Bits of Machine Learning Part 1: Supervised Learning
|
|
|
- Francis Chapman
- 5 years ago
- Views:
Transcription
1 Bits of Machine Learning Part 1: Supervised Learning Alexandre Proutiere and Vahan Petrosyan KTH (The Royal Institute of Technology)
2 Outline of the Course 1. Supervised Learning Regression and Classification Neural Networks (Deep Learning) 2. Unsupervised Learning Clustering Reinforcement Learning 1
3 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given a labeled set of input-ouput pairs (the training set) D n = {(X i, Y i ), i = 1,..., n} We learn the classification function f = 1 if versicolor, f = 1 if virginica 2
4 Learning Unsupervised (or Descriptive) learning Find interesting patterns in the data D n = {X i, i = 1,..., n} We learn there are 2 distinct types of iris and how to distinguish them! 3
5 Examples Supervised learning: digit, flower, picture,... recognition music classification predict prices predict the outcome of chemical reactions source separation: identify the instruments present in a recording... Unsupervised learning: classification (without training set): spam filter, news (google news),... identify structures and causes in the data: e.g. J. Snow cholera deaths vs pollution image segmentation... 4
6 Outline of the Course 1. Supervised Learning Regression and Classification Neural Networks (Deep Learning) 2. Unsupervised Learning Clustering Reinforcement Learning 5
7 Supervised Learning: Outline 1. A statistical framework 2. Algorithms using Local Averaging (k-nn, kernels) 3. Linear regression 4. Support Vector Machines 5. The kernel trick 6. Neural Networks 6
 classification (type, mode, etc) y is a non-deterministic and")
8 1. Supervised learning Training set: D n = {(X i, Y i ), i = 1,..., n} - Input features: X i R d - Output: Y i Y i Y { R finite regression (price, position, etc) classification (type, mode, etc) y is a non-deterministic and complicated function of x i.e., y = f(x) + z where z is unknown (e.g. noise). Goal: learn f. Learning algorithm: 7
9 A Statistical Approach (X i, Y i ), i = 1,..., n are i.i.d. random variables with joint distribution P Model: look for an estimate of f in a class of functions F, e.g. linear, polynomial,... Learning algorithm: A : D n ˆf n F, ˆf n estimates the true function f Performance of predictions defined through a loss function l - Example 1. Regression, Least Squares (LS): Y = R, l(y, y ) = 1 2 y y 2 - Example 2. Classification in Y = {0, 1}: l(y, y ) = 1 y y 8
10 Risks The risk of a prediction function g is R(g) := E P [l(g(x), Y )] (often referred to as out-of-sample error) Target function f := arg min g F R(g) Empirical risk: ˆRn (g) := 1 n n i=1 l(g(x i), Y i ) (often referred to as in-sample error) Law of large numbers: lim n ˆRn (g) = R(g) almost surely Central limit theorem: n( ˆRn (g) R(g)) N (0, var P (l(g(x), Y ))) Consistent algorithm: if lim n E[R( ˆf n )] = R(f ) Warning. Consistency good algorithm (F can be poor, f f ) 9
11 LS regression and binary classification Example 1. Regression, Least Square (LS) Risk R(g) = 1 2 E[ g(x) Y 2 ] Target function f (x) = E[Y X = x] Example 2. Binary classification: Y = { 1, 1} Risk R(g) = P(g(X) Y ) Target function f (x) = arg max k { 1,1} P(Y = k X = x) 10
12 Model selection - Choosing F Avoid overfitting! A few principles: Occam s razor principle: choose the simplest of two models if they explain the data equally well Hadamard s well posed problems: unique solution, smooth in the parameters Regularization: minimize error( ˆf n )+Ω( ˆf n ) Penalizes the model complexity 11
