Course Outline MODEL INFORMATION. Bayes Decision Theory. Unsupervised Learning. Supervised Learning. Parametric Approach. Nonparametric Approach
|
|
|
- Dustin Rogers
- 5 years ago
- Views:
Transcription
1 Course Outline MODEL INFORMATION COMPLETE INCOMPLETE Bayes Decision Theory Supervised Learning Unsupervised Learning Parametric Approach Nonparametric Approach Parametric Approach Nonparametric Approach Optimal Rules Plug-in Rules Density Estimation Geometric Rules (K-NN, MLP) Mixture Resolving Cluster Analysis (Hard, Fuzzy)
2 Two-dimensional Feature Space Supervised Learning
3 Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation Introduction Maximum-Likelihood Estimation Bayesian Estimation Curse of Dimensionality Component analysis & Discriminants
4 Bayesian framework To design an optimal classifier we need: 3 P(w i ) : priors P(x w i ) : class-conditional densities What if this information is not available? Supervised Learning: Design a classifier based on a set of labeled training samples Assume priors are known Sufficient no. of training samples available to estimate P(x w i ) Pattern Classification, Chapter 3
5 Assumption: Parametric model of P(x w i ) is available 4 For example, for Gaussian pdf assume P(x w i ) ~ N( µ i, S i ), i =,..,c Parameters (µ i, S i ) are not known, but labeled training samples are available to estimate them Parameter estimation Maximum-Likelihood (ML) estimation Bayesian estimation For large n, estimates from the two methods are nearly identical Pattern Classification, Chapter 3
6 5 ML parameter estimation (MLE): Parameters are assumed to be fixed but unknown! Best parametric estimates are obtained by maximizing the probability of obtaining the samples observed Bayesian parameter estimation: Unknown parameters are random variables with some known prior distribution; Use prior and samples to obtain the posteriori density Parameter estimate is derived from posteriori & loss fn. Both methods use P(w i x) for decision rule! Pattern Classification, Chapter 3
7 Maximum-Likelihood Parameter Estimation Has good convergence properties as the sample size increases; estimated parameter value approaches the true value as n increases Most simple method for parameter estimation General principle Assume we have c classes and P(x w j ) ~ N( µ j, S j ) P(x w j ) º P (x w j, q j ), where 6 q = ( µ j, S j ) = ( µ j, µ j,..., s j, s j,cov(x m j,x n j )...) Use class w j samples to estimate class w j parameters: µ j, S j Pattern Classification, Chapter 3
8 Use the training samples to estimate q q = (q, q,, q c ); 7 q i (i =,,, c) is parameter for the w i Sample set D contains n iid samples, x, x,, x n P(D P(D q) = k= n ÕP(x k= k q) = F( q) q) is called the likelihood of q w.r.t. the set of samples) ML estimate of q is the value that maximizes P(D q) It is the value of q that best agrees with the observed training samples qˆ Pattern Classification, Chapter 3
9 8 Pattern Classification, Chapter 3
10 ML estimation Let q = (q, q,, q p ) t and Ñ q be the gradient operator 9 Ñ q = é ê ë q ù,,..., ú q q û p t We define l(q) as the log-likelihood function l(q) = ln P(D q) Determine q that maximizes the log-likelihood qˆ = argmaxl( q) q Pattern Classification, Chapter 3
11 0 Set of necessary conditions for an optimum: k= n ( Ñql = å Ñq lnp(xk k= q)) Ñ q l = 0 Pattern Classification, Chapter 3
12 P(x µ) ~ N(µ, S); µ is not known but S is known Samples are drawn from a multivariate Gaussian lnp(x k µ ) = - ln ( [ d p) S ] - (x k - µ ) t - å(x k - µ ) and Ñ qµ lnp(x k µ ) = - å(x k - µ ) The ML estimate for µ must satisfy: k= n å S k= - ( x k - µ ˆ ) = 0 Pattern Classification, Chapter 3
13 Multiplying by S and rearranging terms: µ ˆ = n k= n å x k k= MLE of the mean of the Gaussian distribution is the sample mean Conclusion: Given P(x k w j, q j ), j =,,,c to be Gaussian in d- dimensions, estimate the vector q = (q, q,, q c ) t and then use the maximum a posteriori rule (Bayes decision rule) Pattern Classification, Chapter 3
14 3 ML Estimation: Univariate Gaussian Case: unknown µ & s q = (q, q ) = (µ, s ) For the kth sample (observation) l = lnp(x k q) = æ s ç (lnp(x ç sq Ñql = ç s ç (lnp(x è sq ì ï (xk - q) = 0 q í ï (xk - q) - + ï î q q - lnpq k k ö q)) q)) ø = 0 = - q 0 (x k - q ) Pattern Classification, Chapter 3
15 Pattern Classification, Chapter 3 4 Introduce summation to account for n samples: Combining () and (), we get: n ) (x ; n x n k k k n k k k å µ - = s å = µ = = = = ï ï î ï ï í ì å å = q - q + q - å = - q q = = = = = = n k k n k k k n k k k () 0 ˆ ) ˆ (x ˆ () 0 ) (x ˆ
16 5 ML estimate for s is biased é E êë n S(x n - n i - x) =. An unbiased estimator for S is: ù úû s ¹ s k= n t C = å (xk - µ )(xk - µ ˆ ) $! n!!!! - k= #!!!!!" Sample covariancematrix Pattern Classification, Chapter 3
17 ML vs. Bayesian Parameter Estimation Unknown Parameter is the Prob. of Heads of a coin
18
19
20
21
22 Bayesian Estimation (Bayesian learning) In MLE q was supposed to have a fixed value In Bayesian learning q is a random variable Direct estimation of posterior probabilities P(w i x) lies at the heart of Bayesian classification Goal: compute P(w i x, D) Given the training sample set D, Bayes formula can be written P( w i x, D ) = c P(x w åp(x w j= i, D ).P( w j i, D ).P( w D ) j D ) Pattern Classification, Chapter 3
