Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
|
|
|
- Jeffery Francis
- 5 years ago
- Views:
Transcription

1 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1
2 2 Factor or Component Analysis We study phenomena that can not be directly observed ego, personality, intelligence in psychology Underlying factors that govern the observed data We want to identify and operate with underlying latent factors rather than the observed data E.g. topics in news articles Transcription factors in genomics We want to discover and exploit hidden relationships beautiful car and gorgeous automobile are closely related So are driver and automobile But does your search engine know this? Reduces noise and error in results
3 3 Factor or Component Analysis, cond. We have too many observations and dimensions To reason about or obtain insights from To visualize Too much noise in the data Need to reduce them to a smaller set of factors Better representation of data without losing much information Can build more effective data analyses on the reduced-dimensional space: classification, clustering, pattern recognition Combinations of observed variables may be more effective bases for insights, even if physical meaning is obscure
4 4 The goal: Discover a new set of factors/dimensions/axes against which to represent, describe or evaluate the data For more effective reasoning, insights, or better visualization Reduce noise in the data Typically a smaller set of factors: dimension reduction Better representation of data without losing much information Can build more effective data analyses on the reduced-dimensional space: classification, clustering, pattern recognition Factors are combinations of observed variables May be more effective bases for insights, even if physical meaning is obscure Observed data are described in terms of these factors rather than in terms of original variables/dimensions
5 5 Basic Concept Areas of variance in data are where items can be best discriminated and key underlying phenomena observed Areas of greatest signal in the data If two items or dimensions are highly correlated or dependent They are likely to represent highly related phenomena If they tell us about the same underlying variance in the data, combining them to form a single measure is reasonable Parsimony Reduction in Error So we want to combine related variables, and focus on uncorrelated or independent ones, especially those along which the observations have high variance We want a smaller set of variables that explain most of the variance in the original data, in more compact and insightful form
6 6 Basic Concept What if the dependences and correlations are not so strong or direct? And suppose you have 3 variables, or 4, or 5, or 10000? Look for the phenomena underlying the observed covariance/co-dependence in a set of variables Once again, phenomena that are uncorrelated or independent, and especially those along which the data show high variance These phenomena are called factors or principal components or independent components, depending on the methods used Factor analysis: based on variance/covariance/correlation Independent Component Analysis: based on independence

7 An example: 7
8 Original Variable B Principal Component Analysis Most common form of factor analysis The new variables/dimensions Are linear combinations of the original ones Are uncorrelated with one another Orthogonal in original dimension space Capture as much of the original variance in the data as possible Are called Principal Components PC 2 Original Variable A Orthogonal directions of greatest variance in data Projections along PC1 discriminate the data most along any one axis PC 1 8
9 Original Variable B 9 Principal Component Analysis PC 2 PC 1 First principal component is the direction of greatest variability (covariance) in the data Second is the next orthogonal (uncorrelated) direction of greatest variability So first remove all the variability along the first component, and then find the next direction of greatest variability Original Variable A And so on
10 10 Computing the Components Data points are vectors in a multidimensional space Projection of vector x onto an axis (dimension) u is u T x Direction of greatest variability is that in which the average square of the projection is greatest I.e. u such that E((u T x) 2 ) over all x is maximized (we subtract the mean along each dimension, and center the original axis system at the centroid of all data points, for simplicity) This direction of u is the direction of the first Principal Component
11 Computing the Components E(S i (u T x i ) 2 ) = E ((u T X) (u T X) T ) = E (u T XX T u) The matrix C = XX T contains the correlations (similarities) of the original axes based on how the data values project onto them So we are looking for u that maximizes u T Cu, subject to u being unit-length It is maximized when u is the principal eigenvector of the matrix C, in which case u T Cu = u T lu = l if u is unit-length, where l is the principal eigenvalue of the correlation matrix C The eigenvalue denotes the amount of variability captured along that dimension 11
12 12 Why the Eigenvectors? Maximise u T XX T u s.t u T u = 1 Construct Langrangian u T XX T u λu T u Vector of partial derivatives set to zero xx T u λu = (xx T λi) u = 0 As u 0 then u must be an eigenvector of XX T with eigenvalue λ
13 Computing the Components Similarly for the next axis, etc. So, the new axes are the eigenvectors of the matrix of correlations of the original variables, which captures the similarities of the original variables based on how data samples project to them Geometrically: centering followed by rotation Linear transformation 13
14 14 PCs, Variance and Least-Squares The first PC retains the greatest amount of variation in the sample The k th PC retains the kth greatest fraction of the variation in the sample The k th largest eigenvalue of the correlation matrix C is the variance in the sample along the k th PC The least-squares view: PCs are a series of linear least squares fits to a sample, each orthogonal to all previous ones
15 How Many PCs? For n original dimensions, correlation matrix is nxn, and has up to n eigenvectors. So n PCs. Where does dimensionality reduction come from? Can ignore the components of lesser significance Variance (%) PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 You do lose some information, but if the eigenvalues are small, you don t lose much n dimensions in original data calculate n eigenvectors and eigenvalues choose only the first p eigenvectors, based on their eigenvalues final data set has only p dimensions 15
16 16 Application: Latent Semantic Analysis Motivation Lexical matching at term level inaccurate (claimed) Polysemy words with number of meanings term matching returns irrelevant documents impacts precision Synonomy number of words with same meaning term matching misses relevant documents impacts recall LSA assumes that there exists a LATENT structure in word usage obscured by variability in word choice Analogous to signal + additive noise model in signal processing
17 17 The Vector Space Model Represent each document by a high-dimensional vector in the space of words
18 18 The Corpora Matrix Doc 1 Doc 2 Doc 3... Word X = Word Word Word Word
19 Feature Vector Representation 19
20 Problems Looks for literal term matches Terms in queries (esp short ones) don t always capture user s information need well Problems: Synonymy: other words with the same meaning Car and automobile No associations between words are made in the vector space representation. Polysemy: the same word having other meanings Apple (fruit and company) The vector space model is unable to discriminate between different meanings of the same word. What if we could match against concepts, that represent related words, rather than words themselves 20

21 21 Example of Problems -- Relevant docs may not have the query terms but may have many related terms -- Irrelevant docs may have the query terms but may not have any related terms
22 22 Latent Semantic Indexing (LSI) Uses statistically derived conceptual indices instead of individual words for retrieval Assumes that there is some underlying or latent structure in word usage that is obscured by variability in word choice Key idea: instead of representing documents and queries as vectors in a t-dim space of terms Represent them (and terms themselves) as vectors in a lower-dimensional space whose axes are concepts that effectively group together similar words Uses SVD to reduce document representations, The axes are the Principal Components from SVD So what is SVD? (Deerwester et al., 1990)
23 23 Example Suppose we have keywords Car, automobile, driver, elephant We want queries on car to also get docs about drivers and automobiles, but not about elephants What if we could discover that the cars, automobiles and drivers axes are strongly correlated, but elephants is not How? Via correlations observed through documents If docs A & B don t share any words with each other, but both share lots of words with doc C, then A & B will be considered similar E.g A has cars and drivers, B has automobiles and drivers When you scrunch down dimensions, small differences (noise) gets glossed over, and you get desired behavior
24 Term 24 Latent Semantic Indexing Document =... * * X (m x n) T (m x k) w = K k=1 d k l T L (k x k) k k D T (k x n) This is our compressed representation of a document
25 Eigenvalues & Eigenvectors Eigenvectors (for a square m m matrix S) Example (right) eigenvector eigenvalue How many eigenvalues are there at most? only has a non-zero solution if this is a m-th order equation in λ which can have at most m distinct solutions (roots of the characteristic polynomial) can be complex even though S is real. 25
26 26 Eigenvalues & Eigenvectors For symmetric matrices, eigenvectors for distinct eigenvalues are orthogonal Sv { 1, 2} l { 1, 2} v{ 1, 2 and l1 l2 v1 v2 }, All eigenvalues of a real symmetric matrix are real. 0 for complex l, if S li 0 and S T S l All eigenvalues of a positive semidefinite matrix are nonnegative w n T, w Sw 0, then if Sv lv l 0
27 27 Eigen/diagonal Decomposition Let be a square matrix with m linearly independent eigenvectors (a non-defective matrix) Theorem: Exists an eigen decomposition diagonal Unique for distinct eigenvalues (cf. matrix diagonalization theorem) Columns of U are eigenvectors of S Diagonal elements of are eigenvalues of
28 Singular Value Decomposition For an m n matrix A of rank r there exists a factorization (Singular Value Decomposition = SVD) as follows: A USV T m m m n V is n n The columns of U are orthogonal eigenvectors of AA T. The columns of V are orthogonal eigenvectors of A T A. Eigenvalues l 1 l r of AA T are the eigenvalues of A T A. i l i S diag 1... r Singular values. 28
29 29 SVD and PCA The first root is called the prinicipal eigenvalue which has an associated orthonormal (u T u = 1) eigenvector u Subsequent roots are ordered such that λ 1 > λ 2 > > λ M with rank(d) non-zero values. Eigenvectors form an orthonormal basis i.e. u it u j = δ ij The eigenvalue decomposition of XX T = UΣU T where U = [u 1, u 2,, u M ] and Σ = diag[λ 1, λ 2,, λ M ] Similarly the eigenvalue decomposition of X T X = VΣV T The SVD is closely related to the above X=U Σ 1/2 V T The left singular vectors U, right singular vectors V, singular values = square root of eigenvalues.
30 Example term ch2 ch3 ch4 ch5 ch6 ch7 ch8 ch9 controllability observability realization feedback controller observer transfer function polynomial matrices This happens to be a rank-7 matrix -so only 7 dimensions required U (9x7) = S (7x7) = Singular values = Sqrt of Eigen values of AA T V (7x8) = T
31 Low-rank Approximation Solution via SVD A Udiag(,...,,0,..., 0) V k 1 k T set smallest r-k singular values to zero k A k k i 1 i uv i T i column notation: sum of rank 1 matrices 31
32 32 Approximation error How good (bad) is this approximation? It s the best possible, measured by the Frobenius norm of the error: X rank( X) k : min A X F A A k F k 1... m where the i are ordered such that i i+1. Suggests why Frobenius error drops as k increased.
33 Term 33 SVD Low-rank approximation Whereas the term-doc matrix A may have m=50000, n=10 million (and rank close to 50000) We can construct an approximation A 100 with rank 100. Of all rank 100 matrices, it would have the lowest Frobenius error. Document =... * * X (m x n) T (m x k) L (k x k) D T (k x n) w = C. Eckart, G. Young, The approximation of a matrix by another of lower rank. Psychometrika, 1, , K k=1 d k l T k k
34 Following the Example term ch2 ch3 ch4 ch5 ch6 ch7 ch8 ch9 controllability observability realization feedback controller observer transfer function polynomial matrices This happens to be a rank-7 matrix -so only 7 dimensions required U (9x7) = S (7x7) = Singular values = Sqrt of Eigen values of AA T V (7x8) = T
35 PCs can be viewed as Topics In the sense of having to find quantities that are not observable directly Similarly, transcription factors in biology, as unobservable causal bridges between experimental conditions and gene expression 35
36 36 Querying To query for feedback controller, the query vector would be q = [ ]' (' indicates transpose), Let q be the query vector. Then the document-space vector corresponding to q is given by: q'*u2*inv(s2) = Dq Point at the centroid of the query terms poisitions in the new space. For the feedback controller query vector, the result is: Dq = To find the best document match, we compare the Dq vector against all the document vectors in the 2- dimensional V2 space. The document vector that is nearest in direction to Dq is the best match. The cosine values for the eight document vectors and the query vector are: U2 (9x2) = S2 (2x2) = V2 (8x2) = term ch2 ch3 ch4 ch5 ch6 ch7 ch8 ch9 controllability observability realization feedback controller observer transfer function polynomial matrices


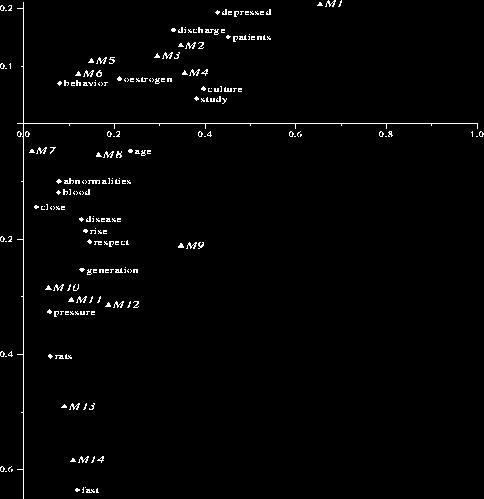
37 Medline data 37



38 K is the number of singular values used Within.40 threshold 38
39 What LSI can do LSI analysis effectively does Dimensionality reduction Noise reduction Exploitation of redundant data Correlation analysis and Query expansion (with related words) Some of the individual effects can be achieved with simpler techniques (e.g. thesaurus construction). LSI does them together. LSI handles synonymy well, not so much polysemy Challenge: SVD is complex to compute (O(n 3 )) Needs to be updated as new documents are found/updated 39
40 40 Summary: Principle Linear projection method to reduce the number of parameters Transfer a set of correlated variables into a new set of uncorrelated variables Map the data into a space of lower dimensionality Form of unsupervised learning Properties It can be viewed as a rotation of the existing axes to new positions in the space defined by original variables New axes are orthogonal and represent the directions with maximum variability Application: In many settings in pattern recognition and retrieval, we have a feature-object matrix. For text, the terms are features and the docs are objects. Could be opinions and users This matrix may be redundant in dimensionality. Can work with low-rank approximation. If entries are missing (e.g., users opinions), can recover if dimensionality is low.
Problems. Looks for literal term matches. Problems:
 Problems Looks for literal term matches erms in queries (esp short ones) don t always capture user s information need well Problems: Synonymy: other words with the same meaning Car and automobile 电脑 vs.
Problems Looks for literal term matches erms in queries (esp short ones) don t always capture user s information need well Problems: Synonymy: other words with the same meaning Car and automobile 电脑 vs.
What is Principal Component Analysis?
 What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Latent Semantic Models. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Latent Semantic Models Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Vector Space Model: Pros Automatic selection of index terms Partial matching of queries
Latent Semantic Models Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Vector Space Model: Pros Automatic selection of index terms Partial matching of queries
Linear Algebra Background
 CS76A Text Retrieval and Mining Lecture 5 Recap: Clustering Hierarchical clustering Agglomerative clustering techniques Evaluation Term vs. document space clustering Multi-lingual docs Feature selection
CS76A Text Retrieval and Mining Lecture 5 Recap: Clustering Hierarchical clustering Agglomerative clustering techniques Evaluation Term vs. document space clustering Multi-lingual docs Feature selection
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Indexing (LSI) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276,
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Principal Component Analysis
 Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
CS 572: Information Retrieval
 CS 572: Information Retrieval Lecture 11: Topic Models Acknowledgments: Some slides were adapted from Chris Manning, and from Thomas Hoffman 1 Plan for next few weeks Project 1: done (submit by Friday).
CS 572: Information Retrieval Lecture 11: Topic Models Acknowledgments: Some slides were adapted from Chris Manning, and from Thomas Hoffman 1 Plan for next few weeks Project 1: done (submit by Friday).
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Notes on Latent Semantic Analysis
 Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
CSE 494/598 Lecture-6: Latent Semantic Indexing. **Content adapted from last year s slides
 CSE 494/598 Lecture-6: Latent Semantic Indexing LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Homework-1 and Quiz-1 Project part-2 released
CSE 494/598 Lecture-6: Latent Semantic Indexing LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Homework-1 and Quiz-1 Project part-2 released
Lecture 19, November 19, 2012
 Machine Learning 0-70/5-78, Fall 0 Latent Space Analysis SVD and Topic Models Eric Xing Lecture 9, November 9, 0 Reading: Tutorial on Topic Model @ ACL Eric Xing @ CMU, 006-0 We are inundated with data
Machine Learning 0-70/5-78, Fall 0 Latent Space Analysis SVD and Topic Models Eric Xing Lecture 9, November 9, 0 Reading: Tutorial on Topic Model @ ACL Eric Xing @ CMU, 006-0 We are inundated with data
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Machine Learning. Data visualization and dimensionality reduction. Eric Xing. Lecture 7, August 13, Eric Xing Eric CMU,
 Eric Xing Eric Xing @ CMU, 2006-2010 1 Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010 Eric Xing Eric Xing @ CMU, 2006-2010 2 Text document retrieval/labelling
Eric Xing Eric Xing @ CMU, 2006-2010 1 Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010 Eric Xing Eric Xing @ CMU, 2006-2010 2 Text document retrieval/labelling
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Manning & Schuetze, FSNLP, (c)
") page 554 554 15 Topics in Information Retrieval co-occurrence Latent Semantic Indexing Term 1 Term 2 Term 3 Term 4 Query user interface Document 1 user interface HCI interaction Document 2 HCI interaction
page 554 554 15 Topics in Information Retrieval co-occurrence Latent Semantic Indexing Term 1 Term 2 Term 3 Term 4 Query user interface Document 1 user interface HCI interaction Document 2 HCI interaction
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Singular Value Decompsition
 Singular Value Decompsition Massoud Malek One of the most useful results from linear algebra, is a matrix decomposition known as the singular value decomposition It has many useful applications in almost
Singular Value Decompsition Massoud Malek One of the most useful results from linear algebra, is a matrix decomposition known as the singular value decomposition It has many useful applications in almost
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Principal Components Analysis (PCA)
") Principal Components Analysis (PCA) Principal Components Analysis (PCA) a technique for finding patterns in data of high dimension Outline:. Eigenvectors and eigenvalues. PCA: a) Getting the data b) Centering
Principal Components Analysis (PCA) Principal Components Analysis (PCA) a technique for finding patterns in data of high dimension Outline:. Eigenvectors and eigenvalues. PCA: a) Getting the data b) Centering
A few applications of the SVD
 A few applications of the SVD Many methods require to approximate the original data (matrix) by a low rank matrix before attempting to solve the original problem Regularization methods require the solution
A few applications of the SVD Many methods require to approximate the original data (matrix) by a low rank matrix before attempting to solve the original problem Regularization methods require the solution
EIGENVALE PROBLEMS AND THE SVD. [5.1 TO 5.3 & 7.4]
![EIGENVALE PROBLEMS AND THE SVD. [5.1 TO 5.3 & 7.4]](/thumbs/95/124092997.jpg "EIGENVALE PROBLEMS AND THE SVD. [5.1 TO 5.3 & 7.4]") EIGENVALE PROBLEMS AND THE SVD. [5.1 TO 5.3 & 7.4] Eigenvalue Problems. Introduction Let A an n n real nonsymmetric matrix. The eigenvalue problem: Au = λu λ C : eigenvalue u C n : eigenvector Example:
EIGENVALE PROBLEMS AND THE SVD. [5.1 TO 5.3 & 7.4] Eigenvalue Problems. Introduction Let A an n n real nonsymmetric matrix. The eigenvalue problem: Au = λu λ C : eigenvalue u C n : eigenvector Example:
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Deriving Principal Component Analysis (PCA)
") -0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
-0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
Dimensionality Reduction
 Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Manning & Schuetze, FSNLP (c) 1999,2000
 1999,2000") 558 15 Topics in Information Retrieval (15.10) y 4 3 2 1 0 0 1 2 3 4 5 6 7 8 Figure 15.7 An example of linear regression. The line y = 0.25x + 1 is the best least-squares fit for the four points (1,1),
558 15 Topics in Information Retrieval (15.10) y 4 3 2 1 0 0 1 2 3 4 5 6 7 8 Figure 15.7 An example of linear regression. The line y = 0.25x + 1 is the best least-squares fit for the four points (1,1),
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Lecture 8. Principal Component Analysis. Luigi Freda. ALCOR Lab DIAG University of Rome La Sapienza. December 13, 2016
 Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Lecture 8 Principal Component Analysis Luigi Freda ALCOR Lab DIAG University of Rome La Sapienza December 13, 2016 Luigi Freda ( La Sapienza University) Lecture 8 December 13, 2016 1 / 31 Outline 1 Eigen
Machine Learning 2nd Edition
 INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
CSE 494/598 Lecture-4: Correlation Analysis. **Content adapted from last year s slides
 CSE 494/598 Lecture-4: Correlation Analysis LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Project-1 Due: February 12 th 2016 Analysis report:
CSE 494/598 Lecture-4: Correlation Analysis LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **Content adapted from last year s slides Announcements Project-1 Due: February 12 th 2016 Analysis report:
CS 3750 Advanced Machine Learning. Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya
 Cem Akkaya") CS 375 Advanced Machine Learning Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya Outline SVD and LSI Kleinberg s Algorithm PageRank Algorithm Vector Space Model Vector space model represents
CS 375 Advanced Machine Learning Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya Outline SVD and LSI Kleinberg s Algorithm PageRank Algorithm Vector Space Model Vector space model represents
Let A an n n real nonsymmetric matrix. The eigenvalue problem: λ 1 = 1 with eigenvector u 1 = ( ) λ 2 = 2 with eigenvector u 2 = ( 1
 λ 2 = 2 with eigenvector u 2 = ( 1") Eigenvalue Problems. Introduction Let A an n n real nonsymmetric matrix. The eigenvalue problem: EIGENVALE PROBLEMS AND THE SVD. [5.1 TO 5.3 & 7.4] Au = λu Example: ( ) 2 0 A = 2 1 λ 1 = 1 with eigenvector
Eigenvalue Problems. Introduction Let A an n n real nonsymmetric matrix. The eigenvalue problem: EIGENVALE PROBLEMS AND THE SVD. [5.1 TO 5.3 & 7.4] Au = λu Example: ( ) 2 0 A = 2 1 λ 1 = 1 with eigenvector
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Machine Learning - MT & 14. PCA and MDS
 Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Multivariate Statistical Analysis
 Multivariate Statistical Analysis Fall 2011 C. L. Williams, Ph.D. Lecture 4 for Applied Multivariate Analysis Outline 1 Eigen values and eigen vectors Characteristic equation Some properties of eigendecompositions
Multivariate Statistical Analysis Fall 2011 C. L. Williams, Ph.D. Lecture 4 for Applied Multivariate Analysis Outline 1 Eigen values and eigen vectors Characteristic equation Some properties of eigendecompositions
Numerical Methods I Singular Value Decomposition
 Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Numerical Methods I Singular Value Decomposition Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 October 9th, 2014 A. Donev (Courant Institute)
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Lecture 24: Principal Component Analysis. Aykut Erdem May 2016 Hacettepe University
 Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
Introduction to Information Retrieval http://informationretrieval.org IIR 18: Latent Semantic Indexing Hinrich Schütze Center for Information and Language Processing, University of Munich 2013-07-10 1/43
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
Linear Methods in Data Mining
 Why Methods? linear methods are well understood, simple and elegant; algorithms based on linear methods are widespread: data mining, computer vision, graphics, pattern recognition; excellent general software
Why Methods? linear methods are well understood, simple and elegant; algorithms based on linear methods are widespread: data mining, computer vision, graphics, pattern recognition; excellent general software
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Machine Learning. B. Unsupervised Learning B.2 Dimensionality Reduction. Lars Schmidt-Thieme, Nicolas Schilling
 Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
PROBABILISTIC LATENT SEMANTIC ANALYSIS
 PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
Machine Learning (Spring 2012) Principal Component Analysis
 Principal Component Analysis") 1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
Matrix decompositions and latent semantic indexing
 18 Matrix decompositions and latent semantic indexing On page 113, we introduced the notion of a term-document matrix: an M N matrix C, each of whose rows represents a term and each of whose columns represents
18 Matrix decompositions and latent semantic indexing On page 113, we introduced the notion of a term-document matrix: an M N matrix C, each of whose rows represents a term and each of whose columns represents
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211 IIR 18: Latent Semantic Indexing Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
Latent Semantic Analysis (Tutorial)
") Latent Semantic Analysis (Tutorial) Alex Thomo Eigenvalues and Eigenvectors Let A be an n n matrix with elements being real numbers. If x is an n-dimensional vector, then the matrix-vector product Ax is
Latent Semantic Analysis (Tutorial) Alex Thomo Eigenvalues and Eigenvectors Let A be an n n matrix with elements being real numbers. If x is an n-dimensional vector, then the matrix-vector product Ax is
Dimensionality Reduction
 Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Latent semantic indexing
 Latent semantic indexing Relationship between concepts and words is many-to-many. Solve problems of synonymy and ambiguity by representing documents as vectors of ideas or concepts, not terms. For retrieval,
Latent semantic indexing Relationship between concepts and words is many-to-many. Solve problems of synonymy and ambiguity by representing documents as vectors of ideas or concepts, not terms. For retrieval,
Singular Value Decomposition
 Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
Chapter 6 Singular Value Decomposition In Chapter 5, we derived a number of algorithms for computing the eigenvalues and eigenvectors of matrices A R n n. Having developed this machinery, we complete our
20 Unsupervised Learning and Principal Components Analysis (PCA)
") 116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Linear Algebra & Geometry why is linear algebra useful in computer vision?
 Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Linear Algebra & Geometry why is linear algebra useful in computer vision? References: -Any book on linear algebra! -[HZ] chapters 2, 4 Some of the slides in this lecture are courtesy to Prof. Octavia
Background Mathematics (2/2) 1. David Barber
 1. David Barber") Background Mathematics (2/2) 1 David Barber University College London Modified by Samson Cheung (sccheung@ieee.org) 1 These slides accompany the book Bayesian Reasoning and Machine Learning. The book and
Background Mathematics (2/2) 1 David Barber University College London Modified by Samson Cheung (sccheung@ieee.org) 1 These slides accompany the book Bayesian Reasoning and Machine Learning. The book and
Data Mining Lecture 4: Covariance, EVD, PCA & SVD
 Data Mining Lecture 4: Covariance, EVD, PCA & SVD Jo Houghton ECS Southampton February 25, 2019 1 / 28 Variance and Covariance - Expectation A random variable takes on different values due to chance The
Data Mining Lecture 4: Covariance, EVD, PCA & SVD Jo Houghton ECS Southampton February 25, 2019 1 / 28 Variance and Covariance - Expectation A random variable takes on different values due to chance The
Face Recognition. Face Recognition. Subspace-Based Face Recognition Algorithms. Application of Face Recognition
 ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
Vector Space Models. wine_spectral.r
 Vector Space Models 137 wine_spectral.r Latent Semantic Analysis Problem with words Even a small vocabulary as in wine example is challenging LSA Reduce number of columns of DTM by principal components
Vector Space Models 137 wine_spectral.r Latent Semantic Analysis Problem with words Even a small vocabulary as in wine example is challenging LSA Reduce number of columns of DTM by principal components
Linear Subspace Models
 Linear Subspace Models Goal: Explore linear models of a data set. Motivation: A central question in vision concerns how we represent a collection of data vectors. The data vectors may be rasterized images,
Linear Subspace Models Goal: Explore linear models of a data set. Motivation: A central question in vision concerns how we represent a collection of data vectors. The data vectors may be rasterized images,
Natural Language Processing. Topics in Information Retrieval. Updated 5/10
 Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
7. Variable extraction and dimensionality reduction
 7. Variable extraction and dimensionality reduction The goal of the variable selection in the preceding chapter was to find least useful variables so that it would be possible to reduce the dimensionality
7. Variable extraction and dimensionality reduction The goal of the variable selection in the preceding chapter was to find least useful variables so that it would be possible to reduce the dimensionality
Intelligent Data Analysis. Mining Textual Data. School of Computer Science University of Birmingham
 Intelligent Data Analysis Mining Textual Data Peter Tiňo School of Computer Science University of Birmingham Representing documents as numerical vectors Use a special set of terms T = {t 1, t 2,..., t
Intelligent Data Analysis Mining Textual Data Peter Tiňo School of Computer Science University of Birmingham Representing documents as numerical vectors Use a special set of terms T = {t 1, t 2,..., t
15 Singular Value Decomposition
 15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Matrices, Vector Spaces, and Information Retrieval
 Matrices, Vector Spaces, and Information Authors: M. W. Berry and Z. Drmac and E. R. Jessup SIAM 1999: Society for Industrial and Applied Mathematics Speaker: Mattia Parigiani 1 Introduction Large volumes
Matrices, Vector Spaces, and Information Authors: M. W. Berry and Z. Drmac and E. R. Jessup SIAM 1999: Society for Industrial and Applied Mathematics Speaker: Mattia Parigiani 1 Introduction Large volumes
1 Linearity and Linear Systems
 Mathematical Tools for Neuroscience (NEU 34) Princeton University, Spring 26 Jonathan Pillow Lecture 7-8 notes: Linear systems & SVD Linearity and Linear Systems Linear system is a kind of mapping f( x)
Mathematical Tools for Neuroscience (NEU 34) Princeton University, Spring 26 Jonathan Pillow Lecture 7-8 notes: Linear systems & SVD Linearity and Linear Systems Linear system is a kind of mapping f( x)
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 2 Often, our data can be represented by an m-by-n matrix. And this matrix can be closely approximated by the product of two matrices that share a small common dimension
Jeffrey D. Ullman Stanford University 2 Often, our data can be represented by an m-by-n matrix. And this matrix can be closely approximated by the product of two matrices that share a small common dimension
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes. October 3, Statistics 202: Data Mining
 Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Combinations of features Given a data matrix X n p with p fairly large, it can
Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Combinations of features Given a data matrix X n p with p fairly large, it can
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Latent Semantic Indexing
 Latent Semantic Indexing 1 Latent Semantic Indexing Term-document matrices are very large, though most cells are zeros But the number of topics that people talk about is small (in some sense) Clothes,
Latent Semantic Indexing 1 Latent Semantic Indexing Term-document matrices are very large, though most cells are zeros But the number of topics that people talk about is small (in some sense) Clothes,
Principal Component Analysis
 B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
Applied Linear Algebra in Geoscience Using MATLAB
 Applied Linear Algebra in Geoscience Using MATLAB Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional Plots Programming in
Applied Linear Algebra in Geoscience Using MATLAB Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional Plots Programming in
CS168: The Modern Algorithmic Toolbox Lecture #10: Tensors, and Low-Rank Tensor Recovery
 CS168: The Modern Algorithmic Toolbox Lecture #10: Tensors, and Low-Rank Tensor Recovery Tim Roughgarden & Gregory Valiant May 3, 2017 Last lecture discussed singular value decomposition (SVD), and we
CS168: The Modern Algorithmic Toolbox Lecture #10: Tensors, and Low-Rank Tensor Recovery Tim Roughgarden & Gregory Valiant May 3, 2017 Last lecture discussed singular value decomposition (SVD), and we
Singular Value Decomposition and Principal Component Analysis (PCA) I
 I") Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Singular Value Decomposition and Principal Component Analysis (PCA) I Prof Ned Wingreen MOL 40/50 Microarray review Data per array: 0000 genes, I (green) i,i (red) i 000 000+ data points! The expression
Fast LSI-based techniques for query expansion in text retrieval systems
 Fast LSI-based techniques for query expansion in text retrieval systems L. Laura U. Nanni F. Sarracco Department of Computer and System Science University of Rome La Sapienza 2nd Workshop on Text-based
Fast LSI-based techniques for query expansion in text retrieval systems L. Laura U. Nanni F. Sarracco Department of Computer and System Science University of Rome La Sapienza 2nd Workshop on Text-based
Announcements (repeat) Principal Components Analysis
 Principal Components Analysis") 4/7/7 Announcements repeat Principal Components Analysis CS 5 Lecture #9 April 4 th, 7 PA4 is due Monday, April 7 th Test # will be Wednesday, April 9 th Test #3 is Monday, May 8 th at 8AM Just hour long
4/7/7 Announcements repeat Principal Components Analysis CS 5 Lecture #9 April 4 th, 7 PA4 is due Monday, April 7 th Test # will be Wednesday, April 9 th Test #3 is Monday, May 8 th at 8AM Just hour long
1 Principal Components Analysis
 Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Singular Value Decomposition. 1 Singular Value Decomposition and the Four Fundamental Subspaces
 Singular Value Decomposition This handout is a review of some basic concepts in linear algebra For a detailed introduction, consult a linear algebra text Linear lgebra and its pplications by Gilbert Strang
Singular Value Decomposition This handout is a review of some basic concepts in linear algebra For a detailed introduction, consult a linear algebra text Linear lgebra and its pplications by Gilbert Strang
CS 340 Lec. 6: Linear Dimensionality Reduction
 CS 340 Lec. 6: Linear Dimensionality Reduction AD January 2011 AD () January 2011 1 / 46 Linear Dimensionality Reduction Introduction & Motivation Brief Review of Linear Algebra Principal Component Analysis
CS 340 Lec. 6: Linear Dimensionality Reduction AD January 2011 AD () January 2011 1 / 46 Linear Dimensionality Reduction Introduction & Motivation Brief Review of Linear Algebra Principal Component Analysis
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
CS168: The Modern Algorithmic Toolbox Lecture #8: How PCA Works
 CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
Neuroscience Introduction
 Neuroscience Introduction The brain As humans, we can identify galaxies light years away, we can study particles smaller than an atom. But we still haven t unlocked the mystery of the three pounds of matter
Neuroscience Introduction The brain As humans, we can identify galaxies light years away, we can study particles smaller than an atom. But we still haven t unlocked the mystery of the three pounds of matter
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 6 1 / 22 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 6 1 / 22 Overview
Dimensionality reduction
 Dimensionality Reduction PCA continued Machine Learning CSE446 Carlos Guestrin University of Washington May 22, 2013 Carlos Guestrin 2005-2013 1 Dimensionality reduction n Input data may have thousands
Dimensionality Reduction PCA continued Machine Learning CSE446 Carlos Guestrin University of Washington May 22, 2013 Carlos Guestrin 2005-2013 1 Dimensionality reduction n Input data may have thousands
Variable Latent Semantic Indexing
 Variable Latent Semantic Indexing Prabhakar Raghavan Yahoo! Research Sunnyvale, CA November 2005 Joint work with A. Dasgupta, R. Kumar, A. Tomkins. Yahoo! Research. Outline 1 Introduction 2 Background
Variable Latent Semantic Indexing Prabhakar Raghavan Yahoo! Research Sunnyvale, CA November 2005 Joint work with A. Dasgupta, R. Kumar, A. Tomkins. Yahoo! Research. Outline 1 Introduction 2 Background
7 Principal Component Analysis
 7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Linear Discriminant Analysis Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki Principal
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Linear Discriminant Analysis Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki Principal
Eigenvalues and diagonalization
 Eigenvalues and diagonalization Patrick Breheny November 15 Patrick Breheny BST 764: Applied Statistical Modeling 1/20 Introduction The next topic in our course, principal components analysis, revolves
Eigenvalues and diagonalization Patrick Breheny November 15 Patrick Breheny BST 764: Applied Statistical Modeling 1/20 Introduction The next topic in our course, principal components analysis, revolves
PRINCIPAL COMPONENTS ANALYSIS
 121 CHAPTER 11 PRINCIPAL COMPONENTS ANALYSIS We now have the tools necessary to discuss one of the most important concepts in mathematical statistics: Principal Components Analysis (PCA). PCA involves
121 CHAPTER 11 PRINCIPAL COMPONENTS ANALYSIS We now have the tools necessary to discuss one of the most important concepts in mathematical statistics: Principal Components Analysis (PCA). PCA involves