GloVe: Global Vectors for Word Representation 1
|
|
|
- Anis Kennedy
- 6 years ago
- Views:
Transcription
1 GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun
2 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results
3 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results
4 One-hot Vectors Words as discrete units.
5 One-hot Vectors Words as discrete units. Represent as one-hot vectors. Example Let our lexicon be: {king, queen, man, woman} king [1, 0, 0, 0] queen [0, 1, 0, 0] man [0, 0, 1, 0] woman [0, 0, 0, 1]
6 One-hot Vectors Words as discrete units. Represent as one-hot vectors. Example Let our lexicon be: {king, queen, man, woman} king [1, 0, 0, 0] queen [0, 1, 0, 0] man [0, 0, 1, 0] woman [0, 0, 0, 1] What would the dot product of the king vector and queen vector be?
7 One-hot Vectors Can we reduce the size of this space from R V to something smaller and thus find a subspace that encodes the relationships between words?
8 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results
9 Co-occurrence Matrix You shall know a word by the company it keeps. - Firth, J. R. Papers in Linguistics, 1957.
10 Co-occurrence Matrix You shall know a word by the company it keeps. - Firth, J. R. Papers in Linguistics, Example Let our corpus be: I like deep learning. I like NLP. I enjoy flying.
11 Word Vectors Co-occurrence Matrix counts I like enjoy deep learning NLP flying. I like enjoy deep learning NLP flying
12 How to make neighbours represent words? Use a co-occurrence matrix X : word-document (Latent Semantic Analysis) word-window (both syntactic and semantic information)
13 Drawbacks of simple cooccurence vectors increase in size with vocabulary very high dimensional sparsity issues
14 Low dimensional vectors Store most of the information in a fixed, small number of dimensions: a dense vector.
15 Low dimensional vectors Store most of the information in a fixed, small number of dimensions: a dense vector. Two possible solutions: Singular Value Decomposition (SVD) based methods // count based prediction Iteration based methods // direct prediction
16 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results
17 SVD 2 Dimensionality Reduction on X 2
18 SVD Model disadvantages The dimensions of the matrix change very often (new words are added very frequently and corpus changes in size). The matrix is extremely sparse since most words do not co-occur. Quadratic cost to train. Requires the incorporation of some hacks on X to account for the drastic imbalance in word frequency.
19 SVD Model disadvantages The dimensions of the matrix change very often (new words are added very frequently and corpus changes in size). The matrix is extremely sparse since most words do not co-occur. Quadratic cost to train. Requires the incorporation of some hacks on X to account for the drastic imbalance in word frequency. Iteration based methods solve many of these issues in a far more elegant manner.
20 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results
21 Neural networks and word embedding The main idea of our model is to predict between a center word w t and context words in terms of word which has a loss function p(context w t ) =... J = 1 p(w t w t ) We will be adjusting the vector representations of words to minimize the loss
22 History of directly learning low-dimensional word vectors Learning representations by back-propagating errors (Rumelhart et al., 1986) A neural probabilistic language model (Bengio et al., 2003) NLP (almost) from Scratch (Collobert & Watson, 2008) Distributed Representations of Words and Phrases and their Compositionality(Mikolov et al., 2013) - word2vec
23 History of directly learning low-dimensional word vectors Learning representations by back-propagating errors (Rumelhart et al., 1986) A neural probabilistic language model (Bengio et al., 2003) NLP (almost) from Scratch (Collobert & Watson, 2008) Distributed Representations of Words and Phrases and their Compositionality(Mikolov et al., 2013) - word2vec
24 word2vec Main idea Predict between every word and its context words.
25 word2vec Main idea Predict between every word and its context words. Skip-grams(SG) Predicting surrounding context words given a center word.
26 word2vec Main idea Predict between every word and its context words. Skip-grams(SG) Predicting surrounding context words given a center word. Continuous Bag of Words (CBOW) Predicting a center word form the surrounding context.
27 word2vec Main idea Predict between every word and its context words. Skip-grams(SG) Predicting surrounding context words given a center word Continuous Bag of Words (CBOW) Predicting a center word form the surrounding context
28 word2vec Skip-gram prediction


29 word2vec Skip-gram prediction 3 3
30 word2vec Question How many vectors represent each word?
31 word2vec Objective function Idea: Maximize the probability of any context word given the current center word: J (θ) = T t=1 m j m, j 0 p(w t+j w t ; θ) T - our text(corpus). For each word t=1...t, we try to predict surrounding words m - size of our window θ represents all variables we will optimize
32 word2vec Negative Log Likelihood J (θ) = T t=1 m j m, j 0 p(w t+j w t ) J(θ) = 1 T T t=1 m j m, j 0 log p(w t+j w t )
33 word2vec Negative Log Likelihood J (θ) = T t=1 m j m, j 0 p(w t+j w t ) J(θ) = 1 T T t=1 m j m, j 0 log p(w t+j w t )
34 word2vec For p(w t+j w t ) the simplest formulation is p(o c) = exp(u o T v c ) V W =1 exp(u w T v c ) o - outside word index c - center word index v c - center vector of index c u o - outside vector of index o
35
36 4 4
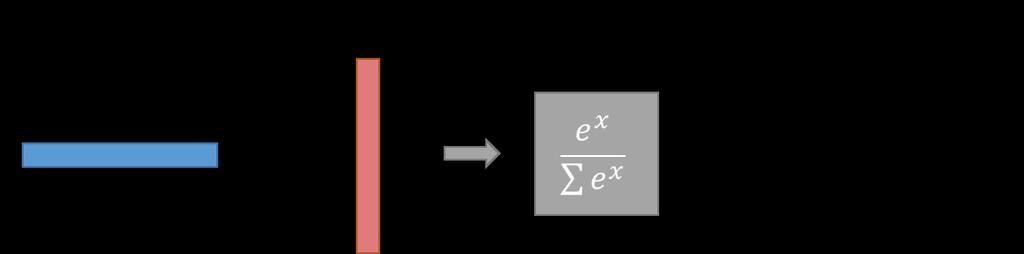
37 Output Layer 5 5
38 word2vec Training the model Compute all vector gradients. We define the set of all parameters in a model in terms of one long vector θ. d - dimension of each vector V - number of words θ = v a.. v zebra u a.. u zebra R 2dV
39 word2vec Gradient Descent To minimize J(θ) over the entire training data would require us to compute gradients for all windows: θ new j = θ old j α θj old J(θ) Using matrix notation θ new = θ old α J(θ) θold θ new = θ old α θ J(θ)
40 word2vec Skip-gram model and negative sampling J t (θ) = log σ(u T o v c ) + k E j P(w) [log σ( uj T v c )] i=1 k - number of negative samples σ(x) - sigmoid function we maximize the probability of two words co-occuring in first log
41 word2vec Skip-gram model and negative sampling Clearer notation: J t (θ) = log σ(uo T v c ) + [log σ( uj T v c )] j P(w)
42 Count based and Direct prediction
43 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results
44 Basics Notation X word-word co-occurrence counts X ij frequency of j occurring in context of i X i = k X ik frequency of word in context of i P ij = P(j i) = X ij /X i probability that word j appears in the context of word i
45 Basics Meaning Extraction Selected co-occurrence probabilities from a 6 billion token corpus Probability and Ratio k = solid k = gas k = water k = fashion P(k ice) P(k steam) P(k ice)/p(k steam)
46 Basics Meaning Extraction Selected co-occurrence probabilities from a 6 billion token corpus Probability and Ratio k = solid k = gas k = water k = fashion P(k ice) P(k steam) P(k ice)/p(k steam) Starting point for word vector learning?
47 Basics Meaning Extraction Selected co-occurrence probabilities from a 6 billion token corpus Probability and Ratio k = solid k = gas k = water k = fashion P(k ice) P(k steam) P(k ice)/p(k steam) Starting point for word vector learning? Ratios of co-occurrence probabilities instead of probabilities themselves.
48 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results
49 The Model Objective Function J = V i,j=1 f (X ij )(w T i w j + b i + b j log(x ij )) where V is the size of the vocabulary.
50 The Model Most General Form F (w i, w j, w k ) = P ik P jk where w R d are word vectors and w R d are separate context word vectors. P ik P jk is extracted from the corpus.
51 The Model Most General Form F (w i, w j, w k ) = P ik P jk where w R d are word vectors and w R d are separate context word vectors. P ik P jk is extracted from the corpus. For F, encode the information from P ik P jk in the word vector space.
52 The Model F (w i, w j, w k ) = P ik P jk
53 The Model F (w i, w j, w k ) = P ik P jk F (w i w j, w k ) = P ik P jk so that we can restrict to the difference of the two target words.
54 The Model F (w i, w j, w k ) = P ik P jk F (w i w j, w k ) = P ik P jk so that we can restrict to the difference of the two target words. Notice that LHS are vectors while RHS is a scalar.
55 The Model F (w i, w j, w k ) = P ik P jk F (w i w j, w k ) = P ik P jk so that we can restrict to the difference of the two target words. Notice that LHS are vectors while RHS is a scalar. Solution: take the dot product of the arguments.
56 The Model F (w i, w j, w k ) = P ik P jk F (w i w j, w k ) = P ik P jk so that we can restrict to the difference of the two target words. Notice that LHS are vectors while RHS is a scalar. Solution: take the dot product of the arguments. F ((w i w j ) T w k ) = P ik P jk
57 The Model F (w i, w j, w k ) = P ik P jk F (w i w j, w k ) = P ik P jk so that we can restrict to the difference of the two target words. Notice that LHS are vectors while RHS is a scalar. Solution: take the dot product of the arguments. F ((w i w j ) T w k ) = P ik P jk For word-word co-occurrence matrices, word and context word are interchangeable.
58 The Model F (w i, w j, w k ) = P ik P jk F (w i w j, w k ) = P ik P jk so that we can restrict to the difference of the two target words. Notice that LHS are vectors while RHS is a scalar. Solution: take the dot product of the arguments. F ((w i w j ) T w k ) = P ik P jk For word-word co-occurrence matrices, word and context word are interchangeable. Exchange w w and X X T.
59 The Model F (w i, w j, w k ) = P ik P jk F (w i w j, w k ) = P ik P jk so that we can restrict to the difference of the two target words. Notice that LHS are vectors while RHS is a scalar. Solution: take the dot product of the arguments. F ((w i w j ) T w k ) = P ik P jk For word-word co-occurrence matrices, word and context word are interchangeable. Exchange w w and X X T. However, doing so does not make the model invariant.
60 The Model To restore the symmetry:
61 The Model To restore the symmetry: F must be a homomorphism between the groups (R, +) and (R >0, ): F ((w i w j ) T w k ) = F (w T i w k ) F (wj T w k )
62 The Model To restore the symmetry: F must be a homomorphism between the groups (R, +) and (R >0, ): F ((w i w j ) T w k ) = F (w T i w k ) F (w T i w k ) = P ik = X ik X i F (wj T w k ) from F ((w i w j ) T w k ) = P ik P jk
63 The Model To restore the symmetry: F must be a homomorphism between the groups (R, +) and (R >0, ): F ((w i w j ) T w k ) = F (w T i w k ) F (w T i w k ) = P ik = X ik X i F (wj T w k ) from F ((w i w j ) T w k ) = P ik P jk F = exp or w T i w k = log(p ik ) = log(x ik ) log(x i )
64 The Model To restore the symmetry: F must be a homomorphism between the groups (R, +) and (R >0, ): F ((w i w j ) T w k ) = F (w T i w k ) F (w T i F (wj T w k ) w k ) = P ik = X ik X i from F ((w i w j ) T w k ) = P ik P jk i w k = log(p ik ) = log(x ik ) log(x i ) F = exp or w T Remove log(xi ) from RHS. But this term is also independent of k so it can be absorbed into a bias b i for w i : wi T w k + b i
65 The Model To restore the symmetry: F must be a homomorphism between the groups (R, +) and (R >0, ): F ((w i w j ) T w k ) = F (w T i w k ) F (w T i F (wj T w k ) w k ) = P ik = X ik X i from F ((w i w j ) T w k ) = P ik P jk i w k = log(p ik ) = log(x ik ) log(x i ) F = exp or w T Remove log(xi ) from RHS. But this term is also independent of k so it can be absorbed into a bias b i for w i : wi T w k + b i Add a bias for wk : wi T w k + b i + b k
66 The Model To restore the symmetry: F must be a homomorphism between the groups (R, +) and (R >0, ): F ((w i w j ) T w k ) = F (w T i w k ) F (w T i F (wj T w k ) w k ) = P ik = X ik X i from F ((w i w j ) T w k ) = P ik P jk i w k = log(p ik ) = log(x ik ) log(x i ) F = exp or w T Remove log(xi ) from RHS. But this term is also independent of k so it can be absorbed into a bias b i for w i : wi T w k + b i Add a bias for wk : wi T w k + b i + b k Finally, wi T w k + b i + b k = log(x ik )
67 The Model w T i w k + b i + b k = log(x ik )
68 The Model w T i w k + b i + b k = log(x ik ) A simplification over F (w i, w j, w k ) = P ik P jk.
69 The Model w T i w k + b i + b k = log(x ik ) A simplification over F (w i, w j, w k ) = P ik P jk. Add an additive shift log(xik ) log(1 + X ik ) to maintain sparsity of X and avoid divergences.
70 The Model w T i w k + b i + b k = log(x ik ) A simplification over F (w i, w j, w k ) = P ik P jk. Add an additive shift log(xik ) log(1 + X ik ) to maintain sparsity of X and avoid divergences. What are the drawbacks to this model?
71 The Model w T i w k + b i + b k = log(x ik ) A simplification over F (w i, w j, w k ) = P ik P jk. Add an additive shift log(xik ) log(1 + X ik ) to maintain sparsity of X and avoid divergences. What are the drawbacks to this model? It weighs all co-occurrences, rare and non-existent ones, equally. Cast the above equation as a least squares problem with a weighting function f (X ij ).
72 The Model Using Least Squares Regression J = V i,j=1 f (X ij )(w T i w k + b i + b j log(x ij )) 2 where V is the size of the vocabulary.
73 The Model Properties of The Weighting Function f (0) = 0. If f is viewed as a continuous function, it should vanish as x 0 fast enough that the lim x 0 f (x)log 2 x is infinite. Xij are co-occurrence counts which are in N 0. If X ij is zero, the logarithm diverges. GloVe trains only on nonzero elements. f (x) should be non-decreasing so that rare co-occurrences are not overweighted. f (x) should be relatively small for large values of x, so that frequent co-occurrences are not overweighted.
74 The Model The Weighting Function f (x) = { (x/x max ) α if x < x max 1 otherwise. x max = 100 for the group s experiments.
75 The Model The Weighting Function f (x) = { (x/x max ) α if x < x max 1 otherwise. x max = 100 for the group s experiments. α = 3/4 Figure: α = 3/4. From Pennington et al 2014, 4.
76 The Model Relation to Skip-gram Softmax model for skip-gram is Q ij = probability that word j appears in context i. exp(w i T w j ) V k=1 exp(w i T w k ) for the
77 The Model Relation to Skip-gram Softmax model for skip-gram is Q ij = probability that word j appears in context i. The implied global objective function is J = logq ij i corpus j context(i) exp(w i T w j ) V k=1 exp(w i T w k ) for the
78 The Model Relation to Skip-gram Softmax model for skip-gram is Q ij = probability that word j appears in context i. The implied global objective function is J = logq ij i corpus j context(i) exp(w i T w j ) V k=1 exp(w i T w k ) for the However, the sum above can be much more efficient: V V J = X ij logq ij i=1 j=1
79 The Model Relation to Skip-gram Softmax model for skip-gram is Q ij = probability that word j appears in context i. The implied global objective function is J = logq ij i corpus j context(i) exp(w i T w j ) V k=1 exp(w i T w k ) for the However, the sum above can be much more efficient: V V J = X ij logq ij i=1 j=1 Recall that X i = k X ik and P ij = P(j i) = X ij /X i
80 The Model Relation to Skip-gram We can rewrite J as J = V i=1 X i V j=1 P ij logq ij = V X i H(P i, Q i ) i=1 where H(P i, Q i ) is the cross entropy of distributions P i and Q i.
81 The Model Relation to Skip-gram We can rewrite J as J = V i=1 X i V j=1 P ij logq ij = V X i H(P i, Q i ) i=1 where H(P i, Q i ) is the cross entropy of distributions P i and Q i. However, cross entropy error is not ideal. Why?
82 The Model Relation to Skip-gram We can rewrite J as J = V i=1 X i V j=1 P ij logq ij = V X i H(P i, Q i ) i=1 where H(P i, Q i ) is the cross entropy of distributions P i and Q i. However, cross entropy error is not ideal. Why? Distributions with long tails are modeled poorly and computational bottleneck.
83 The Model Relation to Skip-gram In a least squares objective, discard normalization factors in Q and P J ˆ= X i ( ˆP ij ˆQ ij ) 2 i,j where ˆP ij = X ij and ˆQ ij = exp(w T i w j ).
84 The Model Relation to Skip-gram In a least squares objective, discard normalization factors in Q and P J ˆ= X i ( ˆP ij ˆQ ij ) 2 i,j where ˆP ij = X ij and ˆQ ij = exp(w T i w j ). Another problem!
85 The Model Relation to Skip-gram In a least squares objective, discard normalization factors in Q and P J ˆ= X i ( ˆP ij ˆQ ij ) 2 i,j where ˆP ij = X ij and ˆQ ij = exp(w T i w j ). Another problem! X ij often takes very large values. Minimize the squared error of the logarithms of ˆP and ˆQ ˆ J = i,j X i (log ˆP ij log ˆQ ij ) 2 = i,j X i (w T i w j logx ij ) 2
86 The Model Relation to Skip-gram ˆ J = i,j f (X ij )(w T i w j logx ij ) 2 which is equivalent to the cost function J = V i,j=1 f (X ij )(w T i w k + b i + b j log(x ij ))
87 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results
88 Intrinsic Evaluation Comparing Intrinsic and Extrinsic Evaluations 6 Intrinsic Evaluation The evaluation of a set of word vectors generated by an embedding technique (such as Word2Vec or GloVe) on specific intermediate subtasks (such as analogy completion). Evaluation on specific subtask Fast to compute performance Helps understand subsystem Needs positive correlation with real task to determine usefulness 6 Mundra, Socher
89 Intrinsic Evaluation Comparing Intrinsic and Extrinsic Evaluations 7 Extrinsic Evaluation The evaluation of a set of word vectors generated by an embedding technique on the real task at hand. Evaluation on a real task Can be slow to compute performance Unclear if subsystem is the problem, other subsystems, or internal interactions If replacing subsystem improves performance, the change is likely good 7 Mundra, Socher
90 Intrinsic Evaluation Example Performance in completing word vector analogies. a : b :: c :?
91 Outline Background One-hot Vectors Co-occurrence Matrix SVD word2vec GloVe Basics The Model Intrinsic Evaluation Results

92 Nearest neighbors 8 The closest words to the target word frog: frogs toad litoria leptodactylidae rana 8
93 Word analogies 9 9
94 Glove Visualization 10 man-woman 10
95 Glove Visualization 11 comparative-superlative 11

96 Results on the word analogy task, given as percent accuracy
97 GloVe vs Skip-Gram

98 Accuracy on the analogy task for 300- dimensional vectors trained on different corpora
99 Conclusion GloVe, is a new global log-bilinear regression model for the unsupervised learning of word representations that outperforms other models on word analogy, word similarity, and named entity recognition tasks.
100 Further Reading T. Mikolov, K. Chen, G. Corrado, J. Dean. Efficient Estimation of Word Representations in Vector Space International Conference on Learning Representations, E. Huang, R. Socher, C.D. Manning, A. Ng. Improving Word Representations via Global Context and Multiple Word Prototypes Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, , 2012.
Neural Word Embeddings from Scratch
 Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Natural Language Processing
 Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
The representation of word and sentence
 2vec Jul 4, 2017 Presentation Outline 2vec 1 2 2vec 3 4 5 6 discrete representation taxonomy:wordnet Example:good 2vec Problems 2vec synonyms: adept,expert,good It can t keep up to date It can t accurate
2vec Jul 4, 2017 Presentation Outline 2vec 1 2 2vec 3 4 5 6 discrete representation taxonomy:wordnet Example:good 2vec Problems 2vec synonyms: adept,expert,good It can t keep up to date It can t accurate
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
DISTRIBUTIONAL SEMANTICS
 COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
Deep Learning. Ali Ghodsi. University of Waterloo
 University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
Word Embeddings 2 - Class Discussions
 Word Embeddings 2 - Class Discussions Jalaj February 18, 2016 Opening Remarks - Word embeddings as a concept are intriguing. The approaches are mostly adhoc but show good empirical performance. Paper 1
Word Embeddings 2 - Class Discussions Jalaj February 18, 2016 Opening Remarks - Word embeddings as a concept are intriguing. The approaches are mostly adhoc but show good empirical performance. Paper 1
An overview of word2vec
 An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
Deep Learning Basics Lecture 10: Neural Language Models. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
CS224n: Natural Language Processing with Deep Learning 1
 CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CME323 Distributed Algorithms and Optimization. GloVe on Spark. Alex Adamson SUNet ID: aadamson. June 6, 2016
 GloVe on Spark Alex Adamson SUNet ID: aadamson June 6, 2016 Introduction Pennington et al. proposes a novel word representation algorithm called GloVe (Global Vectors for Word Representation) that synthesizes
GloVe on Spark Alex Adamson SUNet ID: aadamson June 6, 2016 Introduction Pennington et al. proposes a novel word representation algorithm called GloVe (Global Vectors for Word Representation) that synthesizes
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
arxiv: v3 [cs.cl] 30 Jan 2016
![arxiv: v3 [cs.cl] 30 Jan 2016](/thumbs/72/66377864.jpg "arxiv: v3 [cs.cl] 30 Jan 2016") word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Deep Learning for NLP Part 2
 Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Distributional Semantics and Word Embeddings. Chase Geigle
 Distributional Semantics and Word Embeddings Chase Geigle 2016-10-14 1 What is a word? dog 2 What is a word? dog canine 2 What is a word? dog canine 3 2 What is a word? dog 3 canine 399,999 2 What is a
Distributional Semantics and Word Embeddings Chase Geigle 2016-10-14 1 What is a word? dog 2 What is a word? dog canine 2 What is a word? dog canine 3 2 What is a word? dog 3 canine 399,999 2 What is a
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Lecture 6: Neural Networks for Representing Word Meaning
 Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
CS224n: Natural Language Processing with Deep Learning 1
 CS224n: Natural Language Processing with Deep Learning 1 Lecture Notes: Part I 2 Winter 2017 1 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume
CS224n: Natural Language Processing with Deep Learning 1 Lecture Notes: Part I 2 Winter 2017 1 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Homework 3 COMS 4705 Fall 2017 Prof. Kathleen McKeown
 Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Natural Language Processing with Deep Learning CS224N/Ling284. Richard Socher Lecture 2: Word Vectors
 Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
Word2Vec Embedding. Embedding. Word Embedding 1.1 BEDORE. Word Embedding. 1.2 Embedding. Word Embedding. Embedding.
 c Word Embedding Embedding Word2Vec Embedding Word EmbeddingWord2Vec 1. Embedding 1.1 BEDORE 0 1 BEDORE 113 0033 2 35 10 4F y katayama@bedore.jp Word Embedding Embedding 1.2 Embedding Embedding Word Embedding
c Word Embedding Embedding Word2Vec Embedding Word EmbeddingWord2Vec 1. Embedding 1.1 BEDORE 0 1 BEDORE 113 0033 2 35 10 4F y katayama@bedore.jp Word Embedding Embedding 1.2 Embedding Embedding Word Embedding
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning: A Statistical Perspective
 Introduction Deep Learning: A Statistical Perspective Myunghee Cho Paik Guest lectures by Gisoo Kim, Yongchan Kwon, Young-geun Kim, Wonyoung Kim and Youngwon Choi Seoul National University March-June,
Introduction Deep Learning: A Statistical Perspective Myunghee Cho Paik Guest lectures by Gisoo Kim, Yongchan Kwon, Young-geun Kim, Wonyoung Kim and Youngwon Choi Seoul National University March-June,
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
Neural Networks for NLP. COMP-599 Nov 30, 2016
 Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Bayesian Paragraph Vectors
 Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
arxiv: v2 [cs.cl] 1 Jan 2019
![arxiv: v2 [cs.cl] 1 Jan 2019](/thumbs/93/111679653.jpg "arxiv: v2 [cs.cl] 1 Jan 2019") Variational Self-attention Model for Sentence Representation arxiv:1812.11559v2 [cs.cl] 1 Jan 2019 Qiang Zhang 1, Shangsong Liang 2, Emine Yilmaz 1 1 University College London, London, United Kingdom 2
Variational Self-attention Model for Sentence Representation arxiv:1812.11559v2 [cs.cl] 1 Jan 2019 Qiang Zhang 1, Shangsong Liang 2, Emine Yilmaz 1 1 University College London, London, United Kingdom 2
Neural Networks Language Models
 Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Lecture 7: Word Embeddings
 Lecture 7: Word Embeddings Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 6501 Natural Language Processing 1 This lecture v Learning word vectors
Lecture 7: Word Embeddings Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 6501 Natural Language Processing 1 This lecture v Learning word vectors
Embeddings Learned By Matrix Factorization
 Embeddings Learned By Matrix Factorization Benjamin Roth; Folien von Hinrich Schütze Center for Information and Language Processing, LMU Munich Overview WordSpace limitations LinAlgebra review Input matrix
Embeddings Learned By Matrix Factorization Benjamin Roth; Folien von Hinrich Schütze Center for Information and Language Processing, LMU Munich Overview WordSpace limitations LinAlgebra review Input matrix
Seman&cs with Dense Vectors. Dorota Glowacka
 Semancs with Dense Vectors Dorota Glowacka dorota.glowacka@ed.ac.uk Previous lectures: - how to represent a word as a sparse vector with dimensions corresponding to the words in the vocabulary - the values
Semancs with Dense Vectors Dorota Glowacka dorota.glowacka@ed.ac.uk Previous lectures: - how to represent a word as a sparse vector with dimensions corresponding to the words in the vocabulary - the values
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Language Models. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Language Models Tobias Scheffer Stochastic Language Models A stochastic language model is a probability distribution over words.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Language Models Tobias Scheffer Stochastic Language Models A stochastic language model is a probability distribution over words.
Machine Learning for Smart Learners
 Department of Computer Science Instituto de Matemathics and Statistics University of Sao Paulo, Brazil Sao Paulo School of Advanced Science on Smart Cities 2017 What Is All This Fuss About Machine Learning?
Department of Computer Science Instituto de Matemathics and Statistics University of Sao Paulo, Brazil Sao Paulo School of Advanced Science on Smart Cities 2017 What Is All This Fuss About Machine Learning?
Learning Word Representations by Jointly Modeling Syntagmatic and Paradigmatic Relations
 Learning Word Representations by Jointly Modeling Syntagmatic and Paradigmatic Relations Fei Sun, Jiafeng Guo, Yanyan Lan, Jun Xu, and Xueqi Cheng CAS Key Lab of Network Data Science and Technology Institute
Learning Word Representations by Jointly Modeling Syntagmatic and Paradigmatic Relations Fei Sun, Jiafeng Guo, Yanyan Lan, Jun Xu, and Xueqi Cheng CAS Key Lab of Network Data Science and Technology Institute
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Deep Learning. Language Models and Word Embeddings. Christof Monz
 Deep Learning Today s Class N-gram language modeling Feed-forward neural language model Architecture Final layer computations Word embeddings Continuous bag-of-words model Skip-gram Negative sampling 1
Deep Learning Today s Class N-gram language modeling Feed-forward neural language model Architecture Final layer computations Word embeddings Continuous bag-of-words model Skip-gram Negative sampling 1
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 9: Dimension Reduction/Word2vec Cho-Jui Hsieh UC Davis May 15, 2018 Principal Component Analysis Principal Component Analysis (PCA) Data
STA141C: Big Data & High Performance Statistical Computing Lecture 9: Dimension Reduction/Word2vec Cho-Jui Hsieh UC Davis May 15, 2018 Principal Component Analysis Principal Component Analysis (PCA) Data
Natural Language Processing
 David Packard, A Concordance to Livy (1968) Natural Language Processing Info 159/259 Lecture 8: Vector semantics and word embeddings (Sept 18, 2018) David Bamman, UC Berkeley 259 project proposal due 9/25
David Packard, A Concordance to Livy (1968) Natural Language Processing Info 159/259 Lecture 8: Vector semantics and word embeddings (Sept 18, 2018) David Bamman, UC Berkeley 259 project proposal due 9/25
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
CS230: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention
 CS23: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention Today s outline We will learn how to: I. Word Vector Representation i. Training - Generalize results with word vectors -
CS23: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention Today s outline We will learn how to: I. Word Vector Representation i. Training - Generalize results with word vectors -
Natural Language Processing
 David Packard, A Concordance to Livy (1968) Natural Language Processing Info 159/259 Lecture 8: Vector semantics (Sept 19, 2017) David Bamman, UC Berkeley Announcements Homework 2 party today 5-7pm: 202
David Packard, A Concordance to Livy (1968) Natural Language Processing Info 159/259 Lecture 8: Vector semantics (Sept 19, 2017) David Bamman, UC Berkeley Announcements Homework 2 party today 5-7pm: 202
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Algorithms for NLP. Language Modeling III. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Language Modeling
 Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
A fast and simple algorithm for training neural probabilistic language models
 A fast and simple algorithm for training neural probabilistic language models Andriy Mnih Joint work with Yee Whye Teh Gatsby Computational Neuroscience Unit University College London 25 January 2013 1
A fast and simple algorithm for training neural probabilistic language models Andriy Mnih Joint work with Yee Whye Teh Gatsby Computational Neuroscience Unit University College London 25 January 2013 1
CSC321 Lecture 7 Neural language models
 CSC321 Lecture 7 Neural language models Roger Grosse and Nitish Srivastava February 1, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 7 Neural language models February 1, 2015 1 / 19 Overview We
CSC321 Lecture 7 Neural language models Roger Grosse and Nitish Srivastava February 1, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 7 Neural language models February 1, 2015 1 / 19 Overview We
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Conditional Language modeling with attention
 Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Conditional Language modeling with attention 2017.08.25 Oxford Deep NLP 조수현 Review Conditional language model: assign probabilities to sequence of words given some conditioning context x What is the probability
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
ATASS: Word Embeddings
 ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Machine Learning. B. Unsupervised Learning B.2 Dimensionality Reduction. Lars Schmidt-Thieme, Nicolas Schilling
 Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Data Mining & Machine Learning
 Data Mining & Machine Learning CS57300 Purdue University April 10, 2018 1 Predicting Sequences 2 But first, a detour to Noise Contrastive Estimation 3 } Machine learning methods are much better at classifying
Data Mining & Machine Learning CS57300 Purdue University April 10, 2018 1 Predicting Sequences 2 But first, a detour to Noise Contrastive Estimation 3 } Machine learning methods are much better at classifying
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Linear Models for Regression. Sargur Srihari
 Linear Models for Regression Sargur srihari@cedar.buffalo.edu 1 Topics in Linear Regression What is regression? Polynomial Curve Fitting with Scalar input Linear Basis Function Models Maximum Likelihood
Linear Models for Regression Sargur srihari@cedar.buffalo.edu 1 Topics in Linear Regression What is regression? Polynomial Curve Fitting with Scalar input Linear Basis Function Models Maximum Likelihood
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Linear Regression and Its Applications
 Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Retrieval by Content. Part 2: Text Retrieval Term Frequency and Inverse Document Frequency. Srihari: CSE 626 1
 Retrieval by Content Part 2: Text Retrieval Term Frequency and Inverse Document Frequency Srihari: CSE 626 1 Text Retrieval Retrieval of text-based information is referred to as Information Retrieval (IR)
Retrieval by Content Part 2: Text Retrieval Term Frequency and Inverse Document Frequency Srihari: CSE 626 1 Text Retrieval Retrieval of text-based information is referred to as Information Retrieval (IR)
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Naïve Bayes, Maxent and Neural Models
 Naïve Bayes, Maxent and Neural Models CMSC 473/673 UMBC Some slides adapted from 3SLP Outline Recap: classification (MAP vs. noisy channel) & evaluation Naïve Bayes (NB) classification Terminology: bag-of-words
Naïve Bayes, Maxent and Neural Models CMSC 473/673 UMBC Some slides adapted from 3SLP Outline Recap: classification (MAP vs. noisy channel) & evaluation Naïve Bayes (NB) classification Terminology: bag-of-words
Dimensionality Reduction and Principle Components Analysis
 Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Modeling Topics and Knowledge Bases with Embeddings
 Modeling Topics and Knowledge Bases with Embeddings Dat Quoc Nguyen and Mark Johnson Department of Computing Macquarie University Sydney, Australia December 2016 1 / 15 Vector representations/embeddings
Modeling Topics and Knowledge Bases with Embeddings Dat Quoc Nguyen and Mark Johnson Department of Computing Macquarie University Sydney, Australia December 2016 1 / 15 Vector representations/embeddings
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods.
 Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
1 Inference in Dirichlet Mixture Models Introduction Problem Statement Dirichlet Process Mixtures... 3
 Contents 1 Inference in Dirichlet Mixture Models 2 1.1 Introduction....................................... 2 1.2 Problem Statement................................... 2 1.3 Dirichlet Process Mixtures...............................
Contents 1 Inference in Dirichlet Mixture Models 2 1.1 Introduction....................................... 2 1.2 Problem Statement................................... 2 1.3 Dirichlet Process Mixtures...............................
Lecture 5: Web Searching using the SVD
 Lecture 5: Web Searching using the SVD Information Retrieval Over the last 2 years the number of internet users has grown exponentially with time; see Figure. Trying to extract information from this exponentially
Lecture 5: Web Searching using the SVD Information Retrieval Over the last 2 years the number of internet users has grown exponentially with time; see Figure. Trying to extract information from this exponentially
Deep Learning For Mathematical Functions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Bag of Words Meets Bags of Popcorn
 Sentiment Analysis via and Natural Language Processing Tarleton State University July 16, 2015 Data Description Sentiment Score tf-idf NDSI AFINN List word score invincible 2 mirthful 3 flops -2 hypocritical
Sentiment Analysis via and Natural Language Processing Tarleton State University July 16, 2015 Data Description Sentiment Score tf-idf NDSI AFINN List word score invincible 2 mirthful 3 flops -2 hypocritical
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
13 Searching the Web with the SVD
 13 Searching the Web with the SVD 13.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
13 Searching the Web with the SVD 13.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
9 Searching the Internet with the SVD
 9 Searching the Internet with the SVD 9.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
9 Searching the Internet with the SVD 9.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
Notes on Back Propagation in 4 Lines
 Notes on Back Propagation in 4 Lines Lili Mou moull12@sei.pku.edu.cn March, 2015 Congratulations! You are reading the clearest explanation of forward and backward propagation I have ever seen. In this
Notes on Back Propagation in 4 Lines Lili Mou moull12@sei.pku.edu.cn March, 2015 Congratulations! You are reading the clearest explanation of forward and backward propagation I have ever seen. In this
Neural Networks Lecture 4: Radial Bases Function Networks
 Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
This lecture. Miscellaneous classification methods: Neural networks, Support vector machines, Transformation-based learning, K nearest neighbours.
 This lecture Miscellaneous classification methods: Neural networks, Support vector machines, Transformation-based learning, K nearest neighbours. Neural word-vector representations. CSC401/2511 Spring
This lecture Miscellaneous classification methods: Neural networks, Support vector machines, Transformation-based learning, K nearest neighbours. Neural word-vector representations. CSC401/2511 Spring
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 9: Lexical semantics (Feb 19, 2019) David Bamman, UC Berkeley Lexical semantics You shall know a word by the company it keeps [Firth 1957] Harris 1954
Applied Natural Language Processing Info 256 Lecture 9: Lexical semantics (Feb 19, 2019) David Bamman, UC Berkeley Lexical semantics You shall know a word by the company it keeps [Firth 1957] Harris 1954
DATA MINING AND MACHINE LEARNING. Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
CPSC 340 Assignment 4 (due November 17 ATE)
") CPSC 340 Assignment 4 due November 7 ATE) Multi-Class Logistic The function example multiclass loads a multi-class classification datasetwith y i {,, 3, 4, 5} and fits a one-vs-all classification model
CPSC 340 Assignment 4 due November 7 ATE) Multi-Class Logistic The function example multiclass loads a multi-class classification datasetwith y i {,, 3, 4, 5} and fits a one-vs-all classification model
Continuous Space Language Model(NNLM) Liu Rong Intern students of CSLT
 Liu Rong Intern students of CSLT") Continuous Space Language Model(NNLM) Liu Rong Intern students of CSLT 2013-12-30 Outline N-gram Introduction data sparsity and smooth NNLM Introduction Multi NNLMs Toolkit Word2vec(Deep learing in NLP)
Continuous Space Language Model(NNLM) Liu Rong Intern students of CSLT 2013-12-30 Outline N-gram Introduction data sparsity and smooth NNLM Introduction Multi NNLMs Toolkit Word2vec(Deep learing in NLP)
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo