Information Retrieval and Topic Models. Mausam (Based on slides of W. Arms, Dan Jurafsky, Thomas Hofmann, Ata Kaban, Chris Manning, Melanie Martin)
|
|
|
- Cecilia Perry
- 5 years ago
- Views:
Transcription
1 Information Retrieval and Topic Models Mausam (Based on slides of W. Arms, Dan Jurafsky, Thomas Hofmann, Ata Kaban, Chris Manning, Melanie Martin)
2 Sec. 1.1 Unstructured data in 1620 Which plays of Shakespeare contain the words Brutus AND Caesar but NOT Calpurnia? One could grep all of Shakespeare s plays for Brutus and Caesar, then strip out lines containing Calpurnia? Why is that not the answer? Slow (for large corpora) NOT Calpurnia is non-trivial Other operations (e.g., find the word Romans near countrymen) not feasible Ranked retrieval (best documents to return) Later lectures 2
3 Sec. 1.1 Term-document incidence matrices Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony Brutus Caesar Calpurnia Cleopatra mercy worser Brutus AND Caesar BUT NOT Calpurnia 1 if play contains word, 0 otherwise
4 Sec. 1.1 Incidence vectors So we have a 0/1 vector for each term. To answer query: take the vectors for Brutus, Caesar and Calpurnia (complemented) bitwise AND AND AND = Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony Brutus Caesar Calpurnia Cleopatra mercy worser

5 Sec. 1.1 Answers to query Antony and Cleopatra, Act III, Scene ii Agrippa [Aside to DOMITIUS ENOBARBUS]: Why, Enobarbus, When Antony found Julius Caesar dead, He cried almost to roaring; and he wept When at Philippi he found Brutus slain. Hamlet, Act III, Scene ii Lord Polonius: I did enact Julius Caesar I was killed i the Capitol; Brutus killed me. 5
6 Sec. 6.2 Term-document count matrices Consider the number of occurrences of a term in a document: Each document is a count vector in N V : a column below Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony Brutus Caesar Calpurnia Cleopatra mercy worser
7 Sec tf-idf weighting The tf-idf weight of a term is the product of its tf weight and its idf weight. w (1 log tf ) log t, d 10 ( N Best known weighting scheme in information retrieval Note: the - in tf-idf is a hyphen, not a minus sign! Alternative names: tf.idf, tf x idf Increases with the number of occurrences within a document Increases with the rarity of the term in the collection / df t, d t )
8 Sec Final ranking of documents for a query Score(q,d) = å t ÎqÇd tf.idf t,d 9
9 Sec. 6.3 Binary count weight matrix Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony Brutus Caesar Calpurnia Cleopatra mercy worser Each document is now represented by a real-valued vector of tf-idf weights R V
10 Sec. 6.3 Documents as vectors Now we have a V -dimensional vector space Terms are axes of the space Documents are points or vectors in this space Very high-dimensional: tens of millions of dimensions when you apply this to a web search engine These are very sparse vectors most entries are zero
11 Sec. 6.3 Queries as vectors Key idea 1: Do the same for queries: represent them as vectors in the space Key idea 2: Rank documents according to their proximity to the query in this space proximity = similarity of vectors proximity inverse of distance Recall: We do this because we want to get away from the you re-either-in-or-out Boolean model Instead: rank more relevant documents higher than less relevant documents
12 Sec. 6.3 Formalizing vector space proximity First cut: distance between two points ( = distance between the end points of the two vectors) Euclidean distance? Euclidean distance is a bad idea because Euclidean distance is large for vectors of different lengths.
13 Sec. 6.3 Why distance is a bad idea The Euclidean distance between q and d 2 is large even though the distribution of terms in the query q and the distribution of terms in the document d 2 are very similar.
14 Sec. 6.3 Use angle instead of distance Thought experiment: take a document d and append it to itself. Call this document d. Semantically d and d have the same content The Euclidean distance between the two documents can be quite large The angle between the two documents is 0, corresponding to maximal similarity. Key idea: Rank documents according to angle with query.
15 Sec. 6.3 From angles to cosines The following two notions are equivalent. Rank documents in decreasing order of the angle between query and document Rank documents in increasing order of cosine(query,document) Cosine is a monotonically decreasing function for the interval [0 o, 180 o ]
16 Sec. 6.3 From angles to cosines But how and why should we be computing cosines?
17 Sec. 6.3 Length normalization A vector can be (length-) normalized by dividing each of its components by its length for this we use the L 2 norm: 2 x x 2 Dividing a vector by its L 2 norm makes it a unit (length) vector (on surface of unit hypersphere) Effect on the two documents d and d (d appended to itself) from earlier slide: they have identical vectors after length-normalization. Long and short documents now have comparable weights i i
18 cosine(query,document) V i i V i i V i i i d q q d d d q q d q d q d q ), cos( Dot product Unit vectors q i is the tf-idf weight of term i in the query d i is the tf-idf weight of term i in the document cos(q,d) is the cosine similarity of q and d or, equivalently, the cosine of the angle between q and d. Sec. 6.3
19 Similarity Measures Compared ), min( D Q D Q D Q D Q D Q D Q D Q D Q D Q Simple matching (coordination level match) Dice s Coefficient Jaccard s Coefficient Cosine Coefficient (what we studied) Overlap Coefficient
20 Summary vector space ranking Represent the query as a weighted tf-idf vector Represent each document as a weighted tf-idf vector Compute the cosine similarity score for the query vector and each document vector Rank documents with respect to the query by score Return the top K (e.g., K = 10) to the user
21 Evaluating ranked results: Mean Avg Precision 1 R 2 N 3 N 4 R 5 R 6 N 7 R 8 N 9 N 10 N Assume 10 rel docs in collection
22 Sec. 8.4 Common evaluation measure Mean average precision (MAP) AP: Average of the precision value obtained for the top k documents, each time a relevant doc is retrieved Avoids interpolation, use of fixed recall levels Does weight most accuracy of top returned results MAP for set of queries is arithmetic average of APs Macro-averaging: each query counts equally 29

23 Problems Synonyms: separate words that have the same meaning. E.g. car & automobile They tend to reduce recall Polysems: words with multiple meanings E.g. Java They tend to reduce precision The problem is more general: there is a disconnect between topics and words
24 a more appropriate model should consider some conceptual dimensions instead of words. (Gardenfors)
25 Latent Semantic Analysis (LSA) LSA aims to discover something about the meaning behind the words; about the topics in the documents. What is the difference between topics and words? Words are observable Topics are not. They are latent. How to find out topics from the words in an automatic way? We can imagine them as a compression of words A combination of words Try to formalise this
26 Latent Semantic Analysis Singular Value Decomposition (SVD) A(m*n) = U(m*r) E(r*r) V(r*n) Keep only k eigen values from E A(m*n) = U(m*k) E(k*k) V(k*n) Convert terms and documents to points in k- dimensional space Low-rank approximation

27 Latent Semantic Analysis Singular Value Decomposition {A}={U}{S}{V} T Dimension Reduction {~A}~={~U}{~S}{~V} T
28 Latent Semantic Analysis LSA puts documents together even if they don t have common words if The docs share frequently co-occurring terms Disadvantages: Statistical foundation is missing PLSA addresses this concern!
29 PLSA Latent Variable model for general co-occurrence data Associate each observation (w,d) with a class variable z Є Z{z_1,,z_K} Generative Model Select a doc with probability P(d) Pick a latent class z with probability P(z d) Generate a word w with probability p(w z) d z w N d D
30 PLSA To get the joint probability model
31 Model fitting with EM We have the equation for log-likelihood function from the aspect model, and we need to maximize it. Expectation Maximization (EM) is used for this purpose
32 EM Steps E-Step Expectation step where expectation of the likelihood function is calculated with the current parameter values M-Step Update the parameters with the calculated posterior probabilities Find the parameters that maximizes the likelihood function
33 E Step It is the probability that a word w occurring in a document d, is explained by aspect z (based on some calculations)
34 M Step All these equations use p(z d,w) calculated in E Step Converges to local maximum of the likelihood function
35
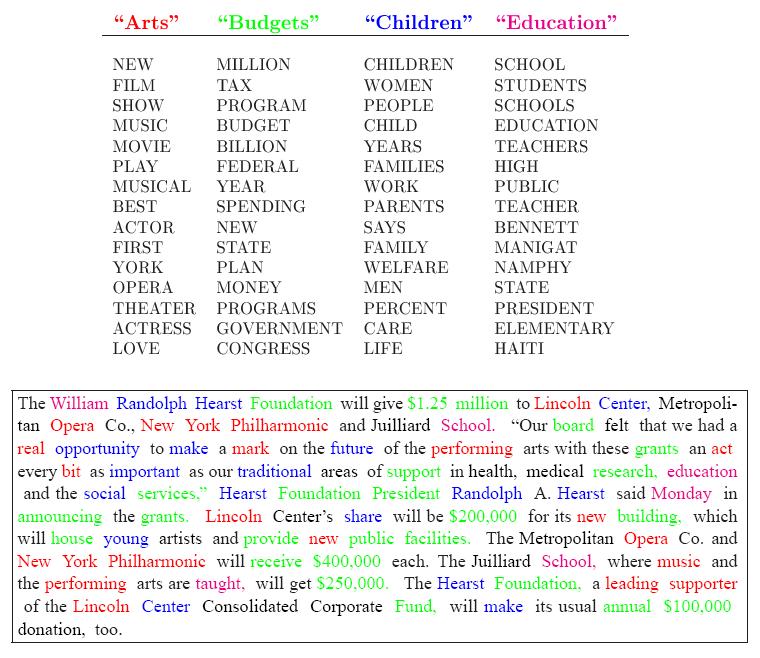
36 The performance of a retrieval system based on this model (PLSI) was found superior to that of both the vector space based similarity (cos) and a non-probabilistic latent semantic indexing (LSI) method. (We skip details here.) From Th. Hofmann, 2000
37 Comparing PLSA and LSA LSA and PLSA perform dimensionality reduction In LSA, by keeping only K singular values In PLSA, by having K aspects Comparison to SVD U Matrix related to P(d z) (doc to aspect) V Matrix related to P(z w) (aspect to term) E Matrix related to P(z) (aspect strength) The main difference is the way the approximation is done PLSA generates a model (aspect model) and maximizes its predictive power Selecting the proper value of K is heuristic in LSA Model selection in statistics can determine optimal K in PLSA
38 Latent Dirichlet Allocation Generative Model Per-document topic proportions Per-word topic assignment Observed word Per-topic word proportions α θ d z w β φ k N d K D
39 Joint Distribution φ i β φ 1:K 49
40 α = 1 50
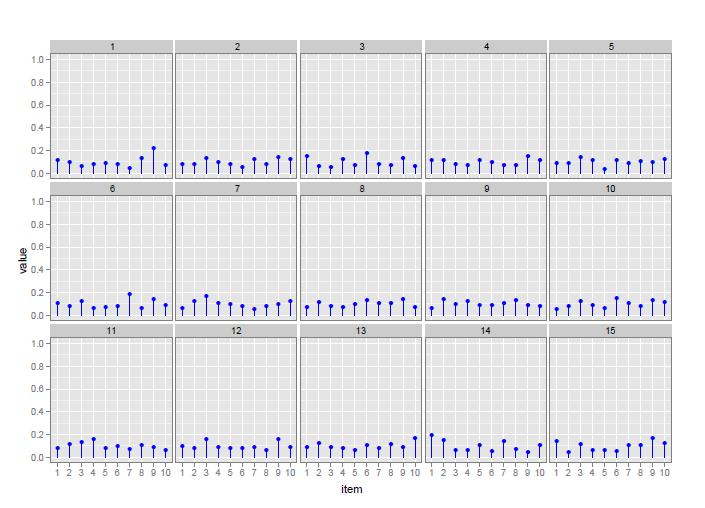
41 α = 10 51

42 α =
43 α = 1 53

44 α =

45 α =
46 LDA vs. PLSA Explicit modeling of sparsity LDA was a rage Lots of tools Often gives similar results 56
Document Similarity in Information Retrieval
 Document Similarity in Information Retrieval Mausam (Based on slides of W. Arms, Dan Jurafsky, Thomas Hofmann, Ata Kaban, Chris Manning, Melanie Martin) Sec. 1.1 Unstructured data in 1620 Which plays of
Document Similarity in Information Retrieval Mausam (Based on slides of W. Arms, Dan Jurafsky, Thomas Hofmann, Ata Kaban, Chris Manning, Melanie Martin) Sec. 1.1 Unstructured data in 1620 Which plays of
Information Retrieval
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Christopher Manning and Prabhakar Raghavan Lecture 6: Scoring, Term Weighting and the Vector Space Model This lecture;
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Christopher Manning and Prabhakar Raghavan Lecture 6: Scoring, Term Weighting and the Vector Space Model This lecture;
Term Weighting and the Vector Space Model. borrowing from: Pandu Nayak and Prabhakar Raghavan
 Term Weighting and the Vector Space Model borrowing from: Pandu Nayak and Prabhakar Raghavan IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes
Term Weighting and the Vector Space Model borrowing from: Pandu Nayak and Prabhakar Raghavan IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes
Information Retrieval
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 6: Scoring, Term Weighting and the Vector Space Model This lecture; IIR Sections
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 6: Scoring, Term Weighting and the Vector Space Model This lecture; IIR Sections
Information Retrieval Using Boolean Model SEEM5680
 Information Retrieval Using Boolean Model SEEM5680 1 Unstructured (text) vs. structured (database) data in 1996 2 2 Unstructured (text) vs. structured (database) data in 2009 3 3 The problem of IR Goal
Information Retrieval Using Boolean Model SEEM5680 1 Unstructured (text) vs. structured (database) data in 1996 2 2 Unstructured (text) vs. structured (database) data in 2009 3 3 The problem of IR Goal
Term Weighting and Vector Space Model. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Term Weighting and Vector Space Model Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Term Weighting and Vector Space Model Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model
 Chapter 6 Scoring term weighting and the vector space model") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Scoring, Term Weighting and the Vector Space
 Scoring, Term Weighting and the Vector Space Model Francesco Ricci Most of these slides comes from the course: Information Retrieval and Web Search, Christopher Manning and Prabhakar Raghavan Content [J
Scoring, Term Weighting and the Vector Space Model Francesco Ricci Most of these slides comes from the course: Information Retrieval and Web Search, Christopher Manning and Prabhakar Raghavan Content [J
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
boolean queries Inverted index query processing Query optimization boolean model January 15, / 35
 boolean model January 15, 2017 1 / 35 Outline 1 boolean queries 2 3 4 2 / 35 taxonomy of IR models Set theoretic fuzzy extended boolean set-based IR models Boolean vector probalistic algebraic generalized
boolean model January 15, 2017 1 / 35 Outline 1 boolean queries 2 3 4 2 / 35 taxonomy of IR models Set theoretic fuzzy extended boolean set-based IR models Boolean vector probalistic algebraic generalized
Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson
 Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics
Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval Lecture 6-2: The Vector Space Model Outline The vector space model 2 Binary incidence matrix Anthony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth...
Introduc*on to Informa(on Retrieval Lecture 6-2: The Vector Space Model Outline The vector space model 2 Binary incidence matrix Anthony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth...
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval Lecture 6-2: The Vector Space Model Binary incidence matrix Anthony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth... ANTHONY BRUTUS CAESAR CALPURNIA
Introduc*on to Informa(on Retrieval Lecture 6-2: The Vector Space Model Binary incidence matrix Anthony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth... ANTHONY BRUTUS CAESAR CALPURNIA
Dealing with Text Databases
 Dealing with Text Databases Unstructured data Boolean queries Sparse matrix representation Inverted index Counts vs. frequencies Term frequency tf x idf term weights Documents as vectors Cosine similarity
Dealing with Text Databases Unstructured data Boolean queries Sparse matrix representation Inverted index Counts vs. frequencies Term frequency tf x idf term weights Documents as vectors Cosine similarity
TDDD43. Information Retrieval. Fang Wei-Kleiner. ADIT/IDA Linköping University. Fang Wei-Kleiner ADIT/IDA LiU TDDD43 Information Retrieval 1
 TDDD43 Information Retrieval Fang Wei-Kleiner ADIT/IDA Linköping University Fang Wei-Kleiner ADIT/IDA LiU TDDD43 Information Retrieval 1 Outline 1. Introduction 2. Inverted index 3. Ranked Retrieval tf-idf
TDDD43 Information Retrieval Fang Wei-Kleiner ADIT/IDA Linköping University Fang Wei-Kleiner ADIT/IDA LiU TDDD43 Information Retrieval 1 Outline 1. Introduction 2. Inverted index 3. Ranked Retrieval tf-idf
Ranked IR. Lecture Objectives. Text Technologies for Data Science INFR Learn about Ranked IR. Implement: 10/10/2018. Instructor: Walid Magdy
 Text Technologies for Data Science INFR11145 Ranked IR Instructor: Walid Magdy 10-Oct-2018 Lecture Objectives Learn about Ranked IR TFIDF VSM SMART notation Implement: TFIDF 2 1 Boolean Retrieval Thus
Text Technologies for Data Science INFR11145 Ranked IR Instructor: Walid Magdy 10-Oct-2018 Lecture Objectives Learn about Ranked IR TFIDF VSM SMART notation Implement: TFIDF 2 1 Boolean Retrieval Thus
Ranked IR. Lecture Objectives. Text Technologies for Data Science INFR Learn about Ranked IR. Implement: 10/10/2017. Instructor: Walid Magdy
 Text Technologies for Data Science INFR11145 Ranked IR Instructor: Walid Magdy 10-Oct-017 Lecture Objectives Learn about Ranked IR TFIDF VSM SMART notation Implement: TFIDF 1 Boolean Retrieval Thus far,
Text Technologies for Data Science INFR11145 Ranked IR Instructor: Walid Magdy 10-Oct-017 Lecture Objectives Learn about Ranked IR TFIDF VSM SMART notation Implement: TFIDF 1 Boolean Retrieval Thus far,
Query. Information Retrieval (IR) Term-document incidence. Incidence vectors. Bigger corpora. Answers to query
 Term-document incidence. Incidence vectors. Bigger corpora. Answers to query") Information Retrieval (IR) Based on slides by Prabhaar Raghavan, Hinrich Schütze, Ray Larson Query Which plays of Shaespeare contain the words Brutus AND Caesar but NOT Calpurnia? Could grep all of Shaespeare
Information Retrieval (IR) Based on slides by Prabhaar Raghavan, Hinrich Schütze, Ray Larson Query Which plays of Shaespeare contain the words Brutus AND Caesar but NOT Calpurnia? Could grep all of Shaespeare
Boolean and Vector Space Retrieval Models CS 290N Some of slides from R. Mooney (UTexas), J. Ghosh (UT ECE), D. Lee (USTHK).
, J. Ghosh (UT ECE), D. Lee (USTHK).") Boolean and Vector Space Retrieval Models 2013 CS 290N Some of slides from R. Mooney (UTexas), J. Ghosh (UT ECE), D. Lee (USTHK). 1 Table of Content Boolean model Statistical vector space model Retrieval
Boolean and Vector Space Retrieval Models 2013 CS 290N Some of slides from R. Mooney (UTexas), J. Ghosh (UT ECE), D. Lee (USTHK). 1 Table of Content Boolean model Statistical vector space model Retrieval
Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson
 Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics Querying
Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics Querying
Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson
 Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Collection Frequency, cf Define: The total
Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Collection Frequency, cf Define: The total
CS 572: Information Retrieval
 CS 572: Information Retrieval Lecture 11: Topic Models Acknowledgments: Some slides were adapted from Chris Manning, and from Thomas Hoffman 1 Plan for next few weeks Project 1: done (submit by Friday).
CS 572: Information Retrieval Lecture 11: Topic Models Acknowledgments: Some slides were adapted from Chris Manning, and from Thomas Hoffman 1 Plan for next few weeks Project 1: done (submit by Friday).
PV211: Introduction to Information Retrieval
 PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 6: Scoring, term weighting, the vector space model Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics,
PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 6: Scoring, term weighting, the vector space model Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics,
CS276A Text Information Retrieval, Mining, and Exploitation. Lecture 4 15 Oct 2002
 CS276A Text Information Retrieval, Mining, and Exploitation Lecture 4 15 Oct 2002 Recap of last time Index size Index construction techniques Dynamic indices Real world considerations 2 Back of the envelope
CS276A Text Information Retrieval, Mining, and Exploitation Lecture 4 15 Oct 2002 Recap of last time Index size Index construction techniques Dynamic indices Real world considerations 2 Back of the envelope
Query CS347. Term-document incidence. Incidence vectors. Which plays of Shakespeare contain the words Brutus ANDCaesar but NOT Calpurnia?
 Query CS347 Which plays of Shakespeare contain the words Brutus ANDCaesar but NOT Calpurnia? Lecture 1 April 4, 2001 Prabhakar Raghavan Term-document incidence Incidence vectors Antony and Cleopatra Julius
Query CS347 Which plays of Shakespeare contain the words Brutus ANDCaesar but NOT Calpurnia? Lecture 1 April 4, 2001 Prabhakar Raghavan Term-document incidence Incidence vectors Antony and Cleopatra Julius
CS 572: Information Retrieval
 CS 572: Information Retrieval Lecture 5: Term Weighting and Ranking Acknowledgment: Some slides in this lecture are adapted from Chris Manning (Stanford) and Doug Oard (Maryland) Lecture Plan Skip for
CS 572: Information Retrieval Lecture 5: Term Weighting and Ranking Acknowledgment: Some slides in this lecture are adapted from Chris Manning (Stanford) and Doug Oard (Maryland) Lecture Plan Skip for
The Boolean Model ~1955
 The Boolean Model ~1955 The boolean model is the first, most criticized, and (until a few years ago) commercially more widespread, model of IR. Its functionalities can often be found in the Advanced Search
The Boolean Model ~1955 The boolean model is the first, most criticized, and (until a few years ago) commercially more widespread, model of IR. Its functionalities can often be found in the Advanced Search
Ricerca dell Informazione nel Web. Aris Anagnostopoulos
 Ricerca dell Informazione nel Web Aris Anagnostopoulos Docenti Dr. Aris Anagnostopoulos http://aris.me Stanza B118 Ricevimento: Inviate email a: aris@cs.brown.edu Laboratorio: Dr.ssa Ilaria Bordino (Yahoo!
Ricerca dell Informazione nel Web Aris Anagnostopoulos Docenti Dr. Aris Anagnostopoulos http://aris.me Stanza B118 Ricevimento: Inviate email a: aris@cs.brown.edu Laboratorio: Dr.ssa Ilaria Bordino (Yahoo!
Lecture 4 Ranking Search Results. Many thanks to Prabhakar Raghavan for sharing most content from the following slides
 Lecture 4 Ranking Search Results Many thanks to Prabhakar Raghavan for sharing most content from the following slides Recap of the previous lecture Index construction Doing sorting with limited main memory
Lecture 4 Ranking Search Results Many thanks to Prabhakar Raghavan for sharing most content from the following slides Recap of the previous lecture Index construction Doing sorting with limited main memory
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
PV211: Introduction to Information Retrieval
 PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 11: Probabilistic Information Retrieval Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk
PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 11: Probabilistic Information Retrieval Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk
MATRIX DECOMPOSITION AND LATENT SEMANTIC INDEXING (LSI) Introduction to Information Retrieval CS 150 Donald J. Patterson
 Introduction to Information Retrieval CS 150 Donald J. Patterson") MATRIX DECOMPOSITION AND LATENT SEMANTIC INDEXING (LSI) Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Latent
MATRIX DECOMPOSITION AND LATENT SEMANTIC INDEXING (LSI) Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Latent
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 5: Scoring, Term Weighting, The Vector Space Model II Paul Ginsparg Cornell
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 5: Scoring, Term Weighting, The Vector Space Model II Paul Ginsparg Cornell
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Natural Language Processing. Topics in Information Retrieval. Updated 5/10
 Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Matrix Decomposition and Latent Semantic Indexing (LSI) Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson
 Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson") Matrix Decomposition and Latent Semantic Indexing (LSI) Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Latent Semantic Indexing Outline Introduction Linear Algebra Refresher
Matrix Decomposition and Latent Semantic Indexing (LSI) Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Latent Semantic Indexing Outline Introduction Linear Algebra Refresher
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PROBABILISTIC LATENT SEMANTIC ANALYSIS
 PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 2: The term vocabulary and postings lists Hinrich Schütze Center for Information and Language Processing, University of Munich
Introduction to Information Retrieval http://informationretrieval.org IIR 2: The term vocabulary and postings lists Hinrich Schütze Center for Information and Language Processing, University of Munich
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-09 1/60 Boolean
Introduction to Information Retrieval http://informationretrieval.org IIR 1: Boolean Retrieval Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-09 1/60 Boolean
Boolean and Vector Space Retrieval Models
 Boolean and Vector Space Retrieval Models Many slides in this section are adapted from Prof. Joydeep Ghosh (UT ECE) who in turn adapted them from Prof. Dik Lee (Univ. of Science and Tech, Hong Kong) 1
Boolean and Vector Space Retrieval Models Many slides in this section are adapted from Prof. Joydeep Ghosh (UT ECE) who in turn adapted them from Prof. Dik Lee (Univ. of Science and Tech, Hong Kong) 1
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Prof. Chris Clifton 6 September 2017 Material adapted from course created by Dr. Luo Si, now leading Alibaba research group 1 Vector Space Model Disadvantages:
CS47300: Web Information Search and Management Prof. Chris Clifton 6 September 2017 Material adapted from course created by Dr. Luo Si, now leading Alibaba research group 1 Vector Space Model Disadvantages:
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Probabilistic Latent Semantic Analysis Denis Helic KTI, TU Graz Jan 16, 2014 Denis Helic (KTI, TU Graz) KDDM1 Jan 16, 2014 1 / 47 Big picture: KDDM
Knowledge Discovery and Data Mining 1 (VO) (707.003) Probabilistic Latent Semantic Analysis Denis Helic KTI, TU Graz Jan 16, 2014 Denis Helic (KTI, TU Graz) KDDM1 Jan 16, 2014 1 / 47 Big picture: KDDM
Embeddings Learned By Matrix Factorization
 Embeddings Learned By Matrix Factorization Benjamin Roth; Folien von Hinrich Schütze Center for Information and Language Processing, LMU Munich Overview WordSpace limitations LinAlgebra review Input matrix
Embeddings Learned By Matrix Factorization Benjamin Roth; Folien von Hinrich Schütze Center for Information and Language Processing, LMU Munich Overview WordSpace limitations LinAlgebra review Input matrix
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Variable Latent Semantic Indexing
 Variable Latent Semantic Indexing Prabhakar Raghavan Yahoo! Research Sunnyvale, CA November 2005 Joint work with A. Dasgupta, R. Kumar, A. Tomkins. Yahoo! Research. Outline 1 Introduction 2 Background
Variable Latent Semantic Indexing Prabhakar Raghavan Yahoo! Research Sunnyvale, CA November 2005 Joint work with A. Dasgupta, R. Kumar, A. Tomkins. Yahoo! Research. Outline 1 Introduction 2 Background
Notes on Latent Semantic Analysis
 Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Yuriy Sverchkov Intelligent Systems Program University of Pittsburgh October 6, 2011 Outline Latent Semantic Analysis (LSA) A quick review Probabilistic LSA (plsa)
Probabilistic Latent Semantic Analysis Yuriy Sverchkov Intelligent Systems Program University of Pittsburgh October 6, 2011 Outline Latent Semantic Analysis (LSA) A quick review Probabilistic LSA (plsa)
Geoffrey Zweig May 7, 2009
 Geoffrey Zweig May 7, 2009 Taxonomy of LID Techniques LID Acoustic Scores Derived LM Vector space model GMM GMM Tokenization Parallel Phone Rec + LM Vectors of phone LM stats [Carrasquillo et. al. 02],
Geoffrey Zweig May 7, 2009 Taxonomy of LID Techniques LID Acoustic Scores Derived LM Vector space model GMM GMM Tokenization Parallel Phone Rec + LM Vectors of phone LM stats [Carrasquillo et. al. 02],
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Manning & Schuetze, FSNLP, (c)
") page 554 554 15 Topics in Information Retrieval co-occurrence Latent Semantic Indexing Term 1 Term 2 Term 3 Term 4 Query user interface Document 1 user interface HCI interaction Document 2 HCI interaction
page 554 554 15 Topics in Information Retrieval co-occurrence Latent Semantic Indexing Term 1 Term 2 Term 3 Term 4 Query user interface Document 1 user interface HCI interaction Document 2 HCI interaction
Complex Data Mining & Workflow Mining. Introduzione al text mining
 Complex Data Mining & Workflow Mining Introduzione al text mining Outline Introduzione e concetti di base Motivazioni, applicazioni Concetti di base nell analisi dei dati complessi Text/Web Mining Concetti
Complex Data Mining & Workflow Mining Introduzione al text mining Outline Introduzione e concetti di base Motivazioni, applicazioni Concetti di base nell analisi dei dati complessi Text/Web Mining Concetti
Manning & Schuetze, FSNLP (c) 1999,2000
 1999,2000") 558 15 Topics in Information Retrieval (15.10) y 4 3 2 1 0 0 1 2 3 4 5 6 7 8 Figure 15.7 An example of linear regression. The line y = 0.25x + 1 is the best least-squares fit for the four points (1,1),
558 15 Topics in Information Retrieval (15.10) y 4 3 2 1 0 0 1 2 3 4 5 6 7 8 Figure 15.7 An example of linear regression. The line y = 0.25x + 1 is the best least-squares fit for the four points (1,1),
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
RETRIEVAL MODELS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Retrieval by Content. Part 2: Text Retrieval Term Frequency and Inverse Document Frequency. Srihari: CSE 626 1
 Retrieval by Content Part 2: Text Retrieval Term Frequency and Inverse Document Frequency Srihari: CSE 626 1 Text Retrieval Retrieval of text-based information is referred to as Information Retrieval (IR)
Retrieval by Content Part 2: Text Retrieval Term Frequency and Inverse Document Frequency Srihari: CSE 626 1 Text Retrieval Retrieval of text-based information is referred to as Information Retrieval (IR)
Information retrieval LSI, plsi and LDA. Jian-Yun Nie
 Information retrieval LSI, plsi and LDA Jian-Yun Nie Basics: Eigenvector, Eigenvalue Ref: http://en.wikipedia.org/wiki/eigenvector For a square matrix A: Ax = λx where x is a vector (eigenvector), and
Information retrieval LSI, plsi and LDA Jian-Yun Nie Basics: Eigenvector, Eigenvalue Ref: http://en.wikipedia.org/wiki/eigenvector For a square matrix A: Ax = λx where x is a vector (eigenvector), and
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 9: Lexical semantics (Feb 19, 2019) David Bamman, UC Berkeley Lexical semantics You shall know a word by the company it keeps [Firth 1957] Harris 1954
Applied Natural Language Processing Info 256 Lecture 9: Lexical semantics (Feb 19, 2019) David Bamman, UC Berkeley Lexical semantics You shall know a word by the company it keeps [Firth 1957] Harris 1954
Content-Addressable Memory Associative Memory Lernmatrix Association Heteroassociation Learning Retrieval Reliability of the answer
 Associative Memory Content-Addressable Memory Associative Memory Lernmatrix Association Heteroassociation Learning Retrieval Reliability of the answer Storage Analysis Sparse Coding Implementation on a
Associative Memory Content-Addressable Memory Associative Memory Lernmatrix Association Heteroassociation Learning Retrieval Reliability of the answer Storage Analysis Sparse Coding Implementation on a
1 Boolean retrieval. Online edition (c)2009 Cambridge UP
2009 Cambridge UP") DRAFT! April 1, 2009 Cambridge University Press. Feedback welcome. 1 1 Boolean retrieval INFORMATION RETRIEVAL The meaning of the term information retrieval can be very broad. Just getting a credit card
DRAFT! April 1, 2009 Cambridge University Press. Feedback welcome. 1 1 Boolean retrieval INFORMATION RETRIEVAL The meaning of the term information retrieval can be very broad. Just getting a credit card
Latent semantic indexing
 Latent semantic indexing Relationship between concepts and words is many-to-many. Solve problems of synonymy and ambiguity by representing documents as vectors of ideas or concepts, not terms. For retrieval,
Latent semantic indexing Relationship between concepts and words is many-to-many. Solve problems of synonymy and ambiguity by representing documents as vectors of ideas or concepts, not terms. For retrieval,
Information Retrieval
 Introduction to Information Retrieval Lecture 11: Probabilistic Information Retrieval 1 Outline Basic Probability Theory Probability Ranking Principle Extensions 2 Basic Probability Theory For events A
Introduction to Information Retrieval Lecture 11: Probabilistic Information Retrieval 1 Outline Basic Probability Theory Probability Ranking Principle Extensions 2 Basic Probability Theory For events A
Document and Topic Models: plsa and LDA
 Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Document and Topic Models: plsa and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline Topic Models plsa LSA Model Fitting via EM phits: link analysis
Chap 2: Classical models for information retrieval
 Chap 2: Classical models for information retrieval Jean-Pierre Chevallet & Philippe Mulhem LIG-MRIM Sept 2016 Jean-Pierre Chevallet & Philippe Mulhem Models of IR 1 / 81 Outline Basic IR Models 1 Basic
Chap 2: Classical models for information retrieval Jean-Pierre Chevallet & Philippe Mulhem LIG-MRIM Sept 2016 Jean-Pierre Chevallet & Philippe Mulhem Models of IR 1 / 81 Outline Basic IR Models 1 Basic
Information Retrieval Basic IR models. Luca Bondi
 Basic IR models Luca Bondi Previously on IR 2 d j q i IRM SC q i, d j IRM D, Q, R q i, d j d j = w 1,j, w 2,j,, w M,j T w i,j = 0 if term t i does not appear in document d j w i,j and w i:1,j assumed to
Basic IR models Luca Bondi Previously on IR 2 d j q i IRM SC q i, d j IRM D, Q, R q i, d j d j = w 1,j, w 2,j,, w M,j T w i,j = 0 if term t i does not appear in document d j w i,j and w i:1,j assumed to
Generic Text Summarization
 June 27, 2012 Outline Introduction 1 Introduction Notation and Terminology 2 3 4 5 6 Text Summarization Introduction Notation and Terminology Two Types of Text Summarization Query-Relevant Summarization:
June 27, 2012 Outline Introduction 1 Introduction Notation and Terminology 2 3 4 5 6 Text Summarization Introduction Notation and Terminology Two Types of Text Summarization Query-Relevant Summarization:
vector space retrieval many slides courtesy James Amherst
 vector space retrieval many slides courtesy James Allan@umass Amherst 1 what is a retrieval model? Model is an idealization or abstraction of an actual process Mathematical models are used to study the
vector space retrieval many slides courtesy James Allan@umass Amherst 1 what is a retrieval model? Model is an idealization or abstraction of an actual process Mathematical models are used to study the
Matrix decompositions and latent semantic indexing
 18 Matrix decompositions and latent semantic indexing On page 113, we introduced the notion of a term-document matrix: an M N matrix C, each of whose rows represents a term and each of whose columns represents
18 Matrix decompositions and latent semantic indexing On page 113, we introduced the notion of a term-document matrix: an M N matrix C, each of whose rows represents a term and each of whose columns represents
Latent Semantic Models. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Latent Semantic Models Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Vector Space Model: Pros Automatic selection of index terms Partial matching of queries
Latent Semantic Models Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Vector Space Model: Pros Automatic selection of index terms Partial matching of queries
Machine Learning for natural language processing
 Machine Learning for natural language processing Classification: k nearest neighbors Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 28 Introduction Classification = supervised method
Machine Learning for natural language processing Classification: k nearest neighbors Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 28 Introduction Classification = supervised method
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
Chapter 10: Information Retrieval. See corresponding chapter in Manning&Schütze
 Chapter 10: Information Retrieval See corresponding chapter in Manning&Schütze Evaluation Metrics in IR 2 Goal In IR there is a much larger variety of possible metrics For different tasks, different metrics
Chapter 10: Information Retrieval See corresponding chapter in Manning&Schütze Evaluation Metrics in IR 2 Goal In IR there is a much larger variety of possible metrics For different tasks, different metrics
Data Mining and Matrices
 Data Mining and Matrices 6 Non-Negative Matrix Factorization Rainer Gemulla, Pauli Miettinen May 23, 23 Non-Negative Datasets Some datasets are intrinsically non-negative: Counters (e.g., no. occurrences
Data Mining and Matrices 6 Non-Negative Matrix Factorization Rainer Gemulla, Pauli Miettinen May 23, 23 Non-Negative Datasets Some datasets are intrinsically non-negative: Counters (e.g., no. occurrences
Linear Algebra Background
 CS76A Text Retrieval and Mining Lecture 5 Recap: Clustering Hierarchical clustering Agglomerative clustering techniques Evaluation Term vs. document space clustering Multi-lingual docs Feature selection
CS76A Text Retrieval and Mining Lecture 5 Recap: Clustering Hierarchical clustering Agglomerative clustering techniques Evaluation Term vs. document space clustering Multi-lingual docs Feature selection
9 Searching the Internet with the SVD
 9 Searching the Internet with the SVD 9.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
9 Searching the Internet with the SVD 9.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
Language Information Processing, Advanced. Topic Models
 Language Information Processing, Advanced Topic Models mcuturi@i.kyoto-u.ac.jp Kyoto University - LIP, Adv. - 2011 1 Today s talk Continue exploring the representation of text as histogram of words. Objective:
Language Information Processing, Advanced Topic Models mcuturi@i.kyoto-u.ac.jp Kyoto University - LIP, Adv. - 2011 1 Today s talk Continue exploring the representation of text as histogram of words. Objective:
topic modeling hanna m. wallach
 university of massachusetts amherst wallach@cs.umass.edu Ramona Blei-Gantz Helen Moss (Dave's Grandma) The Next 30 Minutes Motivations and a brief history: Latent semantic analysis Probabilistic latent
university of massachusetts amherst wallach@cs.umass.edu Ramona Blei-Gantz Helen Moss (Dave's Grandma) The Next 30 Minutes Motivations and a brief history: Latent semantic analysis Probabilistic latent
DISTRIBUTIONAL SEMANTICS
 COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017
 COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
CS 3750 Advanced Machine Learning. Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya
 Cem Akkaya") CS 375 Advanced Machine Learning Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya Outline SVD and LSI Kleinberg s Algorithm PageRank Algorithm Vector Space Model Vector space model represents
CS 375 Advanced Machine Learning Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya Outline SVD and LSI Kleinberg s Algorithm PageRank Algorithm Vector Space Model Vector space model represents
Lecture 5: Web Searching using the SVD
 Lecture 5: Web Searching using the SVD Information Retrieval Over the last 2 years the number of internet users has grown exponentially with time; see Figure. Trying to extract information from this exponentially
Lecture 5: Web Searching using the SVD Information Retrieval Over the last 2 years the number of internet users has grown exponentially with time; see Figure. Trying to extract information from this exponentially
Fall CS646: Information Retrieval. Lecture 6 Boolean Search and Vector Space Model. Jiepu Jiang University of Massachusetts Amherst 2016/09/26
 Fall 2016 CS646: Information Retrieval Lecture 6 Boolean Search and Vector Space Model Jiepu Jiang University of Massachusetts Amherst 2016/09/26 Outline Today Boolean Retrieval Vector Space Model Latent
Fall 2016 CS646: Information Retrieval Lecture 6 Boolean Search and Vector Space Model Jiepu Jiang University of Massachusetts Amherst 2016/09/26 Outline Today Boolean Retrieval Vector Space Model Latent
Vector Space Model. Yufei Tao KAIST. March 5, Y. Tao, March 5, 2013 Vector Space Model
 Vector Space Model Yufei Tao KAIST March 5, 2013 In this lecture, we will study a problem that is (very) fundamental in information retrieval, and must be tackled by all search engines. Let S be a set
Vector Space Model Yufei Tao KAIST March 5, 2013 In this lecture, we will study a problem that is (very) fundamental in information retrieval, and must be tackled by all search engines. Let S be a set
13 Searching the Web with the SVD
 13 Searching the Web with the SVD 13.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
13 Searching the Web with the SVD 13.1 Information retrieval Over the last 20 years the number of internet users has grown exponentially with time; see Figure 1. Trying to extract information from this
Ranked Retrieval (2)
") Text Technologies for Data Science INFR11145 Ranked Retrieval (2) Instructor: Walid Magdy 31-Oct-2017 Lecture Objectives Learn about Probabilistic models BM25 Learn about LM for IR 2 1 Recall: VSM & TFIDF
Text Technologies for Data Science INFR11145 Ranked Retrieval (2) Instructor: Walid Magdy 31-Oct-2017 Lecture Objectives Learn about Probabilistic models BM25 Learn about LM for IR 2 1 Recall: VSM & TFIDF
INF 141 IR METRICS LATENT SEMANTIC ANALYSIS AND INDEXING. Crista Lopes
 INF 141 IR METRICS LATENT SEMANTIC ANALYSIS AND INDEXING Crista Lopes Outline Precision and Recall The problem with indexing so far Intuition for solving it Overview of the solution The Math How to measure
INF 141 IR METRICS LATENT SEMANTIC ANALYSIS AND INDEXING Crista Lopes Outline Precision and Recall The problem with indexing so far Intuition for solving it Overview of the solution The Math How to measure
Modeling Environment
 Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Topic Model Modeling Environment What does it mean to understand/ your environment? Ability to predict Two approaches to ing environment of words and text Latent Semantic Analysis (LSA) Topic Model LSA
Outline for today. Information Retrieval. Cosine similarity between query and document. tf-idf weighting
 Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Information Retrieval. Lecture 6
 Information Retrieval Lecture 6 Recap of the last lecture Parametric and field searches Zones in documents Scoring documents: zone weighting Index support for scoring tf idf and vector spaces This lecture
Information Retrieval Lecture 6 Recap of the last lecture Parametric and field searches Zones in documents Scoring documents: zone weighting Index support for scoring tf idf and vector spaces This lecture
1 Information retrieval fundamentals
 CS 630 Lecture 1: 01/26/2006 Lecturer: Lillian Lee Scribes: Asif-ul Haque, Benyah Shaparenko This lecture focuses on the following topics Information retrieval fundamentals Vector Space Model (VSM) Deriving
CS 630 Lecture 1: 01/26/2006 Lecturer: Lillian Lee Scribes: Asif-ul Haque, Benyah Shaparenko This lecture focuses on the following topics Information retrieval fundamentals Vector Space Model (VSM) Deriving
Lecture 9: Probabilistic IR The Binary Independence Model and Okapi BM25
 Lecture 9: Probabilistic IR The Binary Independence Model and Okapi BM25 Trevor Cohn (Slide credits: William Webber) COMP90042, 2015, Semester 1 What we ll learn in this lecture Probabilistic models for
Lecture 9: Probabilistic IR The Binary Independence Model and Okapi BM25 Trevor Cohn (Slide credits: William Webber) COMP90042, 2015, Semester 1 What we ll learn in this lecture Probabilistic models for
Information Retrieval and Web Search
 Information Retrieval and Web Search IR models: Vector Space Model IR Models Set Theoretic Classic Models Fuzzy Extended Boolean U s e r T a s k Retrieval: Adhoc Filtering Brosing boolean vector probabilistic
Information Retrieval and Web Search IR models: Vector Space Model IR Models Set Theoretic Classic Models Fuzzy Extended Boolean U s e r T a s k Retrieval: Adhoc Filtering Brosing boolean vector probabilistic
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy: