Minimum Error-Rate Discriminant
|
|
|
- Sabrina Campbell
- 5 years ago
- Views:
Transcription
1 Discriminants Minimum Error-Rate Discriminant In the case of zero-one loss function, the Bayes Discriminant can be further simplified: g i (x) =P (ω i x). (29) J. Corso (SUNY at Buffalo) Bayesian Decision Theory 22 / 59
2 Discriminants Uniqueness Of Discriminants Is the choice of discriminant functions unique? J. Corso (SUNY at Buffalo) Bayesian Decision Theory 23 / 59
3 Discriminants Uniqueness Of Discriminants Is the choice of discriminant functions unique? No! Multiply by some positive constant. Shift them by some additive constant. J. Corso (SUNY at Buffalo) Bayesian Decision Theory 23 / 59

4
5 Discriminants Visualizing Discriminants Decision Regions The effect of any decision rule is to divide the feature space into decision regions. Denote a decision region R i for ω i. One not necessarily connected region is created for each category and assignments is according to: If g i (x) >g j (x) j i, then x is in R i. (33) Decision boundaries separate the regions; they are ties among the discriminant functions. J. Corso (SUNY at Buffalo) Bayesian Decision Theory 24 / 59
6 Discriminants Visualizing Discriminants Decision Regions 0.3 p(x ω 1 )P(ω 1 ) p(x ω 2 )P(ω 2 ) R 2 5 R 1 decision boundary 0 R J. Corso (SUNY at Buffalo) Bayesian Decision Theory 25 / 59
7 Discriminants Two-Category Discriminants Dichotomizers In the two-category case, one considers single discriminant What is a suitable decision rule? g(x) =g 1 (x) g 2 (x). (34) J. Corso (SUNY at Buffalo) Bayesian Decision Theory 26 / 59
8 Discriminants Two-Category Discriminants Dichotomizers In the two-category case, one considers single discriminant g(x) =g 1 (x) g 2 (x). (34) The following simple rule is then used: Decide ω 1 if g(x) > 0; otherwise decide ω 2. (35) J. Corso (SUNY at Buffalo) Bayesian Decision Theory 26 / 59
9 Discriminants Two-Category Discriminants Dichotomizers In the two-category case, one considers single discriminant g(x) =g 1 (x) g 2 (x). (34) The following simple rule is then used: Decide ω 1 if g(x) > 0; otherwise decide ω 2. (35) Various manipulations of the discriminant: g(x) =P (ω 1 x) P (ω 2 x) (36) g(x) =ln p(x ω 1) p(x ω 2 ) +lnp (ω 1) P (ω 2 ) (37) J. Corso (SUNY at Buffalo) Bayesian Decision Theory 26 / 59

10
11

12

13

14
15 The Normal Density Entropy Entropy is the uncertainty in the random samples from a distribution. H(p(x)) = p(x)lnp(x)dx (44) The normal density has the maximum entropy for all distributions have a given mean and variance. What is the entropy of the uniform distribution? J. Corso (SUNY at Buffalo) Bayesian Decision Theory 31 / 59
16 The Normal Density Entropy Entropy is the uncertainty in the random samples from a distribution. H(p(x)) = p(x)lnp(x)dx (44) The normal density has the maximum entropy for all distributions have a given mean and variance. What is the entropy of the uniform distribution? The uniform distribution has maximum entropy (on a given interval). J. Corso (SUNY at Buffalo) Bayesian Decision Theory 31 / 59

17

18
19 The Normal Density The Covariance Matrix Σ E[(x µ)(x µ) T ]= (x µ)(x µ) T p(x)dx Symmetric. Positive semi-definite (but DHS only considers positive definite so that the determinant is strictly positive). The diagonal elements σ ii are the variances of the respective coordinate x i. The off-diagonal elements σ ij are the covariances of x i and x j. What does a σ ij =0imply? That coordinates x i and x j are statistically independent. J. Corso (SUNY at Buffalo) Bayesian Decision Theory 33 / 59
20 The Normal Density The Covariance Matrix Σ E[(x µ)(x µ) T ]= (x µ)(x µ) T p(x)dx Symmetric. Positive semi-definite (but DHS only considers positive definite so that the determinant is strictly positive). The diagonal elements σ ii are the variances of the respective coordinate x i. The off-diagonal elements σ ij are the covariances of x i and x j. What does a σ ij =0imply? That coordinates x i and x j are statistically independent. What does Σ reduce to if all off-diagonals are 0? J. Corso (SUNY at Buffalo) Bayesian Decision Theory 33 / 59
21 The Normal Density The Covariance Matrix Σ E[(x µ)(x µ) T ]= (x µ)(x µ) T p(x)dx Symmetric. Positive semi-definite (but DHS only considers positive definite so that the determinant is strictly positive). The diagonal elements σ ii are the variances of the respective coordinate x i. The off-diagonal elements σ ij are the covariances of x i and x j. What does a σ ij =0imply? That coordinates x i and x j are statistically independent. What does Σ reduce to if all off-diagonals are 0? The product of the d univariate densities. J. Corso (SUNY at Buffalo) Bayesian Decision Theory 33 / 59

22

23

24


25
26 The Normal Density Simple Case: Statistically Independent Features with Same Variance What do the decision boundaries look like if we assume Σ i = σ 2 I? They are hyperplanes ω 1 ω p(x ω i ) ω 1 ω ω 1 P(ω 2 )=.5 ω R R 1 R 2 P(ω 1 )=.5 P(ω 2 )=.5 x -2 P(ω 1 )= R 1 R 2 4 P(ω 2 )= P(ω 1 )= R 1 2 Let s see why... J. Corso (SUNY at Buffalo) Bayesian Decision Theory 37 / 59
27

28

29

30


31

32
33 The Normal Density General Case: Arbitrary Σ i J. Corso (SUNY at Buffalo) Bayesian Decision Theory 44 / 59
34 The Normal Density General Case for Multiple Categories R 4 R 3 R 2 R 4 R 1 nquite regions A Complicated for four normal Decisiondistribut Surface! J. Corso (SUNY at Buffalo) Bayesian Decision Theory 45 / 59

35
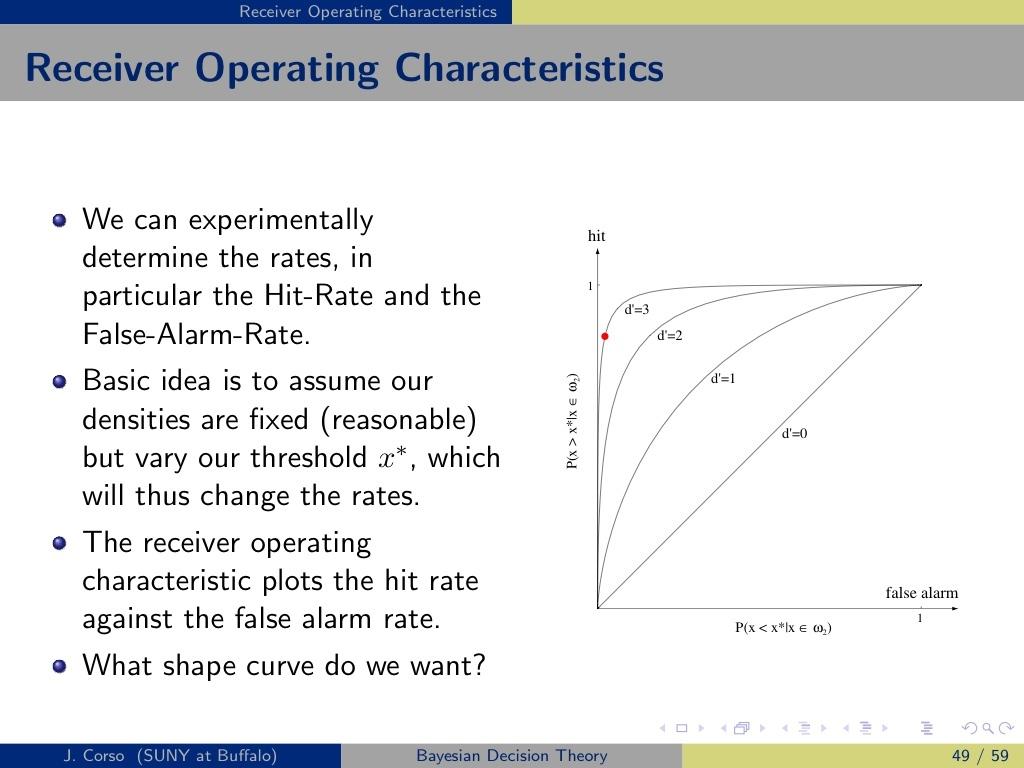
36 Receiver Operating Characteristics Signal Detection Theory The detector uses x to decide if the external signal is present. Discriminability characterizes how difficult it will be to decide if the external signal is present without knowing x. d = µ 2 µ 1 σ (63) Even if we do not know µ 1, µ 2, σ, orx,wecanfindd by using a receiver operating characteristic or ROC curve, as long as we know the state of nature for some experiments J. Corso (SUNY at Buffalo) Bayesian Decision Theory 47 / 59
37 Receiver Operating Characteristics Receiver Operating Characteristics Definitions A Hit is the probability that the internal signal is above x given that the external signal is present P (x >x x ω 2 ) (64) J. Corso (SUNY at Buffalo) Bayesian Decision Theory 48 / 59

38
39 Receiver Operating Characteristics Receiver Operating Characteristics Definitions A Hit is the probability that the internal signal is above x given that the external signal is present P (x >x x ω 2 ) (64) A Correct Rejection is the probability that the internal signal is below x given that the external signal is not present. P (x <x x ω 1 ) (65) A False Alarm is the probability that the internal signal is above x despite there being no external signal present. P (x >x x ω 1 ) (66) J. Corso (SUNY at Buffalo) Bayesian Decision Theory 48 / 59

40
41
42 Missing or Bad Features Missing Features Suppose we have built a classifier on multiple features, for example the lightness and width. What do we do if one of the features is not measurable for a particular case? For example the lightness can be measured but the width cannot because of occlusion. J. Corso (SUNY at Buffalo) Bayesian Decision Theory 50 / 59
43 Missing or Bad Features Missing Features Suppose we have built a classifier on multiple features, for example the lightness and width. What do we do if one of the features is not measurable for a particular case? For example the lightness can be measured but the width cannot because of occlusion. Marginalize! Let x be our full feature feature and x g be the subset that are measurable (or good) and let x b be the subset that are missing (or bad/noisy). We seek an estimate of the posterior given just the good features x g. J. Corso (SUNY at Buffalo) Bayesian Decision Theory 50 / 59
44 Missing or Bad Features Missing Features P (ω i x g )= p(ω i, x g ) p(x g ) (68) = = p(ωi, x g, x b )dx b p(x g ) p(ωi x)p(x)dx b p(x g ) (69) (70) = gi (x)p(x)dx b p(x)dxb (71) We will cover the Expectation-Maximization algorithm later. This is normally quite expensive to evaluate unless the densities are special (like Gaussians). J. Corso (SUNY at Buffalo) Bayesian Decision Theory 51 / 59
45 Bayesian Belief Networks Statistical Independence Two variables x i and x j are independent if p(x i,x j )=p(x i )p(x j ) (72) x 3 x 1 x 2 FIGURE Athree-dimensionaldistributionwhichobeysp(x 1, x 3 ) = p(x 1 )p(x 3 ); thus here x 1 and x 3 are statistically independent but the other feature pairs are not. From: Richard O. Duda, Peter E. Hart, and David G. Stork, Pattern Classification. Copyright c 2001 by John Wiley & Sons, Inc. J. Corso (SUNY at Buffalo) Bayesian Decision Theory 52 / 59
46 Bayesian Belief Networks Simple Example of Conditional Independence From Russell and Norvig Consider a simple example consisting of four variables: the weather, the presence of a cavity, the presence of a toothache, and the presence of other mouth-related variables such as dry mouth. The weather is clearly independent of the other three variables. And the toothache and catch are conditionally independent given the cavity (one as no effect on the other given the information about the cavity). Weather Cavity Toothache Catch J. Corso (SUNY at Buffalo) Bayesian Decision Theory 53 / 59
47 Bayesian Belief Networks Naïve Bayes Rule If we assume that all of our individual features x i,i=1,...,d are conditionally independent given the class, then we have p(ω k x) d i=1 p(x i ω k ) (73) Circumvents issues of dimensionality. Performs with surprising accuracy even in cases violating the underlying independence assumption. J. Corso (SUNY at Buffalo) Bayesian Decision Theory 54 / 59
48
Bayesian Decision Theory Lecture 2
 Bayesian Decision Theory Lecture 2 Jason Corso SUNY at Buffalo 14 January 2009 J. Corso (SUNY at Buffalo) Bayesian Decision Theory Lecture 2 14 January 2009 1 / 58 Overview and Plan Covering Chapter 2
Bayesian Decision Theory Lecture 2 Jason Corso SUNY at Buffalo 14 January 2009 J. Corso (SUNY at Buffalo) Bayesian Decision Theory Lecture 2 14 January 2009 1 / 58 Overview and Plan Covering Chapter 2
p(x ω i 0.4 ω 2 ω
 p( ω i ). ω.3.. 9 3 FIGURE.. Hypothetical class-conditional probability density functions show the probability density of measuring a particular feature value given the pattern is in category ω i.if represents
p( ω i ). ω.3.. 9 3 FIGURE.. Hypothetical class-conditional probability density functions show the probability density of measuring a particular feature value given the pattern is in category ω i.if represents
p(x ω i 0.4 ω 2 ω
 p(x ω i ).4 ω.3.. 9 3 4 5 x FIGURE.. Hypothetical class-conditional probability density functions show the probability density of measuring a particular feature value x given the pattern is in category
p(x ω i ).4 ω.3.. 9 3 4 5 x FIGURE.. Hypothetical class-conditional probability density functions show the probability density of measuring a particular feature value x given the pattern is in category
Lecture Notes on the Gaussian Distribution
 Lecture Notes on the Gaussian Distribution Hairong Qi The Gaussian distribution is also referred to as the normal distribution or the bell curve distribution for its bell-shaped density curve. There s
Lecture Notes on the Gaussian Distribution Hairong Qi The Gaussian distribution is also referred to as the normal distribution or the bell curve distribution for its bell-shaped density curve. There s
Pattern Classification
 Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Parametric Techniques
 Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Parametric Techniques Jason J. Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Parametric Techniques 1 / 39 Introduction When covering Bayesian Decision Theory, we assumed the full probabilistic structure
Bayesian decision theory Introduction to Pattern Recognition. Lectures 4 and 5: Bayesian decision theory
 Bayesian decision theory 8001652 Introduction to Pattern Recognition. Lectures 4 and 5: Bayesian decision theory Jussi Tohka jussi.tohka@tut.fi Institute of Signal Processing Tampere University of Technology
Bayesian decision theory 8001652 Introduction to Pattern Recognition. Lectures 4 and 5: Bayesian decision theory Jussi Tohka jussi.tohka@tut.fi Institute of Signal Processing Tampere University of Technology
Parametric Techniques Lecture 3
 Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
Parametric Techniques Lecture 3 Jason Corso SUNY at Buffalo 22 January 2009 J. Corso (SUNY at Buffalo) Parametric Techniques Lecture 3 22 January 2009 1 / 39 Introduction In Lecture 2, we learned how to
Bayesian Decision Theory
 Bayesian Decision Theory Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551, Fall 2017 c 2017, Selim Aksoy (Bilkent University) 1 / 46 Bayesian
Bayesian Decision Theory Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551, Fall 2017 c 2017, Selim Aksoy (Bilkent University) 1 / 46 Bayesian
EEL 851: Biometrics. An Overview of Statistical Pattern Recognition EEL 851 1
 EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
EEL 851: Biometrics An Overview of Statistical Pattern Recognition EEL 851 1 Outline Introduction Pattern Feature Noise Example Problem Analysis Segmentation Feature Extraction Classification Design Cycle