23 Derivation of the preceding equation: P(x, D w P(x D ) P( w i ) = Thus : P( w P( w i i = ) = P(x Dw åp(x, w j i D ) (Training sample provides this!) x, D ) = j D ) P(x c j= i ).P( D w w åp(x w i, D j i i ) ).P( w i, D ).P( w ) j ) Pattern Classification, Chapter 3
24 Bayesian Parameter Estimation: Gaussian Case 3 Goal: Estimate q using the a-posteriori density P(q D) The univariate Gaussian case: P(µ D) µ is the only unknown parameter P(x µ ) ~ N( µ, s P( µ ) ~ N( µ 0, s 0 ) ) µ 0 and s 0 are known! Pattern Classification, Chapter 4
25 P( µ D ) = = P( D µ ).P( µ ) ò P( D µ ).P( µ )dµ k= n a Õ P(x µ ).P( µ k= Reproducing density k ) () 4 P( µ D ) ~ N( µ n, s n ) () The updated parameters of the prior: µ n = and æ ç èn s n 0 ns s = 0 0 s ns + s 0 0 s ö µ ˆ ø + s n + ns s 0 + s. µ 0 Pattern Classification, Chapter 4
26 5 Pattern Classification, Chapter 4
27 The univariate case P(x D) P(µ D) has been computed P(x D) remains to be computed! 6 P (x D) = ò P(x µ ).P( µ D)dµ is Gaussian It provides: P(x D ) ~ N( µ n, s + s n ) Desired class-conditional density P(x D j, w j ) P(x D j, w j ) together with P(w j ) and using Bayes formula, we obtain the Bayesian classification rule: Max wj [ P( w x, D ] º Max[ P(x w, D ).P( w )] j wj j j j Pattern Classification, Chapter 4
28 Bayesian Parameter Estimation: General Theory 7 P(x D) computation can be applied to any situation in which the unknown density can be parametrized: the basic assumptions are: The form of P(x q) is assumed known, but the value of q is not known exactly Our knowledge about q is assumed to be contained in a known prior density P(q) The rest of our knowledge about q is contained in a set D of n random variables x, x,, x n drawn from P(x) Pattern Classification, Chapter 5
29 The basic problem is:. Compute the posterior density P(q D). Derive P(x D) Using Bayes formula, we have: 8 P( D q).p( q) P( q D ) = òp( D q).p( q)dq And by independence assumption:, P( D q) = k= n Õ k= P(x k q) Pattern Classification, Chapter 5


30 Iris Dataset Three types of iris flower: Setosa, Versicolor, Virginica Four features: Sepal length, sepal width, petal length petal width (all in cm.) 50 patterns/class Available in UCI Machine Learning Repository Fisher, R. A. "The use of multiple measurements in taxonomic problems" Annual Eugenics, 7, Part II, (936)
31 PCA Explained variance ratio st component 0.95 nd component 0.053
32 LDA Explained variance ratio st component 0.99 nd component 0.009
33 ISOMAP
34 Low Dimensional Embedding of High Dimensional Data Given n patterns in a d-dim space, embed the points in m dimensions, m<<d Purpose: data compression; avoid overfitting by reducing dimensionality; find meaningful low-dim structures in their high-dimensional observations Feature selection v. feature extraction Feature extraction: linear v. non-linear Linear feature extraction or projection: unsupervised (PCA) v. supervised (LDA) Non-linear feature extraction (Isompap)
35 Eigen Decomposition Given a linear transformation A, a non-zero vector w is an eigenvector of A if it satisfies the eigenvalue equation for some scalar l Aw = lw Ex. é ù ê ú ë û Solution: Aw - liw = 0 Eigenvalue: Eigenvector: Þ( A- li) w = 0 Þdet( A- li) = 0 é- l ù det ê = 0 - l ú ë û ( -l) - = 0 l - 4l+ 3= 0 Þ l = andl = 3 é- l ùée ù ê 0 l úê ú = ë - ûëe û é- l ùée ù ê 0 l úê ú = ë - ûëe û (Characteristic equation) Eigenvector is normalized as e + e = ée ù é- ù ê ú = ê e ú ë û ë û ée ù é ù ê ú = ê e ú ë û ë û e e
36 y μ = [, ] é5 ù Σ = ê 3 ú ë û x Eigenvectors: Eigenvalues: é ù ê ú ë û é ù ê ú ë û
37 μ = [4,, ] é 0 0ù Σ = ê 0 0 ú ê ú êë0 0 úû é ù ê Eigenvectors: ú ê ú êë úû é ù Eigenvalues: ê ú ê ú êë úû

38 PCA Y = w T X Find a transformation w, such that the w T x is dispersed the most (maximum distribution)
39 Scatter Matrices m = mean vector of all n patterns (grand mean) mi = mean vector of class i patterns S W = within-class scatter matrix. It is proportional to the sample covariance matrix for the pooled d- dimensional data. It is symmetric and positive semidefinite, and is usually nonsingular if n > d S B = between-class scatter matrix. It is symmetric and positive semidefinite, but because it is the outer product of two vectors, its rank is at most (C-) S T = total scatter of all n patterns For any w, S B w is in the direction of (m -m )
 (5)")


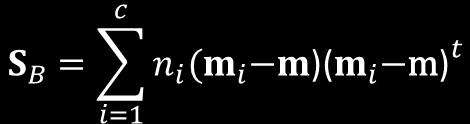

40 (9) (97) (09) (5) (3) (6)
41 Principal Component Analysis (PCA) What is the best representation of n d-dim samples x,,x n by a single point x 0? Find x 0 such that the sum of the squared distances between x 0 and all x k is minimized Define squared-error criterion function J 0 (x 0 ) by n ( x ) = å x -x 0 0 k k = and find x 0 that minimizes J 0. J o The solution is given by x 0 =m, where m is the sample mean, n m= åxk. n k =,
42 Principal Component Analysis Sample mean is a zero-dim representation of data; It does not reveal any of the data variability What is the best one-dim representation? Project data to a line through the sample mean. If e is a unit vector in the direction of the line, equation of the line can be written as x= m+ae, Representing x k by m+a k e, find the optimal set of coefficients a k by minimizing the squared error n n n e = åp m+ ke - xk P = åp ke- xk -m P k= k= J ( a,..., a, ) ( a ) a ( ) n n n t åak PeP åake xk m åpxk m P k= k= k= = - ( - ) + ( - ).
43 Principal Component Analysis Since e = differentiate with respect to a k, and set the derivative to zero t a = e ( x -m). k To obtain a least-squares solution, project the vectors x k to the line in the direction of e that passes through the sample mean What is the best direction e for the line? The solution involves the scatter matrix S n t S= å( xk -m)( xk -m). k = The best direction is the eigenvector of the scatter matrix with the largest eigenvalue k
44 Principal Component Analysis Scatter matrix S T is real and symmetric; it s eigenvectors are orthogonal and form a set of basis vectors for representing any vector x The coefficients a i in Eq. (89) are the components of x in that basis, called the principal components Data points x, x n can be viewed as a cloud in d-dimensions; eigenvectors of the scatter matrix are the principal axes of the point cloud PCA reduces dimensionality by restricting attention to those directions along which the scatter of the cloud is greatest (largest eigenvalues)


















45 Face Representation using PCA and LDA Input face EigenFaces Fisherfaces PCA LDA Reconstructed face Minimize reconstruction error Maximize between-class to within-class scatter
46 Discriminant Analysis PCA finds components that explain data variance; the components may not be useful for discrimination between different classes Since no category label is used, components discarded by PCA might be exactly those that are needed for distinguishing between classes Whereas PCA seeks directions that are effective for representation, discriminant analysis seeks directions that are effective for discrimination Special case of multiple discriminant analysis is Fisher linear discriminant for C=
47 Fisher Linear Discriminant Given n d-dim samples x,..., x n ; n in the subset D labeled ω and n in the subset D labeled ω Find a projection that maintains separation present in the d-dim. space t y = wx Geometrically, if w =, each y i is the projection of the corresponding x i onto a line in the direction of w. The magnitude of w is of no significance, since it merely scales y Find w s.t. if d-dim samples labeled ω fall more or less into one cluster while those labeled ω fall in another, we want the projected points onto the line to be well separated as well
48 Fisher Linear Discriminant Figure 3.5 illustrates the effect of choosing two different values for w for a two-dimensional example. If the original distributions are multimodal and highly overlapping, even the best w is unlikely to provide adequate separation
49 Fisher Linear Discriminant Fisher linear discriminant is the linear function that maximizes ratio of betweenclass scatter to within-class scatter -class classification problem has been converted from the given d-dimensional space to one-dimensional projected space Find a threshold, i.e., a point along the one-dimensional subspace separating the projected points from the two classes
50 Fisher Linear Discriminant In terms of S B and S W, the criterion function J( ) can be written as A vector w that maximizes J( ) must satisfy for some constant λ, which is a generalized eigenvalue problem If S W is nonsingular we can obtain a conventional eigenvalue problem by writing

51 Fisher Linear Discriminant In our particular case, it is unnecessary to solve for the eigenvalues and eigenvectors of due to the fact that S B w is always in the direction of m -m. Since the scale factor for w is immaterial, we can immediately write the solution for the w that optimizes J( ):
52 Fisher Linear Discriminant When the conditional densities p(x ω i ) are multivariate normal with equal covariance Σ, the threshold can be computed directly from the optimal decision boundary (Chapter ) where w 0 is a constant involving w and the prior. Thus, for the normal, equal-covariance case, the optimal decision rule is merely to decide ω if Fisher s linear discriminant exceed some threshold, and to decide ω otherwise.
53 Multiple Discriminant Analysis Generalize -class Fisher s linear discriminant to c-class problem Now, the projection is from a d-dimensional space to a (c - )-dimensional space, d c
54 Multiple Discriminant Analysis Because S B is the sum of c matrices of rank one or less, and because only c of these are independent, S B is of rank c or less. Thus, no more than c of the eigenvalues are nonzero, and so the new dimensionality is up to (c-).
55 Multiple Discriminant Analysis The projection from a d-dimensional space to a (c-)-dimensional space is accomplished by c- discriminant functions If the y i are viewed as components of a vector y and the weight vectors w i are viewed as the columns of a dx(c ) matrix W, then the projection can be written as a single matrix equation The columns of an optimal W are the generalized eigenvectors that correspond to the largest eigenvalues in
56 Multiple Discriminant Analysis Figure 3.6: Three 3-dimensional distributions are projected onto twodimensional subspaces, described by a normal vectors w and w. Informally, multiple discriminant methods seek the optimum such subspace, i.e., the one with the greatest separation of the projected distributions for a given total within-scatter matrix, here as associated with w.


57 T Y = LDA T w X Y = w X Find a transformation w, such that the w T X and w T X are maximally separated & each class is minimally dispersed (maximum separation)
58 PCA vs. LDA PCA LDA Sample mean n n i = µ = å xi µ i = å x N xîw i i Mean for each class Scatter matrix S n å = ( x -µ)( x -µ) i= i i T S w S b c åå = ( x -µ )( x -µ ) i= x ÎC c å i= j i j i j i = N ( µ -µ)( µ -µ) i i i T T Within-class scatter Betweenclass scatter Eigen decomposition Sw = lw S S w - W B = lw Eigen decomposition Y = T w X X is transformed to Y using w
59 Principal Component Analysis (PCA) Example X={(4,),(,4),(,3),(3,6),(4,4)} Statistics µ S = [ ], é ù = ê ú ë û Solve the Eigen value problem Sw = lw
60 Linear Discriminant Analysis (LDA) Example X = {(4,),(,4),(,3),(3,6),(4,4)} X = {(9,0),(6,8),(9,5),(8,7),(0,8)} Class statistics µ = [ ], µ = [ ], µ = [ ] é ù é.89.0 ù S = ê, =.0 3. ú S - ê ú ë û ë û Within and between class scatter S B é7 54ù é ù = ê, ú SW = ê ú ë û ë û Solve the Eigen value problem S S w - W B = lw
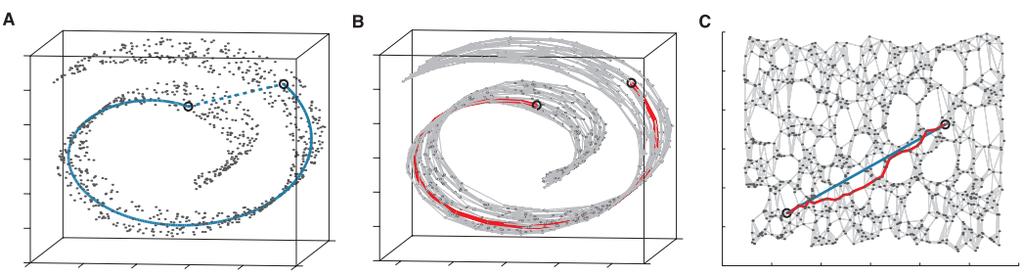
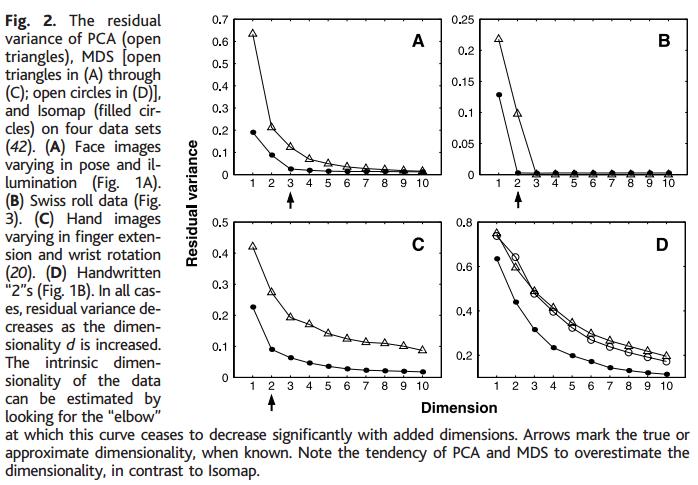
61 A Global Geometric Framework for Nonlinear Dimensionality Reduction Tenenbaum, de Silva and Langford, Science, V. 90, Dec 000 Although input dimensionality may be quite high (e.g for 64x64 pixel images in Fig A), the perceptually meaningful structure has many fewer independent degrees of freedom The images in A lie on an intrinsically 3-dim manifold, or constraint surface (two pose variables & an a lighting angle) Given unordered high-dim inputs, discover low-dim representations PCA finds a linear subspace; Fig. 3A illustrates the challenge of non-linearity; points far apart on the underlying manifold, as measured by their geodesic, or shortest path, distances, may appear close in high-dim input space, as measured by their straight line Euclidean distance.


62

63


64

65
66

67
68
69
70
71
72 Low Dimensional Representations And Multidimensional Scaling (MDS) (Sec 0.4) Given n points (objects) x,, x n. No class labels Suppose only the similarities between the n objects are provided Goal is to represent these n objects in some low dimensional space in such a way that the distances between points in that space corresponds to the dissimilarities in the original space If an accurate representation can be found in or 3 dimensions than we can visualize the structure of the data Find a configuration of points y,, y n for which the n(n-) distances d ij are as close as possible to the original similarities; this is called Multidimensional scaling Two cases Meaningful to talk about the distances between given n

73 Distances Between Given Points is Meaningful
74 Criterion Functions Sum of squared error functions Since they only involve distances between points, they are invariant to rigid body motions of the configuration Criterion functions have been normalized so their minimum values are invariant to dilations of the sample points
75 Finding the Optimum Configuration Use gradient-descent procedure to find an optimal configuration y,, y n

76 Example 0 iterations with J ef
77 Nonmetric Multidimensional Scaling Numerical values of dissimilarities are not as important as their rank order Monotonicity constraint: rank order of d ij = rank order of d ij The degree to which d ij satisfy the monotonicy constraint is measured by Normalize J to prevent it from being collapsed ˆmon
78 Overfitting
79 Problem of Insufficient Data How to train a classifier (e.g., estimate the covariance matrix) when the training set size is small (compared to the number of features) Reduce the dimensionality Select a subset of features Combine available features to get a smaller number of more salient features. Bayesian techniques Assume a reasonable prior on the parameters to compensate for small amount of training data Model Simplification Assume statistical independence Heuristics Threshold the estimated covariance matrix such that only correlations above a threshold are retained.
80 Practical Observations Most heuristics and model simplifications are almost surely incorrect In practice, however, the performance of the classifiers base don model simplification is better than with full parameter estimation Paradox: How can a suboptimal/simplified model perform better than the MLE of full parameter set, on test dataset? The answer involves the problem of insufficient data
81 Insufficient Data in Curve Fitting
82 Curve Fitting Example (contd) The example shows that a 0 th -degree polynomial fits the training data with zero error However, the test or the generalization error is much higher for this fitted curve When the data size is small, one cannot be sure about how complex the model should be A small change in the data will change the parameters of the 0 th -degree polynomial significantly, which is not a desirable quality; stability
83 Handling insufficient data Heuristics and model simplifications Shrinkage is an intermediate approach, which combines common covariance with individual covariance matrices Individual covariance matrices shrink towards a common covariance matrix. Also called regularized discriminant analysis Shrinkage Estimator for a covariance matrix, given shrinkage factor 0 < a <, S i ( a) = ( -a) nis ( -a) n i i + ans + an Further, the common covariance can be shrunk towards the Identity matrix, S ( b ) = ( - b ) S + bi
84 Principle of Parsimony By allowing the covariance matrices of Gaussian conditional densities to be arbitrary, the no. of parameters in the resulting quadratic discriminant analysis to be estimated for large d or C can be rather large In such situations, LDF is often preferred with the principle of parsimony as the main underlying thought Dempster (97) suggested that parameters should be introduced sparingly and only when data indicate they are required. A.P. Dempster (97), Covariance selection, Biometrics 8, 57-75
85 Problems of Dimensionality
86 Introduction Real world applications usually come with a large number of features Text in documents is represented using frequencies of tens of thousands of words Images are often represented by extracting local features from a large number of regions within an image Naive intuition: more the number of features, the better the classification performance? Not always! There are two issues that must be confronted with high dimensional feature spaces How does the classification accuracy depend on the dimensionality and the number of training samples? What is the computational complexity of the classifier?
87 Statistically Independent Features If features are statistically independent, it is possible to get excellent performance as dimensionality increases For a two class problem with multivariate normal classes P ( x w j ) ~ N( µ j, S), and equal prior probabilities, the probability of error is P( e) = p - u ò r where the Mahalanobis distance is defined as r e du T - = ( µ -µ ) S ( µ -µ )
88 Statistically Independent Features When features are independent, the covariance matrix is diagonal, and we have r = d å i= æ µ i - µ ç è s i i ö ø Since r increases monotonically with an increase in the number of features, P(e) decreases As long as the means of features in the differ, the error decreases
89 Increasing Dimensionality If a given set of features does not result in good classification performance, it is natural to add more features High dimensionality results in increased cost and complexity for both feature extraction and classification If the probabilistic structure of the problem is completely known, adding new features will not possibly increase the Bayes risk
90
91 Curse of Dimensionality In practice, increasing dimensionality beyond a certain point in the presence of finite number of training samples often leads to lower performance, rather than better performance The main reasons for this paradox are as follows: the Gaussian assumption, that is typically made, is almost surely incorrect Training sample size is always finite, so the estimation of the class conditional density is not very accurate Analysis of this curse of dimensionality problem is difficult
92 A Simple Example Trunk (PAMI, 979) provided a simple example illustrating this phenomenon. p( w ) = p( w ) = µ = µ,µ = -µ N p( X w ) ~ G( µ,i) p( x w ) = P e i= p p( X w ) ~ G( µ,i) N p( x w ) = P e i= N: Number of features p æ - ç xi - è æ - ç xi - è ö i ø ö i ø µ = i æ ç è i ö th ø = i component of the mean vector æ ö æ ö µ = ç,,,,... µ = ç-, -,-,-,... è 3 4 ø è 3 4 ø
93 Case : Mean Values Known Bayes decision rule: P t Decide w if x µ = x µ + xµ xn µ N x or P e e > - å = N i i i 0 > 0 z N = ò e dz æ ö g = µ - = å g / p µ 4 = ç i è i ø z ( N ) = e dz å ò N i= æ ö ç è i ø - p å æö ç è i ø is a divergent series ( N) 0 as \ N P e
94 Case : Mean Values Unknown m labeled training samples are available t Decide w if x µ ˆ = x ˆ ˆ... ˆ µ + xµ + + xn µ N P m i ˆ,{ i i i µ = å x x is replaced by - x if x Îw i= m Plug-in decision rule e > ( ) ( ) ( t ) ( ) ( t N, m = P w ˆ ˆ ). P x µ ³ 0 xîw + P w. P x µ ³ 0 xîw = P( x t µ ³ 0 xîw ) { due to symmetry t Let z = x µ N = å i = ˆ x i µ ˆ i POOLED ESTIMATE 0 It is difficult to computer the distribution of z
, { Standard Normal ö m ø æö ç è i ø N ( z) = å = + ( z) ( z) æ ç z - E - E = P ³ è VAR VAR g N = - E VAR ( z) ( z) = i ( z) ö ( z) ø ç æ + è å ö m ø N m N i= å æ ç è c N i= ö ø ö + i ø æ ç è N")
95 Case : Mean Values Unknown E lim N ( N, m) = P( z ³ 0 xîw ) P e P e N æ ö ( z) = å = ø i z - E VAR ç è i ( z) ( z) - z ( m, N ) = e dz ò lim P = 0 N N ~ G g / ( m, ) \ P e N N p lim = VAR ç æ + è ( 0, ), { Standard Normal ö m ø æö ç è i ø N ( z) = å = + ( z) ( z) æ ç z - E - E = P ³ è VAR VAR g N = - E VAR ( z) ( z) = i ( z) ö ( z) ø ç æ + è å ö m ø N m N i= å æ ç è c N i= ö ø ö + i ø æ ç è N m
96 Case : Mean Values Unknown
97 Component Analysis and Discriminants Combine features to increase discriminability & reduce dimensionality Project d-dim. data to m dimensions, m<<d Linear combinations are simple & tractable Two approaches for linear transformation PCA (Principal Component Analysis) Pattern Classification, Chapter 96 Projection that best represents the data 8
98 Diagonalization of Covariance Matrix Find a basis for which the components of a random vector X are uncorrelated It can be shown that the eignevectors of the covariance matrix for X form such a basis Covariance matrices (d x d) are positive semidefinite, so there exist d linearly independent eignevectors that form a basis for X If K is the covariance matrix, an eignevector e and an eignevalue a satisfy Ke = ae (K-aI)e = 0
99 y μ = [, ] é5 3ù Σ = ê 3 3 ú ë û x Eigenvectors: Eigenvalues: é ù ê ú ë û é ù ê ú ë û
100 Principal Component Analysis This can be easily verified by writing J 0 n å ( x ) = P( x -m)-( x -m) P 0 0 k k = n n n t åp( x0 m) P å( x0 m) ( xk m) åp( xk m) P k= k= k= = n n n t åp( x0 m) P ( x0 m) å( xk m) åp( xk m) P k= k= k= = n n åp( x0 m) P åp( xk m) P. k= k= = Independent of x 0 Since the second sum is independent of x 0, this expression is minimized by the choice x 0 =m.
101 Principal Component Analysis The scatter matrix is merely (n-) times the sample covariance matrix. It arises here when we substitute a k found in Eq. (83) into Eq. (8) to obtain n n n k k P k P k= k= k= å å å J () e = a - a + x -m n n t [ e ( xk -m)] åpxk -mp k= k= å =- + n n t t ( k )( k ) åp k k= k= å =- e x -m x -m e+ x -m n å t =- ese+ Px -mp. k = k P
102 Principal Component Analysis The vector e that minimizes J also maximizes e t Se. We use the method of Lagrange multipliers (Section A.3 of the Appendix) to maximize e t Se subject to the constraint that e =. Letting λ be the undetermined multiplier, we differentiate u with respect to e to obtain t t = ese-l( ee-) u = Se - le. e Setting this gradient vector equal to zero, e is the eigenvector of the scatter matrix: Se = le.
103 Principal Component Analysis Since e t Se = λ e t e = λ, it follows that to maximize e t Se, we want to select the eigenvector corresponding to the largest eigenvalue of the scatter matrix. In other words, to find the best one-dimensional projection of the d-dimensional data (in the least-sumof-squared-error sense), project the data onto a line through the sample mean in the direction of the eigenvector of the scatter matrix with the largest eigenvalue.
104 is minimized when the vectors e, e d are the d eigenvectors of S with the largest eigenvalues. Principal Component Analysis This result can be readily extended from a onedimensional projection to a d -dimensional projection (d <d). In place of Eq. (8), we write where d d. d ' = +å ai i i= x m e, It is not difficult to show that the criterion function J d' n d' å å ki i k k= i= = ( m+ a e )-x
105 Fisher Linear Discriminant How to find the best direction w that will enable accurate classification? A measure of the separation between the projected points is the difference of the sample means. If m i is the d-dimensional sample mean mi = å x, ni x Î then the sample mean for the projected points is ± mi = n i yîy i D i t t = å wx= wmi n i å xîd i y
106 Fisher Linear Discriminant The distance between the projected means is and we can make this difference as large as we wish merely by scaling w. To obtain good separation of the projected data we really want the difference between the means to be large relative to some measure of the standard deviations for each class. Define the scatter for projected samples labeled ω i by
107 How to solve for the optimal w? Fisher Linear Discriminant Thus, is an estimate of the variance of the pooled data, and is called the total within-class scatter of the projected samples. The Fisher linear discriminant employs that linear function w t x for which the criterion function is maximum (and independent of w ). The vector w maximizing J( ) leads to the best separation between the two projected sets.
![y μ= [, ] é Σ= 5 0 ù ê 0 3 ú ë û x Eigenvectors: Eigenvalues:](/docs-images/94/121346824/images/108-0.jpg "é-0.37-0.9935ù ê -0.9935 0.37 ú ë û é3.757 0 ù ê 0 5.")
108 y μ= [, ] é Σ= 5 0 ù ê 0 3 ú ë û x Eigenvectors: Eigenvalues: é ù ê ú ë û é ù ê ú ë û
Application: Can we tell what people are looking at from their brain activity (in real time)? Gaussian Spatial Smooth
? Gaussian Spatial Smooth") Application: Can we tell what people are looking at from their brain activity (in real time? Gaussian Spatial Smooth 0 The Data Block Paradigm (six runs per subject Three Categories of Objects (counterbalanced
Application: Can we tell what people are looking at from their brain activity (in real time? Gaussian Spatial Smooth 0 The Data Block Paradigm (six runs per subject Three Categories of Objects (counterbalanced
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
MACHINE LEARNING ADVANCED MACHINE LEARNING
 MACHINE LEARNING ADVANCED MACHINE LEARNING Recap of Important Notions on Estimation of Probability Density Functions 22 MACHINE LEARNING Discrete Probabilities Consider two variables and y taking discrete
MACHINE LEARNING ADVANCED MACHINE LEARNING Recap of Important Notions on Estimation of Probability Density Functions 22 MACHINE LEARNING Discrete Probabilities Consider two variables and y taking discrete
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation (part 1)
") HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Classification Methods II: Linear and Quadratic Discrimminant Analysis
 Classification Methods II: Linear and Quadratic Discrimminant Analysis Rebecca C. Steorts, Duke University STA 325, Chapter 4 ISL Agenda Linear Discrimminant Analysis (LDA) Classification Recall that linear
Classification Methods II: Linear and Quadratic Discrimminant Analysis Rebecca C. Steorts, Duke University STA 325, Chapter 4 ISL Agenda Linear Discrimminant Analysis (LDA) Classification Recall that linear
Bayesian Decision and Bayesian Learning
 Bayesian Decision and Bayesian Learning Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1 / 30 Bayes Rule p(x ω i
Bayesian Decision and Bayesian Learning Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1 / 30 Bayes Rule p(x ω i
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Linear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
University of Cambridge Engineering Part IIB Module 4F10: Statistical Pattern Processing Handout 2: Multivariate Gaussians
 Engineering Part IIB: Module F Statistical Pattern Processing University of Cambridge Engineering Part IIB Module F: Statistical Pattern Processing Handout : Multivariate Gaussians. Generative Model Decision
Engineering Part IIB: Module F Statistical Pattern Processing University of Cambridge Engineering Part IIB Module F: Statistical Pattern Processing Handout : Multivariate Gaussians. Generative Model Decision
Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides
 Many thanks to Carlos Thomaz who authored the original version of these slides") Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides Intelligent Data Analysis and Probabilistic Inference Lecture
Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides Intelligent Data Analysis and Probabilistic Inference Lecture
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Data Mining. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
MACHINE LEARNING ADVANCED MACHINE LEARNING
 MACHINE LEARNING ADVANCED MACHINE LEARNING Recap of Important Notions on Estimation of Probability Density Functions 2 2 MACHINE LEARNING Overview Definition pdf Definition joint, condition, marginal,
MACHINE LEARNING ADVANCED MACHINE LEARNING Recap of Important Notions on Estimation of Probability Density Functions 2 2 MACHINE LEARNING Overview Definition pdf Definition joint, condition, marginal,
probability of k samples out of J fall in R.
 Nonparametric Techniques for Density Estimation (DHS Ch. 4) n Introduction n Estimation Procedure n Parzen Window Estimation n Parzen Window Example n K n -Nearest Neighbor Estimation Introduction Suppose
Nonparametric Techniques for Density Estimation (DHS Ch. 4) n Introduction n Estimation Procedure n Parzen Window Estimation n Parzen Window Example n K n -Nearest Neighbor Estimation Introduction Suppose
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation)
") Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Computer Vision Group Prof. Daniel Cremers. 3. Regression
 Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Parametric Techniques
 Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Bayesian Decision Theory
 Bayesian Decision Theory Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551, Fall 2017 c 2017, Selim Aksoy (Bilkent University) 1 / 46 Bayesian
Bayesian Decision Theory Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551, Fall 2017 c 2017, Selim Aksoy (Bilkent University) 1 / 46 Bayesian
Minimum Error Rate Classification
 Minimum Error Rate Classification Dr. K.Vijayarekha Associate Dean School of Electrical and Electronics Engineering SASTRA University, Thanjavur-613 401 Table of Contents 1.Minimum Error Rate Classification...
Minimum Error Rate Classification Dr. K.Vijayarekha Associate Dean School of Electrical and Electronics Engineering SASTRA University, Thanjavur-613 401 Table of Contents 1.Minimum Error Rate Classification...
Parametric Techniques Lecture 3
 Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
University of Cambridge Engineering Part IIB Module 4F10: Statistical Pattern Processing Handout 2: Multivariate Gaussians
 University of Cambridge Engineering Part IIB Module 4F: Statistical Pattern Processing Handout 2: Multivariate Gaussians.2.5..5 8 6 4 2 2 4 6 8 Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2 2 Engineering
University of Cambridge Engineering Part IIB Module 4F: Statistical Pattern Processing Handout 2: Multivariate Gaussians.2.5..5 8 6 4 2 2 4 6 8 Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2 2 Engineering
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
LECTURE NOTE #10 PROF. ALAN YUILLE
 LECTURE NOTE #10 PROF. ALAN YUILLE 1. Principle Component Analysis (PCA) One way to deal with the curse of dimensionality is to project data down onto a space of low dimensions, see figure (1). Figure
LECTURE NOTE #10 PROF. ALAN YUILLE 1. Principle Component Analysis (PCA) One way to deal with the curse of dimensionality is to project data down onto a space of low dimensions, see figure (1). Figure
PCA and LDA. Man-Wai MAK
 PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
ECE662: Pattern Recognition and Decision Making Processes: HW TWO
 ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
Dimension Reduction and Low-dimensional Embedding
 Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Ways to make neural networks generalize better
 Ways to make neural networks generalize better Seminar in Deep Learning University of Tartu 04 / 10 / 2014 Pihel Saatmann Topics Overview of ways to improve generalization Limiting the size of the weights
Ways to make neural networks generalize better Seminar in Deep Learning University of Tartu 04 / 10 / 2014 Pihel Saatmann Topics Overview of ways to improve generalization Limiting the size of the weights
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout 2:. The Multivariate Gaussian & Decision Boundaries
 University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
Manifold Learning and it s application
 Manifold Learning and it s application Nandan Dubey SE367 Outline 1 Introduction Manifold Examples image as vector Importance Dimension Reduction Techniques 2 Linear Methods PCA Example MDS Perception
Manifold Learning and it s application Nandan Dubey SE367 Outline 1 Introduction Manifold Examples image as vector Importance Dimension Reduction Techniques 2 Linear Methods PCA Example MDS Perception
Machine Learning 2017
 Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
5. Discriminant analysis
 5. Discriminant analysis We continue from Bayes s rule presented in Section 3 on p. 85 (5.1) where c i is a class, x isap-dimensional vector (data case) and we use class conditional probability (density
5. Discriminant analysis We continue from Bayes s rule presented in Section 3 on p. 85 (5.1) where c i is a class, x isap-dimensional vector (data case) and we use class conditional probability (density
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
Non-linear Dimensionality Reduction
 Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Introduction to Machine Learning
 Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
Outline Introduction to Machine Learning Bayesian Classification Varun Chandola March 8, 017 1. {circular,large,light,smooth,thick}, malignant. {circular,large,light,irregular,thick}, malignant 3. {oval,large,dark,smooth,thin},
Discriminant analysis and supervised classification
 Discriminant analysis and supervised classification Angela Montanari 1 Linear discriminant analysis Linear discriminant analysis (LDA) also known as Fisher s linear discriminant analysis or as Canonical
Discriminant analysis and supervised classification Angela Montanari 1 Linear discriminant analysis Linear discriminant analysis (LDA) also known as Fisher s linear discriminant analysis or as Canonical
Clustering VS Classification
 MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Machine Learning 2nd Edition
 INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
Machine Learning. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
Supervised Learning: Linear Methods (1/2) Applied Multivariate Statistics Spring 2012
 Applied Multivariate Statistics Spring 2012") Supervised Learning: Linear Methods (1/2) Applied Multivariate Statistics Spring 2012 Overview Review: Conditional Probability LDA / QDA: Theory Fisher s Discriminant Analysis LDA: Example Quality control:
Supervised Learning: Linear Methods (1/2) Applied Multivariate Statistics Spring 2012 Overview Review: Conditional Probability LDA / QDA: Theory Fisher s Discriminant Analysis LDA: Example Quality control:
Pattern Recognition 2
 Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Machine Learning (CS 567) Lecture 5
 Lecture 5") Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Principal Components Analysis. Sargur Srihari University at Buffalo
 Principal Components Analysis Sargur Srihari University at Buffalo 1 Topics Projection Pursuit Methods Principal Components Examples of using PCA Graphical use of PCA Multidimensional Scaling Srihari 2
Principal Components Analysis Sargur Srihari University at Buffalo 1 Topics Projection Pursuit Methods Principal Components Examples of using PCA Graphical use of PCA Multidimensional Scaling Srihari 2
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
ISyE 6416: Computational Statistics Spring Lecture 5: Discriminant analysis and classification
 ISyE 6416: Computational Statistics Spring 2017 Lecture 5: Discriminant analysis and classification Prof. Yao Xie H. Milton Stewart School of Industrial and Systems Engineering Georgia Institute of Technology
ISyE 6416: Computational Statistics Spring 2017 Lecture 5: Discriminant analysis and classification Prof. Yao Xie H. Milton Stewart School of Industrial and Systems Engineering Georgia Institute of Technology
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
L26: Advanced dimensionality reduction
 L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
Maximum Likelihood Estimation. only training data is available to design a classifier
 Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
Introduction to Pattern Recognition [ Part 5 ] Mahdi Vasighi Introduction Bayesian Decision Theory shows that we could design an optimal classifier if we knew: P( i ) : priors p(x i ) : class-conditional
A Unified Bayesian Framework for Face Recognition
 Appears in the IEEE Signal Processing Society International Conference on Image Processing, ICIP, October 4-7,, Chicago, Illinois, USA A Unified Bayesian Framework for Face Recognition Chengjun Liu and
Appears in the IEEE Signal Processing Society International Conference on Image Processing, ICIP, October 4-7,, Chicago, Illinois, USA A Unified Bayesian Framework for Face Recognition Chengjun Liu and
Preprocessing & dimensionality reduction
 Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Expectation Maximization Algorithm
 Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
ECE521 lecture 4: 19 January Optimization, MLE, regularization
 ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
ECE521 lecture 4: 19 January 2017 Optimization, MLE, regularization First four lectures Lectures 1 and 2: Intro to ML Probability review Types of loss functions and algorithms Lecture 3: KNN Convexity
Linear Algebra in Computer Vision. Lecture2: Basic Linear Algebra & Probability. Vector. Vector Operations
 Linear Algebra in Computer Vision CSED441:Introduction to Computer Vision (2017F Lecture2: Basic Linear Algebra & Probability Bohyung Han CSE, POSTECH bhhan@postech.ac.kr Mathematics in vector space Linear
Linear Algebra in Computer Vision CSED441:Introduction to Computer Vision (2017F Lecture2: Basic Linear Algebra & Probability Bohyung Han CSE, POSTECH bhhan@postech.ac.kr Mathematics in vector space Linear
Lecture: Face Recognition
 Lecture: Face Recognition Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 12-1 What we will learn today Introduction to face recognition The Eigenfaces Algorithm Linear
Lecture: Face Recognition Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 12-1 What we will learn today Introduction to face recognition The Eigenfaces Algorithm Linear
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA
, Factor Analysis, Mixtures of PPCA") Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Overview of clustering analysis. Yuehua Cui
 Overview of clustering analysis Yuehua Cui Email: cuiy@msu.edu http://www.stt.msu.edu/~cui A data set with clear cluster structure How would you design an algorithm for finding the three clusters in this
Overview of clustering analysis Yuehua Cui Email: cuiy@msu.edu http://www.stt.msu.edu/~cui A data set with clear cluster structure How would you design an algorithm for finding the three clusters in this
Machine Learning. Data visualization and dimensionality reduction. Eric Xing. Lecture 7, August 13, Eric Xing Eric CMU,
 Eric Xing Eric Xing @ CMU, 2006-2010 1 Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010 Eric Xing Eric Xing @ CMU, 2006-2010 2 Text document retrieval/labelling
Eric Xing Eric Xing @ CMU, 2006-2010 1 Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010 Eric Xing Eric Xing @ CMU, 2006-2010 2 Text document retrieval/labelling
Clustering by Mixture Models. General background on clustering Example method: k-means Mixture model based clustering Model estimation
 Clustering by Mixture Models General bacground on clustering Example method: -means Mixture model based clustering Model estimation 1 Clustering A basic tool in data mining/pattern recognition: Divide
Clustering by Mixture Models General bacground on clustering Example method: -means Mixture model based clustering Model estimation 1 Clustering A basic tool in data mining/pattern recognition: Divide
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
EEL 851: Biometrics. An Overview of Statistical Pattern Recognition EEL 851 1
 EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
High Dimensional Discriminant Analysis
 High Dimensional Discriminant Analysis Charles Bouveyron 1,2, Stéphane Girard 1, and Cordelia Schmid 2 1 LMC IMAG, BP 53, Université Grenoble 1, 38041 Grenoble cedex 9 France (e-mail: charles.bouveyron@imag.fr,
High Dimensional Discriminant Analysis Charles Bouveyron 1,2, Stéphane Girard 1, and Cordelia Schmid 2 1 LMC IMAG, BP 53, Université Grenoble 1, 38041 Grenoble cedex 9 France (e-mail: charles.bouveyron@imag.fr,
Lecture 4: Types of errors. Bayesian regression models. Logistic regression
 Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
PCA and LDA. Man-Wai MAK
 PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
Lecture 16: Modern Classification (I) - Separating Hyperplanes
 - Separating Hyperplanes") Lecture 16: Modern Classification (I) - Separating Hyperplanes Outline 1 2 Separating Hyperplane Binary SVM for Separable Case Bayes Rule for Binary Problems Consider the simplest case: two classes are
Lecture 16: Modern Classification (I) - Separating Hyperplanes Outline 1 2 Separating Hyperplane Binary SVM for Separable Case Bayes Rule for Binary Problems Consider the simplest case: two classes are
Density Estimation: ML, MAP, Bayesian estimation
 Density Estimation: ML, MAP, Bayesian estimation CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Maximum-Likelihood Estimation Maximum
Density Estimation: ML, MAP, Bayesian estimation CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Maximum-Likelihood Estimation Maximum
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Dimensionality Reduction Using PCA/LDA. Hongyu Li School of Software Engineering TongJi University Fall, 2014
 Dimensionality Reduction Using PCA/LDA Hongyu Li School of Software Engineering TongJi University Fall, 2014 Dimensionality Reduction One approach to deal with high dimensional data is by reducing their
Dimensionality Reduction Using PCA/LDA Hongyu Li School of Software Engineering TongJi University Fall, 2014 Dimensionality Reduction One approach to deal with high dimensional data is by reducing their
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Dimension Reduction Techniques. Presented by Jie (Jerry) Yu
 Yu") Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
A Tutorial on Data Reduction. Principal Component Analysis Theoretical Discussion. By Shireen Elhabian and Aly Farag
 A Tutorial on Data Reduction Principal Component Analysis Theoretical Discussion By Shireen Elhabian and Aly Farag University of Louisville, CVIP Lab November 2008 PCA PCA is A backbone of modern data
A Tutorial on Data Reduction Principal Component Analysis Theoretical Discussion By Shireen Elhabian and Aly Farag University of Louisville, CVIP Lab November 2008 PCA PCA is A backbone of modern data
Bayes Decision Theory
 Bayes Decision Theory Minimum-Error-Rate Classification Classifiers, Discriminant Functions and Decision Surfaces The Normal Density 0 Minimum-Error-Rate Classification Actions are decisions on classes
Bayes Decision Theory Minimum-Error-Rate Classification Classifiers, Discriminant Functions and Decision Surfaces The Normal Density 0 Minimum-Error-Rate Classification Actions are decisions on classes
p(d θ ) l(θ ) 1.2 x x x
 l(θ ) 1.2 x x x") p(d θ ).2 x 0-7 0.8 x 0-7 0.4 x 0-7 l(θ ) -20-40 -60-80 -00 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ θ x FIGURE 3.. The top graph shows several training points in one dimension, known or assumed to
p(d θ ).2 x 0-7 0.8 x 0-7 0.4 x 0-7 l(θ ) -20-40 -60-80 -00 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ θ x FIGURE 3.. The top graph shows several training points in one dimension, known or assumed to
Principal Component Analysis and Linear Discriminant Analysis
 Principal Component Analysis and Linear Discriminant Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/29
Principal Component Analysis and Linear Discriminant Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/29
Algorithmisches Lernen/Machine Learning
 Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
1 Data Arrays and Decompositions
 1 Data Arrays and Decompositions 1.1 Variance Matrices and Eigenstructure Consider a p p positive definite and symmetric matrix V - a model parameter or a sample variance matrix. The eigenstructure is
1 Data Arrays and Decompositions 1.1 Variance Matrices and Eigenstructure Consider a p p positive definite and symmetric matrix V - a model parameter or a sample variance matrix. The eigenstructure is
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier