outline 1 Background 2 The Proposed Algorithm Word-Word Co-occurences Matrix Construction Topic Recovery via Bayes Rule Anchor Words Search 3 Experimental Results
17 16 A Geometric Interpretation For infinite documents, the convex hull P of the rows in Q (a 1, a 2,..., a V ) will be a simplex whose vertices correspond to the anchor words. For finite documents, the rows in Q (d 1, d 2,..., d V ) are only approximated to their expectation. Find an approximation to the vertices of P Iteratively find the farthest point from the subspace spanned by the anchor words found so far.
18 Anchor Words Search Algorithm 17
19 18 Outline 1 Background 2 The Proposed Algorithm Word-Word Co-occurences Matrix Construction Topic Recovery via Bayes Rule Anchor Words Search 3 Experimental Results
20 19 Experiments Setup Compare the following four methods: Gibbs sampling [McCallum 2002] Recover [Arora, Ge, and Moitra 2012] RecoverKL RecoverL2 Two real-world data sets: New York Times articles 295k documents, vocabulary size 15k, mean document length 298. NIPS abstracts 1100 documents, vocabulary size 2500, mean document length 68.
21 20 Experiments Setup (Cont.) Semi-synthetic corpora 1 Train a model using MCMC for each real corpora 2 Generate new documents using parameter trained. Performance metrics Reconstruction error: l 1 distance between a learned matrix  and the true matrix A. Held-out probability: probability of previously unseen documents under the learned model Coherence: Coherence(W ) = w 1,w 2 W log D(w 1, w 2 ) + ɛ D(w 2 ) where D(w) and D(w 1, w 2 ) are the number of documents with at least one instance of w, and of w 1 and w 2, respectively.
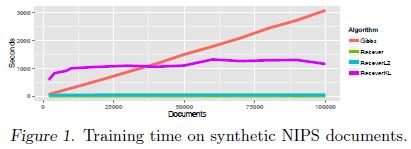
22 Semi-synthetic dataset 21
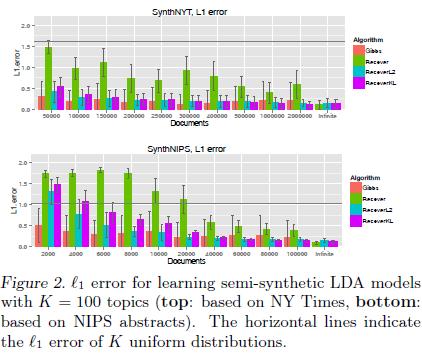
23 Semi-synthetic dataset 22

24 Semi-synthetic+Anchors dataset 23

25 24 Correlation Topics are correlated

26 Real Documents 25
27 26 References I Sanjeev Arora, Rong Ge, Yoni Halpern, David M. Mimno, Ankur Moitra, David Sontag, and Yichen Wu and Michael Zhu. A Practical Algorithm for Topic Modeling with Provable Guarantees. : Proceedings of the International Conference on Machine Learning (ICML). Vol. 28 (2). JMLR: W&CP, 2013, pp Sanjeev Arora, Rong Ge, and Ankur Moitra. Learning Topic Models Going beyond SVD. : Foundations of Computer Science (FOCS), 2012 IEEE 53rd Annual Symposium on. IEEE. 2012, pp Andrew Kachites McCallum. Mallet: A machine learning for language toolkit. (2002). u r l:
Robust Spectral Inference for Joint Stochastic Matrix Factorization
 Robust Spectral Inference for Joint Stochastic Matrix Factorization Kun Dong Cornell University October 20, 2016 K. Dong (Cornell University) Robust Spectral Inference for Joint Stochastic Matrix Factorization
Robust Spectral Inference for Joint Stochastic Matrix Factorization Kun Dong Cornell University October 20, 2016 K. Dong (Cornell University) Robust Spectral Inference for Joint Stochastic Matrix Factorization
A Practical Algorithm for Topic Modeling with Provable Guarantees
 Sanjeev Arora Rong Ge Yoni Halpern David Mimno Ankur Moitra David Sontag Yichen Wu Michael Zhu arora@cs.princeton.edu rongge@cs.princeton.edu halpern@cs.nyu.edu mimno@cs.princeton.edu moitra@ias.edu dsontag@cs.nyu.edu
Sanjeev Arora Rong Ge Yoni Halpern David Mimno Ankur Moitra David Sontag Yichen Wu Michael Zhu arora@cs.princeton.edu rongge@cs.princeton.edu halpern@cs.nyu.edu mimno@cs.princeton.edu moitra@ias.edu dsontag@cs.nyu.edu
Semidefinite Programming Based Preconditioning for More Robust Near-Separable Nonnegative Matrix Factorization
 Semidefinite Programming Based Preconditioning for More Robust Near-Separable Nonnegative Matrix Factorization Nicolas Gillis nicolas.gillis@umons.ac.be https://sites.google.com/site/nicolasgillis/ Department
Semidefinite Programming Based Preconditioning for More Robust Near-Separable Nonnegative Matrix Factorization Nicolas Gillis nicolas.gillis@umons.ac.be https://sites.google.com/site/nicolasgillis/ Department
Appendix A. Proof to Theorem 1
 Appendix A Proof to Theorem In this section, we prove the sample complexity bound given in Theorem The proof consists of three main parts In Appendix A, we prove perturbation lemmas that bound the estimation
Appendix A Proof to Theorem In this section, we prove the sample complexity bound given in Theorem The proof consists of three main parts In Appendix A, we prove perturbation lemmas that bound the estimation
Intersecting Faces: Non-negative Matrix Factorization With New Guarantees
 Rong Ge Microsoft Research New England James Zou Microsoft Research New England RONGGE@MICROSOFT.COM JAZO@MICROSOFT.COM Abstract Non-negative matrix factorization (NMF) is a natural model of admixture
Rong Ge Microsoft Research New England James Zou Microsoft Research New England RONGGE@MICROSOFT.COM JAZO@MICROSOFT.COM Abstract Non-negative matrix factorization (NMF) is a natural model of admixture
Topic Discovery through Data Dependent and Random Projections
 Weicong Ding dingwc@bu.edu Mohammad H. Rohban mhrohban@bu.edu Prakash Ishwar pi@bu.edu Venkatesh Saligrama srv@bu.edu Department of Electrical & Computer Engineering, Boston University, Boston, MA, USA
Weicong Ding dingwc@bu.edu Mohammad H. Rohban mhrohban@bu.edu Prakash Ishwar pi@bu.edu Venkatesh Saligrama srv@bu.edu Department of Electrical & Computer Engineering, Boston University, Boston, MA, USA
Learning SVM Classifiers with Indefinite Kernels
 Learning SVM Classifiers with Indefinite Kernels Suicheng Gu and Yuhong Guo Dept. of Computer and Information Sciences Temple University Support Vector Machines (SVMs) (Kernel) SVMs are widely used in
Learning SVM Classifiers with Indefinite Kernels Suicheng Gu and Yuhong Guo Dept. of Computer and Information Sciences Temple University Support Vector Machines (SVMs) (Kernel) SVMs are widely used in
Algorithms for Generalized Topic Modeling
 Algorithms for Generalized Topic Modeling Avrim Blum Toyota Technological Institute at Chicago avrim@ttic.edu Nika Haghtalab Computer Science Department Carnegie Mellon University nhaghtal@cs.cmu.edu Abstract
Algorithms for Generalized Topic Modeling Avrim Blum Toyota Technological Institute at Chicago avrim@ttic.edu Nika Haghtalab Computer Science Department Carnegie Mellon University nhaghtal@cs.cmu.edu Abstract
Linear dimensionality reduction for data analysis
 Linear dimensionality reduction for data analysis Nicolas Gillis Joint work with Robert Luce, François Glineur, Stephen Vavasis, Robert Plemmons, Gabriella Casalino The setup Dimensionality reduction for
Linear dimensionality reduction for data analysis Nicolas Gillis Joint work with Robert Luce, François Glineur, Stephen Vavasis, Robert Plemmons, Gabriella Casalino The setup Dimensionality reduction for
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY,
 WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 11, 2016 Paper presentations and final project proposal Send me the names of your group member (2 or 3 students) before October 15 (this Friday)
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Oct 11, 2016 Paper presentations and final project proposal Send me the names of your group member (2 or 3 students) before October 15 (this Friday)
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
Document and Topic Models: plsa and LDA
 Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Sparse and Robust Optimization and Applications
 Sparse and and Statistical Learning Workshop Les Houches, 2013 Robust Laurent El Ghaoui with Mert Pilanci, Anh Pham EECS Dept., UC Berkeley January 7, 2013 1 / 36 Outline Sparse Sparse Sparse Probability
Sparse and and Statistical Learning Workshop Les Houches, 2013 Robust Laurent El Ghaoui with Mert Pilanci, Anh Pham EECS Dept., UC Berkeley January 7, 2013 1 / 36 Outline Sparse Sparse Sparse Probability
Robust Statistics, Revisited
 Robust Statistics, Revisited Ankur Moitra (MIT) joint work with Ilias Diakonikolas, Jerry Li, Gautam Kamath, Daniel Kane and Alistair Stewart CLASSIC PARAMETER ESTIMATION Given samples from an unknown
Robust Statistics, Revisited Ankur Moitra (MIT) joint work with Ilias Diakonikolas, Jerry Li, Gautam Kamath, Daniel Kane and Alistair Stewart CLASSIC PARAMETER ESTIMATION Given samples from an unknown
Robustness Meets Algorithms
 Robustness Meets Algorithms Ankur Moitra (MIT) ICML 2017 Tutorial, August 6 th CLASSIC PARAMETER ESTIMATION Given samples from an unknown distribution in some class e.g. a 1-D Gaussian can we accurately
Robustness Meets Algorithms Ankur Moitra (MIT) ICML 2017 Tutorial, August 6 th CLASSIC PARAMETER ESTIMATION Given samples from an unknown distribution in some class e.g. a 1-D Gaussian can we accurately
On Identifiability of Nonnegative Matrix Factorization
 On Identifiability of Nonnegative Matrix Factorization Xiao Fu, Kejun Huang, and Nicholas D. Sidiropoulos Department of Electrical and Computer Engineering, University of Minnesota, Minneapolis, 55455,
On Identifiability of Nonnegative Matrix Factorization Xiao Fu, Kejun Huang, and Nicholas D. Sidiropoulos Department of Electrical and Computer Engineering, University of Minnesota, Minneapolis, 55455,
Sparse Stochastic Inference for Latent Dirichlet Allocation
 Sparse Stochastic Inference for Latent Dirichlet Allocation David Mimno 1, Matthew D. Hoffman 2, David M. Blei 1 1 Dept. of Computer Science, Princeton U. 2 Dept. of Statistics, Columbia U. Presentation
Sparse Stochastic Inference for Latent Dirichlet Allocation David Mimno 1, Matthew D. Hoffman 2, David M. Blei 1 1 Dept. of Computer Science, Princeton U. 2 Dept. of Statistics, Columbia U. Presentation
Algorithms for Generalized Topic Modeling
 Algorithms for Generalized Topic Modeling Avrim Blum Toyota Technological Institute at Chicago avrim@ttic.edu Nika Haghtalab Computer Science Department Carnegie Mellon University nhaghtal@cs.cmu.edu Abstract
Algorithms for Generalized Topic Modeling Avrim Blum Toyota Technological Institute at Chicago avrim@ttic.edu Nika Haghtalab Computer Science Department Carnegie Mellon University nhaghtal@cs.cmu.edu Abstract
Provable Alternating Gradient Descent for Non-negative Matrix Factorization with Strong Correlations
 Provable Alternating Gradient Descent for Non-negative Matrix Factorization with Strong Correlations Yuanzhi Li 1 Yingyu Liang 1 In this paper, we provide a theoretical analysis of a natural algorithm
Provable Alternating Gradient Descent for Non-negative Matrix Factorization with Strong Correlations Yuanzhi Li 1 Yingyu Liang 1 In this paper, we provide a theoretical analysis of a natural algorithm
Conic Scan-and-Cover algorithms for nonparametric topic modeling
 Conic Scan-and-Cover algorithms for nonparametric topic modeling Mikhail Yurochkin Department of Statistics University of Michigan moonfolk@umich.edu Aritra Guha Department of Statistics University of
Conic Scan-and-Cover algorithms for nonparametric topic modeling Mikhail Yurochkin Department of Statistics University of Michigan moonfolk@umich.edu Aritra Guha Department of Statistics University of
Evaluation Methods for Topic Models
 University of Massachusetts Amherst wallach@cs.umass.edu April 13, 2009 Joint work with Iain Murray, Ruslan Salakhutdinov and David Mimno Statistical Topic Models Useful for analyzing large, unstructured
University of Massachusetts Amherst wallach@cs.umass.edu April 13, 2009 Joint work with Iain Murray, Ruslan Salakhutdinov and David Mimno Statistical Topic Models Useful for analyzing large, unstructured
Beyond Log-concavity: Provable Guarantees for Sampling Multi-modal Distributions using Simulated Tempering Langevin Monte Carlo
 Beyond Log-concavity: Provable Guarantees for Sampling Multi-modal Distributions using Simulated Tempering Langevin Monte Carlo Rong Ge *, Holden Lee, Andrej Risteski Abstract A key task in Bayesian statistics
Beyond Log-concavity: Provable Guarantees for Sampling Multi-modal Distributions using Simulated Tempering Langevin Monte Carlo Rong Ge *, Holden Lee, Andrej Risteski Abstract A key task in Bayesian statistics
A Constraint Generation Approach to Learning Stable Linear Dynamical Systems
 A Constraint Generation Approach to Learning Stable Linear Dynamical Systems Sajid M. Siddiqi Byron Boots Geoffrey J. Gordon Carnegie Mellon University NIPS 2007 poster W22 steam Application: Dynamic Textures
A Constraint Generation Approach to Learning Stable Linear Dynamical Systems Sajid M. Siddiqi Byron Boots Geoffrey J. Gordon Carnegie Mellon University NIPS 2007 poster W22 steam Application: Dynamic Textures
Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine
 Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava nitish@cs.toronto.edu Ruslan Salahutdinov rsalahu@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu
Fast Inference and Learning for Modeling Documents with a Deep Boltzmann Machine Nitish Srivastava nitish@cs.toronto.edu Ruslan Salahutdinov rsalahu@cs.toronto.edu Geoffrey Hinton hinton@cs.toronto.edu
arxiv: v1 [cs.cl] 19 Nov 2017
![arxiv: v1 [cs.cl] 19 Nov 2017](/thumbs/73/68303012.jpg "arxiv: v1 [cs.cl] 19 Nov 2017") Prior-aware Dual Decomposition: Document-specific Topic Inference for Spectral Topic Models Moontae Lee 1 David Bindel 1 David Mimno 2 arxiv:1711.07065v1 [cs.cl] 19 Nov 2017 Abstract Spectral topic modeling
Prior-aware Dual Decomposition: Document-specific Topic Inference for Spectral Topic Models Moontae Lee 1 David Bindel 1 David Mimno 2 arxiv:1711.07065v1 [cs.cl] 19 Nov 2017 Abstract Spectral topic modeling
An Introduction to Spectral Learning
 An Introduction to Spectral Learning Hanxiao Liu November 8, 2013 Outline 1 Method of Moments 2 Learning topic models using spectral properties 3 Anchor words Preliminaries X 1,, X n p (x; θ), θ = (θ 1,
An Introduction to Spectral Learning Hanxiao Liu November 8, 2013 Outline 1 Method of Moments 2 Learning topic models using spectral properties 3 Anchor words Preliminaries X 1,, X n p (x; θ), θ = (θ 1,
Algorithmic Aspects of Machine Learning. Ankur Moitra
 Algorithmic Aspects of Machine Learning Ankur Moitra Contents Contents i Preface v 1 Introduction 3 2 Nonnegative Matrix Factorization 7 2.1 Introduction................................ 7 2.2 Algebraic
Algorithmic Aspects of Machine Learning Ankur Moitra Contents Contents i Preface v 1 Introduction 3 2 Nonnegative Matrix Factorization 7 2.1 Introduction................................ 7 2.2 Algebraic
Statistical Debugging with Latent Topic Models
 Statistical Debugging with Latent Topic Models David Andrzejewski, Anne Mulhern, Ben Liblit, Xiaojin Zhu Department of Computer Sciences University of Wisconsin Madison European Conference on Machine Learning,
Statistical Debugging with Latent Topic Models David Andrzejewski, Anne Mulhern, Ben Liblit, Xiaojin Zhu Department of Computer Sciences University of Wisconsin Madison European Conference on Machine Learning,
Combinatorial Topic Models using Small-Variance Asymptotics
 Ke Jiang Suvrit Sra Brian Kulis Ohio State University MIT Boston University Abstract Modern topic models typically have a probabilistic formulation, and derive their inference algorithms based on Latent
Ke Jiang Suvrit Sra Brian Kulis Ohio State University MIT Boston University Abstract Modern topic models typically have a probabilistic formulation, and derive their inference algorithms based on Latent
Nearest Neighbor Gaussian Processes for Large Spatial Data
 Nearest Neighbor Gaussian Processes for Large Spatial Data Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public Health, Johns
Nearest Neighbor Gaussian Processes for Large Spatial Data Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public Health, Johns
PROBABILISTIC LATENT SEMANTIC ANALYSIS
 PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 9 1 / 23 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 9 1 / 23 Overview
A Reduction for Efficient LDA Topic Reconstruction
 A Reduction for Efficient LDA Topic Reconstruction Matteo Almanza Sapienza University Rome, Italy almanza@di.uniroma1.it Flavio Chierichetti Sapienza University Rome, Italy flavio@di.uniroma1.it Alessandro
A Reduction for Efficient LDA Topic Reconstruction Matteo Almanza Sapienza University Rome, Italy almanza@di.uniroma1.it Flavio Chierichetti Sapienza University Rome, Italy flavio@di.uniroma1.it Alessandro
A Two-Level Learning Hierarchy of Nonnegative Matrix Factorization Based Topic Modeling for Main Topic Extraction
 A Two-Level Learning Hierarchy of Nonnegative Matrix Factorization Based Topic Modeling for Main Topic Extraction Hendri Murfi Department of Mathematics, Universitas Indonesia Depok 16424, Indonesia hendri@ui.ac.id
A Two-Level Learning Hierarchy of Nonnegative Matrix Factorization Based Topic Modeling for Main Topic Extraction Hendri Murfi Department of Mathematics, Universitas Indonesia Depok 16424, Indonesia hendri@ui.ac.id
CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization
 CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization Tim Roughgarden February 28, 2017 1 Preamble This lecture fulfills a promise made back in Lecture #1,
CS264: Beyond Worst-Case Analysis Lecture #15: Topic Modeling and Nonnegative Matrix Factorization Tim Roughgarden February 28, 2017 1 Preamble This lecture fulfills a promise made back in Lecture #1,
Sum-of-Squares Method, Tensor Decomposition, Dictionary Learning
 Sum-of-Squares Method, Tensor Decomposition, Dictionary Learning David Steurer Cornell Approximation Algorithms and Hardness, Banff, August 2014 for many problems (e.g., all UG-hard ones): better guarantees
Sum-of-Squares Method, Tensor Decomposition, Dictionary Learning David Steurer Cornell Approximation Algorithms and Hardness, Banff, August 2014 for many problems (e.g., all UG-hard ones): better guarantees
Non-negative Matrix Factorization under Heavy Noise
 Non-negative Matrix Factorization under Heavy Noise Chiranjib Bhattacharyya CHIRU@CSA.IISC.ERNET.IN Navin Goyal NAVINGO@MICROSOFT.COM Ravindran Kannan KANNAN@MICROSOFT.COM Jagdeep Pani PANI.JAGDEEP@GMAIL.COM
Non-negative Matrix Factorization under Heavy Noise Chiranjib Bhattacharyya CHIRU@CSA.IISC.ERNET.IN Navin Goyal NAVINGO@MICROSOFT.COM Ravindran Kannan KANNAN@MICROSOFT.COM Jagdeep Pani PANI.JAGDEEP@GMAIL.COM
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
CLOSE-TO-CLEAN REGULARIZATION RELATES
 Worshop trac - ICLR 016 CLOSE-TO-CLEAN REGULARIZATION RELATES VIRTUAL ADVERSARIAL TRAINING, LADDER NETWORKS AND OTHERS Mudassar Abbas, Jyri Kivinen, Tapani Raio Department of Computer Science, School of
Worshop trac - ICLR 016 CLOSE-TO-CLEAN REGULARIZATION RELATES VIRTUAL ADVERSARIAL TRAINING, LADDER NETWORKS AND OTHERS Mudassar Abbas, Jyri Kivinen, Tapani Raio Department of Computer Science, School of
Understanding Comments Submitted to FCC on Net Neutrality. Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014
 Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014") Understanding Comments Submitted to FCC on Net Neutrality Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014 Abstract We aim to understand and summarize themes in the 1.65 million
Understanding Comments Submitted to FCC on Net Neutrality Kevin (Junhui) Mao, Jing Xia, Dennis (Woncheol) Jeong December 12, 2014 Abstract We aim to understand and summarize themes in the 1.65 million
Learning sets and subspaces: a spectral approach
 Learning sets and subspaces: a spectral approach Alessandro Rudi DIBRIS, Università di Genova Optimization and dynamical processes in Statistical learning and inverse problems Sept 8-12, 2014 A world of
Learning sets and subspaces: a spectral approach Alessandro Rudi DIBRIS, Università di Genova Optimization and dynamical processes in Statistical learning and inverse problems Sept 8-12, 2014 A world of
Convex Optimization in Classification Problems
 New Trends in Optimization and Computational Algorithms December 9 13, 2001 Convex Optimization in Classification Problems Laurent El Ghaoui Department of EECS, UC Berkeley elghaoui@eecs.berkeley.edu 1
New Trends in Optimization and Computational Algorithms December 9 13, 2001 Convex Optimization in Classification Problems Laurent El Ghaoui Department of EECS, UC Berkeley elghaoui@eecs.berkeley.edu 1
Information retrieval LSI, plsi and LDA. Jian-Yun Nie
 Information retrieval LSI, plsi and LDA Jian-Yun Nie Basics: Eigenvector, Eigenvalue Ref: http://en.wikipedia.org/wiki/eigenvector For a square matrix A: Ax = λx where x is a vector (eigenvector), and
Information retrieval LSI, plsi and LDA Jian-Yun Nie Basics: Eigenvector, Eigenvalue Ref: http://en.wikipedia.org/wiki/eigenvector For a square matrix A: Ax = λx where x is a vector (eigenvector), and
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Online Nonnegative Matrix Factorization with General Divergences
 Online Nonnegative Matrix Factorization with General Divergences Vincent Y. F. Tan (ECE, Mathematics, NUS) Joint work with Renbo Zhao (NUS) and Huan Xu (GeorgiaTech) IWCT, Shanghai Jiaotong University
Online Nonnegative Matrix Factorization with General Divergences Vincent Y. F. Tan (ECE, Mathematics, NUS) Joint work with Renbo Zhao (NUS) and Huan Xu (GeorgiaTech) IWCT, Shanghai Jiaotong University
Computer Vision Group Prof. Daniel Cremers. 3. Regression
 Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Convergence Rates of Kernel Quadrature Rules
 Convergence Rates of Kernel Quadrature Rules Francis Bach INRIA - Ecole Normale Supérieure, Paris, France ÉCOLE NORMALE SUPÉRIEURE NIPS workshop on probabilistic integration - Dec. 2015 Outline Introduction
Convergence Rates of Kernel Quadrature Rules Francis Bach INRIA - Ecole Normale Supérieure, Paris, France ÉCOLE NORMALE SUPÉRIEURE NIPS workshop on probabilistic integration - Dec. 2015 Outline Introduction
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 89 Part II
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 89 Part II
Dictionary Learning Using Tensor Methods
 Dictionary Learning Using Tensor Methods Anima Anandkumar U.C. Irvine Joint work with Rong Ge, Majid Janzamin and Furong Huang. Feature learning as cornerstone of ML ML Practice Feature learning as cornerstone
Dictionary Learning Using Tensor Methods Anima Anandkumar U.C. Irvine Joint work with Rong Ge, Majid Janzamin and Furong Huang. Feature learning as cornerstone of ML ML Practice Feature learning as cornerstone
Non-convex Robust PCA: Provable Bounds
 Non-convex Robust PCA: Provable Bounds Anima Anandkumar U.C. Irvine Joint work with Praneeth Netrapalli, U.N. Niranjan, Prateek Jain and Sujay Sanghavi. Learning with Big Data High Dimensional Regime Missing
Non-convex Robust PCA: Provable Bounds Anima Anandkumar U.C. Irvine Joint work with Praneeth Netrapalli, U.N. Niranjan, Prateek Jain and Sujay Sanghavi. Learning with Big Data High Dimensional Regime Missing
Lecture 14: SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices) Lecturer: Sanjeev Arora
 Lecturer: Sanjeev Arora") princeton univ. F 13 cos 521: Advanced Algorithm Design Lecture 14: SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices) Lecturer: Sanjeev Arora Scribe: Today we continue the
princeton univ. F 13 cos 521: Advanced Algorithm Design Lecture 14: SVD, Power method, and Planted Graph problems (+ eigenvalues of random matrices) Lecturer: Sanjeev Arora Scribe: Today we continue the
ECE 598: Representation Learning: Algorithms and Models Fall 2017
 ECE 598: Representation Learning: Algorithms and Models Fall 2017 Lecture 1: Tensor Methods in Machine Learning Lecturer: Pramod Viswanathan Scribe: Bharath V Raghavan, Oct 3, 2017 11 Introduction Tensors
ECE 598: Representation Learning: Algorithms and Models Fall 2017 Lecture 1: Tensor Methods in Machine Learning Lecturer: Pramod Viswanathan Scribe: Bharath V Raghavan, Oct 3, 2017 11 Introduction Tensors
2.1 Optimization formulation of k-means
 MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016 Lecture 2: k-means Clustering Lecturer: Jiaming Xu Scribe: Jiaming Xu, September 2, 2016 Outline Optimization formulation of k-means Convergence
MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016 Lecture 2: k-means Clustering Lecturer: Jiaming Xu Scribe: Jiaming Xu, September 2, 2016 Outline Optimization formulation of k-means Convergence
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Privacy-Preserving Ridge Regression Without Garbled Circuits
 Privacy-Preserving Ridge Regression Without Garbled Circuits Marc Joye NXP Semiconductors, San Jose, USA marc.joye@nxp.com Abstract. Ridge regression is an algorithm that takes as input a large number
Privacy-Preserving Ridge Regression Without Garbled Circuits Marc Joye NXP Semiconductors, San Jose, USA marc.joye@nxp.com Abstract. Ridge regression is an algorithm that takes as input a large number
A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank
 A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank Shoaib Jameel Shoaib Jameel 1, Wai Lam 2, Steven Schockaert 1, and Lidong Bing 3 1 School of Computer Science and Informatics,
A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank Shoaib Jameel Shoaib Jameel 1, Wai Lam 2, Steven Schockaert 1, and Lidong Bing 3 1 School of Computer Science and Informatics,
Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM
 Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM Lee, Ching-pei University of Illinois at Urbana-Champaign Joint work with Dan Roth ICML 2015 Outline Introduction Algorithm Experiments
Distributed Box-Constrained Quadratic Optimization for Dual Linear SVM Lee, Ching-pei University of Illinois at Urbana-Champaign Joint work with Dan Roth ICML 2015 Outline Introduction Algorithm Experiments
Breaking the Limits of Subspace Inference
 Breaking the Limits of Subspace Inference Claudia R. Solís-Lemus, Daniel L. Pimentel-Alarcón Emory University, Georgia State University Abstract Inferring low-dimensional subspaces that describe high-dimensional,
Breaking the Limits of Subspace Inference Claudia R. Solís-Lemus, Daniel L. Pimentel-Alarcón Emory University, Georgia State University Abstract Inferring low-dimensional subspaces that describe high-dimensional,
Rank Selection in Low-rank Matrix Approximations: A Study of Cross-Validation for NMFs
 Rank Selection in Low-rank Matrix Approximations: A Study of Cross-Validation for NMFs Bhargav Kanagal Department of Computer Science University of Maryland College Park, MD 277 bhargav@cs.umd.edu Vikas
Rank Selection in Low-rank Matrix Approximations: A Study of Cross-Validation for NMFs Bhargav Kanagal Department of Computer Science University of Maryland College Park, MD 277 bhargav@cs.umd.edu Vikas
Bayesian Linear Regression [DRAFT - In Progress]
![Bayesian Linear Regression [DRAFT - In Progress]](/thumbs/92/109828713.jpg "Bayesian Linear Regression [DRAFT - In Progress]") Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Chapter 2: Linear Programming Basics. (Bertsimas & Tsitsiklis, Chapter 1)
") Chapter 2: Linear Programming Basics (Bertsimas & Tsitsiklis, Chapter 1) 33 Example of a Linear Program Remarks. minimize 2x 1 x 2 + 4x 3 subject to x 1 + x 2 + x 4 2 3x 2 x 3 = 5 x 3 + x 4 3 x 1 0 x 3
Chapter 2: Linear Programming Basics (Bertsimas & Tsitsiklis, Chapter 1) 33 Example of a Linear Program Remarks. minimize 2x 1 x 2 + 4x 3 subject to x 1 + x 2 + x 4 2 3x 2 x 3 = 5 x 3 + x 4 3 x 1 0 x 3
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Lecture 9: Low Rank Approximation
 CSE 521: Design and Analysis of Algorithms I Fall 2018 Lecture 9: Low Rank Approximation Lecturer: Shayan Oveis Gharan February 8th Scribe: Jun Qi Disclaimer: These notes have not been subjected to the
CSE 521: Design and Analysis of Algorithms I Fall 2018 Lecture 9: Low Rank Approximation Lecturer: Shayan Oveis Gharan February 8th Scribe: Jun Qi Disclaimer: These notes have not been subjected to the
ADVANCED MACHINE LEARNING ADVANCED MACHINE LEARNING. Non-linear regression techniques Part - II
 1 Non-linear regression techniques Part - II Regression Algorithms in this Course Support Vector Machine Relevance Vector Machine Support vector regression Boosting random projections Relevance vector
1 Non-linear regression techniques Part - II Regression Algorithms in this Course Support Vector Machine Relevance Vector Machine Support vector regression Boosting random projections Relevance vector
cross-language retrieval (by concatenate features of different language in X and find co-shared U). TOEFL/GRE synonym in the same way.
. TOEFL/GRE synonym in the same way.") 10-708: Probabilistic Graphical Models, Spring 2015 22 : Optimization and GMs (aka. LDA, Sparse Coding, Matrix Factorization, and All That ) Lecturer: Yaoliang Yu Scribes: Yu-Xiang Wang, Su Zhou 1 Introduction
10-708: Probabilistic Graphical Models, Spring 2015 22 : Optimization and GMs (aka. LDA, Sparse Coding, Matrix Factorization, and All That ) Lecturer: Yaoliang Yu Scribes: Yu-Xiang Wang, Su Zhou 1 Introduction
Introduction to Machine Learning
 Introduction to Machine Learning Logistic Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Logistic Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Stochastic Optimization for Deep CCA via Nonlinear Orthogonal Iterations
 Stochastic Optimization for Deep CCA via Nonlinear Orthogonal Iterations Weiran Wang Toyota Technological Institute at Chicago * Joint work with Raman Arora (JHU), Karen Livescu and Nati Srebro (TTIC)
Stochastic Optimization for Deep CCA via Nonlinear Orthogonal Iterations Weiran Wang Toyota Technological Institute at Chicago * Joint work with Raman Arora (JHU), Karen Livescu and Nati Srebro (TTIC)
Weighted Tensor Decomposition for Learning Latent Variables with Partial Data
 Weighted Tensor Decomposition for Learning Latent Variables with Partial Data Omer Gottesman Weiewei Pan Finale Doshi-Velez Paulson School of Engineering and Applied Sciences, Harvard University Paulson
Weighted Tensor Decomposition for Learning Latent Variables with Partial Data Omer Gottesman Weiewei Pan Finale Doshi-Velez Paulson School of Engineering and Applied Sciences, Harvard University Paulson
CSC2515 Winter 2015 Introduction to Machine Learning. Lecture 2: Linear regression
 CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction
 versus Local (LLE) Methods in Nonlinear Dimensionality Reduction") Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction A presentation by Evan Ettinger on a Paper by Vin de Silva and Joshua B. Tenenbaum May 12, 2005 Outline Introduction The
Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction A presentation by Evan Ettinger on a Paper by Vin de Silva and Joshua B. Tenenbaum May 12, 2005 Outline Introduction The
softened probabilistic
 Justin Solomon MIT Understand geometry from a softened probabilistic standpoint. Somewhere over here. Exactly here. One of these two places. Query 1 2 Which is closer, 1 or 2? Query 1 2 Which is closer,
Justin Solomon MIT Understand geometry from a softened probabilistic standpoint. Somewhere over here. Exactly here. One of these two places. Query 1 2 Which is closer, 1 or 2? Query 1 2 Which is closer,
Algorithms Reading Group Notes: Provable Bounds for Learning Deep Representations
 Algorithms Reading Group Notes: Provable Bounds for Learning Deep Representations Joshua R. Wang November 1, 2016 1 Model and Results Continuing from last week, we again examine provable algorithms for
Algorithms Reading Group Notes: Provable Bounds for Learning Deep Representations Joshua R. Wang November 1, 2016 1 Model and Results Continuing from last week, we again examine provable algorithms for
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
A Spectral Regularization Framework for Multi-Task Structure Learning
 A Spectral Regularization Framework for Multi-Task Structure Learning Massimiliano Pontil Department of Computer Science University College London (Joint work with A. Argyriou, T. Evgeniou, C.A. Micchelli,
A Spectral Regularization Framework for Multi-Task Structure Learning Massimiliano Pontil Department of Computer Science University College London (Joint work with A. Argyriou, T. Evgeniou, C.A. Micchelli,
Fantope Regularization in Metric Learning
 Fantope Regularization in Metric Learning CVPR 2014 Marc T. Law (LIP6, UPMC), Nicolas Thome (LIP6 - UPMC Sorbonne Universités), Matthieu Cord (LIP6 - UPMC Sorbonne Universités), Paris, France Introduction
Fantope Regularization in Metric Learning CVPR 2014 Marc T. Law (LIP6, UPMC), Nicolas Thome (LIP6 - UPMC Sorbonne Universités), Matthieu Cord (LIP6 - UPMC Sorbonne Universités), Paris, France Introduction
Multi-theme Sentiment Analysis using Quantified Contextual
 Multi-theme Sentiment Analysis using Quantified Contextual Valence Shifters Hongkun Yu, Jingbo Shang, MeichunHsu, Malú Castellanos, Jiawei Han Presented by Jingbo Shang University of Illinois at Urbana-Champaign
Multi-theme Sentiment Analysis using Quantified Contextual Valence Shifters Hongkun Yu, Jingbo Shang, MeichunHsu, Malú Castellanos, Jiawei Han Presented by Jingbo Shang University of Illinois at Urbana-Champaign
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model
 Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Tighter Low-rank Approximation via Sampling the Leveraged Element
 Tighter Low-rank Approximation via Sampling the Leveraged Element Srinadh Bhojanapalli The University of Texas at Austin bsrinadh@utexas.edu Prateek Jain Microsoft Research, India prajain@microsoft.com
Tighter Low-rank Approximation via Sampling the Leveraged Element Srinadh Bhojanapalli The University of Texas at Austin bsrinadh@utexas.edu Prateek Jain Microsoft Research, India prajain@microsoft.com
Maximum Likelihood Estimation in Latent Class Models for Contingency Table Data
 Maximum Likelihood Estimation in Latent Class Models for Contingency Table Data Stephen E. Fienberg Department of Statistics, Machine Learning Department, Cylab Carnegie Mellon University May 20, 2008
Maximum Likelihood Estimation in Latent Class Models for Contingency Table Data Stephen E. Fienberg Department of Statistics, Machine Learning Department, Cylab Carnegie Mellon University May 20, 2008
Random Sampling of Bandlimited Signals on Graphs
 Random Sampling of Bandlimited Signals on Graphs Pierre Vandergheynst École Polytechnique Fédérale de Lausanne (EPFL) School of Engineering & School of Computer and Communication Sciences Joint work with
Random Sampling of Bandlimited Signals on Graphs Pierre Vandergheynst École Polytechnique Fédérale de Lausanne (EPFL) School of Engineering & School of Computer and Communication Sciences Joint work with
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
GloVe: Global Vectors for Word Representation 1
 GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
Non-Negative Matrix Factorization
 Chapter 3 Non-Negative Matrix Factorization Part 2: Variations & applications Geometry of NMF 2 Geometry of NMF 1 NMF factors.9.8 Data points.7.6 Convex cone.5.4 Projections.3.2.1 1.5 1.5 1.5.5 1 3 Sparsity
Chapter 3 Non-Negative Matrix Factorization Part 2: Variations & applications Geometry of NMF 2 Geometry of NMF 1 NMF factors.9.8 Data points.7.6 Convex cone.5.4 Projections.3.2.1 1.5 1.5 1.5.5 1 3 Sparsity
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Simple, Efficient and Neural Algorithms for Sparse Coding
 Simple, Efficient and Neural Algorithms for Sparse Coding Ankur Moitra (MIT) joint work with Sanjeev Arora, Rong Ge and Tengyu Ma B. A. Olshausen, D. J. Field. Emergence of simple- cell recepnve field
Simple, Efficient and Neural Algorithms for Sparse Coding Ankur Moitra (MIT) joint work with Sanjeev Arora, Rong Ge and Tengyu Ma B. A. Olshausen, D. J. Field. Emergence of simple- cell recepnve field
Importance Reweighting Using Adversarial-Collaborative Training
 Importance Reweighting Using Adversarial-Collaborative Training Yifan Wu yw4@andrew.cmu.edu Tianshu Ren tren@andrew.cmu.edu Lidan Mu lmu@andrew.cmu.edu Abstract We consider the problem of reweighting a
Importance Reweighting Using Adversarial-Collaborative Training Yifan Wu yw4@andrew.cmu.edu Tianshu Ren tren@andrew.cmu.edu Lidan Mu lmu@andrew.cmu.edu Abstract We consider the problem of reweighting a
Recovery of anisotropic metrics from travel times
 Purdue University The Lens Rigidity and the Boundary Rigidity Problems Let M be a bounded domain with boundary. Let g be a Riemannian metric on M. Define the scattering relation σ and the length (travel
Purdue University The Lens Rigidity and the Boundary Rigidity Problems Let M be a bounded domain with boundary. Let g be a Riemannian metric on M. Define the scattering relation σ and the length (travel
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
20: Gaussian Processes
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 20: Gaussian Processes Lecturer: Andrew Gordon Wilson Scribes: Sai Ganesh Bandiatmakuri 1 Discussion about ML Here we discuss an introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2016 20: Gaussian Processes Lecturer: Andrew Gordon Wilson Scribes: Sai Ganesh Bandiatmakuri 1 Discussion about ML Here we discuss an introduction
Ankur Moitra. c Draft date March 30, Algorithmic Aspects of Machine Learning
 Algorithmic Aspects of Machine Learning Ankur Moitra c Draft date March 30, 2014 Algorithmic Aspects of Machine Learning 2015 by Ankur Moitra. Note: These are unpolished, incomplete course notes. Developed
Algorithmic Aspects of Machine Learning Ankur Moitra c Draft date March 30, 2014 Algorithmic Aspects of Machine Learning 2015 by Ankur Moitra. Note: These are unpolished, incomplete course notes. Developed
Learning Topic Models Going beyond SVD
 Learning Topic Models Going beyond SVD Sanjeev Arora Rong Ge Ankur Moitra April 11, 2012 arxiv:1204.1956v2 [cs.lg] 10 Apr 2012 Abstract Topic Modeling is an approach used for automatic comprehension and
Learning Topic Models Going beyond SVD Sanjeev Arora Rong Ge Ankur Moitra April 11, 2012 arxiv:1204.1956v2 [cs.lg] 10 Apr 2012 Abstract Topic Modeling is an approach used for automatic comprehension and
Bias-Variance Trade-Off in Hierarchical Probabilistic Models Using Higher-Order Feature Interactions
 - Trade-Off in Hierarchical Probabilistic Models Using Higher-Order Feature Interactions Simon Luo The University of Sydney Data61, CSIRO simon.luo@data61.csiro.au Mahito Sugiyama National Institute of
- Trade-Off in Hierarchical Probabilistic Models Using Higher-Order Feature Interactions Simon Luo The University of Sydney Data61, CSIRO simon.luo@data61.csiro.au Mahito Sugiyama National Institute of
Unsupervised Learning with Permuted Data
 Unsupervised Learning with Permuted Data Sergey Kirshner skirshne@ics.uci.edu Sridevi Parise sparise@ics.uci.edu Padhraic Smyth smyth@ics.uci.edu School of Information and Computer Science, University
Unsupervised Learning with Permuted Data Sergey Kirshner skirshne@ics.uci.edu Sridevi Parise sparise@ics.uci.edu Padhraic Smyth smyth@ics.uci.edu School of Information and Computer Science, University
Modeling Environment
 Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
An Extended Frank-Wolfe Method, with Application to Low-Rank Matrix Completion
 An Extended Frank-Wolfe Method, with Application to Low-Rank Matrix Completion Robert M. Freund, MIT joint with Paul Grigas (UC Berkeley) and Rahul Mazumder (MIT) CDC, December 2016 1 Outline of Topics
An Extended Frank-Wolfe Method, with Application to Low-Rank Matrix Completion Robert M. Freund, MIT joint with Paul Grigas (UC Berkeley) and Rahul Mazumder (MIT) CDC, December 2016 1 Outline of Topics
Andriy Mnih and Ruslan Salakhutdinov
 MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative
MATRIX FACTORIZATION METHODS FOR COLLABORATIVE FILTERING Andriy Mnih and Ruslan Salakhutdinov University of Toronto, Machine Learning Group 1 What is collaborative filtering? The goal of collaborative