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout 2:. The Multivariate Gaussian & Decision Boundaries
 University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
University of Cambridge Engineering Part IIB Module 3F3: Signal and Pattern Processing Handout :. The Multivariate Gaussian & Decision Boundaries..15.1.5 1 8 6 6 8 1 Mark Gales mjfg@eng.cam.ac.uk Lent
Bayes Decision Theory
 Bayes Decision Theory Minimum-Error-Rate Classification Classifiers, Discriminant Functions and Decision Surfaces The Normal Density 0 Minimum-Error-Rate Classification Actions are decisions on classes
Bayes Decision Theory Minimum-Error-Rate Classification Classifiers, Discriminant Functions and Decision Surfaces The Normal Density 0 Minimum-Error-Rate Classification Actions are decisions on classes
p(d θ ) l(θ ) 1.2 x x x
 l(θ ) 1.2 x x x") p(d θ ).2 x 0-7 0.8 x 0-7 0.4 x 0-7 l(θ ) -20-40 -60-80 -00 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ θ x FIGURE 3.. The top graph shows several training points in one dimension, known or assumed to
p(d θ ).2 x 0-7 0.8 x 0-7 0.4 x 0-7 l(θ ) -20-40 -60-80 -00 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ θ x FIGURE 3.. The top graph shows several training points in one dimension, known or assumed to
Machine Learning 2017
 Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Bayesian Decision Theory
 Bayesian Decision Theory Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Bayesian Decision Theory Bayesian classification for normal distributions Error Probabilities
Bayesian Decision Theory Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Bayesian Decision Theory Bayesian classification for normal distributions Error Probabilities
Bayesian Decision Theory
 Introduction to Pattern Recognition [ Part 4 ] Mahdi Vasighi Remarks It is quite common to assume that the data in each class are adequately described by a Gaussian distribution. Bayesian classifier is
Introduction to Pattern Recognition [ Part 4 ] Mahdi Vasighi Remarks It is quite common to assume that the data in each class are adequately described by a Gaussian distribution. Bayesian classifier is
44 CHAPTER 2. BAYESIAN DECISION THEORY
 44 CHAPTER 2. BAYESIAN DECISION THEORY Problems Section 2.1 1. In the two-category case, under the Bayes decision rule the conditional error is given by Eq. 7. Even if the posterior densities are continuous,
44 CHAPTER 2. BAYESIAN DECISION THEORY Problems Section 2.1 1. In the two-category case, under the Bayes decision rule the conditional error is given by Eq. 7. Even if the posterior densities are continuous,
Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart
 Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart 1 Motivation and Problem In Lecture 1 we briefly saw how histograms
Statistical and Learning Techniques in Computer Vision Lecture 2: Maximum Likelihood and Bayesian Estimation Jens Rittscher and Chuck Stewart 1 Motivation and Problem In Lecture 1 we briefly saw how histograms
Nonparametric Methods Lecture 5
 Nonparametric Methods Lecture 5 Jason Corso SUNY at Buffalo 17 Feb. 29 J. Corso (SUNY at Buffalo) Nonparametric Methods Lecture 5 17 Feb. 29 1 / 49 Nonparametric Methods Lecture 5 Overview Previously,
Nonparametric Methods Lecture 5 Jason Corso SUNY at Buffalo 17 Feb. 29 J. Corso (SUNY at Buffalo) Nonparametric Methods Lecture 5 17 Feb. 29 1 / 49 Nonparametric Methods Lecture 5 Overview Previously,
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart
 Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart 1 Motivation Imaging is a stochastic process: If we take all the different sources of
Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart 1 Motivation Imaging is a stochastic process: If we take all the different sources of
Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation (part 1)
") HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
Error Rates. Error vs Threshold. ROC Curve. Biometrics: A Pattern Recognition System. Pattern classification. Biometrics CSE 190 Lecture 3
 Biometrics: A Pattern Recognition System Yes/No Pattern classification Biometrics CSE 190 Lecture 3 Authentication False accept rate (FAR): Proportion of imposters accepted False reject rate (FRR): Proportion
Biometrics: A Pattern Recognition System Yes/No Pattern classification Biometrics CSE 190 Lecture 3 Authentication False accept rate (FAR): Proportion of imposters accepted False reject rate (FRR): Proportion
Bayesian Learning. Bayesian Learning Criteria
 Bayesian Learning In Bayesian learning, we are interested in the probability of a hypothesis h given the dataset D. By Bayes theorem: P (h D) = P (D h)p (h) P (D) Other useful formulas to remember are:
Bayesian Learning In Bayesian learning, we are interested in the probability of a hypothesis h given the dataset D. By Bayes theorem: P (h D) = P (D h)p (h) P (D) Other useful formulas to remember are:
Pattern Recognition 2
 Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Bayesian Decision and Bayesian Learning
 Bayesian Decision and Bayesian Learning Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1 / 30 Bayes Rule p(x ω i
Bayesian Decision and Bayesian Learning Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1 / 30 Bayes Rule p(x ω i
Problem Set 2. MAS 622J/1.126J: Pattern Recognition and Analysis. Due: 5:00 p.m. on September 30
 Problem Set MAS 6J/1.16J: Pattern Recognition and Analysis Due: 5:00 p.m. on September 30 [Note: All instructions to plot data or write a program should be carried out using Matlab. In order to maintain
Problem Set MAS 6J/1.16J: Pattern Recognition and Analysis Due: 5:00 p.m. on September 30 [Note: All instructions to plot data or write a program should be carried out using Matlab. In order to maintain
Naïve Bayes classification. p ij 11/15/16. Probability theory. Probability theory. Probability theory. X P (X = x i )=1 i. Marginal Probability
=1 i. Marginal Probability") Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Probability theory Naïve Bayes classification Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. s: A person s height, the outcome of a coin toss Distinguish
Expect Values and Probability Density Functions
 Intelligent Systems: Reasoning and Recognition James L. Crowley ESIAG / osig Second Semester 00/0 Lesson 5 8 april 0 Expect Values and Probability Density Functions otation... Bayesian Classification (Reminder...3
Intelligent Systems: Reasoning and Recognition James L. Crowley ESIAG / osig Second Semester 00/0 Lesson 5 8 april 0 Expect Values and Probability Density Functions otation... Bayesian Classification (Reminder...3
CS 195-5: Machine Learning Problem Set 1
 CS 95-5: Machine Learning Problem Set Douglas Lanman dlanman@brown.edu 7 September Regression Problem Show that the prediction errors y f(x; ŵ) are necessarily uncorrelated with any linear function of
CS 95-5: Machine Learning Problem Set Douglas Lanman dlanman@brown.edu 7 September Regression Problem Show that the prediction errors y f(x; ŵ) are necessarily uncorrelated with any linear function of
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Learning Methods for Linear Detectors
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2011/2012 Lesson 20 27 April 2012 Contents Learning Methods for Linear Detectors Learning Linear Detectors...2
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2011/2012 Lesson 20 27 April 2012 Contents Learning Methods for Linear Detectors Learning Linear Detectors...2
Probability Theory Review Reading Assignments
 Probability Theory Review Reading Assignments R. Duda, P. Hart, and D. Stork, Pattern Classification, John-Wiley, 2nd edition, 2001 (appendix A.4, hard-copy). "Everything I need to know about Probability"
Probability Theory Review Reading Assignments R. Duda, P. Hart, and D. Stork, Pattern Classification, John-Wiley, 2nd edition, 2001 (appendix A.4, hard-copy). "Everything I need to know about Probability"
Advanced statistical methods for data analysis Lecture 1
 Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
ENG 8801/ Special Topics in Computer Engineering: Pattern Recognition. Memorial University of Newfoundland Pattern Recognition
 Memorial University of Newfoundland Pattern Recognition Lecture 6 May 18, 2006 http://www.engr.mun.ca/~charlesr Office Hours: Tuesdays & Thursdays 8:30-9:30 PM EN-3026 Review Distance-based Classification
Memorial University of Newfoundland Pattern Recognition Lecture 6 May 18, 2006 http://www.engr.mun.ca/~charlesr Office Hours: Tuesdays & Thursdays 8:30-9:30 PM EN-3026 Review Distance-based Classification
Linear Classifiers as Pattern Detectors
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2014/2015 Lesson 16 8 April 2015 Contents Linear Classifiers as Pattern Detectors Notation...2 Linear
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2014/2015 Lesson 16 8 April 2015 Contents Linear Classifiers as Pattern Detectors Notation...2 Linear
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Graphical Models - Part I
 Graphical Models - Part I Oliver Schulte - CMPT 726 Bishop PRML Ch. 8, some slides from Russell and Norvig AIMA2e Outline Probabilistic Models Bayesian Networks Markov Random Fields Inference Outline Probabilistic
Graphical Models - Part I Oliver Schulte - CMPT 726 Bishop PRML Ch. 8, some slides from Russell and Norvig AIMA2e Outline Probabilistic Models Bayesian Networks Markov Random Fields Inference Outline Probabilistic
Dimension Reduction and Component Analysis
 Dimension Reduction and Component Analysis Jason Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Dimension Reduction and Component Analysis 1 / 103 Plan We learned about estimating parametric models and
Dimension Reduction and Component Analysis Jason Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Dimension Reduction and Component Analysis 1 / 103 Plan We learned about estimating parametric models and
Contents 2 Bayesian decision theory
 Contents Bayesian decision theory 3. Introduction... 3. Bayesian Decision Theory Continuous Features... 7.. Two-Category Classification... 8.3 Minimum-Error-Rate Classification... 9.3. *Minimax Criterion....3.
Contents Bayesian decision theory 3. Introduction... 3. Bayesian Decision Theory Continuous Features... 7.. Two-Category Classification... 8.3 Minimum-Error-Rate Classification... 9.3. *Minimax Criterion....3.
Quantifying uncertainty & Bayesian networks
 Quantifying uncertainty & Bayesian networks CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2016 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition,
Quantifying uncertainty & Bayesian networks CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2016 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition,
Detection theory 101 ELEC-E5410 Signal Processing for Communications
 Detection theory 101 ELEC-E5410 Signal Processing for Communications Binary hypothesis testing Null hypothesis H 0 : e.g. noise only Alternative hypothesis H 1 : signal + noise p(x;h 0 ) γ p(x;h 1 ) Trade-off
Detection theory 101 ELEC-E5410 Signal Processing for Communications Binary hypothesis testing Null hypothesis H 0 : e.g. noise only Alternative hypothesis H 1 : signal + noise p(x;h 0 ) γ p(x;h 1 ) Trade-off
01 Probability Theory and Statistics Review
 NAVARCH/EECS 568, ROB 530 - Winter 2018 01 Probability Theory and Statistics Review Maani Ghaffari January 08, 2018 Last Time: Bayes Filters Given: Stream of observations z 1:t and action data u 1:t Sensor/measurement
NAVARCH/EECS 568, ROB 530 - Winter 2018 01 Probability Theory and Statistics Review Maani Ghaffari January 08, 2018 Last Time: Bayes Filters Given: Stream of observations z 1:t and action data u 1:t Sensor/measurement
Building C303, Harbin Institute of Technology, Shenzhen University Town, Xili, Shenzhen,Guangdong Yonghui Wu, Yaoyun Zhang;
 SOLUTIONS FOR PATTERN CLASSIFICATION CH. Building C33, Harbin Institute of Technology, Shenzhen University Town, Xili, Shenzhen,Guangdong Province, P.R. China Yonghui Wu, Yaoyun Zhang; yonghui.wu@gmail.com
SOLUTIONS FOR PATTERN CLASSIFICATION CH. Building C33, Harbin Institute of Technology, Shenzhen University Town, Xili, Shenzhen,Guangdong Province, P.R. China Yonghui Wu, Yaoyun Zhang; yonghui.wu@gmail.com
Dimension Reduction and Component Analysis Lecture 4
 Dimension Reduction and Component Analysis Lecture 4 Jason Corso SUNY at Buffalo 28 January 2009 J. Corso (SUNY at Buffalo) Lecture 4 28 January 2009 1 / 103 Plan In lecture 3, we learned about estimating
Dimension Reduction and Component Analysis Lecture 4 Jason Corso SUNY at Buffalo 28 January 2009 J. Corso (SUNY at Buffalo) Lecture 4 28 January 2009 1 / 103 Plan In lecture 3, we learned about estimating
5. Discriminant analysis
 5. Discriminant analysis We continue from Bayes s rule presented in Section 3 on p. 85 (5.1) where c i is a class, x isap-dimensional vector (data case) and we use class conditional probability (density
5. Discriminant analysis We continue from Bayes s rule presented in Section 3 on p. 85 (5.1) where c i is a class, x isap-dimensional vector (data case) and we use class conditional probability (density
Introduction to Machine Learning
 Introduction to Machine Learning Bayesian Classification Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Bayesian Classification Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Informatics 2B: Learning and Data Lecture 10 Discriminant functions 2. Minimal misclassifications. Decision Boundaries
 Overview Gaussians estimated from training data Guido Sanguinetti Informatics B Learning and Data Lecture 1 9 March 1 Today s lecture Posterior probabilities, decision regions and minimising the probability
Overview Gaussians estimated from training data Guido Sanguinetti Informatics B Learning and Data Lecture 1 9 March 1 Today s lecture Posterior probabilities, decision regions and minimising the probability
COM336: Neural Computing
 COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
Problem Set 2. MAS 622J/1.126J: Pattern Recognition and Analysis. Due: 5:00 p.m. on September 30
 Problem Set 2 MAS 622J/1.126J: Pattern Recognition and Analysis Due: 5:00 p.m. on September 30 [Note: All instructions to plot data or write a program should be carried out using Matlab. In order to maintain
Problem Set 2 MAS 622J/1.126J: Pattern Recognition and Analysis Due: 5:00 p.m. on September 30 [Note: All instructions to plot data or write a program should be carried out using Matlab. In order to maintain
x. Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ 2 ).
.") .8.6 µ =, σ = 1 µ = 1, σ = 1 / µ =, σ =.. 3 1 1 3 x Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ ). The Gaussian distribution Probably the most-important distribution in all of statistics
.8.6 µ =, σ = 1 µ = 1, σ = 1 / µ =, σ =.. 3 1 1 3 x Figure 1: Examples of univariate Gaussian pdfs N (x; µ, σ ). The Gaussian distribution Probably the most-important distribution in all of statistics
Algorithm Independent Topics Lecture 6
 Algorithm Independent Topics Lecture 6 Jason Corso SUNY at Buffalo Feb. 23 2009 J. Corso (SUNY at Buffalo) Algorithm Independent Topics Lecture 6 Feb. 23 2009 1 / 45 Introduction Now that we ve built an
Algorithm Independent Topics Lecture 6 Jason Corso SUNY at Buffalo Feb. 23 2009 J. Corso (SUNY at Buffalo) Algorithm Independent Topics Lecture 6 Feb. 23 2009 1 / 45 Introduction Now that we ve built an
Generative classifiers: The Gaussian classifier. Ata Kaban School of Computer Science University of Birmingham
 Generative classifiers: The Gaussian classifier Ata Kaban School of Computer Science University of Birmingham Outline We have already seen how Bayes rule can be turned into a classifier In all our examples
Generative classifiers: The Gaussian classifier Ata Kaban School of Computer Science University of Birmingham Outline We have already seen how Bayes rule can be turned into a classifier In all our examples
Statistical Methods for Particle Physics Lecture 1: parameter estimation, statistical tests
 Statistical Methods for Particle Physics Lecture 1: parameter estimation, statistical tests http://benasque.org/2018tae/cgi-bin/talks/allprint.pl TAE 2018 Benasque, Spain 3-15 Sept 2018 Glen Cowan Physics
Statistical Methods for Particle Physics Lecture 1: parameter estimation, statistical tests http://benasque.org/2018tae/cgi-bin/talks/allprint.pl TAE 2018 Benasque, Spain 3-15 Sept 2018 Glen Cowan Physics
Bayes Rule for Minimizing Risk
 Bayes Rule for Minimizing Risk Dennis Lee April 1, 014 Introduction In class we discussed Bayes rule for minimizing the probability of error. Our goal is to generalize this rule to minimize risk instead
Bayes Rule for Minimizing Risk Dennis Lee April 1, 014 Introduction In class we discussed Bayes rule for minimizing the probability of error. Our goal is to generalize this rule to minimize risk instead
SGN (4 cr) Chapter 5
 Chapter 5") SGN-41006 (4 cr) Chapter 5 Linear Discriminant Analysis Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology January 21, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
SGN-41006 (4 cr) Chapter 5 Linear Discriminant Analysis Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology January 21, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
Decision theory. 1 We may also consider randomized decision rules, where δ maps observed data D to a probability distribution over
 Point estimation Suppose we are interested in the value of a parameter θ, for example the unknown bias of a coin. We have already seen how one may use the Bayesian method to reason about θ; namely, we
Point estimation Suppose we are interested in the value of a parameter θ, for example the unknown bias of a coin. We have already seen how one may use the Bayesian method to reason about θ; namely, we
Clustering VS Classification
 MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Machine Perceptual Learning and Sensory Summer Augmented 6 Computing Announcements Machine Learning Lecture 2 Course webpage http://www.vision.rwth-aachen.de/teaching/ Slides will be made available on
Uncertainty. Variables. assigns to each sentence numerical degree of belief between 0 and 1. uncertainty
 Bayes Classification n Uncertainty & robability n Baye's rule n Choosing Hypotheses- Maximum a posteriori n Maximum Likelihood - Baye's concept learning n Maximum Likelihood of real valued function n Bayes
Bayes Classification n Uncertainty & robability n Baye's rule n Choosing Hypotheses- Maximum a posteriori n Maximum Likelihood - Baye's concept learning n Maximum Likelihood of real valued function n Bayes
Introduction to Signal Detection and Classification. Phani Chavali
 Introduction to Signal Detection and Classification Phani Chavali Outline Detection Problem Performance Measures Receiver Operating Characteristics (ROC) F-Test - Test Linear Discriminant Analysis (LDA)
Introduction to Signal Detection and Classification Phani Chavali Outline Detection Problem Performance Measures Receiver Operating Characteristics (ROC) F-Test - Test Linear Discriminant Analysis (LDA)
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
COMP9414/ 9814/ 3411: Artificial Intelligence. 14. Uncertainty. Russell & Norvig, Chapter 13. UNSW c AIMA, 2004, Alan Blair, 2012
 COMP9414/ 9814/ 3411: Artificial Intelligence 14. Uncertainty Russell & Norvig, Chapter 13. COMP9414/9814/3411 14s1 Uncertainty 1 Outline Uncertainty Probability Syntax and Semantics Inference Independence
COMP9414/ 9814/ 3411: Artificial Intelligence 14. Uncertainty Russell & Norvig, Chapter 13. COMP9414/9814/3411 14s1 Uncertainty 1 Outline Uncertainty Probability Syntax and Semantics Inference Independence
SYDE 372 Introduction to Pattern Recognition. Probability Measures for Classification: Part I
 SYDE 372 Introduction to Pattern Recognition Probability Measures for Classification: Part I Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 Why use probability
SYDE 372 Introduction to Pattern Recognition Probability Measures for Classification: Part I Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 Why use probability
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
LDA, QDA, Naive Bayes
 LDA, QDA, Naive Bayes Generative Classification Models Marek Petrik 2/16/2017 Last Class Logistic Regression Maximum Likelihood Principle Logistic Regression Predict probability of a class: p(x) Example:
LDA, QDA, Naive Bayes Generative Classification Models Marek Petrik 2/16/2017 Last Class Logistic Regression Maximum Likelihood Principle Logistic Regression Predict probability of a class: p(x) Example:
a b = a T b = a i b i (1) i=1 (Geometric definition) The dot product of two Euclidean vectors a and b is defined by a b = a b cos(θ a,b ) (2)
 i=1 (Geometric definition) The dot product of two Euclidean vectors a and b is defined by a b = a b cos(θ a,b ) (2)") This is my preperation notes for teaching in sections during the winter 2018 quarter for course CSE 446. Useful for myself to review the concepts as well. More Linear Algebra Definition 1.1 (Dot Product).
This is my preperation notes for teaching in sections during the winter 2018 quarter for course CSE 446. Useful for myself to review the concepts as well. More Linear Algebra Definition 1.1 (Dot Product).
Algorithmisches Lernen/Machine Learning
 Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
Algorithmisches Lernen/Machine Learning Part 1: Stefan Wermter Introduction Connectionist Learning (e.g. Neural Networks) Decision-Trees, Genetic Algorithms Part 2: Norman Hendrich Support-Vector Machines
Minimum Error Rate Classification
 Minimum Error Rate Classification Dr. K.Vijayarekha Associate Dean School of Electrical and Electronics Engineering SASTRA University, Thanjavur-613 401 Table of Contents 1.Minimum Error Rate Classification...
Minimum Error Rate Classification Dr. K.Vijayarekha Associate Dean School of Electrical and Electronics Engineering SASTRA University, Thanjavur-613 401 Table of Contents 1.Minimum Error Rate Classification...
Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics)
") Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics) Probability quantifies randomness and uncertainty How do I estimate the normalization and logarithmic slope of a X ray continuum, assuming
Brandon C. Kelly (Harvard Smithsonian Center for Astrophysics) Probability quantifies randomness and uncertainty How do I estimate the normalization and logarithmic slope of a X ray continuum, assuming
Bayesian networks. Chapter 14, Sections 1 4
 Bayesian networks Chapter 14, Sections 1 4 Artificial Intelligence, spring 2013, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 14, Sections 1 4 1 Bayesian networks
Bayesian networks Chapter 14, Sections 1 4 Artificial Intelligence, spring 2013, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 14, Sections 1 4 1 Bayesian networks
BAYESIAN DECISION THEORY
 Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
Last updated: September 17, 2012 BAYESIAN DECISION THEORY Problems 2 The following problems from the textbook are relevant: 2.1 2.9, 2.11, 2.17 For this week, please at least solve Problem 2.3. We will
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
Artificial Intelligence Uncertainty
 Artificial Intelligence Uncertainty Ch. 13 Uncertainty Let action A t = leave for airport t minutes before flight Will A t get me there on time? A 25, A 60, A 3600 Uncertainty: partial observability (road
Artificial Intelligence Uncertainty Ch. 13 Uncertainty Let action A t = leave for airport t minutes before flight Will A t get me there on time? A 25, A 60, A 3600 Uncertainty: partial observability (road
Introduction to Bayesian Statistics
 School of Computing & Communication, UTS January, 207 Random variables Pre-university: A number is just a fixed value. When we talk about probabilities: When X is a continuous random variable, it has a
School of Computing & Communication, UTS January, 207 Random variables Pre-university: A number is just a fixed value. When we talk about probabilities: When X is a continuous random variable, it has a
Probability Models for Bayesian Recognition
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG / osig Second Semester 06/07 Lesson 9 0 arch 07 Probability odels for Bayesian Recognition Notation... Supervised Learning for Bayesian
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIAG / osig Second Semester 06/07 Lesson 9 0 arch 07 Probability odels for Bayesian Recognition Notation... Supervised Learning for Bayesian
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Pengju
 Introduction to AI Chapter13 Uncertainty Pengju Ren@IAIR Outline Uncertainty Probability Syntax and Semantics Inference Independence and Bayes Rule Example: Car diagnosis Wumpus World Environment Squares
Introduction to AI Chapter13 Uncertainty Pengju Ren@IAIR Outline Uncertainty Probability Syntax and Semantics Inference Independence and Bayes Rule Example: Car diagnosis Wumpus World Environment Squares
Fundamentals to Biostatistics. Prof. Chandan Chakraborty Associate Professor School of Medical Science & Technology IIT Kharagpur
 Fundamentals to Biostatistics Prof. Chandan Chakraborty Associate Professor School of Medical Science & Technology IIT Kharagpur Statistics collection, analysis, interpretation of data development of new
Fundamentals to Biostatistics Prof. Chandan Chakraborty Associate Professor School of Medical Science & Technology IIT Kharagpur Statistics collection, analysis, interpretation of data development of new
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Detection theory. H 0 : x[n] = w[n]
![Detection theory. H 0 : x[n] = w[n]](/thumbs/89/98950636.jpg "Detection theory. H 0 : x[n] = w[n]") Detection Theory Detection theory A the last topic of the course, we will briefly consider detection theory. The methods are based on estimation theory and attempt to answer questions such as Is a signal
Detection Theory Detection theory A the last topic of the course, we will briefly consider detection theory. The methods are based on estimation theory and attempt to answer questions such as Is a signal
Quantifying Uncertainty & Probabilistic Reasoning. Abdulla AlKhenji Khaled AlEmadi Mohammed AlAnsari
 Quantifying Uncertainty & Probabilistic Reasoning Abdulla AlKhenji Khaled AlEmadi Mohammed AlAnsari Outline Previous Implementations What is Uncertainty? Acting Under Uncertainty Rational Decisions Basic
Quantifying Uncertainty & Probabilistic Reasoning Abdulla AlKhenji Khaled AlEmadi Mohammed AlAnsari Outline Previous Implementations What is Uncertainty? Acting Under Uncertainty Rational Decisions Basic
Final Overview. Introduction to ML. Marek Petrik 4/25/2017
 Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Fusion in simple models
 Fusion in simple models Peter Antal antal@mit.bme.hu A.I. February 8, 2018 1 Basic concepts of probability theory Joint distribution Conditional probability Bayes rule Chain rule Marginalization General
Fusion in simple models Peter Antal antal@mit.bme.hu A.I. February 8, 2018 1 Basic concepts of probability theory Joint distribution Conditional probability Bayes rule Chain rule Marginalization General
INF Introduction to classifiction Anne Solberg Based on Chapter 2 ( ) in Duda and Hart: Pattern Classification
 in Duda and Hart: Pattern Classification") INF 4300 151014 Introduction to classifiction Anne Solberg anne@ifiuiono Based on Chapter 1-6 in Duda and Hart: Pattern Classification 151014 INF 4300 1 Introduction to classification One of the most challenging
INF 4300 151014 Introduction to classifiction Anne Solberg anne@ifiuiono Based on Chapter 1-6 in Duda and Hart: Pattern Classification 151014 INF 4300 1 Introduction to classification One of the most challenging
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Uncertainty & Probabilities & Bandits Daniel Hennes 16.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Uncertainty Probability
Grundlagen der Künstlichen Intelligenz Uncertainty & Probabilities & Bandits Daniel Hennes 16.11.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Uncertainty Probability
Lecture 5: Likelihood ratio tests, Neyman-Pearson detectors, ROC curves, and sufficient statistics. 1 Executive summary
 ECE 830 Spring 207 Instructor: R. Willett Lecture 5: Likelihood ratio tests, Neyman-Pearson detectors, ROC curves, and sufficient statistics Executive summary In the last lecture we saw that the likelihood
ECE 830 Spring 207 Instructor: R. Willett Lecture 5: Likelihood ratio tests, Neyman-Pearson detectors, ROC curves, and sufficient statistics Executive summary In the last lecture we saw that the likelihood
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak
 Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
1 Using standard errors when comparing estimated values
 MLPR Assignment Part : General comments Below are comments on some recurring issues I came across when marking the second part of the assignment, which I thought it would help to explain in more detail
MLPR Assignment Part : General comments Below are comments on some recurring issues I came across when marking the second part of the assignment, which I thought it would help to explain in more detail
Today. Probability and Statistics. Linear Algebra. Calculus. Naïve Bayes Classification. Matrix Multiplication Matrix Inversion
 Today Probability and Statistics Naïve Bayes Classification Linear Algebra Matrix Multiplication Matrix Inversion Calculus Vector Calculus Optimization Lagrange Multipliers 1 Classical Artificial Intelligence
Today Probability and Statistics Naïve Bayes Classification Linear Algebra Matrix Multiplication Matrix Inversion Calculus Vector Calculus Optimization Lagrange Multipliers 1 Classical Artificial Intelligence
Uncertainty. Chapter 13, Sections 1 6
 Uncertainty Chapter 13, Sections 1 6 Artificial Intelligence, spring 2013, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 13, Sections 1 6 1 Outline Uncertainty Probability
Uncertainty Chapter 13, Sections 1 6 Artificial Intelligence, spring 2013, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 13, Sections 1 6 1 Outline Uncertainty Probability
CS 561: Artificial Intelligence
 CS 561: Artificial Intelligence Instructor: TAs: Sofus A. Macskassy, macskass@usc.edu Nadeesha Ranashinghe (nadeeshr@usc.edu) William Yeoh (wyeoh@usc.edu) Harris Chiu (chiciu@usc.edu) Lectures: MW 5:00-6:20pm,
CS 561: Artificial Intelligence Instructor: TAs: Sofus A. Macskassy, macskass@usc.edu Nadeesha Ranashinghe (nadeeshr@usc.edu) William Yeoh (wyeoh@usc.edu) Harris Chiu (chiciu@usc.edu) Lectures: MW 5:00-6:20pm,
Introduction to Machine Learning
 Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
Introduction to Machine Learning Introduction to Probabilistic Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB
Pattern Recognition. Parameter Estimation of Probability Density Functions
 Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Belief and Desire: On Information and its Value
 Belief and Desire: On Information and its Value Ariel Caticha Department of Physics University at Albany SUNY ariel@albany.edu Info-Metrics Institute 04/26/2013 1 Part 1: Belief 2 What is information?
Belief and Desire: On Information and its Value Ariel Caticha Department of Physics University at Albany SUNY ariel@albany.edu Info-Metrics Institute 04/26/2013 1 Part 1: Belief 2 What is information?
Chap 2. Linear Classifiers (FTH, ) Yongdai Kim Seoul National University
 Yongdai Kim Seoul National University") Chap 2. Linear Classifiers (FTH, 4.1-4.4) Yongdai Kim Seoul National University Linear methods for classification 1. Linear classifiers For simplicity, we only consider two-class classification problems
Chap 2. Linear Classifiers (FTH, 4.1-4.4) Yongdai Kim Seoul National University Linear methods for classification 1. Linear classifiers For simplicity, we only consider two-class classification problems