CS 343: Artificial Intelligence
|
|
|
- Felicia Lawrence
- 5 years ago
- Views:
Transcription

1 CS 343: Artificial Intelligence Perceptrons Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at

2 Error-Driven Classification
3 Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered with ScanSoft to offer you the latest version of OmniPage Pro, for just $99.99* - the regular list price is $499! The most common question we've received about this offer is - Is this genuine? We would like to assure you that this offer is authorized by ScanSoft, is genuine and valid. You can get the To receive your $30 Amazon.com promotional certificate, click through to and see the prominent link for the $30 offer. All details are there. We hope you enjoyed receiving this message. However, if you'd rather not receive future s announcing new store launches, please click...
4 What to Do About Errors Problem: there s still spam in your inbox Need more features words aren t enough! Have you ed the sender before? Have 1M other people just gotten the same ? Is the sending information consistent? Is the in ALL CAPS? Do inline URLs point where they say they point? Does the address you by (your) name? Naïve Bayes models can incorporate a variety of features, but tend to do best when homogeneous (e.g. all features are word occurrences) and/or roughly independent
5 Linear Classifiers
6 Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free : 2 YOUR_NAME : 0 MISSPELLED : 2 FROM_FRIEND : 0... SPAM or + PIXEL-7,12 : 1 PIXEL-7,13 : 0... NUM_LOOPS :
7 Some (Simplified) Biology Very loose inspiration: human neurons
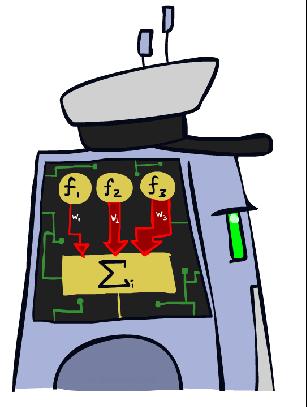
8 Linear Classifiers Inputs are feature values Each feature has a weight Sum is the activation If the activation is: Positive, output +1 Negative, output -1 f 1 f 2 f 3 w 1 w 2 Σ >0? w 3
9 Weights Binary case: compare features to a weight vector Learning: figure out the weight vector from examples # free : 4 YOUR_NAME :-1 MISSPELLED : 1 FROM_FRIEND :-3... # free : 2 YOUR_NAME : 0 MISSPELLED : 2 FROM_FRIEND : 0... Dot product positive means the positive class # free : 0 YOUR_NAME : 1 MISSPELLED : 1 FROM_FRIEND : 1...

10 Decision Rules
11 Binary Decision Rule In the space of feature vectors Examples are points Any weight vector is a hyperplane One side corresponds to Y=+1 Other corresponds to Y=-1 money 2 +1 = SPAM BIAS : -3 free : 4 money : = HAM free

12 Weight Updates
, no change!")
13 Learning: Binary Perceptron Start with weights = 0 For each training instance: Classify with current weights If correct (i.e., y=y*), no change! If wrong: adjust the weight vector
14 Learning: Binary Perceptron Start with weights = 0 For each training instance: Classify with current weights If correct (i.e., y=y*), no change! If wrong: adjust the weight vector by adding or subtracting the feature vector. Subtract if y* is -1.
15 Separable Case Examples: Perceptron

16 Multiclass Decision Rule If we have multiple classes: A weight vector for each class: Score (activation) of a class y: Prediction highest score wins Binary = multiclass where the negative class has weight zero
17 Learning: Multiclass Perceptron Start with all weights = 0 Pick up training examples one by one Predict with current weights If correct, no change! If wrong: lower score of wrong answer, raise score of right answer
18 Properties of Perceptrons Separability: true if some parameters get the training set perfectly correct Separable Convergence: if the training is separable, perceptron will eventually converge (binary case) Mistake Bound: the maximum number of mistakes (binary case) related to the margin or degree of separability Non-Separable
19 Non-Separable Case Examples: Perceptron

20 Improving the Perceptron

")


21 Problems with the Perceptron Noise: if the data isn t separable, weights will thrash Averaging weight vectors over time can help (averaged perceptron) Mediocre generalization: finds a barely separating solution Overtraining: test / held-out accuracy usually rises, then falls Overtraining is a kind of overfitting
22 Fixing the Perceptron Idea: adjust the weight update to mitigate these effects MIRA*: choose an update size that fixes the current mistake but, minimizes the change to w The +1 helps to generalize * Margin Infused Relaxed Algorithm
23 Minimum Correcting Update min not τ=0, or would not have made an error, so min will be where equality holds


24 Maximum Step Size In practice, it s also bad to make updates that are too large Example may be labeled incorrectly You may not have enough features Solution: cap the maximum possible value of τ with some constant C Corresponds to an optimization that assumes non-separable data Usually converges faster than perceptron Usually better, especially on noisy data
25 Linear Separators Which of these linear separators is optimal?
26 Support Vector Machines Maximizing the margin: good according to intuition, theory, practice Only support vectors matter; other training examples are ignorable Support vector machines (SVMs) find the separator with max margin Basically, SVMs are MIRA where you optimize over all examples at once MIRA SVM
27 Classification: Comparison Naïve Bayes Builds a model training data Gives prediction probabilities Strong assumptions about feature independence One pass through data (counting) Perceptrons / MIRA: Makes less assumptions about data Mistake-driven learning Multiple passes through data (prediction) Often more accurate

28 Apprenticeship
 Correct actions: those taken by expert Features defined over (s,a) pairs: f(s,a)")
29 Pacman Apprenticeship! Examples are states s Candidates are pairs (s,a) Correct actions: those taken by expert Features defined over (s,a) pairs: f(s,a) Score of a q-state (s,a) given by: correct action a* How is this VERY different from reinforcement learning?

30 Video of Pacman Apprentice

31 Web Search
32 Extension: Web Search Information retrieval: Given information needs, produce information Includes, e.g. web search, question answering, and classic IR x = Apple Computers Web search: not exactly classification, but rather ranking

33 Feature-Based Ranking x = Apple Computer x, x,
34 Perceptron for Ranking Inputs Candidates Many feature vectors: One weight vector: Prediction: Update (if wrong):
Errors, and What to Do. CS 188: Artificial Intelligence Fall What to Do About Errors. Later On. Some (Simplified) Biology
 Biology") CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
CS 188: Artificial Intelligence Fall 2011 Lecture 22: Perceptrons and More! 11/15/2011 Dan Klein UC Berkeley Errors, and What to Do Examples of errors Dear GlobalSCAPE Customer, GlobalSCAPE has partnered
CS 5522: Artificial Intelligence II
 CS 5522: Artificial Intelligence II Perceptrons Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
CS 5522: Artificial Intelligence II Perceptrons Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
CS 188: Artificial Intelligence. Outline
 CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 23: Perceptrons 11/20/2008 Dan Klein UC Berkeley 1 General Naïve Bayes A general naive Bayes model: C E 1 E 2 E n We only specify how each feature depends
CS 188: Artificial Intelligence Fall 2008 Lecture 23: Perceptrons 11/20/2008 Dan Klein UC Berkeley 1 General Naïve Bayes A general naive Bayes model: C E 1 E 2 E n We only specify how each feature depends
General Naïve Bayes. CS 188: Artificial Intelligence Fall Example: Overfitting. Example: OCR. Example: Spam Filtering. Example: Spam Filtering
 CS 188: Artificial Intelligence Fall 2008 General Naïve Bayes A general naive Bayes model: C Lecture 23: Perceptrons 11/20/2008 E 1 E 2 E n Dan Klein UC Berkeley We only specify how each feature depends
CS 188: Artificial Intelligence Fall 2008 General Naïve Bayes A general naive Bayes model: C Lecture 23: Perceptrons 11/20/2008 E 1 E 2 E n Dan Klein UC Berkeley We only specify how each feature depends
Learning: Binary Perceptron. Examples: Perceptron. Separable Case. In the space of feature vectors
 Linear Classifiers CS 88 Artificial Intelligence Perceptrons and Logistic Regression Pieter Abbeel & Dan Klein University of California, Berkeley Feature Vectors Some (Simplified) Biology Very loose inspiration
Linear Classifiers CS 88 Artificial Intelligence Perceptrons and Logistic Regression Pieter Abbeel & Dan Klein University of California, Berkeley Feature Vectors Some (Simplified) Biology Very loose inspiration
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
CS 188: Artificial Intelligence. Machine Learning
 CS 188: Artificial Intelligence Review of Machine Learning (ML) DISCLAIMER: It is insufficient to simply study these slides, they are merely meant as a quick refresher of the high-level ideas covered.
CS 188: Artificial Intelligence Review of Machine Learning (ML) DISCLAIMER: It is insufficient to simply study these slides, they are merely meant as a quick refresher of the high-level ideas covered.
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
Announcements. CS 188: Artificial Intelligence Spring Classification. Today. Classification overview. Case-Based Reasoning
 CS 188: Artificial Intelligence Spring 21 Lecture 22: Nearest Neighbors, Kernels 4/18/211 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!) Remaining
CS 188: Artificial Intelligence Spring 21 Lecture 22: Nearest Neighbors, Kernels 4/18/211 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!) Remaining
EE 511 Online Learning Perceptron
 Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Kevin Jamison EE 511 Online Learning Perceptron Instructor: Hanna Hajishirzi hannaneh@washington.edu
Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Kevin Jamison EE 511 Online Learning Perceptron Instructor: Hanna Hajishirzi hannaneh@washington.edu
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
Machine Learning. Hal Daumé III. Computer Science University of Maryland CS 421: Introduction to Artificial Intelligence 8 May 2012
 Machine Learning Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421 Introduction to Artificial Intelligence 8 May 2012 g 1 Many slides courtesy of Dan Klein, Stuart Russell, or Andrew
Machine Learning Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421 Introduction to Artificial Intelligence 8 May 2012 g 1 Many slides courtesy of Dan Klein, Stuart Russell, or Andrew
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Deep Learning Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein, Pieter Abbeel, Anca Dragan for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Deep Learning Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein, Pieter Abbeel, Anca Dragan for CS188 Intro to AI at UC Berkeley.
Perceptron. Subhransu Maji. CMPSCI 689: Machine Learning. 3 February February 2015
 Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Natural Language Processing. Classification. Features. Some Definitions. Classification. Feature Vectors. Classification I. Dan Klein UC Berkeley
 Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Classification. Chris Amato Northeastern University. Some images and slides are used from: Rob Platt, CS188 UC Berkeley, AIMA
 Classification Chris Amato Northeastern University Some images and slides are used from: Rob Platt, CS188 UC Berkeley, AIMA Supervised learning Given: Training set {(xi, yi) i = 1 N}, given a labeled set
Classification Chris Amato Northeastern University Some images and slides are used from: Rob Platt, CS188 UC Berkeley, AIMA Supervised learning Given: Training set {(xi, yi) i = 1 N}, given a labeled set
CS 188: Artificial Intelligence Learning :
 CS 188: Artificial Intelligence Learning : Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Lectures on learning Learning: a process
CS 188: Artificial Intelligence Learning : Instructor: Fabrice Popineau [These slides adapted from Stuart Russell, Dan Klein and Pieter Abbeel @ai.berkeley.edu] Lectures on learning Learning: a process
Statistical NLP Spring A Discriminative Approach
 Statistical NLP Spring 2008 Lecture 6: Classification Dan Klein UC Berkeley A Discriminative Approach View WSD as a discrimination task (regression, really) P(sense context:jail, context:county, context:feeding,
Statistical NLP Spring 2008 Lecture 6: Classification Dan Klein UC Berkeley A Discriminative Approach View WSD as a discrimination task (regression, really) P(sense context:jail, context:county, context:feeding,
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Linear Classifiers. Michael Collins. January 18, 2012
 Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
Linear Classifiers Michael Collins January 18, 2012 Today s Lecture Binary classification problems Linear classifiers The perceptron algorithm Classification Problems: An Example Goal: build a system that
Mining of Massive Datasets Jure Leskovec, AnandRajaraman, Jeff Ullman Stanford University
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Approximate Q-Learning. Dan Weld / University of Washington
 Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Hidden Markov Models Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Hidden Markov Models Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
CS 188: Artificial Intelligence Spring Today
 CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
Reinforcement Learning Wrap-up
 Reinforcement Learning Wrap-up Slides courtesy of Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Reinforcement Learning Wrap-up Slides courtesy of Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Bayes Nets: Sampling Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Bayes Nets: Sampling Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Machine Learning for NLP
 Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Decision Networks and Value of Perfect Information Prof. Scott Niekum The niversity of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188
CS 343: Artificial Intelligence Decision Networks and Value of Perfect Information Prof. Scott Niekum The niversity of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188
Logistic Regression. Some slides adapted from Dan Jurfasky and Brendan O Connor
 Logistic Regression Some slides adapted from Dan Jurfasky and Brendan O Connor Naïve Bayes Recap Bag of words (order independent) Features are assumed independent given class P (x 1,...,x n c) =P (x 1
Logistic Regression Some slides adapted from Dan Jurfasky and Brendan O Connor Naïve Bayes Recap Bag of words (order independent) Features are assumed independent given class P (x 1,...,x n c) =P (x 1
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Support Vector Machine. Industrial AI Lab. Prof. Seungchul Lee
 Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Linear discriminant functions
 Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Introduction to AI Learning Bayesian networks. Vibhav Gogate
 Introduction to AI Learning Bayesian networks Vibhav Gogate Inductive Learning in a nutshell Given: Data Examples of a function (X, F(X)) Predict function F(X) for new examples X Discrete F(X): Classification
Introduction to AI Learning Bayesian networks Vibhav Gogate Inductive Learning in a nutshell Given: Data Examples of a function (X, F(X)) Predict function F(X) for new examples X Discrete F(X): Classification
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Binary Classification / Perceptron
 Binary Classification / Perceptron Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Supervised Learning Input: x 1, y 1,, (x n, y n ) x i is the i th data
Binary Classification / Perceptron Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Supervised Learning Input: x 1, y 1,, (x n, y n ) x i is the i th data
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Markov Models Instructors: Dan Klein and Pieter Abbeel --- University of California, Berkeley [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to
CS 188: Artificial Intelligence Markov Models Instructors: Dan Klein and Pieter Abbeel --- University of California, Berkeley [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Linear classifiers Lecture 3
 Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Particle Filters and Applications of HMMs Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro
CS 343: Artificial Intelligence Particle Filters and Applications of HMMs Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
CS 188: Artificial Intelligence Spring 2011 Lecture 12: Probability 3/2/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Announcements P3 due on Monday (3/7) at 4:59pm W3 going out
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Final Examination CS 540-2: Introduction to Artificial Intelligence
 Final Examination CS 540-2: Introduction to Artificial Intelligence May 7, 2017 LAST NAME: SOLUTIONS FIRST NAME: Problem Score Max Score 1 14 2 10 3 6 4 10 5 11 6 9 7 8 9 10 8 12 12 8 Total 100 1 of 11
Final Examination CS 540-2: Introduction to Artificial Intelligence May 7, 2017 LAST NAME: SOLUTIONS FIRST NAME: Problem Score Max Score 1 14 2 10 3 6 4 10 5 11 6 9 7 8 9 10 8 12 12 8 Total 100 1 of 11
Tackling the Poor Assumptions of Naive Bayes Text Classifiers
 Tackling the Poor Assumptions of Naive Bayes Text Classifiers Jason Rennie MIT Computer Science and Artificial Intelligence Laboratory jrennie@ai.mit.edu Joint work with Lawrence Shih, Jaime Teevan and
Tackling the Poor Assumptions of Naive Bayes Text Classifiers Jason Rennie MIT Computer Science and Artificial Intelligence Laboratory jrennie@ai.mit.edu Joint work with Lawrence Shih, Jaime Teevan and
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Non-Linearity. CS 188: Artificial Intelligence. Non-Linear Separators. Non-Linear Separators. Deep Learning I
 Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Non-Linearity CS 188: Artificial Intelligence Deep Learning I Instructors: Pieter Abbeel & Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, Anca
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
The Perceptron algorithm
 The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Bayes Nets Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188
CS 343: Artificial Intelligence Bayes Nets Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Particle Filters and Applications of HMMs Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro
CS 343: Artificial Intelligence Particle Filters and Applications of HMMs Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro
Lecture 3: Multiclass Classification
 Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
COMP 875 Announcements
 Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Classification. Statistical NLP Spring Example: Text Classification. Some Definitions. Block Feature Vectors.
 tatistical NLP pring 0 Lecture : Classification Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example: image of
tatistical NLP pring 0 Lecture : Classification Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example: image of
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Machine Learning A Geometric Approach
 Machine Learning A Geometric Approach Linear Classification: Perceptron Professor Liang Huang some slides from Alex Smola (CMU) Perceptron Frank Rosenblatt deep learning multilayer perceptron linear regression
Machine Learning A Geometric Approach Linear Classification: Perceptron Professor Liang Huang some slides from Alex Smola (CMU) Perceptron Frank Rosenblatt deep learning multilayer perceptron linear regression
Numerical Learning Algorithms
 Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
CSE446: Naïve Bayes Winter 2016
 CSE446: Naïve Bayes Winter 2016 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, Luke ZeIlemoyer Supervised Learning: find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximanon
CSE446: Naïve Bayes Winter 2016 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, Luke ZeIlemoyer Supervised Learning: find f Given: Training set {(x i, y i ) i = 1 n} Find: A good approximanon
Machine Learning (CS 567) Lecture 2
 Lecture 2") Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Probability Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188
CS 343: Artificial Intelligence Probability Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
The Perceptron Algorithm
 The Perceptron Algorithm Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Outline The Perceptron Algorithm Perceptron Mistake Bound Variants of Perceptron 2 Where are we? The Perceptron
The Perceptron Algorithm Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Outline The Perceptron Algorithm Perceptron Mistake Bound Variants of Perceptron 2 Where are we? The Perceptron
Machine Learning, Midterm Exam: Spring 2008 SOLUTIONS. Q Topic Max. Score Score. 1 Short answer questions 20.
 10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Perceptron. by Prof. Seungchul Lee Industrial AI Lab POSTECH. Table of Contents
 Perceptron by Prof. Seungchul Lee Industrial AI Lab http://isystems.unist.ac.kr/ POSTECH Table of Contents I.. Supervised Learning II.. Classification III. 3. Perceptron I. 3.. Linear Classifier II. 3..
Perceptron by Prof. Seungchul Lee Industrial AI Lab http://isystems.unist.ac.kr/ POSTECH Table of Contents I.. Supervised Learning II.. Classification III. 3. Perceptron I. 3.. Linear Classifier II. 3..
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Linear Classifiers. Blaine Nelson, Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
Universität Potsdam Institut für Informatik Lehrstuhl Linear Classifiers Blaine Nelson, Tobias Scheffer Contents Classification Problem Bayesian Classifier Decision Linear Classifiers, MAP Models Logistic
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
CS325 Artificial Intelligence Chs. 18 & 4 Supervised Machine Learning (cont)
") CS325 Artificial Intelligence Cengiz Spring 2013 Model Complexity in Learning f(x) x Model Complexity in Learning f(x) x Let s start with the linear case... Linear Regression Linear Regression price =
CS325 Artificial Intelligence Cengiz Spring 2013 Model Complexity in Learning f(x) x Model Complexity in Learning f(x) x Let s start with the linear case... Linear Regression Linear Regression price =
Models, Data, Learning Problems
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Models, Data, Learning Problems Tobias Scheffer Overview Types of learning problems: Supervised Learning (Classification, Regression,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Models, Data, Learning Problems Tobias Scheffer Overview Types of learning problems: Supervised Learning (Classification, Regression,
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Decision trees COMS 4771
 Decision trees COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random pairs (i.e., labeled examples).
Decision trees COMS 4771 1. Prediction functions (again) Learning prediction functions IID model for supervised learning: (X 1, Y 1),..., (X n, Y n), (X, Y ) are iid random pairs (i.e., labeled examples).
Multiclass Boosting with Repartitioning
 Multiclass Boosting with Repartitioning Ling Li Learning Systems Group, Caltech ICML 2006 Binary and Multiclass Problems Binary classification problems Y = { 1, 1} Multiclass classification problems Y
Multiclass Boosting with Repartitioning Ling Li Learning Systems Group, Caltech ICML 2006 Binary and Multiclass Problems Binary classification problems Y = { 1, 1} Multiclass classification problems Y
#33 - Genomics 11/09/07
 BCB 444/544 Required Reading (before lecture) Lecture 33 Mon Nov 5 - Lecture 31 Phylogenetics Parsimony and ML Chp 11 - pp 142 169 Genomics Wed Nov 7 - Lecture 32 Machine Learning Fri Nov 9 - Lecture 33
BCB 444/544 Required Reading (before lecture) Lecture 33 Mon Nov 5 - Lecture 31 Phylogenetics Parsimony and ML Chp 11 - pp 142 169 Genomics Wed Nov 7 - Lecture 32 Machine Learning Fri Nov 9 - Lecture 33
Algorithms for NLP. Classification II. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Classification II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Minimize Training Error? A loss function declares how costly each mistake is E.g. 0 loss for correct label,
Algorithms for NLP Classification II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Minimize Training Error? A loss function declares how costly each mistake is E.g. 0 loss for correct label,
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Classification: Analyzing Sentiment
 Classification: Analyzing Sentiment STAT/CSE 416: Machine Learning Emily Fox University of Washington April 17, 2018 Predicting sentiment by topic: An intelligent restaurant review system 1 4/16/18 It
Classification: Analyzing Sentiment STAT/CSE 416: Machine Learning Emily Fox University of Washington April 17, 2018 Predicting sentiment by topic: An intelligent restaurant review system 1 4/16/18 It
Natural Language Processing (CSEP 517): Text Classification
: Text Classification") Natural Language Processing (CSEP 517): Text Classification Noah Smith c 2017 University of Washington nasmith@cs.washington.edu April 10, 2017 1 / 71 To-Do List Online quiz: due Sunday Read: Jurafsky
Natural Language Processing (CSEP 517): Text Classification Noah Smith c 2017 University of Washington nasmith@cs.washington.edu April 10, 2017 1 / 71 To-Do List Online quiz: due Sunday Read: Jurafsky
CS340 Machine learning Lecture 5 Learning theory cont'd. Some slides are borrowed from Stuart Russell and Thorsten Joachims
 CS340 Machine learning Lecture 5 Learning theory cont'd Some slides are borrowed from Stuart Russell and Thorsten Joachims Inductive learning Simplest form: learn a function from examples f is the target
CS340 Machine learning Lecture 5 Learning theory cont'd Some slides are borrowed from Stuart Russell and Thorsten Joachims Inductive learning Simplest form: learn a function from examples f is the target
Case Study 1: Estimating Click Probabilities. Kakade Announcements: Project Proposals: due this Friday!
 Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Linear models: the perceptron and closest centroid algorithms. D = {(x i,y i )} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.
} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.") Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 3 We are given a set of training examples, consisting of input-output pairs (x,y), where: 1. x is an item of the type we want to evaluate. 2. y is the value of some
Jeffrey D. Ullman Stanford University 3 We are given a set of training examples, consisting of input-output pairs (x,y), where: 1. x is an item of the type we want to evaluate. 2. y is the value of some