Lexical Translation Models 1I
|
|
|
- Annice Crawford
- 5 years ago
- Views:
Transcription

1 Lexical Translation Models 1I Machine Translation Lecture 5 Instructor: Chris Callison-Burch TAs: Mitchell Stern, Justin Chiu Website: mt-class.org/penn
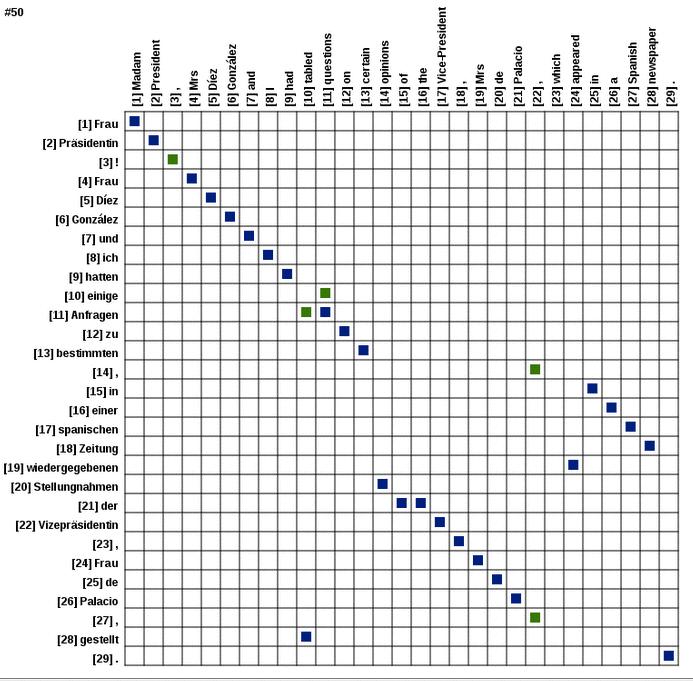
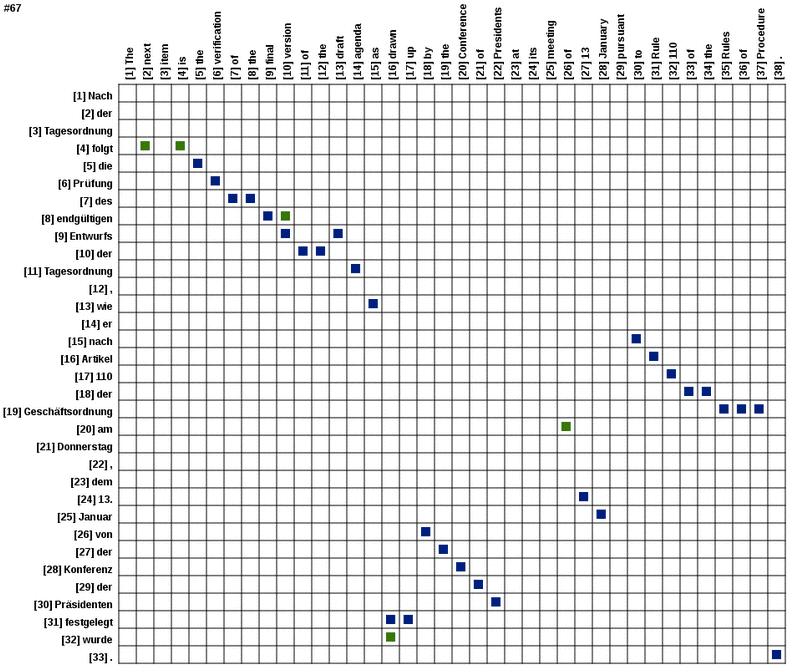
2 Last Time... X p( Translation)= p(, Translation) Alignment = X Alignment Alignment p( p( Alignment) Translation Alignment) {z } {z } X z } { z } { p(e f,m)= a2[0,n] m p(a f,m) p(e i f ai )
3 X p(e f,m)= a2[0,n] m p(a f,m) p(e i f ai ) Alternate ways of defining p(e i f ai,f ai 1 ) the translation probability p(e i f,f 1) ai ai p(e i f ai,e i 1 ) p(e i,e i+1 f ai ) What is the problem here?
4 X p(e f,m)= a2[0,n] m p(a f,m) p(e i f ai ) = X 1 p(e i f ai ) a2[0,n] m 1+n {z } p(a f,m) = X a2[0,n] m 1 Can we do something better here? 1+n p(e i f ai ) = X a2[0,n] m p(a i ) p(e i f ai )
5 0 NULL das Haus ist klein the house is small NULL das Haus ist klein house is small the
6 p(e f,m) = X p(a i ) p(e i f ai ) a2[0,n] m Model 2 = X p(a i i, m, n) p(e i f ai ) a2[0,n] m
7 Model 2 = X p(a i i, m, n) p(e i f ai ) a2[0,n] m Model alignment with an absolute position distribution Probability of translating a foreign word at position to generate the word at position i (with target length mand source length n) p(a i i, m, n) a i EM training of this model is almost the same as with Model 1 (same conditional independencies hold)
8 Model 2 = X p(a i i, m, n) p(e i f ai ) a2[0,n] m natürlich ist das haus klein natürlich natürlich das haus ist klein of course the house is small
9 Model 2 = X p(a i i, m, n) p(e i f ai ) a2[0,n] m Pros Non-uniform alignment model Fast EM training / marginal inference Cons Absolute position is very naive How many parameters to model p(a i i, m, n)
10 }m = 6 Model 2 = X p(a i i, m, n) p(e i f ai ) a2[0,n] m How much do we know when we only know the source & target lengths and the current position? null j 0 =1 j 0 =2 j 0 =3 How many parameters j 0 =4 j 0 =5 do we actually need to model this? i =3 i =2 i =1 i =4 i =5 i =6 }n = 5
11 }m = 6 Model 2 = X p(a i i, m, n) p(e i f ai ) a2[0,n] m pos in target pos in source h(j, i, m, n) = i m j n null j 0 =1 target len source len j 0 =2 j 0 =3 b(j i, m, n) = exp h(j, i, m, n) P j 0 exp h(j 0, i, m, n) j 0 =4 j 0 =5 i =4 i =3 i =2 i =1 i =6 i =5 }n = 5 p(a i i, m, n) = ( p 0 if a i =0 (1 p 0 )b(a i i, m, n) otherwise
12
13

14 Words reorder in groups. Model this!
15 p(e f,m) = X p(a i ) p(e i f ai ) a2[0,n] m Model 2 = X p(a i i, m, n) p(e i f ai ) a2[0,n] m HMM = X p(a i a i 1 ) p(e i f ai ) a2[0,n] m
16 HMM = X p(a i a i 1 ) p(e i f ai ) a2[0,n] m Insight: words translate in groups Condition on previous alignment position Probability of translating a foreign word at position given that the previous position translated was p(a i a i 1 ) EM training of this model using forward-backward algorithm (dynamic programming) a i 1 a i
17 HMM = X p(a i a i 1 ) p(e i f ai ) a2[0,n] m Improvement: model jumps through the source sentence p(a i a i 1 )=j(a i a i 1 ) Relative position model rather than absolute position model
18 HMM = X p(a i a i 1 ) p(e i f ai ) a2[0,n] m Be careful! NULLs must be handled carefully. Here is one option (due to Och): p(a i a i ni )= ( p 0 if a i =0 (1 p 0 )j(a i a i ni ) otherwise n i is the index of the first non-null aligned word in the alignment to the left of i.
19 HMM = X p(a i a i 1 ) p(e i f ai ) a2[0,n] m Other extensions: certain word-types are more likely to be reordered j( f) j( C(f)) Condition the jump probability on the previous word translated j( f,e) j( A(f), B(e)) Condition the jump probability on the previous word translated, and how it was translated
20 Fertility Models The models we have considered so far have been efficient This efficiency has come at a modeling cost: What is to stop the model from translating a word 0, 1, 2, or 100 times? We introduce fertility models to deal with this
21 IBM Model 3
22 Fertility Fertility: the number of English words generated by a foreign word Modeled by categorical distribution Examples: n( f) Unabhaengigkeitserklaerung zum = (zu + dem) Haus
23 Fertility X p(e f,m)= a2[0,n] m p(a f,m) p(e i f ai ) Fertility models mean that we can no longer exploit conditional independencies to write p(a f,m) as a series of local alignment decisions. How do we compute the statistics required for EM training?
24 EM Recipe reminder If alignment points were visible, training fertility models would be easy We would and n( =3 f = Unabhaenigkeitserklaerung) = count(3, Unabhaenigkeitserklaerung) count(unabhaenigkeitserklaerung) But, alignments are not visible n( =3 f = Unabhaenigkeitserklaerung) = E[count(3, Unabhaenigkeitserklaerung)] E[count(Unabhaenigkeitserklaerung)]
25 Expectation & Fertility We need to compute expected counts under p(a f,e,m) Unfortunately p(a f,e,m) doesn t factorize nicely. :( Can we sum exhaustively? How many different a s are there? What to do?
26 Sampling Alignments Monte-Carlo methods Gibbs sampling Importance sampling Particle filtering For historical reasons Use model 2 alignment to start (easy!) Weighted sum over all alignment configurations that are close to this alignment configuration Is this correct? No! Does it work? Sort of.
27
28 Lexical Translation IBM Models 1-5 [Brown et al., 1993] Model 2: absolute position model Model 3: fertility Model 5: non-deficient model Widely used Giza++ toolkit Model 1: lexical translation, uniform alignment Model 4: relative position model (jumps in target string) HMM translation model [Vogel et al., 1996] Relative position model (jumps in source string) Latent variables are more useful these days than the translations
29 Pitfalls of Conditional Models IBM Model 4 alignment Our model's alignm
30 A few tricks... p(f e) p(e f)
31 A few tricks... p(f e) p(e f)
32 A few tricks... p(f e) p(e f)
33 Suggestions for HW1 Matching the baseline will get you a B Implement IBM Model 2 in addition to IBM Model 1 Try the heuristics for merging the many-toone and one-to-many alignments Try to reduce sparse counts by preprocessing your training data Other ideas?

34 Reading Read Chapter 4 from the textbook (today we covered 4.4 through 4.6)
35 Announcements HW1 leaderboard submissions are due by Tuesday at 11:59pm HW1 write ups and code are due 24 hours later
Lexical Translation Models 1I. January 27, 2015
 Lexical Translation Models 1I January 27, 2015 Last Time... X p( Translation)= p(, Translation) Alignment = X Alignment Alignment p( p( Alignment) Translation Alignment) {z } {z } X z } { z } { p(e f,m)=
Lexical Translation Models 1I January 27, 2015 Last Time... X p( Translation)= p(, Translation) Alignment = X Alignment Alignment p( p( Alignment) Translation Alignment) {z } {z } X z } { z } { p(e f,m)=
Word Alignment III: Fertility Models & CRFs. February 3, 2015
 Word Alignment III: Fertility Models & CRFs February 3, 2015 Last Time... X p( Translation)= p(, Translation) Alignment = X Alignment Alignment p( p( Alignment) Translation Alignment) {z } {z } X z } {
Word Alignment III: Fertility Models & CRFs February 3, 2015 Last Time... X p( Translation)= p(, Translation) Alignment = X Alignment Alignment p( p( Alignment) Translation Alignment) {z } {z } X z } {
EM with Features. Nov. 19, Sunday, November 24, 13
 EM with Features Nov. 19, 2013 Word Alignment das Haus ein Buch das Buch the house a book the book Lexical Translation Goal: a model p(e f,m) where e and f are complete English and Foreign sentences Lexical
EM with Features Nov. 19, 2013 Word Alignment das Haus ein Buch das Buch the house a book the book Lexical Translation Goal: a model p(e f,m) where e and f are complete English and Foreign sentences Lexical
Word Alignment. Chris Dyer, Carnegie Mellon University
 Word Alignment Chris Dyer, Carnegie Mellon University John ate an apple John hat einen Apfel gegessen John ate an apple John hat einen Apfel gegessen Outline Modeling translation with probabilistic models
Word Alignment Chris Dyer, Carnegie Mellon University John ate an apple John hat einen Apfel gegessen John ate an apple John hat einen Apfel gegessen Outline Modeling translation with probabilistic models
Machine Translation. CL1: Jordan Boyd-Graber. University of Maryland. November 11, 2013
 Machine Translation CL1: Jordan Boyd-Graber University of Maryland November 11, 2013 Adapted from material by Philipp Koehn CL1: Jordan Boyd-Graber (UMD) Machine Translation November 11, 2013 1 / 48 Roadmap
Machine Translation CL1: Jordan Boyd-Graber University of Maryland November 11, 2013 Adapted from material by Philipp Koehn CL1: Jordan Boyd-Graber (UMD) Machine Translation November 11, 2013 1 / 48 Roadmap
Algorithms for NLP. Machine Translation II. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Machine Translation II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Project 4: Word Alignment! Will be released soon! (~Monday) Phrase-Based System Overview
Algorithms for NLP Machine Translation II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Project 4: Word Alignment! Will be released soon! (~Monday) Phrase-Based System Overview
Out of GIZA Efficient Word Alignment Models for SMT
 Out of GIZA Efficient Word Alignment Models for SMT Yanjun Ma National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Series March 4, 2009 Y. Ma (DCU) Out of Giza
Out of GIZA Efficient Word Alignment Models for SMT Yanjun Ma National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Series March 4, 2009 Y. Ma (DCU) Out of Giza
Machine Translation: Examples. Statistical NLP Spring Levels of Transfer. Corpus-Based MT. World-Level MT: Examples
 Statistical NLP Spring 2009 Machine Translation: Examples Lecture 17: Word Alignment Dan Klein UC Berkeley Corpus-Based MT Levels of Transfer Modeling correspondences between languages Sentence-aligned
Statistical NLP Spring 2009 Machine Translation: Examples Lecture 17: Word Alignment Dan Klein UC Berkeley Corpus-Based MT Levels of Transfer Modeling correspondences between languages Sentence-aligned
Statistical NLP Spring Corpus-Based MT
 Statistical NLP Spring 2010 Lecture 17: Word / Phrase MT Dan Klein UC Berkeley Corpus-Based MT Modeling correspondences between languages Sentence-aligned parallel corpus: Yo lo haré mañana I will do it
Statistical NLP Spring 2010 Lecture 17: Word / Phrase MT Dan Klein UC Berkeley Corpus-Based MT Modeling correspondences between languages Sentence-aligned parallel corpus: Yo lo haré mañana I will do it
Corpus-Based MT. Statistical NLP Spring Unsupervised Word Alignment. Alignment Error Rate. IBM Models 1/2. Problems with Model 1
 Statistical NLP Spring 2010 Corpus-Based MT Modeling correspondences between languages Sentence-aligned parallel corpus: Yo lo haré mañana I will do it tomorrow Hasta pronto See you soon Hasta pronto See
Statistical NLP Spring 2010 Corpus-Based MT Modeling correspondences between languages Sentence-aligned parallel corpus: Yo lo haré mañana I will do it tomorrow Hasta pronto See you soon Hasta pronto See
IBM Model 1 and the EM Algorithm
 IBM Model 1 and the EM Algorithm Philipp Koehn 14 September 2017 Lexical Translation 1 How to translate a word look up in dictionary Haus house, building, home, household, shell. Multiple translations
IBM Model 1 and the EM Algorithm Philipp Koehn 14 September 2017 Lexical Translation 1 How to translate a word look up in dictionary Haus house, building, home, household, shell. Multiple translations
CRF Word Alignment & Noisy Channel Translation
 CRF Word Alignment & Noisy Channel Translation January 31, 2013 Last Time... X p( Translation)= p(, Translation) Alignment Alignment Last Time... X p( Translation)= p(, Translation) Alignment X Alignment
CRF Word Alignment & Noisy Channel Translation January 31, 2013 Last Time... X p( Translation)= p(, Translation) Alignment Alignment Last Time... X p( Translation)= p(, Translation) Alignment X Alignment
IBM Model 1 for Machine Translation
 IBM Model 1 for Machine Translation Micha Elsner March 28, 2014 2 Machine translation A key area of computational linguistics Bar-Hillel points out that human-like translation requires understanding of
IBM Model 1 for Machine Translation Micha Elsner March 28, 2014 2 Machine translation A key area of computational linguistics Bar-Hillel points out that human-like translation requires understanding of
Natural Language Processing (CSEP 517): Machine Translation
: Machine Translation") Natural Language Processing (CSEP 57): Machine Translation Noah Smith c 207 University of Washington nasmith@cs.washington.edu May 5, 207 / 59 To-Do List Online quiz: due Sunday (Jurafsky and Martin, 2008,
Natural Language Processing (CSEP 57): Machine Translation Noah Smith c 207 University of Washington nasmith@cs.washington.edu May 5, 207 / 59 To-Do List Online quiz: due Sunday (Jurafsky and Martin, 2008,
COMS 4705, Fall Machine Translation Part III
 COMS 4705, Fall 2011 Machine Translation Part III 1 Roadmap for the Next Few Lectures Lecture 1 (last time): IBM Models 1 and 2 Lecture 2 (today): phrase-based models Lecture 3: Syntax in statistical machine
COMS 4705, Fall 2011 Machine Translation Part III 1 Roadmap for the Next Few Lectures Lecture 1 (last time): IBM Models 1 and 2 Lecture 2 (today): phrase-based models Lecture 3: Syntax in statistical machine
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
Word Alignment for Statistical Machine Translation Using Hidden Markov Models
 Word Alignment for Statistical Machine Translation Using Hidden Markov Models by Anahita Mansouri Bigvand A Depth Report Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of
Word Alignment for Statistical Machine Translation Using Hidden Markov Models by Anahita Mansouri Bigvand A Depth Report Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of
Discriminative Training. March 4, 2014
 Discriminative Training March 4, 2014 Noisy Channels Again p(e) source English Noisy Channels Again p(e) p(g e) source English German Noisy Channels Again p(e) p(g e) source English German decoder e =
Discriminative Training March 4, 2014 Noisy Channels Again p(e) source English Noisy Channels Again p(e) p(g e) source English German Noisy Channels Again p(e) p(g e) source English German decoder e =
Discrete Latent Variable Models
 Discrete Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 14 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 14 1 / 29 Summary Major themes in the course
Discrete Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 14 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 14 1 / 29 Summary Major themes in the course
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5, 2018 1 Reminders Homework
Quasi-Synchronous Phrase Dependency Grammars for Machine Translation. lti
 Quasi-Synchronous Phrase Dependency Grammars for Machine Translation Kevin Gimpel Noah A. Smith 1 Introduction MT using dependency grammars on phrases Phrases capture local reordering and idiomatic translations
Quasi-Synchronous Phrase Dependency Grammars for Machine Translation Kevin Gimpel Noah A. Smith 1 Introduction MT using dependency grammars on phrases Phrases capture local reordering and idiomatic translations
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging
 Tagging") ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
Latent Variable Models in NLP
 Latent Variable Models in NLP Aria Haghighi with Slav Petrov, John DeNero, and Dan Klein UC Berkeley, CS Division Latent Variable Models Latent Variable Models Latent Variable Models Observed Latent Variable
Latent Variable Models in NLP Aria Haghighi with Slav Petrov, John DeNero, and Dan Klein UC Berkeley, CS Division Latent Variable Models Latent Variable Models Latent Variable Models Observed Latent Variable
statistical machine translation
 statistical machine translation P A R T 3 : D E C O D I N G & E V A L U A T I O N CSC401/2511 Natural Language Computing Spring 2019 Lecture 6 Frank Rudzicz and Chloé Pou-Prom 1 University of Toronto Statistical
statistical machine translation P A R T 3 : D E C O D I N G & E V A L U A T I O N CSC401/2511 Natural Language Computing Spring 2019 Lecture 6 Frank Rudzicz and Chloé Pou-Prom 1 University of Toronto Statistical
COMS 4705 (Fall 2011) Machine Translation Part II
 Machine Translation Part II") COMS 4705 (Fall 2011) Machine Translation Part II 1 Recap: The Noisy Channel Model Goal: translation system from French to English Have a model p(e f) which estimates conditional probability of any English
COMS 4705 (Fall 2011) Machine Translation Part II 1 Recap: The Noisy Channel Model Goal: translation system from French to English Have a model p(e f) which estimates conditional probability of any English
Discrimina)ve Latent Variable Models. SPFLODD November 15, 2011
ve Latent Variable Models. SPFLODD November 15, 2011") Discrimina)ve Latent Variable Models SPFLODD November 15, 2011 Lecture Plan 1. Latent variables in genera)ve models (review) 2. Latent variables in condi)onal models 3. Latent variables in structural SVMs
Discrimina)ve Latent Variable Models SPFLODD November 15, 2011 Lecture Plan 1. Latent variables in genera)ve models (review) 2. Latent variables in condi)onal models 3. Latent variables in structural SVMs
A Discriminative Model for Semantics-to-String Translation
 A Discriminative Model for Semantics-to-String Translation Aleš Tamchyna 1 and Chris Quirk 2 and Michel Galley 2 1 Charles University in Prague 2 Microsoft Research July 30, 2015 Tamchyna, Quirk, Galley
A Discriminative Model for Semantics-to-String Translation Aleš Tamchyna 1 and Chris Quirk 2 and Michel Galley 2 1 Charles University in Prague 2 Microsoft Research July 30, 2015 Tamchyna, Quirk, Galley
Statistical Machine Translation. Part III: Search Problem. Complexity issues. DP beam-search: with single and multi-stacks
 Statistical Machine Translation Marcello Federico FBK-irst Trento, Italy Galileo Galilei PhD School - University of Pisa Pisa, 7-19 May 008 Part III: Search Problem 1 Complexity issues A search: with single
Statistical Machine Translation Marcello Federico FBK-irst Trento, Italy Galileo Galilei PhD School - University of Pisa Pisa, 7-19 May 008 Part III: Search Problem 1 Complexity issues A search: with single
Statistical NLP Spring HW2: PNP Classification
 Statistical NLP Spring 2010 Lecture 16: Word Alignment Dan Klein UC Berkeley HW2: PNP Classification Overall: good work! Top results: 88.1: Matthew Can (word/phrase pre/suffixes) 88.1: Kurtis Heimerl (positional
Statistical NLP Spring 2010 Lecture 16: Word Alignment Dan Klein UC Berkeley HW2: PNP Classification Overall: good work! Top results: 88.1: Matthew Can (word/phrase pre/suffixes) 88.1: Kurtis Heimerl (positional
HW2: PNP Classification. Statistical NLP Spring Levels of Transfer. Phrasal / Syntactic MT: Examples. Lecture 16: Word Alignment
 Statistical NLP Spring 2010 Lecture 16: Word Alignment Dan Klein UC Berkeley HW2: PNP Classification Overall: good work! Top results: 88.1: Matthew Can (word/phrase pre/suffixes) 88.1: Kurtis Heimerl (positional
Statistical NLP Spring 2010 Lecture 16: Word Alignment Dan Klein UC Berkeley HW2: PNP Classification Overall: good work! Top results: 88.1: Matthew Can (word/phrase pre/suffixes) 88.1: Kurtis Heimerl (positional
Overview (Fall 2007) Machine Translation Part III. Roadmap for the Next Few Lectures. Phrase-Based Models. Learning phrases from alignments
 Machine Translation Part III. Roadmap for the Next Few Lectures. Phrase-Based Models. Learning phrases from alignments") Overview Learning phrases from alignments 6.864 (Fall 2007) Machine Translation Part III A phrase-based model Decoding in phrase-based models (Thanks to Philipp Koehn for giving me slides from his EACL
Overview Learning phrases from alignments 6.864 (Fall 2007) Machine Translation Part III A phrase-based model Decoding in phrase-based models (Thanks to Philipp Koehn for giving me slides from his EACL
A Syntax-based Statistical Machine Translation Model. Alexander Friedl, Georg Teichtmeister
 A Syntax-based Statistical Machine Translation Model Alexander Friedl, Georg Teichtmeister 4.12.2006 Introduction The model Experiment Conclusion Statistical Translation Model (STM): - mathematical model
A Syntax-based Statistical Machine Translation Model Alexander Friedl, Georg Teichtmeister 4.12.2006 Introduction The model Experiment Conclusion Statistical Translation Model (STM): - mathematical model
26 : Spectral GMs. Lecturer: Eric P. Xing Scribes: Guillermo A Cidre, Abelino Jimenez G.
 10-708: Probabilistic Graphical Models, Spring 2015 26 : Spectral GMs Lecturer: Eric P. Xing Scribes: Guillermo A Cidre, Abelino Jimenez G. 1 Introduction A common task in machine learning is to work with
10-708: Probabilistic Graphical Models, Spring 2015 26 : Spectral GMs Lecturer: Eric P. Xing Scribes: Guillermo A Cidre, Abelino Jimenez G. 1 Introduction A common task in machine learning is to work with
Probability and Statistics
 Probability and Statistics January 17, 2013 Last time... 1) Formulate a model of pairs of sentences. 2) Learn an instance of the model from data. 3) Use it to infer translations of new inputs. Why Probability?
Probability and Statistics January 17, 2013 Last time... 1) Formulate a model of pairs of sentences. 2) Learn an instance of the model from data. 3) Use it to infer translations of new inputs. Why Probability?
Topics in Natural Language Processing
 Topics in Natural Language Processing Shay Cohen Institute for Language, Cognition and Computation University of Edinburgh Lecture 9 Administrativia Next class will be a summary Please email me questions
Topics in Natural Language Processing Shay Cohen Institute for Language, Cognition and Computation University of Edinburgh Lecture 9 Administrativia Next class will be a summary Please email me questions
Word Alignment by Thresholded Two-Dimensional Normalization
 Word Alignment by Thresholded Two-Dimensional Normalization Hamidreza Kobdani, Alexander Fraser, Hinrich Schütze Institute for Natural Language Processing University of Stuttgart Germany {kobdani,fraser}@ims.uni-stuttgart.de
Word Alignment by Thresholded Two-Dimensional Normalization Hamidreza Kobdani, Alexander Fraser, Hinrich Schütze Institute for Natural Language Processing University of Stuttgart Germany {kobdani,fraser}@ims.uni-stuttgart.de
Phrase-Based Statistical Machine Translation with Pivot Languages
 Phrase-Based Statistical Machine Translation with Pivot Languages N. Bertoldi, M. Barbaiani, M. Federico, R. Cattoni FBK, Trento - Italy Rovira i Virgili University, Tarragona - Spain October 21st, 2008
Phrase-Based Statistical Machine Translation with Pivot Languages N. Bertoldi, M. Barbaiani, M. Federico, R. Cattoni FBK, Trento - Italy Rovira i Virgili University, Tarragona - Spain October 21st, 2008
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 18 Alignment in SMT and Tutorial on Giza++ and Moses)
") CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 18 Alignment in SMT and Tutorial on Giza++ and Moses) Pushpak Bhattacharyya CSE Dept., IIT Bombay 15 th Feb, 2011 Going forward
CS460/626 : Natural Language Processing/Speech, NLP and the Web (Lecture 18 Alignment in SMT and Tutorial on Giza++ and Moses) Pushpak Bhattacharyya CSE Dept., IIT Bombay 15 th Feb, 2011 Going forward
Integrating Morphology in Probabilistic Translation Models
 Integrating Morphology in Probabilistic Translation Models Chris Dyer joint work with Jon Clark, Alon Lavie, and Noah Smith January 24, 2011 lti das alte Haus the old house mach das do that 2 das alte
Integrating Morphology in Probabilistic Translation Models Chris Dyer joint work with Jon Clark, Alon Lavie, and Noah Smith January 24, 2011 lti das alte Haus the old house mach das do that 2 das alte
Soft Inference and Posterior Marginals. September 19, 2013
 Soft Inference and Posterior Marginals September 19, 2013 Soft vs. Hard Inference Hard inference Give me a single solution Viterbi algorithm Maximum spanning tree (Chu-Liu-Edmonds alg.) Soft inference
Soft Inference and Posterior Marginals September 19, 2013 Soft vs. Hard Inference Hard inference Give me a single solution Viterbi algorithm Maximum spanning tree (Chu-Liu-Edmonds alg.) Soft inference
Natural Language Processing Prof. Pushpak Bhattacharyya Department of Computer Science & Engineering, Indian Institute of Technology, Bombay
 Natural Language Processing Prof. Pushpak Bhattacharyya Department of Computer Science & Engineering, Indian Institute of Technology, Bombay Lecture - 21 HMM, Forward and Backward Algorithms, Baum Welch
Natural Language Processing Prof. Pushpak Bhattacharyya Department of Computer Science & Engineering, Indian Institute of Technology, Bombay Lecture - 21 HMM, Forward and Backward Algorithms, Baum Welch
Collaborative Filtering. Radek Pelánek
 Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
Collaborative Filtering Radek Pelánek 2017 Notes on Lecture the most technical lecture of the course includes some scary looking math, but typically with intuitive interpretation use of standard machine
TALP Phrase-Based System and TALP System Combination for the IWSLT 2006 IWSLT 2006, Kyoto
 TALP Phrase-Based System and TALP System Combination for the IWSLT 2006 IWSLT 2006, Kyoto Marta R. Costa-jussà, Josep M. Crego, Adrià de Gispert, Patrik Lambert, Maxim Khalilov, José A.R. Fonollosa, José
TALP Phrase-Based System and TALP System Combination for the IWSLT 2006 IWSLT 2006, Kyoto Marta R. Costa-jussà, Josep M. Crego, Adrià de Gispert, Patrik Lambert, Maxim Khalilov, José A.R. Fonollosa, José
Machine Learning, Fall 2012 Homework 2
 0-60 Machine Learning, Fall 202 Homework 2 Instructors: Tom Mitchell, Ziv Bar-Joseph TA in charge: Selen Uguroglu email: sugurogl@cs.cmu.edu SOLUTIONS Naive Bayes, 20 points Problem. Basic concepts, 0
0-60 Machine Learning, Fall 202 Homework 2 Instructors: Tom Mitchell, Ziv Bar-Joseph TA in charge: Selen Uguroglu email: sugurogl@cs.cmu.edu SOLUTIONS Naive Bayes, 20 points Problem. Basic concepts, 0
1. Markov models. 1.1 Markov-chain
 1. Markov models 1.1 Markov-chain Let X be a random variable X = (X 1,..., X t ) taking values in some set S = {s 1,..., s N }. The sequence is Markov chain if it has the following properties: 1. Limited
1. Markov models 1.1 Markov-chain Let X be a random variable X = (X 1,..., X t ) taking values in some set S = {s 1,..., s N }. The sequence is Markov chain if it has the following properties: 1. Limited
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Better Conditional Language Modeling. Chris Dyer
 Better Conditional Language Modeling Chris Dyer Conditional LMs A conditional language model assigns probabilities to sequences of words, w =(w 1,w 2,...,w`), given some conditioning context, x. As with
Better Conditional Language Modeling Chris Dyer Conditional LMs A conditional language model assigns probabilities to sequences of words, w =(w 1,w 2,...,w`), given some conditioning context, x. As with
Machine Learning for OR & FE
 Machine Learning for OR & FE Hidden Markov Models Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com Additional References: David
Machine Learning for OR & FE Hidden Markov Models Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com Additional References: David
Theory of Alignment Generators and Applications to Statistical Machine Translation
 Theory of Alignment Generators and Applications to Statistical Machine Translation Raghavendra Udupa U Hemanta K Mai IBM India Research Laboratory, New Delhi {uraghave, hemantkm}@inibmcom Abstract Viterbi
Theory of Alignment Generators and Applications to Statistical Machine Translation Raghavendra Udupa U Hemanta K Mai IBM India Research Laboratory, New Delhi {uraghave, hemantkm}@inibmcom Abstract Viterbi
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Logical Form 5 Famous Valid Forms. Today s Lecture 1/26/10
 Logical Form 5 Famous Valid Forms Today s Lecture 1/26/10 Announcements Homework: --Read Chapter 7 pp. 277-298 (doing the problems in parts A, B, and C pp. 298-300 are recommended but not required at this
Logical Form 5 Famous Valid Forms Today s Lecture 1/26/10 Announcements Homework: --Read Chapter 7 pp. 277-298 (doing the problems in parts A, B, and C pp. 298-300 are recommended but not required at this
PAPER Bayesian Word Alignment and Phrase Table Training for Statistical Machine Translation
 1536 IEICE TRANS. INF. & SYST., VOL.E96 D, NO.7 JULY 2013 PAPER Bayesian Word Alignment and Phrase Table Training for Statistical Machine Translation Zezhong LI a, Member, Hideto IKEDA, Nonmember, and
1536 IEICE TRANS. INF. & SYST., VOL.E96 D, NO.7 JULY 2013 PAPER Bayesian Word Alignment and Phrase Table Training for Statistical Machine Translation Zezhong LI a, Member, Hideto IKEDA, Nonmember, and
Programming Assignment 4: Image Completion using Mixture of Bernoullis
 Programming Assignment 4: Image Completion using Mixture of Bernoullis Deadline: Tuesday, April 4, at 11:59pm TA: Renie Liao (csc321ta@cs.toronto.edu) Submission: You must submit two files through MarkUs
Programming Assignment 4: Image Completion using Mixture of Bernoullis Deadline: Tuesday, April 4, at 11:59pm TA: Renie Liao (csc321ta@cs.toronto.edu) Submission: You must submit two files through MarkUs
Probabilistic Graphical Models Homework 2: Due February 24, 2014 at 4 pm
 Probabilistic Graphical Models 10-708 Homework 2: Due February 24, 2014 at 4 pm Directions. This homework assignment covers the material presented in Lectures 4-8. You must complete all four problems to
Probabilistic Graphical Models 10-708 Homework 2: Due February 24, 2014 at 4 pm Directions. This homework assignment covers the material presented in Lectures 4-8. You must complete all four problems to
Midterm sample questions
 Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Conditional Random Fields
 Conditional Random Fields Micha Elsner February 14, 2013 2 Sums of logs Issue: computing α forward probabilities can undeflow Normally we d fix this using logs But α requires a sum of probabilities Not
Conditional Random Fields Micha Elsner February 14, 2013 2 Sums of logs Issue: computing α forward probabilities can undeflow Normally we d fix this using logs But α requires a sum of probabilities Not
Syntax-Based Decoding
 Syntax-Based Decoding Philipp Koehn 9 November 2017 1 syntax-based models Synchronous Context Free Grammar Rules 2 Nonterminal rules NP DET 1 2 JJ 3 DET 1 JJ 3 2 Terminal rules N maison house NP la maison
Syntax-Based Decoding Philipp Koehn 9 November 2017 1 syntax-based models Synchronous Context Free Grammar Rules 2 Nonterminal rules NP DET 1 2 JJ 3 DET 1 JJ 3 2 Terminal rules N maison house NP la maison
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
Cross-Lingual Language Modeling for Automatic Speech Recogntion
 GBO Presentation Cross-Lingual Language Modeling for Automatic Speech Recogntion November 14, 2003 Woosung Kim woosung@cs.jhu.edu Center for Language and Speech Processing Dept. of Computer Science The
GBO Presentation Cross-Lingual Language Modeling for Automatic Speech Recogntion November 14, 2003 Woosung Kim woosung@cs.jhu.edu Center for Language and Speech Processing Dept. of Computer Science The
4 : Exact Inference: Variable Elimination
 10-708: Probabilistic Graphical Models 10-708, Spring 2014 4 : Exact Inference: Variable Elimination Lecturer: Eric P. ing Scribes: Soumya Batra, Pradeep Dasigi, Manzil Zaheer 1 Probabilistic Inference
10-708: Probabilistic Graphical Models 10-708, Spring 2014 4 : Exact Inference: Variable Elimination Lecturer: Eric P. ing Scribes: Soumya Batra, Pradeep Dasigi, Manzil Zaheer 1 Probabilistic Inference
Discriminative Training
 Discriminative Training February 19, 2013 Noisy Channels Again p(e) source English Noisy Channels Again p(e) p(g e) source English German Noisy Channels Again p(e) p(g e) source English German decoder
Discriminative Training February 19, 2013 Noisy Channels Again p(e) source English Noisy Channels Again p(e) p(g e) source English German Noisy Channels Again p(e) p(g e) source English German decoder
Introduction to Artificial Intelligence (AI)
") Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
Bayesian Networks (Part I)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
Gaussian Process Approximations of Stochastic Differential Equations
 Gaussian Process Approximations of Stochastic Differential Equations Cédric Archambeau Centre for Computational Statistics and Machine Learning University College London c.archambeau@cs.ucl.ac.uk CSML
Gaussian Process Approximations of Stochastic Differential Equations Cédric Archambeau Centre for Computational Statistics and Machine Learning University College London c.archambeau@cs.ucl.ac.uk CSML
Expectation Maximization (EM)
") Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Hidden Markov Models: All the Glorious Gory Details
 Hidden Markov Models: All the Glorious Gory Details Noah A. Smith Department of Computer Science Johns Hopkins University nasmith@cs.jhu.edu 18 October 2004 1 Introduction Hidden Markov models (HMMs, hereafter)
Hidden Markov Models: All the Glorious Gory Details Noah A. Smith Department of Computer Science Johns Hopkins University nasmith@cs.jhu.edu 18 October 2004 1 Introduction Hidden Markov models (HMMs, hereafter)
Hidden Markov Models in Language Processing
 Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Supplementary Notes on Inductive Definitions
 Supplementary Notes on Inductive Definitions 15-312: Foundations of Programming Languages Frank Pfenning Lecture 2 August 29, 2002 These supplementary notes review the notion of an inductive definition
Supplementary Notes on Inductive Definitions 15-312: Foundations of Programming Languages Frank Pfenning Lecture 2 August 29, 2002 These supplementary notes review the notion of an inductive definition
Pair Hidden Markov Models
 Pair Hidden Markov Models Scribe: Rishi Bedi Lecturer: Serafim Batzoglou January 29, 2015 1 Recap of HMMs alphabet: Σ = {b 1,...b M } set of states: Q = {1,..., K} transition probabilities: A = [a ij ]
Pair Hidden Markov Models Scribe: Rishi Bedi Lecturer: Serafim Batzoglou January 29, 2015 1 Recap of HMMs alphabet: Σ = {b 1,...b M } set of states: Q = {1,..., K} transition probabilities: A = [a ij ]
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Stephen Scott.
 1 / 21 sscott@cse.unl.edu 2 / 21 Introduction Designed to model (profile) a multiple alignment of a protein family (e.g., Fig. 5.1) Gives a probabilistic model of the proteins in the family Useful for
1 / 21 sscott@cse.unl.edu 2 / 21 Introduction Designed to model (profile) a multiple alignment of a protein family (e.g., Fig. 5.1) Gives a probabilistic model of the proteins in the family Useful for
Algorithms for Syntax-Aware Statistical Machine Translation
 Algorithms for Syntax-Aware Statistical Machine Translation I. Dan Melamed, Wei Wang and Ben Wellington ew York University Syntax-Aware Statistical MT Statistical involves machine learning (ML) seems crucial
Algorithms for Syntax-Aware Statistical Machine Translation I. Dan Melamed, Wei Wang and Ben Wellington ew York University Syntax-Aware Statistical MT Statistical involves machine learning (ML) seems crucial
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Machine Translation. Uwe Dick
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Machine Translation Uwe Dick Google Translate Rosetta Stone Hieroglyphs Demotic Greek Machine Translation Automatically translate
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Machine Translation Uwe Dick Google Translate Rosetta Stone Hieroglyphs Demotic Greek Machine Translation Automatically translate
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 11 Oct, 3, 2016 CPSC 422, Lecture 11 Slide 1 422 big picture: Where are we? Query Planning Deterministic Logics First Order Logics Ontologies
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 11 Oct, 3, 2016 CPSC 422, Lecture 11 Slide 1 422 big picture: Where are we? Query Planning Deterministic Logics First Order Logics Ontologies
Learning to translate with neural networks. Michael Auli
 Learning to translate with neural networks Michael Auli 1 Neural networks for text processing Similar words near each other France Spain dog cat Neural networks for text processing Similar words near each
Learning to translate with neural networks Michael Auli 1 Neural networks for text processing Similar words near each other France Spain dog cat Neural networks for text processing Similar words near each
Searching Algorithms. CSE21 Winter 2017, Day 3 (B00), Day 2 (A00) January 13, 2017
, Day 2 (A00) January 13, 2017") Searching Algorithms CSE21 Winter 2017, Day 3 (B00), Day 2 (A00) January 13, 2017 Selection Sort (MinSort) Pseudocode Rosen page 203, exercises 41-42 procedure selection sort(a 1, a 2,..., a n : real numbers
Searching Algorithms CSE21 Winter 2017, Day 3 (B00), Day 2 (A00) January 13, 2017 Selection Sort (MinSort) Pseudocode Rosen page 203, exercises 41-42 procedure selection sort(a 1, a 2,..., a n : real numbers
Homework 6: Image Completion using Mixture of Bernoullis
 Homework 6: Image Completion using Mixture of Bernoullis Deadline: Wednesday, Nov. 21, at 11:59pm Submission: You must submit two files through MarkUs 1 : 1. a PDF file containing your writeup, titled
Homework 6: Image Completion using Mixture of Bernoullis Deadline: Wednesday, Nov. 21, at 11:59pm Submission: You must submit two files through MarkUs 1 : 1. a PDF file containing your writeup, titled
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
order is number of previous outputs
 Markov Models Lecture : Markov and Hidden Markov Models PSfrag Use past replacements as state. Next output depends on previous output(s): y t = f[y t, y t,...] order is number of previous outputs y t y
Markov Models Lecture : Markov and Hidden Markov Models PSfrag Use past replacements as state. Next output depends on previous output(s): y t = f[y t, y t,...] order is number of previous outputs y t y
Hidden Markov models
 Hidden Markov models Charles Elkan November 26, 2012 Important: These lecture notes are based on notes written by Lawrence Saul. Also, these typeset notes lack illustrations. See the classroom lectures
Hidden Markov models Charles Elkan November 26, 2012 Important: These lecture notes are based on notes written by Lawrence Saul. Also, these typeset notes lack illustrations. See the classroom lectures
Lecture 18: Analysis of variance: ANOVA
 Lecture 18: Announcements: Exam has been graded. See website for results. Lecture 18: Announcements: Exam has been graded. See website for results. Reading: Vasilj pp. 83-97. Lecture 18: Announcements:
Lecture 18: Announcements: Exam has been graded. See website for results. Lecture 18: Announcements: Exam has been graded. See website for results. Reading: Vasilj pp. 83-97. Lecture 18: Announcements:
Statistical Methods for NLP
 Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Statistical Methods for NLP Stochastic Grammars Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(22) Structured Classification
Statistical Machine Translation
 Statistical Machine Translation -tree-based models (cont.)- Artem Sokolov Computerlinguistik Universität Heidelberg Sommersemester 2015 material from P. Koehn, S. Riezler, D. Altshuler Bottom-Up Decoding
Statistical Machine Translation -tree-based models (cont.)- Artem Sokolov Computerlinguistik Universität Heidelberg Sommersemester 2015 material from P. Koehn, S. Riezler, D. Altshuler Bottom-Up Decoding
Machine Learning & Data Mining Caltech CS/CNS/EE 155 Hidden Markov Models Last Updated: Feb 7th, 2017
 1 Introduction Let x = (x 1,..., x M ) denote a sequence (e.g. a sequence of words), and let y = (y 1,..., y M ) denote a corresponding hidden sequence that we believe explains or influences x somehow
1 Introduction Let x = (x 1,..., x M ) denote a sequence (e.g. a sequence of words), and let y = (y 1,..., y M ) denote a corresponding hidden sequence that we believe explains or influences x somehow
Lecture 6 April
 Stats 300C: Theory of Statistics Spring 2017 Lecture 6 April 14 2017 Prof. Emmanuel Candes Scribe: S. Wager, E. Candes 1 Outline Agenda: From global testing to multiple testing 1. Testing the global null
Stats 300C: Theory of Statistics Spring 2017 Lecture 6 April 14 2017 Prof. Emmanuel Candes Scribe: S. Wager, E. Candes 1 Outline Agenda: From global testing to multiple testing 1. Testing the global null
Stat 406: Algorithms for classification and prediction. Lecture 1: Introduction. Kevin Murphy. Mon 7 January,
 1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
1 Stat 406: Algorithms for classification and prediction Lecture 1: Introduction Kevin Murphy Mon 7 January, 2008 1 1 Slides last updated on January 7, 2008 Outline 2 Administrivia Some basic definitions.
Fast Collocation-Based Bayesian HMM Word Alignment
 Fast Collocation-Based Bayesian HMM Word Alignment Philip Schulz ILLC University of Amsterdam P.Schulz@uva.nl Wilker Aziz ILLC University of Amsterdam W.Aziz@uva.nl Abstract We present a new Bayesian HMM
Fast Collocation-Based Bayesian HMM Word Alignment Philip Schulz ILLC University of Amsterdam P.Schulz@uva.nl Wilker Aziz ILLC University of Amsterdam W.Aziz@uva.nl Abstract We present a new Bayesian HMM
Bayesian Networks BY: MOHAMAD ALSABBAGH
 Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Sampling Alignment Structure under a Bayesian Translation Model
 Sampling Alignment Structure under a Bayesian Translation Model John DeNero, Alexandre Bouchard-Côté and Dan Klein Computer Science Department University of California, Berkeley {denero, bouchard, klein}@cs.berkeley.edu
Sampling Alignment Structure under a Bayesian Translation Model John DeNero, Alexandre Bouchard-Côté and Dan Klein Computer Science Department University of California, Berkeley {denero, bouchard, klein}@cs.berkeley.edu
Probability Review. September 25, 2015
 Probability Review September 25, 2015 We need a tool to 1) Formulate a model of some phenomenon. 2) Learn an instance of the model from data. 3) Use it to infer outputs from new inputs. Why Probability?
Probability Review September 25, 2015 We need a tool to 1) Formulate a model of some phenomenon. 2) Learn an instance of the model from data. 3) Use it to infer outputs from new inputs. Why Probability?
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 18: HMMs and Particle Filtering 4/4/2011 Pieter Abbeel --- UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew Moore
CS 188: Artificial Intelligence Spring 2011 Lecture 18: HMMs and Particle Filtering 4/4/2011 Pieter Abbeel --- UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew Moore
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
A minimalist s exposition of EM
 A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
Nonparameteric Regression:
 Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Hidden Markov Models. Vibhav Gogate The University of Texas at Dallas
 Hidden Markov Models Vibhav Gogate The University of Texas at Dallas Intro to AI (CS 4365) Many slides over the course adapted from either Dan Klein, Luke Zettlemoyer, Stuart Russell or Andrew Moore 1
Hidden Markov Models Vibhav Gogate The University of Texas at Dallas Intro to AI (CS 4365) Many slides over the course adapted from either Dan Klein, Luke Zettlemoyer, Stuart Russell or Andrew Moore 1
Today. Statistical Learning. Coin Flip. Coin Flip. Experiment 1: Heads. Experiment 1: Heads. Which coin will I use? Which coin will I use?
 Today Statistical Learning Parameter Estimation: Maximum Likelihood (ML) Maximum A Posteriori (MAP) Bayesian Continuous case Learning Parameters for a Bayesian Network Naive Bayes Maximum Likelihood estimates
Today Statistical Learning Parameter Estimation: Maximum Likelihood (ML) Maximum A Posteriori (MAP) Bayesian Continuous case Learning Parameters for a Bayesian Network Naive Bayes Maximum Likelihood estimates