13 2. Local averaging algorithms Principle: predict for x based on neighbours of x in the training data n ˆf n (x) = Ψ( W i (x)y i ), i=1 n W i (x) = 1 i=1 Ψ( ) = for regression, Ψ( ) = sgn( ) for binary classification 12
14 Examples Prediction function: ˆfn (x) = Ψ( n i=1 W i(x)y i ), n i=1 W i(x) = 1 k-n.n.: W i (x) = { 1/k if X i is one of the k-n.n. of x 0 otherwise Nadaraya-Watson algorithm: W i (x) K ( x X i ) h, e.g. K( ) = e 2 13
15 Performance analysis Stone s theorem: Conditions for W i under which the corresponding algorithm is consistent! Example: LS target function f (x) = E[Y X = x]. Distribution P on (X, Y ). Assume that: 1. X lies in A bounded a.s. under P 2. For all x A, var(y X = x) σ 2 3. f is L-lipschitz Then the k-n.n. estimator satisfies: E(R( ˆf n )) R(f ) σ2 k + cl2 ( ) 2/d k n The k-n.n. algorithm is consistent with P if k goes to infinity sublinearly with n. 14
16 3. Linear regression: Minimizing the empirical risk F = set of linear functions from R d (X i R d ) to R (Y i R) Function f θ F parametrized by θ R d+1 : (by convention x 0 = 1) f θ (x) = θ 0 + θ 1 x θ d x d = θ x Least square model. Empirical risk of θ: ˆR n (θ) = 1 n 2n i=1 (f θ(x i ) Y i ) 2 Minimal risk achieved for θ = (X X) 1 X y where y = [Y 1... Y n ] and X is a matrix whose i-th line is X i 15
17 Gradient Descents for Regression Alternative methods to find θ : sequential algorithms. Batch gradient descent. Repeat: n k {0, 1,..., d}, θ k := θ k α (Y i f θ (X i ))X ik Stochastic gradient descent. Repeat: 1. Select a sample i uniformly at random 2. Perform a descent using (X i, Y i ) only i=1 k {0, 1,..., d}, θ k := θ k α(y i f θ (X i ))X ik 16
18 Linear regression: Regularization For d > n, X X R d d is not invertible, so θ is not uniquely defined. Need to put additional constraints on the model to get a well-posed problem Regularization: add a cost for the magnitude of θ 1 min θ 2n n (f θ (X i ) Y i ) 2 + λω(θ) i=1 Ridge: Ω(θ) = θ 2 2 LASSO: Ω(θ) = θ 1 l p : Ω(θ) = θ p p small (< 1): sparse solutions but hard optimization problems p large ( 1): less sparse solutions but convex optimization problems 17
19 Linear regression: Regularization Regularization: add a cost for the magnitude of θ 1 min θ 2n n (f θ (X i ) Y i ) 2 + λω(θ) i=1 λ > 0 controls the bias-variance trade-off - High value of λ: the data has a low weight in the objective function (low variance but high bias) - Low value of λ: the data has a high weight in the objective function (low bias but high variance) Solution for Ridge regression: θ = (X X + nλi) 1 X y Prediction: For all x R d, ˆf λ (x) = y (X X + nλi) 1 X x 18
20 4. Support Vector Machines SVM is a classification algorithm aiming at maximizing the margin of the separating hyperplane The data points (or vectors) realizing the minimum distance to this hyperplane are support vectors (as they carry the hyperplane) 19
21 Support Vector Machines: Derivation Separating hyperplane H θ,b : θ x + b = 0 θ and b are normalized so that θ X sv + b = 1 where X sv is any support vector, i.e., arg min i d(x i, H θ,b ). With this choice, the margin is simply 2/ θ 2. Max margin problem. { { max θ,b 1/ θ 2 s.t. min i θ X i + b = 1 min θ,b θ 2 2 s.t. Y i (θ X i + b) 1, i A simple quadratic program... 20
22 Support Vector Machines: Derivation Lagrangian: L(θ, b, α) = 1 2 θ θ i α i(y i (θ X i + b) 1) Dual problem. { max α i α i 1 2 i j Y iy j Xi X jα i α j s.t. α i 0, i, i α iy i = 0 A quadratic program: given the solution α, we have the following: (complementary slackness) α i > 0 iff X i is a support vector (hyperplane): θ = i α i Y ix i and b: Y i (θ X i + b) = 1 if α i > 0 (prediction function): ˆfn (x) = sgn( i α i Y ix i x + b) Remark. The solution and the prediction can be computed by just evaluating inner products X i X j and X i x. 21
23 Support Vector Machines vs. Local Averaging The predictor ressembles that of a local averaging algorithm: g(x) = sgn( i W i (x)y i + b) with W i (x) = α i X i x But: W i (x) is not local anymore... as the support vectors span the entire data 22
24 SVM: Extensions What if the data is not linearly separable? Data almost linearly separable Soft-margin SVM (impose a cost of misclassification) Data not linearly separable at all Go to a higher dimensional space where the data becomes separable The Kernel trick 23
25 4. SVM with the kernel trick Non-linear transformation: φ : R d R e where e d Apply the SVM in R e with the training data (φ(x i ), Y i ) i=1,...,n The optimal prediction can be constructed by only considering scalar products K(X i, X j ) = φ(x i ) φ(x j ), and K(X i, x) = φ(x i ) φ(x) K is called a kernel (by definition if all its matrices are semi-definite positive) Kernel trick: The knowledge of K is enough; we can use spaces with arbitrary large dimension! 24
26 SVM with the kernel trick SVM with kernel K. 1. Using QP packages, find α solution of: { max α i α i 1 2 i j Y iy j K(X i, X j )α i α j s.t. α i 0, i, i α iy i = 0 2. Prediction function: ˆfK (x) = sgn( i α i Y ik(x i, x) + b) 25
27 Kernels K is a kernel iff there exists an Hilbert space and φ such that K(x, x ) = φ(x) φ(x ) (Aronszajn s theorem) Examples: - Polynomial kernel: K(x, x ) = (1 + x x ) p (e = 1 + pd) - Gaussian kernel: K(x, x ) = exp( x x 2 /h) (e = ) - Kernel cookbook: duvenaud/cookbook/index.html 26
28 Outline of the Course 1. Supervised Learning Regression and Classification Neural Networks (Deep Learning) 2. Unsupervised Learning Clustering Reinforcement Learning 27

29 6. Neural networks Loosely inspired by how the brain works 1. Construct a network of simplified neurones, with the hope of approximating and learning any possible function 1 Mc Culloch-Pitts,
30 The perceptron The first artificial neural network with one layer, and σ(x) = sgn(x) (classification) Input x R d, output in { 1, 1}. Can represent separating hyperplanes. 29
31 Multilayer perceptrons They can represent any function of R d to { 1, 1}... but the structure depends on the unknown target function f, and is difficult to optimise 30
32 From perceptrons to neural networks... and the number of layers can rapidly grow with the complexity of the function A key idea to make neural networks practical: soft-thresholding... 31
33 Soft-thresholding Replace hard-thresholding function σ by smoother functions Theorem (Cybenko 1989) Any continuous function f from [0, 1] d to R can be approximated as a function of the form: N j=1 α jσ(w j x + b j), where σ is any sigmoid function. 32
34 Soft-thresholding Cybenko s theorem tells us that f can be represented using a single hidden layer network... A non-constructive proof: how many neurones do we need? Might depend on f... 33
")
35 Neural networks A feedforward layered network (deep learning = enough layers) 34
36 Deep Learning and the ILSVR challenge Deep learning outperformed any other techniques in all major machine learning competitions (image classification, speech recognition and natural language processing) The ImageNet Large Scale Visual Recognition Challenge (ILSVRC). 1. Training: 1.2 million images ( ), labeled one out of 1000 categories 2. Test: images ( ) 3. Error measure: The teams have to predict 5 (out of 1000) classes and an image is considered to be correct if at least one of the predictions is the ground truth. 2 35

37 ILSVR challenge 1 From Stanford CS231n lecture notes 36

38 Architectures 37
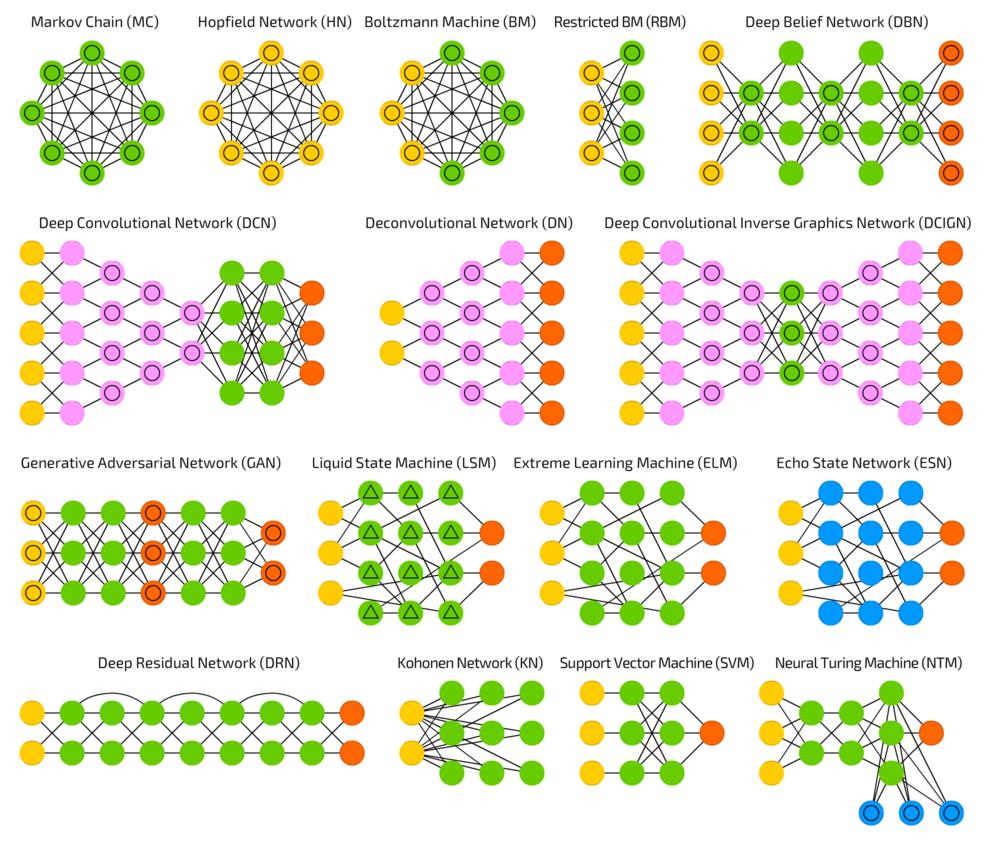
39 Architectures 38
40 Computing with neural networks Layer 0: inputs x = (x (0) 1,..., x(0) ) and x(0) 0 = 1 x (l) i d Layer 1,..., L 1: hidden layer l, d (l) + 1 nodes, state of node i, with x (l) 0 = 1 Layer L: output y = x (L) 1 Signal at k: s (l) k State at k: x (l) k = d (l 1) i=0 w (l) ik x(l 1) i = σ(s (l) k ) Output: the state of y = x (L) 1 39
41 Training neural networks The output of the network is a function of w = (w (l) ij ) i,j,l: y = f w (x) We wish to optimise over w to find the most accurate estimation of the target function Training data: (X 1, Y 1 ),..., (X n, Y n ) R d { 1, 1} Objective: find w minimising the empirical risk: E(w) := R(f w ) = 1 2n n f w (X l ) Y l 2 l=1 40
42 Stochastic Gradient Descent E(w) = 1 n 2n l=1 E l(w) where E l (w) := f w (X l ) Y l 2 In each iteration of the SGD algorithm, only one function E l is considered... Parameter. learning rate α > 0 1. Initialization. w := w 0 2. Sample selection. Select l uniformly at random in {1,..., n} 3. GD iteration. w := w α E l (w), go to 2. Is there an efficient way of computing E l (w)? 41
43 Backpropagation We fix l, and introduce e(w) = E l (w). Let us compute e(w): e w (l) ij = e s (l) j }{{} :=δ (l) j s(l) j w (l) ij }{{} =x (l 1) i The sensitivity of the error w.r.t. the signal at node j can be computed recursively... 42
44 Backward recursion Output layer. δ (L) 1 := e s (L) 1 From layer l to layer l 1. δ (l 1) i := e = s (l 1) i and e(w) = (σ(s (L) 1 ) Y l ) 2 δ (L) 1 = 2(x (L) 1 Y l )σ (s (L) 1 ) d (l) j=1 e s (l) j }{{} :=δ (l) j s(l) j x (l 1) i }{{} =w (l) ij x(l 1) i s (l 1) i }{{} =σ (s (l 1) i ) Summary. E l w (l) ij d (l) = δ (l) j x (l 1) i, δ (l 1) i = j=1 δ (l) j w (l) ij σ (s (l 1) i ) 43
45 Backpropagation algorithm Parameter. Learning rate α > 0 Input. (X 1, Y 1 ),..., (X n, Y n ) R d { 1, 1} 1. Initialization. w := w 0 2. Sample selection. Select l uniformly at random in {1,..., n} 3. Gradient of E l. x (0) i := X li for all i = 1,... d Forward propagation: compute the state and signal at each node (x (l) i, s (l) i ) Backward propagation: propagate back Y l to compute δ (l) at each node and the partial derivative E l w (l) ij 4. GD iteration. w := w α E l (w), go to 2. i 44

46 Example: tensorflow 45
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
Advanced Machine Learning
 Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
Advanced Machine Learning Lecture 4: Deep Learning Essentials Pierre Geurts, Gilles Louppe, Louis Wehenkel 1 / 52 Outline Goal: explain and motivate the basic constructs of neural networks. From linear
CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
 Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Lecture 2 Machine Learning Review
 Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
MLPR: Logistic Regression and Neural Networks
 MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
Outline. MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition. Which is the correct model? Recap.
 Outline MLPR: and Neural Networks Machine Learning and Pattern Recognition 2 Amos Storkey Amos Storkey MLPR: and Neural Networks /28 Recap Amos Storkey MLPR: and Neural Networks 2/28 Which is the correct
Outline MLPR: and Neural Networks Machine Learning and Pattern Recognition 2 Amos Storkey Amos Storkey MLPR: and Neural Networks /28 Recap Amos Storkey MLPR: and Neural Networks 2/28 Which is the correct
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Indirect Rule Learning: Support Vector Machines. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Support Vector Machine
 Support Vector Machine Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Linear Support Vector Machine Kernelized SVM Kernels 2 From ERM to RLM Empirical Risk Minimization in the binary
Support Vector Machine Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Linear Support Vector Machine Kernelized SVM Kernels 2 From ERM to RLM Empirical Risk Minimization in the binary
ECE662: Pattern Recognition and Decision Making Processes: HW TWO
 ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie
 A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Lecture 6. Regression
 Lecture 6. Regression Prof. Alan Yuille Summer 2014 Outline 1. Introduction to Regression 2. Binary Regression 3. Linear Regression; Polynomial Regression 4. Non-linear Regression; Multilayer Perceptron
Lecture 6. Regression Prof. Alan Yuille Summer 2014 Outline 1. Introduction to Regression 2. Binary Regression 3. Linear Regression; Polynomial Regression 4. Non-linear Regression; Multilayer Perceptron
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Recap from previous lecture
 Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Recap from previous lecture Learning is using past experience to improve future performance. Different types of learning: supervised unsupervised reinforcement active online... For a machine, experience
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Machine Learning And Applications: Supervised Learning-SVM
 Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
This is an author-deposited version published in : Eprints ID : 17710
 Open Archive TOULOUSE Archive Ouverte (OATAO) OATAO is an open access repository that collects the work of Toulouse researchers and makes it freely available over the web where possible. This is an author-deposited
Open Archive TOULOUSE Archive Ouverte (OATAO) OATAO is an open access repository that collects the work of Toulouse researchers and makes it freely available over the web where possible. This is an author-deposited
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
Statistical learning theory, Support vector machines, and Bioinformatics
 1 Statistical learning theory, Support vector machines, and Bioinformatics Jean-Philippe.Vert@mines.org Ecole des Mines de Paris Computational Biology group ENS Paris, november 25, 2003. 2 Overview 1.
1 Statistical learning theory, Support vector machines, and Bioinformatics Jean-Philippe.Vert@mines.org Ecole des Mines de Paris Computational Biology group ENS Paris, november 25, 2003. 2 Overview 1.
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
CIS 520: Machine Learning Oct 09, Kernel Methods
 CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc.
 Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Linear Models for Regression CS534
 Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Kernel Learning via Random Fourier Representations
 Kernel Learning via Random Fourier Representations L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Module 5: Machine Learning L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Kernel Learning via Random
Kernel Learning via Random Fourier Representations L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Module 5: Machine Learning L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Kernel Learning via Random
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Lecture 10: A brief introduction to Support Vector Machine
 Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Binary Classification / Perceptron
 Binary Classification / Perceptron Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Supervised Learning Input: x 1, y 1,, (x n, y n ) x i is the i th data
Binary Classification / Perceptron Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Supervised Learning Input: x 1, y 1,, (x n, y n ) x i is the i th data
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I
 Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 2012 Engineering Part IIB: Module 4F10 Introduction In
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 6: Multi-Layer Perceptrons I Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 2012 Engineering Part IIB: Module 4F10 Introduction In
Tutorial on Machine Learning for Advanced Electronics
 Tutorial on Machine Learning for Advanced Electronics Maxim Raginsky March 2017 Part I (Some) Theory and Principles Machine Learning: estimation of dependencies from empirical data (V. Vapnik) enabling
Tutorial on Machine Learning for Advanced Electronics Maxim Raginsky March 2017 Part I (Some) Theory and Principles Machine Learning: estimation of dependencies from empirical data (V. Vapnik) enabling
CS798: Selected topics in Machine Learning
 CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Lecture 18: Kernels Risk and Loss Support Vector Regression. Aykut Erdem December 2016 Hacettepe University
 Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Generalization theory
 Generalization theory Daniel Hsu Columbia TRIPODS Bootcamp 1 Motivation 2 Support vector machines X = R d, Y = { 1, +1}. Return solution ŵ R d to following optimization problem: λ min w R d 2 w 2 2 + 1
Generalization theory Daniel Hsu Columbia TRIPODS Bootcamp 1 Motivation 2 Support vector machines X = R d, Y = { 1, +1}. Return solution ŵ R d to following optimization problem: λ min w R d 2 w 2 2 + 1
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods.
 Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Pattern Recognition 2018 Support Vector Machines
 Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Support Vector Machines
 Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
6.036 midterm review. Wednesday, March 18, 15
 6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 03: Multi-layer Perceptron Outline Failure of Perceptron Neural Network Backpropagation Universal Approximator 2 Outline Failure of Perceptron Neural Network Backpropagation
CS489/698: Intro to ML Lecture 03: Multi-layer Perceptron Outline Failure of Perceptron Neural Network Backpropagation Universal Approximator 2 Outline Failure of Perceptron Neural Network Backpropagation
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Support Vector Machine and Neural Network Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 1 Announcements Due end of the day of this Friday (11:59pm) Reminder
CS249: ADVANCED DATA MINING Support Vector Machine and Neural Network Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 1 Announcements Due end of the day of this Friday (11:59pm) Reminder
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
LECTURE NOTE #NEW 6 PROF. ALAN YUILLE
 LECTURE NOTE #NEW 6 PROF. ALAN YUILLE 1. Introduction to Regression Now consider learning the conditional distribution p(y x). This is often easier than learning the likelihood function p(x y) and the
LECTURE NOTE #NEW 6 PROF. ALAN YUILLE 1. Introduction to Regression Now consider learning the conditional distribution p(y x). This is often easier than learning the likelihood function p(x y) and the
Lecture 10: Support Vector Machine and Large Margin Classifier
 Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
Learning with kernels and SVM
 Learning with kernels and SVM Šámalova chata, 23. května, 2006 Petra Kudová Outline Introduction Binary classification Learning with Kernels Support Vector Machines Demo Conclusion Learning from data find
Learning with kernels and SVM Šámalova chata, 23. května, 2006 Petra Kudová Outline Introduction Binary classification Learning with Kernels Support Vector Machines Demo Conclusion Learning from data find
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Neural Networks. Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016
 Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Neural Networks Yan Shao Department of Linguistics and Philology, Uppsala University 7 December 2016 Outline Part 1 Introduction Feedforward Neural Networks Stochastic Gradient Descent Computational Graph
Oslo Class 2 Tikhonov regularization and kernels
 RegML2017@SIMULA Oslo Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT May 3, 2017 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n
RegML2017@SIMULA Oslo Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT May 3, 2017 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients