The representation of word and sentence
|
|
|
- Elwin Kelly
- 5 years ago
- Views:
Transcription
1 2vec Jul 4, 2017
2 Presentation Outline 2vec 1 2 2vec

3 discrete representation taxonomy:wordnet Example:good 2vec
4 Problems 2vec synonyms: adept,expert,good It can t keep up to date It can t accurate similarity
5 Vector representation 2vec One-hot vector [0, 0, 0,...1, 0,...0, 0] take too much space Vectors are orthogonal Hard to compute similarity
6 Dense vector 2vec Represent a vector by its neighbors Example: The cat is running in a room A dog is walking in a bedroom
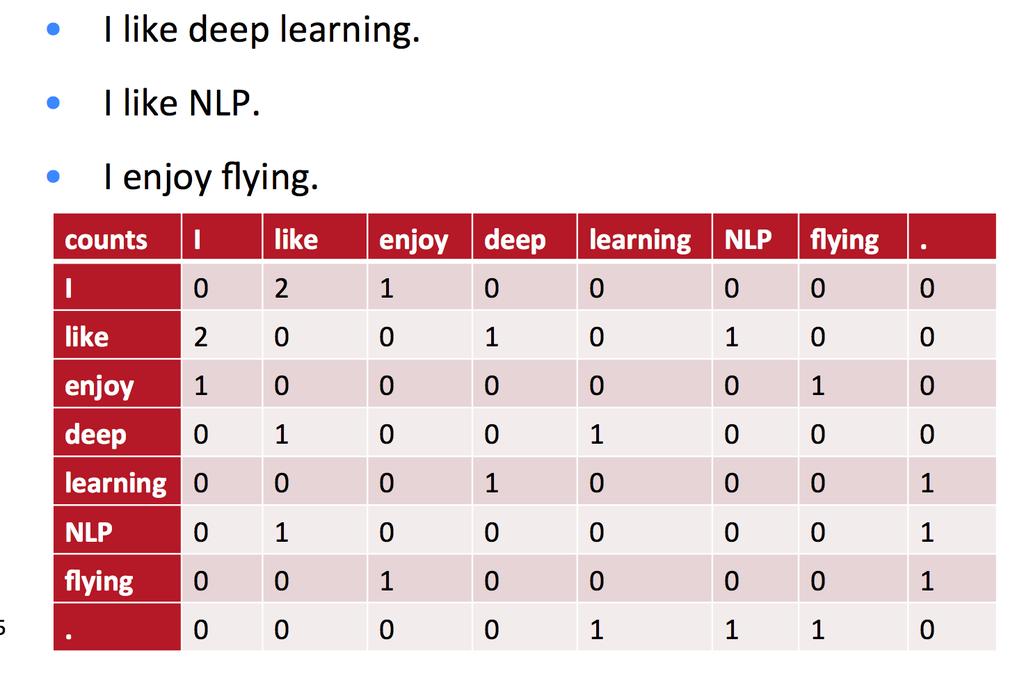
7 Co-occurrence Matrix 2vec
8 problem 2vec extremely sparse hard to update high dimension
9 A neural probabilistic language model (Bengio et al., 2003) 2vec
10 Presentation Outline 2vec 1 2 2vec
11 Most common methed: 2vec 2vec CBOW one-hot vector for the s around the center : x c m, x c m+1,...x c 1, x c+1,...x c+m v i = V x i.(i = c m,...c + m) ˆv = mean(v) Z = U ˆv ŷ = stmax(z) J(θ) = log P (u c ˆv) = u T c ˆv + log V j=1 exp(ut j ˆv)
12 skip-gram 2vec one-hot vector center x c v c = V x c z = U v c ŷ = stmax(z) J(θ) = 2m j=0 ut c m+j v c + 2mlog V k=1 exp(ut k v c)
13 2vec
14 Presentation Outline 2vec 1 2 2vec
15 2vec 2vec can capture complex linguistic patterns but can t get global co-occurence statistics combines Co-occurrence Matrix and 2vex Q ij = exp(wt i w j) V (from skip-gram) k=1 exp(wt i ŵj) J = i corpus,j context(i) logq ij hard to compute
16 2vec J = V V i=1 j=1 X ijlogq ij (X ij )is from co-occurrence matrix X J = V i=1 X ih(p i, Q i ) Replace cross entropy with Least square: J = ij X i( ˆP ij ˆQ ij ) 2 ( ˆP ij = X ij, ˆQ ij = exp(w T i ŵ j )) X ij may be large J = ij X i(log ˆP ij log ˆQ ij ) 2 = ij X i(w T i ŵ j X ij ) 2 final: J = ij f(x ij)(w T i ŵ j X ij ) 2
17 2vec
18 Presentation Outline 2vec 1 2 2vec
19 evaluate a 2vec Evaluation methods for unsupervised s(tobias Schnabel) Intrinsic: Use vectors as inputs for an elaborate machine learning system King - queen = man -woman bad - worst = good -best fast but unsure Extrinsic: Compute on your task slow but useful
20 Presentation Outline 2vec 1 2 2vec
21 ? 2vec Performance is heavily dependent on the model used for Performance increases with larger corpus sizes: Performance is lower for extremely low as well as for extremely high dimensional vectors.but larger dimensions will lead to better performance. Corpus domain is more important than corpus size. small corpus(< 500M) uses skip-gram, big corpus use CBOW iteration at least 50 dimension
22 Ambiguity 2vec A may have several meanings.like: tie Linear Algebraic Structure Word Senses, with Applications to Polysemy(Sanjeev Arora) tie = α 1 tie 1 + α 2 tie 2 + α 3 tie α i related to frequence tie i Given vector, about 60000, upper bound m,find a set context vectora 1, A 2...such that: v w = w i=1 α wja j + n w at most k α i are nonzero. Just sparse coding(k-svd) Find a set base in vector space, each can be represent by base.

23 Ambiguity 2vec
24 Problems 2vec powerful,strong and Paris are equally distant Word vector will lose the ordering the s and ignore semantics the s.
25 Presentation Outline 2vec 1 2 2vec
26 Doc2vec Distributed Representations s and Documents Distributed Memory Model Paragraph Vectors (PV-DM) The paragraph token can be thought as another 2vec
27 Distributed Bag Words version Paragraph Vector (PV-DBOW) 2vec Combination two metheds works better
28 A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS(Sanjeev Arora,2017) 2vec
29 some other method Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks 2vec MV-RNN s (Matrix-Vector Recursive Neural Networks
30 2vec That s all.thanks.
GloVe: Global Vectors for Word Representation 1
 GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Word Embeddings 2 - Class Discussions
 Word Embeddings 2 - Class Discussions Jalaj February 18, 2016 Opening Remarks - Word embeddings as a concept are intriguing. The approaches are mostly adhoc but show good empirical performance. Paper 1
Word Embeddings 2 - Class Discussions Jalaj February 18, 2016 Opening Remarks - Word embeddings as a concept are intriguing. The approaches are mostly adhoc but show good empirical performance. Paper 1
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Natural Language Processing
 Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Deep Learning Basics Lecture 10: Neural Language Models. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Deep Learning. Ali Ghodsi. University of Waterloo
 University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
An overview of word2vec
 An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
CS224n: Natural Language Processing with Deep Learning 1
 CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CS224n: Natural Language Processing with Deep Learning 1
 CS224n: Natural Language Processing with Deep Learning 1 Lecture Notes: Part I 2 Winter 2017 1 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume
CS224n: Natural Language Processing with Deep Learning 1 Lecture Notes: Part I 2 Winter 2017 1 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume
Neural Word Embeddings from Scratch
 Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
arxiv: v3 [cs.cl] 30 Jan 2016
![arxiv: v3 [cs.cl] 30 Jan 2016](/thumbs/72/66377864.jpg "arxiv: v3 [cs.cl] 30 Jan 2016") word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
CS230: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention
 CS23: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention Today s outline We will learn how to: I. Word Vector Representation i. Training - Generalize results with word vectors -
CS23: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention Today s outline We will learn how to: I. Word Vector Representation i. Training - Generalize results with word vectors -
Natural Language Processing
 Natural Language Processing Language models Based on slides from Michael Collins, Chris Manning and Richard Soccer Plan Problem definition Trigram models Evaluation Estimation Interpolation Discounting
Natural Language Processing Language models Based on slides from Michael Collins, Chris Manning and Richard Soccer Plan Problem definition Trigram models Evaluation Estimation Interpolation Discounting
Lecture 6: Neural Networks for Representing Word Meaning
 Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Seman&cs with Dense Vectors. Dorota Glowacka
 Semancs with Dense Vectors Dorota Glowacka dorota.glowacka@ed.ac.uk Previous lectures: - how to represent a word as a sparse vector with dimensions corresponding to the words in the vocabulary - the values
Semancs with Dense Vectors Dorota Glowacka dorota.glowacka@ed.ac.uk Previous lectures: - how to represent a word as a sparse vector with dimensions corresponding to the words in the vocabulary - the values
Neural Networks Language Models
 Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Homework 3 COMS 4705 Fall 2017 Prof. Kathleen McKeown
 Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Machine Learning for Smart Learners
 Department of Computer Science Instituto de Matemathics and Statistics University of Sao Paulo, Brazil Sao Paulo School of Advanced Science on Smart Cities 2017 What Is All This Fuss About Machine Learning?
Department of Computer Science Instituto de Matemathics and Statistics University of Sao Paulo, Brazil Sao Paulo School of Advanced Science on Smart Cities 2017 What Is All This Fuss About Machine Learning?
DISTRIBUTIONAL SEMANTICS
 COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
lecture 6: modeling sequences (final part)
") Natural Language Processing 1 lecture 6: modeling sequences (final part) Ivan Titov Institute for Logic, Language and Computation Outline After a recap: } Few more words about unsupervised estimation of
Natural Language Processing 1 lecture 6: modeling sequences (final part) Ivan Titov Institute for Logic, Language and Computation Outline After a recap: } Few more words about unsupervised estimation of
Distributional Semantics and Word Embeddings. Chase Geigle
 Distributional Semantics and Word Embeddings Chase Geigle 2016-10-14 1 What is a word? dog 2 What is a word? dog canine 2 What is a word? dog canine 3 2 What is a word? dog 3 canine 399,999 2 What is a
Distributional Semantics and Word Embeddings Chase Geigle 2016-10-14 1 What is a word? dog 2 What is a word? dog canine 2 What is a word? dog canine 3 2 What is a word? dog 3 canine 399,999 2 What is a
Sequence Models. Ji Yang. Department of Computing Science, University of Alberta. February 14, 2018
 Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
Sequence Models Ji Yang Department of Computing Science, University of Alberta February 14, 2018 This is a note mainly based on Prof. Andrew Ng s MOOC Sequential Models. I also include materials (equations,
NLP: N-Grams. Dan Garrette December 27, Predictive text (text messaging clients, search engines, etc)
") NLP: N-Grams Dan Garrette dhg@cs.utexas.edu December 27, 2013 1 Language Modeling Tasks Language idenfication / Authorship identification Machine Translation Speech recognition Optical character recognition
NLP: N-Grams Dan Garrette dhg@cs.utexas.edu December 27, 2013 1 Language Modeling Tasks Language idenfication / Authorship identification Machine Translation Speech recognition Optical character recognition
Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2)
 SVM-based Sentiment Detection of Reviews (Part 2)") Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2) Simone Teufel (Lead demonstrator Guy Aglionby) sht25@cl.cam.ac.uk; ga384@cl.cam.ac.uk This is the
Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2) Simone Teufel (Lead demonstrator Guy Aglionby) sht25@cl.cam.ac.uk; ga384@cl.cam.ac.uk This is the
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Language Models. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Language Models Tobias Scheffer Stochastic Language Models A stochastic language model is a probability distribution over words.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Language Models Tobias Scheffer Stochastic Language Models A stochastic language model is a probability distribution over words.
Natural Language Processing
 David Packard, A Concordance to Livy (1968) Natural Language Processing Info 159/259 Lecture 8: Vector semantics and word embeddings (Sept 18, 2018) David Bamman, UC Berkeley 259 project proposal due 9/25
David Packard, A Concordance to Livy (1968) Natural Language Processing Info 159/259 Lecture 8: Vector semantics and word embeddings (Sept 18, 2018) David Bamman, UC Berkeley 259 project proposal due 9/25
Word2Vec Embedding. Embedding. Word Embedding 1.1 BEDORE. Word Embedding. 1.2 Embedding. Word Embedding. Embedding.
 c Word Embedding Embedding Word2Vec Embedding Word EmbeddingWord2Vec 1. Embedding 1.1 BEDORE 0 1 BEDORE 113 0033 2 35 10 4F y katayama@bedore.jp Word Embedding Embedding 1.2 Embedding Embedding Word Embedding
c Word Embedding Embedding Word2Vec Embedding Word EmbeddingWord2Vec 1. Embedding 1.1 BEDORE 0 1 BEDORE 113 0033 2 35 10 4F y katayama@bedore.jp Word Embedding Embedding 1.2 Embedding Embedding Word Embedding
Learning Word Representations by Jointly Modeling Syntagmatic and Paradigmatic Relations
 Learning Word Representations by Jointly Modeling Syntagmatic and Paradigmatic Relations Fei Sun, Jiafeng Guo, Yanyan Lan, Jun Xu, and Xueqi Cheng CAS Key Lab of Network Data Science and Technology Institute
Learning Word Representations by Jointly Modeling Syntagmatic and Paradigmatic Relations Fei Sun, Jiafeng Guo, Yanyan Lan, Jun Xu, and Xueqi Cheng CAS Key Lab of Network Data Science and Technology Institute
ATASS: Word Embeddings
 ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
Neural Networks for NLP. COMP-599 Nov 30, 2016
 Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
CME323 Distributed Algorithms and Optimization. GloVe on Spark. Alex Adamson SUNet ID: aadamson. June 6, 2016
 GloVe on Spark Alex Adamson SUNet ID: aadamson June 6, 2016 Introduction Pennington et al. proposes a novel word representation algorithm called GloVe (Global Vectors for Word Representation) that synthesizes
GloVe on Spark Alex Adamson SUNet ID: aadamson June 6, 2016 Introduction Pennington et al. proposes a novel word representation algorithm called GloVe (Global Vectors for Word Representation) that synthesizes
Natural Language Processing
 David Packard, A Concordance to Livy (1968) Natural Language Processing Info 159/259 Lecture 8: Vector semantics (Sept 19, 2017) David Bamman, UC Berkeley Announcements Homework 2 party today 5-7pm: 202
David Packard, A Concordance to Livy (1968) Natural Language Processing Info 159/259 Lecture 8: Vector semantics (Sept 19, 2017) David Bamman, UC Berkeley Announcements Homework 2 party today 5-7pm: 202
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Embeddings Learned By Matrix Factorization
 Embeddings Learned By Matrix Factorization Benjamin Roth; Folien von Hinrich Schütze Center for Information and Language Processing, LMU Munich Overview WordSpace limitations LinAlgebra review Input matrix
Embeddings Learned By Matrix Factorization Benjamin Roth; Folien von Hinrich Schütze Center for Information and Language Processing, LMU Munich Overview WordSpace limitations LinAlgebra review Input matrix
Contents. (75pts) COS495 Midterm. (15pts) Short answers
 COS495 Midterm. (15pts) Short answers") Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Deep Learning For Mathematical Functions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Language Models. Data Science: Jordan Boyd-Graber University of Maryland SLIDES ADAPTED FROM PHILIP KOEHN
 Language Models Data Science: Jordan Boyd-Graber University of Maryland SLIDES ADAPTED FROM PHILIP KOEHN Data Science: Jordan Boyd-Graber UMD Language Models 1 / 8 Language models Language models answer
Language Models Data Science: Jordan Boyd-Graber University of Maryland SLIDES ADAPTED FROM PHILIP KOEHN Data Science: Jordan Boyd-Graber UMD Language Models 1 / 8 Language models Language models answer
Algorithms for NLP. Language Modeling III. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Conditional Language Modeling. Chris Dyer
 Conditional Language Modeling Chris Dyer Unconditional LMs A language model assigns probabilities to sequences of words,. w =(w 1,w 2,...,w`) It is convenient to decompose this probability using the chain
Conditional Language Modeling Chris Dyer Unconditional LMs A language model assigns probabilities to sequences of words,. w =(w 1,w 2,...,w`) It is convenient to decompose this probability using the chain
a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM
![a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM](/thumbs/92/107948882.jpg "a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM") c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook
 Sumit Chopra Facebook") Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Recurrent Neural Networks (Part - 2) Sumit Chopra Facebook Recap Standard RNNs Training: Backpropagation Through Time (BPTT) Application to sequence modeling Language modeling Applications: Automatic speech
Deep Learning. Language Models and Word Embeddings. Christof Monz
 Deep Learning Today s Class N-gram language modeling Feed-forward neural language model Architecture Final layer computations Word embeddings Continuous bag-of-words model Skip-gram Negative sampling 1
Deep Learning Today s Class N-gram language modeling Feed-forward neural language model Architecture Final layer computations Word embeddings Continuous bag-of-words model Skip-gram Negative sampling 1
Improved Learning through Augmenting the Loss
 Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Improved Learning through Augmenting the Loss Hakan Inan inanh@stanford.edu Khashayar Khosravi khosravi@stanford.edu Abstract We present two improvements to the well-known Recurrent Neural Network Language
Generic Text Summarization
 June 27, 2012 Outline Introduction 1 Introduction Notation and Terminology 2 3 4 5 6 Text Summarization Introduction Notation and Terminology Two Types of Text Summarization Query-Relevant Summarization:
June 27, 2012 Outline Introduction 1 Introduction Notation and Terminology 2 3 4 5 6 Text Summarization Introduction Notation and Terminology Two Types of Text Summarization Query-Relevant Summarization:
Lecture 7: Word Embeddings
 Lecture 7: Word Embeddings Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 6501 Natural Language Processing 1 This lecture v Learning word vectors
Lecture 7: Word Embeddings Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 6501 Natural Language Processing 1 This lecture v Learning word vectors
Bringing machine learning & compositional semantics together: central concepts
 Bringing machine learning & compositional semantics together: central concepts https://githubcom/cgpotts/annualreview-complearning Chris Potts Stanford Linguistics CS 244U: Natural language understanding
Bringing machine learning & compositional semantics together: central concepts https://githubcom/cgpotts/annualreview-complearning Chris Potts Stanford Linguistics CS 244U: Natural language understanding
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
Features of Statistical Parsers
 Features of tatistical Parsers Preliminary results Mark Johnson Brown University TTI, October 2003 Joint work with Michael Collins (MIT) upported by NF grants LI 9720368 and II0095940 1 Talk outline tatistical
Features of tatistical Parsers Preliminary results Mark Johnson Brown University TTI, October 2003 Joint work with Michael Collins (MIT) upported by NF grants LI 9720368 and II0095940 1 Talk outline tatistical
(2pts) What is the object being embedded (i.e. a vector representing this object is computed) when one uses
 What is the object being embedded (i.e. a vector representing this object is computed) when one uses") Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Contents (75pts) COS495 Midterm 1 (15pts) Short answers........................... 1 (5pts) Unequal loss............................. 2 (15pts) About LSTMs........................... 3 (25pts) Modular
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
Maschinelle Sprachverarbeitung Parsing with Probabilistic Context-Free Grammar Ulf Leser Content of this Lecture Phrase-Structure Parse Trees Probabilistic Context-Free Grammars Parsing with PCFG Other
APPLIED DEEP LEARNING PROF ALEXIEI DINGLI
 APPLIED DEEP LEARNING PROF ALEXIEI DINGLI TECH NEWS TECH NEWS HOW TO DO IT? TECH NEWS APPLICATIONS TECH NEWS TECH NEWS NEURAL NETWORKS Interconnected set of nodes and edges Designed to perform complex
APPLIED DEEP LEARNING PROF ALEXIEI DINGLI TECH NEWS TECH NEWS HOW TO DO IT? TECH NEWS APPLICATIONS TECH NEWS TECH NEWS NEURAL NETWORKS Interconnected set of nodes and edges Designed to perform complex
Topic Models and Applications to Short Documents
 Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Modeling Environment
 Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Slide credit from Hung-Yi Lee & Richard Socher
 Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Slide credit from Hung-Yi Lee & Richard Socher 1 Review Recurrent Neural Network 2 Recurrent Neural Network Idea: condition the neural network on all previous words and tie the weights at each time step
Deep Learning for NLP Part 2
 Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Learning to translate with neural networks. Michael Auli
 Learning to translate with neural networks Michael Auli 1 Neural networks for text processing Similar words near each other France Spain dog cat Neural networks for text processing Similar words near each
Learning to translate with neural networks Michael Auli 1 Neural networks for text processing Similar words near each other France Spain dog cat Neural networks for text processing Similar words near each
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
The Noisy Channel Model and Markov Models
 1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
arxiv: v2 [cs.cl] 1 Jan 2019
![arxiv: v2 [cs.cl] 1 Jan 2019](/thumbs/93/111679653.jpg "arxiv: v2 [cs.cl] 1 Jan 2019") Variational Self-attention Model for Sentence Representation arxiv:1812.11559v2 [cs.cl] 1 Jan 2019 Qiang Zhang 1, Shangsong Liang 2, Emine Yilmaz 1 1 University College London, London, United Kingdom 2
Variational Self-attention Model for Sentence Representation arxiv:1812.11559v2 [cs.cl] 1 Jan 2019 Qiang Zhang 1, Shangsong Liang 2, Emine Yilmaz 1 1 University College London, London, United Kingdom 2
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Latent Dirichlet Allocation and Singular Value Decomposition based Multi-Document Summarization
 Latent Dirichlet Allocation and Singular Value Decomposition based Multi-Document Summarization Rachit Arora Computer Science and Engineering Indian Institute of Technology Madras Chennai - 600 036, India.
Latent Dirichlet Allocation and Singular Value Decomposition based Multi-Document Summarization Rachit Arora Computer Science and Engineering Indian Institute of Technology Madras Chennai - 600 036, India.
Part A. P (w 1 )P (w 2 w 1 )P (w 3 w 1 w 2 ) P (w M w 1 w 2 w M 1 ) P (w 1 )P (w 2 w 1 )P (w 3 w 2 ) P (w M w M 1 )
P (w 2 w 1 )P (w 3 w 1 w 2 ) P (w M w 1 w 2 w M 1 ) P (w 1 )P (w 2 w 1 )P (w 3 w 2 ) P (w M w M 1 )") Part A 1. A Markov chain is a discrete-time stochastic process, defined by a set of states, a set of transition probabilities (between states), and a set of initial state probabilities; the process proceeds
Part A 1. A Markov chain is a discrete-time stochastic process, defined by a set of states, a set of transition probabilities (between states), and a set of initial state probabilities; the process proceeds
Notes on the framework of Ando and Zhang (2005) 1 Beyond learning good functions: learning good spaces
 1 Beyond learning good functions: learning good spaces") Notes on the framework of Ando and Zhang (2005 Karl Stratos 1 Beyond learning good functions: learning good spaces 1.1 A single binary classification problem Let X denote the problem domain. Suppose we
Notes on the framework of Ando and Zhang (2005 Karl Stratos 1 Beyond learning good functions: learning good spaces 1.1 A single binary classification problem Let X denote the problem domain. Suppose we
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Regression. Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning)
 to continuous labels given a training set (supervised learning)") Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
Linear Regression Regression Goal: Learn a mapping from observations (features) to continuous labels given a training set (supervised learning) Example: Height, Gender, Weight Shoe Size Audio features
CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam This examination consists of 14 printed sides, 5 questions, and 100 points. The exam accounts for 17% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam This examination consists of 14 printed sides, 5 questions, and 100 points. The exam accounts for 17% of your total grade.
Bayesian Paragraph Vectors
 Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Collapsed Variational Bayesian Inference for Hidden Markov Models
 Collapsed Variational Bayesian Inference for Hidden Markov Models Pengyu Wang, Phil Blunsom Department of Computer Science, University of Oxford International Conference on Artificial Intelligence and
Collapsed Variational Bayesian Inference for Hidden Markov Models Pengyu Wang, Phil Blunsom Department of Computer Science, University of Oxford International Conference on Artificial Intelligence and
Recap: Language models. Foundations of Natural Language Processing Lecture 4 Language Models: Evaluation and Smoothing. Two types of evaluation in NLP
 Recap: Language models Foundations of atural Language Processing Lecture 4 Language Models: Evaluation and Smoothing Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipp
Recap: Language models Foundations of atural Language Processing Lecture 4 Language Models: Evaluation and Smoothing Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipp
Lab 12: Structured Prediction
 December 4, 2014 Lecture plan structured perceptron application: confused messages application: dependency parsing structured SVM Class review: from modelization to classification What does learning mean?
December 4, 2014 Lecture plan structured perceptron application: confused messages application: dependency parsing structured SVM Class review: from modelization to classification What does learning mean?
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 9: Dimension Reduction/Word2vec Cho-Jui Hsieh UC Davis May 15, 2018 Principal Component Analysis Principal Component Analysis (PCA) Data
STA141C: Big Data & High Performance Statistical Computing Lecture 9: Dimension Reduction/Word2vec Cho-Jui Hsieh UC Davis May 15, 2018 Principal Component Analysis Principal Component Analysis (PCA) Data
Towards Universal Sentence Embeddings
 Towards Universal Sentence Embeddings Towards Universal Paraphrastic Sentence Embeddings J. Wieting, M. Bansal, K. Gimpel and K. Livescu, ICLR 2016 A Simple But Tough-To-Beat Baseline For Sentence Embeddings
Towards Universal Sentence Embeddings Towards Universal Paraphrastic Sentence Embeddings J. Wieting, M. Bansal, K. Gimpel and K. Livescu, ICLR 2016 A Simple But Tough-To-Beat Baseline For Sentence Embeddings
CSC321 Lecture 10 Training RNNs
 CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
Notes on Latent Semantic Analysis
 Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
1. Ignoring case, extract all unique words from the entire set of documents.
 CS 378 Introduction to Data Mining Spring 29 Lecture 2 Lecturer: Inderjit Dhillon Date: Jan. 27th, 29 Keywords: Vector space model, Latent Semantic Indexing(LSI), SVD 1 Vector Space Model The basic idea
CS 378 Introduction to Data Mining Spring 29 Lecture 2 Lecturer: Inderjit Dhillon Date: Jan. 27th, 29 Keywords: Vector space model, Latent Semantic Indexing(LSI), SVD 1 Vector Space Model The basic idea
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017
 COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
Intrinsic Subspace Evaluation of Word Embedding Representations
 Intrinsic Subspace Evaluation of Word Embedding Representations Yadollah Yaghoobzadeh, Hinrich Schütze ACL 2016 CIS - LMU Munich 1 Outline 1. Background 2. Intrinsic Subspace Evaluation 3. Extrinsic Evaluation:
Intrinsic Subspace Evaluation of Word Embedding Representations Yadollah Yaghoobzadeh, Hinrich Schütze ACL 2016 CIS - LMU Munich 1 Outline 1. Background 2. Intrinsic Subspace Evaluation 3. Extrinsic Evaluation: