Lecture 8: Maximum Likelihood Estimation (MLE) (cont d.) Maximum a posteriori (MAP) estimation Naïve Bayes Classifier
|
|
|
- Osborne Phillips
- 6 years ago
- Views:
Transcription
1 Lecture 8: Maximum Likelihood Estimation (MLE) (cont d.) Maximum a posteriori (MAP) estimation Naïve Bayes Classifier Aykut Erdem March 2016 Hacettepe University
2 Flipping a Coin Last time Flipping a Coin I have a coin, if I flip it, what s the probability that it will fall with the head up? Let us flip it a few times to estimate the probability: slide by Barnabás Póczos & Alex Smola The estimated probability is: 3/5 Frequency of heads 13 2
3 Last time Flipping a Coin The estimated probability is: 3/5 Frequency of heads slide by Barnabás Póczos & Alex Smola Questions: (1) Why frequency of heads??? (2) How good is this estimation??? (3) Why is this a machine learning problem??? We are going to answer these questions 3
4 Question (1) Why frequency of heads??? Frequency of heads is exactly the maximum likelihood estimator for this problem MLE has nice properties (interpretation, statistical guarantees, simple) slide by Barnabás Póczos & Alex Smola 4
5 MLE distribution MLEfor forbernoulli Bernoulli distribution Data, D = P(Heads) = θ, P(Tails) = 1-θ Flips are i.i.d.: slide by Barnabás Póczos & Alex Smola Independent events Identically distributed according to Bernoulli distribution MLE: Choose θ that maximizes the probability of observed data 5 17
6 MLE distribution MLEfor forbernoulli Bernoulli distribution Data, D = P(Heads) = θ, P(Tails) = 1-θ Flips are i.i.d.: slide by Barnabás Póczos & Alex Smola Independent events Identically distributed according to Bernoulli distribution MLE: Choose θ that maximizes the probability of observed data 6 17
7 MLE distribution MLEfor forbernoulli Bernoulli distribution Data, D = P(Heads) = θ, P(Tails) = 1-θ Flips are i.i.d.: slide by Barnabás Póczos & Alex Smola Independent events Identically distributed according to Bernoulli distribution MLE: Choose θ that maximizes the probability of observed data 7 17
8 MLE distribution MLEfor forbernoulli Bernoulli distribution Data, D = P(Heads) = θ, P(Tails) = 1-θ Flips are i.i.d.: slide by Barnabás Póczos & Alex Smola Independent events Identically distributed according to Bernoulli distribution MLE: Choose θ that maximizes the probability of observed data 8 17

9 Maximum Likelihood Maximum Likelihood Estimation Estimation MLE: Choose θ that maximizes the probability of observed data Maximum Likelihood Estimation Independent independentdraws draws ose θ that maximizes the probability of observed data iden,cally Identically distributed distributed slide by Barnabás Póczos & Alex Smola 18 9
10 Maximum Likelihood Maximum Likelihood Estimation Estimation MLE: Choose θ that maximizes the probability of observed data Maximum Likelihood Estimation Independent draws independent draws ose θ that maximizes the probability of observed data iden,cally Identically distributed distributed slide by Barnabás Póczos & Alex Smola 18 10
11 Maximum Likelihood Maximum Likelihood Estimation Estimation MLE: Choose θ that maximizes the probability of observed data Maximum Likelihood Estimation Independent draws independent draws ose θ that maximizes the probability of observed data identically Identically distributed distributed slide by Barnabás Póczos & Alex Smola 18 11
12 Maximum Likelihood Maximum Likelihood Estimation Estimation MLE: Choose θ that maximizes the probability of observed data Maximum Likelihood Estimation Independent draws independent draws ose θ that maximizes the probability of observed data identically Identically distributed distributed slide by Barnabás Póczos & Alex Smola 18 12
13 Maximum Likelihood Maximum Likelihood Estimation Estimation MLE: Choose θ that maximizes the probability of observed data Maximum Likelihood Estimation Independent draws independent draws ose θ that maximizes the probability of observed data identically Identically distributed distributed slide by Barnabás Póczos & Alex Smola 18 13
14 Maximum Maximum Likelihood Likelihood Estimation Maximum Estimation Likelihood Estimation Estimation LE: Choose θ that maximizes the probability of observed data MLE: MLE:Choose Choose θthat thatmaximizes maximizesthe theprobability probability of of observed observed data data Independent draws Identically distributed slide by Barnabás Póczos & Alex Smola That s exactly the Frequency of heads
15 Maximum Maximum Likelihood Likelihood Estimation Maximum Estimation Likelihood Estimation Estimation LE: Choose θ that maximizes the probability of observed data MLE: MLE:Choose Choose θthat thatmaximizes maximizesthe theprobability probability of of observed observed data data Independent draws Identically distributed slide by Barnabás Póczos & Alex Smola That s exactly the Frequency of heads
16 Maximum Maximum Likelihood Likelihood Estimation Maximum Estimation Likelihood Estimation Estimation LE: Choose θ that maximizes the probability of observed data MLE: MLE:Choose Choose θthat thatmaximizes maximizesthe theprobability probability of of observed observed data data Independent draws Identically distributed slide by Barnabás Póczos & Alex Smola That s exactly the Frequency of heads
17 Question (2) How good is this MLE estimation??? slide by Barnabás Póczos & Alex Smola 17
18 How many flips do I need? I flipped the coins 5 times: 3 heads, 2 tails What if I flipped 30 heads and 20 tails? slide by Barnabás Póczos & Alex Smola Which estimator should we trust more? The more the merrier??? 18
19 Simple bound Let θ* be the true parameter. For n = αh+αt, and For any ε>0: Hoeffding s inequality: slide by Barnabás Póczos & Alex Smola 19
20 Probably Approximate Correct (PAC) Learning I want to know the coin parameter θ, within ε = 0.1 error with probability at least 1-δ = How many flips do I need? slide by Barnabás Póczos & Alex Smola Sample complexity: 20
21 Question (3) Why is this a machine learning problem??? improve their performance (accuracy of the predicted prob. ) at some task (predicting the probability of heads) with experience (the more coins we flip the better we are) slide by Barnabás Póczos & Alex Smola 21
22 What continuous What about about continuous features? features? Let us try Gaussians slide by Barnabás Póczos & Alex Smola σ2 µ=0 σ2 µ=
23 MLE for Gaussian mean and variance Choose θ= (µ,σ 2 ) that maximizes the probability of observed data Independent draws Identically distributed slide by Barnabás Póczos & Alex Smola 23

24 MLE mean MLEfor forgaussian Gaussian mean and variance variance and slide by Barnabás Póczos & Alex Smola Note: MLE for the variance of a Gaussian is biased Note: MLE for result the variance Gaussian is biased [Expected of estimationofis a not the true parameter!] [Expected result of estimation is not the true parameter!] Unbiased variance estimator: Unbiased variance estimator: 24 27
25 What about prior knowledge? (MAP Estimation) 25
26 What about prior knowledge? We know the coin is close to What can we do now? The Bayesian way Rather than estimating a single θ, we obtain a distribution over possible values of θ Before data After data
27 Prior distribution What prior? What distribution do we want for a prior? Represents expert knowledge (philosophical approach) Simple posterior form (engineer s approach) Uninformative priors: Uniform distribution Conjugate priors: Closed-form representation of posterior P(θ) and P(θ D) have the same form 27
28 In order to proceed we will need: Bayes Rule 28
29 Chain Rule Rule & & Bayes Bayes Rule Chain Rule Chain rule: Bayes rule: Bayes ruleisisimportant important for Bayes rule forreverse reverseconditioning. conditioning

30 Bayesian Learning Use Bayes rule: Or equivalently: posterior likelihood prior 30
 posterior is Beta distribution P( ) and P( D) have the same form! [Conjugate prior] 31")
31 MAP estimation for Binomial distribution Coin flip problem Likelihood is Binomial If the prior is Beta distribution, ) posterior is Beta distribution P( ) and P( D) have the same form! [Conjugate prior] 31
32 Beta distribution More concentrated as values of α, β increase 32
33 Beta conjugate prior As n = α H + αt increases As we get more samples, effect of prior is washed out 33



34 Han Solo and Bayesian Priors C3PO: Sir, the possibility of successfully navigating an asteroid field is approximately 3,720 to 1! Han: Never tell me the odds! 34
35 MLE vs. MAP! Maximum Likelihood estimation (MLE) Choose value that maximizes the probability of observed data! Maximum a posteriori (MAP) estimation Choose value that is most probable given observed data and prior belief When is MAP same as MLE? 35
36 From Binomial to Multinomial Example: Dice roll problem (6 outcomes instead of 2) Likelihood is ~ Multinomial(θ = {θ 1, θ 2,..., θ k }) If prior is Dirichlet distribution, et distribution, Then posterior is Dirichlet distribution For Multinomial, conjugate prior is Dirichlet distribution. 36

37 Bayesians vs. Frequentists You are no good when sample is small You give a different answer for different priors 37
38 Recap: What about prior knowledge? (MAP Estimation) 38
39 Recap: What about prior knowledge? We know the coin is close to What can we do now? The Bayesian way Rather than estimating a single θ, we obtain a distribution over possible values of θ Before data After data

40 Recap: Chain Rule & Bayes Rule Chain rule: Bayes rule: 40
41 Recap: Bayesian Learning D is the measured data Our goal is to estimate parameter θ Use Bayes rule: Or equivalently: posterior likelihood prior 41
42 Recap: MAP estimation for Binomial distribution In the coin flip problem: Likelihood is Binomial: If the prior is Beta: then the posterior is Beta distribution 42
43 Recap: Beta conjugate prior As n = α H + αt increases As we get more samples, effect of prior is washed out 43
44 Application of Bayes Rule 44

45 AIDS test (Bayes rule) Data Approximately 0.1% are infected Test detects all infections Test reports positive for 1% healthy people Probability of having AIDS if test is positive Only 9%!
46 Improving the diagnosis Use a weaker follow-up test! Approximately 0.1% are infected Test 2 reports positive for 90% infections Test 2 reports positive for 5% healthy people = 64%!
47 AIDS test (Bayes rule) Why can t we use Test 1 twice? Outcomes are not independent, but tests 1 and 2 conditionally independent (by assumption): 47
48 The Naïve Bayes Classifier 48
49 Data for spam filtering date time recipient path IP number sender encoding many more features R Delivered-To: alex.smola@gmail.com Received: by with SMTP id s51cs361171web; Tue, 3 Jan :17: (PST) Received: by with SMTP id s17mr eba ; Tue, 03 Jan :17: (PST) Return-Path: <alex+caf_=alex.smola=gmail.com@smola.org> Received: from mail-ey0-f175.google.com (mail-ey0-f175.google.com [ ]) by mx.google.com with ESMTPS id n4si eef (version=tlsv1/sslv3 cipher=other); Tue, 03 Jan :17: (PST) Received-SPF: neutral (google.com: is neither permitted nor denied by best guess record for domain of alex+caf_=alex.smola=gmail.com@smola.org) clientip= ; Authentication-Results: mx.google.com; spf=neutral (google.com: is neither permitted nor denied by best guess record for domain of alex +caf_=alex.smola=gmail.com@smola.org) smtp.mail=alex+caf_=alex.smola=gmail.com@smola.org; dkim=pass (test mode) header.i=@googl .com Received: by eaal1 with SMTP id l1so eaa.6 for <alex.smola@gmail.com>; Tue, 03 Jan :17: (PST) Received: by with SMTP id ie18mr bkc ; Tue, 03 Jan :17: (PST) X-Forwarded-To: alex.smola@gmail.com X-Forwarded-For: alex@smola.org alex.smola@gmail.com Delivered-To: alex@smola.org Received: by with SMTP id k6cs206093bki; Tue, 3 Jan :17: (PST) Received: by with SMTP id bh19mr vdb ; Tue, 03 Jan :17: (PST) Return-Path: <althoff.tim@googl .com> Received: from mail-vx0-f179.google.com (mail-vx0-f179.google.com [ ]) by mx.google.com with ESMTPS id dt4si vdb (version=tlsv1/sslv3 cipher=other); Tue, 03 Jan :17: (PST) Received-SPF: pass (google.com: domain of althoff.tim@googl .com designates as permitted sender) client-ip= ; Received: by vcbf13 with SMTP id f13so vcb.10 for <alex@smola.org>; Tue, 03 Jan :17: (PST) DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed; d=googl .com; s=gamma; h=mime-version:sender:date:x-google-sender-auth:message-id:subject :from:to:content-type; bh=wcbdz5sxac25dph02xcrydodts993hkwsavxpgrfh0w=; b=wk2b2+exwnf/gvtkw6uuvkup4xeoknljq3usytm0rark8dsfjyoqsiheap9yssxp6o 7ngGoTzYqd+ZsyJfvQcLAWp1PCJhG8AMcnqWkx0NMeoFvIp2HQooZwxSOCx5ZRgY+7qX uibbdna4ludxj6ufe16spldckptd8oz3gr7+o= MIME-Version: 1.0 Received: by with SMTP id e17mr vcp ; Tue, 03 Jan :17: (PST) Sender: althoff.tim@googl .com Received: by with HTTP; Tue, 3 Jan :17: (PST) Date: Tue, 3 Jan :17: X-Google-Sender-Auth: 6bwi6D17HjZIkxOEol38NZzyeHs Message-ID: <CAFJJHDGPBW+SdZg0MdAABiAKydDk9tpeMoDijYGjoGO-WC7osg@mail.gmail.com> Subject: CS 281B. Advanced Topics in Learning and Decision Making

50 Naïve Bayes Assumption Naïve Bayes assumption: Features X 1 and X 2 are conditionally independent given the class label Y: More generally: 50
51 Naïve Bayes Assumption, Example Task: Predict whether or not a picnic spot is enjoyable Training Data: X = (X 1 X 2 X 3 X d ) Y n rows Naïve Bayes assumption: How many parameters to estimate? (X is composed of d binary features, Y has K possible class labels) (2 d -1)K vs (2-1)dK 1 51
52 Naïve Bayes Classifier Given: Class prior P(Y) d conditionally independent features X 1, X d given the class label Y For each X i feature, we have the conditional likelihood P(X i Y) Naïve Bayes Decision rule: 52
53 Naïve Bayes Algorithm for discrete features Training data: n d-dimensional discrete features + K class labels We need to estimate these probabilities! Estimate them with MLE (Relative Frequencies)! 53


54 Naïve Bayes Algorithm for discrete features We need to estimate these probabilities! Estimators For Class Prior For Likelihood NB Prediction for test data: 19 54
55 Subtlety: Insufficient training data For example, What now??? 21 55
56 Naïve Bayes Alg Discrete features Training data: Use your expert knowledge & apply prior distributions: Add m virtual examples Same as assuming conjugate priors Assume priors: MAP Estimate: called Laplace smoothing # virtual examples with Y = b 56 22
57 Case Study: Text Classification 57
58 Is this spam? 58
59 Positive or negative movie review? unbelievably disappointing Full of zany characters and richly applied satire, and some great plot twists this is the greatest screwball comedy ever filmed It was pathetic. The worst part about it was the boxing scenes. slide by Dan Jurafsky 59

60 What is the subject of this article? MEDLINE Article MeSH Subject Category Hierarchy Antogonists and Inhibitors? Blood Supply Chemistry slide by Dan Jurafsky Drug Therapy Embryology Epidemiology 60
61 Text Classification Assigning subject categories, topics, or genres Spam detection Authorship identification Age/gender identification Language Identification Sentiment analysis slide by Dan Jurafsky 61
62 Text Classification: definition Input: - a document d - a fixed set of classes C = {c1, c2,, cj} Output: a predicted class c C slide by Dan Jurafsky 62
63 Hand-coded rules Rules based on combinations of words or other features - spam: black-list-address OR ( dollars AND have been selected ) Accuracy can be high - If rules carefully refined by expert But building and maintaining these rules is expensive slide by Dan Jurafsky 63
64 Text Classification and Naive Bayes Classify s - Y = {Spam, NotSpam} Classify news articles - Y = {what is the topic of the article?} What are the features X? The text! Let X i represent i th word in the document 64
65 X i represents i th word in document 65
66 NB for Text Classification A problem: The support of P(X Y) is huge! Article at least 1000 words, X={X 1,,X 1000 } X i represents i th word in document, i.e., the domain of X i is the entire vocabulary, e.g., Webster Dictionary (or more). X i 2 {1,,50000} ) K( ) parameters to estimate without the NB assumption. 66
67 NB for Text Classification X i 2 {1,,50000} ) K( ) parameters to estimate. NB assumption helps a lot!!! If P(X i =x i Y=y) is the probability of observing word x i at the i th position in a document on topic y ) 1000K( ) parameters to estimate with NB assumption NB assumption helps, but still lots of parameters to estimate. 6726
68 Bag of words model Typical additional assumption: Position in document doesn t matter: P(X i =x i Y=y) = P(X k =x i Y=y) Bag of words model order of words on the page ignored The document is just a bag of words: i.i.d. words Sounds really silly, but often works very well! ) K( ) parameters to estimate The probability of a document with words x 1,x 2, 68 27
69 The bag of words representation I love this movie! It's sweet, but with satirical humor. The dialogue is great and the adventure scenes are fun It manages to be whimsical and romantic while laughing at the conventions of the fairy tale genre. I would recommend it to just about anyone. I've seen it several times, and I'm always happy to see it again whenever I have a friend who hasn't seen it yet. γ( )=c slide by Dan Jurafsky 69
70 The bag of words representation γ( I love this movie! It's sweet, but with satirical humor. The dialogue is great and the adventure scenes are fun It manages to be whimsical and romantic while laughing at the conventions of the fairy tale genre. I would recommend it to just about anyone. I've seen it several times, and I'm always happy to see it again whenever I have a friend who hasn't seen it yet. )=c slide by Dan Jurafsky 70
71 The bag of words representation: using a subset of words γ( x love xxxxxxxxxxxxxxxx sweet xxxxxxx satirical xxxxxxxxxx xxxxxxxxxxx great xxxxxxx xxxxxxxxxxxxxxxxxxx fun xxxx xxxxxxxxxxxxx whimsical xxxx romantic xxxx laughing xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx recommend xxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx x several xxxxxxxxxxxxxxxxx xxxxx happy xxxxxxxxx again xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxx )=c slide by Dan Jurafsky 71
72 The bag of words representation great 2 γ( love 2 recommend 1 laugh 1 happy )=c slide by Dan Jurafsky 72
73 Doc Words Class ˆP(c) = N c N ˆP(w c) = count(w,c)+1 count(c)+ V Training 1 Chinese Beijing Chinese c 2 Chinese Chinese Shanghai c 3 Chinese Macao c 4 Tokyo Japan Chinese j Test 5 Chinese Chinese Chinese Tokyo Japan? slide by Dan Jurafsky Priors: P(c)= 3 4 P(j)= 1 4 Choosing a class: P(c d5) 3/4 * (3/7) 3 * 1/14 * 1/ Conditional Probabilities: P(Chinese c) = (5+1) / (8+6) = 6/14 = 3/7 P(Tokyo c) = (0+1) / (8+6) = 1/14 P(j d5) 1/4 * (2/9) 3 * 2/9 * 2/9 P(Japan c) = (0+1) / (8+6) = 1/ P(Chinese j) = (1+1) / (3+6) = 2/9 P(Tokyo j) = (1+1) / (3+6) = 2/9 P(Japan j) = (1+1) / (3+6) = 2/9 73
74 What if features are continuous? e.g., character recognition: Xi is intensity at i th pixel i Gaussian Naïve Bayes (GNB): Naïve Bayes (GNB): Different mean and variance for each class k and each pixel i. Sometimes assume variance is independent of Y (i.e., σi), or independent of Xi (i.e., σk) or both (i.e., σ) 74
75 Estimating parameters: Y discrete, X i continuous 75
76 Estimating parameters: Y discrete, X i continuous Maximum likelihood estimates: i th pixel in j th training image k th class j th training image 76
77 Twenty news groups results Naïve Bayes: 89% accuracy 77
78 Case Study: Classifying Mental States 78
79 Example: GNB for classifying mental states ~1 mm resolution ~2 images per sec. 15,000 voxels/image non-invasive, safe measures Blood Oxygen Level Dependent (BOLD) response [Mitchell et al.] 79

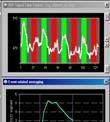
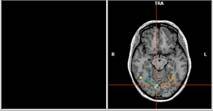
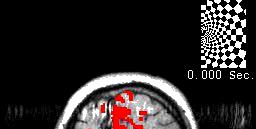
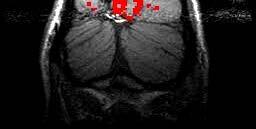
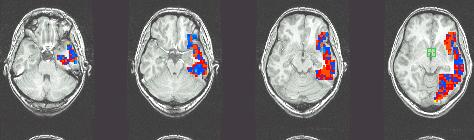
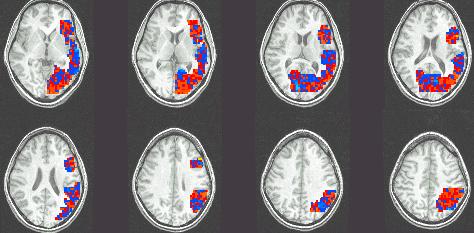
80 Brain scans can track activation with precision and sensitivity

81 Learned Naïve Bayes Models Means for P(BrainActivity WordCategory) Tool words Pairwise classification accuracy: 78-99%, 12 participants Building Building words [Mitchell et al.] 81
82 What you should know Naïve Bayes classifier What s the assumption Why we use it How do we learn it Why is Bayesian (MAP) estimation important Text classification Bag of words model Gaussian NB Features are still conditionally independent Each feature has a Gaussian distribution given class 82
Text Classification and Naïve Bayes
 Text Classification and Naïve Bayes The Task of Text Classification Many slides are adapted from slides by Dan Jurafsky Is this spam? Who wrote which Federalist papers? 1787-8: anonymous essays try to
Text Classification and Naïve Bayes The Task of Text Classification Many slides are adapted from slides by Dan Jurafsky Is this spam? Who wrote which Federalist papers? 1787-8: anonymous essays try to
Nonlinearity & Preprocessing
 Nonlinearity & Preprocessing Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR: x = (x 1, x 2, x 1 x 2 ) income: add degree + major Perceptron Map data into feature space
Nonlinearity & Preprocessing Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR: x = (x 1, x 2, x 1 x 2 ) income: add degree + major Perceptron Map data into feature space
Machine Learning. Classification. Bayes Classifier. Representing data: Choosing hypothesis class. Learning: h:x a Y. Eric Xing
 Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Naïve Bayes Classifier Eric Xing Lecture 3, January 23, 2006 Reading: Chap. 4 CB and handouts Classification Representing data: Choosing hypothesis
Machine Learning 10-701/15 701/15-781, 781, Spring 2008 Naïve Bayes Classifier Eric Xing Lecture 3, January 23, 2006 Reading: Chap. 4 CB and handouts Classification Representing data: Choosing hypothesis
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Introduction to Machine Learning CMU-10701 2. MLE, MAP, Bayes classification Barnabás Póczos & Aarti Singh 2014 Spring Administration http://www.cs.cmu.edu/~aarti/class/10701_spring14/index.html Blackboard
Probability Review and Naïve Bayes
 Probability Review and Naïve Bayes Instructor: Alan Ritter Some slides adapted from Dan Jurfasky and Brendan O connor What is Probability? The probability the coin will land heads is 0.5 Q: what does this
Probability Review and Naïve Bayes Instructor: Alan Ritter Some slides adapted from Dan Jurfasky and Brendan O connor What is Probability? The probability the coin will land heads is 0.5 Q: what does this
Last Time. Today. Bayesian Learning. The Distributions We Love. CSE 446 Gaussian Naïve Bayes & Logistic Regression
 CSE 446 Gaussian Naïve Bayes & Logistic Regression Winter 22 Dan Weld Learning Gaussians Naïve Bayes Last Time Gaussians Naïve Bayes Logistic Regression Today Some slides from Carlos Guestrin, Luke Zettlemoyer
CSE 446 Gaussian Naïve Bayes & Logistic Regression Winter 22 Dan Weld Learning Gaussians Naïve Bayes Last Time Gaussians Naïve Bayes Logistic Regression Today Some slides from Carlos Guestrin, Luke Zettlemoyer
Introduction to Machine Learning
 Introduction to Machine Learning 4. Perceptron and Kernels Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Perceptron Hebbian learning & biology Algorithm
Introduction to Machine Learning 4. Perceptron and Kernels Alex Smola Carnegie Mellon University http://alex.smola.org/teaching/cmu2013-10-701 10-701 Outline Perceptron Hebbian learning & biology Algorithm
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Naïve Bayes. Vibhav Gogate The University of Texas at Dallas
 Naïve Bayes Vibhav Gogate The University of Texas at Dallas Supervised Learning of Classifiers Find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximation to f : X Y Examples: what are
Naïve Bayes Vibhav Gogate The University of Texas at Dallas Supervised Learning of Classifiers Find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximation to f : X Y Examples: what are
Lecture 2: Probability, Naive Bayes
 Lecture 2: Probability, Naive Bayes CS 585, Fall 205 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp205/ Brendan O Connor Today Probability Review Naive Bayes classification
Lecture 2: Probability, Naive Bayes CS 585, Fall 205 Introduction to Natural Language Processing http://people.cs.umass.edu/~brenocon/inlp205/ Brendan O Connor Today Probability Review Naive Bayes classification
Lecture 10: Linear Discriminant Functions Perceptron. Aykut Erdem March 2016 Hacettepe University
 Lecture 10: Linear Discriminant Functions Perceptron Aykut Erdem March 2016 Hacettepe University Administrative Project proposal due today! a half page description problem to be investigated, why it is
Lecture 10: Linear Discriminant Functions Perceptron Aykut Erdem March 2016 Hacettepe University Administrative Project proposal due today! a half page description problem to be investigated, why it is
Probabilistic Graphical Models
 Probabilistic Graphical Models Carlos Carvalho, Mladen Kolar and Robert McCulloch 11/19/2015 Classification revisited The goal of classification is to learn a mapping from features to the target class.
Probabilistic Graphical Models Carlos Carvalho, Mladen Kolar and Robert McCulloch 11/19/2015 Classification revisited The goal of classification is to learn a mapping from features to the target class.
Generative v. Discriminative classifiers Intuition
 Logistic Regression Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features Y target
Logistic Regression Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features Y target
Generative v. Discriminative classifiers Intuition
 Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 1 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features
Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 1 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features
Classification, Linear Models, Naïve Bayes
 Classification, Linear Models, Naïve Bayes CMSC 470 Marine Carpuat Slides credit: Dan Jurafsky & James Martin, Jacob Eisenstein Today Text classification problems and their evaluation Linear classifiers
Classification, Linear Models, Naïve Bayes CMSC 470 Marine Carpuat Slides credit: Dan Jurafsky & James Martin, Jacob Eisenstein Today Text classification problems and their evaluation Linear classifiers
Bayes Rule. CS789: Machine Learning and Neural Network Bayesian learning. A Side Note on Probability. What will we learn in this lecture?
 Bayes Rule CS789: Machine Learning and Neural Network Bayesian learning P (Y X) = P (X Y )P (Y ) P (X) Jakramate Bootkrajang Department of Computer Science Chiang Mai University P (Y ): prior belief, prior
Bayes Rule CS789: Machine Learning and Neural Network Bayesian learning P (Y X) = P (X Y )P (Y ) P (X) Jakramate Bootkrajang Department of Computer Science Chiang Mai University P (Y ): prior belief, prior
Point Estimation. Vibhav Gogate The University of Texas at Dallas
 Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer. Basics: Expectation and Variance Binary Variables
Point Estimation Vibhav Gogate The University of Texas at Dallas Some slides courtesy of Carlos Guestrin, Chris Bishop, Dan Weld and Luke Zettlemoyer. Basics: Expectation and Variance Binary Variables
CSE546: Naïve Bayes Winter 2012
 CSE546: Naïve Bayes Winter 2012 Luke Ze=lemoyer Slides adapted from Carlos Guestrin and Dan Klein Supervised Learning: find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximamon to f :
CSE546: Naïve Bayes Winter 2012 Luke Ze=lemoyer Slides adapted from Carlos Guestrin and Dan Klein Supervised Learning: find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximamon to f :
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
Accouncements. You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF
 Figure for problem 9 should be in the PDF") Accouncements You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF Please do not zip these files and submit (unless there are >5 files) 1 Bayesian Methods Machine Learning
Accouncements You should turn in a PDF and a python file(s) Figure for problem 9 should be in the PDF Please do not zip these files and submit (unless there are >5 files) 1 Bayesian Methods Machine Learning
Introduc)on to Bayesian methods (con)nued) - Lecture 16
on to Bayesian methods (con)nued) - Lecture 16") Introduc)on to Bayesian methods (con)nued) - Lecture 16 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Vibhav Gogate Outline of lectures Review of
Introduc)on to Bayesian methods (con)nued) - Lecture 16 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, Dan Klein, and Vibhav Gogate Outline of lectures Review of
Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2
 Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
CS 188: Artificial Intelligence Spring Today
 CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
Dimensionality reduction
 Dimensionality Reduction PCA continued Machine Learning CSE446 Carlos Guestrin University of Washington May 22, 2013 Carlos Guestrin 2005-2013 1 Dimensionality reduction n Input data may have thousands
Dimensionality Reduction PCA continued Machine Learning CSE446 Carlos Guestrin University of Washington May 22, 2013 Carlos Guestrin 2005-2013 1 Dimensionality reduction n Input data may have thousands
CSE446: Naïve Bayes Winter 2016
 CSE446: Naïve Bayes Winter 2016 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, Luke ZeIlemoyer Supervised Learning: find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximanon
CSE446: Naïve Bayes Winter 2016 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, Luke ZeIlemoyer Supervised Learning: find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximanon
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Machine Learning CMPT 726 Simon Fraser University. Binomial Parameter Estimation
 Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Machine Learning CMPT 726 Simon Fraser University Binomial Parameter Estimation Outline Maximum Likelihood Estimation Smoothed Frequencies, Laplace Correction. Bayesian Approach. Conjugate Prior. Uniform
Point Estimation. Maximum likelihood estimation for a binomial distribution. CSE 446: Machine Learning
 Point Estimation Emily Fox University of Washington January 6, 2017 Maximum likelihood estimation for a binomial distribution 1 Your first consulting job A bored Seattle billionaire asks you a question:
Point Estimation Emily Fox University of Washington January 6, 2017 Maximum likelihood estimation for a binomial distribution 1 Your first consulting job A bored Seattle billionaire asks you a question:
Naïve Bayes, Maxent and Neural Models
 Naïve Bayes, Maxent and Neural Models CMSC 473/673 UMBC Some slides adapted from 3SLP Outline Recap: classification (MAP vs. noisy channel) & evaluation Naïve Bayes (NB) classification Terminology: bag-of-words
Naïve Bayes, Maxent and Neural Models CMSC 473/673 UMBC Some slides adapted from 3SLP Outline Recap: classification (MAP vs. noisy channel) & evaluation Naïve Bayes (NB) classification Terminology: bag-of-words
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Introduction to AI Learning Bayesian networks. Vibhav Gogate
 Introduction to AI Learning Bayesian networks Vibhav Gogate Inductive Learning in a nutshell Given: Data Examples of a function (X, F(X)) Predict function F(X) for new examples X Discrete F(X): Classification
Introduction to AI Learning Bayesian networks Vibhav Gogate Inductive Learning in a nutshell Given: Data Examples of a function (X, F(X)) Predict function F(X) for new examples X Discrete F(X): Classification
Text Classification and Naïve Bayes
 Text Classification and Naïve Bayes The Task of Text Classifica1on Many slides are adapted from slides by Dan Jurafsky Is this spam? Who wrote which Federalist papers? 1787-8: anonymous essays try to convince
Text Classification and Naïve Bayes The Task of Text Classifica1on Many slides are adapted from slides by Dan Jurafsky Is this spam? Who wrote which Federalist papers? 1787-8: anonymous essays try to convince
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 26, 2015 Today: Bayes Classifiers Conditional Independence Naïve Bayes Readings: Mitchell: Naïve Bayes
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 26, 2015 Today: Bayes Classifiers Conditional Independence Naïve Bayes Readings: Mitchell: Naïve Bayes
Bayesian Classifiers, Conditional Independence and Naïve Bayes. Required reading: Naïve Bayes and Logistic Regression (available on class website)
") Bayesian Classifiers, Conditional Independence and Naïve Bayes Required reading: Naïve Bayes and Logistic Regression (available on class website) Machine Learning 10-701 Tom M. Mitchell Machine Learning
Bayesian Classifiers, Conditional Independence and Naïve Bayes Required reading: Naïve Bayes and Logistic Regression (available on class website) Machine Learning 10-701 Tom M. Mitchell Machine Learning
Bayesian Models in Machine Learning
 Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
Bayesian Models in Machine Learning Lukáš Burget Escuela de Ciencias Informáticas 2017 Buenos Aires, July 24-29 2017 Frequentist vs. Bayesian Frequentist point of view: Probability is the frequency of
COMP 328: Machine Learning
 COMP 328: Machine Learning Lecture 2: Naive Bayes Classifiers Nevin L. Zhang Department of Computer Science and Engineering The Hong Kong University of Science and Technology Spring 2010 Nevin L. Zhang
COMP 328: Machine Learning Lecture 2: Naive Bayes Classifiers Nevin L. Zhang Department of Computer Science and Engineering The Hong Kong University of Science and Technology Spring 2010 Nevin L. Zhang
The Naïve Bayes Classifier. Machine Learning Fall 2017
 The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Naïve Bayes Introduction to Machine Learning. Matt Gormley Lecture 18 Oct. 31, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
Outline. Supervised Learning. Hong Chang. Institute of Computing Technology, Chinese Academy of Sciences. Machine Learning Methods (Fall 2012)
") Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Linear Models for Regression Linear Regression Probabilistic Interpretation
Naïve Bayes. Jia-Bin Huang. Virginia Tech Spring 2019 ECE-5424G / CS-5824
 Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Hypothesis testing Machine Learning CSE546 Kevin Jamieson University of Washington October 30, 2018 2018 Kevin Jamieson 2 Anomaly detection You are
Announcements Proposals graded Kevin Jamieson 2018 1 Hypothesis testing Machine Learning CSE546 Kevin Jamieson University of Washington October 30, 2018 2018 Kevin Jamieson 2 Anomaly detection You are
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, 2013
 Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 23: Perceptrons 11/20/2008 Dan Klein UC Berkeley 1 General Naïve Bayes A general naive Bayes model: C E 1 E 2 E n We only specify how each feature depends
CS 188: Artificial Intelligence Fall 2008 Lecture 23: Perceptrons 11/20/2008 Dan Klein UC Berkeley 1 General Naïve Bayes A general naive Bayes model: C E 1 E 2 E n We only specify how each feature depends
General Naïve Bayes. CS 188: Artificial Intelligence Fall Example: Overfitting. Example: OCR. Example: Spam Filtering. Example: Spam Filtering
 CS 188: Artificial Intelligence Fall 2008 General Naïve Bayes A general naive Bayes model: C Lecture 23: Perceptrons 11/20/2008 E 1 E 2 E n Dan Klein UC Berkeley We only specify how each feature depends
CS 188: Artificial Intelligence Fall 2008 General Naïve Bayes A general naive Bayes model: C Lecture 23: Perceptrons 11/20/2008 E 1 E 2 E n Dan Klein UC Berkeley We only specify how each feature depends
Machine Learning for natural language processing
 Machine Learning for natural language processing Classification: Naive Bayes Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 20 Introduction Classification = supervised method for
Machine Learning for natural language processing Classification: Naive Bayes Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 20 Introduction Classification = supervised method for
Generative Classifiers: Part 1. CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang
 Generative Classifiers: Part 1 CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang 1 This Week Discriminative vs Generative Models Simple Model: Does the patient
Generative Classifiers: Part 1 CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang 1 This Week Discriminative vs Generative Models Simple Model: Does the patient
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Machine Learning. Hal Daumé III. Computer Science University of Maryland CS 421: Introduction to Artificial Intelligence 8 May 2012
 Machine Learning Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421 Introduction to Artificial Intelligence 8 May 2012 g 1 Many slides courtesy of Dan Klein, Stuart Russell, or Andrew
Machine Learning Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421 Introduction to Artificial Intelligence 8 May 2012 g 1 Many slides courtesy of Dan Klein, Stuart Russell, or Andrew
Estimating Parameters
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 13, 2012 Today: Bayes Classifiers Naïve Bayes Gaussian Naïve Bayes Readings: Mitchell: Naïve Bayes
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 13, 2012 Today: Bayes Classifiers Naïve Bayes Gaussian Naïve Bayes Readings: Mitchell: Naïve Bayes
CS 361: Probability & Statistics
 October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
October 17, 2017 CS 361: Probability & Statistics Inference Maximum likelihood: drawbacks A couple of things might trip up max likelihood estimation: 1) Finding the maximum of some functions can be quite
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Machine Learning for Computational Advertising
 Machine Learning for Computational Advertising L1: Basics and Probability Theory Alexander J. Smola Yahoo! Labs Santa Clara, CA 95051 alex@smola.org UC Santa Cruz, April 2009 Alexander J. Smola: Machine
Machine Learning for Computational Advertising L1: Basics and Probability Theory Alexander J. Smola Yahoo! Labs Santa Clara, CA 95051 alex@smola.org UC Santa Cruz, April 2009 Alexander J. Smola: Machine
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 4, 2015 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 4, 2015 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, What about continuous variables?
 Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Classification & Information Theory Lecture #8
 Classification & Information Theory Lecture #8 Introduction to Natural Language Processing CMPSCI 585, Fall 2007 University of Massachusetts Amherst Andrew McCallum Today s Main Points Automatically categorizing
Classification & Information Theory Lecture #8 Introduction to Natural Language Processing CMPSCI 585, Fall 2007 University of Massachusetts Amherst Andrew McCallum Today s Main Points Automatically categorizing
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University August 30, 2017 Today: Decision trees Overfitting The Big Picture Coming soon Probabilistic learning MLE,
CS 188: Artificial Intelligence. Machine Learning
 CS 188: Artificial Intelligence Review of Machine Learning (ML) DISCLAIMER: It is insufficient to simply study these slides, they are merely meant as a quick refresher of the high-level ideas covered.
CS 188: Artificial Intelligence Review of Machine Learning (ML) DISCLAIMER: It is insufficient to simply study these slides, they are merely meant as a quick refresher of the high-level ideas covered.
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
Naïve Bayes Introduction to Machine Learning. Matt Gormley Lecture 3 September 14, Readings: Mitchell Ch Murphy Ch.
 School of Computer Science 10-701 Introduction to Machine Learning aïve Bayes Readings: Mitchell Ch. 6.1 6.10 Murphy Ch. 3 Matt Gormley Lecture 3 September 14, 2016 1 Homewor 1: due 9/26/16 Project Proposal:
School of Computer Science 10-701 Introduction to Machine Learning aïve Bayes Readings: Mitchell Ch. 6.1 6.10 Murphy Ch. 3 Matt Gormley Lecture 3 September 14, 2016 1 Homewor 1: due 9/26/16 Project Proposal:
Machine Learning, Fall 2012 Homework 2
 0-60 Machine Learning, Fall 202 Homework 2 Instructors: Tom Mitchell, Ziv Bar-Joseph TA in charge: Selen Uguroglu email: sugurogl@cs.cmu.edu SOLUTIONS Naive Bayes, 20 points Problem. Basic concepts, 0
0-60 Machine Learning, Fall 202 Homework 2 Instructors: Tom Mitchell, Ziv Bar-Joseph TA in charge: Selen Uguroglu email: sugurogl@cs.cmu.edu SOLUTIONS Naive Bayes, 20 points Problem. Basic concepts, 0
Lecture 9: Naive Bayes, SVM, Kernels. Saravanan Thirumuruganathan
 Lecture 9: Naive Bayes, SVM, Kernels Instructor: Outline 1 Probability basics 2 Probabilistic Interpretation of Classification 3 Bayesian Classifiers, Naive Bayes 4 Support Vector Machines Probability
Lecture 9: Naive Bayes, SVM, Kernels Instructor: Outline 1 Probability basics 2 Probabilistic Interpretation of Classification 3 Bayesian Classifiers, Naive Bayes 4 Support Vector Machines Probability
Computational Cognitive Science
 Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Computational Cognitive Science Lecture 8: Frank Keller School of Informatics University of Edinburgh keller@inf.ed.ac.uk Based on slides by Sharon Goldwater October 14, 2016 Frank Keller Computational
Introduction to Machine Learning
 Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction to Machine Learning Generative Models Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Machine Learning: Assignment 1
 10-701 Machine Learning: Assignment 1 Due on Februrary 0, 014 at 1 noon Barnabas Poczos, Aarti Singh Instructions: Failure to follow these directions may result in loss of points. Your solutions for this
10-701 Machine Learning: Assignment 1 Due on Februrary 0, 014 at 1 noon Barnabas Poczos, Aarti Singh Instructions: Failure to follow these directions may result in loss of points. Your solutions for this
Computational Cognitive Science
 Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
Computational Cognitive Science Lecture 9: Bayesian Estimation Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 17 October, 2017 1 / 28
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Parametric Models: from data to models
 Parametric Models: from data to models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Jan 22, 2018 Recall: Model-based ML DATA MODEL LEARNING MODEL MODEL INFERENCE KNOWLEDGE Learning:
Parametric Models: from data to models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Jan 22, 2018 Recall: Model-based ML DATA MODEL LEARNING MODEL MODEL INFERENCE KNOWLEDGE Learning:
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
UVA CS / Introduc8on to Machine Learning and Data Mining
 UVA CS 4501-001 / 6501 007 Introduc8on to Machine Learning and Data Mining Lecture 13: Probability and Sta3s3cs Review (cont.) + Naïve Bayes Classifier Yanjun Qi / Jane, PhD University of Virginia Department
UVA CS 4501-001 / 6501 007 Introduc8on to Machine Learning and Data Mining Lecture 13: Probability and Sta3s3cs Review (cont.) + Naïve Bayes Classifier Yanjun Qi / Jane, PhD University of Virginia Department
Generative Learning algorithms
 CS9 Lecture notes Andrew Ng Part IV Generative Learning algorithms So far, we ve mainly been talking about learning algorithms that model p(y x; θ), the conditional distribution of y given x. For instance,
CS9 Lecture notes Andrew Ng Part IV Generative Learning algorithms So far, we ve mainly been talking about learning algorithms that model p(y x; θ), the conditional distribution of y given x. For instance,
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
Naïve Bayes Classifiers and Logistic Regression. Doug Downey Northwestern EECS 349 Winter 2014
 Naïve Bayes Classifiers and Logistic Regression Doug Downey Northwestern EECS 349 Winter 2014 Naïve Bayes Classifiers Combines all ideas we ve covered Conditional Independence Bayes Rule Statistical Estimation
Naïve Bayes Classifiers and Logistic Regression Doug Downey Northwestern EECS 349 Winter 2014 Naïve Bayes Classifiers Combines all ideas we ve covered Conditional Independence Bayes Rule Statistical Estimation
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
CS 6140: Machine Learning Spring What We Learned Last Week. Survey 2/26/16. VS. Model
 Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Assignment
Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Assignment
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 2, 2015 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 2, 2015 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Machine Learning Tom M. Mitchell Machine Learning Department Carnegie Mellon University. September 20, 2012
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 20, 2012 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 20, 2012 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
CS 6140: Machine Learning Spring 2016
 CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa?on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis?cs Assignment
CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa?on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis?cs Assignment
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Introduction to Probabilistic Machine Learning
 Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Introduction to Probabilistic Machine Learning Piyush Rai Dept. of CSE, IIT Kanpur (Mini-course 1) Nov 03, 2015 Piyush Rai (IIT Kanpur) Introduction to Probabilistic Machine Learning 1 Machine Learning
Probability and Estimation. Alan Moses
 Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Probability and Estimation Alan Moses Random variables and probability A random variable is like a variable in algebra (e.g., y=e x ), but where at least part of the variability is taken to be stochastic.
Bayes Theorem & Naïve Bayes. (some slides adapted from slides by Massimo Poesio, adapted from slides by Chris Manning)
") Bayes Theorem & Naïve Bayes (some slides adapted from slides by Massimo Poesio, adapted from slides by Chris Manning) Review: Bayes Theorem & Diagnosis P( a b) Posterior Likelihood Prior P( b a) P( a)
Bayes Theorem & Naïve Bayes (some slides adapted from slides by Massimo Poesio, adapted from slides by Chris Manning) Review: Bayes Theorem & Diagnosis P( a b) Posterior Likelihood Prior P( b a) P( a)
Bayesian Methods. David S. Rosenberg. New York University. March 20, 2018
 Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
Bayesian Methods David S. Rosenberg New York University March 20, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 March 20, 2018 1 / 38 Contents 1 Classical Statistics 2 Bayesian
Machine Learning CSE546 Sham Kakade University of Washington. Oct 4, What about continuous variables?
 Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Logistic Regression. Some slides adapted from Dan Jurfasky and Brendan O Connor
 Logistic Regression Some slides adapted from Dan Jurfasky and Brendan O Connor Naïve Bayes Recap Bag of words (order independent) Features are assumed independent given class P (x 1,...,x n c) =P (x 1
Logistic Regression Some slides adapted from Dan Jurfasky and Brendan O Connor Naïve Bayes Recap Bag of words (order independent) Features are assumed independent given class P (x 1,...,x n c) =P (x 1
CS4705. Probability Review and Naïve Bayes. Slides from Dragomir Radev
 CS4705 Probability Review and Naïve Bayes Slides from Dragomir Radev Classification using a Generative Approach Previously on NLP discriminative models P C D here is a line with all the social media posts
CS4705 Probability Review and Naïve Bayes Slides from Dragomir Radev Classification using a Generative Approach Previously on NLP discriminative models P C D here is a line with all the social media posts
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
CPSC 340: Machine Learning and Data Mining MLE and MAP Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. 1 Admin Assignment 4: Due tonight. Assignment 5: Will be released
Fundamentals. CS 281A: Statistical Learning Theory. Yangqing Jia. August, Based on tutorial slides by Lester Mackey and Ariel Kleiner
 Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Fundamentals CS 281A: Statistical Learning Theory Yangqing Jia Based on tutorial slides by Lester Mackey and Ariel Kleiner August, 2011 Outline 1 Probability 2 Statistics 3 Linear Algebra 4 Optimization
Today. Statistical Learning. Coin Flip. Coin Flip. Experiment 1: Heads. Experiment 1: Heads. Which coin will I use? Which coin will I use?
 Today Statistical Learning Parameter Estimation: Maximum Likelihood (ML) Maximum A Posteriori (MAP) Bayesian Continuous case Learning Parameters for a Bayesian Network Naive Bayes Maximum Likelihood estimates
Today Statistical Learning Parameter Estimation: Maximum Likelihood (ML) Maximum A Posteriori (MAP) Bayesian Continuous case Learning Parameters for a Bayesian Network Naive Bayes Maximum Likelihood estimates
Loss Functions, Decision Theory, and Linear Models
 Loss Functions, Decision Theory, and Linear Models CMSC 678 UMBC January 31 st, 2018 Some slides adapted from Hamed Pirsiavash Logistics Recap Piazza (ask & answer questions): https://piazza.com/umbc/spring2018/cmsc678
Loss Functions, Decision Theory, and Linear Models CMSC 678 UMBC January 31 st, 2018 Some slides adapted from Hamed Pirsiavash Logistics Recap Piazza (ask & answer questions): https://piazza.com/umbc/spring2018/cmsc678
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class